
MFM: A Multiple-Features Model for Leisure Event Recommendation in Geotagged Social Networks


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Literature Review
2.1. Event-Based Recommendation Methods
2.2. Solution to Cold-Start Problems in EBSNs
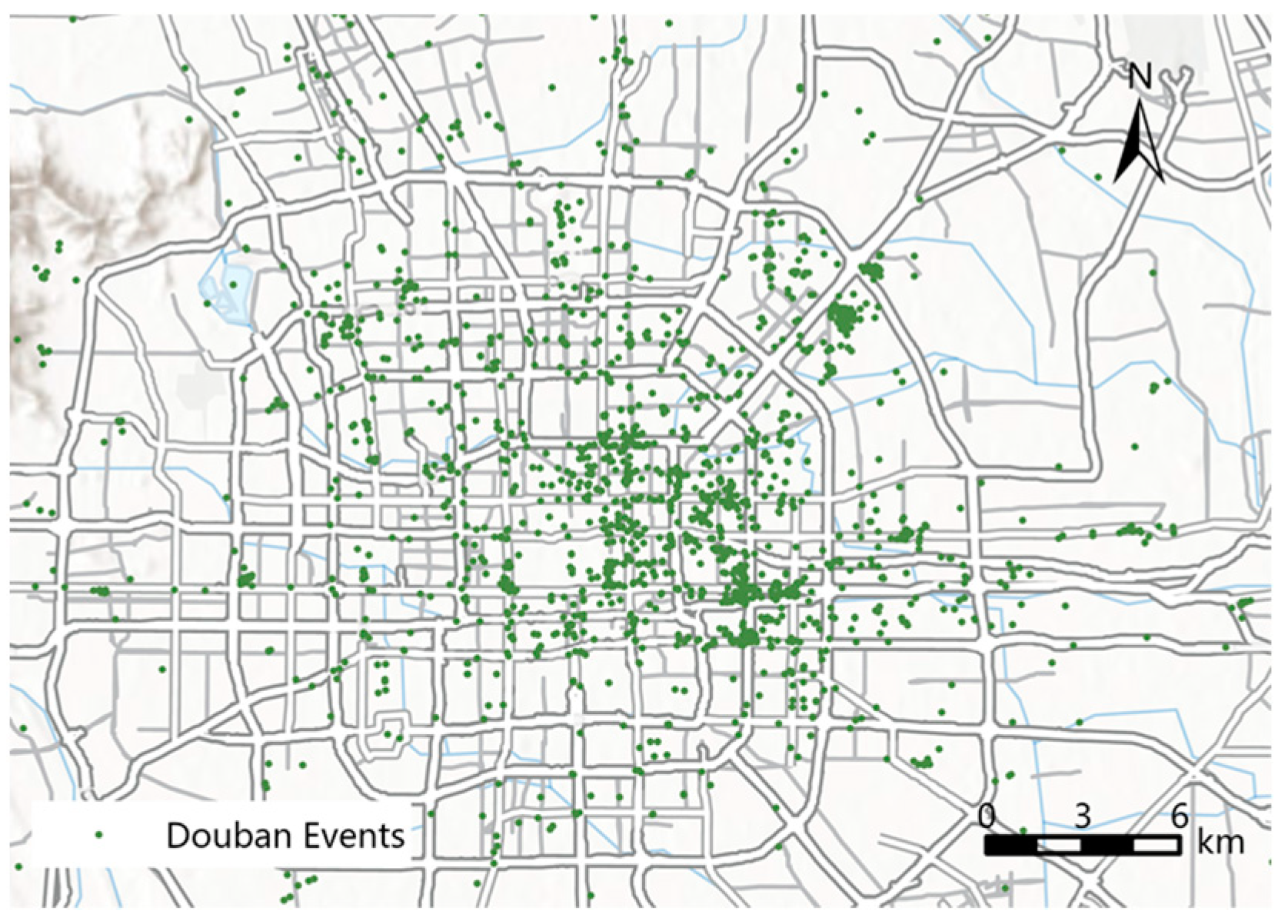
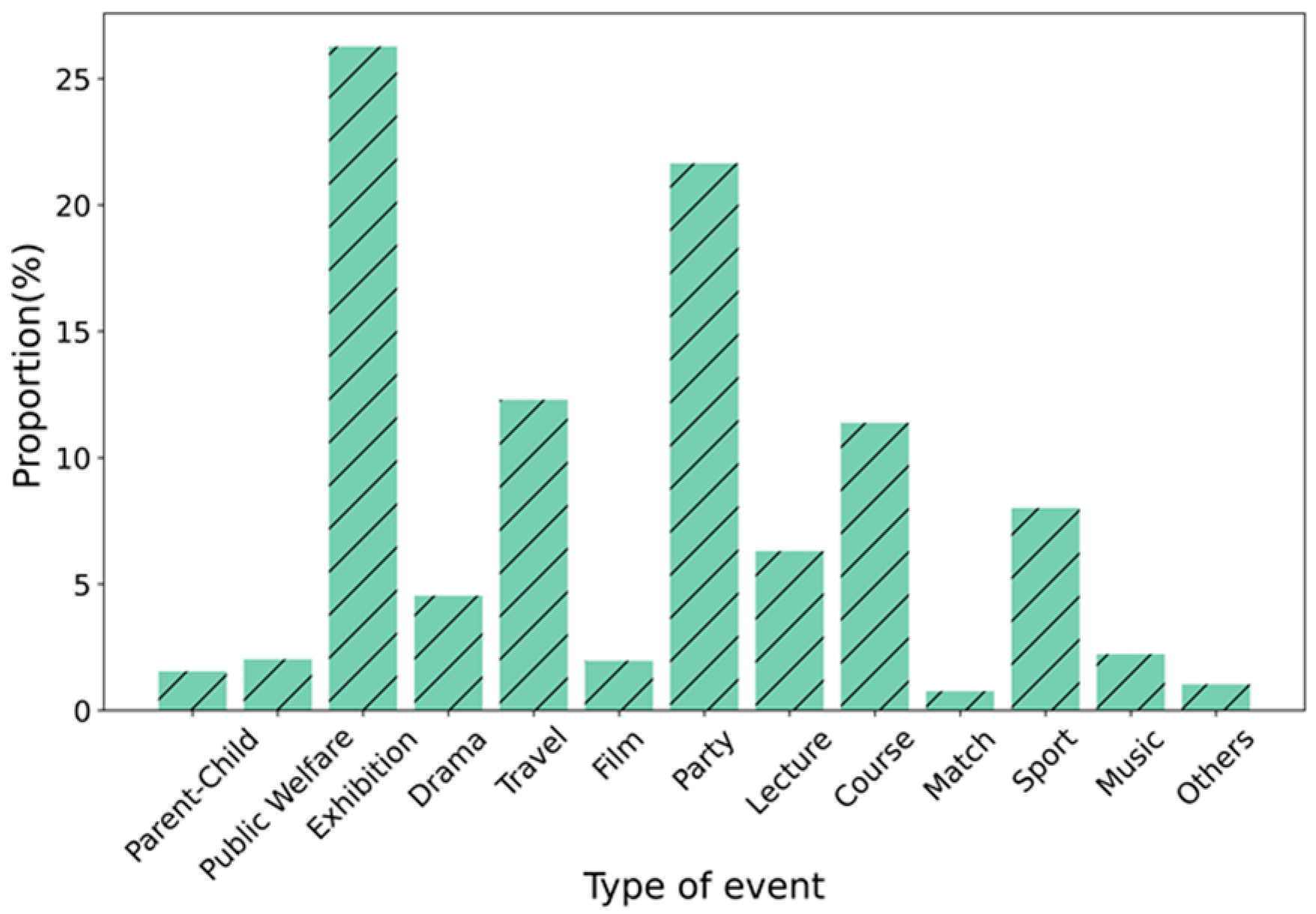
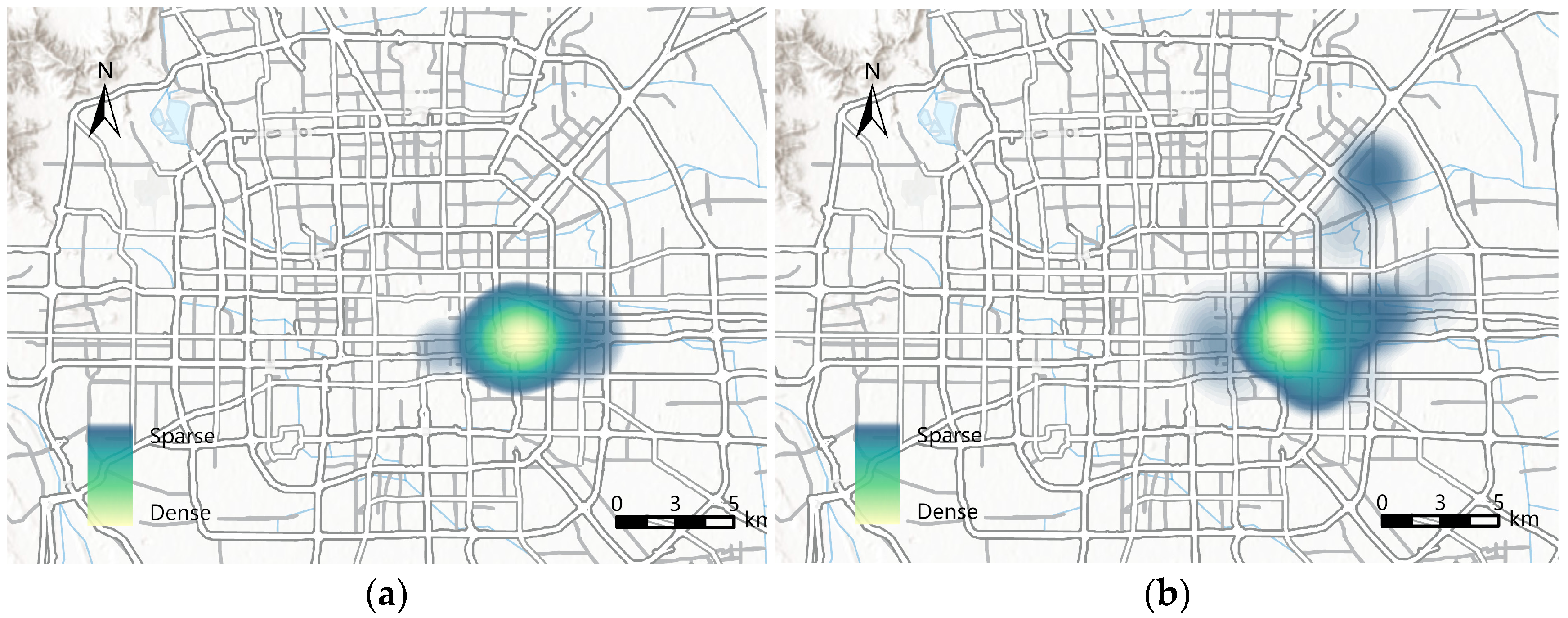
3. Research Datasets
3.1. Data Acquisition and Preprocessing
3.2. Data Characteristics
4. Methodology
4.1. Problem Definition
4.2. Model Overview
4.3. User Preference Modelling
4.3.1. User Preference for Event
- Content
- (1)
- Type features
- (2)
- Text features
- 2.
