


Deep Learning and Cloud-Based Computation for Cervical Spine Fracture Detection System



Abstract
1. Introduction
2. Materials and Methods
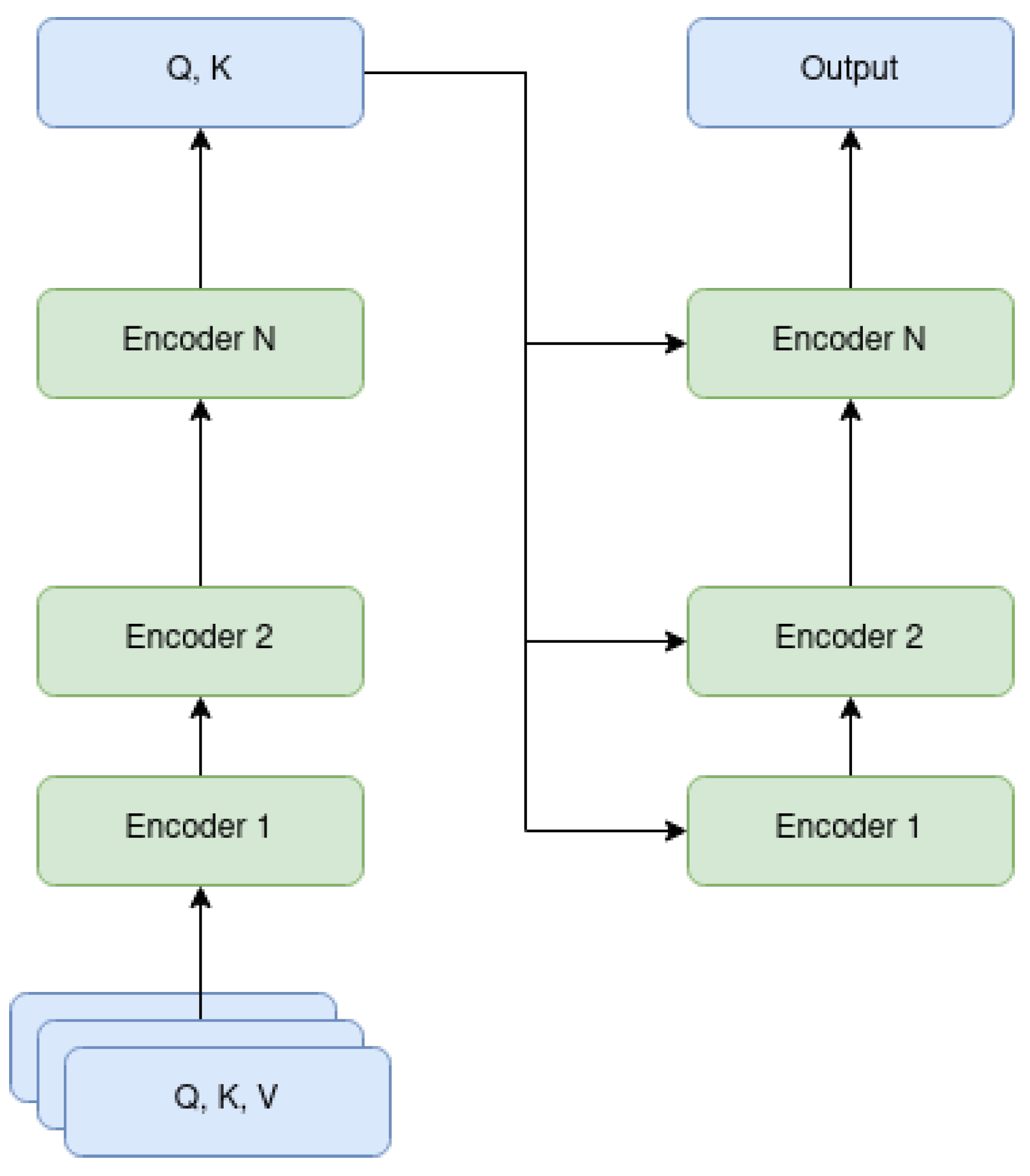
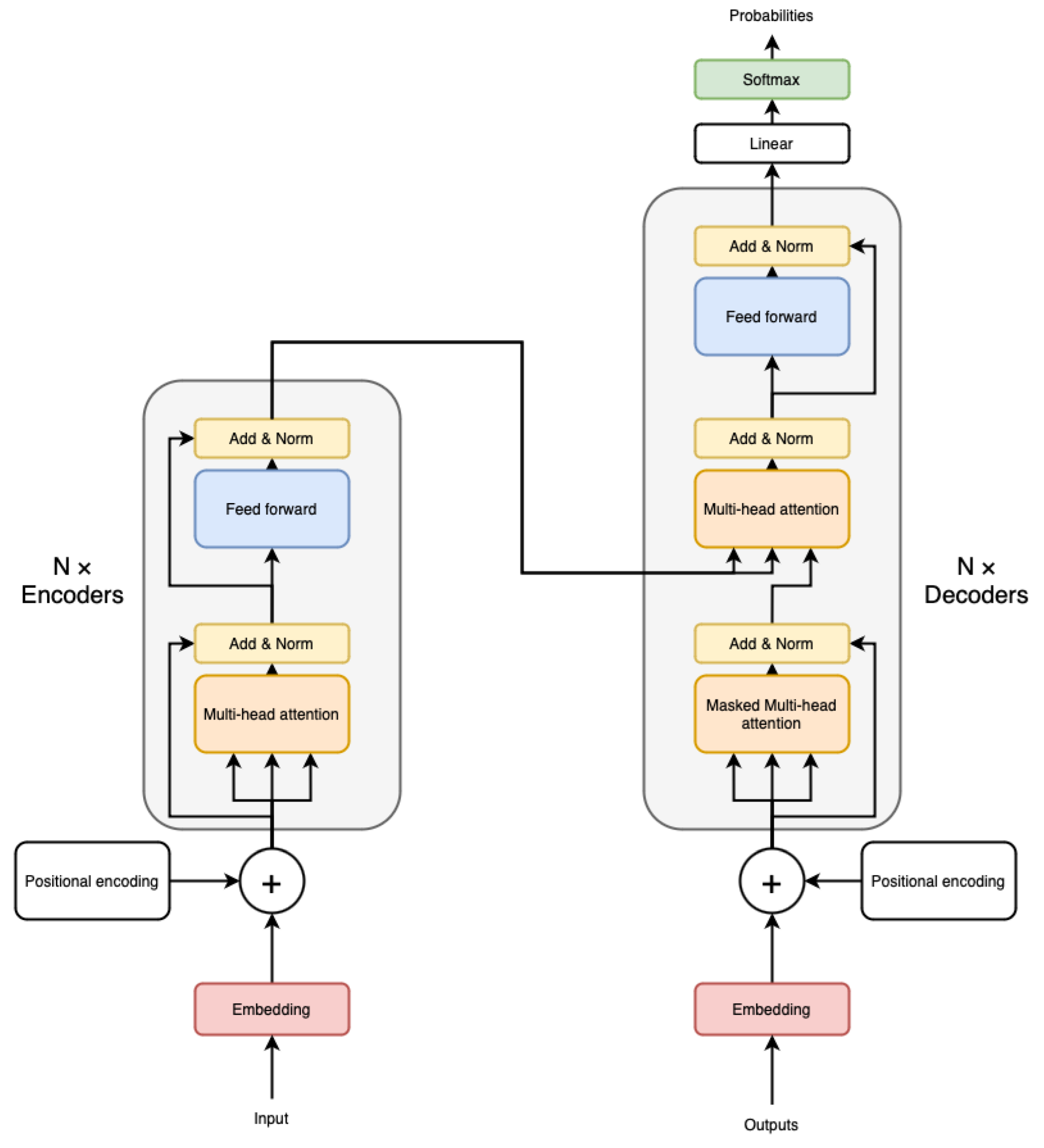
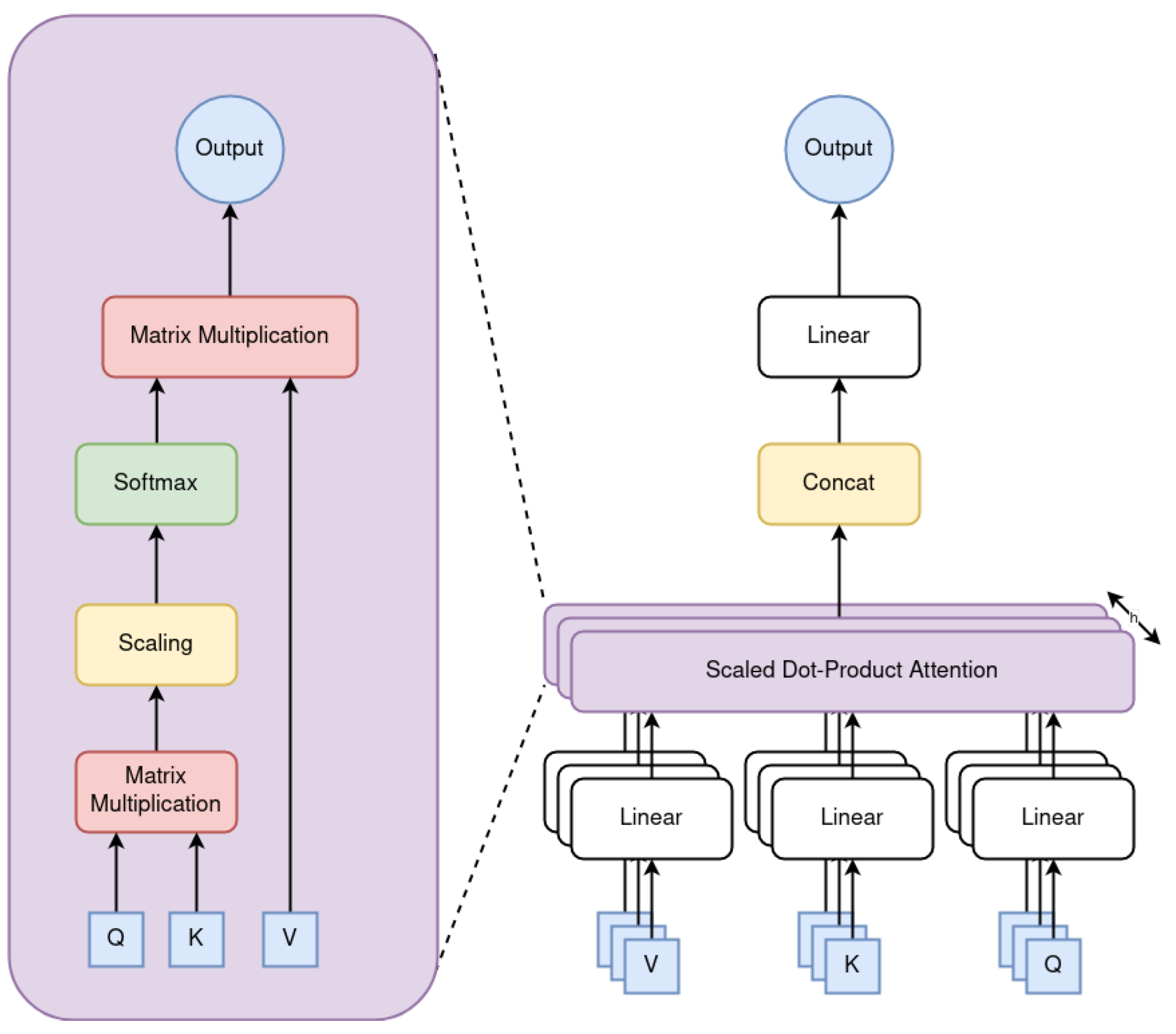
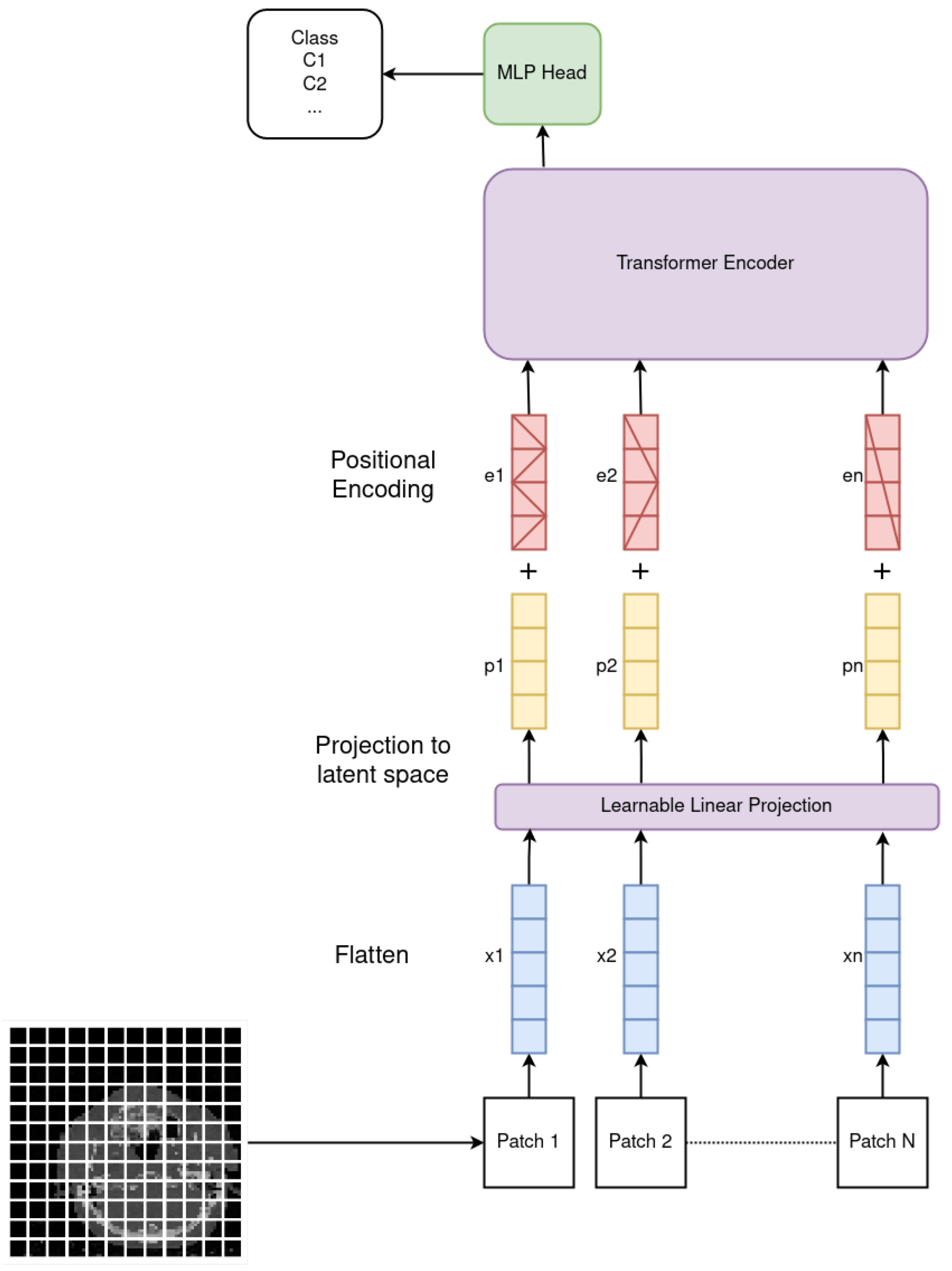
2.1. Vision Transformer
2.2. Attention Masks
2.3. Dataset
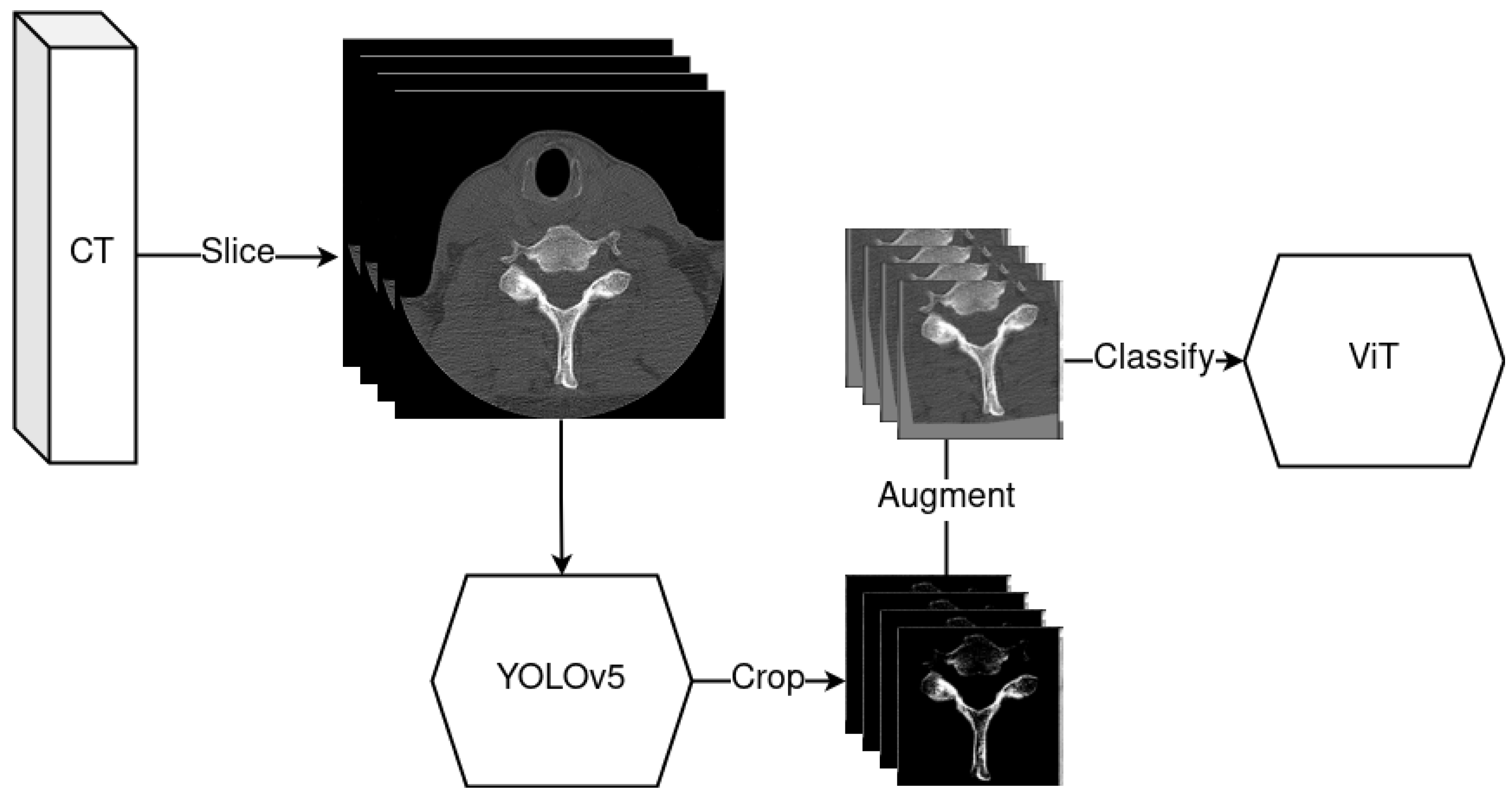
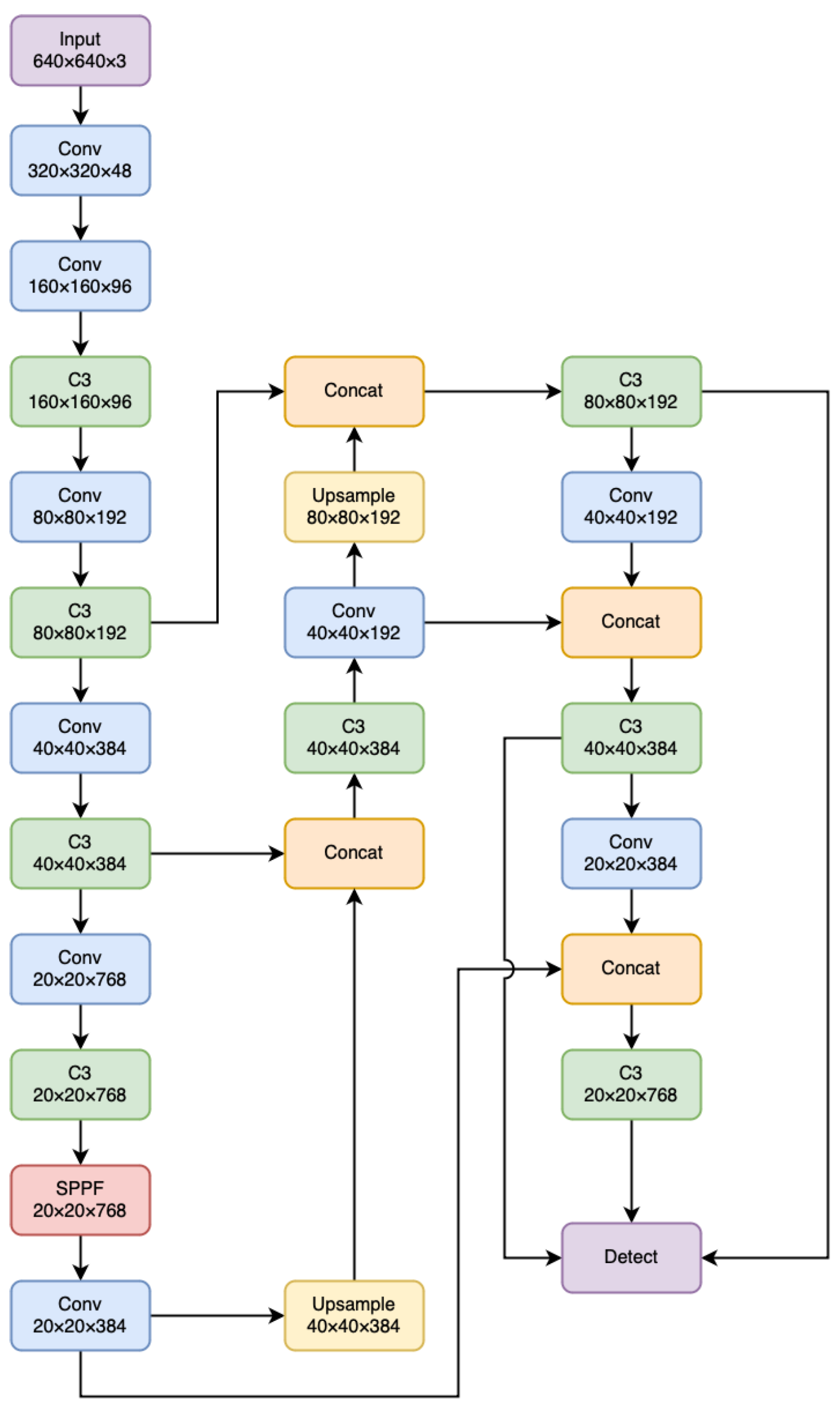
2.4. YOLOv5—Object Detection Model
