
Application of Voiceprint Recognition Technology Based on Channel Confrontation Training in the Field of Information Security

Abstract
1. Introduction
2. Related Works
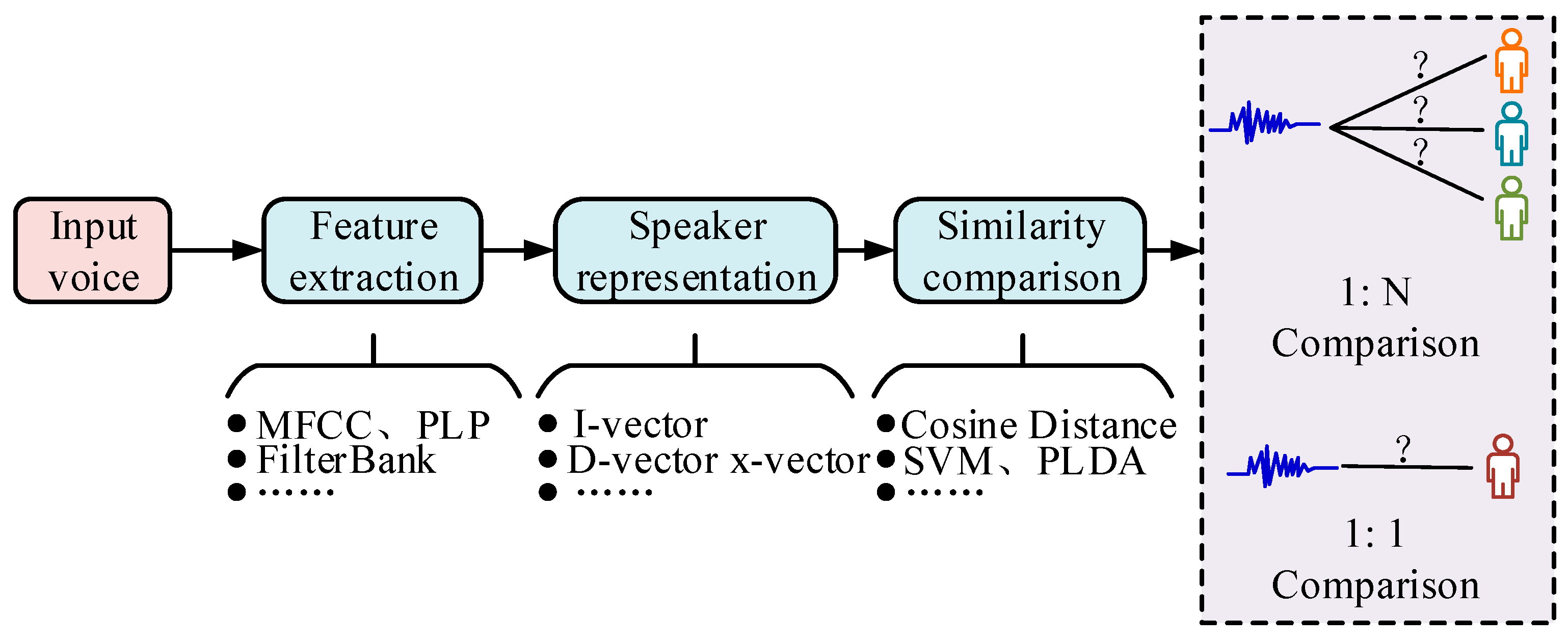
3. Study of Speaker Recognition Techniques Based on