Due to the widespread use of AIS equipment, the long-term collection of AIS records has become a valuable source of big data for maritime traffic analysis. The AIS data used in this study is collected from AIS receiving stations along Taiwan’s coast, which are managed by the Maritime and Port Bureau, Ministry of Transportation and Communications, Taiwan. The AIS data cover the entire year of 2022, amounting to nearly six billion historical records and a file size of approximately 2 terabytes (TB). However, AIS information is compressed during transmission, and after decoding and restoration as numerical records, each AIS record is discrete with no temporal and spatial connections. Additionally, each AIS record is discrete. Without temporal and spatial connections, a single AIS record provides only a ship’s state at a specific time, limiting its usefulness, which is regrettable. Hence, it is crucial to investigate extracting valuable features from AIS records and converting them into actionable knowledge for maritime decision-making.
3.1. AIS Pre-Processing
AIS is a system aiding ship navigation, with functions like ship identification, information exchange, target tracking, and automatic calculation of CPA and TCPA, etc. These functions enable authorities to monitor ship activity efficiently, improving maritime navigation safety. According to Series [
14], 27 distinct AIS information types are classified into static, dynamic, and voyage categories, with the primary fields listed in
Table 1. Among these, MMSI is part of the static information category, and each AIS transceiver has a unique MMSI, enabling the identification of individual ships or devices. AIS data is transmitted every few seconds via two specific digital VHF (Very High Frequency) channels within a confined geographic area. The transmission frequency depends on ship speed and turning rate, with faster and turning ships providing more frequent updates. AIS transponders operate continuously, irrespective of a ship’s location, whether offshore, in coastal or inland waters, or at anchor.
The data quality of AIS significantly affects the performance of ship-type recognition and the classification model. Referring to Tsou [
15], this study utilizes big data analysis to cleanse, store, and identify raw data, streamlining the extensive and disorganized digital records. First, the data processing was conducted according to the AIS standard of the International Telecommunication Union (ITU) [
14]. The AIS data with apparent abnormalities, such as longitude exceeding 180°, latitude exceeding 90°, etc., was cleared. Secondly, the AIS data is sorted by MMSI and timestamp to obtain the trajectory information for each ship. Next, if a ship lacks data for over 30 min, its speed drops below 1 knot, or latitude and longitude change exceeding 0.01°, the trajectory is split into two sub-trajectories. Furthermore, AIS static and voyage information are prone to manual input errors and omissions, which are more frequent than dynamic information directly sourced from navigation instruments [
16]. Consequently, in the data cleaning process, this study must also verify the accuracy of static data. Finally, the static, dynamic, and voyage data of ship platform shape and navigation parameters are extracted, which include MMSI that can identify a single ship, navigation parameters (SOG, COG, THD, Longitude, Latitude), ship-geometric parameters (A, B, C, D, Draught), and the “Record Time” that can create AIS time–space sequences.
After data pre-processing, this study employed GIS to import AIS data into a map platform, establishing ship navigation trajectories through spatial geometric calculations. This provided a visual representation of the spatiotemporal aspects in AIS data, and spatial statistical analysis was performed to create feature data for subsequent modeling.
Figure 1 displays the distribution of AIS data points for ships in the waters around Taiwan on a specific day in 2022. There is a noticeable concentration of AIS signals in the Taiwan Strait, while the Eastern Pacific Ocean has fewer and less dense signals.
