1. Introduction
With the development of computer vision and intelligent surveillance technology, moving target detection technology has become a hot topic of research at present. The effectiveness of detection affects the subsequent behavioral analysis and identification tracking. Moving target detection is widely used in intelligent transportation, medicine, aerospace remote sensing, unmanned aerial vehicles, disaster rescue, and many other fields, with positive prospects.
Target detection involves a wide range of fields and a huge amount of data processing in the detection process. Therefore, detection capability and real-time performance will become urgent problems if deployed on devices with low computational resources. Compared with deep learning methods, traditional detection algorithms have apparent advantages in computational capacity. Conventional mainstream detection generally includes three types: optical flow method, inter-frame difference method, and background difference method. The optical flow method [
1] can detect independent moving targets without the need to know information about the scene; however, it is susceptible to environmental factors. The calculation is also time-consuming. The inter-frame difference method [
2,
3] has high stability and low complexity, but it cannot extract the entire region of the target. The background difference method [
4] has a wider application scenario than the previous two algorithms. It divides the foreground and background by comparing the difference between the background model and the current frame. The main background difference methods commonly used are the Gaussian mixture model [
5,
6] and the Vibe algorithm. The Gaussian mixture model is highly adaptable to the scene. However, it is computationally intensive and cannot meet real-time demand.
The Vibe algorithm [
7,
8] has a simple concept, high stability, and rapid computation. It is suitable for real-time detection in static scenes. However, the Vibe algorithm also suffers from significant drawbacks. The Vibe algorithm uses the initial frame to build the background model. There are moving targets in the initial frame, or the background change rate does not match the update rate of the sample model, which may produce ghosting phenomena [
9]. Wind, sunlight, or camera shake may cause changes in the background, resulting in a lot of noise interference. In addition, if a moving target blocks the light, the color projected on the shadow area will be darker than the background color. Obvious pixel differences can cause the background to be misclassified as foreground. In addition, a limited sample model or a high similarity between foreground and background can lead to missing target edges. Deep-learning-based target detection techniques require high-arithmetic resources and are difficult to deploy on small devices. The detection accuracy of traditional vision-based detection techniques is low. In this paper, we develop an improved ViBe algorithm that integrates traditional detection techniques with deep learning. With the limited arithmetic resources, the detection accuracy is improved by suppressing ghosting and noise. Its main contributions are as follows.
We adopt a shallow convolutional layer of a pre-trained neural network to extract the underlying features and calculate the signal-to-noise ratio between the features of each channel. Then, the feature images with the highest correlation are selected for fusion. Finally, the fused image is modeled by replacing the image of the original frame with the fused image. This method suppresses the redundant information with weak correlation, achieves the purpose of removing background noise, and establishes the foundation for the subsequent background modeling.
Based on the newly synthesized images, we use the histogram similarity method to compare the similarity frame by frame. Then, three frames with large differences in similarity are selected for inter-frame differencing. Finally, the background model is completed by morphological filling to obtain a clear foreground target. This approach suppresses the ghosting generated by the modeling process while eliminating the problem of target holes.
We introduce a spatio-temporal adaptive factor to adjust the threshold value dynamically. This method solves the problem of poor background suitability and enhances the ability to adjust to changes in light. In addition, setting the inter-frame average value measures the speed of the target’s movement. This approach dynamically updates the neighborhood pixels so that the update rate of the model matches the background change rate to adapt to the changes in the scene.
In this paper,
Section 2 reviews the previous related work.
Section 3 briefly reviews the detection principles of the Vibe algorithm. In
Section 4, the proposed algorithm is described in detail.
Section 5 provides the dataset and performance metrics. The feasibility is verified by ablative experiments and compared with the performance of the vibe algorithm. Finally,
Section 6 concludes the article.
2. Related Works
In dynamic target detection, background modeling is widely used to detect foreground targets in video frames. The background model and simulation accuracy directly affect the effectiveness of detection. Any motion target detection algorithm has to meet the processing requirements of different scenes as much as possible. However, background modeling and simulation becomes more difficult due to the complexity of the scene and various environmental disturbances. The basic idea of the ViBe algorithm is to store for each pixel a set of values that were obtained in the past at the same or adjacent positions. Then, the difference between the current pixel and the pixel in the sample is compared to determine whether it is a background point or not. Compared to traditional detection algorithms, the optical flow method detects the changing image of a frame in a graphics program in the time and space domain gradients but is influenced by environmental factors and is computationally time-consuming. The inter-frame difference method finds the detected object by comparing the difference between two consecutive frames, but the detection effect is usually residual and affected by the inter-frame time interval. The advantage of the ViBe algorithm is that it is computationally small, fast, and real-time. In contrast to deep learning methods, it does not require training on specific scenes and is unsupervised methods. However, it also has disadvantages, such as ghosting, shadows, and incomplete targets. Researchers have proposed many improved algorithms for moving target detection for the above shortcomings.
To address the above problems, Piccardi M et al. [
10] proposed a background modeling method based on a mean-shift procedure in 2004. The convergence property based on mean shift enables the system to implement background modeling. In addition, histogram-based computation and local attraction enable it to meet the stringent real-time requirements of video processing. Mittal A et al. [
11] proposed to use a hybrid model to represent pixels in a panoramic view and construct background images of static parts of the scene. The method detects moving objects in a video sequence, detects active patterns on a wide field of view, and moving objects removed from the video. Zhang H et al. [
12] proposed a method based on thread block coordinates, optimized divergence angle, computed kernel function, and CUDA (computing unified device architecture). The improved algorithm achieved ghosting elimination and avoided large irrelevant background edges and achieved better accuracy and precision. Shao X et al. [
13] proposed a motion target detection method based on the Vibe algorithm. The background model is initialized using consecutive multi-frame images, which solves the ghosting phenomenon generated by the presence of moving targets in the initial frames. However, this algorithm cannot eliminate the foreground shadow problem caused by light and increases the algorithm’s time complexity. Hayat MA et al. [
14] proposed calculating the maximum Euclidean distance using the grey scale values of odd frames. The background model is then updated using the current pixel grey scale value instead of the Euclidean distance sample value in the background model. It suppresses the effect of ghosting on the background model. Singh RP et al. [
15] proposed a pixel sample consensus technique for segmenting the foreground, which uses a segmentation mask approach to analyze the possibility of being absorbed and speed up ghost image suppression. However, it is too computationally intensive and cannot effectively eliminate the ghost region. In the same year, Sudha D et al. [
16] used an improved Yolo-fusion Vibe algorithm. The authors combined the Kalman filter algorithm and particle filtering techniques to find upcoming vehicles. The detection accuracy is improved without unduly increasing the computational resource consumption. However, the parameters of the algorithm cannot be adaptively adjusted. The regions with depth variations are not well handled.
In recent years, researchers have considered noise point elimination and suppression of ghosting phenomena to be equally important. Yan Q et al. [
17] proposed initializing the background model with the average pixel values of multi-frame images. In addition, setting adaptive thresholds enhances the adaptability of the model when calculating the Euclidean distance between the current pixel value and the background model. This algorithm increases the computation and complexity of the model. Wang T et al. [
18] designed an improved Vibe algorithm incorporating CLD (Color Layout Descriptor). They designed the adaptive thresholding method in the background model to reduce the error detection rate by differential operation. However, the algorithm has poor real-time performance, and allows empty regions in foreground detection. In 2022, Lyu C et al. [
19] used the EffificientNetB0 lightweight network combined with fusion Vibe for leak detection, significantly improving detection accuracy. However, it is only suitable for small target-specific scenario detection. To solve the problem of multi-scale moving objects and dynamic background in real surveillance tasks, Subudhi B et al. [
20] proposed to model each pixel in the kernel-induced space using the possibility fuzzy cost function. Using the induced kernel function to project the low-dimensional data into the high-dimensional space, a robust background model will be constructed using the likelihood function based on the density of the data in the time domain, avoiding noise and outliers. In 2023, Qi, Q et al. [
21] designed a novel Regional Multi-Feature Frequency (RMFF) for detecting multi-scale moving objects in dynamic backgrounds. Background changes are ignored through spatial relationships between pixels and eigenfrequencies over time in the neighborhood. Multi-scale superpixels are then used to utilize the structural information present in the real-world scene to better delineate the background from the foreground and improve the robustness of the algorithm. However, Multi-Feature Frequency detects multi-scale moving targets in dynamic backgrounds, which is highly accurate but results in consuming too much arithmetic resources and cannot be deployed on devices with less arithmetic power. Ju J et al. [
22] proposed a detection algorithm that combines the smoothed three-frame difference method and the robust principal component analysis (RPCA) method. Smoothed frames weaken the effect of illumination variation, while RPCA enables data dimensionality reduction. Both provide suppression of noise. However, they are prone to crashing when processing large amounts of image data. Zheng D et al. [
23] uses a Gaussian modeling algorithm with a three-frame difference method logical operation to suppress target voids and breaks. In addition, a method based on a U-net network is proposed to attenuate the dependence of the number of data sets by calculating the inverse of the positive and negative sample ratios as sample weights to deal with the imbalance of the data and set the threshold to predict the results. The method can reduce the targeted null and enhance certain anti-interference abilities. Although the number of samples is small, the introduction of deep learning also consumes some arithmetic resources.
