1. Introduction
Unmanned underwater vehicles (UUVs) can perform several more complex tasks, including exploration of the marine environment and extraction of underwater resources, as well as military exploration and surveillance missions in particular sea areas [
1]. Trajectory tracking control, as one of the critical technologies of UUVs, is an essential prerequisite for accomplishing specific tasks [
2]. For this reason, the study of trajectory tracking control for UUVs in marine missions is very important.
Common UUV trajectory tracking control methods for complex and unknown marine environments include PID control, sliding mode control, fuzzy control, adaptive control, predictive control, etc. [
3]. Carlos et al. used the proposed two-level nonlinear PID to complete the depth-tracking control of an underwater glider [
4]. Adrian et al. proposed a strategy based on the combination of integral sliding mode control technology and a super twist controller, which has achieved good results in the three-dimensional trajectory tracking control of a four-degree-of-freedom underwater vehicle [
5]. Yin et al. solved the problem of dynamic trajectory tracking of UUV using the variable fuzzy predictive control method [
6]. Compared with these methods, model predictive control (MPC) has an advantage in solving multi-input and multi-output motion control problems with constraints. Its ability to model prediction for the future is an effect that cannot be achieved by traditional control methods [
7].
For such a highly nonlinear, multi-degree-of-freedom, strongly coupled, and the time-varying system as UUV, the design of its nonlinear model predictive control (NMPC) is faced with many problems. It is mainly reflected in the fact that, for complex UUV system models, it is easy to have insufficient search ability and unstable accuracy in predicting future states [
8]. Due to the severe influence of the underwater environment, the UUV underwater exploration task’s path is often complex, requiring a lot of calculation and time to solve optimization problems [
9]. Houska et al. proposed an automatically generated microsecond NMPC real-time iterative algorithm. The algorithm reduces the number of iterations by decreasing the accuracy of the optimization solution at the beginning. However, this has some degree of impact on global optimization performance [
10]. Zhang applied a robust linearized MPC to ensure the stability of surface ships in a disturbing environment [
11]. Clearly, for highly nonlinear and disturbed UUV control systems, the linearization technique is minimal when the reference trajectory changes substantially, and it is easy to cause a significant overshoot [
12,
13]. Liu et al. studied an improved NMPC method, using a nonlinear disturbance observer (NDOB) to estimate the environmental disturbance, which enhanced the robustness of the controller. To improve the control performance of USV trajectory tracking, the event-triggering mechanism reduces the calculation speed of NMPC in trajectory tracking control, making it challenging to ensure real-time control [
14]. Li et al. used the dynamic real-time optimization (DRTO) formula with closed-loop prediction to coordinate the distributed model predictive controller. It replaces MPC quadratic programming subproblem with an equivalent Karush Kuhn Tucker (KKT) first-order optimality condition, which improves the optimization speed. The control accuracy still needs to be effectively solved [
15]. Shen et al. studied NMPC for autonomous underwater vehicle (AUV) trajectory tracking control and proposed an improved continuation/generalized minimum residual (C/GMRES) algorithm on the optimization algorithm [
16]. This way, the contradiction between the short sampling period and the high requirement of online calculation can be alleviated. However, the stability of the numerical algorithm in the global optimization process has yet to be well improved, which needs to be further solved. Therefore, an urgent problem needing to be solved is how to make new attempts and improvements to the optimization algorithm of NMPC to alleviate the high requirements for online computing and improve the algorithm’s stability in the optimization process.
The research and development of UUV in the optimization algorithm of NMPC trajectory tracking control are mainly faced with real-time control performance and stability problems [
17]. Currently, the heuristic swarm intelligence optimization algorithm is widely used to optimize various industrial sites [
18]. Compared with other algorithms, it has a faster convergence speed and can reduce computational work. However, it also needs more stability and can guarantee the optimal solution. Compared with other population intelligence algorithms, GWO has the advantages of fast convergence speed, strong robustness, and high accuracy. Recently, it has been widely used in various optimization strategy problems [
19]. However, GWO also has the issues of slow convergence speed and access to falls into local optimal solutions [
20]. Many researchers have also proposed many improved GWO algorithms for this purpose. Mittal et al. adjusted the parameters of the convergence factor by using the exponential decay function and proposed an enhanced GWO algorithm to improve the optimization performance of the GWO algorithm [
21]. Wen et al. combined the decay function with the logarithmic function and proposed a nonlinear decay convergence factor adjustment based on the particle swarm algorithm method [
22,
23]. Chu et al. presented adaptive nonlinear model predictive control technology and designed a trajectory tracking controller for AUV. By establishing the RBF neural network prediction model, the adaptive GWO algorithm is used to solve the optimization problem. However, the convergence speed in the optimization process needs to be balanced on the whole, which is easy to make the optimization fall into the local optimum and reduce the control accuracy [
24]. Although the above research aims to balance global exploration and local exploitation in the optimization solution process, they overemphasize the ability in one aspect. This causes the decay rate of the convergence factor to be relatively fast or slow in the whole world, which makes it difficult to effectively balance the searchability and convergence rate of the optimization and does not provide the best solution for the decay form of the convergence factor. Therefore, it is necessary to propose new solutions to better balance the global exploration and local exploitation capabilities in GWO. It is essential to improve the real-time performance of nonlinear model predictive control efficiency and ensure the global exploration accuracy of control.
This paper studies the trajectory tracking control method of UUV based on NMPC. Based on the above problems, the contributions made in this paper are summarized as follows:
The NMPC method is applied to the trajectory tracking control of UUV, and the nonlinear model predictive controller is designed. By predicting the state of the established model at each sampling time point in the future, the tracking effect of the determined trajectory is improved.
An improved nonlinear convergence factor GWO is proposed and applied to the designed NMPC to improve the optimization performance of the NMPC and ensure the stability of the trajectory tracking control effect.
The designed NMPC is transplanted in the ROS-based UUV simulation environment. In a simulation environment, the trajectory tracking tests are carried out on different reference trajectories in the built experimental simulation environment to verify the effectiveness of the proposed trajectory tracking method of the UUV.
The main structure of this paper is as follows: The problems studied in this paper are introduced in
Section 2, including the kinematic and dynamic models of the underwater vehicle and the trajectory tracking. The design process of the NMPC is described in
Section 3. The simulation experiment carried out under the UUV environment is shown in
Section 4, including the construction of the test environment and the results of optimization and tracking. The last part synthesizes the consequences related to the simulation experiments and the further work that can be carried out in the future.
