

A Novel JSF-Based Fast Implementation Method for Multiple-Point Multiplication


Abstract
:1. Introduction
1.1. Related Work
1.2. Objectives and Contribution
2. Preliminaries
2.1. Basic Operation
2.2. 256-Bit Curve
2.3. Other Operations
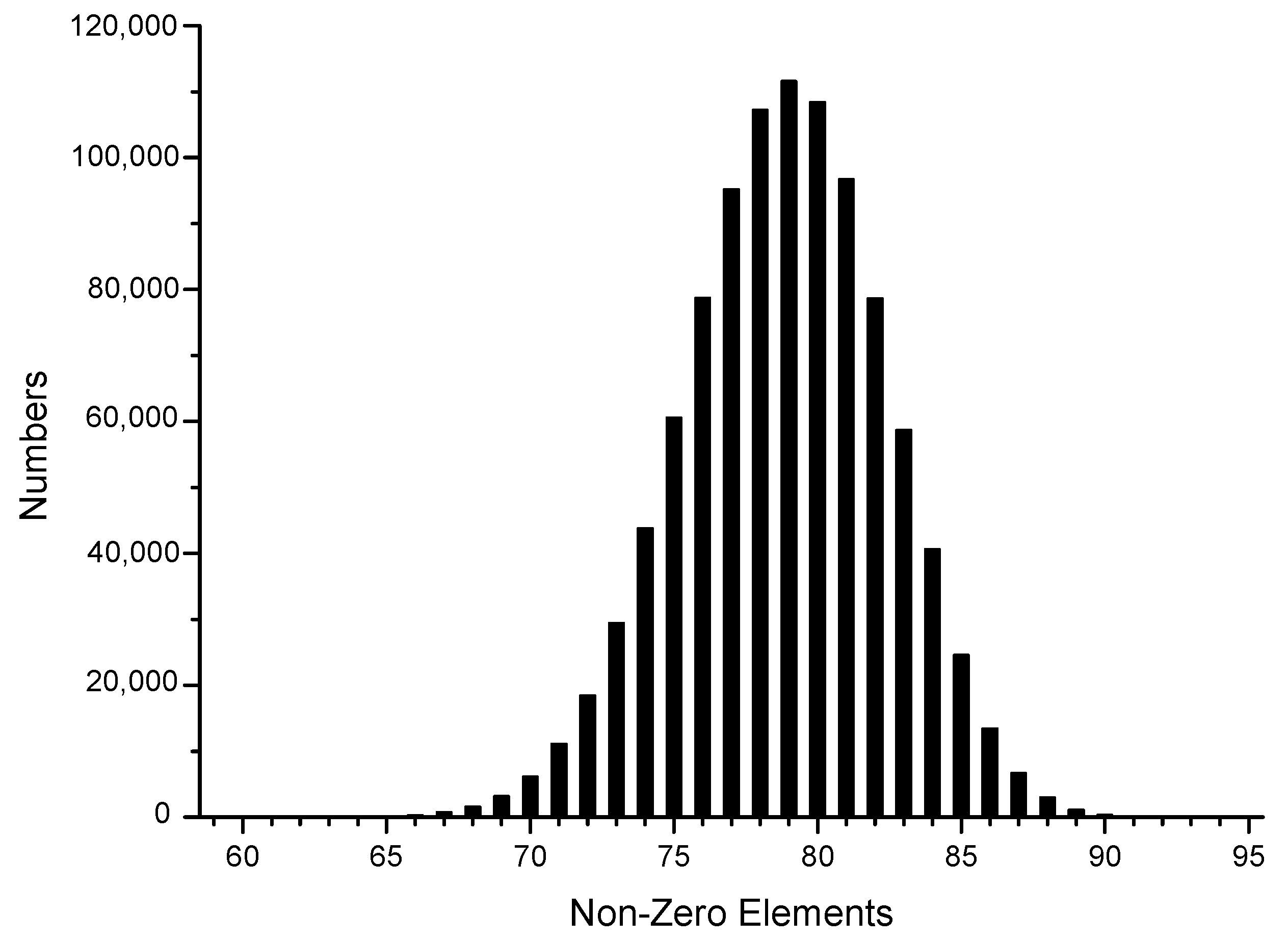
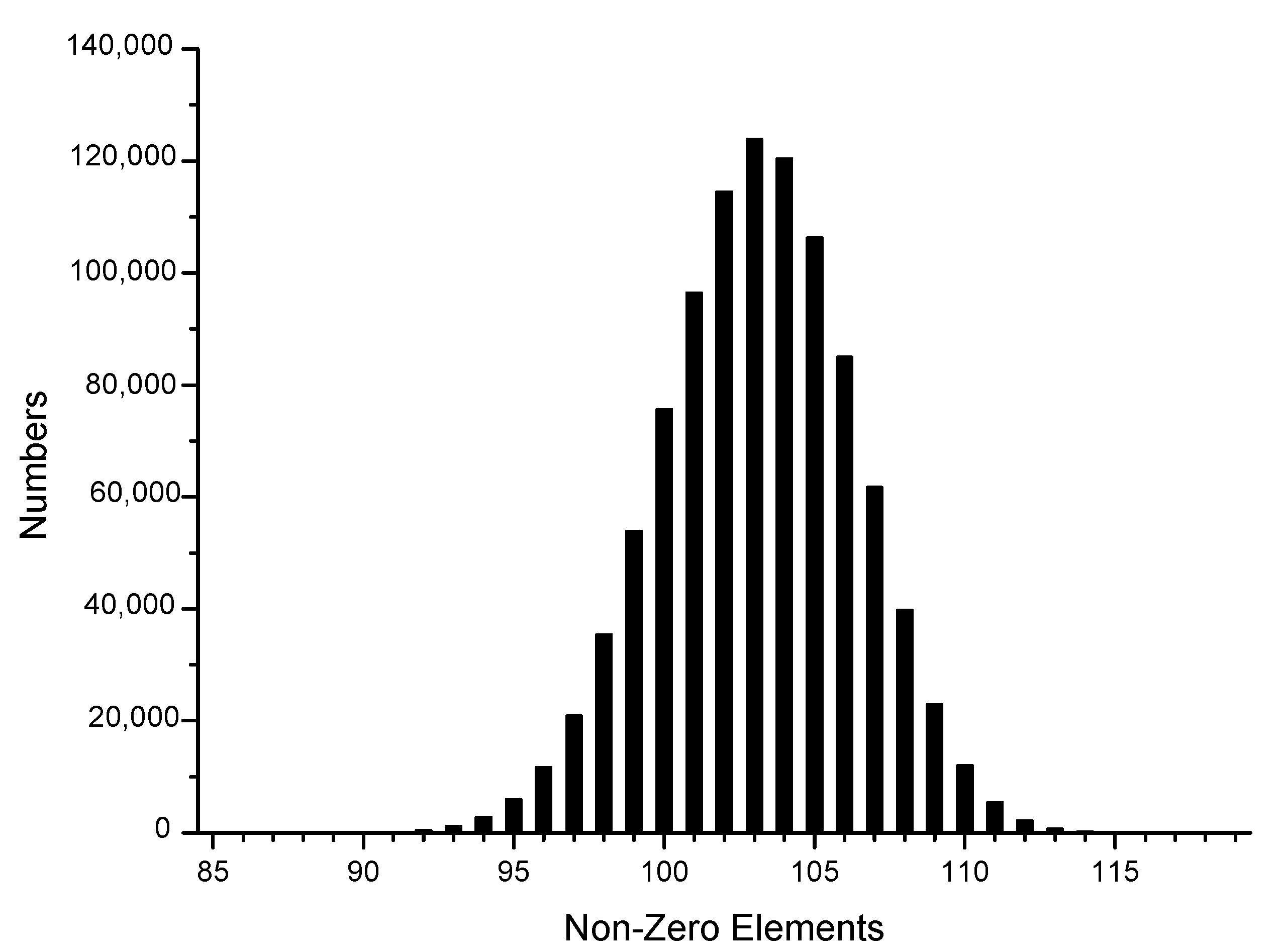
2.4. Sparse Form
2.4.1. NAF
2.4.2. JSF
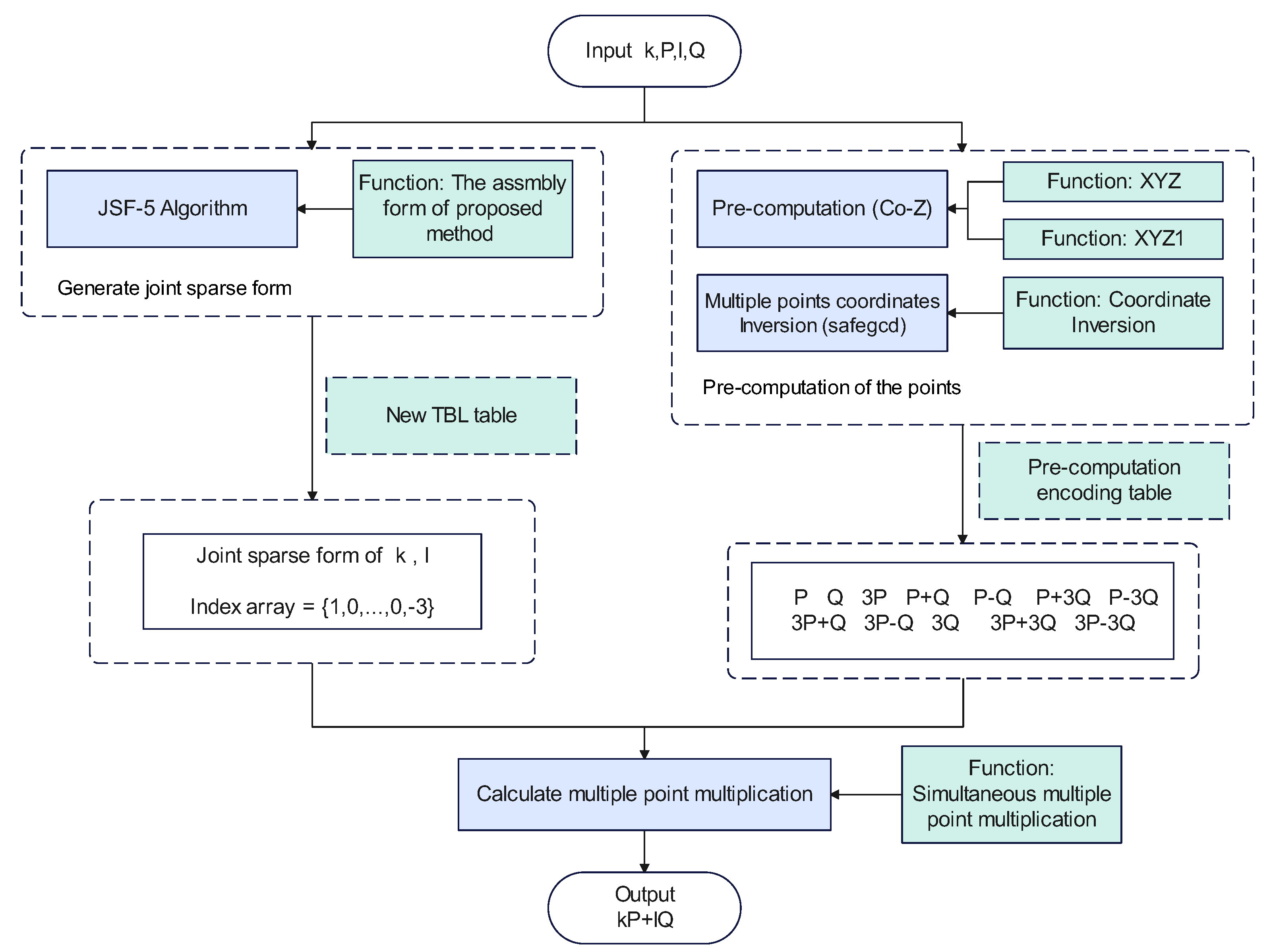
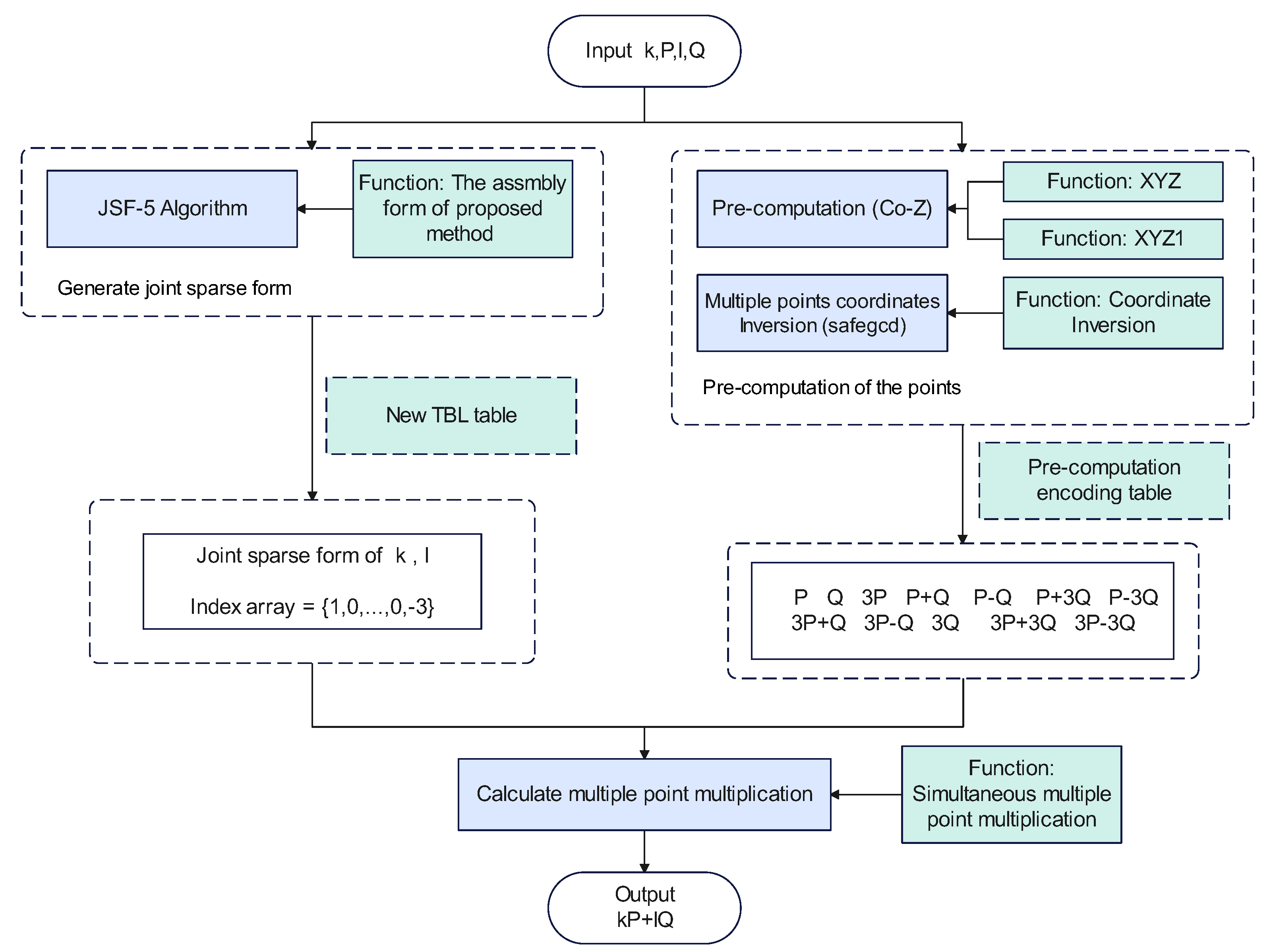
3. Using Coordinate Inversion for Pre-Computed Data
3.1. Pre-Computed Complexity Analysis
3.2. Pre-Computed Storage Table Encoding
| Algorithm 1 Function |
|
| Algorithm 2 Function |
|
| Algorithm 3 Pre-computation |
|
4. Improving the Operational Efficiency of the Method Execution Phase
4.1. JSF-5 Encoding Method and Table Look-Up Method
- If the scalars involved in the operation are all even, then the current bit of the JSF-5 result is 0; the output results are shown in Table 10;
