
Integrating Relational Structure to Heterogeneous Graph for Chinese NL2SQL Parsers

Abstract
1. Introduction
- We propose a novel method for Chinese cross-domain NL2SQL based on a heterogeneous graph and relative position attention mechanism, which has the advantage of generality across databases compared with previous works.
- We design a graph-pruning task to prune the heterogeneous graph based on natural language questions for better utilization.
- The empirical results show that our method achieves better performance on the challenging CSpider benchmarks.
2. Related Work
2.1. Natural Language to SQL
2.1.1. Question and Database Schema Joint Encoding
2.1.2. Structured Query Language Decoding
2.1.3. Pre-Trained Word Representation Enhancement
2.2. Heterogeneous Graph Neural Networks
3. Methodology
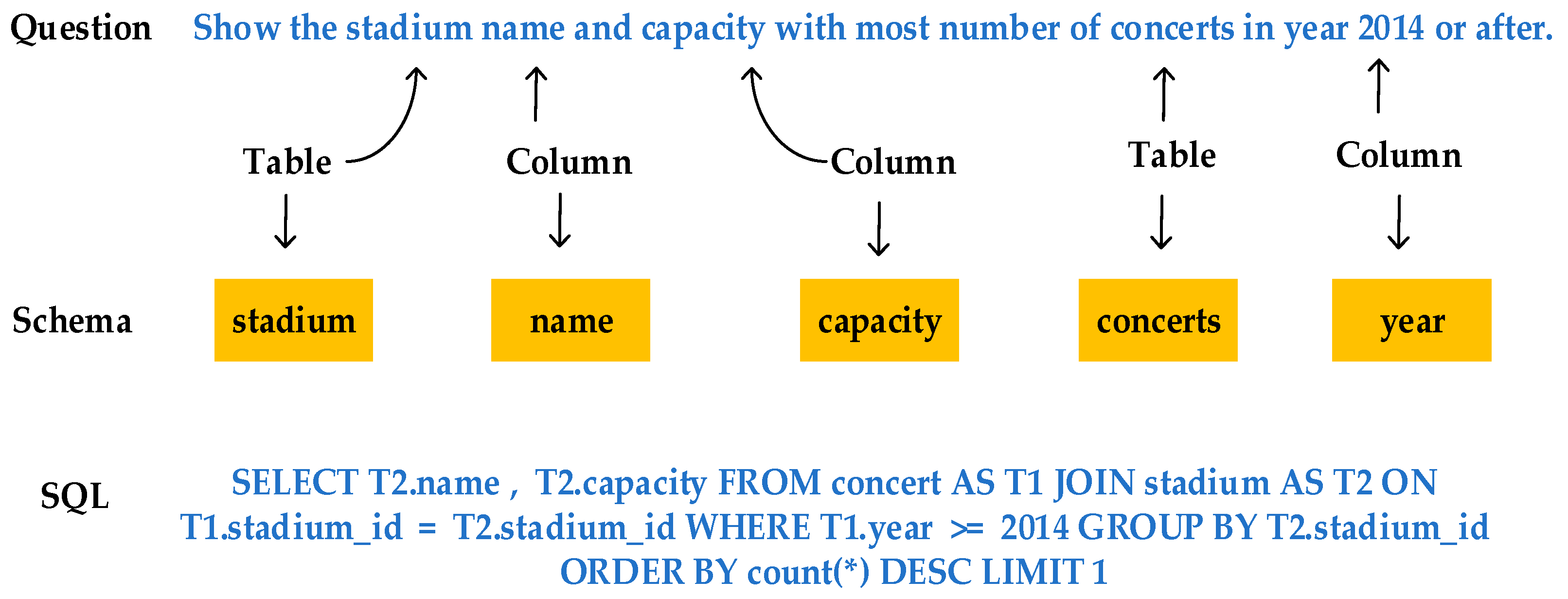
3.1. Problem Definition
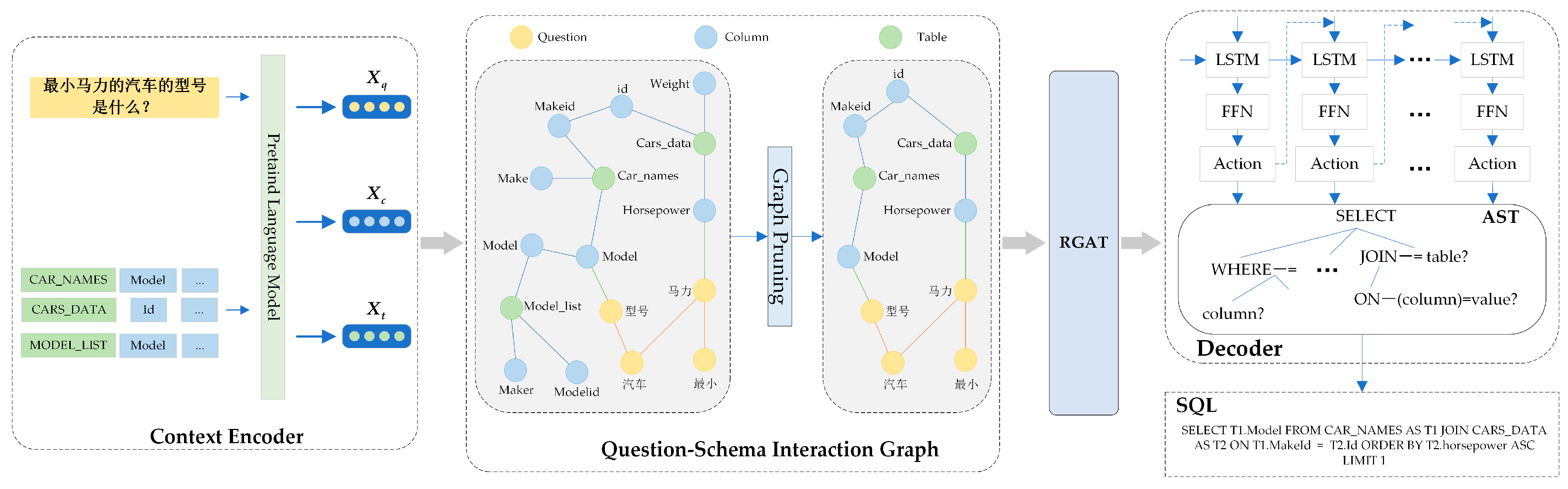
3.2. Architecture of the Proposed Model
3.2.1. Context Encoder
3.2.2. Question–Schema Interaction Graph
- 1.
- Schema Structure
- 2.
- Schema Linking
- 3.
