

Radar Spectrum Image Classification Based on Deep Learning



Abstract
:1. Introduction
1.1. Research Background and Scientific Significance
1.2. Research Status
1.3. Radar Signal Source Recognition Based on Deep Learning
- (1)
- In this paper, a deep-learning method is designed to distinguish the types of radar emitter signals only according to the spectrum images of radar signals. The manually designed neural network is used to automatically extract the features of radar emitter spectrum signals, and then the accurate classification of radar emitter signals is realized according to the obtained features.
- (2)
- In this paper, considering the characteristics of radar spectrum image, if only two-dimensional convolution is used to extract spectral image features, the local feature similarity is large, and the discrimination degree is not high. Therefore, we use a one-dimensional convolution structure to replace the two-dimensional convolution structure in EfficientNetv2-s. Thus, feature details with a certain degree of discrimination can be extracted, and the number of model parameters and computational complexity can be reduced to a certain extent.
- (3)
- In this paper, the structure of the attention mechanism in EfficientNetv2-s is modified, the idea of reducing the dimension first and increasing the dimension is abandoned, and the global pooling features are directly implemented through one-dimensional convolution to achieve cross-dimensional information interaction, so as to obtain more targeted attention weights.
2. Related Work
2.1. 1D Convolution
2.2. EfficientNetv2 Introduction
3. Efficientnetv2-S Based on One-Dimensional Convolution
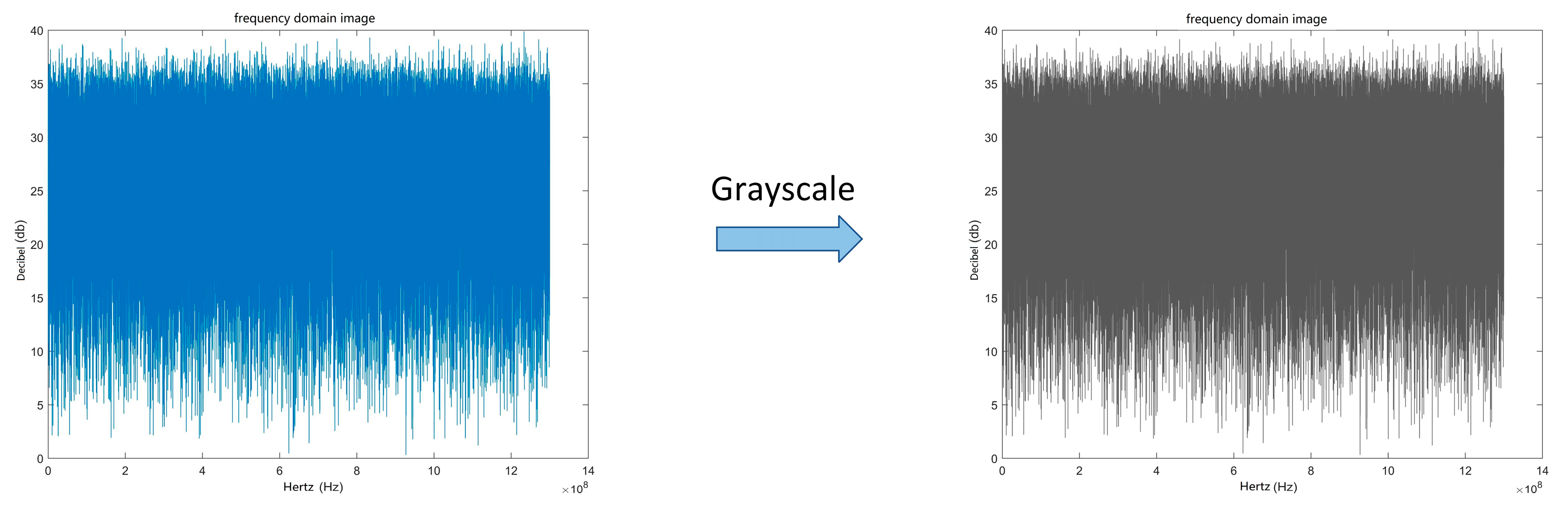
3.1. Data Preprocessing
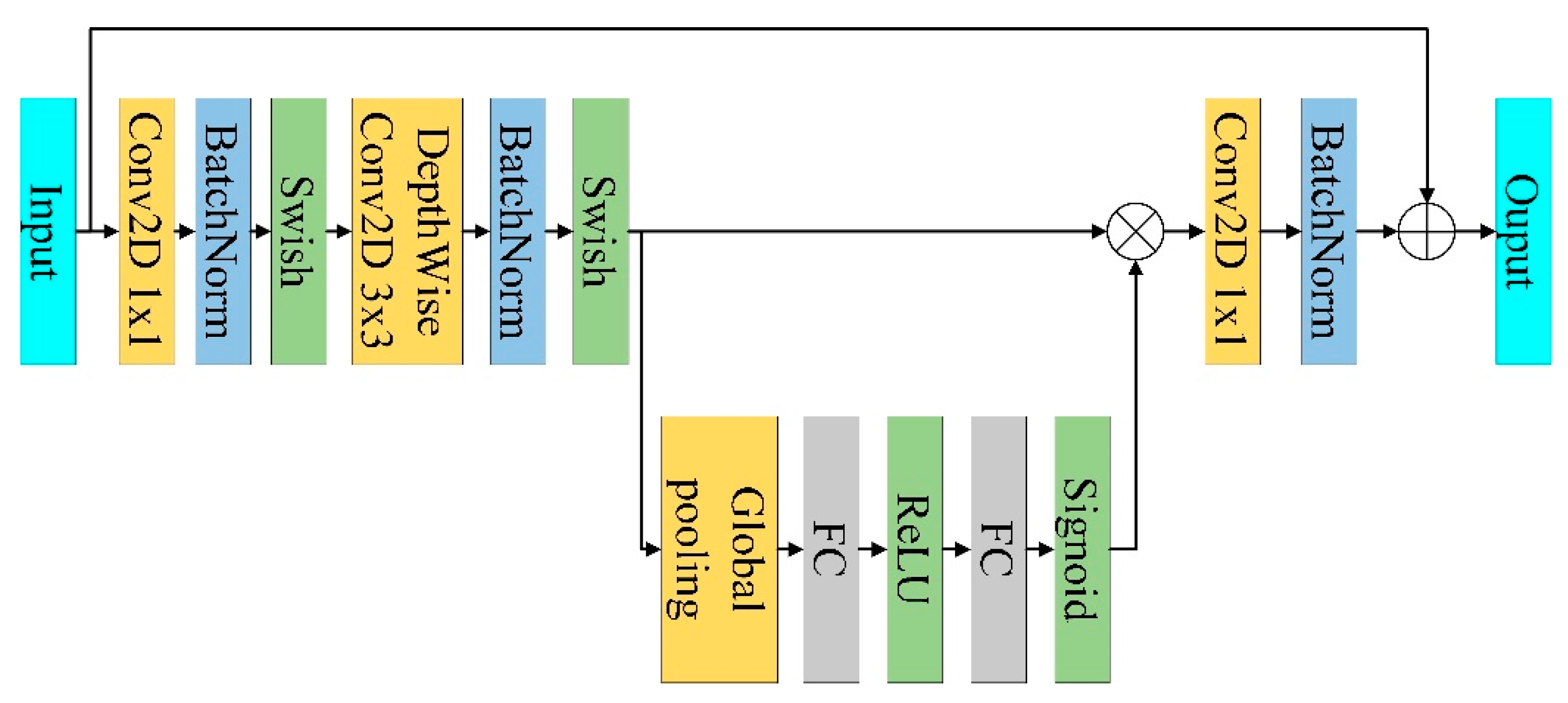
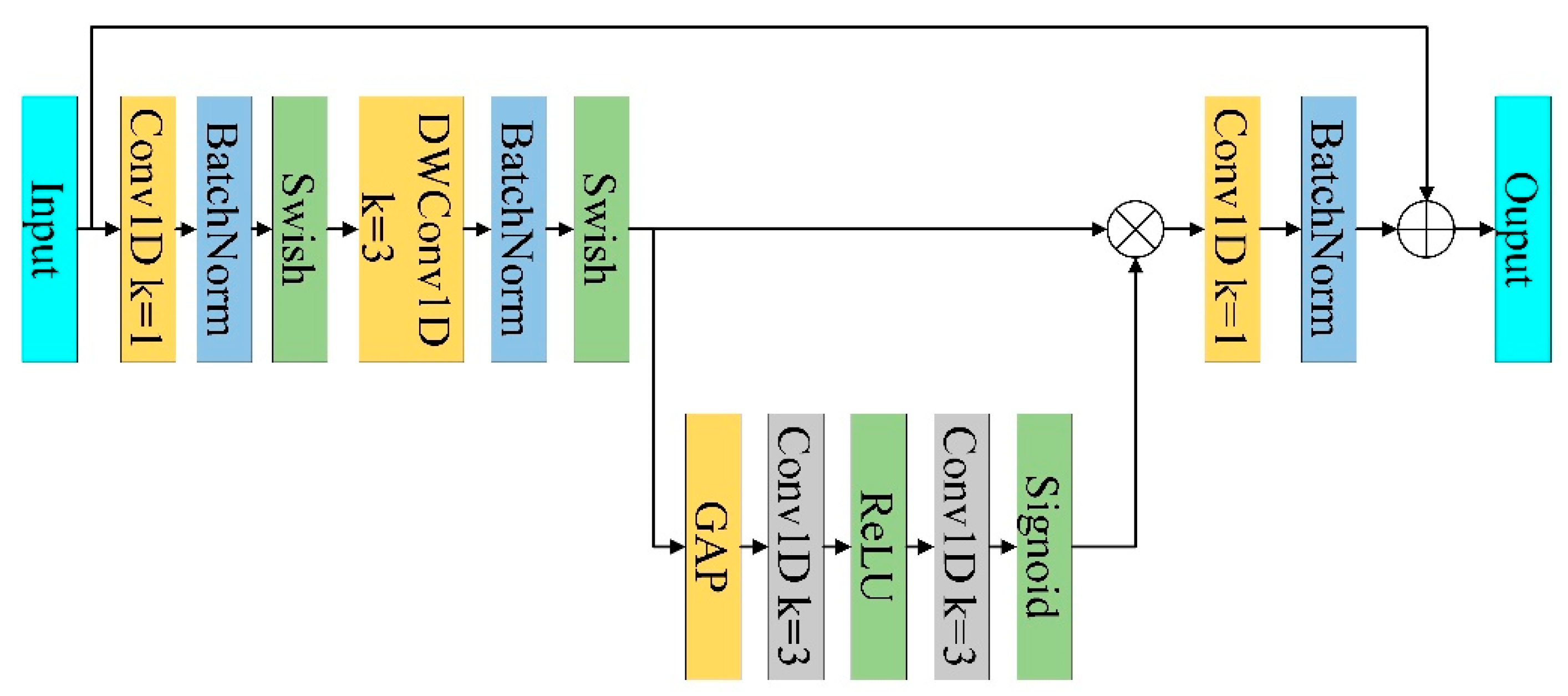
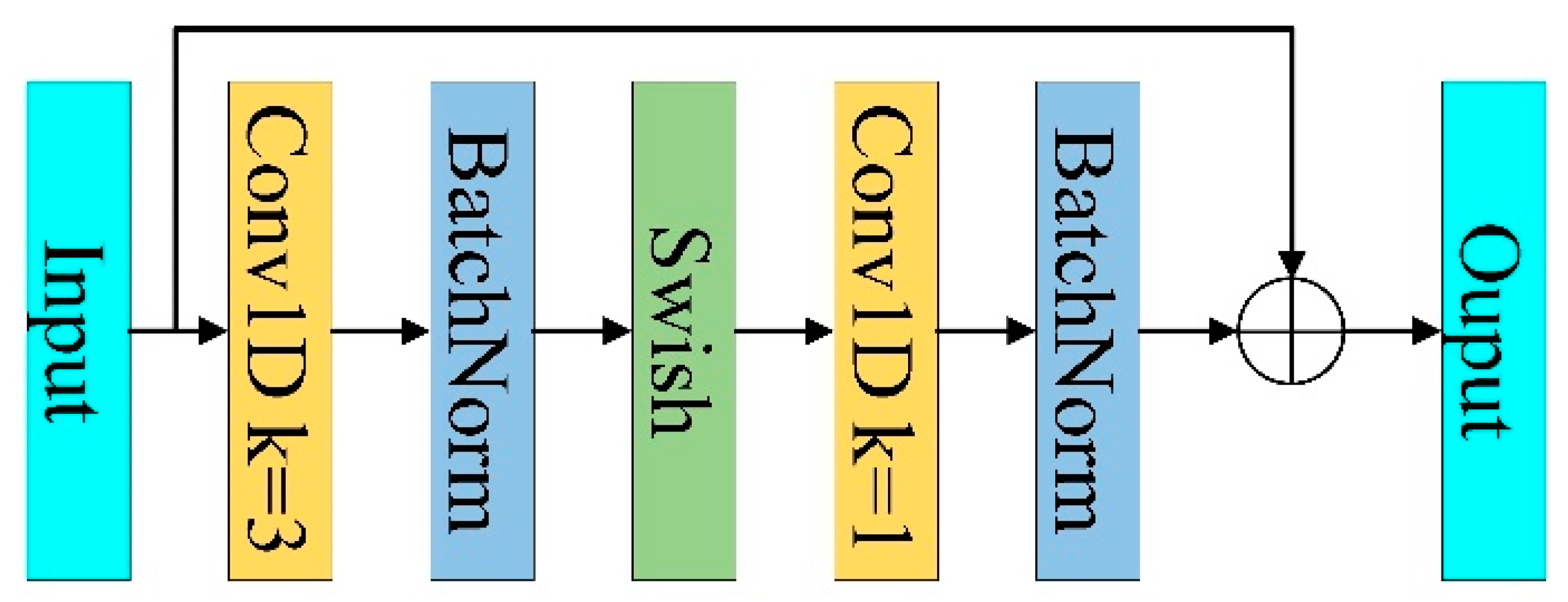
3.2. MBConv and Fused-MBConv Based on One-Dimensional Convolution
3.3. Improved SE Attention Module
3.4. Our Function
4. Experiment
4.1. Data Set
4.2. Experimental Setup
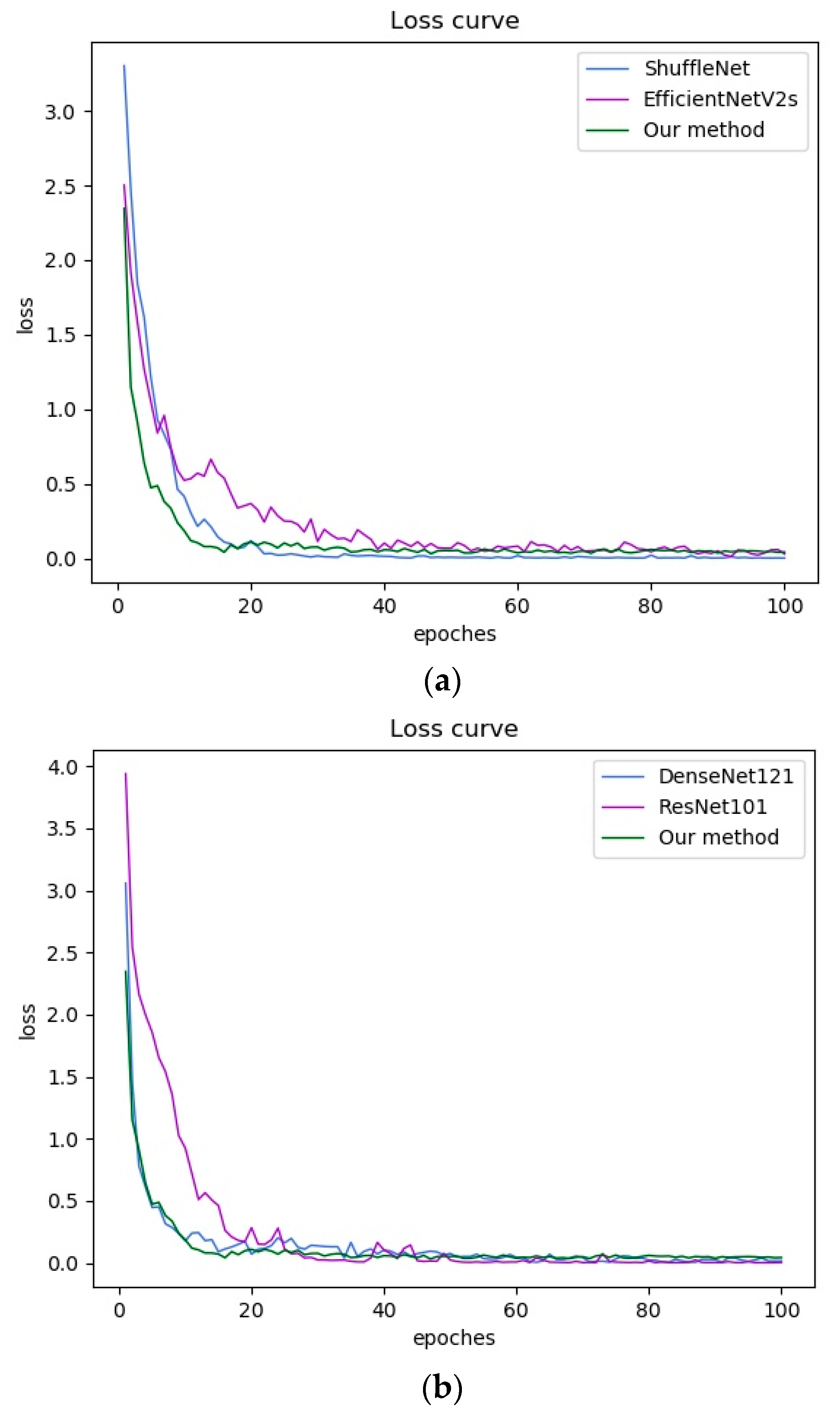
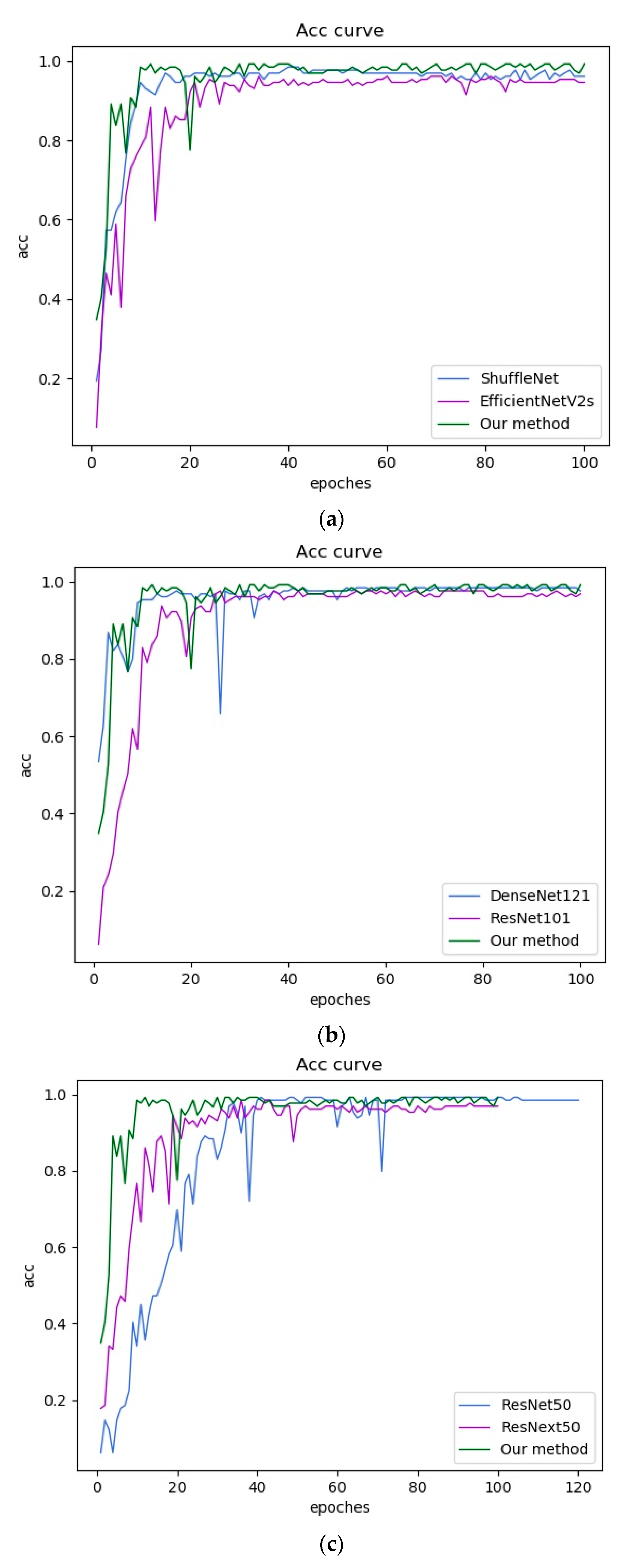
