
Research on a High-Performance Rock Image Classification Method


Abstract
:1. Introduction
2. Related Work
2.1. Target Object Positioning
2.2. Learning More Discriminating Features
3. Method
3.1. Object Positioning
3.2. Part Comparison Learning
3.3. Model Training Optimization
3.4. Knowledge Distillation Training Optimization
4. Experiments and Discussions
4.1. Datasets and Implementation Details
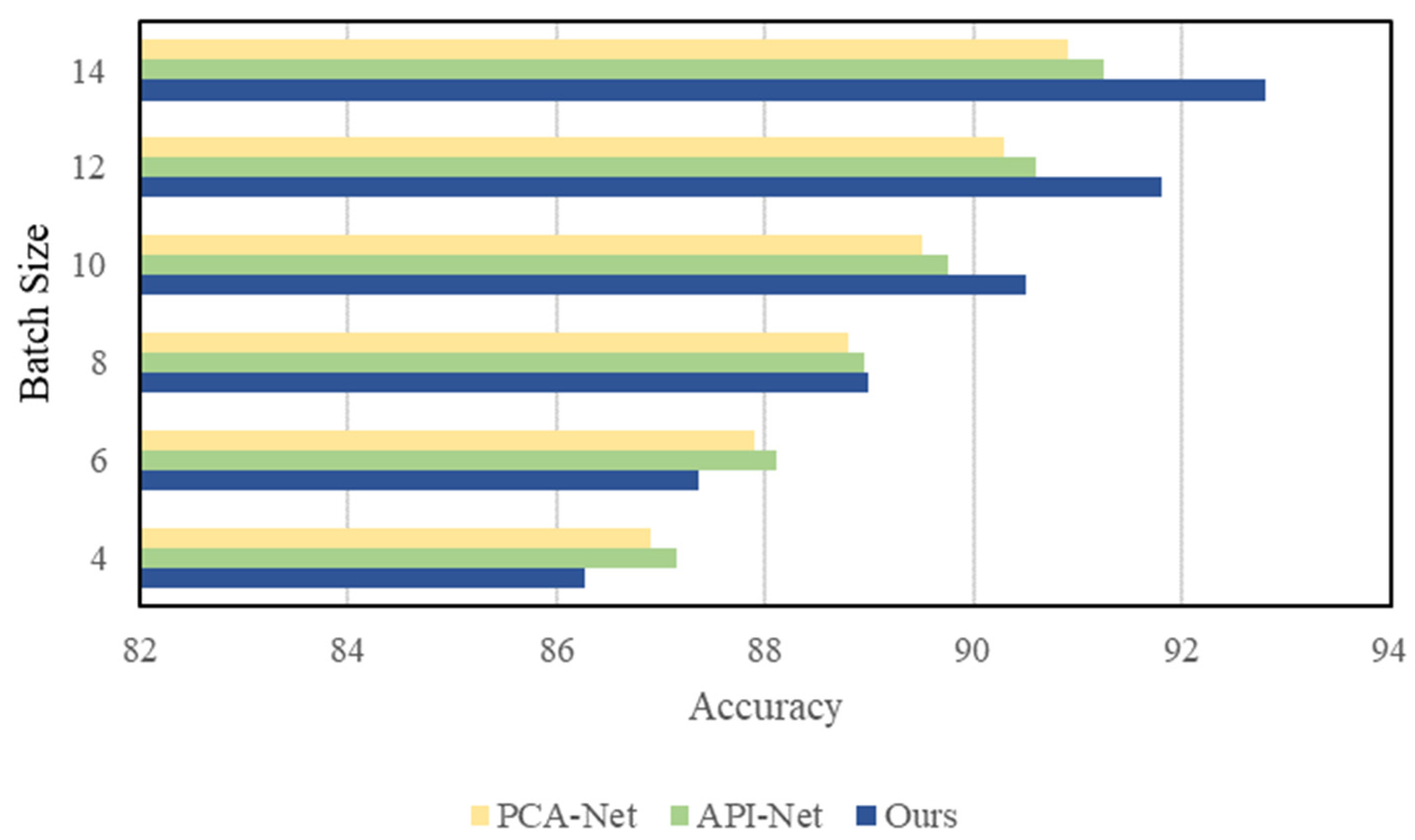
4.2. Experimental Results
4.3. Ablation Study
4.4. Visualization
4.5. Small Model Distillation Effect
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chatterjee, S. Vision-based rock-type classification of limestone using multi-class support vector machine. Appl. Intell. 2013, 39, 14–27. [Google Scholar] [CrossRef]
- Deng, C.; Pan, H.; Fang, S.; Konaté, A.A.; Qin, R. Support vector machine as an alternative method for lithology classification of crystalline rocks. J. Geophys. Eng. 2017, 14, 341–349. [Google Scholar] [CrossRef]
- Perez, C.A.; Saravia, J.A.; Navarro, C.F.; Schulz, D.A.; Aravena, C.M.; Galdames, F.J. Rock lithological classification using multi-scale Gabor features from sub-images, and voting with rock contour information. Int. J. Miner. Process. 2015, 144, 56–64. [Google Scholar] [CrossRef]
- Liang, Y.; Cui, Q.; Luo, X.; Xie, Z. Research on Classification of Fine-Grained Rock Images Based on Deep Learning. Comput. Intell. Neurosci. 2021, 2021, 5779740. [Google Scholar]
- Guojian, C.; Peisong, L. Rock thin-section image classification based on residual neural network. In Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 9–11 April 2021; pp. 521–524. [Google Scholar]
- Pascual, A.; Lei, S.; Szoke-Sieswerda, J.; Mcisaac, K.; Osinski, G. Towards natural scene rock image classification with convolutional neural networks. In Proceedings of the 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019; pp. 1–4. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Baboo; Santhosh, S.; Devi, M.R. An analysis of different resampling methods in Coimbatore, District. Glob. J. Comput. Sci. Technol. 2010, 10, 61–66. [Google Scholar]
- Yan, J.; Lin, S.; Kang, S.B.; Tang, X. Learning the change for automatic image cropping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Zhao, G.; Cai, Z.; Wang, X.; Dang, X. GAN Data Augmentation Methods in Rock Classification. Appl. Sci. 2023, 13, 5316. [Google Scholar] [CrossRef]
- Zin, T.T.; Tin, P.; Toriu, T.; Hama, H. Background modeling using special type of Markov Chain. IEICE Electron. Express 2011, 8, 1082–1088. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Lin, D.; Shen, X.; Lu, C.; Jia, J. Deep LAC: Deep localization, alignment and classification for fine-grained recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7–12 June 2015; pp. 1666–1674. [Google Scholar]
