1. Introduction
With the rapid improvement in the data rate in 5G communications, a significant number of computation-sensitive services, such as AR and VR, real-time navigation, and autonomous driving, are emerging [
1,
2,
3,
4]. Autonomous driving technology, including target detection, information perception, and intelligent decision making, requires computation resources to process various tasks within a limited latency [
5]. However, the computation capabilities of the vehicular terminals are generally limited and cannot meet real-time task processing requirements [
6,
7]. Although the remote computation cloud has enough computation resources to provide efficient computing services, the long-distance data transmission of the task files between the remote cloud and the local vehicular terminals will lead to significant communication delays [
8,
9]. To address this problem, vehicle edge computing (VEC) is widely recognized as a promising solution to enhance computing service performance, where the computation resources are pushed to the radio access networks and provide computing service close to the vehicular terminals [
10,
11,
12].
From the cost perspective of network operators, the computation resources of VEC clouds may be limited [
13,
14]. During peak traffic, offloading tasks from vehicular terminals increase sharply. As a result, the VEC cloud will be overloaded, and performance degradation in task processing is incurred [
15,
16]. In order to cope with this problem, an efficient task scheduling strategy based on VEC servers is indeed required [
17]. To this end, we apply efficient deep reinforcement learning (DRL) to design a task scheduling algorithm based on multi-agent deep Q networks (MADQN) for improving computing efficiency and thereby reducing the task processing delay.
Current works generally assume that the computation resources of the server are enough to process the offloading tasks from vehicular terminals [
6,
7]. However, as mentioned above, the computation resources configured in the VEC server are generally limited. Especially during peak periods, the VEC server is overloaded, which will prolong the task processing delay because of the increase in the queuing time. In order to enhance the computing efficiency of the VEC server, this paper solves the task scheduling problem to improve the execution efficiency of VEC servers in mobile edge computing networks. We assume that each VEC server has multiple threads and consider a parallel task scheduling scheme. We model the target thread decision of computation tasks as a multi-agent DRL problem, which is then solved by using a DRL-based approach to improve the computing efficiency and reduce the task processing delay. The main contributions of this paper are summarized as follows:
We model the task decision of the target thread as a multi-agent DRL problem and employ recent progress in DRL to develop a distributed task decision algorithm based on the MADQN framework, which enhances the computing efficiency of the VEC server.
We illustrate that via an appropriate training mechanism with a time-related reward, the task decisions can learn from interactions with the VEC environment and decide upon a clever strategy in a distributed manner that simultaneously ensures the rapid convergence of the proposed algorithm and reduces the task processing delay.
We use the intensive and diversified computing task data to carry out simulation experiments, and the experiment results demonstrate the effectiveness of the proposed algorithm. Compared with the existing benchmark algorithms, the DRL-based algorithm proposed in this paper can obtain a lower system delay and has relatively stable performance gain in dense multiple-task computing scenarios.
The remainder of the paper is summarized as follows. We discuss the related work in
Section 2. Then, we introduce the system model, which includes the task-computing model and problem statement. In
Section 4 and
Section 5, we describe the MADQN algorithm framework of task scheduling. Finally, we show the simulation results in
Section 6 and conclude our work in
Section 7.
2. Related Work
Currently, research on task scheduling for vehicular networks has received extensive attention. However, most existing works highly depend on the static system model. The authors of [
18] proposed a genetic algorithm-based approach to minimize the weighted sum of the service time and energy consumption by jointly optimizing the task caching and computation offloading in VEC networks. The authors of [
19] applied Lyapunov optimization technology and the greedy heuristics approach to minimize the response time in caching-assisted vehicular edge computing. Meanwhile, energy consumption was taken into account. The authors of [
20] proposed a heuristic algorithm based on the ant colony algorithm to solve the service arrangement problem among fog computing nodes. However, the accuracy of both intelligent algorithms and heuristic algorithms greatly depends on accurate system models. Practically, the offloading tasks from vehicular terminals belong to a dynamical process, and thus the traditional static models cannot capture the dynamic features of offloading tasks [
21]. Deep reinforcement learning, integrating the perceptual ability of deep learning (DL), and the decision making ability of reinforcement learning (RL) can be used to solve the decision-making problem in complex environments [
22,
23].
At present, many scholars have used the DRL method to solve the problem of an optimal task scheduling strategy [
24,
25,
26,
27]. The authors of [
24] used the Markov decision process (MDP) to establish a task scheduling model to solve the problems of task processing delay and system energy consumption minimization in VEC task scheduling scenarios, and then they optimized the task scheduling scheme through the DRL method. The experiment results verified the effectiveness of the DRL method in solving complex decision-making problems. The authors of [
25] used the DRL method to optimize the scheduling strategy of joint wireless transmission and computing resources for the vehicle-road cloud cooperation scenario to reduce the task processing delay. The authors of [
26] proposed a dynamic framing offloading algorithm based on a double deep Q network to minimize the total delay and waiting time of computing offloading in vehicular edge computing networks. The authors of [
27] used the DRL method to design an optimized content caching scheme under the high mobility of vehicles and dynamic wireless channels. However, with the development of vehicular networks, the computing dimension of task files is increasing sharply, and the traditional DRL methods cannot adapt to scenarios of highly complex task computing [
28,
29].
Fortunately, artificial intelligence algorithms based on multi-agent deep reinforcement learning (MADRL) can efficiently solve complex computation problems [
30]. The authors of [
23] applied the MADRL method to obtain a spectrum allocation scheme of vehicle-to-infrastructure (V2I) links for maximizing the overall network throughout. The authors in that paper assumed that each vehicle-to-vehicle (V2V) link worked as an agent, and multiple V2V agents jointly explored the environment. Then, they optimized the power control and spectral allocation strategies according to their own observations from the environment state. The authors of [
31] designed the MADRL algorithm to solve the optimal decision problem of task offloading from the VEC vehicle terminals and for minimizing the task execution delay. The existing works assumed that the computing resources of edge servers are sufficient. However, during peak traffic, the edge server cannot effectively schedule the computing tasks with limited resources, which results in computation performance degradation and decreases the service quality of the VEC. To this end, we propose a DRL-based framework to solve this problem and design a MADQN-based task scheduling scheme to decrease the task processing latency for VEC networks.
3. System Model
In this section, we first describe the system model, and the task scheduling problem is then formulated. The characteristics of the computation task scheduling problem based on the DRL approach are further analyzed.
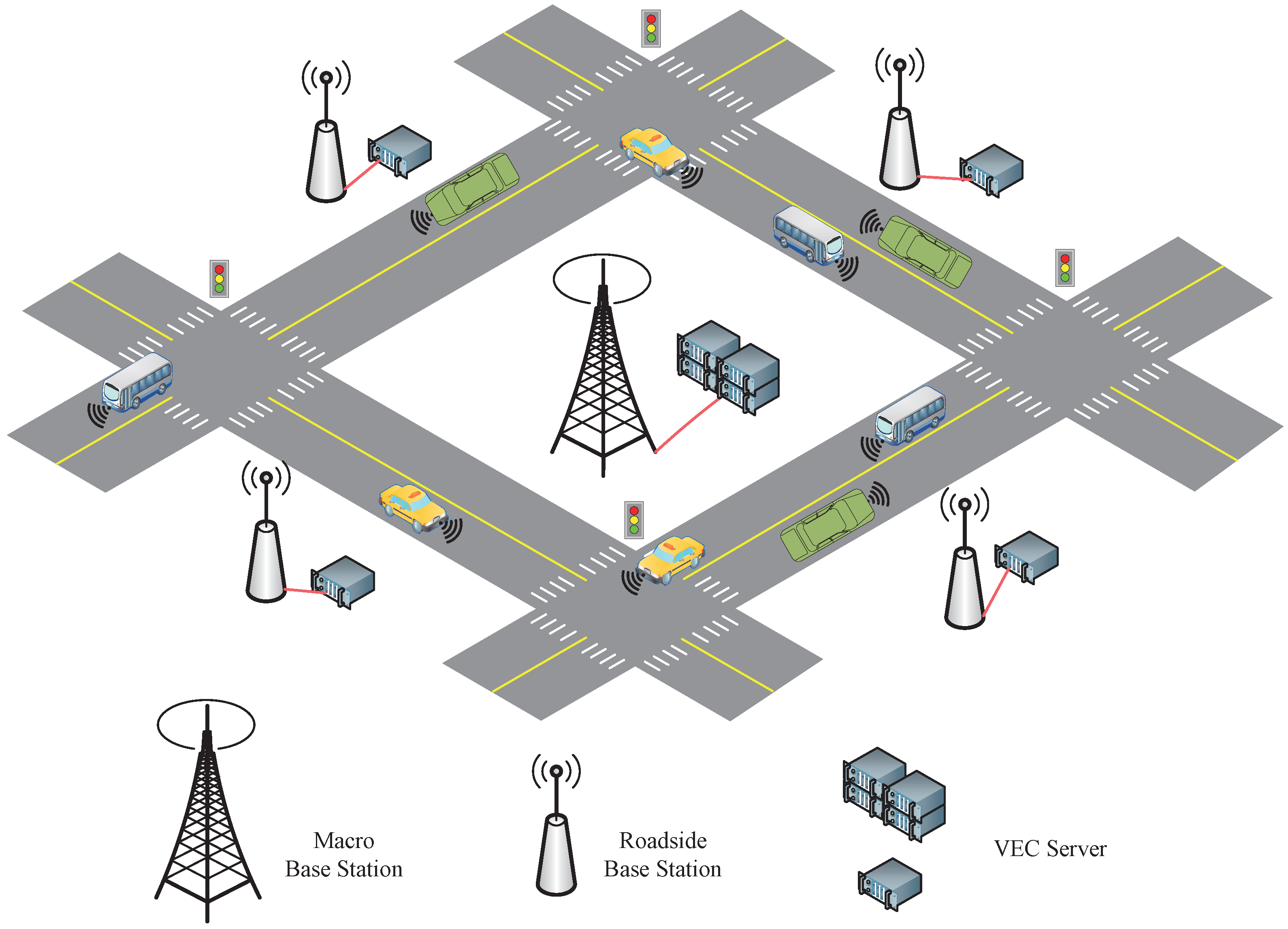
We consider the VEC scenario of a vehicular network shown in
Figure 1. The VEC server is connected to the macro base station (BS), which acts as a data center for model training. Each roadside BS is connected to the VEC server by optical fiber. We assume that each VEC server has
M threads. The thread set of the VEC server is denoted by
. The corresponding computation resources of thread
m (
) is denoted by
in GHz/s. The computation tasks offloaded by vehicular terminals are modeled according to a uniform distribution [
32]. The set
represents the computation tasks cached in the VEC server. Each computation task
k (
) has two parameters: task file size
in MB and delay constraint
in
. Both
and
are modeled according to a uniform distribution [
21]. Set
represents the waiting time of the threads in the VEC server. This means that the scheduled task may not be processed immediately when the target thread is busing.
