1. Introduction
Semantic segmentation is a difficult task in remote sensing image analysis and processing [
1,
2]. As a classical computer vision problem, full-pixel semantic segmentation means that each individual pixel in an image is assigned a different class ID according to the object of interest to which it belongs. Such algorithms have been deployed in various fields, especially resource planning, and are proven to be an improvement. In recent years, along with the rapid development of related technologies and optical sensors in the field of remote sensing, the cost of acquiring remote sensing images is now lower, the resolution is higher, and the information contained in remote sensing images is richer [
3], which creates better conditions for remote sensing image information extraction, in conjunction with the demand of researchers to extract detailed information from the region of interest in remote sensing images gradually increasing, and the combination of computer vision and remote sensing fields becoming more and more intense [
4]. Land use cover is gradually becoming one of the hot spots [
5], or LUCC for short, and is currently at the center of global environmental change assessments [
6].
For the realization of remote sensing image land use classification, the target remote sensing image must be segmented at the pixel level. The most accurate method to get land feature classification information is manual annotation; however, this method is costly and inefficient, and cannot be applied to a large amount of data [
7]. Some intuitive methods have been used earlier to reduce the workload. Semantic segmentation, for example, is usually based on low-level image features such as gray level and texture information, threshold-based segmentation, edge-based segmentation, region-based image segmentation [
8], and specific theory-based image segmentation, which use the low-order visual information of images themselves, such as grayscale information and edge information, but often only extract the low-level features of the image, and it is difficult to cope with data with richer feature information and more image classes. Therefore, traditional segmentation methods are only applicable to specific tasks and rely too much on expertise for setting hyperparameters, which are not very generalizable and not very efficient [
9].
In modern times, deep convolutional neural networks (CNNs) [
10] have been widely used in remote sensing image analysis tasks and show good performances in segmentation tasks due to their powerful recognition ability [
11]. Advances in remote sensing technology enable us to obtain higher quality images, creating sufficient conditions for the integration of this field with deep learning [
12,
13]. Still, unlike the semantic segmentation of traditional images, the land cover classification based on deep learning is still a challenging task [
14], and the main reasons are as follows:
- (1)
Unlike ordinary images, the composition of remote sensing images is more complex, in which there are many kinds of targets and the features between different targets that vary greatly, so it is more difficult to carry out segmentation compared with ordinary scenes [
15].
- (2)
The large differences in imaging conditions can easily cause objects with the same semantic classification ID to show different features at different spatial locations, which can also easily produce more noise when conducting imaging. For example, highways with regular shapes and colors and rural roads have different features, but they all belong to the same semantic concept [
16].
- (3)
The network model with a high classification accuracy usually has a complex structure, high model complexity, and slow inference speed, which are not conducive to application in practical scenarios, so it is necessary to trade off between algorithm complexity and segmentation accuracy [
17].
In summary, a powerful segmentation model should not only be able to accurately identify the semantic information of the target, but also enhance the edge extraction of adjacent targets, which puts higher demands on the feature extraction effect.
The powerful feature representation and learning capability of convolutional networks are more suitable for more centralized processing of large-scale data, saving labor and improving recognition efficiency. Deep neural networks have strong spatial context information mining abilities and better feature fusion effects compared with traditional methods, so more and more researchers use deep learning as the preferred method.
FCN is a framework for image semantic segmentation proposed by Jonathan Long et al. in 2015 [
18]. FCN replaces all the fully connected layers of CNN with convolutional layers, the output of the network is a heat map, and the size of the input image is not limited. SegNet [
19] is also based on FCN and modifies the VGG-16 network to obtain a semantic segmentation network, which is more accurate than the traditional model. DeepLab v3+ [
20] is a classical architecture, which features the elimination of repeated upsampling and proposes a multi-scale structure based on extended convolution; dilated convolution is introduced to balance model accuracy and time consumption. Ronnerberge et al. propose U-Net [
21], a U-type network based on an encoder and decoder, using skpi-connections to recover lost information during downsampling. The PSPNet [
22] proposed based on a pyramid pooling module for scene parsing is also commonly used. This network can aggregate contextual information from different regions to mine global contextual information.
