


Reviewing Multimodal Machine Learning and Its Use in Cardiovascular Diseases Detection


Abstract
1. Introduction
1.1. Machine Learning Domain Challenges
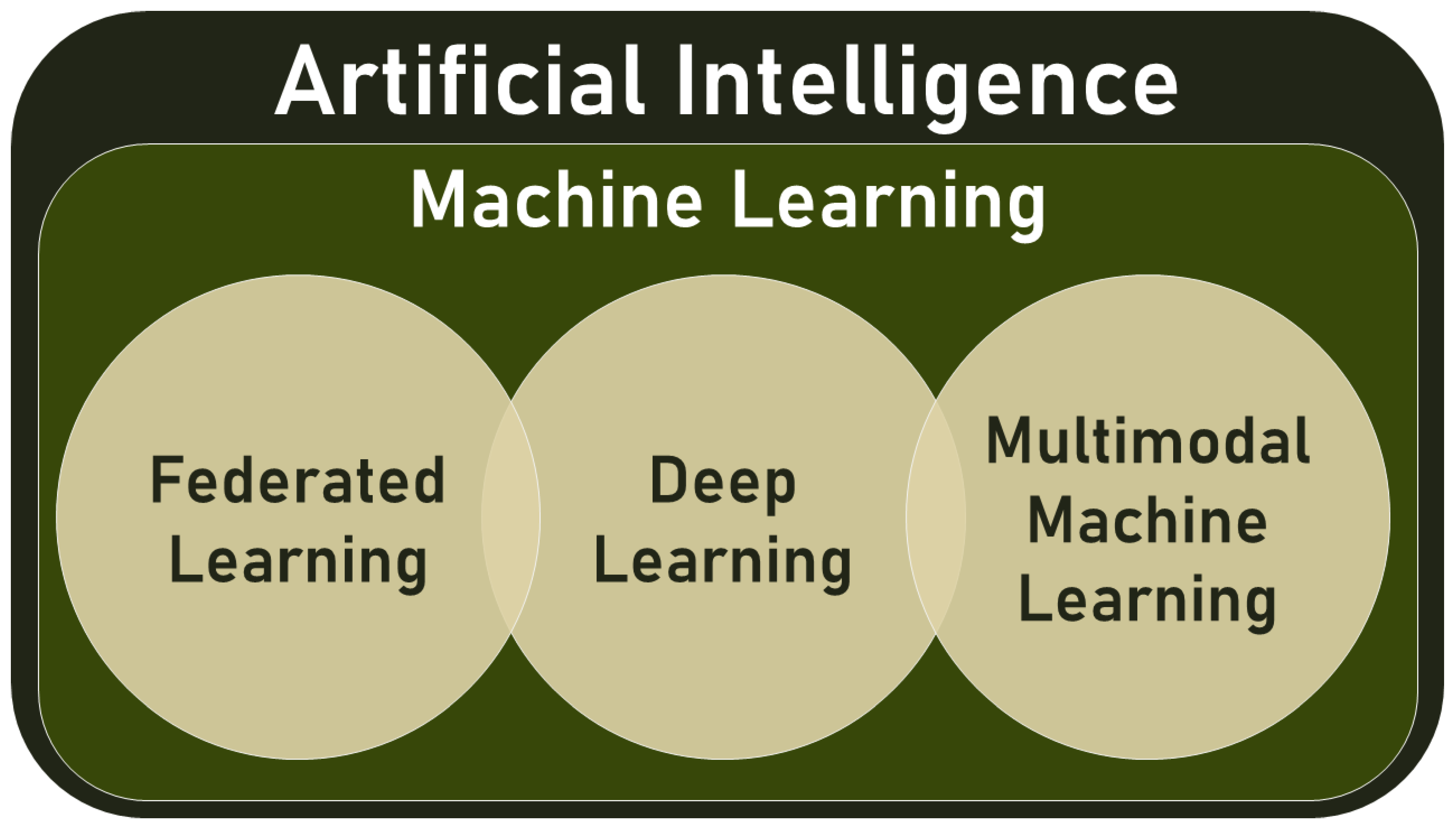
1.2. Heterogeneity: Motivation(s) behind Multimodal ML
- Structured vs. unstructured data: structured data are highly organized and usually follow a specific schema, while unstructured data have no predefined structure or organization;
- Numeric vs. categorical data: Numeric data are quantitative and can be expressed as numbers, while categorical data are qualitative and represent discrete values, such as colors, types, or labels;
- Temporal data: This type of data contains time-stamped information and can be used to analyze patterns and trends over time;
- Multimodal data: This type of data combines different types of information, such as text, audio, images, and videos.
1.3. Machine Learning and Healthcare
1.4. Review Framework: Scope, Outline and Main Contributions
1.4.1. Scope of Research
1.4.2. Research Questions
- What is Multimodal Machine Learning?
- What are the motivations for this technology?
- What are the technical perspectives on which Multimodal ML is based?
- What are the differences between Multimodal ML, classical ML, Multimodal datasets, ensemble ML and other techniques?
- What are the existing Multimodal ML frameworks, and what contributions do each make?
- What is the state of the art in the use of Multimodal ML in CVD prediction, and what technical summaries can be derived?
- What challenges still impede progress in this area, and what approaches could be taken to overcome these issues?
1.4.3. Outline
1.4.4. Comparison with Previous Review Frameworks
1.4.5. Key Findings and Contributions
- Discuss fusion and its fundamental role in defining the structure of Multimodal ML;
- Establish clear and precise boundaries to distinguish between Multimodal ML, traditional ML, multimodal datasets, multilabel models, and ensemble learning;
- Propose a new description for the different workflows that can be followed in the implementation of Multimodal ML algorithms;
- Discuss existing frameworks in the area of Multimodal ML and evaluate the contributions to this area;
- Review and discuss the state of the art of Multimodal ML in the diagnosis of CVDs;
- Examine the technical details associated with these implementations;
- Present completely and in detail the challenges that hinder Multimodal ML and the possible future perspectives that can be pursued to increase the efficiency of the technology.