is modeled according to a Gaussian distribution, while
denotes the target thread index of computation task
k and
if the computation task
k selects the thread
m; otherwise,
. We assume that each computation task can only occupy one thread, and thus
for a given task
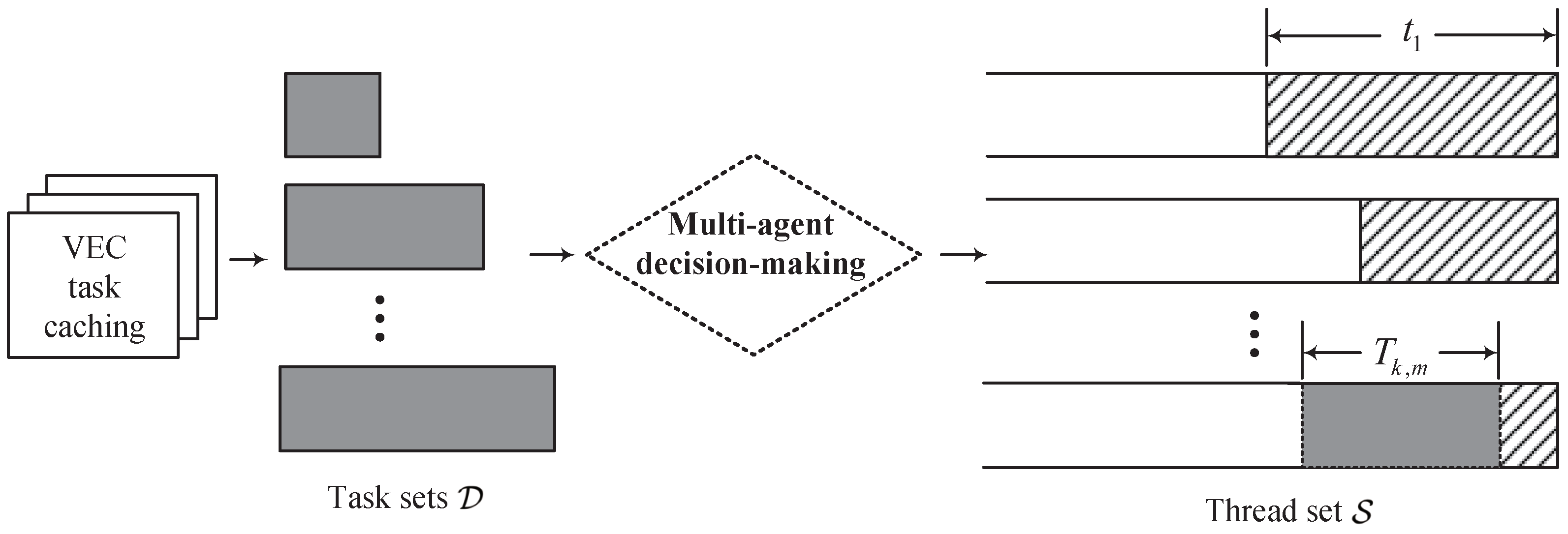
k. We model each selecting action of the target thread as an agent and perform a multi-agent decision mechanism. The DRL-based framework of task scheduling in the VEC server is shown in
Figure 2.
3.1. Task Computing Model
If the task
k selects the thread
m, then the task processing delay
of task
k in thread
m is given by
where
e denotes the computational intensity (in CPU cycles per MB), representing how many CPU cycles are needed to process one MB of data. From the latency calculation in Equation (1), we can see that both the task file size
and computation resources
have a significant impact on
. We denote the processing delay of thread
m as
, which can be calculated by
where
represents the task waiting time of thread
m. From Equation (2), we can notice that
increases with the number of tasks scheduled to thread
m. Parallel task scheduling is adopted in this model, and then the total task processing delay
of the VEC server is calculated as follows:
From Equation (3), we can find that has an important impact on . In order to reduce , avoiding scheduling a large task to a thread with fewer computation resources is necessary.
3.2. Problem Statement
The overall goal of the task scheduling strategy is to minimize the total task processing delay under delay constraints. The optimization problem can be expressed as
where
represents the delay constraints of the computation task,
represents the target thread index, and
means that each task can only be scheduled by one thread. Because of the integer constraint (
), the optimization problem in Equation (4) is NP-hard [
21].
4. Multi-Agent DQN-Based Task Scheduling
The task scheduling scenario for the VEC server in a vehicular network is shown in
Figure 2. Multiple computation tasks attempt to occupy thread resources, which is formulated as a multi-agent DRL problem. Each computation task acts as an agent and interacts with the VEC thread environment to obtain experiences by receiving observation results, which are then applied to modify their policy and enhance the computing efficiency of the VEC server. While computation task scheduling may result in a competitive game problem, we transform it into a cooperative mode by employing the same reward based on the task processing delay to improve the computing efficiency of the VEC server.
The proposed MADQN-based approach is divided into two stages: the centralized learning (training) phase and the distributed implementation phase. In the centralized learning phase, each task agent can easily obtain a computing efficiency-oriented reward and then refine its actions to an optimal strategy by updating its deep Q network (DQN). In the distributed implementation phase, each task agent observes the local environment state and then picks an action on the basis of its learned DQN. The main elements of the MADQN-based task scheduling design are described as followed in detail.