- Question Dependency Structure
3.2.3. Relation-Aware Graph Encoder
3.2.4. Graph Pruning
3.2.5. Decoder
4. Experiments
4.1. Dataset
4.2. Evaluation Metrics
4.3. Parameter Setting
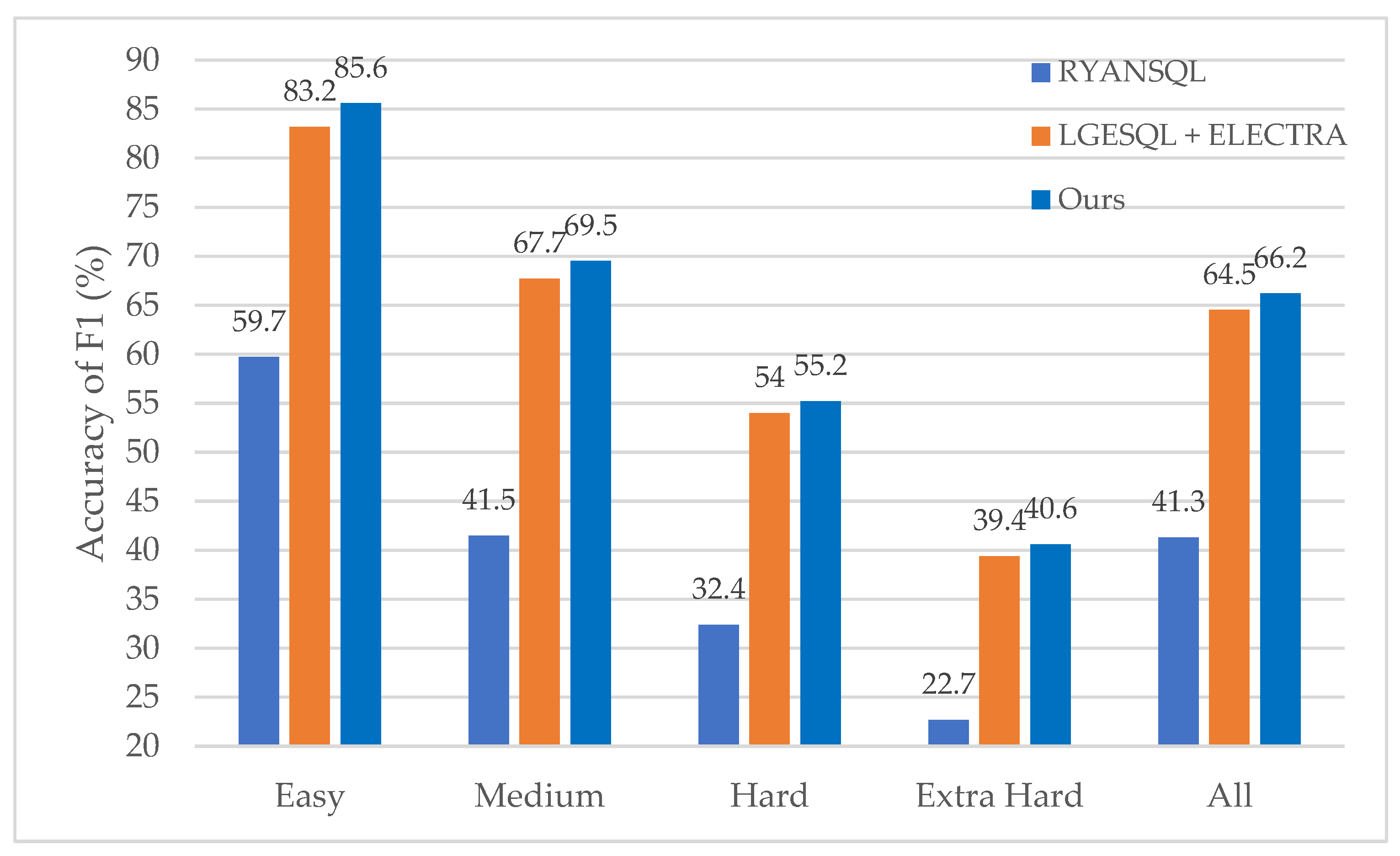
4.4. Model Comparisons
4.5. Ablation Study
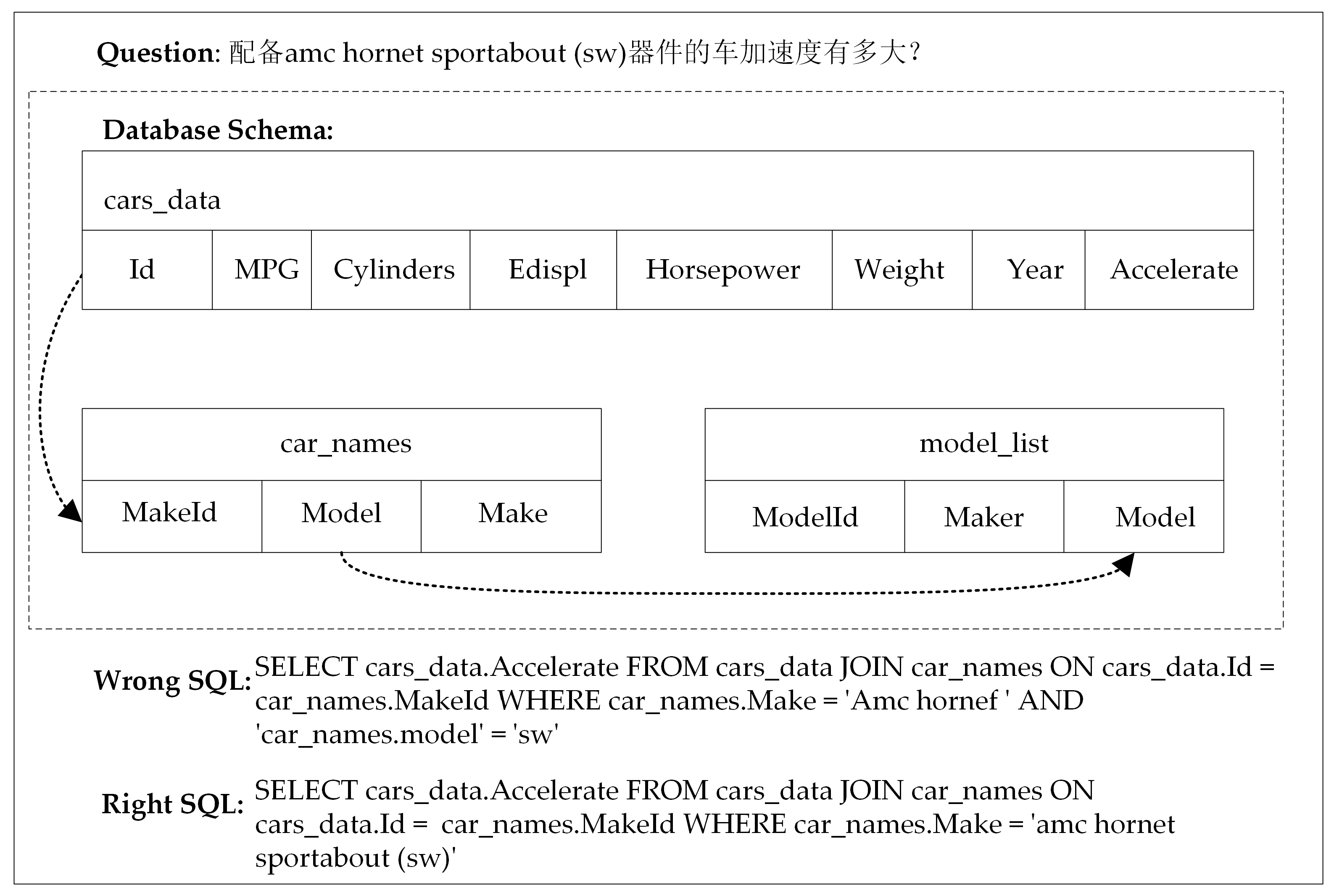
4.6. Case Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Katsogiannis-Meimarakis, G.; Koutrika, G. A Survey on Deep Learning Approaches for Text-to-SQL. VLDB J. 2023, 1–32. [Google Scholar] [CrossRef]
- Codd, E.F. A Relational Model of Data for Large Shared Data Banks. Commun. ACM 1970, 13, 377–387. [Google Scholar] [CrossRef]
- Chamberlin, D.D.; Astrahan, M.M.; Eswaran, K.P.; Griffiths, P.P.; Lorie, R.A.; Mehl, J.W.; Reisner, P.; Wade, B.W. SEQUEL 2: A Unified Approach to Data Definition, Manipulation, and Control. IBM J. Res. Dev. 1976, 20, 560–575. [Google Scholar] [CrossRef]
- Zhou, G.; Luo, P.; Cao, R.; Xiao, Y.; Lin, F.; Chen, B.; He, Q. Tree-Structured Neural Machine for Linguistics-Aware Sentence Generation. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Wang, B.; Titov, I.; Lapata, M. Learning Semantic Parsers from Denotations with Latent Structured Alignments and Abstract Programs. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 3772–3783. [Google Scholar]
- Wang, B.; Shin, R.; Liu, X.; Polozov, O.; Richardson, M. RAT-SQL: Relation-Aware Schema Encoding and Linking for Text-to-SQL Parsers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Cedarville, OH, USA, 2020; pp. 7567–7578. [Google Scholar]
- Cao, R.; Chen, L.; Chen, Z.; Zhao, Y.; Zhu, S.; Yu, K. LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 1–6 August 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 2541–2555. [Google Scholar]
- A New Model for Learning in Graph Domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 2, pp. 729–734.
