

Applying Advanced Lightweight Architecture DSGSE-Yolov5 to Rapid Chip Contour Detection


Abstract
:1. Introduction
2. Related Work
2.1. Literature Review
2.2. Chip Contour Detection Models
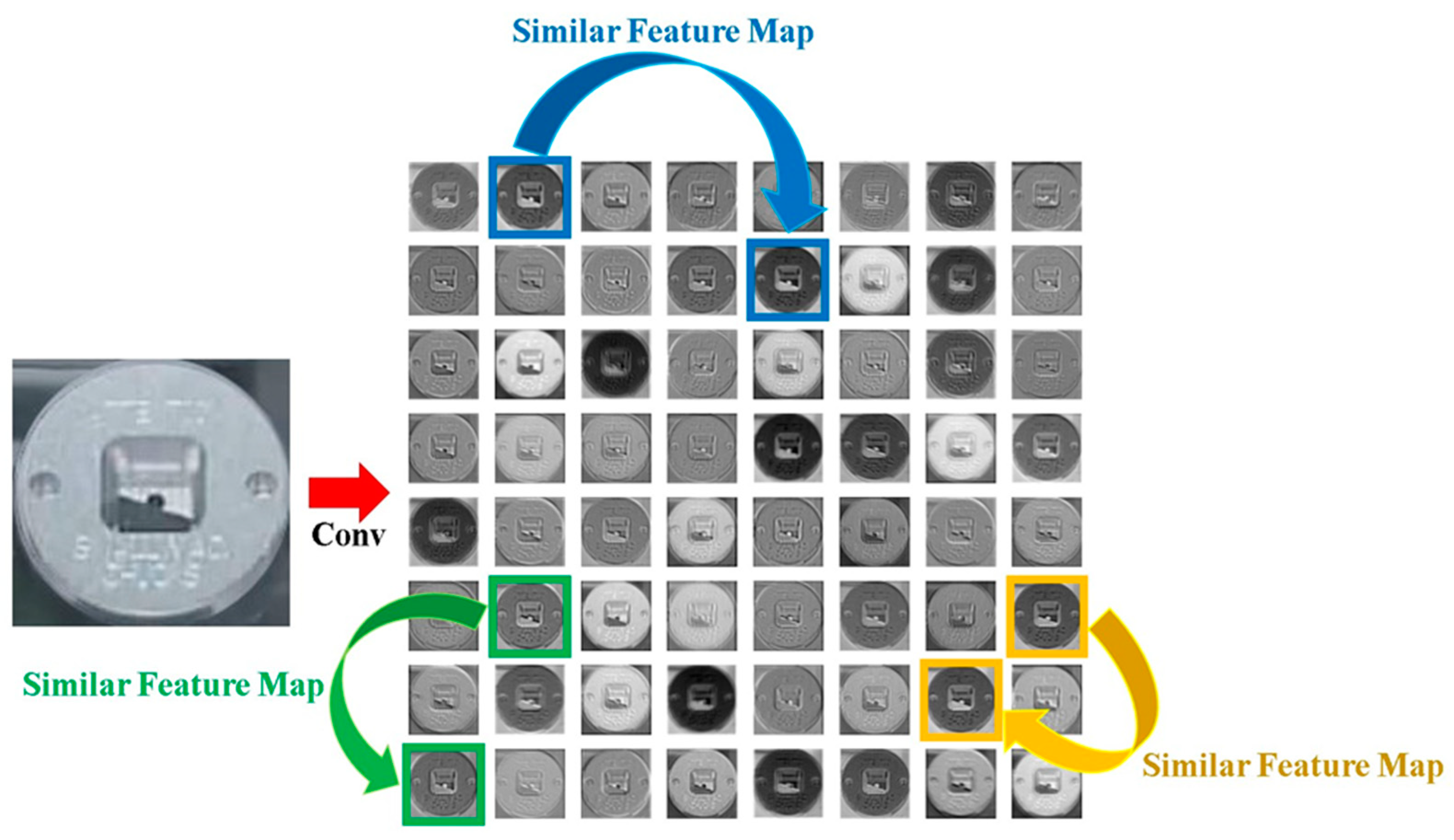
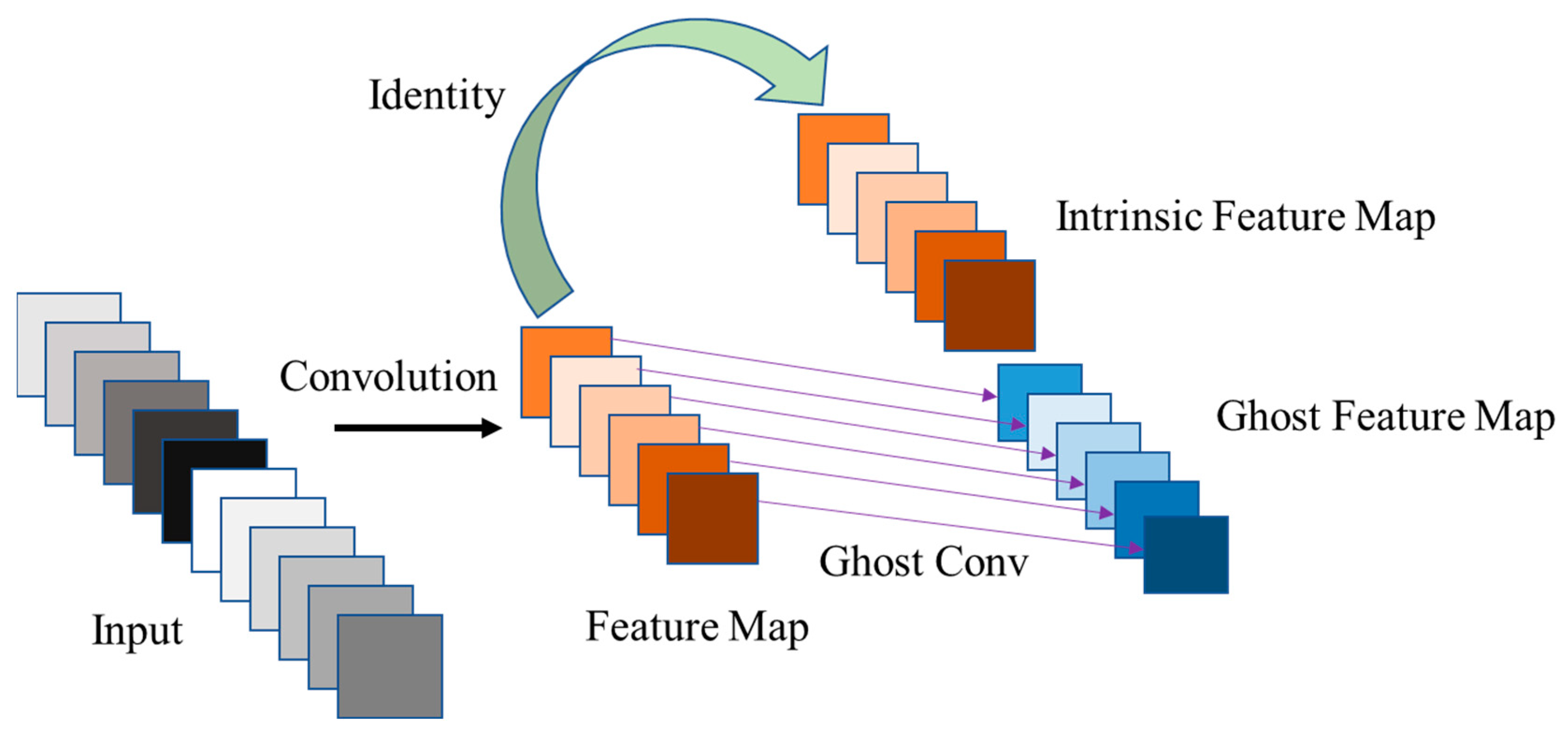
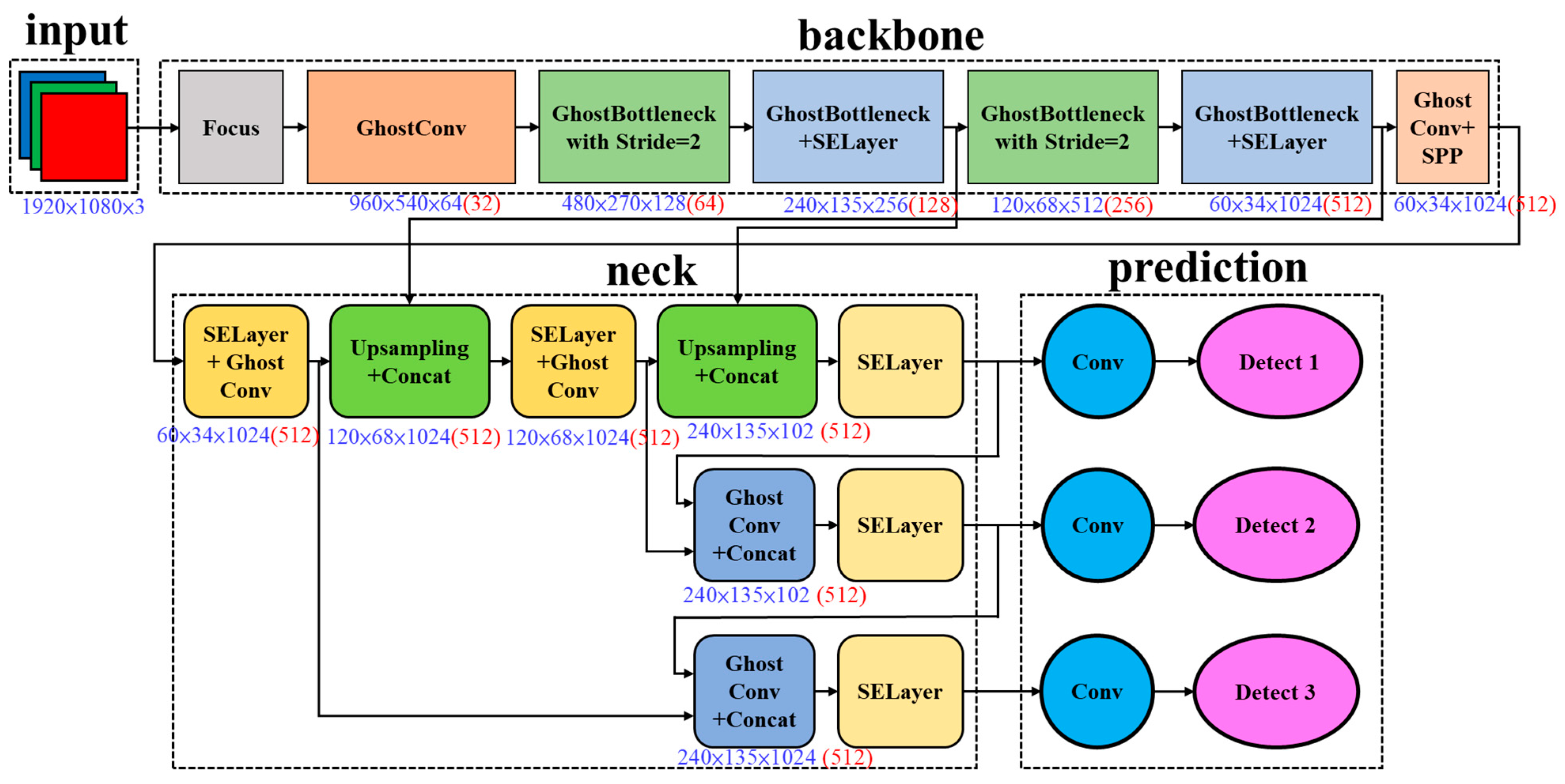
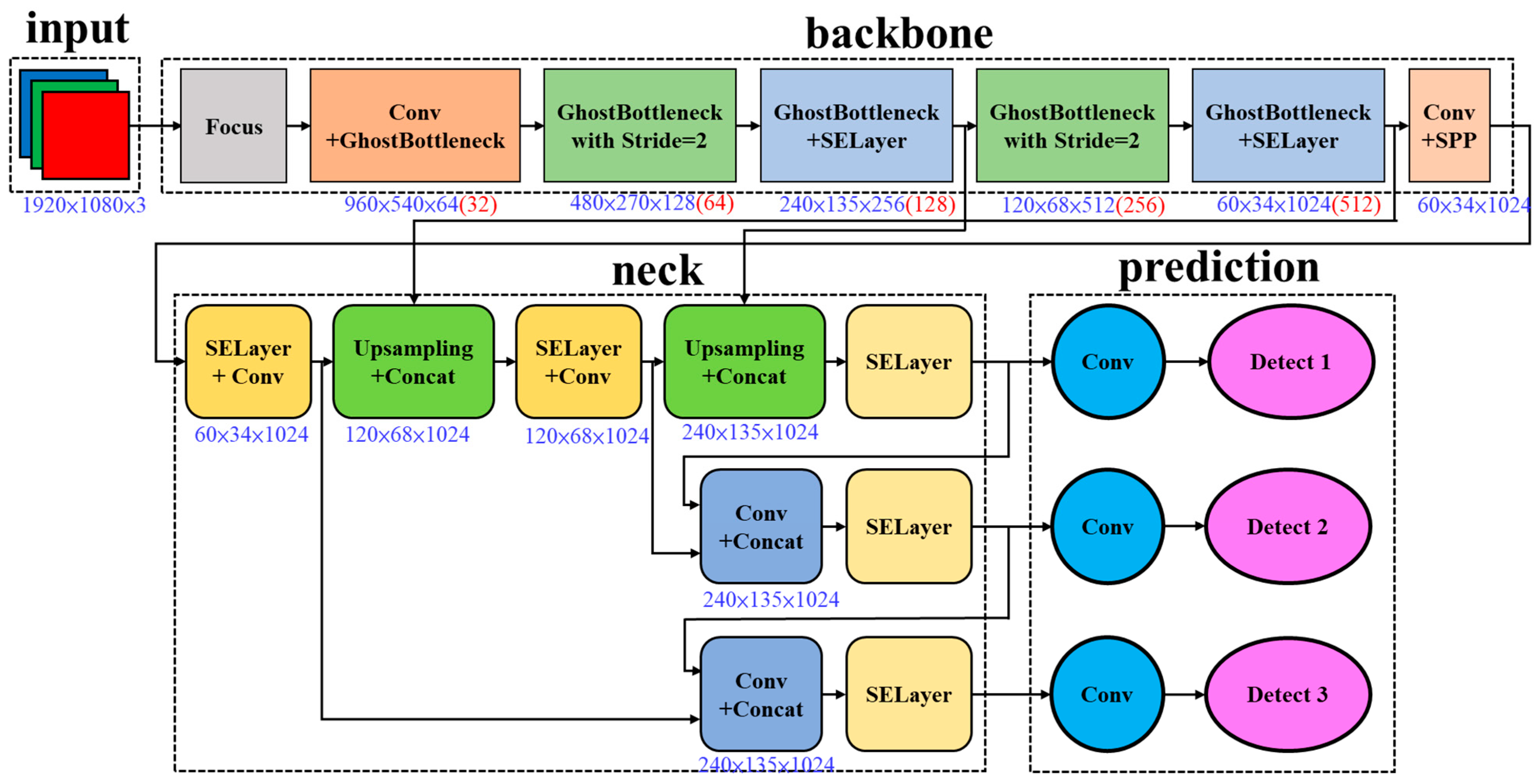
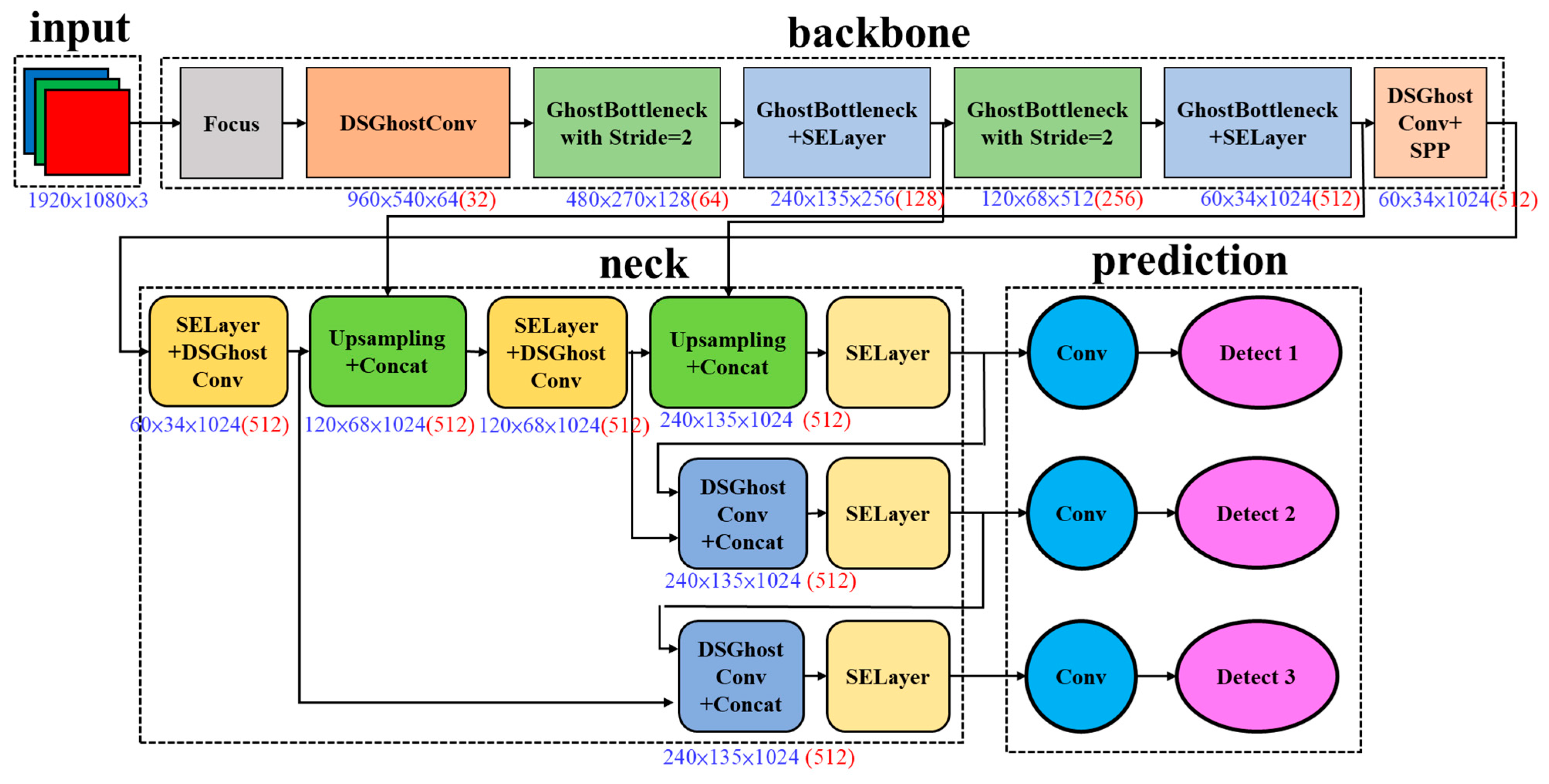
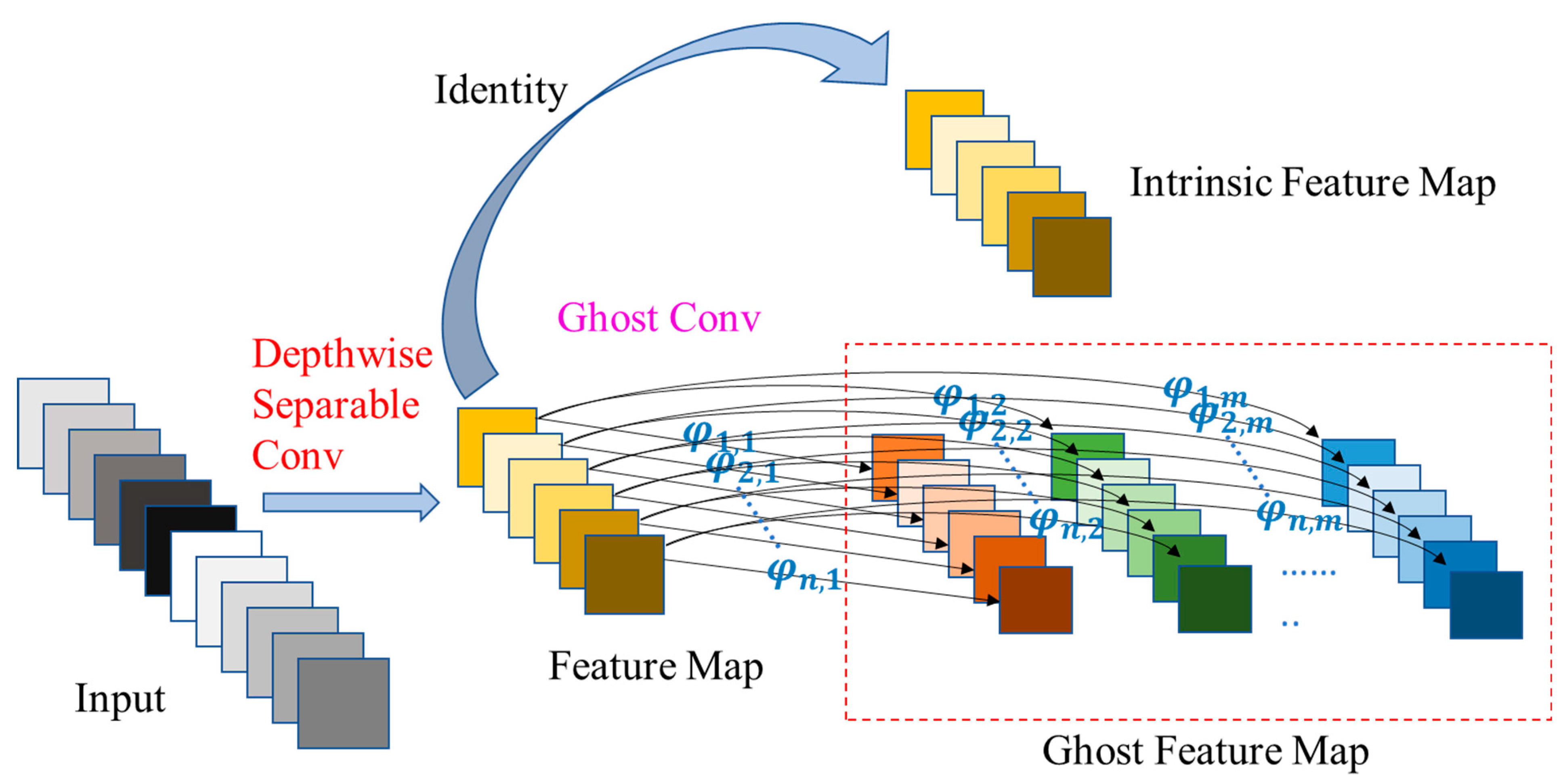
3. Method
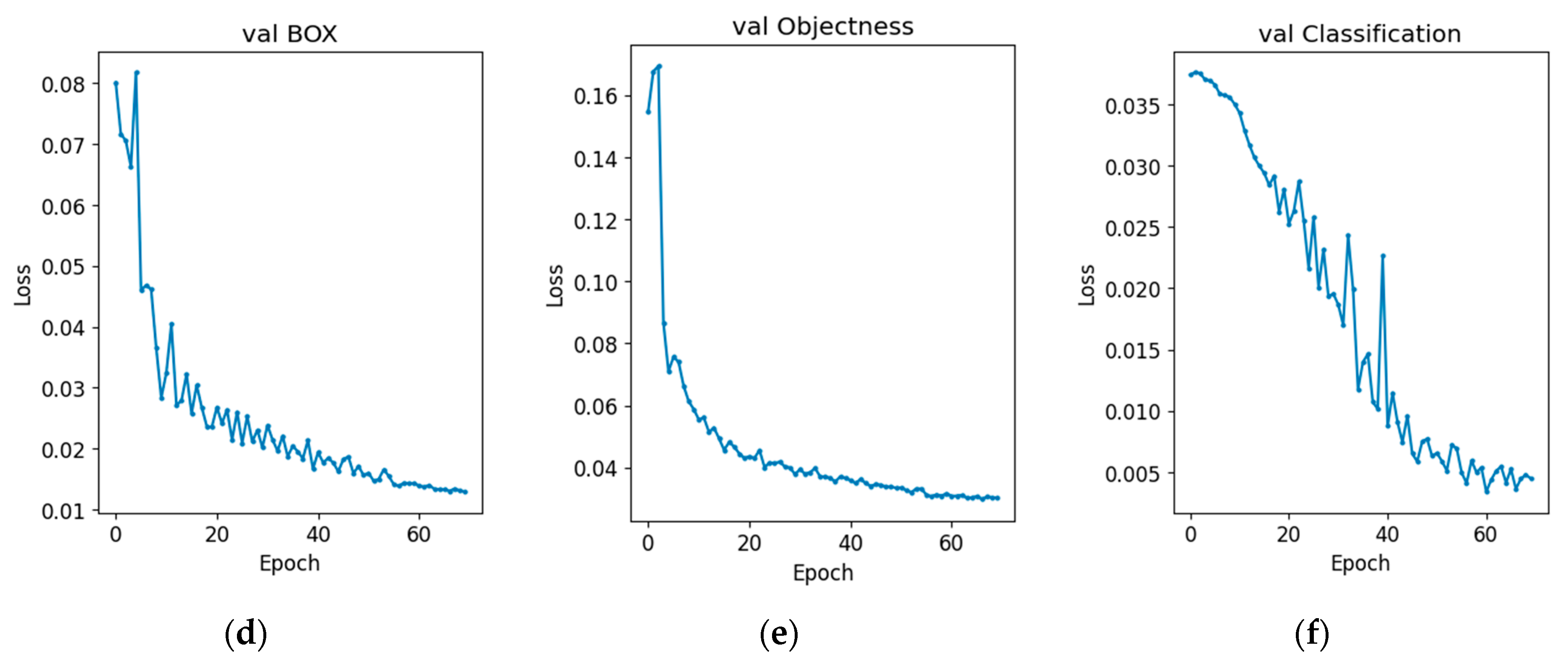
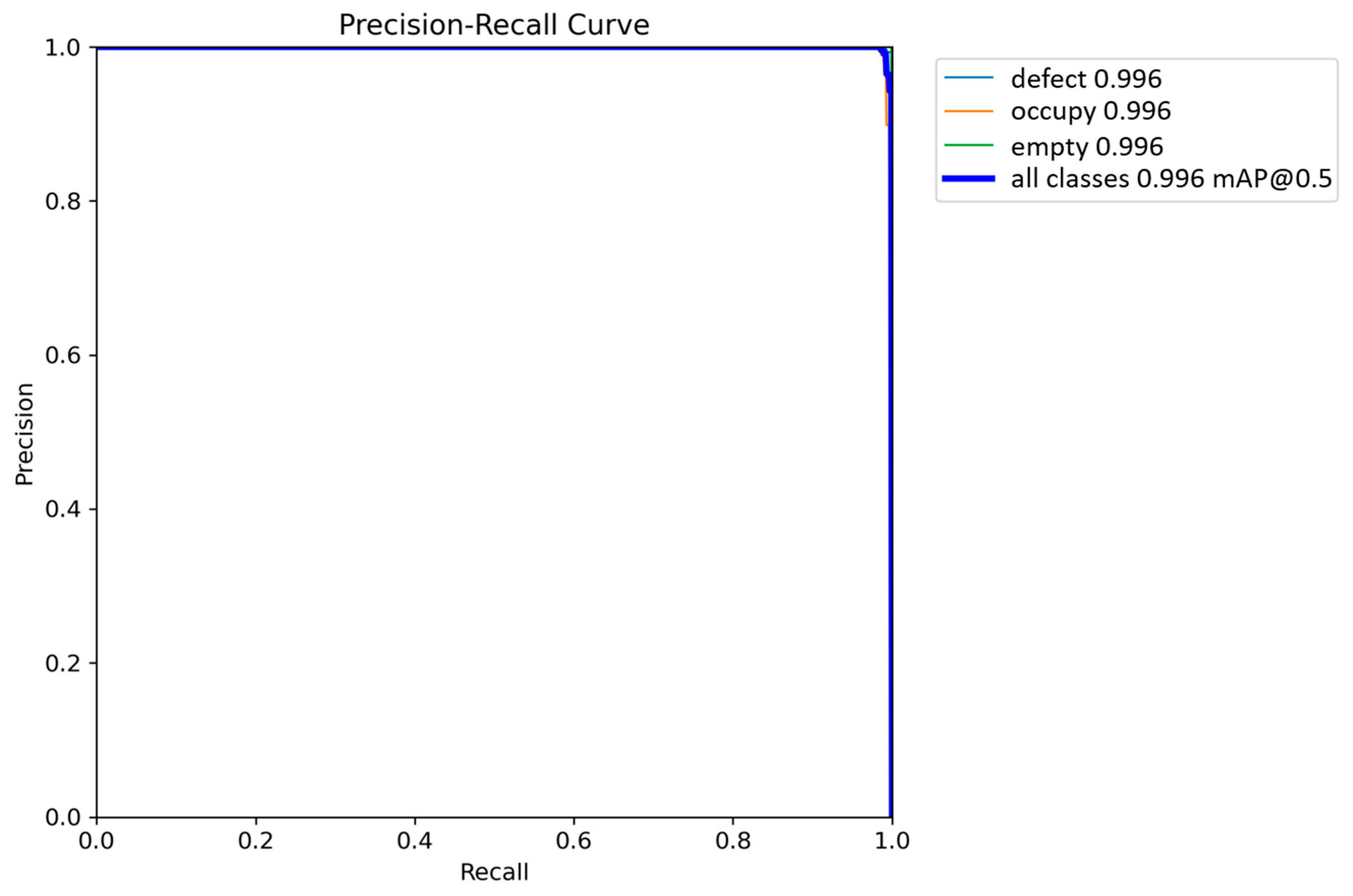
4. Experiment Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, Y.L.; Chiang, Y.M.; Hsu, H.C. Capacitor Detection in PCB Using Yolo Algorithm. In Proceedings of the 2018 IEEE International Conference on System Science and Engineering, New Taipei, Taiwan, 28–30 June 