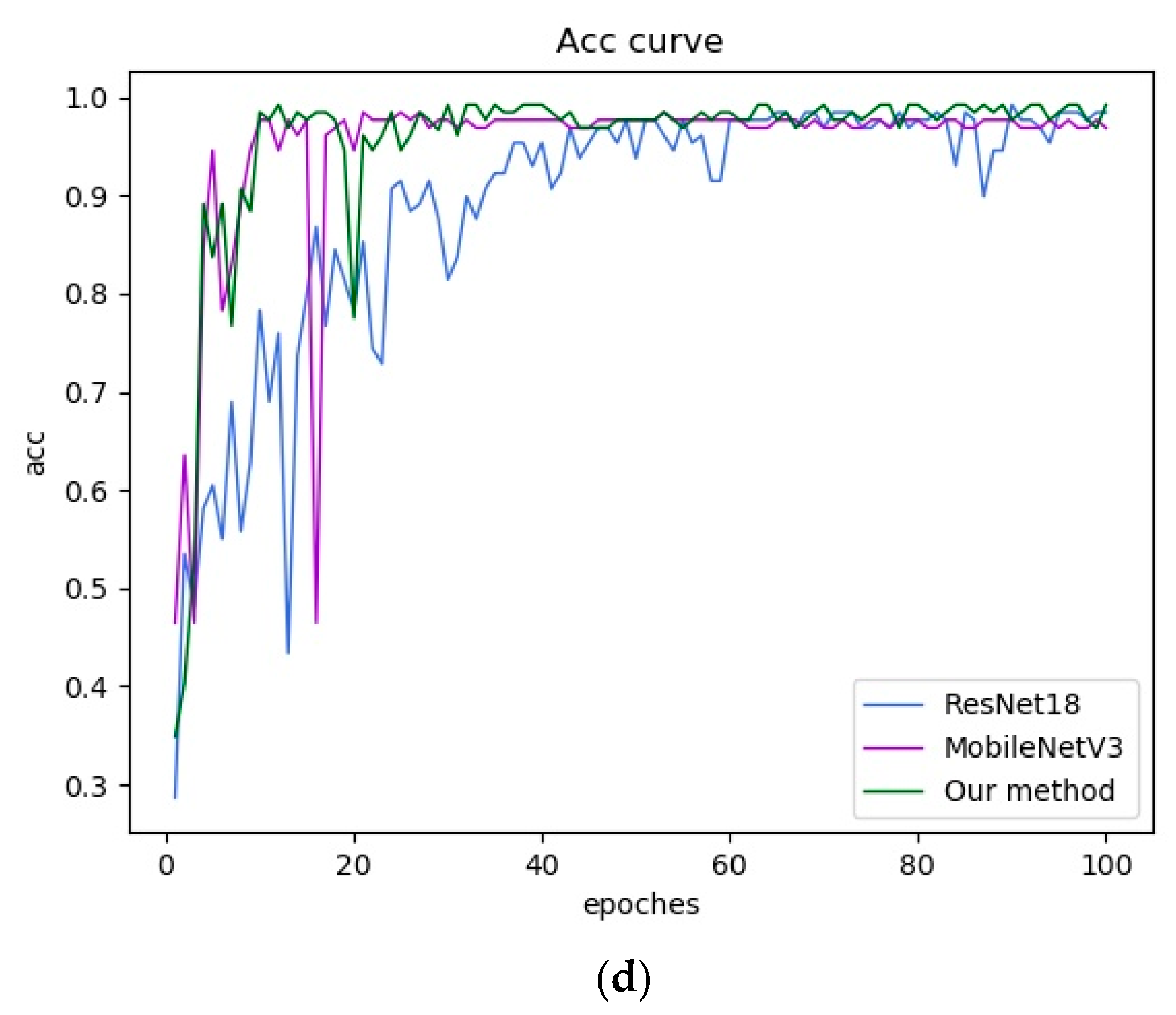
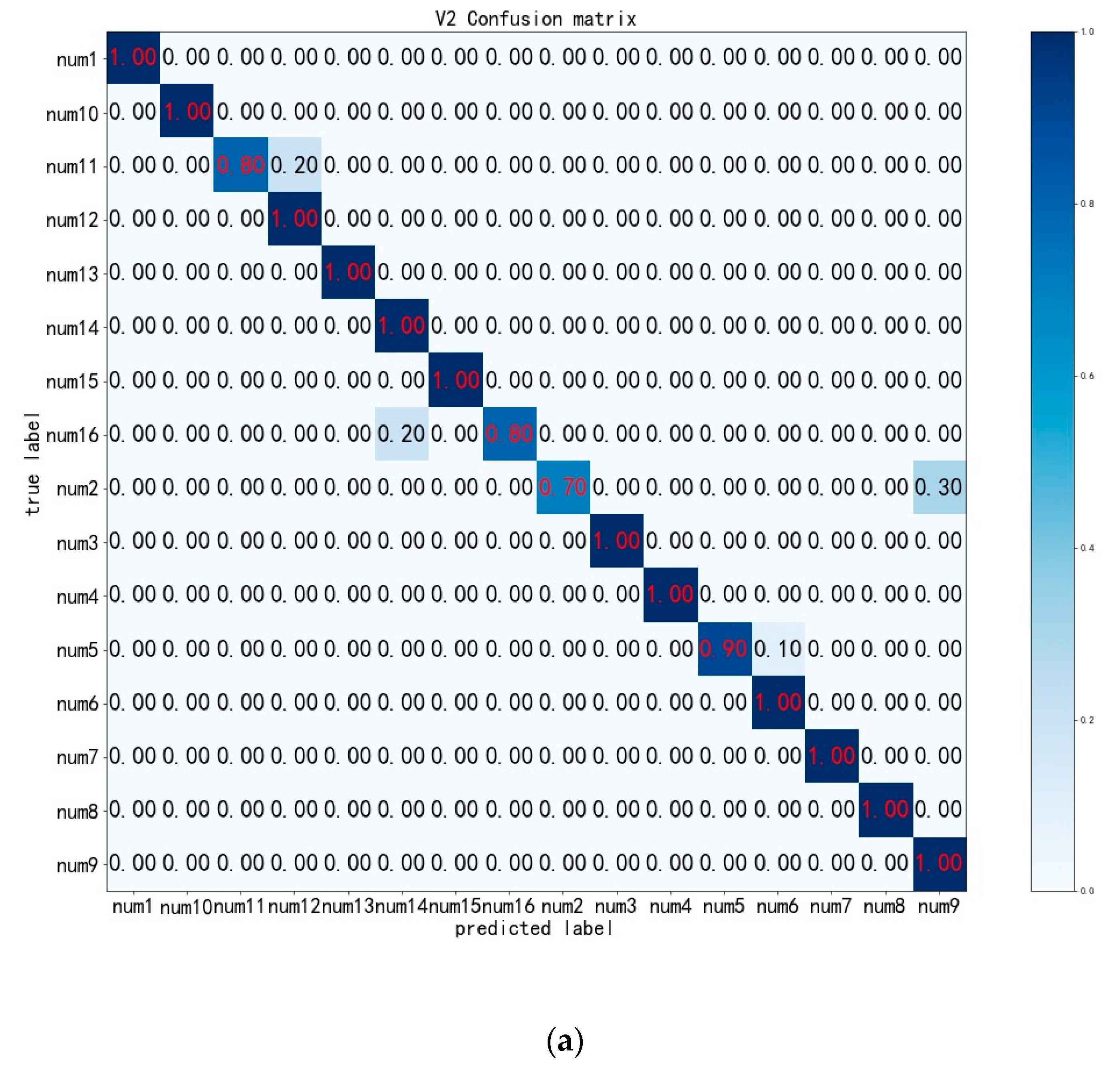
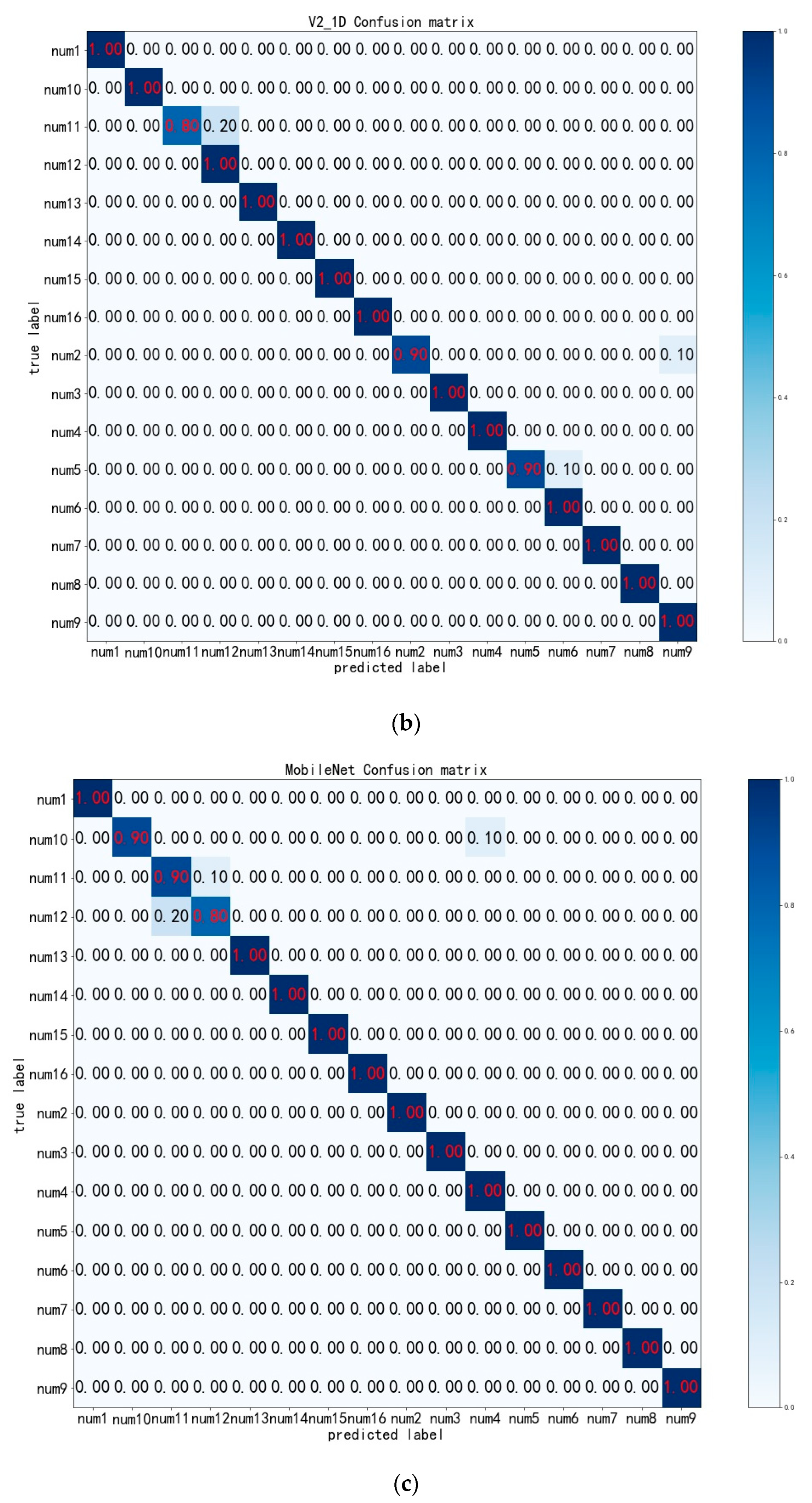
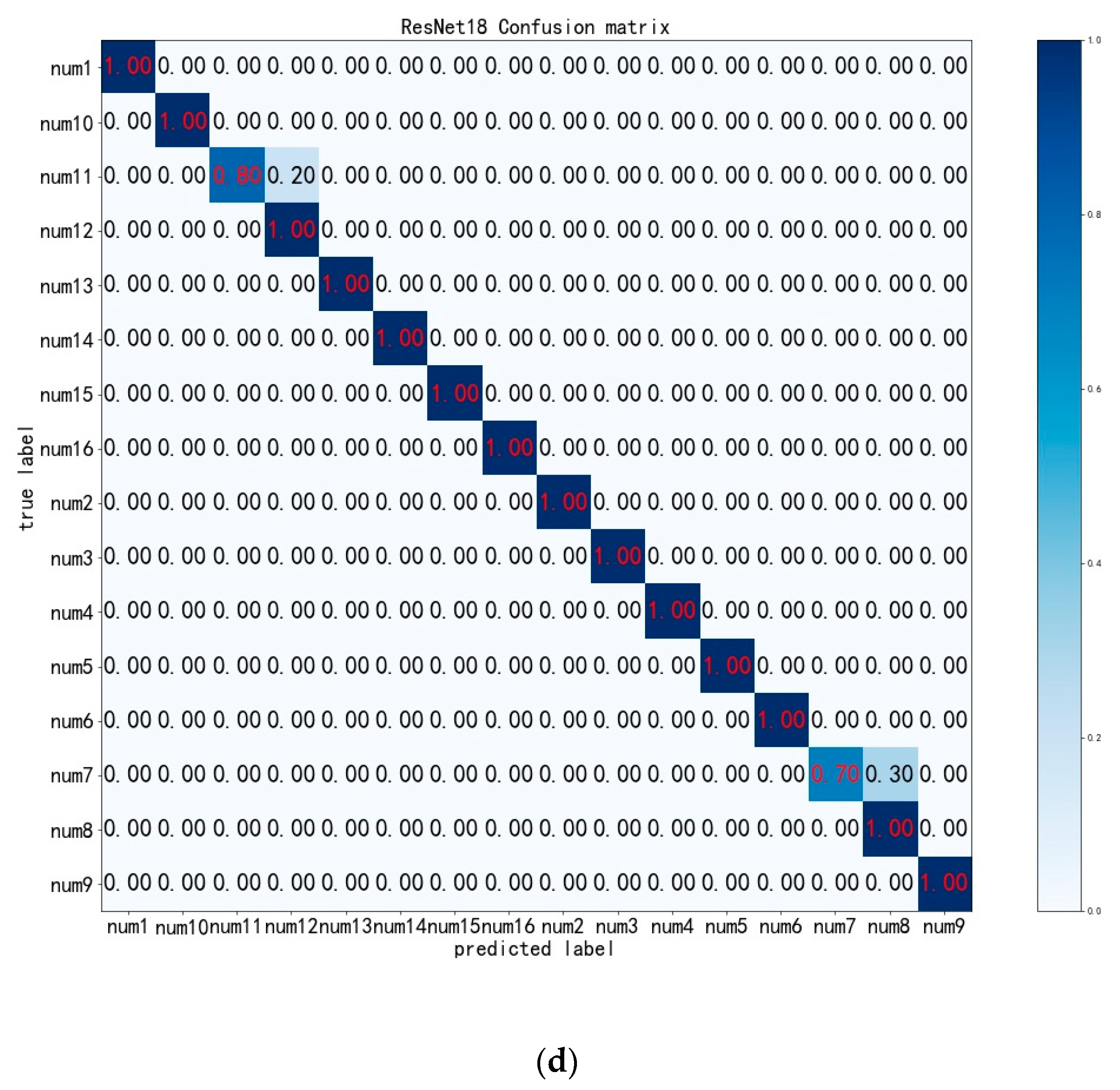
4.3. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tang, J.-R.; Zhu, Y.-Q.; Xu, Q. Study of Radar Emitter Recognition by Using Neural Networks. J. Air Force Radar Acad. 2007, 21, 25–27. [Google Scholar]
- Wei, Q.; Ping, L.; Xu, F. An algorithm of signal sorting and recognition of phased array radars. In Proceedings of the IEEE 10th International Conference on Signal Processing Proceedings, Beijing, China, 24–28 October 2010. [Google Scholar]
- Hu, K.; Wang, H.-Y. Decision Tree Radar Emitter Recognition Based on Rough Set. Comput. Simul. 2011, 28, 4. [Google Scholar]
- Guan, X.; Guo, Q.; Zhang, Z.-C. Radar Emitter Signal Recognition Based on Kernel Function SVM. J. Proj. Rocket. Missiles Guid. 2011, 31, 4. [Google Scholar]
- Kvasnov, A. Methodology of classification and recognition the radar emission sources based on Bayesian programming. IET Radar Sonar Navig. 2020, 14, 1175–1182. [Google Scholar] [CrossRef]
