
IoV Vulnerability Classification Algorithm Based on Knowledge Graph

Abstract
:1. Introduction
- We propose a new vulnerability classification algorithm. To improve the classification performance of imbalanced samples, we offer a new vulnerability classification algorithm, KG-KNN, based on weighted Euclidean distance and the feature knowledge graph. This algorithm increases the correlation distance between features in a similarity calculation, achieving a multi-dimensional similarity calculation and overcoming the limitations of imbalanced sample classification.
- Construct the feature knowledge graph based on the optimal feature word set. This paper integrates vulnerability information from multiple sources, extracts the optimal feature word set, and constructs a feature knowledge graph to solve the problem of dispersed vulnerability information of the IoV and obtain the association distance.
- We propose a weighted Euclidean distance algorithm. This paper introduces the concept of association distance, improves the traditional Euclidean distance algorithm, and presents a weighted Euclidean distance algorithm to solve the problem that the samples of a few categories cannot fully extract the feature values.
2. Related Work
2.1. Dimensionality Reduction Processing Technique
2.2. Classification Algorithm
3. Background
3.1. Knowledge Graph
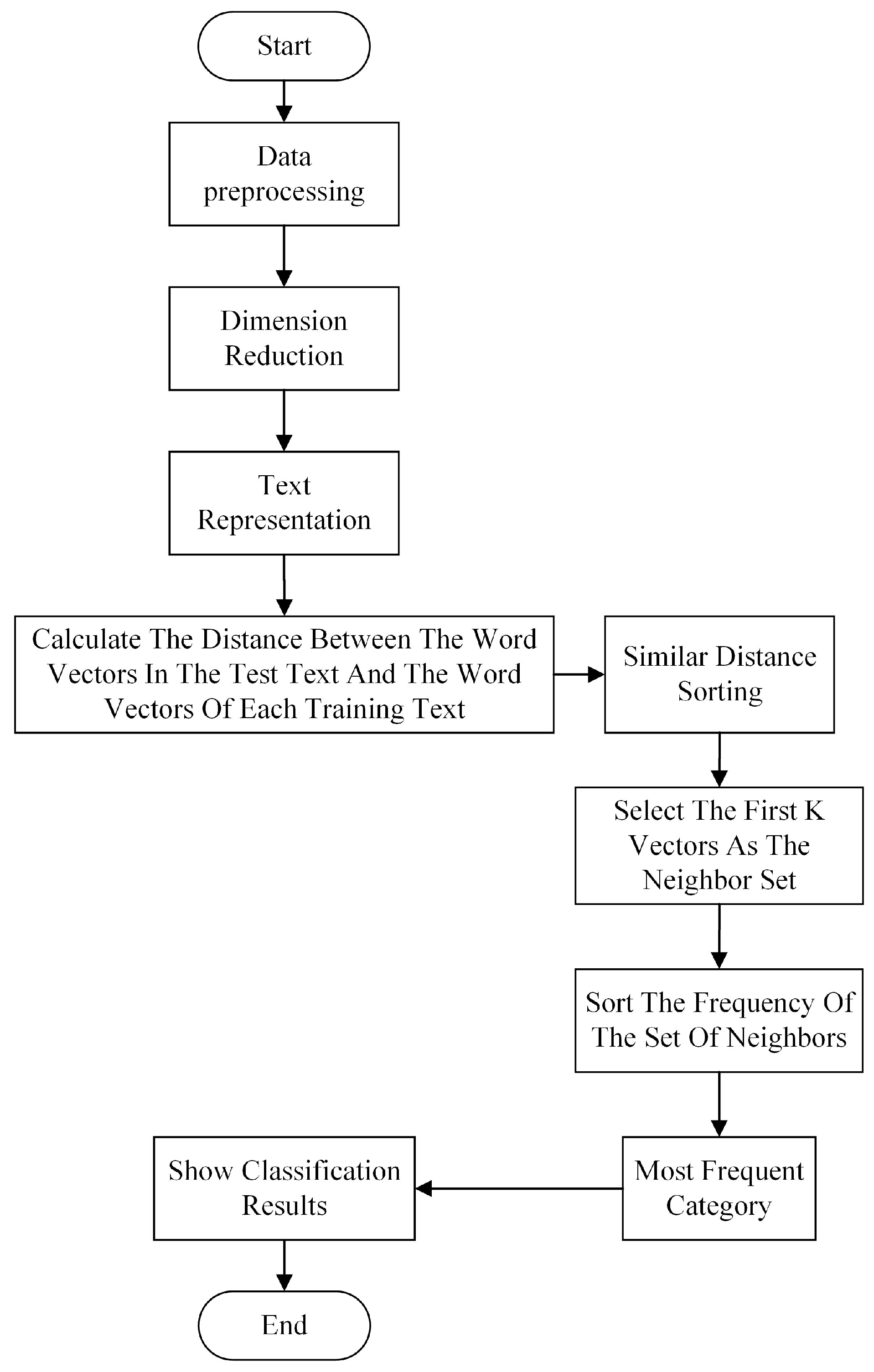
3.2. K-Nearest Neighbor Classification Algorithm
- Divide the preprocessed samples into a training sample set and a test sample set;
- Choose an appropriate distance equation to calculate the distance between the word vectors in the test samples and the word vectors in each training sample;
- Sort the word vectors of the training samples in the order of distance from most petite to most significant;
- Setting the value of parameter k and selecting the top K-word vectors from the previously sorted queue as the set of neighbors;
- Calculate the frequency of occurrence of the first K vectors and record it;
- Return the category with the highest frequency of occurrence of the first K vectors as the predicted classification of the test sample.
