

Multiple Access for Heterogeneous Wireless Networks with Imperfect Channels Based on Deep Reinforcement Learning

Abstract
:1. Introduction
- We introduce a novel multiple access protocol, PPOMA, which is designed based on the PPO algorithm from deep reinforcement learning. PPOMA offers faster convergence, improved sampling capabilities, and enhanced exploration abilities. These features enable the effective resolution of the multiple access problem in heterogeneous wireless networks, ultimately enhancing network performance.
- We conduct simulation experiments with the PPOMA protocol under both perfect and imperfect channel conditions, considering various real-world factors like channel interference and packet loss. This comprehensive evaluation provides a more objective assessment of PPOMA’s performance and brings us closer to real-world scenarios.
- By comparing the experimental results with existing multiple access protocols, we find that PPOMA outperforms them by achieving higher overall throughput and faster convergence in different channel conditions. This satisfies the demands of practical communication systems for efficiency and reliability. We believe that PPOMA holds great potential and broad applicability in the field of multiple access protocols.
2. Related Works
- (1)
- PPO employs a clipping mechanism to limit the range of policy updates, ensuring that each policy update remains within a reasonable range and avoids significant fluctuations. This stabilizes parameter updates, resulting in faster convergence.
- (2)
- It utilizes importance sampling, estimating the value of previous policies with samples generated by the current policy. This enhances the efficiency of sampling, enabling more effective use of historical data and reducing the number of required samples, thus accelerating training.
- (3)
- PPO exhibits stronger exploration capabilities. This is because PPO falls under the category of policy-based learning methods. It directly employs neural networks to approximate the policy function for the purpose of updating policy, enabling agents to explore more flexibly during the learning process. In contrast, DQN is a value-based learning method that focuses on approximating the optimal action-value function to find the best policy, which can limit its exploration capabilities.
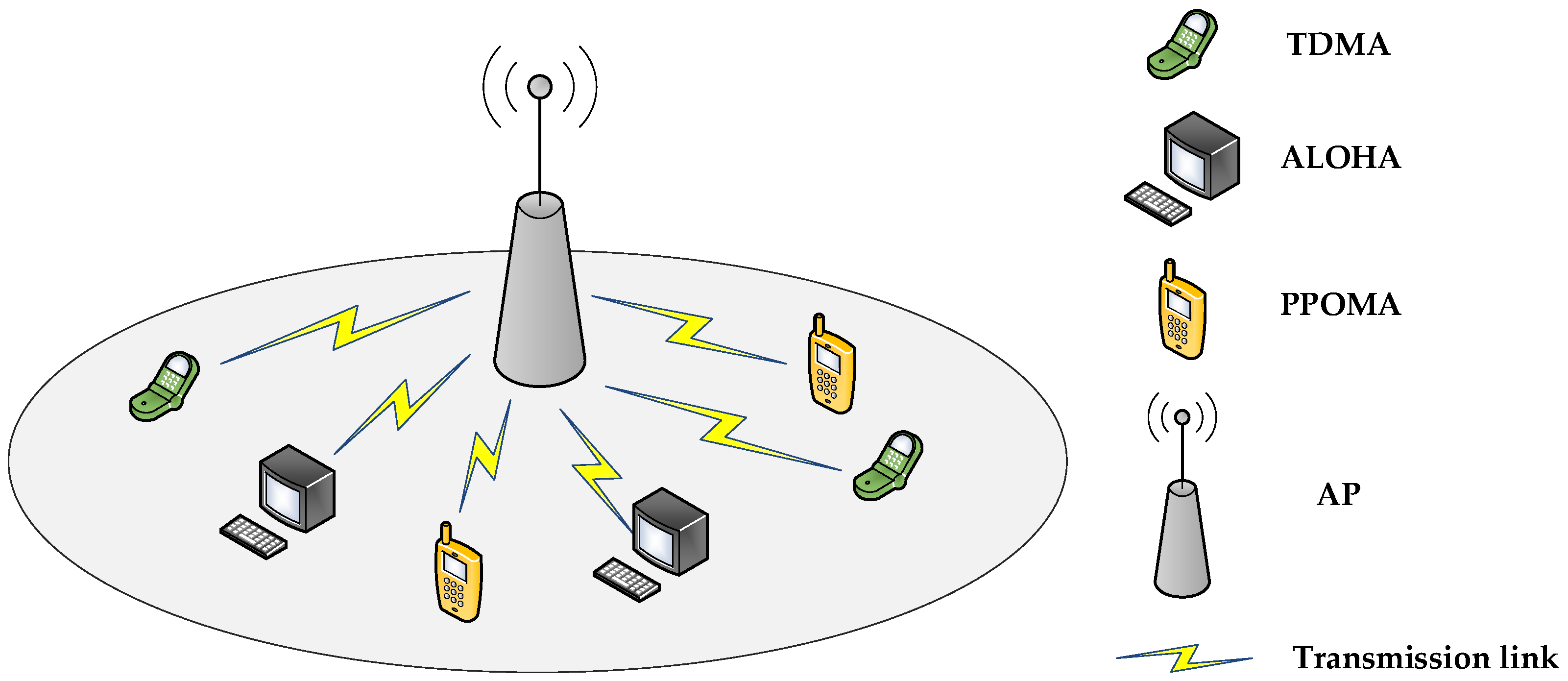
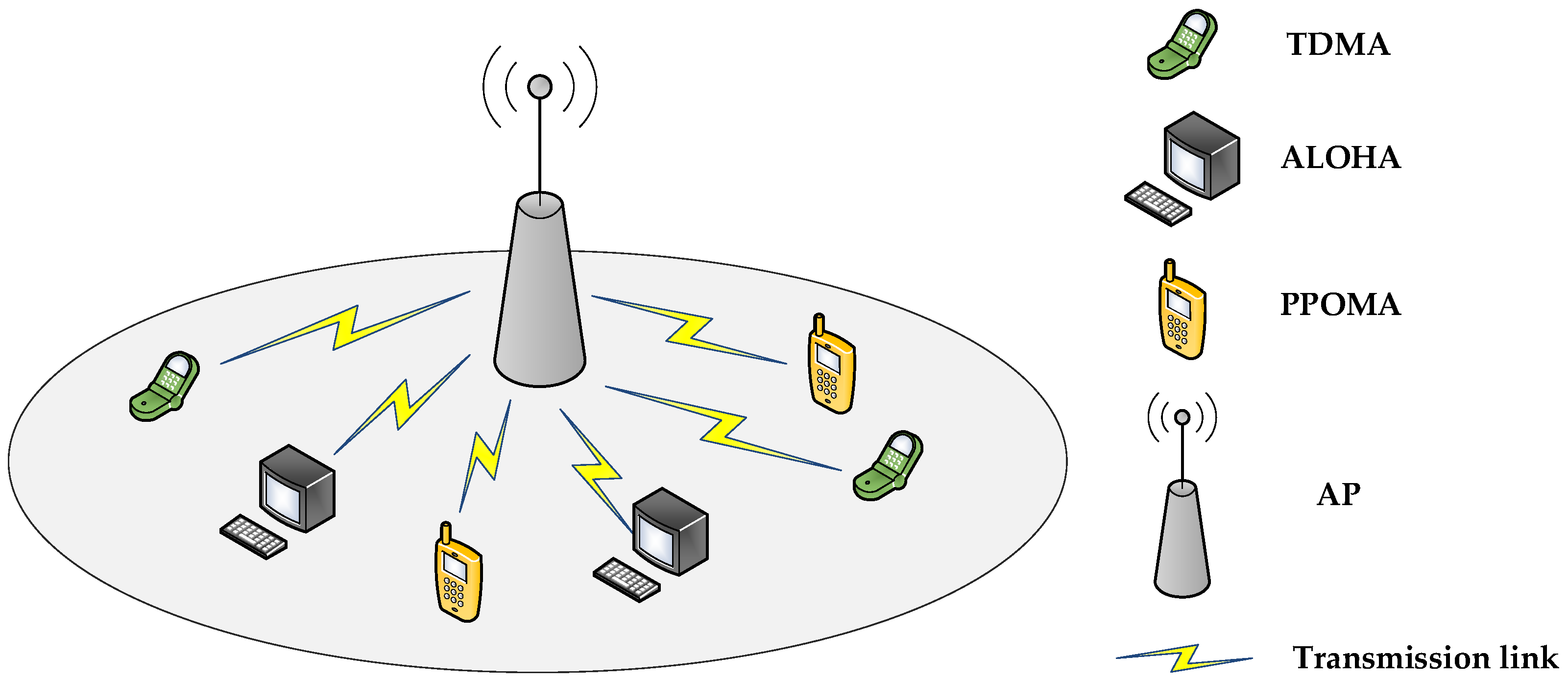
3. System Model
4. PPOMA Protocol Design
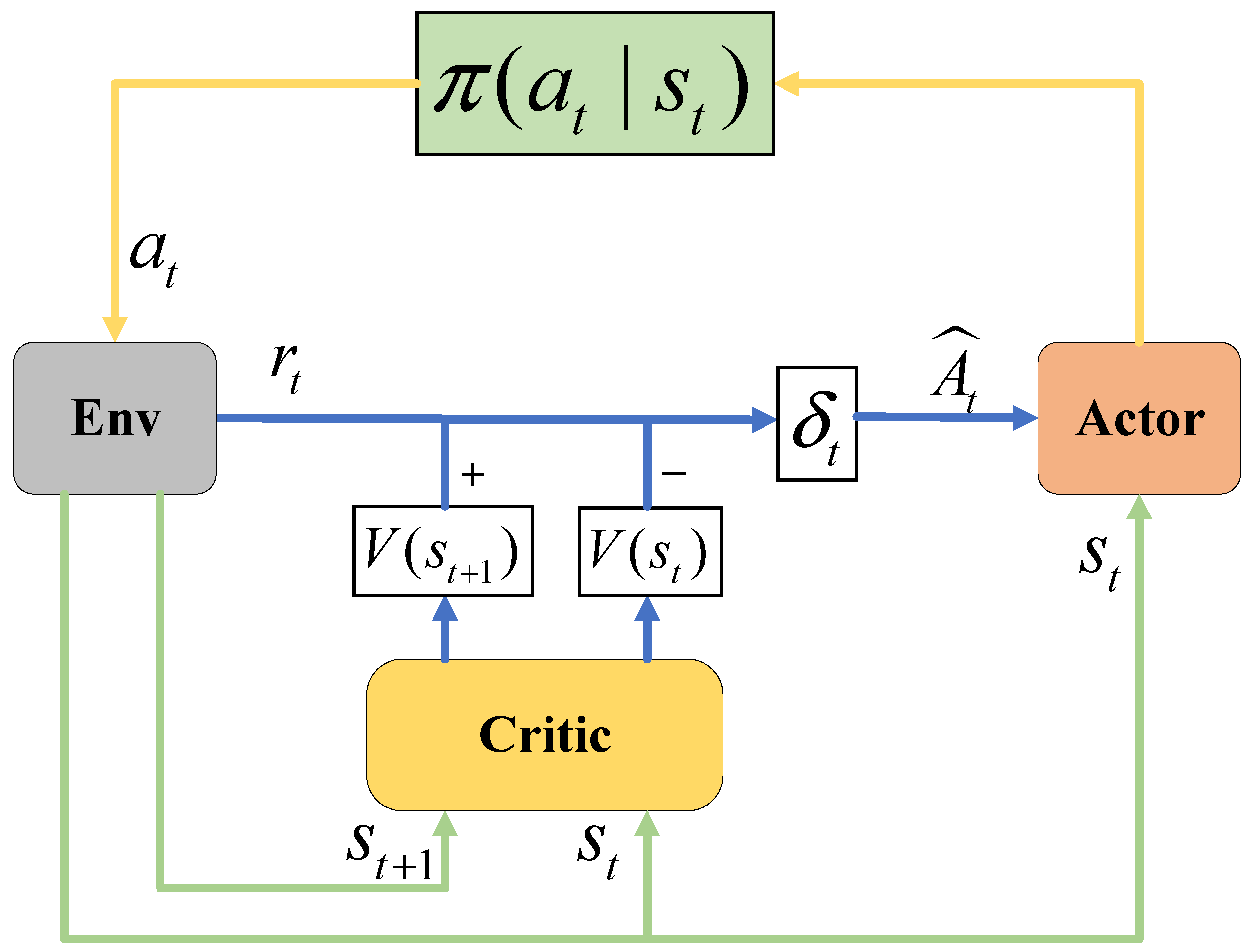
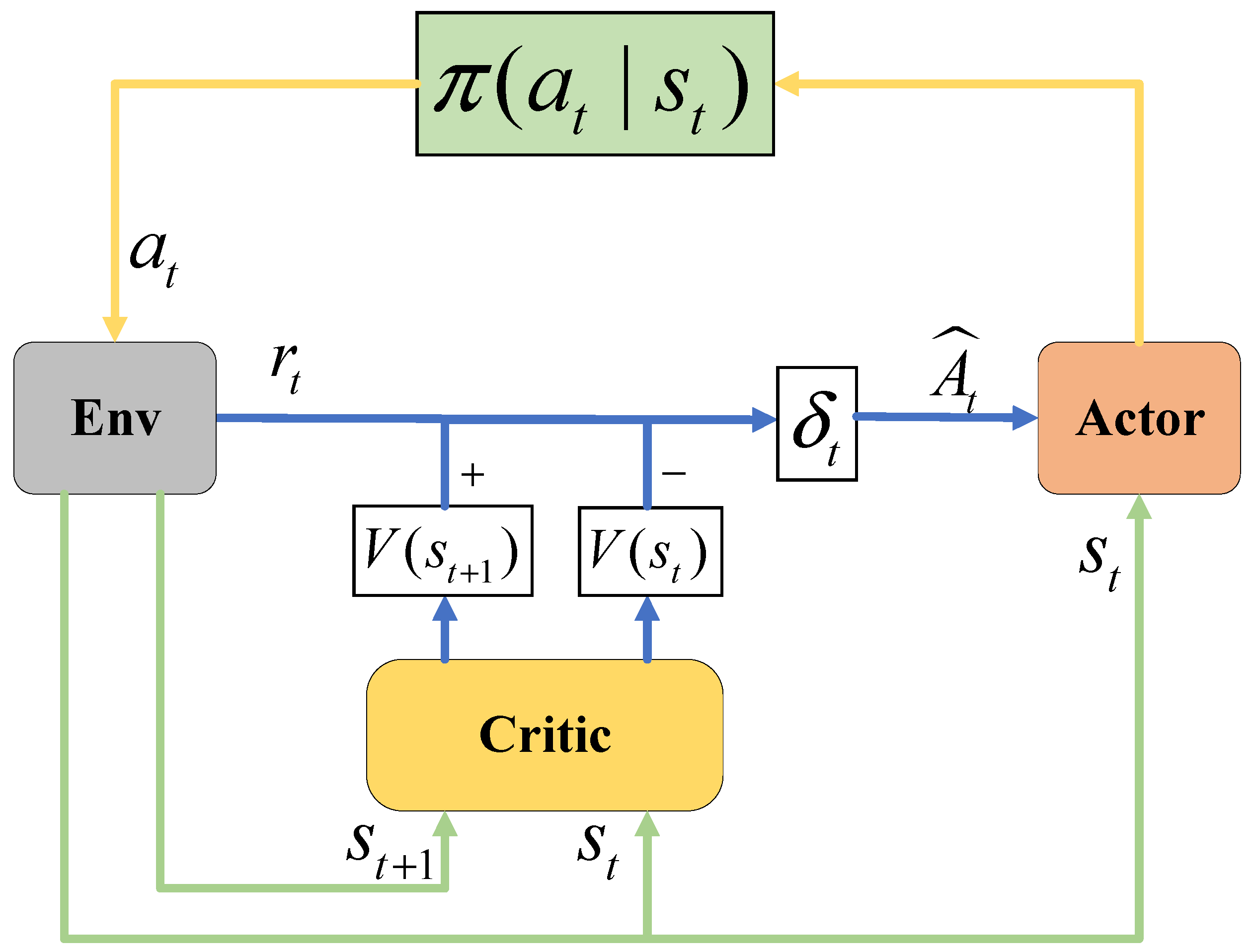
4.1. Overview of PPO Algorithm
| Algorithm 1: PPOMA |
| Initialize Initialize the parameter of actor as , the parameter of critic as , the parameter of actor–target as For do Input into actor and output Sample action based on the probability Observe Compute from Store If Remainder then Update by setting End if Input into actor–target and output Input into critic and output Calculate Calculate Update and by using gradient descent Minimize End for |
