Abstract
In the intelligentization process of power transmission towers, automated identification of stamped characters is crucial. Currently, manual methods are predominantly used, which are time-consuming, labor-intensive, and prone to errors. For small-sized characters that are incomplete, connected, and irregular in shape, existing OCR technologies also struggle to achieve satisfactory recognition results. Thus, an approach utilizing an improved deep neural network model to enhance the recognition performance of stamped characters is proposed. Based on the backbone network of YOLOv5, a multi-scale residual attention encoding mechanism is introduced during the upsampling process to enhance the weights of small and incomplete character targets. Additionally, a selectable clustering minimum iteration center module is introduced to optimize the selection of clustering centers and integrate multi-scale information, thereby reducing random errors. Experimental verification shows that the improved model significantly reduces the instability caused by random selection of clustering centers during the clustering process, accelerates the convergence of small target recognition, achieves a recognition accuracy of 97.6% and a detection speed of 43 milliseconds on the task of stamped character recognition, and significantly outperforms existing Fast-CNN, YOLOv5, and YOLOv6 models in terms of performance, effectively enhancing the precision and efficiency of automatic identification.
1. Introduction
Angle steel is the main component material of an electric power tower; each angle steel tower contains hundreds or even thousands of angle steel parts. From unloading to shipment, the angle parts will go through the processes of hole-making, backing, trimming, galvanizing, sorting, packing, and so on. Each part is given a dedicated steel stamp number, usually generated using a character mold punch. As the steel stamp character carries production information such as dispatch number, equipment number, worker code, processing time, it is crucial for product quality control and responsibility tracing. At present, the main use of traditional manual identification methods is not only inefficient but also susceptible to subjective bias, there is an urgent need for technological innovation to achieve automatic identification [1,2]. Although the existing OCR (Optical Character Recognition) equipment [3] and advanced machine vision technology in many application areas has been quite mature, in the field of transmission tower angle steel parts steel stamp character recognition, there are still accuracy and consistency problems; it is difficult to meet the requirements of industrial applications. This limitation is mainly due to the steel characters in the manufacturing and the use of various complex factors that may occur in the process, such as steel parts embossed with characters of the material, concave and convex height, tilt angle, mutilation, adhesion, and small size and shape irregularities, etc., resulting in uneven distribution of the grayscale of the image and clarity degradation. The characters in the segmentation and recognition process of the error rate are higher, and the angle embossed character recognition has brought a huge challenge. Most of the traditional character recognition methods are based on the similarity of template matching, edge information in the image, shape features, and statistical classification techniques. To address the feature extraction problem of steel-stamped characters, Geng et al. [4] used a method based on fractal dimension and Hidden Markov features to binarize the characters and then used multiple classifiers to recognize the embossed characters of license plates. Zhang et al. [5] proposed an embossed character segmentation method, which firstly screens the embossed character region, then performs morphological optimization, and combines the extracted embossed character features with a BP neural network to achieve embossed character recognition. These methods are sensitive to image noise and small deformations of embossed characters, and it is difficult to deal with character sets with concave and convex features and recognize embossed characters in complex backgrounds.
In recent years, image recognition methods based on deep learning [6] have gained widespread attention for their fast and accurate performance, among which, YOLO (You Only Look Once), proposed by Redmon et al. [7,8,9,10,11,12,13,14], defines target recognition as a regression problem, and directly predicts the bounding box and category probabilities from the full image through a single neural network for end-to-end optimization, which has become one of the most popular methods for image recognition. Jaderberg et al. [15] proposed a method using synthetic data and artificial neural networks for natural scene text recognition, significantly improving recognition accuracy. Shi et al. [16] introduced an end-to-end trainable neural network for image-based sequence recognition, particularly useful for scene text recognition. Graves et al. [17] developed a multidimensional recurrent neural network for offline handwriting recognition, demonstrating its effectiveness in handling complex handwriting sequences. In many specific application areas, in order to further improve the accuracy of recognition, many scholars have carried out a lot of innovative research work based on the YOLO model framework. For example, Zhao Yan et al. [18] proposed a detection model by combining the Darknet framework and the YOLOv4 algorithm and enhanced the model’s ability to detect multi-scale defects in circuit board characters by designing reasonable anchors using the k-means clustering algorithm. Y.S. Si et al. [19] proposed an improved YOLOv4 model by employing MSRCP (Multi-scale retinex with chromaticity preservation) algorithm for image enhancement in low-light environments, as well as incorporating an RFB-s structure in the model backbone to improve the change of cow body pattern in terms of its robustness. In addition, by improving the Non-Maximum Suppression (NMS) algorithm, the accuracy of the model in recognizing the target is improved. Huaibo Song et al. [20] improved the YOLOv5s detection network by introducing the Mixed Depth Separable Convolution (MixConv, MDC) module and combining it with the Squeeze-and-Excitation (SE) module in order to reduce the model parameters with essentially no loss of model accuracy. In this improvement, the conventional convolution, normalization, and activation function (CBH) module in the backbone part of the feature extraction network of the YOLO v5-MDC network is replaced with the MDC module, which effectively reduces the model parameters. Although the above-improved target detection methods based on the YOLO network model have improved the detection accuracy in specific applications, they generally suffer from high model complexity and slow training speed. At the same time, these features further increase the difficulty of detection when dealing with objects with small dimensions, different location information, and irregular morphology.
For the current power tower parts angle steel concave and convex characteristics and image noise and other problems, this paper designs a multi-scale residual attention coding algorithm module and selectable clustering minimum iteration center to improve the model of YOLOv5, and proposes a new deep learning network model based on the recognition of embossed characters of steel parts, which has a total of two innovations: (1) In the YOLOv5 architecture, the model is improved through the use of the Spatial Pyramid in the fast space pyramid Pooling (SPPF) and the downsampling phase of the backbone network by integrating the channel multiscale residual attention coding algorithm, which enhances the network’s ability in terms of extracting shallow features and assigning weights to the detection targets, thus optimizing the overall detection performance; and (2) Designing a method of selecting the cluster centers aiming at selecting, in each iteration, cluster centers that can minimize the differences within the clusters, ensuring that the cluster centers selected in each iteration best represent the characteristics of individual characters, thereby improving the accurate recognition of the shape and size of embossed characters. The main contents of this paper are structured as follows: The first part briefly describes the current state of research and the structure of the paper on the target detection of steel imprinted characters on angles; the second part briefly describes the challenges faced by the production of angles for transmission towers and the automated recognition of imprinted characters; the third part proposes the recognition model YOLOv5-R for mutilated and tiny imprinted characters; the fourth part compares the improved model with other models in terms of experiments and performance analyses on different types of angle embossed characters in detection tasks; and finally, the superiority of the improved model and its application potential are summarized.
2. Power Tower Angle Steel Parts Processing
2.1. Angle Steel Tower Parts Processing Process and Steel Stamping
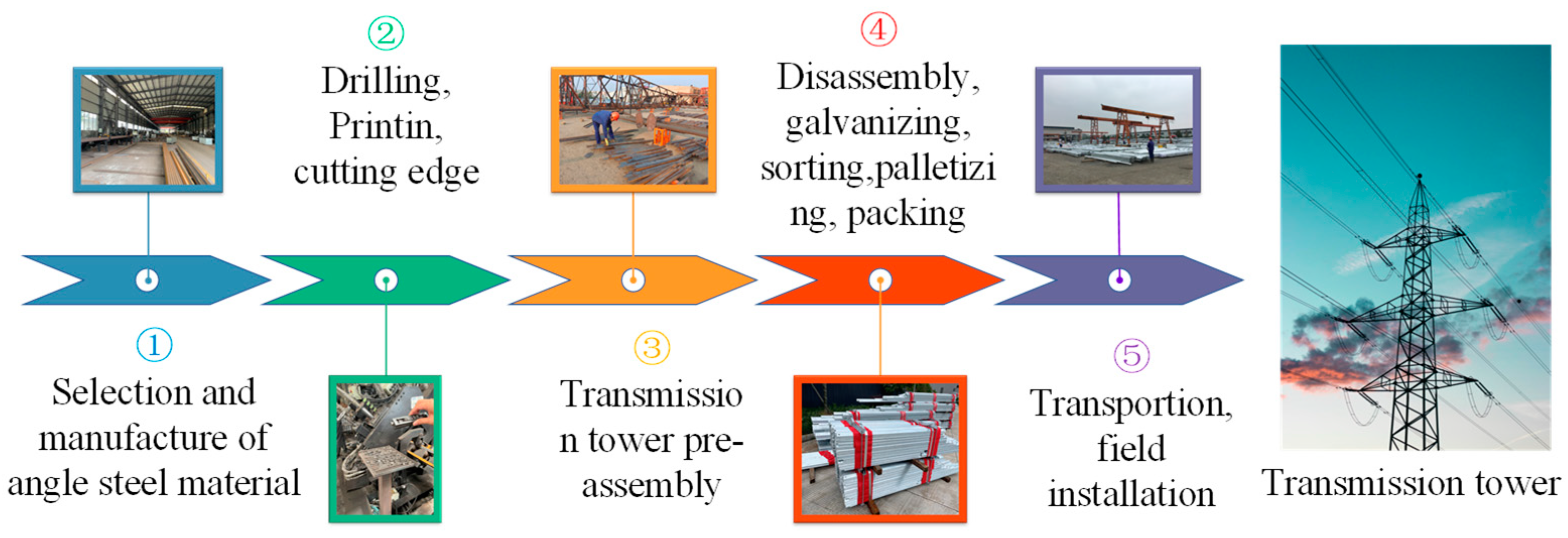
The power angle steel tower parts manufacturing process can be divided into undercutting, stamping, trimming, pre-assembly, galvanizing, sorting, classification, packing, factory, and assembly, as shown in Figure 1. To ensure the stability and safety of power transmission, strict control of the angle manufacturing process is particularly important, from the selection of raw materials to the final product of strict inspection, each step requires meticulous management and operation. One of the key steps is character imprinting, which involves imprinting important information such as the production lot number, material type, and production date on the steel. This information is important for product tracking, maintenance, and quality control.
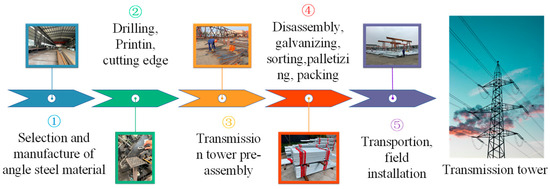
Figure 1.
Transmission Tower Manufacturing Flow Chart.
Embossing techniques include cold embossing and hot embossing: Cold embossing uses high pressure at room temperature to permanently press characters into a metal surface through a mold. Hot embossing is done at higher temperatures and provides deeper markings for applications that require very high abrasion resistance. Both methods must ensure embossing quality and durability with precise control of several technical parameters [21]. First, the design of the mold must be precise to match the size, shape, and expected depth of the desired character. Second, embossing equipment selection needs to take into account productivity, automation, and operational flexibility. At present, automated embossing machines can improve production efficiency and reduce human errors, which are especially suitable for mass production and are gradually popularized and applied in some enterprises.
2.2. Challenges of Angle Steel Embossed Character Recognition
The embossed characters on the angle steel parts of power towers carry key information, such as production batch, material type, and manufacturing date, which are crucial for tracking the product, maintenance, and quality monitoring, but at present, it mainly relies on manual recognition, which has many problems such as low efficiency and high error rate. The existing mature OCR technology landscape is widely used in various fields, but the power pylons steel stamp character recognition makes it difficult to obtain ideal results. The main reasons are as follows. First of all, based on the mold stamping out of the steel characters, because of character mold wear and tear or even breakage, among other reasons, resulting in stamping out of the steel characters, there is poor consistency, mutilation, and other issues. Secondly, the imprinted characters may be subjected to environmental factors such as corrosion or wear and tear and become illegible; this physical wear and tear or chemical corrosion will lead to fuzzy edges of the characters, the font being faded, or even part of the characters disappearing, as shown in Figure 2. Third, during production and use, the angle may be covered with grease or other types of contaminants that can form a covering layer on the surface of the characters, significantly reducing their visibility. These reasons bring great challenges to the recognition of steel imprinted characters for power pylons.

Figure 2.
Part of angle steel embossed. (a) Galvanized Angle stamping characters; (b) Incomplete Angle stamping characters; (c) Rusted Angle stamping characters; (d) Ungalvanized Angle stamping characters; (e) Laser printed steel plate stamping characters.
