1. Introduction
Neurodegenerative diseases such as Alzheimer’s disease, Parkinson’s disease, and multiple sclerosis are chronic and progressive disorders that are characterized by the gradual and ongoing death of neurons, leading to a variety of motor and cognitive symptoms that can significantly impact a patient’s quality of life. Parkinson’s disease, in particular, has both motor and non-motor symptoms, with freezing of gait (FoG) being a significant and persistent symptom that can result in decreased mobility and an increased risk of falls.
Diagnosis of Parkinson’s disease typically relies on score-based tests that evaluate the progression of symptoms, including motor and cognitive functions. These tests can include the Unified Parkinson’s Disease Rating Scale (UPDRS) and the Movement Disorder Society-Unified Parkinson’s Disease Rating Scale (MDS-UPDRS). FoG is a challenging symptom to diagnose and monitor due to its unpredictable nature. Therefore, continuous monitoring is necessaryto identify the optimal course of treatment that can minimize the effects of the condition on the patient’s daily activities and overall mobility. Recent advances in smart phones have enabled the use of sensors such as accelerometers to detect and monitor FoG and provide real-time feedback on gait patterns. The ability to provide continuous monitoring and collect data can assist clinicians in comprehending the frequency and intensity of FoG episodes, thereby enabling them to effectively customize treatment plans.
Moreover, automatically identifying FoG episodes can significantly reduce the workload of medical personnel, who previously had to manually review video footage of each patient. Additionally, it can provide valuable analytics and early warning systems to alert caregivers when an episode occurs.
To predict FoG episodes, various methods have been proposed, such as fixed thresholds and advanced deep neural network models. Machine learning and deep learning techniques have shown better performance compared to other methods, despite the complexity of sensor readings and the unpredictable nature of FoG episodes [
1,
2,
3]. Specifically, several successful attempts have been made utilizing data derived from sensors and applying a selection of machine and deep learning methods in order to identify FoG episodes [
4,
5,
6,
7,
8,
9,
10]. Common architectures such as LSTMs, CNNs, and combinations of both have been used, and an inception based model was developed [
11]. Finally, most studies have not validated their methods across multiple datasets, providing no evidence that the suggested model’s performance would be consistent on other datasets.
This study presents a modified inception base framework with easily adjustable hyperparameters, providing a more generic approach to detect FoG episodes. Specifically, the immediate contributions of this work are as follows:
This paper is organized into several sections. In
Section 2, we present existing methodologies and the current state of the art in FoG detection.
Section 3 describes the datasets used in the study, as well as the proposed network architectures. Next, in
Section 4, we present the results of the conducted experiments and provide details about the proposed methodologies. Finally, in
Section 5, we provide concluding remarks on the study and highlight observations and recommendations for future research.
2. Related Work
The Daphnet dataset is a widely used benchmark dataset for the detection of FoG in individuals with Parkinson’s disease. It was developed as part of a study by Bachlin et al. [
13] and consists of data from three sensors measuring the gait of ten patients with Parkinson’s disease. Their proposed system for online detection of FoG was based on frequency components of movements and achieved sensitivity and specificity of 73.1% and 81.6%, respectively. Subsequent studies by the same authors showed potential to improve these metrics to 85.9% and 90.9%, respectively.Furthermore, the system provides auditory guidance and a distinct sound when an episode is detected.
