
Deep-Reinforcement-Learning-Based Dynamic Ensemble Model for Stock Prediction


Abstract
:1. Introduction
- Our framework constructs base predictors of different prediction styles by selecting different neural network structures (such as GRU, ALSTM, and Transformer), loss functions, and the number of hidden layers to cope with the complex and ever-changing stock market. Furthermore, we use deep reinforcement learning to explore the optimal weight allocation of base predictors, converting the problem of optimal configuration of base predictor weights into a deep-reinforcement-learning task.
- Improving the design of only environmental rewards in the return function of the existing deep-reinforcement-learning algorithm, and introducing real-time investment income as an additional feedback signal to the deep-reinforcement-learning algorithm. By constructing a hybrid reward function, our DRL-DEM can maximize investment return.
- Using an iterative algorithm to simultaneously train the base predictors and deep-reinforcement learning. DRL-DEM optimize the weight of the ensemble model and update the network parameters of the base predictor at the same time, so that the base predictors can be adaptively adjusted to the feedback signal, and we realize the global collaboration of the ensemble model optimization to improve the prediction accuracy of the model.
2. Related Work
2.1. Stock Prediction Based on Deep Learning
2.2. Ensemble Methods Based on Deep Reinforcement Learning
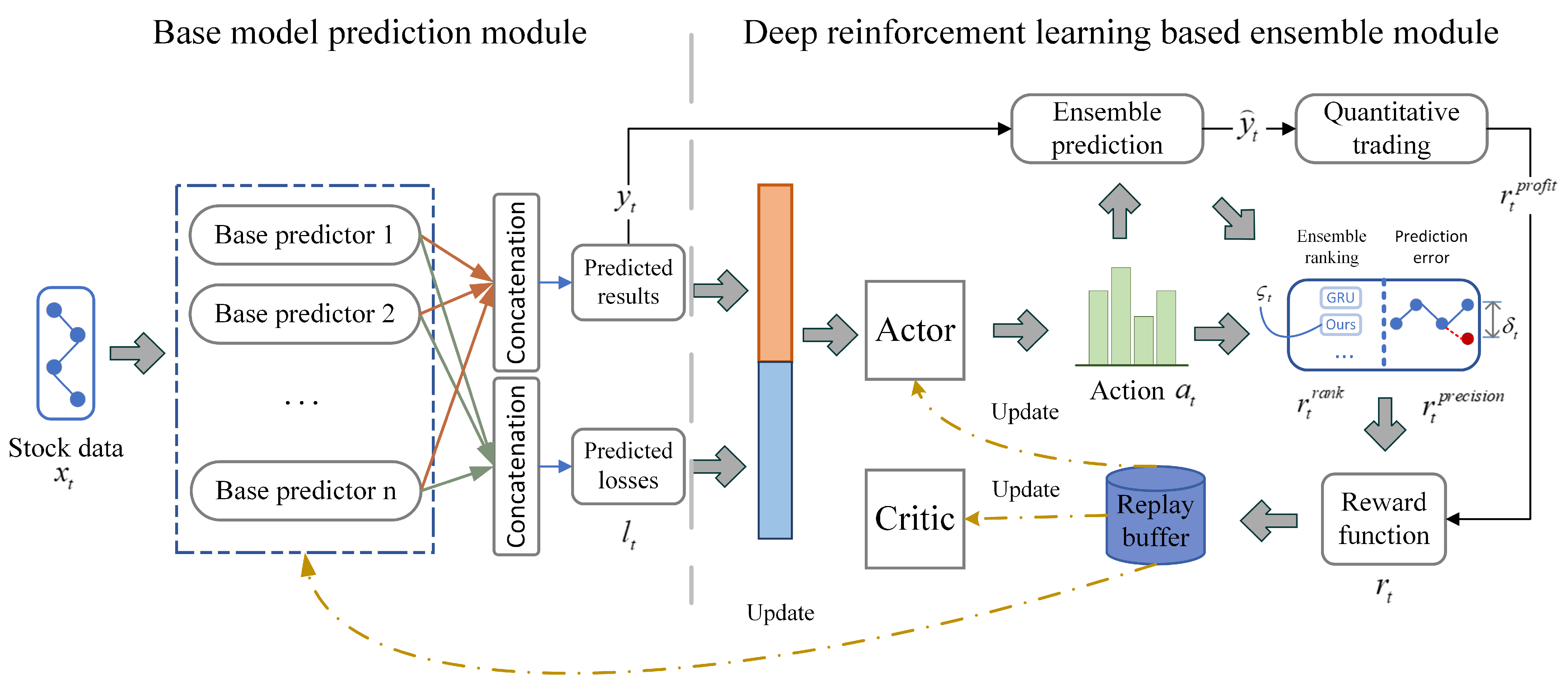
3. DRL-DEM Structure
3.1. Definition of the Problem
- is the state space, the state describes the stock data at time t along with the historical losses of the base predictors , where m represents the number of stocks, k represents the number of feature factors, and n represents the number of base predictors.
- is the action space, and action describes the weights of n base predictors corresponding to m stocks at time t.
- is transformed into according to the transition distribution, and action does not affect the next state .
- represents the immediate reward generated by taking action in state and transitioning to the new state .
- The discount factor describes the trade-off for future performance.