2. Problem Description
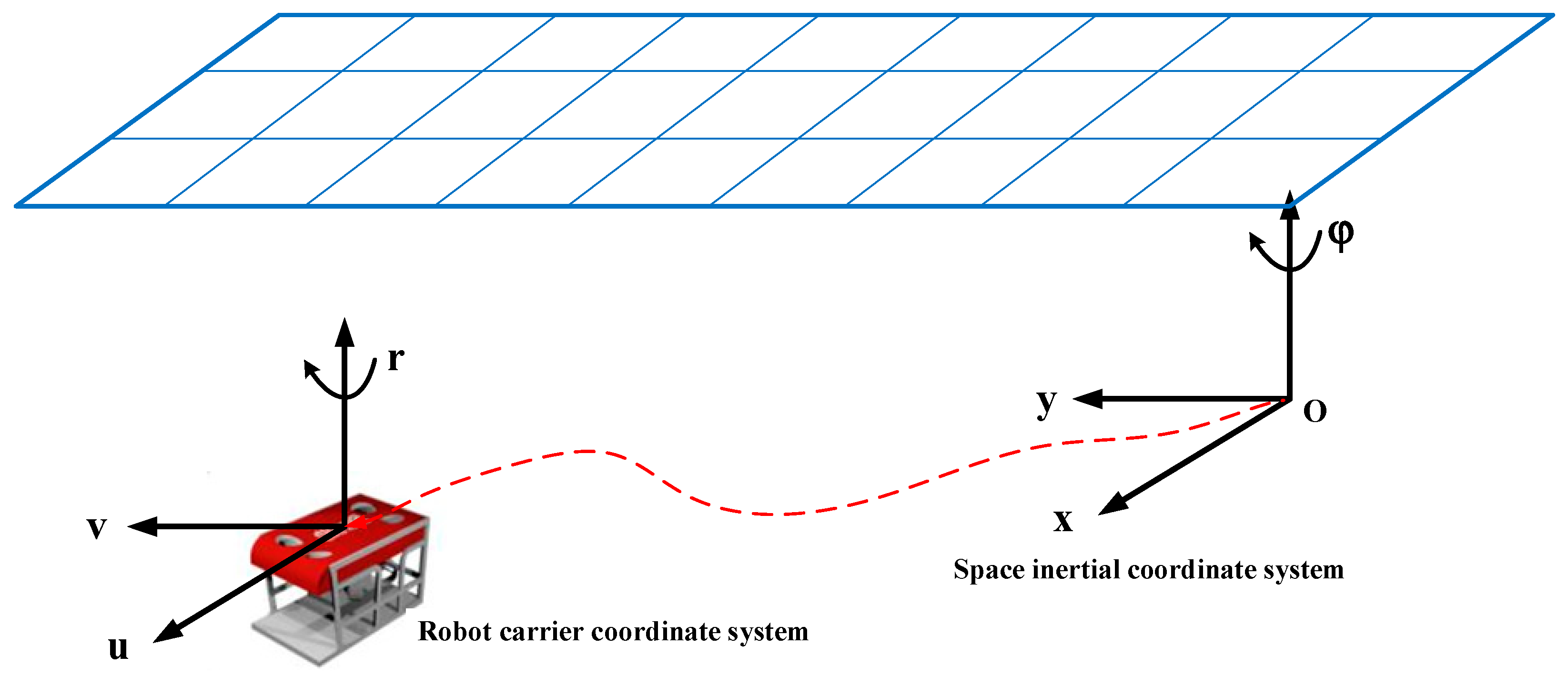
The control objectives of UUV in the motion process include the robot’s position, posture, velocity, and angular velocity [
24], involving six degrees of freedom of motion control. These control variables are often artificially decoupled into two types in engineering applications: horizontal plane control and vertical plane control. This paper mainly studies the trajectory tracking of the horizontal plane control; thus, the model is simplified to a three-degree-of-freedom model in the horizontal plane. As shown in
Figure 1, the three-degree-of-freedom model of the UUV and its coordinate system are described.
According to the Newton–Euler equations of motion for a rigid body in a fluid [
25], the dynamic equations of motion of UUV in the established coordinate system can be derived:
where
denotes the position and orientation of UUV in an inertial coordinate system.
indicates the velocity of UUV in the moving coordinate system.
denotes the thrust force.
represents the UUV inertia matrix, including the additional mass. The additional mass represents the additional inertial force generated by the change of fluid velocity around the vehicle.
is the damping matrix, the restoring force
. The Coriolis matrix is expressed as:
Expanding the element expression in dynamic Equation (1), we have:
The kinematics equation of UUV under the established coordinate system can be described as [
26]:
According to the conversion relationship between the UUV carrier coordinate system and the inertial coordinate system, the velocity conversion matrix of the UUV three-degree of freedom model in the horizontal plane can be established. The definition is as follows:
Expanding the element expression of kinematic Equation (5), we have:
Binding the dynamic equations and kinematic equations together, the control system model is established as follows:
where
, represents the state volume of the UUV.
, represents the amount of control over the horizontal motion of the UUV.
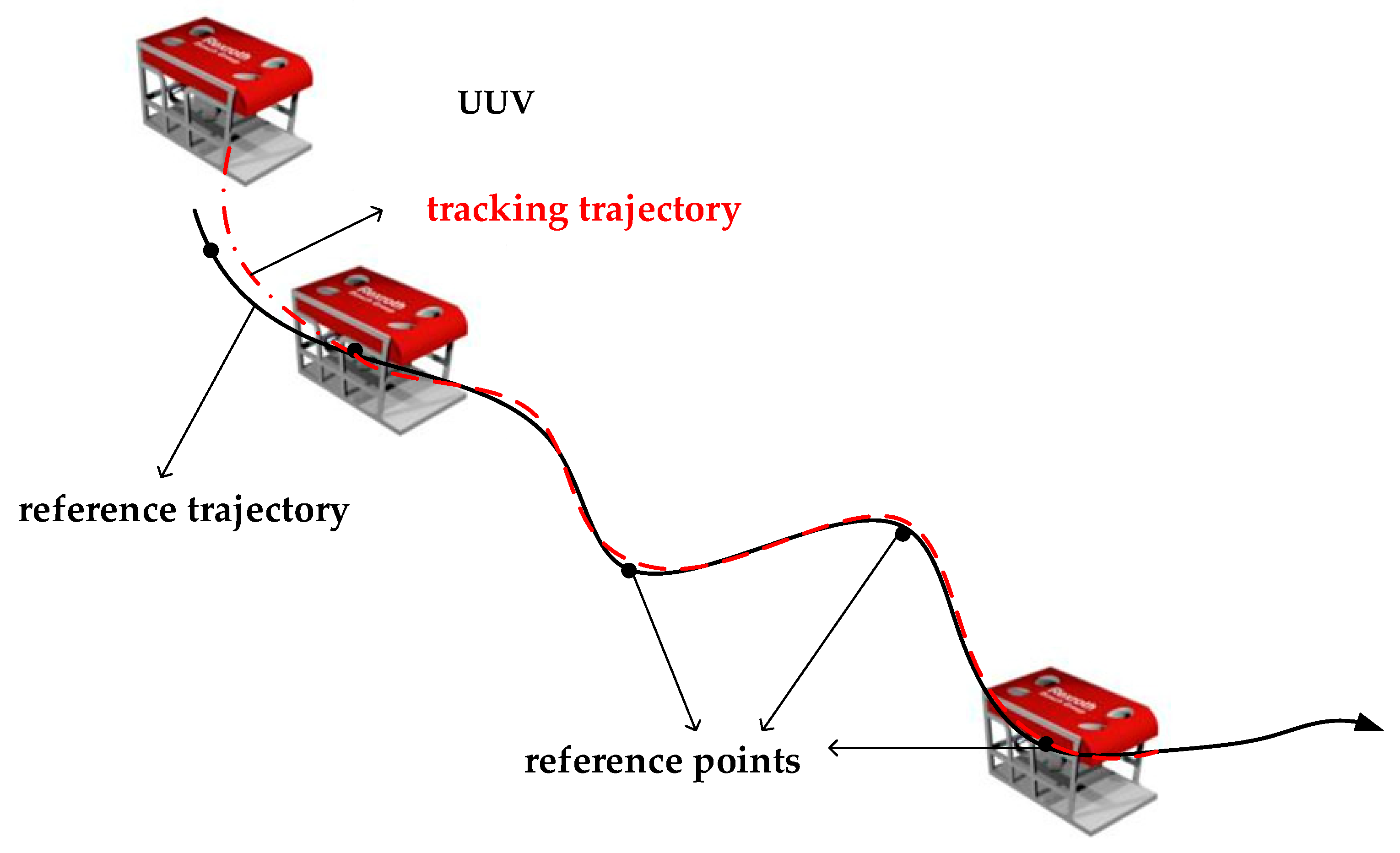
The trajectory tracking process of the UUV studied in this paper is shown in
Figure 2 below.
In the inertial coordinate system, the UUV starts from its initial position. A given reference path consisting of
N discrete reference points
should not only meet the physical property constraints of the UUV itself, but also meet the kinematic equations. For which the reference points
, all should satisfy the following differential relation [
27,
28]:
where
,
and
indicate the coordinate position and heading angle of the reference point in the space inertial coordinate system, respectively.
,
and
represent the linear velocity and angular velocity of the reference point of the robot carrier coordinate system, respectively.