3.2. The Changhua Wind Farm Channel
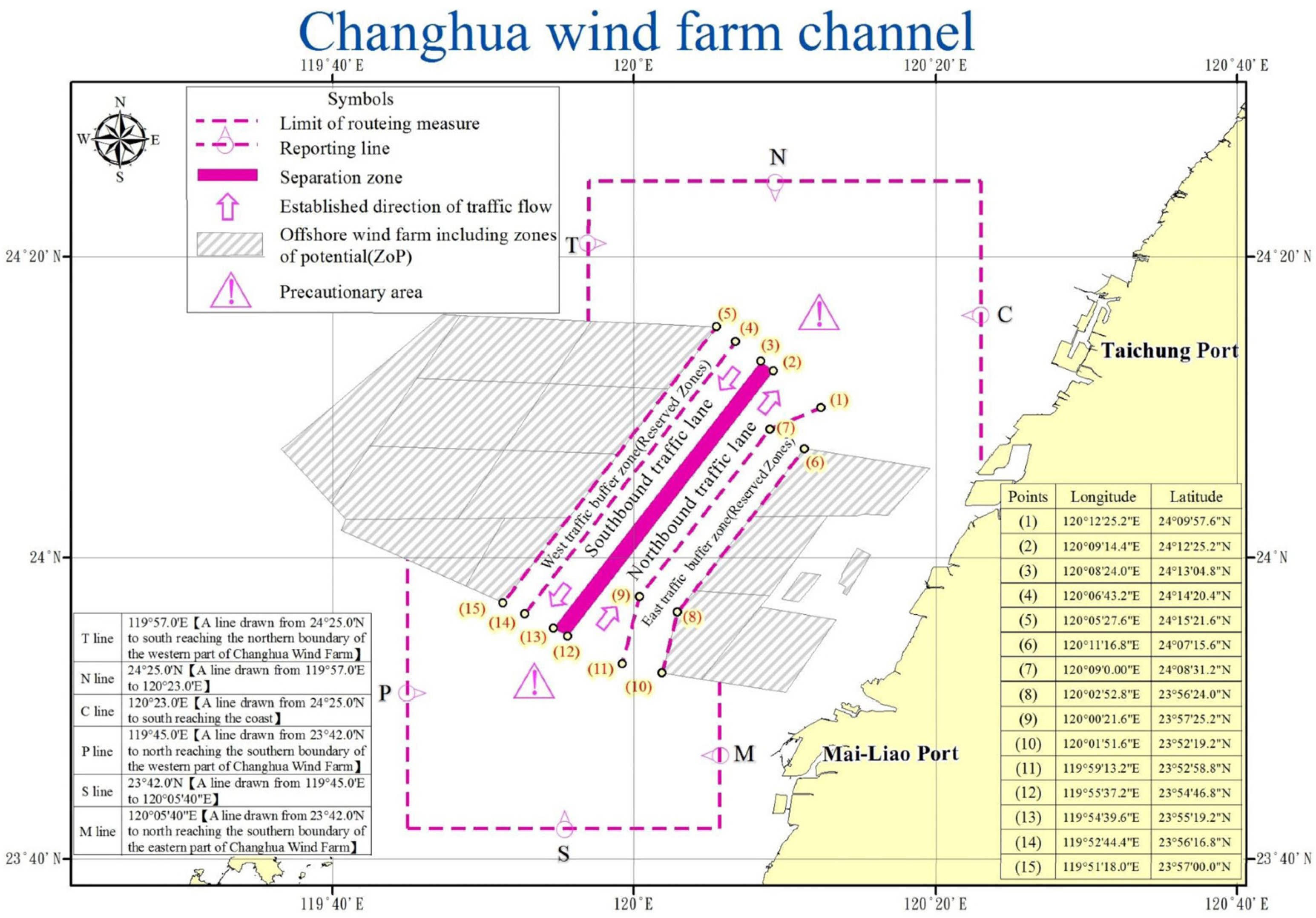
In line with government energy policies, substantial offshore wind farm development is scheduled for Taiwan’s western waters. Changhua offshore waters are the first area for large-scale construction. Therefore, the Changhua wind farm channel was officially implemented in October 2021, the first wind farm channel in Taiwan, as shown in
Figure 2. The gray areas on both sides are wind farm locations. A traffic separation system is adopted, according to International Regulations for Preventing Collisions at Sea (COLREGs) [
17], which consists of a southbound traffic lane, a northbound traffic lane, a separation zone, and buffer zones on both sides. The width of the northbound and southbound channels is 2 nm.
