
Hierarchical Decentralized Federated Learning Framework with Adaptive Clustering: Bloom-Filter-Based Companions Choice for Learning Non-IID Data in IoV


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- To accommodate the evolving intelligent transportation scenarios, we introduce a Hierarchical Decentralized Federated Learning framework, H-DFL, for the distributed training of vehicles in IoV.
- We explore a novel paradigm of vehicle clustering according to the data complementarity of vehicles. We take merge-CBF [18] to represent local data in a compact way, in order to support exchange compact representations and judge the data complementarity of other vehicles. Finally, we cluster vehicles with complementary data into one group and train local models with the group.
- On a higher level, base stations maintain the local models of different groups, while submitting them to a data center to obtain a global aggregation to cover more features. In an asynchronous manner, base stations judge whether the local models need to be updated according to the global model.
- We evaluate our proposed method and baselines using two real-world datasets on the Sim4DistrDL simulation platform. The simulation results validate the effectiveness and superiority of our approach against existing baselines.
2. Related Work
3. Preliminary
3.1. Federated Averaging
3.2. Consensus Learning
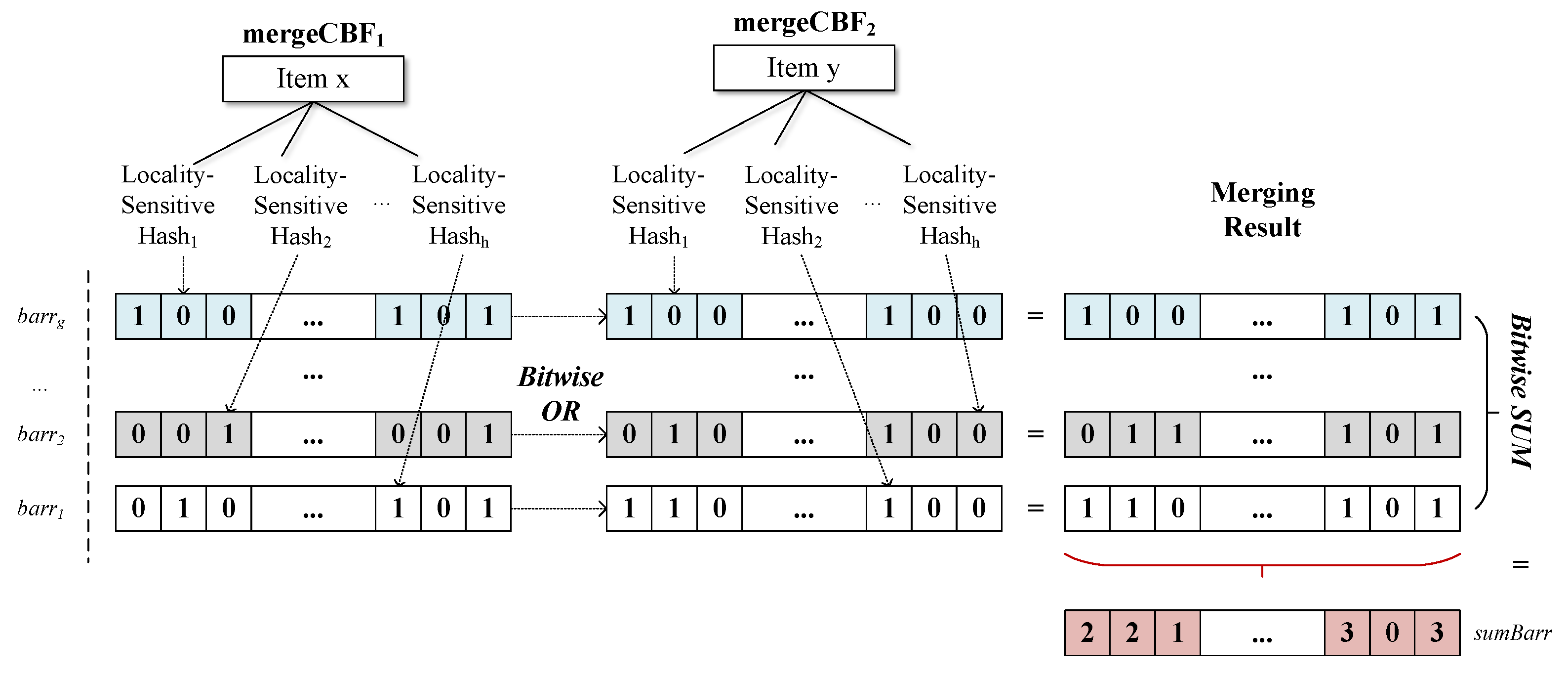
3.3. Mergeable Counting Bloom Filter
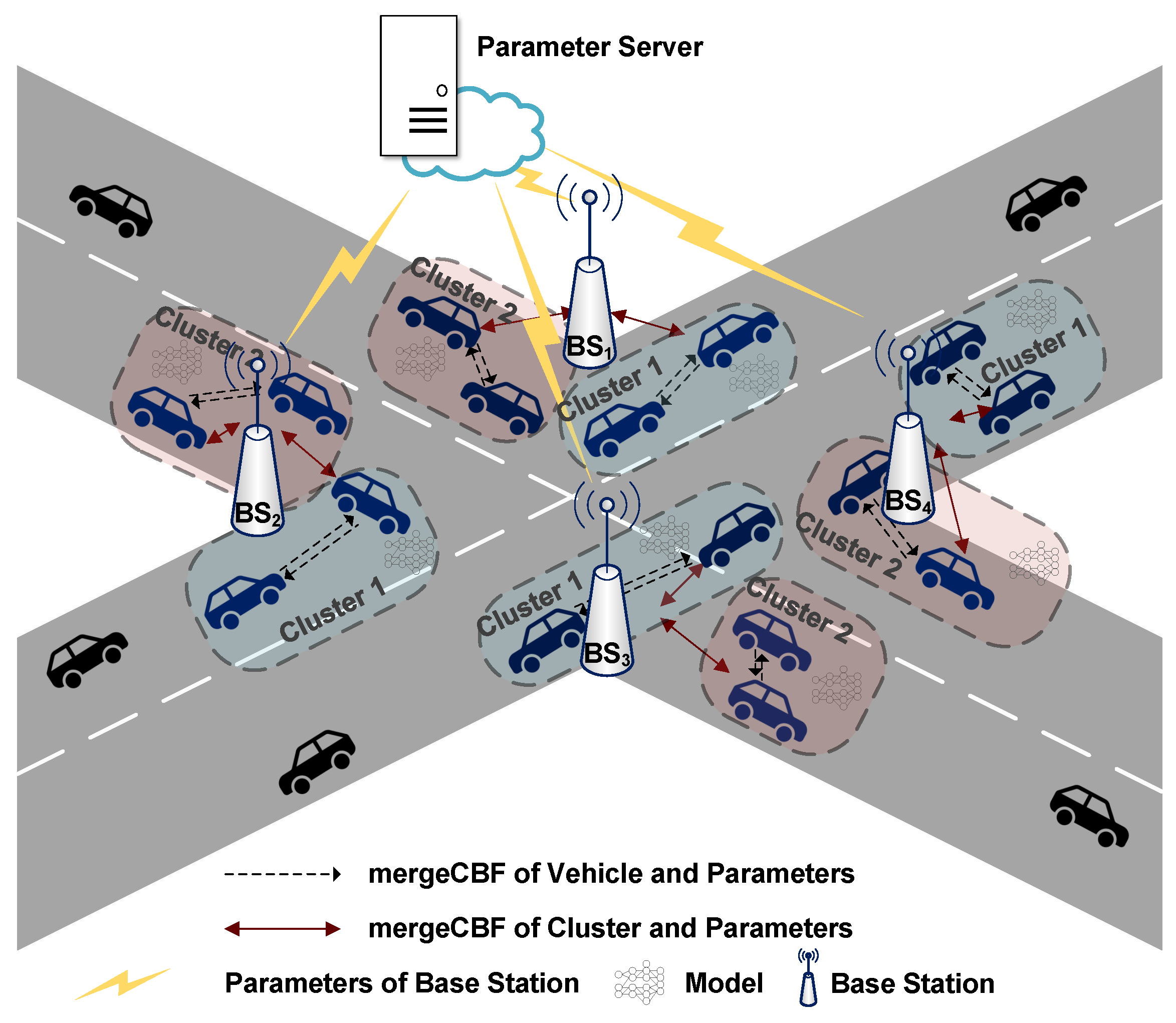
4. Adaptive Hierarchical Decentralized Federated Learning
4.1. Framework
4.2. Vehicle-Side Clustering and Cooperation Based on mergeCBF Filters
| Algorithm 1 Data Distribution Statistics |
|
4.3. Global Aggregation Based on Gradient Difference
| Algorithm 2 Hierarchical Decentralized Federated Learning Algorithm |
|
5. Experiments
5.1. Experimental Details
5.1.1. Simulation Setup
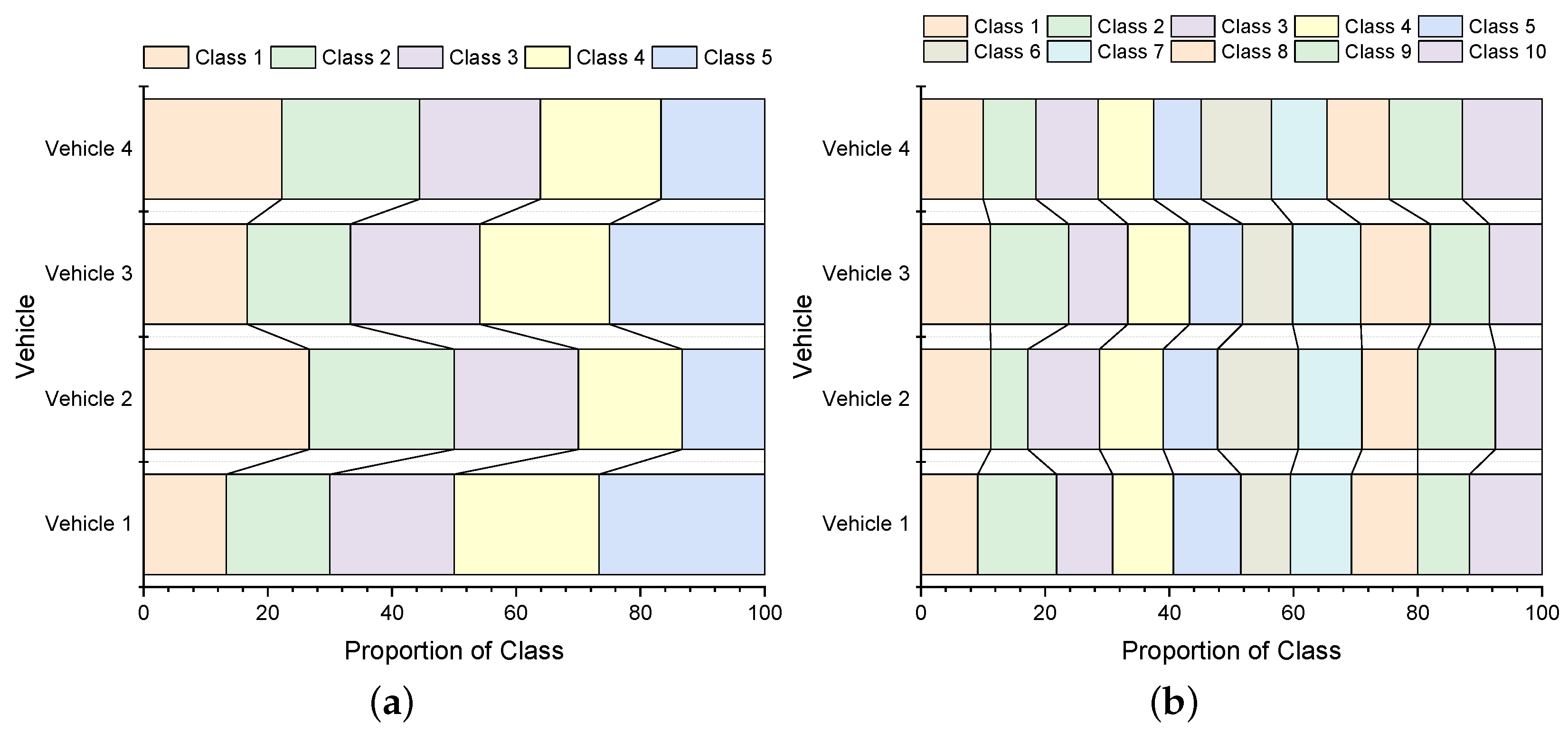
5.1.2. Training Tasks and Data Redistribution
5.1.3. Baselines
5.1.4. Evaluation Metrics
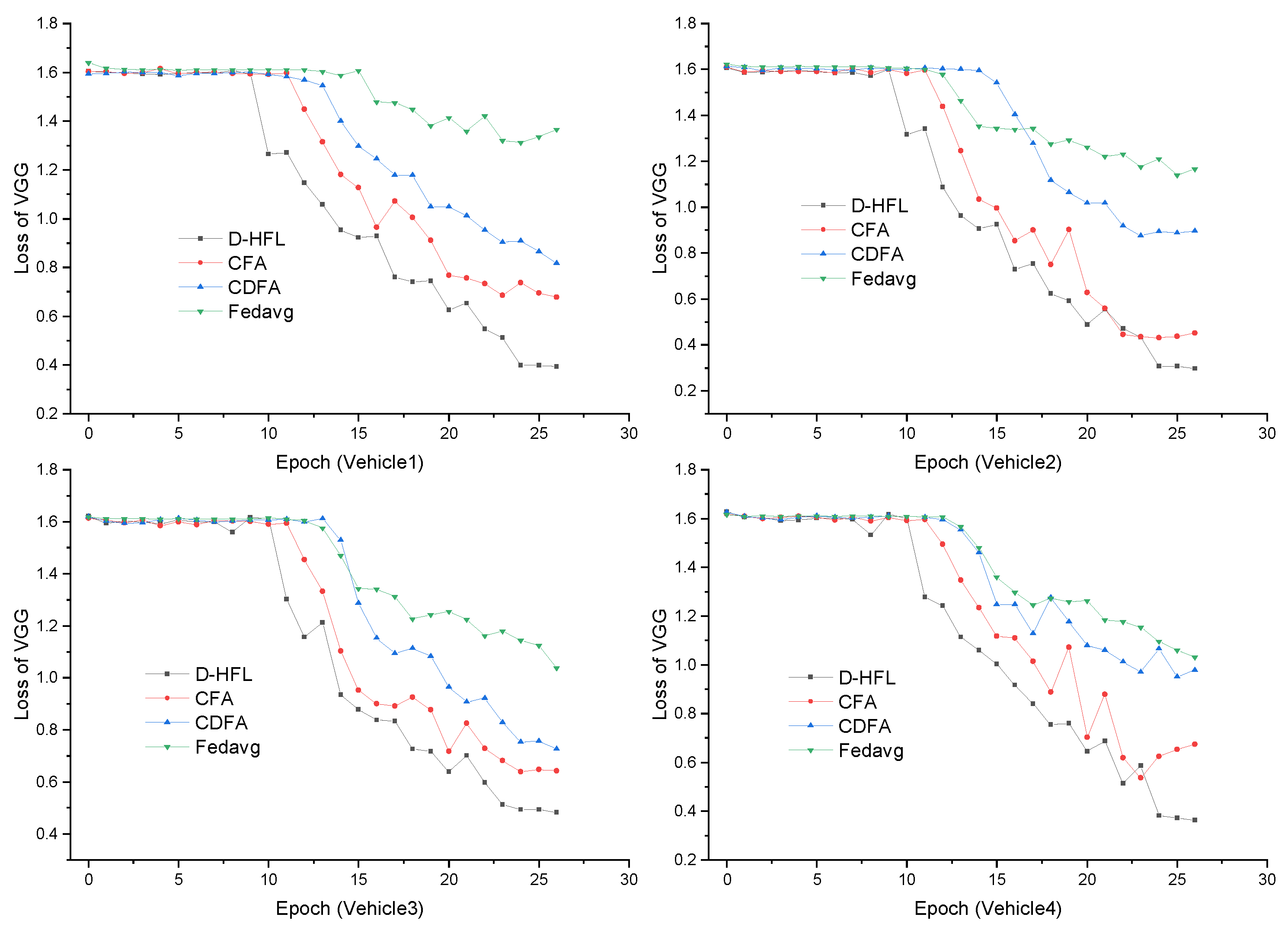
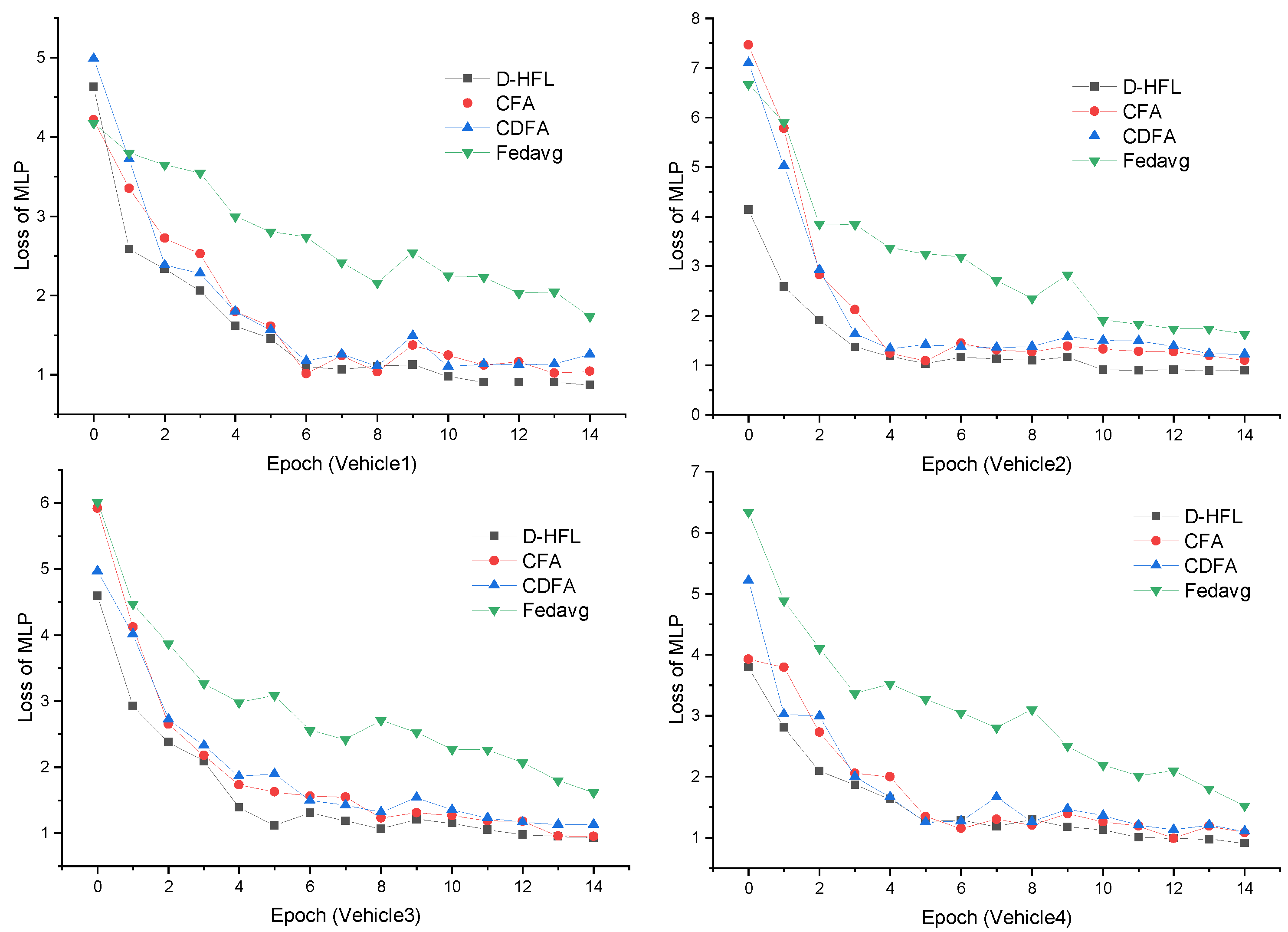
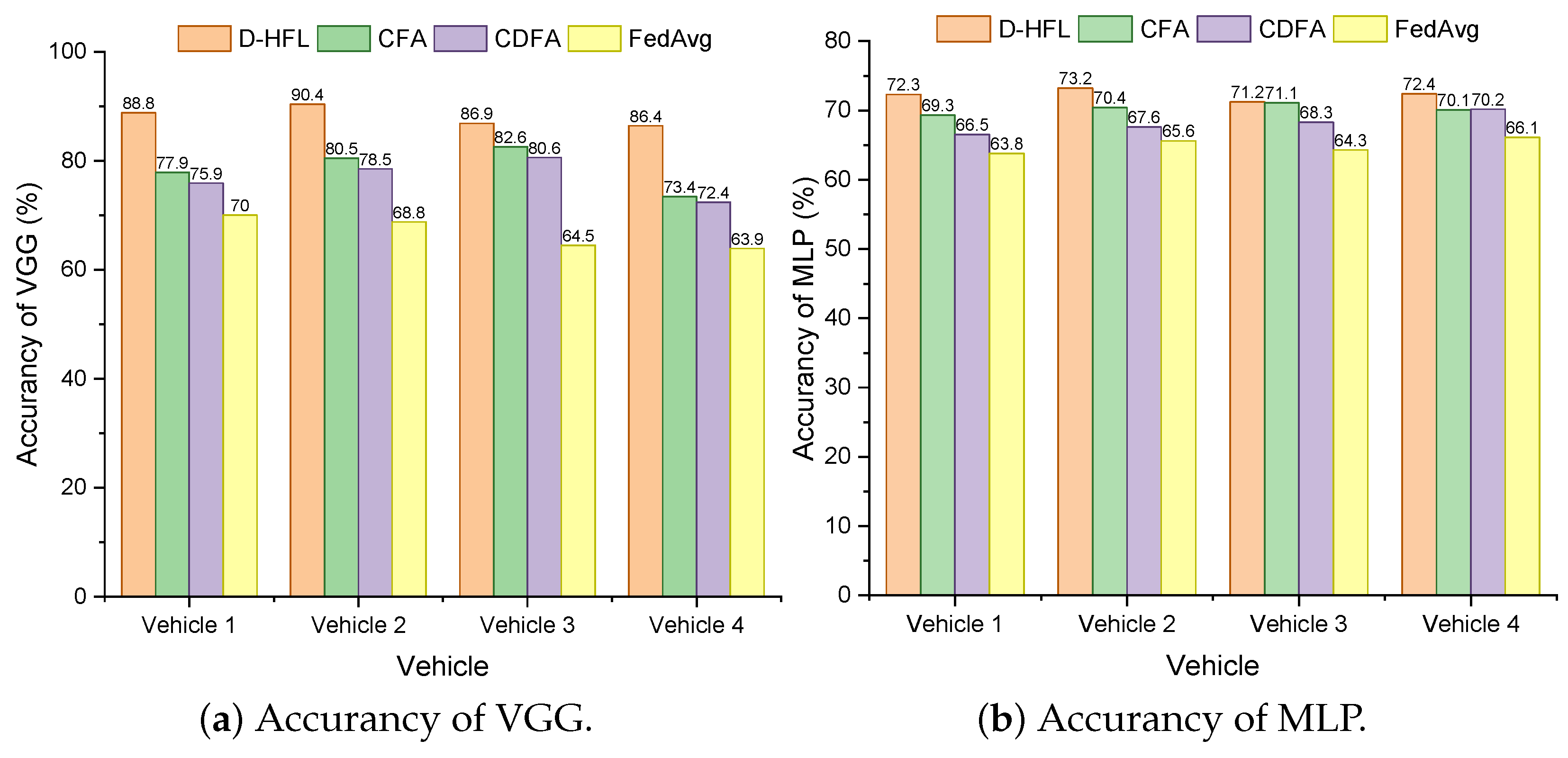
5.2. Performance in Different Training Tasks
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tsaramirsis, G.; Kantaros, A.; Al-Darraji, I.; Piromalis, D.; Apostolopoulos, C.; Pavlopoulou, A.; Alrammal, M.; Ismail, Z.; Buhari, S.M.; Stojmenovic, M.; et al. A modern approach towards an industry 4.0 model: From driving technologies to management. J. Sens. 2022, 2022, 5023011. [Google Scholar] [CrossRef]
- Khattak, S.B.A.; Nasralla, M.M.; Farman, H.; Choudhury, N. Performance Evaluation of an IEEE 802.15. 4-Based Thread Network for Efficient Internet of Things Communications in Smart Cities. Appl. Sci. 2023, 13, 7745. [Google Scholar] [CrossRef]