The above researchers have used different types of methods to improve the detection accuracy, including improvements based on the traditional background disparity method and improvements based on the deep learning method. Both suppress ghosting and noise to improve the detection accuracy. Most of the improvements based on the traditional method are through background modeling, increasing the update rate of the model, etc. The method has low-detection accuracy, but is fast and has high real-time performance. Deep learning-based methods have high-detection accuracy, but consume large computing resources and are difficult to deploy on small surveillance devices. In this paper, the proposed algorithm combines traditional background differencing and deep learning, and implants a shallow network of VGG16 based on the improvement of the traditional ViBe algorithm, which reduces the detection efficiency by a small amount but ensures better detection results.
Based on the above research, this paper uses the VGG network and frame difference method to complete the background modeling. In addition, an adaptive threshold is employed to adjust the relationship between the background change rate and the update rate. The ghost image and noise point are suppressed under the premise of limited computational resources.
4. The Proposed Algorithm
The ghosting phenomenon is mainly caused by two factors: one being the presence of a moving target in the initial frame and the other being the state transition of the moving target. In addition, thresholds used in the Vibe algorithm are fixed empirical values, so many false detections exist in complex scenarios.
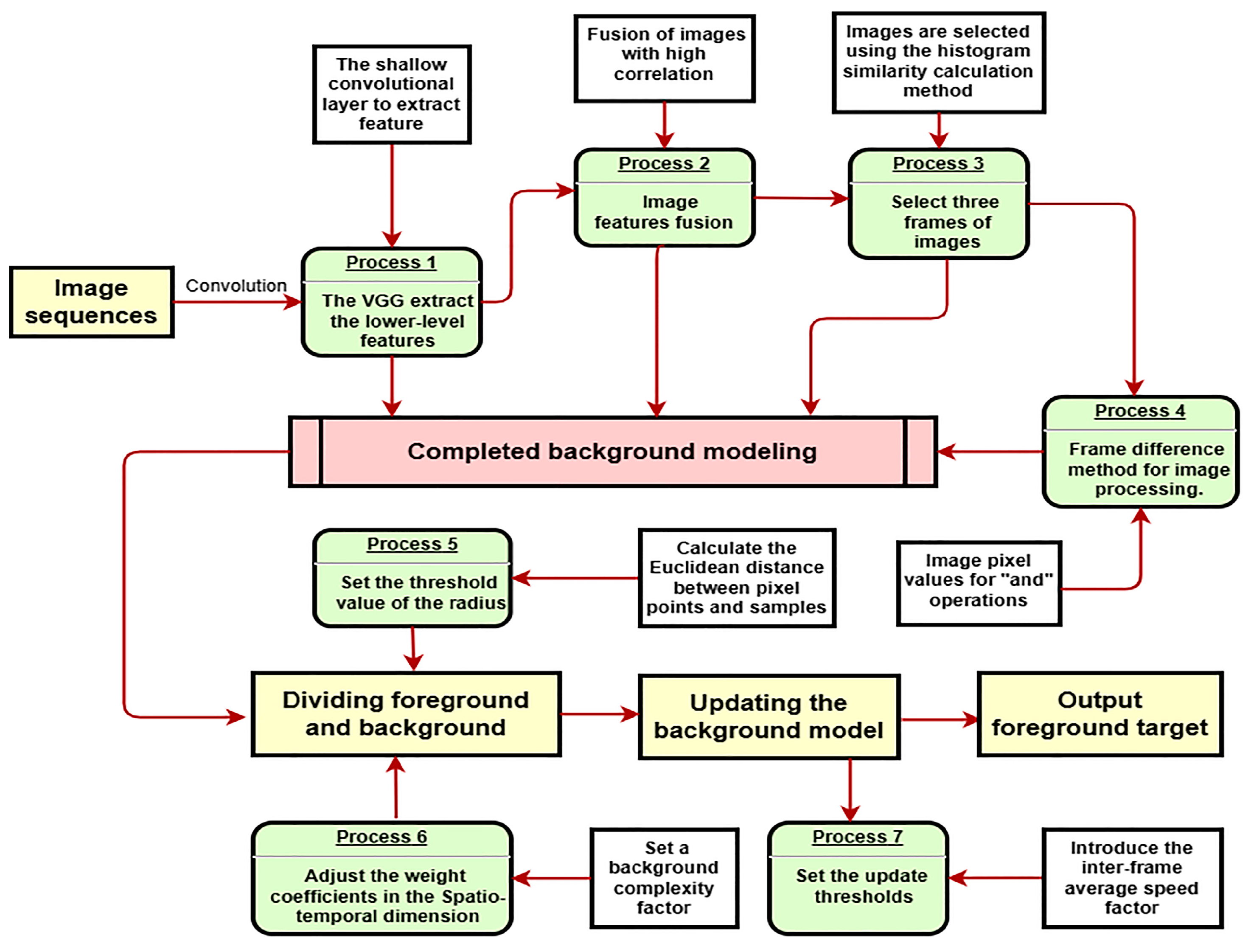
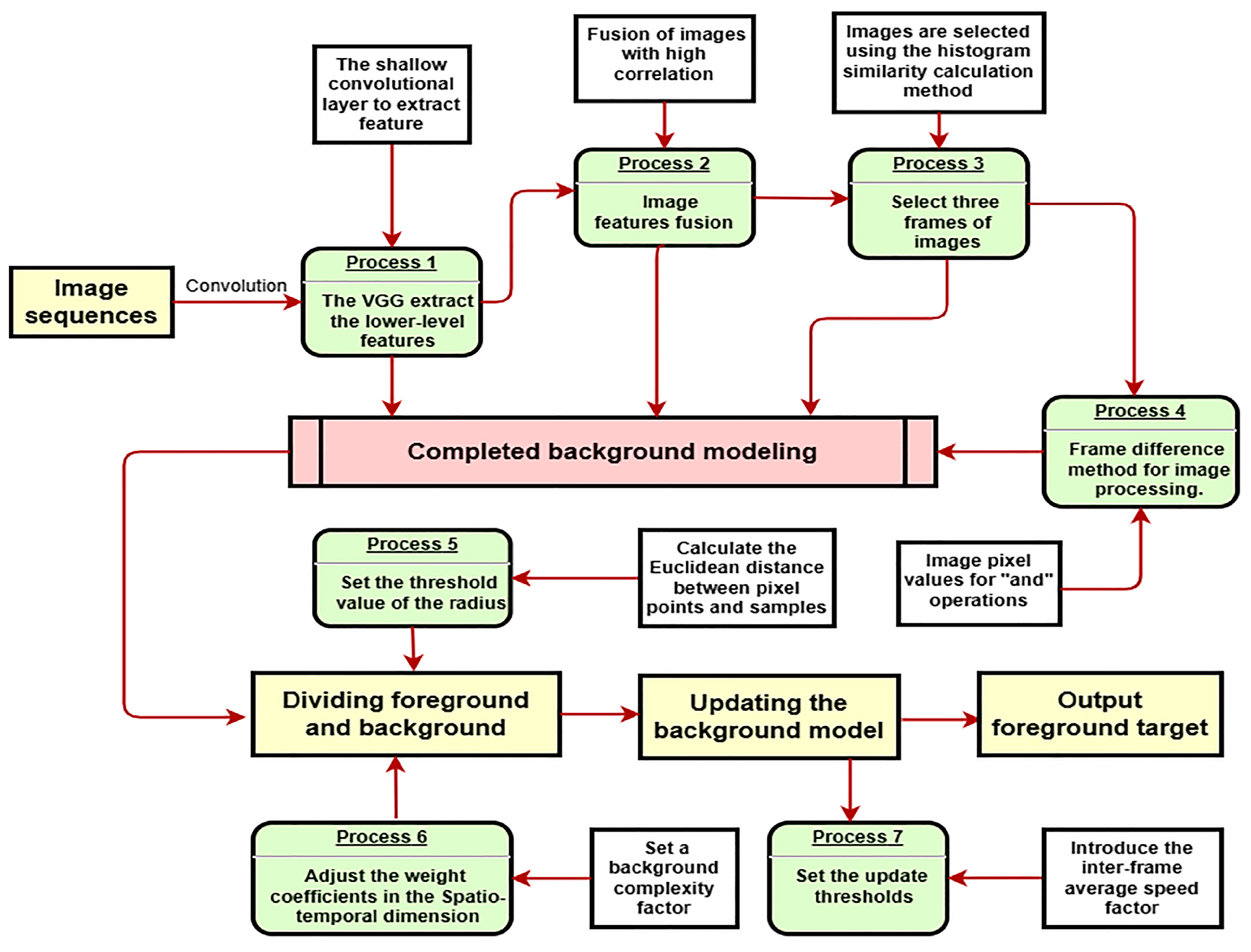
Based on this, this paper proposes an improved Vibe algorithm based on adaptive thresholding and a deep learning-driven frame difference method. The algorithm first uses shallow convolutional to extract the lower-level features to synthesize the new image. Then, three new frames are selected by a histogram similarity algorithm to do the difference operation. Finally, the background modeling is completed by initializing the parameters. In addition, adaptive thresholds and inter-frame averaging coefficients are set in this paper. The spatio-temporal adaptive threshold is led to distinguish between foreground and background accurately; the inter-frame average is used to measure the relationship between the rate of change in the background and the rate of update of the model.
