



Rolling Bearing Fault Feature Selection Method Based on a Clustering Hybrid Binary Cuckoo Search

Abstract
1. Introduction
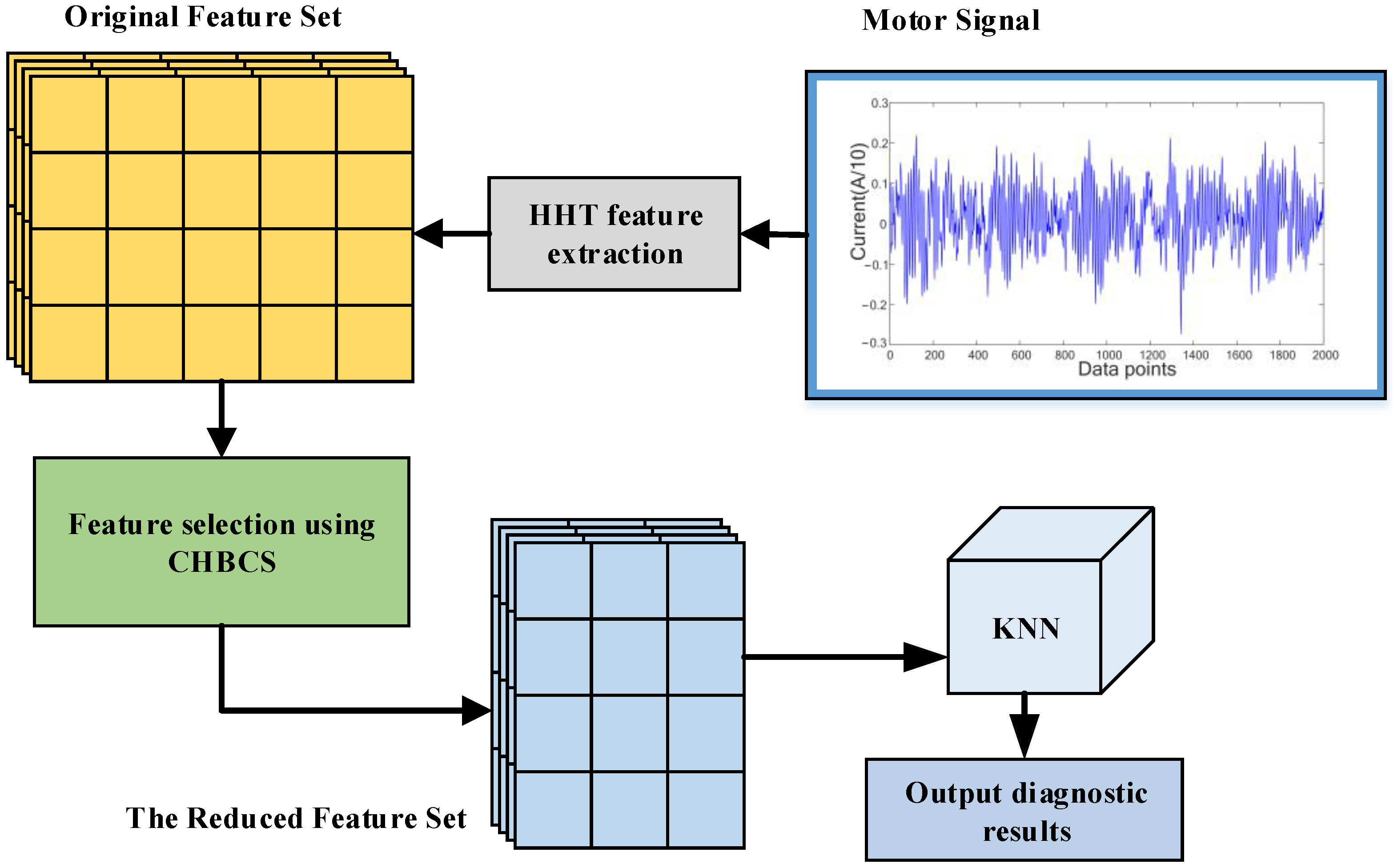
- Propose a strategy to extract the time–frequency domain features of motor signals based on the Hilbert–Huang transform.