- Ngo, H.; Fang, H.; Wang, H. Cooperative Perception With V2V Communication for Autonomous Vehicles. IEEE Trans. Veh. Technol. 2023, 1–10. [Google Scholar] [CrossRef]
- Ali, Y.; Haque, M.M.; Mannering, F. Assessing traffic conflict/crash relationships with extreme value theory: Recent developments and future directions for connected and autonomous vehicle and highway safety research. Anal. Methods Accid. Res. 2023, 39, 100276. [Google Scholar] [CrossRef]
- Piromalis, D.; Kantaros, A. Digital twins in the automotive industry: The road toward physical-digital convergence. Appl. Syst. Innov. 2022, 5, 65. [Google Scholar] [CrossRef]
- Taslimasa, H.; Dadkhah, S.; Neto, E.C.P.; Xiong, P.; Ray, S.; Ghorbani, A.A. Security issues in Internet of Vehicles (IoV): A comprehensive survey. Internet Things 2023, 22, 100809. [Google Scholar] [CrossRef]
- Wang, Y.; Su, Z.; Guo, S.; Dai, M.; Luan, T.H.; Liu, Y. A survey on digital twins: Architecture, enabling technologies, security and privacy, and future prospects. IEEE Internet Things J. 2023, 10, 14965–14987. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Liu, R.; Pan, J. CRS: A Privacy-preserving Two-layered Distributed Machine Learning Framework for IoV. IEEE Internet Things J. 2023. [Google Scholar] [CrossRef]