4.1. State and Observation Space
In the multi-agent RL of the task scheduling problem, each task
k acts as an agent, collectively interacting with the unknown VEC environment [
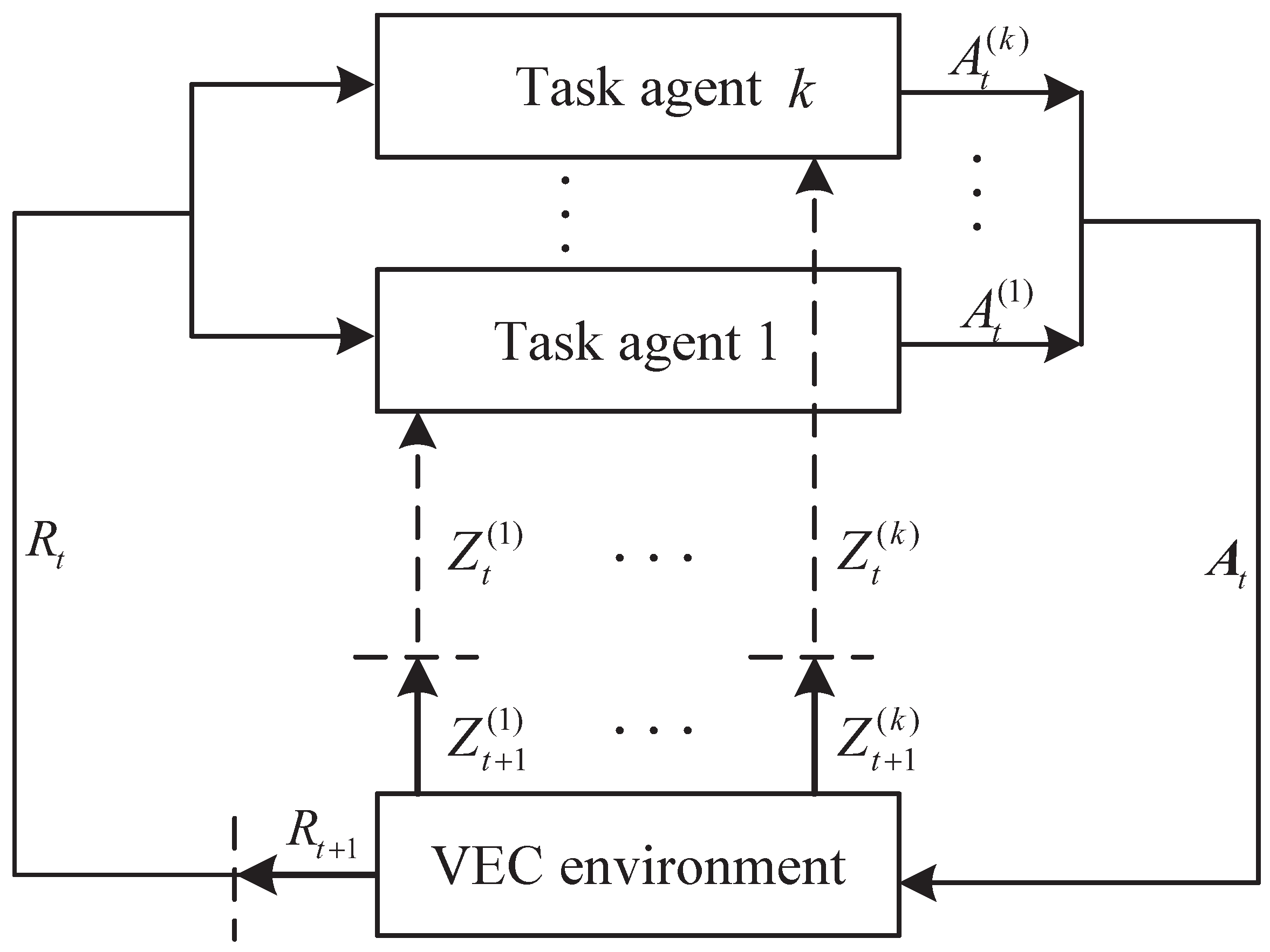
21]. This problem can be formulated as a Markov decision process (MDP). As illustrated in
Figure 3, given the current VEC environment state
at each time
t, each task agent
k gains an observation result
, determines the function
O with
, and then executes an action
. Thus, these agents form a joint action
. Subsequently, a reward
is achieved by the agent
k, and the VEC environment turns into the next state
with a probability
. In the next step
, each agent receives the new observations
. It is worth noting that all task agents employ the same reward to encourage cooperative behavior among task agents.
The true VEC environment state
includes all computation resources of all threads and all agents’ behaviors. However, each task agent can only observe a part of the VEC environment. The observation space of task agent
k contains the computation resources of the VEC thread
, the processing delay
of the VEC thread
m, the file size
of the input task, and the delay constraint
. Therefore, the observation function for task agent
k can be expressed as
4.2. Action Space
The task scheduling strategy based on the MADQN approach is to select the optimal thread to minimize the task processing delay. While the VEC server breaks into M threads, at each time t, each agent k decides the target thread m to use to process the task from the M threads. As a result, the action of each task agent is to select the target thread and decide the value of the target thread index .
4.3. Reward Design
The computing efficiency of the VEC server can be improved when the designed reward correlates with the system objective. Our objectives are twofold: minimizing the task processing latency of thread
m and the total latency of the VEC server while increasing the success process probability of computation tasks under a certain time constraint
. Therefore, the system reward must be consistent with the objective of improving the system’s performance. In response to the objective of reducing the task processing latency, the designed reward at each time slot
t is formulated as follows:
From the reward function in Equation (9), we can observe that the designed reward
is a negative value, which means that it is a better choice to keep the load balance among the threads in the VEC server. The objective of learning based on the MADQN approach is to find the optimal strategy
that maximizes the expected return from any state
s, denoted by
, which is defined as the cumulative rewards with a discount fraction
; in other words, we have
5. MADQN-Based Task Scheduling Algorithm
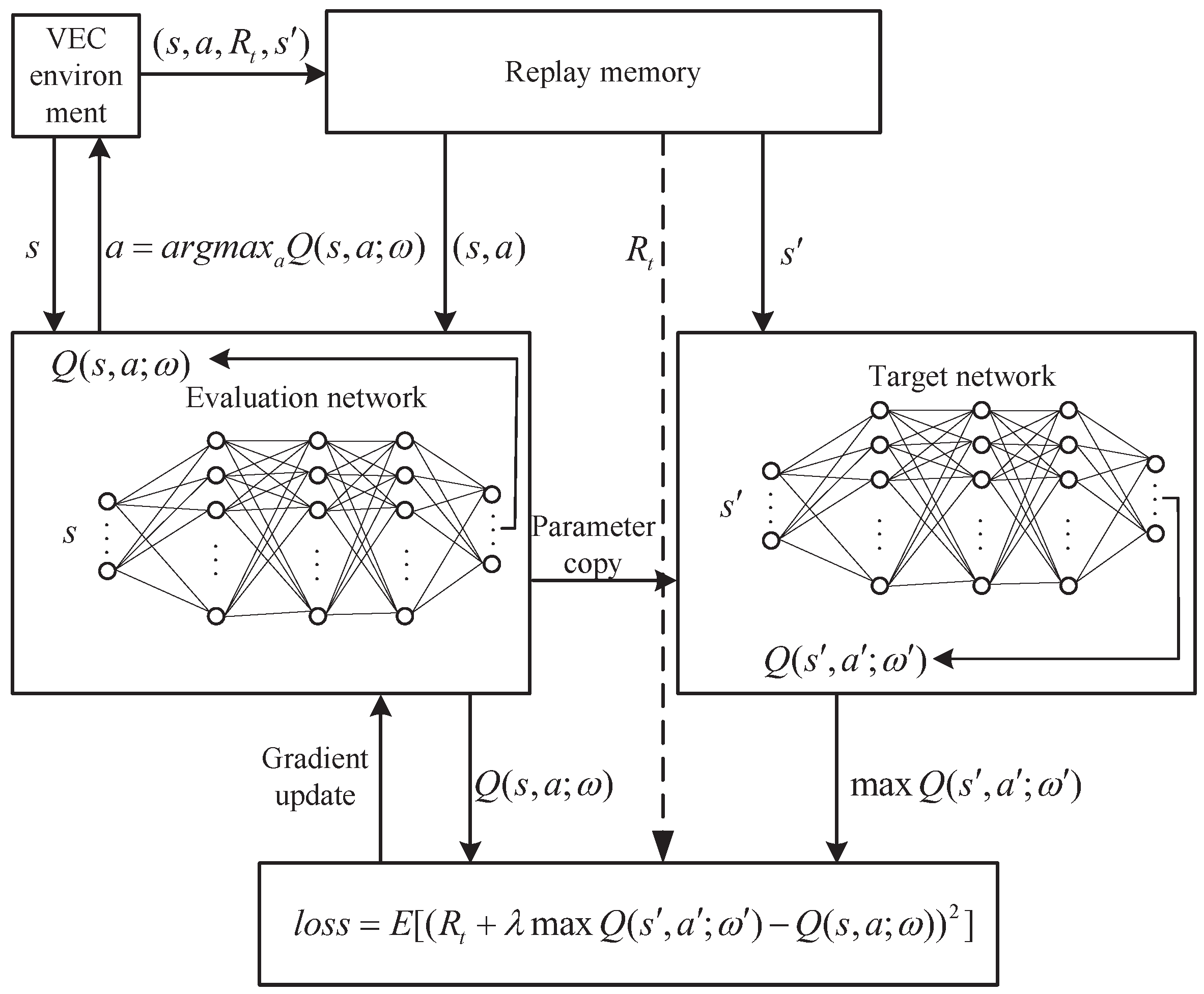
The structure of MADQN-based task scheduling is shown in
Figure 4. In the learning process, an evaluation network is constructed to generate scheduling policies. The input parameter is the server state space
s, and the output result is the scheduling function of the corresponding action-value function
, where
is the weight parameter of the evaluation network. The function
represents the next state, and
is the weight parameters of the target network, which are duplicated from the training Q network parameter set
.
The evaluation network and target network of each task agent in this paper are composed of an input layer, three hidden layers, and an output layer. Each layer is composed of multiple neurons and connected with the neurons in the next layer. There are relevant weight parameters between the interconnected neurons. Different weight parameters indicate the importance of variables. Larger weight parameters contribute more to the output. In this paper, the number of neurons of the input layer is the length of the state space s. The number of neurons in the three hidden layers is 256, 128, and 64. The number of neurons in the output layer is the number of server threads M. When the agent selects the maximum scheduling value function Q from the output layer, it also indicates the selection of server threads.