3.3. Vulnerability Classification
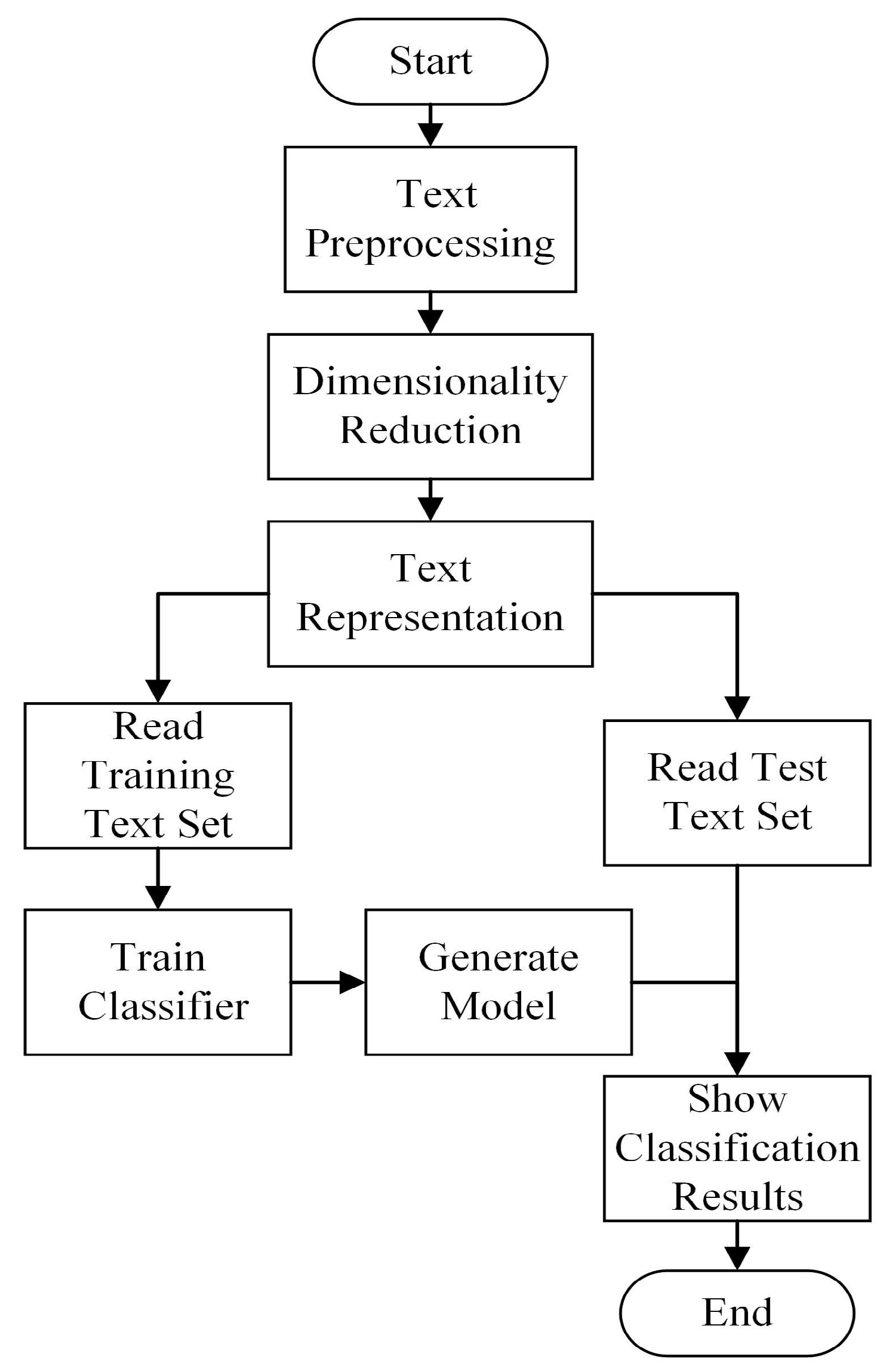
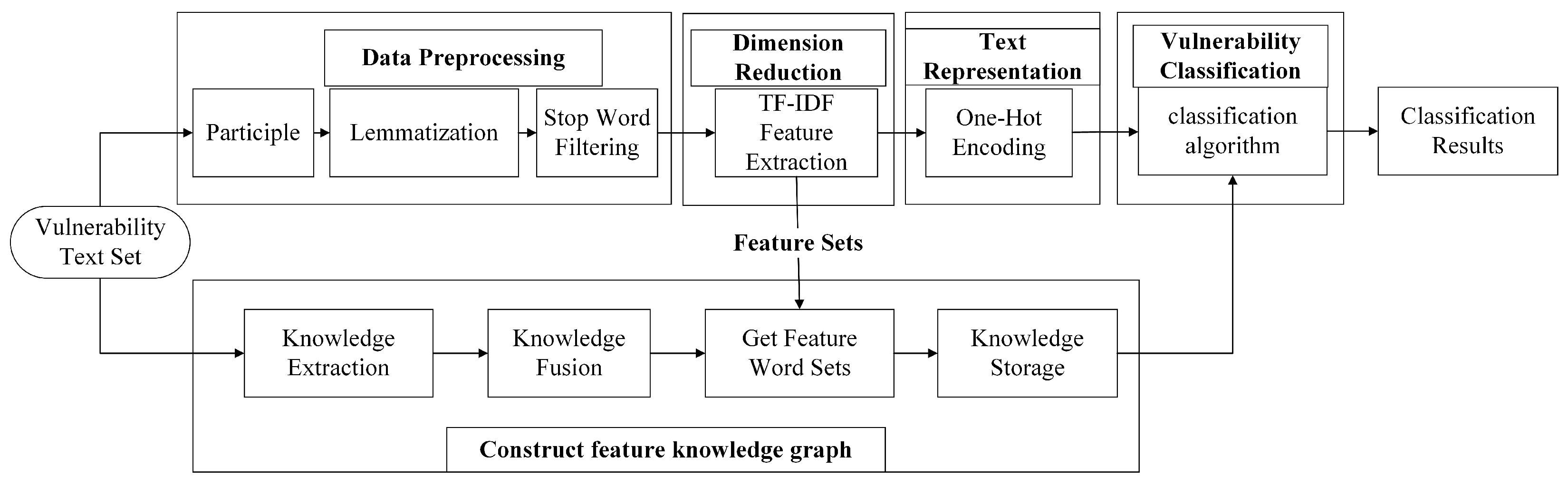
- Text preprocessing: Before classifying the vulnerability text, preprocessing operations are necessary. These typically involve removing punctuation, splitting words, reducing linguistic complexity, and applying deactivation filtering.
- Dimensionality reduction processing: Dimensionality reduction processing techniques are used to filter irrelevant or redundant features and retain the most distinguishable and relevant features to form the optimal set of features;
- Text representation: The classifier cannot recognize the form of the above feature set, and it needs to be converted into a declaration that the machine learning algorithm can identify to carry out the next classification task;
- Classification: According to the characteristics of the vulnerability text, select the appropriate classification algorithm, use the training set for training, obtain the proper classifier parameters, and then input the test set into the classifier to obtain the classification results.