4.2. Action, Observation, State, and Reward
5. Performance Evaluation
5.1. Simulation Setup
5.2. Baseline and Performance Metrics
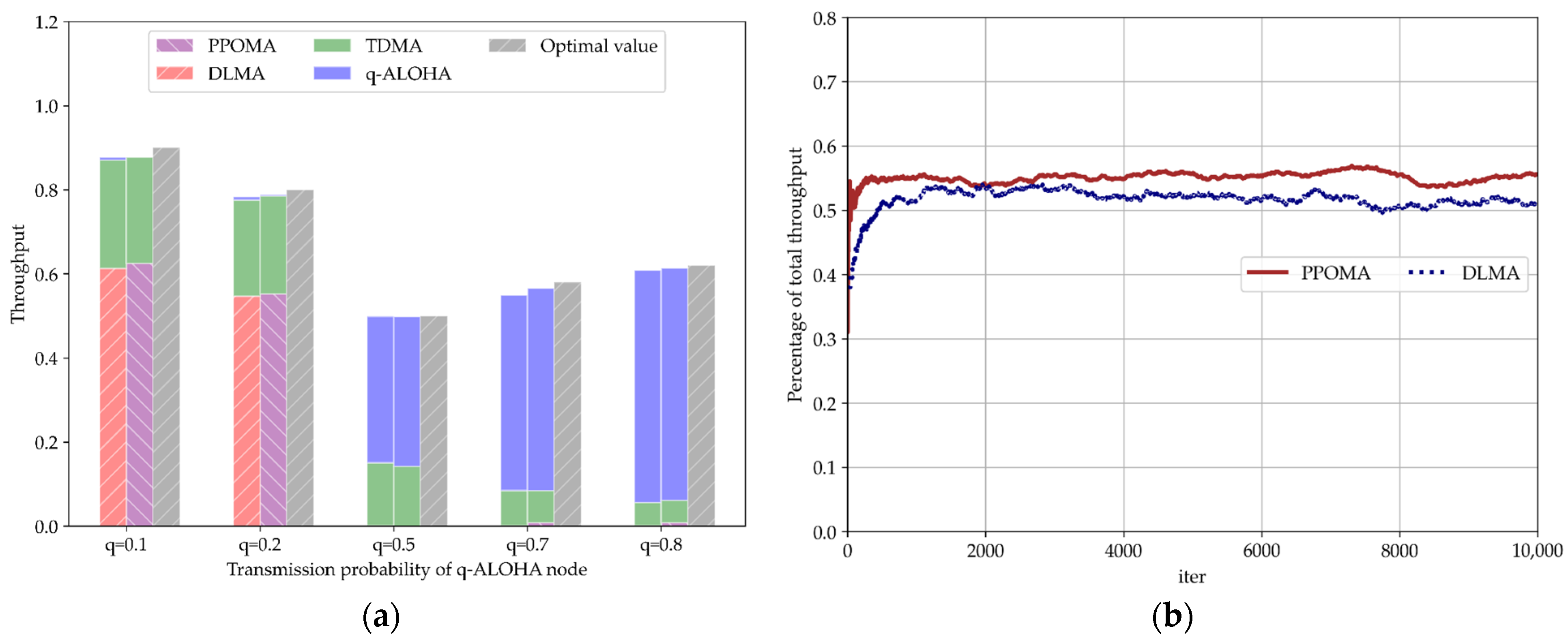
5.3. Comparison of Total Throughput under Perfect Channel Conditions
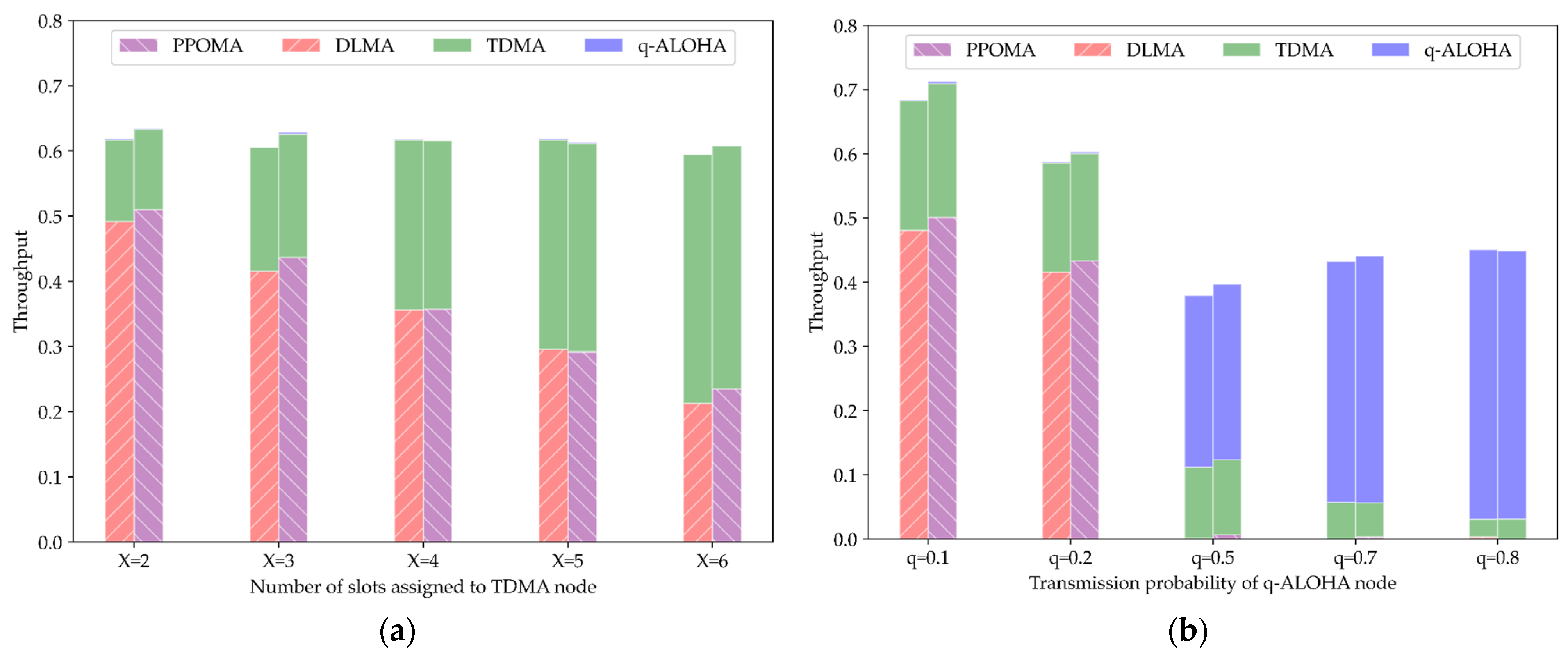
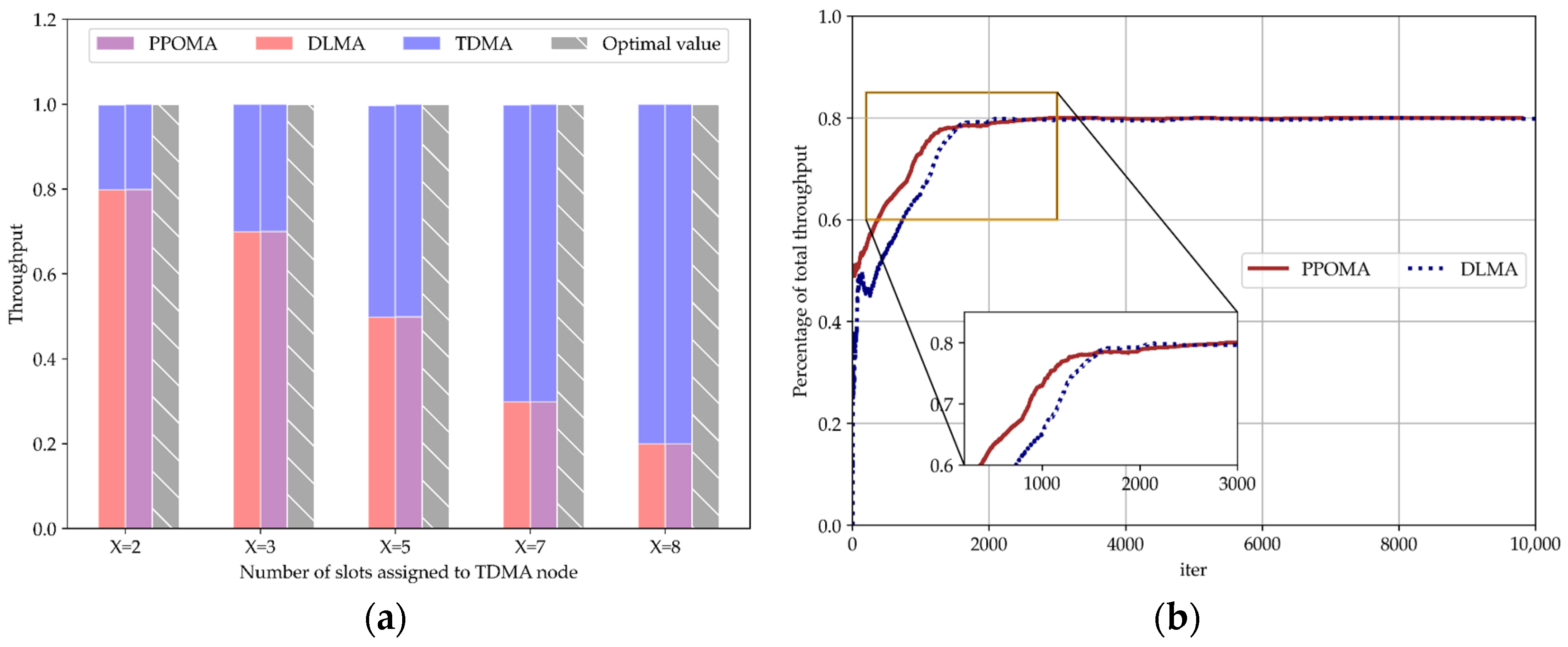
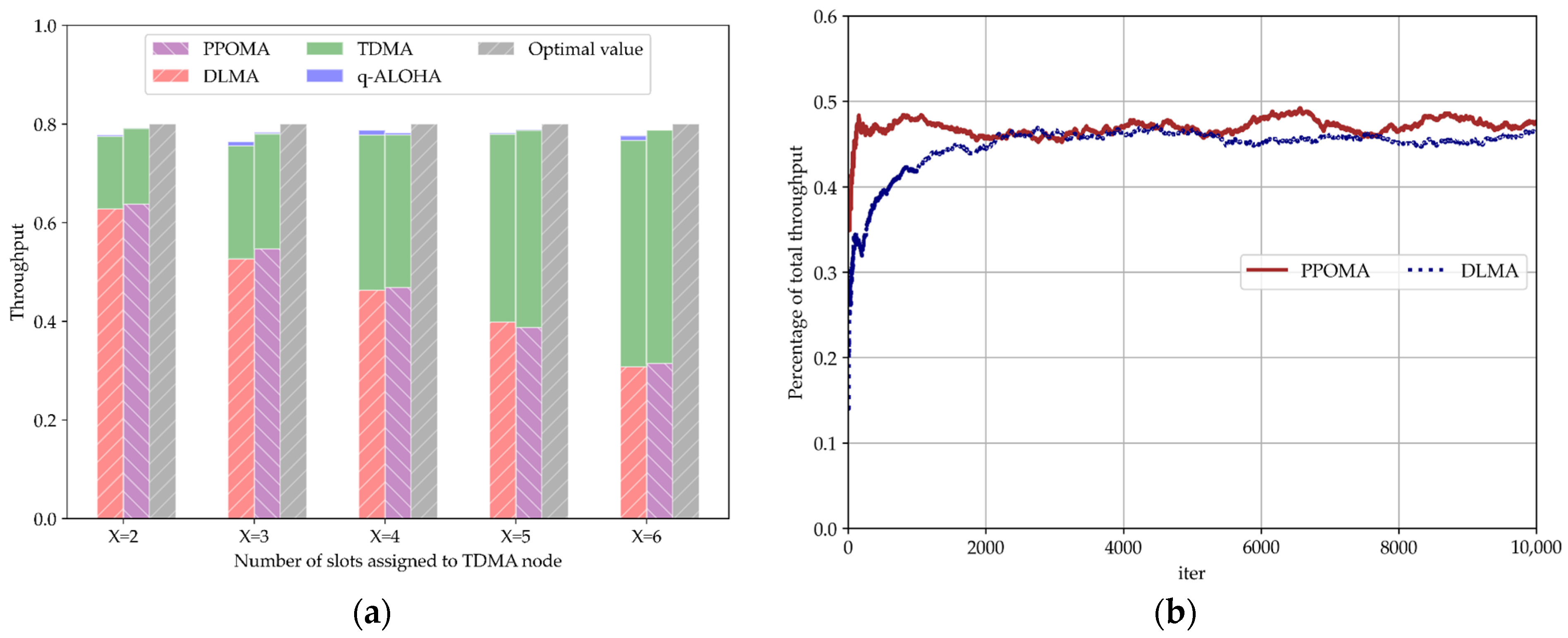
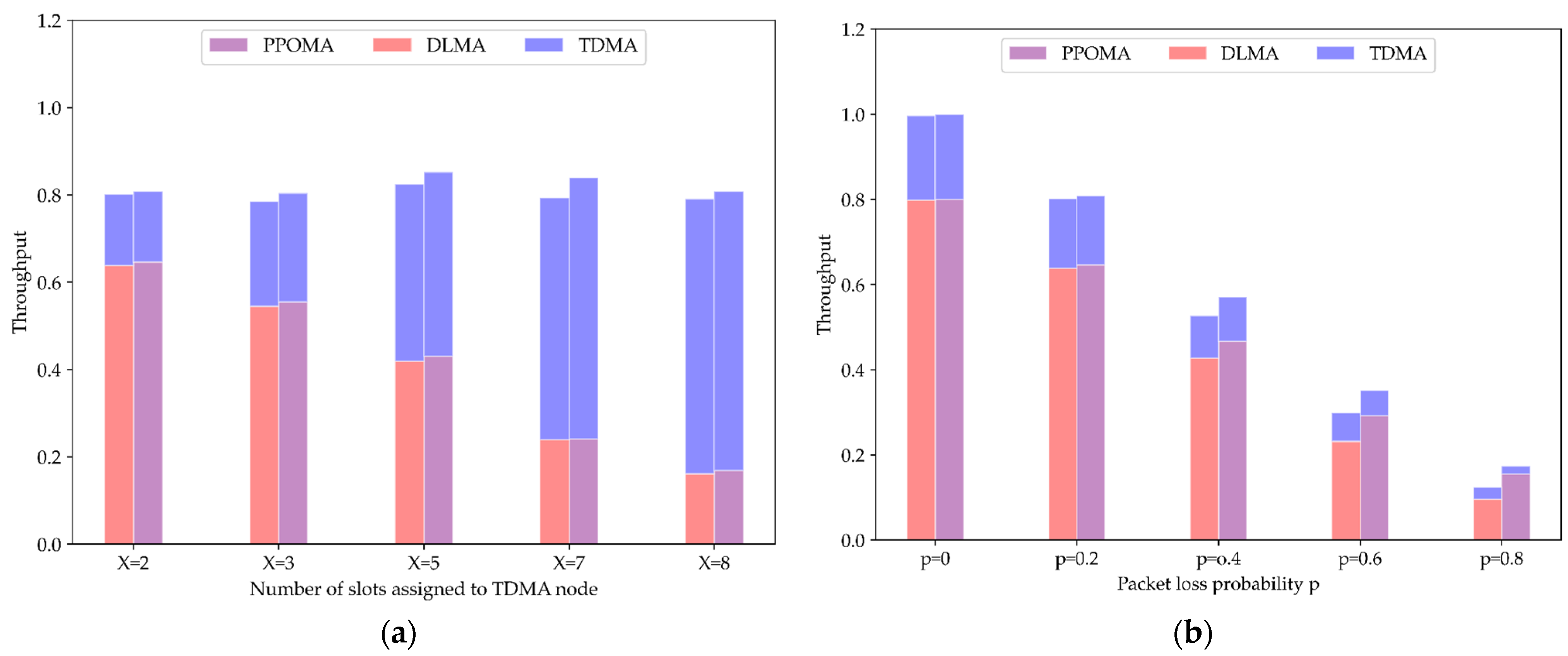
5.3.1. Coexistence of PPOMA Nodes with TDMA Nodes
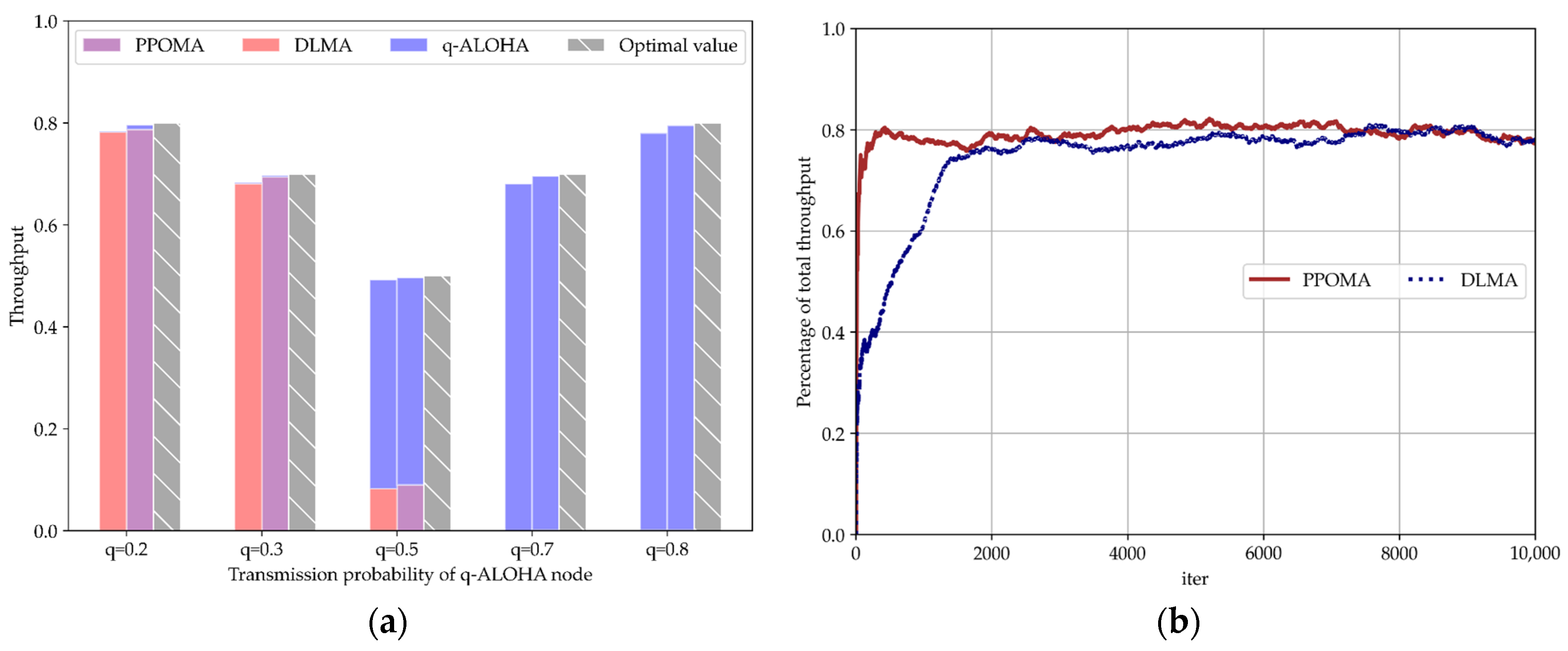
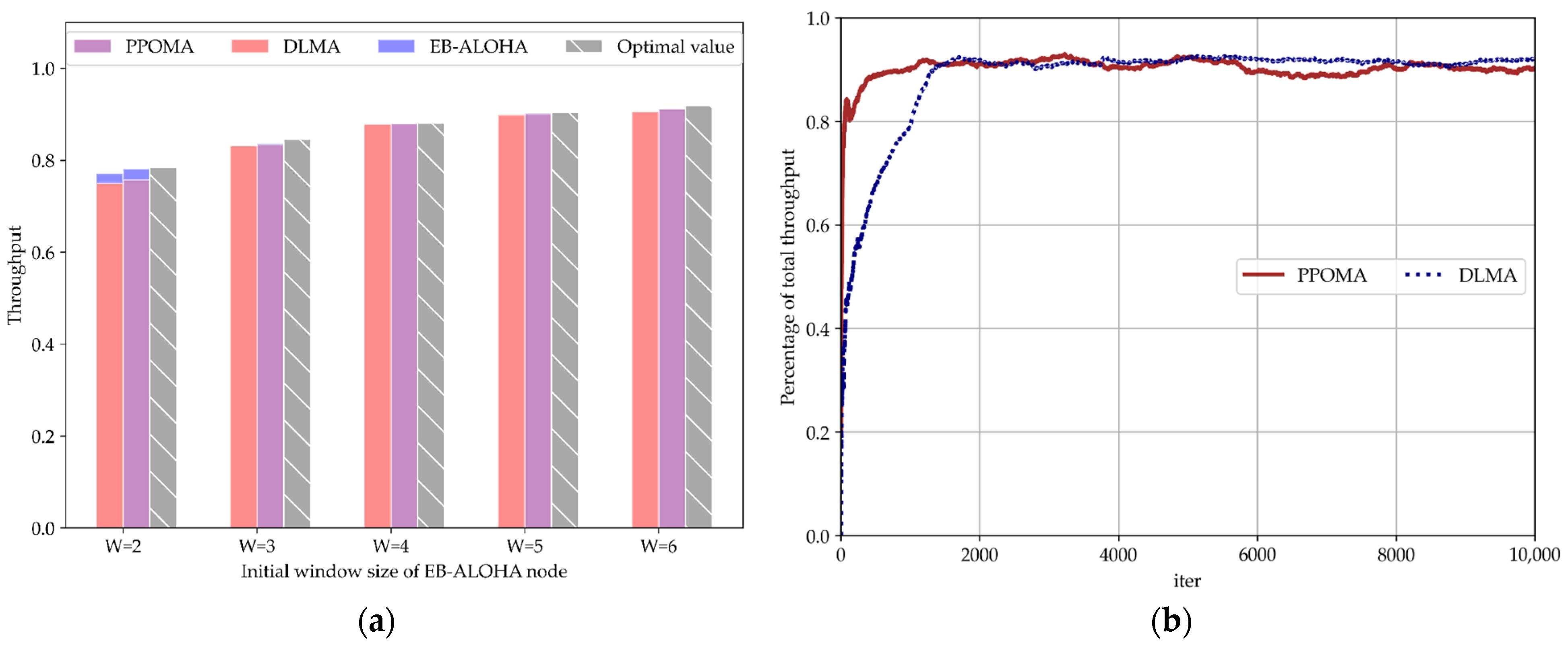
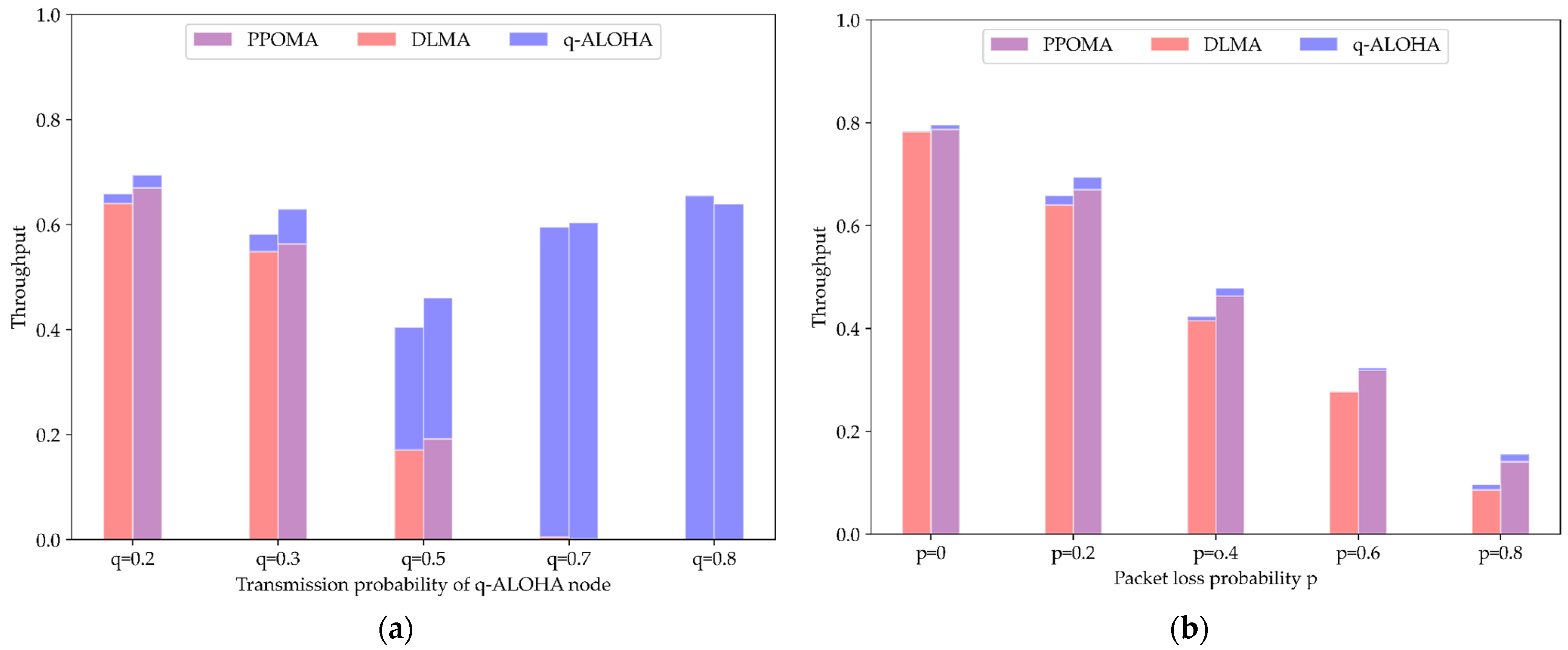
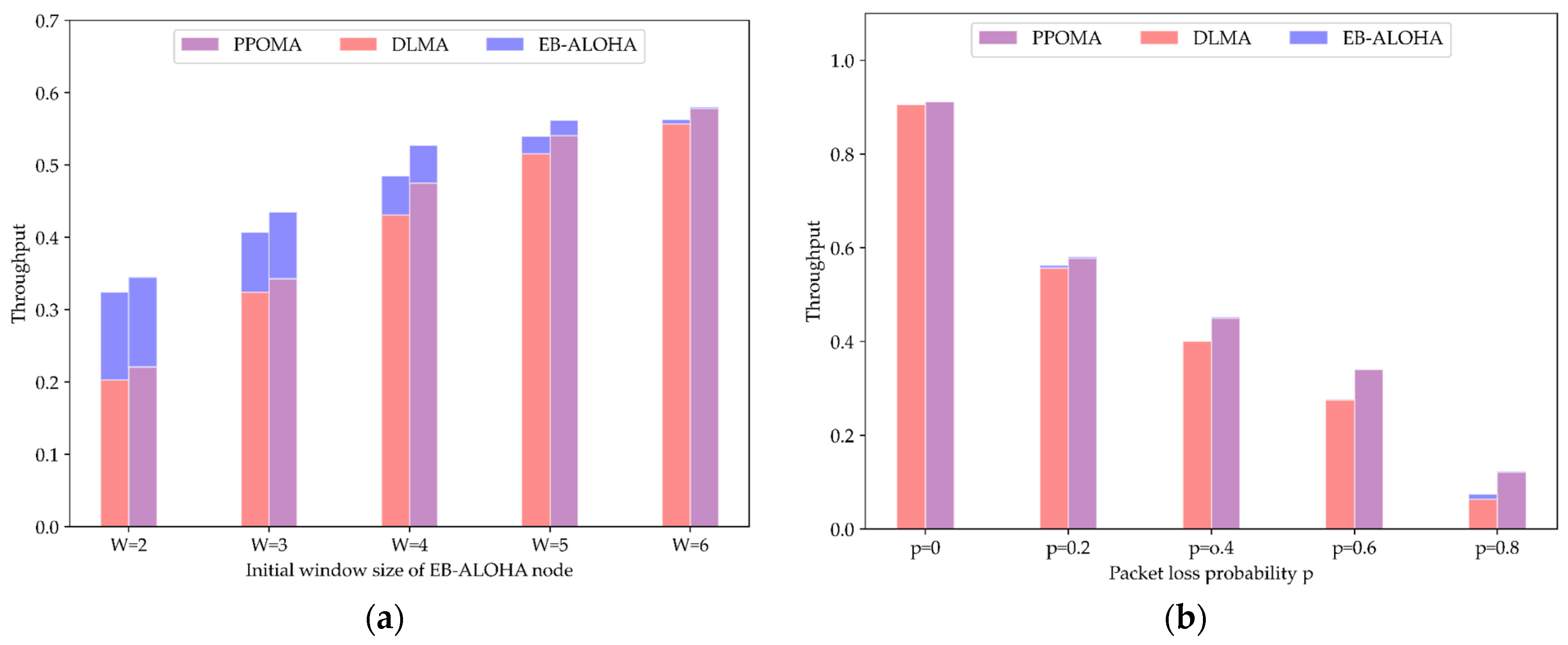
5.3.2. Coexistence of PPOMA Nodes with ALOHA Nodes
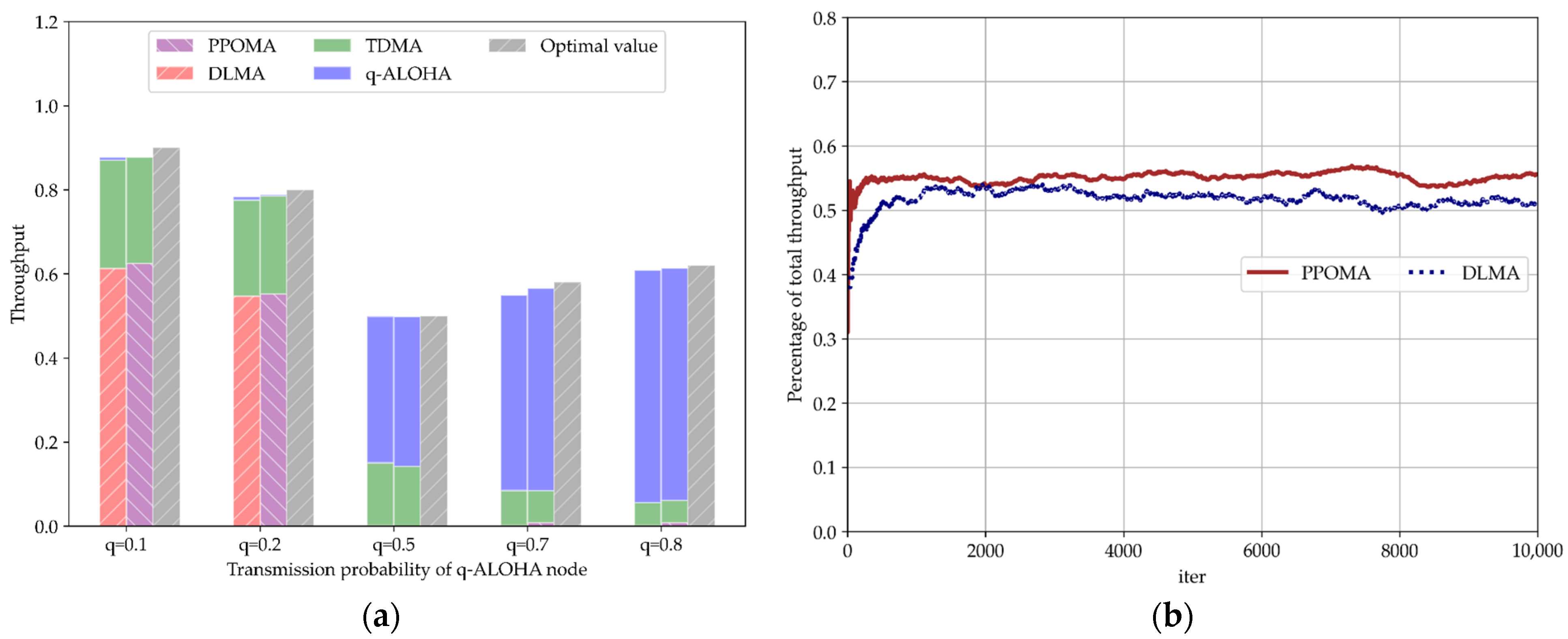
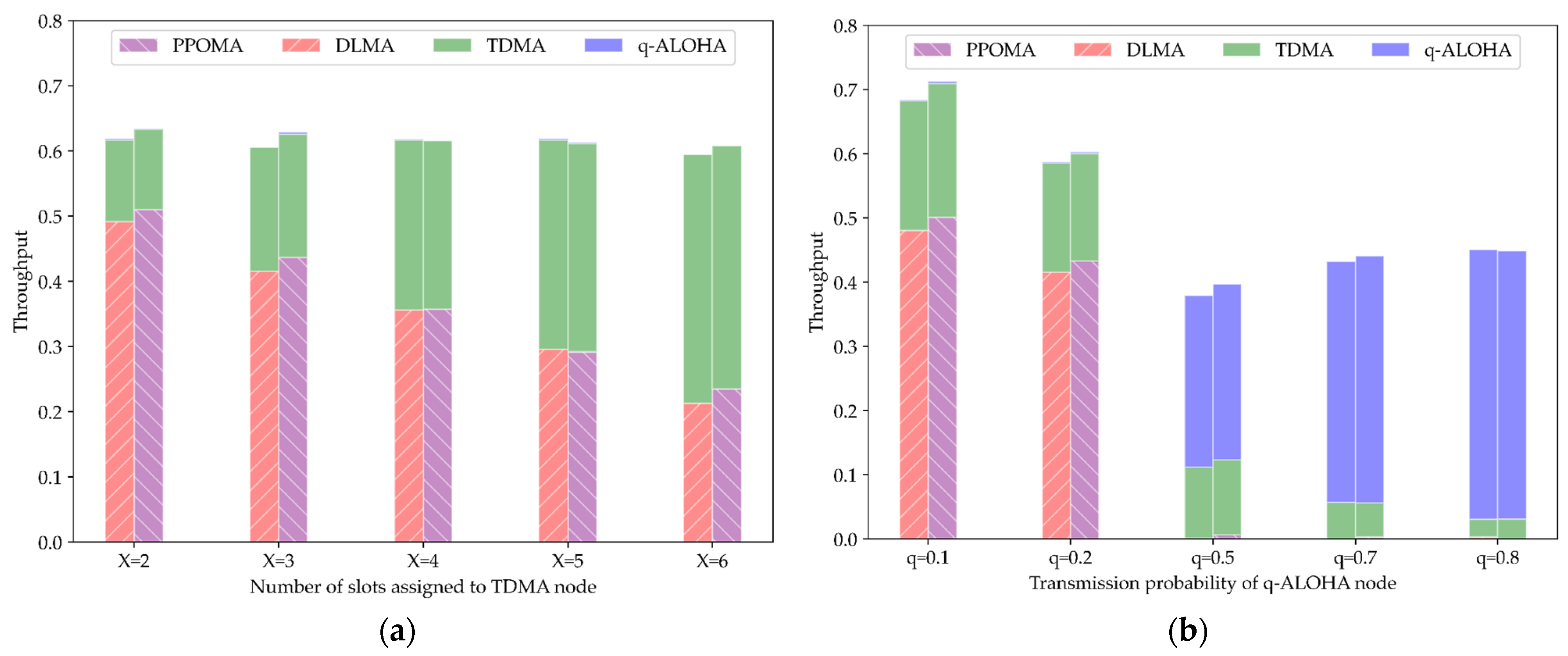
5.3.3. Coexistence of PPOMA Nodes with TDMA and ALOHA Nodes
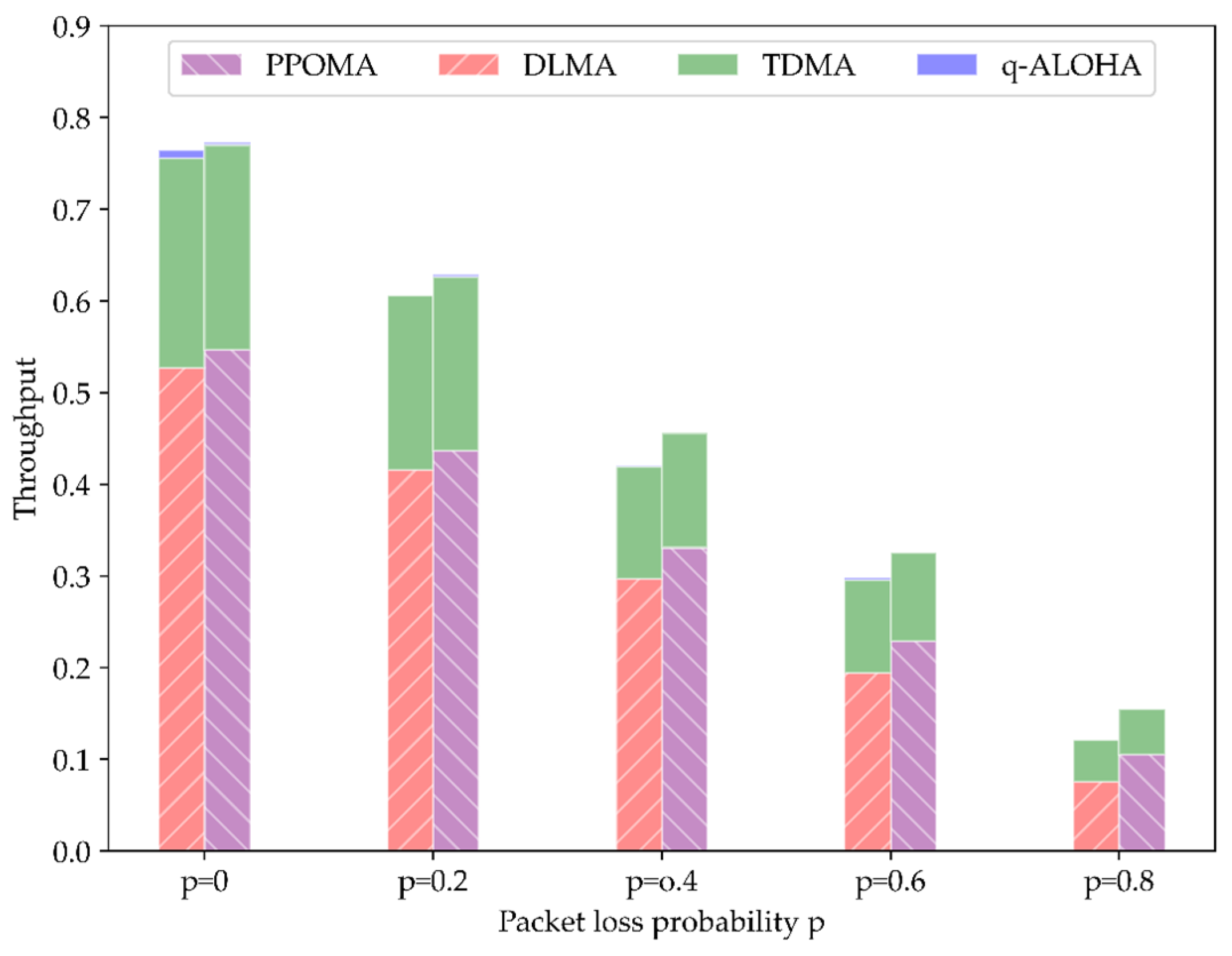
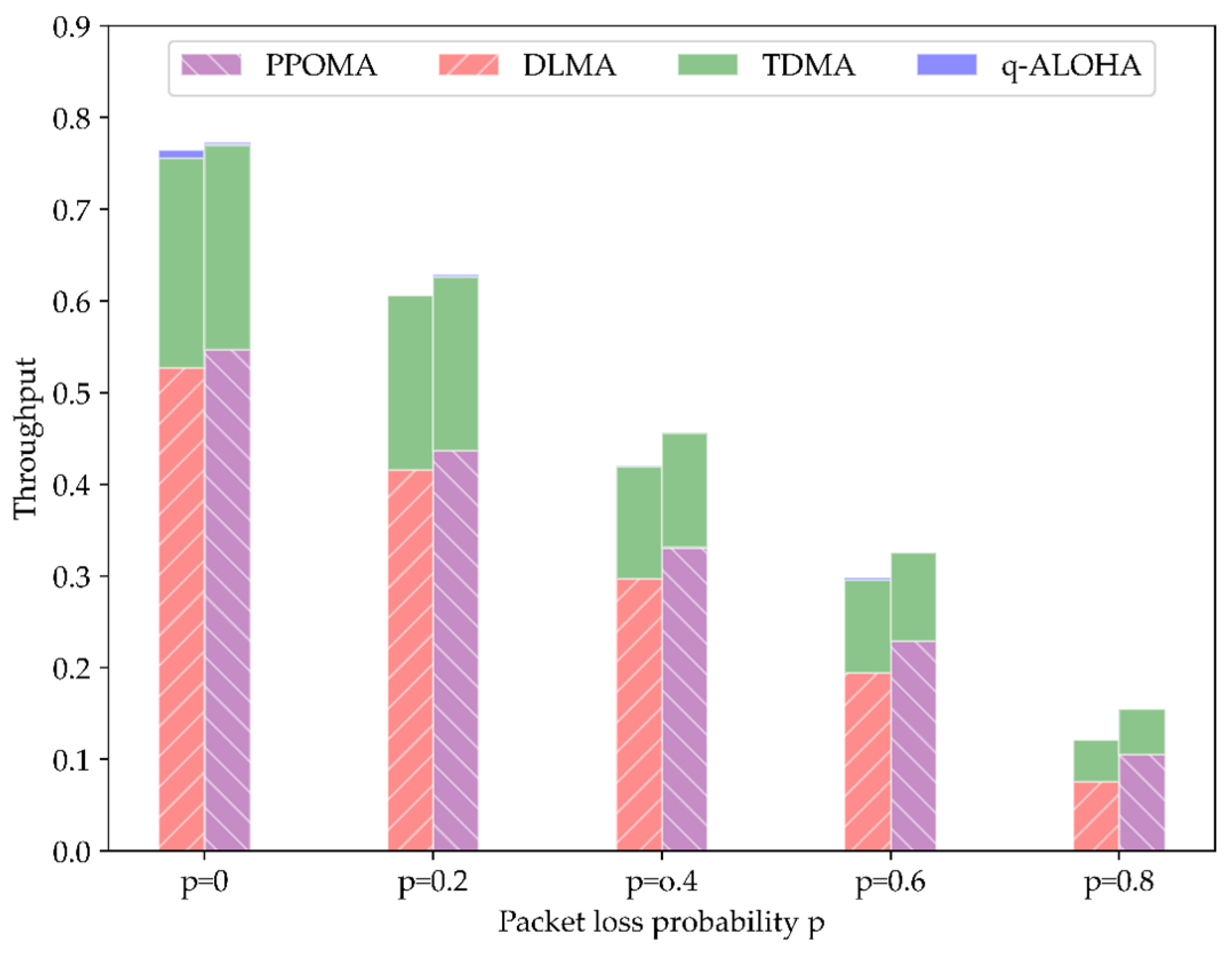
5.4. Comparison of Total Throughput under Imperfect Channel Conditions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Agiwal, M.; Roy, A.; Saxena, N. Next Generation 5G Wireless Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2016, 18, 1617–1655. [Google Scholar] [CrossRef]
- Odarchenko, R.; Iavich, M.; Iashvili, G.; Fedushko, S.; Syerov, Y. Assessment of Security KPIs for 5G Network Slices for Special Groups of Subscribers. BDCC 2023, 7, 169. [Google Scholar] [CrossRef]
- Patel, N.J.; Jadhav, A. A Systematic Review of Privacy Preservation Models in Wireless Networks. Int. J. Wirel. Microw. Technol. 2023, 13, 7–22. [Google Scholar] [CrossRef]