3.2. DRL-DEM Overall Framework
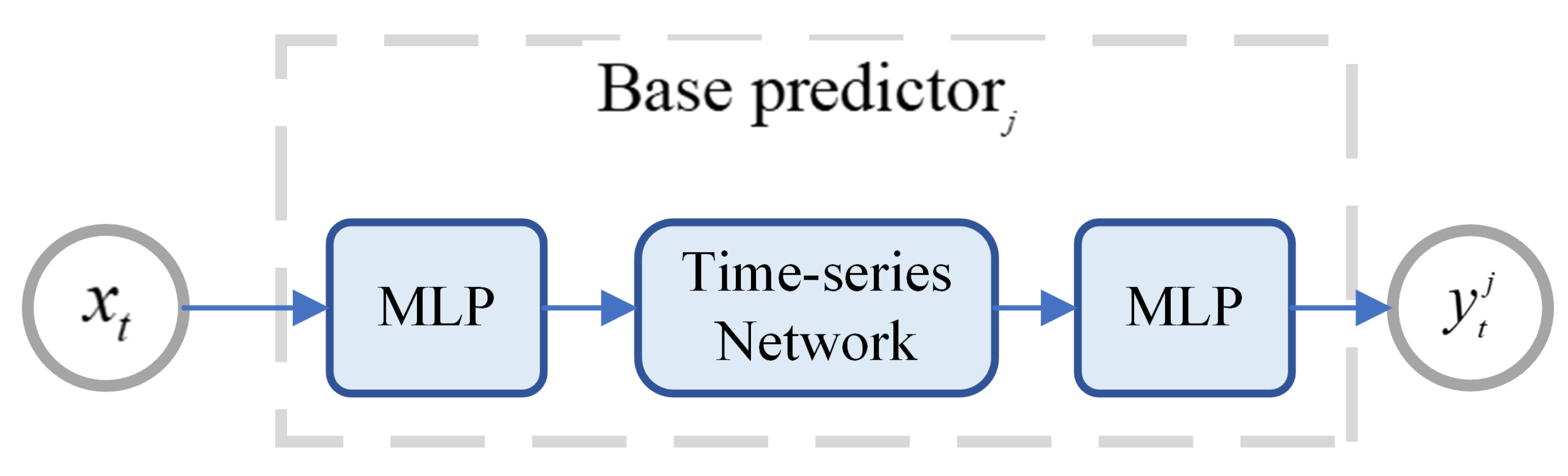
3.3. Base Model Prediction Module
3.4. Deep-Reinforcement-Learning-Based Ensemble Module
3.4.1. Agent of DRL-DEM
3.4.2. Calculation Method of Ensemble Prediction
3.4.3. Hybrid Reward Function for DRL-DEM
3.4.4. Quantitative Trading Investment Strategy
3.5. DRL-DEM Objective Function and Algorithm Flow
| Algorithm 1 DRL-DEM Algorithm Flow |
|
4. Experimental Results and Analysis
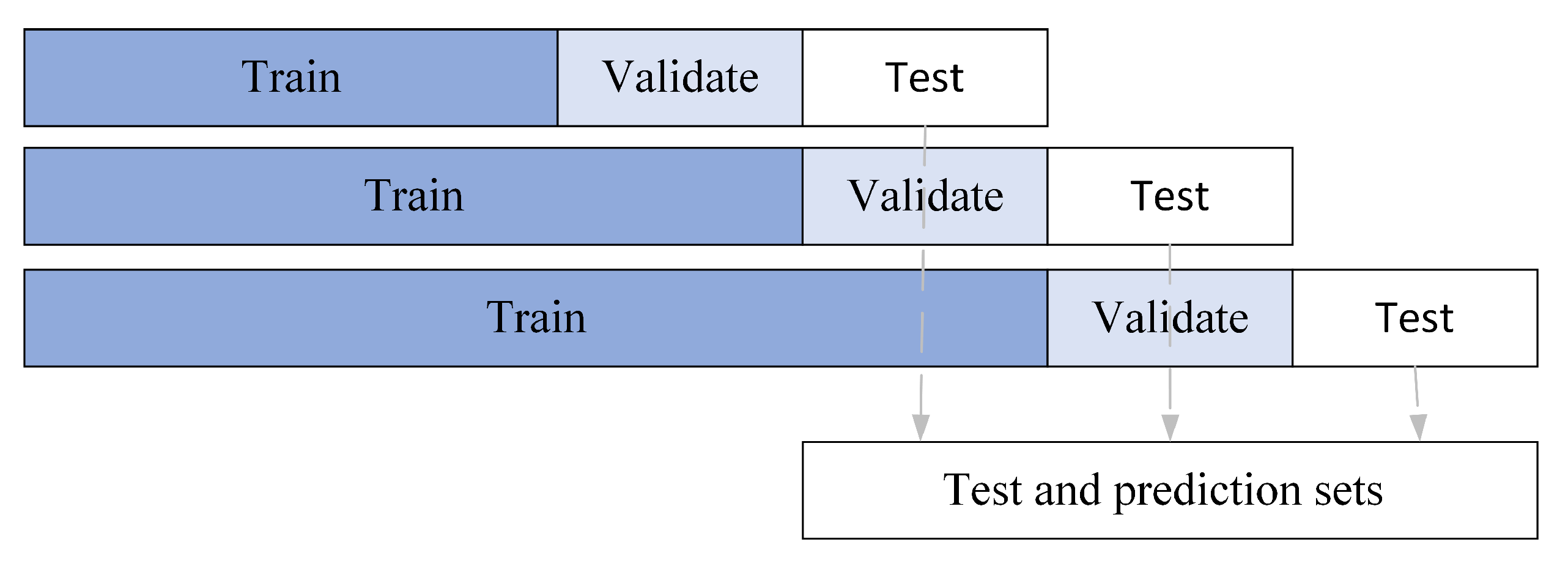
4.1. Dataset
4.2. Experimental Settings
4.2.1. Base Predictor Settings
- Base Predictor 1: GRU time-series network with 64 hidden units, trained using Mean Squared Error Loss.
- Base Predictor 2: GRU time-series network with 128 hidden units, trained using Smooth L1 Loss.
- Base Predictor 3: ALSTM time-series network with 64 hidden units, trained using Mean Squared Error Loss.
- Base Predictor 4: ALSTM time-series network with 128 hidden units, trained using Smooth L1 Loss.
- Base Predictor 5: Transformer time-series network with 64 hidden units, trained using Mean Squared Error Loss.
- Base Predictor 6: Transformer time-series network with 128 hidden units, trained using Smooth L1 Loss.
4.2.2. Hyperparameter Settings
4.2.3. Investment Strategy Settings
4.3. Evaluation Indicators
4.3.1. Prediction Accuracy Evaluation Component
- Mean Square Error (MSE): measures the average error of the model. The smaller the value, the smaller the error between the model’s prediction and the actual observed value, and the better the model performance.where is the predicted value and is the true value.
- Symmetric Mean Absolute Percentage Error (SMAPE): measures the percentage error of the model. The smaller the value, the better the model performance.where is the predicted value and is the true value.
4.3.2. Portfolio Return Evaluation Component
- Cumulative Return (CR): represents the total return from the initial investment to the end. The larger the value, the better the model performance.where is the total assets at time t, is the initial assets.
- Sharpe Ratio (SR): SR is used to evaluate the profitability and risk tolerance of the model. The larger the value, the better the model performance.where is the expectation of portfolio return, is the risk-free interest rate, and is the standard deviation of portfolio return.
- Annualized Rate of Return (ARR): represents the average return of the investment portfolio within one year. The larger the value, the better the model performance.where e represents the transaction duration, 252 represents the number of trading days in a year.
- Maximum Drawdown (MDD): represents the maximum short-term loss suffered during the entire investment process. The smaller the value, the better the model performance.