4. Design Strategy
4.1. System Design
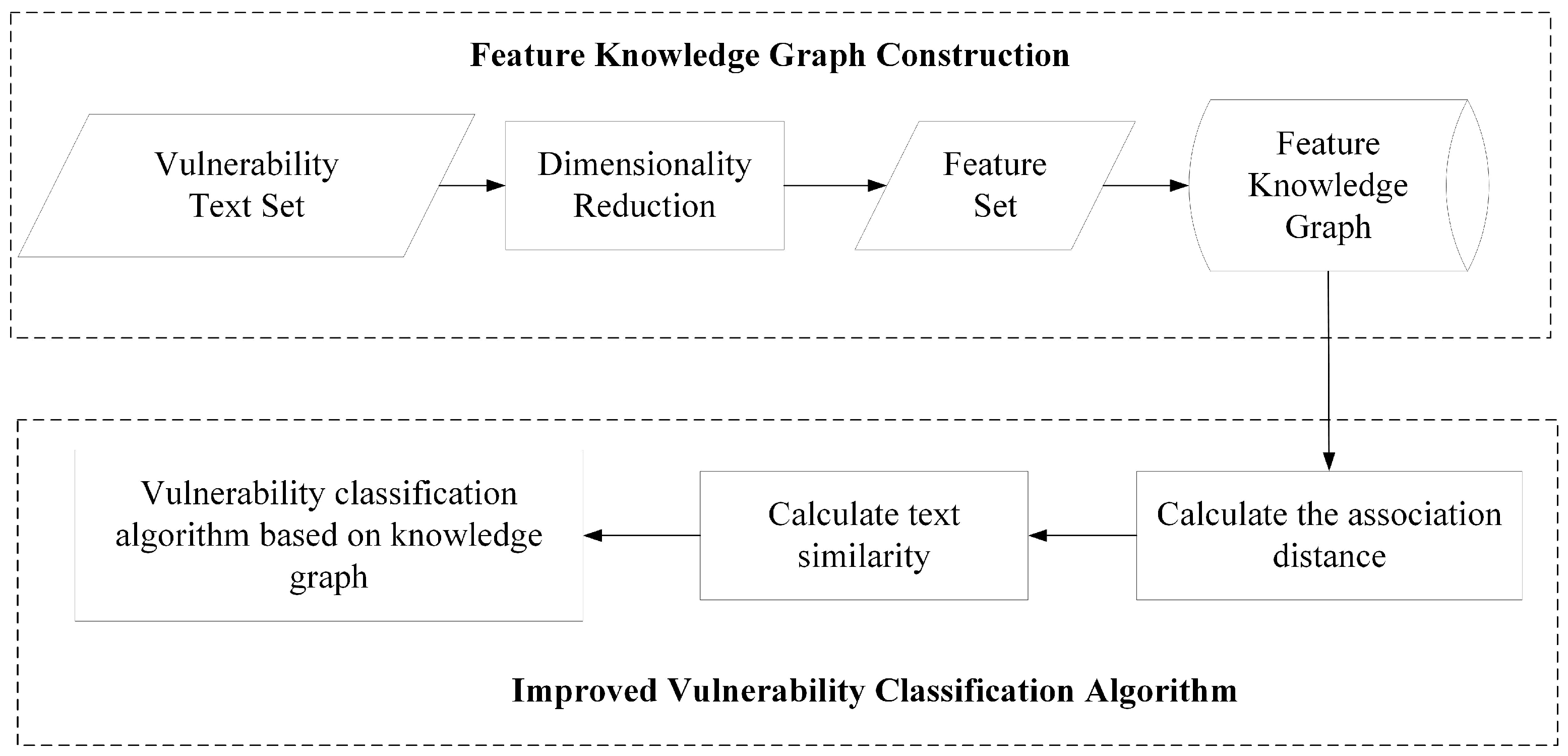
- Feature knowledge graph construction: After the vulnerability text is processed by dimensionality reduction, its feature set is fused into the IoV vulnerability knowledge graph to construct a unique feature knowledge graph;
- Improvement in vulnerability classification algorithm: Calculate the association distance between feature words according to the feature knowledge graph and use its combination with the Euclidean distance to calculate the text similarity to realize the improvement in the vulnerability classification algorithm.
4.2. Performance Metrics
4.2.1. Precision Rate
4.2.2. Recall Rate
4.2.3. F1 Score
4.2.4. Macro Average
4.2.5. Weighted Average
5. Methodology
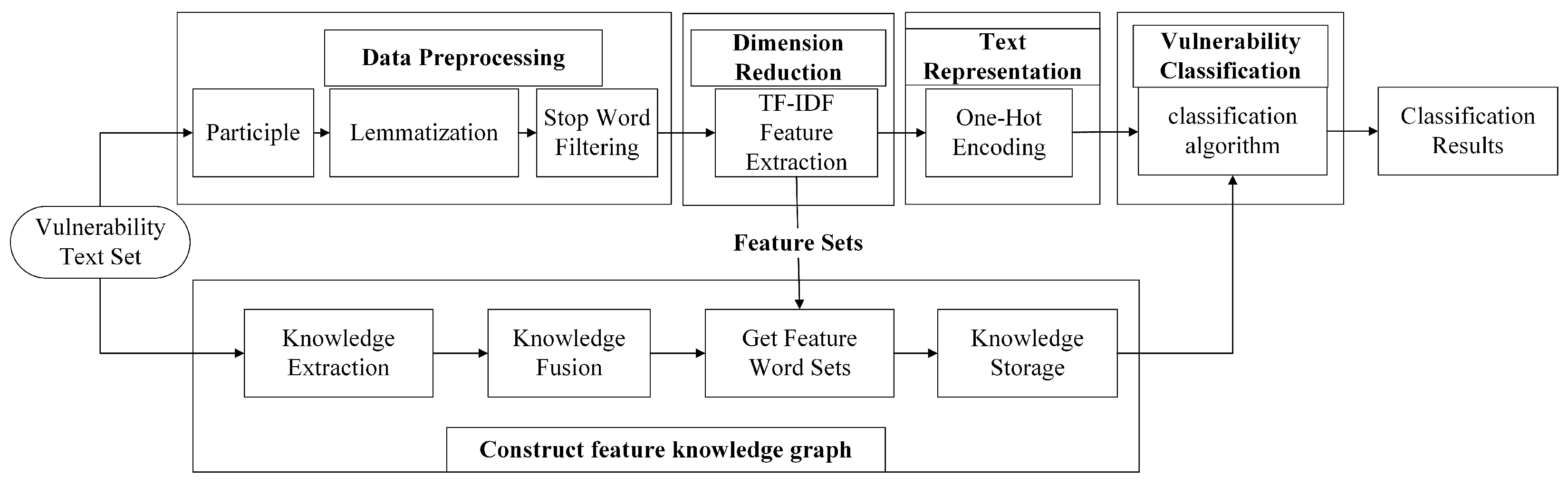
5.1. Data Preprocessing
- Participle. The purpose of word separation is to cut the continuous text sequence into separate words or lexical units, which provides the basis for the subsequent text-processing tasks. With its diverse segmentation patterns and wide range of application areas, Jieba word segmentation has become the most commonly used Chinese text segmentation tool in China. In this paper, we use the precise mode of stuttering participle, which will try to cut the text into the most reasonable word combinations according to the dictionary and algorithm.
- Lemmatization. The purpose of lexical reduction is to reduce different forms of words to their root forms to reduce the vocabulary’s diversity and dimensionality. This paper uses the NLTK natural language processing tool library for the word form reduction operation. After decomposing each text into a list of words, we perform word form reduction on each word by referencing the word form relations in the WordNet database to convert the terms into their original forms or stems.
- Stop word filtering. The purpose of deactivation word filtering is to reduce the noise and redundant information in the text to improve the efficiency and accuracy of the subsequent text analysis task. In this paper, we utilize the TF-IDF algorithm to filter out stop words, and we apply Equation (9) to identify and exclude frequently occurring words that do not contribute significantly to the classification task. These words are then incorporated into the Chinese stop words list to create a specialized stop words list tailored to the characteristics of vulnerability data.