In order to investigate the application of deep learning in the task of high-resolution remote sensing image segmentation and to gain a comprehensive understanding of the latest developments in this field, we conducted a search on the Google Scholar, WoS, and Scopus databases using the keywords “high-resolution remote sensing image”, “deep learning”, “semantic segmentation”, “network architecture”, and other related terms. By combining the search results of these databases, we collected a significant number of methods based on deep learning for the segmentation of high-resolution remote sensing images. UNet++ [
23] appears in which densely nested skpi-connections are used to connect the encoder and decode, and is supplemented with a deep supervision mechanism to accelerate network training convergence, but its use of large intermediate convolution leads to computational costs and dense skip-connections introduce some redundant information. FarSeg [
24], proposed by Zheng et al. in 2020, addresses the problem of false positives and foreground-background imbalance using a relationship-based and optimization-based foreground modeling approach, where the relationship-based approach is somewhat similar to the self-attentive mechanism, and the approach is worthwhile. Chen proposed Trans-UNet [
25] in 2021 and, through the global-based self-attention mechanism and skip connection, it can effectively obtain the overall information, so that the model can focus on more detailed features to identify fine spatial information. Attention-UNet [
26] focuses more on the focused regions of the image, but lacks attention to semantic concepts, causing the encoder and decoder a large semantic gap between the feature maps, which may not capture different levels of features during decoding. SegFormer [
27] is an improved approach based on Transformer, which enables semantic segmentation of images by dividing them into a series of blocks, each of which is processed by a set of Transformer encoders and decoders. The model uses a self-attentive mechanism to handle spatial relationships in images. In remote sensing image segmentation, the frequently used single-scale convolutional kernels can limit the range of feature extraction, so some researchers proposed the multi-scale full convolutional network (MSFCN) [
28], which has multi-scale convolutional kernels, a channel attention block (CAB), and a global pooling module (GPM), thus improving the performance and stability of the model. The DIResUNet [
29] model is based on UNet and consists of an initial module, an optimized residual block, and a dense global spatial pyramid pooling (DGSPP) module. The model further improves the performance and stability of the model by extracting multi-level features and extracting global information in parallel, which is an efficient overall approach. DPPNet [
30] is an efficient image segmentation model which consists of a deep pyramid pool (DPP) block and a dense block of deep multi-expansion residual connections. The model takes full advantage of the dense pyramid structure, while considering multiple levels of features in prediction.
Based on the aforementioned discussion, because the high-resolution remote sensing images are richer in feature types and details compared with ordinary images, there is an unbalanced target distribution. In addition, some targets with small sizes or small sample sizes are easily misclassified, which increases the classification difficulty of the network. The features in remote sensing images have complex structures and rich texture information, and there are some cases with the same target class but large feature differences and some with different target classes but similar features, which put forward higher requirements on the feature extraction and abstraction ability of the network. In this study, we adopt UNet as the benchmark model and combine various attention mechanisms, and the attention fusion module for feature fusion at skip-connection, to improve the generalization ability of the model and to better cope with these problems. Due to the rich contextual information of remote sensing images, the algorithm requires upsampling of non-uniformly sampled data. Therefore, in this paper, we adopt a different upsampling operator from the traditional method, CARAFE (Content-Aware Reassembly of Features), which can adaptively adjust the size and shape of the convolution kernel, and, by learning the interrelationship of features, can better adapt to non-uniformly sampled data and improve the segmentation performance of the network with less computation to optimize the accuracy of target edge segmentation.
- (1)
Based on the coordinated attention mechanism, the residual network was used in the backbone network to alleviate the problems of gradient dispersion and gradient explosion as the network deepened. At the same time, the generalization performance and fine-grained feature extraction ability of the backbone network were improved without increasing the amount of calculations.