- If the scalars are all odd, according to the algorithm, the expected output result will correspond to the storage code; the output results are shown in Table 11;
- If one the scalars involved in the operation is odd and one even, the result is counted; the output results are shown Table 12.
| Algorithm 4 New encoding JSF-5 method |
|
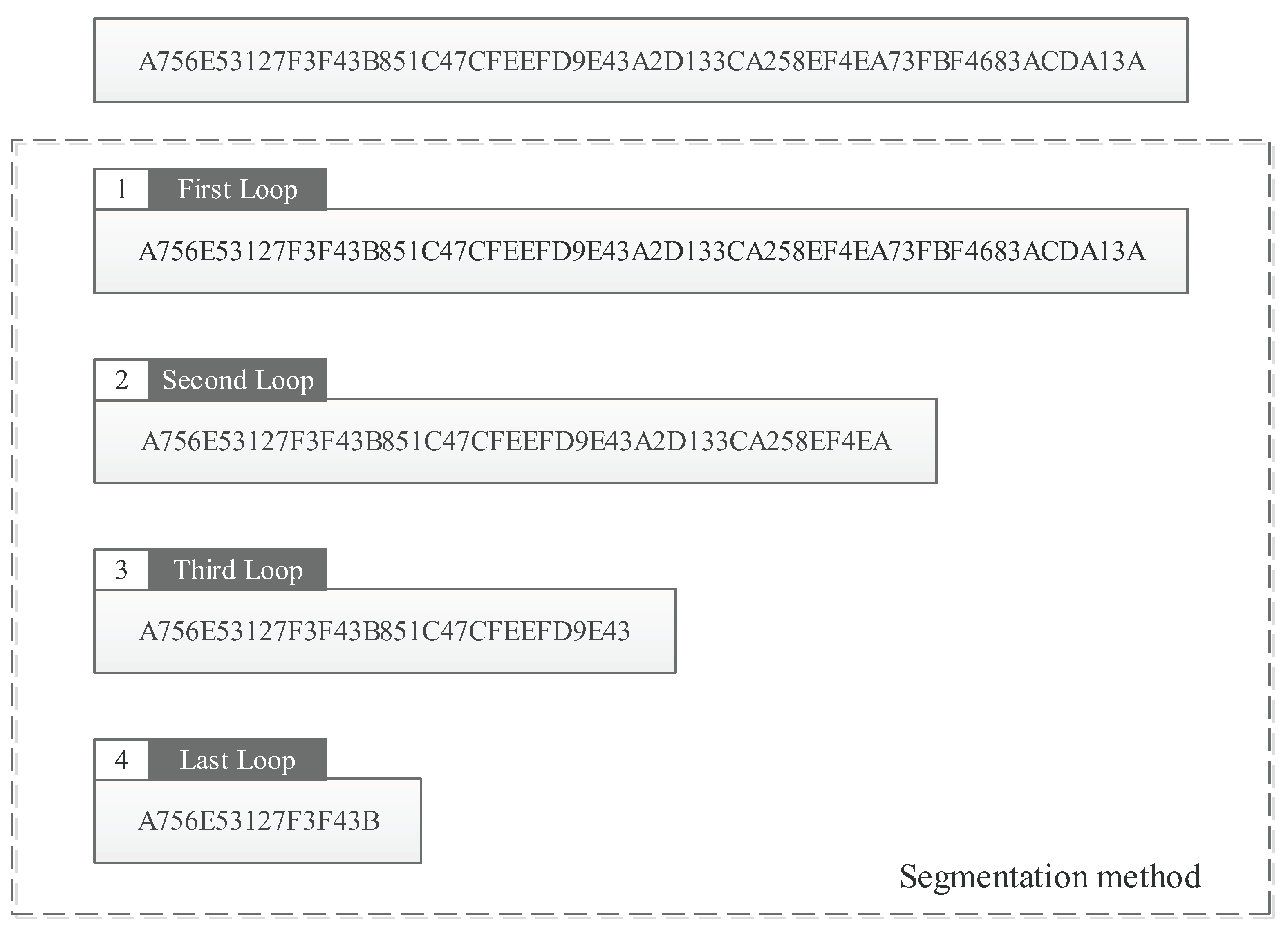
4.2. Segmentation Method for New Encoding JSF-5
4.3. Assembly Implementation of the New Encoding JSF-5 Segmentation Method
5. Experiment
5.1. Experimental Preparation
5.1.1. Experimental Environment
- Comet Lake: Intel Core i7-10700@2.9 GHz with a single channel of DDR4 16 GB 2933 MHz memory (Intel Corporation, Santa Clara, CA, USA);
- Coffee Lake: Intel Core i9-9900K@3.6 GHz with four channels of DDR4 32 GB 3200 MHz memory;
- Raptor Lake: Intel Core i7-13700K@3.4 GHz with dual-channel DDR5 32 GB 4800 MHz memory;
- Zen 4: AMD Ryzen 7 7700X@4.5GHz with dual-channel DDR5 32 GB 4800 MHz memory (AMD, Santa Clara, CA, USA).