5.2. Dimension Reduction
- Calculate the value of each word using Equation (7)where i denotes the word, j denotes the document, is the number of times word i appears in document j, and is the sum of the number of times all words appear in document j.
- Calculate the value of each word using Equation (8)where denotes the total number of documents in the corpus, denotes the number of documents containing the word i, and to avoid the denominator being 0, it is generally used .
- Calculate the value of each word using Equation (9)
- 800 feature words are selected, which have larger values.Table 1 shows a vulnerability description and its dimensionality reduction results.
5.3. Construct Feature Knowledge Graph
- Knowledge extraction. The first step in constructing a knowledge graph is knowledge extraction. This paper obtains a large amount of structured data after the automated extraction of IoV vulnerability data from vulnerability repositories such as NVD, VULHUB, and CVE. Each data column is considered a specific entity, attribute, and relationship, and the table structure and data in the vulnerability repositories are converted into RDF graphs through direct mapping.
- Knowledge fusion. After executing the knowledge extraction operation, the next crucial step involves integrating the IoV vulnerability data sourced from different vulnerability repositories. This integration process aims to resolve conflicts, eliminate duplications, and rectify inconsistencies, encompassing essential tasks such as entity alignment, entity disambiguation, and attribute alignment. The refined and processed data will be stored in documents, serving as a robust and precise basis for the subsequent construction of the knowledge graph.
- Get feature word sets. After fusing the vulnerability data, we proceed with the preprocessing and dimensionality reduction of the vulnerability description text to extract the most relevant features and their correlations. Simultaneously, we store the generated optimal feature vocabulary and associated vulnerability information in a CSV file. We have elucidated the detailed steps of these preprocessing and dimensionality reduction operations in Section 5.1 and Section 5.2.
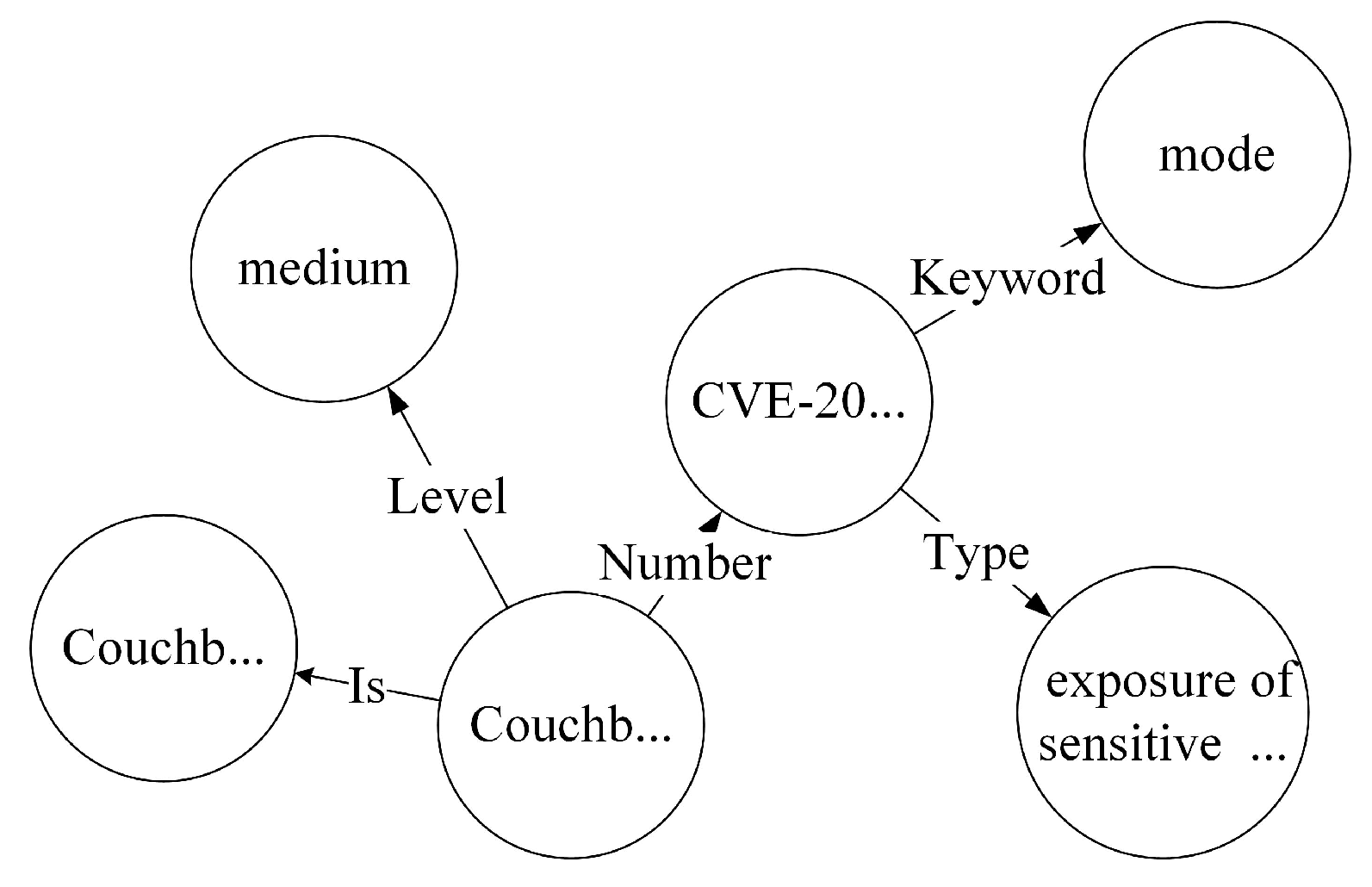
- Knowledge storage. We have selected the Neo4j graph database for storing vulnerability data. We reserved the above-mentioned integrated data in CSV files and imported them into Neo4j. We constructed entities and relationships using the Cypher query language, ultimately creating the feature knowledge graph. As illustrated in Figure 5, CVE-2021-43963 is the assigned vulnerability number, categorized as having a medium risk level, falling under the information exposure type, and matching the keyword ‘mode’.
5.4. Text Representation
- Determine the categorization variables. First, it is necessary to determine which features are categorization variables, i.e., the number of elements;
- Establish a vocabulary. A vocabulary needs to be built for each categorical variable, listing all its possible values and assigning a unique index or number to each matter;
- One-hot encoding. For each sample categorical variable, map its raw fetches to the corresponding vocabulary index and convert that index to a binary vector. In this vector, the element corresponding to the index position is 1, and the rest of the parts are 0. The vector representation of the partial vulnerability description text is shown in Table 2.
