1. Introduction
The presence of façade defects is a pressing issue in the operational phase of buildings, which is commonly attributed to mechanical and environmental factors. Typical defects manifest as concrete peeling, decorative spalling, component cracks, large-scale deformation, tile injury, moisture damage, etc. [
1,
2,
3,
4]. These defects can affect the appearance and reduce the service life expectancy of the building. More seriously, the façade falling objects may cause safety accidents and irreparable losses [
5]. Structural damage detection is an integral part of structural health monitoring (SHM) and is essential for ensuring the safe operation of buildings [
6]. As a component of structural damage detection, the detection of building façade defects can enable the government and management to gain a precise comprehension of the comprehensive status of the building façade, thereby facilitating the establishment of rational maintenance programs. It is an effective approach to reduce building maintenance costs, extend building service life, and mitigate the impact of façade damage [
7]. Policies for regular standardized visual inspections are now being developed in many countries and regions [
8,
9]. The detection of building façade defects has become a critical component of building maintenance.
Visual inspection is an easy and trustworthy method to evaluate the condition of a building façade [
10]. Conventional building façade inspection usually requires professionals with specialized tools to reach the inspection location, where visual observation, hammering, and other techniques are utilized for the assessment. These methods rely on the expertise and experience of the inspectors, which are subjective, dangerous, and inefficient [
11]. Owing to the incremental quantity and growing size of buildings, manual visual inspection methods have become inadequate for fulfilling the demands of large-scale inspection. With the advancement of technology, many new methods (such as laser scanning, 3D thermal imaging, and SLAM) are being utilized for façade damage inspection via drones and robotic platforms [
12]. These new methods are more convenient and safer compared with traditional techniques, but they are time-consuming and high-cost [
13]. So, these methods are also confronting challenges in meeting the demands for large-scale inspections. Therefore, the development of a more precise and efficient method for detecting façade defects is necessary to enhance inspection efficiency and decrease computational costs [
14].
Recent years have seen widespread adoption of deep learning in SHM, particularly in structural damage detection [
15,
16]. Object detection algorithms based on deep learning can be classified into two primary categories. One category is the two-stage region-proposal-based algorithm represented by region-based convolutional neural networks (R-CNN) [
17]. The other is the single-stage regression-based algorithm represented by You Only Look Once (YOLO) [
18] and Single Shot MultiBox Detector (SSD) [
19]. In 2014, Girshick et al. presented R-CNN algorithm, which represented the first successful implementation of deep learning techniques for the task of object detection. In this algorithm, selective search algorithm [
20] is initially employed to extract candidate regions. These regions are subsequently resized to a fixed size and input into a convolutional neural network sequentially for feature extraction. The extracted features are then subjected to support vector machine (SVM) classification and region regression to obtain location information. However, R-CNN has some limitations, including intricate and computationally intensive calculations. To solve these problems, Ren et al. proposed Faster R-CNN [
21] algorithm, which is based on Fast R-CNN [
22]. The Faster R-CNN algorithm introduced region proposal network (RPN) as a replacement for selective search algorithm. RPN is capable of predicting the region of interest. The anchor box mechanism and the border regression mechanism are also introduced in Faster R-CNN to enable it to directly generate candidate regions with multiple scales and multiple aspect ratios. These methods have reduced the computational cost of the inference process. Compared with R-CNN, the accuracy and speed of detection have been improved substantially in Faster R-CNN.
Numerous scholars have conducted research on the detection of building façade defects using two-stage algorithms. These studies primarily focus on the effectiveness of feature extraction techniques and the accuracy of the detection methods. Murad Samhouri et al. [
23] proposed a CNN-based method for the classification of erosion, material degradation, chromatic alterations in stone, and damage in the façades of architectural heritage sites. Despite having good reliability, with an average detection accuracy of 95%, the proposed method exhibits a high computational cost due to the large number of model parameters, which results in a slow inference speed. Kisu Lee et al. [
24] proposed a Faster-R-CNN-based defects detection system for building façade. Four typical defects of building façade (delamination, cracks, peeling paint, and water leakage) can be detected by this system. The model achieves an average accuracy of 62.7%, but its performance in real-time detection is unsatisfactory. Jingjing Guo et al. [
25] combined a rule-based deep learning method with Mask R-CNN. Different annotation rules and suggested weighting rules are used separately during data annotation and model training phases of this method, resulting in a 27.9% growth in defects detection accuracy, and the stability of façade defects detection has effectively improved. This method focuses on improving detection accuracy, and the efficiency is not high.
The single-stage algorithm demonstrates greater efficiency in comparison to the two-stage algorithm because it achieves object detection through a singular feature extraction process. However, it is imperative to realize that the accuracy of the single-stage algorithm is susceptible to compromise. M Mishra et al. [
26] proposed a YOLOv5-based structural defects detection method to detect four types of defects: discoloration, exposed bricks, cracks, and spalling. Their model achieved 93.7% mAP on their custom dataset and has ample potential for real-time detection. Idjaton K et al. [
27] proposed a YOLOv5 network incorporating Transformer for detecting spalled areas in limestone walls. The network’s accuracy has achieved 79%, representing a significant improvement over the original YOLOv5x. However, the addition of a Transformer structure causes significant resource consumption during the network training. Chaoxian Liu et al. [
28] proposed a lightweight YOLOv5 network, which incorporates the convolutional block attention module (CBAM), bi-directional feature pyramid network (BiFPN), and depthwise separable convolution (DSConv). The improved network achieves more than 90% detection accuracy for a wide range of defects targets, with an inference speed of 24 FPS.
Current single-stage object detection algorithms are developing rapidly. YOLOv7 [
29] used strategies such as re-parameterized and label matching to construct the network and achieves 56.8% accuracy on the COCO dataset [
30]. YOLOv7 has enormous potential in façade defects detection. However, there is less research on the application of YOLOv7 in building façade defects detection, and there is still room to improve the speed and accuracy of this model in defects detection.
In response to these above problems, an improved YOLOv7-based defects detection method for building façade named BFD-YOLO is proposed in this paper. Firstly, to improve the network’s inference speed, the MobileOne [
31] lightweight network module is introduced into YOLOv7, which effectively reduces the inference time consumption. Secondly, the image background of the building façade is complex, and the object detection algorithm needs to mitigate the interference of the complex background. Hence, the coordinate attention [
32] mechanism is incorporated to enhance the feature extraction capability of the network and make the network focus more on key information. Finally, the SCYLLA-IoU (SIoU) [
33] regression loss function is introduced to improve the convergence speed of the network and reduce the false detection problem. The experimental results demonstrate that our method achieves satisfactory performance on building façade defects in complex environments.