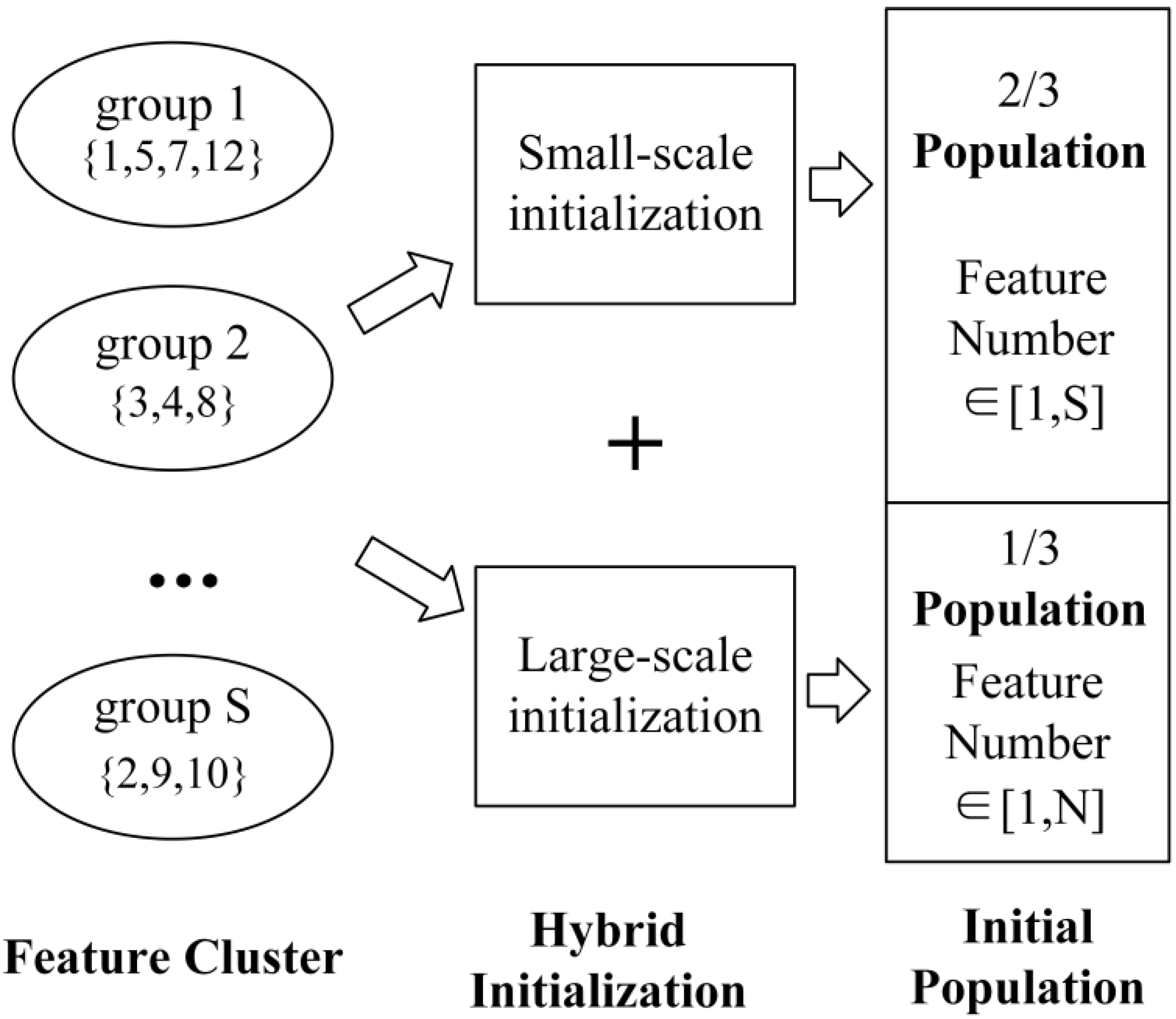
- In order to reduce redundant features in a population, a clustering hybrid initialization method is presented. The method uses the Louvain algorithm to cluster features and initializes the population according to the clustering information and the number of features, which can effectively remove redundant features.
- A mutation strategy based on Levy flights is proposed to improve the update formula. This strategy can effectively utilize the high-quality information of the population by guiding the subsequent search with several high-quality individuals.
- The proposed dynamic (Pa) probability strategy adaptively adjusts the (Pa) probability based on population rankings to preserve the high-quality solution of the current population.