- Choudhury, N.; Nasralla, M.M. A proposed resource-aware time-constrained scheduling mechanism for dsme based iov networks. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–7. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Savazzi, S.; Nicoli, M.; Rampa, V. Federated learning with cooperating devices: A consensus approach for massive IoT networks. IEEE Internet Things J. 2020, 7, 4641–4654. [Google Scholar] [CrossRef]
- Pokhrel, S.R.; Choi, J. A decentralized federated learning approach for connected autonomous vehicles. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Seoul, Republic of Korea, 6–9 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Soto, I.; Calderon, M.; Amador, O.; Urueña, M. A survey on road safety and traffic efficiency vehicular applications based on C-V2X technologies. Veh. Commun. 2022, 33, 100428. [Google Scholar] [CrossRef]
- Barbieri, L.; Savazzi, S.; Brambilla, M.; Nicoli, M. Decentralized federated learning for extended sensing in 6G connected vehicles. Veh. Commun. 2022, 33, 100396. [Google Scholar] [CrossRef]
- Nishio, T.; Yonetani, R. Client selection for federated learning with heterogeneous resources in mobile edge. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Li, B.; Jiang, Y.; Pei, Q.; Li, T.; Liu, L.; Lu, R. Feel: Federated end-to-end learning with non-iid data for vehicular ad hoc networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 16728–16740. [Google Scholar] [CrossRef]
