

Quo Vadis Machine Learning-Based Systems Condition Prognosis?—A Perspective



{kind=link}
{kind=link}
{kind=link}
Abstract
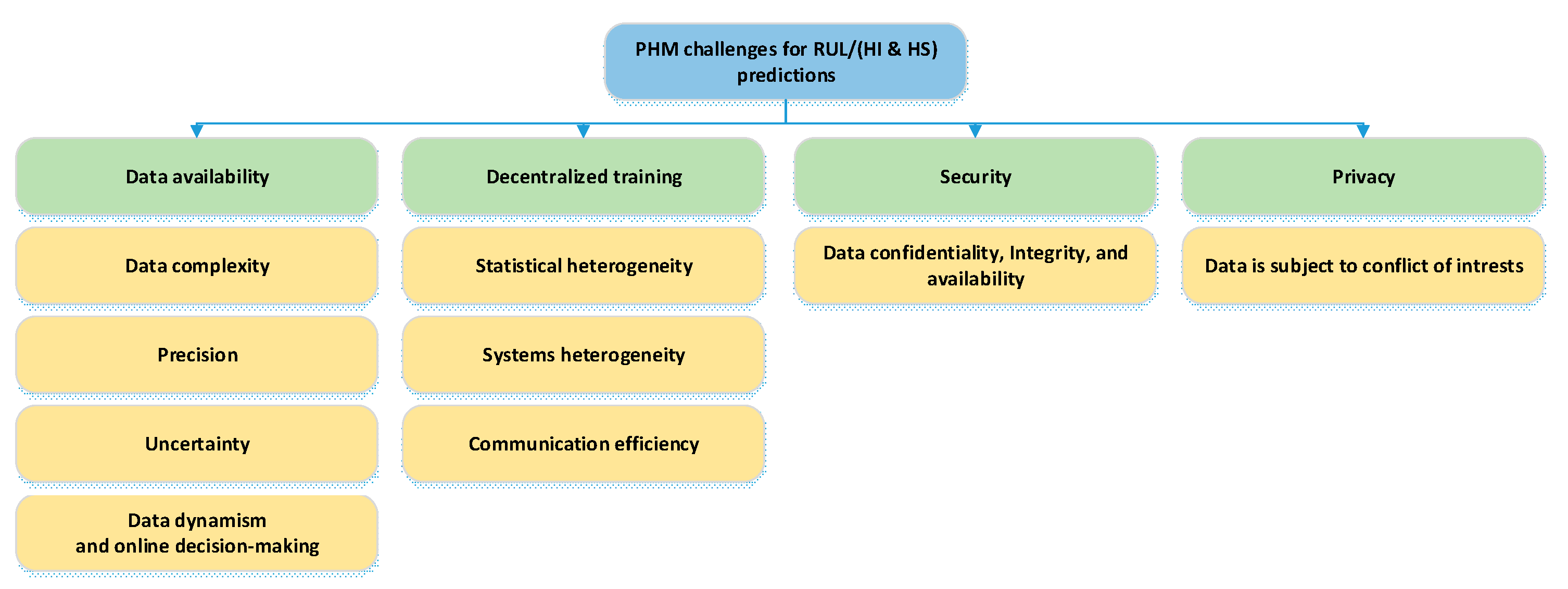
:1. Mains Challenges
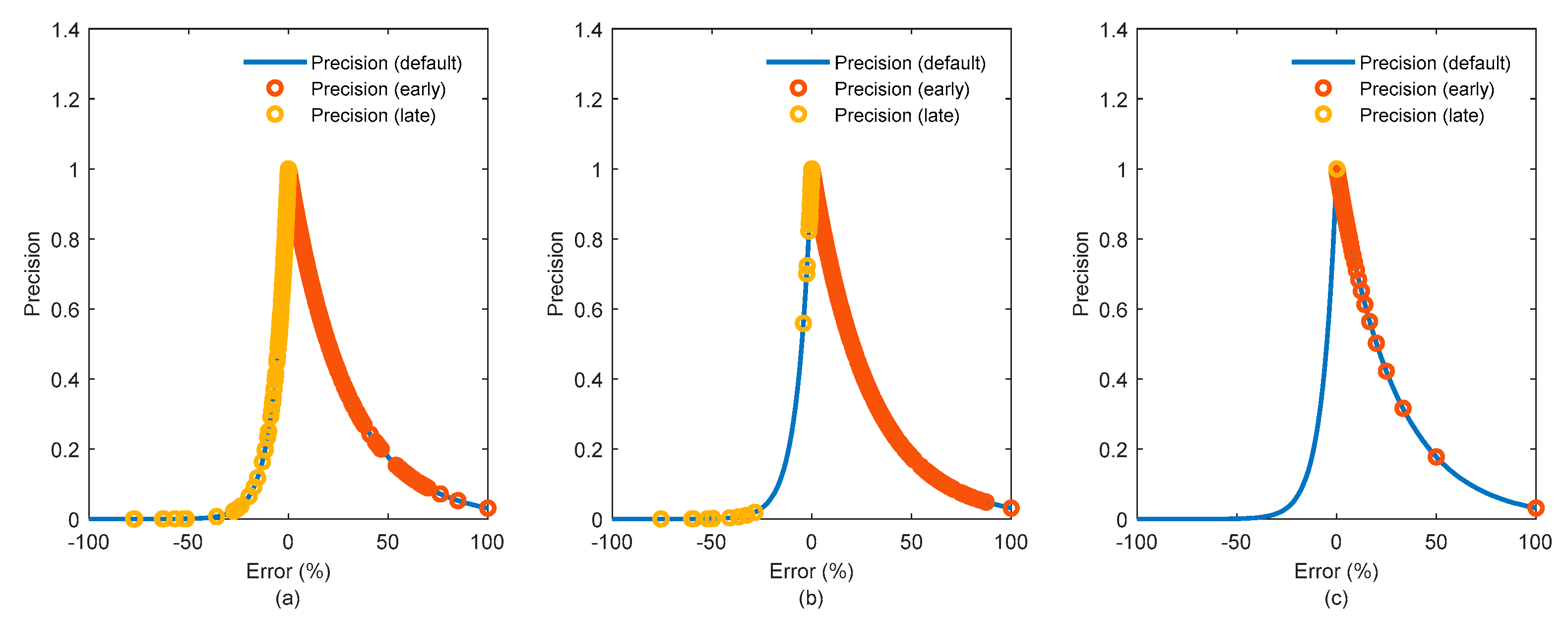
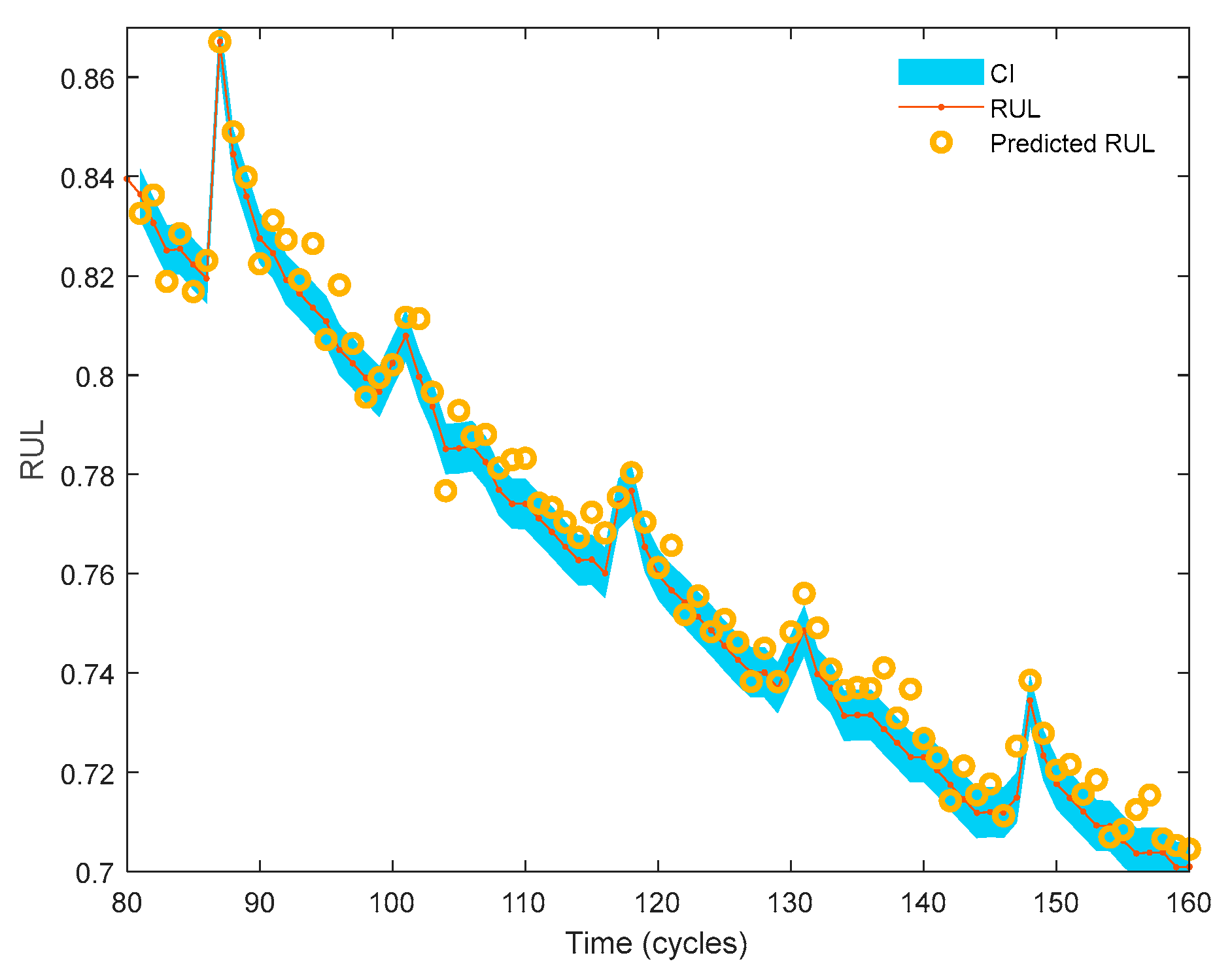
1.1. Modeling Complexity
1.2. Decentralized Training
1.3. Security and Privacy
2. What Do We Have to Work Towards?
2.1. Reducing Complexity
2.2. Federated Learning
2.3. Security
3. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Berghout, T.; Mouss, M.-D.; Mouss, L.; Benbouzid, M. ProgNet: A Transferable Deep Network for Aircraft Engine Damage Propagation Prognosis under Real Flight Conditions. Aerospace 2022, 10, 10. [Google Scholar] [CrossRef]
- Lei, Y.; Li, N.; Guo, L.; Li, N.; Yan, T.; Lin, J. Machinery health prognostics: A systematic review from data acquisition to RUL prediction. Mech. Syst. Signal Process. 2018, 104, 799–834. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M. A Systematic Guide for Predicting Remaining Useful Life with Machine Learning. Electronics 2022, 11, 1125. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M.; Muyeen, S.M. Machine Learning for Cybersecurity in Smart Grids: A Comprehensive Review-based Study on Methods, Solutions, and Prospects. Int. J. Crit. Infrastruct. Prot. 2022, 38, 100547. [Google Scholar] [CrossRef]
- Nectoux, P.; Gouriveau, R.; Medjaher, K.; Ramasso, E.; Chebel-Morello, B.; Zerhouni, N.; Varnier, C. PRONOSTIA: An experimental platform for bearings accelerated degradation tests. In Proceedings of the IEEE International Conference on Prognostics and Health Management, PHM’12, Denver, CO, USA, 18–21 June 2012; pp. 1–8. [Google Scholar]