3. Improved Network
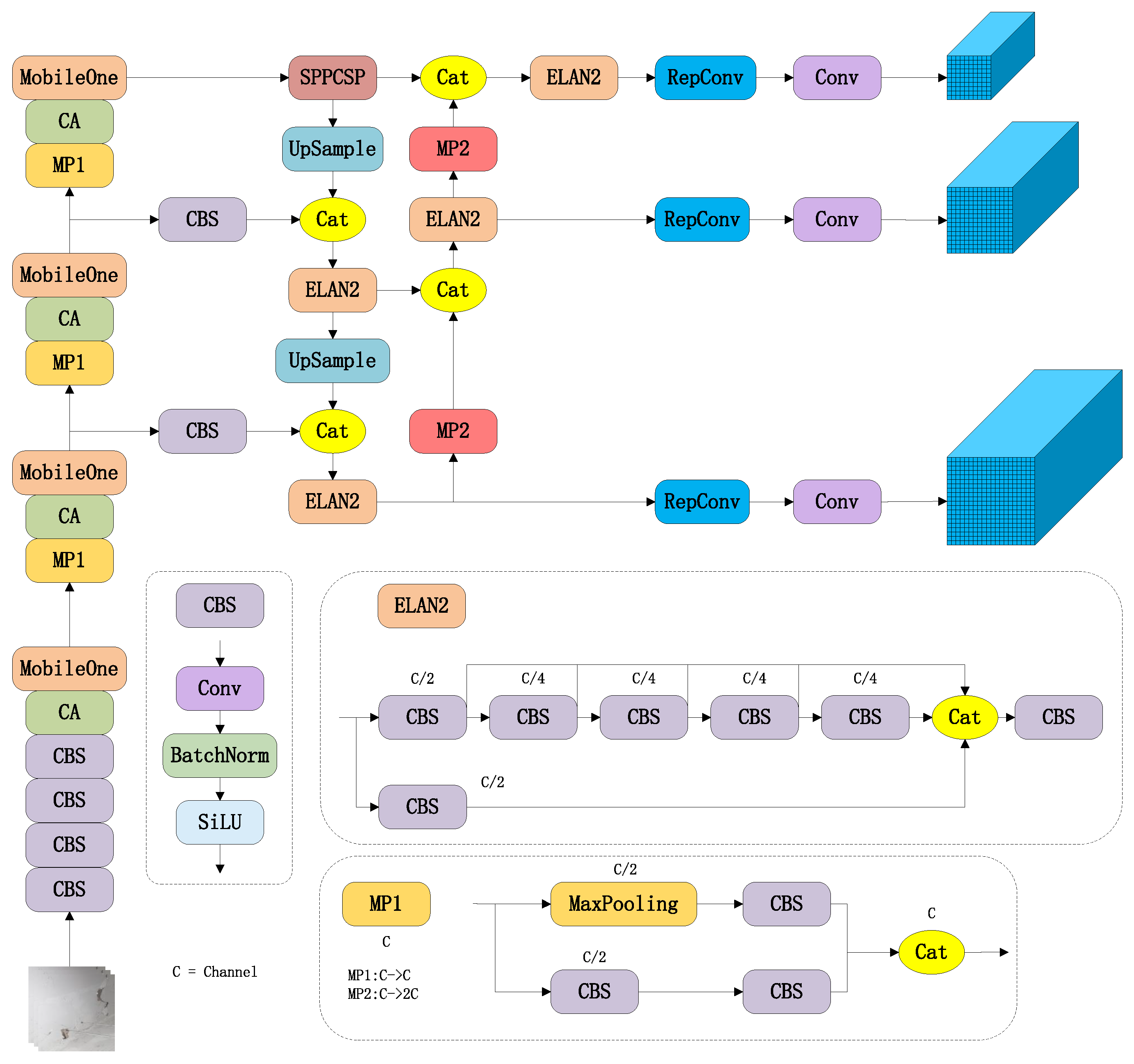
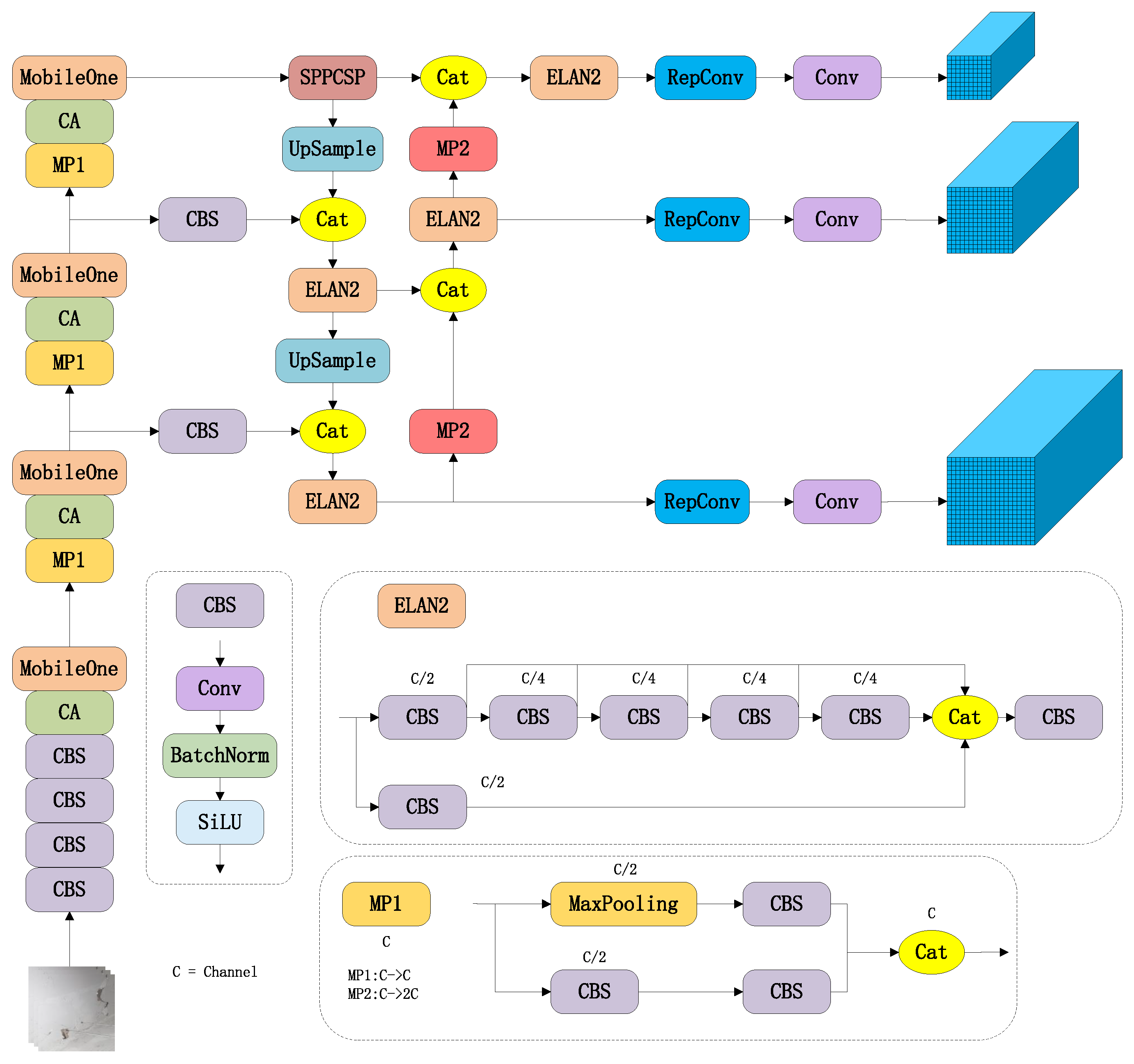
The improved YOLOv7 structure in this paper is shown in
Figure 4.
It can be divided into the backbone and the head. The function of the backbone network is to extract features. The original backbone of YOLOv7 is composed of several CBS, MP, and ELAN modules. The CBS is a module consisting of convolution kernel, batch normalization, and SiLU activation function. The MP is consisting of MaxPooling and CBS. The improved backbone replaced the ELAN module with the MobileOne module to increase speed, and a coordinate attention module was added after each MobileOne module. The proposed improvement method has the capability to attend to salient features and suppress extraneous information in the input image, thereby improving detection accuracy effectively.
The head of the network is a PaFPN structure, which consists of a SPPCPC, several ELAN2, CatConv, and three RepVGG blocks. The design of ELAN adopts the gradient path design strategy. In contrast to the data path design strategy, the gradient path design strategy focuses on analyzing the sources and composition of gradients to design network architectures that effectively utilize network parameters. The implementation of this strategy can make the network architecture more lightweight. The distinction between ELAN and ELAN2 lies in the difference in their number of channels. The structural re-parameterization method is applied to the RepVGG block. A multi-branch structure for training and a single-branch structure for inference were used by this method to improve the performance during training and the speed during inference. After outputting three feature maps, the head generates three different-sized prediction results through three RepConv modules.
3.1. MobileOne Module
Calculating cost is an important factor to consider for building façade defects detection. The question of how to enhance computational efficiency while maintaining the efficacy of network detection is of significant value. Generally, there exists a positive correlation between the accuracy of a model and its complexity. However, the increase in complexity will reduce the inference speed of the model and decrease memory utilization [
35]. To solve this problem, MobileOne module is incorporated into the YOLOv7’s backbone. MobileOne is an efficient backbone network. In order to maintain the advantages of multi-branch structures during training and the advantages of regular structures during inference, over-parametrization and re-parametrization methods are used to alter the network architecture. Specifically, an over-parametrization structure is used for training and a re-parametrization structure is used for inference to build the network. The reduction in model parameters brought about by re-parameterization can improve the inference performance of the network.