- Liu, W.; Xu, Z.; Tian, J.; Zhang, Y. Towards In-Network Compact Representation: Mergeable Counting Bloom Filter Vis Cuckoo Scheduling. IEEE Access 2021, 9, 55329–55339. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Ng, J.S.; Xiong, Z.; Jin, J.; Zhang, Y.; Niyato, D.; Leung, C.; Miao, C. Decentralized edge intelligence: A dynamic resource allocation framework for hierarchical federated learning. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 536–550. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Ng, J.S.; Xiong, Z.; Niyato, D.; Miao, C. Evolutionary edge association and auction in hierarchical federated learning. In Federated Learning over Wireless Edge Networks; Springer: Berlin/Heidelberg, Germany, 2022; pp. 117–145. [Google Scholar]
- Li, Y.; Wang, X.; Sun, R.; Xie, X.; Ying, S.; Ren, S. Trustiness-based hierarchical decentralized federated learning. Knowl.-Based Syst. 2023, 276, 110763. [Google Scholar] [CrossRef]
- Cho, Y.J.; Gupta, S.; Joshi, G.; Yağan, O. Bandit-based communication-efficient client selection strategies for federated learning. In Proceedings of the 2020 54th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 1–4 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1066–1069. [Google Scholar]
- Ribero, M.; Vikalo, H. Communication-efficient federated learning via optimal client sampling. arXiv 2020, arXiv:2007.15197. [Google Scholar]
