
Evo-MAML: Meta-Learning with Evolving Gradient

Abstract
:
1. Introduction
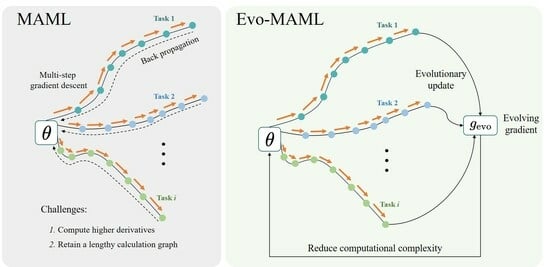
- We present Evolving MAML (Evo-MAML), a novel meta-learning method that incorporates evolving gradient. Evo-MAML addresses the challenges of low computational efficiency and eliminates the need to compute second-order derivatives.
- Theoretical analysis and empirical experiments demonstrate that Evo-MAML exhibits lower computational complexity, memory usage, and time requirements compared to MAML. These improvements make Evo-MAML more practical and efficient for meta-learning tasks.
- We evaluate the performance of Evo-MAML in both the few-shot learning and meta-reinforcement learning domains. Our results show that Evo-MAML competes favorably with current first-order approximation methods, highlighting its generality and effectiveness across different application areas.
2. Related Works
3. Proposed Method
3.1. Problem Formulation
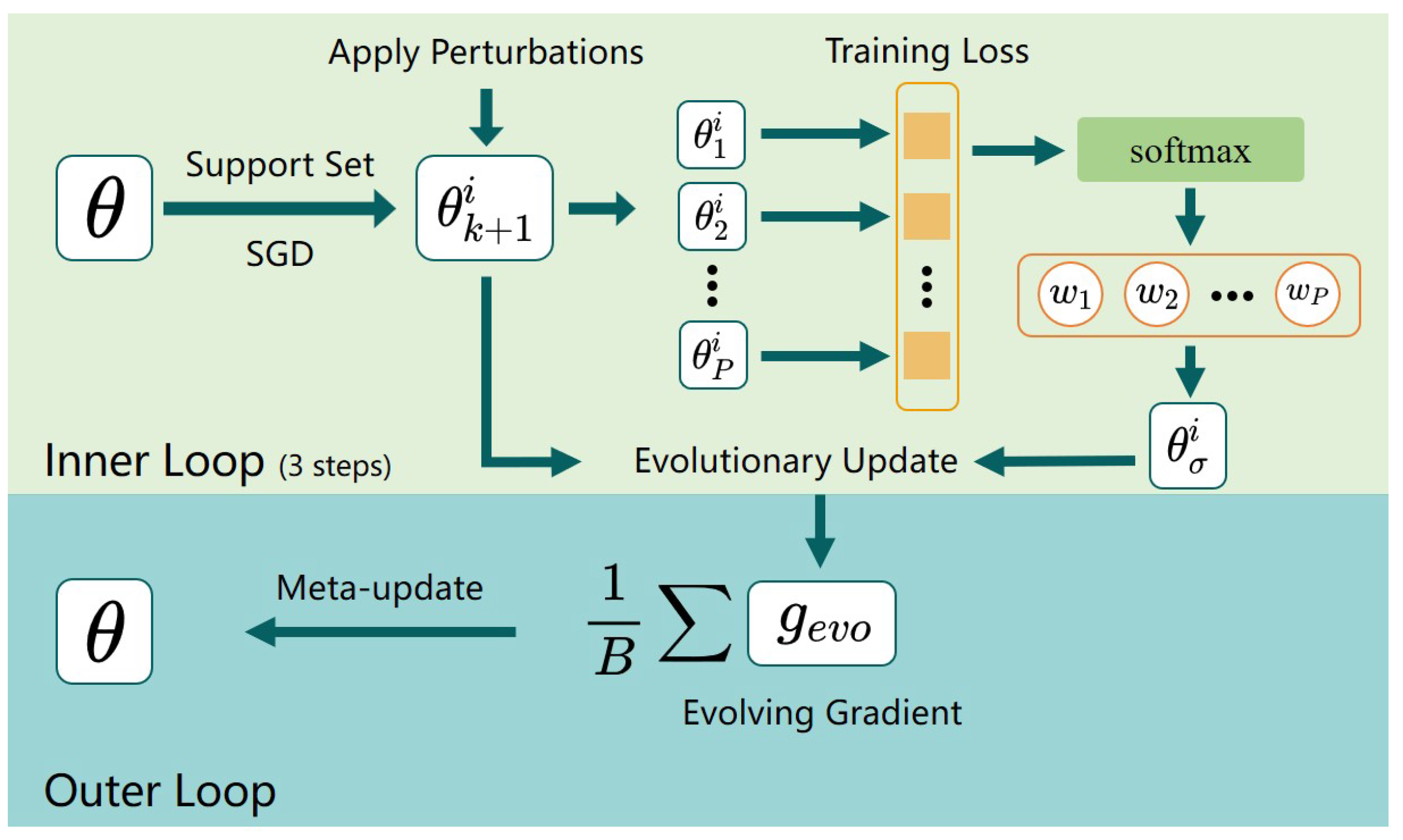
3.2. Evolving MAML Algorithm
| Algorithm 1: Evolving Model-Agnostic Meta-Learning (Evo-MAML) |
 |
3.3. Theoretical Analysis
4. Experiments and Results
- RQ1: Does Evo-MAML yield better results in few-shot learning problems compared to MAML?