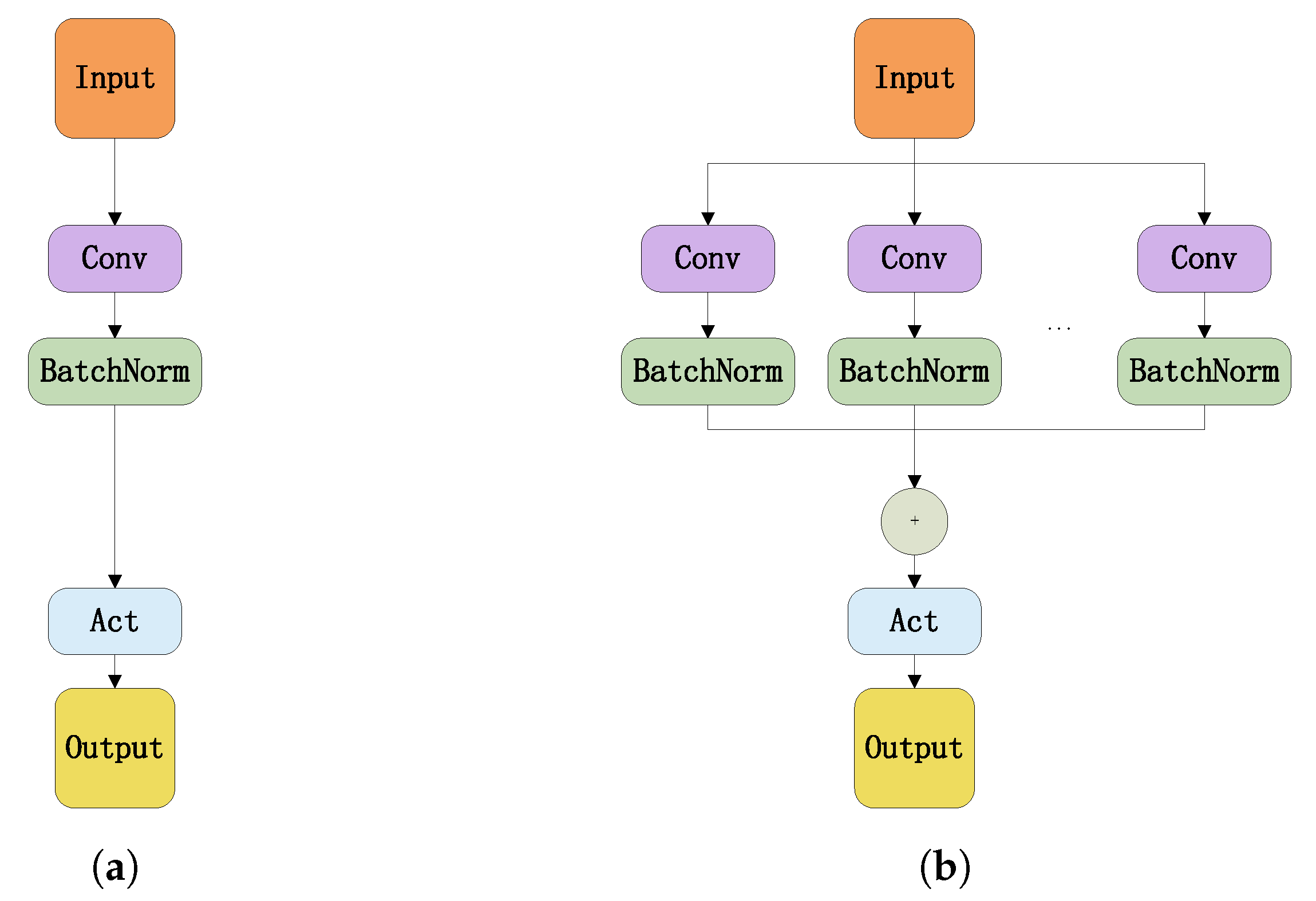
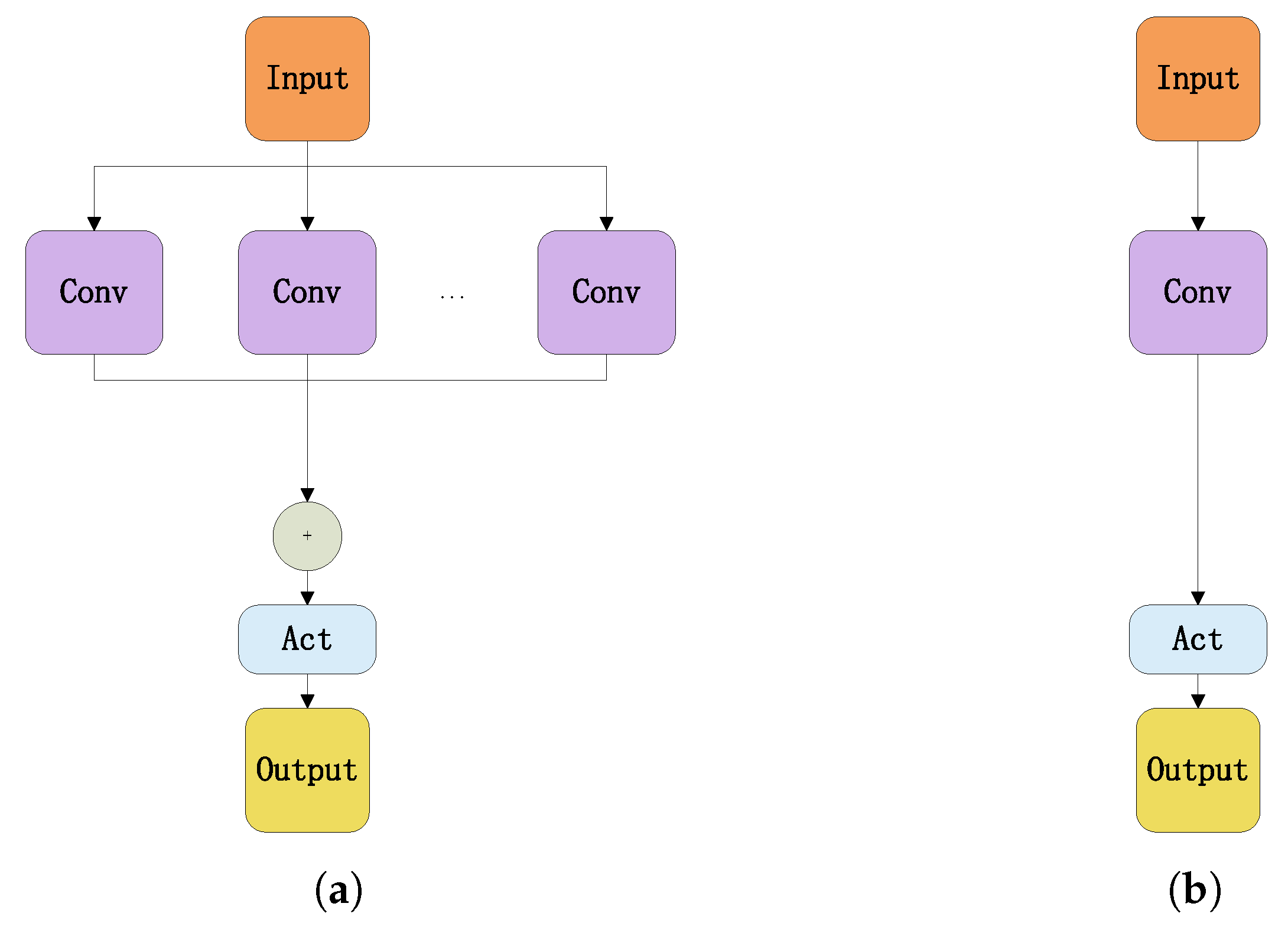
3.1.1. Over-Parametrization Structure
The regular convolution kernel and the over-parameterized convolution kernel are illustrated in
Figure 5a and
Figure 5b, respectively.
The regular convolution module is composed of convolution kernel, batch normalization, and activation function. In contrast, several identical parallel branches were contained by over-parameterized convolution and the outputs of all branches are summed before entering the activation function. The addition of branching structures can enhance the representational capacity of the model. By increasing the complexity during training, the performance of the model has been improved.