2. Materials and Methods: What Is Multimodal ML?
2.1. Overview and Definition(s)
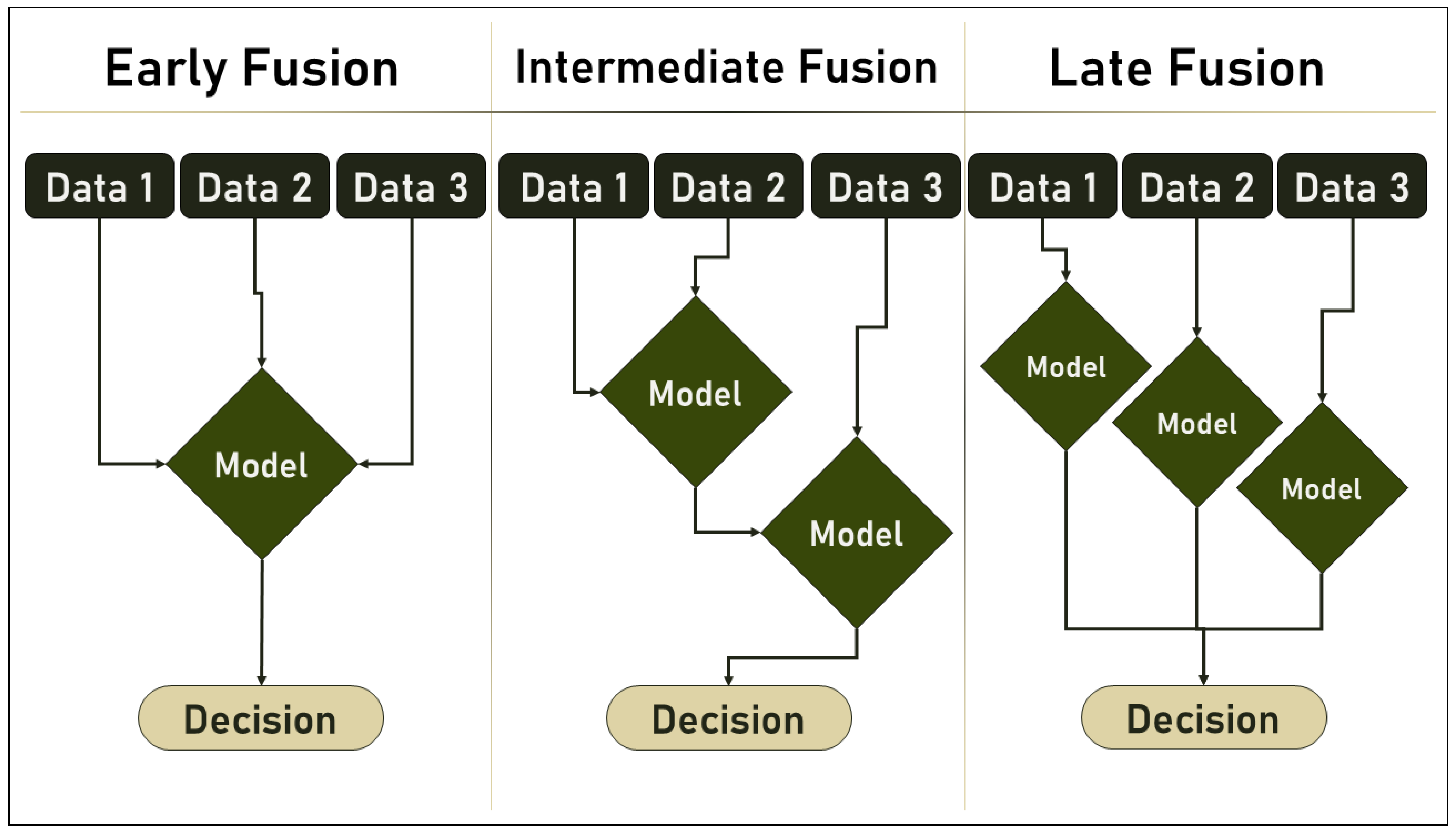
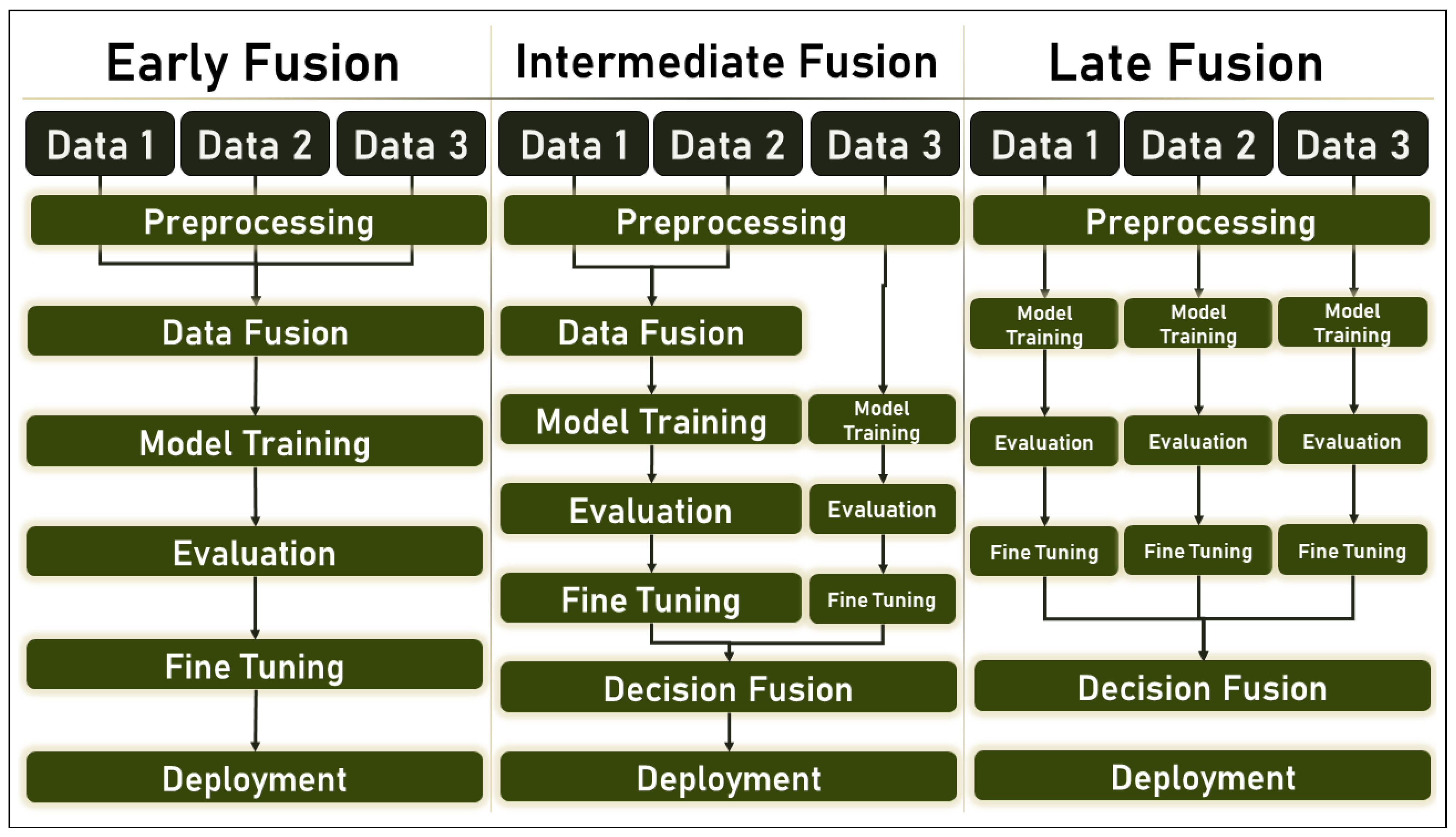
2.2. Multimodal ML and Data Fusion
- Early Fusion: also called Low-Level Fusion, is the simplest form of data fusion in which disparate data sources are merged into a single feature vector before being used by a single Machine Learning algorithm. Therefore, it can be referred to as a multiple-data, single-algorithm technique.
- Intermediate Fusion: is also referred to as Medium-Level Fusion, joint fusion, or Feature-Level Fusion, and occurs in the intermediate phase between the input and output of a ML architecture when all data sources have the same representation format. In this phase, features are combined to perform various tasks such as feature selection, decision-making, or predictions based on historical data.
- Late Fusion: also known as decision-level fusion, defines the aggregation of decisions from multiple ML algorithms, each trained with different data sources. In addition, various rules are used to determine how decisions from different classifiers are combined, e.g.,:
- –
- Max-fusion
- –
- Averaged-fusion
- –
- Bayes’ rule-based
- –
- Even rules learned using a metaclassifier
- Hybrid Fusion: defines the use of more than one fusion discipline in a single deep algorithm.
2.3. Multimodal ML: Technical Perspectives
2.3.1. Data Preparation
2.3.2. Model Architecture
2.3.3. Training Strategies
2.3.4. Evaluation Metrics
2.3.5. Generalization
2.3.6. Interpretability
2.3.7. Scalability
2.4. Multimodal ML and Other Technologies: Borderlines
2.4.1. Multimodal ML vs. Multimodal Datasets
2.4.2. Multimodal ML vs. Multilabel Models
2.4.3. Multimodal ML vs. Ensemble Learning
- Bagging (Bootstrap Aggregating): is the process of training several models using random subsets of the training data to minimize overfitting;
- Boosting is a technique in which models are trained progressively, and the weights of misclassified data points are raised to enhance performance;
- Stacking is the process of training many models and combining their predictions with another model to obtain the final forecast.
2.5. Multimodal ML Available Frameworks
- MMF (a framework for multimodal AI models) [54]: is a PyTorch-based modular framework. MMF comes with cutting-edge vision and language pretrained models, a slew of ready-to-use standard datasets, common layers and model components, and training and inference utilities. MMF is also utilized by various Facebook product teams for multimodal understanding of use cases, allowing them to swiftly put research into production;
- TinyMNet (a flexible system, algorithm co-designed multimodal learning framework for tiny devices) [55]: a unique multimodal learning framework that can handle multimodal inputs of images and audio and can be re-configured for individual application needs. TinyM2Net also enables the system and algorithm to incorporate fresh sensor data that are tailored to a variety of real-world settings. The suggested framework is built on a convolutional neural network, which has previously been recognized as one of the most promising methodologies for audio and visual data classification;
- A Unified Deep Learning Framework for Multimodal Multi-Dimensional Data [56]: is a framework capable of bridging the gap between data sufficiency/readiness and model availability/capability. For successful deployments, the framework is verified on multimodal, multi-dimensional data sets. The suggested architecture, which serves as a foundation, may be developed to solve a broad range of data science challenges utilizing Deep Learning;
- HAIM (unified Holistic AI in Medicine) [57]: It is a framework for developing and testing AI systems that make use of multimodal inputs. It employs generalizable data preprocessing and Machine Learning modeling steps that are easily adaptable for study and application in healthcare settings.