- Conneau, A.; Lample, G. Cross-Lingual Language Model Pretraining. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Wallach, H., Larochelle, H., Beygelzimer, A., dAlché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Baxter, I.D.; Yahin, A.; Moura, L.; Sant’Anna, M.; Bier, L. Clone Detection Using Abstract Syntax Trees. In Proceedings of the International Conference on Software Maintenance (Cat. No. 98CB36272), Bethesda, MD, USA, 20 November 1998; IEEE: Piscataway, NJ, USA, 1998; pp. 368–377. [Google Scholar]
- Min, Q.; Shi, Y.; Zhang, Y. A Pilot Study for Chinese SQL Semantic Parsing. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 3650–3656. [Google Scholar]
- Katsogiannis-Meimarakis, G.; Koutrika, G. A Deep Dive into Deep Learning Approaches for Text-to-SQL Systems. In Proceedings of the 2021 International Conference on Management of Data, Virtual Event China, 9 June 2021; ACM: New York, NY, USA, 2021; pp. 2846–2851. [Google Scholar]
- Guo, J.; Zhan, Z.; Gao, Y.; Xiao, Y.; Lou, J.-G.; Liu, T.; Zhang, D. Towards Complex Text-to-SQL in Cross-Domain Database with Intermediate Representation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 4524–4535. [Google Scholar]
- Yu, T.; Li, Z.; Zhang, Z.; Zhang, R.; Radev, D. TypeSQL: Knowledge-Based Type-Aware Neural Text-to-SQL Generation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Cedarville, OH, USA, 2018; pp. 588–594. [Google Scholar]
- Bogin, B.; Gardner, M.; Berant, J. Global Reasoning over Database Structures for Text-to-SQL Parsing. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Cedarville, OH, USA, 2019; pp. 3657–3662. [Google Scholar]
- Chen, Z.; Chen, L.; Zhao, Y.; Cao, R.; Xu, Z.; Zhu, S.; Yu, K. ShadowGNN: Graph Projection Neural Network for Text-to-SQL Parser. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 5567–5577. [Google Scholar]
- Yin, P.; Neubig, G. A Syntactic Neural Model for General-Purpose Code Generation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Cedarville, OH, USA, 2017; pp. 440–450. [Google Scholar]
- Rubin, O.; Berant, J. SmBoP: Semi-Autoregressive Bottom-up Semantic Parsing. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 311–324. [Google Scholar]
- Scholak, T.; Schucher, N.; Bahdanau, D. PICARD: Parsing Incrementally for Constrained Auto-Regressive Decoding from Language Models. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 9895–9901. [Google Scholar]
- Yu, T.; Zhang, R.; Yang, K.; Yasunaga, M.; Wang, D.; Li, Z.; Ma, J.; Li, I.; Yao, Q.; Roman, S.; et al. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Cedarville, OH, USA, 2018; pp. 3911–3921. [Google Scholar]
- Yu, T.; Wu, C.-S.; Lin, X.V.; Wang, B.; Tan, Y.C.; Yang, X.; Radev, D.; Socher, R.; Xiong, C. GraPPa: Grammar-Augmented Pre-Training for Table Semantic Parsing. arXiv 2021, arXiv:2009.13845. [Google Scholar]
- Shi, P.; Ng, P.; Wang, Z.; Zhu, H.; Li, A.H.; Wang, J.; dos Santos, C.N.; Xiang, B. Learning Contextual Representations for Semantic Parsing with Generation-Augmented Pre-Training. arXiv 2020, arXiv:2012.10309. [Google Scholar] [CrossRef]