The flow of the implementation steps of the improved Vibe algorithm is shown in
Figure 2.
4.1. Description of Improved Background Modelling Methods
The Vibe algorithm initializes the background model with the first frame. A moving target in the initial frame is judged to be the background causing misjudgment and resulting in ghost regions. The frame difference method can extract the foreground area by background subtraction. However, it requires a certain degree of target movement speed. When the target moves faster, it can cause an oversized outline in the foreground area and lead to false detections when filling. When the target moves slowly, it can cause a lot of overlap in the foreground region and affect the detection accuracy. In this paper, we first use a shallow convolutional layer of pre-trained neural networks to extract the lower-level features of the image. Then, features with high correlation are selected to synthesize the new image. Furthermore, a histogram similarity algorithm is used to select the three frames with significant differences for the difference operation. Finally, the background modeling is completed by filling in the image initialization parameters.
4.2. The Underlying Features Extraction of VGG16
The deep convolutional network can extract abstract features; it needs to be trained for specific scenarios and consume a lot of computational resources. The proposed method adopts a shallow convolutional layer of pre-trained VGG16 neural networks to extract the lower-level features of the image. These features include multiple channels. These channels contain the primary information in the image and a large amount of redundant information. Applying primary information channels to the Vibe algorithm can reduce data processing and eliminate redundant interference in the scene.
VGG16 is a traditional model with a simple structure and extensive application. The model includes 13 convolutional layers and 3 fully connected layers. It uses 64 convolutional kernels to extract features of the image. First, the inner product of the original image and the inverse convolution kernel is calculated to obtain a convolution image. Then, the entire image is traversed based on the defined step size. The convolution operation makes the image size smaller, so the image needs to be filled to restore the original size. We set the original image as
M(h, w), the convolution kernel as
K(m, n), and the convolutional image as
C(x, y). The formulation of the convolution operation is as follows.
In the VGG16 network, both CONV3–128 and CONV3–64 can extract shallow features of images. CONV3–64 indicates that the dimension becomes 64 after the third layer of convolution and, similarly, CONV3–128 indicates that the dimension becomes 128 after the third layer of convolution; it is shown from the occupied memory in
Figure 3 that CONV3–128 requires a large number of parameters and more. The advantage of Vibe algorithm is that it consumes less arithmetic resources and has high real-time performance. The use of CONV3–128 greatly enhances the arithmetic power. In small devices with limited arithmetic resources, the choice of CONV3–64 to extract features is more responsive and better meets the demand for real-time.
The underlying features extracted by VGG have multiple channels contain redundant information, as well as primary information about the image. The underlying features extracted by the underlying network layer include color, lines, edge shapes, spatial relationships, etc.
However, the effect map of the background difference method is a binarized image and only considers whether the current frame contains a moving target. The modeling only needs to judge the pixel value of the current frame and the neighboring pixels. It is equivalent to the filtering operation of the original video image, i.e., to suppress the interference of irrelevant noise. The main channel features are extracted and fused into a new image instead of the input image, and then the feature image is processed by background differencing, which improves the performance of the differencing method.
We adopt the shallow convolutional layer of VGG16 to extract the generic features of original images and obtain 64 feature images. Some feature images are presented as noisy images; others show the original images’ main features. According to the similarity between the convolutional feature map and the original map, we extract the main convolutional features that represent the image. The main convolutional features representing the image are extracted based on the similarity between the convolutional feature map and the original mapping. The shallow network with smaller perceptual fields and overlapping areas can extract more details. The effect map of vibe is a binarized image. The generated graph of the vibe algorithm is a binarized image. The modeling process only needs to obtain information such as spatial location and pixel values. Therefore, it is necessary to increase the weight of this part in the feature fusion process and reduce the weight of the redundant information with weak correlation. Finally, the new image is used to replace the current frame of the original image.
The prerequisite for subsequent background modeling is provided.
PSNR (Peak Signal-to-Noise Ratio) indicates the strength of correlation between the feature image and the original image. Higher values indicate a stronger correlation and vice versa. The formulation of the
PSNR is as follows.
In the formula: Max represents the maximum pixel value of the original image; MSE represents the mean square error of the original image and the feature map; H and W represent the image height and width.
