
A Study on Pavement Classification and Recognition Based on VGGNet-16 Transfer Learning


Abstract
:1. Introduction
2. Materials and Methods
2.1. VGGNet-16 Network Model Training Process
- (1)
- The VGGNet-16 network reads the virtual pavement training dataset (x, y) and inputs the xi of each image in the virtual dataset into the input layer of the network model. After propagating the designed network forward, the output result obtained in the output layer of the model is called the predicted output, ;
- (2)
- The predicted output, is then compared with the desired output, y. In classification problems, the cross-entropy loss function is often used to represent the difference between the predicted and desired outputs.
- (3)
- The J obtained from the data image input to the neural network is often a large number, which means that there is a certain deviation between J and 0. This deviation is passed from the output layer to the input layer through the backpropagation (BP) algorithm [35], in which the weights and biases in the network model are finely adjusted, based on the gradient, to reduce the value of J.
- (4)
- Then, according to the parameter gradient obtained via the backpropagation algorithm, the convolutional neural network model will update the parameters in the model, based on this gradient descent method, as a way to reduce the value of the loss function. The process of updating the parameters of the model parameter θ(w,b) is as follows.
- (5)
- At this point, one learning or training process of the neural network model is now complete. The next step is to repeat the forward and backward propagation process as many times as necessary until the end of training.
2.2. Transfer Learning Process
2.3. Improvement of the Activation Function
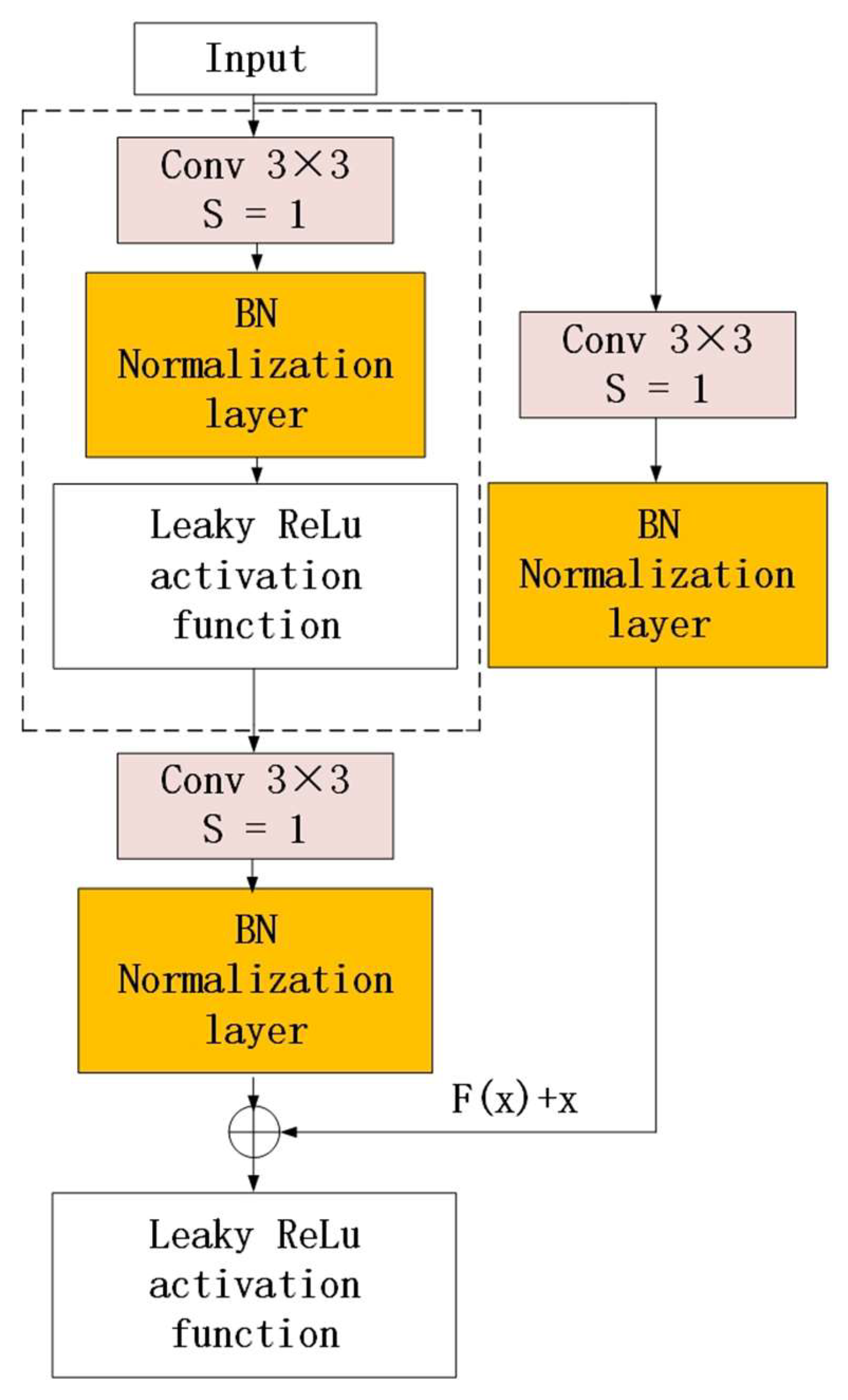
2.4. Introduction of Residual Structure
2.5. Fill Dropout Inactive Layer
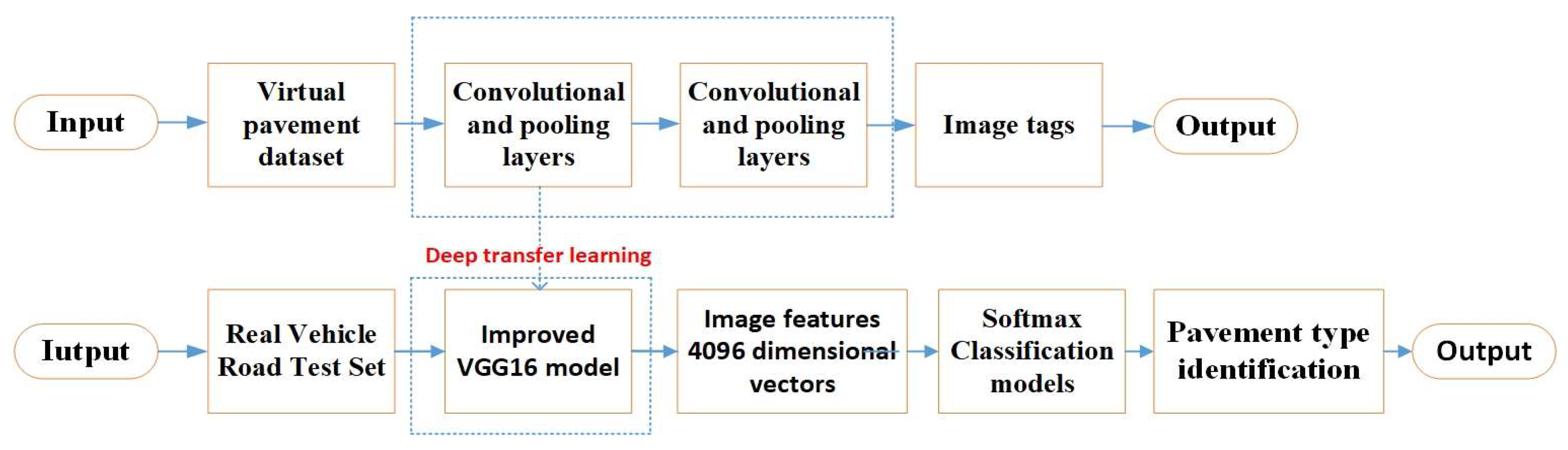
2.6. Model Building for VGGNet-16 Transfer Learning
- (1)
- Image acquisition: Based on the vehicle vision sensor used to detect the road surface traveled by the car in real time, the characteristic information of the road surface is accepted and released in the domain controller after pre-processing measures such as light enhancement.