- Context
- (1)
- Weekday feature
- (2)
- Day-hour feature
- (3)
- Spatial location features
- (4)
- Cost features
4.3.2. User Preference for Organizer
4.3.3. Event Preferences of the User’s Closest Friends
4.4. Model Training
| Algorithm 1. Training algorithm. |
| Input: |
| Output: |
| Foreach (,) in Do //Please refer to the text above for the meaning of each variable. |
| Extract ( from |
| ForeachinDo |
| End Foreach |
| Extractfrom |
| Extractfrom |
| ForeachinDo |
| = sum |
| End Foreach |
| = /5 |
| Add (,,,) to |
| End Foreach |
4.5. Prediction
| Algorithm 2. Prediction algorithm. |
| Input: |
| Output: |
| Foreach in Do //Please refer to the text above for the meaning of each variable. |
Foreach
in
 Do
Do |
| Extract from |
| Extract from |
| Foreach in Do |
| = sum |
| End Foreach |
| = /5 |
| = |
| Add to |
| End Foreach |
| End Foreach |
| = LFM |
| Foreach in Do |
| = topK |
| End Foreach |
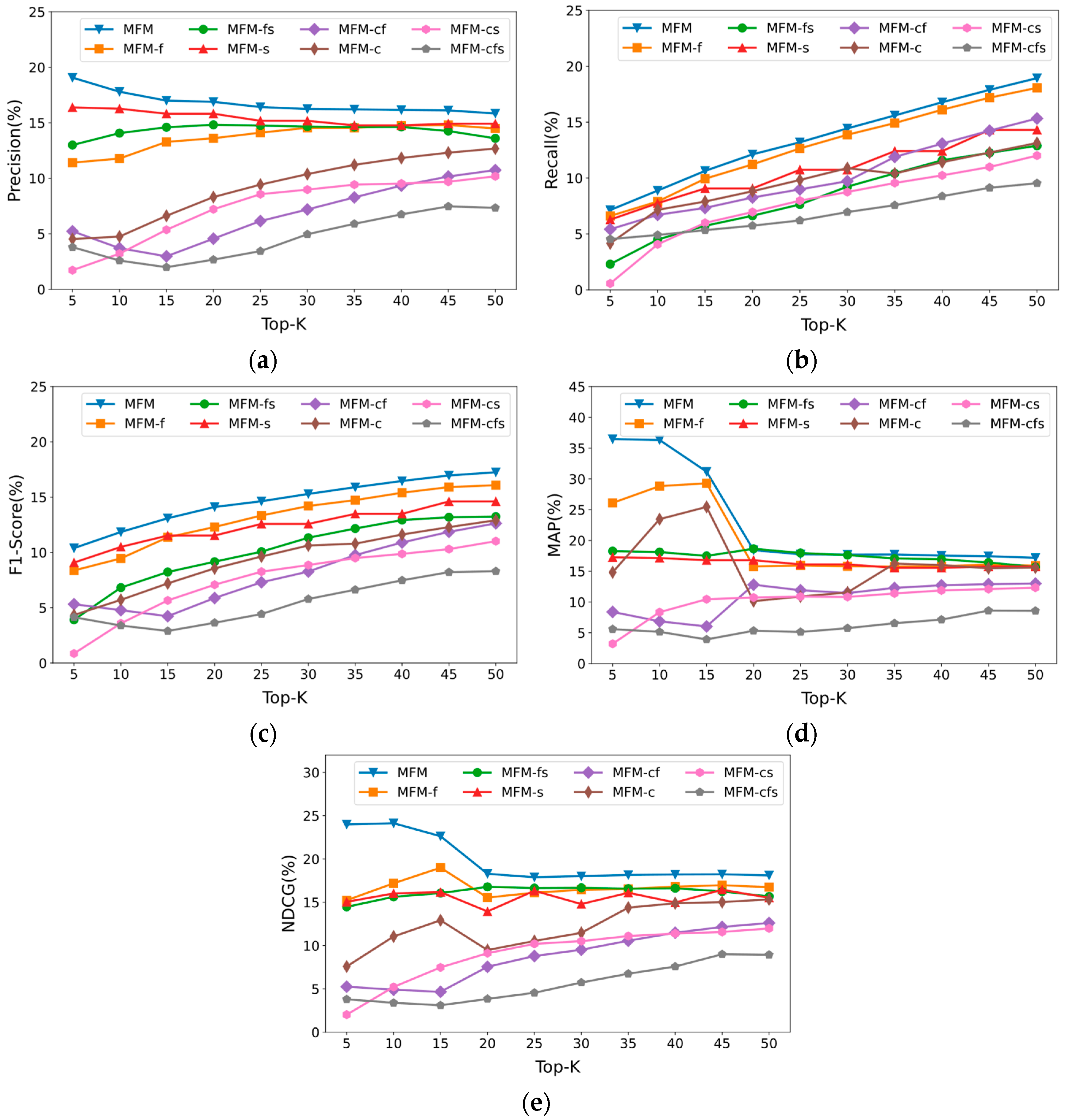
5. Experimental Evaluation and Discussion
5.1. Evaluation Metric
5.2. Performance Evaluation
- MP: The MP algorithm is a baseline model that evaluates user activity based on the number of events attended by a user. It considers this as an indicator of user activity and recommends the most recently active users to the target event. By prioritizing users who have recently attended many events, the MP algorithm aims to recommend users who are actively engaged in the system.