- (2)
We propose an attention fusion module for skip-connection to improve the network feature fusion capability.
- (3)
We use a content-aware reorganization module CARAFE [
31] in the decoder instead of the traditional upsampling method to improve the contextual information aggregation capability without increasing the computational effort.
2. Methods
This model utilizes the UNet architecture as the baseline for its structure design. The UNet model is symmetrical in structure and follows the classical encoder-decoder structure. After the encoder performs successive convolution and downsampling, a feature map with a small resolution but condensed high-dimensional semantic representation is generated, and the upsampling part is called expanding path, which actually localizes the target object and is symmetric with the downsampling part. Additionally, each layer uses the copy and crop method to complete the skip-connection operation, and the segmentation result with the same size as the original image is obtained after continuous upsampling. The combination of high-dimensional and low-dimensional feature maps makes the information extracted by the model more comprehensive, enabling the model to be more sensitive to detailed information. The skip-connection operation directly concatenates the more accurate gradient, point, line, and other information in the encoder of the same layer into the decoder of the same layer.
When applying UNet to remote sensing image segmentation, several drawbacks arise. Firstly, its architecture, based on a full convolutional neural network and multiple upsampling and downsampling operations, incurs a significant amount of memory and computational overhead. The resolution degradation caused by scaling is not conducive to improving the segmentation effect. Secondly, convolution and pooling operations tend to cause the loss of boundary information. Finally, the baseline model lacks corresponding measures to cope with the noise in the image. This task is challenging when applied to remote sensing images with a large number of targets with complex features.
To address these problems, this study introduces multiple attention mechanisms applied at different locations in the network. Additionally, an efficient upsampling method is embedded to propose a UNet based on CARAFE and multiple attention mechanisms, which we call CA-UNet.
2.1. Structure of CA-UNet
In CA-UNet, we use the residual block and coordinate attention module to construct the encoder to improve the fine-grained extraction ability of the target in the backbone network, and to reduce the detail loss caused by the pooling layer during downsampling. For the downsampling operation, this model uses a 3 × 3, step 2 convolution for the downsampling operation to improve the feature extraction capability of the model. Instead of the traditional upsampling method, CA-UNet uses the CARAFE operator in the decoder. Attention fusion modules are also constructed to combine spatial and channel attention fusion features in different feature layers. The overall network structure is shown in
Figure 1. The functionality and construction method of each module are described below.
2.2. Residual Encoder Based on Coordinate Attention
Deep networks have a higher error convergence rate compared to shallow networks, which can lead to degradation problems. Hence, adding more layers to the model may sometimes result in reduced performance. The residual block [
32] solves these problems without increasing the number of parameters and the computational complexity of the model. Part of the input in this structure is not passed through the convolutional network to the output, which retains part of the shallow information and avoids the loss of feature information due to the deepening of the feature extraction network; previous experiments also show that the identity shortcut connection structure can achieve better results. The specific process is shown in
Figure 2. Batch normalization is a popular regularization technique used in deep neural networks to normalize inputs in each batch, resulting in better fitting of the activation function of the network, reduced gradient disappearance or explosion, accelerated model training, and improved model accuracy. In residual networks, BN is often combined with the ReLU activation function to address the problem of gradient disappearance caused by ReLU’s gradient of 0 in the negative part. Furthermore, BN can mitigate model instability that may arise when the gradient of ReLU activation becomes large due to large input, and limit the input range to a suitable range, thereby improving model robustness and generalizability.