- (2)
- VGGNet-16 transfer model construction: In this paper, we introduce the Leaky ReLU activation function to replace the ReLU activation function in the original model and fill in the residual structure and dropout inactive layer, etc., to improve the network structure of VGGNet-16 and adjust the parameters. The pre-trained model is then saved from the input layer to the Block4_conv3 layer. The ConvBNLR module consists of a convolutional layer and a normalization layer with a Leaky ReLU activation function, where the convolutional kernel size is set to the feature matrix with a step size of 1. The overall model consists of two ConvBNLR modules, three residual modules, a Maxpooling layer for image size reduction, and a sufficiently connected layer to output three classifications using the Softmax function for classification. The improved VGGNet-16 model reduces the number of parameters in the network model by successive stacks of convolutional kernels with the size of the convolutional kernel, while ensuring the same perceptual field. Then, it increases the number of nonlinear units in the model by adding a residual structure after the VGG module using jump connections, which solves the gradient disappearance and improves the performance of the network’s deep learning. The parameters of the original model of VGGNet-16 are concentrated in the fully connected layer, in order to prevent overfitting, improve the classification accuracy of the pavement, and accelerate the convergence of the network model. After freezing the pre-trained weights, a global average pooling layer, a flattened layer, two dropout inactive layers, and three fully connected layers are added in turn. The input data training set is standardized by uniform size [0.5, 0.5, 0.5] processing, using the Leaky ReLU function after the connection layer and the last classifier using the Softmax function (for the output category of 3 classes of pavement), outputting 3 categories and labeling the categories as 0 for wet asphalt pavement, 1 for dry asphalt pavement, 2 for snow and ice pavement, 3 for concrete pavement output, 4 for gravel pavement output, and 5 for jointed pavement output. The modified VGGNet-16 network model and the technical flow of this research paper are shown in Figure 5.
