
Monocular Depth Estimation Algorithm Integrating Parallel Transformer and Multi-Scale Features

Abstract
:1. Introduction
- (1)
- A new algorithm incorporating a new backbone network is proposed for self-supervised monocular depth estimation. This method solves the problem of limited receptive fields in a separate CNN network by using a parallel Transformer network and makes a certain contribution to increasing feature richness and effectiveness.
- (2)
- Compared with existing similar algorithms, the proposed new algorithm shows higher accuracy on the KITTI dataset and achieves better results under the same conditions through improvements. The effectiveness of the improvements in each part of this article is demonstrated through ablation experiments.
2. Related Work
2.1. Deep Learning and Monocular Depth Estimation
2.2. Application of Transformer in Monocular Depth Estimation
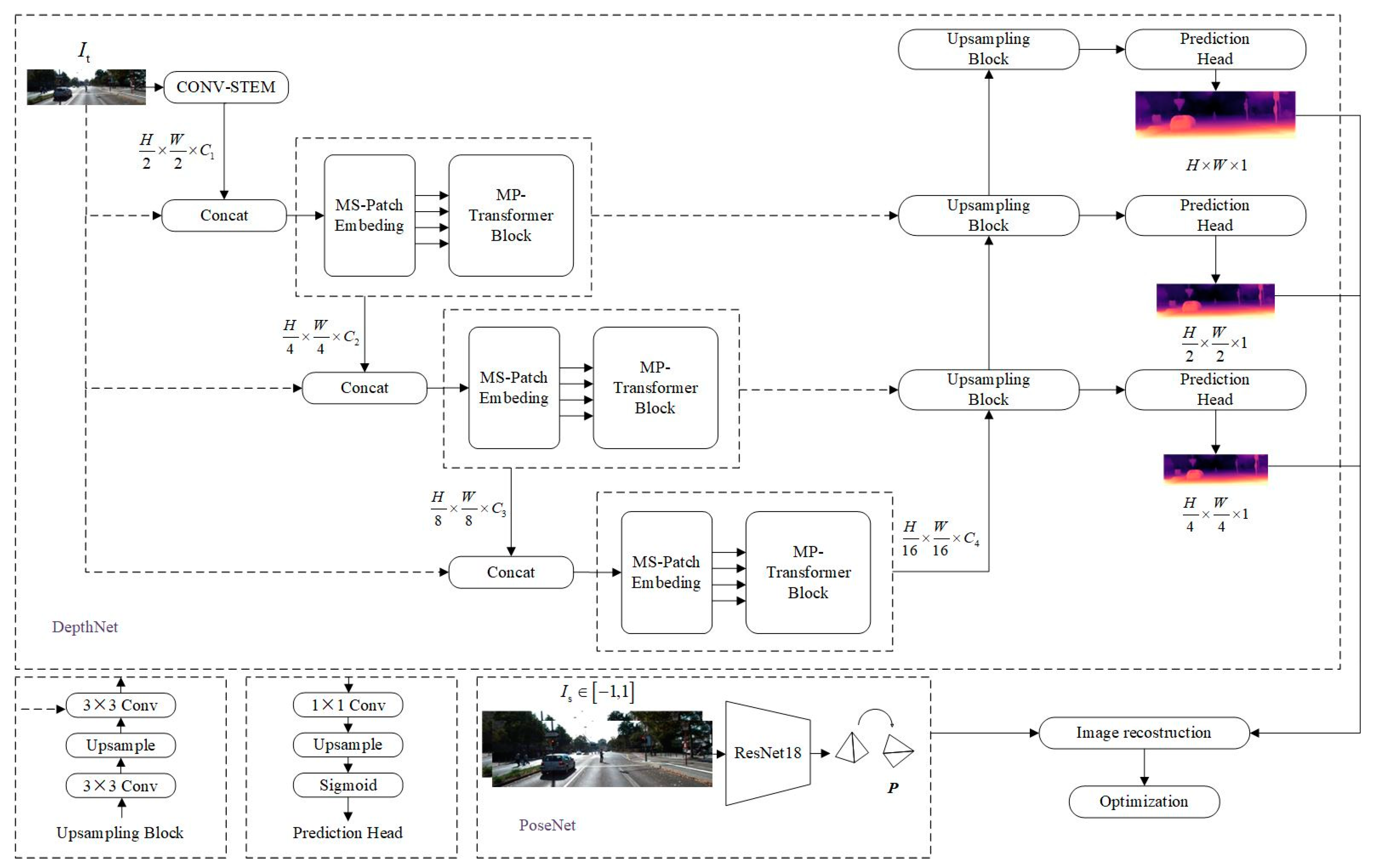
3. Self-Supervised Learning Network Structure
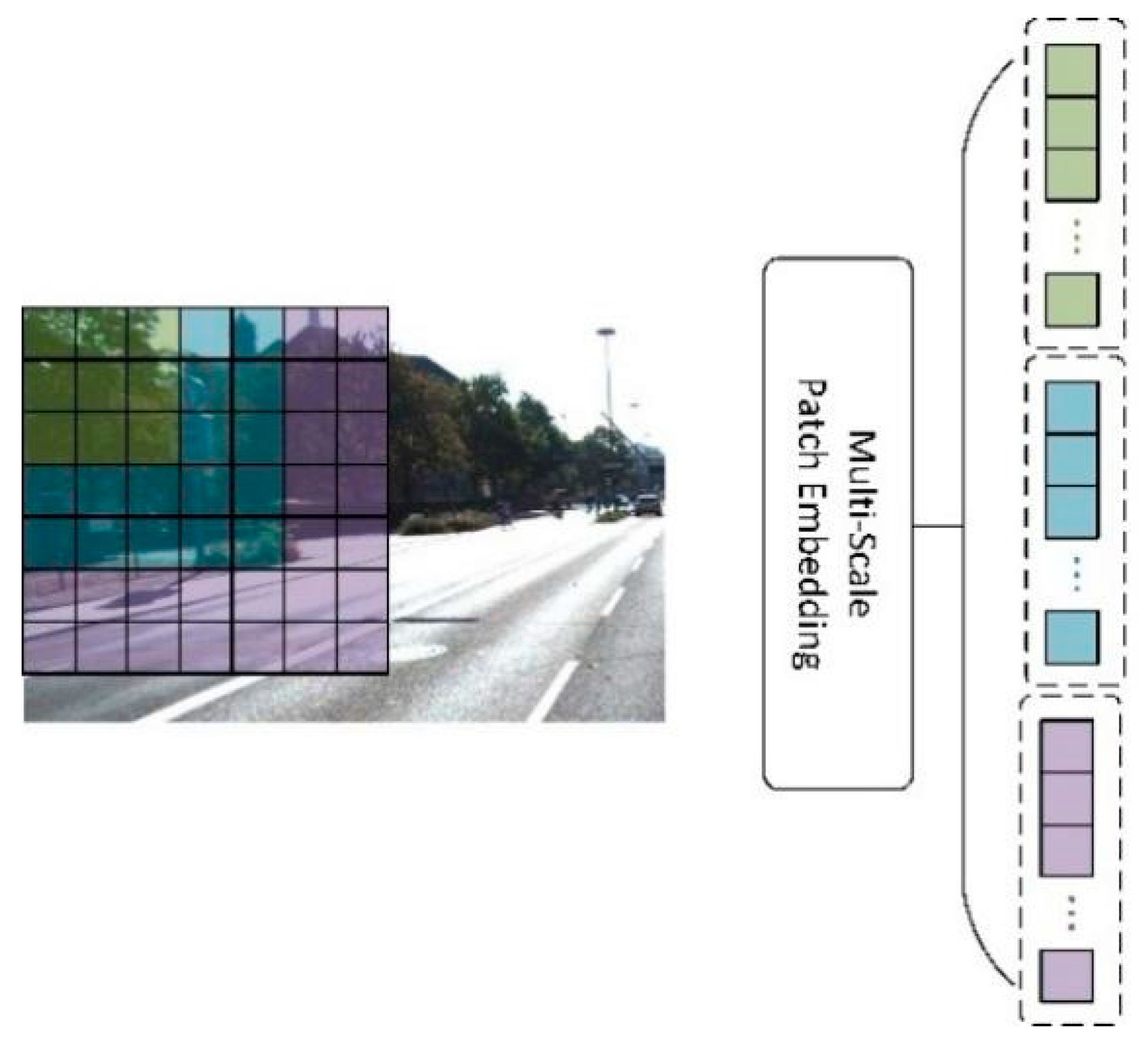
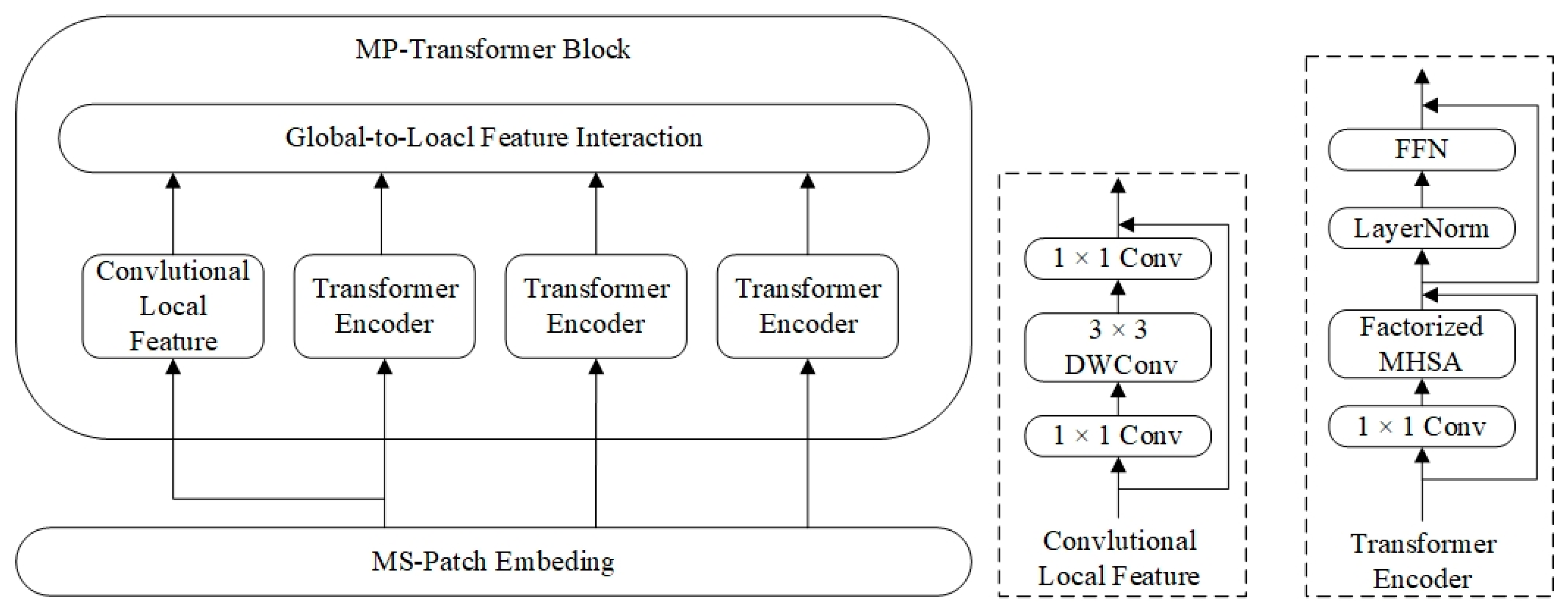
3.1. DepthNet
3.2. PoseNet
3.3. Loss Function
- (1)
- Image reconstruction loss. Self-supervised monocular depth estimation uses a deep network and relative pose to complete the image reconstruction task, but depth estimation is an uncertainty problem. When the relative pose is known, there can be multiple simultaneous and reasonable depth results to satisfy the image reconstruction requirements. By formulating this problem as training, the photometric reprojection loss is defined as follows:
- (2)
4. Algorithm Implementation Details
4.1. Hyperparameters
4.2. Data Augmentation and Evaluation Metrics
5. Testing Results
5.1. Datasets
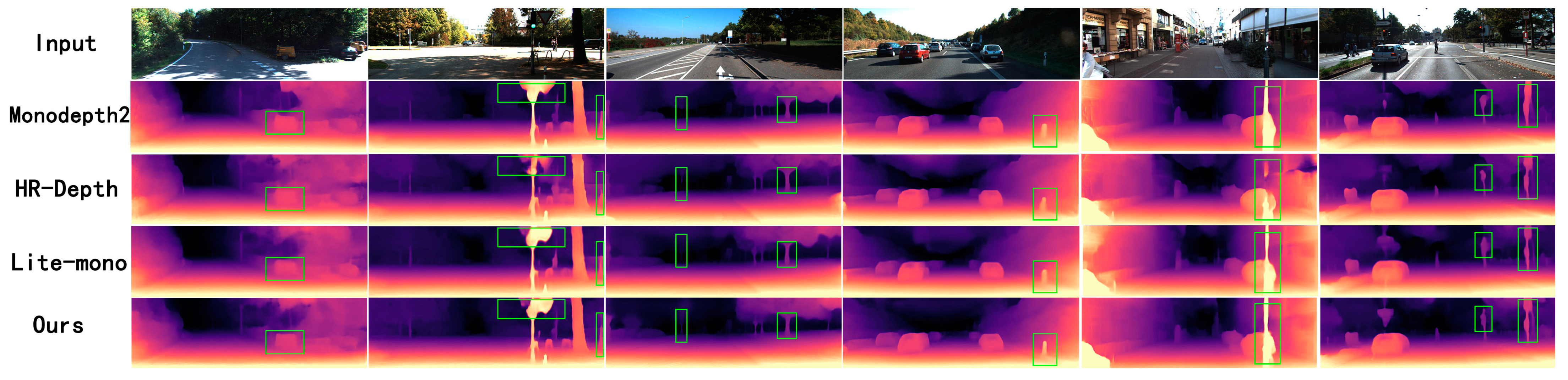