Changhua Offshore is a vital water area connecting Kaohsiung Port with Taipei and Keelung Ports. It is also an international shipping route connecting Northeast Asia to Southeast Asia. Many ships pass through this area, and the traffic is very heavy.
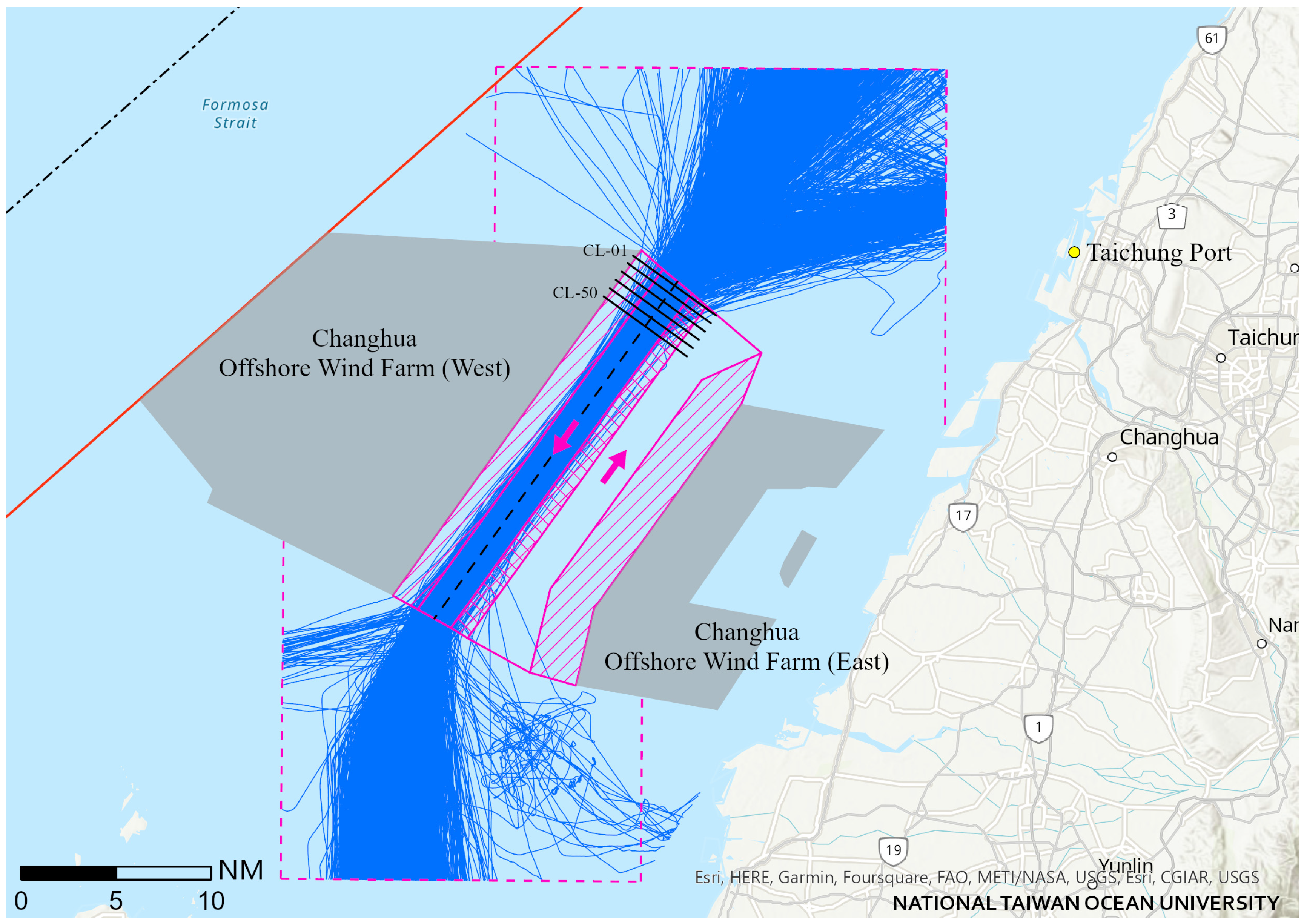
Figure 3 shows the maritime traffic density map before and after the implementation of the Changhua wind farm channel. Before the implementation of the channel, the ship tracks spread widely, and the southbound and northbound tracks overlapped. After the channel implementation, most ship tracks are concentrated in the southbound and northbound lanes, with only a few offshore wind farm construction ships, maintenance ships, and some fishing boats crossing these lanes. The Maritime and Port Bureau, MOTC, has established the “Changhua VTS” to surveil and manage traffic lanes for safe navigation. On average, there are at least 150 ships passing through this channel every day, and most of the ships can sail in compliance with the channel regulations.