2. Related Work
3. Feature Extraction
4. Feature Selection of the Clustering Hybrid Binary Cuckoo Search
4.1. Binary Cuckoo Search Algorithm
4.2. Clustering Hybrid Initialization Method
4.2.1. Feature Clustering
4.2.2. Hybrid Initialization
4.3. Mutation Strategy Based on Levy Flight
4.4. Dynamic Pa Probability Strategy
4.5. k-Nearest Neighbors Classifier and Fitness Function
4.6. Feature Selection Based on the Clustering Hybrid Binary Cuckoo Search
5. Experiments and Analysis
5.1. Performance Analysis of the CHBCS Algorithm
5.1.1. UCI Dataset
5.1.2. Experiment Setting
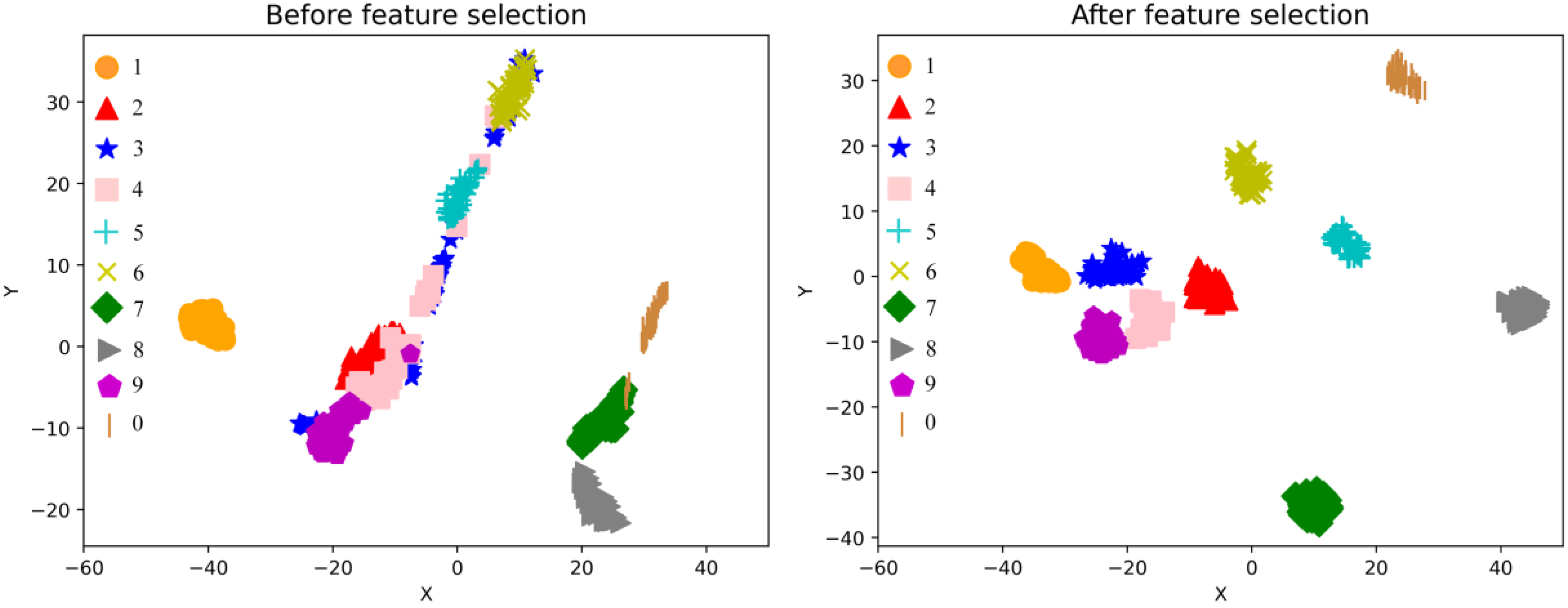
5.1.3. Effect of Initialization Strategy on Feature Selection
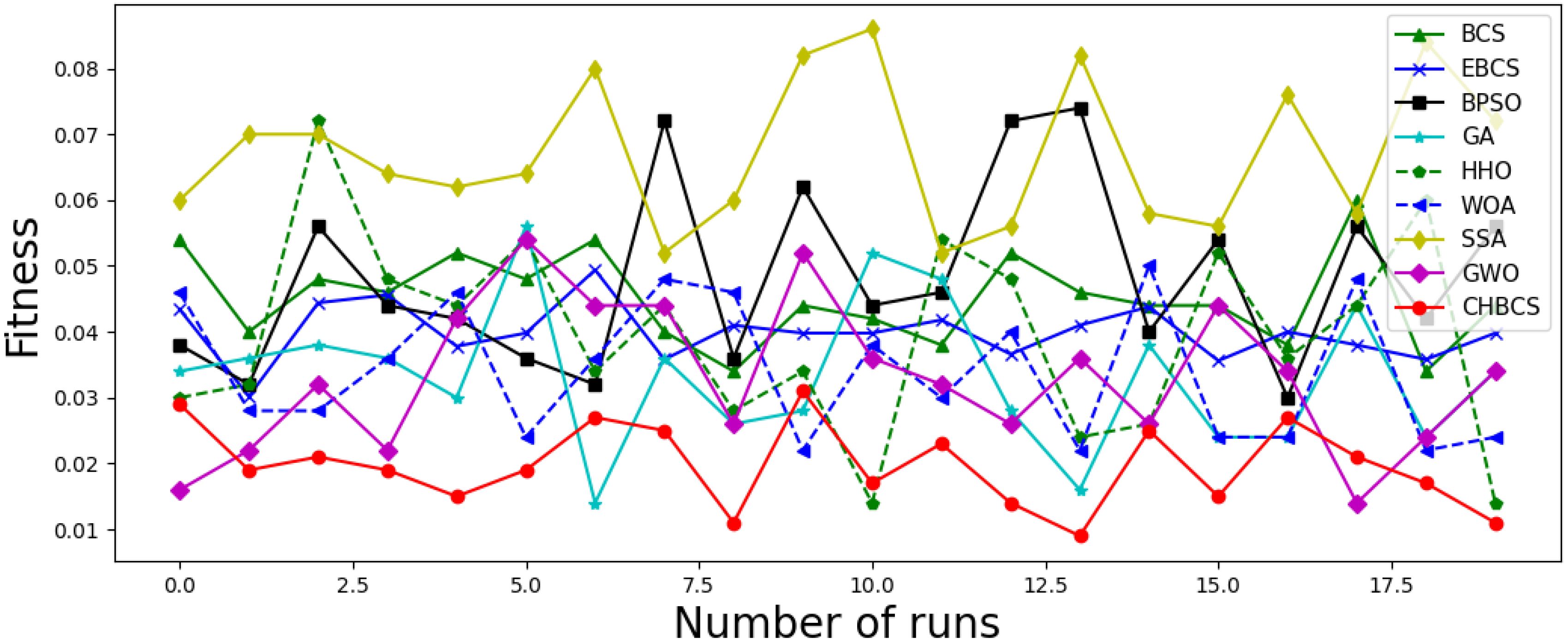
5.1.4. Comparison with Other Cuckoo Search Algorithms
5.2. Bearing Fault Diagnosis Experiment
5.2.1. Data Sources
5.2.2. Experimental Design
5.2.3. Experimental Results and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neupane, D.; Seok, J. Bearing Fault Detection and Diagnosis Using Case Western Reserve University Dataset With Deep Learning Approaches: A Review. IEEE Access 2020, 8, 93155–93178. [Google Scholar] [CrossRef]
- Nyanteh, Y.; Edrington, C.; Srivastava, S.; Cartes, D. Application of artificial intelligence to real-time fault detection in permanent-magnet synchronous machines. IEEE Trans. Ind. Appl. 2013, 49, 1205–1214. [Google Scholar] [CrossRef]
- Lin, S.L. Application of Machine Learning to a Medium Gaussian Support Vector Machine in the Diagnosis of Motor Bearing Faults. Electronics 2021, 10, 2266. [Google Scholar] [CrossRef]
- Hou, J.B.; Wu, Y.; Ahmad, A.S.; Gong, H.; Liu, L. A Novel Rolling Bearing Fault Diagnosis Method Based on Adaptive Feature Selectionand Clustering. IEEE Access 2021, 9, 99756–99767. [Google Scholar] [CrossRef]
- Zhang, X.; Zhao, B.Y.; Lin, Y. Machine Learning Based Bearing Fault Diagnosis Using the Case Western Reserve University Data: A Review. IEEE Access 2021, 9, 155598–155608. [Google Scholar] [CrossRef]
- Dhamande, L.S.; Chaudhari, M.B. Compound gear-bearing fault feature extraction using statistical features based on time-frequency method. Measurement 2018, 125, 63–77. [Google Scholar] [CrossRef]
- Tian, J.; Morillo, C.; Azarian, M.H.; Pecht, M. Motor Bearing Fault Detection Using Spectral Kurtosis-Based Feature Extraction Coupled With K -Nearest Neighbor Distance Analysis. IEEE Trans. Ind. Electron. 2016, 63, 1793–1803. [Google Scholar] [CrossRef]
