
A Visually Enhanced Neural Encoder for Synset Induction



Abstract
:1. Introduction
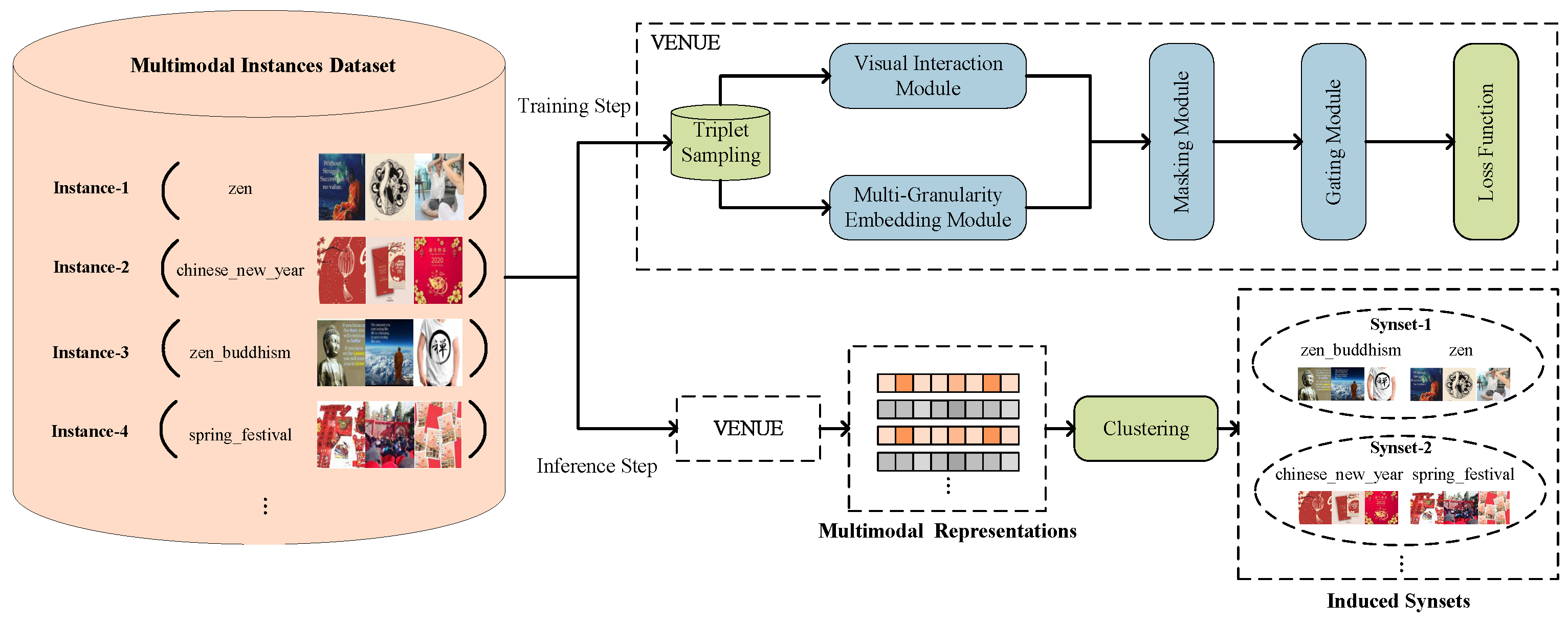
- We propose the VENUE encoder to learn visually-enhanced multimodal representations for the task of synset induction. The entire network is trained in an end-to-end fashion with a triplet loss. The learned representations are then used for clustering to induce the synsets.
- We design the visual interaction and the masking modules to cope with the noise in images. The former is built by capturing the inter-modal correlations among multiple images. The latter is built by the inter-modal interaction between visual and textual modalities. In addition, we design a gating module to regulate the visual and textual contributions for semantics.
- We collect the MMAI-Synset dataset to evaluate the multimodal synset induction task. Extensive experiments are conducted to show that our VENUE encoder outperforms strong baselines on three groups of popular metrics. The MMAI-Synset dataset and the source code for our experiments are made publicly available for advancing the multimedia community (https://github.com/cgpeter96/MMAI-synset, accessed on 15 August 2023).