5.2. Experiment Analysis
6. Ablation Experiments
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Jun-Jun, J.; Zhen-Yu, L.; Xian-Ming, L. Deep Learning Based Monocular Depth Estimation:A Survey. Chin. J. Comput. 2022, 45, 1276–1307. [Google Scholar]
- Ullman, S. The interpretation of structure from motion. Proc. R. Soc. Lond. Ser. B Biol. Sci. 1979, 203, 405–426. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. Int. J. Comput. Vis. 2002, 47, 7–42. [Google Scholar] [CrossRef]
- Marr, D.; Poggio, T. A Computational Theory of Human Stereo Vision. Proc. R. Soc. Lond. Ser. B 1979, 204, 301–328. [Google Scholar]
- Palomer, A.; Ridao, P.; Forest, J.; Ribas, D. Underwater laser scanner: Ray-based model and calibration. IEEE/ASME Trans. Mechatron. 2019, 24, 1986–1997. [Google Scholar] [CrossRef]
- Gu, C.; Cong, Y.; Sun, G. Three birds, one stone: Unified laser-based 3-D reconstruction across different media. IEEE Trans. Instrum. Meas. 2020, 70, 1–12. [Google Scholar] [CrossRef]
- Zhang, R.; Tsai, P.-S.; Cryer, J.E.; Shah, M. Shape-from-shading: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 690–706. [Google Scholar] [CrossRef]
- Asada, N.; Fujiwara, H.; Matsuyama, T. Edge and depth from focus. Int. J. Comput. Vis. 1998, 26, 153–163. [Google Scholar] [CrossRef]
- Favaro, P.; Soatto, S. A geometric approach to shape from defocus. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 406–417. [Google Scholar] [CrossRef] [PubMed]
- Garg, R.; Bg, V.K.; Carneiro, G.; Reid, I. Unsupervised cnn for single view depth estimation: Geometry to the rescue. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings Part VIII 14. Springer: Cham, Switzerland, 2016; pp. 740–756. [Google Scholar]