- ML4VocalDelivery [58]: a novel Multimodal Machine Learning technique that uses pairwise comparisons and a multimodal orthogonal fusing algorithm to create large-scale objective assessment findings of teacher voice delivery in terms of fluency and passion;
- Specific Knowledge Oriented Graph (SKOG) [59]: a technique for addressing multimodal analytics within a single data processing approach in order to obtain a streamlined architecture that can fully use the potential of Big Data infrastructures’ parallel processing.
2.6. Training and Evaluation of Multimodal ML Algorithms
3. Results: Multimodal ML in Action
3.1. Multimodal ML: Fields of Implementation
- Healthcare: in medical imaging, Multimodal ML can be used to integrate information from different imaging modalities such as MRI, CT, and PET scans to improve diagnosis and treatment planning. It can also be used to classify and predict disease based on a mix of clinical, genetic, and imaging data;
- Autonomous Vehicles: by combining data from numerous sensors, the Multimodal ML can help self-driving vehicles better understand their surroundings. This has the potential to improve object recognition, navigation and safety;
- Natural Language Processing: by blending audio and text data, Multimodal ML can improve speech recognition and natural language comprehension. This can help voice assistants, chatbots and other applications improve their accuracy;
- Robotics: by combining inputs from sensors such as cameras, microphones, and touch sensors, Multimodal ML can be used to improve robot perception and interaction. This has the potential to improve navigation, object recognition, and human–robot interaction;
- Education: this technology is used in education to analyze student data from numerous sources, such as exams, quizzes, and essays, to make individualized learning suggestions and improve student performance;
- Agriculture: this technology can revolutionize agriculture by enabling the optimization of farming processes. It can be used for crop yield prediction, pest and disease detection, precision agriculture, and crop optimization by combining data from multiple sources, such as satellite imagery, weather data, and soil moisture sensors;
- Internet of Things (IoTs): this technology can be used in the context of the Internet of Things to make better use of data provided by networked devices. Multimodal ML can enable more accurate and robust models for predicting, monitoring, and managing IoT systems by incorporating data from many sources, such as sensors, cameras, and audio recordings, leading to advances in areas such as energy management, transportation, and smart cities.
3.2. Multimodal ML in Healthcare
3.3. Multimodal ML and Cardiovascular Diseases: State-of-the-Art
3.4. Multimodal ML and CVDs: Discussion
3.4.1. Models Performance: Competition between Multimodal and Classical ML
3.4.2. Real World vs. Research Implementations
- Improved Diagnostic Accuracy: Multimodal ML models can evaluate multiple sources of patient data, such as medical imaging, electronic health records, and genetic information, to make more accurate and thorough diagnoses. This can help physicians identify diseases and conditions at an early stage when they are more curable;
- Personalized Treatment: multimodal ML models can be trained on large data sets to identify trends and predict outcomes for individual patients. This can help physicians tailor treatments and therapies to the unique needs of each patient, leading to better outcomes and fewer side effects;
- Efficient Resource Allocation: Multimodal ML models can help physicians allocate resources more efficiently by identifying patients who are at higher risk for poor outcomes or need more intensive care. This has the potential to reduce healthcare costs while improving overall system efficiency;
- Improved patient experience: Multimodal ML models can help clinicians identify patients who need more individualized care or are at risk for problems or adverse events. This can help improve patient satisfaction and overall quality of care.
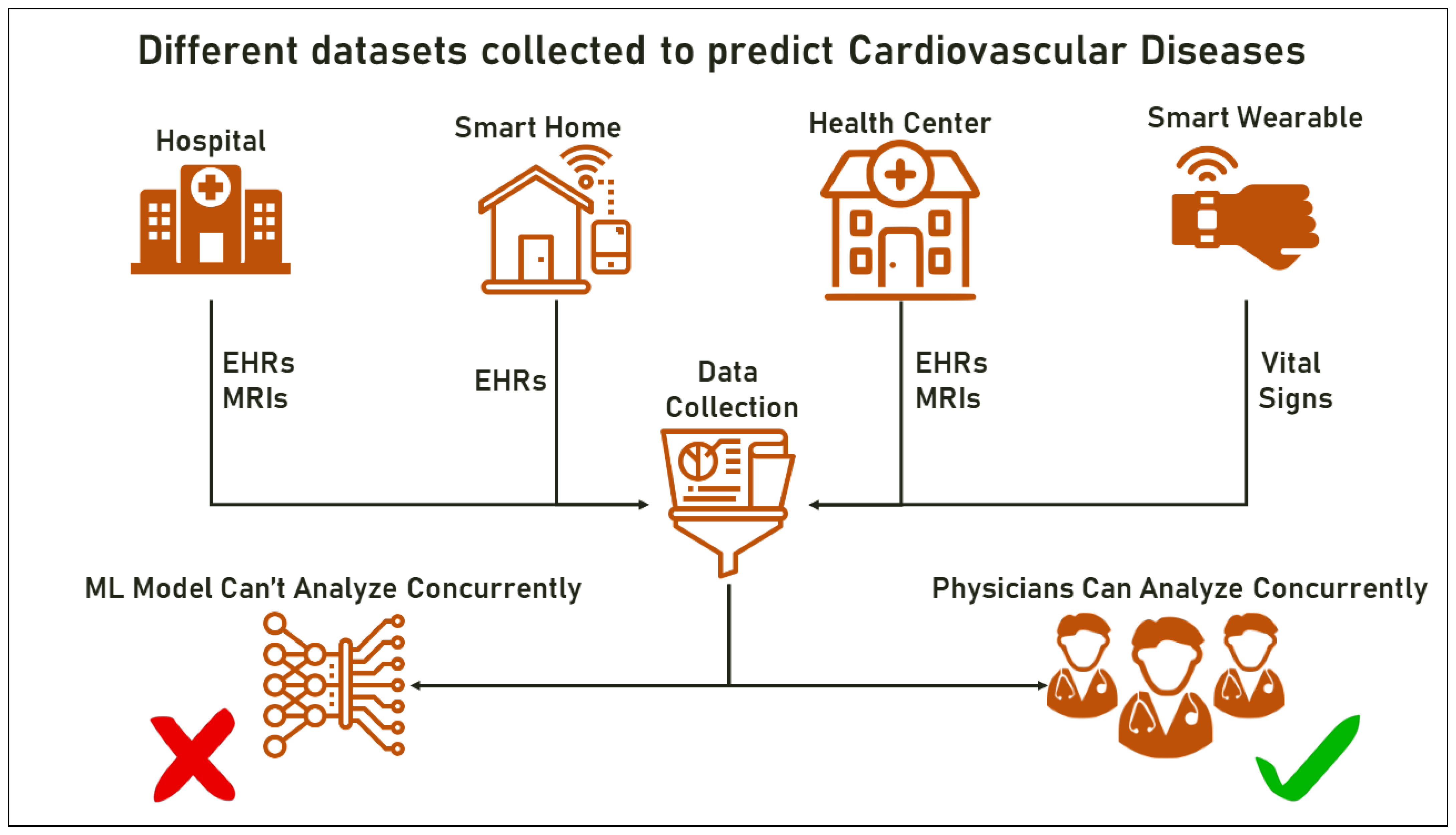
3.4.3. Use of Smart Wearables and IoTs
3.4.4. Limitations in the Use of Multimodal ML for Disease Prediction
3.5. Multimodal ML in CVDs: A Technical Overview
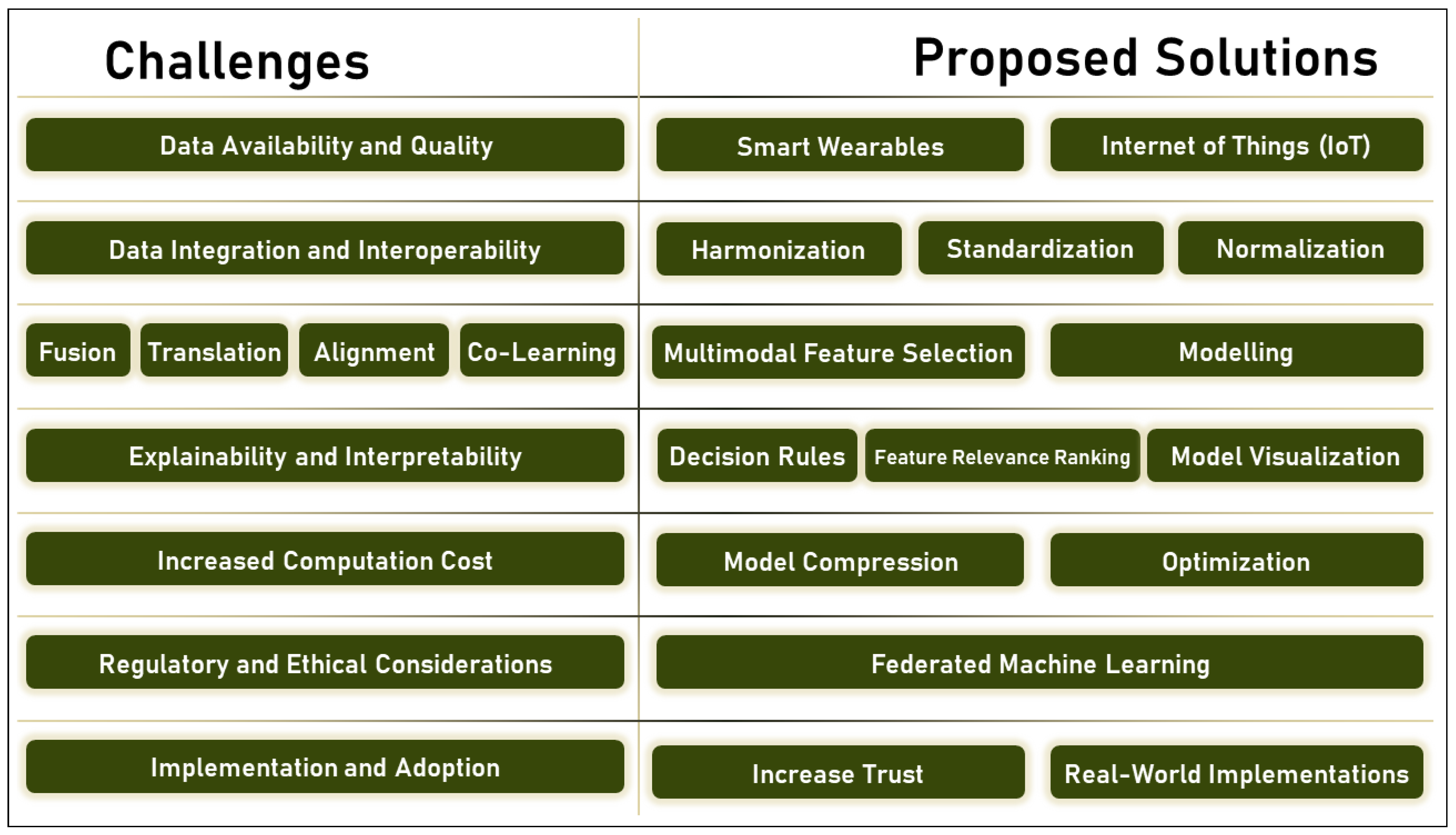
4. Discussion: Challenges and Future Perspectives
4.1. Challenges
4.1.1. Data Availability and Quality
4.1.2. Data Representation
4.1.3. Data Integration and Interoperability
4.1.4. Fusion
4.1.5. Translation
4.1.6. Alignment
4.1.7. Explainability and Interpretability
4.1.8. Co-Learning
4.1.9. Increased Computation Cost
4.1.10. Regulatory and Ethical Considerations
4.1.11. Implementation and Adoption
- RQ1: Multimodal ML needs sufficient data to be trained. Are the needed data sets available? And is their quality acceptable?
- RQ2: Multimodal ML deals with heterogeneous data that has different formats and structures. What approaches can be taken to represent the data used in this technology?
- RQ3: How can the heterogeneous data used in Multimodal ML be integrated and shared?
- RQ4: What are the best approaches for fusion, and how to choose between the different options available?
- RQ5: Given that different models can lead to the same result in different ways, how does one choose the optimal path?
- RQ6: How to align and link two different modalities, especially in the middle and late fusion cases?
- RQ7: The Multimodal ML is known for its black box identity. Is there a way to explain the methods by which a model arrives at its result?
- RQ8: In Multimodal ML, different models can be integrated to solve a complex task. What techniques can be applied to ensure efficient knowledge transfer between these models?
- RQ9: Heterogeneity and diversity in both models and data add to computational costs. How can this problem be dealt with to improve the usability and feasibility of the models?
- RQ10: How to ensure data exchange between multimodal ML facilities to comply with existing regulations and laws?
- RQ11: How can trust in multimodal ML be strengthened to promote its adoption in different areas of life?
4.2. Future Perspectives
4.2.1. Use Convenient Tools to Collect More Data
4.2.2. Automate and Boost Data Preprocessing
4.2.3. Employment of Advanced Data Integration Tools
4.2.4. Embedding Modern Techniques to Enhance Explainability
- Feature relevance ranking: include methods such as permutation significance and partial dependency plots to give insights into the importance and correlations of input variables, allowing for a better understanding of the model’s decision-making process and boosting transparency and interpretability in healthcare applications;