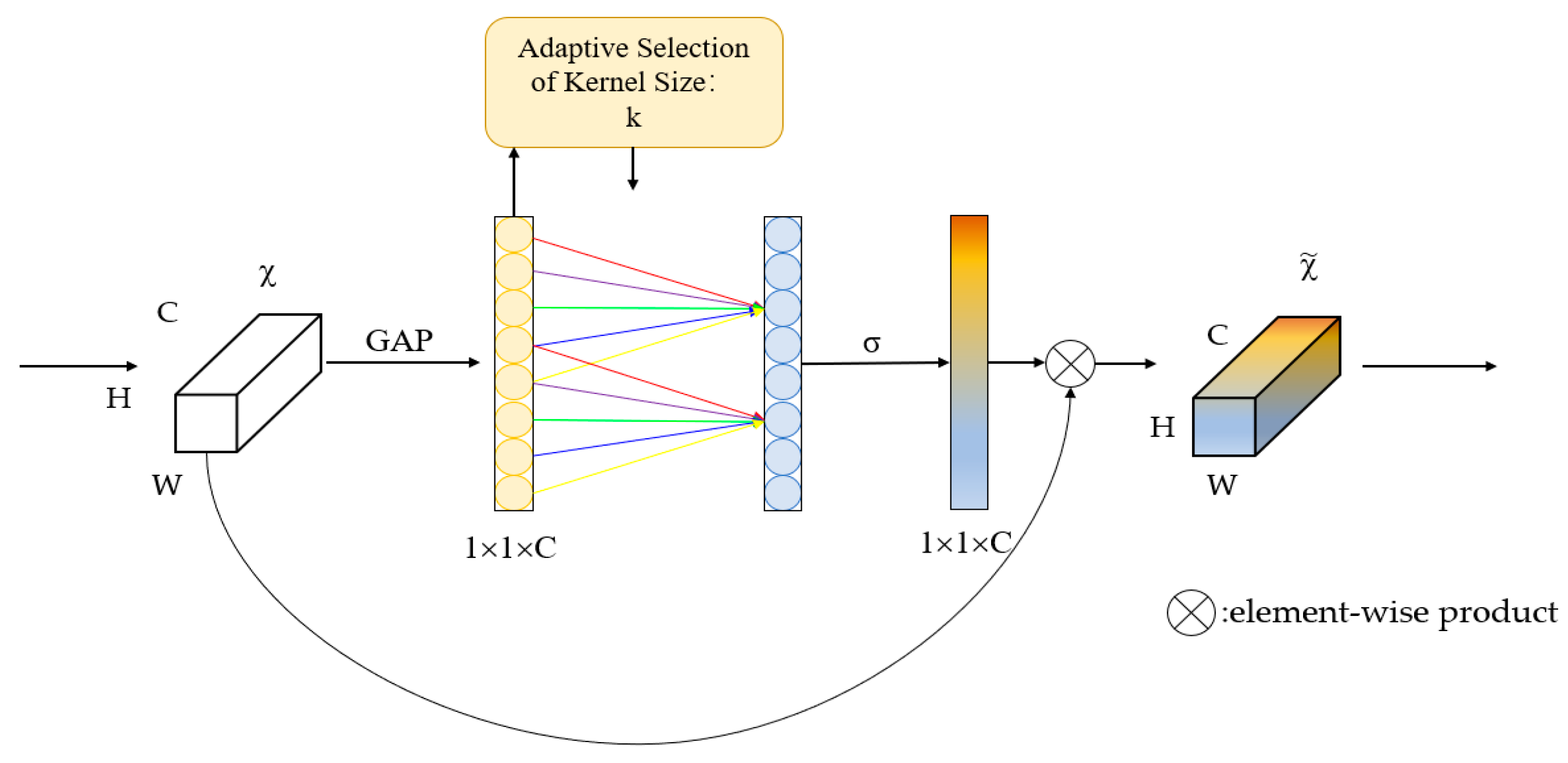
However, only utilizing the residual module in the backbone does not effectively improve the performance of the encoder. When we consider the computational effort and the network performance, the attention module is an essential part used to tell a model “what” and “where” to attend and it has been widely used in various deep learning models to improve network performance; the most commonly used attention modules [
33] are squeeze-and-excitation (SE) attention [
34] and CBAM [
35]. SE block has been extensively applied in remote sensing image segmentation tasks in recent years. However, the SE block design only considers the influence of channel relationships on features, ignoring spatial location information. In remote sensing image segmentation tasks, spatial location information is crucial for generating spatially selective attention maps. The lack of spatial location information modeling may lead to the inability of attention maps to accurately represent the spatial relationships between pixels, thus affecting the segmentation accuracy. Although CBAM considers information in both spatial and channel dimensions, it is computationally intensive and increases the model’s complexity and computational cost, making it less suitable for scenes requiring high computational resources. Additionally, CBAM performance is highly dependent on the convolutional layer input, and for some special scenes or irregular remote sensing image inputs, it may not be able to extract features accurately or make effective adjustments, resulting in degraded image segmentation performances. We introduce a lightweight coordinate attention module [
36], which is different from the previous mechanism. Coordinate attention is an attention mechanism that can focus on specific locations in remote sensing images that require special attention. It has been shown to improve the recognition of multi-scale target information and enhance model robustness by adjusting the weights for each location and channel to enhance the variability of features. Additionally, it does not add a significant computational cost, making it a practical choice for various applications. By using coordinate attention, a model can make more comprehensive use of image information.