2. Problem Formulation
3. Our Approach
3.1. Visual Interaction Module
3.2. Multi-Granularity Embedding Module
3.3. Masking Module
3.4. Gating Module
3.5. Loss Function and Training Algorithm
| Algorithm 1 Training Algorithm of Our VENUE Model. |
|
3.6. Inference
4. Experimental Settings
4.1. Dataset
4.2. Metrics
4.3. Implementation Details
4.4. Baseline
- (1)
- word2vec + k-means/HAC. This approach takes the pretrained word2vec as the tag representation and induces synset by the k-means or the HAC algorithm.
- (2)
- CNN + k-means/HAC. This method takes the visual features extracted from the convolutional neural network (i.e., CNN) and induces synset by the k-means or HAC algorithms.
- (3)
- + k-means/HAC. This approach takes the concatenated feature of the pre-trained word2vec and visual features as input, then induces synset by the k-means or HAC algorithm.
- (4)
- SynsetMine [14] is a text-based method. In our experiments, we keep only the textual parts of multimodal instances, leaving out the visual parts. This method takes the pre-trained word2vec as a tag representation and then induces synset through a proposed SynsetMine framework. It builds a classifier to determine whether to merge a new instance into the current set and then efficiently generates entity synonym sets from a given tag set. In our experiments, we follow the experimental setting of SynsetMine and use the pre-trained word2vec provided by the authors to initialize the embedding layer. Then, we use the textual data to train the SynsetMine model with the supervised signal. After the training, according to the semantics of words, SynsetMine performs greedy clustering to induce synset by merging tags one by one.
- (5)
- Infomap [30] is originally proposed for a community detection algorithm https://www.mapequation.org/infomap/ (accessed on 15 August 2023) based on the graph structure and information theoretic approach. This method is widely used in community detection and synset induction. The basic idea of Infomap is first to generate a sequence by constructing transition probabilities, random walk on the graph, and then hierarchically encode the sequence to minimize the objective function. Finally, Infomap achieves a clustering goal. In our experiment, we first use the pre-trained word2vec to represent the tag. Then, we construct a graph based on the Euclidean distance between words and apply the Infomap algorithm to synset induction.
- (6)
- MWSI [17] proposes a multimodal unsupervised clustering method that uses pre-trained visual and textual features to cluster multimodal instances. To fit our settings, we use a variant of MWSI without performing synonymy detection. The reason is that there is no ambiguity problem with our built MMAI-Synset dataset. In particular, we use the visual and textual features with an early fusion, which is proposed in MWSI [17]. Then, we obtain the multimodal representations. Finally, we use the hierarchical clustering algorithm to group the image sets which have identical meanings.
- (7)
- CLIP (Contrastive Language-Image Pretraining) [31] is a multimodal neural network pre-trained model. This model is trained on a super large-scale dataset having 400 million image-text pairs collected from the Internet. CLIP directly learns the multimodal semantic correlations from the raw text of images, which leverages a much broader source of supervision. This pre-trained model can enable the zero-cost transfer of the model to downstream tasks non-trivially without the need for any dataset-specific training. With this idea, in our experiments, we directly apply the CLIP model as an encoder to extract multimodal representations without any modification or training. We adopt the official version of CLIP https://github.com/openai/CLIP (accessed on 15 August 2023) with the vision transformer image encoder and prompt engineering such as “a photo of #tag” for text encoding. Then, we perform the HAC algorithm among the multimodal representations to cluster the target synsets.