- Zhang, N.; Donahue, J.; Girshick, R.B.; Darrell, T. Part-based R-CNNs for fine-grained category detection. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 1173–1182. [Google Scholar]
- Zhang, H.; Xu, T.; Elhoseiny, M.; Huang, X.; Zhang, S.; Elgammal, A.; Metaxas, D. SPDA-CNN: Unifying semantic part detection and abstraction for fine-grained recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 1143–1152. [Google Scholar]
- Huang, S.; Xu, Z.; Tao, D.; Zhang, Y. Part-stacked CNN for fine-grained visual categorization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 1173–1182. [Google Scholar]
- Uijlings, J.; van de Sande, K.; Gevers, T.; Smeulders, A. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Fu, J.; Zheng, H.; Mei, T. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar]
- Zheng, H.; Fu, J.; Mei, T.; Luo, J. Learning multi-attention convolutional neural network for fine-grained image recognition. In Proceedings of the ICCV, Venice, Italy, 22–29 October 2017; pp. 5209–5217. [Google Scholar]
- Ding, Y.; Zhou, Y.; Zhu, Y.; Ye, Q.; Jiao, J. Selective sparse sampling for fine-grained image recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6599–6608. [Google Scholar]
- Zhang, F.; Li, M.; Zhai, G.; Liu, Y. Multi-branch and multi-scale attention learning for fine-grained visual categorization. In Proceedings of the MultiMedia Modeling: 27th International Conference, MMM 2021, Prague, Czech Republic, 22–24 June 2021; pp. 136–147. [Google Scholar]
- Lin, T.Y.; RoyChowdhury, A.; Maji, S. Bilinear CNN models for fine-grained visual recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1449–1457. [Google Scholar]
- Ji, R.; Li, J.; Zhang, L. Siamese self-supervised learning for fine-grained visual classification. Comput. Vis. Image Underst. 2023, 229, 103658. [Google Scholar] [CrossRef]
- Gao, Y.; Han, X.; Wang, X.; Huang, W.; Scott, M. Channel interaction networks for fine-grained image categorization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10818–10825. [Google Scholar]
- Chen, Y.; Bai, Y.; Zhang, W.; Mei, T. Progressive co-attention network for fine-grained visual classification. In Proceedings of the 2021 International Conference on Visual Communications and Image Processing (VCIP), Munich, Germany, 5–8 December 2021; pp. 1–5. [Google Scholar]
- Zhuang, P.; Wang, Y.; Qiao, Y. Learning attentive pairwise interaction for fine-grained classification. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34. [Google Scholar]
- Chen, J.; Li, H.; Liang, J.; Su, X.; Zhai, Z.; Chai, X. Attention-based cropping and erasing learning with coarse-to-fine refinement for fine-grained visual classification. Neurocomputing 2022, 501, 359–369. [Google Scholar] [CrossRef]