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Wavelet filter-based weak signature detection method and its application on rolling element bearing prognostics. J. Sound Vib. 2006, 289, 1066–1090. [Google Scholar] [CrossRef]
- Gouriveau, R.; Medjaher, K.; Ramasso, E.; Zerhouni, N. PHM—Prognostics and health management De la surveillance au pronostic de défaillances de systèmes complexes. Tech. Ing. Fonct. Strat. Maint. 2013, 148625958. [Google Scholar] [CrossRef]
- Saha, B.; Goebel, K. Battery Data Set; NASA AMES Prognostics Center of Excellence Data Set Repository: Washington, DC, USA, 2007. [Google Scholar]
- Juričić, Ð.; Kocare, N.; Boškoski, P. On Optimal Threshold Selection for Condition Monitoring. In Advances in Condition Monitoring of Machinery in Non-Stationary Operations, Proceedings of the Fourth International Conference on Condition Monitoring of Machinery in Non-Stationary Operations, CMMNO’2014, Lyon, France, 15–17 December 2014; Chaari, F., Zimroz, R., Bartelmus, W., Haddar, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 4, pp. 237–249. [Google Scholar] [CrossRef]
- Abdar, M.; Pourpanah, F.; Hussain, S.; Rezazadegan, D.; Liu, L.; Ghavamzadeh, M.; Fieguth, P.; Cao, X.; Khosravi, A.; Acharya, U.R.; et al. A review of uncertainty quantification in deep learning: Techniques, applications and challenges. Inf. Fusion 2021, 76, 243–297. [Google Scholar] [CrossRef]
- Alves, D.S.; Daniel, G.B.; de Castro, H.F.; Machado, T.H.; Cavalca, K.L.; Gecgel, O.; Dias, J.P.; Ekwaro-Osire, S. Uncertainty quantification in deep convolutional neural network diagnostics of journal bearings with ovalization fault. Mech. Mach. Theory 2020, 149, 103835. [Google Scholar] [CrossRef]