As shown in
Figure 3, for the coordinate information embedding part, given any input tensor, the module uses two pooling kernels (H, 1) and (1, W) to encode and calculate each channel along the horizontal and vertical coordinates, and aggregates features in the spatial direction through the transformation of the two directions to generate a pair of feature maps. For each pixel point of the feature map, a coordinate vector is generated to encode its position within the feature map. This coordinate vector is then embedded into the feature vector using a fully connected layer to enhance the location information’s influence on the feature representation. The resulting feature vector and the location-embedded coordinate vector are then concatenated and embedded into a vector of dimension C using another fully connected layer. This vector represents the pixel point’s weight on different channels. The channel-embedded vector is then normalized using a function to obtain the weight of the pixel on all channels, which is subsequently multiplied with the feature vector to obtain the weighted feature vector of the pixel. This process enables the network to learn which locations require special attention during computation. The resulting weighted feature maps are globally pooled and averaged over the channel dimensions to obtain the average of each channel. Next, the weights of each channel are obtained through two fully connected layers and the sigmoid function. Finally, these weights are multiplied with the feature maps to obtain the weighted feature maps, allowing the network to learn which channels require special attention during computation. The resulting weighted feature maps are then concatenated in the channel dimension to obtain the final feature maps. This approach captures the dependence of one spatial direction while retaining the precise information of the other, which helps the model to locate the desired area of attention. In the coordinated attention generation stage, the second transformation is used to encode location information using the globalized receptive field, which satisfies the following three conditions. Firstly, this transformation should be as simple as possible to ensure that it does not increase the computational burden; secondly, to improve the information extraction ability and conversion efficiency, the information captured in the previous stage should be fully utilized; finally, the relationship between the channels should not be ignored. This encoding process allows us to coordinate attention to more accurately locate the exact position of the target object, thus facilitating better recognition throughout the model.
2.3. Feature Fusion Decoder Based on Attention Mechanism and CARAFE
During the down-sampling process, the resolution of the image is gradually reduced to obtain image information of different scales. This allows the network to extract features at different levels of abstraction, starting from low-level information, such as points, lines, and gradients in the underlying features, and gradually moving towards more abstract information such as contours and shapes. The entire network combines these “fine to coarse” features to obtain a comprehensive representation of the image. In the decoding stage, the upsampling operator is used to restore the feature map to its original size, enabling the network to generate precise predictions. Feature upsampling is a crucial component of modern convolutional network architecture and is particularly important in tasks such as instance segmentation. The methods commonly used in previous studies for upsampling, namely bilinear interpolation, deconvolution, and transposed convolution, have limitations when applied to feature-rich and detailed images such as remote sensing images. Bilinear interpolation uses a weighted average of neighboring pixels, but this method fails to capture the intricate texture information in the image, resulting in a less-detailed image after upsampling. Furthermore, bilinear interpolation is a global upsampling method that applies zoom to all pixels of the image, potentially introducing noise or artifacts that can degrade the accuracy of remote sensing image segmentation. Deconvolution, while capable of producing high-quality upscaled images, requires many reverse convolution operations and is computationally expensive for larger input images used in remote sensing image segmentation. Moreover, the upsampling process may cause pixel misalignment, further degrading image quality. Transposed convolution also suffers from computational intensity and produces a tessellation effect or high-frequency noise in the reconstructed high-resolution images. Therefore, alternative methods, such as sub-pixel convolution, nearest-neighbor interpolation, and pixel shuffle, have been proposed to address these issues in remote sensing image segmentation. In this model, the lightweight CARAFE [
31] is used as the upsampling operator. Compared to traditional upsampling methods, CARAFE can effectively suppress the tessellation effect and noise. By introducing an asymmetric convolution kernel and deformable convolution operation, it can better preserve the spatial feature information of the input feature map and improve the quality of the reconstructed image. Instead of manually specifying the output size, the output size is adaptively adjusted according to the input feature map, making it more flexible for different remote sensing image segmentation tasks of varying sizes. Additionally, it boasts a higher computational efficiency.