In the training process, the loss function is used to evaluate the accuracy of the network. The goal of training is to minimize the loss function by adjusting the weight parameters. In the process of weight parameter updating, only the weight parameters of the evaluation network are updated. The weight parameters of the target network are updated by copying from the evaluation network after a certain number of rounds. In this way, the target of the evaluation network weight update is a fixed target for a period of time, increasing learning stability. Each task agent has an independent evaluation network and target network, which is an independent DQN, while the experienced playback is public to encourage task agents to explore the environment cooperatively.
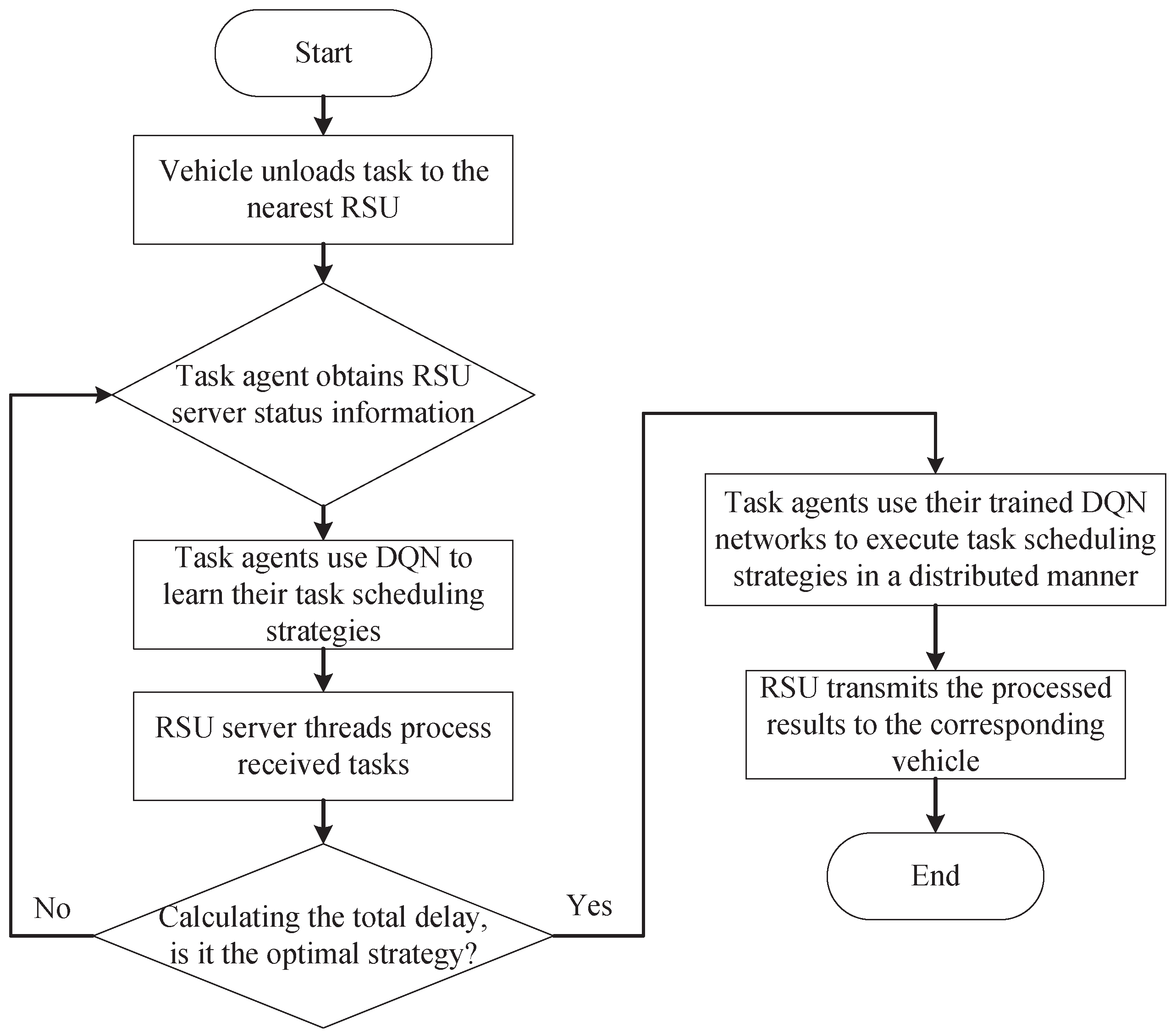
5.1. Training Process
We utilized the DRL experiential replay to effectively train the multi-tasking agent for learning the selection strategy of the target thread. The MADQN-based training process is shown in
Figure 5.
In the training process, each episode begins with a randomly initialized VEC environment state, including
, which is the parameter of the evaluation network. Then, the evaluation network receives the environment state
and the output results of all action value functions
, which can be calculated as
where
is defined in Equation (9). Then, the largest Q value from the action value function
is obtained, and the action corresponding to the largest Q value
is executed. The environment turns into the next state
and saves the transition tuple
in a replay memory.
A batch of experiences in each episode
is uniformly sampled from the replay memory, which will be used as the input of the target network. Then, the target network outputs all the action values
of the next state
and calculates the target value
of the evaluation network.
can be computed as follows:
The goal of training is to minimize the loss function
to ensure the correctness of the fitting of any given observation. The
function is defined as follows:
where
B is the sample size. The weight parameters are adjusted through gradient descent so that the model can determine the direction of error reduction. The gradient descent of the loss function can be calculated as follows:
Then, the evaluation network weight parameter is further updated to
, which can be calculated as follows:
where
is the learning rate of the evaluation network. After the weight parameter
has been updated, the environment turns into the next state
. The weight parameter
of the target network is duplicated from set
periodically. The algorithm procedure is illustrated in Algorithm 1. In Algorithm 1, we use an
-greedy strategy to explore the state and action space. This means that the random action is checked with the probability of
, and the action with the maximum Q value is checked with the probability of
. Here,
is a global variable which decreases with the number of training sessions and finally tends toward a fixed value.
| Algorithm 1: Task scheduling algorithm based on MADQN |
- 1:
for each episode do - 2:
for each step t do - 3:
for each agent do - 4:
Evaluating network reception , choose action at random with probability , with probability choose action , decreases with training sessions; - 5:
end for - 6:
To perform an action ,get environmental rewards , the environment updates to the next state ; - 7:
for each agents do - 8:
Saves experience to experience playback - 9:
end for - 10:
end for - 11:
for each agents do - 12:
Select a batch of experiences from experience playback - 13:
Calculate the target value according to Equation (12) - 14:
Update according to Equation (15) to reduce loss - 15:
The weight of the target network is updated every a certain episode - 16:
end for - 17:
end for
|
5.2. Distributed Implementation
In the distributed implementation stage, at each time slot t, the task agent k receives the VEC environment state and chooses an optimal action value based on its trained Q network. Then, each thread of the VEC server starts to process the received tasks. It is worth noting that the intensive training procedure of VEC computation in Algorithm 1 can be executed offline. When the environment features have been changed significantly, the trained Q network needs to be updated according to the environmental dynamics and system performance requirements.
6. Simulation Results
In this section, the experiment results are provided to verify the effectiveness of the MADQN-based task scheduling strategy for vehicular networks. The software environment for the simulation experiments was Python 3.6, and the convolutional neural network was created based on TensorFlow. The hardware platform for the simulation experiments was based on a desktop computer. Unless otherwise stated, the major simulation parameter settings of the VEC environment and neural network are shown in
Table 1.