- Guan, X.Y.; Chen, G. Sharing pattern feature selection using multiple improved genetic algorithms and its application in bearing fault diagnosis. J. Mech. Sci. Technol. 2019, 33, 129–138. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N.; Yao, X. A survey on evolutionary computation approaches to feature selection. IEEE Trans. Evol. Comput. 2016, 20, 606–626. [Google Scholar] [CrossRef]
- Mao, W.T.; Wang, L.Y.; Feng, N. A New Fault Diagnosis Method of Bearings Based on Structural Feature Selection. Electronics 2020, 8, 1406. [Google Scholar] [CrossRef]
- Liu, H.; Yu, L. Toward integrating feature selection algorithms for classification and clustering. IEEE Trans. Knowl. Data Eng. 2005, 17, 491–502. [Google Scholar]
- Tam, W.; Cheng, L.; Wang, T.; Xia, W.; Chen, L. An improved genetic algorithm based robot path planning method without collision in confined workspace. Int. J. Model. Identif. Control 2019, 33, 120–129. [Google Scholar] [CrossRef]
- Shafqat, W.; Malik, S.; Lee, K.T.; Kim, D.H. PSO Based Optimized Ensemble Learning and Feature Selection Approach for Efficient Energy Forecast. Electronics 2021, 10, 2188. [Google Scholar] [CrossRef]
- Al-tashi, Q.; Kadir, S.J.A.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Binary Optimization Using Hybrid Grey Wolf Optimization for Feature Selection. IEEE Access 2019, 7, 39496–39508. [Google Scholar] [CrossRef]
- Anter, A.M.; Muntaz, A. Feature selection strategy based on hybrid crow search optimization algorithm integrated with chaos theory and fuzzy c-means algorithm for medical diagnosis problems. Soft Comput. 2020, 24, 1565–1584. [Google Scholar] [CrossRef]
- Yang, X.S.; Deb, S. Cuckoo Search via Lévy flights. In Proceedings of the 2009 World Congress on Nature & Biologically Inspired Computing, Coimbatore, India, 9–11 December 2009. [Google Scholar]
- Gandomi, A.H.; Yang, X.S.; Alavi, A.H. Cuckoo search algorithm: A metaheuristic approach to solve structural optimization problems. Eng. Comput. 2013, 29, 17–35. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.J.; BrowneSchool, W.N. Particle swarm optimisation for feature selection in classification: Novel initialisation and updating mechanisms. Appl. Soft Comput. 2014, 18, 261–276. [Google Scholar] [CrossRef]
- Cui, B.; Pan, H.; Wang, Z. Fault diagnosis of roller bearings base on the local wave and approximate entropy. J. North Univ. China 2012, 33, 552–558. [Google Scholar]