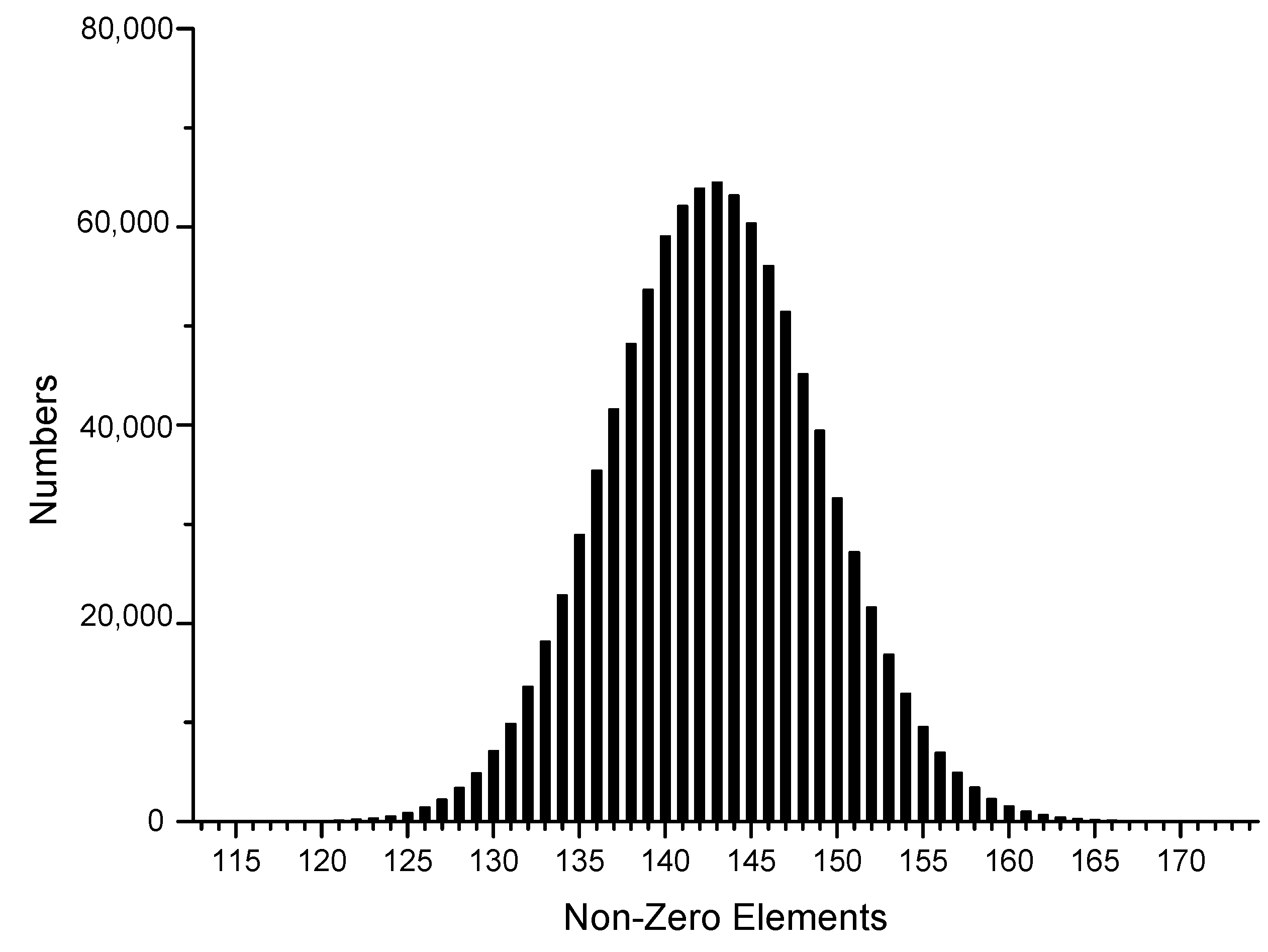
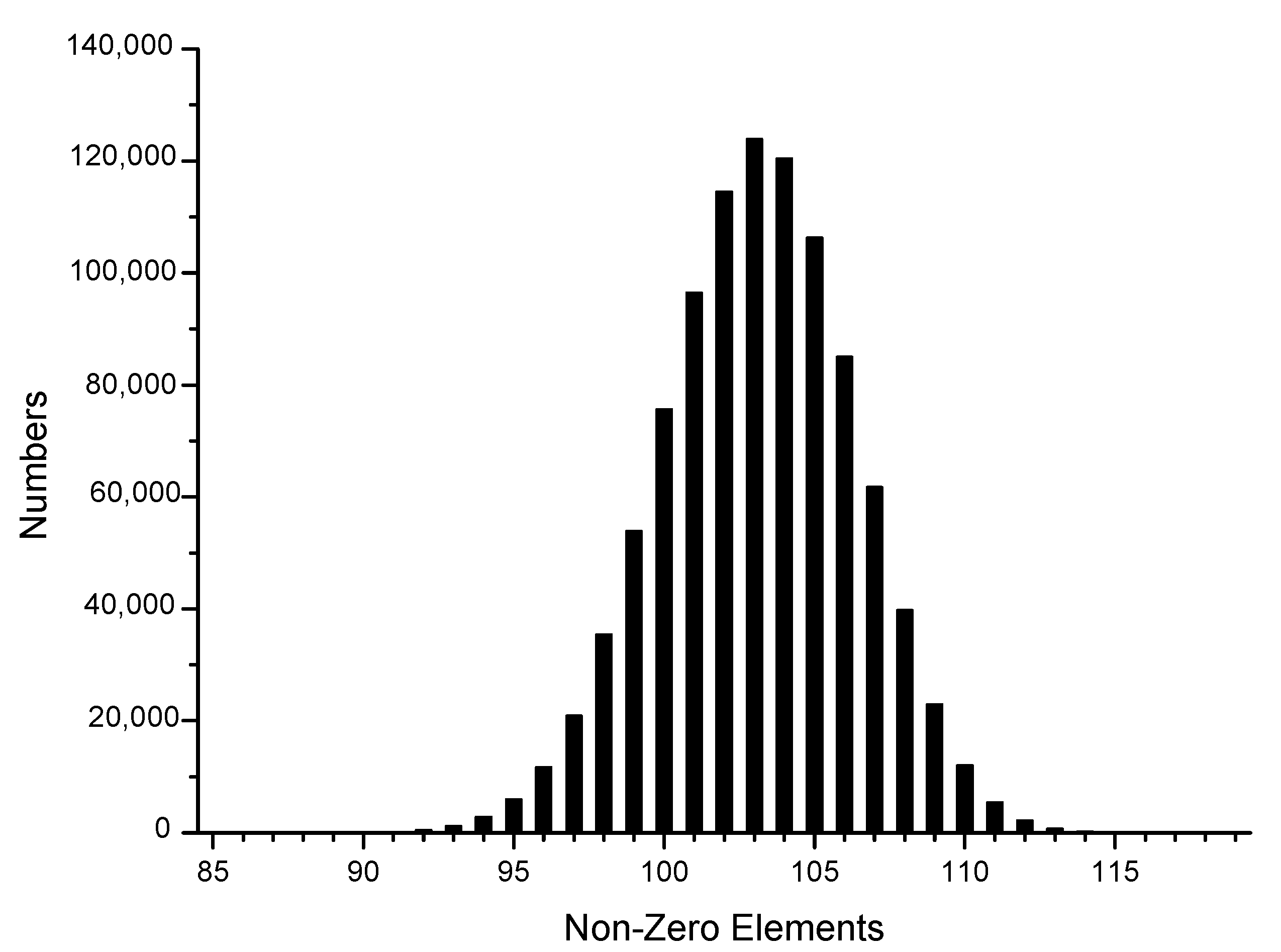
5.1.2. Relevant Data Test
5.1.3. Experimental Theoretical Results
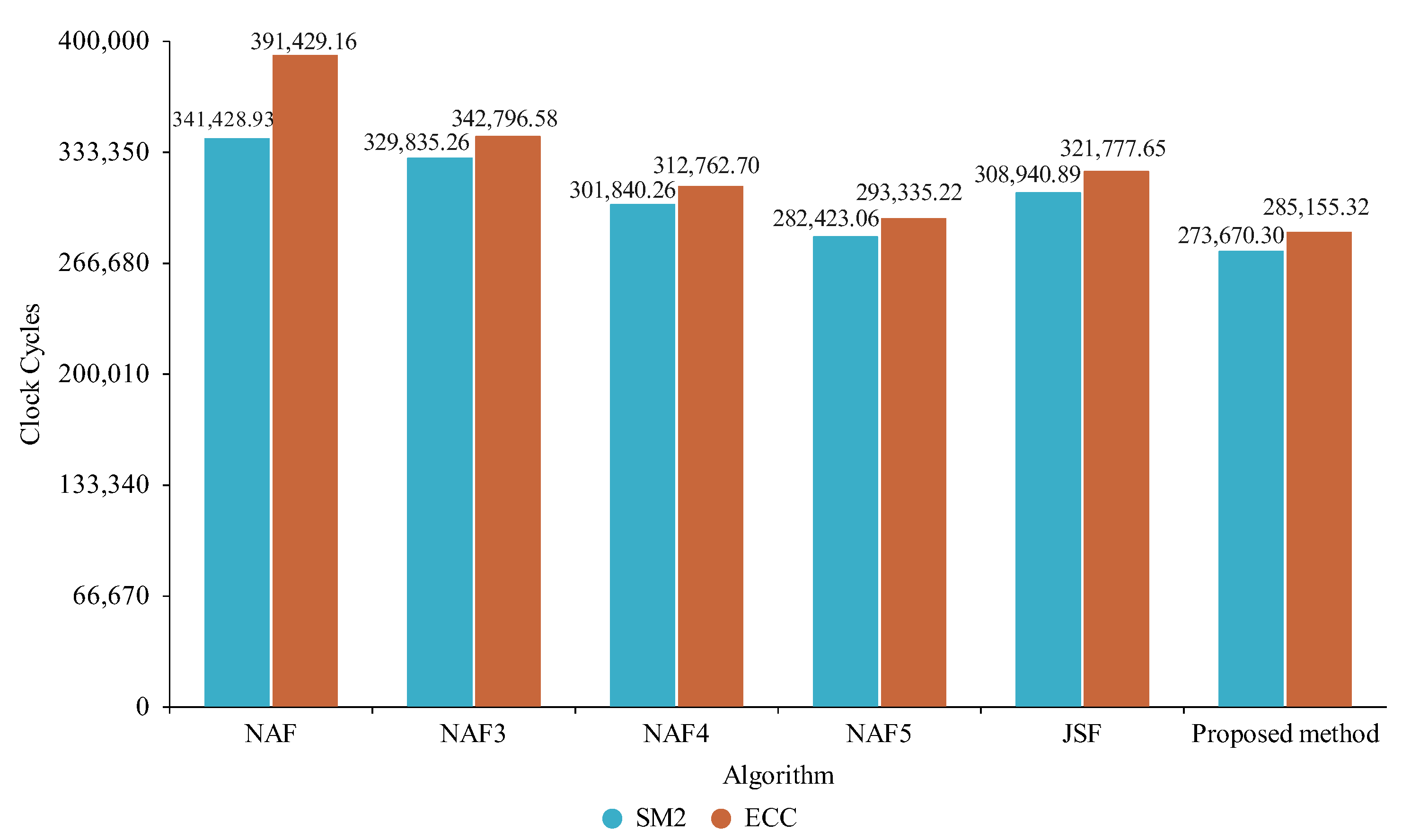
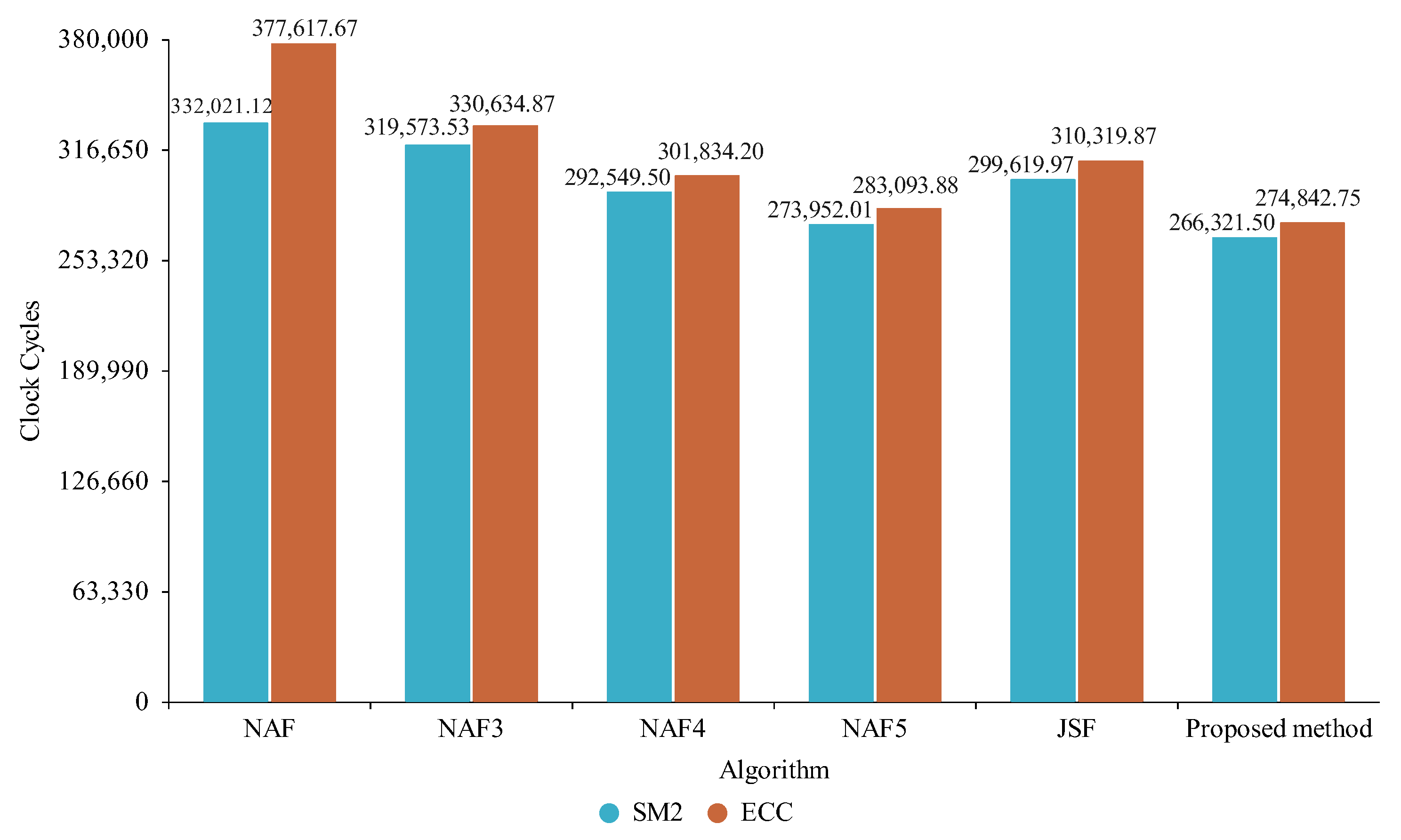
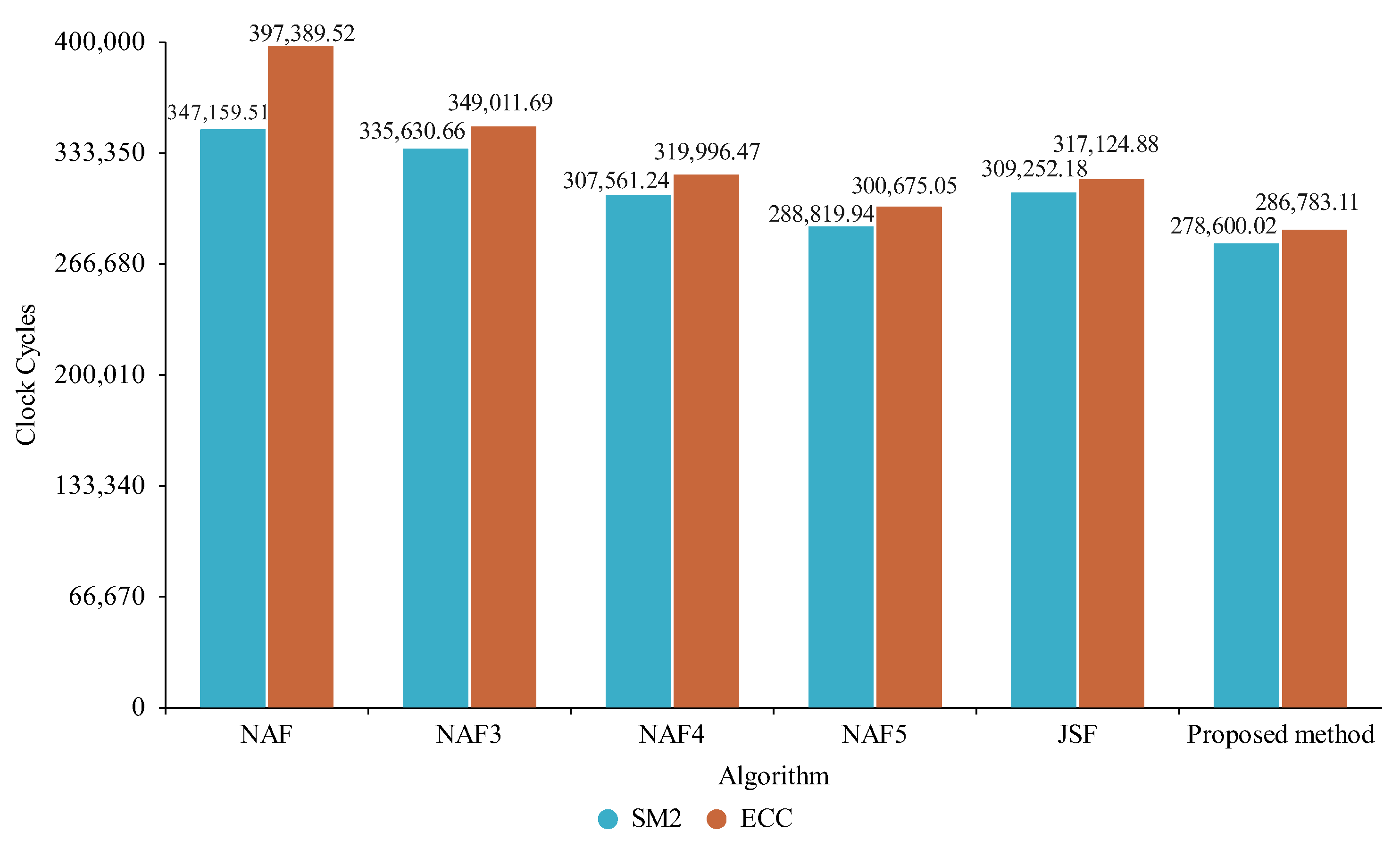
5.2. Experimental Results
6. Results
6.1. Analysis and Discussion
6.2. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
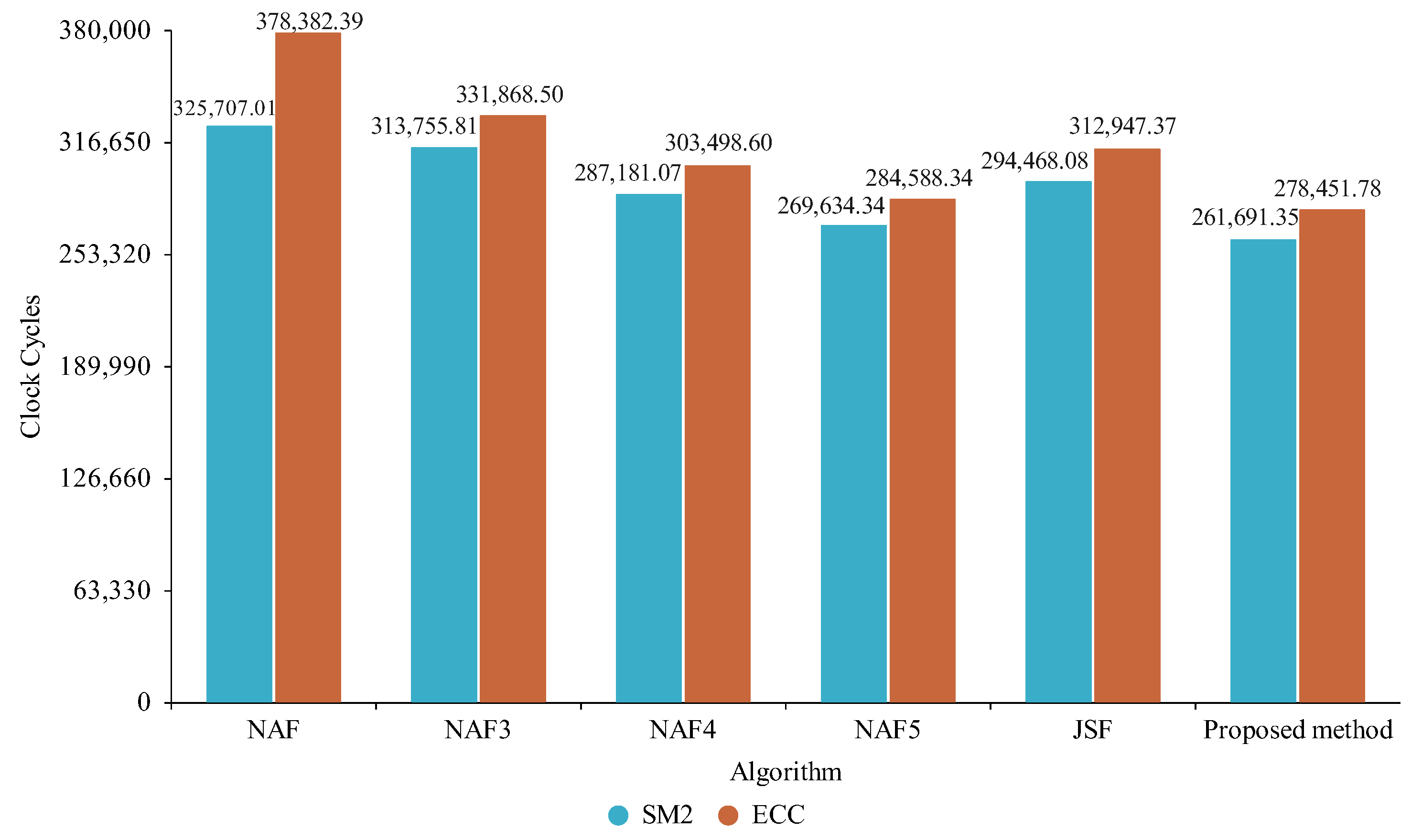{kind=link}
| Operation | Cost | Case One | Case Two | Case Three |
|---|---|---|---|---|
| Tripling |
| Operation | Sum of the Basic Operations | Case One | Case Two | Case Three |
|---|---|---|---|---|
| Representation Form | NAF | 3-NAF | 4-NAF | 5-NAF | JSF | JSF-5 |
|---|---|---|---|---|---|---|
| Single-scalar | 86 | 65 | 52 | 43 | ||
| Hamming weight | ||||||
| Joint | 143 | 113 | 93 | 79 | 143 | 103 |
| Hamming weight |
| Architecture | Algorithm | nistp256r1 Curve | SM2 Curve | ||||
|---|---|---|---|---|---|---|---|
| Case One | Case Two | Case Three | Case One | Case Two | Case Three | ||
| Comet Lake | NAF | 343,623.53 | 371,196.61 | 427,097.38 | 319,117.73 | 344,681.11 | 396,507.48 |
| 3-NAF | 343,848.24 | 371,549.6 | 427,706.93 | 319,226.94 | 344,909.25 | 396,973.48 | |
| 4-NAF | 304,231.25 | 328,446.36 | 377,631.19 | 282,436.95 | 304,887.11 | 350,487.04 | |
| 5-NAF | 289,000.41 | 312,476.01 | 360,181.83 | 268,277.51 | 290,042.06 | 334,270.78 | |
| JSF | 319,622.7 | 341,830.58 | 387,755.54 | 297,367.5 | 317,956.73 | 360,534.39 | |
| Proposed method | 282,998.63 | 304,338.72 | 348,528.09 | 262,633.23 | 282,417.92 | 323,386.49 | |
| Coffee Lake | NAF | 305,038.52 | 329,469.16 | 378,999.05 | 288,864.69 | 311,968.93 | 358,809.71 |
| 3-NAF | 305,127.4 | 329,671.7 | 379,428.91 | 288,877.34 | 312,089.07 | 359,144.84 | |
| 4-NAF | 269,963.97 | 291,419.34 | 334,998.69 | 255,579.73 | 275,870.23 | 317,083.55 | |
| 5-NAF | 256,423.08 | 277,223.22 | 319,492.12 | 242,745.96 | 262,416.82 | 302,390.82 | |
| JSF | 284,217.95 | 303,894.85 | 344,585.85 | 269,529.52 | 288,138.11 | 326,619.89 | |
| Proposed method | 251,016.5 | 269,924.51 | 309,077.72 | 237,575.33 | 255,456.78 | 292,484.27 | |
| Raptor Lake | NAF | 273,109.03 | 294,864.95 | 338,972.18 | 274,222.93 | 296,070.2 | 340,362.63 |
| 3-NAF | 272,956.31 | 294,813.45 | 339,123.12 | 274,075.46 | 296,024.37 | 340,520.09 | |
| 4-NAF | 241,463.74 | 260,570.13 | 299,378.30 | 242,454.39 | 261,641.01 | 300,612.13 | |
| 5-NAF | 229,280.78 | 247,803.68 | 285,444.86 | 230,222.73 | 248,823.4 | 286,622.64 | |
| JSF | 254,136.26 | 271,658.88 | 307,894.92 | 255,147.86 | 272,744.05 | 309,132.25 | |
| Proposed method | 226,331.12 | 243,169.03 | 278,035.66 | 227,256.82 | 244,165.43 | 279,178.46 | |
| Zen 4 | NAF | 267,629 | 289,056.06 | 332,496.57 | 258,985.14 | 279,703.32 | 321,706.68 |
| 3-NAF | 267,672.41 | 289,199.16 | 332,839.05 | 258,987.81 | 279,802.38 | 321,998.52 | |
| 4-NAF | 236,819.48 | 255,637.06 | 293,858.61 | 229,132.04 | 247,327.07 | 284,284.13 | |
| 5-NAF | 224,904.32 | 243,147.23 | 280,219.43 | 217,594.79 | 235,234.16 | 271,079.9 | |
| JSF | 249,675.52 | 266,933.27 | 302,621.57 | 241,825.5 | 258,512.31 | 293,019.93 | |
| Proposed method | 220,880.81 | 237,464.2 | 271,803.79 | 213,697.38 | 229,732.14 | 262,935.66 | |
| Algorithm A1 Binary multiple-point multiplication |
|
| Algorithm A2 JSF-5 single-array method |
|
| Algorithm A3 Computing the w-NAF of a positive integer |
|
| Algorithm A4 JSF-5 |
|
| Algorithm A5 Coordinate Inversion |
|
| Algorithm A6 New encoding JSF-5 segmentation method |
|
| Algorithm A7 Assembly implementation of the proposed method |
|
References
- ElGamal, T. A public key cryptosystem and a signature scheme based on discrete logarithms. IEEE Trans. Inf. Theory 1985, 31, 469–472. [Google Scholar] [CrossRef]
- Rivest, R.L.; Shamir, A.; Adleman, L. A method for obtaining digital signatures and public-key cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Yao, X.; Chen, Z.; Tian, Y. A lightweight attribute-based encryption scheme for the Internet of Things. Future Gener. Comput. Syst. 2015, 49, 104–112. [Google Scholar] [CrossRef]
- Tidrea, A.; Korodi, A.; Silea, I. Elliptic Curve Cryptography Considerations for Securing Automation and SCADA Systems. Sensors 2023, 23, 2686. [Google Scholar] [CrossRef]
- Yang, Y.S.; Lee, S.H.; Wang, J.M.; Yang, C.S.; Huang, Y.M.; Hou, T.W. Lightweight Authentication Mechanism for Industrial IoT Environment Combining Elliptic Curve Cryptography and Trusted Token. Sensors 2023, 23, 4970. [Google Scholar] [CrossRef]
- Khan, N.A.; Awang, A. Elliptic Curve Cryptography for the Security of Insecure Internet of Things. In Proceedings of the 2022 International Conference on Future Trends in Smart Communities (ICFTSC), Kuching, Malaysia, 1–2 December 2022; pp. 59–64. [Google Scholar]