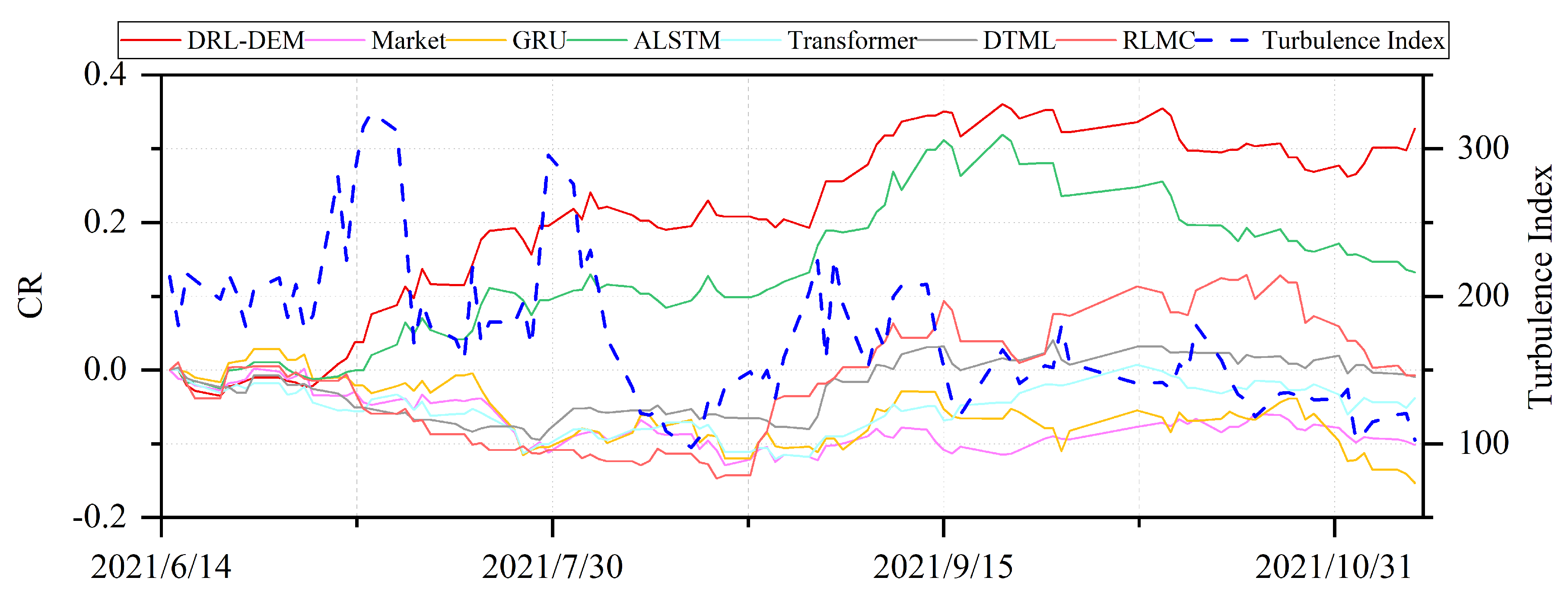
- Turbulence index: measure recent market risk conditions. The index value is usually stable within a certain threshold. If the index suddenly breaks through, it indicates an extreme situation in the market.where is the return on assets at the current moment t, is the average of historical returns, and is the covariance of historical returns.
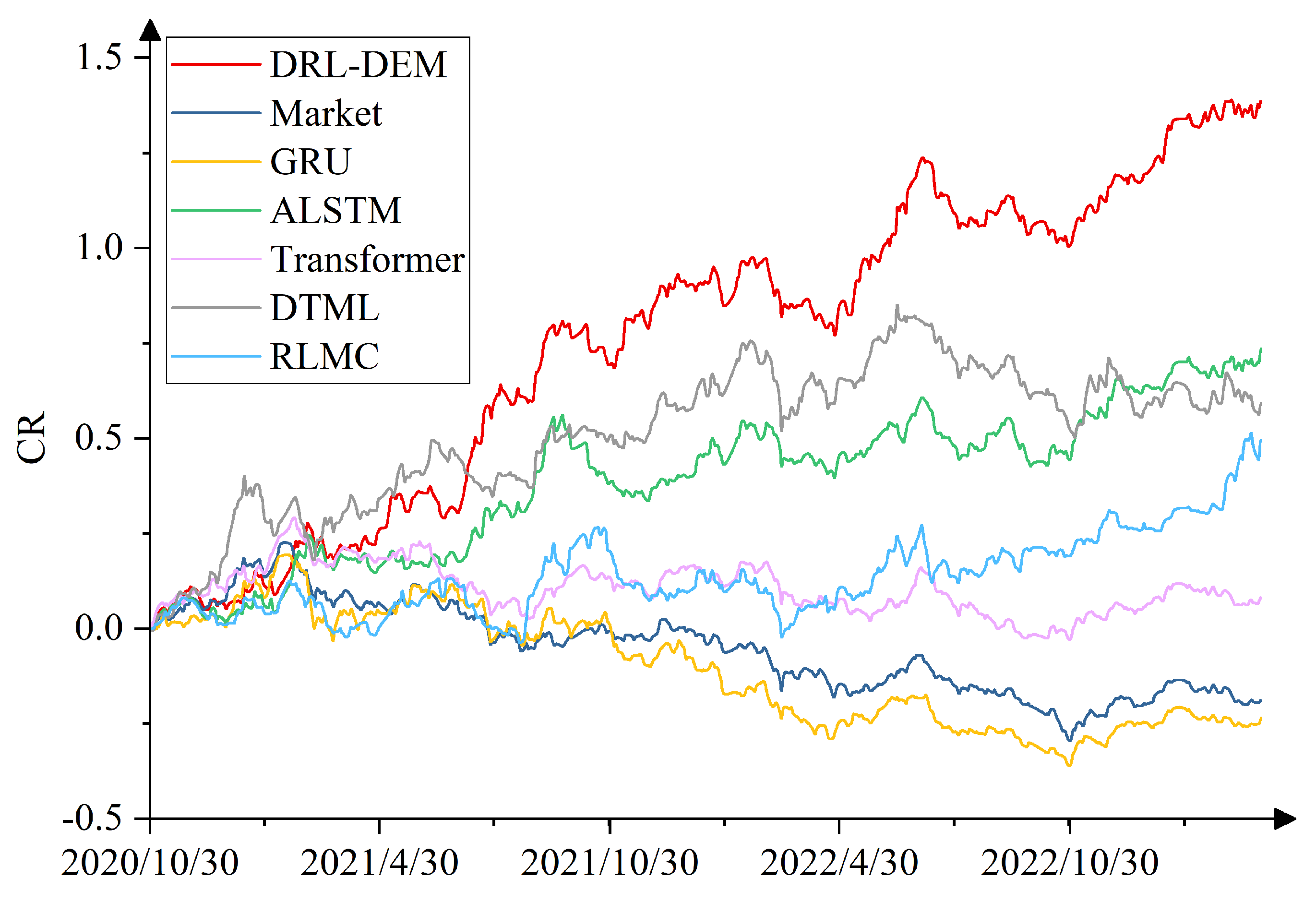
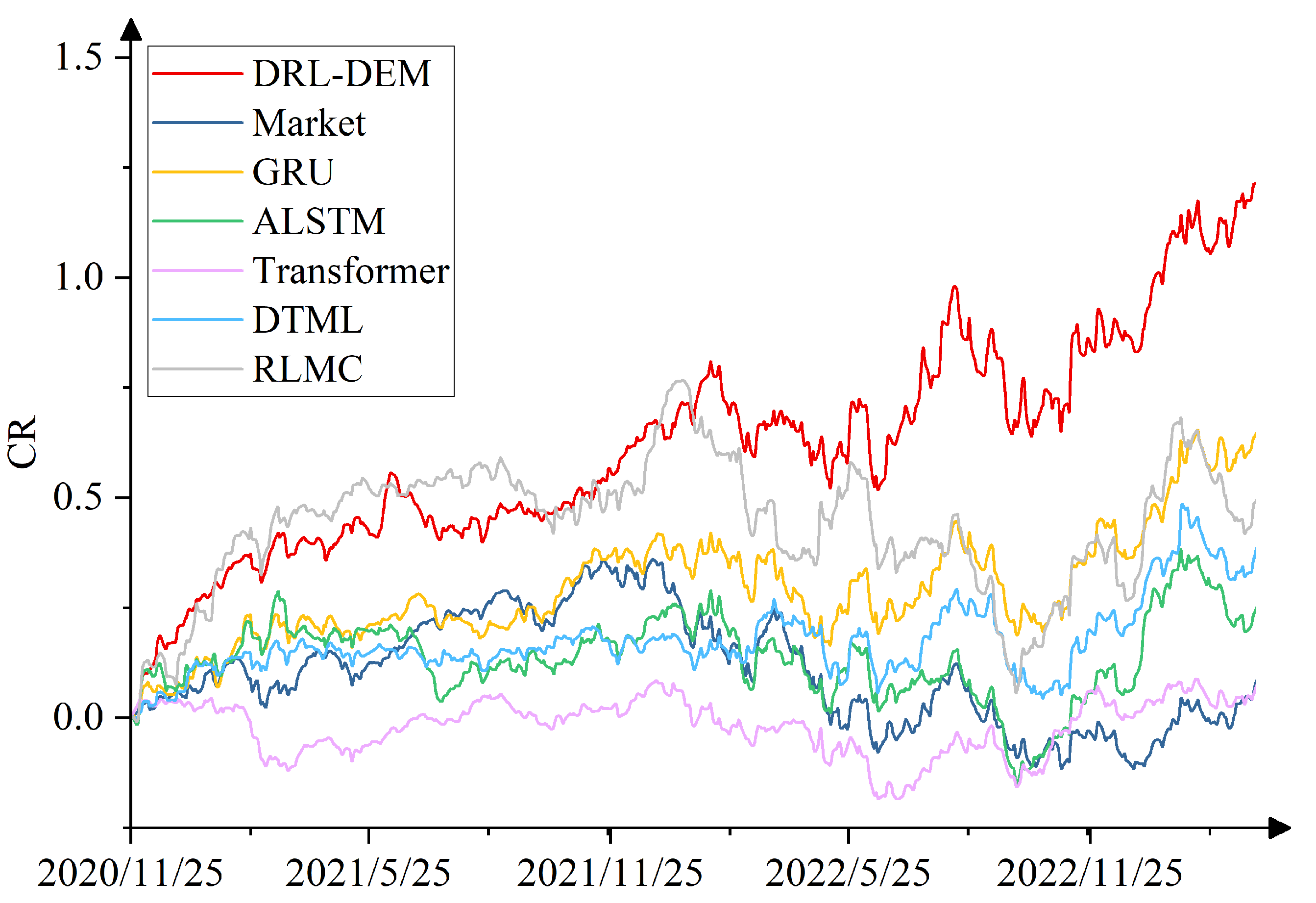
4.4. Comparison Experiment
- Market: A widely adopted benchmark investment strategy that involves buying a broad market index from the first day of the test set and holding it until the last day of the test set, with no active trading decisions. We use the SSE50 index as the market benchmark for the SSE50 dataset, and the NASDAQ 100 index as the market benchmark for the NASDAQ 100 dataset.
- GRU [28]: Controls the flow of information through a gating mechanism and is a simple benchmark widely used in stock prediction.