- Zhou, T.; Brown, M.; Snavely, N.; Lowe, D.G. Unsupervised learning of depth and ego-motion from video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1851–1858. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Firman, M.; Brostow, G.J. Digging into self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3828–3838. [Google Scholar]
- Eigen, D.; Puhrsch, C.; Fergus, R. Depth map prediction from a single image using a multi-scale deep network. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar]
- Laina, I.; Rupprecht, C.; Belagiannis, V.; Tombari, F.; Navab, N. Deeper depth prediction with fully convolutional residual networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 239–248. [Google Scholar]
- Ramamonjisoa, M.; Du, Y.; Lepetit, V. Predicting sharp and accurate occlusion boundaries in monocular depth estimation using displacement fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14648–14657. [Google Scholar]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Yin, Z.; Shi, J. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1983–1992. [Google Scholar]
- Casser, V.; Pirk, S.; Mahjourian, R.; Angelova, A. Unsupervised monocular depth and ego-motion learning with structure and semantics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 1–8. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Varma, A.; Chawla, H.; Zonooz, B.; Arani, E. Transformers in self-supervised monocular depth estimation with unknown camera intrinsics. arXiv 2022, arXiv:2202.03131. [Google Scholar]
- Bae, J.; Moon, S.; Im, S. Deep digging into the generalization of self-supervised monocular depth estimation. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; pp. 187–196. [Google Scholar]