- Zhong, L.; Wu, Q.; Xie, J.; Li, J.; Qin, B. A secure versatile light payment system based on blockchain. Future Gener. Comput. Syst. 2019, 93, 327–337. [Google Scholar] [CrossRef]
- Gutub, A. Efficient utilization of scalable multipliers in parallel to compute GF (p) elliptic curve cryptographic operations. Kuwait J. Sci. Eng. 2007, 34, 165–182. [Google Scholar]
- Johnson, D.; Menezes, A.; Vanstone, S. The elliptic curve digital signature algorithm (ECDSA). Int. J. Inf. Secur. 2001, 1, 36–63. [Google Scholar] [CrossRef]
- Islam, M.M.; Hossain, M.S.; Hasan, M.K.; Shahjalal, M.; Jang, Y.M. FPGA implementation of high-speed area-efficient processor for elliptic curve point multiplication over prime field. IEEE Access 2019, 7, 178811–178826. [Google Scholar] [CrossRef]
- Khleborodov, D. Fast elliptic curve point multiplication based on binary and binary non-adjacent scalar form methods. Adv. Comput. Math. 2018, 44, 1275–1293. [Google Scholar] [CrossRef]
- Solinas, J.A. Low-Weight Binary Representation for Pairs of Integers; Combinatorics and Optimization Research Report CORR 2001-41; Centre for Applied Cryptographic Research, University of Waterloo: Waterloo, ON, Canada, 2001. [Google Scholar]
- Wang, W.; Fan, S. Attacking OpenSSL ECDSA with a small amount of side-channel information. Sci. China Inf. Sci. 2018, 61, 032105. [Google Scholar] [CrossRef]
- Koyama, K.; Tsuruoka, Y. Speeding up elliptic cryptosystems by using a signed binary window method. In Proceedings of the Advances in Cryptology—CRYPTO’92: 12th Annual International Cryptology Conference, Santa Barbara, CA, USA, 16–20 August 1992; Springer: Berlin/Heidelberg, Germany, 1993; pp. 345–357. [Google Scholar]
- Brickell, E.F.; Gordon, D.M.; McCurley, K.S.; Wilson, D.B. Fast exponentiation with precomputation. In Proceedings of the Advances in Cryptology—EUROCRYPT’92: Workshop on the Theory and Application of Cryptographic Techniques, Balatonfüred, Hungary, 24–28 May 1992; Springer: Berlin/Heidelberg, Germany, 2001; pp. 200–207. [Google Scholar]
- Li, X.; Hu, L. A Fast Algorithm on Pairs of Scalar Multiplication for Elliptic Curve Cryptosystems. In Proceedings of the CHINACRYPT’2004, Shanghai, China, 1 March 2004; pp. 93–99. [Google Scholar]
- Wang, N. The Algorithm of New Five Elements Joint Sparse Form and Its Applications. Acta Electron. Sin. 2011, 39, 114. [Google Scholar]
- Luo, G.; Fu, S.; Gong, G. Speeding up multi-scalar multiplication over fixed points towards efficient zksnarks. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2023, 2023, 358–380. [Google Scholar] [CrossRef]
- Wu, G.; He, Q.; Jiang, J.; Zhang, Z.; Zhao, Y.; Zou, Y.; Zhang, J.; Wei, C.; Yan, Y.; Zhang, H. Topgun: An ECC Accelerator for Private Set Intersection. ACM Trans. Reconfig. Technol. Syst. 2023. [Google Scholar] [CrossRef]
- Sajid, A.; Sonbul, O.S.; Rashid, M.; Zia, M.Y.I. A Hybrid Approach for Efficient and Secure Point Multiplication on Binary Edwards Curves. Appl. Sci. 2023, 13, 5799. [Google Scholar] [CrossRef]
- Bernstein, D.J.; Yang, B.Y. Fast constant-time gcd computation and modular inversion. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2019, 340–398. [Google Scholar] [CrossRef]
- Bernstein, D.J.; Yang, B.Y. Fast Constant-Time GCD and Modular Inversion. 2019. Available online: https://gcd.cr.yp.to/software.html (accessed on 6 April 2023).
- Alkim, E.; Cheng, D.Y.L.; Chung, C.M.M.; Evkan, H.; Huang, L.W.L.; Hwang, V.; Li, C.L.T.; Niederhagen, R.; Shih, C.J.; Wälde, J.; et al. Polynomial Multiplication in NTRU Prime: Comparison of Optimization Strategies on Cortex-M4. Cryptology ePrint Archive, Paper 2020/1216. 2020. Available online: https://eprint.iacr.org/2020/1216 (accessed on 13 May 2023).
- Bajard, J.C.; Fukushima, K.; Plantard, T.; Sipasseuth, A. Fast verification and public key storage optimization for unstructured lattice-based signatures. J. Cryptogr. Eng. 2023, 13, 373–388. [Google Scholar] [CrossRef]
- Meloni, N. New point addition formulae for ECC applications. In Proceedings of the Arithmetic of Finite Fields: First International Workshop, WAIFI 2007, Madrid, Spain, 21–22 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 189–201. [Google Scholar]
- Dahmen, E. Efficient Algorithms for Multi-Scalar Multiplications. Diploma Thesis, Technical University of Darmstadt, Darmstadt, Germany, 2005. [Google Scholar]
- Goundar, R.R.; Joye, M.; Miyaji, A.; Rivain, M.; Venelli, A. Scalar multiplication on Weierstraß elliptic curves from Co-Z arithmetic. J. Cryptogr. Eng. 2011, 1, 161–176. [Google Scholar] [CrossRef]