- ALSTM [10]: Combines LSTM, which is used to capture long- and short-term dependencies of stock data, and the self-attention mechanism, which allows the model to dynamically focus on information at different time steps based on the context.
- Transformer [11]: As a deep learning architecture that processes stock data through self-attention and multi-attention mechanisms, as well as positional coding.
- DTML [30]: Extracting stock contexts through attention mechanism, fusing the overall market trend to generate multi-level contexts, and utilizing Transformer to learn dynamic asymmetric correlations among stocks.
- RLMC [20]: Training an agent to automate the optimal selection and combination of multiple predictive models through deep reinforcement learning.
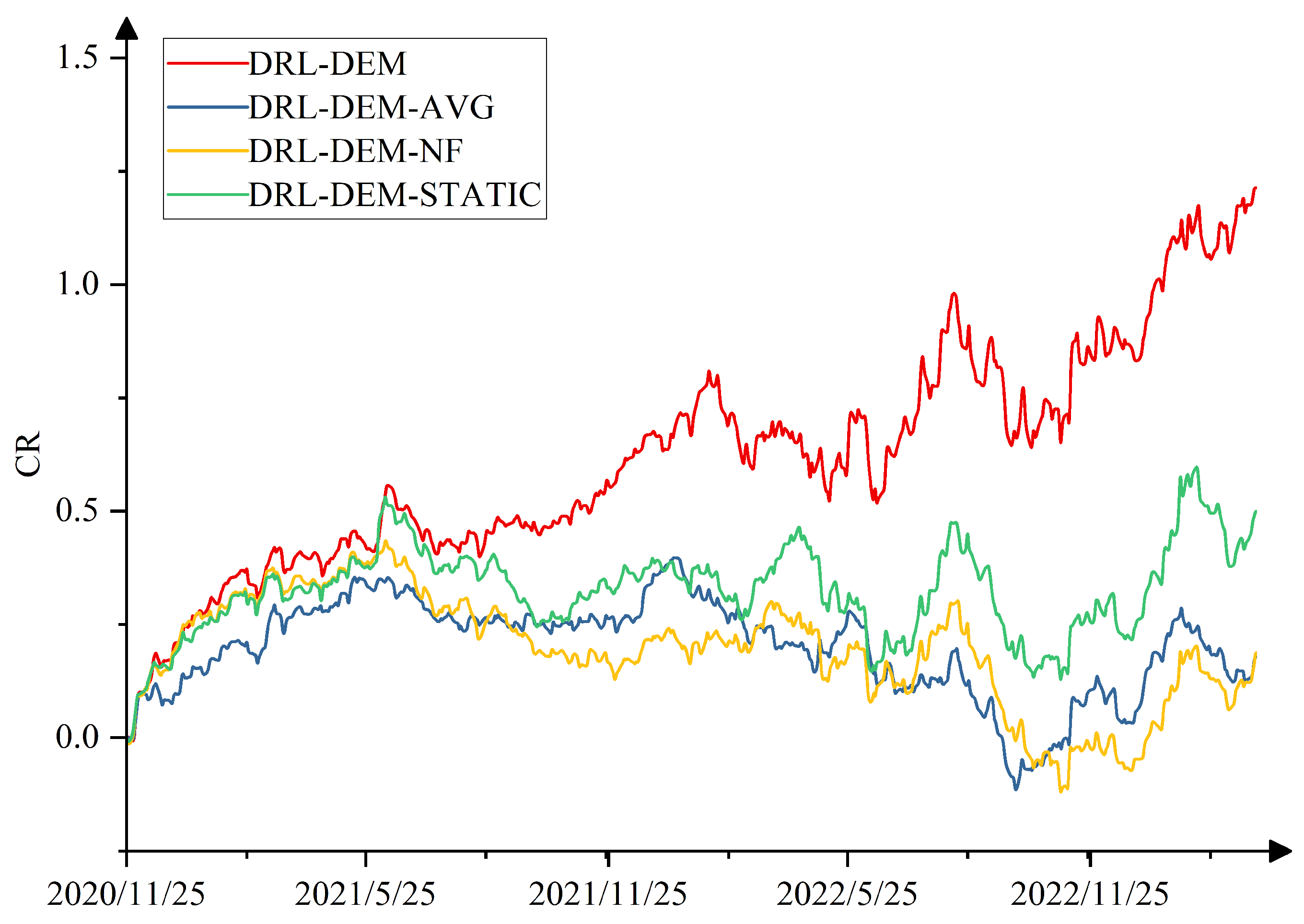
4.5. Ablation Experiment
- DRL-DEM-AVG: Without adopting the weight allocation method based on deep reinforcement learning, weights are evenly distributed among individual base predictors.