- Zhang, N.; Nex, F.; Vosselman, G.; Kerle, N. Lite-mono: A lightweight cnn and transformer architecture for self-supervised monocular depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 18537–18546. [Google Scholar]
- Lee, Y.; Kim, J.; Willette, J.; Hwang, S.J. Mpvit: Multi-path vision transformer for dense prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 7287–7296. [Google Scholar]
- Xu, W.; Xu, Y.; Chang, T.; Tu, Z. Co-scale conv-attentional image transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 9981–9990. [Google Scholar]
- Zhou, H.; Greenwood, D.; Taylor, S. Self-supervised monocular depth estimation with internal feature fusion. arXiv 2021, arXiv:2110.09482. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2650–2658. [Google Scholar]
- Lyu, X.; Liu, L.; Wang, M.; Kong, X.; Liu, L.; Liu, Y.; Chen, X.; Yuan, Y. Hr-depth: High resolution self-supervised monocular depth estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; pp. 2294–2301. [Google Scholar]
- Zhang, S.; Zhang, J.; Tao, D. Towards scale-aware, robust, and generalizable unsupervised monocular depth estimation by integrating IMU motion dynamics. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 143–160. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual, 11–17 October 2021; pp. 10012–10022. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Lower is Better | Higher is Better | |||||
|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | RMSE log | ||||
| GeoNet [17] | 0.149 | 1.060 | 5.567 | 0.226 | 0.796 | 0.935 | 0.975 |
| Monodepth2-Resnet18 [12] | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.981 |
| Monodepth2-Resnet50 [12] | 0.110 | 0.831 | 4.642 | 0.187 | 0.883 | 0.962 | 0.982 |