- Liu, Q.; Chen, B.; Guo, J.; Ziyadi, M.; Lin, Z.; Chen, W.; Lou, J.-G. TAPEX: Table Pre-Training via Learning a Neural SQL Executor. arXiv 2022, arXiv:2107.07653. [Google Scholar]
- Zeng, Y.; Li, Z.; Tang, Z.; Chen, Z.; Ma, H. Heterogeneous Graph Convolution Based on In-Domain Self-Supervision for Multimodal Sentiment Analysis. Expert Syst. Appl. 2023, 213, 119240. [Google Scholar] [CrossRef]
- Mo, X.; Tang, R.; Liu, H. A Relation-Aware Heterogeneous Graph Convolutional Network for Relationship Prediction. Inf. Sci. 2023, 623, 311–323. [Google Scholar] [CrossRef]
- Fei, H.; Wu, S.; Ren, Y.; Zhang, M. Matching Structure for Dual Learning. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S., Eds.; PMLR. Volume 162, pp. 6373–6391. [Google Scholar]
- Fang, Y.; Li, X.; Ye, R.; Tan, X.; Zhao, P.; Wang, M. Relation-Aware Graph Convolutional Networks for Multi-Relational Network Alignment. ACM Trans. Intell. Syst. Technol. 2023, 14, 37. [Google Scholar] [CrossRef]
- Fei, H.; Li, F.; Li, B.; Ji, D. Encoder-Decoder Based Unified Semantic Role Labeling with Label-Aware Syntax. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 2–9 February 2021; Volume 35, pp. 12794–12802. [Google Scholar]
- Wu, S.; Fei, H.; Li, F.; Zhang, M.; Liu, Y.; Teng, C.; Ji, D. Mastering the Explicit Opinion-Role Interaction: Syntax-Aided Neural Transition System for Unified Opinion Role Labeling. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; Volume 36, pp. 11513–11521. [Google Scholar]
- Yu, B.; Mengge, X.; Zhang, Z.; Liu, T.; Yubin, W.; Wang, B. Learning to Prune Dependency Trees with Rethinking for Neural Relation Extraction. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; International Committee on Computational Linguistics: Praha, Czech Republic, 2020; pp. 3842–3852. [Google Scholar]
- Yu, S.; Mazaheri, A.; Jannesari, A. Topology-Aware Network Pruning Using Multi-Stage Graph Embedding and Reinforcement Learning. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; Chaudhuri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S., Eds.; PMLR. Volume 162, pp. 25656–25667. [Google Scholar]
- Fei, H.; Wu, S.; Li, J.; Li, B.; Li, F.; Qin, L.; Zhang, M.; Zhang, M.; Chua, T.-S. LasUIE: Unifying Information Extraction with Latent Adaptive Structure-Aware Generative Language Model. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2022; Volume 35, pp. 15460–15475. [Google Scholar]
- Wang, K.; Shen, W.; Yang, Y.; Quan, X.; Wang, R. Relational Graph Attention Network for Aspect-Based Sentiment Analysis. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Cedarville, OH, USA, 2020; pp. 3229–3238. [Google Scholar]
- Forta, B. Sams Teach Yourself SQL in 10 Minutes; Pearson Education: London, UK, 2013; ISBN 0-672-33607-3. [Google Scholar]