5. Results and Analysis
5.1. Performance of Synset Induction
5.2. Ablation Studies
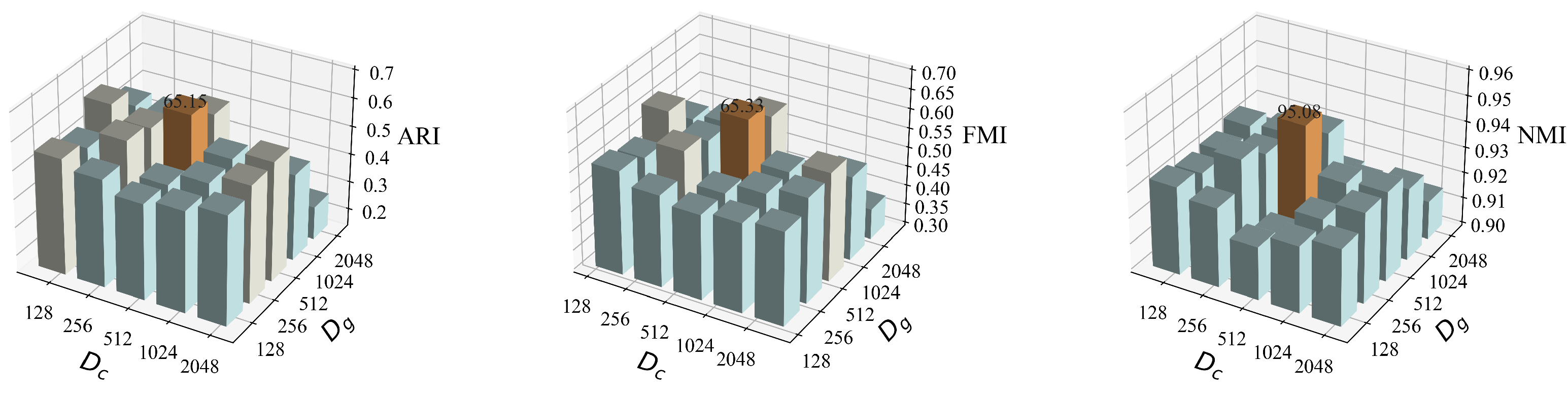
5.3. Model Parameters
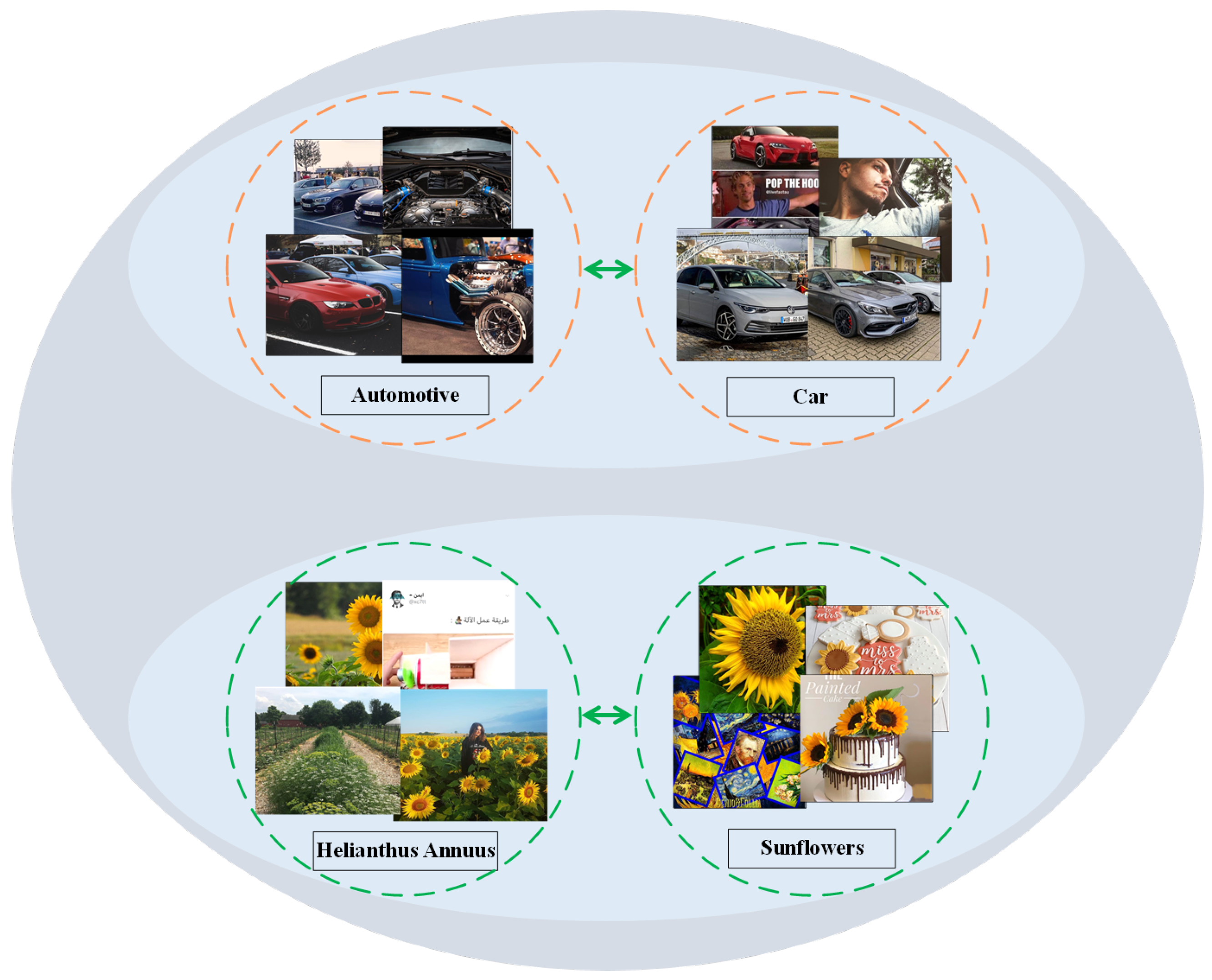
5.4. Qualitative Analysis
6. Related Work
6.1. Synset Induction
6.2. Learning Multimodal Semantic Representation
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Baltrušaitis, T.; Ahuja, C.; Morency, L.-P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. 2019, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Yao, T.; Zhu, S.; Saddik, A.E. Deep learning–based multimedia analytics: A review. ACM Trans. Multimedia Comput. Commun. Appl. 2019, 15, 1–26. [Google Scholar] [CrossRef]
- Zhu, W.; Wang, X.; Li, H. Multi-modal deep analysis for multimedia. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3740–3764. [Google Scholar] [CrossRef]
- Vinyals, O.; Toshev, A.; Bengio, S.; Erhan, D. Show and tell: A neural image caption generator. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7 June 2015; pp. 3156–3164. [Google Scholar] [CrossRef]
- Wei, H.; Li, Z.; Huang, F.; Zhang, C.; Ma, H.; Shi, Z. Integrating scene semantic knowledge into image captioning. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–22. [Google Scholar] [CrossRef]
- Zha, Z.-J.; Liu, D.; Zhang, H.; Zhang, Y.; Wu, F. Context-aware visual policy network for fine-grained image captioning. IEEE Trans. Pattern Analysis Mach. Intell. 2022, 44, 710–722. [Google Scholar] [CrossRef] [PubMed]
- Turney, P.D. Mining the web for synonyms: PMI-IR versus LSA on TOEFL. In Proceedings of the 12th European Conference on Machine Learning (ECML), Freiburg, Germany, 5 September 2001; pp. 491–502. [Google Scholar]
- Nakashole, N.; Weikum, G.; Suchanek, F. PATTY: A taxonomy of relational patterns with semantic types. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CCL), Abu Dhabi, United Arab Emirates, 7 September 2012; pp. 1135–1145. [Google Scholar]
- Shen, J.; Wu, Z.; Lei, D.; Shang, J.; Ren, X.; Han, J. SetExpan: Corpus-based set expansion via context feature selection and rank ensemble. In Machine Learning and Knowledge Discovery in Databases; Ceci, M., Hollmén, J., Todorovski, L., Vens, C., Džeroski, S., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 288–304. [Google Scholar]
- Qu, M.; Ren, X.; Han, J. Automatic synonym discovery with knowledge bases. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13 August 2017; pp. 997–1005. [Google Scholar]