- DRL-DEM-NF: Without introducing real-time market feedback, only two components of the mixed reward function, namely ensemble prediction accuracy reward and ensemble prediction model ranking reward, are retained.
- DRL-DEM-STATIC: Without employing the global collaborative optimization approach, base predictors are no longer updated during the training process.
4.6. Parametric Analysis
4.6.1. Base Predictor Volume Analysis
4.6.2. Time-Series Step Analysis
4.6.3. Hyperparametric Analysis
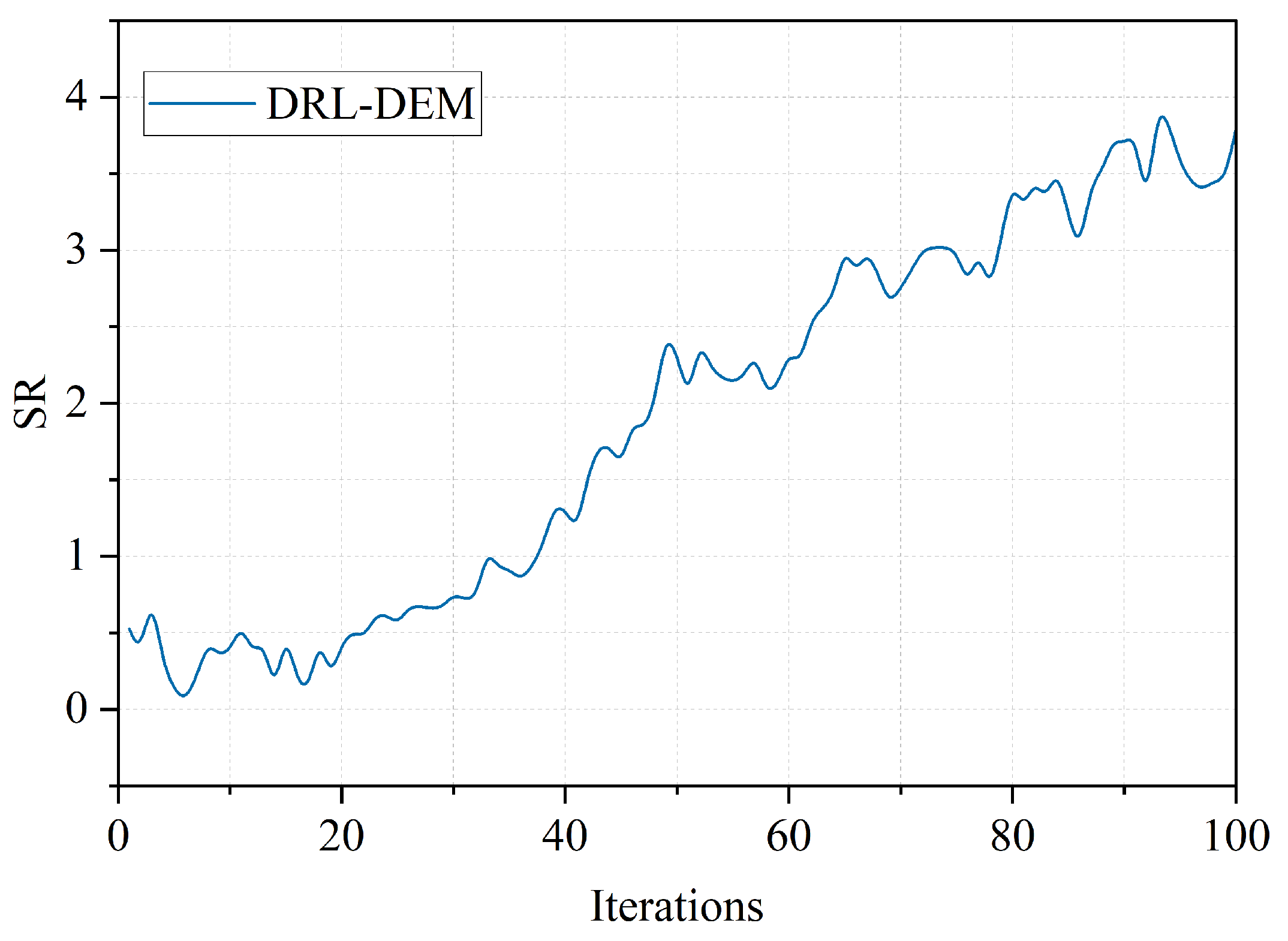
4.7. Algorithm Performance Analysis
4.8. Case Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DRL-DEM | Deep-Reinforcement-Learning-Based Dynamic Ensemble Model for Stock Prediction |
| ARIMA | Autoregressive Integrated Moving Average |
| VAR | Vector Autoregressive |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| BMPM | Base Model Prediction Module |
| MLP | Multilayer Perceptron |
| MSE | Mean Square Error |
| SMAPE | Symmetric Mean Absolute Percentage Error |
| CR | Cumulative Return |
| SR | Sharpe Ratio |
| ARR | Annualized Rate of Return |
| MDD | Maximum Drawdown |
References
- Nti, I.K.; Adekoya, A.F.; Wevori, B.A. A comprehensive evaluation of ensemble learning for stock-market prediction. J. Big Data 2008, 7, 20. [Google Scholar] [CrossRef]
- Khashei, M.; Hajirahimi, Z. A comparative study of series ARIMA/MLP hybrid models for stock price forecasting. Commun. Stat. Simul. Comput. 2019, 48, 2625–2640. [Google Scholar] [CrossRef]
- Pradhan, R.P. Information communications technology (ICT) infrastructure impact on stock market-growth nexus: The panel VAR model. In Proceedings of the 2014 IEEE International Conference on Industrial Engineering and Engineering Management, Selangor, Malaysia, 9–12 December 2014; pp. 607–611. [Google Scholar]
- Eapen, J.; Verma, A.; Bein, D. Improved big data stock index prediction using deep learning with CNN and GRU. Int. J. Big Data Intell. 2020, 7, 202–210. [Google Scholar] [CrossRef]
- Swathi, T.; Kasiviswanath, N.; Rao, A.A. An optimal deep learning-based LSTM for stock price prediction using twitter sentiment analysis. Appl. Intell. 2022, 52, 13675–13688. [Google Scholar] [CrossRef]
- Olorunnimbe, K.; Viktor, H. Deep learning in the stock market—A systematic survey of practice, backtesting, and applications. Artif. Intell. Rev. 2023, 56, 2057–2109. [Google Scholar] [CrossRef] [PubMed]
- Nelson, D.M.Q.; Pereira, A.C.M.; De Oliveira, R.A. Stock market’s price movement prediction with LSTM neural networks. In Proceedings of the 2017 International Joint Conference on Neural Networks, Anchorage, AK, USA, 14–19 May 2017; pp. 1419–1426. [Google Scholar]
- Liu, Y.; Liu, X.; Zhang, Y.; Li, S. CEGH: A hybrid model using CEEMD, entropy, GRU, and history attention for intraday stock market forecasting. Entropy 2022, 25, 71. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Du, J.; Xue, Z.; Kou, F. Prediction of financial big data stock trends based on attention mechanism. In Proceedings of the 2020 IEEE International Conference on Knowledge Graph, Nanjing, China, 9–11 August 2020; pp. 152–156. [Google Scholar]