5.5. Vulnerability Classification Algorithm Based on Feature Knowledge Graph (KG-KNN)
- Data preprocessing. The obtained vulnerability description text set is subjected to preprocessing operations such as word splitting, word shape reduction, and deactivation word filtering on the training and test text sets. The detailed steps are described in Section 5.1.
- Dimension reduction. Use the TF-IDF algorithm to reduce dimensionality on the training text set and test text set after the preprocessing operations to form the training text feature set and test text feature set. The detailed steps are described in Section 5.2.
- Text representation. The text representation is of the training text feature set and test text feature set using solo thermal coding to obtain the feature representation set. The detailed steps are described in Section 5.3.
- Partition the dataset. Following an 8:2 split, the feature representation set is divided into two mutually exclusive parts. One part serves as the training text feature set, while the remaining data is designated as the test text feature set.
- Calculate the word vector distance. Let is the n-dimensional vector after the text representation of the test text feature set and is the n-dimensional sample vector in the training set . Calculate the distance between the word vectors in the test text and the word vectors in each training text as follows:
- –
- Set two-word vectors and and use them to represent the similarity distance between the test text set and the training text set;
- –
- Calculate the Euclidean distance between word vectors using Equation (1);
- –
- Obtain the shortest path length of the two-word vectors corresponding to the feature words in the feature knowledge graph, where when ;
- –
- Calculate the average value of the sum of the shortest path lengths of all feature words in the sample vector in the knowledge graph according to Equation (10), called the association distance , where m represents the number of feature words with the shortest path not being 0;
- –
- According to Equation (11), use the correlation distance to weigh the Euclidean distance and obtain the final sample distance .
- Training data sorting. Sort the vectors of training data in the order of final sample distances from the most minor to the most significant;
- Select k neighbors. Set the size of parameter k and select the top k vectors from the above-sorted queue as the set of neighbors;
- Calculate frequency. Calculate the frequency of occurrence of the first k vectors and sort them in descending order;
- Return prediction results. Return the category with the highest frequency as the predicted classification of the test data.
6. Experiment
6.1. Experiment Configuration
6.2. Experimental Dataset
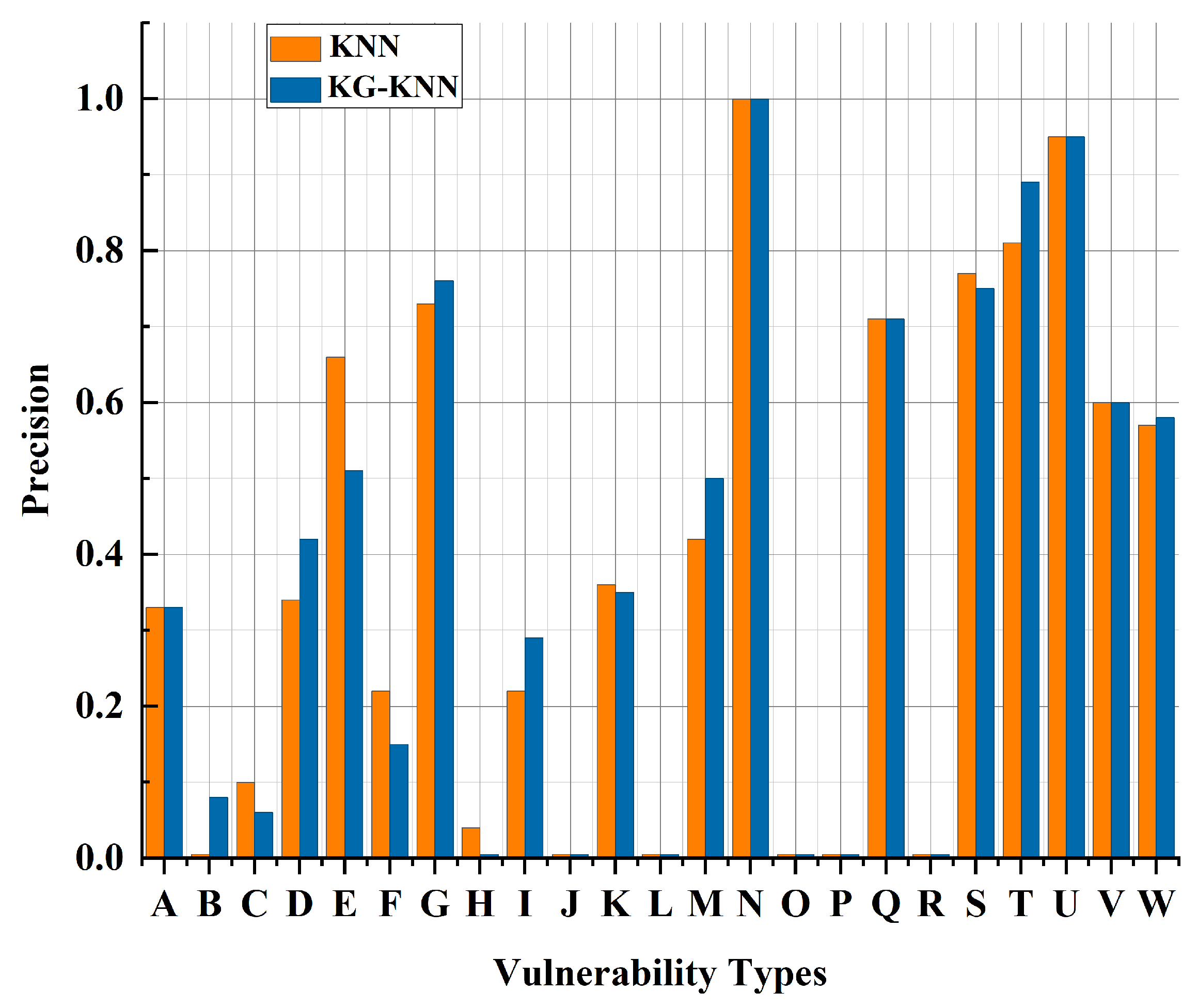
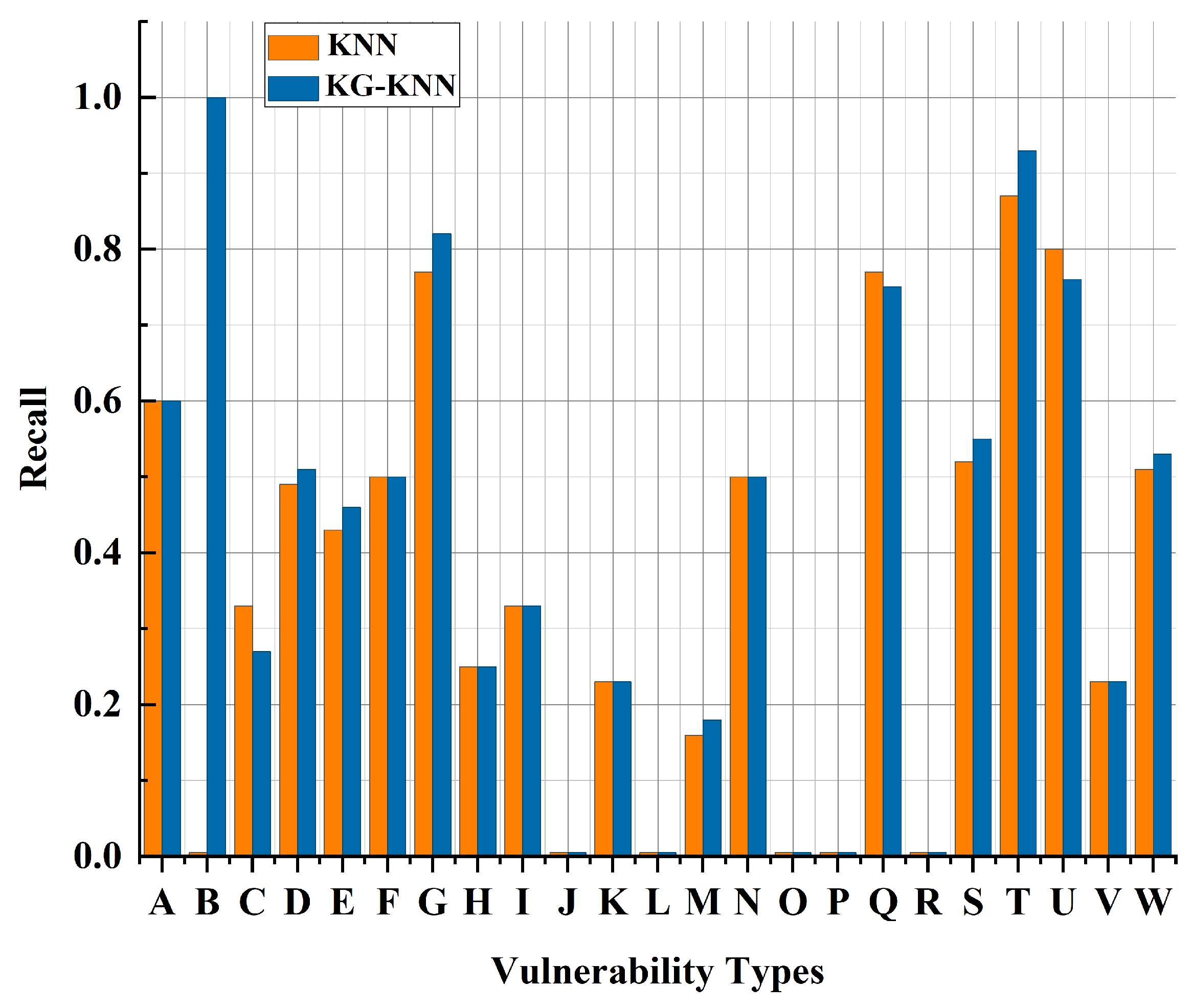
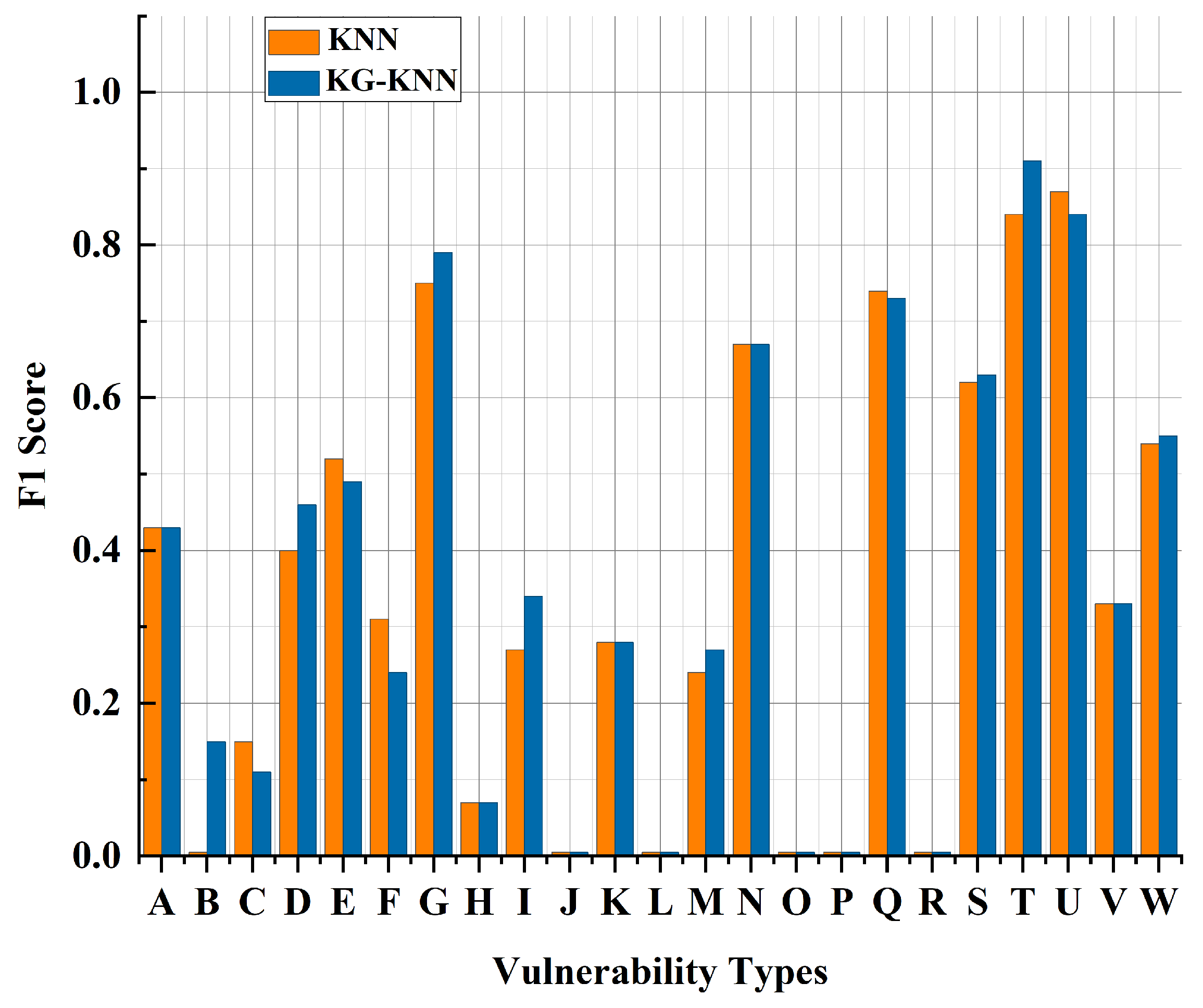
6.3. Analysis of Experimental Results
6.3.1. Validation Experiment
6.3.2. Comparative Experiment
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, C.; Li, H.; Li, H.; Fu, R.; Liu, Y.; Wan, S. Efficiency and Fairness Oriented Dynamic Task Offloading in Internet of Vehicles. IEEE Trans. Green Commun. Netw. 2022, 6, 1481–1493. [Google Scholar] [CrossRef]
- Liu, X.; Zhao, S.; Tan, L.; Tan, Y.; Wang, Y.; Ye, Z.; Hou, C.; Xu, Y.; Liu, S.; Wang, G. Frontier and hot topics in electrochemiluminescence sensing technology based on CiteSpace bibliometric analysis. Biosens. Bioelectron. 2022, 201, 113932. [Google Scholar] [CrossRef]