- Zhang, C.; Li, Y.; Du, N.; Fan, W.; Yu, P.S. Entity synonym discovery via multipiece bilateral context matching. In Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence (IJCAI), International Joint Conferences on Artificial Intelligence Organization, Yokohama, Japan, 7 January 2020; pp. 1431–1437. [Google Scholar] [CrossRef]
- Lossio-Ventura, J.; Bian, J.; Jonquet, C.; Roche, M.; Teisseire, M. A novel framework for biomedical entity sense induction. J. Biomed. 2018, 84, 31–41. [Google Scholar] [CrossRef] [PubMed]
- Mamou, J.; Pereg, O.; Wasserblat, M.; Dagan, I.; Goldberg, Y.; Eirew, A.; Green, Y.; Guskin, S.; Izsak, P.; Korat, D. Term set expansion based on multi-context term embeddings: An end-to-end workflow. In Proceedings of the The 27th International Conference on Computational Linguistics (COLING), Santa Fe, NM, USA, 20 August 2018. [Google Scholar]
- Shen, J.; Lyu, R.; Ren, X.; Vanni, M.; Sadler, B.; Han, J. Mining entity synonyms with efficient neural set generation. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Washington, DC, USA, 7 February 2019; Volume 33, pp. 249–256. [Google Scholar] [CrossRef]
- Wang, Z.; Yue, X.; Moosavinasab, S.; Huang, Y.; Lin, S.; Sun, H. Surfcon: Synonym discovery on privacy-aware clinical data. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4 August 2019; pp. 1578–1586. [Google Scholar]
- Pei, S.; Yu, L.; Zhang, X. Set-aware entity synonym discovery with flexible receptive fields. IEEE Trans. Knowl. Data Eng. 2023, 35, 891–904. [Google Scholar] [CrossRef]
- Tomason, J.; Mooney, R.J. Multi-modal word synset induction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18 June 2018; pp. 7794–7803. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems (NIPS); The MIT Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Pinheiro, P.O.; Collobert, R. From image-level to pixel-level labeling with convolutional networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7 June 2015; pp. 1713–1721. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7 June 2015; pp. 815–823. [Google Scholar]
- Tang, Z.; Huang, J. Harmonious multi-branch network for person re-identification with harder triplet loss. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–21. [Google Scholar] [CrossRef]
- Rosenberg, A.; Hirschberg, J. V-measure: A conditional entropy-based external cluster evaluation measure. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 410–420. [Google Scholar]
- Halkidi, M.; Batistakis, Y.; Vazirgiannis, M. On clustering validation techniques. J. Intell. Inf. Syst. 2001, 17, 107–145. [Google Scholar] [CrossRef]