- Peha, J.M. Sharing Spectrum Through Spectrum Policy Reform and Cognitive Radio. Proc. IEEE 2009, 97, 708–719. [Google Scholar] [CrossRef]
- Ali, Z.; Naz, F.; Javed; Qurban, M.; Yasir, M.; Jehangir, S. Analysis of VoIP over Wired & Wireless Network with Implementation of QoS CBWFQ & 802.11e. Int. J. Comput. Netw. Inf. Secur. 2020, 12, 43–49. [Google Scholar] [CrossRef]
- Hao, H.; Wang, Y.; Shi, Y.; Li, Z.; Wu, Y.; Li, C. IoT-G: A Low-Latency and High-Reliability Private Power Wireless Communication Architecture for Smart Grid. In Proceedings of the 2019 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Beijing, China, 21–23 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-Level Control through Deep Reinforcement Learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
- Lample, G.; Chaplot, D.S. Playing FPS Games with Deep Reinforcement Learning. Proc. AAAI Conf. Artif. Intell. 2017, 31, 10827. [Google Scholar] [CrossRef]
- Zhu, P.; Dai, W.; Yao, W.; Ma, J.; Zeng, Z.; Lu, H. Multi-Robot Flocking Control Based on Deep Reinforcement Learning. IEEE Access 2020, 8, 150397–150406. [Google Scholar] [CrossRef]
- Tung, T.-Y.; Kobus, S.; Roig, J.P.; Gunduz, D. Effective Communications: A Joint Learning and Communication Framework for Multi-Agent Reinforcement Learning Over Noisy Channels. IEEE J. Sel. Areas Commun. 2021, 39, 2590–2603. [Google Scholar] [CrossRef]