- Sarkar, B.; Takeyeva, D.; Guchhait, R.; Sarkar, M. Optimized radio-frequency identification system for different warehouse shapes. Knowl.-Based Syst. 2022, 258, 109811. [Google Scholar] [CrossRef]
- Friji, H.; Khanfor, A.; Ghazzai, H.; Massoud, Y. An End-to-End Smart IoT-Driven Navigation for Social Distancing Enforcement. IEEE Access 2022, 10, 76824–76841. [Google Scholar] [CrossRef]
- Domeyer, J.E.; Lee, J.D.; Toyoda, H.; Mehler, B.; Reimer, B. Driver-Pedestrian Perceptual Models Demonstrate Coupling: Implications for Vehicle Automation. IEEE Trans. Hum.-Mach. Syst. 2022, 52, 557–566. [Google Scholar] [CrossRef]
- Wu, Y.; Dai, H.N.; Wang, H.; Xiong, Z.; Guo, S. A Survey of Intelligent Network Slicing Management for Industrial IoT: Integrated Approaches for Smart Transportation, Smart Energy, and Smart Factory. IEEE Commun. Surv. Tutor. 2022, 24, 1175–1211. [Google Scholar] [CrossRef]
- Bang, A.O.; Rao, U.P.; Visconti, A.; Brighente, A.; Conti, M. An IoT Inventory Before Deployment: A Survey on IoT Protocols, Communication Technologies, Vulnerabilities, Attacks, and Future Research Directions. Comput. Secur. 2022, 123, 102914. [Google Scholar] [CrossRef]
- Man, D.; Zeng, F.; Lv, J.; Xuan, S.; Yang, W.; Guizani, M. AI-based Intrusion Detection for Intelligence Internet of Vehicles. IEEE Consum. Electron. Mag. 2021, 12, 109–116. [Google Scholar] [CrossRef]
- Alabbad, Y.; Demir, I. Comprehensive flood vulnerability analysis in urban communities: Iowa case study. Int. J. Disaster Risk Reduct. 2022, 74, 102955. [Google Scholar] [CrossRef]
- Li, B.; Xu, H.; Zhao, Q.; Su, P.; Chabbi, M.; Jiao, S.; Liu, X. OJXPerf: Featherlight object replica detection for Java programs. In Proceedings of the 44th International Conference on Software Engineering, Pittsburgh, PA, USA, 8–27 May 2022; pp. 1558–1570. [Google Scholar]
- Li, B.; Zhao, Q.; Jiao, S.; Liu, X. DroidPerf: Profiling Memory Objects on Android Devices. In Proceedings of the 29th Annual International Conference on Mobile Computing and Networking, Madrid, Spain, 2–6 October 2023; pp. 1–15. [Google Scholar]
- Luo, Q.; Liu, J. Wireless telematics systems in emerging intelligent and connected vehicles: Threats and solutions. IEEE Wirel. Commun. 2018, 25, 113–119. [Google Scholar] [CrossRef]
- Li, B.; Su, P.; Chabbi, M.; Jiao, S.; Liu, X. DJXPerf: Identifying Memory Inefficiencies via Object-Centric Profiling for Java. In Proceedings of the 21st ACM/IEEE International Symposium on Code Generation and Optimization, Montréal, QC, Canada, 25 February–1 March 2023; pp. 81–94. [Google Scholar]
- Guo, J.; Liu, Z.; Tian, S.; Huang, F.; Li, J.; Li, X.; Igorevich, K.K.; Ma, J. Tfl-dt: A trust evaluation scheme for federated learning in digital twin for mobile networks. IEEE J. Sel. Areas Commun. 2023, 41, 3548–3560. [Google Scholar] [CrossRef]
- Bundak, C.E.A.; Abd Rahman, M.A.; Karim, M.K.A.; Osman, N.H. Fuzzy rank cluster top k Euclidean distance and triangle based algorithm for magnetic field indoor positioning system. Alex. Eng. J. 2022, 61, 3645–3655. [Google Scholar] [CrossRef]
- Zebari, R.; Abdulazeez, A.; Zeebaree, D.; Zebari, D.; Saeed, J. A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction. J. Appl. Sci. Technol. Trends 2020, 1, 56–70. [Google Scholar] [CrossRef]
- Islam, M.M.; Chuenpagdee, R. Towards a classification of vulnerability of small-scale fisheries. Environ. Sci. Policy 2022, 134, 1–12. [Google Scholar] [CrossRef]
- Khaire, U.M.; Dhanalakshmi, R. Stability of feature selection algorithm: A review. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 1060–1073. [Google Scholar] [CrossRef]