- Model visualization: such as decision trees and heatmaps that provide a graphical representation of the model’s decision-making process, allowing for better understanding of the factors that influence the model’s predictions and increasing the transparency and interpretability of the technology;
- Decision rules: by providing clear and understandable rationales for the model’s predictions, decision rules that specify explicit decision criteria based on the input data improve the interpretability and transparency of machine learning models in healthcare.
- Probabilistic approach: employ probabilistic reasoning to represent and manage the uncertainty inherent in medical data allowing for transparent decision-making that can be easily understood by healthcare practitioners;
- Neuro-fuzzy techniques: combine the benefits of neural networks and fuzzy logic to generate more interpretable models that can deal with imprecise and uncertain inputs.
4.2.5. Implementing Necessary Methods to Guarantee Knowledge Transfer
4.2.6. Reducing Computation Cost
4.2.7. Increase Trust and Feasibility to Raise the Technology Adoption
- TR1: Data collection tools such as smart wearables and IoTs are very helpful in augmenting the data collected for multimodal ML algorithms;
- TR2: Data harmonization, standardization, and normalization are highly feasible for integrating heterogeneous data in the multimodal ML domain;
- TR3: Multimodal feature selection and modeling are techniques that can help ensure knowledge transfer between different modalities in a multimodal ML system;
- TR4: For better explainability and interpretability of a multimodal ML model, decision rules, feature relevance ranking, and model visualization are practical and feasible methods;
- TR5: Model compression and optimization are great tools for reducing computational costs in multimodal ML;
- TR6: Current and trending ML topics, such as Federated Machine Learning, can help overcome privacy and confidentiality issues in the Multimodal ML domain;
- TR7: Increasing feasibility, improving performance, and implementation in real-world scenarios are all factors that can help expand the adoption of multimodal ML technology in healthcare and, in particular, in Cardiovascular Disease detection.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moor, J. The Dartmouth College artificial intelligence conference: The next fifty years. AI Mag. 2006, 27, 87. [Google Scholar]
- Simone, N.; Ballatore, A. Imagining the thinking machine: Technological myths and the rise of artificial intelligence. Convergence 2020, 26, 3–18. [Google Scholar]
- John, M. What Is Artificial Intelligence; Stanford University: Stanford, CA, USA, 2007. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Kline, A.; Wang, H.; Li, Y.; Dennis, S.; Hutch, M.; Xu, Z.; Luo, Y. Multimodal Machine Learning in Precision Health. arXiv 2022, arXiv:2204.04777. [Google Scholar]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Giuseppe, B. Machine Learning Algorithms; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Yann, L.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar]
- Mohammad, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Reviewing Federated Machine Learning and Its Use in Diseases Prediction. Sensors 2023, 23, 2112. [Google Scholar] [CrossRef]
- Tadas, B.; Ahuja, C.; Morency, L. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar]
- Pallathadka, H.; Mustafa, M.; Sanchez, D.T.; Sajja, G.S.; Gour, S.; Naved, M. Impact of machine learning on management, healthcare and agriculture. Mater. Today Proc. 2021; in press. [Google Scholar] [CrossRef]
- Ghazal, T.M.; Hasan, M.K.; Alshurideh, M.T.; Alzoubi, H.M.; Ahmad, M.; Akbar, S.S.; Al Kurdi, B.; Akour, I.A. IoT for smart cities: Machine learning approaches in smart healthcare—A review. Future Internet 2021, 13, 218. [Google Scholar] [CrossRef]
- Erickson, B.J.; Korfiatis, P.; Akkus, Z.; Kline, T.L. Machine learning for medical imaging. Radiographics 2017, 37, 505. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine learning: Algorithms, real-world applications and research directions. SN Comput. Sci. 2021, 2, 1–21. [Google Scholar] [CrossRef] [PubMed]
- Sharma, N.; Sharma, R.; Jindal, N. Machine learning and deep learning applications-a vision. Glob. Transitions Proc. 2021, 2, 24–28. [Google Scholar] [CrossRef]
- Zantalis, F.; Koulouras, G.; Karabetsos, S.; Kandris, D. A review of machine learning and IoT in smart transportation. Future Internet 2019, 11, 94. [Google Scholar] [CrossRef]
- Xin, Y.; Kong, L.; Liu, Z.; Chen, Y.; Li, Y.; Zhu, H.; Gao, M.; Hou, H.; Wang, C. Machine learning and deep learning methods for cybersecurity. IEEE Access 2018, 6, 35365–35381. [Google Scholar] [CrossRef]
- Nagarhalli, T.P.; Vaze, V.; Rana, N.K. Impact of machine learning in natural language processing: A review. In Proceedings of the Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), IEEE, Tirunelveli, India, 4–6 February 2021; pp. 1529–1534. [Google Scholar]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed]
- Larrañaga, P.; Atienza, D.; Diaz-Rozo, J.; Ogbechie, A.; Puerto-Santana, C.; Bielza, C. Industrial Applications of Machine Learning; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- L’heureux, A.; Grolinger, K.; Elyamany, H.F.; Capretz, M.A. Machine learning with big data: Challenges and approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A.V. Machine learning on big data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef]
- Injadat, M.; Moubayed, A.; Nassif, A.B.; Shami, A. Machine learning towards intelligent systems: Applications, challenges, and opportunities. Artif. Intell. Rev. 2021, 54, 3299–3348. [Google Scholar] [CrossRef]
- Leskovec, J.; Rajaraman, A.; Ullman, J.D. Mining of Massive Data Sets; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Paleyes, A.; Urma, R.G.; Lawrence, N.D. Challenges in deploying machine learning: A survey of case studies. ACM Comput. Surv. 2020, 55, 1–29. [Google Scholar] [CrossRef]
- Char, D.S.; Shah, N.H.; Magnus, D. Implementing machine learning in health care—Addressing ethical challenges. N. Engl. J. Med. 2018, 378, 981. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Rosario, M.; Mukhopadhyay, S.C.; Liu, Z.; Slomovitz, D.; Samantaray, S.R. Advances on sensing technologies for smart cities and power grids: A review. IEEE Sens. J. 2017, 17, 7596–7610. [Google Scholar]
- Total Data Volume Worldwide 2010–2025|Statista. Petroc Taylor. 8 September 2022. Statista. Available online: https://www.statista.com/statistics/871513/worldwide-data-created/ (accessed on 15 February 2023).