- (3)
- Pavement recognition decision: This is calculated according to the pavement acquisition image, combined with the data pre-training weights, based on a deep learning transfer model, which is used to complete the construction of the pavement classification recognition model.
3. Results
3.1. Data Image Processing
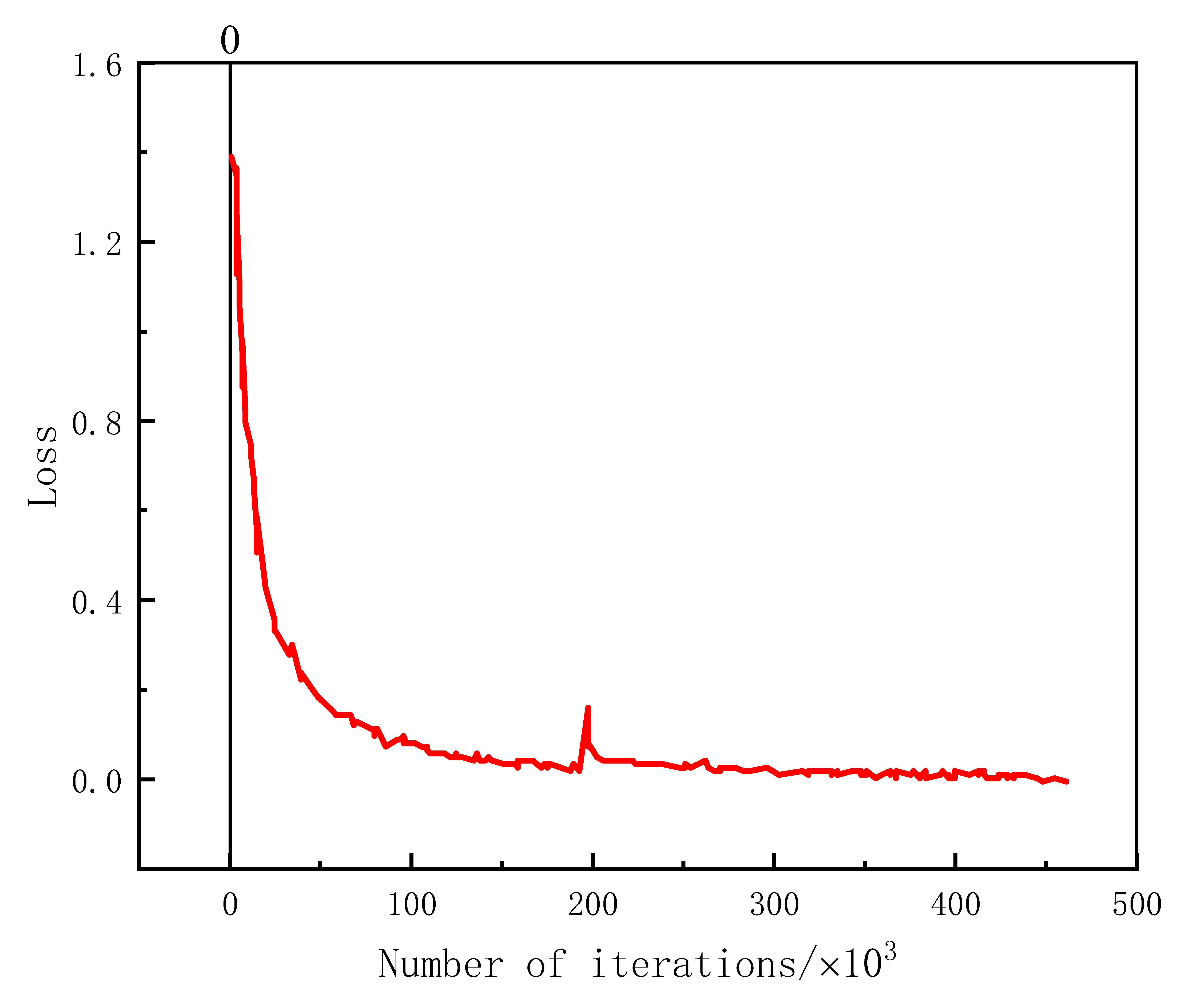
3.2. VGGNet-16 Model Parameter Settings and Training Results
3.3. Pavement Output Results, Based on In-Vehicle Vision Sensors
3.4. Accuracy of the Improved Network Model Versus the Original Model
3.5. Model Performance Comparison Test
3.6. Model Performance Comparison Test
4. Conclusions
- (1)
- In this paper, by introducing the Leaky ReLU activation function to replace the activation function in the original model, adding three residual structures and two dropout inactive layers to improve the VGGNet-16 model with parameter adjustment, we propose a model combining transfer learning and the improved VGGNet-16 model for pavement classification recognition. After extensive training, the accuracy of recognition can reach 96.87%, which effectively solves the problem of low efficiency and accuracy of traditional machine learning for pavement recognition; it senses the type of pavement in advance and plays an important early warning role for safety.
- (2)
- In this paper, five models are compared; the improved VGGNet-16 model shows a larger improvement in accuracy compared to the remaining four models, but there is still some room for improvement in terms of training time. At the same time, this paper provides poorer results on the training set for the recognition of muddy roads or unpaved roads, which is a direction to explore to achieve continued optimization of the network.