- Zheng, J.; Cheng, J.; Yang, Y.; Luo, S. A rolling bearing fault diagnosis method based on multi-scale fuzzy entropy and variable predictive model-based class discrimination. Mech. Mach. Theory 2014, 78, 187–200. [Google Scholar] [CrossRef]
- Tang, X.H.; Wang, J.C.; Lu, J.G.; Liu, G.K.; Chen, J.D. Improving Bearing Fault Diagnosis Using Maximum Information Coefficient Based Feature Selection. Appl. Sci. 2018, 8, 2143. [Google Scholar] [CrossRef]
- Tang, X.H.; He, Q.; Gu, X.; Li, C.J.; Zhang, H.; Lu, J.G. A novel bearing fault diagnosis method based on GL-mRMR-SVM. Processes 2020, 8, 784. [Google Scholar] [CrossRef]
- Lu, L.; Yan, J.H.; de Silva, C.W. Dominant feature selection for the fault diagnosis of rotary machines using modified genetic algorithm and empirical mode decomposition. J. Sound Vib. 2015, 344, 464–483. [Google Scholar] [CrossRef]
- Rauber, T.W.; De, A.B.F.; Varejao, F.M. Heterogeneous Feature Models and Feature Selection Applied to Bearing Fault Diagnosis. IEEE Trans. Ind. Electron. 2015, 62, 637–646. [Google Scholar] [CrossRef]
- Shan, Y.H.; Zhou, J.Z.; Jiang, W.; Liu, J.; Xu, Y.H.; Zhao, Y.J. A fault diagnosis method for rotating machinery based on improved variational mode decomposition and a hybrid artificial sheep algorithm. Meas. Sci. Technol. 2019, 30, 055002. [Google Scholar] [CrossRef]
- Nayana, B.R.; Geethanjali, P. Improved Identification of Various Conditions of Induction Motor Bearing Faults. IEEE Trans. Instrum. Meas. 2020, 69, 1908–1919. [Google Scholar] [CrossRef]
- Lee, C.Y.; Le, T.A. An Enhanced Binary Particle Swarm Optimization for Optimal Feature Selection in Bearing Fault Diagnosis of Electrical Machines. IEEE Access 2021, 9, 102671–102686. [Google Scholar] [CrossRef]
- Rodrigues, D.; Pereira, L.A.M.; Almeida, T.N.S.; Papa, J.P.; Souza, A.N.; Ramos, C.C.O.; Yang, X.S. BCS: A Binary Cuckoo Search algorithm for feature selection. In Proceedings of the 2013 IEEE International Symposium on Circuits and Systems, Beijing, China, 19–23 May 2013. [Google Scholar]
- Salesi, S.; Cosma, G. A novel extended binary cuckoo search algorithm for feature selection. In Proceedings of the 2017 2nd International Conference on Knowledge Engineering and Applications 2017, London, UK, 21–23 October 2017. [Google Scholar]
- Pandey, A.C.; Rajipoot, D.S.; Saraswat, M. Feature selection method based on hybrid data transformation and binary binomial cuckoo search. J. Ambient. Intell. Humaniz. Comput. 2019, 11, 719–738. [Google Scholar] [CrossRef]