We investigated the convergence behaviors of the proposed MADQN-based algorithm, with the training rewards versus the number of training episodes shown in
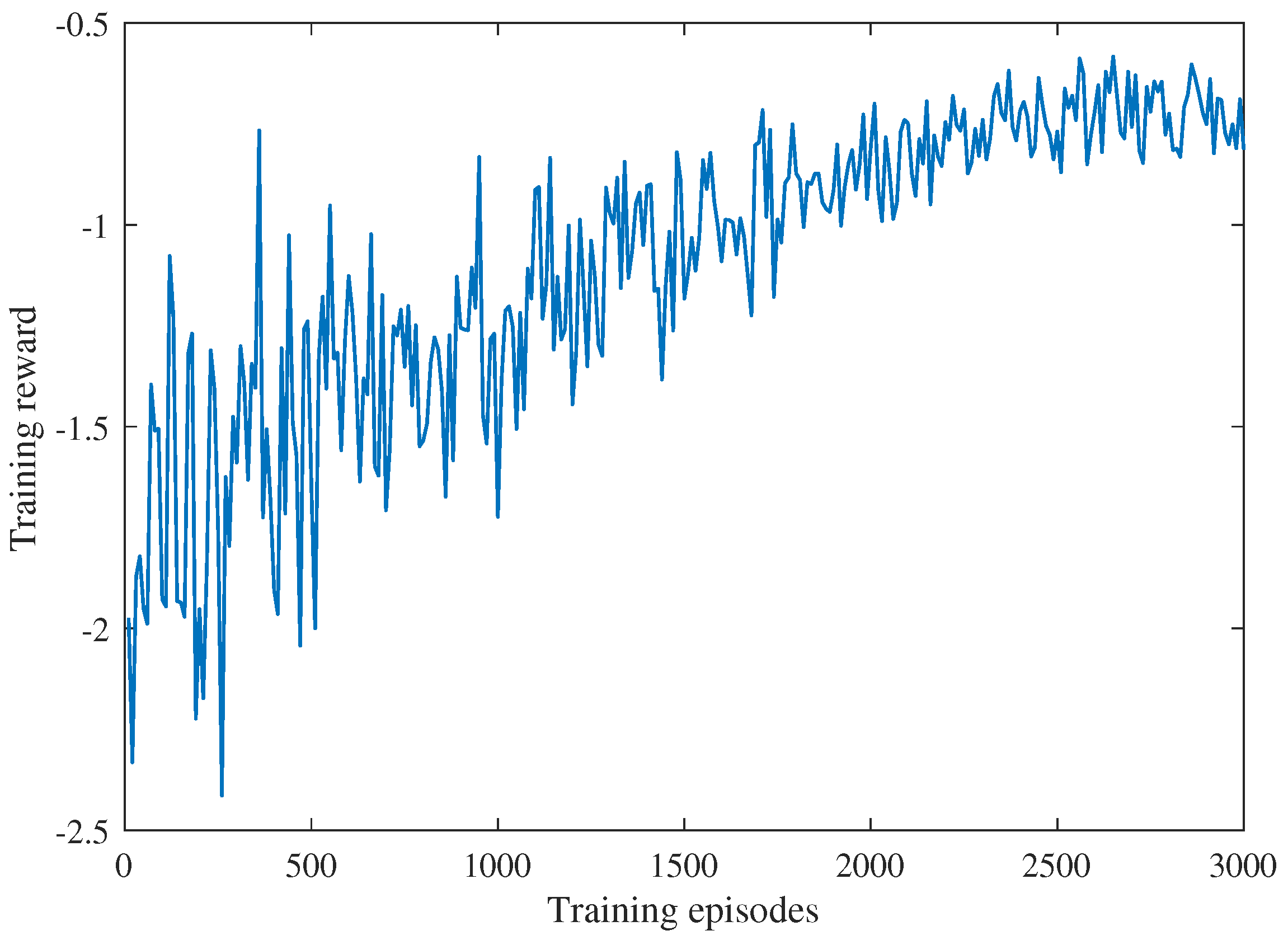
Figure 6. We can see that the training rewards improved with the number of training episodes. It has been demonstrated that the proposed MADQN-based algorithm is effective. The training rewards gradually converged when the episode count reached approximately 2500. In order to provide a security guarantee of algorithm convergence, the number of training episodes was set to 3000 for each agent in the Q networks.
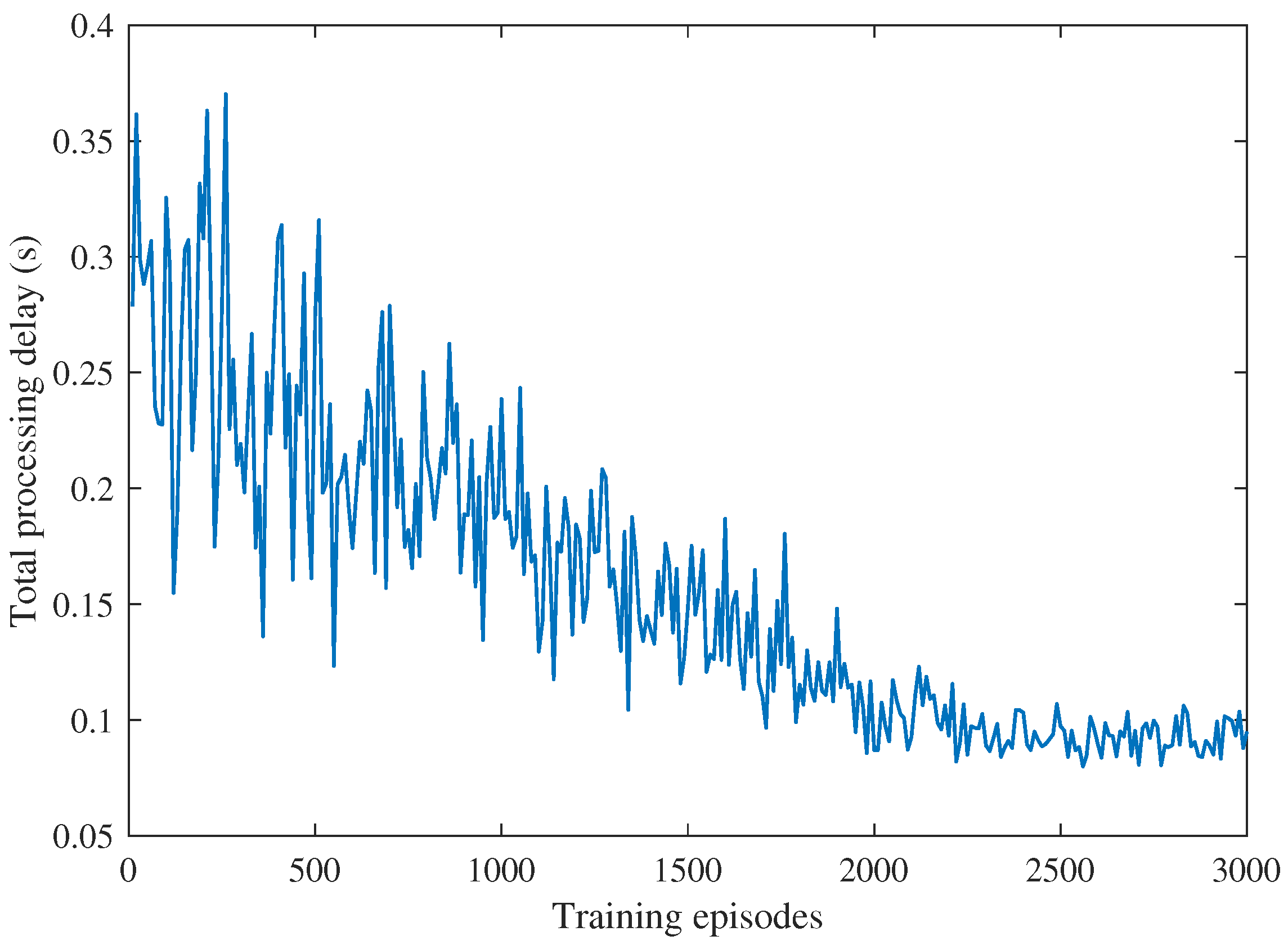
Figure 7 shows the total processing delay versus the number of training episodes. We can see that with the increase in the number of training episodes, the total processing delay decreased. This further demonstrates the effectiveness of the proposed MADQN-based algorithm.
In order to verify the performance of the proposed algorithm, the following two baseline algorithms were executed:
Single-agent deep Q networks (SADQN) is a traditional deep reinforcement learning algorithm which was proposed in [
34], where at each time slot
t, only one task agent replaces its action while the other agents’ actions remain unchanged.
The shortest time (ST) scheduling algorithm, proposed in [
35], is an algorithm where the task agent always selects the thread with the lowest processing time.