- Qi, J.; Tang, J.; He, Z.; Wan, X.; Cheng, Y.; Zhou, C.; Wang, X.; Zhang, Q.; Lin, Z. RASAT: Integrating Relational Structures into Pretrained Seq2Seq Model for Text-to-SQL. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; Association for Computational Linguistics: Cedarville, OH, USA, 2022; pp. 3215–3229. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-Attention with Relative Position Representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018; Association for Computational Linguistics: Cedarville, OH, USA, 2018; pp. 464–468. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Li, L.; Geng, R.; Li, B.; Ma, C.; Yue, Y.; Li, B.; Li, Y. Graph-to-Text Generation with Dynamic Structure Pruning. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; International Committee on Computational Linguistics: Praha, Czech Republic, 2022; pp. 6115–6127. [Google Scholar]
- Popescu, A.-M.; Etzioni, O.; Kautz, H. Towards a Theory of Natural Language Interfaces to Databases. In Proceedings of the 8th International Conference on Intelligent User Interfaces, Miami, FL, USA, 12–15 January 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 149–157. [Google Scholar]
- Tang, L.R.; Mooney, R.J. Automated Construction of Database Interfaces: Intergrating Statistical and Relational Learning for Semantic Parsing. In Proceedings of the 2000 Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora, Hong Kong, China, 7–8 October 2000; Association for Computational Linguistics: Cedarville, OH, USA, 2000; pp. 133–141. [Google Scholar]
- Zelle, J.M.; Mooney, R.J. Learning to Parse Database Queries Using Inductive Logic Programming. In Proceedings of the Thirteenth National Conference on Artificial Intelligence—Volume 2, Portland, OR, USA, 4–8 August 1996; AAAI Press: Washington, DC, USA, 1996; pp. 1050–1055. [Google Scholar]
- Iyer, S.; Konstas, I.; Cheung, A.; Krishnamurthy, J.; Zettlemoyer, L. Learning a Neural Semantic Parser from User Feedback. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Cedarville, OH, USA, 2017; pp. 963–973. [Google Scholar]
- Li, F.; Jagadish, H.V. Constructing an Interactive Natural Language Interface for Relational Databases. Proc. VLDB Endow. 2014, 8, 73–84. [Google Scholar] [CrossRef]
- Yaghmazadeh, N.; Wang, Y.; Dillig, I.; Dillig, T. SQLizer: Query Synthesis from Natural Language. Proc. ACM Program. Lang. 2017, 1, 63. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.; Bethard, S.J.; McClosky, D. The Stanford CoreNLP Natural Language Processing Toolkit. In Proceedings of the Association for Computational Linguistics (ACL) System Demonstrations, Baltimore, MD, USA, 22–27 June 2014; pp. 55–60. [Google Scholar]
- Gal, Y.; Ghahramani, Z. A Theoretically Grounded Application of Dropout in Recurrent Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: Red Hook, NY, USA, 2016; Volume 29. [Google Scholar]
- Yu, T.; Yasunaga, M.; Yang, K.; Zhang, R.; Wang, D.; Li, Z.; Radev, D. SyntaxSQLNet: Syntax Tree Networks for Complex and Cross-Domain Text-to-SQL Task. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Cedarville, OH, USA, 2018; pp. 1653–1663. [Google Scholar]
- Choi, D.; Shin, M.C.; Kim, E.; Shin, D.R. RYANSQL: Recursively Applying Sketch-Based Slot Fillings for Complex Text-to-SQL in Cross-Domain Databases. Comput. Linguist. 2021, 47, 309–332. [Google Scholar] [CrossRef]