| HR-depth [30] | 0.109 | 0.792 | 4.632 | 0.182 | 0.884 | 0.962 | 0.983 |
| DynaDepth-ResNet50 [31] | 0.109 | 0.787 | 4.705 | 0.195 | 0.869 | 0.958 | 0.981 |
| Lite-mono [22] | 0.107 | 0.765 | 4.561 | 0.183 | 0.886 | 0.963 | 0.983 |
| Ours | 0.103 | 0.736 | 4.454 | 0.179 | 0.897 | 0.965 | 0.983 |
| Method | Network Type | Feature Interation Module | Lower is Better | Higher is Better | |||||
|---|---|---|---|---|---|---|---|---|---|
| Abs Rel | Sq Rel | RMSE | RMSE log | ||||||
| A | CNN | 0.115 | 0.903 | 4.863 | 0.193 | 0.877 | 0.959 | 0.981 | |
| B | Single Transformer | 0.120 | 0.879 | 4.957 | 0.197 | 0.855 | 0.954 | 0.980 | |
| C | Single Transformer | yes | 0.109 | 0.835 | 4.647 | 0.185 | 0.886 | 0.962 | 0.982 |
| Ours | Parallel Transformer | yes | 0.103 | 0.736 | 4.454 | 0.179 | 0.897 | 0.965 | 0.983 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Tan, C.; Yan, Y. Monocular Depth Estimation Algorithm Integrating Parallel Transformer and Multi-Scale Features. Electronics 2023, 12, 4669. https://doi.org/10.3390/electronics12224669
Wang W, Tan C, Yan Y. Monocular Depth Estimation Algorithm Integrating Parallel Transformer and Multi-Scale Features. Electronics. 2023; 12(22):4669. https://doi.org/10.3390/electronics12224669
Chicago/Turabian StyleWang, Weiqiang, Chao Tan, and Yunbing Yan. 2023. "Monocular Depth Estimation Algorithm Integrating Parallel Transformer and Multi-Scale Features" Electronics 12, no. 22: 4669. https://doi.org/10.3390/electronics12224669
APA StyleWang, W., Tan, C., & Yan, Y. (2023). Monocular Depth Estimation Algorithm Integrating Parallel Transformer and Multi-Scale Features. Electronics, 12(22), 4669. https://doi.org/10.3390/electronics12224669