

A Novel Spatial–Temporal Network for Gait Recognition Using Millimeter-Wave Radar Point Cloud Videos


Abstract
:1. Introduction
- A 4D-RPCV-based spatial–temporal network is proposed to better capture the motion dynamics of gait for accurate human identification, which is capable of modeling walking motion from time-varying sparse radar point clouds.
- A Transformer encoder architecture is introduced in the proposed network to learn radar point features’ sequences, capturing the spatial–temporal dependencies that contribute to accurate gait recognition.
- A 4D RPCV human gait dataset was built on real mmWave MIMO frequency-modulated continuous wave (FMCW) radar measurements, which involved 15 volunteers walking along different paths. Furthermore, experiments on this dataset showed that the proposed spatial–temporal network effectively improved the accuracy of gait recognition.
2. Related Works
3. Frequency-Modulated Continuous Wave-MIMO Radar System
4. Method
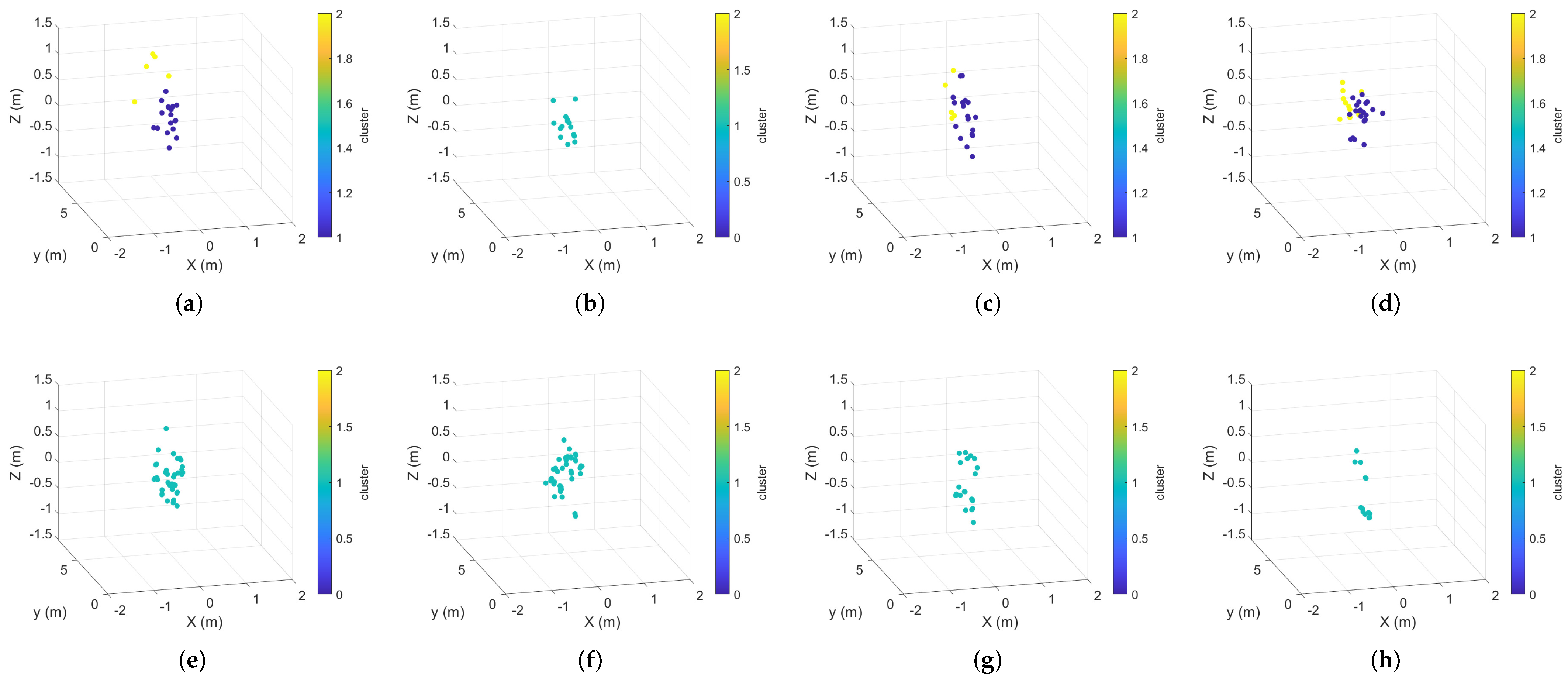
4.1. Four-Dimensional Radar Point Cloud Videos
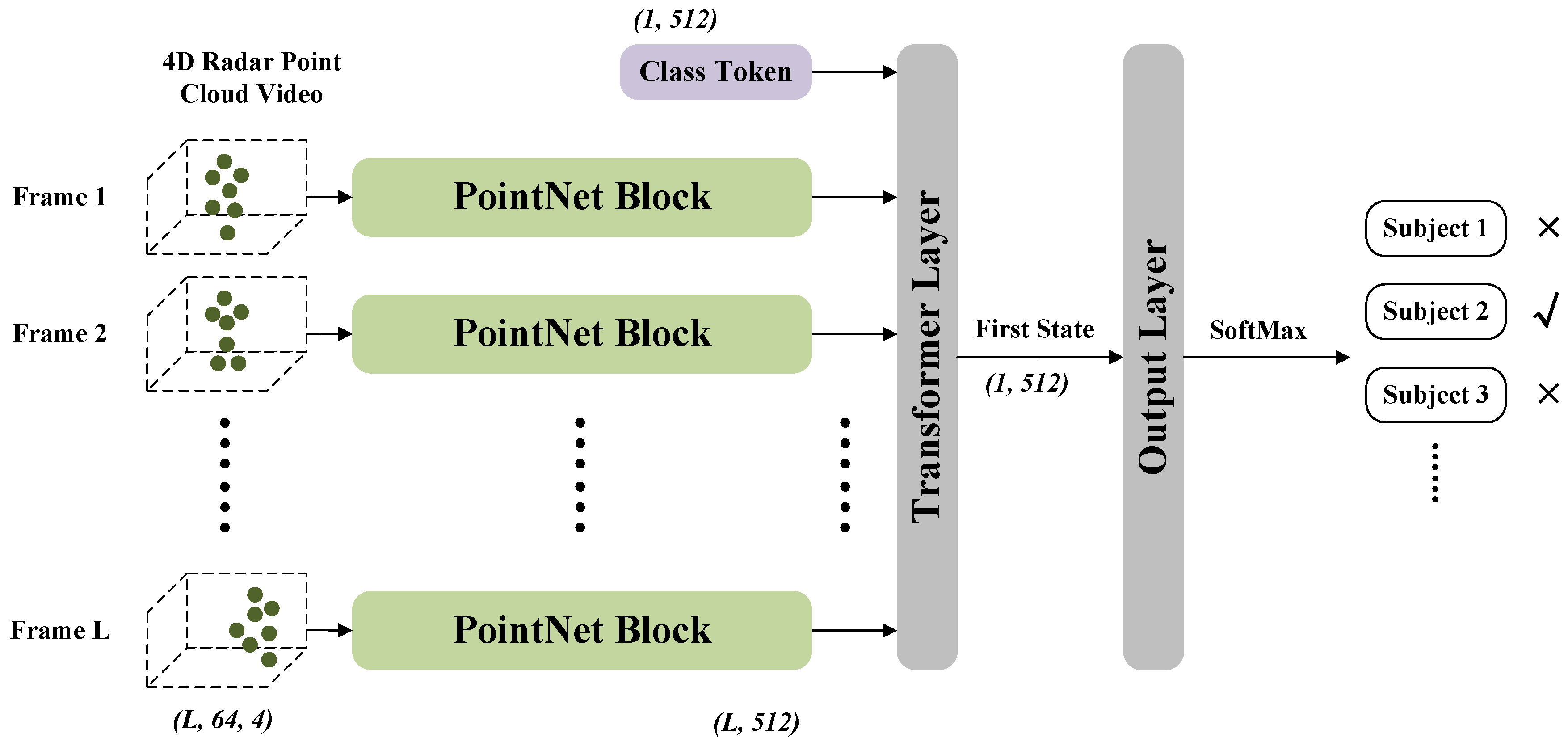
4.2. Spatial–Temporal Network
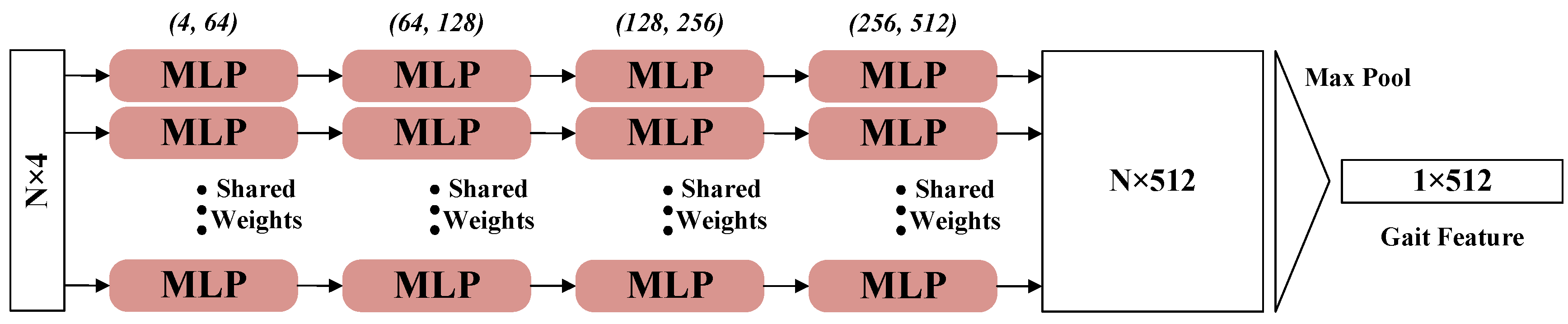
4.2.1. PointNet Block
4.2.2. Transformer Layer
4.2.3. Output Layer
5. Experimental Results and Analysis
5.1. Data Collection
5.2. Implementation Details
5.3. Performance Analysis
5.3.1. Comparison of Performance
5.3.2. Impact of Hidden Dimension
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wan, C.; Wang, L.; Phoha, V.V. A survey on gait recognition. ACM Comput. Surv. (CSUR) 2018, 51, 1–35. [Google Scholar] [CrossRef]