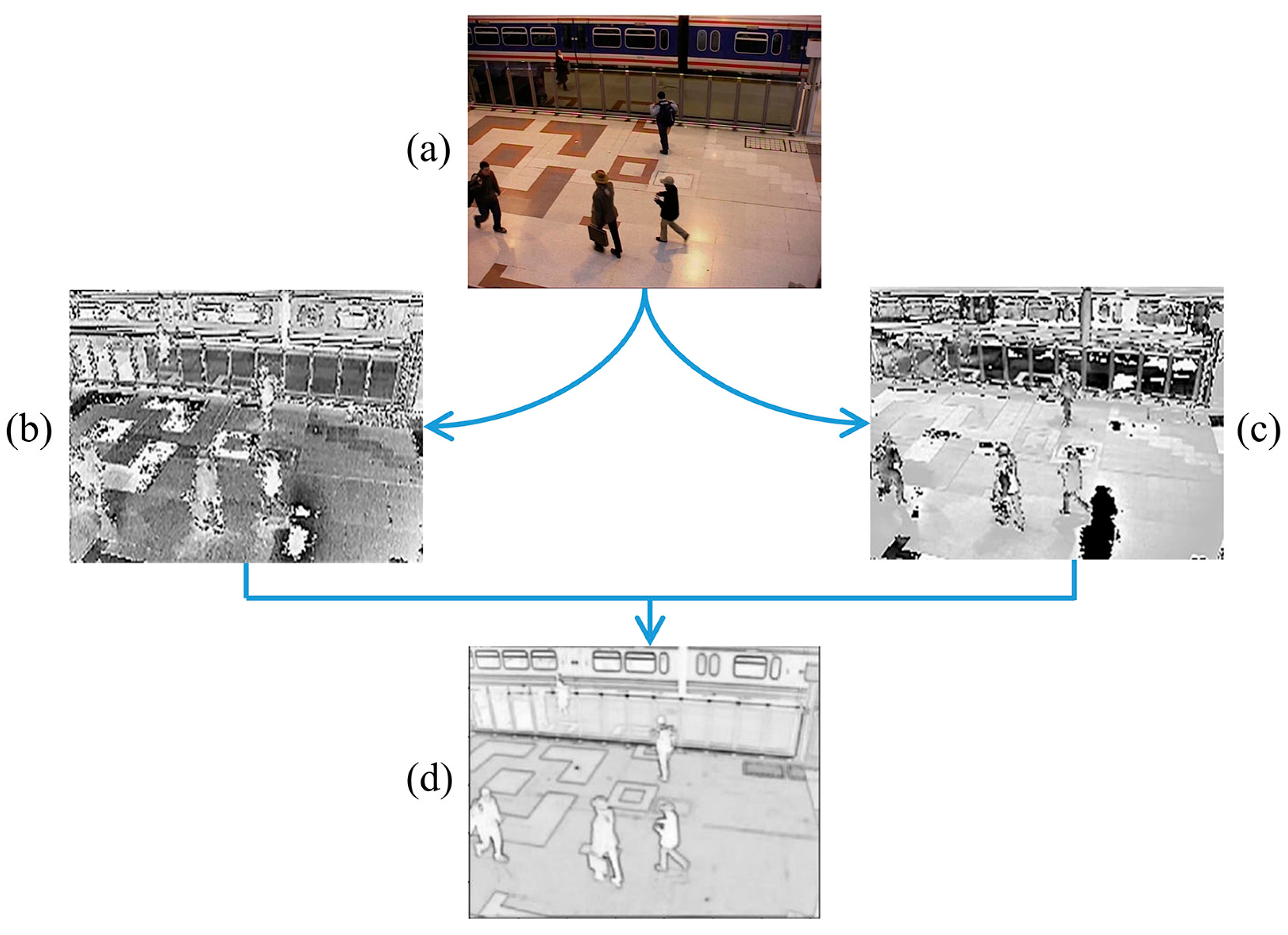
The size of
PSNR can be obtained by calculating the Equation. The (a,b) in
Figure 4 represent the convolutional images with the largest
PSNR, and the index of the feature map is noted. The distribution of features extracted from the convolution layers of different video frames of the same scene is the same. The index of the maximum value of the input frame can be used as the index of the convolutional features of the subsequent video frames, so only the first n channels with the maximum
PSNR need to be used for feature fusion. The feature fusion method uses series feature fusion; first, two features are directly connected in series, and then the output feature sizes are summed, and finally normalized to obtain the feature image. The experimental results are shown in
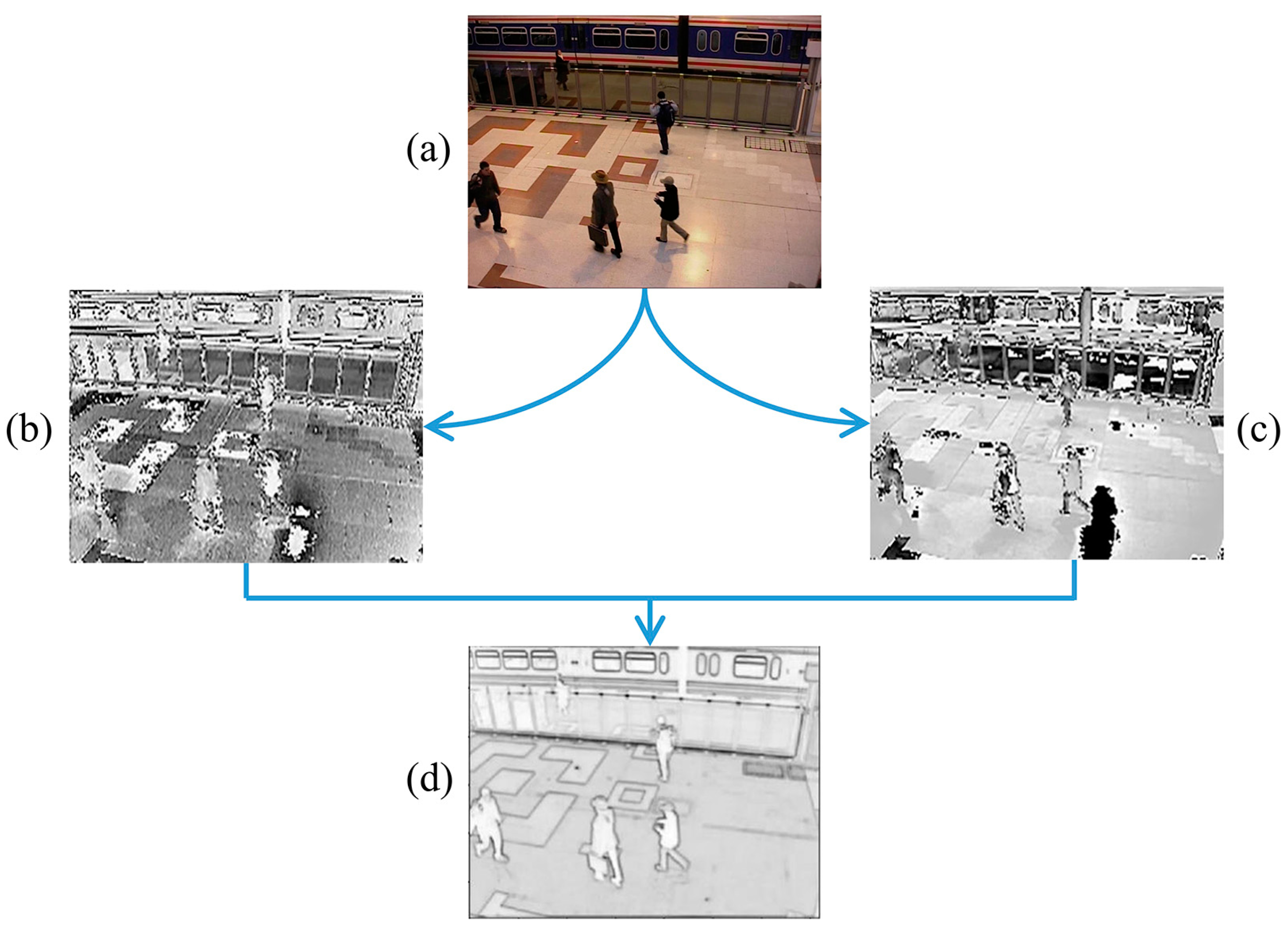
Figure 4. The featured image is subsequently used instead of the input image for background differential processing.
The result of feature fusion, shown in
Figure 4d, represents the image after feature fusion. The results show that the shallow convolutional layer extracts the low-level features and the input more closely. It contains features of color, texture, edge, and corner information of the image. The shallow layer network has a smaller perceptual field and smaller overlapping area to capture more details. It ensures the results are closer to the original image and weakens the interference caused by the fusion of other features. Compared with deep features, shallow feature fusion reduces computational resources and improves detection efficiency. In addition, there is no need for training in a specific situation.
4.3. Improved Three-Frame Differential Method
The traditional three-frame differencing algorithm takes three sequential frames and performs the difference operation. It eliminates background interference in static scenes and has a higher stability level. However, it cannot extract the complete area of the target and is dependent on the inter-frame time interval. We propose to combine the improved frame difference method with the Vibe algorithm so that they complement each other and improve the effectiveness of target detection. The three-frame differential method is affected by the moving speed of the target. Slow speed causes a large overlap and fast speed causes a larger contour. In order to improve the overlapping problem and increase the detection effect, this paper uses the histogram similarity algorithm combined with the frame difference method to extract the motion target contour. The difference between the initial frame and the neighboring frames is measured first, and then three frames are selected instead of three consecutive frames in the frame difference method, and the final pixels are filled to obtain the real background.
A histogram similarity algorithm was used to measure the differences between the images. First, VGG16 synthesized new images that were captured frame by frame. Second, the Bhattacharyya coefficients were applied to compare the differences between the images to obtain the image similarity values. Its value ranges between [0, 1], where 0 means different and 1 means similar. The calculation of the Bhattacharya coefficient is as follows.
p and
p′ represent two frames for comparison.