- Vinh, N.X.; Epps, J.; Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- Mahajan, D.; Girshick, R.; Ramanathan, V.; He, K.; Paluri, M.; Li, Y.; Bharambe, A.; Maaten, L.V. Exploring the limits of weakly supervised pretraining. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 185–201. [Google Scholar]
- Řehůřek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, ELRA, Valletta, Malta, 22 May 2010; pp. 45–50. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Rosvall, M.; Bergstrom, C.T. Maps of random walks on complex networks reveal community structure. Proc. Natl. Acad. Sci. USA 2008, 105, 1118–1123. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual Event, 24 July 2021; Volume 139, pp. 8748–8763. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25 October 2014; pp. 1532–1543. [Google Scholar]
- Yin, Q.; Wu, S.; Wang, L. Partially tagged image clustering. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 30 September 2015; pp. 4012–4016. [Google Scholar]
- Chang, J.; Wang, L.; Meng, G.; Xiang, S.; Pan, C. Deep adaptive image clustering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22 October 2017; pp. 5879–5887. [Google Scholar]
- Yao, Y.; Shen, F.; Zhang, J.; Liu, L.; Tang, Z.; Shao, L. Extracting multiple visual senses for web learning. IEEE Trans. Multimed. 2018, 21, 184–196. [Google Scholar] [CrossRef]
- Li, Y.; Hu, P.; Liu, Z.; Peng, D.; Zhou, J.T.; Peng, X. Contrastive clustering. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7 February 2021. [Google Scholar]
- Kiros, R.; Salakhutdinov, R.; Zemel, R.S. Unifying visual-semantic embeddings with multimodal neural language models. In Proceedings of the Neural Information Processing Systems (NIPS), Deep Learning Workshop, Montreal, QC, Canada, 8 December 2014. [Google Scholar]
- Vendrov, I.; Kiros, R.; Fidler, S.; Urtasun, R. Order-embeddings of images and language. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April 2016. [Google Scholar]
- Mao, J.; Xu, J.; Jing, K.; Yuille, A.L. Training and evaluating multimodal word embeddings with large-scale web annotated images. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Barcelona, Spain, 5 December 2016; pp. 442–450. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7 December 2015; pp. 91–99. [Google Scholar]
- Anderson, P.; He, X.; Buehler, C.; Teney, D.; Johnson, M.; Gould, S.; Zhang, L. Bottom-up and top-down attention for image captioning and visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18 June 2018; pp. 6077–6086. [Google Scholar]