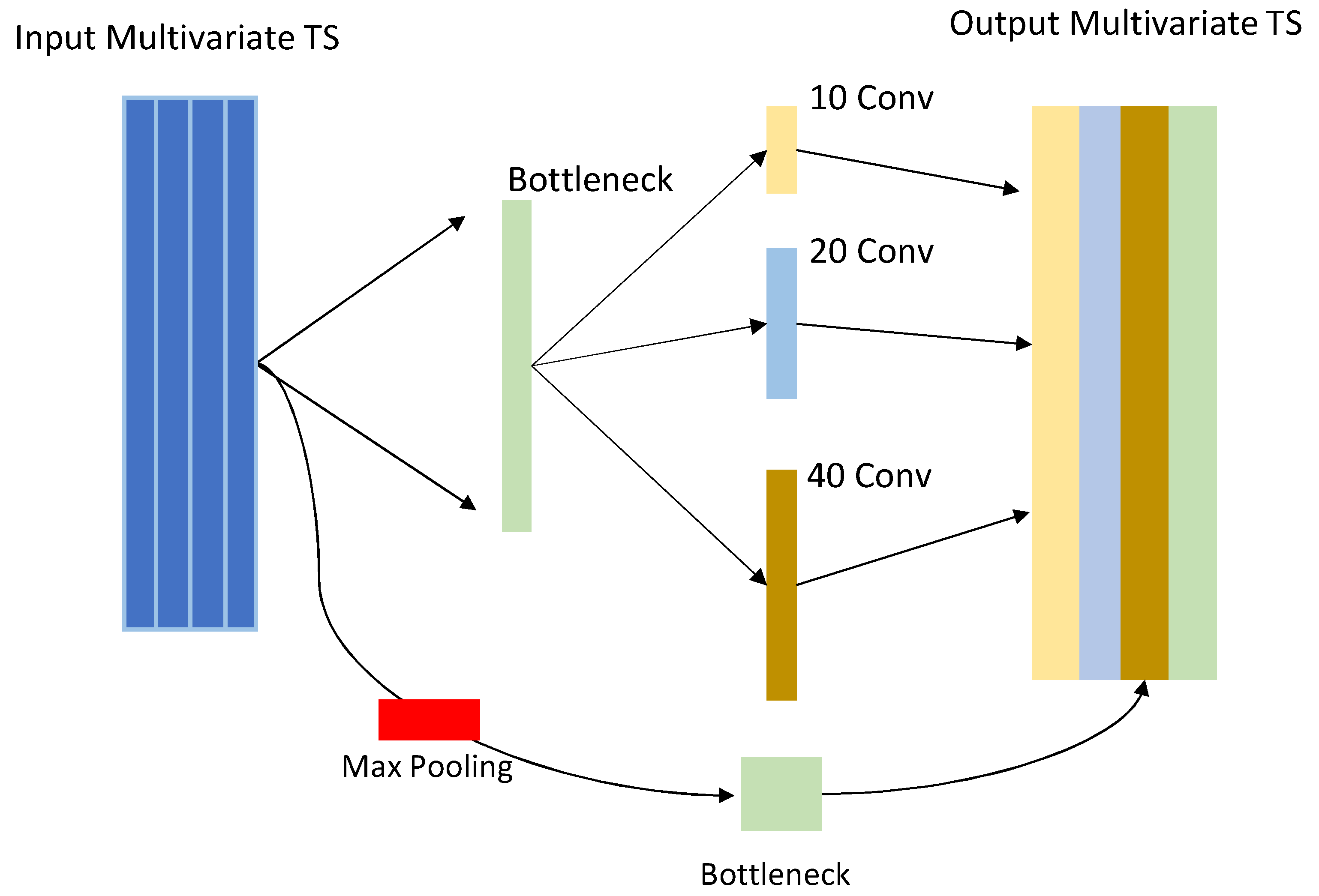
In [
11], the authors proposed a new deep learning architecture for FoG detection based on the Inception Res-net model introduced by Google, which utilizes 1D convolution and MaxPooling in parallel. The output is then fed to different convolution layers with varying dimensions and a 1x1 convolutional layer. To evaluate the performance of iSPLInception, tests were conducted on various human activity recognition datasets, including the Daphnet dataset, which was split into specific training, validation, and test sets. The iSPLInception model outperformed the other deep learning methodologies, with an F1 score of 94% on the test set.
Moreover, a deep learning model called DeepFoG was developed in [
4], for detection of freezing of gait (FoG) episodes in Parkinson’s disease patients using wrist-worn IMU sensors, which allows for the easy deployment of the proposed system. The authors compared their proposed methodology to decision trees and XGBoost and found that the DeepFoG model outperformed the other models, achieving 90% specificity and sensitivity on a 10-KFold validation and 88% and 83%, respectively for LOSO CV.