3. Network Model
3.1. Angle Steel Embossed Character Recognition Based on YOLOv5
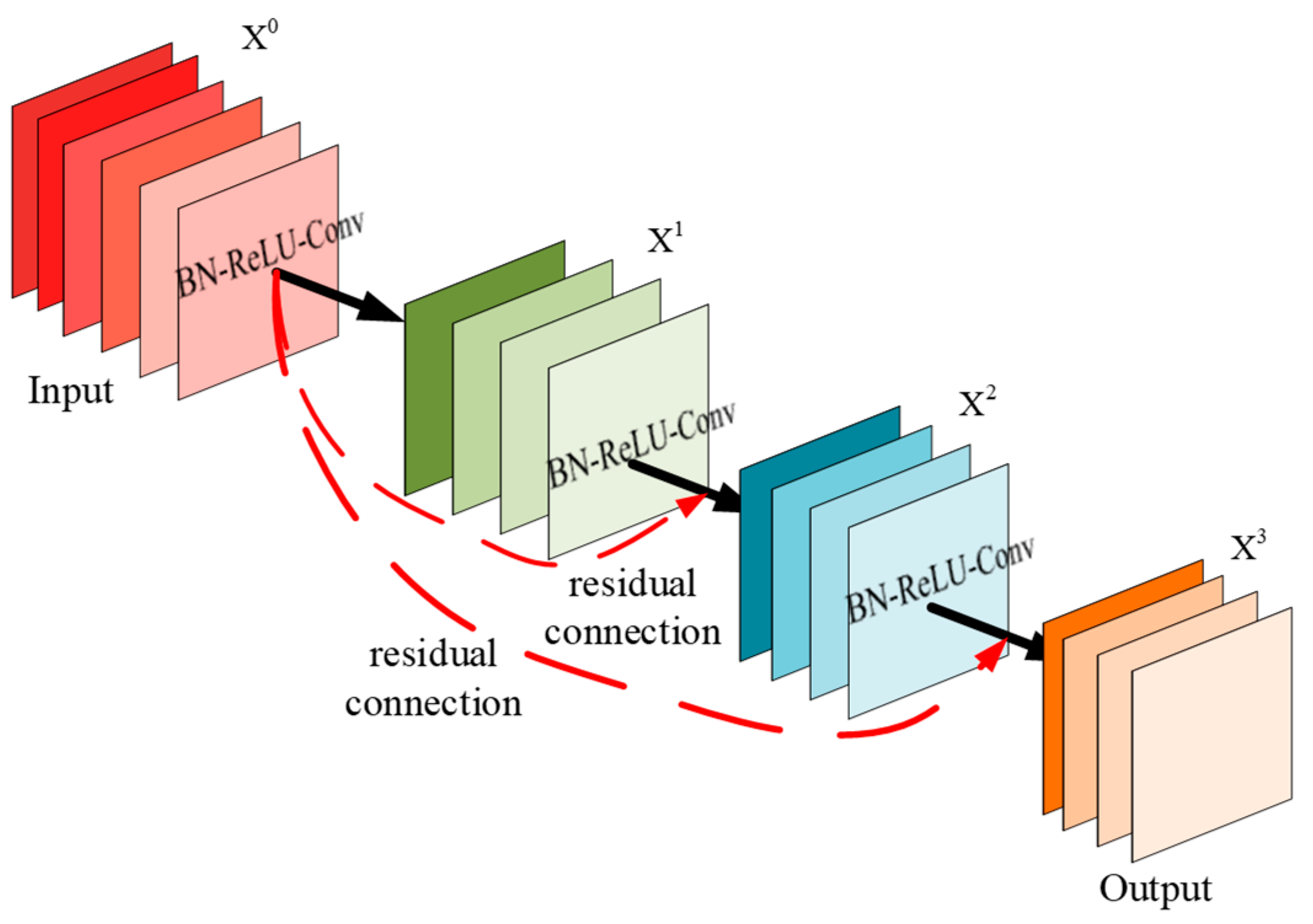
The YOLO improves processing efficiency by simplifying target detection to a single regression analysis. The neural network divides the image into multiple grids, with each grid cell independently predicting its internal target. Batch normalization and ReLU activation functions are configured after each convolutional layer to optimize nonlinear processing capability and overall stability. YOLOv5 is designed to optimize efficiency and speed, making it suitable for resource-constrained environments while maintaining good detection accuracy. Its core architecture includes multilayered convolutional layers, residual blocks, and an anchor box mechanism. Convolutional layers capture visual features at various levels using multi-scale convolutional kernels, while residual blocks solve the problem of gradient vanishing in deep networks through skip connections. The anchor box mechanism, by presetting bounding boxes of different sizes and ratios, accelerates the model’s convergence speed for targets of various sizes and shapes, improving detection accuracy, as shown in Figure 3. The arrows in the figure represent the flow of data through the layers of the model, indicating the sequence of operations performed. The straight black arrows denote the standard forward pass through the Batch Normalization (BN), ReLU activation, and Convolution (Conv) layers, while the curved red arrows indicate the residual connections that add the input of a block to its output, helping to mitigate the vanishing gradient problem in deep networks.
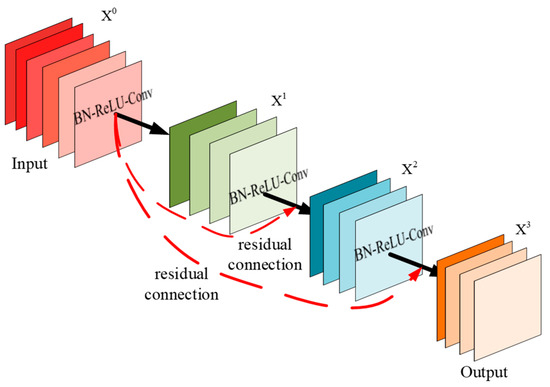
Figure 3.
Residual network structure.
However, YOLOv5 performs poorly in recognizing damaged and rusty embossed characters. These characters are usually small and prone to damage, leading to missed or incorrect detections. Additionally, corrosion and wear can make it difficult to distinguish characters from the background, reducing recognition accuracy. While the standard anchor box mechanism optimizes detection for targets of various sizes and shapes, its preset sizes and ratios may not be sufficient to cover all character variants, affecting the model’s flexibility and adaptability. Residual blocks may fail to adequately retain critical information when dealing with these detailed and damaged characters, resulting in decreased recognition accuracy. To address these shortcomings, we introduced a multi-scale feature fusion mechanism that better captures different levels of information in images, improving detection capabilities for complex scenes and small targets. Additionally, we optimized the YOLOv5 anchor box mechanism to better suit small target detection by introducing a dynamic anchor box adjustment strategy that adjusts anchor box sizes dynamically based on target size and shape, thereby improving detection accuracy. Furthermore, we incorporated an attention mechanism into the network to enhance the model’s focus on key features, thereby improving overall detection performance. With self-attention and channel attention mechanisms, the model can more effectively distinguish targets from the background, increasing recognition accuracy.
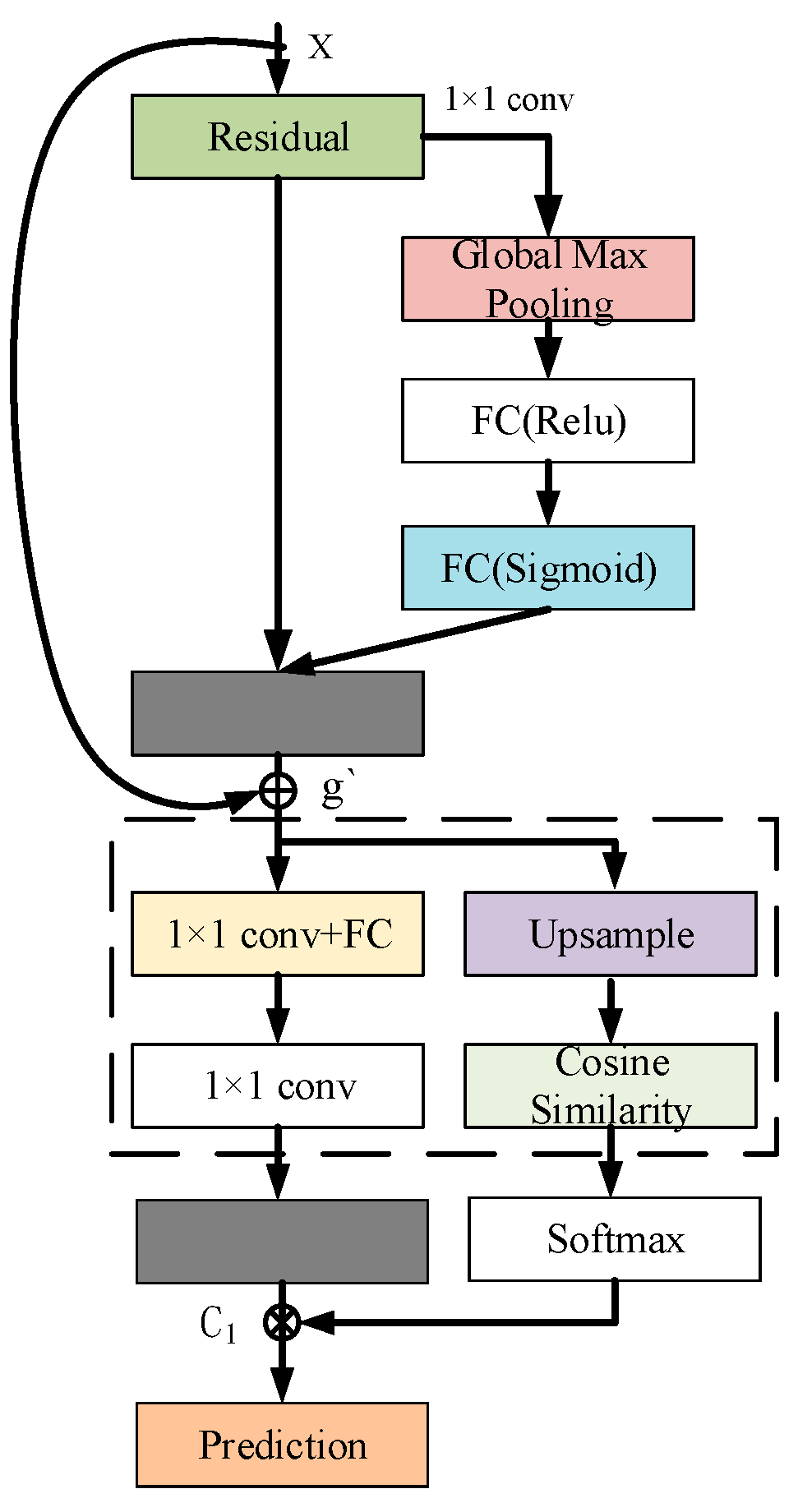
3.2. Multi-Scale Residual Channel Attention Coding Mechanism Design (MSRC)
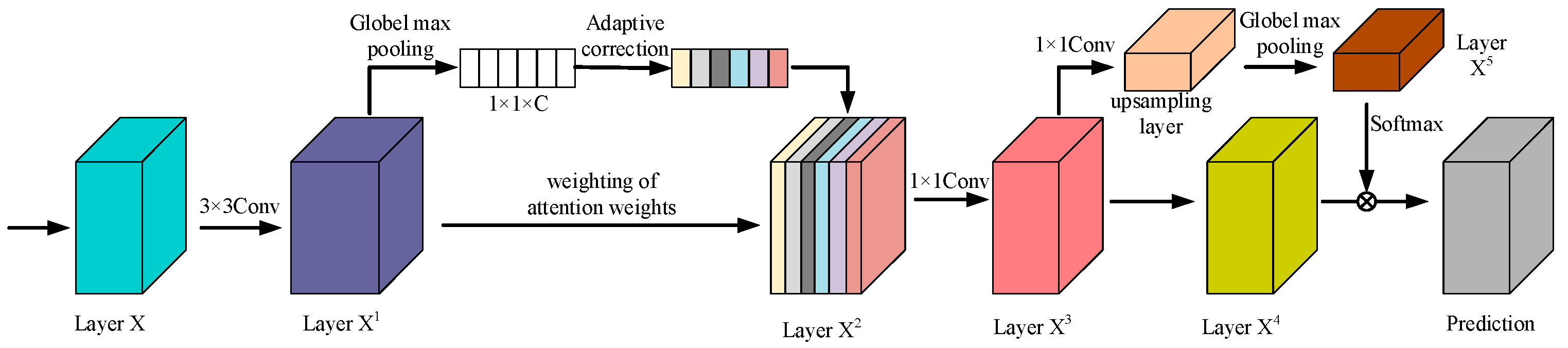
Attention mechanism networks in image processing can finely control the channel and spatial dimensions of the model and use masks to precisely manage the attention, thus improving recognition accuracy. These include self-attention, domain attention, and channel and spatial attention modules (CAM and SAM). Although this enhances the image processing performance, the model still struggles to distinguish the nuances between background noise and the actual target when dealing with small or crippled targets, limiting the recognition rate. In addition, these problems may be further amplified when the depth and complexity of the model increase, affecting the memory and utilization of earlier features, thus limiting the improvement of recognition accuracy. To overcome these limitations, in this paper, we design a multi-scale residual channel attention coding algorithm mechanism that eliminates the insufficient filtering of non-critical information, thereby enhancing small target and residual recognition, the structure of which is shown in Figure 4. This mechanism can significantly improve the recognition accuracy of the model by enhancing the function of feature extraction and information integration, especially when dealing with low-resolution and small-volume targets.