- Kiela, D.; Bottou, L. Learning image embeddings using convolutional neural networks for improved multi-modal semantics. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25 October 2014; pp. 36–45. [Google Scholar]
- Thoma, S.; Rettinger, A.; Both, F. Knowledge fusion via embeddings from text, knowledge graphs, and images. arXiv 2017, arXiv:1704.06084. [Google Scholar]
- Wang, S.; Zhang, J.; Zong, C. Learning multimodal word representation via dynamic fusion methods. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence (AAAI), New Orleans, LO, USA, 7 February 2018; pp. 5973–5980. [Google Scholar]
- Wang, S.; Zhang, J.; Zong, C. Associative multichannel autoencoder for multimodal word representation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Brussels, Belgium, 31 October 2018; pp. 115–124. [Google Scholar] [CrossRef]
- Berger, U.; Stanovsky, G.; Abend, O.; Frermann, L. A Computational Acquisition Model for Multimodal Word Categorization. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 3819–3835. [Google Scholar]
- Yin, S.; Fu, C.; Zhao, S.; Li, K.; Sun, X.; Xu, T.; Chen, E. A Survey on Multimodal Large Language Models. arXiv 2023, arXiv:2306.13549v1. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Characteristics | Quantity |
|---|---|---|
| 1 | # Noun Phrases | 8509 |
| 2 | # Images | 425,450 |
| 3 | # Instances for Training | 7833 |
| 4 | # Instances for Testing | 676 |
| 5 | # Synonyms for Training | 3911 |
| 6 | # Synonyms for Testing | 209 |
| Tag Length | Training Set (%) | Testing Set (%) |
|---|---|---|
| 1 | 49.60 | 46.62 |
| 2 | 37.60 | 38.80 |
| 3 | 10.50 | 11.50 |
| 4 | 0.22 | 0.74 |
| Encoder | Clustering | h | c | v | p | r | f | ARI | FMI | NMI |
|---|---|---|---|---|---|---|---|---|---|---|
| word2vec | k-means | 89.19 | 91.22 | 90.19 | 39.89 | 54.70 | 46.13 | 45.91 | 46.71 | 90.20 |
| CNN | 80.38 | 85.31 | 82.77 | 16.37 | 33.91 | 22.08 | 27.71 | 23.56 | 82.81 | |
| 83.07 | 87.18 | 85.07 | 22.62 | 41.58 | 29.30 | 28.98 | 30.67 | 85.10 | ||
| word2vec | HAC | 90.09 | 94.65 | 92.31 | 36.85 | 73.14 | 49.00 | 48.76 | 51.96 | 92.35 |
| CNN | 72.50 | 85.91 | 78.64 | 4.44 | 43.44 | 8.05 | 7.46 | 13.89 | 78.92 | |
| 85.31 | 92.09 | 88.57 | 22.26 | 62.99 | 32.90 | 32.54 | 37.45 | 88.64 | ||
| SynsetMine [14] | - | 94.26 | 91.69 | 92.96 | 58.80 | 55.81 | 57.26 | 57.12 | 57.28 | 92.97 |
| InfoMap [30] | - | 98.63 | 87.07 | 92.49 | 69.97 | 30.56 | 42.54 | 42.42 | 46.24 | 92.67 |
| MWSI [17] | HAC | 94.11 | 93.49 | 93.80 | 53.19 | 66.09 | 58.94 | 58.78 | 59.29 | 93.80 |