- Berghout, T.; Mouss, L.-H.; Bentrcia, T.; Benbouzid, M. A Semi-Supervised Deep Transfer Learning Approach for Rolling-Element Bearing Remaining Useful Life Prediction. IEEE Trans. Energy Convers. 2022, 37, 1200–1210. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated Learning; Synthesis Lectures on Artificial Intelligence and Machine Learning; Morgan & Claypool Publishers: San Rafael, CA, USA, 2020; Volume 13, pp. 1–207. [Google Scholar] [CrossRef]
- Berghout, T.; Mouss, L.H.; Kadri, O.; Saïdi, L.; Benbouzid, M. Aircraft engines Remaining Useful Life prediction with an adaptive denoising online sequential Extreme Learning Machine. Eng. Appl. Artif. Intell. 2020, 96, 103936. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Berghout, T.; Bentrcia, T.; Ferrag, M.A.; Benbouzid, M. A Heterogeneous Federated Transfer Learning Approach with Extreme Aggregation and Speed. Mathematics 2022, 10, 3528. [Google Scholar] [CrossRef]
- Ma, X.; Wen, C.; Wen, T. An Asynchronous and Real-time Update Paradigm of Federated Learning Diagnosisfor Fault. IEEE Trans. Ind. Inform. 2021, 3203, 8531–8540. [Google Scholar] [CrossRef]
- Xue, M.A.; Chenglin, W.E.N. An Asynchronous Quasi-Cloud/Edge/Client Collaborative Federated Learning Mechanism for Fault Diagnosis. Chin. J. Electron. 2021, 30, 969–977. [Google Scholar] [CrossRef]
- Berghout, T.; Benbouzid, M. EL-NAHL: Exploring labels autoencoding in augmented hidden layers of feedforward neural networks for cybersecurity in smart grids. Reliab. Eng. Syst. Saf. 2022, 226, 108680. [Google Scholar] [CrossRef]
- Bellani, L.; Compare, M.; Baraldi, P.; Zio, E. Towards Developing a Novel Framework for Practical PHM: A Sequential Decision Problem solved by Reinforcement Learning and Artificial Neural Networks. Int. J. Progn. Heal. Manag. 2019, 31, 211051503. [Google Scholar]