To assist the Ship Traffic Service (VTS) operation, tracking ship behavior, anomaly detection, and warnings prediction are crucial topics in developing modern intelligent waterway systems [
18]. Nevertheless, a prerequisite for setting up this system is comprehending ship types, their distinct maneuvering capabilities, and cargo characteristics across various ship types. This study primarily creates a ship classification algorithm for the Changhua wind farm channel, focusing on the cargo ship classification problem. The AIS trajectory data with ship-type codes between 70 and 79, indicating cargo ships, is extracted based on reporting lines on the north and south sides of the channel.
Figure 4 displays some ship trajectories along the southbound traffic lane.
In order to analyze the navigation characteristics of ships in the channel effectively, the data representing the track line are normalized. Refer to Huang et al. [
19] to create a set of analysis gate lines perpendicular to the southbound traffic lane in the head section of the channel. The distance between two adjacent crossing-line is taken as a constant of 100 m, and there are 50 crossing-lines in total. Through the spatial analytical calculations, each trajectory passing through the channel intersects with the crossing lines. The ship’s lateral position, speed, and heading data, provided by the AIS information, are recorded at each crossing line so that the temporal and spatial distribution of the training data is consistent.
In this study, a data-driven supervised learning approach is applied to differentiate between four cargo ship types: container ships, bulk carriers, general cargo ships, and vehicle carriers. Each ship’s registration ship type and ship dimensions (length and width) were individually obtained from the internet using MMSI to create a training and testing dataset for ship classification. The sample quantities for the four ship types are detailed in
Table 2.
3.3. Feature Extraction
Selecting the appropriate features is crucial for classifier performance and has a significant impact. Some papers have already introduced various features for classifying ship types, including motion behavior and geometric features [
4]. Kraus et al. [
20] extracted geographical features, such as the distance to the coast and to classify fishing boats, cargo ships, and oil tankers. Yan et al. [
1] extracted the ship geometric features like length, width, and shape complexity to distinguish fishing boats, cargo ships, passenger ferries, oil tankers, and tugs. Moreover, Sheng et al. [
2] derived trajectory features from the kinematic pattern to classify fishing boats and cargo ships. Baeg and Hammond [
4] introduced an innovative method using ink features designed for sketch recognition to quantify ship trajectory characteristics, enabling the differentiation of fishing boats and cargo ships, as well as passenger ferries and oil tankers.
Previous research results have indicated the potential of using multiple features for ship-type classification. Some features and classifiers have been employed for classifying diverse ship types, including fishing boats, tugs, cargo ships, passenger ferries, and oil tankers. These ship types in AIS data are distinguished by unique codes, such as 30, 31–32, 60–69, 70–79, and 80–89, respectively. To enhance the navigation safety and efficiency of maritime supervision, this study aims to develop a ship-type classifier based on normal navigation behavior models for specific cargo ships (bulk carriers, container ships, general cargo ships, and vehicle carriers) within the cargo ship category numbered 70–79. Kraus et al. [
20] classified ship types using ship-geometric and trajectory behavior features from AIS data. Ship-geometric features include parameters like ship length, width, perimeter, area, aspect ratio, and shape complexity extracted from AIS static information. Trajectory behavior features encompass parameters related to ship movement, including latitude, longitude, speed, heading, turning rate, and trajectory extracted from AIS dynamic information.