- Washington, L.C. Elliptic Curves: Number Theory and Cryptography; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Hutter, M.; Joye, M.; Sierra, Y. Memory-constrained implementations of elliptic curve cryptography in co-Z coordinate representation. In Progress in Cryptology—AFRICACRYPT 2011, Proceedings of the 4th International Conference on Cryptology in Africa, Dakar, Senegal, 5–7 July 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 170–187. [Google Scholar]
- Yu, W.; Wang, K.; Li, B.; Tian, S. Montgomery algorithm over a prime field. Chin. J. Electron. 2019, 28, 39–44. [Google Scholar] [CrossRef]
- Lee, Y.K.; Sakiyama, K.; Batina, L.; Verbauwhede, I. Elliptic-curve-based security processor for RFID. IEEE Trans. Comput. 2008, 57, 1514–1527. [Google Scholar] [CrossRef]
- Burmester, M.; De Medeiros, B.; Motta, R. Robust, anonymous RFID authentication with constant key-lookup. In Proceedings of the 2008 ACM Symposium on Information, Computer and Communications Security, Tokyo, Japan, 18–20 March 2008; pp. 283–291. [Google Scholar]
- Lee, Y.K.; Verbauwhede, I. A compact architecture for montgomery elliptic curve scalar multiplication processor. In Proceedings of the Information Security Applications: 8th International Workshop, WISA 2007, Jeju Island, Republic of Korea, 27–29 August 2007; Revised Selected Papers 8. Springer: Berlin/Heidelberg, Germany, 2007; pp. 115–127. [Google Scholar]
- Liu, S.; Zhang, Y.; Chen, S. Fast Scalar Multiplication Algorithm Based on Co Z Operation and Conjugate Point Addition. Int. J. Netw. Secur. 2021, 23, 914–923. [Google Scholar]
- Goundar, R.R.; Joye, M.; Miyaji, A. Co-Z addition formulæ and binary ladders on elliptic curves. In Proceedings of the Cryptographic Hardware and Embedded Systems, CHES 2010: 12th International Workshop, Santa Barbara, CA, USA, 17–20 August 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 65–79. [Google Scholar]
- Longa, P.; Gebotys, C. Novel precomputation schemes for elliptic curve cryptosystems. In Proceedings of the Applied Cryptography and Network Security: 7th International Conference, ACNS 2009, Paris-Rocquencourt, France, 2–5 June 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 71–88. [Google Scholar]
- Kocher, P.; Jaffe, J.; Jun, B. Differential power analysis. In Proceedings of the Advances in Cryptology—CRYPTO’99: 19th Annual International Cryptology Conference, Santa Barbara, CA, USA, 15–19 August 1999; Springer: Berlin/Heidelberg, Germany, 1999; pp. 388–397. [Google Scholar]
- Yen, S.M.; Joye, M. Checking before output may not be enough against fault-based cryptanalysis. IEEE Trans. Comput. 2000, 49, 967–970. [Google Scholar]
- Sung-Ming, Y.; Kim, S.; Lim, S.; Moon, S. A countermeasure against one physical cryptanalysis may benefit another attack. In Proceedings of the Information Security and Cryptology—ICISC 2001: 4th International Conference Seoul, Republic of Korea, 6–7 December 2001; Springer: Berlin/Heidelberg, Germany, 2002; pp. 414–427. [Google Scholar]
- Shah, Y.A.; Javeed, K.; Azmat, S.; Wang, X. A high-speed RSD-based flexible ECC processor for arbitrary curves over general prime field. Int. J. Circuit Theory Appl. 2018, 46, 1858–1878. [Google Scholar] [CrossRef]
- Shah, Y.A.; Javeed, K.; Azmat, S.; Wang, X. Redundant-Signed-Digit-Based High Speed Elliptic Curve Cryptographic Processor. J. Circuits Syst. Comput. 2019, 28, 1950081. [Google Scholar] [CrossRef]
- Karakoyunlu, D.; Gurkaynak, F.K.; Sunar, B.; Leblebici, Y. Efficient and side-channel-aware implementations of elliptic curve cryptosystems over prime fields. IET Inf. Secur. 2010, 4, 30–43. [Google Scholar] [CrossRef]
- Kim, K.H.; Choe, J.; Kim, S.Y.; Kim, N.; Hong, S. Speeding up regular elliptic curve scalar multiplication without precomputation. Adv. Math. Commun. 2020, 14, 703–726. [Google Scholar] [CrossRef]
- Liu, Z.; Seo, H.; Castiglione, A.; Choo, K.K.R.; Kim, H. Memory-efficient implementation of elliptic curve cryptography for the Internet-of-Things. IEEE Trans. Dependable Secur. Comput. 2018, 16, 521–529. [Google Scholar] [CrossRef]
- Unterluggauer, T.; Wenger, E. Efficient pairings and ECC for embedded systems. In Proceedings of the Cryptographic Hardware and Embedded Systems—CHES 2014: 16th International Workshop, Busan, Republic of Korea, 23–26 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 298–315. [Google Scholar]
- Alrimeih, H.; Rakhmatov, D. Fast and flexible hardware support for ECC over multiple standard prime fields. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2014, 22, 2661–2674. [Google Scholar] [CrossRef]
- FIPS 186-5. Available online: https://csrc.nist.gov/publications/detail/fips/186/4/final (accessed on 16 April 2023).