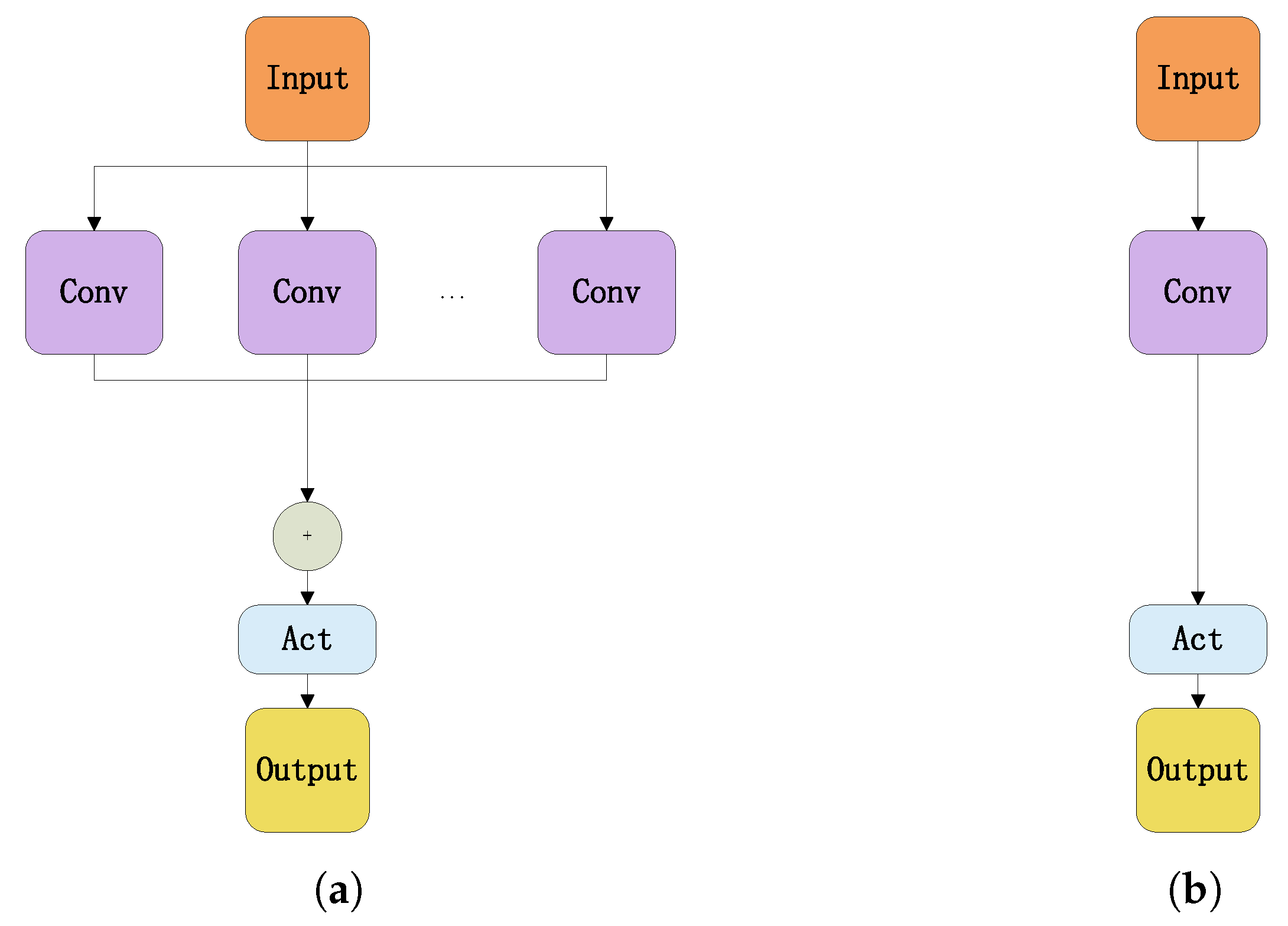
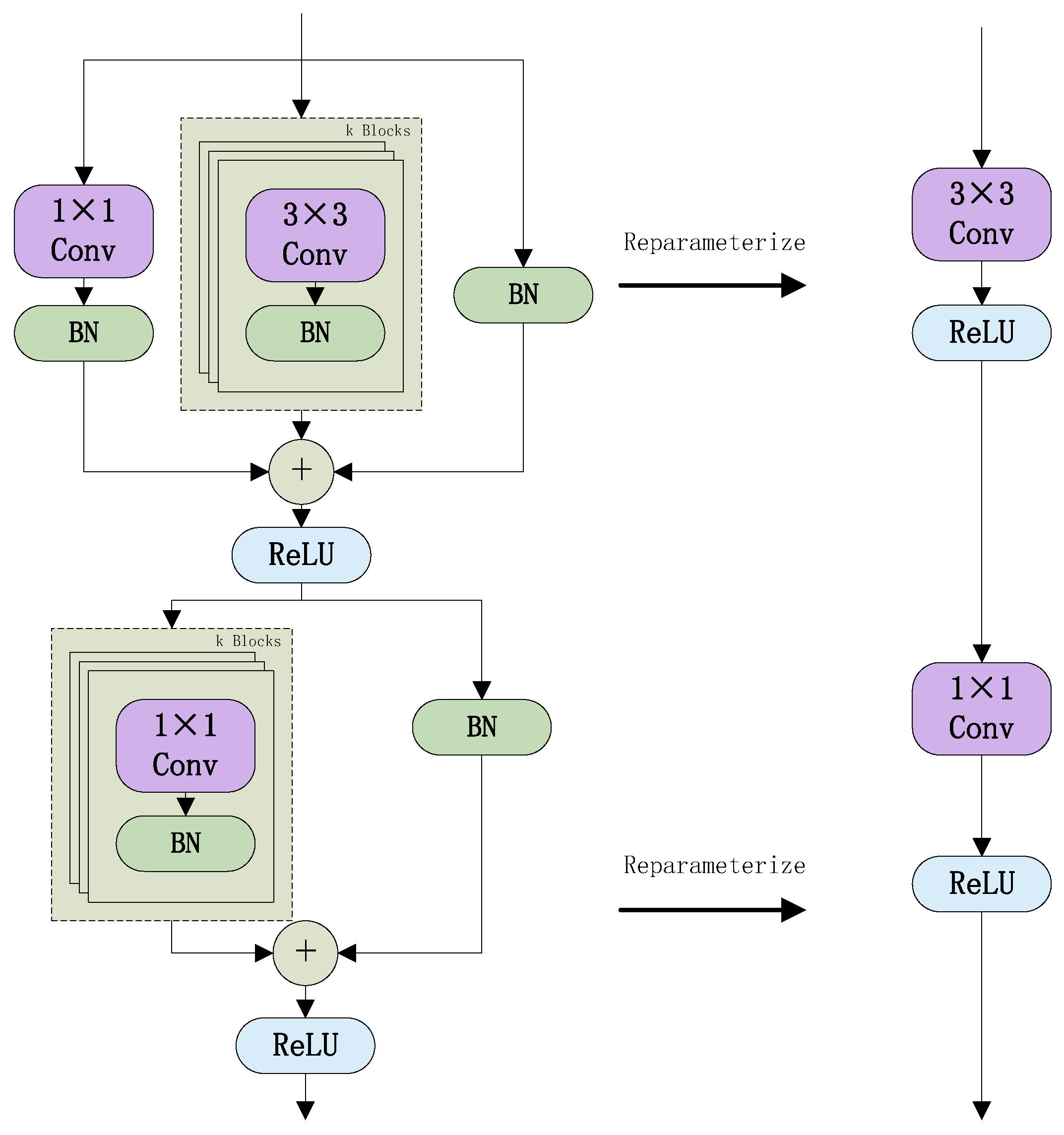
3.1.2. Re-Parametrization Structure
The re-parameterization process is shown in
Figure 6. For multiple convolution modules with the same hyperparameters, every Conv-BN branch can be merged into a single convolution module by using the convolution and BN merge method, and all convolution modules can be combined into a new convolution module by using the multi-branch sum method. In the inference phase, the over-parameterized module has only one convolution module and one activation function module, the same as the regular convolution module. The transformation of the multi-branch structure into a single-branch structure results in a reduction in the number of parameters and inference time of the model.
3.1.3. MobileOne Module
The primary structure of MobileOne module is analogous to that of MobileNetV1, with the key distinction being the integration of over-parameterization and re-parameterization methods. MobileOne module structure is shown in
Figure 7. The left-hand side of
Figure 7 shows the structure of MobileOne module during training, which is composed of a depthwise convolution layer in the upper half and a pointwise convolution layer in the lower half. Depthwise convolution layer is essentially a grouped convolution, which is composed of three branches. The left branch is a
Conv, the middle branch has
k over-parameterized
convolutions, and the right branch is a jump connection containing a batch normalization. The number of convolutional groups is equivalent to the quantity of input channels. The pointwise convolution layer is composed of two branches, the left branch has
k over-parameterized
convolutions, and the right branch is a jump connection containing a batch normalization. In this paper,
k is set at 4.