- Xiao, W.; Wu, H.; Yang, C. Support vector machine radar emitter identification algorithm based on AP clustering. In Proceedings of the 2013 International Conference on Quality, Reliability, Risk, Maintenance, and Safety Engineering (QR2MSE), Chengdu, China, 15–18 July 2013. [Google Scholar]
- Zhu, X.-L.; Cai, Q.; Zhou, M.-L. Radar Radiation Source Identification Based on BP Neural Net and Bayes Reasoning. Shipboard Electron. Countermeas. 2012, 35, 4. [Google Scholar]
- Matuszewski, J.; Sikorska-Lukasiewicz, K. Neural network application for emitter identification. In Proceedings of the International Radar Symposium, Prague, Czech Republic, 28–30 June 2017; pp. 1–8. [Google Scholar]
- Liu, K.; Wang, J.-G. An Intelligent Recognition Method Based on Neural Network for Unknown Radar Emitter. Electron. Inf. Warf. Technol. 2013, 28, 5. [Google Scholar]
- Zhu, W.; Meng, L.; Zeng, C. Research on Online Learning of Radar emitter identification Based on Hull Vector. In Proceedings of the IEEE Second International Conference on Data Science in Cyberspace, Shenzhen, China, 26–29 June 2017. [Google Scholar]