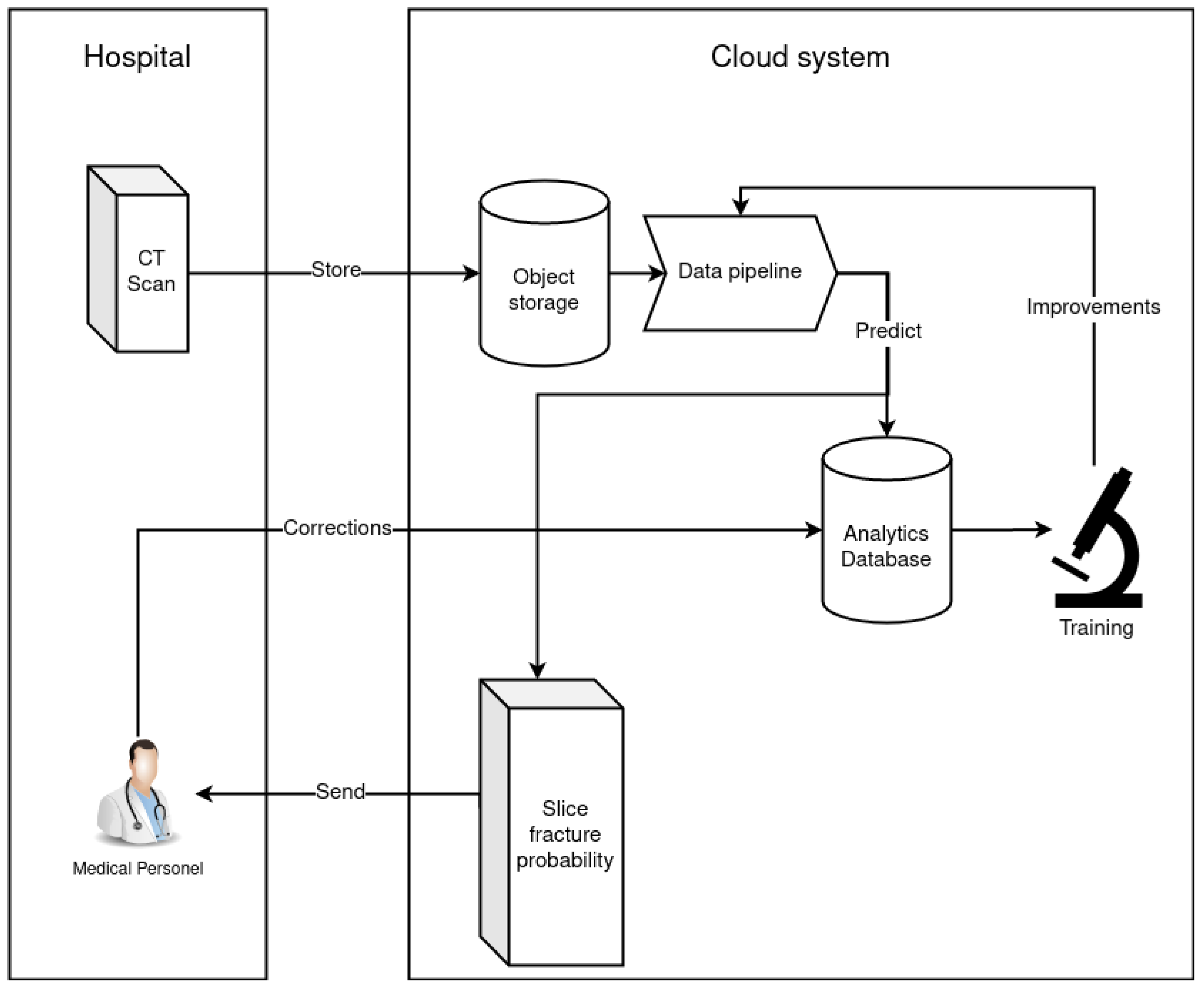
2.5. Data Pipeline
2.6. Model Training
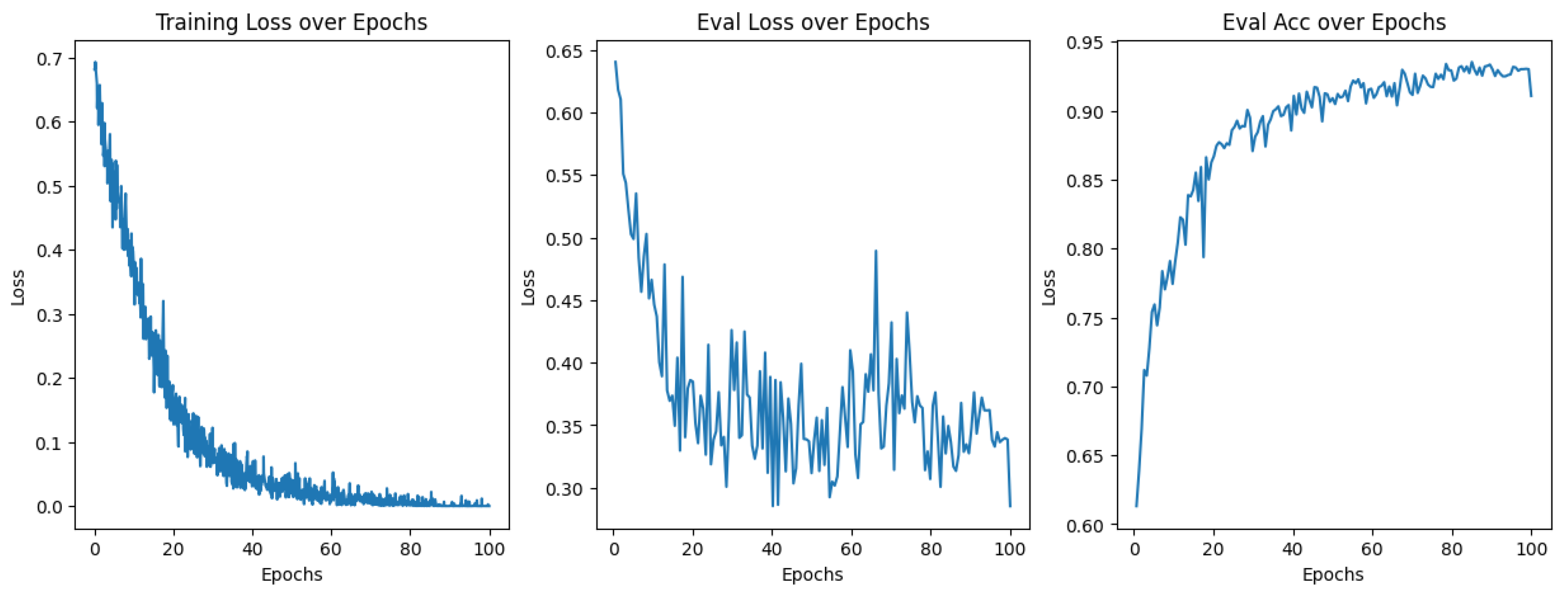
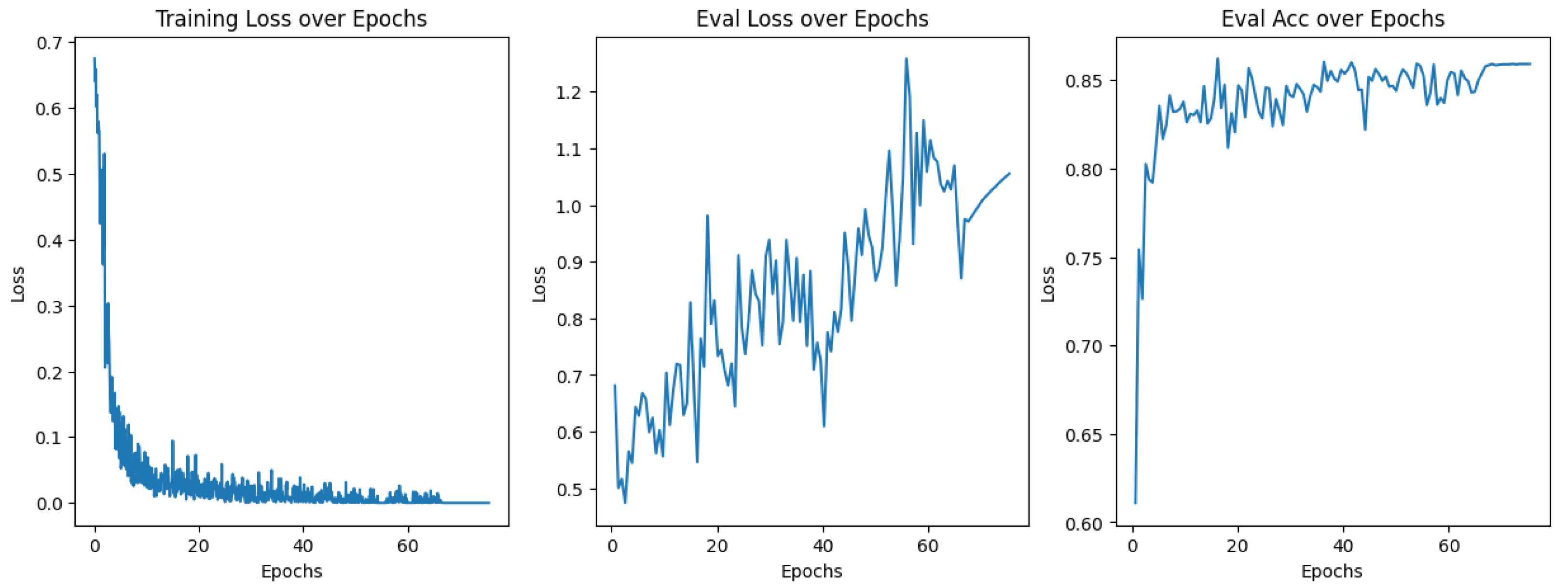
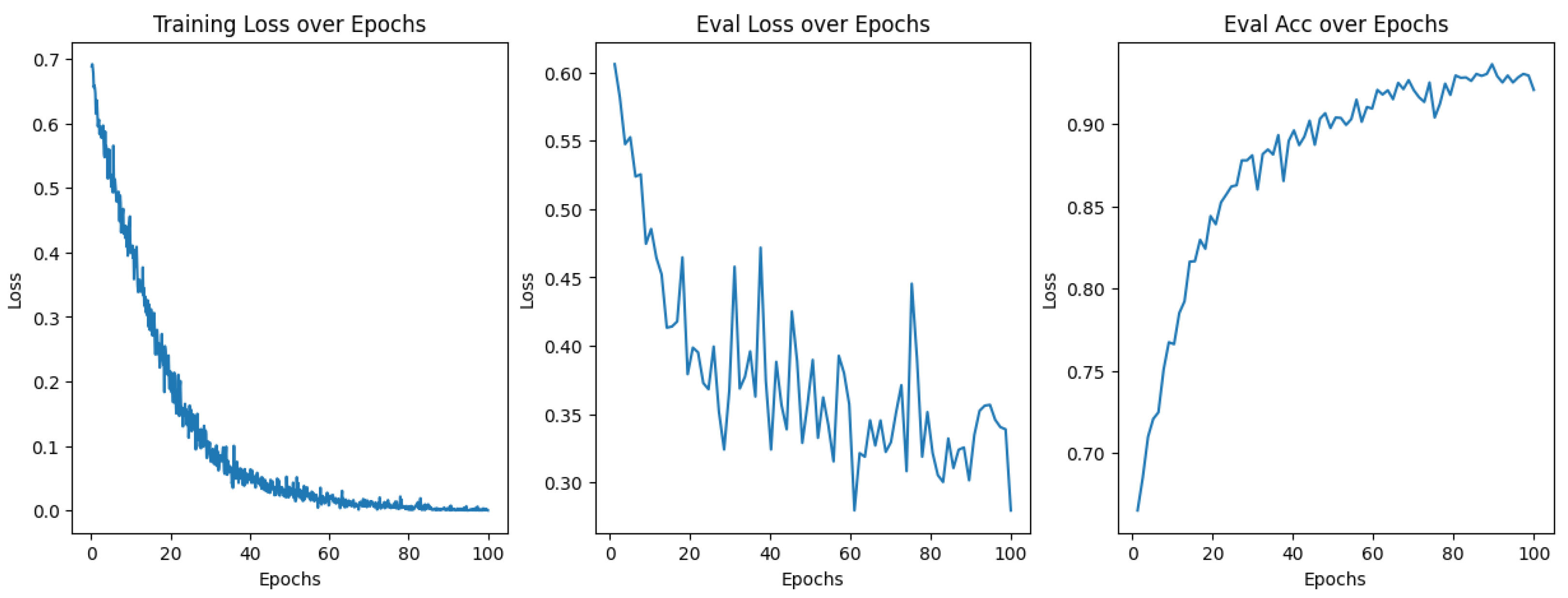
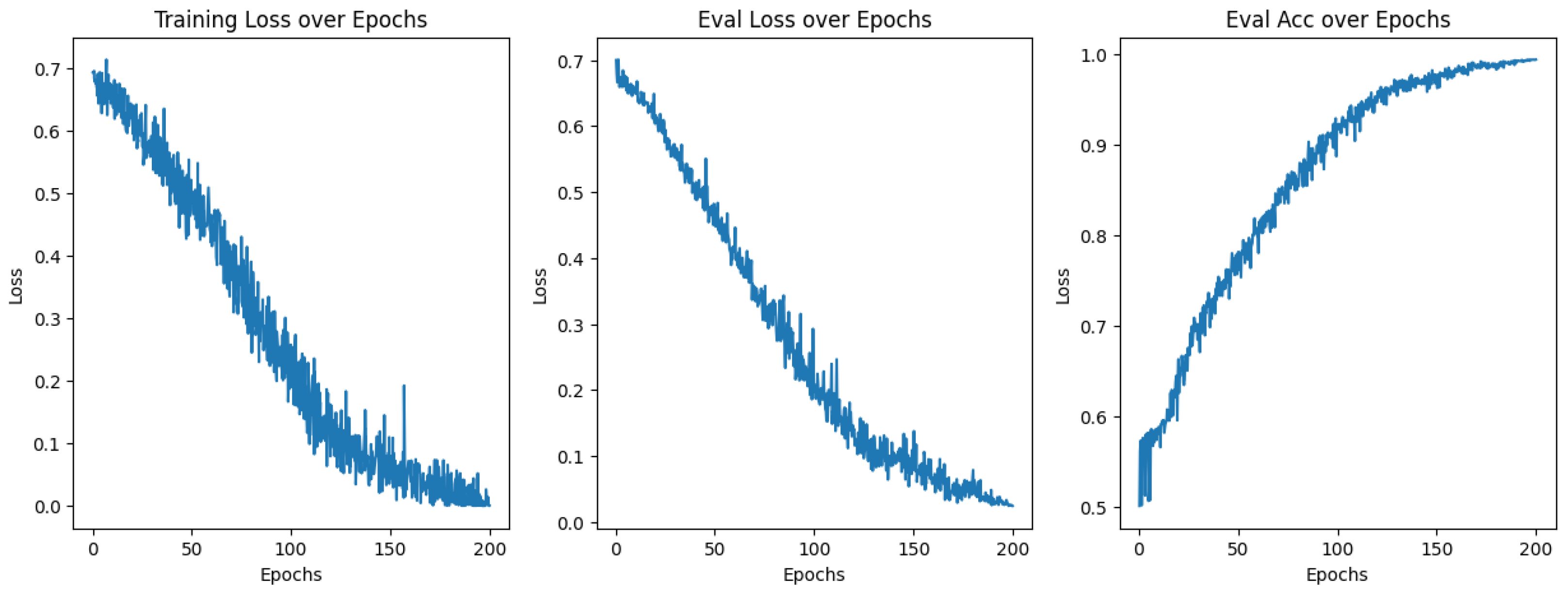
3. Results
3.1. Model Training
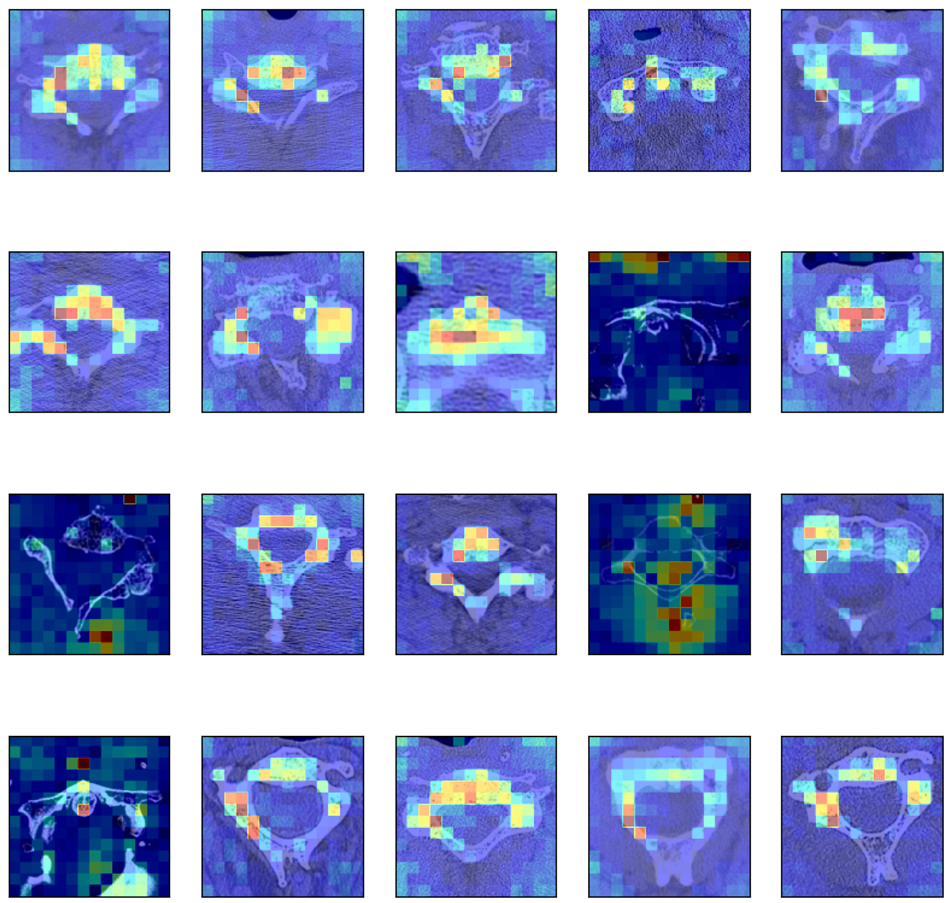
3.2. Attention Masks
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ViT | Vision Transformer |
| CNN | Convolutional Neural Network |
| CT | Computer Tomography |