- Yang, Y.; Pedersen, J.O. A comparative study on feature selection in text categorization. In Proceedings of the ICML, Nashville, TN, USA, 8–12 July 1997; Volume 97, p. 35. [Google Scholar]
- Zhang, C.; Mousavi, A.A.; Masri, S.F.; Gholipour, G.; Yan, K.; Li, X. Vibration feature extraction using signal processing techniques for structural health monitoring: A review. Mech. Syst. Signal Process. 2022, 177, 109175. [Google Scholar] [CrossRef]
- Lewis, D.D. Feature selection and feature extraction for text categorization. In Proceedings of the Speech and Natural Language: Proceedings of a Workshop Held at Harriman, New York, NY, USA, 23–26 February 1992. [Google Scholar]
- Rahman, M.A.; Hossain, M.F.; Hossain, M.; Ahmmed, R. Employing PCA and t-statistical approach for feature extraction and classification of emotion from multichannel EEG signal. Egypt. Inform. J. 2020, 21, 23–35. [Google Scholar] [CrossRef]
- Alqahtani, H.; Kumar, G. A deep learning-based intrusion detection system for in-vehicle networks. Comput. Electr. Eng. 2022, 104, 108447. [Google Scholar] [CrossRef]
- Qaiser, S.; Ali, R. Text mining: Use of TF-IDF to examine the relevance of words to documents. Int. J. Comput. Appl. 2018, 181, 25–29. [Google Scholar] [CrossRef]
- Domeniconi, C.; Peng, J.; Gunopulos, D. Adaptive metric nearest neighbor classification. In Proceedings of the Proceedings IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2000 (Cat. No. PR00662), Hilton Head, SC, USA, 15 June 2000; IEEE: Piscataway, NJ, USA, 2000; Volume 1, pp. 517–522. [Google Scholar]
- Chen, Z.; Zhang, Y.; Chen, Z. A categorization framework for common computer vulnerabilities and exposures. Comput. J. 2010, 53, 551–580. [Google Scholar] [CrossRef]
- Song, H.M.; Woo, J.; Kim, H.K. In-vehicle network intrusion detection using deep convolutional neural network. Veh. Commun. 2020, 21, 100198. [Google Scholar] [CrossRef]
- Zhang, S. Cost-sensitive KNN classification. Neurocomputing 2020, 391, 234–242. [Google Scholar] [CrossRef]
- Yang, L.; Moubayed, A.; Shami, A. MTH-IDS: A multitiered hybrid intrusion detection system for internet of vehicles. IEEE Internet Things J. 2021, 9, 616–632. [Google Scholar] [CrossRef]
- Ding, H.; Chen, L.; Dong, L.; Fu, Z.; Cui, X. Imbalanced data classification: A KNN and generative adversarial networks-based hybrid approach for intrusion detection. Future Gener. Comput. Syst. 2022, 131, 240–254. [Google Scholar] [CrossRef]
- Zeng, X.; Tu, X.; Liu, Y.; Fu, X.; Su, Y. Toward better drug discovery with knowledge graph. Curr. Opin. Struct. Biol. 2022, 72, 114–126. [Google Scholar] [CrossRef]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Philip, S.Y. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 494–514. [Google Scholar] [CrossRef]
- Dai, Z.; Li, D.; Zhou, Z.; Zhou, S.; Liu, W.; Liu, J.; Wang, X.; Ren, X. A strategy for high performance of energy storage and transparency in KNN-based ferroelectric ceramics. Chem. Eng. J. 2022, 427, 131959. [Google Scholar] [CrossRef]
- Patel, S.P.; Upadhyay, S.H. Euclidean distance based feature ranking and subset selection for bearing fault diagnosis. Expert Syst. Appl. 2020, 154, 113400. [Google Scholar] [CrossRef]
- Cheng, W.; Zhu, X.; Chen, X.; Li, M.; Lu, J.; Li, P. Manhattan distance-based adaptive 3D transform-domain collaborative filtering for laser speckle imaging of blood flow. IEEE Trans. Med. Imaging 2019, 38, 1726–1735. [Google Scholar] [CrossRef]
- Liu, D.; Chen, X.; Peng, D. Some cosine similarity measures and distance measures between q-rung orthopair fuzzy sets. Int. J. Intell. Syst. 2019, 34, 1572–1587. [Google Scholar] [CrossRef]