In [
14], the authors aimed to identify FoG episodes using the Daphnet dataset. They employed several machine learning models, along with different preprocessing steps, achieving an improvement in sensitivity compared to the literature. They reported that the best overall model was an ensemble method, but it is unclear whether the impact of the prepossessing methods had any effects on performance.
Similarly, in [
5], different convolutional LSTM architectures were developed to identify FoG occurrences. The best model was composed of a combination of 1D convolutional layers, squeeze and excitation blocks, and attention-enhanced LSTM layers. The authors evaluated the performance of their model using two techniques: leave one subject out (LOSO) and 10-fold cross validation. Furthermore, they used data augmentation to balance FoG and non-FoG episodes, although the exact method used was not mentioned. The final results indicated that the proposed deep neural network can outperform the competition in terms of both sensitivity and specificity for the R10Fold and in AUC (0.945) for the LOSO validation.
Tautan et al. [
6] developed a similar approach to detect FoG episodes using the Daphnet dataset as in [
5]. They utilized a deep convolutional network based on AlexaNet. The network consisted of five 1D convolutional layers; three dense layers; and several dropout, batch normalization, and pooling layers. In this case, 10-KFold cross validation was used, with nine of the samples used for training and one used for testing. Overall, the best results were acquired from a balanced dataset, with the algorithm achieving a mean specificity of 83.77% and a mean sensitivity of 81.78%.
In [
15], an autoencoder was developed to denoise and enrich accelerometer and gyroscope data for FoG detection. The autoencoder consisted of 15 layers of 1D convolutional, max-pooling, and upsampling layers. The output of the autoencoder was used as input to several machine learning algorithms, including naive Bayes, SVMs, random forest, and ensemble models for FoG or non-FoG episode classification. The random forest model achieved the best performance, with a sensitivity of 90.94% and specificity of 67.04%, using a 2-s window and replacing extreme values in the signal with the mean of the time series (four-sigma rule).
Hssayeni et al. [
8] proposed a more sophisticated model than those presented in previous studies by employing an ensemble of models to predict motor performance, as measured by the UPDRS-III test. The dataset used in their study consisted of measurements taken from two sensors located on the wrist and ankle of 24 patients (PAMAP2). The authors employed three different models in their ensemble, including a dual-channel LSTM trained using transfer learning and two CNN-LSTMs (one using one-dimensional convolution and the other using two-dimensional convolution). In addition to the raw signal and frequency-related features, one of the models also included manually created features. The predictions of the three models were then averaged to produce the final UPDRS-III score. The evaluation metrics used were correlation and mean absolute error, which achieved
= 0.79 and 5.95, respectively. These results demonstrated that the ensemble models were highly effective in predicting the UPDRS score.
In [
9], a bidirectional LSTM network was used to predict the risk of falls in patients with multiple sclerosis using data from gyroscopic and accelerometer measurements collected from sensors placed on patients’ core and legs. They compared the performance of various machine learning models, and the best results were obtained with the Bi-LSTM model.
In ref. [
7], the authors utilized, two- and three-layer LSTMs to detect freezing-of-gait (FoG) episodes in Parkinson’s disease patients using plantar pressure data. The models were validated using one-freeze-held validation, and the two-layered LSTM was found to be superior.
Finally, the authors of ref. [
10] used transfer learning to develop LSTM models to predict FoG events in Parkinson’s disease patients using the Daphnet dataset. Their second scheme of transfer learning consistently outperformed the existing recurrent model, with an accuracy score over 90% in all prediction horizons and subjects’ training data percentages.
Most of the related works in this field rely on IMU sensors to identify Parkinson’s disease (PD)-related symptoms. However, other types of sensors are also capable of identifying these symptoms. For instance, Farhani et al. [
16] used data from 15 patients wearing an EMG sensor to train a Bi-LSTM. They employed a regularized evolutionary algorithm to set the hyperparameters of the model instead of doing so manually. Their objectives were to classify the tasks each patient was conducting and to detect PD-related tremors. Their results showed that the mean achieved accuracy for both tasks was over 84%, which is well above chance levels. Cole et al. [
17] used a similar type of sensor, in addition to accelerometer readings, to identify freezing-of-gait (FoG) episodes. They employed a DNN, which achieved a sensitivity of 83% and a specificity of 97% on a per-second basis.