The steps to improve the three-frame differencing method are as follows.
Screening of the three frames. Using the first frame Ms1 as the base, the histogram similarity algorithm is used to traverse the image frame by frame to calculate the difference. When the similarity is less than the threshold value, we set the current frame as Ms2, and then take Ms2 as the base to obtain Ms3.
Extraction of the target contour. Let Ms2 and Ms1 do the difference operation to obtain the result as I1, then let Ms3 and Ms2 do the difference operation to obtain the result I2, and finally, let I1 and I2 take the intersection to obtain the result I12.
Filling the background image. The background area is filled using morphological filtering such as expansion, erosion, and open and close operations.
- 3.
Background modeling. A random sampling of each pixel point and neighboring pixel points is performed to build a background model sample.
4.4. Description of the Improved Thresholds Method
The Vibe algorithms use fixed thresholds, which can lead to a significant number of false detections in complex scenes. To address the poor background applicability and noise points caused by fixed thresholds, this paper establishes an adaptive threshold for each pixel based on the spatio-temporal domain. It eliminates false detections caused by insignificant grayscale differences and also removes noise interference. As a result, it can better distinguish the foreground and background. Finally, an inter-frame average velocity value is led to adjust the relationship between background change rate and model update rate, which prevents the background model from being contaminated.
4.5. Adaptive Thresholds in the Spatio-Temporal Domain
In complex scenes, the background can be affected by external factors such as light, camera shake, and weather changes. The Vibe algorithm uses a fixed threshold to determine whether the current pixel point matches the sample pixel point. Once the background difference method identifies the background point as the foreground point, it can cause misjudgment affecting the detection effect. If the threshold value set is too large, it will cause missed detection, and if it is too small, it will cause false detection [
25]. Therefore, this paper leads to an adaptive threshold based on the spatio-temporal domain. It optimizes the error detection caused by the fixed threshold and improves the detection accuracy.
The time dimension introduces a time metric factor, which is calculated as shown in Equation (8). Where denotes the minimum Euclidean distance between the current pixel point and the sample model pixel point at moment t, and MN (x, y) denotes the coordinates of the current pixel point position, and MB (x, y) denotes the coordinates of the pixel points in the sample set, respectively. denotes the average minimum distance of the pixel point from the sample set in period t.
The neighborhood standard deviation is used in the spatial dimension to measure the complexity of the background changes [
26,
27]. It measures the degree of difference between the current and average pixel values. The threshold can be adaptively adjusted to the appropriate size when the background changes.
M(x, y) represents the current pixel position of the region, and then the average pixel value M and the standard deviation
dspace of the pixels in the region are calculated [
28]. The calculation formulas are shown in Equations (9) and (10).
The mixed background complexity can be expressed as Equation (11), where
,
are the weight coefficients.
The calculation of the adaptive thresholding is shown as in Equation (12). where R′(x, y) denotes the adaptive threshold, R(x, y) denotes the fixed threshold and is the set scale factor.
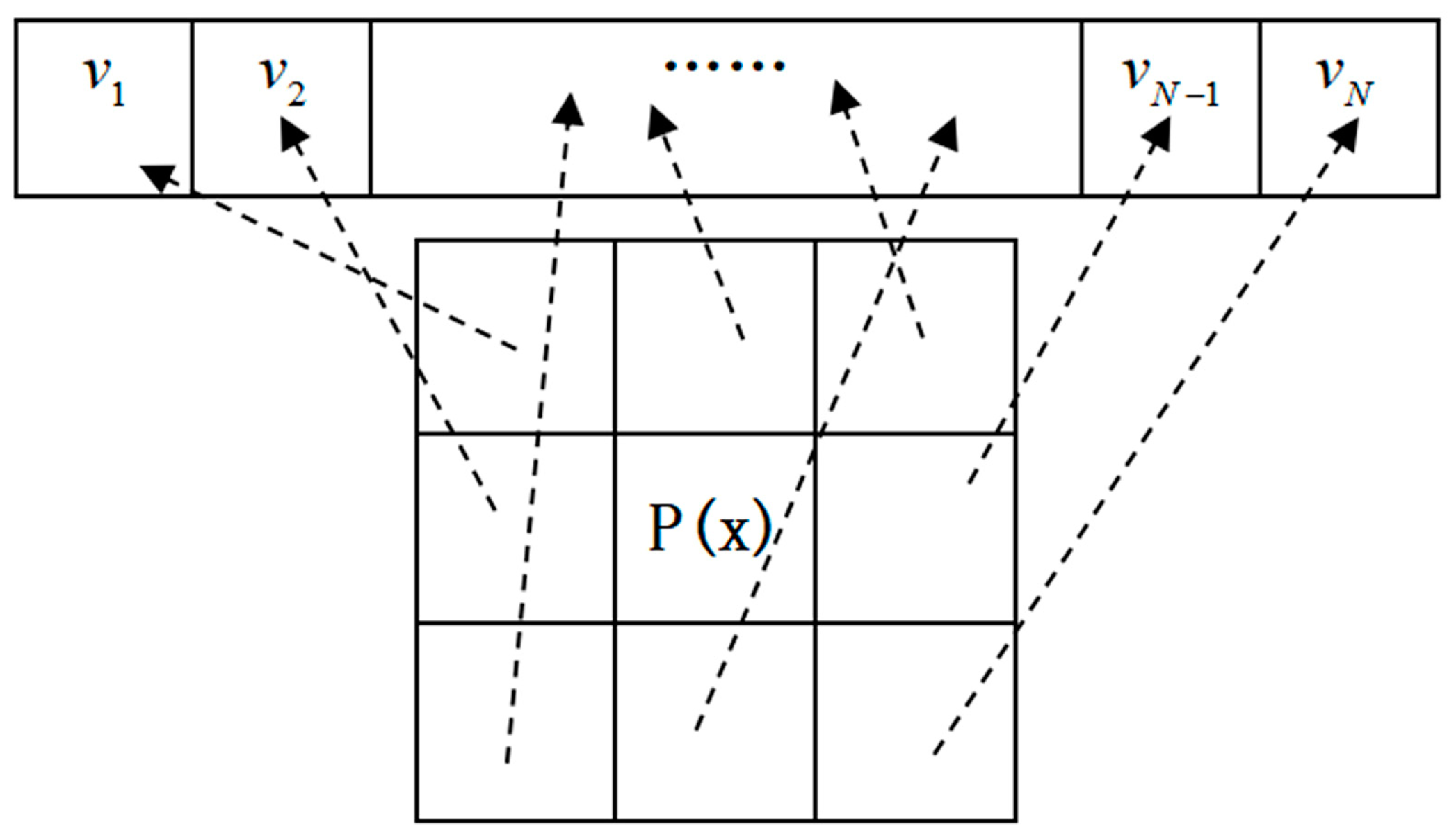
The comparison of adaptive segmentation threshold and fixed threshold is shown in
Figure 5a,b represent low- and high-dynamic background-fixed thresholds
R, while Figure c represents the high-background adaptive threshold
R(x, y).
P(x, y) is the background point in the low-dynamic background. Using a fixed threshold,
P(x, y) becomes the front point in the highly dynamic background. While an adaptive threshold
R(x, y) is adopted,
P(x, y) is transformed into a background point again. The size of the threshold value determines the sensitivity of the model.
4.6. Background Update Phase Improvements
The background model is affected by external factors such as weather and light. The mismatch between the background update rate and the background change rate may lead to false detection. In this paper, we adopt an inter-frame average speed factor to measure the foreground’s movement speed and dynamically adjust the model’s update rate. Where
f represents the number of frames and
di represents the deviation in position of the foreground between adjacent frames. The inter-frame average speed factor
is expressed as Equation (13).
The Vibe algorithm sets the value of the update rate
to 16. In this paper, the model update rates are divided into three categories, which are determined based on the empirical values of the set frame rates
.