- LBTM: The location-based topic model [51] extracts the users’ content and spatial and temporal preference features from their historical events to search for historical events similar to the target event. It then calculates the preference scores of users who participated in these historical events for the target event based on the time similarity between the historical events and the target event. Finally, it recommends the users with the highest score for the target event.
- COBM: The context- and organizer-based model [31] is designed to solve the cold-start problem of new published events. It extracts the users’ content interest and geographical preference from the events the user has participated in and combines the influence of the event organizer for generating the recommendation.
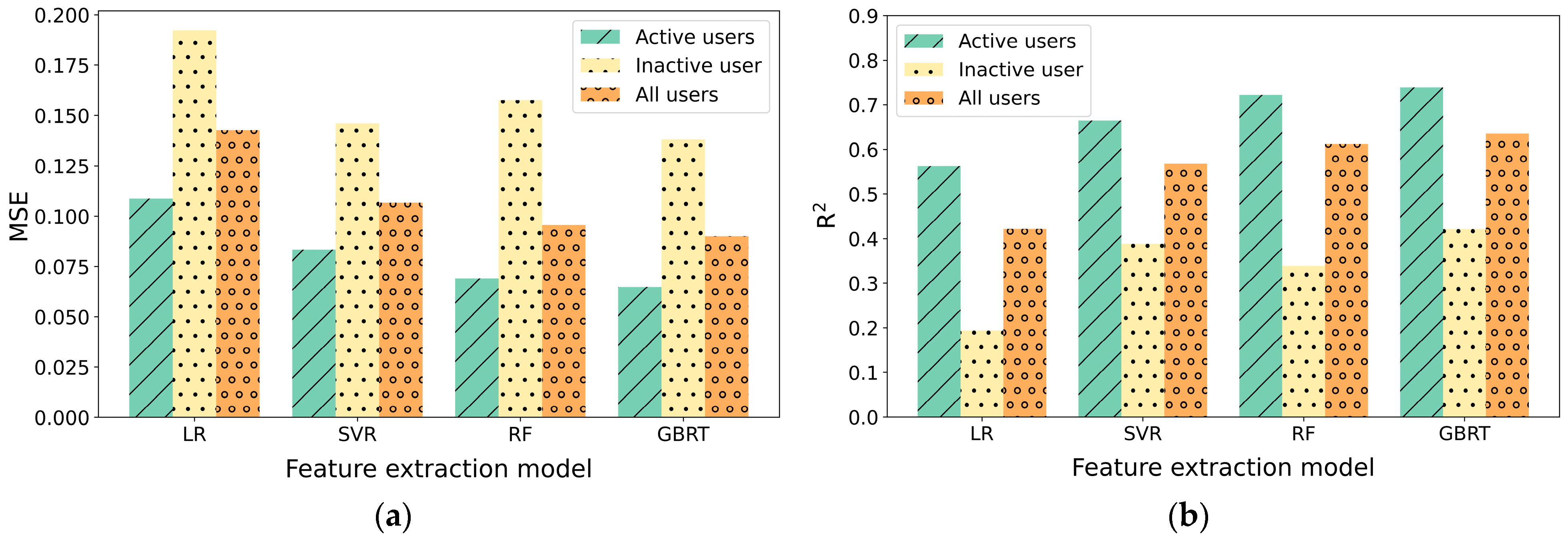
5.3. Feature Experiments
5.4. Comparison of Training Methods
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Park, S.; Choi, B.; Choi, C.; Kang, J.M.; Lee, J. Relationship between education, leisure activities, and cognitive functions in older adults. Aging Ment Health 2019, 23, 1651–1660. [Google Scholar] [CrossRef] [PubMed]
- Pressman, S.D.; Matthews, K.A.; Cohen, S.; Martire, L.M.; Scheier, M.; Baum, A.; Schulz, R. Association of enjoyable leisure activities with psychological and physical well-being. Psychosom. Med. 2009, 71, 725. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zheng, Y. How do academic stress and leisure activities influence college students’ emotional well-being? A daily diary investigation. J. Adolesc. 2017, 60, 114–118. [Google Scholar] [CrossRef] [PubMed]
- Fancourt, D.; Aughterson, H.; Finn, S.; Walker, E.; Steptoe, A. How leisure activities affect health: A narrative review and multi-level theoretical framework of mechanisms of action. Lancet Psychiatry 2021, 8, 329–339. [Google Scholar] [CrossRef] [PubMed]
- Wendel-Vos, G.W.; Schuit, A.J.; Tijhuis, M.A.R.; Kromhout, D. Leisure time physical activity and health-related quality of life: Cross-sectional and longitudinal associations. Qual Life Res. 2004, 13, 667–677. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; He, Q.; Tian, Y.; Lee, W.C.; McPherson, J.; Han, J. Event-based social networks: Linking the online and offline social worlds. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012. [Google Scholar]
- Yu, Z.; Du, R.; Guo, B.; Xu, H.; Gu, T.; Wang, Z.; Zhang, D. Who should I invite for my party? Combining user preference and influence maximization for social events. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp ‘15), Osaka, Japan, 7–11 September 2015. [Google Scholar]
- Zhang, X.; Zhao, J.; Cao, G. Who will attend?—Predicting event attendance in event-based social network. In Proceedings of the 16th IEEE International Conference on Mobile Data Management, Pittsburgh, PA, USA, 15–18 June 2015. [Google Scholar]
- Xu, M.; Liu, S. Semantic-enhanced and context-aware hybrid collaborative filtering for event recommendation in event-based social networks. IEEE Access 2019, 7, 17493–17502. [Google Scholar] [CrossRef]
- Wang, Z.; He, P.; Shou, L.; Chen, K.; Wu, S.; Chen, G. Toward the new item problem: Context-enhanced event recommendation in event-based social networks. In Proceedings of the 37th European Conference on Information Retrieval (ECIR 2015), Vienna, Austria, 29 March–2 April 2015. [Google Scholar]