- (3)
- Future work will combine the method proposed in this paper with the vehicle-based three-degree-of-freedom dynamics simulation to verify the adhesion coefficient of the driving road surface, propose a fusion strategy based on dynamics information and visual information, and design a study on the recognition of early warning cues and the recognition of road surface types and adhesion coefficients.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, S.Q.; Wu, Y.Y.; Wang, S.Y. Determination of dangerous water level in road area based on support vector machine. Highw. Traffic Technol. 2022, 38, 151–155. [Google Scholar] [CrossRef]
- Zeng, J.X.; Zhang, J.X.; Cao, D.D.; Wu, Y.; Chen, G. Intelligent inspection of asphalt pavement leveling using KNN method. J. South China Univ. Technol. (Nat. Sci. Ed.) 2022, 50, 50–56. [Google Scholar] [CrossRef]
- Liu, Y.H.; Wang, Y.; Tan, S.Q. Naive Bayesian network classification model based on K-means clustering. J. Chongqing Technol. Bus. Univ. (Nat. Sci. Ed.) 2012, 29, 36–41. (In Chinese) [Google Scholar] [CrossRef]
- Ji, G.S.; Chen, P.L.; Song, H. Review of decision tree classification algorithms. Sci. Technol. Plaza 2007, 9–12. [Google Scholar]
- Liu, X.Y.; Huang, D.Q. Research on the classification method of road wet image based on SVM classifier. J. Wuhan Univ. Technol. (Transp. Sci. Eng. Ed.) 2011, 35, 784–787+792. [Google Scholar]
- Li, C.; Ji, Y.W.; Wang, Z.P.; Dou, X. Design of road icing detection system based on OpenCV + Python. J. Shaanxi Univ. Sci. Technol. (Nat. Sci. Ed.) 2017, 35, 158–164. [Google Scholar]
- Wan, J. Research on the Discrimination of Slippery Condition of Road Surface Based on Machine Vision. Master’s Thesis, Wuhan University of Technology, Wuhan, China, 2009. [Google Scholar] [CrossRef]
- Li, Q.S.; Yao, M.L.; Zhu, Q. Real-time recognition system of asphalt pavement texture based on tilt photography technology. For. Eng. 2023, 39, 149–156. [Google Scholar]
- Uriana Bai, Y.; Han, J.F. A deep learning-based identification method for highway pavement damage detection. Comput. Simul. 2023, 40, 208–212. [Google Scholar]
- Yang, L.M.; Huang, D.Q.; Wei, X.; Wang, J. Research on recognition of slippery state of road surface based on deep learning. Mod. Electron. Technol. 2022, 45, 137–142. [Google Scholar] [CrossRef]
- Shen, X.G. An overview of deep learning. Digit. User 2017, 63. [Google Scholar]
- Nanjing Lantai Traffic Facilities Co. A Pedestrian Crossing Signal System and Method with a Red Light Forensic Function. Patent CN201610874173.5, 18 January 2017. [Google Scholar]