By transforming the solution based on Equation (8), the real-time state quantities can be expressed in terms of position points
and
in the horizontal plane as:
The function of the NMPC trajectory tracking controller designed in this paper is to solve the corresponding control law for each sampling time, so that the actual state of UUV at each time can track the reference state as much as possible. Considering that UUV is affected by hydrodynamics and hydrodynamic effects in the ROS environment, the controller optimizes the control objective function through improved IGWO. Thus, the current control quantity can be determined, and the control law can be automatically adjusted to change the UUV’s motion state; thus, it can always move on the desired trajectory.
3. Controller Design
In this section, an NMPC controller for trajectory tracking control of UUV is designed, which improves the iterative calculation rate and real-time control by enhancing the traditional optimization algorithm. The control stability and accuracy of the system model are compensated by strengthening the optimal global exploration and local exploitation ability. At the same time, the improved optimization method can realize the controller algorithm’s online parameter adjustment to meet the UUV’s control requirements in the experimental environment to improve the comprehensive control performance of the controller.
3.1. Nonlinear Model Predictive Controller
In the NMPC proposed in this paper, the UUV system model is nonlinear; therefore, the corresponding predictive model is also nonlinear. However, similar to the traditional MPC, its core is to optimize the control variables for each sampling period, starting from the system’s current state. The objective function is optimized through the improved optimization algorithm in the finite prediction time domain to obtain an optimal control law, and the first control quantity of the sequence is applied to the controlled UUV system.
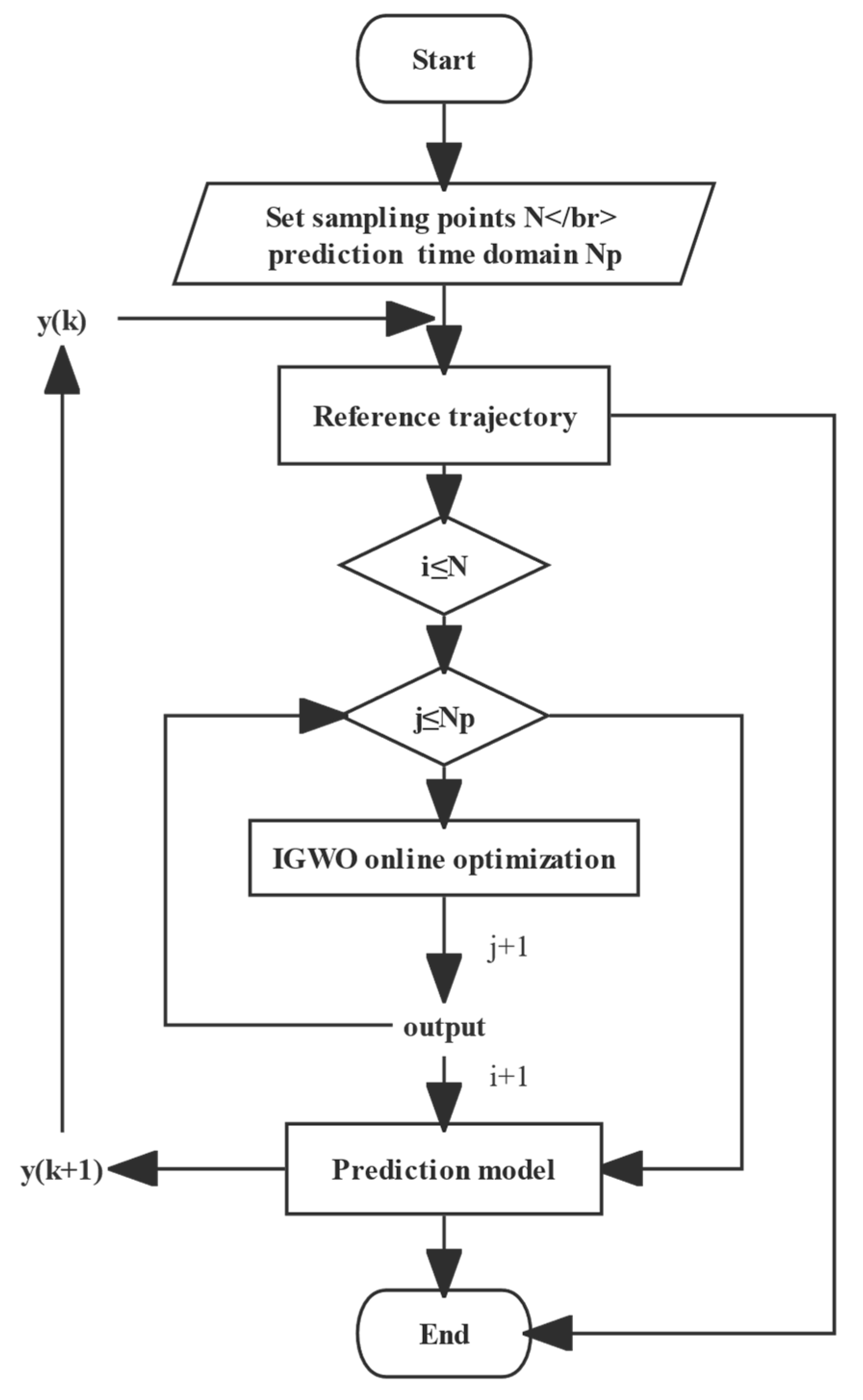
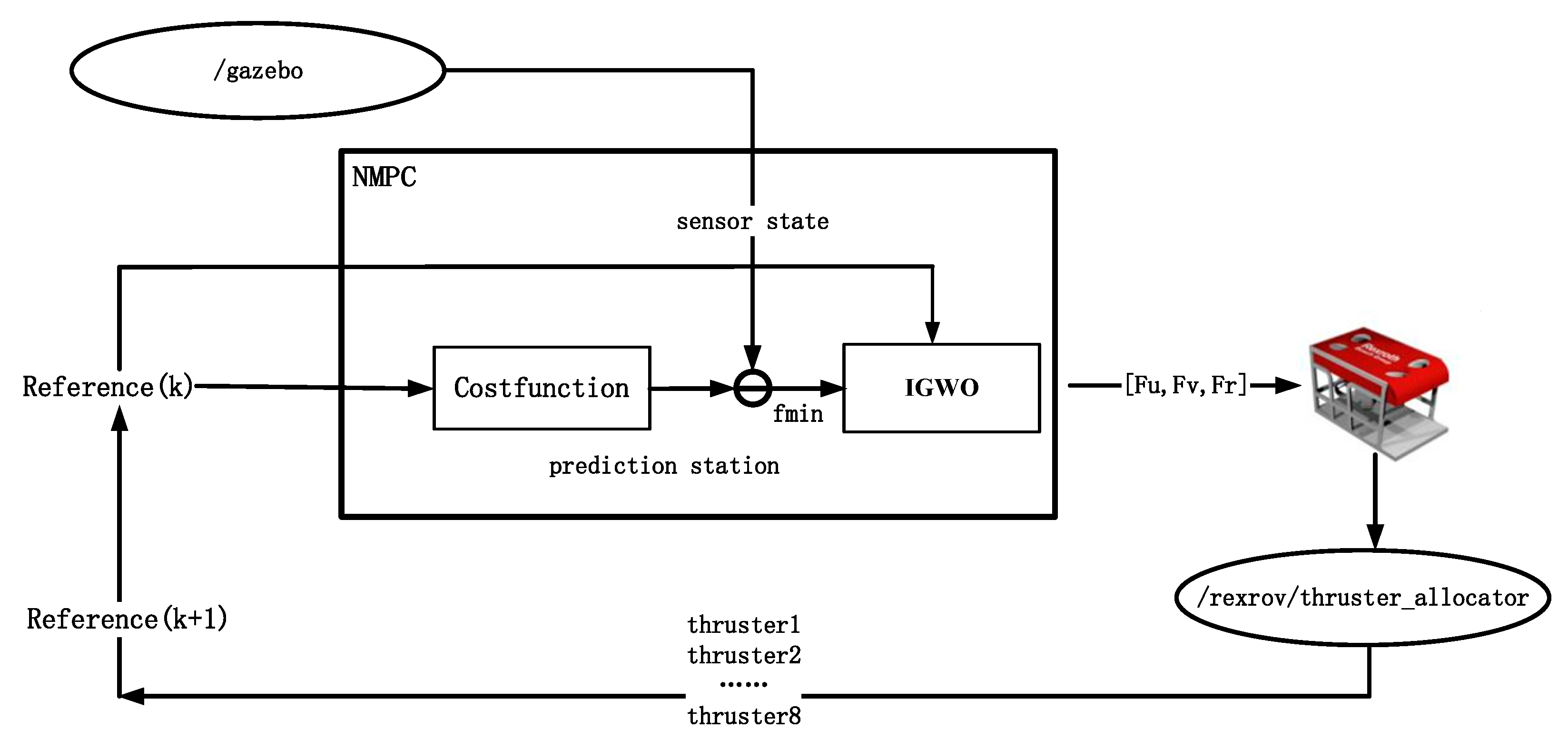
The NMPC framework built in this paper is shown in
Figure 3. The process includes the generation of reference trajectory, rolling optimization, model prediction, and introduction of the control law. At each sampling time, the controller performs rolling optimization in a finite time domain for a given reference trajectory to obtain the optimal control output u at the corresponding time. Then, this is applied to the UUV system and the corresponding prediction model to obtain the system’s current output and prediction output, denoted as
and
, respectively. The deviation
between them is fed back to the objective function of the optimizer through the predictor. On the other hand, the system output
acquired through the sensor is taken as the following initial information and transmitted to the optimizer, etc., until the whole process is completed.
