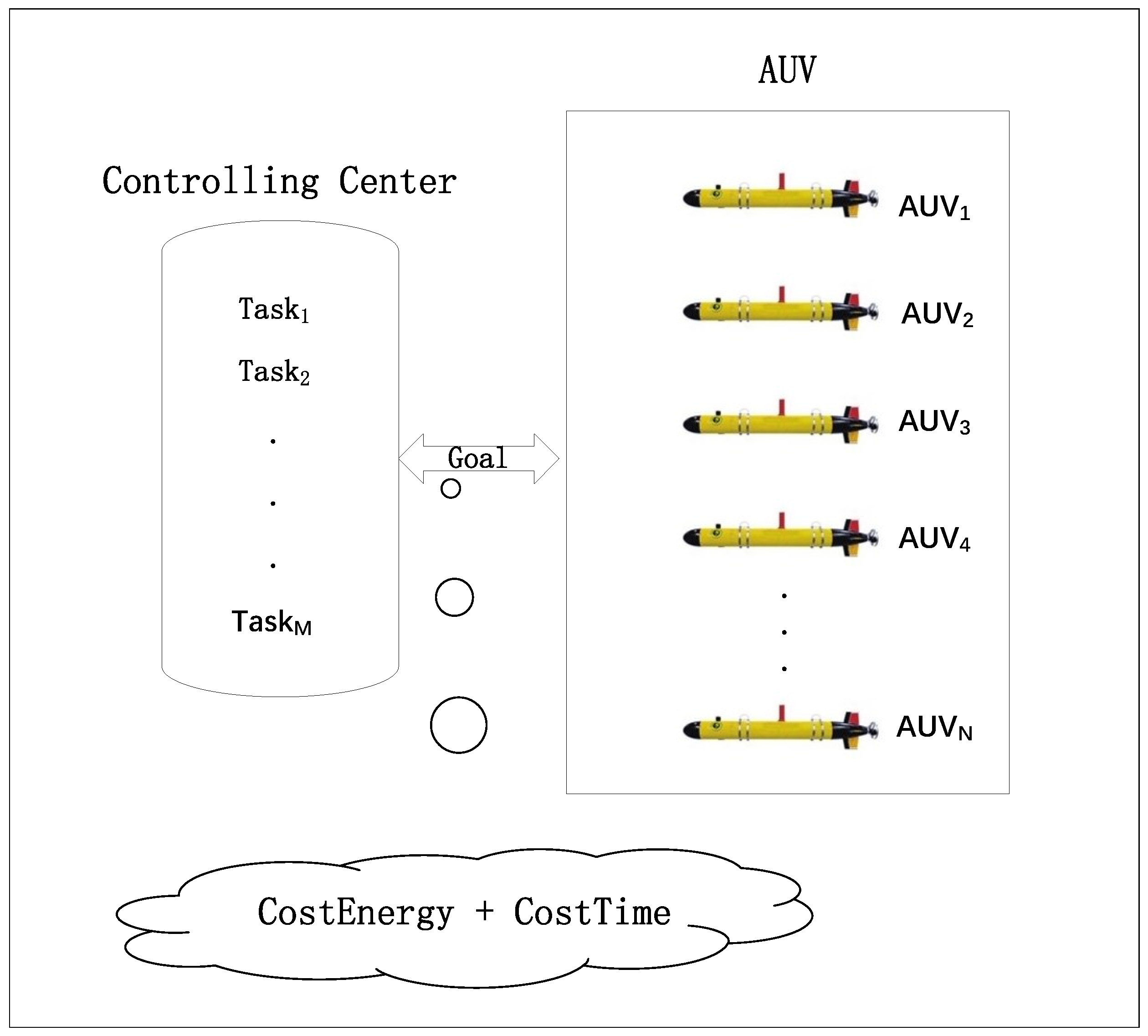
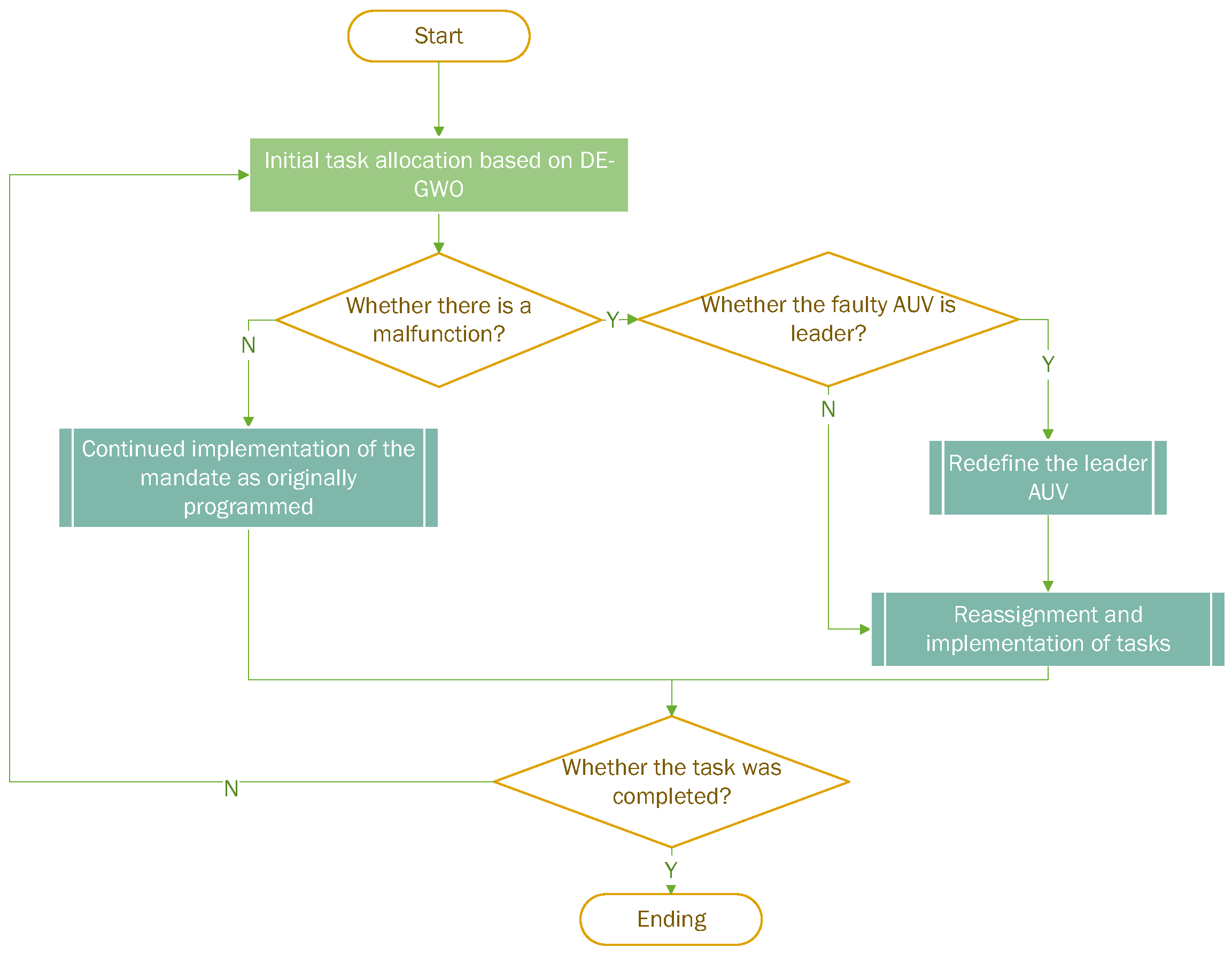
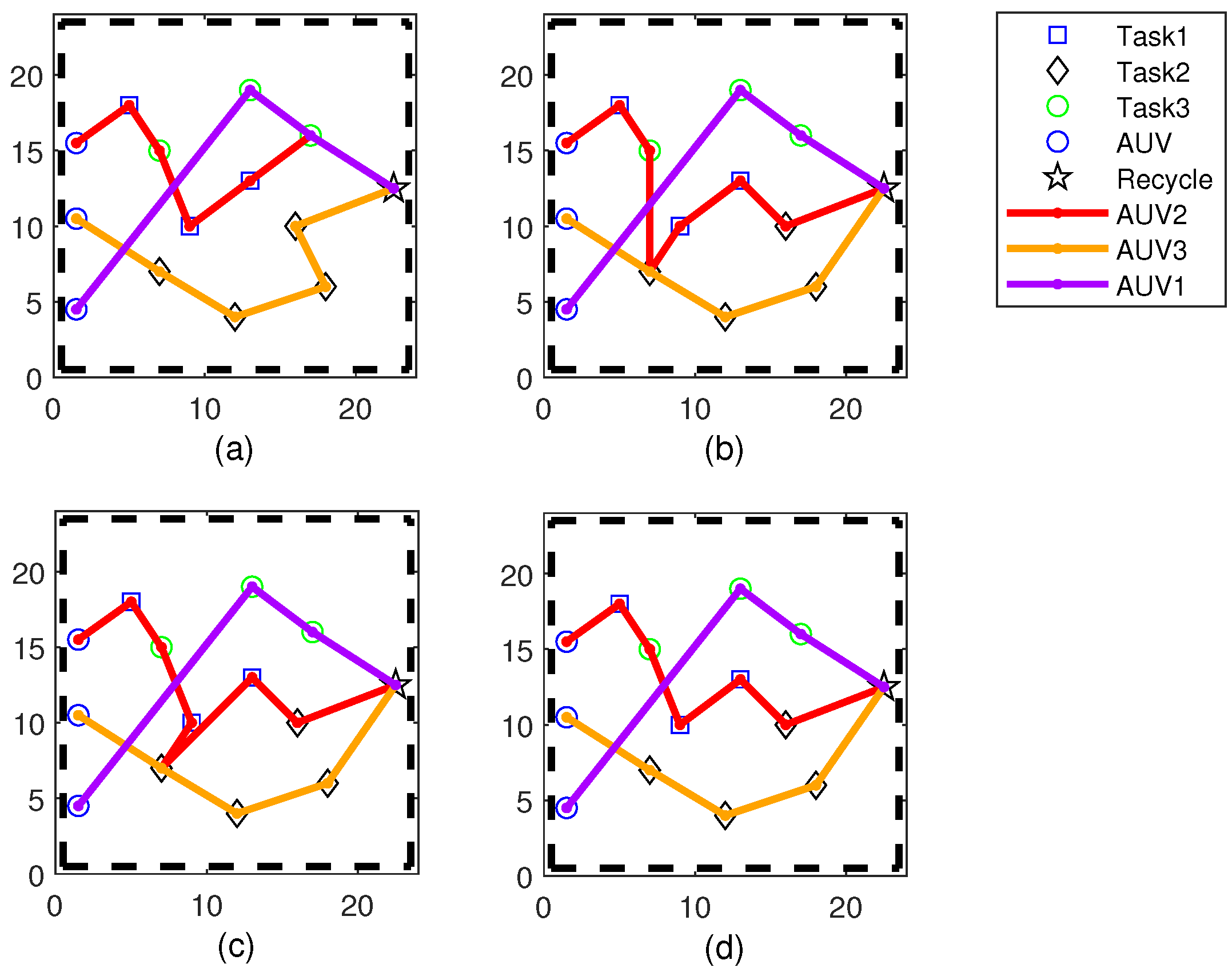