- Cho, Y.J.; Wang, J.; Joshi, G. Client selection in federated learning: Convergence analysis and power-of-choice selection strategies. arXiv 2020, arXiv:2010.01243. [Google Scholar]
- Ruan, Y.; Zhang, X.; Liang, S.C.; Joe-Wong, C. Towards flexible device participation in federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Virtual, 13–15 April 2021; pp. 3403–3411. [Google Scholar]
- Ji, S.; Jiang, W.; Walid, A.; Li, X. Dynamic sampling and selective masking for communication-efficient federated learning. IEEE Intell. Syst. 2021, 37, 27–34. [Google Scholar] [CrossRef]
- Liu, G.; Ma, X.; Yang, Y.; Wang, C.; Liu, J. Federaser: Enabling efficient client-level data removal from federated learning models. In Proceedings of the 2021 IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), Tokyo, Japan, 25–28 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–10. [Google Scholar]
- Goetz, J.; Malik, K.; Bui, D.; Moon, S.; Liu, H.; Kumar, A. Active federated learning. arXiv 2019, arXiv:1909.12641. [Google Scholar]
- Cho, Y.J.; Wang, J.; Joshi, G. Towards understanding biased client selection in federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, PMLR, Virtual, 28–30 March 2022; pp. 10351–10375. [Google Scholar]
- Tan, Y.; Long, G.; Liu, L.; Zhou, T.; Lu, Q.; Jiang, J.; Zhang, C. Fedproto: Federated prototype learning across heterogeneous clients. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 8432–8440. [Google Scholar]