The flow chart of the controller proposed in this paper is shown in
Figure 4 below:
3.2. Objective Function and Constraints
The corresponding model parameters of the UUV can be obtained through model analysis. Combined with the dynamic model (1), the matrix expansion in the equation is solved to collate the expressions for the linear velocity of the vehicle in each axis direction and the angular velocity of rotation around each axis. Given the robot’s initial position, the velocity vector of three degrees of freedom in the horizontal direction at each time in the prediction time domain is recorded as
, i.e.,
. It can be expressed as Formula (10):
where
,
N is the predicted time domain.
and
respectively, represent the linear damping coefficients of the linear velocity along the x and y axes and the angular velocity in the Z-axis rotation direction.
and
represent the quadratic damping coefficients of the linear velocity along the x and y axes and the angular velocity along the Z-axis, respectively.
and
represent the components of the inertia matrix in the x and y directions and the z-axis rotation direction, respectively, recorded as:
, where
m is the mass of the vehicle,
is the inertial rotation corresponding to the z-axis in the inertial coordinate system,
and
are recorded as additional mass components along the x and y axes and the direction of rotation along the z-axis, respectively.
Combining the velocity solution formula in Formula (10), the velocity prediction vector corresponding to each sampling time in the prediction time domain can be obtained. On this basis, the positional vector of UUV in the prediction time domain is obtained from the kinematic equations. Thus, the state variables corresponding to each sampling time in the prediction time domain of the UUV are obtained, denoted as .
The minimum value of the quadratic objective function is usually used to express the optimization performance index at moment
k. The expressions are as follows:
where
is the difference between the reference pose and the corresponding predicted pose state of the model in the unit prediction time domain.
is the difference between the corresponding velocity at the reference point and the predicted velocity of the model.
is the control increment corresponding to the control variable at any sampling moment in the predicted time domain.
and
denote the upper and lower limits corresponding to
and
, respectively. Among the above constraints,
and
are soft constraints, the constraint range mainly reflects the accuracy of control effect. According to the specific test environment and task requirements, it is enough to meet the required constraints as much as possible. However,
is limited by the control performance of different UUVs and needs to be strictly controlled within the rated control range.
and
denote the prediction time domain and control time domain, respectively.
is the weight coefficient of attitude state quantity and
is the weight coefficient of velocity state quantity. The larger the corresponding weighting coefficient, the more significant the proportion in the objective function. When the objective function is optimized, the impact on the results will be more pronounced, thus indicating that the corresponding control state is valued more in the control effect.
3.3. IGWO with Nonlinear Convergence Factor for NMPC Optimization
This section will introduce the proposed theoretical elements for improving GWO. We first submit the motivation and principle of algorithm improvement. Secondly, optimizing the above objective functions on the NMPC controller designed by the improved IGWO is introduced.
3.3.1. IGWO with Nonlinear Convergence Factor
The grey wolf optimization algorithm (GWO) is a population-based optimization algorithm proposed by Mirjalili et al. [
19]. Inspired by the lifestyle of the gray wolf population, the algorithm simulates the social leadership and hunting behavior of gray wolves. In the GWO, the most suitable solution in the population is named alpha (α) wolf, the second and third best solutions are called beta (β) wolf and delta (δ) wolf, respectively, and in addition, all other individuals in the population are noted as omega (ω). The corresponding mathematical model can be established according to the encirclement mechanism of the gray wolf population chasing prey during hunting:
where
denotes the position coordinates of the gray wolf.
t denotes the current number of iterations.
denotes the position vector of the prey.
and
denote the coefficient vectors.
and
are random vectors in the range [0,1], and
decays linearly from 2 to 0 during the iterations as follows:
where
t denotes the number of current iterations, and
Maxiter denotes the total number of iterations.
The specific locations of the other wolves in the population were updated according to the locations of α, β and δ wolves as follows:
where
,
and
are equivalent to
, and
,
and
are equivalent to
.
All population-based optimization algorithms aim to achieve a balance between global exploration and local exploitation in the process of finding the global optimal solution. The traditional GWO algorithm has a convergence factor that decays linearly from 2 to 0 during iteration. The transition between global exploration and local exploitation is generated adaptively with the iterative process [
27]. Half of the iterations are used for global exploration
, and the other half for local exploitation
. However, considering that the search process of the GWO algorithm is nonlinear and highly complex, the linear decay process of the convergence factor needs to reflect the actual search process well.
This paper proposes a new IGWO algorithm based on a nonlinear decay function to adjust the system convergence factor. On the one hand, inspired by the characteristics of the cosine function, a new strategy of nonlinear adjustment of convergence factor is proposed. On the other hand, inspired by the particle swarm optimization algorithm, a location update strategy based on memory guidance is proposed from the global optimal location and the individual historical optimal location.
The proposed adjustment strategy for the nonlinear convergence factor
in this paper is taken as:
where
and
are the initial and final values of
, respectively, which take the values of 2 and 0 in this paper.