- Abd El Aziz, M.; Hassanien, A.E. Modified cuckoo search algorithm with rough sets for feature selection. Neural. Comput. Appl. 2018, 29, 925–934. [Google Scholar] [CrossRef]
- Kelidari, M.; Hamidzadeh, J. Feature selection by using chaotic cuckoo optimization algorithm with levy flight, opposition-based learning and disruption operator. Soft Comput. 2021, 25, 2911–2933. [Google Scholar] [CrossRef]
- Alia, A.; Taweel, A. Enhanced Binary Cuckoo Search with Frequent Values and Rough Set Theory for Feature Selection. IEEE Access 2021, 9, 119430–119453. [Google Scholar] [CrossRef]
- Kabla, A.; Mokrani, K. Bearing fault diagnosis using Hilbert-Huang transform (HHT) and support vector machine (SVM). Mech. Ind. 2016, 17, 3. [Google Scholar] [CrossRef]
- Chegini, S.N.; Bagheri, A.; Najafi, F. A new intelligent fault diagnosis method for bearing in different speeds based on the FDAF-score algorithm, binary particle swarm optimization, and support vector machine. Soft Comput. 2019, 24, 10005–10023. [Google Scholar] [CrossRef]
- Sosa-Cabrera, G.; García-Torres, M.; Gómez-Guerrero, S.; Schaerer, C.E.; Divina, F. A Multivariate approach to the Symmetrical Uncertainty Measure: Application to Feature Selection Problem. Inf. Sci. 2019, 2019, 494. [Google Scholar] [CrossRef]
- Chen, Q.; Zhao, L.; Lu, J.; Kuang, G.; Wang, N.; Jiang, Y. Modified two-dimensional Otsu image segmentation algorithm and fast realisation. IET Image Process. 2012, 6, 426–433. [Google Scholar] [CrossRef]
- Traag, V.A. Faster unfolding of communities: Speeding up the Louvain algorithm. Phys. Rev. E 2015, 92, 032801. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.F.; Wang, S.; Wei, B.K.; Chen, W.W.; Zhang, Y.F. Weighted K-NN Classification Method of Bearings Fault Diagnosis with Multi-Dimensional Sensitive Features. IEEE Access 2021, 9, 45428–45440. [Google Scholar] [CrossRef]
- Ouadfel, S.; Elaziz, M.A. Enhanced Crow Search Algorithm for Feature Selection. Expert Syst. Appl. 2020, 159, 113572. [Google Scholar] [CrossRef]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]
- Li, W.; Chao, X.Q. Improved particle swarm optimization method for feature selection. J. Front. Comput. Sci. Technol. 2019, 13, 990–1004. [Google Scholar]