5. Experimental Results and Analysis
To verify the feasibility and effectiveness of the proposed algorithm, we conducted experiments on ghosting suppression and noise elimination. The hardware environment of the experimental platform is an ordinary computer with an Intel I5 processor at 2.60 GHz and 8 G of RAM. Ablative experiments were conducted for the three improvement points separately. The experimental results are shown in
Figure 5,
Figure 6,
Figure 7 and
Figure 8. The materials used in the experiments are videos from the CDW-2014 dataset and self-built campus videos. The CDW-2014 dataset contains 11 video categories (Baseline, Dynamic Background, Camera Jitter, Intermittent Object, Motion, Shadow, Thermal, Bad Weather, Low Framerate, Night Videos, PTZ, Turbulence), each category has four to six video sequences. The dataset scenarios are complex and varied with different video sequences located in different scenarios and subject to different environments, so that the background changes in different situations. Different data were used in the experiments to highlight the generalization of the algorithm. The software environment is Pycharm and OpenCV3 computer vision open-source library. The programming language is Python. First, ablation experiments are conducted to verify its feasibility. Second, the Vibe algorithm is compared with the improved algorithms in the literature [
22,
23]. Finally, the effectiveness of the proposed algorithm in eliminating ghosting and suppressing noise interference is verified by different performance metrics. Experimental results demonstrate that this method can effectively eliminate ghosts and suppress noise interference caused by background changes.
5.1. Algorithm Performance Evaluation
To quantitatively evaluate the quality criteria of the proposed algorithm, this paper evaluates the model’s strengths and weaknesses in five aspects [
26,
27]: Accuracy, Precision, Recall, F-measure, and Balance error rate (PCW), and tests them on different datasets. These metrics are calculated as follows.
where
Tp represents the number of points correctly identified as foreground;
Fp represents the number of points incorrectly detected as foreground;
Ff is mistakenly detected as foreground point background points.
5.2. Experiment of Ghost Elimination
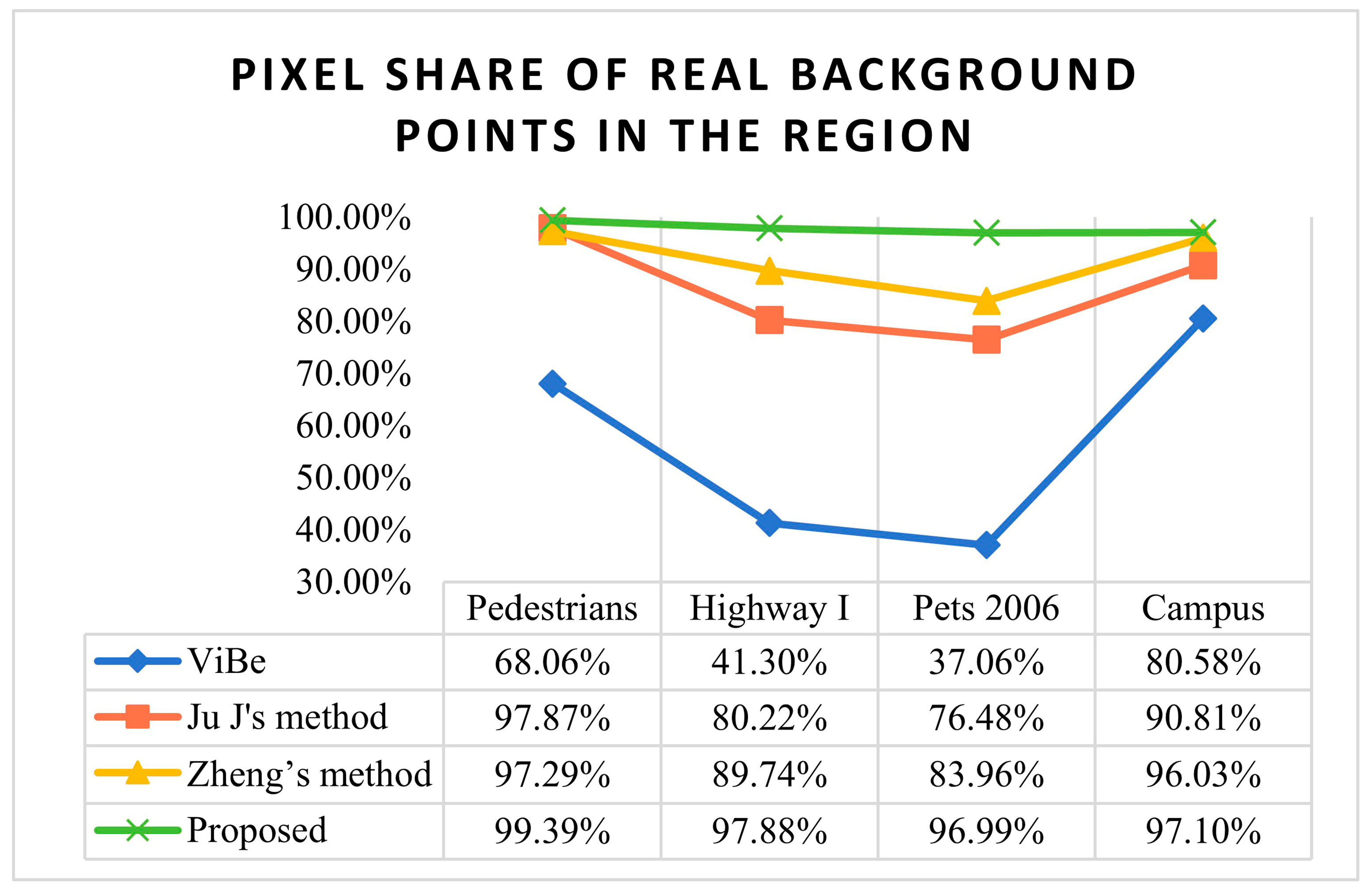
The ghosting elimination experiments were validated not only on the CDW public datasets, such as “Highway I”, “Pets 2006”, and “Pedestrians”, but also using our campus’ self-built datasets. The experimental results are shown in
Figure 6. In addition to the Vibe algorithm, the foreground extraction algorithms of Ju J et al. and Zheng D et al. were compared in the experiments. In
Figure 6, we notice that the Vibe algorithm leaves many ghost pixels, which affects the detection effectiveness. Ju J adopts the improved frame difference method to extract the foreground, which has some suppression effect, but still leaves some ghost pixels. Based on this, Zheng D et al. apply deep learning-driven GMM algorithm modeling to achieve suppression in four sets of data. However, the target still has gaps and noise points affecting the detection accuracy. The extraction effects of different improved algorithms are shown in
Figure 6.
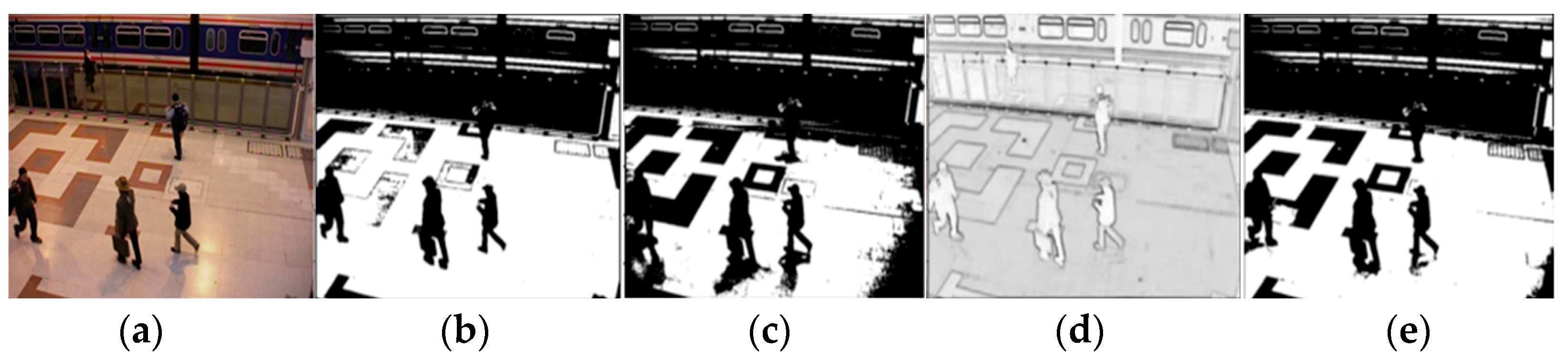
The ghost shadow experiment is to eliminate the residual shadow behind the motion area. There are no clear quantitative indicators for ghost elimination experiments. However, to quantitatively analyze the effect of ghost shadow elimination, an additional experiment is added. As shown in
Figure 7, a ghost suspicious area is set behind the moving target. The image ROI region is extracted, and the number of foreground spots and background spots is counted in the rectangular box. Pixels with a pixel value of 0 are real background points and pixels with a pixel value of 255 are ghost points. The effect of ghost shadow elimination was analyzed by calculating the percentage of the number of pixels in the region.