- Wang, Y.X.; Xiao, X.L.; Wang, P.F.; Xiang, J.F. Improved YOLOv5s algorithm for small target smoke flame detection. Comput. Eng. Appl. 2023, 59, 72–81. [Google Scholar]
- Wang, T.; Wang, N.; Cui, Y.P.; Liu, J. A deep learning-based feature learning approach for medical electronic data. J. Appl. Sci. 2023, 41, 41–54. [Google Scholar]
- Kang, G.H.; Jin, C.D.; Guo, Y.J.; Qiao, S.Y. Deep learning-based predictive control of combinatorial spacecraft models. J. Astronaut. 2019, 40, 1322–1331. [Google Scholar]
- Xu, B.B.; Sham, C.T.; Huang, J.J.; Shen, H.W.; Chen, X.Q. A review of graph convolutional neural networks. J. Comput. Sci. 2020, 43, 755–780. [Google Scholar]
- Ben, F.; Qiang, T. Research on parameter optimization method based on VGG16 network. J. Hubei Norm. Univ. (Nat. Sci. Ed.) 2023, 43, 44–50. [Google Scholar]
- He, C.C. Estimation of Pavement Adhesion Coefficient Based on Multi-Sensor Data Fusion. Master’s Thesis, Jilin University, Changchun, China, 2021. [Google Scholar]
- Zhang, Z.; Sun, C.; Bridgelall, R.; Sun, M. Application of a Machine Learning Method to Evaluate Road Roughness from Connected Vehicles. J. Transp. Eng. Part B Pavements 2018, 144, 4018043. [Google Scholar] [CrossRef]
- Llopis-Castelló, D.; Paredes, R.; Parreño-Lara, M.; García-Segura, T.; Pellicer, E. Automatic classification and quantification of basic distresses on urban flexible pavement through convolutional neural networks. J. Transp. Eng. Part B Pavements 2021, 147, 04021063. [Google Scholar] [CrossRef]
- Doycheva, K.; Koch, C.; König, M. GPU-enabled pavement distress image classification in real time. J. Comput. Civ. Eng. 2017, 31, 04016061. [Google Scholar] [CrossRef]
- Hadjidemetriou, G.M.; Christodoulou, S.E. Vision-and entropy-based detection of distressed areas for integrated pavement condition assessment. J. Comput. Civ. Eng. 2019, 33, 04019020. [Google Scholar] [CrossRef]
- Liu, X.P.; Luan, X.; Xie, Y.X.; Huang, M.Z. Transfer learning research and algorithms Review. J. Chang. Univ. 2018, 28–31, 36. [Google Scholar]
- Zhou, K. Research on Road Surface Water Condition Detection System for Active Safety of Automobiles. Master’s Thesis, Chang’an University, Xi’an, China, 2021. [Google Scholar]
- Chongqing University of Posts and Telecommunications. A Pavement Crack Detection Method with Improved ResNet-50 Network Structure. Patent CN202210253649.9, 28 June 2022. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.Y.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