- Fang, X.; Ye, M. Robust federated learning with noisy and heterogeneous clients. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10072–10081. [Google Scholar]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Fan, L.; Cao, P.; Almeida, J.; Broder, A.Z. Summary cache: A scalable wide-area web cache sharing protocol. IEEE/ACM Trans. Netw. 2000, 8, 281–293. [Google Scholar] [CrossRef]
- El-Ghamrawy, S.M. A knowledge management framework for imbalanced data using frequent pattern mining based on bloom filter. In Proceedings of the 2016 11th International Conference on Computer Engineering & Systems (ICCES), Cairo, Egypt, 20–21 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 226–231. [Google Scholar]
- Liu, X.; Xu, Z.; Qin, Y.; Tian, J. A discrete-event-based simulator for distributed deep learning. In Proceedings of the 2022 IEEE Symposium on Computers and Communications (ISCC), Rhodes, Greece, 30 June–3 July 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–7. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Timofte, R.; Zimmermann, K.; Van Gool, L. Multi-view traffic sign detection, recognition, and 3D localisation. Mach. Vis. Appl. 2014, 25, 633–647. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Nair, V.; Hinton, G. The CIFAR-10 Dataset. 2014, Volume 55. Available online: http://www.cs.toronto.edu/kriz/cifar.html (accessed on 13 August 2009).