- Tang, X.-J.; Chen, W.-G.; Xi, L.-F. The Radar Emitter Identification Algorithm Based on AdaBoost and Decision Tree. Electron. Inf. Warf. Technol. 2018, 33, 6. [Google Scholar]
- Jin, Q.; Wang, H.; Yang, K. Radar emitter identification based on EPSD-DFN. In Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018. [Google Scholar]
- Guo, Q.; Nan, P.; Wan, J. Signal classification method based on data mining for multi-mode radar. J. Syst. Eng. Electron. 2016, 27, 1010–1017. [Google Scholar] [CrossRef]
- Tang, J.; Zhu, J.; Zhao, Y. Automatic recognition of radar signals based on time-frequency image character. In Proceedings of the IET International Radar Conference 2013, Xi’an, China, 14–16 April 2013. [Google Scholar]
- Wu, J.-C.; Qu, Z.-Y.; Chen, X. Radar emitter signal recognition method based on time-frequency energy distribution. J. Air Force Early Warn. Acad. 2020, 34, 4. [Google Scholar]
- Tavakoli, E.T.; Falahati, A. Radar Signal Recognition by CWD Picture Features. Int. J. Commun. Netw. Syst. Sci. 2012, 5, 238–242. [Google Scholar] [CrossRef]
- Liang, H.; Han, J. Sorting Radar Signal Based on Wavelet Characteristics of Wigner-Ville Distribution. J. Electron. 2013, 30, 454–462. [Google Scholar] [CrossRef]
- Ye, W.-Q.; Yu, Z.-F. Signal Recognition Method Based on Joint Time-Frequency Radiant Source. Electron. Inf. Warf. Technol. 2018, 33, 5. [Google Scholar]
- Lunden, J.; Koivunen, V. Automatic Radar Waveform Recognition. IEEE J. Sel. Top. Signal Process. 2007, 1, 124–136. [Google Scholar] [CrossRef]
- Xin, W.; Xu, W.; Wei, H. Radar Emitter Recognition Algorithm Based on Two-dimensional Feature Similarity Coefficient. Shipboard Electron. Countermeas. 2020, 43, 7. [Google Scholar]
- Hinton, G.E.; Osindero, S.; The, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Le, Q.-V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML 2019), Long Beach, CA, USA, 10–15 June 2019. [Google Scholar]