- Public Key Cryptographic Algorithm SM2 Based on Elliptic Curves. Available online: http://www.sca.gov.cn/sca/xwdt/2010-12/17/1002386/files/b791a9f908bb4803875ab6aeeb7b4e03.pdf (accessed on 5 April 2023).
- Gueron, S.; Krasnov, V. Fast prime field elliptic-curve cryptography with 256-bit primes. J. Cryptogr. Eng. 2015, 5, 141–151. [Google Scholar] [CrossRef]
- Rivain, M. Fast and Regular Algorithms for Scalar Multiplication over Elliptic Curves. Cryptology ePrint Archive. 2011. Available online: https://eprint.iacr.org/2011/338 (accessed on 14 May 2023).
- Awaludin, A.M.; Larasati, H.T.; Kim, H. High-speed and unified ECC processor for generic Weierstrass curves over GF (p) on FPGA. Sensors 2021, 21, 1451. [Google Scholar] [CrossRef]
- Eid, W.; Al-Somani, T.F.; Silaghi, M.C. Efficient Elliptic Curve Operators for Jacobian Coordinates. Electronics 2022, 11, 3123. [Google Scholar] [CrossRef]
- Rashid, M.; Imran, M.; Sajid, A. An efficient elliptic-curve point multiplication architecture for high-speed cryptographic applications. Electronics 2020, 9, 2126. [Google Scholar] [CrossRef]
- Li, W.; Yu, W.; Wang, K. Improved tripling on elliptic curves. In Proceedings of the Information Security and Cryptology: 11th International Conference, Inscrypt 2015, Revised Selected Papers 11. Beijing, China, 1–3 November 2015; Springer: Berlin/Heidelberg, Germany, 2016; pp. 193–205. [Google Scholar]
- Doche, C.; Icart, T.; Kohel, D.R. Efficient scalar multiplication by isogeny decompositions. In Proceedings of the Public Key Cryptography, New York, NY, USA, 24–26 April 2006; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3958, pp. 191–206. [Google Scholar]
- Dimitrov, V.; Imbert, L.; Mishra, P.K. Efficient and secure elliptic curve point multiplication using double-base chains. In Proceedings of the Advances in Cryptology—ASIACRYPT 2005: 11th International Conference on the Theory and Application of Cryptology and Information Security, Chennai, India, 4–8 December 2005; Springer: Berlin/Heidelberg, Germany, 2005; pp. 59–78. [Google Scholar]
- Longa, P.; Miri, A. Fast and flexible elliptic curve point arithmetic over prime fields. IEEE Trans. Comput. 2008, 57, 289–302. [Google Scholar] [CrossRef]
- Ciet, M.; Joye, M.; Lauter, K.; Montgomery, P.L. Trading inversions for multiplications in elliptic curve cryptography. Des. Codes Cryptogr. 2006, 39, 189–206. [Google Scholar] [CrossRef]
- Longa, P.; Miri, A. New Composite Operations and Precomputation Scheme for Elliptic Curve Cryptosystems over Prime Fields (Full Version). Cryptology ePrint Archive. 2008. Available online: https://eprint.iacr.org/2008/051 (accessed on 15 April 2023).
- Longa, P.; Miri, A. New Multibase Non-Adjacent Form Scalar Multiplication and Its Application to Elliptic Curve Cryptosystems (Extended Version). Cryptology ePrint Archive. 2008. Available online: https://eprint.iacr.org/2008/052 (accessed on 15 April 2023).
- Joye, M. Highly regular right-to-left algorithms for scalar multiplication. In Proceedings of the Cryptographic Hardware and Embedded Systems-CHES 2007: 9th International Workshop, Vienna, Austria, 10–13 September 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 135–147. [Google Scholar]
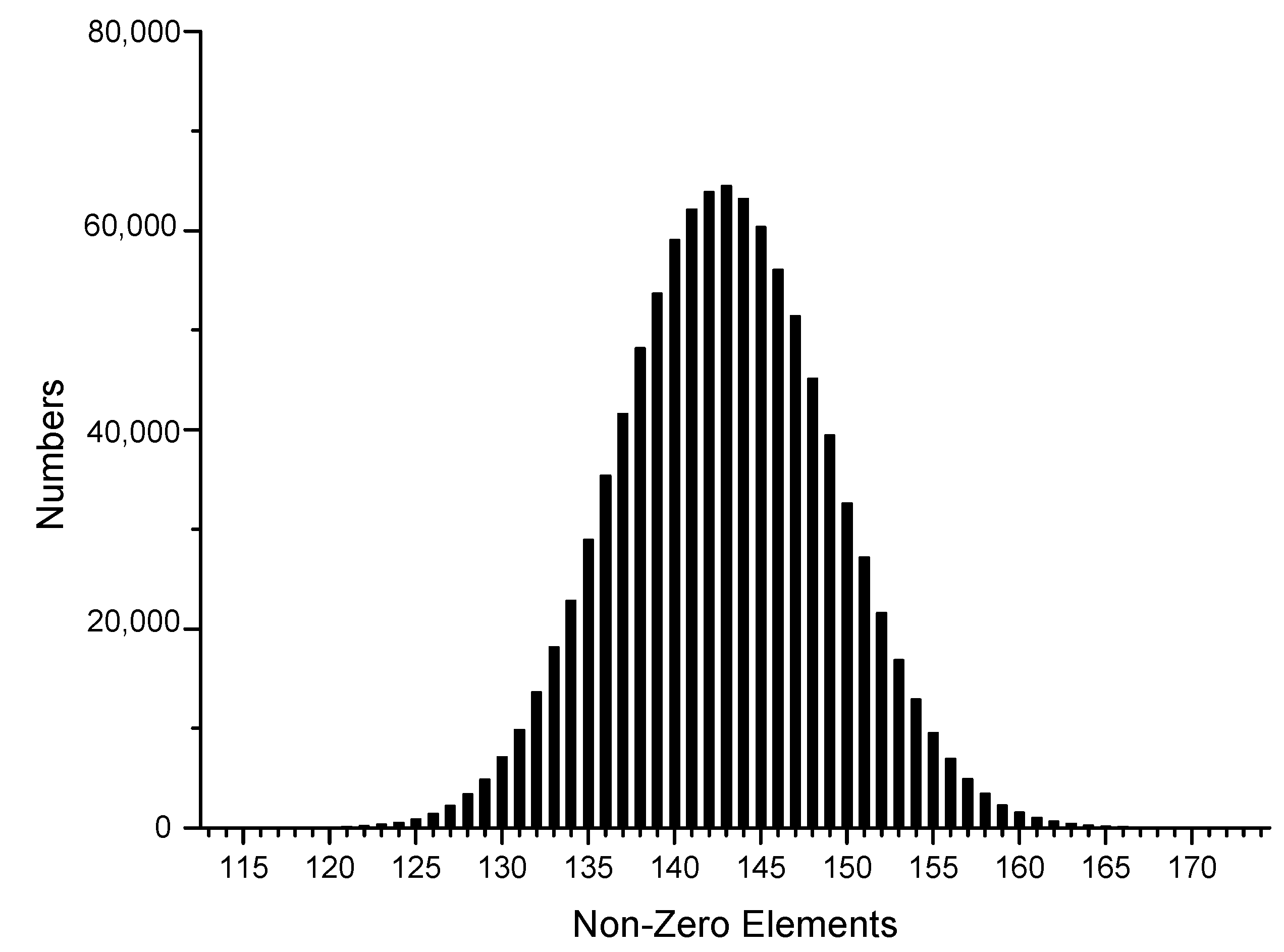
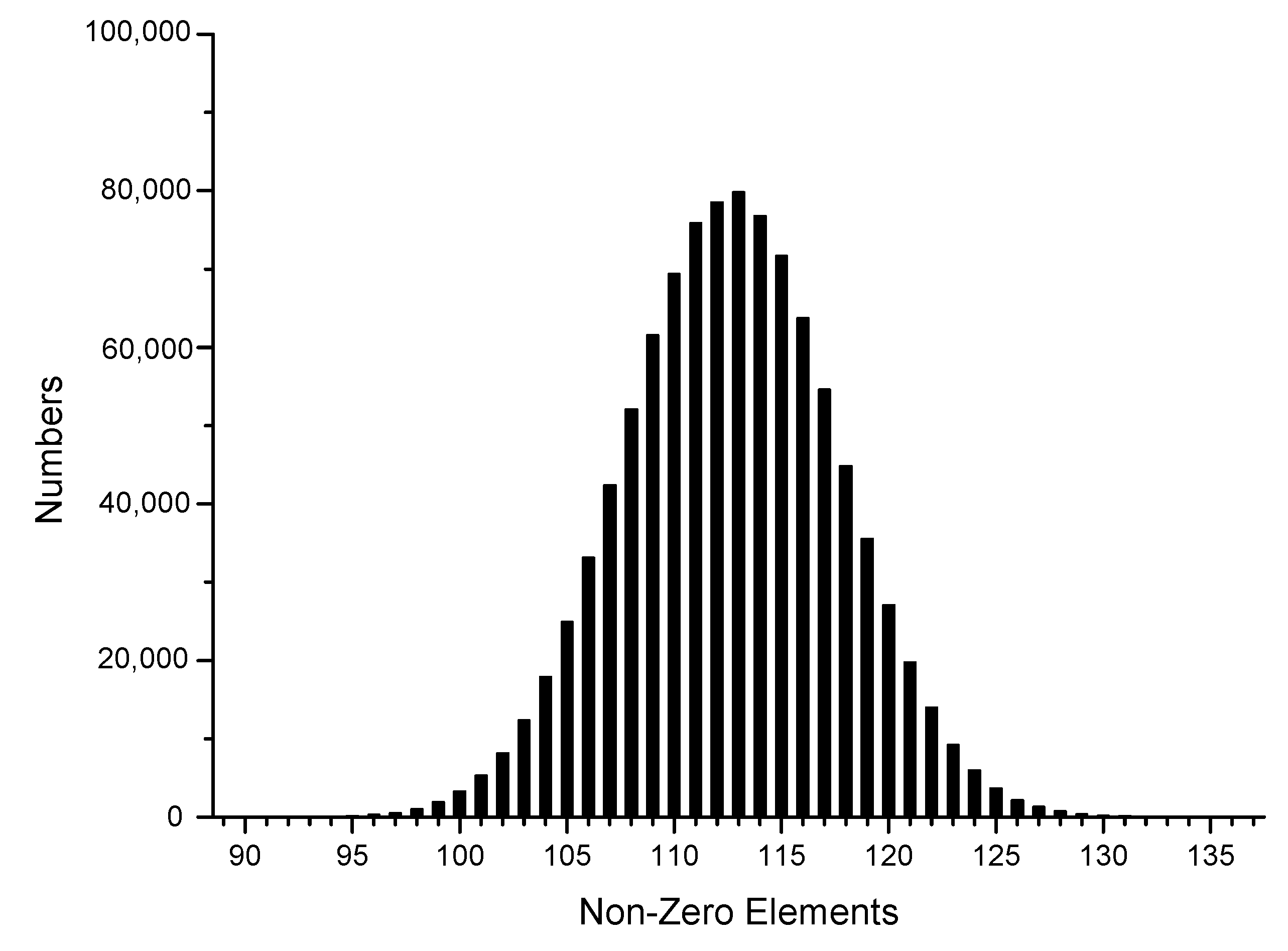
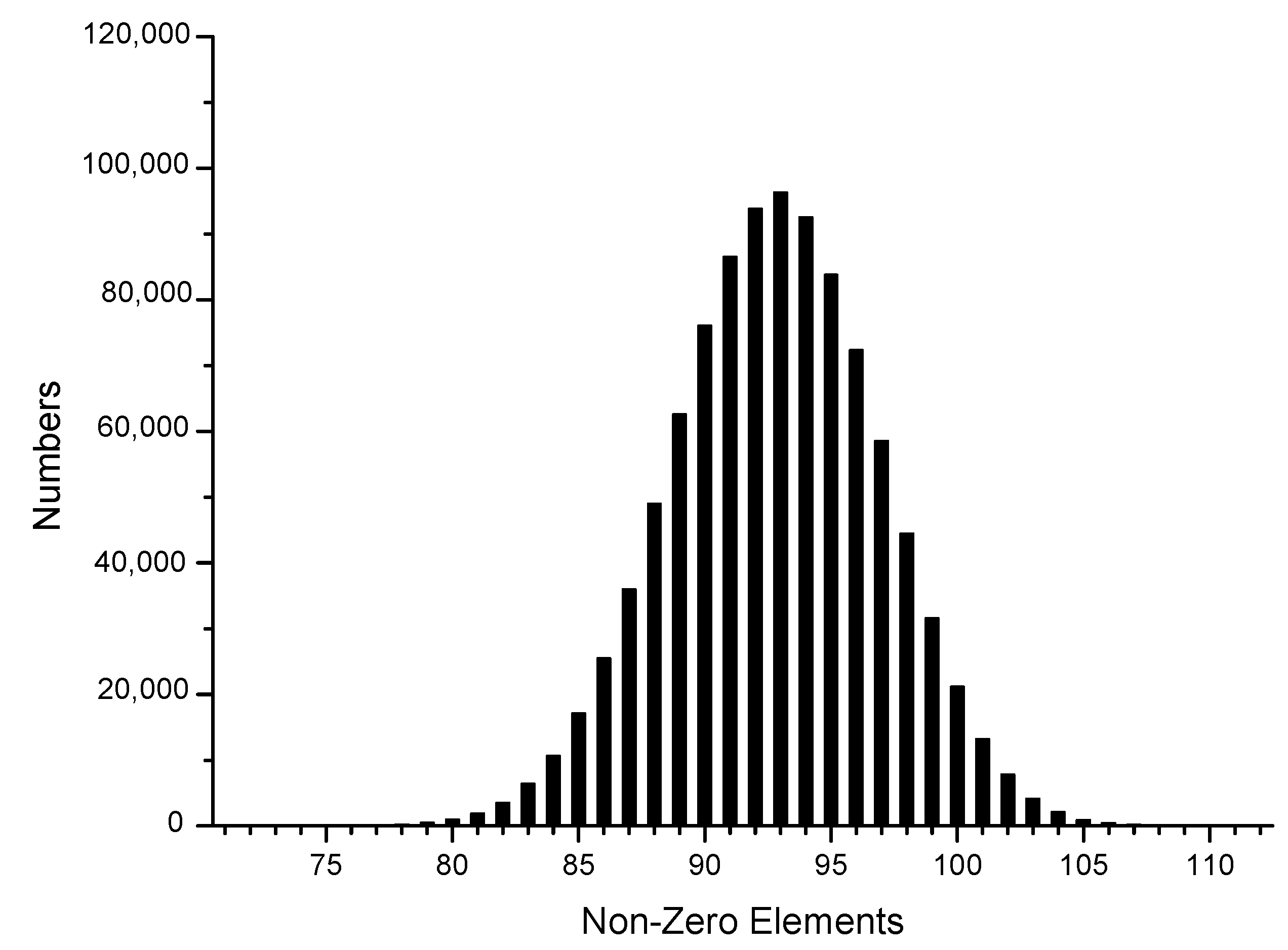
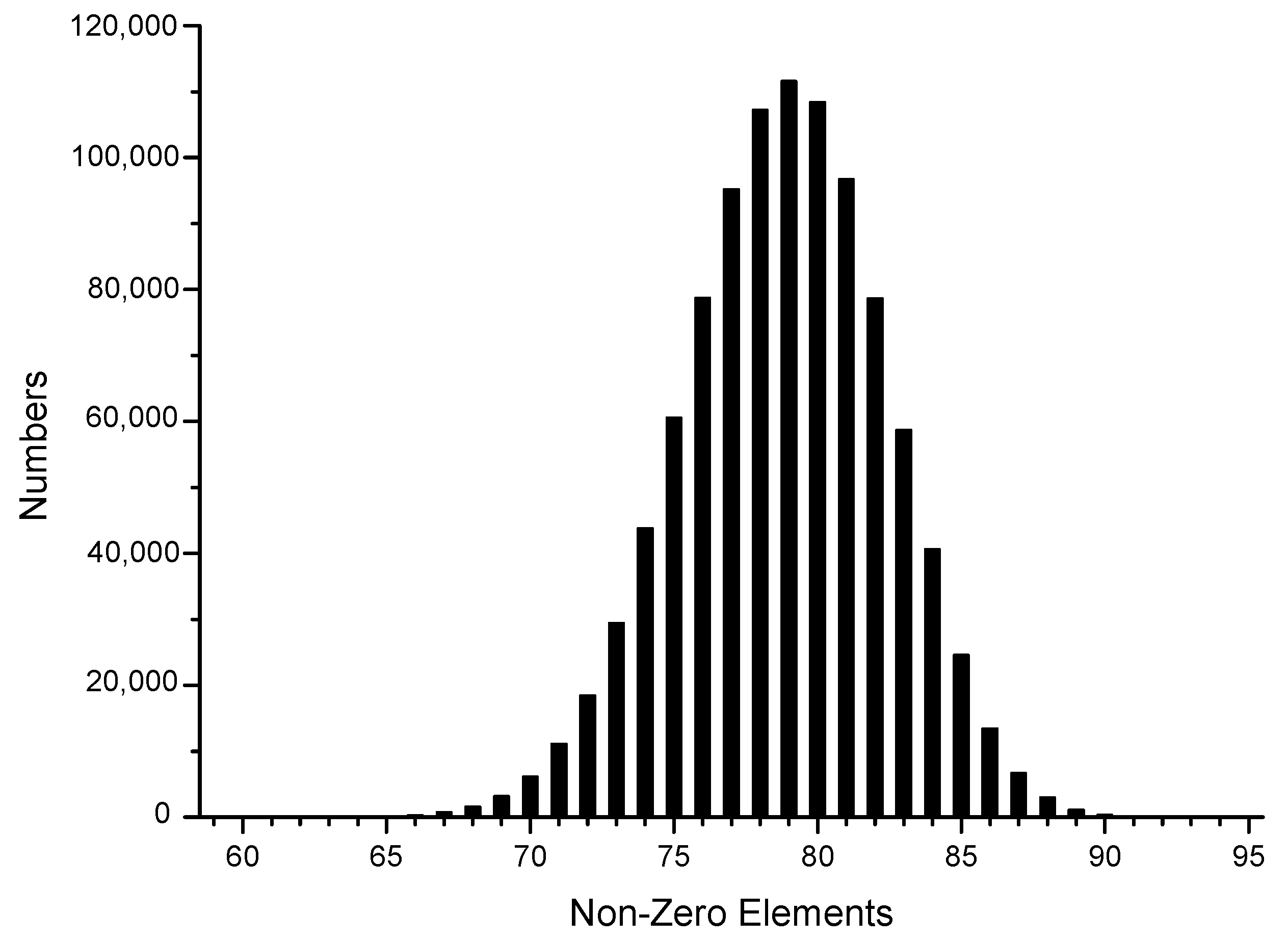