- Cheng, L.C.; Huang, Y.H.; Wu, M.E. Applied attention-based LSTM neural networks in stock prediction. In Proceedings of the 2018 IEEE International Conference on Big Data, Seattle, WA, USA, 10–13 December 2018; pp. 4716–4718. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: Results, findings, conclusion and way forward. Int. J. Forecast. 2018, 34, 802–808. [Google Scholar] [CrossRef]
- Samal, S.; Dash, R. A novel MCDM ensemble approach of designing an ELM based predictor for stock index price forecasting. Intell. Decis. Technol. 2022, 16, 387–406. [Google Scholar] [CrossRef]
- Shrivastav, L.K.; Kumar, R. An ensemble of random forest gradient boosting machine and deep learning methods for stock price prediction. J. Inf. Technol. 2022, 15, 1–19. [Google Scholar] [CrossRef]
- Kuncheva, L.I.; Whitaker, C.J. Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach. Learn. 2003, 51, 181–207. [Google Scholar] [CrossRef]
- Mehta, S.; Rana, P.; Singh, S.; Sharma, A.; Agarwal, P. Ensemble learning approach for enhanced stock prediction. In Proceedings of the Twelfth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2019; pp. 1–5. [Google Scholar]
- Zhao, J.; Takai, A.; Kita, E. Weight-training ensemble model for stock price forecast. In Proceedings of the 2022 IEEE International Conference on Data Mining Workshops, Orlando, FL, USA, 28 November–1 December 2022; pp. 1–6. [Google Scholar]
- Nti, I.K.; Adekoya, A.F.; Wevori, B.A. Efficient stock-market prediction using ensemble support vector machine. Open Comput. Sci. 2020, 10, 153–163. [Google Scholar] [CrossRef]
- Sun, M.; Wang, J.; Li, Q.; Zhou, J.; Cui, C.; Jian, M. Stock index time series prediction based on ensemble learning model. J. Comput. Methods Sci. Eng. 2023, 23, 63–74. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, D.; Boulet, B. Reinforcement learning based dynamic model combination for time series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; pp. 6639–6647. [Google Scholar]
- Lemke, C.; Gabrys, B. Meta-learning for time series forecasting and forecast combination. Neurocomputing 2010, 73, 2006–2016. [Google Scholar] [CrossRef]
- Latif, R.M.A.; Naeem, M.R.; Rizwan, O.; Farhan, M. A smart technique to forecast karachi stock market share-values using ARIMA model. In Proceedings of the 2021 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 13–14 December 2021; pp. 317–322. [Google Scholar]
- Tian, J.; Wang, Y.; Cui, W.; Zhao, K. Simulation analysis of financial stock market based on machine learning and GARCH model. J. Intell. Fuzzy Syst. 2021, 40, 2277–2287. [Google Scholar] [CrossRef]
- Jiang, J.; Liu, J.; Rizwan, O.; Farhan, M. Predicting stock market n-days ahead using SVM optimized by selective thresholds. In Proceedings of the 12th International Conference on Machine Learning and Computing, Shenzhen, China, 15–17 February 2020; pp. 11–16. [Google Scholar]
- Yin, Q.; Zhang, R.; Liu, Y.; Shao, X.L. Forecasting of stock price trend based on CART and similar stock. In Proceedings of the 4th International Conference on Systems and Informatics, Hangzhou, China, 11–13 November 2017; pp. 1503–1508. [Google Scholar]