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef]
- Lidong, W. Heterogeneous data and big data analytics. Autom. Control. Inf. Sci. 2017, 3, 8–15. [Google Scholar]
- Geert, L.; Ciompi, F.; Wolterink, J.M.; de Vos, B.D.; Leiner, T.; Teuwen, J.; Išgum, I. State-of-the-art deep learning in cardiovascular image analysis. JACC Cardiovasc. Imaging 2019, 12, 1549–1565. [Google Scholar]
- Mohammad, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Smart Wearables for the Detection of Cardiovascular Diseases: A Systematic Literature Review. Sensors 2023, 23, 828. [Google Scholar] [CrossRef]
- Aamir, J.; Zghyer, F.; Kim, C.; Spaulding, E.M.; Isakadze, N.; Ding, J.; Kargillis, D.; Gao, Y.; Rahman, F.; Brown, D.E.; et al. Medicine 2032: The future of cardiovascular disease prevention with machine learning and digital health technology. Am. J. Prev. Cardiol. 2022, 12, 100379. [Google Scholar]
- Ramesh, A.N.; Kambhampati, C.; Monson, J.R.L.; Drew, P.J. Artificial intelligence in medicine. Ann. R. Coll. Surg. Engl. 2004, 86, 334. [Google Scholar] [CrossRef]
- Maddox, T.M.; Rumsfeld, J.S.; Payne, P.R. Questions for artificial intelligence in health care. JAMA 2019, 321, 31–32. [Google Scholar] [CrossRef]
- Amine, M.M.; Adda, M.; Bouzouane, A.; Ibrahim, H. Machine learning and smart devices for diabetes management: Systematic review. Sensors 2022, 22, 1843. [Google Scholar] [CrossRef]
- Shweta, C.; Biswas, N.; Jones, L.D.; Kesari, S.; Ashili, S. Smart Consumer Wearables as Digital Diagnostic Tools: A Review. Diagnostics 2022, 12, 2110. [Google Scholar] [CrossRef]
- Mohammad, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Smart Wearables for the Detection of Occupational Physical Fatigue: A Literature Review. Sensors 2022, 22, 7472. [Google Scholar] [CrossRef]
- Yukang, X. A review on intelligent wearables: Uses and risks. Hum. Behav. Emerg. Technol. 2019, 1, 287–294. [Google Scholar]
- Marie, C.; Estève, D.; Fourniols, J.; Escriba, C.; Campo, E. Smart wearable systems: Current status and future challenges. Artif. Intell. Med. 2012, 56, 137–156. [Google Scholar]
- Chinthaka, J.S.M.D.A.; Ganegoda, G.U. Involvement of machine learning tools in healthcare decision making. J. Healthc. Eng. 2021, 2021, 6679512. [Google Scholar]
- Sameer, Q. Artificial intelligence and machine learning in precision and genomic medicine. Med. Oncol. 2022, 39, 120. [Google Scholar]
- Arjun, P. Machine Learning and AI for Healthcare; Apress: Coventry, UK, 2019. [Google Scholar]
- Nitish, S.; Salakhutdinov, R.R. Multimodal learning with deep boltzmann machines. Adv. Neural Inf. Process. Syst. 2014, 15, 2949–2980. [Google Scholar]
- White, F.E. Data Fusion Lexicon; Joint Directors of Labs: Washington, DC, USA, 1991. [Google Scholar]
- Baronio, M.A.; Cazella, S.C. Multimodal Deep Learning for Computer-Aided Detection and Diagnosis of Cancer: Theory and Applications. Enhanc. Telemed. Health Adv. Iot Enabled Soft Comput. Framew. 2021, 267–287. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Challenges and applications in multimodal machine learning. In The Handbook of Multimodal-Multisensor Interfaces: Signal Processing, Architectures, and Detection of Emotion and Cognition—Volume 2; Association for Computing Machinery and Morgan & Claypool: San Rafael, CA, USA, 2018; pp. 17–48. [Google Scholar] [CrossRef]
- Anil, R.; Walambe, R.; Ramanna, S.; Kotecha, K. Multimodal co-learning: Challenges, applications with datasets, recent advances and future directions. Inf. Fusion 2022, 81, 203–239. [Google Scholar]
- Grigorios, T.; Katakis, I. Multi-label classification: An overview. Int. J. Data Warehous. Min. 2007, 3, 1–13. [Google Scholar]
- Min-Ling, Z.; Zhou, Z. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar]
- Xibin, D.; Yu, Z.; Cao, W.; Shi, Y.; Ma, Q. A survey on ensemble learning. Front. Comput. Sci. 2020, 14, 241–258. [Google Scholar]
- Omer, S.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar]
- Announcing MMF: A Framework for Multimodal AI Models. Available online: https://ai.facebook.com/blog/announcing-mmf-a-framework-for-multimodal-ai-models/ (accessed on 18 February 2023).