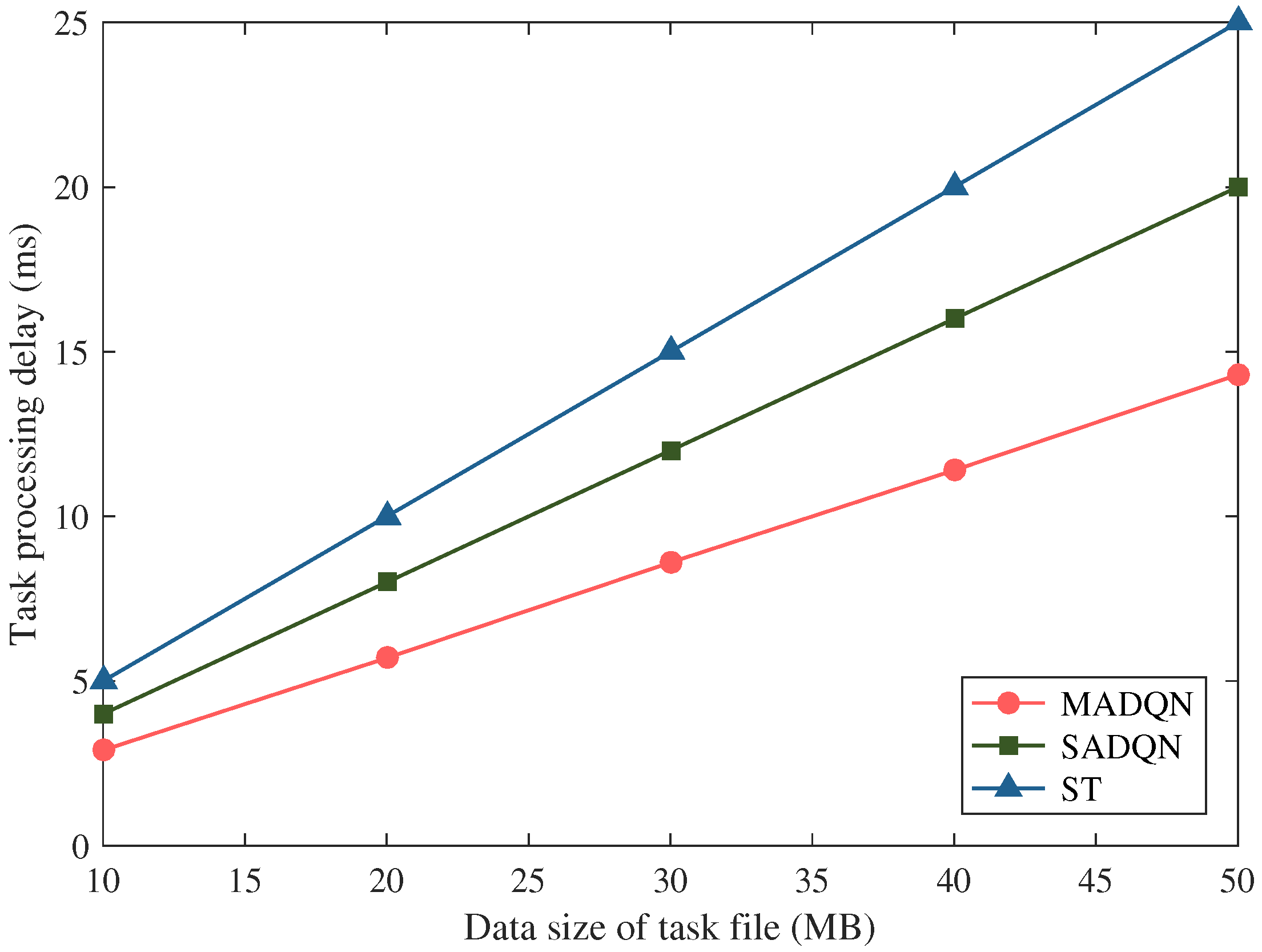
Figure 8 shows the impact of the data size of the task file on the task processing delay of different scheduling algorithms, including the SADQN, ST, and our proposed MADQN-based algorithms. We can see from
Figure 8 that our proposed MADQN-based algorithm obtained the minimum task processing delay compared with the scheduling algorithms based on SADQN and the ST. With the increase in the data size of the task files, the task processing delay gradually increased. Intuitively, the larger the data size of the task file, the longer the execution time for a given computing resource. We can further observe that the performance gains obtained by the proposed MADQN-based algorithm were improved compared with scheduling algorithms based on SADQN and the ST. It is worth noting that our proposed MADQN-based algorithm reduced the task processing delay by more than 28% and 40% compared with the SADQN algorithm and ST algorithm, respectively, when the data size of the input tasks was greater than 50 MB.
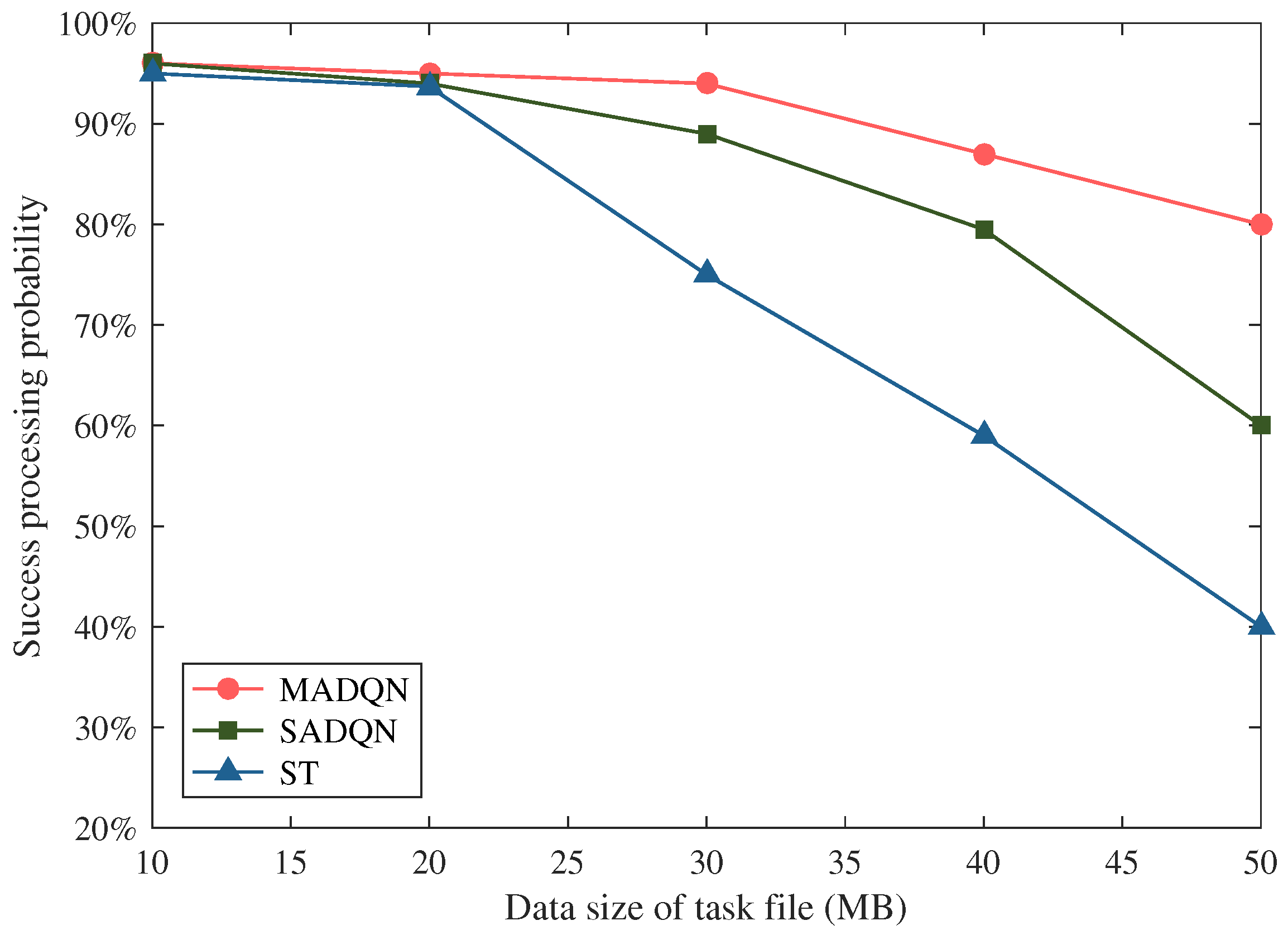
The effect of the data size of the task file on the successful processing probability of computation tasks is shown in
Figure 9, where the data size of the computation task file is uniformly distributed with U(5,50) MB. We can see that the success probability of task processing decreased with the increasing data size of the task file. This is due to the fact that a larger file size requires more computation resources. When the VEC server was overloaded, the degradation in computing efficiency resulted in an increase in the task processing delay, which led to a reduction in the successful processing probability. It is worth noting that compared with the SADQN and ST algorithms, the proposed MADQN-based algorithm could achieve significant performance gains in the successful processing probability of more than 30% when the data size of the task file was greater than 50 MB.