- Tedeschini, B.C.; Savazzi, S.; Stoklasa, R.; Barbieri, L.; Stathopoulos, I.; Nicoli, M.; Serio, L. Decentralized federated learning for healthcare networks: A case study on tumor segmentation. IEEE Access 2022, 10, 8693–8708. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, S.; Liu, Z.; Xu, Z.; Liu, W.; Tian, J. Hierarchical Decentralized Federated Learning Framework with Adaptive Clustering: Bloom-Filter-Based Companions Choice for Learning Non-IID Data in IoV. Electronics 2023, 12, 3811. https://doi.org/10.3390/electronics12183811
Liu S, Liu Z, Xu Z, Liu W, Tian J. Hierarchical Decentralized Federated Learning Framework with Adaptive Clustering: Bloom-Filter-Based Companions Choice for Learning Non-IID Data in IoV. Electronics. 2023; 12(18):3811. https://doi.org/10.3390/electronics12183811
Chicago/Turabian StyleLiu, Siyuan, Zhiqiang Liu, Zhiwei Xu, Wenjing Liu, and Jie Tian. 2023. "Hierarchical Decentralized Federated Learning Framework with Adaptive Clustering: Bloom-Filter-Based Companions Choice for Learning Non-IID Data in IoV" Electronics 12, no. 18: 3811. https://doi.org/10.3390/electronics12183811
APA StyleLiu, S., Liu, Z., Xu, Z., Liu, W., & Tian, J. (2023). Hierarchical Decentralized Federated Learning Framework with Adaptive Clustering: Bloom-Filter-Based Companions Choice for Learning Non-IID Data in IoV. Electronics, 12(18), 3811. https://doi.org/10.3390/electronics12183811