- Hasib-Al, R.; Ovi, P.R.; Gangopadhyay, A.; Mohsenin, T. TinyM2Net: A Flexible System Algorithm Co-designed Multimodal Learning Framework for Tiny Devices. arXiv 2022, arXiv:2202.04303. [Google Scholar]
- Pengcheng, X.; Shu, C.; Goubran, R. A Unified Deep Learning Framework for Multi-Modal Multi-Dimensional Data. In Proceedings of the 2019 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Istanbul, Turkey, 26–28 June 2019; pp. 1–6. [Google Scholar]
- Ma, S.L.R.Y.; Zeng, C.; Boussioux, L.; Carballo, K.V.; Na, L.; Wiberg, H.M.; Li, M.L.; Fuentes, I.; Bertsimas, D. Integrated multimodal artificial intelligence framework for healthcare applications. NPJ Digit. Med. 2022, 5, 149. [Google Scholar]
- Hang, L.; Kang, Y.; Hao, Y.; Ding, W.; Wu, Z.; Liu, Z. A Multimodal Machine Learning Framework for Teacher Vocal Delivery Evaluation. In Proceedings of the Artificial Intelligence in Education: 22nd International Conference, AIED 2021, Utrecht, The Netherlands, 14–18 June 2021; Springer International Publishing: Cham, Switzerland, 2021. Part II. pp. 251–255. [Google Scholar]
- Valerio, B.; Ceravolo, P.; Maghool, S.; Siccardi, S. Toward a general framework for multimodal big data analysis. Big Data 2022, 10, 408–424. [Google Scholar]
- YJing, A.; Liang, N.; Pitts, B.J.; Prakah-Asante, K.O.; Curry, R.; Blommer, M.; Swaminathan, R.; Yu, D. Multimodal Sensing and Computational Intelligence for Situation Awareness Classification in Autonomous Driving. IEEE Trans. Hum.-Mach. Syst. 2023, 53, 270–281. [Google Scholar]
- Azin, A.; Saha, R.; Jakubovitz, D.; Peyre, J. AutoFraudNet: A Multimodal Network to Detect Fraud in the Auto Insurance Industry. arXiv 2023, arXiv:2301.07526. [Google Scholar]
- Arnab, B.; Ahmed, M.U.; Begum, S. A Systematic Literature Review on Multimodal Machine Learning: Applications, Challenges, Gaps and Future Directions. IEEE Access 2023, 11, 14804–14831. [Google Scholar]
- Lemay, P.C.S.D.G.; Owen, C.L.; Woodward-Greene, M.J.; Sun, J. Multimodal AI to Improve Agriculture. IT Prof. 2021, 23, 53–57. [Google Scholar]
- Yuchen, Z.; Barnaghi, P.; Haddadi, H. Multimodal federated learning on iot data. In Proceedings of the 2022 IEEE/ACM Seventh International Conference on Internet-of-Things Design and Implementation (IoTDI), Milano, Italy, 4–6 May 2022; pp. 43–54. [Google Scholar]
- Min, C.; Hao, Y.; Hwang, K.; Wang, L.; Wang, L. Disease prediction by machine learning over big data from healthcare communities. IEEE Access 2017, 5, 8869–8879. [Google Scholar]
- Bersche, G.S.; Shibahara, T.; Agboola, S.; Otaki, H.; Sato, J.; Nakae, T.; Hisamitsu, T.; Kojima, G.; Felsted, J.; Kakarmath, S.; et al. A machine learning model to predict the risk of 30-day readmissions in patients with heart failure: A retrospective analysis of electronic medical records data. Bmc Med. Inform. Decis. Mak. 2018, 18, 1–17. [Google Scholar]
- Yuan, L.; Mao, C.; Yang, Y.; Wang, F.; Ahmad, F.S.; Arnett, D.; Irvin, M.R.; Shah, S.J. Integrating hypertension phenotype and genotype with hybrid non-negative matrix factorization. Bioinformatics 2019, 35, 1395–1403. [Google Scholar]
- Rao, W.R.R.D.C.; Ellison, R.C.; Arnett, D.K.; Heiss, G.; Oberman, A.; Eckfeldt, J.H.; Leppert, M.F.; Province, M.A.; Mockrin, S.C.; Hunt, S.C.; et al. NHLBI family blood pressure program: Methodology and recruitment in the HyperGEN network. Ann. Epidemiol. 2000, 10, 389–400. [Google Scholar]
- Xiaosong, W.; Peng, Y.; Lu, L.; Lu, Z.; Summers, R.M. Tienet: Text-image embedding network for common thorax disease classification and reporting in chest x-rays. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9049–9058. [Google Scholar]
- Xiaosong, W.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Dina, D.; Kohli, M.D.; Rosenman, M.B.; Shooshan, S.E.; Rodriguez, L.; Antani, S.; Thoma, G.R.; McDonald, C.J. Preparing a collection of radiology examinations for distribution and retrieval. J. Am. Med. Inform. Assoc. 2016, 23, 304–310. [Google Scholar]
- Yixue, H.; Usama, M.; Yang, J.; Hossain, M.S.; Ghoneim, A. Recurrent convolutional neural network based multimodal disease risk prediction. Future Gener. Comput. Syst. 2019, 92, 76–83. [Google Scholar]
- Yikuan, L.; Wang, H.; Luo, Y. A comparison of pre-trained vision-and-language models for multimodal representation learning across medical images and reports. In Proceedings of the 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Seoul, Republic of Korea, 16–19 December 2020; pp. 1999–2004. [Google Scholar]
- Pollard, J.A.E.W.T.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.; Peng, Y.; Lu, Z.; Mark, R.G.; Berkowitz, S.J.; Horng, S. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs. arXiv 2019, arXiv:1901.07042. [Google Scholar]
- Ilan, S.; Cirulli, E.T.; Huang, L.; Napier, L.A.; Heister, R.R.; Hicks, M.; Cohen, I.V.; Yu, H.C.; Swisher, C.L.; Schenker-Ahmed, N.M.; et al. An unsupervised learning approach to identify novel signatures of health and disease from multimodal data. Genome Med. 2020, 12, 1–14. [Google Scholar]
- Esra, Z.; Madai, V.I.; Khalil, A.A.; Galinovic, I.; Fiebach, J.B.; Kelleher, J.D.; Frey, D.; Livne, M. Multimodal Fusion Strategies for Outcome Prediction in Stroke. In Proceedings of the 13th International Conference on Health Informatics, Valletta, Malta, 24–26 February 2020; pp. 421–428. [Google Scholar]
- Benjamin, H.; Pittl, S.; Ebinger, M.; Oepen, G.; Jegzentis, K.; Kudo, K.; Rozanski, M.; Schmidt, W.U.; Brunecker, P.; Xu, C.; et al. Prospective study on the mismatch concept in acute stroke patients within the first 24 h after symptom onset-1000Plus study. BMC Neurol. 2009, 9, 60. [Google Scholar]
- Shih-Cheng, H.; Pareek, A.; Zamanian, R.; Banerjee, I.; Lungren, M.P. Multimodal fusion with deep neural networks for leveraging CT imaging and electronic health record: A case-study in pulmonary embolism detection. Sci. Rep. 2020, 10, 1–9. [Google Scholar]
- Ayoub, B.; Groenhof, T.K.J.; Veldhuis, W.B.; de Jong, P.A.; Asselbergs, F.W.; Oberski, D.L. Multimodal learning for cardiovascular risk prediction using EHR data. arXiv 2020, arXiv:2008.11979. [Google Scholar]
- Gerarda, S.P.C.; Algra, A.; Laak, M.F.V.D.; Grobbee, D.E.; Graaf, Y.V.D. Second manifestations of ARTerial disease (SMART) study: Rationale and design. Eur. J. Epidemiol. 1999, 15, 773–781. [Google Scholar]
- Gianluca, B.; Neuberger, U.; Mahmutoglu, M.A.; Foltyn, M.; Herweh, C.; Nagel, S.; Schönenberger, S.; Heiland, S.; Ulfert, C.; Ringleb, P.A.; et al. Multimodal predictive modeling of endovascular treatment outcome for acute ischemic stroke using machine-learning. Stroke 2020, 51, 3541–3551. [Google Scholar]
- Makoto, N.; Kiuchi, K.; Nishimura, K.; Kusano, K.; Yoshida, A.; Adachi, K.; Hirayama, Y.; Miyazaki, Y.; Fujiwara, R.; Sommer, P.; et al. Accessory pathway analysis using a multimodal deep learning model. Sci. Rep. 2021, 11, 8045. [Google Scholar]
- Larry, H.; Kim, R.; Tokcan, N.; Derksen, H.; Biesterveld, B.E.; Croteau, A.; Williams, A.M.; Mathis, M.; Najarian, K.; Gryak, J. Multimodal tensor-based method for integrative and continuous patient monitoring during postoperative cardiac care. Artif. Intell. Med. 2021, 113, 102032. [Google Scholar]
- Mohammad, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Cardiovascular Events Prediction using Artificial Intelligence Models and Heart Rate Variability. Procedia Comput. Sci. 2022, 203, 231–238. [Google Scholar]
- Matthew, T. Gesture recognition. In Handbook of Virtual Environments; CRC Press: Boca Raton, FL, USA, 2002; pp. 263–278. [Google Scholar]
- Armando, P.; Mital, M.; Pisano, P.; Giudice, M.D. E-health and wellbeing monitoring using smart healthcare devices: An empirical investigation. Technol. Forecast. Soc. Chang. 2020, 153, 119226. [Google Scholar]
- Nasiri, A.Z.; Rahmani, A.M.; Hosseinzadeh, M. The role of the Internet of Things in healthcare: Future trends and challenges. Comput. Methods Programs Biomed. 2021, 199, 105903. [Google Scholar]
- K, D.S.; Kory, J. A review and meta-analysis of multimodal affect detection systems. Acm Comput. Surv. 2015, 47, 1–36. [Google Scholar]
- Yoshua, B.; Courville, A.; Vincent, P. Representation learning: A review and new perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar]