- Lu, W.; Li, J.; Li, Y.; Sun, A.; Wang, J. A CNN-LSTM based model to forecast stock price. Complexity 2020, 2020, 6622927. [Google Scholar] [CrossRef]
- Deepika, N.; Nirupamabhat, M. An optimized machine learning model for stock trend anticipation. Ing. Syst. d’Inf. 2020, 25, 783–792. [Google Scholar] [CrossRef]
- Gao, Y.; Wang, R.; Zhou, E. Stock prediction based on optimized LSTM and GRU models. Sci. Program. 2021, 2021, 4055281. [Google Scholar] [CrossRef]
- Li, H.; Shen, Y.; Zhu, Y. Stock price prediction using attention-based multi-input LSTM. In Proceedings of the 10th Asian Conference on Machine Learning, Beijing, China, 14–16 November 2018; pp. 454–469. [Google Scholar]
- Yoo, J.; Soun, Y.; Park, Y.C.; Kang, U. Accurate multivariate stock movement prediction via data-axis transformer with multi-level contexts. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Singapore, 14–18 August 2021; pp. 2037–2045. [Google Scholar]
- Collopy, F.; Armstrong, J.S. Rule-based forecasting: Development and validation of an expert systems approach to combining time series extrapolations. Manag. Sci. 1992, 38, 1394–1414. [Google Scholar] [CrossRef]
- Talagala, T.S.; Hyndman, R.J.; Athanasopoulos, G. Meta-learning how to forecast time series. J. Forecast. 2018, 6, 16. [Google Scholar]
- Montero-manso, P.; Athanasopoulos, G.; Hyndman, R.J.; Talagala, T.S. FFORMA: Feature-based forecast model averaging. Int. J. Forecast. 2020, 36, 86–92. [Google Scholar] [CrossRef]
- Feng, C.; Sun, M.; Zhang, J. Reinforced deterministic and probabilistic load forecasting via Q-learning dynamic model selection. IEEE Trans. Smart Grid 2019, 11, 1377–1386. [Google Scholar] [CrossRef]
- Saadallah, A.; Morik, K. Online ensemble aggregation using deep reinforcement learning for time series forecasting. In Proceedings of the 8th IEEE International Conference on Data Science and Advanced Analytics, Porto, Portugal, 6–9 October 2021; pp. 1–8. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Ensemble/ Non-Ensemble | Applied Models | Source of Dataset | Performance Metrics |
|---|---|---|---|---|
| SVM [24] | Non-Ensemble | SVM | NASDAQ Index | Accuracy |
| DTML [30] | Non-Ensemble | ALSTM, Transformer | NDX100, CSI300, etc. | Accuracy, MCC |
| CNN-LSTM [26] | Non-Ensemble | CNN, LSTM | Shanghai Composite Index | RMSE, MAE, |
| ABC-LSTM [27] | Non-Ensemble | ABC, LSTM | AAPL, AMZN, INFY, TCS, ORCL, and MSFT | MAPE, MSE, etc. |
| GASVM [18] | Ensemble | SVM, GA | Banks and oil company stocks on the GSE | Accuracy, RMSE etc. |
| LSTM-AdaBoost.R2 [19] | Ensemble | LST, AdaBoost.R2 | SSEC, CSI300, and SZSC | RMSE, MAPE |
| RLMC [20] | Ensemble | GRU, LSTM, dialated CNN etc., DRL | ETT, Climate, etc. | MAE, sMAPE |
| OEA-RL [35] | Ensemble | ARIMA, ETS etc.; DRL | Meteorological data, Water resources data, etc. | Avg. Rank |
| Dataset | Training Set | Validation Set | Test Set | |||
|---|---|---|---|---|---|---|
| SSE 50 | Period | Sample Size | Period | Sample Size | Period | Sample Size |
| 1 | 2011/10/18–2019/12/27 | 1997 | 2019/12/30–2020/10/29 | 200 | 2020/10/30–2021/8/20 | 200 |
| 2 | 2011/10/18–2020/10/29 | 2197 | 2020/10/30–2021/8/20 | 200 | 2021/8/23–2022/6/23 | 200 |