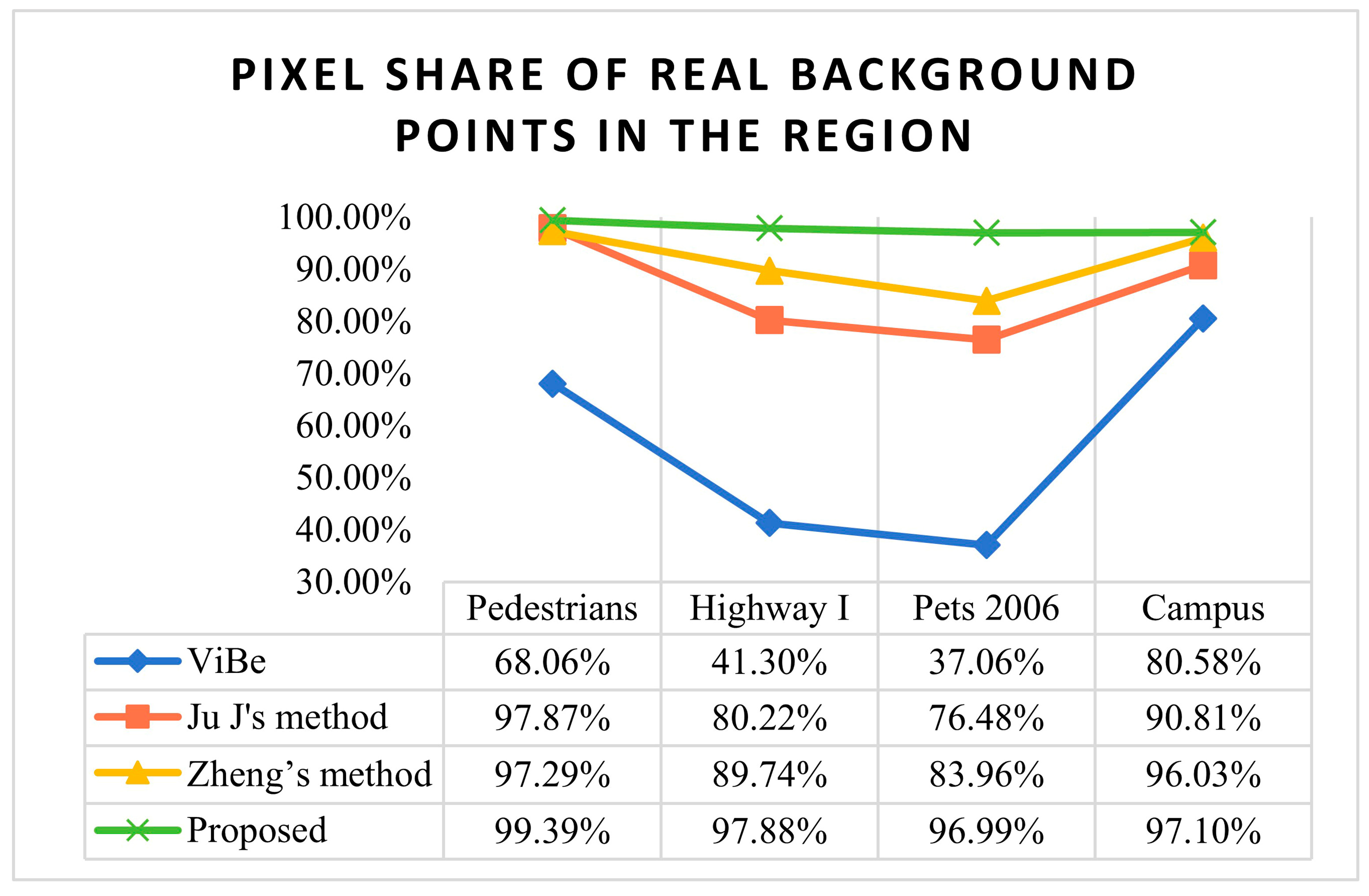
Table 1 shows the number of front points and background points in the region. The number of front points is the number of points judged as ghosting points, and the total number of pixel points in the region is the number of background points in the real region. The larger the percentage of predicted background points, the better the effect of ghost removal. The percentage of the number of background points is shown in
Figure 8.
The set ghosting area is the real background points, and the foreground pixel points are the ghosting pixels. The ratio of the number of background point pixels to the total pixels in the region represents the ghosting elimination rate. Tested on three public video sequences and one self-constructed dataset, by comparison, Ju J and Zheng D’s method has some suppression effect on ghosting, but the stability varies greatly for different datasets. However, the proposed algorithm is the most stable, and the ghosting elimination rate can reach as low as 96.99% and as high as 99.39%. The method obviously suppresses the ghosting phenomenon and ensures the integrity of the experimental results. The experimental results reveal that the proposed algorithm not only has a significant extraction effect on the public dataset but also still has a good suppression effect on the self-built campus dataset for ghost shadow elimination.
5.3. Experiment of Eliminating Noise
In the noise cancellation experiment, we selected data from public datasets such as “Office”, “Highway II”, and “Snowfall”, and verified the detection effectiveness in our campus’ self-built dataset. The detection effectiveness of different algorithms is shown in
Figure 9. The Vibe algorithm is sensitive to sudden changes in light, leaf shaking, rain, and snow, leading to background points being falsely detected as foreground. Ju J propose an improved algorithm combining the smoothed frame difference and the robust principal component analysis. Zheng D adopt a deep learning-driven improved GMM algorithm for background modeling. In addition, the background image is optimized by fusing the frame difference method and morphological filtering. In this paper, we improved the foreground segmentation and model updating in addition to the optimized background model. We adopted an adaptive threshold to suppress noise interference to adjust the relationship between the update rate and background change rate.
The detection effectiveness figure reveals that Vibe has a significant number of noise points and contains the problem of target voids. Ju J and Zheng’s method have a certain extent of suppression effectiveness. In contrast, the proposed method has more obvious suppression effectiveness on noise points. It also strengthens the anti-interference capability. The following graphs quantify the above detection results in terms of accuracy, recall, balance error rate, and balance error rate. The data for each group of metrics is shown in
Table 2, and the comparison effect is shown in Bar
Figure 10.
Compared with Vibe’s algorithm, the detection of Ju J and Zhang’s method on different datasets is basically improved. The noise points are also suppressed. The detection accuracy of Zhang’s method on Highway II decreased slightly, with the F-measure dropping by about 4%. Due to the light, a lot of shadows were left when detecting the vehicles, and the morphologically processed noise points were amplified, which affected the detection accuracy. The algorithm in this paper has a high accuracy of 96.68% on the Campus dataset and the value of PCW is as low as 13.12%. The effects are substantially improved on all other datasets. By comparing several methods, the proposed algorithm has the best performance in terms of suppression of ghosting and elimination of noise with the highest stability. However, this method still has a drawback in the computation of image similarity and the introduction of adaptive factors increases the computation time. Therefore, the proposed algorithm is more effective in detecting images with a smaller percentage of foreground pixels.
5.4. The Ablative Experiments
The image of the graph synthesized by VGG16 replaced the first frame image relative to the filtering operation performed on the image. To verify the effectiveness of the method, ablative experiments were conducted. The noise point tests were performed separately with the first frame image and the image after synthesis using the feature map, and the experimental results are shown in
Figure 11.
After graying binarization of the two images, they were compared with the foreground binarized image pixels. By calculating the number of pixels in the image other than the foreground pixels, we found that the number of noise points caused by light was greatly suppressed after the binarization of the original image and the fused feature map, which also made the background clearer.