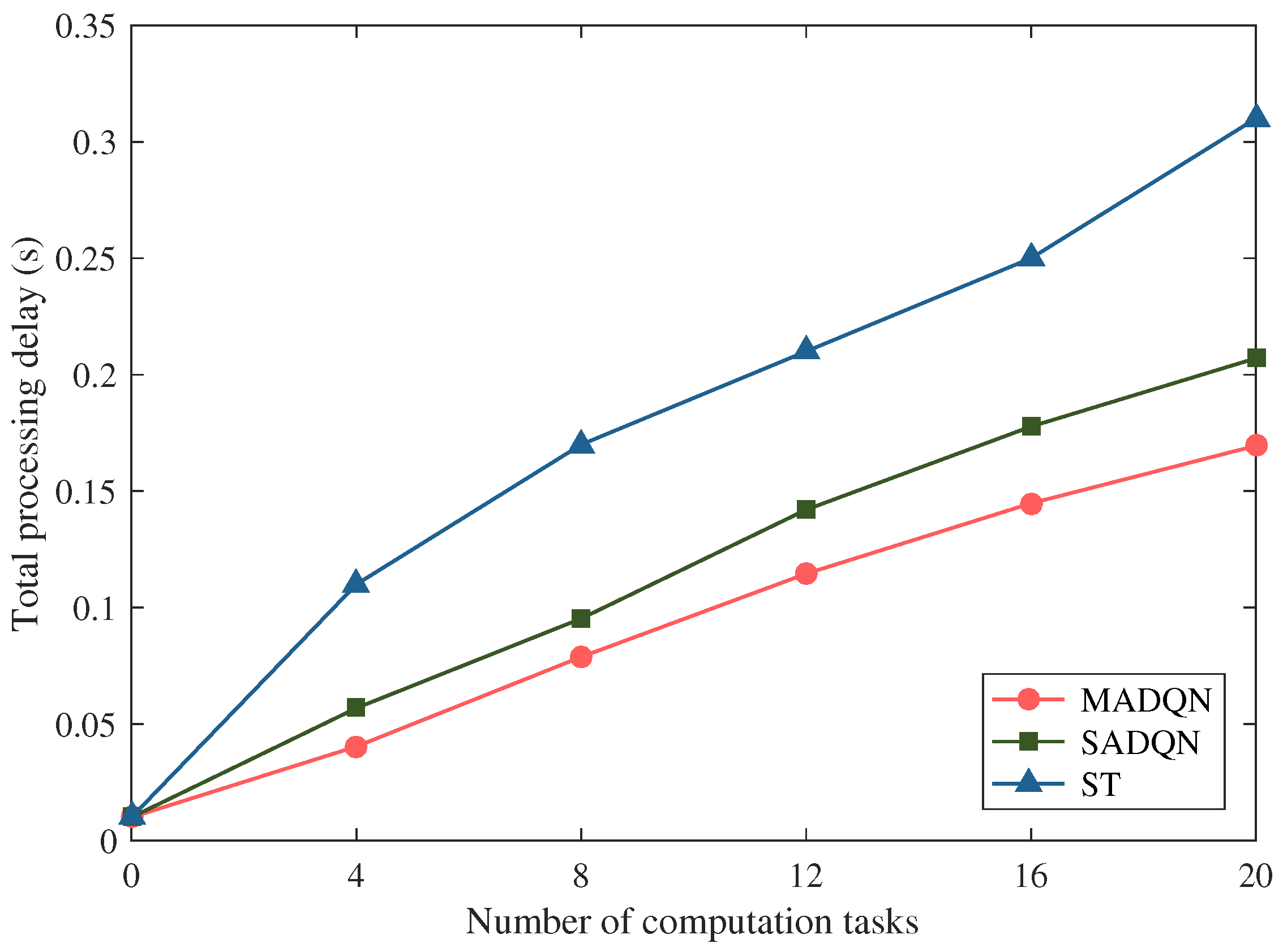
We further investigated the effect of the number of computation tasks on the total processing delay, where the data size of the computation tasks was uniformly distributed with U(5,50) MB. From
Figure 10, we can note that the total processing delay of different scheduling algorithms increased with the increasing number of computation tasks. We can further observe that our proposed MADQN-based algorithm obtained the minimum task processing delay. With the ever-increasing number of computation tasks, the performance gain obtained by the proposed algorithm improved continuously. Compared with the SADQN algorithm and the ST algorithm, the proposed MADQN based algorithm was superior because a distributed implemented approach was introduced and task processing was conducted in a parallel manner by the proposed algorithm, which is more suitable for solving complex problems. The total processing delay of the MADQN-based algorithm decreased by more than 2% when the number of computation tasks was more than four.
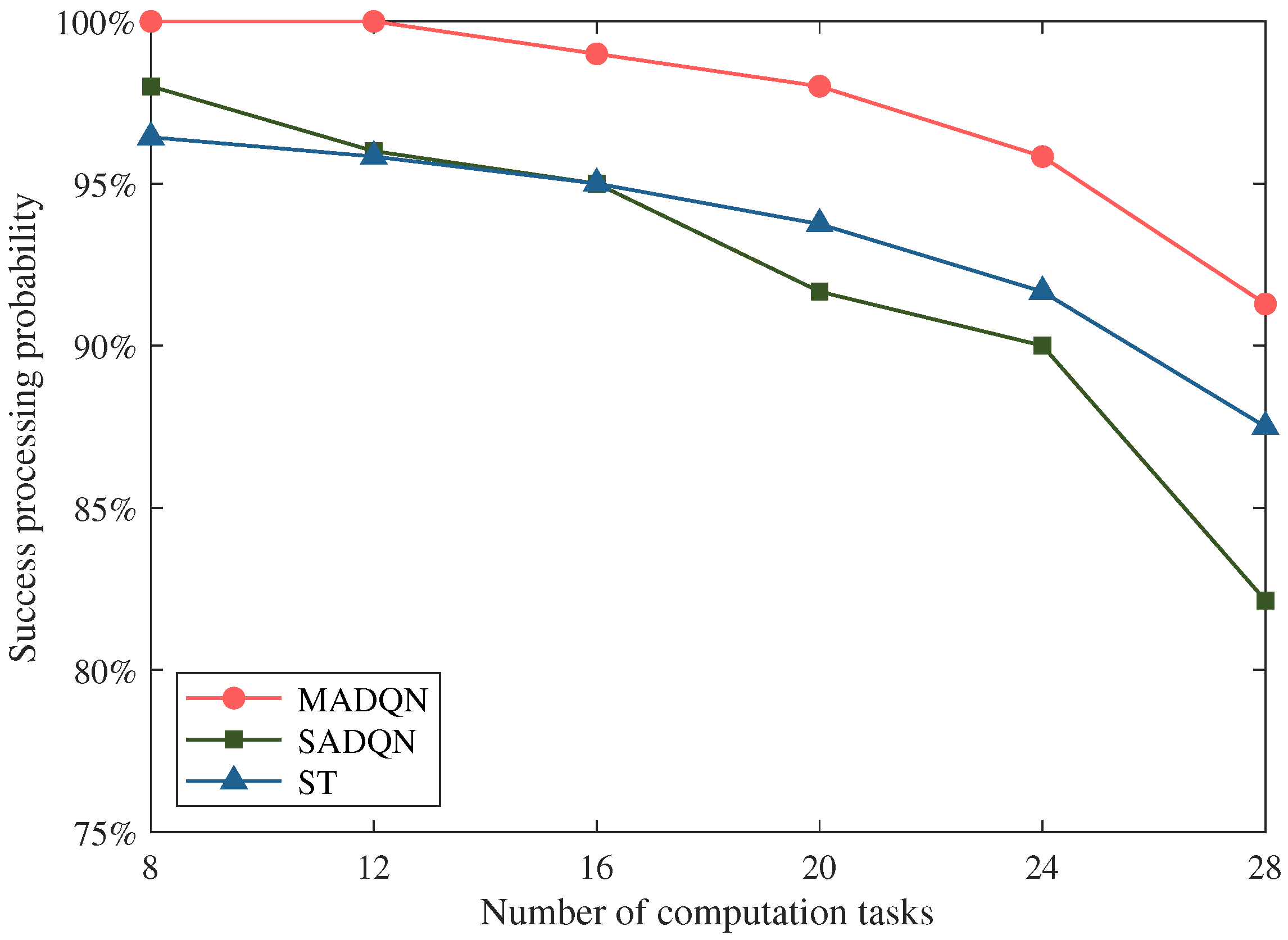
The impact of the number of computation tasks on the successful processing probability with different scheduling algorithms was investigated, with the results shown in
Figure 11. We can see from
Figure 11 that with the increasing number of computation tasks, the successful processing probabilities of different scheduling algorithms decreased. This is due to the fact that a large number of computation tasks require more computing resources. As the number of computation tasks increases, the VEC servers are overloaded, the computing efficiency decreases, and thus the successful processing probability decreases. Fortunately, we can observe that the proposed algorithm outperformed the traditional SADQN algorithm and ST algorithm. Even when the workload of the VEC servers was deeply saturated, the significant performance improvement obtained by the proposed algorithm was greater than 5% compared with the traditional algorithms. This indicates that the proposed algorithm based on MADQN in this paper is effective for VEC servers in peak traffic periods.