| CLIP [31] | HAC | 91.48 | 95.73 | 93.56 | 40.86 | 79.95 | 54.08 | 53.86 | 57.16 | 93.56 |
| VENUE | k-means | 92.53 | 94.72 | 93.61 | 53.60 | 73.64 | 62.04 | 61.89 | 62.83 | 93.61 |
| HAC | 96.41 | 93.79 | 95.08 | 62.81 | 67.95 | 65.28 | 65.15 | 65.33 | 95.08 |
| Encoder | Clustering | h | c | v | p | r | f | ARI | FMI | NMI |
|---|---|---|---|---|---|---|---|---|---|---|
| VENUE (w/o att) | k-means | 89.55 | 90.97 | 90.26 | 44.31 | 54.46 | 48.86 | 48.85 | 49.12 | 90.26 |
| VENUE (w/o mge) | 87.64 | 89.40 | 88.52 | 36.19 | 47.52 | 41.09 | 40.85 | 41.47 | 88.52 | |
| VENUE (w/o mask) | 92.29 | 93.37 | 92.83 | 55.61 | 64.98 | 59.93 | 59.78 | 60.11 | 92.83 | |
| VENUE (w/o gate) | 91.65 | 93.14 | 92.39 | 52.76 | 65.10 | 58.28 | 58.12 | 58.60 | 92.39 | |
| VENUE | 92.53 | 94.72 | 93.61 | 53.60 | 73.64 | 62.04 | 61.89 | 62.83 | 93.61 | |
| VENUE (w/o att) | HAC | 91.33 | 95.71 | 93.47 | 40.70 | 79.33 | 53.80 | 53.58 | 56.82 | 93.47 |
| VENUE (w/o mge) | 93.16 | 92.38 | 92.77 | 50.25 | 61.51 | 55.31 | 55.14 | 55.60 | 92.77 | |
| VENUE (w/o mask) | 94.96 | 94.20 | 94.58 | 54.51 | 70.30 | 61.41 | 61.25 | 61.90 | 94.58 | |
| VENUE (w/o gate) | 95.13 | 92.87 | 93.99 | 53.73 | 63.37 | 58.15 | 57.99 | 58.35 | 93.99 | |
| VENUE | 96.41 | 93.79 | 95.08 | 62.81 | 67.95 | 65.28 | 65.15 | 65.33 | 95.08 |
| # Synset | Ground Truth | Word2Vec | VENUE |
|---|---|---|---|
| 1 | {oil_paints, old_paint, oil} | {oil_paints, oil_paint, oil, the_stones} | {oil_paints, oil_paint, oil} |
| 2 | {king, monarch, queue} | {helena, king, queue} | {king, monarch, queue} |
| {monarch} | |||
| 3 | {streetcar, tram, trolley_car, trolley} | {trolley_car, trolley, njt} | {streetcar, tram, trolley} |
| {streetcar, cp_rail, cpr, canadian_pacific_railway} | {trolley_car, njt} |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, G.; Feng, F.; Zhang, G.; Li, X.; Li, R. A Visually Enhanced Neural Encoder for Synset Induction. Electronics 2023, 12, 3521. https://doi.org/10.3390/electronics12163521
Chen G, Feng F, Zhang G, Li X, Li R. A Visually Enhanced Neural Encoder for Synset Induction. Electronics. 2023; 12(16):3521. https://doi.org/10.3390/electronics12163521
Chicago/Turabian StyleChen, Guang, Fangxiang Feng, Guangwei Zhang, Xiaoxu Li, and Ruifan Li. 2023. "A Visually Enhanced Neural Encoder for Synset Induction" Electronics 12, no. 16: 3521. https://doi.org/10.3390/electronics12163521
APA StyleChen, G., Feng, F., Zhang, G., Li, X., & Li, R. (2023). A Visually Enhanced Neural Encoder for Synset Induction. Electronics, 12(16), 3521. https://doi.org/10.3390/electronics12163521