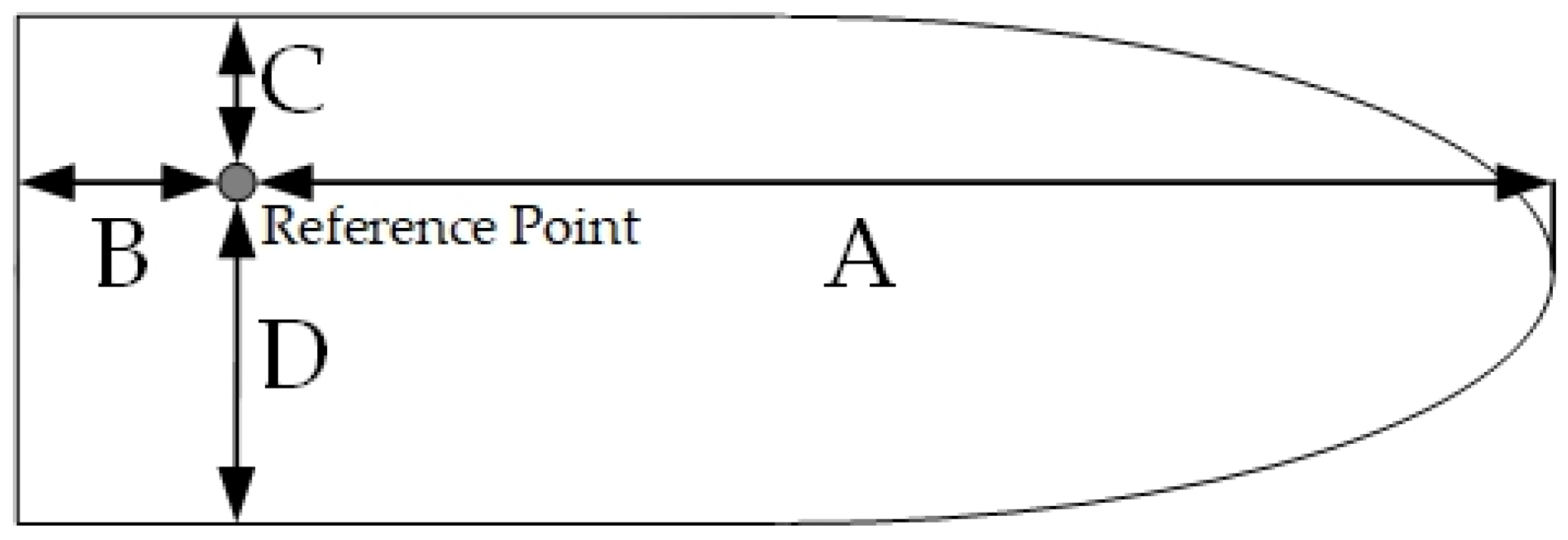
One of the goals of this study is to test and select ship classification features based on AIS static and dynamic data and suggest precise and efficient classification methods. In AIS static information, the data fields
A,
B,
C, and
D represent the distances from the antenna or reference point O to the bow, stern, port side, and starboard side of the ship, as shown in
Figure 5. Ship length and ship width features can be calculated using the following equations:
where
L represents the ship’s total length, and
W represents the ship’s width.