- RQ2: Does Evo-MAML exhibit improved performance in meta-reinforcement learning tasks?
- RQ3: How do the computational and memory requirements of Evo-MAML compare to those of MAML?
4.1. Experimental Settings
4.1.1. Few-Shot Learning Settings
4.1.2. Meta-Reinforcement Learning Settings
4.2. Results
4.2.1. Performance on Few-Shot Learning
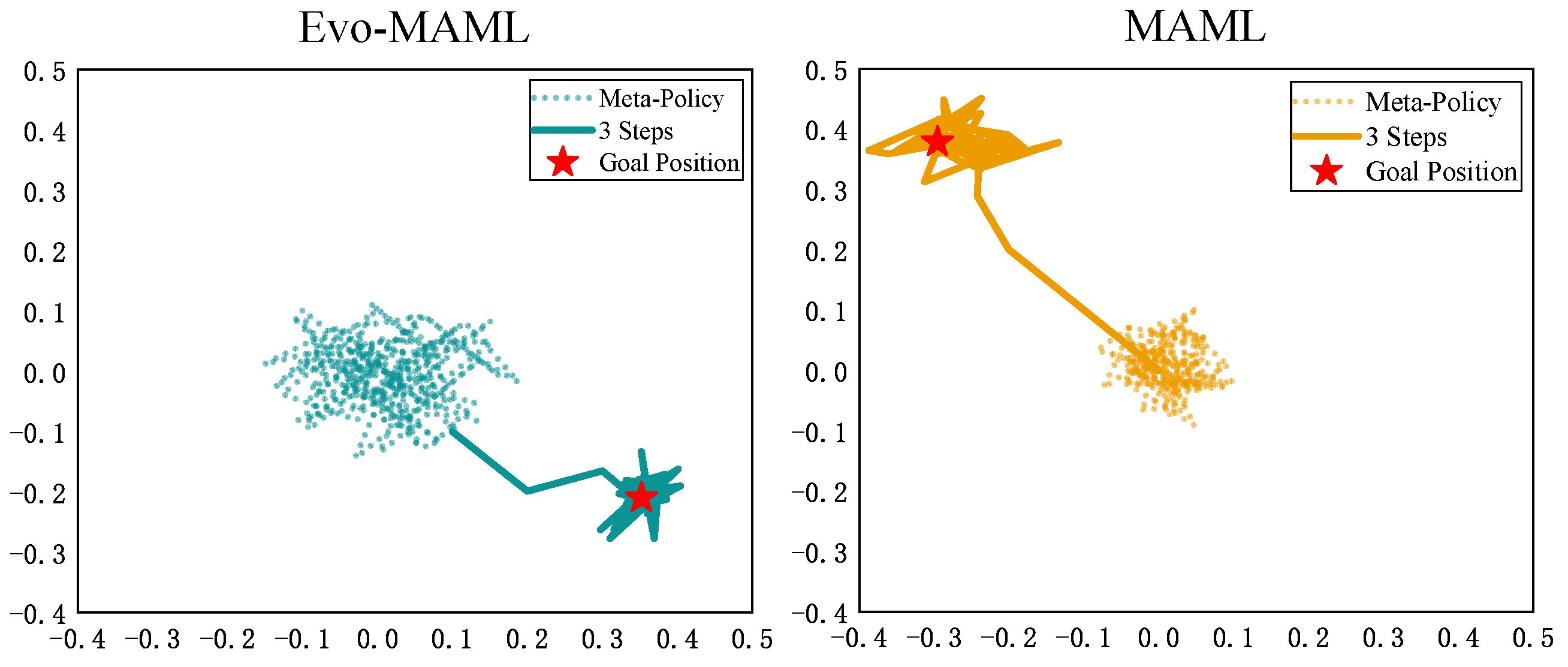
4.2.2. Performance on Meta-Reinforcement Learning
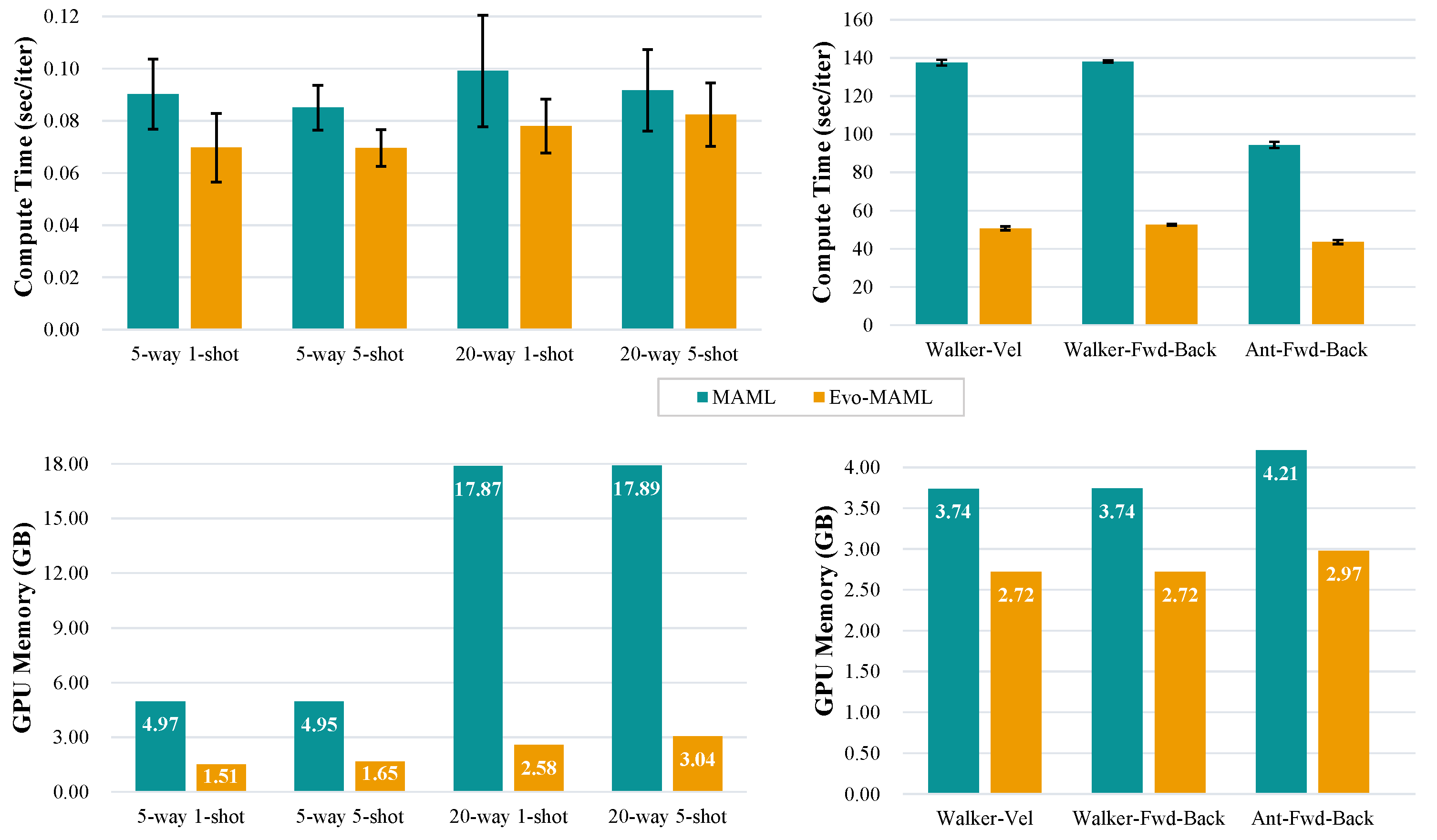
4.2.3. Performance on Computation and Memory
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MAML | Model-Agnostic Meta-Learning |
| Evo-MAML | Evolving MAML |
| ES-MAML | Evolution Strategies MAML |
| iMAML | Implicit MAML |
| SGD | Stochastic Gradient Descent |
References
- Schmidhuber, J.; Zhao, J.; Wiering, M. Simple principles of metalearning. Tech. Rep. IDSIA 1996, 69, 1–23. [Google Scholar]
- Russell, S.; Wefald, E. Principles of metareasoning. Artif. Intell. 1991, 49, 361–395. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Zhang, Z.; Wu, Z.; Zhang, H.; Wang, J. Meta-Learning-Based Deep Reinforcement Learning for Multiobjective Optimization Problems. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Grigsby, J.; Sekhon, A.; Qi, Y. ST-MAML: A stochastic-task based method for task-heterogeneous meta-learning. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, Online, 1–5 August 2022; pp. 2066–2074. Available online: https://proceedings.mlr.press/v180/wang22c.html (accessed on 10 September 2023).