The right-hand side of
Figure 7 shows the structure of MobileOne module during inference. The upper and lower parts are the re-parameterized structure of depthwise convolution layer and pointwise convolution layer, respectively. Depthwise convolution consists of three branches. In the first branch of depthwise convolution, the zero padding method is used to convert the
convolution kernel to a
convolution kernel. This
convolution kernel is merged with the batch normalization to become the first new
convolution kernel. Equations (
1) and (
2) are used to calculate the weights
and biases
of the new convolution kernel.
where
and
b are the weights and biases of the convolution,
,
,
, and
are the weights, biases, means, and variances of batch normalization, and
is a small value to prevent division by zero. The merging of the convolution and batch normalization in the second branch utilizes the same methodology. The parameters of the
k convolution kernel are summed after the merger to become the second new
convolution kernel. The third branch has no convolution layer, so a
convolution kernel is built before the batch normalization layer to ensure that the three branches can be fused. The
convolution kernel is merged with the batch normalization to form the third new
convolution kernel. These three new
convolution kernels are fused to form the re-parameterized structure of depthwise convolution. The same method is used for the re-parameterized structure of pointwise convolution.
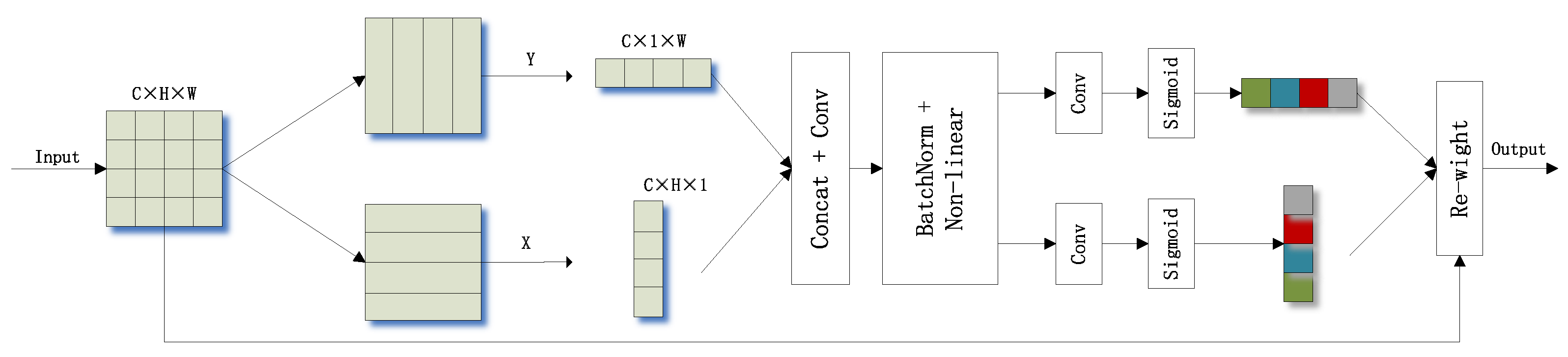
3.2. Coordinate Attention Module
Some defects are challenging to detect by the detector due to the effects of light, weather, background, size, and shape. In order to highlight the features in the image that are beneficial for detection, suppress the noise that causes interference, and make the network focus on a part of the image rather than the whole region during detection, the coordinate attention (CA) module is added to YOLOv7.
Channel attention mechanisms (e.g., SE, GSoP) [
36,
37] and spatial attention mechanisms (e.g., EMANet) [
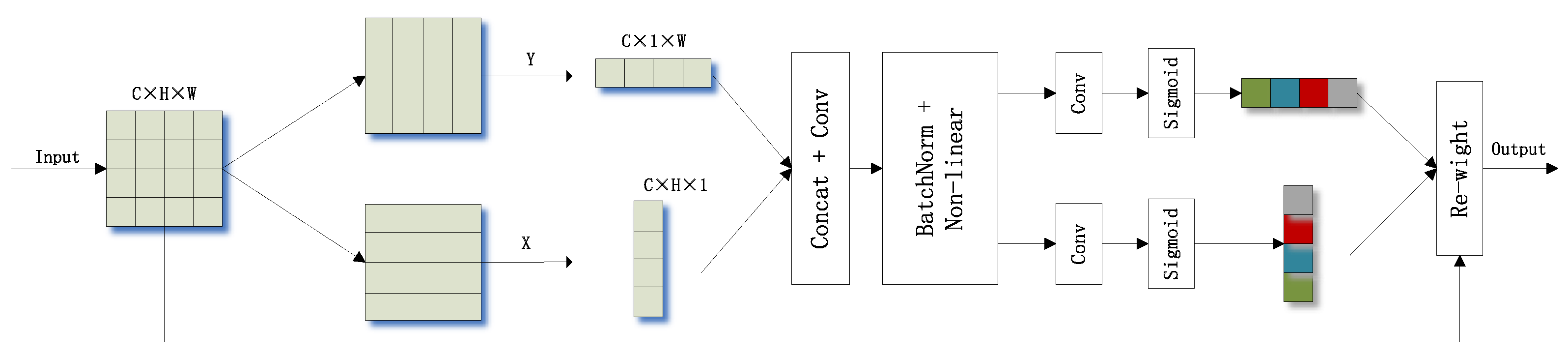
38] have achieved significant results. However, channel attention mechanisms only consider inter-channel information and ignore location information, while spatial attention mechanisms can only extract local relations and cannot extract long-distance relations. A lightweight channel attention mechanism called coordinate attention is proposed by Hou, Q et al. to solve these problems. The processing of CA is shown in
Figure 8. It can be seen that CA encodes horizontal and vertical location information into channel attention, which allows the network to focus on an extensive range of location information without incurring excessive computational effort.
Coordinate attention encodes channel relationships and long-term dependencies by precise location information, which can be divided into two steps: coordinate information embedding and coordinate attention generation.
3.2.1. Coordinate Information Embedding
The global pooling approach is usually used for global encoding in the channel attention mechanism. However, this approach compresses the global spatial information into the channel descriptors, making it difficult to preserve crucial spatial information. For the input
X, CA encodes features from two directions, horizontal and vertical, by using pooling kernels
and
, respectively, which enables the attention module to capture remote spatial interactions with precise location information. The global pooling approach is decomposed according to the following Equation (
3).
According to Equation (
3), the output of the
c dimension feature is
These two transformations ((
4) and (
5)) output two direction-aware feature maps that integrate features from the horizontal and vertical directions, respectively.
3.2.2. Coordinate Attention Generation
The above operation can obtain global receptive field and positional information, and the intermediate feature containing both horizontal and vertical spatial information
f can obtained by connecting
and
with a
convolution kernel
through Equation (
6)
where
is the output of all channels at the height
h,
is the output of all channels at the width
w,
is the activation function, and
r is the ratio of downsampled. Subsequently,
f is divided horizontally and vertically into two independent feature maps
and
. Then, convolution and activation are performed on
and
to obtain the horizontal and vertical attention weights
and
by Equations (
7) and (
8)
where
and
are
convolution kernels, and
is the Sigmoid function.
Finally,
and
are combined into a weight matrix and the
of the coordinate attention mechanism is calculated using Equation (
9).
where
denotes the horizontal attention weight for height
i on channel
c, and
denotes the vertical attention weight for width
j on channel
c.
The transitions in coordinate attention are concise and efficient. By utilizing positional information to locate areas of interest while effectively capturing the relationships between channels, the ability to identify targets is enhanced.
3.3. SIoU Loss
In the object detection algorithm, many bounding boxes with high confidence are generated around the real target, and the non-maximum suppression (NMS) algorithm is used to remove the duplicate bounding boxes so that there is only one detection box for each object. The conventional NMS algorithm generates bounding boxes based on object detection scores. Firstly, the list of candidate boxes is sorted in descending order according to the confidence level. Then, the bounding box A with the highest confidence level is selected, added to the output list, and removed from the list of bounding boxes. Finally, the intersection over union (IoU) values of A and all detected boxes in the candidate box list are calculated, and the bounding boxes larger than the threshold value (the threshold value is usually chosen as 0.5) are removed. The algorithm keeps repeating the above process until the list of bounding boxes is empty and returns the output list.