- Wang, Z.; Zhang, Y.; Li, Y.; Wang, Q.; Xia, F. Exploiting social influence for context-aware event recommendation in event-based social networks. In Proceedings of the IEEE Conference on Computer Communications (IEEE INFOCOM 2017), Atlanta, GA, USA, 1–4 May 2017. [Google Scholar]
- Chin, A.; Tian, J.; Han, J.; Niu, J. A study of offline events and its influence on online social connections in douban. In Proceedings of the 2013 IEEE International Conference on Green Computing and Communications and IEEE Internet of Things and IEEE Cyber, Physical and Social Computing, Beijing, China, 20–23 August 2013. [Google Scholar]
- Liao, Y.; Lam, W.; Bing, L.; Shen, X. Joint modeling of participant influence and latent topics for recommendation in event-based social networks. ACM Trans. Inf. Syst. 2018, 36, 1–31. [Google Scholar] [CrossRef]
- Liu, C.Y.; Zhou, C.; Wu, J.; Xie, H.; Hu, Y.; Guo, L. Cpmf: A collective pairwise matrix factorization model for upcoming event recommendation. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017. [Google Scholar]
- Zhang, W.; Wang, J. A collective bayesian poisson factorization model for cold-start local event recommendation. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘15), Sydney, Australia, 10–13 August 2015. [Google Scholar]
- Zhu, Y.; Zhong, E.; Pan, S.J.; Wang, X.; Zhou, M.; Yang, Q. Predicting user activity level in social networks. In Proceedings of the 22nd ACM International Conference on Information & Knowledge Management (CIKM ‘13), New York, NY, USA, 27 October 2013–1 November 2013. [Google Scholar]
- Du, R.; Yu, Z.; Mei, T.; Wang, Z.; Wang, Z.; Guo, B. Predicting activity attendance in event-based social networks: Content, context and social influence. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp 2014), Seattle, WA, USA, 13–17 September 2014. [Google Scholar]
- Xu, T.; Zhong, H.; Zhu, H.; Xiong, H.; Chen, E.; Liu, G. Exploring the impact of dynamic mutual influence on social event participation. In Proceedings of the 2015 SIAM International Conference on Data Mining (SDM15), Vancouver, BC, Canada, 30 April 2015–2 May 2015. [Google Scholar]
- Li, M.; Huang, D.; Wei, B.; Wang, C.D. Event recommendation via collective matrix factorization with event-user neighborhood. In Proceedings of the International Conference on Intelligent Science and Big Data Engineering (IScIDE 2017), Dalian, China, 22–23 September 2017. [Google Scholar]
- Liu, S.; Wang, B.; Xu, M. Event recommendation based on graph random walking and history preference reranking. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ‘17), New York, NY, USA, 7–11 August 2017. [Google Scholar]
- Wu, C.; Wang, J.; Liu, J.; Liu, W. Recurrent neural network based recommendation for time heterogeneous feedback. Knowl.-Based Syst. 2016, 109, 90–103. [Google Scholar] [CrossRef]
- Cornelis, C.; Guo, X.; Lu, J.; Zhang, G. A Fuzzy Relational Approach to Event Recommendation. In Proceedings of the 2nd Indian International Conference on Artificial Intelligence (IICAI-05), Pune, India, 20–22 December 2005. [Google Scholar]
- Zhang, Y.; Wu, H.; Panangadan, A.; Prasanna, V.K. Integration of heterogeneous web services for event-based social networks. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration (IRI ‘15), Washington, DC, USA, 13–15 August 2015. [Google Scholar]
- Wang, Y.; Tang, J. Event2Vec: Learning event representations using spatial-temporal information for recommendation. In Proceedings of the 23rd Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2019), Macau, China, 14–17 April 2019. [Google Scholar]