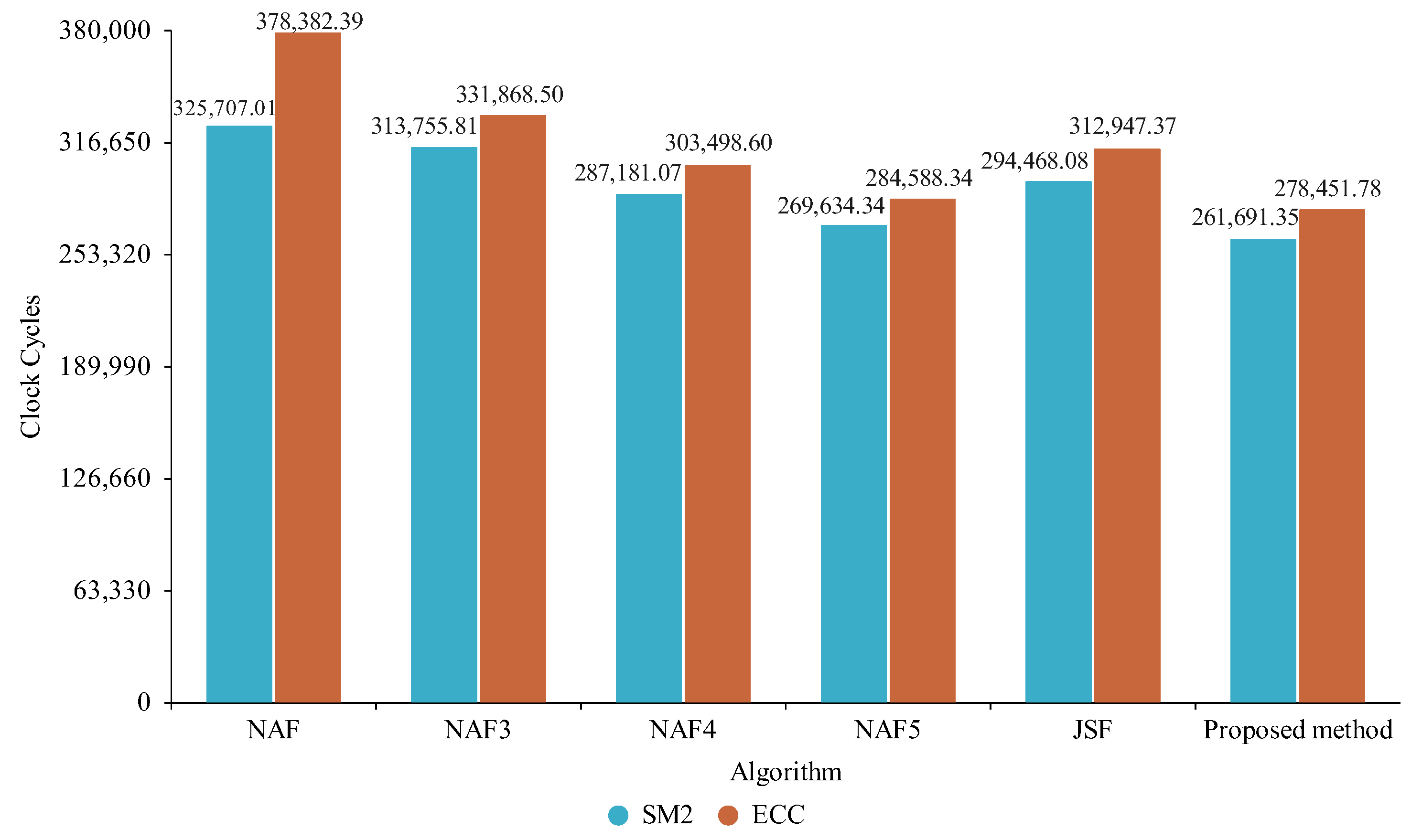
| Calculate , |
| Calculate . |
| If , the arithmetic cost can be reduced to |
| t() = |
| Calculate , |
| t() = |
| Raptor Lake | Comet Lake | Coffee Lake | Zen 4 |
|---|---|---|---|
| 2975 | 2876 | 2970 | 2818 |
| w | Hamming Weight | |
|---|---|---|
| 2 | ||
| 3 | ||
| 4 | ||
| 5 |
| Algorithm | Hamming Weight | Number of Point Additions |
|---|---|---|
| JSF | ||
| JSF-5 |
| Algorithm | Sum of Basic Operation | Case One | Case Two | Case Three |
|---|---|---|---|---|
| NAF | 0 | 0 | 0 | 0 |
| 3-NAF | ||||
| 4-NAF | ||||
| 5-NAF | ||||
| JSF | ||||
| Proposed method |
| Algorithm | Sum of Basic Operation | Case One | Case Two | Case Three |
|---|---|---|---|---|
| NAF | ||||
| 3-NAF | ||||
| 4-NAF | ||||
| 5-NAF | ||||
| JSF | ||||
| Proposed JSF-5 |
| Algorithm | Sum of Basic Operation | Case One | Case Two | Case Three |
|---|---|---|---|---|
| NAF | ||||
| 3-NAF | ||||
| 4-NAF | ||||
| 5-NAF | ||||
| JSF | ||||
| Proposed JSF-5 |
| Operation | Encoding | Operation | Encoding |
|---|---|---|---|
| P | 1 | Q | 5 |
| 4 | 6 | ||
| 3 | 15 | ||
| 16 | 14 | ||
| 8 | 2 | ||
| 12 | 18 |
| Operation | Encoding | Operation | Encoding |
|---|---|---|---|
| P | 1 | Q | 5 |
| 4 | 6 | ||
| 2 | 10 | ||
| 11 | 9 | ||
| 7 | 3 | ||
| 8 | 12 |
| Output | Output | ||||
|---|---|---|---|---|---|
| 6 | 6 | 0 | 6 | 2 | 0 |
| 6 | 4 | 0 | 6 | 0 | 0 |
| 4 | 4 | 0 | 4 | 6 | 0 |
| 4 | 2 | 0 | 4 | 0 | 0 |
| 2 | 6 | 0 | 2 | 4 | 0 |
| 2 | 2 | 0 | 2 | 0 | 0 |
| 0 | 6 | 0 | 0 | 0 | 0 |
| 0 | 2 | 0 | 0 | 4 | 0 |
| Output | Output | ||||
|---|---|---|---|---|---|
| 7 | 7 | −6 | 7 | 5 | −11 |
| 7 | 3 | 9 | 7 | 1 | 4 |
| 5 | 7 | −11 | 5 | 5 | −12 |
| 5 | 3 | 8 | 5 | 1 | −9 |
| 3 | 3 | 12 | 3 | 1 | 7 |
| 3 | 5 | −8 | 3 | 7 | −3 |
| 1 | 7 | −4 | 1 | 1 | 6 |
| 1 | 3 | 11 | 1 | 5 | −9 |
| Output | Output | ||||
|---|---|---|---|---|---|
| 7 | 6 | 1 | 7 | 4 | −1 |
| 7 | 2 | 1 | 7 | 0 | −1 |
| 5 | 6 | −1 | 5 | 4 | 1 |
| 5 | 2 | −1 | 5 | 0 | 1 |
| 3 | 6 | 1 | 3 | 4 | −1 |
| 3 | 2 | 1 | 3 | 0 | −1 |
| 1 | 6 | −1 | 1 | 4 | 1 |
| 1 | 2 | −1 | 1 | 0 | 1 |
| 6 | 7 | 5 | 6 | 5 | −5 |
| 6 | 3 | 5 | 6 | 1 | −5 |
| 4 | 7 | −5 | 4 | 5 | 5 |
| 4 | 3 | −5 | 4 | 1 | 5 |
| 2 | 7 | 5 | 2 | 5 | −5 |
| 2 | 3 | 5 | 2 | 1 | −5 |
| 0 | 7 | −5 | 0 | 5 | 5 |
| 0 | 3 | −5 | 0 | 1 | 5 |
| Array Position | JSF-5 TBL Table | |||||||
|---|---|---|---|---|---|---|---|---|
| 0–31 | 0, 0, 0, 0 | 0, 1, 5, 0 | 0, 0, 0, 0 | 0, −1, −5, 0 | 0, 0, 0, 0 | 0, 1, 5, 0 | 0, 0, 0, 0 | 0, −1, −5, 0 |
| 32–63 | 1, 0, 1, 0 | 1, 1, 6, 0 | −1, 0, −1, 0 | 1, 3, 11, 0 | 1, 0, 1, 0 | 1, −3, −9, 0 | −1, 0, −1, 0 | 1, −1, −4, 0 |
| 64–95 | 0, 0, 0, 0 | 0, −1, −5, 0 | 0, 0, 0, 0 | 0, 1, 5, 0 | 0, 0, 0, 0 | 0, −1, −5, 0 | 0, 0, 0, 0 | 0, 1, 5, 0 |
| 96–127 | −1, 0, −1, 0 | 3, 1, 7, 0 | 1, 0, 1, 0 | 3, 3, 12, 0 | −1, 0, −1, 0 | 3, −3, −8, 0 | 1, 0, 1, 0 | 3, −1, −3, 0 |
| 128–159 | 0, 0, 0, 0 | 0, 1, 5, 0 | 0, 0, 0, 0 | 0, −1, −5, 0 | 0, 0, 0, 0 | 0, 1, 5, 0 | 0, 0, 0, 0 | 0, −1, −5, 0 |
| 160–191 | 1, 0, 1, 0 | −3, 1, 3, 0 | −1, 0, −1, 0 | −3, 3, 8, 0 | 1, 0, 1, 0 | −3, −3, −12, 0 | −1, 0, −1, 0 | −3, −1, −7, 0 |
| 192–223 | 0, 0, 0, 0 | 0, −1, −5, 0 | 0, 0, 0, 0 | 0, 1, 5, 0 | 0, 0, 0, 0 | 0, −1, −5, 0 | 0, 0, 0, 0 | 0, 1, 5, 0 |
| 224–255 | −1, 0, −1, 0 | −1, 1, 4, 0 | 1, 0, 1, 0 | −1, 3, 9, 0 | −1, 0, −1, 0 | −1, −3, −11, 0 | 1, 0, 1, 0 | −1, −1, −6, 0 |