Research shows that deep learning architectures have achieved significant success in detecting FoG episodes, especially when combined with certain preprocessing methods. Among the state-of-the-art architectures used for FoG detection, convolutional and recurrent neural networks are considered the most effective. Convolutional networks offer the advantage of automatically identifying and extracting features without the need for manual feature engineering. On the other hand, recurrent networks are able to capture long-term dependencies in the data and are therefore often effective predictors. In addition to these architectures, attention mechanisms are also commonly used to further weight the connections within the network. Combining all these methodologies can achieve state-of-the-art results, as demonstrated in a recent study [
5].
However, it is worth noting that the Daphnet dataset is commonly used as a benchmark in FoG detection research, despite being relatively small. There is a clear need for larger datasets with more patients to bridge this gap. A new dataset introduced by Ribeiro De Souza et al. [
12] containing data from IMU sensors from 35 patients aims to address this issue.
Moreover, it is observed that most studies employ a single dataset to evaluate their proposed model. It would be beneficial for future research to evaluate models on multiple datasets to ensure their effectiveness across different patient populations and settings.
The selection of IMU datasets was primarily influenced by their widespread availability in wearable devices, which allows for continuous monitoring of patients without requiring special equipment or environments. Medical advisors of the ALAMEDA project also recommended the use of a particular sensor due to the clinical focus of the project to investigate digital biomarkers using these type of sensors in home environments. Moreover, IMUs have been extensively used in previous studies to monitor Parkinson’s disease symptoms compared to other types of sensors [
18]. Finally, as mentioned before, a common issue for labeled PD datasets is the limited number of participants. This issue is observed less often in IMU datasets. For instance, in [
12], the IMU based dataset includes 35 patients, which is a relatively large sample compared to most datasets used for this purpose.
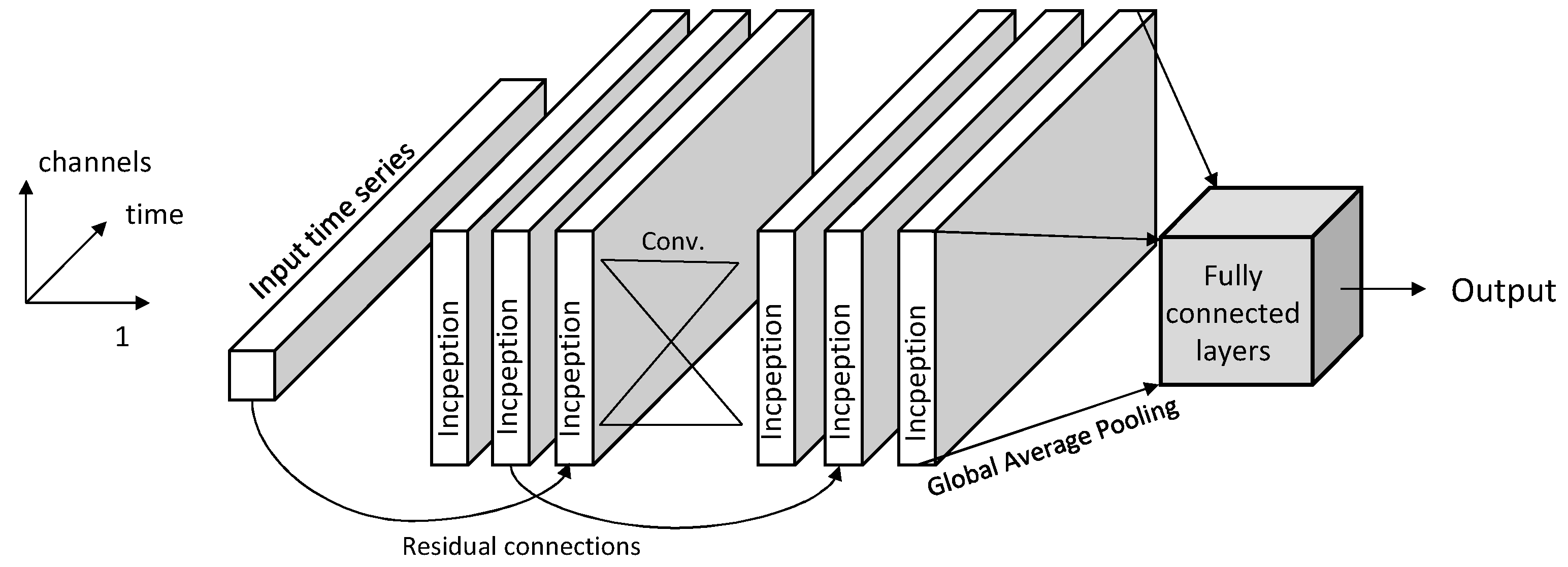
This study draws inspiration from the inception-based architecture presented in [
