
DBENet: Dual-Branch Brightness Enhancement Fusion Network for Low-Light Image Enhancement


Abstract
:1. Introduction
- We propose a new hierarchical structure ( DBENet ) for enhancing low-light conditions in the real world. This framework includes networks for enhancing illumination maps, denoising chromatic information, and feature map fusion, respectively;
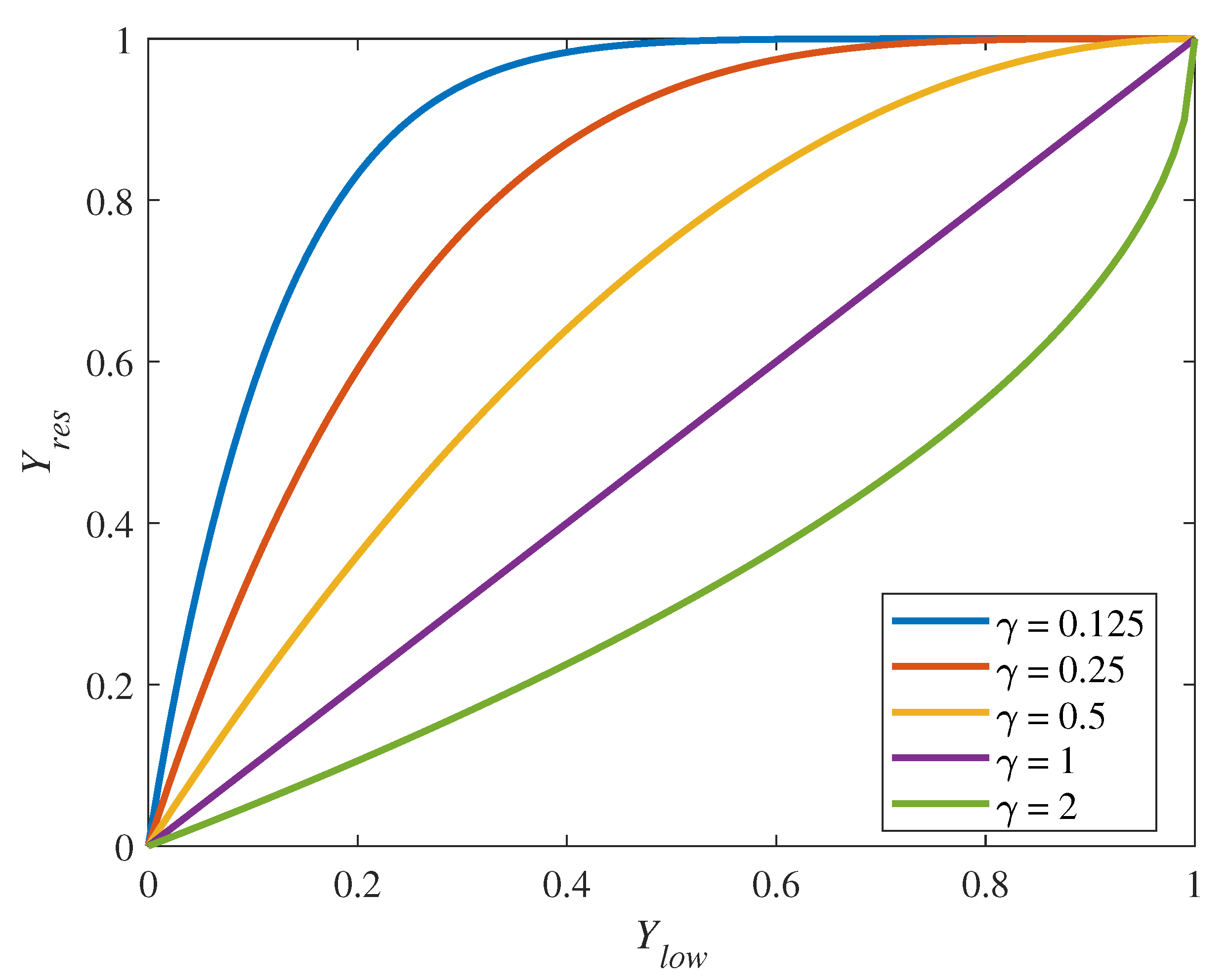
- We employed a CNN branch to predict the gamma matrix and utilized nonlinear mapping to regulate brightness variations, effectively suppressing overexposure during the enhancement process;
- Our method outperforms existing techniques on benchmark datasets, achieving significant improvements in evaluation metrics such as MAE, PSNR, SSIM, LPIPS (reference), and NIQE (no-reference), demonstrating its superior efficiency.