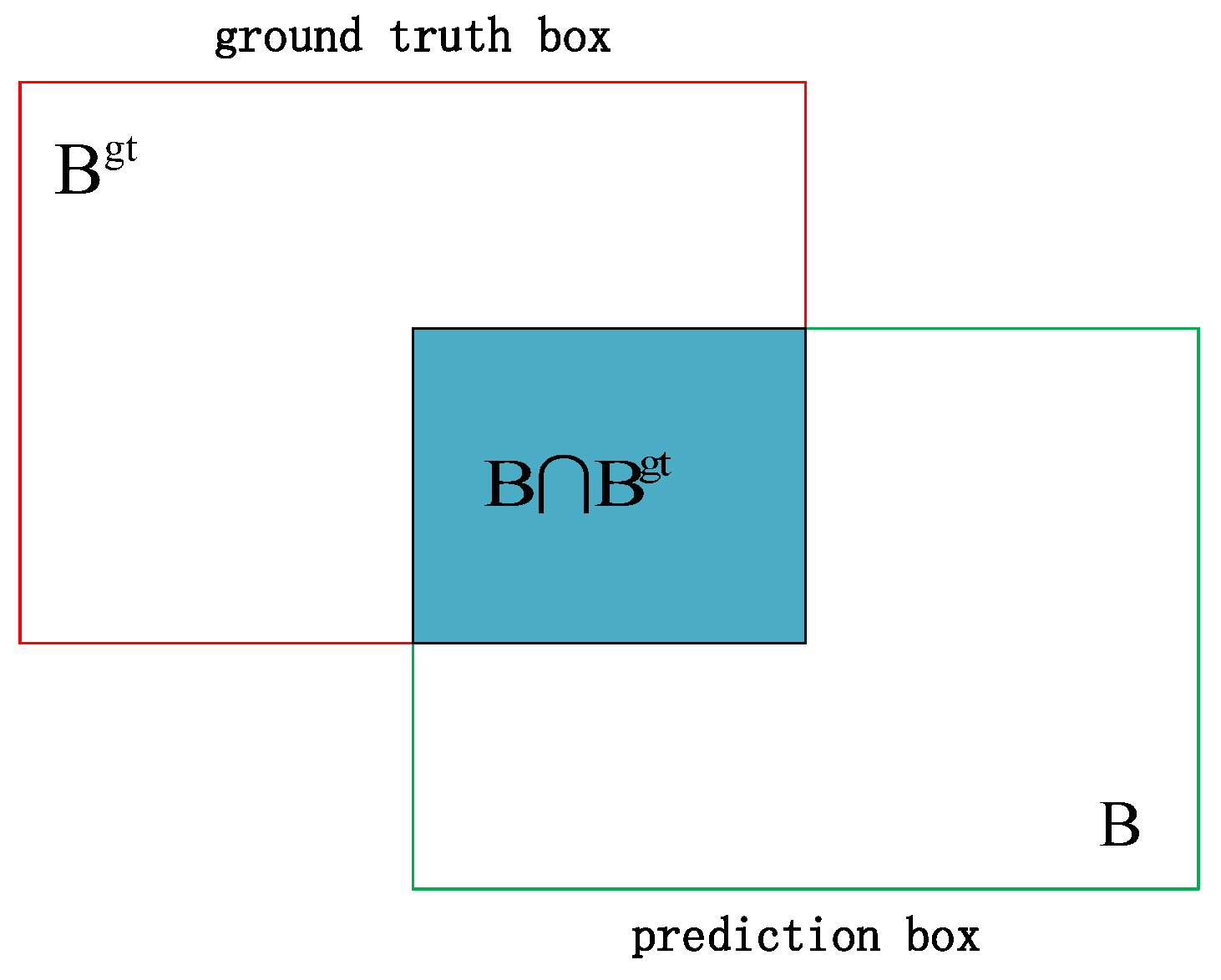
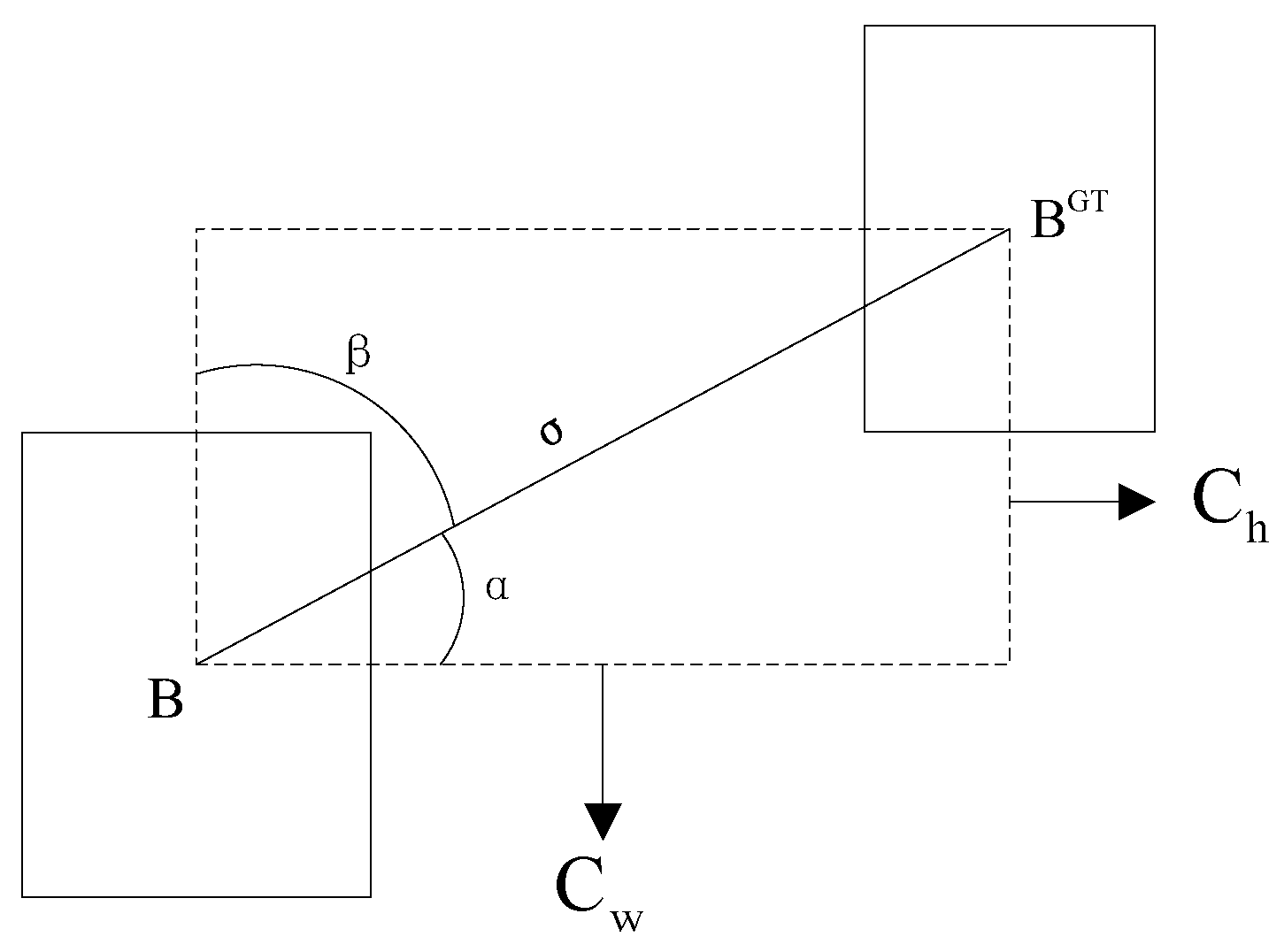
The IoU refers to the ratio of the intersection area and union area of the predicted box and the ground truth box, as shown in
Figure 9. Equations (
10) and (
11) are the equations for IoU and the IoU loss
where
B is the predicted box and
is the ground truth box. The value of
is positively correlated with the degree of overlap between the predicted box and the ground truth box. The IoU is widely applied in object detection algorithms. Nevertheless, there are two issues with IoU, as shown in
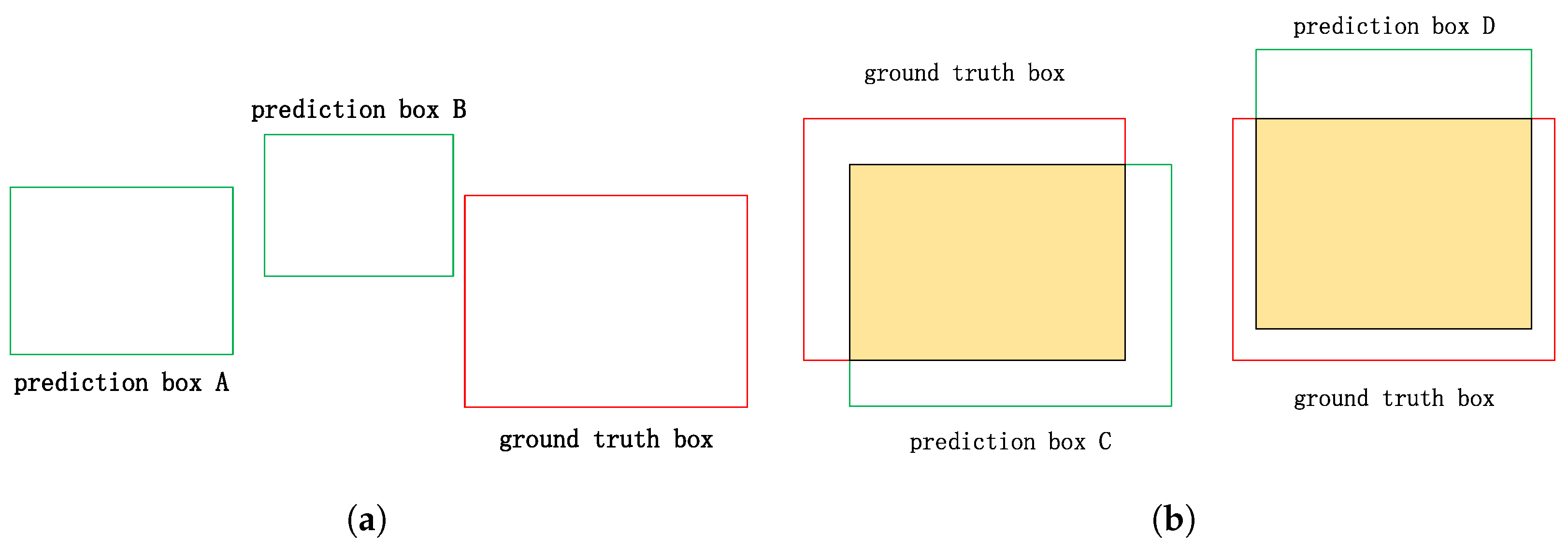
Figure 10.