The novel parameter introduced in this study, which represents the ratio of bridge position to the ship’s length, has been named “Bridge Position Ratio”. Because most antenna positions or reference O points are located on the bridge, this value can be obtained from field A. This parameter is essential because, due to the influence of the shipbuilding industry, large or ultra-large container ships (≥18,000 TEU) adopt the form of double bridges, and the antenna or reference O point will be set on the front bridge, which is different from traditional container ships. Generally, container ships still have space for stacking containers behind the bridge. Still, the main loading positions of bulk carriers and general cargo ships are in front of the bridge, so the value A of bulk carriers and general cargo ships will be closer to the ship’s length. This study also encompasses parameters such as perimeter, area, aspect ratio, and shape complexity, references employed by Wang et al. [
5], Lang et al. [
13], and Yan et al. [
1]. The definitions are provided in the following equations:
where
Ps represents Naive Perimeter,
As represents Naive Area,
AR represents Aspect Ratio,
Cs represents Shape Complexity, and
BP represents Bridge Position Ratio.
In addition to the seven ship-geometric features in this study, trajectory behavior features were extracted from AIS dynamic information to enhance the accuracy of ship-type classification. In processing dynamic information data, through the crossing-line method in
Section 3.2, the dynamic information initially recorded on the AIS is converted to a specific crossing-line dataset, and the coordinate data (longitude and latitude) are converted into the lateral position of each crossing-line. With the centerline of the southbound lane as the reference point, positive values signify a right-side deviation, while negative values indicate a left-side deviation. In addition to reducing data dimensionality, this approach establishes a consistent standard for subsequent training data. Fifty sample data points were extracted from each ship’s trajectory, calculating six variables for each trajectory: the median values of ship speed, course, and lateral position (denoted as
Smed,
Cmed, and
Tmed, respectively), as well as the interquartile range (IQR) (represented as
Siqr,
Ciqr, and
Tiqr). These variables capture the speed, course, and position deviation of each trajectory, with their respective variability ranges representing the navigational characteristics of the ships. Additionally, this study includes the ship’s draft as a feature. Due to their smaller size, general cargo ships typically have shallower drafts compared to bulk carriers and container ships. Moreover, container ships typically have significantly shallower drafts compared to bulk carriers of similar length.
This study extracted a total of 14 features from 9785 ship trajectory samples. The feature vector can be expressed as follows:
In the above formula, draft (D), median of Transverse deviation from channel central line (Tmed), median of speed over ground (Smed), median of course over ground (Cmed), Interquartile range of Transverse deviation (Tiqr), Interquartile range of speed over ground (Siqr), Interquartile range of course over ground (Ciqr).
This study collected 9785 trajectory data points from ships navigating southbound in the Changhua Wind Farm Channel since 2022. These ships are categorized into four types: bulk carriers, container ships, general cargo ships, and vehicle carriers. Statistics for ship-geometric and trajectory behavior features are detailed in
Table 3 and
Table 4, respectively.
Table 3 displays the statistical characteristics of ship-geometric features. The statistics for the ship’s length show an average length of 200.1 m and a median length of 190 m. The slightly lower median compared to the mean suggests that the distribution of the ship’s lengths is relatively balanced, with no severe outliers significantly affecting the mean. The standard deviation (64.6 m) compared to the IQR (139 m) indicates a wide dispersion in the ship’s lengths, and there is significant variability in the lengths of ships within the middle 50% of the data range. The statistics for draft reveal an average draft of 8.7 m, which is very close to the median draft of 8.6 m. Most ships have draft depths falling within the range of 7.3 to 9.8 m. The similar IQR (2.5 m) and standard deviation (2.1 m) further suggest high data centrality, with minimal differences in draft depths among the majority of ships. For most geometric features of ships, there is only a slight difference between their mean and median values. However, certain features such as
W,
As,
AR,
Cs, and
BP exhibit smaller interquartile ranges compared to the standard deviation, implying the presence of a few outliers or anomalies that contribute to increased overall data variability.