- Zhang, L.; Tan, J.; Liang, Y.-C.; Feng, G.; Niyato, D. Deep Reinforcement Learning-Based Modulation and Coding Scheme Selection in Cognitive Heterogeneous Networks. IEEE Trans. Wirel. Commun. 2018, 18, 3281–3294. [Google Scholar] [CrossRef]
- Mota, M.P.; Araujo, D.C.; Costa Neto, F.H.; De Almeida, A.L.F.; Cavalcanti, F.R. Adaptive Modulation and Coding Based on Reinforcement Learning for 5G Networks. In Proceedings of the 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, M.; Wei, X.; Kwong, S.; Jia, W.; Fang, B. Rate Control Method Based on Deep Reinforcement Learning for Dynamic Video Sequences in HEVC. IEEE Trans. Multimed. 2021, 23, 1106–1121. [Google Scholar] [CrossRef]
- He, C.; Hu, Y.; Chen, Y.; Zeng, B. Joint Power Allocation and Channel Assignment for NOMA with Deep Reinforcement Learning. IEEE J. Sel. Areas Commun. 2019, 37, 2200–2210. [Google Scholar] [CrossRef]
- Lei, W.; Ye, Y.; Xiao, M. Deep Reinforcement Learning-Based Spectrum Allocation in Integrated Access and Backhaul Networks. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 970–979. [Google Scholar] [CrossRef]
- Xiong, X.; Zheng, K.; Lei, L.; Hou, L. Resource Allocation Based on Deep Reinforcement Learning in IoT Edge Computing. IEEE J. Sel. Areas Commun. 2020, 38, 1133–1146. [Google Scholar] [CrossRef]
- Huang, J.; Yang, Y.; He, G.; Xiao, Y.; Liu, J. Deep Reinforcement Learning-Based Dynamic Spectrum Access for D2D Communication Underlay Cellular Networks. IEEE Commun. Lett. 2021, 25, 2614–2618. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X.; Wan, P.; Shao, R. Intelligent Dynamic Spectrum Access Using Deep Reinforcement Learning for VANETs. IEEE Sens. J. 2021, 21, 15554–15563. [Google Scholar] [CrossRef]