11], as well as successful convolution-based approaches. Furthermore, the reweight mechanism that was used in the literature drives us to include such a component in our proposed methodologies. An inception-based framework was created that is easily parameterized and adjusted to sensor-based datasets with very good performance, as we demonstrate herein. More specifically, we developed two models that improve upon the previously proposed inception module, making it more appropriate for smaller datasets and reducing the risk of overfitting by reducing the number of parameters while still capturing hierarchical dependencies. Additionally, the models employ squeeze and excitation techniques to reweight the convoluted channels based on the information they contain, resulting in improved performance. Finally, a previously unused dataset was used to validate the models’ effectiveness, combined with a well-established benchmark dataset.
4. Results
4.1. Performance of the Models on the Daphnet Dataset
As mentioned before, the particular split was unbalanced; thus, in order to enhance the learning ability of the model, an oversampling method was employed only in the training phase. Two ways of oversampling were selected: one using signal rotations by 90 degrees and another using signal permutations. The amount of examples generated from each method was set following a cumulative strategy; examples of the minority class are generated until they reach 20% using signal rotations and, an additional 10% is added using permutation. Overall, the minority class of the datasets reaches 30%. This procedure was only applied to the training dataset and not the test and validation sets.
The configurations of the two proposed models were determined after several runs based on empirical evaluation using the proposed metrics and are illustrated in
Table 4. Regarding the InSEption model, the framework and modules described in the previous section were used. More precisely, the final architecture consisted of six inception layers with the squeeze and excitation add-on followed by five dense to refine the information extracted from the convolutions. This network is quite deep and complex, which is needed to extract all useful information from all the different patient datasets. The loss function used was binary cross entropy, which is the most common function for binary classification purposes. The batch size for training of the network was 128, with a learning rate of 0.0001 utilizing the Adam optimizer and its momentum adjustments. For the later dense layers, the amount of dropout was set to 25%. Finally, to avoid overfitting, early stopping was used, measuring the error of the validation set and stopping the training phase when 70 consecutive epochs did not result in any improvement in loss reduction.