- Wang, B.; Lapata, M.; Titov, I. Meta-Learning for Domain Generalization in Semantic Parsing. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; Association for Computational Linguistics: Cedarville, OH, USA, 2021; pp. 366–379. [Google Scholar]
- Clark, K.; Luong, M.-T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-Training Text Encoders as Discriminators Rather than Generators. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. OpenReview.net; 2020. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Node A | Node B | Edge Label |
|---|---|---|
| Column | Column | Same-Table |
| Foreign-F | ||
| Foreign -R | ||
| Column | Table | Primary-Key |
| Has | ||
| Table | Table | Foreign-Key-Tab-F |
| Foreign-Key-Tab-R | ||
| Foreign-Key-Tab-B | ||
| Question | Table | None-Linking |
| Partial-Linking | ||
| Exact-Linking | ||
| Question | Column | None-Linking |
| Partial-Linking | ||
| Exact-Linking | ||
| Value-Linking | ||
| Question | Question | Syntax-F |
| Syntax-R | ||
| Syntax-None |
| CSpider | # Q | # SQL | # DB | # Table/DB | |
| all | 9691 | 5263 | 166 | 5.28 | |
| train | 6831 | 3493 | 99 | 5.38 | |
| dev | 954 | 589 | 25 | 4.16 | |
| test | 1906 | 1193 | 42 | 5.69 |
| Model | EM (%) |
|---|---|
| SyntaxSQLNet | 16.4 |
| RYANSQL | 41.3 |
| RAT-SQL | 41.4 |
| DG-SQL | 50.4 |
| LGESQL | 58.6 |
| RAT-SQL + GraPPa | 59.7 |
| LGESQL + Infoxlm | 61.0 |
| LGESQL + ELECTRA | 64.5 |
| Ours | 66.2 |
| Component | Easy (%) | Medium (%) | Hard (%) | Extra Hard (%) | All (%) |
|---|---|---|---|---|---|
| SELECT | 88.0 | 75.0 | 87.4 | 73.5 | 80.0 |
| WHERE | 79.6 | 65.2 | 52.7 | 46.9 | 62.5 |
| WHERE (no OP) | 80.6 | 68.0 | 65.9 | 55.9 | 68.1 |
| GROUP (no HAVING) | 78.3 | 78.6 | 78.6 | 73.7 | 77.2 |
| GROUP | 73.9 | 72.5 | 76.2 | 71.3 | 72.8 |
| ORDER | 60.0 | 68.4 | 78.2 | 78.0 | 73.0 |
| AND/OR | 99.6 | 98.0 | 96.7 | 92.5 | 97.3 |
| IUEN | - | - | 35.3 | 35.1 | 34.1 |
| KEYWORDS | 90.9 | 91.1 | 80.0 | 72.4 | 85.2 |
| Model | EM (%) |
|---|---|
| Ours | 66.2 |
| w/o GP | 65.9 |
| w/o RS | 65.5 |
| w/o RS+GP | 64.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, C.; Zhang, W.; Huang, M.; Feng, S.; Wu, Y. Integrating Relational Structure to Heterogeneous Graph for Chinese NL2SQL Parsers. Electronics 2023, 12, 2093. https://doi.org/10.3390/electronics12092093
Ma C, Zhang W, Huang M, Feng S, Wu Y. Integrating Relational Structure to Heterogeneous Graph for Chinese NL2SQL Parsers. Electronics. 2023; 12(9):2093. https://doi.org/10.3390/electronics12092093
Chicago/Turabian StyleMa, Changzhe, Wensheng Zhang, Mengxing Huang, Siling Feng, and Yuanyuan Wu. 2023. "Integrating Relational Structure to Heterogeneous Graph for Chinese NL2SQL Parsers" Electronics 12, no. 9: 2093. https://doi.org/10.3390/electronics12092093
APA StyleMa, C., Zhang, W., Huang, M., Feng, S., & Wu, Y. (2023). Integrating Relational Structure to Heterogeneous Graph for Chinese NL2SQL Parsers. Electronics, 12(9), 2093. https://doi.org/10.3390/electronics12092093