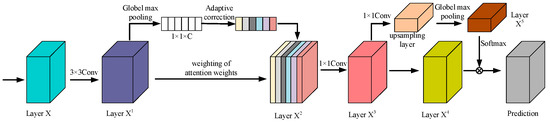
Figure 4.
Multi-scale residual channel attention coding structure.
A multi-scale residual attention coding algorithm finely handles the feature map, which effectively enhances the representation of features and the continuous flow of information by combining the residual learning technique and the attention mechanism in deep learning. The algorithm first applies residual connections that allow gradients to flow directly through the network, preventing information from being lost during deep transfer. A 1 × 1 convolutional kernel is then used to reduce the dimensionality of the feature map, which not only simplifies the computational requirements of the model but, at the same time, preserves the most critical information. The global pooling step follows immediately after the spatial compression of the features, capturing the most globally important features and providing an accurate basis for the final attentional weighting. The normalized exponential function (Softmax function) is then used to assign the attentional weights, which enhances the model’s ability to determine the importance of features by amplifying meaningful feature differences and normalizing the weights, as shown in Figure 5. Additionally, the Softmax function is applied at the final classification stage to convert the output logits into a probability distribution, enabling the model to assign a class label to each detected object with a confidence score. The calculation of the attentional weights not only relies on the amount of information in the features themselves but also takes into account the relative importance between the features with the following formula:
where represents the attention weight of the i feature map, exp denotes the natural exponential function, which is used to ensure that the weight is positive and amplifies the differences in the vector representation of the feature maps, and denotes to ensure that the sum of the attention weights of all the feature maps is 1, which is achieved by summing the exponential weights of all the feature maps to achieve the normalization of the weights. Then the algorithm adjusts all feature maps to the same size weights using the corresponding attention weights, and fuses the weighted feature map phases to form the final fused feature map; the fusion formula is as follows:
where g denotes the fused feature map, is the result of the i feature map by 1 × 1 convolution processing, and denotes traversing all feature maps and adding their weighted results to get the final fused feature map.
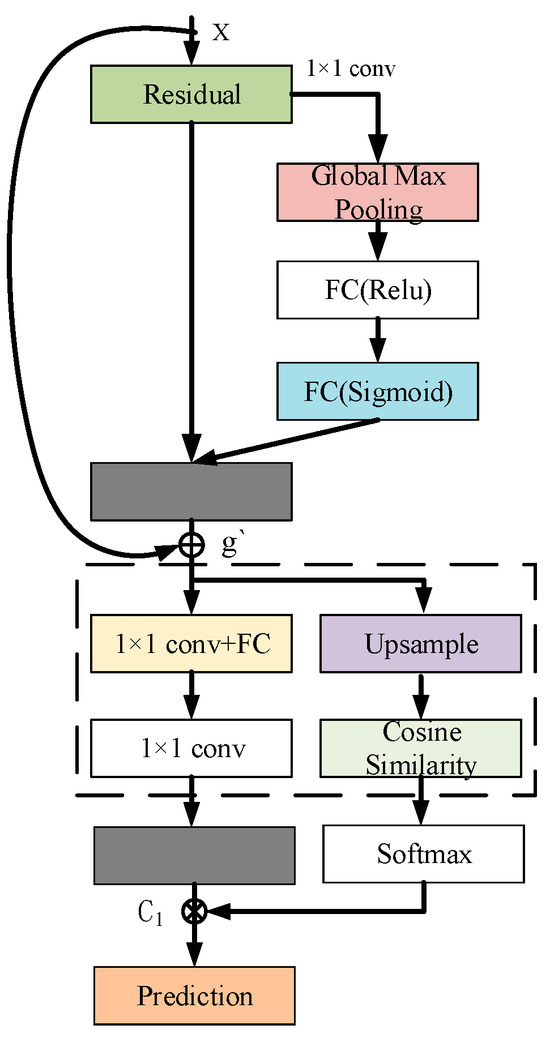
Figure 5.
Multi-scale residual channel unit.
Residual attention coding calculates the degree of match between the feature maps and the predefined templates through cosine similarity, which further evaluates the model’s key to feature recognition accuracy. Cosine similarity measures the similarity between two vectors through dot product and mode length normalization, which effectively determines the consistency between the model output and the target template, as shown in the following equation:
where, denotes the similarity between the and the template b, denotes the vector representation of the i feature map after a series of processing, F(b) denotes the vector representation of the feature map as the reference template after the same processing, ⋅ is used to calculate the dot product of the two vectors, and denotes the modes of and . Finally, to evaluate the attention weight of each feature map, the computed similarity metric is fed into the Softmax layer for normalization, the similarity is converted into probability. Finally, the sum of weighted feature maps is generated by increasing the attentional weights of the up-sampled C1 and the corresponding other predictor heads Ci to the same size and number of channels, which is calculated as follows:
where A denotes the sum of weighted feature maps.
3.3. Design of Optional Clustering Minimum Iteration Center Module (OCMC)
In the YOLOv5 algorithm, the traditional K-means algorithm [22,23] is used to optimize the anchor frame size. The distance from the sample points to the cluster center is minimized by randomly selecting the initial cluster center and iteratively updating the position. Despite its simplicity and efficiency, the K-means algorithm still faces problems such as high computational complexity and dependence on a priori knowledge of the number of clusters. This is especially true when dealing with high-dimensional data or large-scale datasets since the distance from all data points to existing clustering centers needs to be calculated each time a new center is selected. Secondly, the a priori selection that still relies on the number of clusters is often difficult to determine in practical applications. In addition, Euclidean distance, as the core metric of clustering, may not be sufficient to express the actual similarity between data points in some application scenarios.
In order to deal with small and residual targets more effectively, an optimized clustering algorithm is proposed, and this algorithm replaces the traditional Euclidean distance by using the intersection and union ratio (IoU) as a new distance metric, because the traditional Euclidean distance cannot accurately reflect the similarity between anchor frames in target detection. The IoU, on the other hand, takes into account the degree of overlap of the anchor frames in target detection, and it is a more reasonable metric for assessing the similarity between anchor frames. In this way, the problem of random selection of clustering centers can be effectively avoided, and the clustering process can more accurately reflect the shape and size differences of targets. The algorithm will randomly select a sample from the data set as the first clustering center. For each sample not selected as the center, its distance is calculated to the nearest clustering center, and the calculated distance is taken as the probability of selecting the next clustering center proportional to the inverse of the IoU distance; the formula is as follows:
where x denotes the sample, C denotes the clustering center, D denotes the distance metric, and IoU denotes the ratio of the area of the intersection region of the two bounding boxes to the area of their concurrent region. This probabilistic model ensures that the selection of clustering centers considers both randomness and reflects the actual physical proximity between samples. During the iteration process, each cluster center is assigned to the nearest cluster center based on the distance of each sample IOU. The center of each cluster is then updated such that the sum of the IOU distances of all samples within the cluster is minimized. The algorithm terminates when the change in the cluster center is less than a threshold or the maximum number of iterations is reached, which is calculated as follows:
where Cnew denotes the new clustering center.
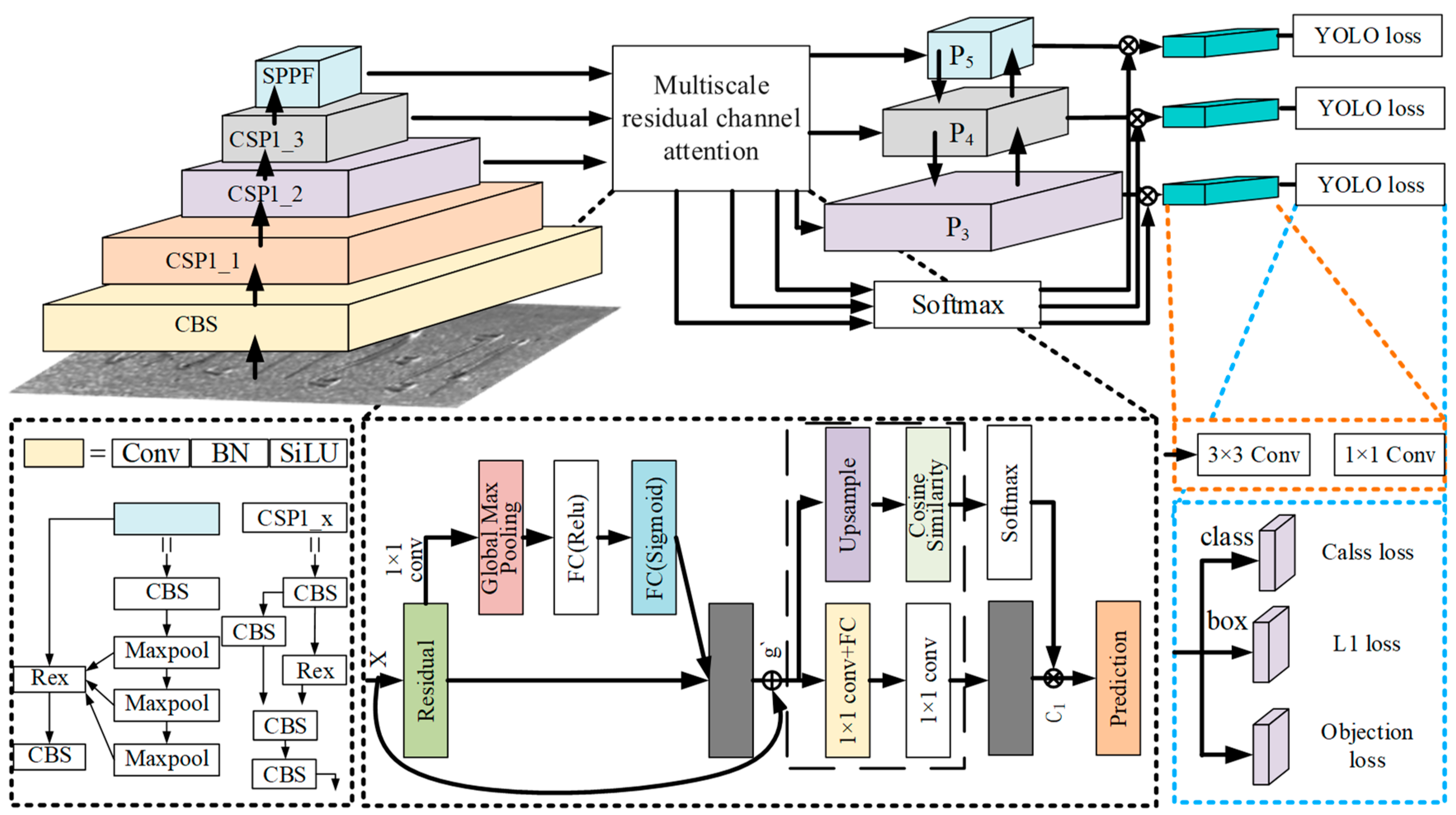
3.4. Overall Framework of the Improved YOLOv5-R Network Model
To improve the detection accuracy of small-size and crippled targets, we introduce the design of an optional clustering minimum iteration center module. By implementing a multi-scale residual attention coding mechanism, extracting channel features through global maximum pooling, and adjusting the response strength of each channel using the sigmoid activation function, the model’s ability to handle complex backgrounds and multi-size targets is enhanced, improving its capture of key features. This module optimizes the clustering process by introducing the intersection and union ratio (IoU) as a new distance metric to replace the traditional Euclidean distance, reducing the dependence on the a priori knowledge of the number of clusters and reflecting more accurately the similarity of the anchor frames in the detection of the targets, so as to improve the efficiency and accuracy of clustering. The structure of the improved YOLOv5-R neural network is shown in Figure 6, which is based on the YOLOv5 architecture and integrates the backbone network, the multi-scale residual attention mechanism, the feature pyramid, and the detection head. To optimize performance and retain more image details, the model is designed with a specified input image size of 3 × 640 × 640. The input image is first passed through high-resolution Convolutional Blocks (Channel Block Squeeze (CBS)), which use cascading to extract complex and abstract features of the image layer by layer. The image features then enter the multi-level CSP1_X (Common Spatial Pattern) module, while CSP1_X represents the orange, purple, and gray feature layers in the figure. Each module handles features at a certain granularity and reduces the computational cost and the model parameters through the strategy of segmentation and merging. After the feature map is further refined, it is fed into a multi-scale residual attention coding mechanism, which reduces the dimensionality while retaining the key information through a 1 × 1 convolution kernel, and Global Max Pooling (GMP) to extract the salient features in the map. The weights of the features processed by Global Max Pooling are then computed by a normalized exponential function and integrated into a comprehensive feature graph for enhancing the accuracy of target segmentation. The processed feature maps through the attention module are downsampled to compress the image resolution while retaining the core information. The processed feature maps are input into the feature pyramid network on the one hand, and additionally, the classification probability is computed through the Softmax layer, which is combined with the convolutional features of the CSP module in the feature pyramid through the multiplication operation, to ensure that the output classification results have a high confidence level. Figure 6 shows the structure and information flow of the entire model. The upper half of the figure demonstrates how the multi-scale residual attention encoding mechanism is integrated into the feature pyramid to enhance feature extraction and target detection capabilities. The input image first passes through high-resolution convolution blocks (CBS), and then enters multi-level CSP1_X modules for feature extraction. The feature map is further processed through the multi-scale residual attention encoding mechanism and then enters the feature pyramid network for final target detection. The lower half of the figure details the specific operational processes of certain modules in the upper half, including the multi-scale residual attention module, CBS (Channel Block Squeeze) modules for extracting high and complex abstract features of the image, CSP (Cross Stage Partial Network) modules for processing features through partitioning and merging strategies to reduce computational cost and model parameters, and SPPF (Spatial Pyramid Pooling-Fast) modules for further refining and fusing feature maps. The orange dashed lines indicate feature maps processed through 3 × 3 convolutions, which capture more local information and details. These feature maps are then processed through 1 × 1 convolutions (yellow dashed lines) to reduce dimensionality, simplify computation, and retain essential features. Finally, the processed features are passed to the detection head, ultimately used for target detection, as indicated by the blue dashed lines.