The experiments were conducted to test the ablation of the three improvement points proposed in this paper. The experimental results are shown in
Figure 12.
Figure 12c shows the processed image of the Vibe in the pedestrians’ dataset, and
Figure 12d uses the improved three-frame difference method to fuse the processed image of the Vibe. The image clearly shows the ghosting phenomenon of the Vibe [
25], which is due to the existence of motion targets in the initial frame. The single-frame initialization modeling cannot handle the situation. At the same time, the improved algorithm uses the VGG network to eliminate redundant terms. The histogram similarity selects three frames with relatively significant differences to do the difference operation to avoid the ghosting problem caused by using only the initial frame.
Figure 13a shows 188 frame images in the campus dataset.
Figure 13c is the result of Vibe processing with a large amount of noise interference.
Figure 13d is the result of processing using spatio-temporal domain thresholding. The adaptive setting of the threshold value R not only makes the foreground background delineation more accurate but also optimizes the problem of the high-false-detection rate of the traditional algorithm.
Figure 14a shows 108 frames of data in the CDW-2014 dataset.
Figure 14c shows that when the sudden change of light causes the background to change rapidly, the model cannot be updated in time, leading to false detection.
Figure 14d adds the inter-frame average velocity factor. It adaptively adjusts the background model’s update factor according to the foreground objects’ motion speed. The background change rate is matched with the model update rate to reduce the false detection rate.
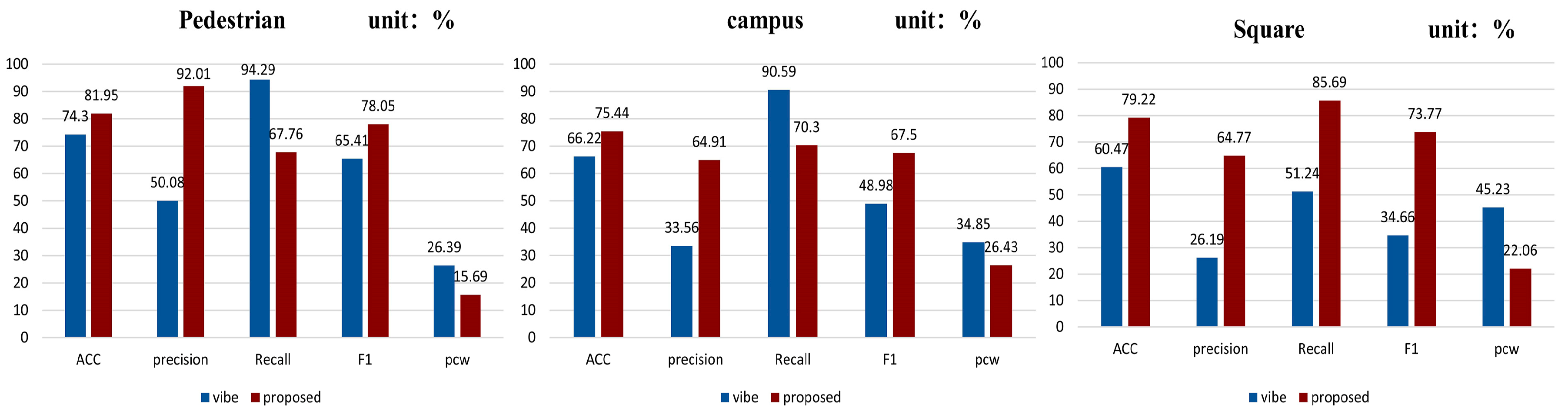
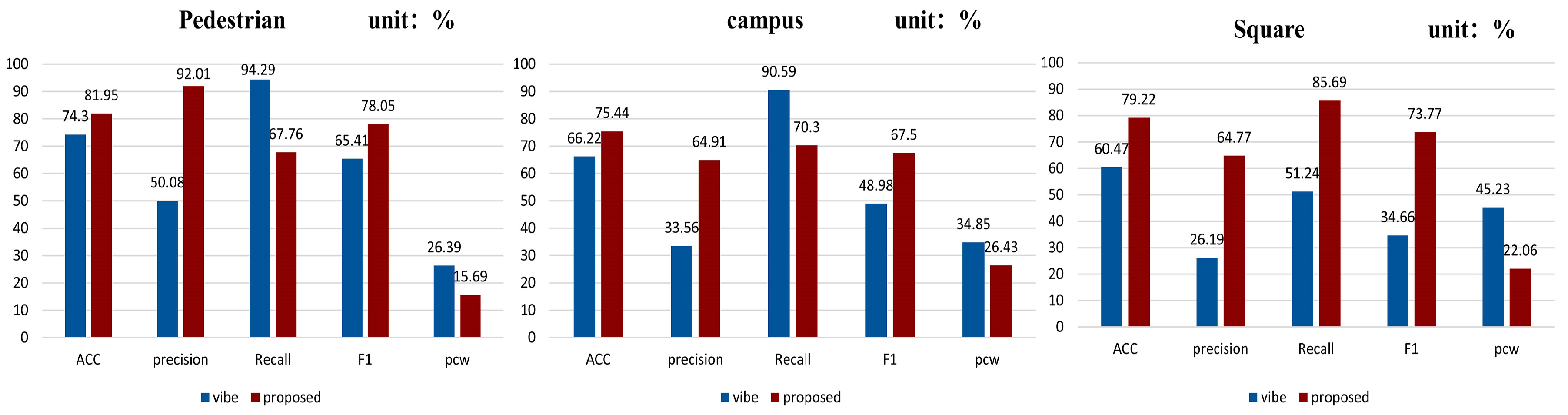
The quantitative analysis of the ablative experiments on three sets of video data is performed in terms of precision, accuracy, recall, F-measure (F1), and balance error rate. The experimental results are shown in
Figure 15.
Different datasets (including self-constructed datasets) have a large degree of influence on the evaluation metrics. Differences in the background complexity of the dataset, the number of noise points, and the rate of change of the foreground all lead to large differences in performance metrics. Ablation experiments were conducted on three video datasets with different improvement points. The histogram shows that the Vibe algorithm has a higher recall rate with lower precision. We use the F1 Index to consider the detection effect comprehensively. On the three datasets, we found that the F1 values were substantially elevated, reaching a maximum of 78.05%. The data comparison revealed that it proves the feasibility of the proposed algorithm and quantitatively shows the detection enhancement effect. The value of PCW indicates that the Vibe algorithm has a higher error detection. In comparison, the improved algorithm has a low PCW value of 15.69% on the pedestrian dataset, which significantly reduces the false detection rate and improves the detection accuracy.













{kind=link}
{kind=link}
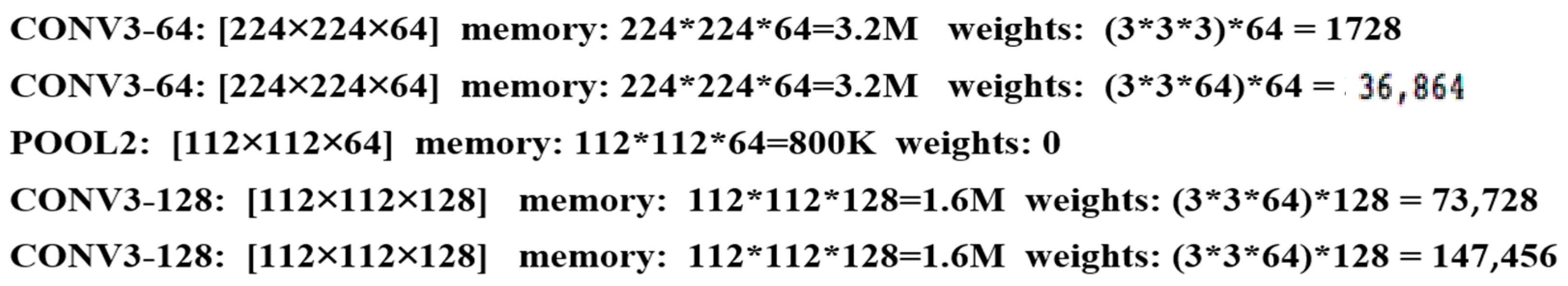{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}