- Fan, C.; Liang, J.; Shen, C.; Hou, S.; Huang, Y.; Yu, S. OpenGait: Revisiting Gait Recognition Towards Better Practicality. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9707–9716. [Google Scholar]
- Singh, J.P.; Jain, S.; Arora, S.; Singh, U.P. Vision-based gait recognition: A survey. IEEE Access 2018, 6, 70497–70527. [Google Scholar] [CrossRef]
- Shen, C.; Yu, S.; Wang, J.; Huang, G.Q.; Wang, L. A comprehensive survey on deep gait recognition: Algorithms, datasets and challenges. arXiv 2022, arXiv:2206.13732. [Google Scholar]
- Sepas-Moghaddam, A.; Etemad, A. Deep gait recognition: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 264–284. [Google Scholar] [CrossRef] [PubMed]
- Muro-De-La-Herran, A.; Garcia-Zapirain, B.; Mendez-Zorrilla, A. Gait analysis methods: An overview of wearable and non-wearable systems, highlighting clinical applications. Sensors 2014, 14, 3362–3394. [Google Scholar] [CrossRef] [PubMed]
- Marsico, M.D.; Mecca, A. A survey on gait recognition via wearable sensors. ACM Comput. Surv. (CSUR) 2019, 52, 1–39. [Google Scholar] [CrossRef]
- Zhang, J.; Xi, R.; He, Y.; Sun, Y.; Guo, X.; Wang, W.; Na, X.; Liu, Y.; Shi, Z.; Gu, T. A Survey of mmWave-Based Human Sensing: Technology, Platforms and Applications. IEEE Commun. Surv. Tutor. 2023, 52, 2052–2087. [Google Scholar] [CrossRef]
- Gurbuz, S.Z.; Amin, M.G. Radar-based human-motion recognition with deep learning: Promising applications for indoor monitoring. IEEE Signal Process. Mag. 2019, 36, 16–28. [Google Scholar] [CrossRef]