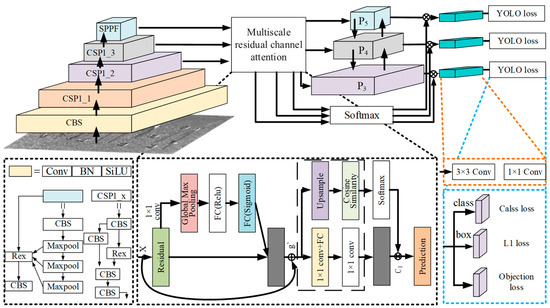
Figure 6.
Structure diagram of YOLOv5-R network model.
The arrows indicate the flow of data through the network layers, while the different colors represent various op-erations and modules. Beige represents Convolutional Block Squeeze (CBS) modules for high-resolution feature extrac-tion. Orange, purple, and gray indicate different levels of the Common Spatial Pattern (CSP) network (CSP1_1, CSP1_2, CSP1_3) for feature processing. Light blue represents the Spatial Pyramid Pooling-Fast (SPPF) module for refining fea-ture maps. Light green shows processed feature maps at different scales (P3, P4, P5) for detection. Blue represents the YOLO loss layers for class, box, and objection losses. Yellow represents 1 × 1 convolution layers for dimensionality re-duction, and orange dashed lines indicate 3 × 3 convolution layers for capturing details. Blue dashed lines show the final steps to target detection. Black arrows show data flow, red arrows represent residual connections, and blue arrows lead to YOLO loss calculation. These details help to understand the structure and functionality of the model.
4. Experiment and Analysis
4.1. Experimental Environment
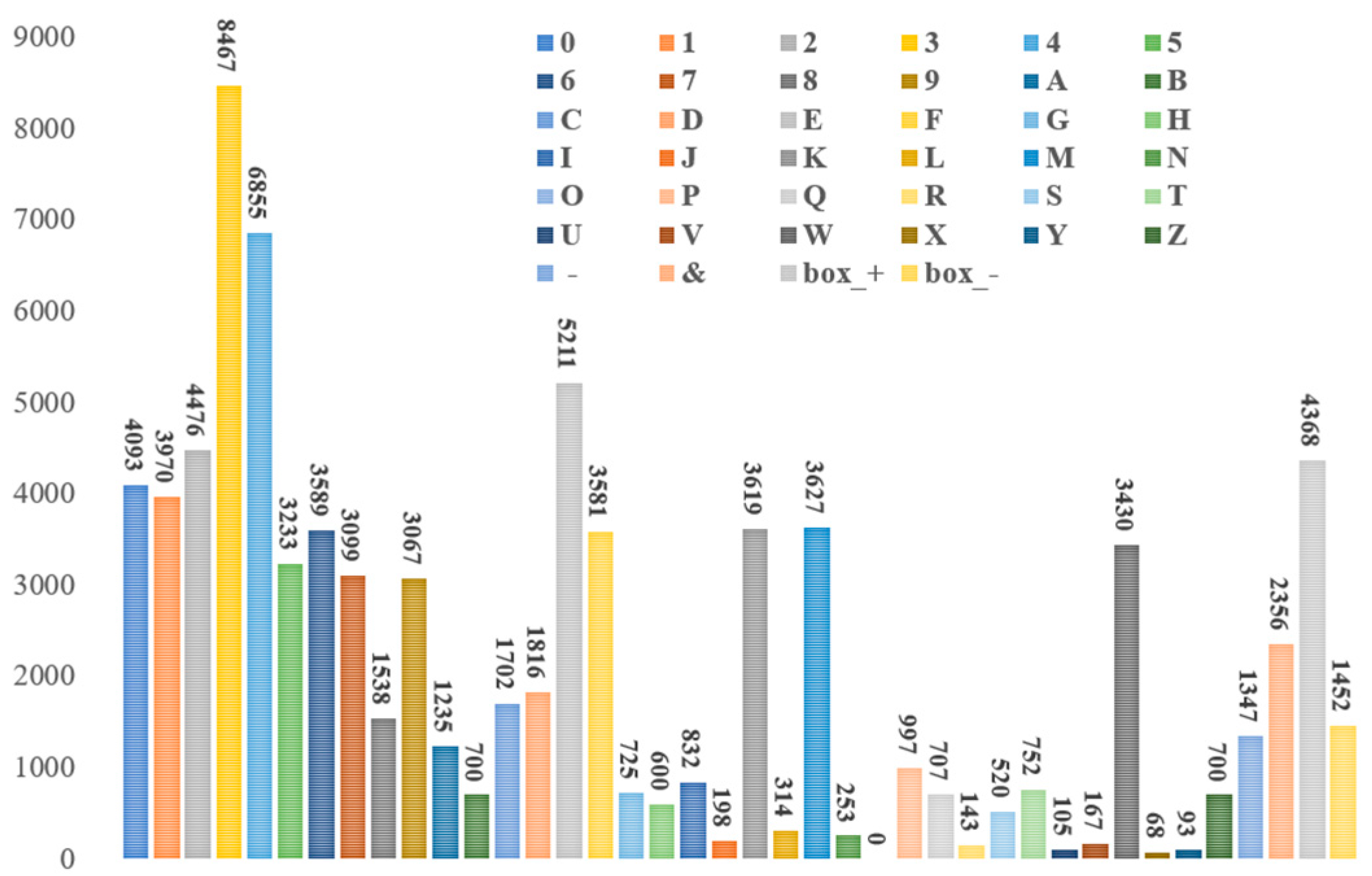
The homemade experimental dataset comes from an angle steel manufacturing company, where photos were collected using smartphones sourced from Apple Inc. (Cupertino, CA, USA) and Huawei Technologies Co., Ltd. (Shenzhen, Guangdong, China), totaling 5212 photos of angles and plates, as shown in Figure 2. The collection process needs to be conducted under good lighting conditions to avoid shadows and reflections, ensuring image quality and character clarity. The resolution of the captured images is 1280 × 1280 pixels, and preprocessing includes cropping the regions containing the embossed characters and converting the images to grayscale to reduce the impact of lighting and color variations. The processed images are annotated using the makesense.ai web tool to accurately label the position and category of each character. The annotated images and character information are stored in a database, forming a complete dataset. The dataset includes images of angle steel embossed characters, their positional coordinates, and category labels. During data collection, different types of angle steel, various shooting angles, and lighting conditions are covered as much as possible to ensure the diversity and representativeness of the dataset. The image resolution is adjusted to 640 × 640 pixels for the experiments. Character labels include the numbers 0 to 9, letters A to Z (note that the letter “O” and the number “0” are the same in the actual dataset, so the number “0” is used uniformly), the special symbol “&” (representing the company code), and the labels “box-” and “box+”, where “box+” indicates forward stenciled characters and “box-” indicates inverted stenciled characters. These are categorized into 40 categories, as shown in Figure 7. 80% of the dataset forms the training set, and the remaining 20% forms the test set for performance evaluation. In the experiments, a desktop device with an NVIDIA GeForce RTX 1650 4 GB graphics card is used, and the Pytorch deep learning framework is employed for training and testing, as shown in Table 1.
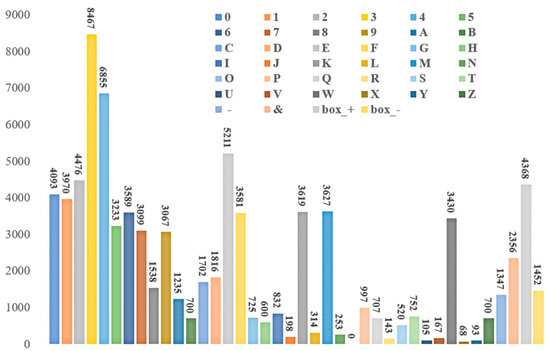
Figure 7.
Number of different categories in the captive dataset.

Table 1.
Desktop environment.
4.2. Performance Metrics
In order to judge the performance of an optimization model, a set of reliable evaluation metrics is essential. These metrics not only provide internal criteria for evaluating the performance of a model but are often used as a reference for external evaluations. The evaluation of most classification models usually considers the following key metrics, including precision, recall, detection elapsed time, and mean average precision (mAP).
where TP (True Positives) denotes the number of positive category samples correctly predicted as positive by the model, FP (False Positives) denotes the number of negative category samples incorrectly predicted as positive by the model, FN (False Negatives) denotes the number of positive category samples incorrectly predicted as negative by the model, and N denotes the total number of categories and represents the average precision of the i category.
4.3. Validation of Module Performance
4.3.1. Validation of Multi-Scale Residual Channel Attention Encoding Mechanism
The multi-scale residual attention encoding mechanism enhances the feature extraction process by incorporating attention mechanisms and multi-scale processing. The attention mechanism dynamically adjusts the weights in the feature maps, highlighting important regions in the image, thus more effectively handling small, incomplete, and irregularly shaped characters. Additionally, multi-scale processing captures features at different scales enable the model to recognize characters of varying sizes and complexities. The attention layers calculate the weights for each feature map, emphasizing the most relevant parts of the input image. This is particularly useful for small and irregularly shaped characters, as the network can focus more on these challenging areas. By processing the input at multiple scales, the network can capture both coarse and fine details, which is crucial for recognizing characters with significant variations in size and completeness.
To validate the effectiveness of the multi-scale residual attention encoding mechanism for small and incomplete characters, a comparative experiment was designed to compare the MSRA model and the baseline model. The dataset includes various small, incomplete, and irregularly shaped characters from actual industrial applications, ensuring the experiment’s authenticity and representativeness. The dataset was preprocessed with operations such as image scaling, normalization, and noise removal to meet the model’s input requirements, ensuring a balanced distribution of characters of different types and complexities. The baseline model and the MSRA model were then trained separately. During the training process, the same training set and validation set were used, with identical training parameters (using the Adam optimizer, a learning rate of 0.001, a batch size of 8, and 200 epochs) to ensure a fair comparison. The hardware and software environments used for training were kept consistent.