- Zheng, Z.; Jiang, S.; Feng, R.; Ge, L.; Gu, C. Survey of Reinforcement-Learning-Based MAC Protocols for Wireless Ad Hoc Networks with a MAC Reference Model. Entropy 2023, 25, 101. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, T.; Liew, S. Deep-Reinforcement Learning Multiple Access for Heterogeneous Wireless Networks. IEEE J. Sel. Areas Commun. 2019, 37, 1277–1290. [Google Scholar] [CrossRef]
- Yu, Y.; Liew, S.C.; Wang, T. Multi-Agent Deep Reinforcement Learning Multiple Access for Heterogeneous Wireless Networks with Imperfect Channels. IEEE Trans. Mob. Comput. 2022, 21, 3718–3730. [Google Scholar] [CrossRef]
- Kaur, A.; Thakur, J.; Thakur, M.; Kumar, K.; Prakash, A.; Tripathi, R. Deep Recurrent Reinforcement Learning-Based Distributed Dynamic Spectrum Access in Multichannel Wireless Networks with Imperfect Feedback. IEEE Trans. Cogn. Commun. Netw. 2023, 9, 281–292. [Google Scholar] [CrossRef]
- Naparstek, O.; Cohen, K. Deep Multi-User Reinforcement Learning for Dynamic Spectrum Access in Multichannel Wireless Networks. In Proceedings of the GLOBECOM 2017—2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, J.; Headley, W.C.; Buehrer, R.M. Deep Reinforcement Learning for Dynamic Spectrum Access in Wireless Networks. In Proceedings of the MILCOM 2018—2018 IEEE Military Communications Conference (MILCOM), Los Angeles, CA, USA, 29–31 October 2018; pp. 207–212. [Google Scholar] [CrossRef]