- Le, H.T.; Phung, S.L.; Bouzerdoum, A. Human gait recognition with micro-Doppler radar and deep autoencoder. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 3347–3352. [Google Scholar]
- Addabbo, P.; Bernardi, M.L.; Biondi, F.; Cimitile, M.; Clemente, C.; Orlando, D. Temporal convolutional neural networks for radar micro-Doppler based gait recognition. Sensors 2021, 21, 381. [Google Scholar] [CrossRef]
- Yang, Y.; Ge, Y.; Li, B.; Wang, Q.; Lang, Y.; Li, K. Multiscenario Open-Set Gait Recognition Based on Radar Micro-Doppler Signatures. IEEE Trans. Instrum. Meas. 2022, 71, 1–13. [Google Scholar] [CrossRef]
- Chen, V.C.; Li, F.; Ho, S.S.; Wechsler, H. Micro-Doppler effect in radar: Phenomenon, model, and simulation study. IEEE Trans. Aerosp. Electron. Syst. 2006, 42, 2–21. [Google Scholar] [CrossRef]
- Chen, Z.; Li, G.; Fioranelli, F.; Griffiths, H. Personnel recognition and gait classification based on multistatic micro-Doppler signatures using deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 669–673. [Google Scholar] [CrossRef]
- Kim, Y.; Alnujaim, I.; Oh, D. Human activity classification based on point clouds measured by millimeter wave MIMO radar with deep recurrent neural networks. IEEE Sens. J. 2021, 21, 13522–13529. [Google Scholar] [CrossRef]
- Meng, Z.; Fu, S.; Yan, J.; Liang, H.; Zhou, A.; Zhu, S.; Ma, H.; Liu, J.; Yang, N. Gait recognition for co-existing multiple people using millimeter wave sensing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 849–856. [Google Scholar]