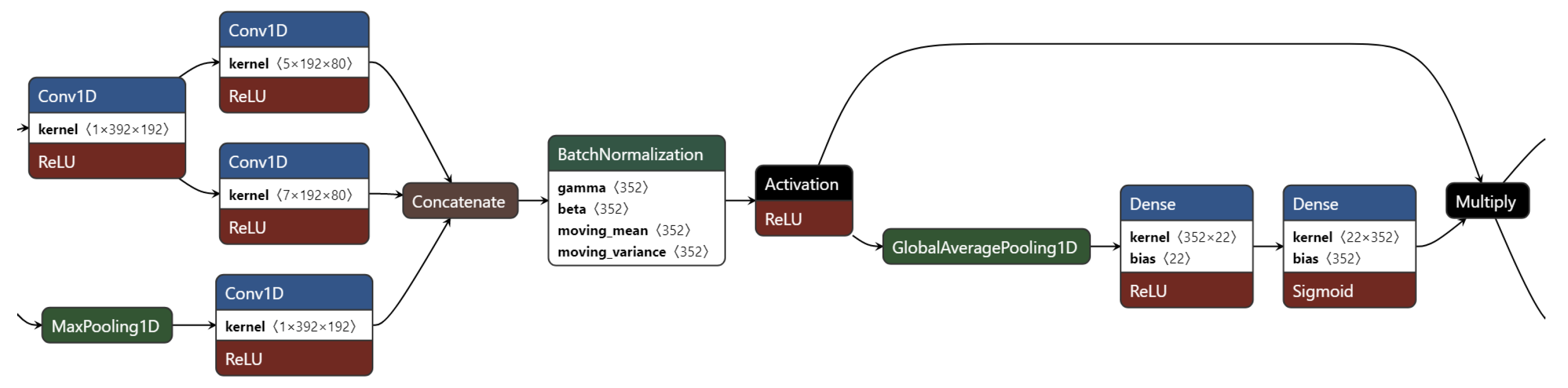
The most significant parts of the InSEption network, the inception module and its connection to the squeeze and excitation block, are shown in
Figure 5.
The parameters defined in the LN-Inception model are quite similar to InSEption after being validated by a series of experiments; again, six inception layers were used with 100, 80, 60, 40, 20, and 8 filters. Another five dense layers were added after, with 128, 64, 32, 16, and 8 neurons, respectively. The learning rate was 0.0001, and the dropout for the dense section of the network was 0.25. Finally, residual connections were included, but the initial bottleneck stage was excluded. The configuration is summed up in
Table 4. For model training, the batch size was set to 64, along with 5000 epochs, with early stopping after 70 epochs.
The CNN benchmark model and the LSTM model have similar configurations. The CNN layers in both models had sizes of 100-80-60-40-20-8, while the dense layers were 128-64-32-8-1. The batch size for the CNN model was 128, and the learning and dropout rates were set to 0.0001 and 0.25, respectively. The LSTM model had LSTM layers with sizes of 256-128-64-32-16-8 using a “tanh” activation function, and the batch size was set to 64. Both architectures are shown in
Table 5.
Regarding the results of the proposed models, F1 score was used as in the benchmark paper. The metrics were set up in the “micro” setting, which is similar to accuracy. However, accuracy for imbalanced datasets is not a suitable metric due to the increased weight that allocates to the majority class. Nevertheless, in order to compare our models with the particular inception-based model, this was necessary.
Comparing our methodologies with the existing method, it is evident that both Inception modifications perform better than the benchmark. In terms of accuracy or micro F1 score, the InSEption model outperforms the other two models 0.5%. However, the real improvement in performance is in terms of the macro F1 score, for which the proposed models reach 71% and 67%, meaning that they outperform the benchmark by 6% and 2%, respectively. Furthermore, in terms of precision and recall, the iSPLInception model fails to perform better than the proposed models. For the precision, which indicates the ability to retrieve relevant instances, the difference is 2% for the InSEption method, while for the recall, which measures the fraction of the total relevant items retrieved, there is a significant improvement by 5% when utilizing the InSEption network. Additionally, both benchmarks fail to be comparable with the inception-based models in terms of macro F1, precision, and recall, while in terms of micro F1 or accuracy, their results are closer to the best. However, due to the imbalances of the data, accuracy is not suitable to measure the performance, which we expect to be quite high. Finally, the CNN model seems to perform better than the LSTM model, reinforcing our initial strategy, which involves the development of an approach based on convolutions. The complete performance of the models can be found in
Table 6.
In conclusion, the impact of normalization, squeeze and excitation, and oversampling using more sophisticated and domain-specific methods is quite significant for this split. However, in order for these methods to perform even better, larger datasets are required.