- Jha, M.S.; Weber, P.; Theilliol, D.; Ponsart, J.C.; Maquin, D. A reinforcement learning approach to health aware control strategy. In Proceedings of the 27th Mediterranean Conference on Control and Automation, Akko, Israel, 1–4 July 2019; pp. 171–176. [Google Scholar] [CrossRef]
- Skordilis, E.; Moghaddass, R. A deep reinforcement learning approach for real-time sensor-driven decision making and predictive analytics. Comput. Ind. Eng. 2020, 147, 106600. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Rosero, R.L.; Silva, C.; Ribeiro, B. Remaining Useful Life Estimation in Aircraft Components with Federated Learning. In Proceedings of the 5th European Conference of the PHM Society 2020, Virtual Event, 21–27 July 2020; PMH Society: Portland, OR, USA, 2020; Volume 5, pp. 1–8. [Google Scholar]
- Dhada, M.; Jain, A.K.; Parlikad, A.K. Empirical convergence analysis of federated averaging for failure prognosis. IFAC PapersOnLine 2020, 53, 360–365. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benbouzid, M.; Berghout, T. Quo Vadis Machine Learning-Based Systems Condition Prognosis?—A Perspective. Electronics 2023, 12, 527. https://doi.org/10.3390/electronics12030527
Benbouzid M, Berghout T. Quo Vadis Machine Learning-Based Systems Condition Prognosis?—A Perspective. Electronics. 2023; 12(3):527. https://doi.org/10.3390/electronics12030527
Chicago/Turabian StyleBenbouzid, Mohamed, and Tarek Berghout. 2023. "Quo Vadis Machine Learning-Based Systems Condition Prognosis?—A Perspective" Electronics 12, no. 3: 527. https://doi.org/10.3390/electronics12030527
APA StyleBenbouzid, M., & Berghout, T. (2023). Quo Vadis Machine Learning-Based Systems Condition Prognosis?—A Perspective. Electronics, 12(3), 527. https://doi.org/10.3390/electronics12030527