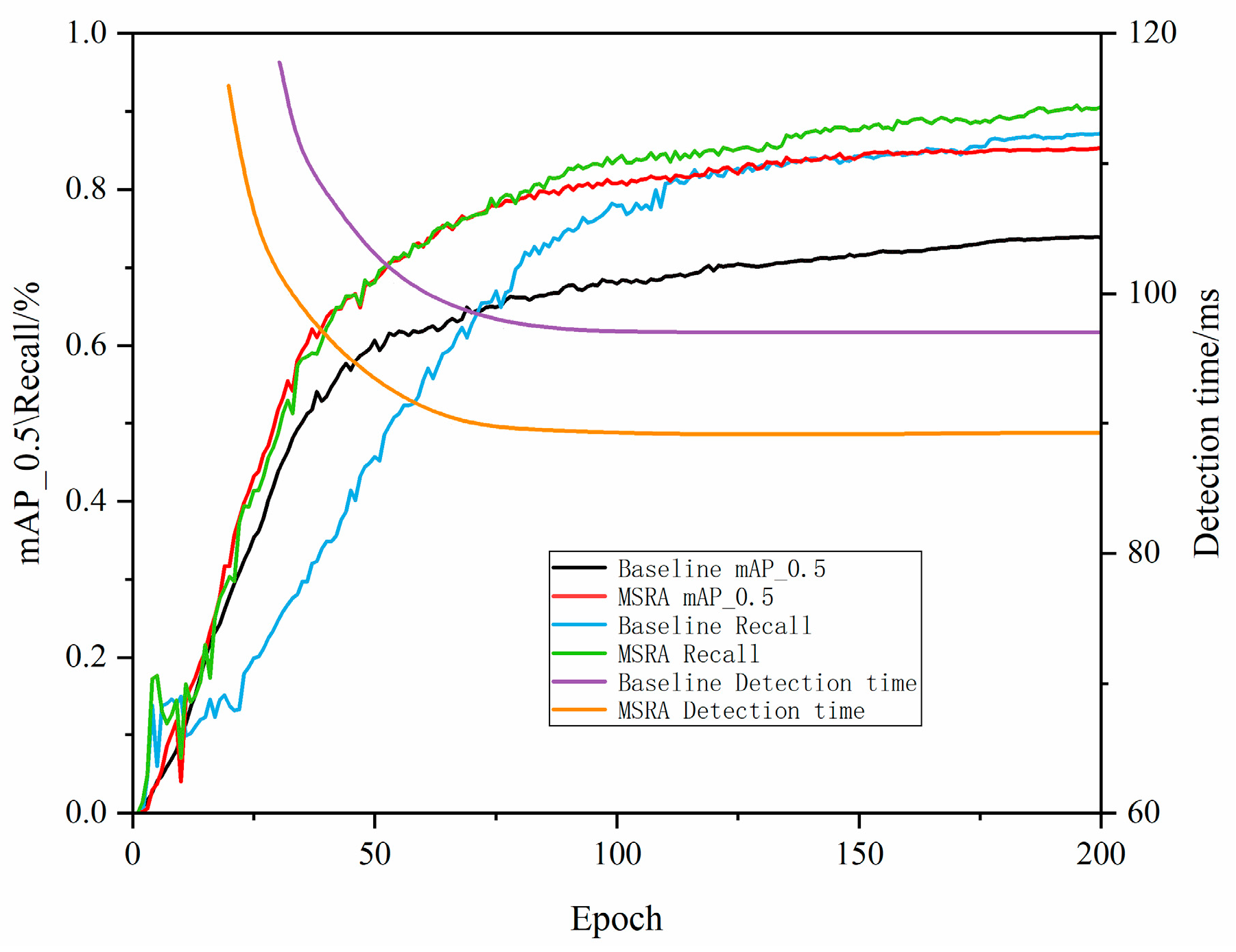
As shown in Figure 8, the comparative performance of the baseline model and the model with the MSRA module in terms of mAP_0.5, recall, and detection time is evident. The final mAP_0.5 of the baseline model is 65%, while the MSRA model achieves 82%, an improvement of 26%; the baseline model’s final recall is 70%, while the MSRA model achieves 84%, an improvement of 20%; the baseline model’s final detection time is 110 ms, while the MSRA model achieves 80 ms, a reduction of 27%. These data indicate that the MSRA module significantly improves the model’s mAP_0.5 and recall while significantly reducing detection time, demonstrating clear performance advantages.
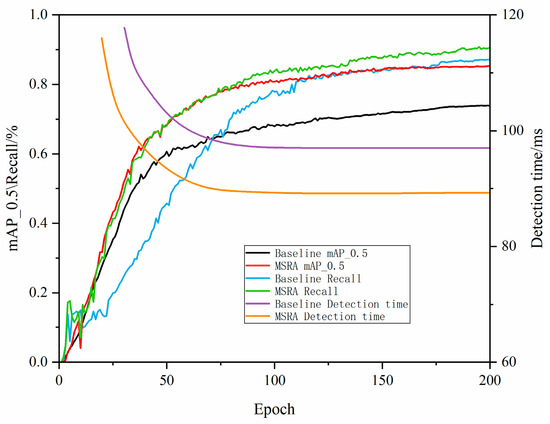
Figure 8.
Performance comparison of different models on mAP_0.5, recall and detection time.
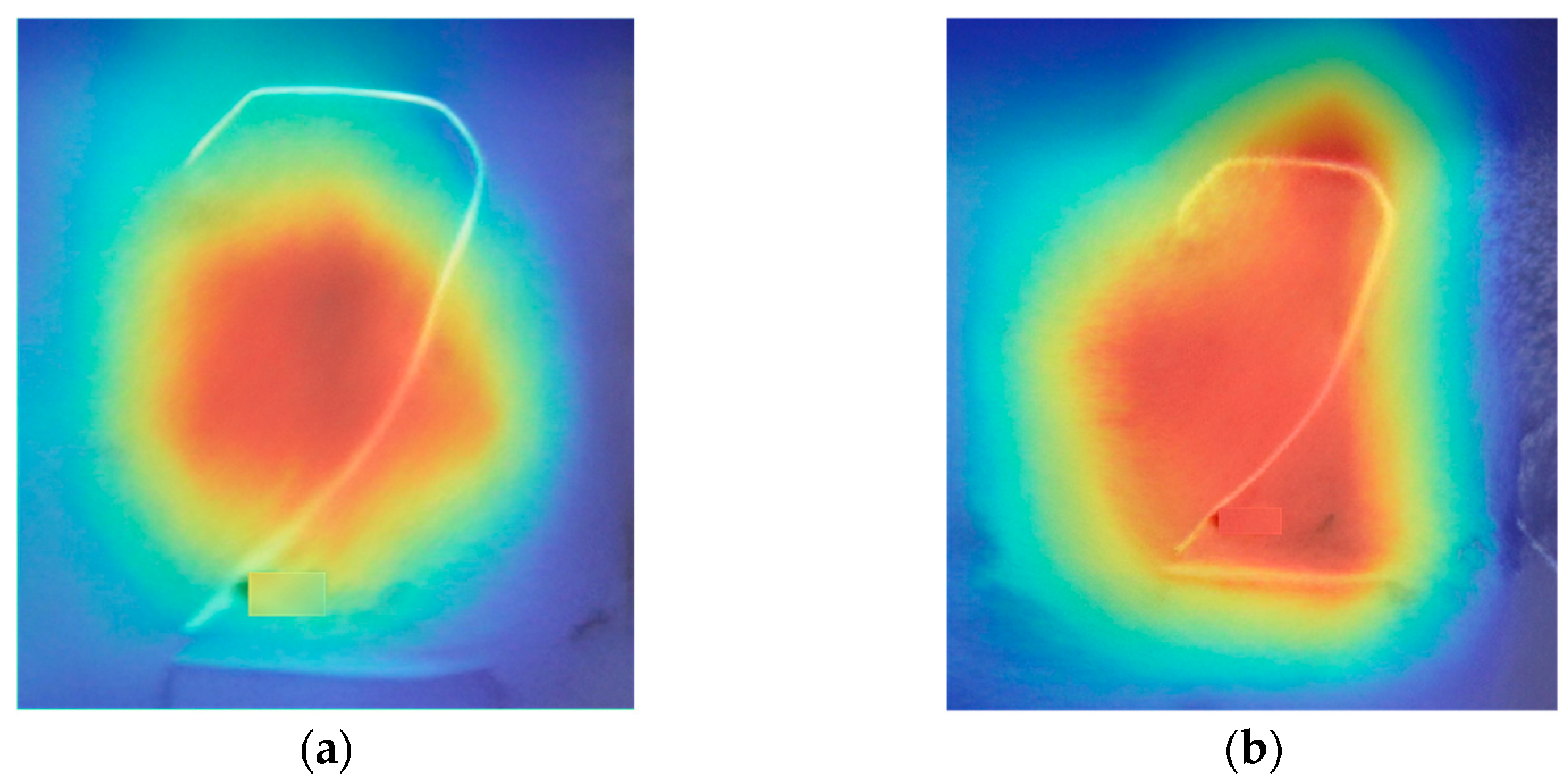
Furthermore, as shown in Figure 9, Figure 9a represents the feature heatmap of the baseline model, while Figure 9b represents the feature heatmap of the model with the MSRA module. The red areas indicate the regions of high attention by the model, deemed the most important feature regions, while the blue and green areas indicate regions of lower attention. The heatmaps show that the baseline model’s performance in character feature extraction is limited, primarily focusing on the central areas of the characters, with less attention to the edges and details. In contrast, the MSRA model exhibits high attention across the entire character area, especially at the edges and details. The red areas cover more detailed parts of the characters, indicating that the MSRA module significantly enhances the model’s ability to extract character features. By comparing these two feature heatmaps, it is evident that the model’s ability to extract character features is significantly enhanced with the addition of the multi-scale residual module, allowing it to more comprehensively focus on various parts of the characters, particularly the details and edges.
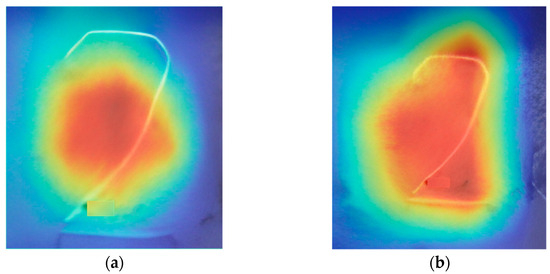
Figure 9.
Heat map of character features of different models. (a) Characteristic heat map of the baseline model. (b) Characteristic heat map of the MSRA model.
4.3.2. Validation of Optional Clustering Minimum Iteration Center Module
The optional clustering minimum iteration center module optimizes the selection of clustering centers, reducing random errors in the clustering process and accelerating convergence. This module dynamically selects the optimal clustering centers based on data characteristics, avoiding the slow convergence and instability of traditional clustering methods caused by improper initial center selection. To validate the effectiveness of the selectable clustering minimum iteration center module (OCMC), a set of comparative experiments was designed to test the model’s performance. Two models were designed for the experiment: one with the OCMC module and the other as a baseline model (Baseline). The experiment used clustering accuracy, number of iterations to converge, and recognition accuracy as the main evaluation metrics. The Adam optimizer was used with an initial learning rate of 0.001, which was reduced by 50% every 10 epochs. The dataset was divided into training, validation, and test sets. During the model training phase, the baseline model and the OCMC model were trained separately with the same training parameters (such as learning rate, batch size, and number of training epochs) and hardware and software environments. During the training process, loss values and accuracy were recorded. In the performance evaluation phase, the model’s performance was evaluated on an independent test set, with multiple tests conducted for each model to average out random errors.