- Abbas, M.; Xiao, Q.; Chen, L.; Chen, P.Y.; Chen, T. Sharp-MAML: Sharpness-Aware Model-Agnostic Meta Learning. In Proceedings of the 39th International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; Volume 162, pp. 10–32. [Google Scholar] [CrossRef]
- Bohdal, O.; Yang, Y.; Hospedales, T. EvoGrad: Efficient Gradient-Based Meta-Learning and Hyperparameter Optimization. Adv. Neural Inf. Process. Syst. 2021, 34, 22234–22246. [Google Scholar]
- Antoniou, A.; Edwards, H.; Storkey, A. How to Train Your MAML. In Proceedings of the 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-SGD: Learning to Learn Quickly for Few-Shot Learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Yu, T.; Quillen, D.; He, Z.; Julian, R.; Narayan, A.; Shively, H.; Adithya, B.; Hausman, K.; Finn, C.; Levine, S. Meta-World: A Benchmark and Evaluation for Multi-Task and Meta Reinforcement Learning. In Proceedings of the Conference on Robot Learning, PMLR, Virtual, 16–18 November 2020; pp. 1094–1100. [Google Scholar] [CrossRef]
- Nichol, A.; Achiam, J.; Schulman, J. On First-Order Meta-Learning Algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Rajeswaran, A.; Finn, C.; Kakade, S.M.; Levine, S. Meta-learning with implicit gradients. In Proceedings of the Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. Available online: https://api.semanticscholar.org/CorpusID:202542766 (accessed on 10 September 2023).
- Ye, H.J.; Chao, W.L. How to Train Your MAML to Excel in Few-Shot Classification. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022; Available online: https://openreview.net/forum?id=49h_IkpJtaE (accessed on 10 September 2023).
- Song, X.; Gao, W.; Yang, Y.; Choromanski, K.; Pacchiano, A.; Tang, Y. ES-MAML: Simple Hessian-Free Meta Learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2020. [Google Scholar]
- Houthooft, R.; Chen, R.Y.; Isola, P.; Stadie, B.C.; Wolski, F.; Ho, J.; Abbeel, P. Evolved Policy Gradients. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; Volume 31. [Google Scholar]
- Thrun, S.; Pratt, L. Learning to learn: Introduction and overview. In Learning to Learn; Springer: Berlin/Heidelberg, Germany, 1998; pp. 3–17. [Google Scholar]
- Xi, B.; Li, J.; Li, Y.; Song, R.; Hong, D.; Chanussot, J. Few-Shot Learning With Class-Covariance Metric for Hyperspectral Image Classification. IEEE Trans. Image Process. 2022, 31, 5079–5092. [Google Scholar] [CrossRef] [PubMed]
- Gao, F.; Cai, L.; Yang, Z.; Song, S.; Wu, C. Multi-distance metric network for few-shot learning. Int. J. Mach. Learn. Cybern. 2022, 13, 2495–2506. [Google Scholar] [CrossRef]
- Mishra, N.; Rohaninejad, M.; Chen, X.; Abbeel, P. A Simple Neural Attentive Meta-Learner. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Munkhdalai, T.; Yuan, X.; Mehri, S.; Trischler, A. Rapid adaptation with conditionally shifted neurons. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3664–3673. [Google Scholar]
- Qiao, S.; Liu, C.; Shen, W.; Yuille, A.L. Few-shot image recognition by predicting parameters from activations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7229–7238. [Google Scholar]
- Yoon, J.; Kim, T.; Dia, O.; Kim, S.; Bengio, Y.; Ahn, S. Bayesian model-agnostic meta-learning. In Proceedings of the Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 2–8 December 2018; Volume 31. [Google Scholar]