- Ma, T.; Chen, R.; Zhou, F.; Wang, S.; Wang, X. Context based multi-source feature aware event recommendation algorithm. In Proceedings of the 2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Lars, S.T. Bpr: Bayesian personalized ranking from implicit feedback. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence (UAI ‘09), Montreal, QC, Canada, 18–21 June 2009. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Singh, A.P.; Gordon, G.J. Relational learning via collective matrix factorization. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘08), Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘08), Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Jiang, J.Y.; Li, C.T. Analyzing social event participants for a single organizer. In Proceedings of the 10th International AAAI Conference on Web and Social Media (ICWSM-16), Cologne, Germany, 17–20 May 2016. [Google Scholar]
- Li, S.; Cheng, X.; Su, S.; Sun, H. Exploiting organizer influence and geographical preference for new event recommendation. Expert Syst. 2017, 34, e12190. [Google Scholar] [CrossRef]
- Minkov, E.; Charrow, B.; Ledlie, J.; Teller, S.; Jaakkola, T. Collaborative future event recommendation. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management-CIKM’10; ACM Press: New York, NY, USA, 2010; p. 819. [Google Scholar]
- Hoang, D.T.; Tran, V.C.; Dosam, H.B. Social network-based event recommendation. In Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2017; Volume 10448. [Google Scholar]
- Zhang, Y.; Wu, H.; Sorathia, V.; Prasanna, V.K. Event recommendation in social networks with linked data enablement. In Proceedings of the 15th International Conference on Enterprise Information Systems-Volume 2: ICElS, Angers, France, 4–7 July 2013; pp. 371–379. [Google Scholar]
- Li, X.; Cheng, X.; Su, S.; Li, S.; Yang, J. A hybrid collaborative fi ltering model for social in fluence prediction in event-based social networks. Neurocomputing 2016, 230, 197–209. [Google Scholar] [CrossRef]
- Ogundele, T.J.; Member, S. SoCaST: Personalized Event Recommendations for Event-Based Social Networks: A Multi-Criteria Decision Making Approach. IEEE Access 2018, 6, 27579–27592. [Google Scholar] [CrossRef]
- Pham, T.A.N.; Li, X.; Cong, G.; Zhang, Z. A general graph-based model for recommendation in event-based social networks. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering (ICDE), Seoul, Republic of Korea, 13–17 April 2015. [Google Scholar]
- Li, B.; Wang, B.; Mo, Y.; Yang, L.T. A novel random walk and scale control method for event recommendation. In Proceedings of the 2016 Intl IEEE Conferences on Ubiquitous Intelligence & Computing, Advanced and Trusted Computing, Scalable Computing and Communications, Cloud and Big Data Computing, Internet of People, and Smart World Congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), Toulouse, France, 18–21 July 2016. [Google Scholar]
- Jamali, M.; Ester, M. A matrix factorization technique with trust propagation for recommendation in social networks. In Proceedings of the 4th ACM Conference on Recommender Systems (RecSys ‘10), Barcelona, Spain, 26–30 September 2010. [Google Scholar]
- Ma, T.; Chen, R.; Zhou, F.; Wang, S.; Wang, X. Social Event Recommendation Based on Social Relationship and Attention Mechanism. In Proceedings of the 2021 6th International Conference on Mathematics and Artificial Intelligence (ICMAI 2021), Chengdu, China, 19–21 March 2021. [Google Scholar]