- Cheng, Y.; Liu, Y. Person reidentification based on automotive radar point clouds. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Canil, M.; Pegoraro, J.; Rossi, M. MilliTRACE-IR: Contact tracing and temperature screening via mmWave and infrared sensing. IEEE J. Sel. Top. Signal Process. 2021, 16, 208–223. [Google Scholar] [CrossRef]
- Xue, H.; Ju, Y.; Miao, C.; Wang, Y.; Wang, S.; Zhang, A.; Su, L. mmMesh: Towards 3D real-time dynamic human mesh construction using millimeter-wave. In Proceedings of the 19th Annual International Conference on Mobile Systems, Applications, and Services, Virtual, 24 June–2 July 2021; pp. 269–282. [Google Scholar]
- Guan, J.; Madani, S.; Jog, S.; Gupta, S.; Hassanieh, H. Through fog high-resolution imaging using millimeter wave radar. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11464–11473. [Google Scholar]
- Cao, D.; Liu, R.; Li, H.; Wang, S.; Jiang, W.; Lu, C.X. Cross vision-rf gait re-identification with low-cost rgb-d cameras and mmwave radars. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2022, 6, 1–25. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Lien, J.; Gillian, N.; Karagozler, M.E.; Amihood, P.; Schwesig, C.; Olson, E.; Raja, H.; Poupyrev, I. Soli: Ubiquitous gesture sensing with millimeter wave radar. ACM Trans. Graph. (TOG) 2016, 35, 1–19. [Google Scholar] [CrossRef]
- Li, X.; He, Y.; Jing, X. A survey of deep learning-based human activity recognition in radar. Remote Sens. 2019, 11, 1068. [Google Scholar] [CrossRef]
- Sengupta, A.; Jin, F.; Zhang, R.; Cao, S. mm-Pose: Real-time human skeletal posture estimation using mmWave radars and CNNs. IEEE Sens. J. 2020, 20, 10032–10044. [Google Scholar] [CrossRef]