- Albrecht, J.P. How the GDPR will change the world. Eur. Data Prot. L. Rev. 2016, 2, 287. [Google Scholar] [CrossRef]
- Parasol, M. The impact of China’s 2016 Cyber Security Law on foreign technology firms, and on China’s big data and Smart City dreams. Comput. Law Secur. Rev. 2018, 34, 67–98. [Google Scholar] [CrossRef]
- Gray, W.; Zheng, H.R. General Principles of Civil Law of the People’s Republic of China. Am. J. Comp. Law 1986, 34, 715–743. [Google Scholar] [CrossRef]
- Chik, W.B. The Singapore Personal Data Protection Act and an assessment of future trends in data privacy reform. Comput. Law Secur. Rev. 2013, 29, 554–575. [Google Scholar] [CrossRef]
- Islam, M.K.; Rastegarnia, A.; Sanei, S. Signal Artifacts and Techniques for Artifacts and Noise Removal. In Signal Processing Techniques for Computational Health Informatics; Springer: Cham, Switzerland, 2021; pp. 23–79. [Google Scholar]
- Daly, I.; Billinger, M.; Scherer, R.; Müller-Putz, G. On the automated removal of artifacts related to head movement from the EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 2013, 21, 427–434. [Google Scholar] [CrossRef]
- Dyk, V.; A, D.; Meng, X. The art of data augmentation. J. Comput. Graph. Stat. 2001, 10, 1–50. [Google Scholar]
- Dalwinder, S.; Singh, B. Investigating the impact of data normalization on classification performance. Appl. Soft Comput. 2020, 97, 105524. [Google Scholar]
- Jameel, M.A.; Hassan, M.M.; Kadir, D.H. Improving classification performance for a novel imbalanced medical dataset using SMOTE method. Int. J. 2020, 9, 3161–3172. [Google Scholar]
- Ganesh, K.; Basri, S.; Imam, A.A.; Khowaja, S.A.; Capretz, L.F.; Balogun, A.O. Data harmonization for heterogeneous datasets: A systematic literature review. Appl. Sci. 2021, 11, 8275. [Google Scholar]
- Michal, S.G.; Rubinfeld, D.L. Data standardization. NYUL Rev. 2019, 94, 737. [Google Scholar]
- Maksymilian, W.; Chen, K. Feature importance ranking for deep learning. Adv. Neural Inf. Process. Syst. 2020, 33, 5105–5114. [Google Scholar]
- Angelos, C.; Martins, R.M.; Jusufi, I.; Kerren, A. A survey of surveys on the use of visualization for interpreting machine learning models. Inf. Vis. 2020, 19, 207–233. [Google Scholar]
- Alberto, B.; Domingo-Ferrer, J. Machine learning explainability through comprehensible decision trees. In Machine Learning and Knowledge Extraction: Third IFIP TC 5, TC 12, WG 8.4, WG 8.9, WG 12.9 International Cross-Domain Conference, CD-MAKE 2019, Canterbury, UK, 26–29 August 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 15–26. [Google Scholar]
- Stephan, W. Towards Explainable Artificial Intelligence: Interpreting Neural Network Classifiers with Probabilistic Prime Implicants; Technische Universitaet: Berlin, Germany, 2022. [Google Scholar]
- Edwin, L. Evolving fuzzy and neuro-fuzzy systems: Fundamentals, stability, explainability, useability, and applications. In Handbook on Computer Learning and Intelligence: Volume 2: Deep Learning, Intelligent Control and Evolutionary Computation; World Scientific: Singapore, 2022; pp. 133–234. [Google Scholar]
- Shima, K.; Eftekhari, M. Feature selection using multimodal optimization techniques. Neurocomputing 2016, 171, 586–597. [Google Scholar]
- Tejalal, C.; Mishra, V.; Goswami, A.; Sarangapani, J. A comprehensive survey on model compression and acceleration. Artif. Intell. Rev. 2020, 53, 5113–5155. [Google Scholar]
- Shiliang, S.; Cao, Z.; Zhu, H.; Zhao, J. A survey of optimization methods from a machine learning perspective. IEEE Trans. Cybern. 2019, 50, 3668–3681. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Challenges | |
|---|---|---|
| Data-Related Challenges [21,22] | Data Availability and Accessibility [23] | |
| Data Locality [16] | ||
| Data Readiness [23] | Data Heterogeneity | |
| Noise and Signal Artifacts | ||
| Missing Data | ||
| Classes Imbalance | ||
| Data Volume | Course of Dimensionality | |
| Bonferroni principle [24] | ||
| Feature Representation and Selection | ||
| Models Related Challenges [25,26] | Accuracy and Performance | |
| Model Evaluation | ||
| Variance and Bias | ||
| Explainability | ||
| Implementation-Related Challenges [23,27] | Real-Time Processing | |
| Model Selection | ||
| Execution Time and Complexity | ||
| General Challenges [25,26] | User Data Privacy and Confidentiality | |
| User Technology Adoption and Engagement | ||
| Ethical Constraints | ||
| Attribute | Early | Intermediate/Joint | Late/Decision |
|---|---|---|---|
| Ability to handle missing data | no | no | yes |
| Scalable | no | yes | yes |
| Multiple models needed | no | yes | yes |
| Improved accuracy | yes | yes | yes |
| Voting/weighting issues | no | yes | yes |
| Interaction effects across sources | yes | yes | no |
| Interpretable | yes | no | no |
| Implemented in health | yes | yes | yes |
| Technology \Specs | Definition | Main Goal | Perform Better than ML | Merge Datasources | Merge Models |
|---|---|---|---|---|---|
| Multimodal Datasets | Datasets that include multiple modalities of data | Enable Multimodal Machine Learning | Not Applicable | Yes | Not Applicable |
| Multilabel Learning | A supervised learning technique in which an instance can be assigned to multiple labels | Accurately label instances with multiple labels | Not Applicable | No | No |
| Ensemble Learning | Combines multiple models to improve the accuracy of the prediction | Improve prediction Accuracy | Yes | No | Yes |
| Multimodal ML | Combines multiple types of models/data to improve performance and feasibility | Improve Performance | Yes | Yes | Yes |
| Ref | Year | Type | Parameter Studied | Predicted Outcome | Model | Architecture | Datasets Used | Performance |
|---|---|---|---|---|---|---|---|---|
| [65] | 2017 | Classification | EHR Data | Hypertension | Convolutional Neural Network | Data Fusion | Private Data | Accuracy: 94.8% |
| [66] | 2018 | Classification | EHR Data | Thirty-day readmission risk for heart failure patients | Deep Unified Networks (DUNs) | Data Fusion | Enterprise Data Warehouse (EDW) Research Patient Data Repository (RPDR) | Accuracy: 76.4% |
| [67] | 2018 | Clustering | Phenotype and Genotype Information | Hypertension | Hybrid Non-Negative Matrix Factorization (HNMF) model | Data Fusion | HyperGEN dataset [68] | Accuracy: 96% |
| [69] | 2018 | Classification | Chest X-Ray Clinical Free-Text Radiological Report Scan | Several CVDs | Text-Image Embedding network (TieNet) | Data Fusion | ChestX-Ray14 dataset [70] OpenI Chest X-Ray dataset [71] | AUC: 0.9 |
| [72] | 2019 | Classification | EHR Data | Cardiovacsular Risk Prediction | Recurrent Convolutional Neural Network | Data Fusion | obtained from a grade-A hospital of second class in Wuhan | Accuracy: 96% |
| [73] | 2020 | Classification | MIMIC-CXR Radiographs and Associated Reports | Atelectasis, Pleural Effusion, Cardiomegaly, Edema | four pre-trained Vision+Language models: LXMERT / VisualBERT / UNIER / PixelBERT | Hybrid Fusion | MIMIC-CXR Chest X-Ray Dataset [74] OpenI Chest X-Ray Dataset [71] | Enhanced accuracy of classification |
| [75] | 2020 | Clustering | MetabolomeMicrobiomeGeneticsAdvanced Imaging | Cardiometabolic Syndrome | Combianation of unsupervised ML Models | Hybrid Fusion | Private Data | - |
| [76] | 2020 | Classification | Neuroimaging InformationClinical Metadata | Stroke | 3D Convolutional Neural Network Multilayer Perceptron | Model Fusion | Hotter Dataset [77] | AUC: 0.90 |
| [78] | 2020 | Classification | Computed Tomography Pulmonary Angiography ScansEHR | Pulmonary Embolism (PE) | Combination of ML Models | Hybrid Fusion | Data obtained from Stanford University Medical Center (SUMC) | AUC: 0.947 |
| [79] | 2020 | Classification | EHR Data | Cardiovascular Risk | Bidirectional Long Short-Term Memory (BiLSTM) Recurrent Neural Network | Hybrid Fusion | Second Manifestations of ARTerial Disease (SMART) Study [80] | AUC: 0.847 |
| [81] | 2020 | Classification | Different Cardiac CT Images and EHR Data | Acute Ischemic Stroke | Gradient Boosting Classifiers | Data Fusion | obtained from Department of Neuroradiology at Heidelberg University Hospital (Heidelberg, Germany) | AUC: 0.856 |