4.2. Performance of the Models on the IMU Dataset
For comparison and evaluation purposes, a new dataset was utilized [
12]. The preprocessing procedure used was similar to that applied in the previous cases. The dates were concatenated into 2-second windows with an overlap of 16 observations in order to create enough examples from each patient. This process was repeated for each patient. The labels were generated again based on the most observed label in each segment. Finally, the datasets were concatenated together to create a single dataset.
For cross validation, a five-KFold was selected using the stratified KFold method to ensure that the proportions of each class were maintained in the subdatasets. This allowed for five different training and validation procedures to be conducted, with a more conventional split of 80% for training and validation and 20% for testing. Out of the 80% that was used for non-testing purposes, 10% comprised the validation set. The performance of the model was evaluated using three common metrics: specificity, sensitivity, and macro F1. These metrics provided insight into the model’s ability to correctly identify instances of each class and the overall balance between precision and recall.
Initially, tests were run on the imbalanced dataset without implementing any balancing techniques; however, the results were not up to the desired level of accuracy. To address this issue, additional samples were created specifically for training purposes using the methods described in
Section 4. The inverse signal method was used to generate samples until the imbalanced class reached 25%, and an additional 10% was created using the permutation method. The application of these techniques greatly improved the metrics and elevated the accuracy of the network’s predictions. It is worth noting that the oversampling methods were only applied during training.
Again, as in the other experiments, the framework remained the same. The final architecture of the InSEption network was identical to that used in the iSPLInception comparison. The specific parameters are illustrated in
Table 7. The only differences are the dropout rate and the batch size, which are 15% and 32 in both networks, respectively. Other than that, both the network layers and size were the same. All the parameters were selected based on several experiments and their results.
The parameters used in the LN-Inception model were kept the same as those used in the InSEption model. However, the practical difference between the two networks lies in the absence of bottleneck and squeeze and excitation blocks in the LN-Inception model. This change in the architecture is intended to result in a simplified model that is still capable of producing high-quality results.
The architecture of the benchmark models was kept the same as in the previous experiment; the only changes were the batch size, which was set to 32, and the dropout rate, which was 15%. The overall architecture and hyperparameters can be found in
Table 8. In terms of evaluation metrics, we decided to expand beyond the sensitivity, specificity, and F1 score that were used in previous tests, since there were no models for comparison. Thus, we included two additional metrics in our analysis: the area under the curve and geometric mean. These metrics provide a more comprehensive picture of the model’s performance by taking into account the results of the confusion matrix in settings other than the usual F1 score [
30,
31]. Moreover, for the geometric mean, we substituted the true positive and true negative values with their success rates to improve interpretability. This substitution is equivalent to using sensitivity and specificity, and it ensures that the results are bound between 0 and 1, with 1 indicating the best performance; this approach was introduced in [
32,
33]. Regarding the results of the two models for this dataset, the InSEption module performs better than LN-Inception by a slight margin. More specifically, in terms of sensitivity, the difference for the first model is 1%, although in terms of specificity, both scored the same. The F1 and AUC scores indicate that, again, the squeeze and excitation blocks were beneficial, with a 0.3% and 0.5% difference against the LN-Inception, respectively. The scores that are shown in
Table 9 are the means of the 5K cross validation procedures that were conducted.
Compared to the benchmark models, the two proposed models show a significant improvement in terms of macro F1 score, with increases in sensitivity, specificity, geometric mean, and AUC between 1 and 2%, depending on the metric. Overall, the results on this dataset suggest that it is easier for a model to correctly predict examples, possibly due to the higher number of positive class examples compared to the Daphnet dataset.
In conclusion, the proposed methods have proven to be highly effective in classifying time-series data, particularly in detecting freezing-of-gait (FoG) episodes. The results show that the models are capable of accurately identifying both classes with high F1 and AUC scores, demonstrating their ability to effectively learn patterns and distinguish between FoG and normal walking patterns. Furthermore, the oversampling techniques employed to balance the dataset only during training were proven to be effective, as they did not compromise the model’s ability to predict the majority class, instead improving its ability to detect the minority class. During the prediction stage, the class distribution remained similar to the original dataset, with approximately 18% of instances classified as FoG and 82% classified as normal. These results highlight the strength of the proposed models and suggest that they could be effectively utilized in real-world applications for monitoring and detection of FoG episodes in Parkinson’s disease patients.