- Chen, T.Y. New Chebyshev distance measures for Pythagorean fuzzy sets with applications to multiple criteria decision analysis using an extended ELECTRE approach. Expert Syst. Appl. 2020, 147, 113164. [Google Scholar] [CrossRef]
- Astorino, A.; Fuduli, A. The proximal trajectory algorithm in SVM cross validation. IEEE Trans. Neural Netw. Learn. Syst. 2015, 27, 966–977. [Google Scholar] [CrossRef]
- Wang, Z.; Na, J.; Zheng, B. An improved knn classifier for epilepsy diagnosis. IEEE Access 2020, 8, 100022–100030. [Google Scholar] [CrossRef]
- Almutairi, S.; Barnawi, A. Securing DNN for smart vehicles: An overview of adversarial attacks, defenses, and frameworks. J. Eng. Appl. Sci. 2023, 70, 16. [Google Scholar] [CrossRef]
- Huang, G.; Li, Y.; Wang, Q.; Ren, J.; Cheng, Y.; Zhao, X. Automatic classification method for software vulnerability based on deep neural network. IEEE Access 2019, 7, 28291–28298. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Dimensionality Reduction Results |
|---|---|
| An authenticated, remote attacker can gain access to a dereferenced pointer contained in a request. The accesses can subsequently lead to local overwriting of memory in the CmpTraceMgr, whereby the attacker can neither gain the values read internally nor control the values to be written. If invalid memory is accessed, this results in a crash. | [‘attacker’, ‘control’, ‘access’, ‘request’, ‘authenticated’] |
| CVE | Word Set | Word Vector |
|---|---|---|
| CVE-2014-10374 | ‘Fitbit’:0 ‘activity’:0 ‘-’:0 ‘tracker’:0 ‘is’:0 ‘USA’:1 ‘Fitbit’:0 ‘company’:1 ‘of’:0 ‘One’:0 ‘Smart’:1 ‘Sports’:0 ‘Watch’:1 … | [000010100101 …1100101…1011111…] |
| System Configuration | Configuration Information |
|---|---|
| Operating system | Windows 11 |
| Version | 22H2 |
| Memory | 16 GB |
| Central Processing Unit | R7 5800H |
| Solid-State Disk | 512 GB |
| lname | CVE | CWE | ltype | CVSS | ldetail |
|---|---|---|---|---|---|
| IBM Sterling File Gateway 2.2.0.0 through | CVE-2020-4654 | CWE-287 | improper authentication | low | IBM Sterling File Gateway 2.2.0.0 through 6.1.1.0 could allow an authenticated user to obtain sensitive… |
| Access Control Vulnerability in Citrix Systems Gateway Plug-in | CVE-2020-8199 | CWE-269 | improper privilege management | low | Citrix Systems Gateway Plug-in is a plug-in developed by Citrix Systems, a US-based company… |
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| SVM | 21 | 15 | 15 |
| KNN | 34 | 32 | 31 |
| DNN security | 24 | 21 | 21 |
| TFI-DNN | 29 | 27 | 26 |
| KG-KNN | 36 | 36 | 33 |
| Model | Precision | Recall | F1 Score |
|---|---|---|---|
| SVM | 52 | 41 | 39 |
| KNN | 60 | 55 | 56 |
| DNN | 57 | 52 | 53 |
| TFI-DNN | 59 | 56 | 56 |
| KG-KNN | 61 | 56 | 57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Wang, Y.; Song, J.; Cheng, H. IoV Vulnerability Classification Algorithm Based on Knowledge Graph. Electronics 2023, 12, 4749. https://doi.org/10.3390/electronics12234749
Wang J, Wang Y, Song J, Cheng H. IoV Vulnerability Classification Algorithm Based on Knowledge Graph. Electronics. 2023; 12(23):4749. https://doi.org/10.3390/electronics12234749
Chicago/Turabian StyleWang, Jiuru, Yifang Wang, Jingcheng Song, and Hongyuan Cheng. 2023. "IoV Vulnerability Classification Algorithm Based on Knowledge Graph" Electronics 12, no. 23: 4749. https://doi.org/10.3390/electronics12234749
APA StyleWang, J., Wang, Y., Song, J., & Cheng, H. (2023). IoV Vulnerability Classification Algorithm Based on Knowledge Graph. Electronics, 12(23), 4749. https://doi.org/10.3390/electronics12234749