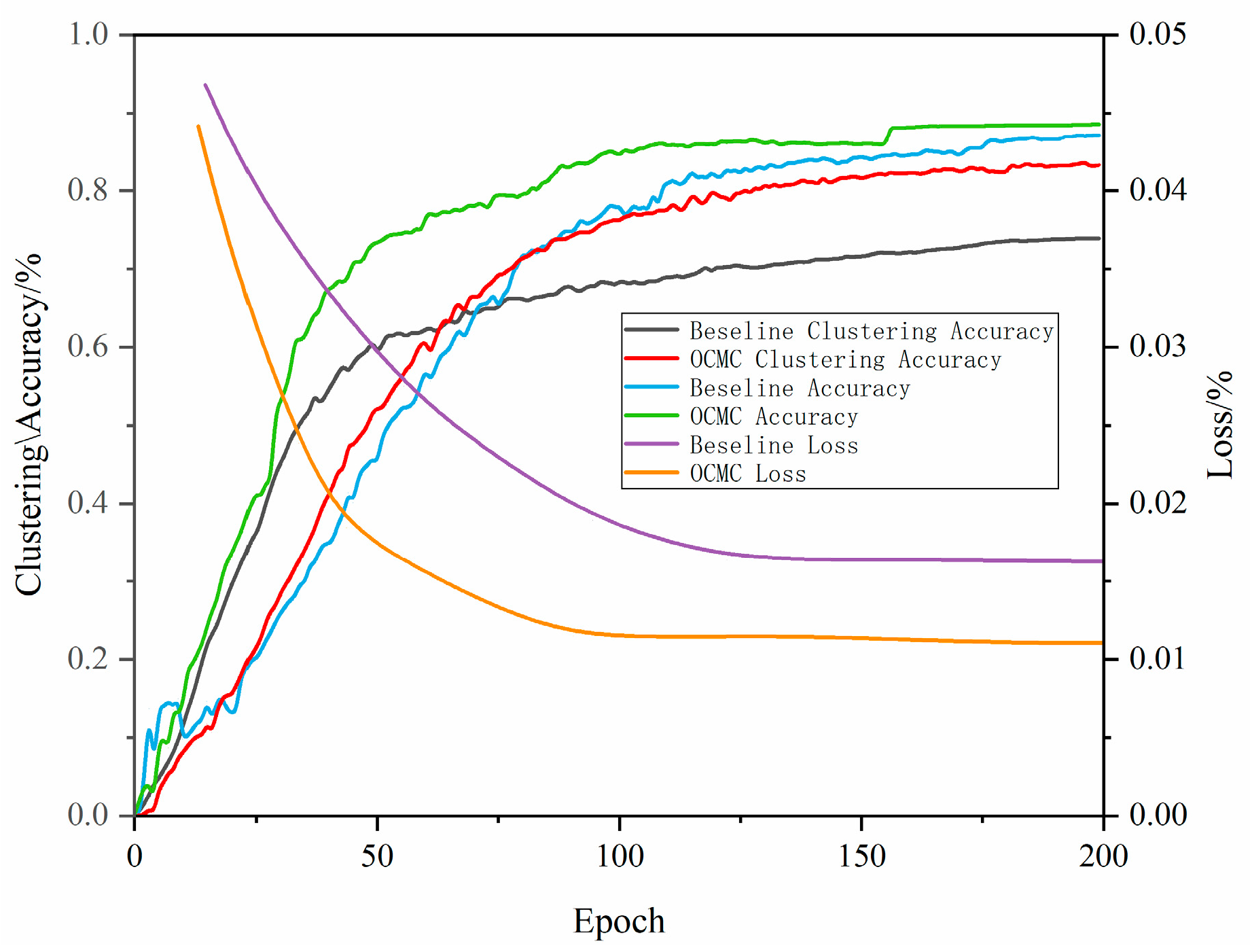
As shown by the experimental results in Figure 10, the model with the SC module outperforms the baseline model in all key metrics. The final clustering accuracy of the baseline model is 75%, while the SC model achieves 78%; the final overall accuracy of the baseline model is 82%, while the OCMC model achieves 84%. The loss curve of the baseline model shows a slow decrease in loss value over the first 150 iterations, eventually stabilizing at a final loss of 0.02. In contrast, the loss curve of the OCMC model shows a rapid decrease in loss value over the first 90 iterations, remaining relatively stable in subsequent iterations, with a final loss of 0.01. This indicates that the OCMC model converges significantly faster than the baseline model, achieving a lower loss value in a shorter time, demonstrating significant advantages in improving model training efficiency and performance.
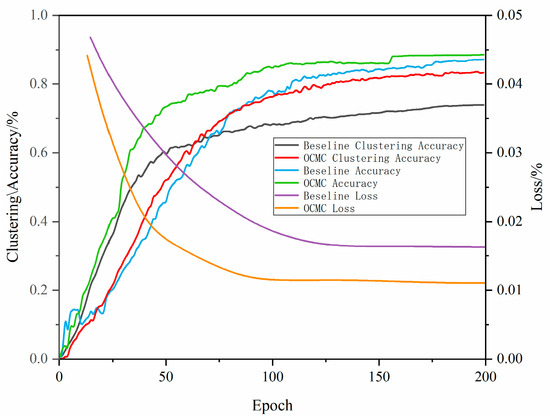
Figure 10.
Performance comparison of different models in terms of clustering accuracy, number of convergence iterations, and recognition accuracy.
4.3.3. Ablation Experiment
To demonstrate the effectiveness of the Multiscale Residual Channel Attention Model (MSRC) and the Optional Clustering Center Iteration Module (OCMC), this experiment was carried out on a homemade dataset with ablation experiments, the results of which are shown in Figure 11. The homemade dataset consists of various small, incomplete, and irregularly shaped characters from actual industrial applications. The dataset was preprocessed through image scaling, normalization, and noise removal to ensure consistency and balance. The details of the dataset are as follows: source—angle steel manufacturer, sample size—5212 images, and resolution—original images at 1280 × 1280 pixels, resized to 640 × 640 pixels for experiments. We conducted the experiments under the following settings: Adam optimizer, learning rate of 0.001 (reduced by 50% every 10 epochs), batch size of 8, 200 epochs, hardware—NVIDIA GeForce RTX1650 4 GB, and software—Pytorch framework.
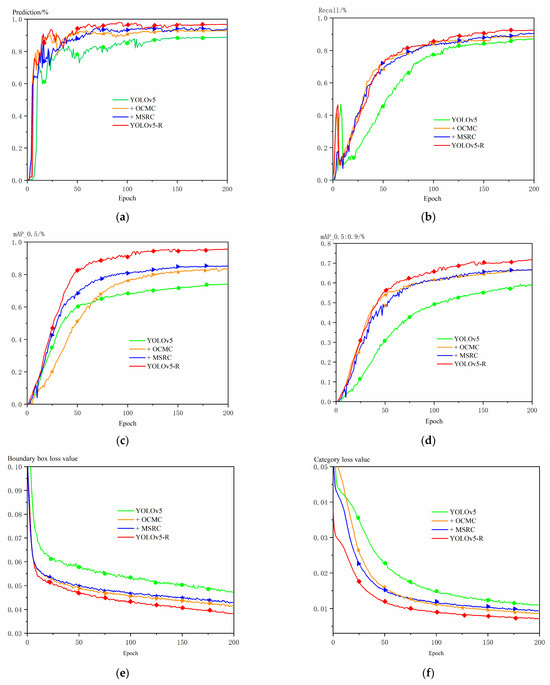
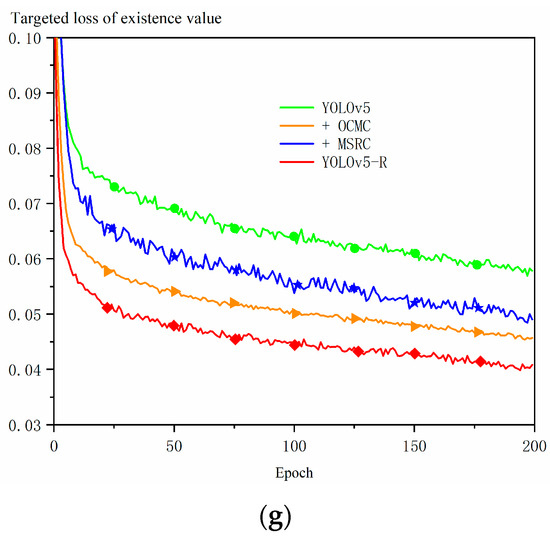
Figure 11.
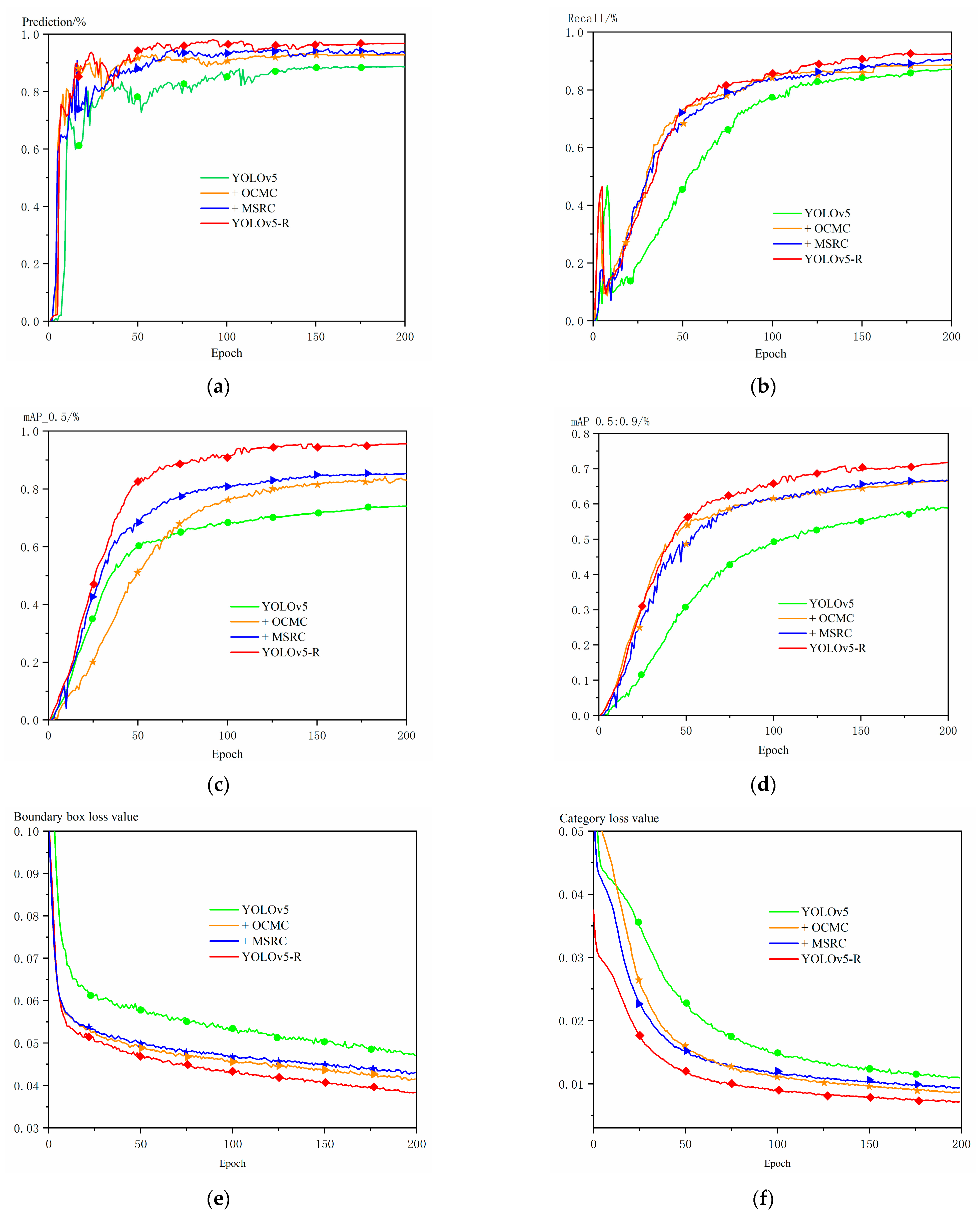
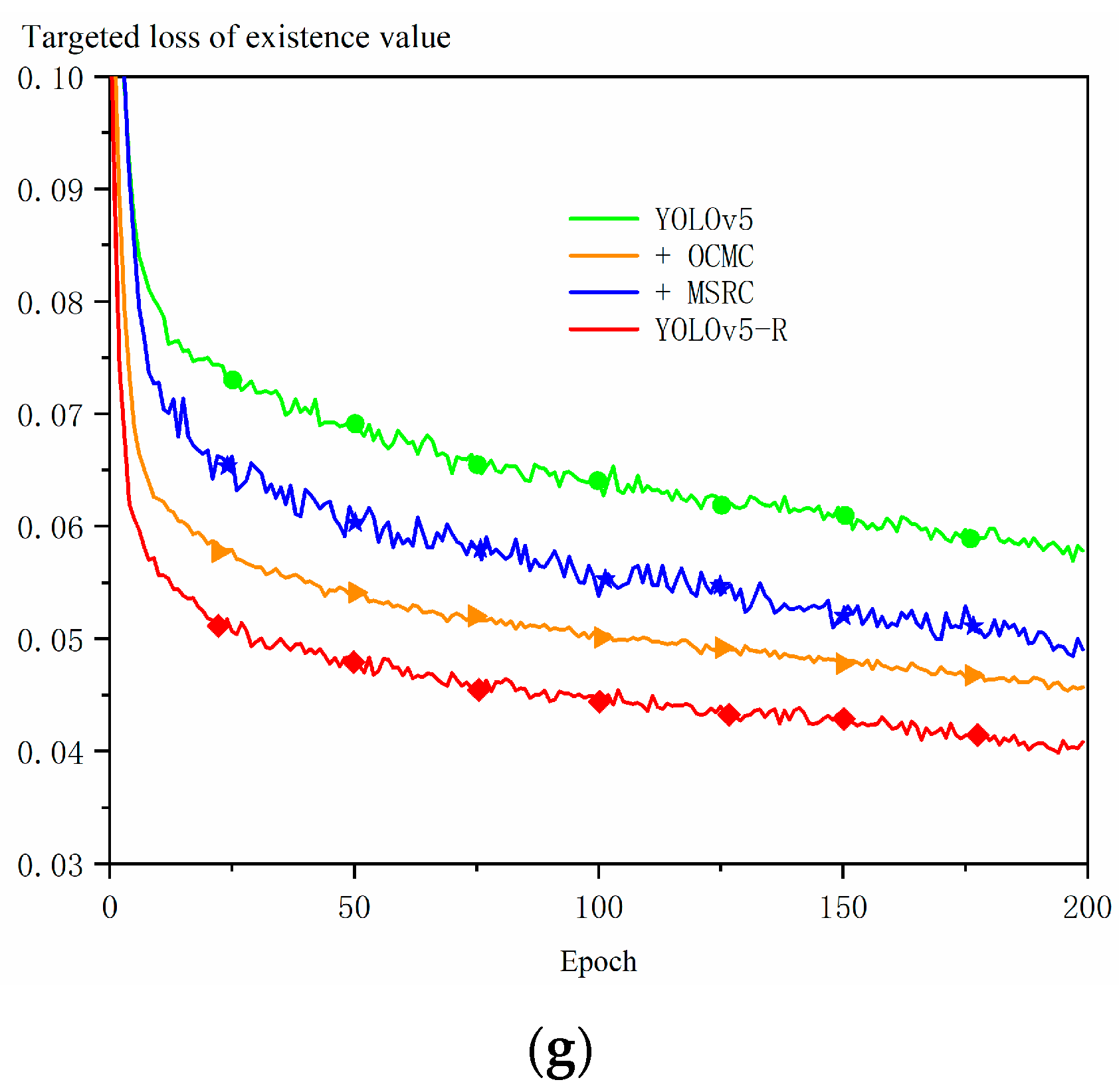
Ablation experiments with YOLOv5-R, MSRC, and OCMC: + indicates addition of modules. (a) prediction; (b) recall; (c) mAP_0.5; (d) mAP_0.5:0.9; (e) boundary box loss values; (f) category loss values; (g) targeted loss of existence value.