2018; pp. 1–4. [Google Scholar]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-Based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Chang, B.R.; Tsai, H.-F.; Hsieh, C.-W. Location and Timestamp Based Chip Contour Detection Using LWMG-Yolov5. Comput. Ind. Eng. 2023, 180, 109277. [Google Scholar] [CrossRef]
- Chang, B.R.; Tsai, H.-F.; Chang, F.-Y. Chip Contour Detection and Recognition Based on Deep-Learning Approaches. In Proceedings of the 2023 5th International Conference on Emerging Networks Technologies, Okinawa, Japan, 22–24 September 2023. [Google Scholar]
- Chang, B.R.; Tsai, H.-F.; Chang, F.-Y. Boosting the Response of Object Detection and Steering Angle Prediction for Self-Driving Control. Electronics 2023, 12, 4281. [Google Scholar] [CrossRef]
- Rajaram, R.N.; Ohn-Bar, E.; Trivedi, M.M. Refinenet: Refining Object Detectors for Autonomous Driving. IEEE Trans. Intell. Veh. 2016, 1, 358–368. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 1800–1807. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Lin, B.; Wang, J.; Yang, X.; Tang, Z.; Li, X.; Duan, C.; Zhang, X. Defect contour detection of complex structural chips. Math. Probl. Eng. 2021, 2021, 5518675. [Google Scholar] [CrossRef]
- Zheng, P.; Lou, J.; Wan, X.; Luo, Q.; Li, Y.; Xie, L.; Zhu, Z. LED Chip Defect Detection Method Based on a Hybrid Algorithm. Int. J. Intell. Syst. 2023, 2023, 4096164. [Google Scholar] [CrossRef]
- Dahai, L.; Zhihui, C.; Xianqi, L.; Qi, Z.; Nanxing, W. A lightweight convolutional neural network for recognition and classification for Si3N4 chip substrate surface defects. Ceram. Int. 2023, 49, 35608–35616. [Google Scholar] [CrossRef]