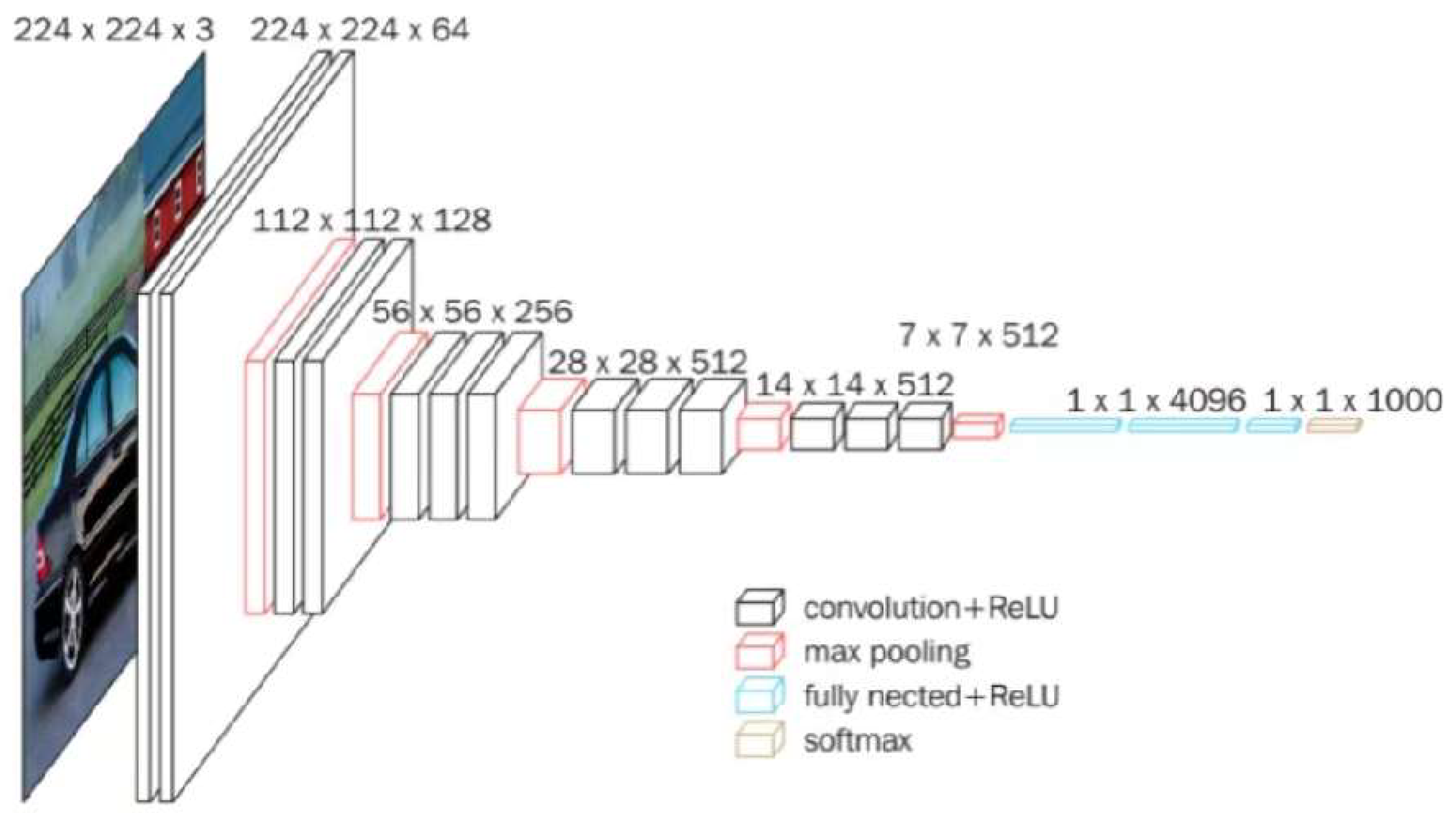
- Simonyan, K.; Andrew, Z. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Song, H.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.A.; Dally, W.J. EIE: Efficient Inference Engine on Compressed Deep Neural Network. ACM SIGARCH Comput. Archit. News 2016, 44, 243–254. [Google Scholar]
- Anju, U.; Sowmya, V.; Soman, K.P. Deep AlexNet with Reduced Number of Trainable Parameters for Satellite Image Classification. Procedia Comput. Sci. 2018, 143, 931–938. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Chen, B.C.; Hong, J.M.; Yin, J. Transfer learning-based graph classification. Small Microcomput. Syst. 2011, 32, 2379–2382. [Google Scholar]
- Huang, K.; Han, W.; Chen, J.J. Drosophila optimized BP neural network pavement adhesion coefficient estimation. Manuf. Autom. 2023, 45, 134–138. (In Chinese) [Google Scholar] [CrossRef]
- Guo, W.Q.; Xu, C.; Xiao, Q.K.; Li, M.R. BN parameter learning algorithm based on variable weight transfer learning. Comput. Appl. Res. 2021, 38, 110–114. [Google Scholar]
- Wang, C.; Xue, X.J.; Li, H.; Zhang, G.Y.; Wang, H.R.; Zhao, L. Underwater image enhancement based on color correction and improved two-dimensional gamma function. J. Electron. Meas. Instrum. 2021, 35, 171–178. [Google Scholar]
- Li, H.-F. A new wavelet denoising method under non-Gaussian distributed noise. J. Hubei Univ. Technol. 2011, 26, 136–139. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ConvNet Configuration | |||||
|---|---|---|---|---|---|
| A | A-LRN | B | C | D(VGGNet-16) | E(VGGNet-19) |
| 11 weight layers | 11 weight layers | 13 weight layers | 16 weight layers | 16 weight layers | 19 weight layers |
| Input (RGB image) | |||||
| Conv3-64 | Conv3-64 LRN | Conv3-64 Conv3-64 | Conv3-64 Conv3-64 | Conv3-64 Conv3-64 | Conv3-64 Conv3-64 |
| MaxPool | |||||
| Conv3-128 | Conv3-128 | Conv3-128 Conv3-128 | Conv3-128 Conv3-128 | Conv3-128 Conv3-128 | Conv3-128 Conv3-128 |
| Maxpool | |||||
| Conv3-256 Conv3-256 | Conv3-256 Conv3-256 | Conv3-256 Conv3-256 | Conv3-256 Conv3-256 Conv1-256 | Conv3-256 Conv3-256 Conv3-256 | Conv3-256 Conv3-256 Conv3-256 Conv3-256 |
| Maxpool | |||||
| Conv3-512 Conv3-512 | Conv3-512 Conv3-512 | Conv3-512 Conv3-512 | Conv3-512 Conv3-512 Conv3-512 | Conv3-512 Conv3-512 Conv3-512 | Conv3-512 Conv3-512 Conv3-512 Conv3-512 |
| Maxpool | |||||
| Conv3-512 Conv3-512 | Conv3-512 Conv3-512 | Conv3-512 Conv3-512 | Conv3-512 Conv3-512 Conv1-512 | Conv3-512 Conv3-512 Conv3-512 | Conv3-512 Conv3-512 Conv3-512 Conv3-512 |
| Maxpool | |||||