Figure 10a shows one scenario. Two predicted boxes, A and B, have no intersection with the ground truth box. According to Equation (
11), their losses are both 1. However, predicted box B is closer to the ground truth box than predicted box A; therefore, the loss of predicted box B should be smaller.
Figure 10b shows the other scenario. Predicted boxes C and D differ in their spatial relationships with the ground truth box. Yet, the loss remains the same for both. It is difficult to determine which predicted box is more accurate in this situation. These existing problems lead to less efficient convergence of IoU.
Compared with the IoU, the SIoU considers not only the overlapping area, distance, and aspect but also the angle between two bounding boxes. The SIoU loss function consists of four cost functions, which are angle cost, distance cost, shape cost, and IoU cost.
3.3.1. Angle Cost
In the early stage of training an object detection network, the situation that the predicted box and the ground truth box do not intersect often happens. Therefore, how to quickly converge the distance between the predicted box and the ground truth is a question worthy of consideration. The SIoU first determines which direction is closer between the predicted box and the ground truth box in X-axis and Y-axis. Then, it moves towards the ground truth box in the closer direction.
Figure 11 shows the boundary regression of SIoU, where
is the angle between the line connecting the center points of the two boxes and the x-axis,
is the angle with the y-axis,
is the height difference between the center point of the ground truth box and the predicted box, and
is the distance between the center point of the real box and the predicted box.
If
, the convergence process will first minimize
and otherwise minimize
. The angle cost
is calculated by Equations (
12) and (
13)
3.3.2. Distance Cost
The distance cost
is calculated by Equations (
14) and (
15)
where
and
represent the distance error in horizontal and vertical directions, respectively.
and
are the width and height of the smallest external rectangle of the ground truth and predicted boxes, and
is the angle cost calculated in the previous section.
3.3.3. Shape Cost
The calculation formula of shape cost
is as follows.
where
and
represent the normalization coefficients in the horizontal and vertical directions, respectively.
indicates the degree of concern about shape cost, which takes values between 2 and 6 depending on the dataset, and
is set to 4 in this paper.
3.3.4. IoU Cost
The IoU cost in SIoU is the same as the normal IoU and is calculated using (
10). The overall loss calculation formula for SIoU is shown below.