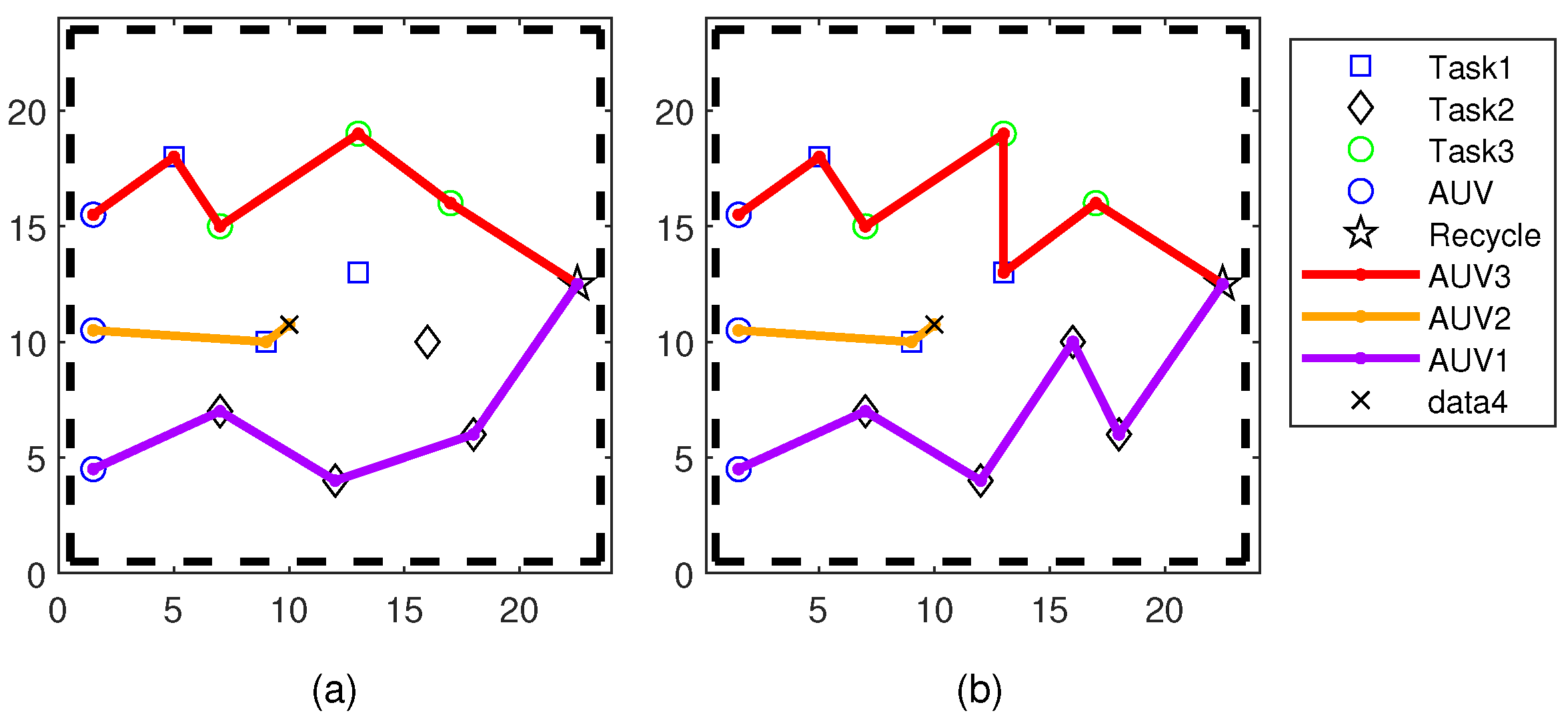
In order to solve the issue of local optimality during the task allocation process, we propose the DE-GWO algorithm. Additionally, we propose the reassignment strategy for the AUV experiencing faults during task execution. Our algorithm is superior to other methods.