- Mirjalili, S.; Lewis, A. S-shaped versus V-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Tan, F.; Fu, X.Z.; Zhang, Y.P. A genetic algorithm-based method for feature subset selection. Soft Comput. 2008, 12, 111–120. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H.L. Harris hawks optimization: Algorithm and applications. Future Gener. Comput. Sys. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The whale optimization algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp swarm algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Jiang, W.; Xu, Y.H.; Chen, Z.; Zhang, N.; Zhou, J.Z. Fault diagnosis for rolling bearing using a hybrid hierarchical method based on scale-variable dispersion entropy and parametric t-SNE algorithm. Measurement 2022, 191, 110843. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | The Number of Features | The Number of Samples | The Number of Classes |
|---|---|---|---|
| BreastEW | 30 | 569 | 2 |
| Exactly | 13 | 1000 | 2 |
| HeartEW | 13 | 270 | 2 |
| Hillvalley | 100 | 606 | 15 |
| Libras | 90 | 360 | 3 |
| Musk1 | 166 | 476 | 2 |
| Sonarall | 60 | 208 | 2 |
| Spectf | 44 | 267 | 2 |
| WDBC | 30 | 569 | 2 |
| Dataset | BCS (Rand) | BCS (BC) | BCS (CH) |
|---|---|---|---|
| BreastEW | 0.0291 | 0.0289 | 0.0281 |
| Exactly | 0.0011 | 0.0035 | 0.0006 |
| HeartEW | 0.1437 | 0.1470 | 0.1425 |
| Hillvalley | 0.3932 | 0.3901 | 0.3865 |
| Libras | 0.2296 | 0.2272 | 0.2264 |
| Musk1 | 0.7890 | 0.0904 | 0.0730 |
| Sonarall | 0.1187 | 0.1173 | 0.1170 |
| Spectf | 0.1602 | 0.1651 | 0.1589 |
| WDBC | 0.0300 | 0.0291 | 0.0271 |
| Dataset | Algorithm | Error ± Std | NO. ± Std |
|---|---|---|---|
| BreastEW | BCS | 0.0276 ± 4.68 × 10−3 | 5.50 ± 1.11 |
| EBCS | 0.0277 ± 4.53 × 10−3 | 5.35 ± 1.10 | |
| CHBCS | 0.0252 ± 4.33 × 10−3 | 4.85 ± 1.52 | |
| Exactly | BCS | 0.0111 ± 2.50 × 10−3 | 6.65 ± 0.72 |
| EBCS | 0.0006 ± 1.62 × 10−3 | 6.15 ± 0.35 | |
| CHBCS | 0.0000 ± 0.00 | 6.00 ± 0.00 | |
| HeartEW | BCS | 0.1451 ± 6.58 × 10−3 | 3.80 ± 0.87 |
| EBCS | 0.1436 ± 7.00 × 10−3 | 3.12 ± 0.30 | |
| CHBCS | 0.1399 ± 2.51 × 10−3 | 3.10 ± 0.30 | |
| Hillvalley | BCS | 0.3956 ± 6.53 × 10−3 | 8.75 ± 4.81 |
| EBCS | 0.3889 ± 6.87 × 10−3 | 6.55 ± 3.15 | |
| CHBCS | 0.3679 ± 8.15 × 10−3 | 6.10 ± 2.87 | |
| Libras | BCS | 0.1947 ± 0.85 × 10−3 | 20.15 ± 6.77 |
| EBCS | 0.1968 ± 1.07 × 10−2 | 16.80 ± 7.17 | |
| CHBCS | 0.1797 ± 0.99 × 10−3 | 18.80 ± 4.31 | |
| Musk1 | BCS | 0.0820 ± 5.59 × 10−3 | 9.52 ± 2.52 |
| EBCS | 0.0891 ± 1.10 × 10−2 | 10.05 ± 2.43 | |
| CHBCS | 0.0578 ± 1.26 × 10−2 | 8.20 ± 3.16 | |
| Sonarall | BCS | 0.0916 ± 1.14 × 10−2 | 17.95 ± 5.01 |
| EBCS | 0.1007 ± 9.80 × 10−3 | 16.40 ± 2.98 | |
| CHBCS | 0.0822 ± 1.19 × 10−2 | 15.15 ± 5.43 | |
| Spectf | BCS | 0.1584 ± 1.23 × 10−2 | 7.50 ± 3.00 |