Channel Confrontation Training
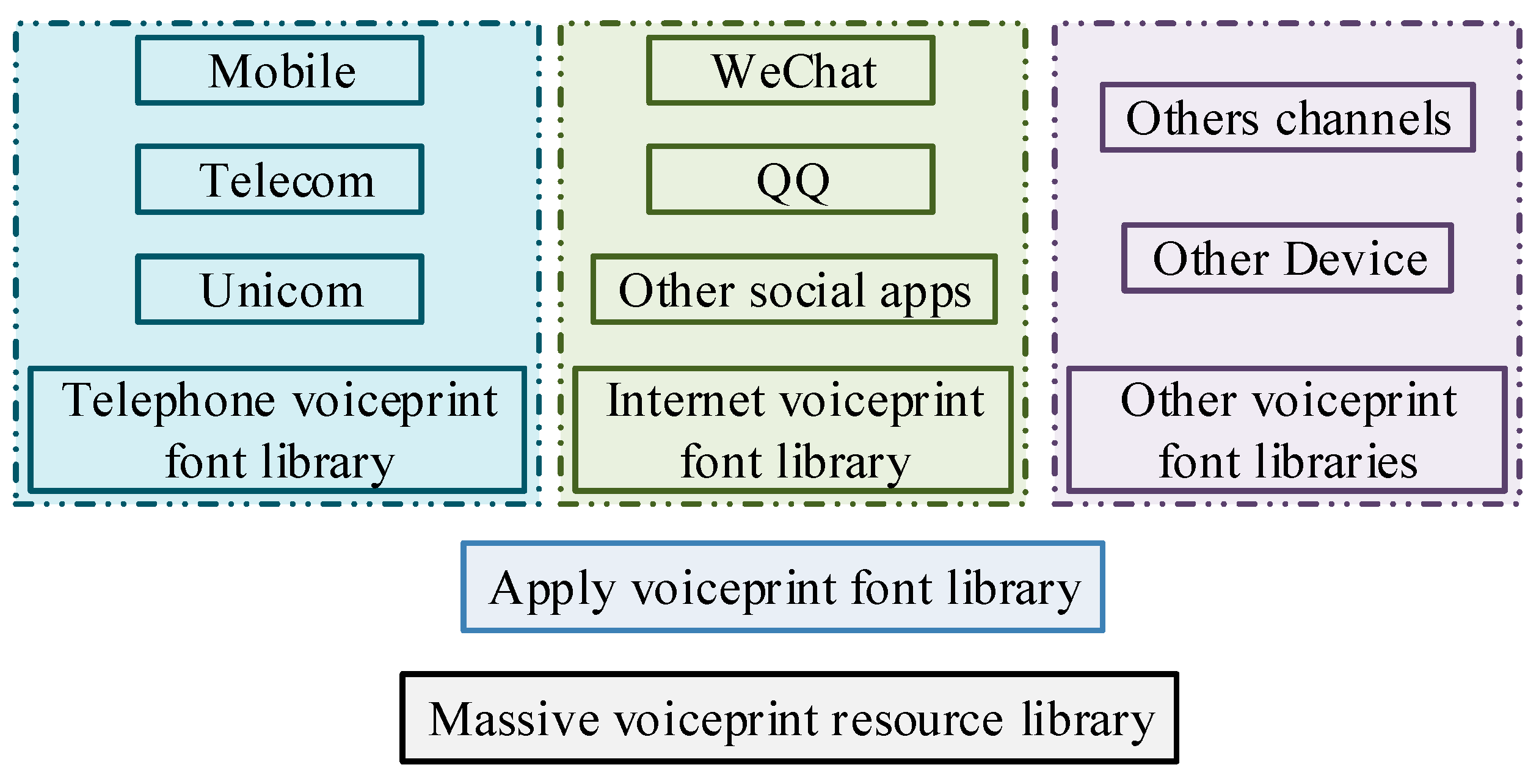
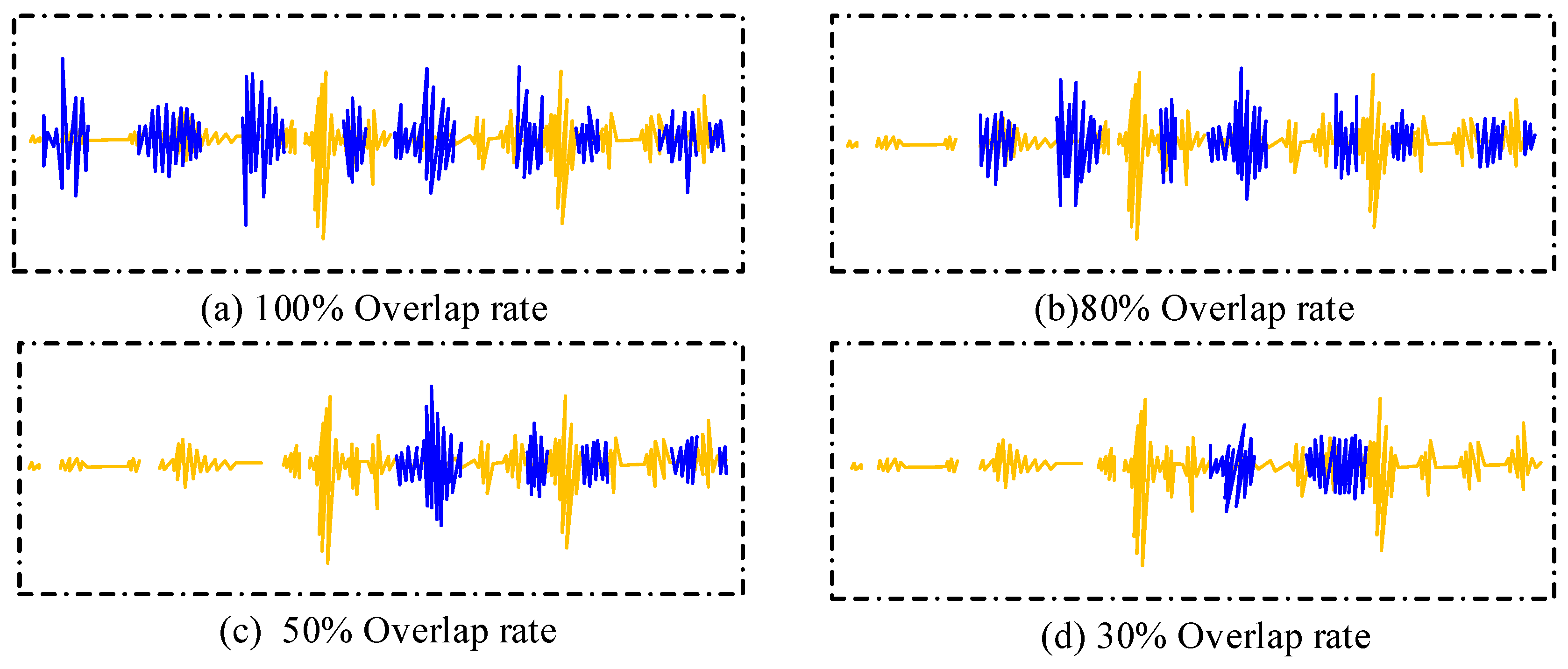