3.1. Overview of the Proposed Algorithm
Given the discrete nature of the Multi-AUV task-allocation problem, the GWO algorithm requires a discretization operation to map the task-allocation problem model. The number of tasks to be executed by the Multi-AUV setup determines the location dimension for each gray wolf in the population. For example, if there are N tasks that need completion, each gray wolf’s location is represented as an N-dimensional vector. Once the gray wolf population is positioned, we sort each individual’s position within the N-dimensional space by magnitude to generate the task sequence for the AUVs. Furthermore, the task sequences are randomly grouped based on the number of AUVs. This random grouping adds an element of discretization to both the algorithm and the task sequences for each AUV. Consequently, the position of each gray wolf signifies how the AUV task sequences are allocated and organized. If the generated task allocation plan fails to meet the Multi-AUV task allocation constraints, we regenerate the locations and groupings of gray wolves until the plan aligns with the task requirements. Through continuous iterations of the algorithm, we ultimately obtain an allocation that optimizes the objective function.
The GWO algorithm faces challenges related to poor population diversity and premature convergence when solving complex problems. To address these issues in the context of Multi-AUV task allocation, this study initially employed Singer chaotic mapping to initialize the gray wolf population, thereby enhancing population diversity. This approach ensures a uniform distribution of gray wolves within the search space, which, in turn, boosts the algorithm’s global search capability and introduces greater randomness and diversity into the sequence of Multi-AUV tasks. Singer chaotic mapping is a type of chaotic mapping known for its numerous advantages, including a simple structure, high randomness, and a uniform distribution [
41]. Its mathematical expression is as follows:
In this equation,
and
are used to initialize the gray wolf population position.
is defined as follows:
In this equation, and are the upper and lower bounds of the search space, respectively.
Meanwhile, this paper employed a strategy of nonlinear convergence to enhance the convergence factor and optimize the position update formula in the GWO algorithm, aiming to boost its global search capabilities. Considering the fast convergence speed of the DE algorithm and its role in strengthening information exchange between individuals in the population while improving population diversity through mutation, this paper introduced the crossover, selection, and mutation operations of the DE algorithm during the evolution of the GWO algorithm. This promotes continuous evolution among gray wolf individuals through the survival of the fittest, thus enhancing the population diversity of the GWO algorithm and improving its ability to escape local optima.
In the standard GWO algorithm, the vector
A represents the extent of prey search undertaken by the gray wolf population. The convergence factor
a is crucial in balancing the algorithm’s local and global search capabilities. The convergence factor
a affects the coefficient vector
A as follows:
In this equation,
T is the maximum number of iterations of the algorithm and
is a random vector between [0, 1]. When solving complex problems, it is important to consider the update strategy of a linearly decreasing convergence factor. The strategy causes the algorithm to fall into local optimum during the iteration. To enhance the algorithm’s global search ability, this paper used a nonlinear update strategy for the convergence factor, formulated as follows:
In this equation, represents the current number of iterations and represents the maximum number of iterations of the algorithm. The convergence factor a decreases nonlinearly from 2 to 0 during the iteration process. It takes a larger value in the early iterations, decaying more slowly, thus improving the global search capability. In the late iterations, the convergence factor quickly reduces to 0, facilitating a swift convergence of the algorithm.
In the standard GWO algorithm,
and
together guide the gray wolves in the population to update their positions so as to gradually approach the target, and the formula is expressed as follows:
In the aforementioned equation,
,
, and
represent the positions of the
-wolf,
-wolf, and
-wolf, correspondingly, in the present iteration. Additionally, the search steps conducted in adherence to the guidelines of the
-wolf,
-wolf, and
-wolf are identified by
,
, and
, respectively.