- Tan, M.; Le, Q.-V. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Jie, H.; Li, S.; Gang, S. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 42, 2011–2023. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Operator | Stride |
|---|---|---|
| 0 | Conv1D, k = 3 | 2 |
| 1 | Fused-MBConv1D1, k = 3 | 1 |
| 2 | Fused-MBConv1D4, k = 3 | 2 |
| 3 | Fused-MBConv1D4, k = 3 | 2 |
| 4 | MBConv1D4, k = 3, SE | 2 |
| 5 | MBConv1D6, k = 3, SE | 1 |
| 6 | MBConv1D6, k = 3, SE | 2 |
| 7 | Conv1D, k = 1 and Pooling and FC | - |
| Method | Input Size | FLOPs | Top1 Accuracy | Top5 Accuracy |
|---|---|---|---|---|
| MobileNetV3 | 224 * 224 | 0.059 G | 97.96 ± 0.05% | 100% |
| ResNet-18 | 224 * 224 | 1.740 G | 96.89 ± 0.15% | 100% |
| ResNet-50 | 224 * 224 | 3.798 G | 96.87 ± 0.25% | 100% |
| ResNet-101 | 224 * 224 | 7.521 G | 96.87 ± 0.25% | 99.3 ± 0.2% |
| ResNeXt-50 | 224 * 224 | 6.658 G | 95.62 ± 0.15% | 100% |
| DenseNet-121 | 224 * 224 | 2.787 G | 96.87 ± 0.05% | 100% |
| ShuffleNet | 224 * 224 | 0.142 G | 95.00 ± 0.15% | 100% |
| EfficientNetv2-s | 224 * 224 | 5.342 G | 95.00 ± 0.15% | 100% |
| Our method | 224 * 224 | 0.212 G | 98.12 ± 0.25% | 100% |