- Xia, Z.; Ding, G.; Wang, H.; Xu, F. Person identification with millimeter-wave radar in realistic smart home scenarios. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Pegoraro, J.; Rossi, M. Real-time people tracking and identification from sparse mm-wave radar point-clouds. IEEE Access 2021, 9, 78504–78520. [Google Scholar] [CrossRef]
- Patole, S.M.; Torlak, M.; Wang, D.; Ali, M. Automotive radars: A review of signal processing techniques. IEEE Signal Process. Mag. 2017, 34, 22–35. [Google Scholar] [CrossRef]
- Soumekh, M. Array imaging with beam-steered data. IEEE Trans. Image Process. 1992, 1, 379–390. [Google Scholar] [CrossRef] [PubMed]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. Proc. Kdd 1996, 96, 226–231. [Google Scholar]





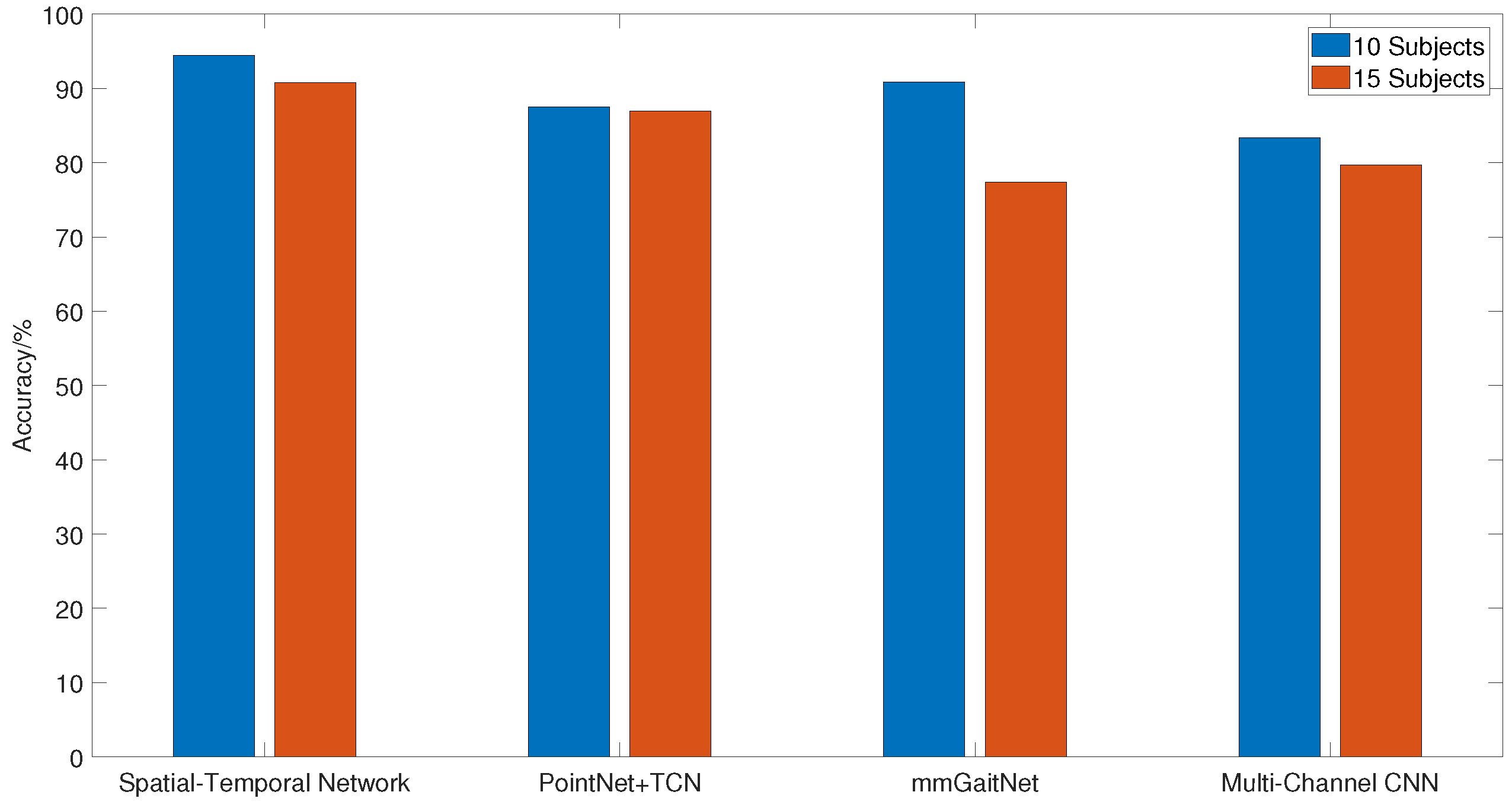

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Start frequency | 77 GHz |
| Chirp bandwidth | 2529 MHz |
| Chirp duration | 32 µs |
| Frame duration | 62 ms |
| Number of samples per chirp | 256 |
| Number of chirps per frame | 128 |
| Number of TX antennas | 12 |
| Number of RX antennas | 16 |
| Range resolution | 5.93 cm |
| Velocity resolution | 0.0311 m/s |
| Azimuth resolution | 1.4 |
| Elevation resolution | 18 |
| Height (cm) | Weights (kg) | Gender | Ages | Height (cm) | Weights (kg) | Gender | Ages | ||
|---|---|---|---|---|---|---|---|---|---|
| Person 1 | 172 | 65 | male | 41 | Person 9 | 171 | 66 | male | 22 |
| Person 2 | 177 | 66 | male | 25 | Person 10 | 166 | 52 | female | 23 |
| Person 3 | 165 | 56 | female | 26 | Person 11 | 177 | 83 | male | 22 |