- Chang, H.-H.; Song, H.; Yi, Y.; Zhang, J.; He, H.; Liu, L. Distributive Dynausingmic Spectrum Access Through Deep Reinforcement Learning: A Reservoir Computing-Based Approach. IEEE Internet Things J. 2018, 6, 1938–1948. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, P.; Yu, G.; Wang, S. Deep Reinforcement Learning Heterogeneous Channels for Poisson Multiple Access. Mathematics 2023, 11, 992. [Google Scholar] [CrossRef]
- Ma, R.T.B.; Misra, V.; Rubenstein, D. An Analysis of Generalized Slotted-Aloha Protocols. IEEEACM Trans. Netw. 2009, 17, 936–949. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning, Second Edition: An Introduction; MIT Press: Cambridge, MA, USA, 2018; ISBN 978-0-262-35270-3. [Google Scholar]
- Grondman, I.; Busoniu, L.; Lopes, G.A.D.; Babuska, R. A Survey of Actor-Critic Reinforcement Learning: Standard and Natural Policy Gradients. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 1291–1307. [Google Scholar] [CrossRef]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust Region Policy Optimization. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 1 June 2015; pp. 1889–1897. [Google Scholar] [CrossRef]
- Keras: Deep Learning for Humans. Available online: https://keras.io/ (accessed on 19 October 2023).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, T.; Liew, S.C. Model-Aware Nodes in Heterogeneous Networks. Available online: https://github.com/YidingYu/DLMA/blob/master/DLMA-benchmark.pdf (accessed on 15 October 2023).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameters | Value |