The MSRC enhances the shallow features by using the global attention mechanism, and then supplements the shallow information by using higher-level contextual information, so that the model pays more attention to the features of the small targets and residual characters, thus improving the detection performance of the small targets. As can be seen from the data distribution in Figure 2, the size of the characters is smaller compared to the corners, so the detection of embossed characters is more difficult. Figure 11a–d demonstrate the results of the ablation experiments for the MSRC and OCMC modules. The results show that the MSRC and OCMC modules contribute significantly to the benchmark model. In the comparison with the benchmark model, the model with only the addition of the MSRC and OCMC modules has slightly higher detection of embossed characters with crippled small targets than the benchmark model in terms of accuracy, recall, and mAP_0.5 and mAP_0.5:0.9 metrics, which verifies the effectiveness of the MSRC and OCMC. Among them, the MSRC module is more effective in the detection ability of embossed characters compared to OCMC. In addition, when MSRC and OCMC are stacked at the same time, does the overall performance of the model get improved? From the results in Figure 11a–d, it can be seen that the fused model YOLOv5-R enhances the recognition performance of embossed characters to different degrees when compared with the addition of MSRC and OCMC only, respectively, and improves the values of the various evaluation metrics by about 10% compared with the baseline model.
The Optional Clustering Iterative Center Module (OCMC) enables the model to recognize and classify targets more accurately by selectively clustering features and performing iterative optimization, grouping the features using a clustering algorithm, and continuously optimizing the location of the feature center. As shown in Figure 11e–g, the model with the addition of the OCMC module and the MSRC module significantly reduces the values of the bounding box loss value, the classification loss value, and the target presence loss value, while the baseline model, YOLOv5, exhibits higher losses. In particular, the OCMC module has lower loss values than the MSRC module for bounding box prediction, indicating that it has higher accuracy in bounding box prediction and can locate target location information and classify targets more accurately.
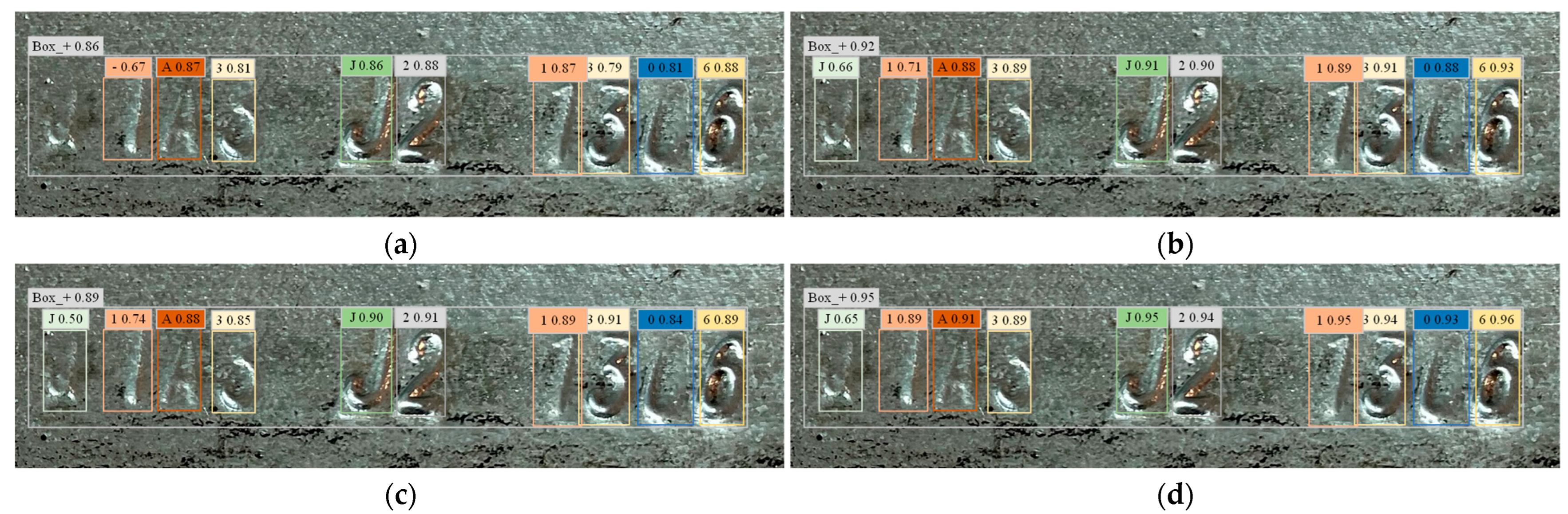
To further demonstrate the effectiveness of the improved models, Figure 12 illustrates the performance comparison of different algorithms incorporating various modules in recognizing embossed characters on steel parts. Figure 12a shows the recognition results using the original YOLOv5 algorithm, Figure 12b presents the performance with the MSRC module added, Figure 12c depicts the results with the OCMC module, and Figure 12d shows the outcomes using the enhanced YOLOv5-R algorithm. Each figure annotates the detected characters’ bounding boxes and the corresponding confidence scores.
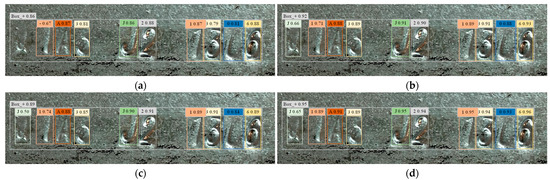
Figure 12.
Performance comparison of different modules in recognizing embossed characters on steel parts. (a) YOLOv5; (b) MSRC; (c) OCMC; (d) YOLOv5-R.
Comparatively, the average confidence score of the original YOLOv5 is 0.78, with significant false positives and false negatives. Incorporating the MSRC module improves the average confidence score to 0.84, reducing false positives and false negatives. The OCMC module further enhances performance, achieving an average confidence score of 0.87 and significantly minimizing false positives and false negatives. The enhanced YOLOv5-R algorithm performs the best, with an average confidence score of 0.90 and the fewest false positives and false negatives. This analysis demonstrates that the addition of these modules enhances the algorithms’ robustness and accuracy in handling complex scenarios such as blurred or incomplete characters, validating the effectiveness of the optimization strategies.
4.4. Experimental Results and Analysis
4.4.1. Experiments on the Chars74K Dataset
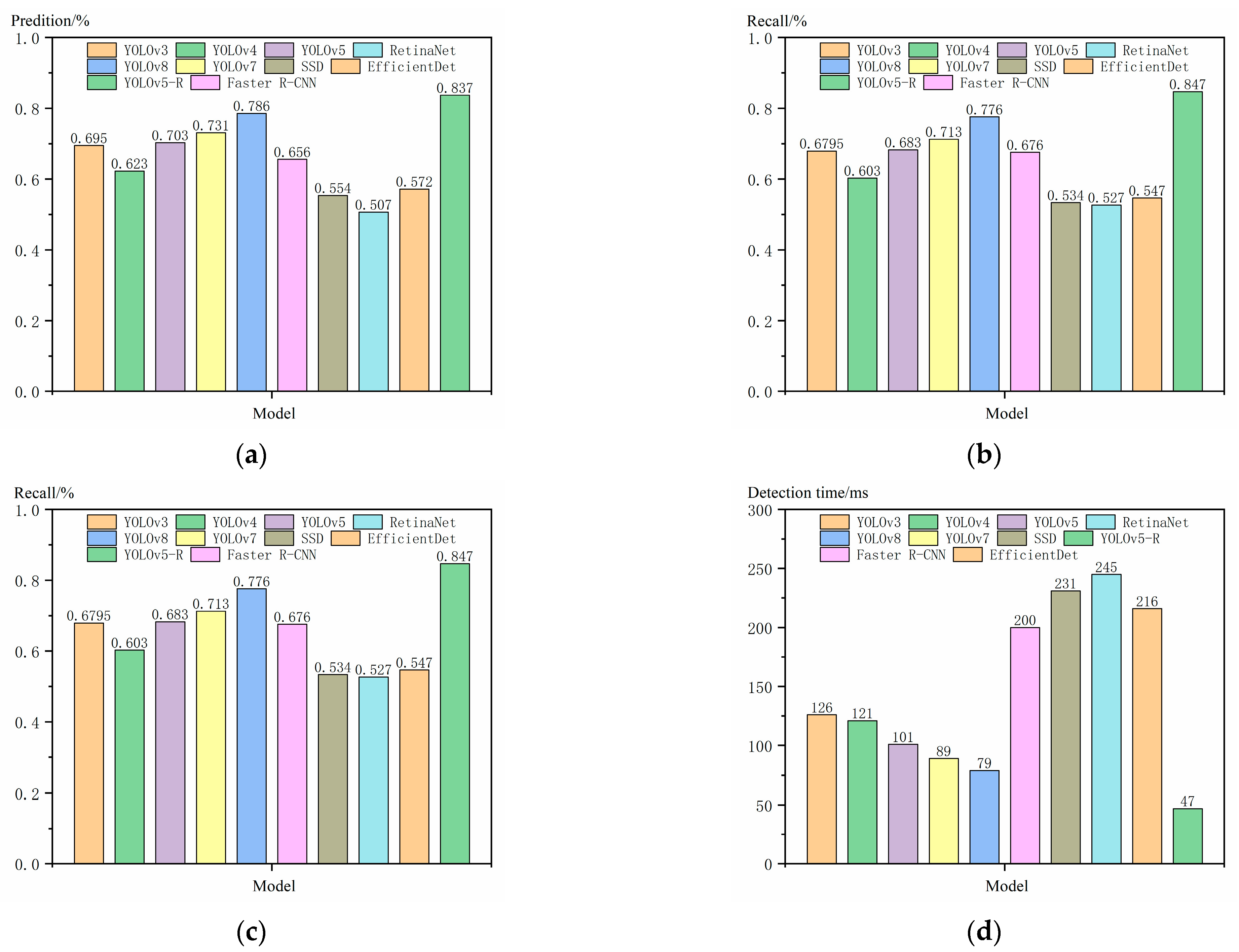
To evaluate the effectiveness of the proposed method, we analyzed it in comparison with other models on the Chars74K dataset, and the experimental results are shown in Figure 13. The comparison models include the single-stage detection models YOLOv3, YOLOv4, YOLOv5, YOLOv7, YOLOv8, SSD, RetinaNet, and EfficientDet, as well as the two-stage detection model Faster R-CNN [24]. Lightweight convolutional neural network (CNN) models have gained widespread attention and applications due to their efficient computational performance and low resource consumption. For example, WearNet [25], a novel lightweight CNN structure designed for surface scratch detection, reduces the number of training parameters and the number of network layers through customized convolutional blocks, while maintaining a high classification accuracy.