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Aboah, A.; Wang, B.; Bagci, U.; Adu-Gyamfi, Y. Real-Time Multi-Class Helmet Violation Detection Using Few-Shot Data Sampling Technique and Yolov8. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5349–5357. [Google Scholar]
- Wu, B.C.; Iandola, F.; Jin, P.H.; Keutzer, K. SqueezeDet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 129–137. [Google Scholar]
- Chang, B.R.; Tsai, H.F.; Chou, H.L. Accelerating the Response of Self-Driving Control by Using Rapid Object Detection and Steering Angle Prediction. Electronics 2023, 12, 2161. [Google Scholar] [CrossRef]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. Yolov4-5D: An effective and efficient object detector for autonomous driving. IEEE Trans. Instrum. Meas. 2021, 70, 4503613. [Google Scholar] [CrossRef]
- Marco, V.S.; Taylor, B.; Wang, Z.; Elkhatib, Y. Optimizing Deep Learning Inference on Embedded Systems through Adaptive Model Selection. arXiv 2019, arXiv:1911.04946. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, C.; Qu, L. An Object Detection Network for Embedded System. In Proceedings of the 2019 IEEE International Conferences on Ubiquitous Computing & Communications and Data Science and Computational Intelligence and Smart Computing, Networking and Services, Shenyang, China, 21–23 October 2019; pp. 506–512. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Ding, W.; Huang, Z.; Huang, Z.; Tian, L.; Wang, H.; Feng, S. Designing Efficient Accelerator of Depthwise Separable Convolutional Neural Network on FPGA. J. Syst. Archit. 2019, 97, 278–286. [Google Scholar] [CrossRef]