| Person 4 | 172 | 52 | male | 23 | Person 12 | 160 | 51 | female | 26 |
| Person 5 | 168 | 64 | male | 24 | Person 13 | 169 | 66 | male | 35 |
| Person 6 | 183 | 61 | male | 23 | Person 14 | 171 | 69 | male | 23 |
| Person 7 | 170 | 62 | female | 22 | Person 15 | 180 | 74 | male | 21 |
| Person 8 | 178 | 70 | male | 24 |
| Input | Network | Accuracy |
|---|---|---|
| 4D Radar Point Cloud Videos | Spatial–Temporal Network (Ours) | 94.44% |
| PointNet + BiLSTM | 86.11% | |
| PointNet + TCN | 87.50% | |
| mmGaitNet | 90.88% | |
| Micro-Doppler Signatures | Multi-Channel CNN | 83.33% |
| Hidden dimension | 256 | 512 | 1024 |
|---|---|---|---|
| Accuracy | 92.71% | 94.44% | 94.17% |
| Parameters | 0.540 m | 1.656 m | 6.447 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, C.; Liu, Z. A Novel Spatial–Temporal Network for Gait Recognition Using Millimeter-Wave Radar Point Cloud Videos. Electronics 2023, 12, 4785. https://doi.org/10.3390/electronics12234785
Ma C, Liu Z. A Novel Spatial–Temporal Network for Gait Recognition Using Millimeter-Wave Radar Point Cloud Videos. Electronics. 2023; 12(23):4785. https://doi.org/10.3390/electronics12234785
Chicago/Turabian StyleMa, Chongrun, and Zhenyu Liu. 2023. "A Novel Spatial–Temporal Network for Gait Recognition Using Millimeter-Wave Radar Point Cloud Videos" Electronics 12, no. 23: 4785. https://doi.org/10.3390/electronics12234785
APA StyleMa, C., & Liu, Z. (2023). A Novel Spatial–Temporal Network for Gait Recognition Using Millimeter-Wave Radar Point Cloud Videos. Electronics, 12(23), 4785. https://doi.org/10.3390/electronics12234785