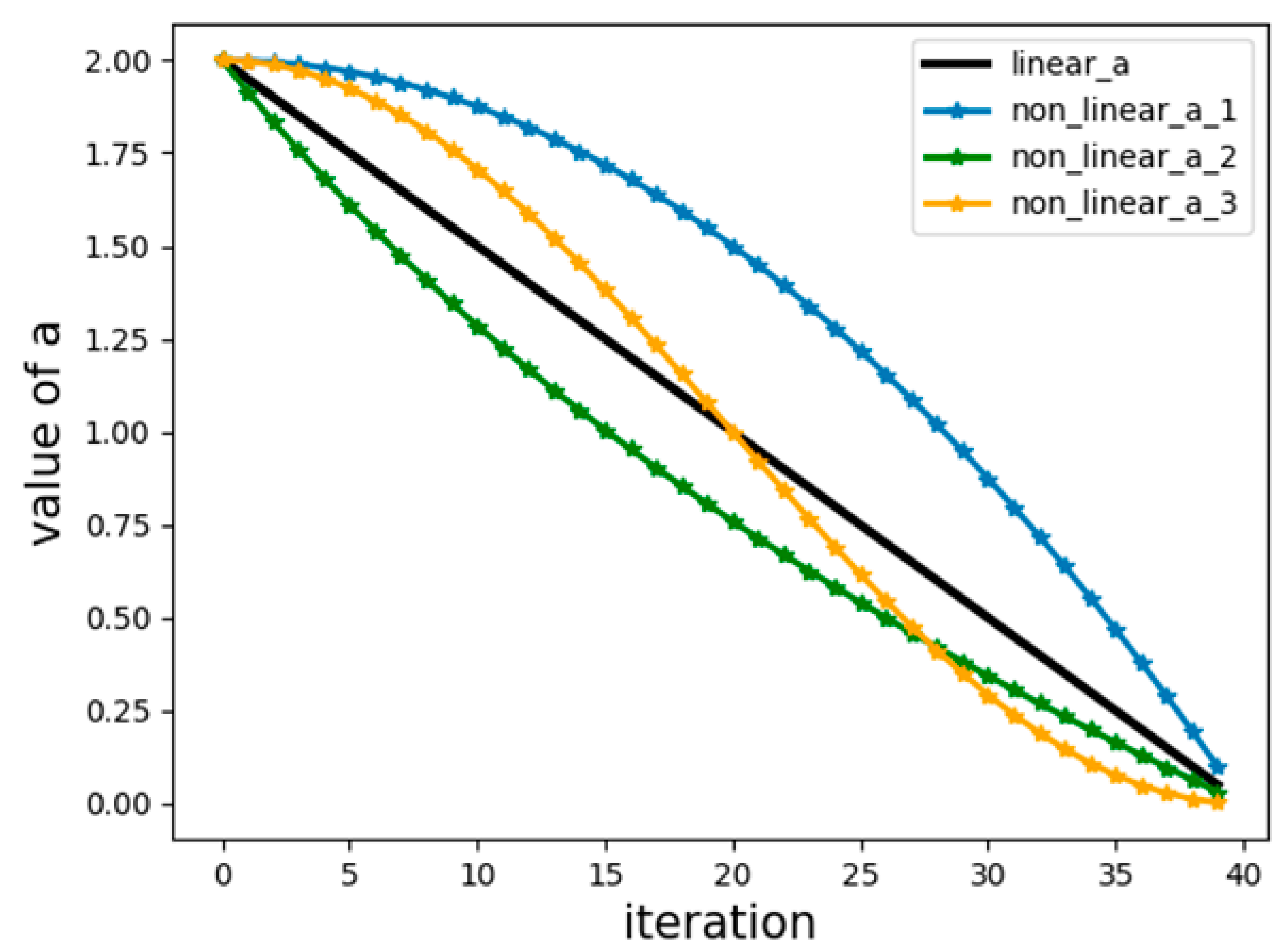
A comparison of the decay curves of
linear decreasing strategy, several other nonlinear decreasing strategies, and the nonlinear decreasing strategy proposed in this paper is given in
Figure 5.
It can be seen from
Figure 5 that, compared with the original linear decline strategy, the first half of “non_linear_a_1” has a slow decay rate, and the second half has a fast decay rate, which places more emphasis on local exploitation. In contrast, “non_linear_a_2” is just the opposite, placing more emphasis on global exploration. The improved strategy combines their advantages of them, reducing the decay speed of the first half and accelerating the decay speed of the second half, respectively, as shown in “non_linear_a_3”. The improved decay strategy balances global exploration and local exploitation and increases global exploration ability and convergence speed in the later period.
In the location update equation of the traditional GWO algorithm, information about the current position of alpha (α) wolf (global optimal solution), beta (β) wolf, and delta (δ) wolf agents are shared with the next generation of agents. As a result, the lack of diversity among agents causes the iterative process to fall into a local optimum easily. The individual historical best information is not systematically utilized in the algorithm. Therefore, GWO is a population-based memoryless stochastic optimization technique. In this paper, we propose a new memory-guided location update criterion based on the global best ( location and individual historical best location ().
The memory-guided location update equation proposed in this paper is calculated as follows:
where
t is the current iteration number.
and
are both random numbers uniformly distributed between [0,1].
and
denote the individual learning factor and global learning factor, both between [0,1], which take the value of 0.5 in this paper.
and
denote the local optimal solution and the global optimal solution in the iterative process.
w denotes the inertia weight, similar to the particle swarm algorithm, the size of
w decreases linearly from the initial value (
) to the final value (
), and the values taken in this paper are 0.9 and 0.1, respectively, and the calculation formula is as follows.
3.3.2. IGWO Optimizes the Objective Function
The improved IGWO is mainly used to optimize the objective function proposed previously. Given the gray wolf population and the maximum number of iterations to the NMPC controller, they are recorded as SearchAgentsNum and Maxiteration, respectively. The initial state of the objective function is marked as the initial position of the wolf population. The top three wolves with the best fitness are searched iteratively by inputting all gray wolf populations into the objective function for calculation. Since the objective function constructed above mainly represents the performance of position error on UUV trajectory tracking, when the objective function value reaches the minimum, the alpha (α) wolf in the corresponding population can be regarded as the current optimal solution. This way, the controller compares the maximum number of iterations, synthesize the results of multiple iterations, and selects an optimal result from the historical optimal solution and the current optimal solution as the output.
Algorithm of the whole optimization solution process is as follows (Algorithm 1).
| Algorithm 1. Pseudo code IGWO to optimize the objective function |
| Input SearchAgentsNum, MaxIteration, ObjectiveFunction |
| Initialize grey wolf population, and , and |
| Update the position of the initial gray wolf population |
While (num < SearchAgentsNum)
Calculate the fitness of gray wolf individuals according to the ObjectiveFunction,
and preserve the top three wolves with the best fitness as alpha (α), beta (β) and
delta (δ) |
While (iteration < MaxIteration)
Update the current position of Grey Wolf
Update , and
Calculate the fitness of all gray wolves
Update fitness and position of alpha (α), beta (β) and delta (δ) |
| Output position of alpha (α) |
3.4. Stability Analysis of NMPC
As a control algorithm for rolling optimization solutions in the finite time domain, NMPC has been successfully applied in the industry since the late 1980s. The stability of model predictive control has been gradually proved, and ideas on different bases have emerged. This paper mainly adopts adding terminal constraints [
29,
30].
Here we consider a general model of controlled object:
where
represents the state quantity of the robot at time
k;
represents the control amount at time
k.
The control function of each cycle is to solve the following optimization proposition:
where
N represents the prediction time domain, and
, when and only when
,
,
is true. We can set up a nonlinear predictive control terminal constraint set optimization method, and introduce new variables into the optimization problem to reduce the conservatism of solving terminal constraint conditions. In addition, it can theoretically ensure that a wider range of terminal constraint sets
can be obtained [
31]. The terminal constraint set is guaranteed to be a positive invariant set under the effect of terminal control law. For general MPC, it is equivalent to the zero point as the end point; thus, we may add a terminal constraint here:
For simplicity, it may be assumed that the control time domain and prediction time domain are equal and set to
N, and it should be noted that
and
here are both constrained, that is:
where
and
are non-empty sets containing distant points. At the same time, we assume that
and
are an equilibrium state of the system, that is
. And at each moment, the corresponding optimal sequence is obtained by solving:
, only the first control action
is applied to the object. Then suppose that the optimization proposition of each cycle has a feasible solution and can be solved to obtain the global optimum, then we can assume that the system is stable at
and
.
The proof of stability here adopts the traditional Lyapunov stability proof in the control theory, that is, to find a Lyapunov function of the system, which is positive definite, and its reciprocal is negative definite (the function value decreases). The idea here is to take the optimal value (
) of the objective function of the optimization proposition in each period as the Lyapunov function. The positive definiteness of
has been explained in the previous assumptions. What we need to prove now is the negative definiteness of its reciprocal, that is,
. As the same as other stability-proof methods, it is assumed that the model is unbiased and does not consider noise interference. Therefore, the predicted system state is consistent with the actual object state, if
then
. Thus, they are:
We can ensure that based on the above formula, according to the terminal constraint in Equation (20) above. At the same time, according to , we prove that . Therefore, is a Lyapunov function of the original system, and the Lyapunov stability of the original system at the origin can be verified. From this, we can preliminarily analyze that the stability of NMPC is reliable.