As shown in
Figure 4, given a feature mapping χ of size C × H × W and an upsampling rate σ, CARAFE will generate a new feature mapping of size C × σH × σW for the new feature mapping
. For each target position,
, of the output,
, there is a corresponding position,
, at the input, where
and
, and here
represents the neighborhood of
k ×
k size centered at position
. The kernel prediction module predicts an associated position,
, for each position,
, based on the neighbors of
, as Equations (1) and (2) show:
Each location on χ corresponds to
target locations on
. Each target location requires a recombination kernel of size
. The content encoder takes the compressed feature mapping as the input and encodes the content to generate the reorganization kernel; the kernel normalization applies the softmax function to each reorganization kernel. For each reorganization kernel,
, the content-aware reganization module reassembles the features within the local region by means of the ϕ function, which is simply a weighting operator. For the target location of
and the corresponding square region centered at
,
the reorganization process is shown in the following Equation (3):
In the reorganized kernel, , each pixel in the region affects the upsampled pixels, , differently according to the feature content rather than the location distance. Since the relevant regions can get more attention, the semantic expression ability of the reorganized feature map is stronger. The parameters for the three submodules in the Kernel Prediction Module are set as follows. The Channel Compressor module uses a 1 × 1 convolutional layer to compress the input feature channels. The Content Encoder module sets the encoder parameters as , where increasing the kencoder expands the perceptual field of the encoder. However, the computational complexity increases exponentially with the increase in kernel size, so it was decided to use the researcher’s experience and set to achieve a trade-off between performance and efficiency. Finally, in the Kernel Normalizer module, each recombination kernel is spatially normalized with a softmax function before being applied to the input feature map to achieve true mapping.
The skip-connection of UNet is an effective way to retain the feature information at different scales; however, the simple stitching method has some disadvantages, which may result in the loss of critical feature information, and may not handle the relationship between feature maps of different resolutions effectively, leading to the loss of detailed information. Remote sensing images have a higher resolution than traditional images, containing more feature scales, and, thus, cross-layer connection methods need be selected and optimized carefully when being applied to remote sensing image segmentation to address the limitations of the simple stitching method. This paper designs an attention fusion module that combines different attention modules to enhance the recognition capability, strengthen the recognition of the distinction between the targets at different scales, refine the features between the different classes of targets, and solve the multi-scale problem.
As shown in
Figure 5. This module takes feature maps extracted from the encoder and decoder as inputs. The final feature map is then restored to the same spatial resolution as the input image, and the output of the attention mechanism is re-connected with the feature map after the corresponding operation. All three convolutional kernels are 1 × 1 in size, and the information from multiple channels is fused through channel conversion to enhance the network’s information extraction capability.