Table 4 displays the statistical measures of trajectory behavior characteristics. The trajectory speed (
Smed) statistics show an average speed value of 13.2 knots, closely aligned with the median of 12.9 knots. This indicates a relatively balanced distribution of sailing speeds, with minimal impact from extreme values. The IQR of 3.7 knots, larger than the standard deviation of 2.8 knots, suggests that most ship speeds are distributed within a narrow range. The average speed variation range (
Siqr) is 0.2 knots with a median of 0.1 knots and a standard deviation of 0.2 knots. The low average and standard deviation indicate that most trajectories exhibit a very narrow range of speed variation, implying stable speeds. The maximum value of 9.3 knots points to the presence of outliers, suggesting more considerable speed variations under certain conditions or for specific ship types. The trajectory course (
Cmed) statistics show an average course value of 215.2 degrees, closely matching the median of 215 degrees. The IQR of 2.8 degrees, nearly equivalent to the standard deviation of 3.2 degrees, indicates high centrality in the dataset. This suggests that most ships maintain a stable course with minimal directional changes, adhering to navigation guidelines. The average course variation range (
Ciqr) is 2.2 degrees with a standard deviation of 2.8 degrees. The IQR of 1.3 degrees and a standard deviation of 2.8 degrees in
Ciqr reflect a more comprehensive range of changes in some trajectories, indicative of diverse navigational behaviors in complex channel environments or adverse weather. Regarding the lateral offset position (
Tmed), the average value is −172 m, and the median is −170 m. This suggests that most ships’ lateral offsets are to the left of the channel’s centerline within a relatively fixed range. The IQR of 950 m and a standard deviation of 803 m show that ships effectively maintain their intended paths within the 2-nm-wide channel. However, extreme values (minimum −10,773 m, maximum 3575 m) indicate significant lateral deviations in some cases, possibly due to emergency maneuvers, strong wind and wave effects, or navigational errors. The average lateral offset variation range (
Tiqr) is 169 m with a standard deviation of 207 m, highlighting significant differences in lateral deviation across trajectories. This variability may reflect responses to channel width, traffic density, or environmental factors. The maximum value of 3298 m suggests significant lateral deviations under special navigational circumstances.