| [82] | 2021 | Classification | Electrocardiograph (ECG)Chest X-Ray | Cardiac Accessory Pathways (APs) Syndrome | Deep Convolutional Neural Network (DCNN) | Data Fusion | Private Data | - |
| [83] | 2021 | Classification | Salient Physiological SignalsEHR Data | Hemodynamic Decompensation | Used a novel tensor-based dimensionality reduction with the below models: Naive Bayes SVM Random Forest Adaboost LUCCK | Data Fusion | Collected retrospectively from Michigan Medicine data systems | AUC: 0.89 |
| Ref# | Multimodal ML Beats ML (Performance) | Real-World Implementation | Smart Wearables/IoTs Included |
|---|---|---|---|
| [65] | Yes | Yes | No |
| [66] | No | Yes | No |
| [67] | Yes | Public Dataset(s) | Yes |
| [69] | Yes | Public Dataset(s) | No |
| [72] | Yes | Yes | No |
| [73] | Yes | Public Dataset(s) | No |
| [75] | Not Available | Yes | Yes |
| [76] | Yes | Public Dataset(s) | No |
| [78] | Results Match | Yes | No |
| [79] | Results Match | Public Dataset(s) | No |
| [81] | Results Match | Yes | No |
| [82] | Not Available | Yes | No |
| [83] | Results Match | Yes | No |
| Ref# | Model | Workflow Description | Training Parameters |
|---|---|---|---|
| [65] | CNN-Based Multimodal Disease Risk Prediction (CNN-MDRP) Algorithm | 1. Data Representation: text is represented in the form of vector 2. Convolution Layer: perform convolution operation on vectors of 5 words 3. Pool Layer: use the max pooling (1-max pooling) operation on the input of the convolution layer 4. Full Connection Layer: pooling layer is connected with a fully connected neural network 5. Classifier: the full connection layer links to a softmax classifier | Iterations: 200 Sliding Window: 7 Running Time: 1637.2 s |
| [66] | Deep Unified Networks (DUNs) | 1. All inner layers of DUNs can learn the prediction task from the training data to avoid over-fitting 2. The DUNs architecture has horizontally shallow and vertically deep layers to prevent gradient vanishing and explosion 3. There are only two horizontal layers from the data unit nodes to the output node, regardless of how many layers deep the architecture is vertically 4. Only the harmonizing and decision units have learning parameters | Number of epochs: 100 Number of inner layers: 5 Number of inner neurons: 759 Number of maxout: – Activation function: Sigmoid Dropout rate of: input layer: 0.397/inner layers 0.433 |
| [67] | Hybrid Non-Negative Matrix Factorization (HNMF) model | 1. Impute missing values in the phenotypic variables 2. For genetic variants, first annotate the variants and then keep those that are likely gene disruptive (LGD) 3. The preprocessed phenotypic measurements and genetic variants are then used as input to the HNMF model 4. The patient factor matrix is then used as the feature matrix to perform regression analysis to predict main cardiac mechanistic outcomes | Up to 50 iterations |
| [69] | Text–Image Embedding Network (TieNet) | 1. Data Preprocessing and word embedding 2. Training TieNet model 3. Joint Learning for results fusion 4. Evaluation | Dropout: 0.5 L2 Regularization: 0.0001 for. Adam optimizer with a mini-batch size of 32 Learning Rate of: 0.001 Hidden Layer with 350 units |
| [72] | Recurrent Convolutional Neural Network | 1. Structured Data: extract relevant data, supplement missing data, make correlation analysis to look for the relation among data and apply dimension reduction to obtain corresponding structured features 2. Unstructured Textual Data: first, use numerical values to present unstructured textual data based on work embedding. Then, the features of textual data are extracted based on RCNN 3. Use Deep Belief Network (DBN) to fuse features and predict disease risks | up to 200 iterations |
| [73] | VisualBERT, UNITER, LXMERT, and PixelBER | 1. The feature map (7 × 7 × 1024) of CheXNet is first flattened by spatial dimensions (49 × 1024) then down-sampled to 36 1024-long visual features 2. Models are then trained with the data 3. Results are fused | Epochs: PixelBERT: 18 / other 3 models 6 SGD optimizer weight decay 5 × 10 learning rate 0.01 Each model can be fit into 1 Tesla K40 GPU when using a batch size of 16 |
| [75] | Collection of unsupervised ML models | 1. Data collection and data features 2. Data preprocessing 3. Network analysis 4. Key biomarker selection and Markov network construction 5. Stratifying individuals with similar biomarker signatures 6. Validation cohort | - |
| [76] | 3D Convolutional Neural Network Multilayer Perceptron | All models were trained on a binary classification task using binary cross-entropy loss | Loss function: Binary cross-entropy loss Adam optimizer Initial weights were sampled from a Glorot uniform distribution Output layer activation function: Softmax function Early stopping used to prevent over-fitting |
| [78] | Different ML models | Seven different workflows based on the difference between models | Batch Size: 256 Epochs: 200 |
| [79] | Bidirectional Long Short-Term Memory (BiLSTM) Recurrent Neural Network | 1. Embedding Layer: To extract the semantic information of radiology reports 2. Bidirectional-LSTM Layer: to achieve another representation of radiology reports 3. Dropout 4. Concatenation Layer 5. Dense Layers | Embedding dimension (d): 500 #neurons in LSTM layer: 100 CNN filter size: 5 filters in CNN: 128 neurons in dense layers: 64 Dropout rate: 0.2 Recurrent dropout rate: 0.2 Batch size: 64 epochs: 20 Optimization method ADAM |
| [81] | Gradient Boosting Classifiers | Integrative assessment of clinical, multimodal imaging, and angiographic characteristics with Machine Learning Allowed to accurately predict the clinical outcome following endovascular treatment for acute ischemic stroke | - |
| [82] | Deep Convolutional Neural Networks (DCNN) | First Model to analyze ECG ———————————————– 1. Convolutional Neural Network (CNN) 2. A one-dimensional CNN model was used to input the ECG data 3. The network model contained 16 convolution layers Followed by a fully connected layer 4. Then a Softmax layer, which calculated the probability of each of the four as the output in the last layer Second Model to analyze X-Ray images ———————————————– 1. A two-dimensional CNN model Then apply fusion to merge results | First Model Parameters: Adamax optimizer with the default parameters 1 = 0.9, 2 = 0.999, and a mini-batch size of 32 |
| [83] | Random Forest Naive Bayes Support Vector Machine Adaboost Learning Using Concave and Convex Kernels (LUCCK) | 1. Apply feature extraction on fused data composed of Salient Physiological Signals and EHR data 2. Apply Tensor reduction functionality 3. Train the Machine Learning model | Naive Bayes: (NB) no hyperparameter tuning was trained Support Vector Machines: used linear, radial basis function (RBF), and 3rd-order polynomial kernels Random Forest: number of trees: 50, 75, and 100/minimum leaf size: 1, 5, 10, 15, and 20/node splitting criterion: cross entropy and Gini impurity/number of predictors to sample: [10, 20, …, 100]/maximum number of decision splits for the decision trees: 0.25, 0.50, 0.75, or 1.0 Adaboost: learning rate: 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moshawrab, M.; Adda, M.; Bouzouane, A.; Ibrahim, H.; Raad, A. Reviewing Multimodal Machine Learning and Its Use in Cardiovascular Diseases Detection. Electronics 2023, 12, 1558. https://doi.org/10.3390/electronics12071558
Moshawrab M, Adda M, Bouzouane A, Ibrahim H, Raad A. Reviewing Multimodal Machine Learning and Its Use in Cardiovascular Diseases Detection. Electronics. 2023; 12(7):1558. https://doi.org/10.3390/electronics12071558
Chicago/Turabian StyleMoshawrab, Mohammad, Mehdi Adda, Abdenour Bouzouane, Hussein Ibrahim, and Ali Raad. 2023. "Reviewing Multimodal Machine Learning and Its Use in Cardiovascular Diseases Detection" Electronics 12, no. 7: 1558. https://doi.org/10.3390/electronics12071558
APA StyleMoshawrab, M., Adda, M., Bouzouane, A., Ibrahim, H., & Raad, A. (2023). Reviewing Multimodal Machine Learning and Its Use in Cardiovascular Diseases Detection. Electronics, 12(7), 1558. https://doi.org/10.3390/electronics12071558