2. Related Works
2.1. Non-Learning-Based Methods
2.2. Learning-Based Methods
3. The Proposed Network
3.1. CNN Branch
3.2. U-Net Branch
3.3. Fusion Module
3.4. Loss Function
4. Experimental Results and Analysis
4.1. Experimental Settings
4.2. Subjective Visual Evaluation
4.3. Objective Evaluation
4.4. Ablation Study
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclatures
| DBENet | Dual-Branch Brightness Enhancement Fusion Network |
| FM | Fusion Module |
| MAE | Mean Absolute Error |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index Measure |
| LPIPS | Learned Perceptual Image Patch Similarity |
| NIQE | Natural Image Quality Evaluator |
References
- Meng, L.; Li, H.; Chen, B.C.; Lan, S.; Wu, Z.; Jiang, Y.G.; Lim, S.N. Adavit: Adaptive vision transformers for efficient image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12309–12318. [Google Scholar]
- Fang, W.; Wang, L.; Ren, P. Tinier-YOLO: A real-time object detection method for constrained environments. IEEE Access 2019, 8, 1935–1944. [Google Scholar] [CrossRef]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- Fujiyoshi, H.; Hirakawa, T.; Yamashita, T. Deep learning-based image recognition for autonomous driving. IATSS Res. 2019, 43, 244–252. [Google Scholar] [CrossRef]
- Stark, J.A. Adaptive image contrast enhancement using generalizations of histogram equalization. IEEE Trans. Image Process. 2000, 9, 889–896. [Google Scholar] [CrossRef]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. Vlsi Signal Process. Syst. Signal, Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Li, L.; Si, Y.; Jia, Z. Remote sensing image enhancement based on non-local means filter in NSCT domain. Algorithms 2017, 10, 116. [Google Scholar] [CrossRef]
- Lam, E.Y. Combining gray world and retinex theory for automatic white balance in digital photography. In Proceedings of the Ninth International Symposium on Consumer Electronics, Macau SAR, China, 14–16 June 2005; pp. 134–139. [Google Scholar]
- Xie, C.; Tang, H.; Fei, L.; Zhu, H.; Hu, Y. IRNet: An Improved Zero-Shot Retinex Network for Low-Light Image Enhancement. Electronics 2023, 12, 3162. [Google Scholar] [CrossRef]
- Park, J.S.; Soh, J.W.; Cho, N.I. Generation of high dynamic range illumination from a single image for the enhancement of undesirably illuminated images. Multimed. Tools Appl. 2019, 78, 20263–20283. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Deng, X.; Zhang, Y.; Xu, M.; Gu, S.; Duan, Y. Deep Coupled Feedback Network for Joint Exposure Fusion and Image Super-Resolution. IEEE Trans. Image Process. Publ. IEEE Signal Process. Soc. 2021, 30, 3098–3112. [Google Scholar] [CrossRef]
- Lu, H.; Gong, J.; Liu, Z.; Lan, R.; Pan, X. FDMLNet: A Frequency-Division and Multiscale Learning Network for Enhancing Low-Light Image. Sensors 2022, 22, 8244. [Google Scholar] [CrossRef]
- Guo, X.; Hu, Q. Low-light image enhancement via breaking down the darkness. Int. J. Comput. Vis. 2023, 131, 48–66. [Google Scholar] [CrossRef]
- Zhang, J.; Ji, R.; Wang, J.; Sun, H.; Ju, M. DEGAN: Decompose-Enhance-GAN Network for Simultaneous Low-Light Image Lightening and Denoising. Electronics 2023, 12, 3038. [Google Scholar] [CrossRef]
- Ahn, H.; Keum, B.; Kim, D.; Lee, H.S. Adaptive local tone mapping based on retinex for high dynamic range images. In Proceedings of the 2013 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 11–14 January 2013; pp. 153–156. [Google Scholar]
- Huang, S.C.; Cheng, F.C.; Chiu, Y.S. Efficient contrast enhancement using adaptive gamma correction with weighting distribution. IEEE Trans. Image Process. 2012, 22, 1032–1041. [Google Scholar] [CrossRef] [PubMed]
- Ooi, C.H.; Isa, N.A.M. Quadrants dynamic histogram equalization for contrast enhancement. IEEE Trans. Consum. Electron. 2010, 56, 2552–2559. [Google Scholar] [CrossRef]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef]
- Jobson, D.J.; Rahman, Z.u.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef]
- Rahman, Z.u.; Jobson, D.J.; Woodell, G.A. Multi-scale retinex for color image enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing, Austin, TX, USA, 19 September 1996; Volume 3, pp. 1003–1006. [Google Scholar]
- Jobson, D.J.; Rahman, Z.u.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vision Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Land, E.H.; McCann, J.J. Lightness and retinex theory. Josa 1971, 61, 1–11. [Google Scholar] [CrossRef]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. In Proceedings of the British Machine Vision Conference, British Machine Vision Association, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the BMVC, Newcastle, UK, 3–6 September 2018; Volume 220, p. 4. [Google Scholar]
- Zheng, C.; Shi, D.; Shi, W. Adaptive Unfolding Total Variation Network for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 4439–4448. [Google Scholar]
- Wu, W.; Weng, J.; Zhang, P.; Wang, X.; Yang, W.; Jiang, J. URetinex-Net: Retinex-Based Deep Unfolding Network for Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5901–5910. [Google Scholar]
- Chenxi Wang Hongujun Wu and Zhi Jin. FourLLIE: Boosting Low-Light Image Enhancement by Fourier Frequency Information. In Proceedings of the ACM MM, Thessaloniki, Greece, 12–15 June 2023.