- Misra, D. Mish: A Self Regularized Non-monotonic Activation Function. arXiv 2020, arXiv:1908.08681v3. [Google Scholar]
- Saqlain, M.; Abbas, Q.; Lee, J.Y. A Deep Convolutional Neural Network for Wafer Defect Identification on an Imbalanced Dataset in Semiconductor Manufacturing Processes. IEEE Trans. Semicond. Manuf. 2020, 33, 436–444. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specification | Yolov5 | M3-Yolov5 | FGHSE-Yolov5 | GSEH-Yolov5 | DSGSE-Yolov5s |
|---|---|---|---|---|---|
| Parameter | 7,251,912 | 3,205,296 | 2,606,944 | 4,182,136 | 2,213,726 |
| Flop (Gflops.) | 16.8 | 6.0 | 4.6 | 6.9 | 4.3 |
| Metrics | Yolov5 | M3-Yolov5 | FGHSE-Yolov5 | GSEH-Yolov5 | DSGSE-Yolov5s |
|---|---|---|---|---|---|
| FPS | 5.75 | 6.46 | 10.13 | 8.47 | 13.39 |
| Precision (%) | 98.57 | 98.94 | 99.29 | 99.53 | 99.56 |
| Recall (%) | 98.01 | 98.27 | 98.86 | 99.14 | 99.22 |
| F1-score | 0.985 | 0.986 | 0.991 | 0.993 | 0.995 |
| Accuracy (%) | 98.91 | 99.13 | 99.33 | 99.51 | 99.55 |
| Measures | Yolov5 | M3-Yolov5 | FGHSE-Yolov5 | GSEH-Yolov5 | DSGSE-Yolov5s |
|---|---|---|---|---|---|
| FPS | 5.75 | 6.46 | 10.13 | 8.47 | 13.39 |
| Inference time | 0.1739 | 0.1548 | 0.0987 | 0.1181 | 0.0747 |
| Processing time | 0.2239 | 0.2048 | 0.1487 | 0.1681 | 0.1247 |
| Success Rate | 0.5583 | 0.6104 | 0.8405 | 0.7438 | 1.0025 |
| Accuracy (%) | 98.91 | 99.13 | 99.33 | 99.51 | 99.55 |
| Yield (%) | 55.22 | 60.50 | 83.49 | 74.01 | 99.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, B.R.; Tsai, H.-F.; Chang, F.-Y. Applying Advanced Lightweight Architecture DSGSE-Yolov5 to Rapid Chip Contour Detection. Electronics 2024, 13, 10. https://doi.org/10.3390/electronics13010010
Chang BR, Tsai H-F, Chang F-Y. Applying Advanced Lightweight Architecture DSGSE-Yolov5 to Rapid Chip Contour Detection. Electronics. 2024; 13(1):10. https://doi.org/10.3390/electronics13010010
Chicago/Turabian StyleChang, Bao Rong, Hsiu-Fen Tsai, and Fu-Yang Chang. 2024. "Applying Advanced Lightweight Architecture DSGSE-Yolov5 to Rapid Chip Contour Detection" Electronics 13, no. 1: 10. https://doi.org/10.3390/electronics13010010
APA StyleChang, B. R., Tsai, H.-F., & Chang, F.-Y. (2024). Applying Advanced Lightweight Architecture DSGSE-Yolov5 to Rapid Chip Contour Detection. Electronics, 13(1), 10. https://doi.org/10.3390/electronics13010010