represent the positions of individual gray wolves in the population after position updating led by the
-wolf,
-wolf, and
-wolf, respectively;
,
,
and
,
,
are the corresponding coefficient vectors. In order to improve the GWO algorithm’s ability to escape local optima and prevent algorithm stagnation when the
-wolf,
-wolf, and
-wolf are trapped in local optima, we propose a dynamic weighting strategy in this paper. The population’s position is updated using the following formula:
In the equation above, the objective function calculates the adaptation values of the -wolf, -wolf, and -wolf, denoted as for , respectively. The corresponding weights of the adaptation values are given by for . Following the movement of the gray wolf, the task sequence uses a grouping method that selects the most-effective allocation scheme between the original method and the -wolf grouping method to improve the algorithm’s ability to find the optimal solution.
The paper addressed the issue of premature convergence and limited global search capabilities in the standard GWO algorithm. To overcome these challenges, the paper suggested the DE algorithm, which provides faster convergence and enhances population diversity through information exchange during the mutation process among individuals. Through a comprehensive comparison and analysis of the advantages and disadvantages of both algorithms, this paper introduced the DE-GWO algorithm as an effective solution for Multi-AUV task allocation. When updating the positions of individual gray wolves, the DE algorithm utilizes the mutation, crossover, and selection operations to increase the diversity of the gray wolf population, improve the algorithm’s global search capabilities, aid in escaping local optima, and expedite the convergence speed.
After revising the position under the guidance of the
-,
-, and
-wolves, the individuals of the gray wolf population underwent a mutation operation utilizing the DE/best/1 mutation strategy outlined in
Table 1. The mutation process involves selecting the
-wolf of the gray wolf population and summing the deviation vectors of two chosen gray wolf individuals after weighting them accordingly, resulting in the creation of a mutated individual. The variant individuals will generate task sequences randomly to group them, which will increase diversity in the allocation scheme. Then, either the variant individual or target individual will be chosen randomly as the newborn individual for the current iteration, as described below:
In this equation, represents a random number between , denotes the crossover probability, and signifies the variant individual.