| DL | Deep Learning |
| ML | Machine Learning |
| AR | Attention Rollout |
| MLP | Multi Layer Perceptron |
| MHA | Multi Head Attention |
| AWS | Amazon Web Services |
Appendix A





References
- Dong, Y.; Peng, R.; Kang, H.; Song, K.; Guo, Q.; Zhao, H.; Zhu, M.; Zhang, Y.; Guan, H.; Li, F. Global incidence, prevalence, and disability of vertebral fractures: A systematic analysis of the global burden of disease study 2019. Spine J. 2022, 22, 857–868. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. Spinal Cord Injury. 2013. Available online: https://www.who.int/news-room/fact-sheets/detail/spinal-cord-injury (accessed on 19 March 2023).
- Ismael Aguirre, M.F.; Tsirikos, A.I.; Clarke, A. Spinal injuries in the elderly population. Orthop. Trauma 2020, 34, 272–277. [Google Scholar] [CrossRef]
- Fehlings, M.G.; Perrin, R.G. The Timing of Surgical Intervention in the Treatment of Spinal Cord Injury: A Systematic Review of Recent Clinical Evidence. Spine 2006, 31, S28–S35. [Google Scholar] [CrossRef]
- Meena, T.; Roy, S. Bone Fracture Detection Using Deep Supervised Learning from Radiological Images: A Paradigm Shift. Diagnostics 2022, 12, 2420. [Google Scholar] [CrossRef]
- Perotte, R.; Lewin, G.O.; Tambe, U.; Galorenzo, J.B.; Vawdrey, D.K.; Akala, O.O.; Makkar, J.S.; Lin, D.J.; Mainieri, L.; Chang, B.C. Improving Emergency Department Flow: Reducing Turnaround Time for Emergent CT Scans. AMIA Annu. Symp. Proc. 2018, 2018, 897–906. [Google Scholar] [PubMed]
- Amazon Corporation. AWS SageMaker; Amazon Corporation: Seattle, WA, USA, 2023. [Google Scholar]
- Microsoft Corporation. Train and Deploy Machine Learning Anywhere; Microsoft Corporation: Redmond, WA, USA, 2022. [Google Scholar]
- Farhadi, F.; Barnes, M.R.; Sugito, H.R.; Sin, J.M.; Henderson, E.R.; Levy, J.J. Applications of artificial intelligence in orthopaedic surgery. Front. Med. Technol. 2022, 4, 995526. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Abnar, S.; Zuidema, W. Quantifying Attention Flow in Transformers. arXiv 2020, arXiv:2005.00928. [Google Scholar]
- Flanders, A.; Carr, C.; Colak, E.; Kitamura, F.; Lin, H.M.; Rudie, J.; Mongan, J.; Andriole, K.; Prevedello, L.; Riopel, M.; et al. RSNA 2022 Cervical Spine Fracture Detection. 2022. Available online: https://www.kaggle.com/competitions/rsna-2022-cervical-spine-fracture-detection/overview (accessed on 5 March 2023).