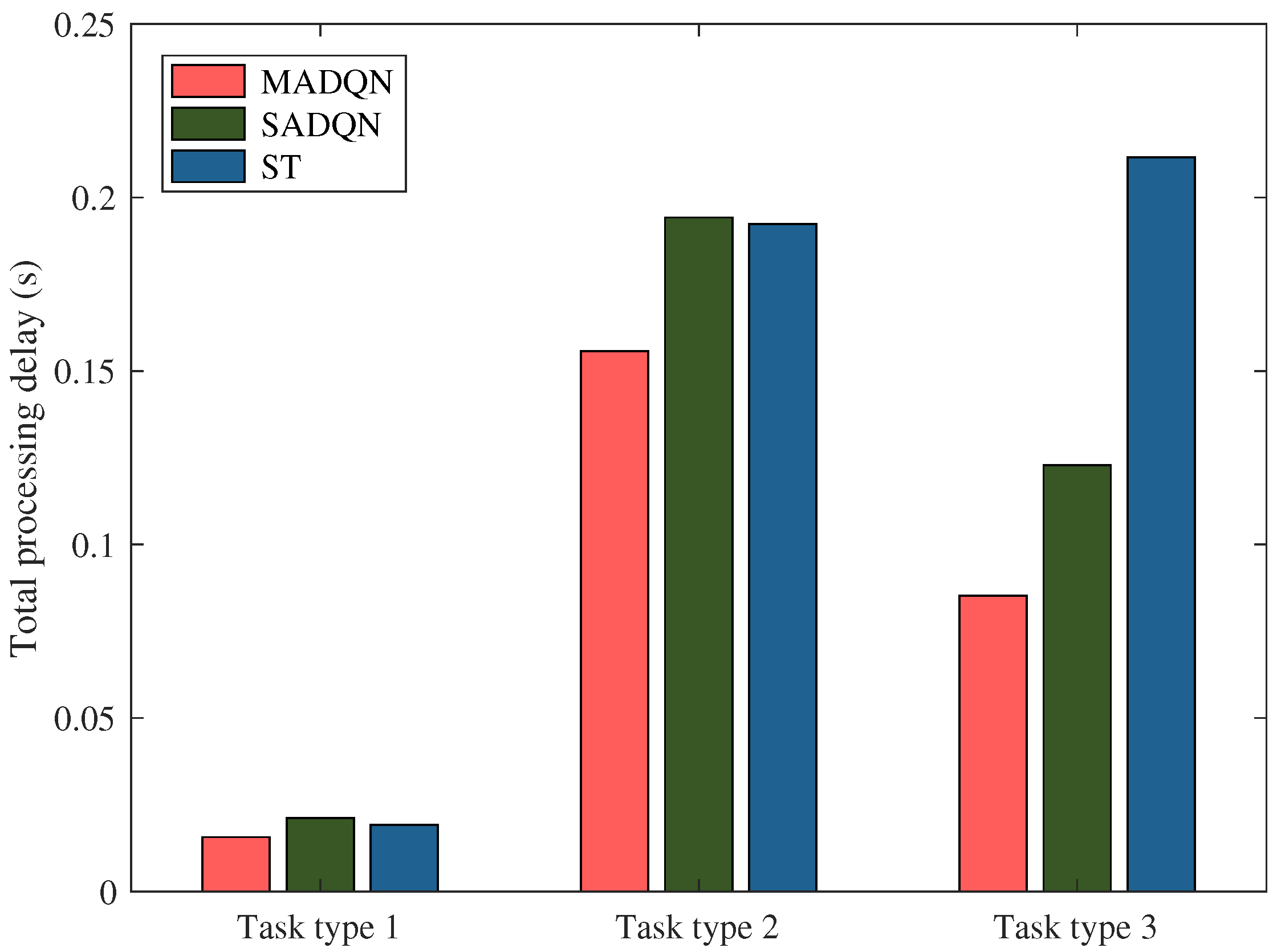
In order to demonstrate the superiority of the proposed algorithm based on MADQN, we investigate the calculation performance of different algorithms with diversified computation tasks (task types shown in
Table 2), where task types 1, 2, and 3 represent the scenarios of a light load, medium load and heavy load for the VEC servers, respectively. From
Figure 12, we can clearly observe that the proposed MADQN-based algorithm can significantly reduce the task processing delay for the different computing scenarios of VEC servers with a light load, medium load or heavy load. Especially under the condition of a heavy load, the total processing delay can be reduced by more than 20% compared with the traditional algorithms. The reason behind the performance growth is the fact that the proposed MADQN-based algorithm introduces a distributed implementation method and parallel task processing. The experiment demonstrated that the proposed algorithm is effective in enhancing the computing efficiency of VEC servers.
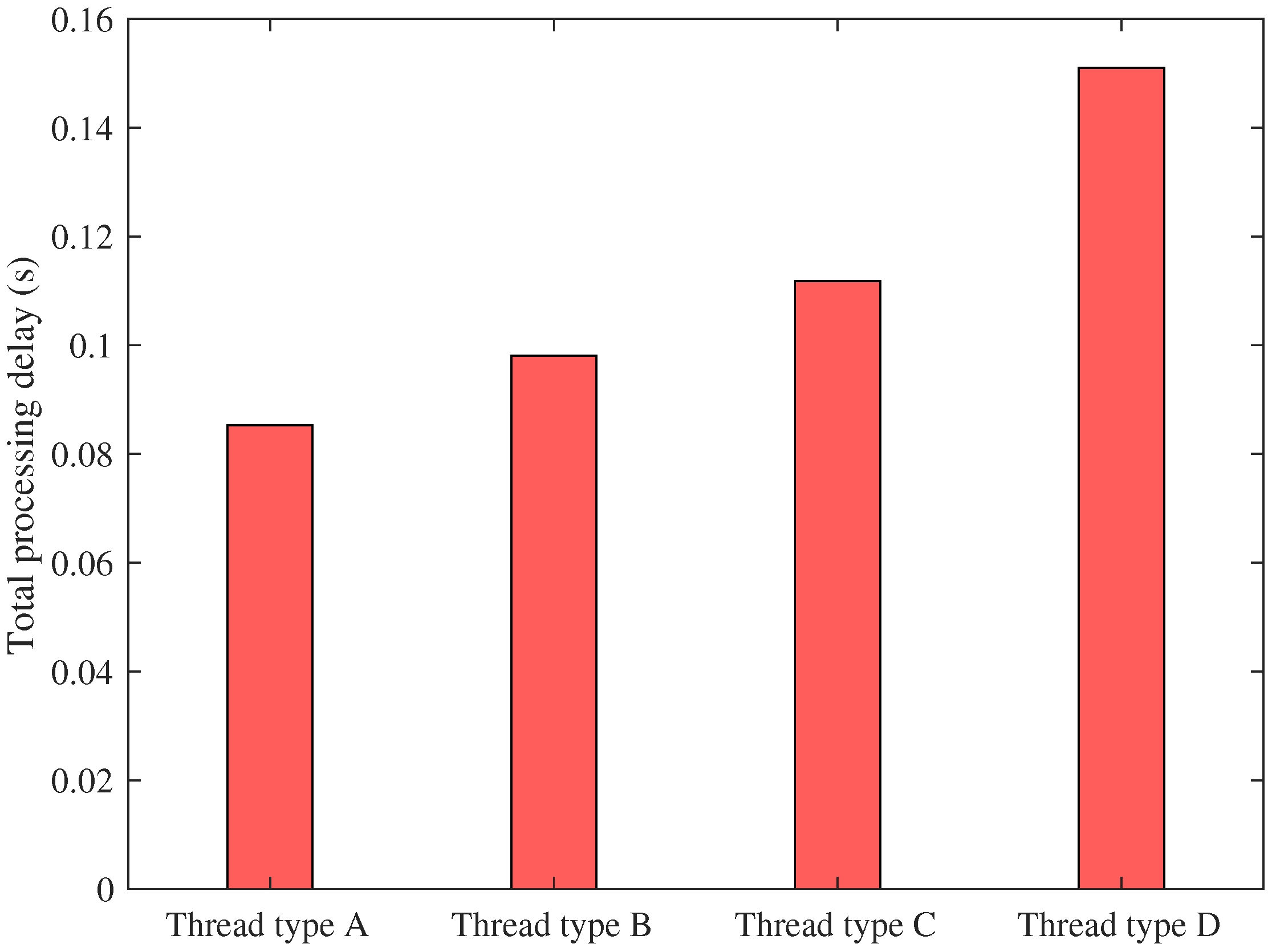
In order to provide a design perspective for VEC server deployment, we investigated the effect of different computing resource configurations of threads on the total processing delay, where the configured computing resources are shown in
Table 3. Thread type A represents the most unbalanced computing resource configuration, and thread type D represents that all thread resources are equal. The total processing delays for different thread configurations are shown in
Figure 13, where the total computing resources were constant. We can note that thread type A, with the most unbalanced resource configuration, required the minimum latency. This means that distinguished resource configurations for different threads in the VEC servers is a better choice.
7. Conclusions
In order to reduce the task processing delay of the VEC server and improve the service quality of vehicular networks, the proposed MADQN-based algorithm was divided into two stages: centralized training in a data training center and distributed implementation on the VEC servers adjacent to the vehicular terminals. Our objective was to minimize the task processing delay, especially during the peak period of traffic in vehicular networks. The experiment results demonstrated that the proposed MADQN-based algorithm could obtain significant performance gains compared with the traditional SADQN algorithm and ST algorithm. We have illustrated the effectiveness of the proposed algorithm. Compared with traditional algorithms, the total processing delay can be reduced by more than 5% when the VEC servers are overloaded.
In the future, we will consider the scenarios of joint wireless channels and vehicle mobility to design a more realistic VEC environment. At the same time, we will further investigate the application of other DRL algorithms, such as Duel DQN and D3QN, for VEC networks.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}