3.2. Steps of DE-GWO
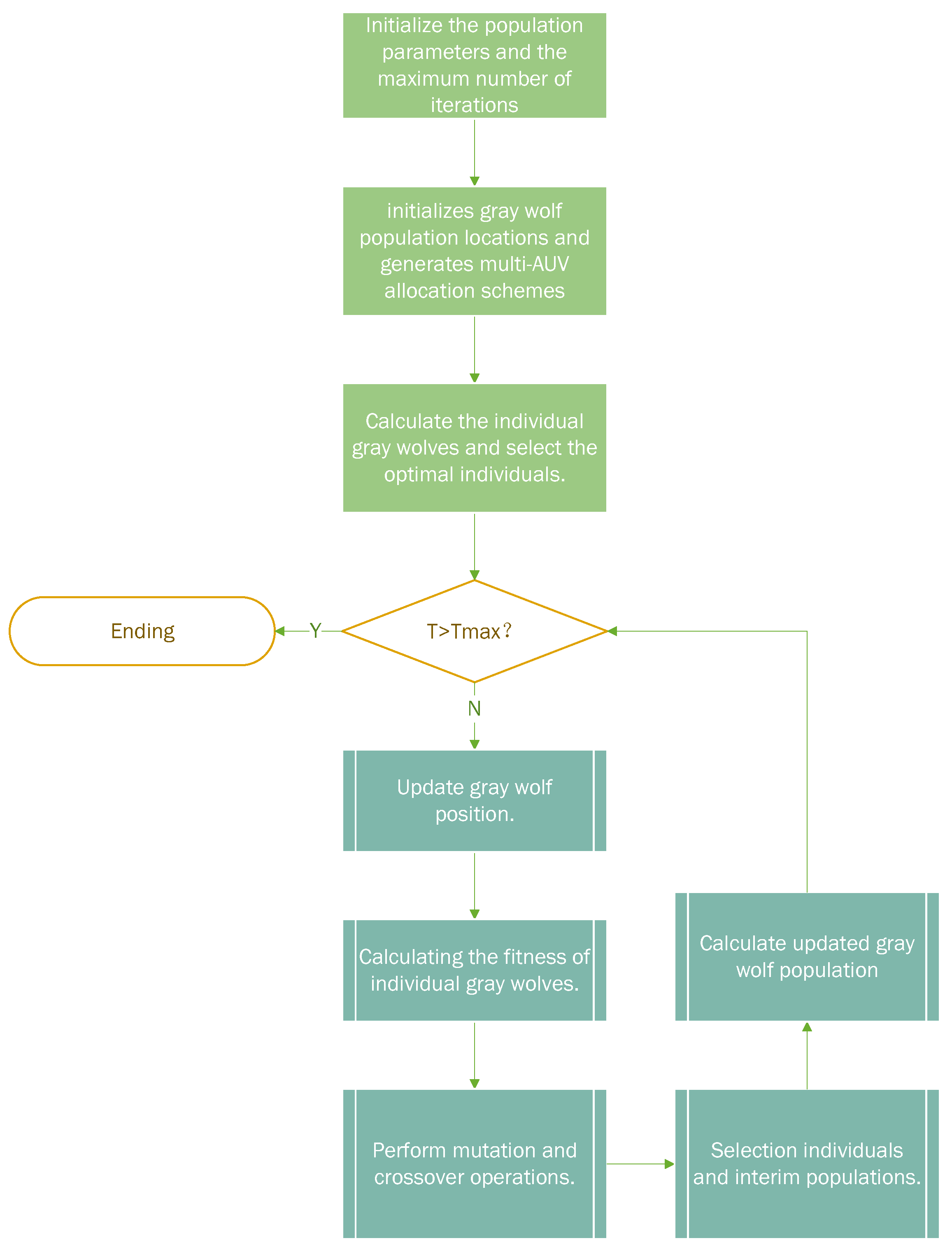
The DE-GWO algorithm utilized in this study was derived from the GWO algorithm, which draws parallels between the solution process of the Multi-AUV multi-task issue and the gray wolf searching for prey in the search space. The gray wolf stands for a set of feasible solutions for the Multi-AUV task assignment, with the optimal solution being the location of the prey. The flowchart of the DE-GWO algorithm is shown in
Figure 2:
Step 1: First, the necessary algorithm parameters are initialized, including a population N of 20, a of 1000, and a of 0.8.
Step 2: The population positions are initialized using Singer chaotic mapping and denoted as . Subsequently, these positions are sorted in ascending order, and the task sequences for the Multi-AUV system are generated. These task sequences are then grouped together to establish the Multi-AUV task allocation scheme.
Step 3: Calculate the objective function value of the individual gray wolves in the population, and rank the individuals based on the size of the objective function value, then select the optimal top three gray wolf individuals denoted as , , and , respectively.
Step 4: Calculate the convergence factor
a using Equations (
16) and (
17), and determine the values of
A and
C. Update the positions of the individual gray wolves in the population using Equation (
22), and compute the updated population’s objective function value.
Step 5: Choose the DE/Best/1 mutation strategy from
Table 1 for the mutation operation. Then, perform the crossover operation, using Equation (
23) to generate a temporary population, and calculate the objective function value for each gray wolf in this population.
Step 6: Perform a one-to-one selection operation between individuals in the temporary population and the individuals in the original population. Retain the individuals with better fitness values in the original population for the next iteration. This selection process ensures that the population evolves over the iterations, with individuals having better fitness values being preserved for further exploration in the search space.
Step 7: Sort the gray wolf individuals in the resulting population after the update according to the size of the fitness value, and update the positions of the gray wolf individuals , , and , with the top three fitness values.
Step 8: If the current number of iterations reaches the maximum number of iterations of the algorithm, the optimal result is output and the algorithm is terminated; otherwise, skip to Step 4.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}