Compared with the traditional IoU algorithm, SIoU considers the angle between the predicted box and the ground truth box and proposes a more accurate loss calculation method, which is conducive to improving the accuracy and efficiency of the regression. Therefore, SIoU is used by BFD-YOLO as the loss function.
5. Conclusions
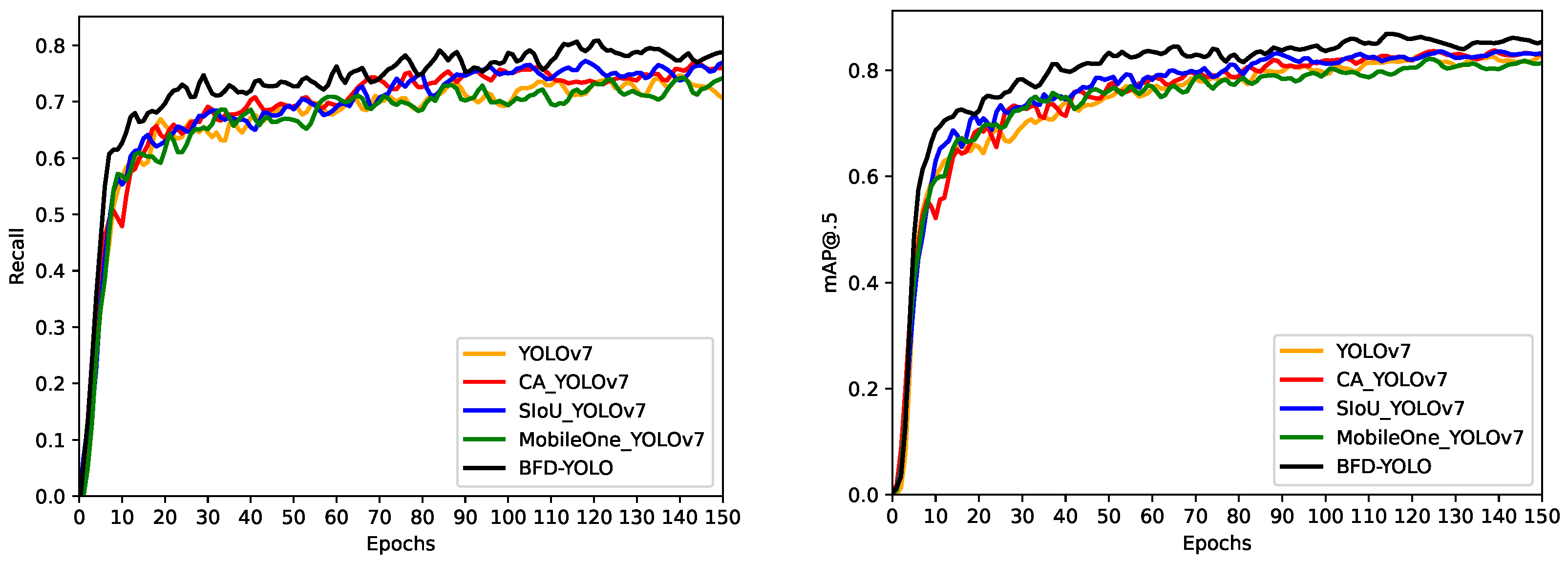
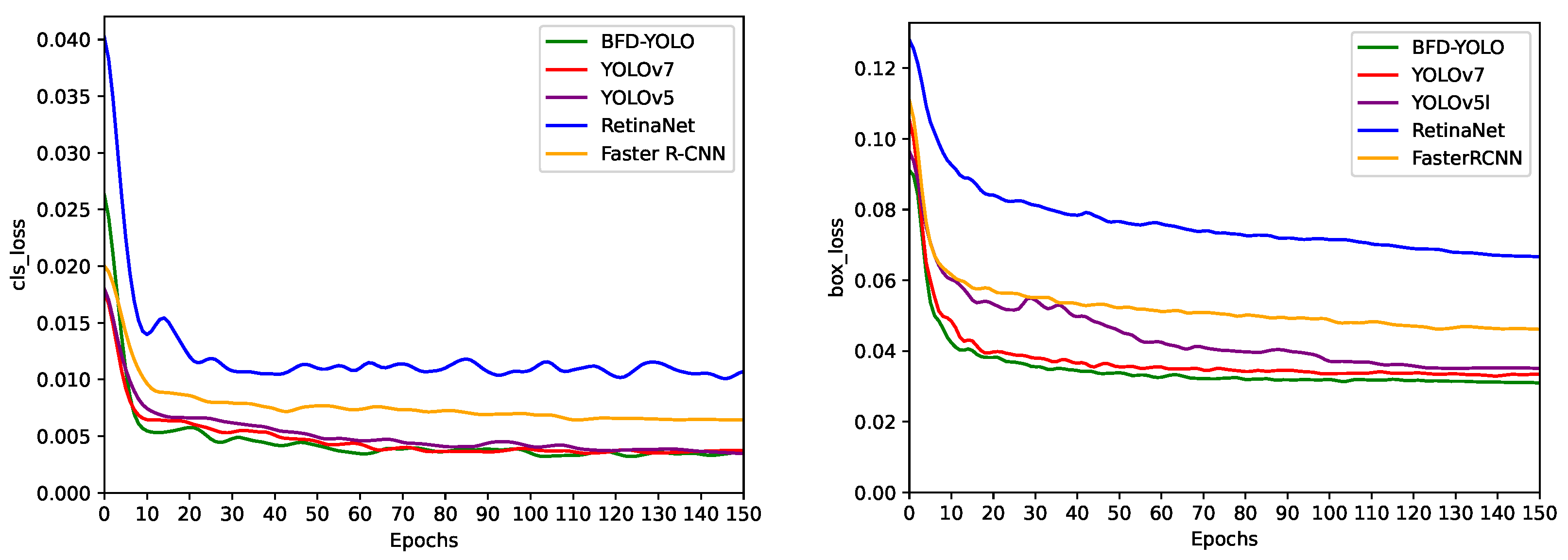
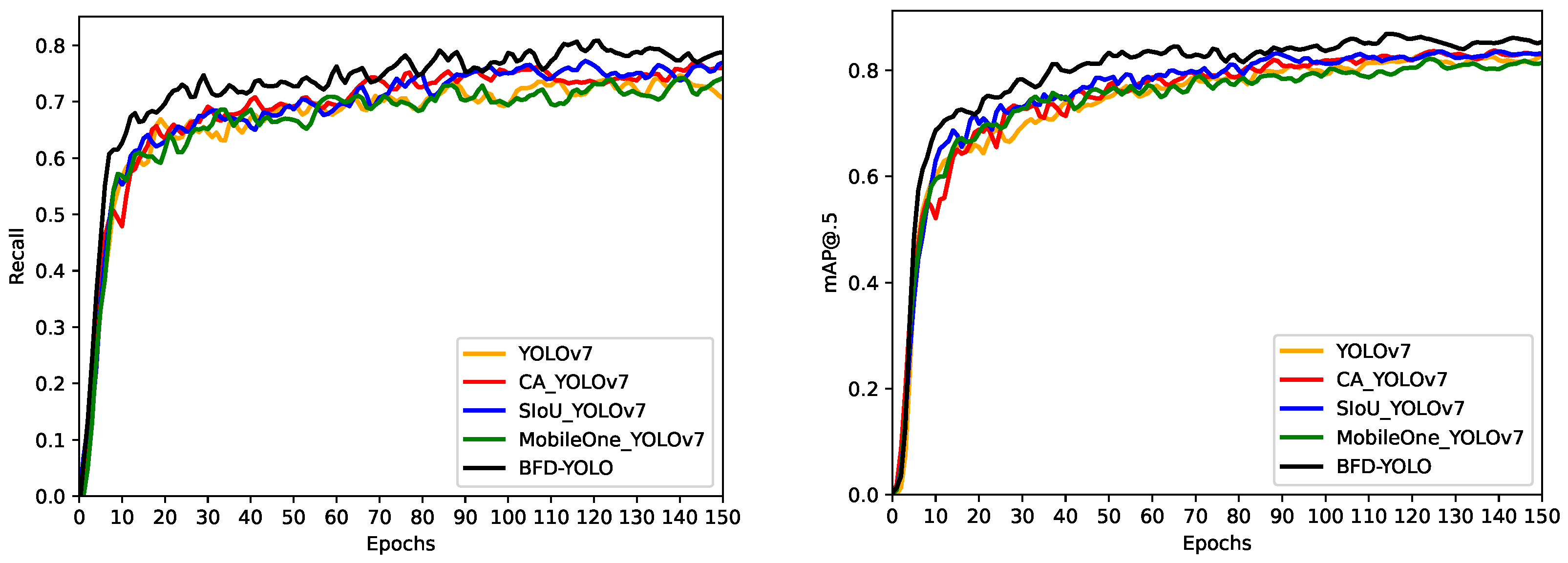
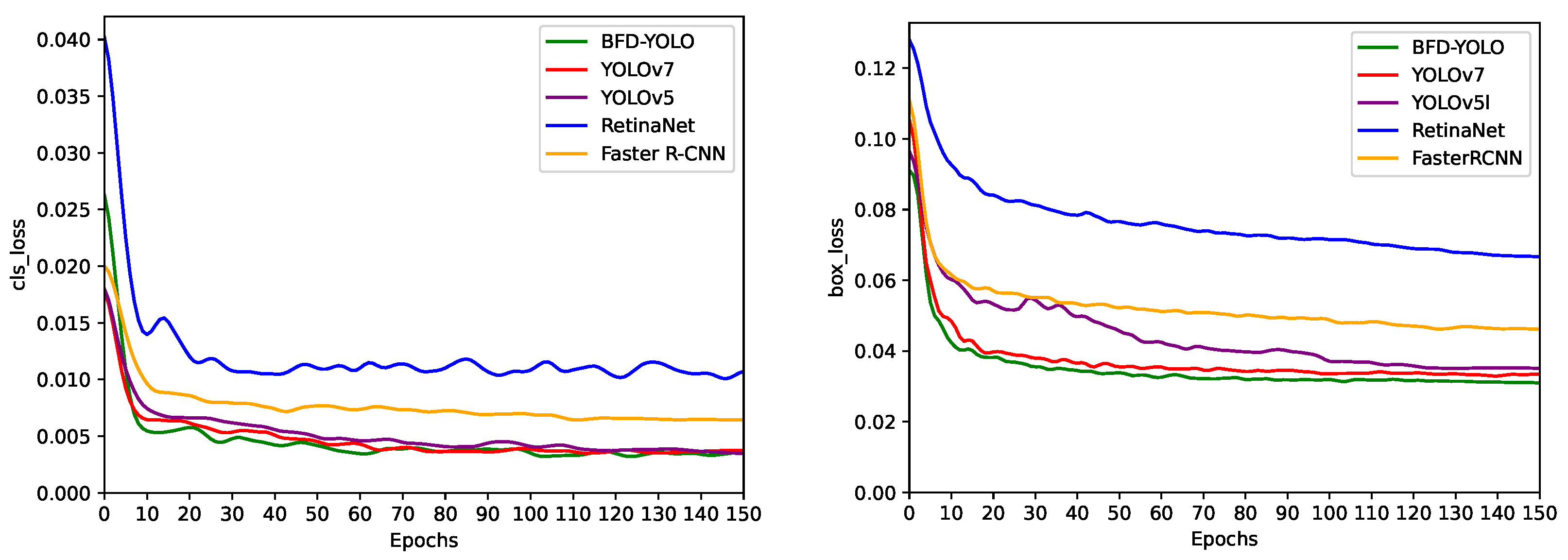
This paper proposes an improved YOLOv7 façade defects detection method named BFD-YOLO, which can achieve high speed and accurate detection of façade defects on buildings. The experimental analysis shows that the incorporation of over-parametrization and re-parameterization methods enables the model to efficiently acquire more features, and the incorporation of the MobileOne module can reduce the parameter amount and complexity of the network, thus decreasing the inference time effectively. The coordinate attention takes into account inter-channel information and orientation-related positional information, which helps the model to better localize and identify targets. So, the combination of coordinate attention and YOLOv7 can effectively enhance the feature extraction capability and improve the object detection accuracy of the network. SIoU added the orientation factor to the calculation of IoU and redefined the penalty metrics to more accurately reflect the relationship between the predicted box and the ground truth box and improve the convergence speed of the model. The utilization of SIoU effectively improves the recall rate and enhances the convergence ability of the network. Based on the original YOLOv7, the precision of BFD-YOLO increased by 2.2%, while its recall and mAP@.5 increased by 2.1% and 2.9%, respectively. In comparison to other models, this method has obvious advantages and the FPS of 76 can meet the requirements of real-time detection. Moreover, we expanded on the open dataset to construct a dataset containing three types of façade defects.
Currently, the development trend of building façade defect detection is automation and intelligence. The method proposed in this paper can help realize this goal. We are now trying to use the industrial-grade drone (Phantom 4 RTK) to automatically photograph building façades on a planned flight path and detect defects using BFD-YOLO on real-time image transfer data. The detected damage will be localized to the 3D reconstruction model of the building. In future research, we will expand the type and number of the dataset to increase the types of defects that can be detected by the proposed method. Meanwhile, we will explore more effective methods to improve the accuracy and speed of defect detection.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}