| Method | Params |
|---|---|
| MobileNetV3 | 1.85 M |
| ResNet-18 | 11.17 M |
| ResNet-50 | 37.59 M |
| ResNet-101 | 23.53 M |
| ResNeXt-50 | 42.53 M |
| DenseNet-121 | 7.97 M |
| ShuffleNet | 1.26 M |
| EfficientNetv2-s | 20.21 M |
| Our method | 19.47 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Li, K.; Zheng, Y.; Li, X.; Mao, Y. Radar Spectrum Image Classification Based on Deep Learning. Electronics 2023, 12, 2110. https://doi.org/10.3390/electronics12092110
Sun Z, Li K, Zheng Y, Li X, Mao Y. Radar Spectrum Image Classification Based on Deep Learning. Electronics. 2023; 12(9):2110. https://doi.org/10.3390/electronics12092110
Chicago/Turabian StyleSun, Zhongsen, Kaizhuang Li, Yu Zheng, Xi Li, and Yunlong Mao. 2023. "Radar Spectrum Image Classification Based on Deep Learning" Electronics 12, no. 9: 2110. https://doi.org/10.3390/electronics12092110
APA StyleSun, Z., Li, K., Zheng, Y., Li, X., & Mao, Y. (2023). Radar Spectrum Image Classification Based on Deep Learning. Electronics, 12(9), 2110. https://doi.org/10.3390/electronics12092110