- Murphy, A. Windowing (CT). Reference Article, Radiopaedia.org. 2017. Available online: https://radiopaedia.org/articles/52108 (accessed on 5 March 2023). [CrossRef]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Michael, K.; TaoXie; Fang, J.; Imyhxy; et al. ultralytics/yolov5: v7.0—YOLOv5 SOTA Realtime Instance Segmentation. 2022. Available online: https://zenodo.org/record/7347926#.ZEE-y85ByUk (accessed on 5 March 2023). [CrossRef]
- Bogdan Pruszyński, A.C. Radiologia Diagnostyka Obrazowa RTG TK USG i MR; PZWL Wydawnictwo Lekarskie: Warszawa, Poland, 2014; p. 54. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2019, arXiv:1711.05101. [Google Scholar]
- Hugo, T.; Matthieu, C.; Matthijs, D.; Francisco, M.; Alexandre, S.; Herve, J. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 10347–10357. [Google Scholar]
- Hendrycks, D.; Mu, N.; Cubuk, E.D.; Zoph, B.; Gilmer, J.; Lakshminarayanan, B. AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty. arXiv 2019. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. RandAugment: Practical automated data augmentation with a reduced search space. arXiv 2019. [Google Scholar] [CrossRef]
- Burns, J.E.; Yao, J.; Summers, R.M. Vertebral Body Compression Fractures and Bone Density: Automated Detection and Classification on CT Images. Radiology 2017, 284, 788–797. [Google Scholar] [CrossRef] [PubMed]
- Wang, G.; Wu, Y.; Sun, Q.; Yang, B.; Zheng, Z. SID2T: A Self-attention Model for Spinal Injury Differential Diagnosis. In Proceedings of the Intelligent Computing Theories and Application, 18th International Conference, ICIC 2022, Xi’an, China, 7–11 August 2022; Huang, D.S., Jo, K.H., Jing, J., Premaratne, P., Bevilacqua, V., Hussain, A., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 650–662. [Google Scholar]
- Small, J.E.; Osler, P.; Paul, A.B.; Kunst, M. CT Cervical Spine Fracture Detection Using a Convolutional Neural Network. AJNR Am. J. Neuroradiol. 2021, 42, 1341–1347. [Google Scholar] [CrossRef]
- Nafisah, S.I.; Muhammad, G.; Hossain, M.S.; AlQahtani, S.A. A Comparative Evaluation between Convolutional Neural Networks and Vision Transformers for COVID-19 Detection. Mathematics 2023, 11, 1489. [Google Scholar] [CrossRef]
- He, K.; Gan, C.; Li, Z.; Rekik, I.; Yin, Z.; Ji, W.; Gao, Y.; Wang, Q.; Zhang, J.; Shen, D. Transformers in medical image analysis. Intell. Med. 2023, 3, 59–78. [Google Scholar] [CrossRef]
- Li, J.; Chen, J.; Tang, Y.; Wang, C.; Landman, B.A.; Zhou, S.K. Transforming medical imaging with Transformers? A comparative review of key properties, current progresses, and future perspectives. Med. Image Anal. 2023, 85, 102762. [Google Scholar] [CrossRef] [PubMed]
- Radanliev, P.; De Roure, D. Disease X vaccine production and supply chains: Risk assessing healthcare systems operating with artificial intelligence and industry 4.0. Health Technol. 2023, 13, 11–15. [Google Scholar] [CrossRef] [PubMed]
- Inukollu, V.N.; Arsi, S.; Ravuri, S.R. Security issues associated with big data in cloud computing. Int. J. Netw. Secur. Its Appl. 2014, 6, 45. [Google Scholar] [CrossRef]
- Safi, S.; Thiessen, T.; Schmailzl, K.J. Acceptance and Resistance of New Digital Technologies in Medicine: Qualitative Study. JMIR Res. Protoc. 2018, 7, e11072. [Google Scholar] [CrossRef]
- John, N.; Shenoy, S. Health cloud—Healthcare as a service(HaaS). In Proceedings of the 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014; pp. 1963–1966. [Google Scholar] [CrossRef]
- Park, H.; Yoo, Y.; Seo, G.; Han, D.; Yun, S.; Kwak, N. C3: Concentrated-Comprehensive Convolution and its application to semantic segmentation. arXiv 2019, arXiv:1812.04920. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Computer Vision—ECCV 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 346–361. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transform | Settings | Probability |
|---|---|---|
| RandomRotation | 10 deg. | 1 |
| RandomTranslation | 10% width, 10% height | 1 |
| RandomHorizontalFlip | Not applicable | 0.5 |
| RandomVerticalFlip | Not applicable | 0.5 |
| RandomGaussianBlur | kernel size = (5, 9), sigma = (0.1, 5) | 0.5 |
| Model | Patch Size | Latent Space Dim | Encoder Blocks | MLP Heads | Parameters Total |
|---|---|---|---|---|---|
| ViT-B32 | 32 × 32 | 768 | 12 | 12 | 87,466,819 |
| ViT-B16 | 16 × 16 | 768 | 12 | 12 | 87,466,819 |
| DeIT-T16 | 16 × 16 | 192 | 12 | 3 | 5,524,802 |
| Model | Augmentation | Accuracy |
|---|---|---|
| ViT-B16 | No | 85% |
| ViT-B16 | Yes | 91% |
| ViT-B32 | Yes | 92% |
| DeIT-T16 (200 Epochs) | Yes | 98% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chłąd, P.; Ogiela, M.R. Deep Learning and Cloud-Based Computation for Cervical Spine Fracture Detection System. Electronics 2023, 12, 2056. https://doi.org/10.3390/electronics12092056
Chłąd P, Ogiela MR. Deep Learning and Cloud-Based Computation for Cervical Spine Fracture Detection System. Electronics. 2023; 12(9):2056. https://doi.org/10.3390/electronics12092056
Chicago/Turabian StyleChłąd, Paweł, and Marek R. Ogiela. 2023. "Deep Learning and Cloud-Based Computation for Cervical Spine Fracture Detection System" Electronics 12, no. 9: 2056. https://doi.org/10.3390/electronics12092056
APA StyleChłąd, P., & Ogiela, M. R. (2023). Deep Learning and Cloud-Based Computation for Cervical Spine Fracture Detection System. Electronics, 12(9), 2056. https://doi.org/10.3390/electronics12092056