For feature maps with different dimensions and different features, an appropriate attention mechanism should be selected to enable the network to locate the regions of interest for refinement more easily. In U-shaped networks, shallow feature maps are characterized by having large resolutions, where the spatial feature distribution has a significant impact on fusion. To address this issue, we have employed a spatial attention-based fusion module in CA-UNet. First, we reduce the number of channels by passing the input feature map through a 1 × 1 convolutional layer to reduce the computational effort. Next, we compute the Query (the output of the previous layer), Key (indicating the feature associated with Query), and Value (indicating the object to be weighted average, representing the intermediate feature map of the current layer) using three different 1 × 1 convolutional layers. We then compute the Attention Score based on the Query and Key, with Attention Score = Query × Key. The attention score is normalized by softmax to obtain the Attention Map, whose value ranges from 0 to 1, indicating the weight of each position under the attention mechanism. We weigh and fuse the Attention Map with Value to obtain the final output feature map. The fusion is performed in the channel or spatial dimension, and we use a 1 × 1 convolutional layer in this paper.
High-dimensional features are typically compressed based on their channels before being fused using the channel attention module for the smaller-scaled feature maps. In this study, we propose an enhanced channel attention mechanism, as traditional channel attention modules that capture the dependencies of all channels are not always necessary or efficient. This model uses ECANet [
37], which removes the fully connected layer of the original channel attention module and learns directly by a 1D convolution on the globally averaged pooled features. The size of the convolution kernel affects the number of channels to be considered for the calculation of each weight of the attention mechanism, the coverage of cross-channel interactions. The process is shown in
Figure 6, in which two convolutional layers are used, a 1 × 1 convolutional layer for feature map compression and a 3 × 3 convolutional layer for generating the attention map. In addition, the padding of the convolution kernel is set to 1 in order to keep the size of the input and output feature maps the same. The weights of each position in the attention map are mapped by the Sigmoid activation function.
5. Conclusions
We propose a U-shaped network (CA-UNet) based on a multi-attention mechanism and CARAFE for the semantic segmentation of high-resolution remote sensing images. We construct a residual encoder based on the coordinate attention mechanism in the backbone. The residual block enhances the nonlinear fitting ability of the network, combines with the coordinate attention to enhance the focus on spatial location information, and more accurately captures key features. This helps to identify small targets and boundaries between different targets in remote sensing segmentation tasks and improves the multi-scale information feature extraction ability of the model.
The skip-connection is an important structure of UNet, and we embed an attention fusion module in this position to combine spatial attention and channel attention. The comprehensive use of features of different scales is crucial when segmenting remote sensing images, as the size and shape of different targets are different, and this module can further improve the performance of the model. Finally, we use the CARAFE operator to replace the traditional upsampling module. This operator is less computationally intensive and obtains more accurate contextual information through adaptive feature reorganization. It alleviates the information loss problem when upsampling and is very effective for segmenting targets of different scales and sizes of remote sensing images.
Our method achieved an mIOU of 72.83% on the Lu County land cover dataset, which is much higher than the baseline model UNet of 67.19%, and also has advantages over other commonly used models in the experiments. In the experiments conducted on the WHDLD dataset, our model achieved an mIOU of 63.27%, which is higher than the 59.24% of UNet and also achieved better results compared to other commonly used models in the experiments. Our model performs well on multi-classified remote sensing image datasets, especially multi-classified land cover datasets, with a high segmentation accuracy and strong generalizability. However, it also has some limitations, such as a larger image resolution and finer and denser target recognition problems. In addition, the segmentation of remote sensing images with large noise is also a difficult problem.
We plan to conduct further research and focus on more efficient algorithm designs to make it easier to deploy and combine with radar, multi-modal data fusion such as spectral data to improve segmentation accuracy and robustness. Finally, we aim to combine with other algorithms such as path planning to realize end-to-end applications.
Previous research has been widely used in the medical, military, and autonomous driving fields. The segmentation of high-resolution remote sensing images based on deep learning is also gaining more and more attention from researchers [
38]. With wide practical significance, it has been widely used in agriculture [
39,
40,
41,
42], environmental monitoring, urban planning, etc.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}