|---|---|
| state history length | 20 |
| learning rate in Adam optimizer | 0.001 |
| target network update frequency F | 10 |
| target network update weight w | 0.9 |
| discount factor | 0.99 |
| value in the Clip function ε | 0.2 |
| number of training batches B | 10 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Y.; Lou, J.; Wang, T.; Shi, J.; Zhang, T.; Paul, A.; Wu, Z. Multiple Access for Heterogeneous Wireless Networks with Imperfect Channels Based on Deep Reinforcement Learning. Electronics 2023, 12, 4845. https://doi.org/10.3390/electronics12234845
Xu Y, Lou J, Wang T, Shi J, Zhang T, Paul A, Wu Z. Multiple Access for Heterogeneous Wireless Networks with Imperfect Channels Based on Deep Reinforcement Learning. Electronics. 2023; 12(23):4845. https://doi.org/10.3390/electronics12234845
Chicago/Turabian StyleXu, Yangzhou, Jia Lou, Tiantian Wang, Junxiao Shi, Tao Zhang, Agyemang Paul, and Zhefu Wu. 2023. "Multiple Access for Heterogeneous Wireless Networks with Imperfect Channels Based on Deep Reinforcement Learning" Electronics 12, no. 23: 4845. https://doi.org/10.3390/electronics12234845
APA StyleXu, Y., Lou, J., Wang, T., Shi, J., Zhang, T., Paul, A., & Wu, Z. (2023). Multiple Access for Heterogeneous Wireless Networks with Imperfect Channels Based on Deep Reinforcement Learning. Electronics, 12(23), 4845. https://doi.org/10.3390/electronics12234845