- Li, R.; Lv, S.; Zhu, H.; Song, X. Spatial-Temporal Topic Model for Cold-Start Event Recommendation. IEEE Access 2020, 8, 214050–214060. [Google Scholar] [CrossRef]
- Daly, E.M.; Geyer, W. Effective event discovery: Using location and social information for scoping event recommendations. In Proceedings of the 5th ACM Conference on Recommender Systems (RecSys ‘11), Chicago, IL, USA, 23–27 October 2011. [Google Scholar]
- Liu, C.C. Search recommendation model based on user search behavior and gradual forgetting collaborative filtering strategy. J. China Univ. Posts Telecommun. 2010, 17, 110–117. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Jamali, M.; Ester, M. Trustwalker: A random walk model for combining trust-based and item-based recommendation. In Proceedings of the 15th ACM SIsGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘09), Paris, France, 28 June 2009–1 July 2009. [Google Scholar]
- Zhang, S.; Lv, Q. Hybrid EGU-based group event participation prediction in event-based social networks. Knowl.-Based Syst. 2018, 143, 19–29. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Kertész, J. Detecting the overlapping and hierarchical community structure in complex networks. New J. Phys. 2009, 11, 033015. [Google Scholar] [CrossRef]
- Jiang, J.Y.; Li, C.T. Who should I invite: Predicting event participants for a host user. Knowl. Inf. Syst. 2019, 59, 629–650. [Google Scholar] [CrossRef]
- Hannon, J.; Bennett, M.; Smyth, B. Recommending twitter users to follow using content and collaborative filtering approaches. In Proceedings of the 4th ACM Conference on Recommender Systems (RecSys ‘10), Barcelona, Spain, 26–30 September 2010. [Google Scholar]
- Järvelin, K.; Kekäläinen, J. Cumulated gain-based evaluation of IR techniques. ACM Trans. Inf. Syst. 2002, 20, 422–446. [Google Scholar] [CrossRef]
- Trinh, T.; Nguyen, N.T.; Wu, D.; Huang, J.Z.; Emara, T.Z. A new location-based topic model for event attendees recommendation. In Proceedings of the 2019 IEEE-RIVF International Conference on Computing and Communication Technologies (RIVF), Danang, Vietnam, 20–22 March 2019. [Google Scholar]
- Cauteruccio, F.; Stamile, C.; Terracina, G.; Ursino, D.; Sappey-Mariniery, D. An automated string-based approach to White Matter fiber-bundles clustering. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Cauteruccio, F.; Stamile, C.; Terracina, G.; Ursino, D.; Sappey-Mariniery, D. An automated string-based approach to extracting and characterizing White Matter fiber-bundles. Compt. Biol. Med. 2016, 77, 64–75. [Google Scholar] [CrossRef] [PubMed]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Peng, X.; Niu, Y.; Gui, Z. MFM: A Multiple-Features Model for Leisure Event Recommendation in Geotagged Social Networks. Electronics 2024, 13, 112. https://doi.org/10.3390/electronics13010112
Wu Y, Peng X, Niu Y, Gui Z. MFM: A Multiple-Features Model for Leisure Event Recommendation in Geotagged Social Networks. Electronics. 2024; 13(1):112. https://doi.org/10.3390/electronics13010112
Chicago/Turabian StyleWu, Yazhao, Xia Peng, Yueyan Niu, and Zhiming Gui. 2024. "MFM: A Multiple-Features Model for Leisure Event Recommendation in Geotagged Social Networks" Electronics 13, no. 1: 112. https://doi.org/10.3390/electronics13010112
APA StyleWu, Y., Peng, X., Niu, Y., & Gui, Z. (2024). MFM: A Multiple-Features Model for Leisure Event Recommendation in Geotagged Social Networks. Electronics, 13(1), 112. https://doi.org/10.3390/electronics13010112