5. Discussion and Future Work
The aim of this work was to explore the potential of various deep learning architectures for prediction of episodes of freezing of gait (FoG), a debilitating symptom that significantly affects the quality of life of Parkinson’s disease (PD) patients. The early detection and classification of FoG episodes can aid practitioners in understanding the symptoms of each patient and in developing more effective strategies to treat the disease.
To achieve this goal, two inception-based models were introduced. The first model is named LN-Inception, and it is a simpler version of the original inception network for time-series classification [
25]. Practically, the number of parallel convolutions was reduced, and the normalization levels increased. The second proposed methodology is the InSEption network, which, with the exception of the inception modules, integrates squeeze and excitation blocks after each convolutional stage.
In order to evaluate the effectiveness of the proposed models, the Daphnet dataset was utilized, and results were compared to existing literature, specifically the iSPLInception network, which is the only inception network that has been used with this dataset. The findings indicate that both proposed models surpassed the state-of-the-art performance in terms of all metrics that were used in [
11]. The most significant improvement was observed in the macro F1 score, for which the models demonstrated an improvement of 2% and 6%, with the InSEption network exhibiting the highest performance.
The last experiments were carried out utilizing an additional dataset related to FoG (freezing of gait) episodes, which was collected from an IMU (inertial measuring unit) sensor. This resulted in six features for each participant. It is important to note that this dataset is relatively new, and no established benchmarks exist, making this study unique and potentially contributing to the creation of benchmark standards for future research in this area. For the evaluation, data for each patient were organized similarly to the Daphnet dataset.
Regarding the results, it can be observed that both models performed exceptionally well, achieving high scores for both the F1 and AUC metrics, with scores of 96.9% and 97.2% for F1 and 98.1% and 98.6% for AUC, respectively. These scores were notably higher than those of the two custom models that were developed for comparison. Furthermore, both had sensitivity, specificity, and GM scores over 97%. The reason we utilized AUC and GM as evaluation metrics in this setting is that there is no established benchmark in the literature for comparison that specifies the metrics to be used. In addition, the use of these metrics allowed us to further validate the effectiveness of our models. The results demonstrated that our proposed models outperformed created custom benchmark models in terms of these metrics. The best-performing network was, again, InSEption. In order for these results to be achieved, the abovementioned oversampling methods were employed.
In summary, this study highlights the benefits of using the inception mechanism to extract multiple hierarchical features from signal data. Additionally, the positive impact of incorporating squeeze and excitation blocks and problem-specific oversampling methods further enhances the overall performance of the proposed models. The results of this study demonstrate the potential of the inception-based deep learning architectures for prediction of FoG episodes in PD patients and their suitability for integration into wearable IoT devices for real-time monitoring and early intervention. Additionally, due to the different features of the two dataset and their satisfactory performances, the inception methodologies constitute a potentially very efficient way to treat signal or sensor datasets.
In regard to future research, it may be worthwhile to investigate the use of time-dependent modules, such as gated recurrent units (GRUs), long short-term memory (LSTM) networks, or attention mechanisms, to further exploit the features extracted from the convolutional layers and incorporate additional temporal information, as has been successfully done in previous studies [
5,
9]. Additionally, it would be valuable to evaluate the proposed methodologies on larger Parkinson’s-related datasets, such as mPower, or on other activity recognition datasets in order to determine their generalizability and efficacy across a wider range of tasks. Furthermore, in addition to the proposed variations, transfer learning could be explored as a potential approach, building upon the methods introduced in previous works [
8,
10]. With transfer learning, the proposed models could be trained extensively on a large dataset, then fine-tuned for predictions on another dataset, potentially incorporating more generalized knowledge and avoiding overfitting. These avenues of research could help to further validate the potential of these models for use in wearable IoT devices for real-time monitoring and early intervention in conditions such as freezing of gait (FoG).


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}