| EBCS | 0.1631 ± 7.71 × 10−3 | 6.55 ± 1.73 | |
| CHBCS | 0.1456 ± 1.02 × 10−2 | 5.15 ± 2.35 | |
| WDBC | BCS | 0.0287 ± 4.45 × 10−3 | 5.70 ± 1.14 |
| EBCS | 0.0286 ± 4.78 × 10−3 | 5.15 ± 1.28 | |
| CHBCS | 0.0262 ± 4.87 × 10−3 | 4.80 ± 1.45 |
| NO. | Failure Mode | Fault Location | Fault Size (Inches) | Number of Samples |
|---|---|---|---|---|
| 1 | B07 | B | 0.007 | 50 |
| 2 | B14 | B | 0.014 | 50 |
| 3 | B21 | B | 0.021 | 50 |
| 4 | IR07 | IR | 0.007 | 50 |
| 5 | IR14 | IR | 0.014 | 50 |
| 6 | IR21 | IR | 0.021 | 50 |
| 7 | OR07 | OR(6:00) | 0.007 | 50 |
| 8 | OR14 | OR(6:00) | 0.014 | 50 |
| 9 | OR21 | OR(6:00) | 0.021 | 50 |
| 0 | normal | - | - | 50 |
| Algorithm | Parameter Setting |
|---|---|
| BCS | N = 50; Tmax = 100; Pa = 0.25 |
| EBCS | N = 50; Tmax = 100; Pa = 0.25 |
| BPSO | N = 50; Tmax = 100; c1 = 0.9; c2 = 0.5 |
| GA | N = 50; Tmax = 100; Cp = 0.8; Mp = 0.01 |
| HHO | N = 50; Tmax = 100; β = 0.25 |
| WOA | N = 50; Tmax = 100; α decreases linearly from 2 to 0 |
| SSA | N = 50; Tmax = 100; c1 and c2 are randomly distributed |
| GWO | N = 50; Tmax = 100; α decreases linearly from 2 to 0 |
| CHBCS | N = 50; Tmax = 100 |
| Algorithm | Error | No. | Fitness |
|---|---|---|---|
| ALL | 0.0600 | 50.00 | 0.1540 |
| BCS | 0.0197 | 13.05 | 0.0438 |
| EBCS | 0.0249 | 9.05 | 0.0399 |
| BPSO | 0.0243 | 12.45 | 0.0468 |
| GA | 0.0229 | 6.30 | 0.0333 |
| HHO | 0.02320 | 5.40 | 0.0396 |
| WOA | 0.0256 | 5.50 | 0.0341 |
| SSA | 0.0283 | 18.25 | 0.0620 |
| GWO | 0.0257 | 4.95 | 0.0330 |
| CHBCS | 0.0113 | 4.75 | 0.0197 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Xin, Y.; Chen, T.; Feng, B. Rolling Bearing Fault Feature Selection Method Based on a Clustering Hybrid Binary Cuckoo Search. Electronics 2023, 12, 459. https://doi.org/10.3390/electronics12020459
Sun L, Xin Y, Chen T, Feng B. Rolling Bearing Fault Feature Selection Method Based on a Clustering Hybrid Binary Cuckoo Search. Electronics. 2023; 12(2):459. https://doi.org/10.3390/electronics12020459
Chicago/Turabian StyleSun, Lijun, Yan Xin, Tianfei Chen, and Binbin Feng. 2023. "Rolling Bearing Fault Feature Selection Method Based on a Clustering Hybrid Binary Cuckoo Search" Electronics 12, no. 2: 459. https://doi.org/10.3390/electronics12020459
APA StyleSun, L., Xin, Y., Chen, T., & Feng, B. (2023). Rolling Bearing Fault Feature Selection Method Based on a Clustering Hybrid Binary Cuckoo Search. Electronics, 12(2), 459. https://doi.org/10.3390/electronics12020459