In summary, the statistical data on speed, course, and lateral offset variations reveal high consistency and predictability in ship speeds and courses on the channel. Most ships maintain a stable course and lateral offset, indicating adherence to navigation guidelines and channel stability. However, the data also imply potential speed and course variations under specific conditions. These insights are crucial for channel management and maritime safety strategy development, highlighting the need for tailored navigational protocols.
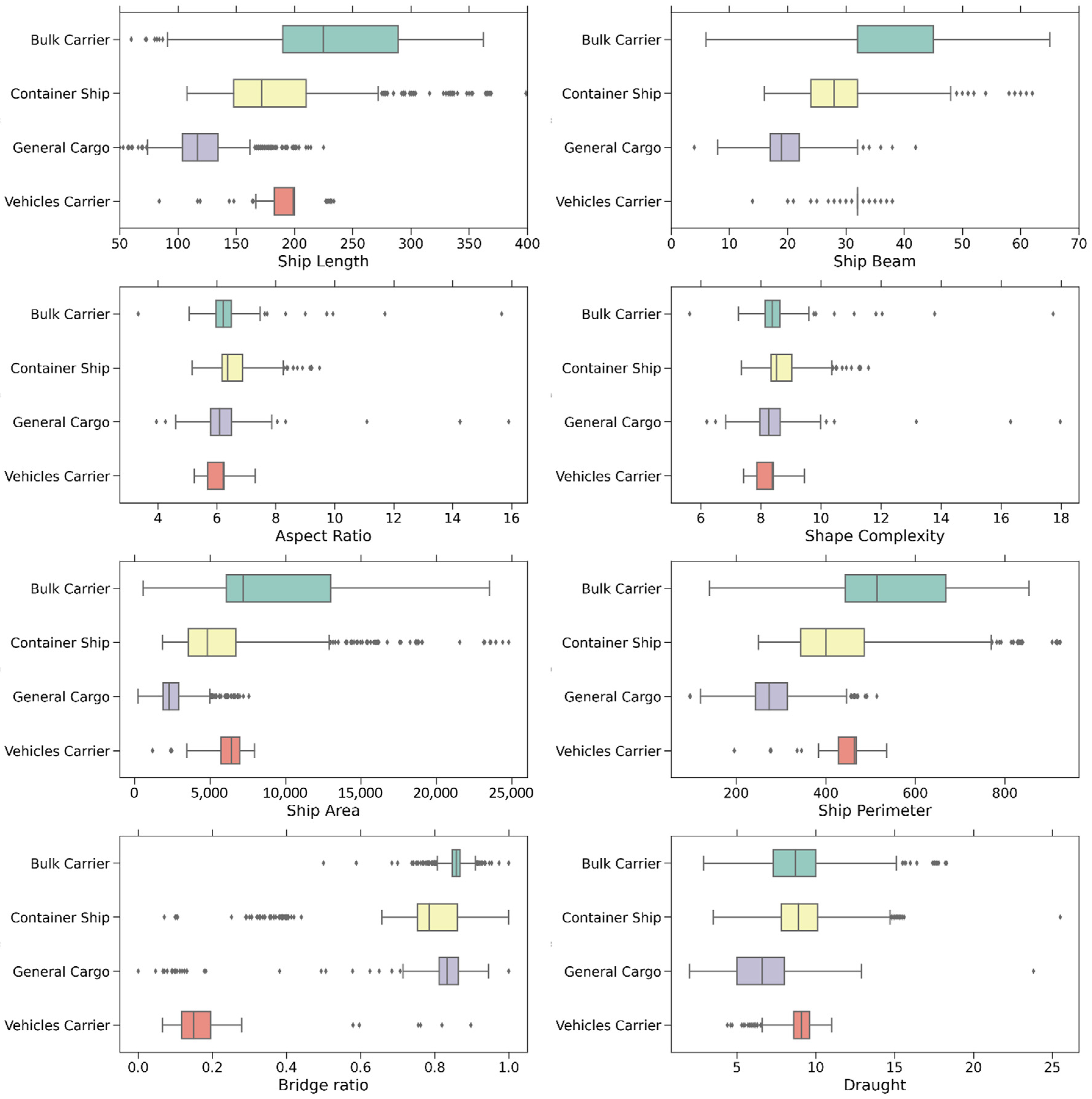
Subsequently, this study further divided the data into four ship types and created box plots for comparative analysis.
Figure 6 presents the ship-geometric features of these four ship types, while
Figure 7 illustrates their trajectory behavior characteristics in the southbound traffic lane. Bulk carriers, container ships, and general cargo ships exhibit significant differences in length, width, area, and perimeter. Bulk carriers, larger in tonnage, typically show more extraordinary lengths and widths (approximately 180–300 m in length, 30–45 m in width), with outliers indicating the presence of smaller ships. In contrast, general cargo ships, usually smaller in tonnage, display shorter lengths and narrower widths (approximately 100–150 m in length, 15–25 m in width), clustering within a more compact range. The IQR and the distribution of outliers for general cargo ships are markedly different from the other three ship types. Vehicle carriers, while similar in principal dimensions to other types, differ distinctly in bridge position ratio (
BP), with bridges often located near the bow, as opposed to the stern placement in other cargo ships. Container ships, typically medium-sized and concentrated in the 150–220 m range, include outliers representing significantly larger ships, such as ultra-large container ships (≥18,000 TEU) with double bridges. However, the aspect ratio (
AR) and shape complexity (
Cs), indicators of ship maneuverability, overlap considerably among the four types.
Regarding trajectory behavior characteristics, the speeds of container ships and vehicle carriers mainly range between 14 and 18 knots, higher than the 9–13 knots range of bulk and general cargo ships. However, the trajectory course and lateral position distribution are similar among all four ship types, showing only minor variations. The majority of ships maintain courses within a 2-degree deviation from the traffic lane direction, and their lateral positions are within a 0.5 nm range on either side of the traffic lane’s centerline. This distribution suggests that most ships adhere to channel navigation guidelines, with outliers indicating anomalies in navigation characteristics such as speed, course, or position.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}