Figure 13.
Comparison of improved experimental results. (a) YOLOv3; (b) YOLOv4; (c) YOLOv5-R; (d) YOLOv7; (e) YOLOv8; (f) SSD; (g) RetinaNet; (h) EfficientDet; (i) Faster R-CNN.
The recognition performance of different object detection networks on various types of embossed characters on angle steel is shown in Figure 13. A comprehensive comparison reveals that under various states of embossed characters, the YOLOv5-R object detection algorithm can accurately detect incomplete and rusted embossed characters, demonstrating exceptionally high recognition accuracy. In contrast, the other eight object detection algorithms exhibit varying degrees of false detections and missed detections. Compared to other models, YOLOv8 has the fewest instances of false detections and missed detections, second only to YOLOv5-R. This is primarily because the experiment simulated the recognition performance under poor factory conditions. Therefore, the YOLOv5-R algorithm proposed in this study excels in recognizing embossed characters and is highly capable of adapting to the demands of challenging factory environments.
Figure 14 shows that the improved YOLOv5-R model, compared to the benchmark model YOLOv5, has all evaluation metrics improved. Among them, the accuracy, recall, and mAP_0.5 are improved by 13.4%, 16.4%, and 13.4%, respectively, and the detection time is reduced by 54 ms. In addition, YOLOv5-R also shows significant advantages in comparison with other models. Although YOLOv3 and YOLOv4 perform better in terms of detection speed, they are significantly lower than YOLOv5-R in terms of accuracy and recall. YOLOv7 and YOLOv8 are close to YOLOv5-R in some metrics, but their overall performance is still not as good as that of YOLOv5-R. Faster R-CNN performs well in terms of detection accuracy, but it is slower in terms of detection speed. YOLOv5-R is nearly five times faster in detection time and also has significant advantages in accuracy and recall. SSD and RetinaNet are both lower than YOLOv5-R in accuracy and recall and have longer detection times. Although EfficientDet performs well in terms of efficiency, it still has lower accuracy and recall than YOLOv5-R on the Chars74K dataset and a longer detection time. The results show that the improved YOLOv5-R model outperforms the benchmark model YOLOv5 and other comparative models in various evaluation metrics.
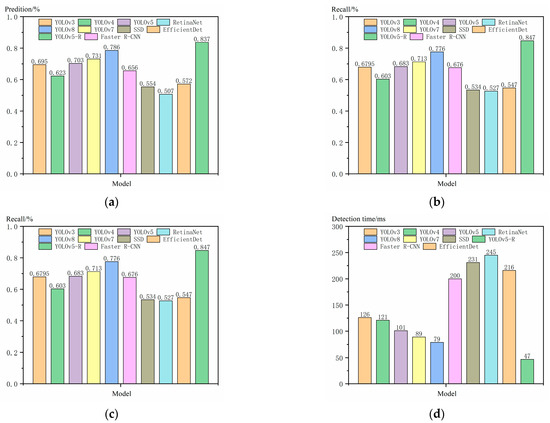
Figure 14.
Experimental Comparison of Character Recognition on Chars74K Dataset. (a) predition; (b) recall; (c) mAP_0.5; (d) detection time.
4.4.2. Experimenting with Homemade Datasets
To evaluate the performance of the model proposed in this paper in steel embossed character recognition, the experiments compare it with the current popular Fast-CNN [26] and YOLOv5 models. Figure 15 illustrates the recognition results for three different types of steel embossed characters (normal, galvanized, and rusted stubs). Among them, Figure 15a shows the original images of each type of steel part, Figure 15b shows the recognition results of this paper’s model, and Figure 15c,d show the recognition results of YOLOv5 and Fast-CNN models, respectively.

Figure 15.
Different model recognition renderings.
As can be seen from Figure 15, the steel embossed characters recognized by the YOLOv5 and Fast-CNN network models show the phenomenon of missed detection and misrecognition, in which the misrecognition of galvanized and rusted and mutilated steel parts is more serious, and when the IoU of the recognized character is less than 0.5, the number inside the box on the embossed character in the figure, it is judged to be misrecognized. The recognition map obtained by the model in this paper can still be correctly recognized and does not produce a leakage phenomenon under galvanized and rusted defective steel parts. This indicates that adding the multi-scale residual attention coding module to the network model can effectively enhance the model’s ability to capture fine-grained features and increase the weight of edge information, thus maintaining high recognition accuracy and reducing information loss in complex backgrounds. In addition, the traditional YOLOv5 model using a k-means++ clustering algorithm to determine the anchor frame size may be affected by the initial center selection and outliers, which limits the model’s adaptability to the actual data distribution. Fast-CNN, on the other hand, faces high computational and training costs while lacking sufficient generalization ability, although it learns the bounding box directly from the data through its region suggestion network. Therefore, in this paper, based on the k-means++ clustering algorithm, we design the module of selectable clustering minimum iteration center, which realizes the fine selection of anchor box candidate sets by minimizing the IoU loss in clustering, thus reducing the machinability and improving the characterization ability of anchor boxes in the iterative process.
To validate the performance of the improved model, the experiments were tested against the R-CNN family [26] and other YOLO versions using different evaluation metrics, and the results of the experiments are shown in Table 2. The recall is used in the experiments as a measure of the proportion of all actual positive instances that have been correctly recognized, and mAP50% refers to the average precision of the region of overlap between the predicted frames and the real frames for all kinds of predicted frames with IoU thresholds exceeding 0.5.
Table 2.
Comparison of model experiment results.
As shown in Table 2, the improved network model outperforms Fast-CNN, YOLOv5s, and YOLOv7 on several performance evaluation metrics, and is close to the performance of the current state-of-the-art YOLO family of network models, YOLOv8. Relative to the benchmark YOLOv5 network model, this paper’s model improves recognition accuracy by 8.3%, increases recall by 8.0%, and improves mAP50% by 7.8%, while reducing the detection speed by 35 ms. This performance advantage stems from the introduction of a multi-scale residual attention coding module, which efficiently analyzes and processes the image features in detail at different layers to effectively capture features from fine-grained to coarse-grained, which improves the model’s ability to recognize and localize diverse targets in complex scenes, and greatly enhances the model’s target recognition accuracy and processing speed. In addition, the selectable clustering minimum iteration center module introduced in the model reduces randomness and error by optimizing the selection of clustering centers, significantly reduces instability and error due to random selection of clustering centers, accelerates the convergence speed of the clustering algorithm and reduces the number of required iterations, effectively improving the accuracy and efficiency of target detection when processing large amounts of data. Additionally, to validate the practical application of the improved model, the performance of the equipment in a factory environment was considered. In actual factory settings, desktop computers typically have lower performance, so reducing detection computation time is crucial for improving system response speed and overall efficiency. The improved model achieved a detection time of less than 50 milliseconds on a device equipped with an NVIDIA GeForce RTX1650 graphics card, which means that in real production deployments, real-time, efficient character recognition can be achieved, significantly increasing production efficiency and reducing human errors. Furthermore, reducing computation time helps lower energy consumption and operational costs, making the system more sustainable and cost-effective. This enhancement ensures that the system can be widely deployed in various industrial environments without significant modifications or additional investments in hardware.
5. Conclusions
This study developed an optimized stamped character recognition algorithm based on the YOLOv5 architecture, incorporating an efficient multi-scale channel attention mechanism to reduce resource consumption while processing irrelevant information, significantly enhancing the weighting of key feature channels. A selectable clustering minimum iteration center module was also integrated to optimize the feature capture efficiency for small and irregular stamped characters. The test results show that, compared to existing methods, this model demonstrated superior comprehensive performance in extracting features from fine or incomplete stamped characters, achieving an 8.3% increase in recognition accuracy, an 8% increase in recall rate, and a 46 ms reduction in detection time compared to the baseline YOLOv5 model. The model simplified the network structure and enhanced recognition accuracy and processing speed. The next phase of research will explore how to strengthen the robustness of the model while reducing its parameters for more effective application in smart manufacturing.
Although the proposed method performs excellently in recognizing embossed characters on power transmission towers, its design and optimization are tailored for this specific application. For tasks such as handwritten character recognition, printed character recognition, or other industrial character recognition, the characters involved have different features and challenges. Therefore, the performance of this method in these scenarios may not be as outstanding as in power transmission tower character recognition. To improve generalizability, adjustments and optimizations are needed based on specific applications, such as training on datasets of handwritten characters or optimizing the model to handle higher character clarity. Nevertheless, the effectiveness of this method in other types of character recognition tasks still requires further validation and optimization.
Author Contributions
All authors contributed to the study conception and design. S.Y., S.T. and W.B. performed material preparation, data collection and analysis. The first draft of the manuscript was written by J.F. and all authors commented on previous versions of the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
Author Shaozhang Tang was employed by the company Taichang Group Wenzhou Taichang Tower Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Zheng, P.; Wang, H.; Sang, Z.; Zhong, R.Y.; Liu, C.; Mubarok, K.; Yu, S.; Xu, X. Smart manufacturing systems for Industry 4.0: Conceptual framework, scenarios, and future perspectives. Front. Mech. Eng. 2018, 13, 137–150. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, P.; Wergeles, N.; Shang, Y. A survey and performance evaluation of deep learning methods for small object detection. Expert Syst. Appl. 2021, 172, 114602. [Google Scholar] [CrossRef]
- Smith, R. An overview of the Tesseract OCR engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; Volume 2, pp. 629–633. [Google Scholar]
- Geng, Q.T.; Zhang, H.W. License plate recognition based on fractal and hidden Markov feature. Opt. Precis. Eng. 2013, 21, 3198–3203. [Google Scholar] [CrossRef]
- Li, G.P.; Yan, Z. The method of character recognition based on projection transformation combined with ls-svm. Adv. Mater. Res. 2012, 468, 3050–3055. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, H.; Ke, H.; Zhang, X. DDH-YOLOv5: Improved YOLOv5 based on Double IoU-aware Decoupled Head for object detection. J. Real-Time Image Process. 2022, 19, 1023–1033. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Wei, X. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Rahman, S.; Rony, J.H.; Uddin, J.; Samad, M. Time Obstacle Detection with YOLOv8 in a WSN Using UAV Aerial Photography. J. Imaging 2023, 9, 216. [Google Scholar] [CrossRef] [PubMed]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Synthetic data and artificial neural networks for natural scene text recognition. arXiv 2014, arXiv:1406.2227. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Graves, A.; Schmidhuber, J. Offline handwriting recognition with multidimensional recurrent neural networks. In Proceedings of the 21st International Conference on Neural Information Processing Systems (NIPS’08), Vancouver, BC, Canada, 8–10 December 2008; Curran Associates Inc.: Red Hook, NY, USA, 2008; pp. 545–552. [Google Scholar]
- Zhao, Y.; Kong, X.W.; Ma, C.B.; Yang, H. Real-Time Circuit Board Fault Detection Algorithm Based on Darknet Network and YOLO4. Comput. Meas. Control 2023, 31, 101–108. [Google Scholar]
- Si, Y.S.; Xiao, J.X.; Liu, G.; Wang, K.Q. Individual identification of lying cows based on MSRCP with improved YOLO v4. J. Agric. Mach. 2023, 54, 243–250, 262. [Google Scholar]
- Song, H.B.; Wang, Y.F.; Duan, Y.H.; Song, L. Detection of heavily adherent wheat kernels based on YOLO v5-MDC. J. Agric. Mach. 2022, 53, 245–253. [Google Scholar]
- Yu, S.S.; Chu, S.W.; Wang, C.M.; Chan, Y.K.; Chang, T.C. Two improved k-means algorithms. Appl. Soft Comput. 2018, 68, 747–755. [Google Scholar] [CrossRef]
- Bahmani, B.; Moseley, B.; Vattani, A.; Kumar, R.; Vassilvitskii, S. Scalable k-means++. arXiv 2012, arXiv:1203.6402. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Zhang, L.; Wu, C.; Cui, Z.; Niu, C. A new lightweight deep neural network for surface scratch detection. Int. J. Adv. Manuf. Technol. 2022, 123, 1999–2015. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ye, H.; Shen, L.; Li, M.; Zhang, Q. Bubble defect control in low-cost roll-to-roll ultraviolet imprint lithography. Micro Nano Lett. 2014, 9, 28–30. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).