| 3 | 2011/10/18–2021/8/20 | 2397 | 2021/8/23–2022/6/23 | 200 | 2022/6/24–2023/3/31 | 189 |
| Dataset | Training Set | Validation Set | Test Set | |||
|---|---|---|---|---|---|---|
| NASDAQ 100 | Period | Sample Size | Period | Sample Size | Period | Sample Size |
| 1 | 2010/8/2–2020/2/11 | 2399 | 2020/2/12–2020/11/24 | 200 | 2020/11/25–2021/9/13 | 200 |
| 2 | 2010/8/2–2020/11/24 | 2599 | 2020/11/25–2021/9/13 | 200 | 2021/9/14–2022/6/29 | 200 |
| 3 | 2010/8/2–2021/9/13 | 2799 | 2021/9/14–2022/6/29 | 200 | 2022/6/30–2023/3/31 | 190 |
| Model | SSE 50 | NASDAQ 100 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SR | MDD | CR | ARR | MSE | SMAPE | SR | MDD | CR | ARR | MSE | SMAPE | |
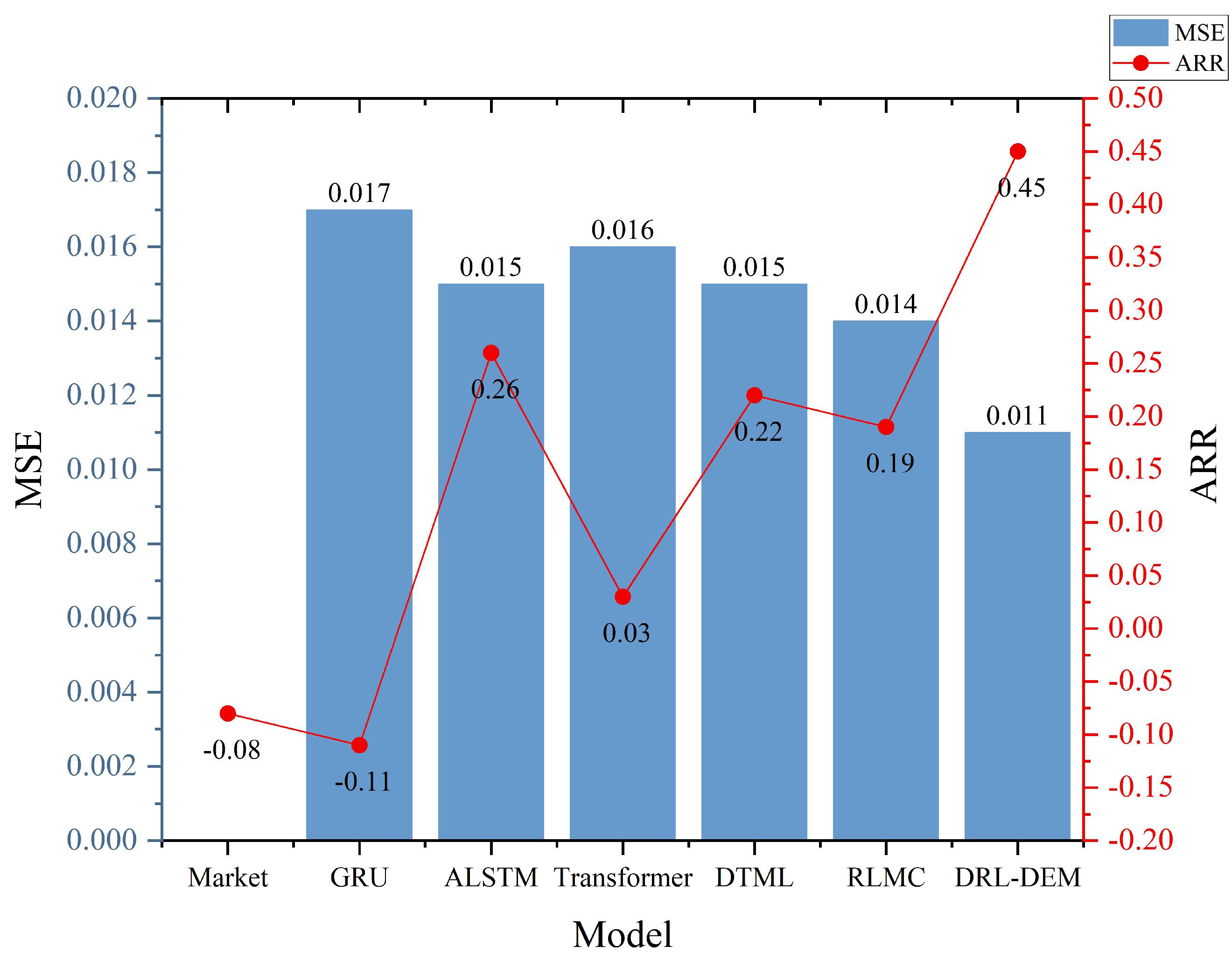
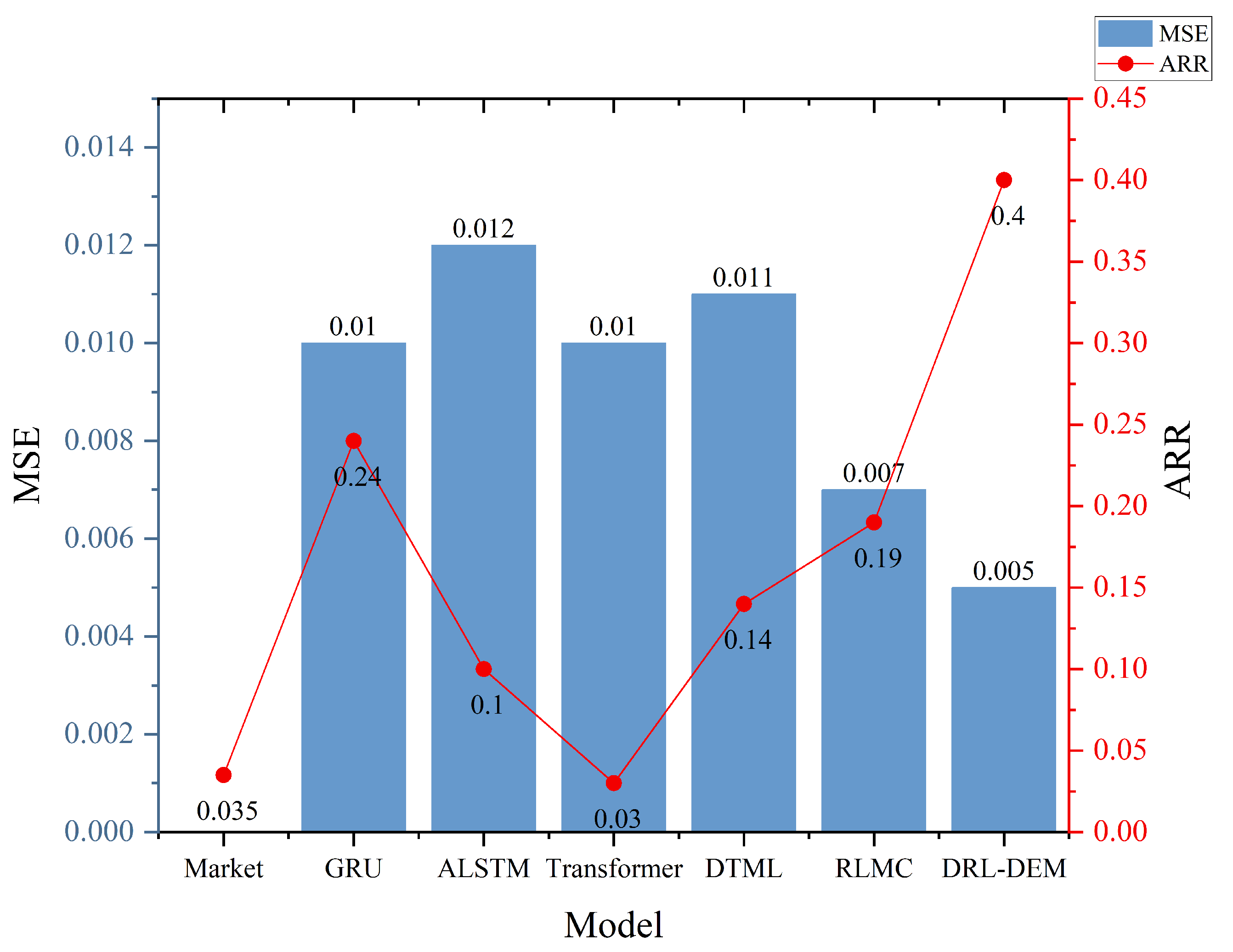
| Market | −0.60 | 0.43 | −0.19 | −0.08 | 0.02 | 0.36 | 0.08 | 0.035 | ||||
| GRU | −0.61 | 0.46 | −0.23 | −0.11 | 0.017 | 9.60 | 0.84 | 0.19 | 0.64 | 0.24 | 0.010 | 8.48 |
| ALSTM | 1.21 | 0.14 | 0.73 | 0.26 | 0.015 | 9.09 | 0.26 | 0.35 | 0.25 | 0.10 | 0.012 | 8.89 |
| Transformer | 0.02 | 0.25 | 0.08 | 0.03 | 0.016 | 8.99 | 0.003 | 0.25 | 0.07 | 0.03 | 0.010 | 8.49 |
| DTML | 0.85 | 0.20 | 0.59 | 0.22 | 0.015 | 9.07 | 0.55 | 0.20 | 0.38 | 0.14 | 0.011 | 8.68 |
| RLMC | 0.68 | 0.23 | 0.49 | 0.19 | 0.014 | 8.99 | 0.59 | 0.40 | 0.49 | 0.19 | 0.007 | 6.94 |
| DRL-DEM | 2.20 | 0.11 | 1.38 | 0.45 | 0.011 | 7.41 | 1.53 | 0.17 | 1.21 | 0.40 | 0.005 | 6.19 |
| Model | SSE 50 | NASDAQ 100 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SR | MDD | CR | ARR | MSE | SMAPE | SR | MDD | CR | ARR | MSE | SMAPE | |
| DRL-DEM-AVG | −0.04 | 0.22 | 0.05 | 0.02 | 0.015 | 9.03 | 0.22 | 0.37 | 0.19 | 0.08 | 0.010 | 8.30 |
| DRL-DEM-NF | 0.76 | 0.20 | 0.44 | 0.17 | 0.011 | 7.53 | 0.19 | 0.39 | 0.18 | 0.07 | 0.006 | 6.20 |
| DRL-DEM-STATIC | 0.37 | 0.18 | 0.25 | 0.10 | 0.013 | 8.49 | 0.66 | 0.27 | 0.50 | 0.19 | 0.007 | 7.90 |
| DRL-DEM | 2.20 | 0.11 | 1.38 | 0.45 | 0.011 | 7.41 | 1.53 | 0.17 | 1.21 | 0.40 | 0.005 | 6.19 |
| Number of Base Predictors | Selected Base Predictors | MSE | SMAPE |
|---|---|---|---|
| 3 | 1, 3 and 5 | 0.0149 | 8.96 |
| 4 | 1, 2, 3 and 5 | 0.0135 | 8.02 |
| 5 | 1, 2, 3, 4 and 5 | 0.0127 | 7.97 |
| 6 | 1, 2, 3, 4, 5 and 6 | 0.0110 | 7.41 |
| 7 | 1, 2, 3, 4, 5, 6 and 7 | 0.0133 | 8.14 |
| 8 | 1, 2, 3, 4, 5, 6, 7 and 8 | 0.0128 | 7.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, W.; Xie, L.; Xu, H. Deep-Reinforcement-Learning-Based Dynamic Ensemble Model for Stock Prediction. Electronics 2023, 12, 4483. https://doi.org/10.3390/electronics12214483
Lin W, Xie L, Xu H. Deep-Reinforcement-Learning-Based Dynamic Ensemble Model for Stock Prediction. Electronics. 2023; 12(21):4483. https://doi.org/10.3390/electronics12214483
Chicago/Turabian StyleLin, Wenjing, Liang Xie, and Haijiao Xu. 2023. "Deep-Reinforcement-Learning-Based Dynamic Ensemble Model for Stock Prediction" Electronics 12, no. 21: 4483. https://doi.org/10.3390/electronics12214483
APA StyleLin, W., Xie, L., & Xu, H. (2023). Deep-Reinforcement-Learning-Based Dynamic Ensemble Model for Stock Prediction. Electronics, 12(21), 4483. https://doi.org/10.3390/electronics12214483