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Li, C.; Guo, C.; Feng, R.; Zhou, S.; Loy, C.C. CuDi: Curve Distillation for Efficient and Controllable Exposure Adjustment. arXiv 2022, arXiv:2207.14273. [Google Scholar]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), Virtual, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5637–5646. [Google Scholar]
- Hue Nguyen and Diep Tran and Khoi Nguyen and Rang Nguyen. PSENet: Progressive Self-Enhancement Network for Unsupervised Extreme-Light Image Enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023.
- Ko, K.; Kim, C.-S. IceNet for interactive contrast enhancement. IEEE Access 2021, 9, 168342–168354. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Method | MAE↓ | PSNR↑ | SSIM↑ | LPIPS↓ |
|---|---|---|---|---|---|
| LOL | Input | 0.3914 | 7.7733 | 0.1952 | 0.4191 |
| HE | 0.1879 | 12.918 | 0.3369 | 0.4376 | |
| Tone Mapping | 0.1517 | 16.5034 | 0.5092 | 0.2312 | |
| RUAS | 0.1534 | 16.4047 | 0.4997 | 0.1937 | |
| Retinex-Net | 0.1255 | 16.7740 | 0.4196 | 0.3758 | |
| SCI | 0.1912 | 14.784 | 0.5220 | 0.2385 | |
| Zero-DCE | 0.1860 | 14.7971 | 0.5573 | 0.2368 | |
| RRDNet | 0.2739 | 11.4037 | 0.4575 | 0.2480 | |
| Ours | 0.1007 | 19.8625 | 0.8149 | 0.1152 | |
| VE-LOL (real) | Input | 0.3131 | 9.7168 | 0.1989 | 0.3472 |
| HE | 0.4901 | 13.1314 | 0.3760 | 0.4140 | |
| Tone Mapping | 0.1298 | 17.2469 | 0.5262 | 0.2349 | |
| RUAS | 0.1621 | 15.3255 | 0.4878 | 0.2165 | |
| Retinex-Net | 0.1313 | 16.0971 | 0.4011 | 0.4368 | |
| SCI | 0.1470 | 17.3035 | 0.5336 | 0.2021 | |
| Zero-DCE | 0.1320 | 17.9992 | 0.5719 | 0.2154 | |
| RRDNet | 0.2089 | 13.9818 | 0.4832 | 0.1896 | |
| Ours | 0.0099 | 19.8285 | 0.8437 | 0.1086 |
| Method | LOL | VE-LOL (Real) | LIME | MEF |
|---|---|---|---|---|
| HE | 8.1541 | 8.7654 | 6.8883 | 3.5638 |
| Tone Mapping | 7.8310 | 7.9683 | 3.9201 | 3.5254 |
| RUAS | 6.3400 | 6.5330 | 5.3642 | 5.4255 |
| Retinex-Net | 8.8781 | 9.4276 | 4.7669 | 4.4097 |
| SCI | 7.8766 | 8.0461 | 4.2064 | 3.6277 |
| Zero-DCE | 7.7925 | 8.0449 | 3.9733 | 3.3023 |
| RRDNet | 7.4777 | 7.7131 | 4.0689 | 3.4796 |
| Ours | 5.2485 | 5.0481 | 4.3475 | 4.2920 |
| Methods | PSNR | SSIM |
|---|---|---|
| CNN branch | 18.6481 | 0.7128 |
| U-Net branch | 17.5846 | 0.7813 |
| DBENet | 19.8625 | 0.8149 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Wen, C.; Liu, W.; He, W. DBENet: Dual-Branch Brightness Enhancement Fusion Network for Low-Light Image Enhancement. Electronics 2023, 12, 3907. https://doi.org/10.3390/electronics12183907
Chen Y, Wen C, Liu W, He W. DBENet: Dual-Branch Brightness Enhancement Fusion Network for Low-Light Image Enhancement. Electronics. 2023; 12(18):3907. https://doi.org/10.3390/electronics12183907
Chicago/Turabian StyleChen, Yongqiang, Chenglin Wen, Weifeng Liu, and Wei He. 2023. "DBENet: Dual-Branch Brightness Enhancement Fusion Network for Low-Light Image Enhancement" Electronics 12, no. 18: 3907. https://doi.org/10.3390/electronics12183907
APA StyleChen, Y., Wen, C., Liu, W., & He, W. (2023). DBENet: Dual-Branch Brightness Enhancement Fusion Network for Low-Light Image Enhancement. Electronics, 12(18), 3907. https://doi.org/10.3390/electronics12183907