| FC4096 | |||||
| FC4096 | |||||
| FC1000 | |||||
| SoftMax | |||||
| Type of Pavement | Dataset Display | Number of Images/Times | Number of Training Sets/Times | Number of Validation Sets/Times | Number of Test Sets/Times |
|---|---|---|---|---|---|
| Wet asphalt pavement |  | 1200 | 1000 | 500 | 150 |
| Dry asphalt pavement |  | 1500 | 800 | 400 | 150 |
| Snow and ice on roads |  | 1700 | 1100 | 600 | 150 |
| Gravel pavement |  | 1100 | 900 | 400 | 150 |
| Connecting pavement |  | 500 | 200 | 100 | 150 |
| Cement pavement |  | 1500 | 1200 | 600 | 150 |
| Parameters | Numerical Values |
|---|---|
| C | 3 × 3 |
| Padding | 2 × 2 |
| Stride | 1 |
| Dropout | 0.5 |
| Epoch | 100 |
| Batch size | 8 |
| Adam ) | 1 × 10−3, 0.9, 0.9 |
| Activation Function | Training Set Accuracy | Test Set Accuracy |
|---|---|---|
| Using ReLU activation function | 94.98% | 90.52% |
| Using Leaky ReLU activation function | 98.23% | 94.57% |
| Model Structure | Weighted Space | Number of Trainable Parameters | Training Set Accuracy | Test Set Accuracy |
|---|---|---|---|---|
| No dropout layer | 91.3 | 11.6 | 95.17 | 93.46 |
| Residual-free structure | 89.3 | 11.4 | 94.82 | 94.08 |
| Improvements to VGGNet-16 | 91.2 | 11.8 | 98.25 | 96.87 |
| Five Network Models | Weighted Space | Number of Training Parameters | Training Set Accuracy/% | Test Set Accuracy/% | Time Taken for Test/sec |
|---|---|---|---|---|---|
| AlexNet | 164 | 21.6 | 95.28 | 95.37 | 63.17 |
| ResNet50 | 180 | 23.5 | 97.46 | 96.47 | 58.15 |
| InceptionV3 | 167 | 21.8 | 91.19 | 94.79 | 52.84 |
| VGGNet-16 | 256 | 33.6 | 95.83 | 96.19 | 56.74 |
| VGGNet-16 transfer | 91.2 | 11.8 | 98.25 | 96.87 | 51.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zou, J.; Guo, W.; Wang, F. A Study on Pavement Classification and Recognition Based on VGGNet-16 Transfer Learning. Electronics 2023, 12, 3370. https://doi.org/10.3390/electronics12153370
Zou J, Guo W, Wang F. A Study on Pavement Classification and Recognition Based on VGGNet-16 Transfer Learning. Electronics. 2023; 12(15):3370. https://doi.org/10.3390/electronics12153370
Chicago/Turabian StyleZou, Junyi, Wenbin Guo, and Feng Wang. 2023. "A Study on Pavement Classification and Recognition Based on VGGNet-16 Transfer Learning" Electronics 12, no. 15: 3370. https://doi.org/10.3390/electronics12153370
APA StyleZou, J., Guo, W., & Wang, F. (2023). A Study on Pavement Classification and Recognition Based on VGGNet-16 Transfer Learning. Electronics, 12(15), 3370. https://doi.org/10.3390/electronics12153370