| Operation | ADD | SUB | 2X | 3X | 4X | 8X |
|---|---|---|---|---|---|---|
| Numbers | 418.5 | 1706.5 | 407 | 151 | 151 | 151 |
| Architecture | Curve | ADD | SUB | 2X | 3X | 4X | 8X |
|---|---|---|---|---|---|---|---|
| Comet Lake | nistp256r1 | 24.50 | 31.32 | 20.08 | 20.89 | 19.93 | 19.69 |
| SM2 | 25.03 | 31.52 | 20.64 | 21.70 | 20.42 | 20.25 | |
| Coffee Lake | nistp256r1 | 18.91 | 27.57 | 15.50 | 16.80 | 15.35 | 15.44 |
| SM2 | 21.44 | 28.46 | 16.40 | 16.66 | 15.96 | 16.12 | |
| Raptor Lake | nistp256r1 | 6.15 | 6.41 | 12.86 | 15.24 | 12.20 | 12.42 |
| SM2 | 7.67 | 6.10 | 12.46 | 15.16 | 12.13 | 12.63 | |
| Zen 4 | nistp256r1 | 11.05 | 11.15 | 12.25 | 13.40 | 11.55 | 10.80 |
| SM2 curve | 10.7 | 10.29 | 11.25 | 13.30 | 11.10 | 11.00 |
| Architecture | Curve | Clock Cycles Consumed |
|---|---|---|
| Comet Lake | nistp256r1 | 27.14 |
| SM2 | 27.50 | |
| Coffee Lake | nistp256r1 | 22.93 |
| SM2 | 23.98 | |
| Raptor Lake | nistp256r1 | 8.30 |
| SM2 | 8.28 | |
| Zen 4 | nistp256r1 | 11.40 |
| SM2 | 10.71 |
| Algorithm | Comet Lake | Coffee Lake | Raptor Lake | Zen 4 |
|---|---|---|---|---|
| NAF | 7403.95 | 7137.10 | 7822.61 | 6352.62 |
| 3-NAF | 6044.00 | 5821.92 | 6419.55 | 5164.59 |
| 4-NAF | 5213.45 | 5024.53 | 5530.54 | 4452.62 |
| 5-NAF | 4682.22 | 4507.97 | 4945.97 | 3960.53 |
| JSF | 14,281.36 | 13,675.65 | 13,213.60 | 12,394.62 |
| JSF-5 | 12,743.82 | 12,254.46 | 12,657.90 | 11,822.74 |
| Proposed method | 6650.02 | 6453.95 | 6200.18 | 5598.06 |
| Proposed method in assembly | 3585.34 | 3447.29 | 5866.41 | 3748.62 |
| Architecture | Curve | A | M | S | I |
|---|---|---|---|---|---|
| Comet Lake | nistp256r1 | 27.14 | 75.46 | 60.45 | 4287.60 |
| SM2 | 27.50 | 69.96 | 56.48 | 4211.25 | |
| Coffee Lake | nistp256r1 | 22.93 | 66.86 | 52.96 | 4133.13 |
| SM2 | 23.98 | 63.23 | 50.40 | 4067.77 | |
| Raptor Lake | nistp256r1 | 8.30 | 59.54 | 58.05 | 4880.29 |
| SM2 | 8.28 | 59.79 | 49.26 | 4873.46 | |
| Zen 4 | nistp256r1 | 11.40 | 58.64 | 57.10 | 3557.01 |
| SM2 | 10.71 | 56.70 | 44.10 | 3556.65 |
| Architecture | Curve | NAF | 3-NAF | 4-NAF | 5-NAF | JSF |
|---|---|---|---|---|---|---|
| Comet Lake | nistp256r1 | 27.15% | 16.82% | 8.83% | 2.79% | 11.38% |
| SM2 | 19.85% | 17.03% | 9.33% | 3.10% | 11.42% | |
| Coffee Lake | nistp256r1 | 27.22% | 16.87% | 8.94% | 2.91% | 11.43% |
| SM2 | 19.79% | 16.66% | 8.97% | 2.79% | 11.11% | |
| Raptor Lake | nistp256r1 | 27.83% | 17.83% | 10.38% | 4.62% | 9.57% |
| SM2 | 19.75% | 16.99% | 9.42% | 3.54% | 9.91% | |
| Zen 4 | nistp256r1 | 26.41% | 16.10% | 8.25% | 2.16% | 11.02% |
| SM2 | 19.65% | 16.59% | 8.88% | 2.95% | 11.13% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Fu, Y. A Novel JSF-Based Fast Implementation Method for Multiple-Point Multiplication. Electronics 2023, 12, 3530. https://doi.org/10.3390/electronics12163530
Chen X, Fu Y. A Novel JSF-Based Fast Implementation Method for Multiple-Point Multiplication. Electronics. 2023; 12(16):3530. https://doi.org/10.3390/electronics12163530
Chicago/Turabian StyleChen, Xinze, and Yong Fu. 2023. "A Novel JSF-Based Fast Implementation Method for Multiple-Point Multiplication" Electronics 12, no. 16: 3530. https://doi.org/10.3390/electronics12163530
APA StyleChen, X., & Fu, Y. (2023). A Novel JSF-Based Fast Implementation Method for Multiple-Point Multiplication. Electronics, 12(16), 3530. https://doi.org/10.3390/electronics12163530