- Rao, Y.; Chen, G.; Lu, J.; Zhou, J. Counterfactual attention learning for fine-grained visual categorization and re-identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1025–1034. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.0253. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y.U. A discriminative feature learning approach for deep face recognition. In Proceedings of the ECCV, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Ramprasaath; Selvaraju, R.; Cogswell, M.; Das, A.; Vedantam, R.; DeviParikh; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Rock Type | Number |
|---|---|
| dolomite | 7924 |
| marble | 11,658 |
| basalt | 19,678 |
| Basic Model | Train Acc@1 (%) | Test Acc@1 (%) | Backbone |
|---|---|---|---|
| AlexNet | 96.8 | 73.1 | |
| LeNet | 50.1 | 50.5 | |
| GoogLeNet | 86.6 | 76.3 | |
| VGG16 | 76.1 | 72.3 | |
| ResNet-50 | 79.6 | 72.4 | |
| Fine-Grained Model | |||
| Bilinear CNN (2015) | 85.4 | 85.3 | VGG16 |
| PCA-Net (2021) | 94.9 | 90.8 | ResNet-101 |
| API-Net (2020) | 99.8 | 91.2 | ResNet-101 |
| MMAL-Net (2021) | 99.7 | 91.9 | ResNet-50 |
| Ours | 99.8 | 93.1 | ResNet-101 |
| Area Mask | Center Loss | Area Scale () | Acc@1 (%) |
|---|---|---|---|
| √ | 92.0 | ||
| √ | 91.2 | ||
| √ | √ | 92.2 | |
| √ | √ | 92.8 | |
| √ | √ | √ | 93.1 |
| Models | Params | FLOPs | Inference Time (ms) | ACC@1 (%) Baseline | Acc@1 (%) Distilled | |
|---|---|---|---|---|---|---|
| (Teacher) | FPCN | 46.06 M | 28,210 M | 13.98 | 93.1 | |
| (Student) | ResNet18 | 11.89 M | 7294 M | 2.61 | 73.8 | 74.7 (+0.9) |
| (Student) | ResNet34 | 22.00 M | 14,713 M | 5.63 | 74.7 | 76.1 (+1.4) |
| (Student) | ResNet50 | 25.76 M | 16,529 M | 7.50 | 76.5 | 77.1 (+0.6) |
| (Student) | MobileNetV1 | 4.2 M | 1080 M | 0.82 | 68.7 | 71.1 (+2.4) |
| (Student) | MobileNetV2 | 3.4 M | 1080 M | 0.64 | 70.9 | 73.5 (+2.6) |
| (Student) | ShuffleNet(V2) | 3.4 M | 947 M | 0.73 | 70.5 | 73.6 (+3.1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, M.; Gui, Z.; Gao, Z. Research on a High-Performance Rock Image Classification Method. Electronics 2023, 12, 4805. https://doi.org/10.3390/electronics12234805
Ma M, Gui Z, Gao Z. Research on a High-Performance Rock Image Classification Method. Electronics. 2023; 12(23):4805. https://doi.org/10.3390/electronics12234805
Chicago/Turabian StyleMa, Mingshuo, Zhiming Gui, and Zhenji Gao. 2023. "Research on a High-Performance Rock Image Classification Method" Electronics 12, no. 23: 4805. https://doi.org/10.3390/electronics12234805
APA StyleMa, M., Gui, Z., & Gao, Z. (2023). Research on a High-Performance Rock Image Classification Method. Electronics, 12(23), 4805. https://doi.org/10.3390/electronics12234805