- Rakelly, K.; Zhou, A.; Finn, C.; Levine, S.; Quillen, D. Efficient off-policy meta-reinforcement learning via probabilistic context variables. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 10–15 June 2019; pp. 5331–5340. [Google Scholar]
- Zintgraf, L.; Shiarlis, K.; Igl, M.; Schulze, S.; Gal, Y.; Hofmann, K.; Whiteson, S. VariBAD: A very good method for Bayes-adaptive deep RL via meta-learning. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar]
- Khodak, M.; Balcan, M.F.F.; Talwalkar, A.S. Adaptive gradient-based meta-learning methods. In Proceedings of the Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Raghu, A.; Raghu, M.; Bengio, S.; Vinyals, O. Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Lee, Y.; Choi, S. Gradient-based meta-learning with learned layerwise metric and subspace. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2927–2936. [Google Scholar]
- Stadie, B.; Yang, G.; Houthooft, R.; Chen, X.; Duan, Y.; Wu, Y.; Abbeel, P.; Sutskever, I. Some Considerations on Learning to Explore via Meta-Reinforcement Learning. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. On the Convergence Theory of Gradient-Based Model-Agnostic Meta-Learning Algorithms. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Okinawa, Japan, 16–18 April 2019. [Google Scholar]
- Lake, B.M.; Salakhutdinov, R.; Gross, J.; Tenenbaum, J.B. One shot learning of simple visual concepts. Cogn. Sci. 2011, 33, 2568–2573. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.P.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Todorov, E.; Erez, T.; Tassa, Y. MuJoCo: A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 5026–5033. [Google Scholar] [CrossRef]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking Deep Reinforcement Learning for Continuous Control. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Meta-Gradient Approximation |
|---|---|
| MAML [3] | |
| Evo-MAML (ours) |
| Algorithm | Omniglot [30] | MiniImagenet [31] | ||||
|---|---|---|---|---|---|---|
| 5-Way 1-Shot | 5-Way 5-Shot | 20-Way 1-Shot | 20-Way 5-Shot | 5-Way 1-Shot | 5-Way 5-Shot | |
| MAML [3] | 98.70 ± 0.40% | 99.90 ± 0.10% | 95.80 ± 0.30% | 98.90 ± 0.20% | 48.70 ± 1.84% | 63.11 ± 0.92% |
| First-Order MAML [3] | 98.30 ± 0.50% | 99.20 ± 0.20% | 89.40 ± 0.50% | 97.90 ± 0.10% | 48.07 ± 1.75% | 63.15 ± 0.91% |
| Reptile [11] | 97.68 ± 0.04% | 99.48 ± 0.06% | 89.43 ± 0.14% | 97.12 ± 0.32% | 49.97 ± 0.32% | 65.99 ± 0.58% |
| iMAML [12] | 99.50 ± 0.26% | 99.74 ± 0.11% | 96.18 ± 0.36% | 99.14 ± 0.1% | 49.30 ± 1.88% | 66.13 ± 0.37% |
| Evo-MAML (ours) | 99.61 ± 0.31% | 99.76 ± 0.05% | 97.42 ± 0.01% | 99.53 ± 0.10% | 50.58 ± 0.01% | 66.73 ± 0.04% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Yuan, W.; Chen, S.; Hu, Z.; Li, P. Evo-MAML: Meta-Learning with Evolving Gradient. Electronics 2023, 12, 3865. https://doi.org/10.3390/electronics12183865
Chen J, Yuan W, Chen S, Hu Z, Li P. Evo-MAML: Meta-Learning with Evolving Gradient. Electronics. 2023; 12(18):3865. https://doi.org/10.3390/electronics12183865
Chicago/Turabian StyleChen, Jiaxing, Weilin Yuan, Shaofei Chen, Zhenzhen Hu, and Peng Li. 2023. "Evo-MAML: Meta-Learning with Evolving Gradient" Electronics 12, no. 18: 3865. https://doi.org/10.3390/electronics12183865
APA StyleChen, J., Yuan, W., Chen, S., Hu, Z., & Li, P. (2023). Evo-MAML: Meta-Learning with Evolving Gradient. Electronics, 12(18), 3865. https://doi.org/10.3390/electronics12183865