5. Conclusions
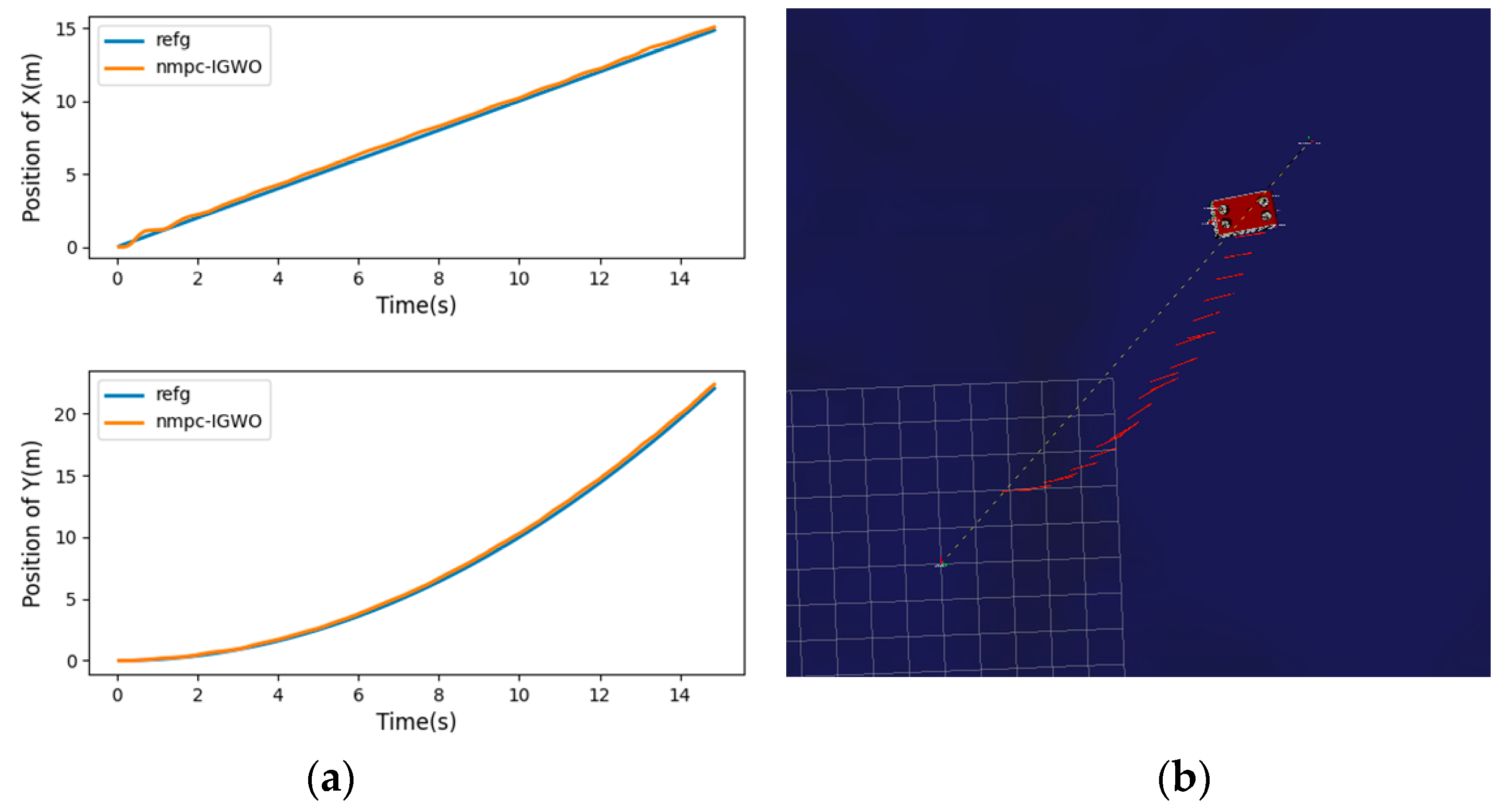
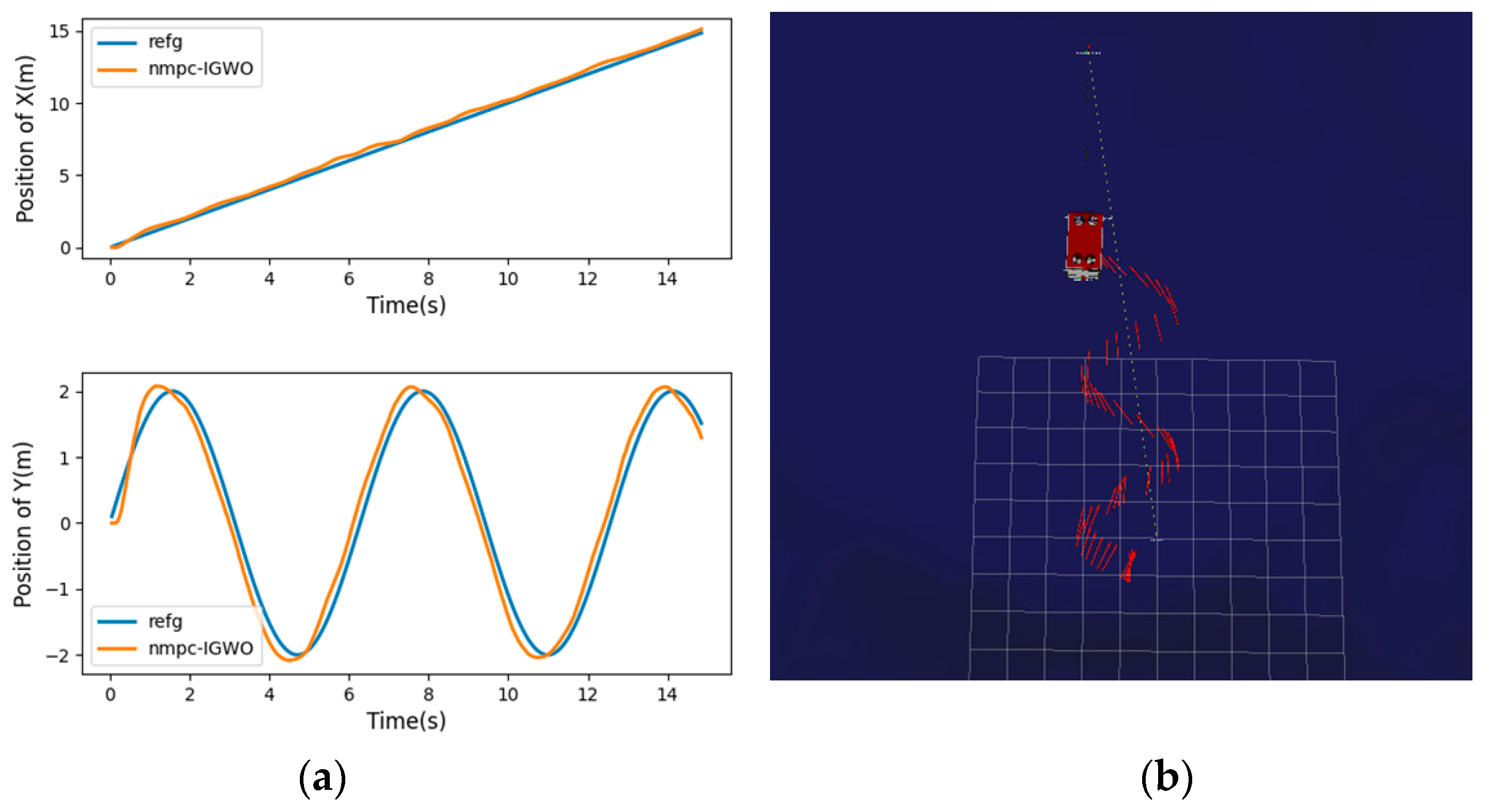
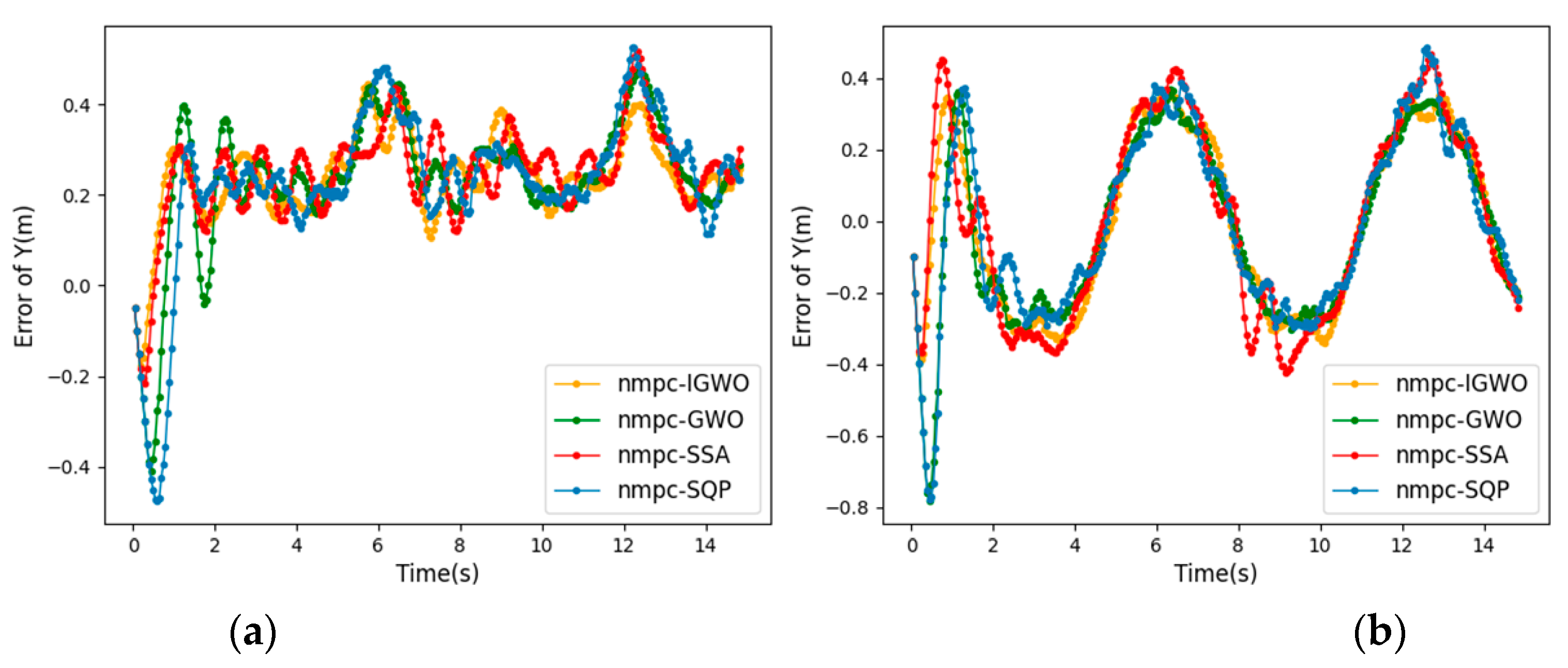
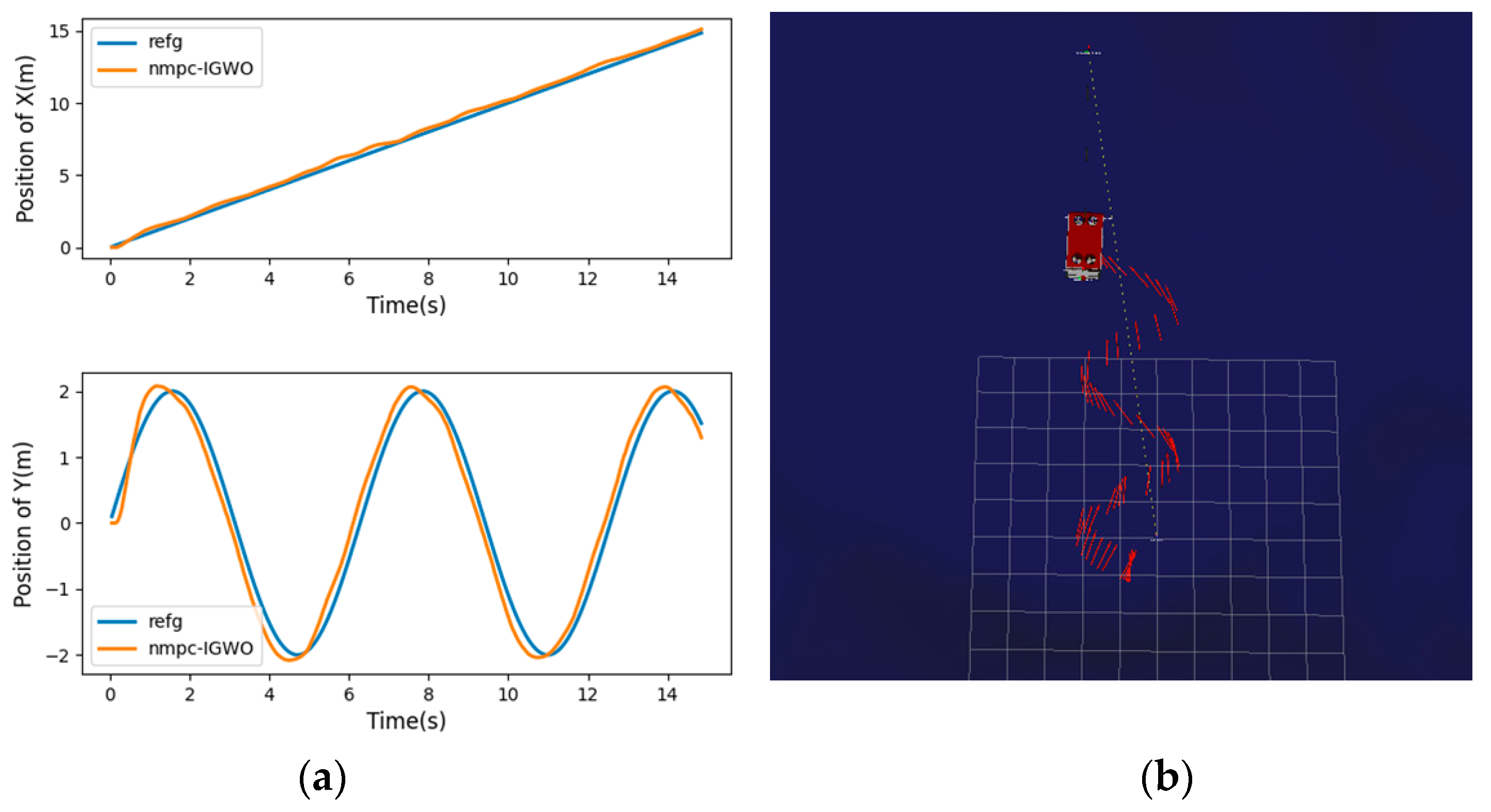
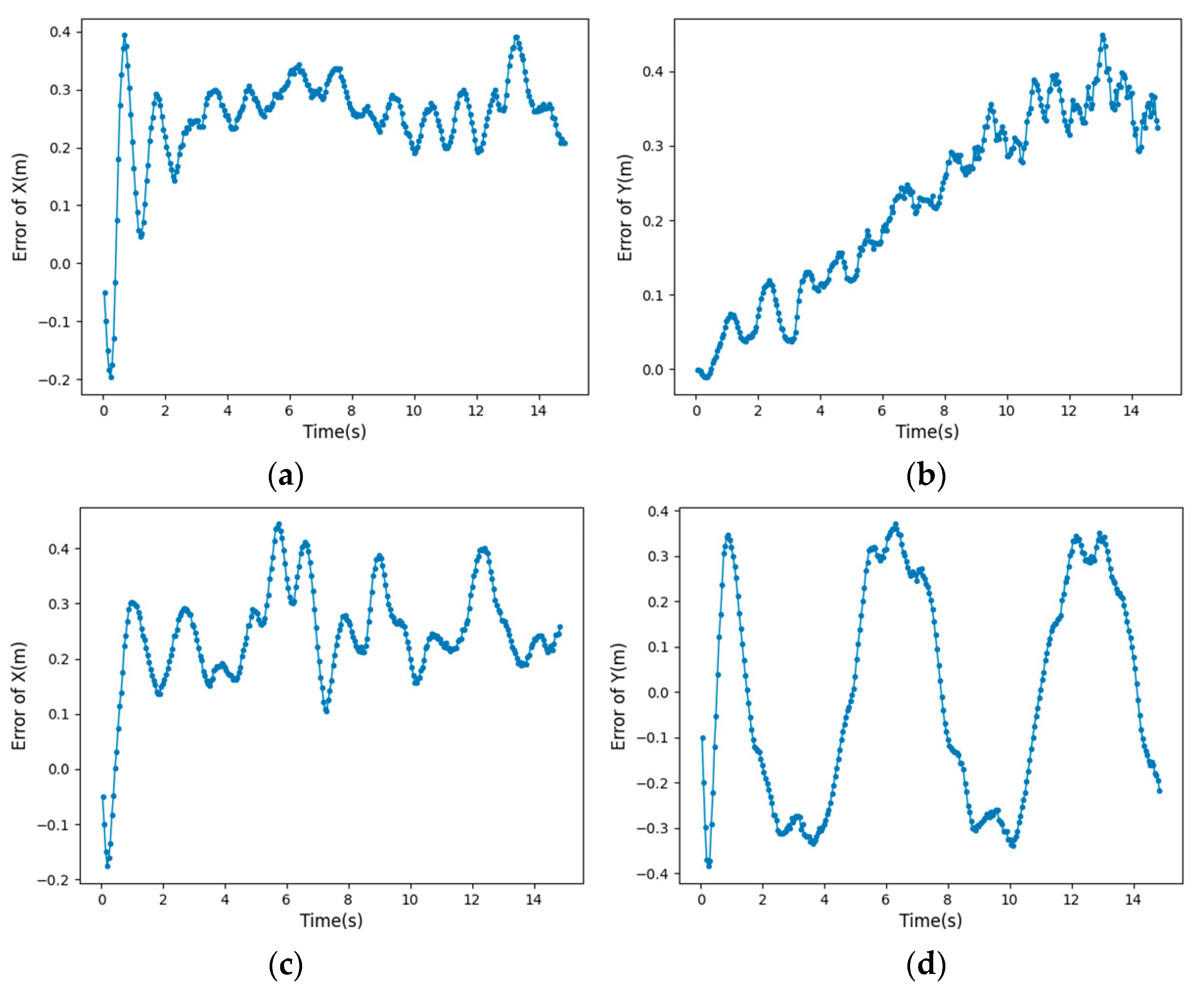
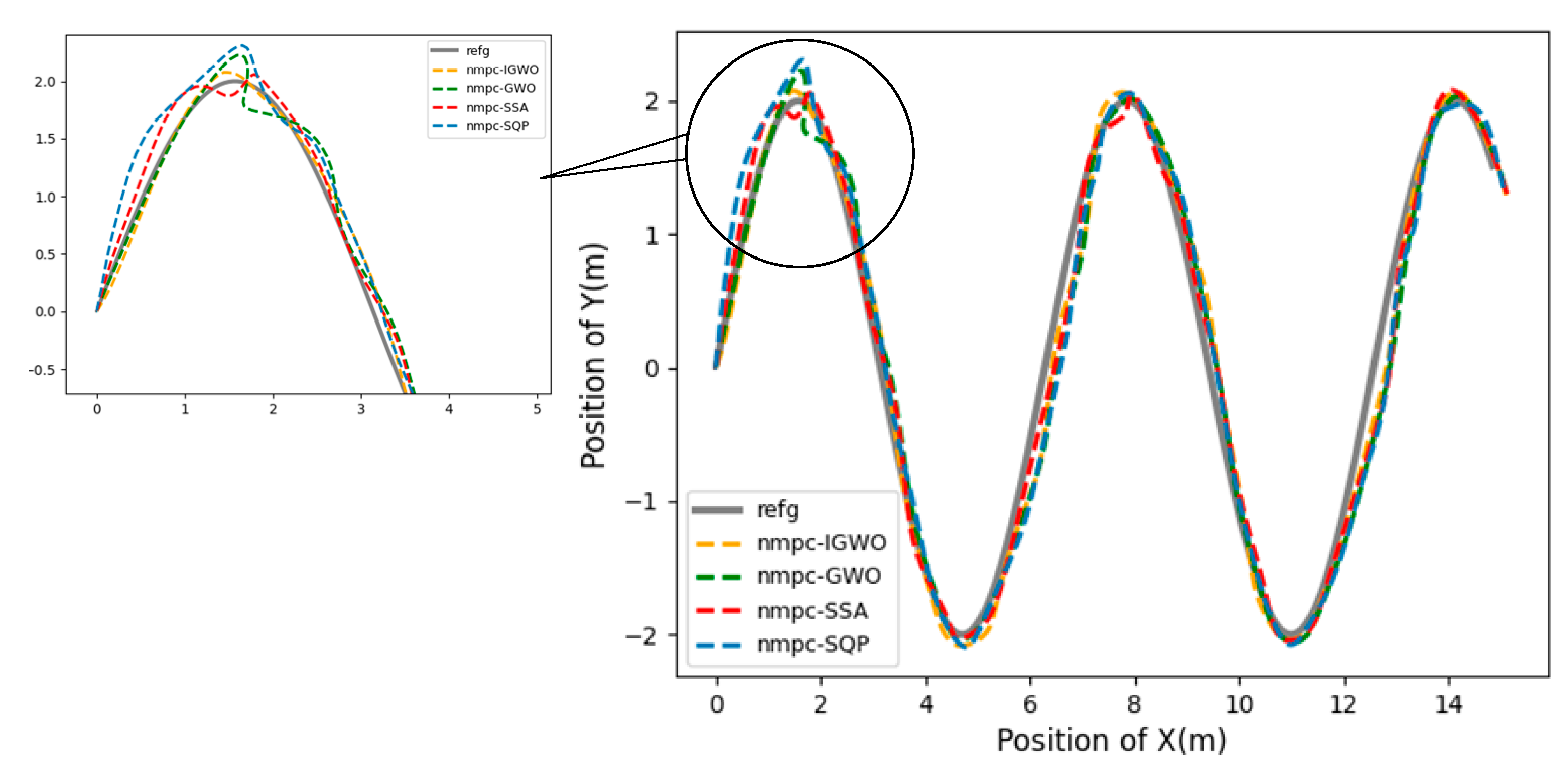
This paper proposes a new IGWO-NMPC trajectory tracking algorithm for UUVs, which combines NMPC with an improved GWO algorithm with nonlinear decay. The NMPC is used to adjust the prediction error of the UUV’s future state, and the decay rate of the convergence factor is controlled from fast to slow, which increases the global exploration ability in the early stage and improves the convergence rate in the later stage. It effectively reduces the fluctuation range of tracking error and the time required for stability. The problems such as the insufficient stability of the trajectory tracking controller of the UUV and the poor real-time performance of the NMPC are solved. The simulation experiments of tracking different trajectories show that the IGWO-NMPC has universal applicability and high tracking performance in trajectory tracking control.
In marine environment exploration and other tasks, the UUV is affected by the unknown underwater environment on the one hand, and on the other hand, UUV is a nonlinear system with multiple degrees of freedom and strong coupling, which makes the task execution difficult. As one of the key technologies of UUV, trajectory tracking control is widely used in the fields of autonomous operation and automatic control, and can effectively solve the exploration tasks in the unknown ocean field and other harsh environments that are not convenient for personnel to carry out. The research of this paper is devoted to designing a nonlinear model predictive controller, and proposes an improved optimization algorithm for the controller. It can more restore the control effect of UUV, and solve the problems such as the insufficient stability of the trajectory tracking controller of the UUV and the poor real-time performance of the NMPC. In addition, how to make new improvement attempts on the traditional framework and objective function of NMPC, and apply the improved trajectory tracking controller to the reliable vehicles. At the same time, explore how to combine with other decision-making technologies such as trajectory planning to realize the autonomous navigation control of UUV. And the experimental verification in underwater missions will be the goal of our future work.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}