3.1. A Voice Information Database of the Speaker Recognition System
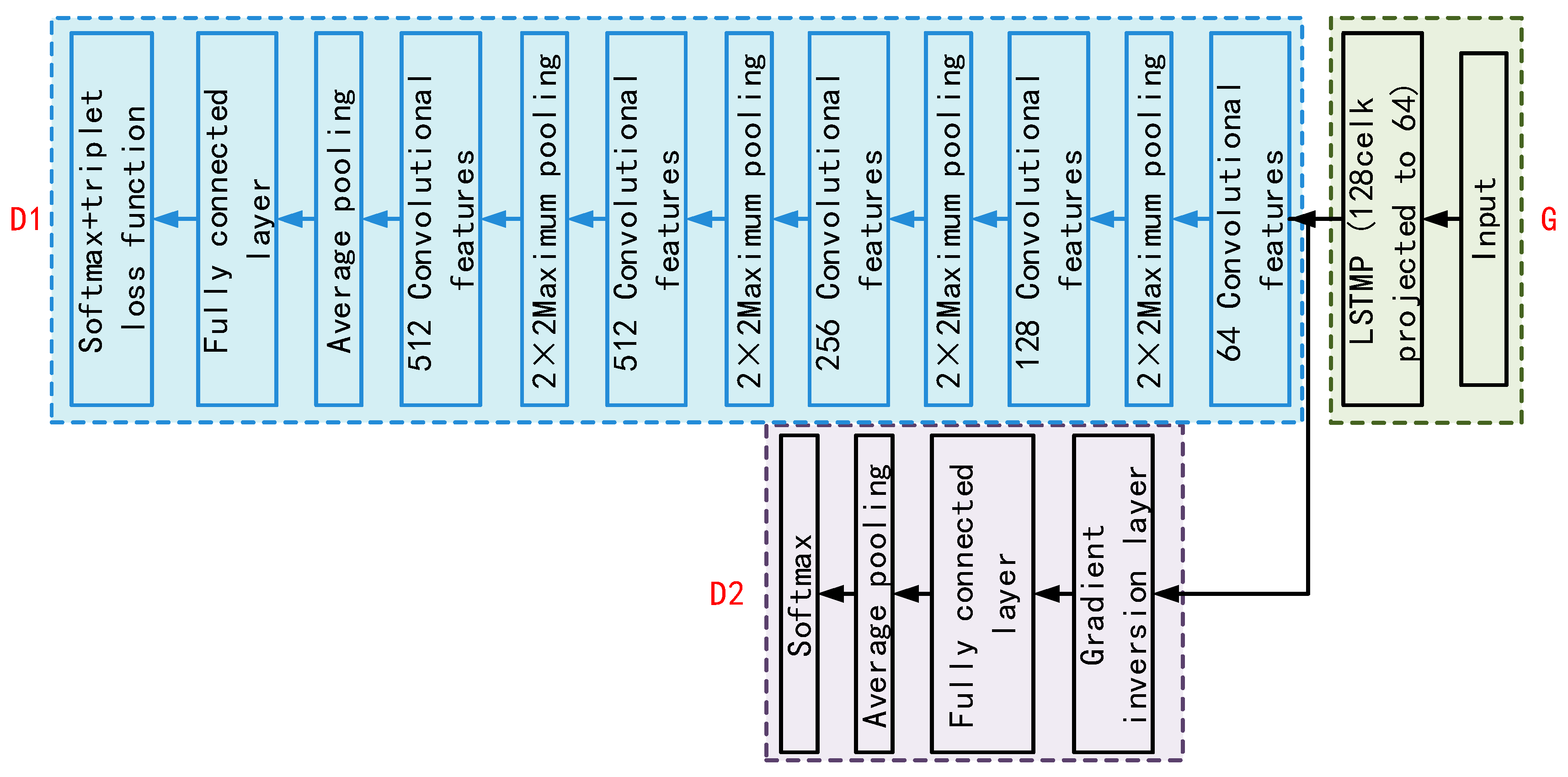
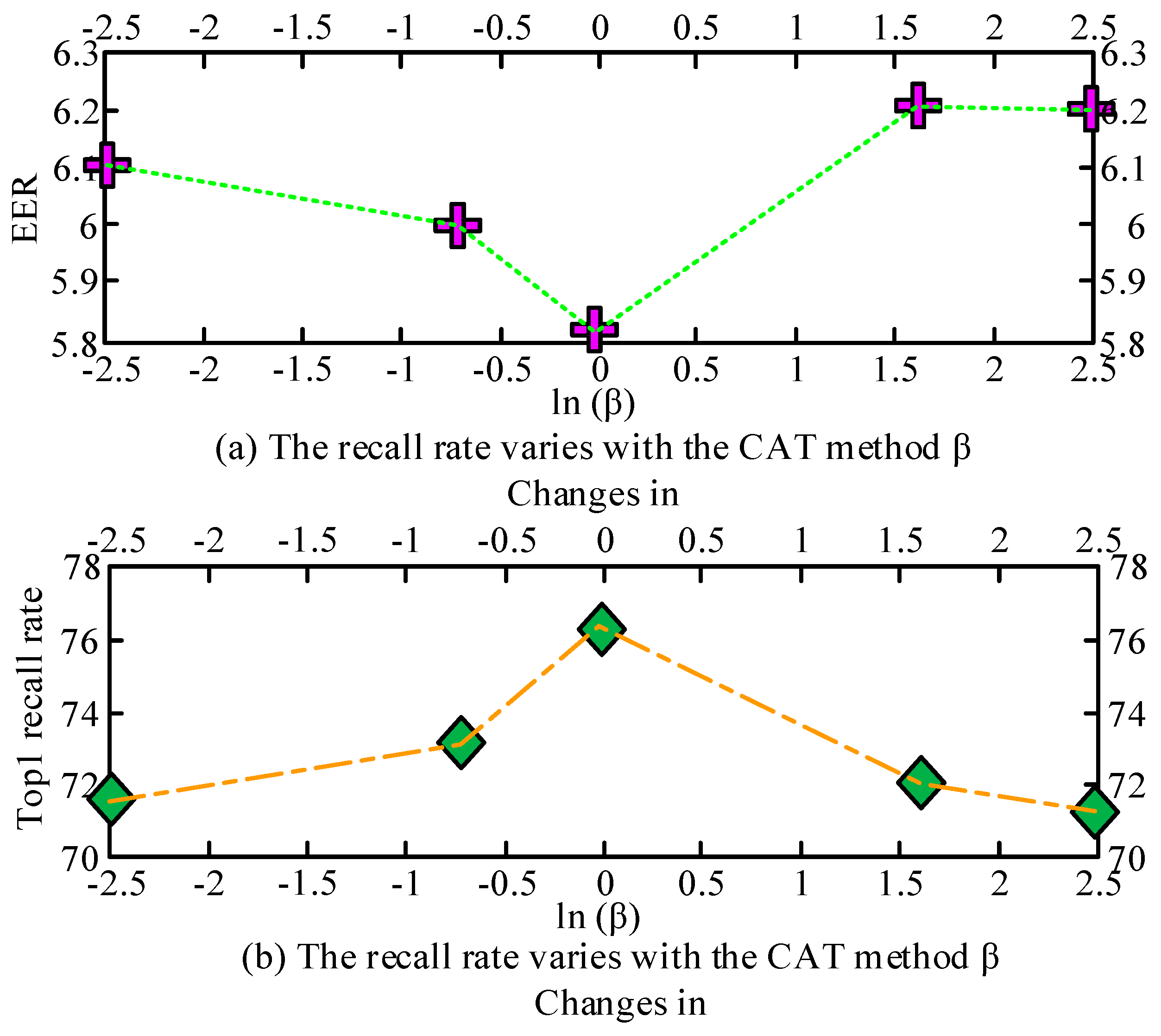
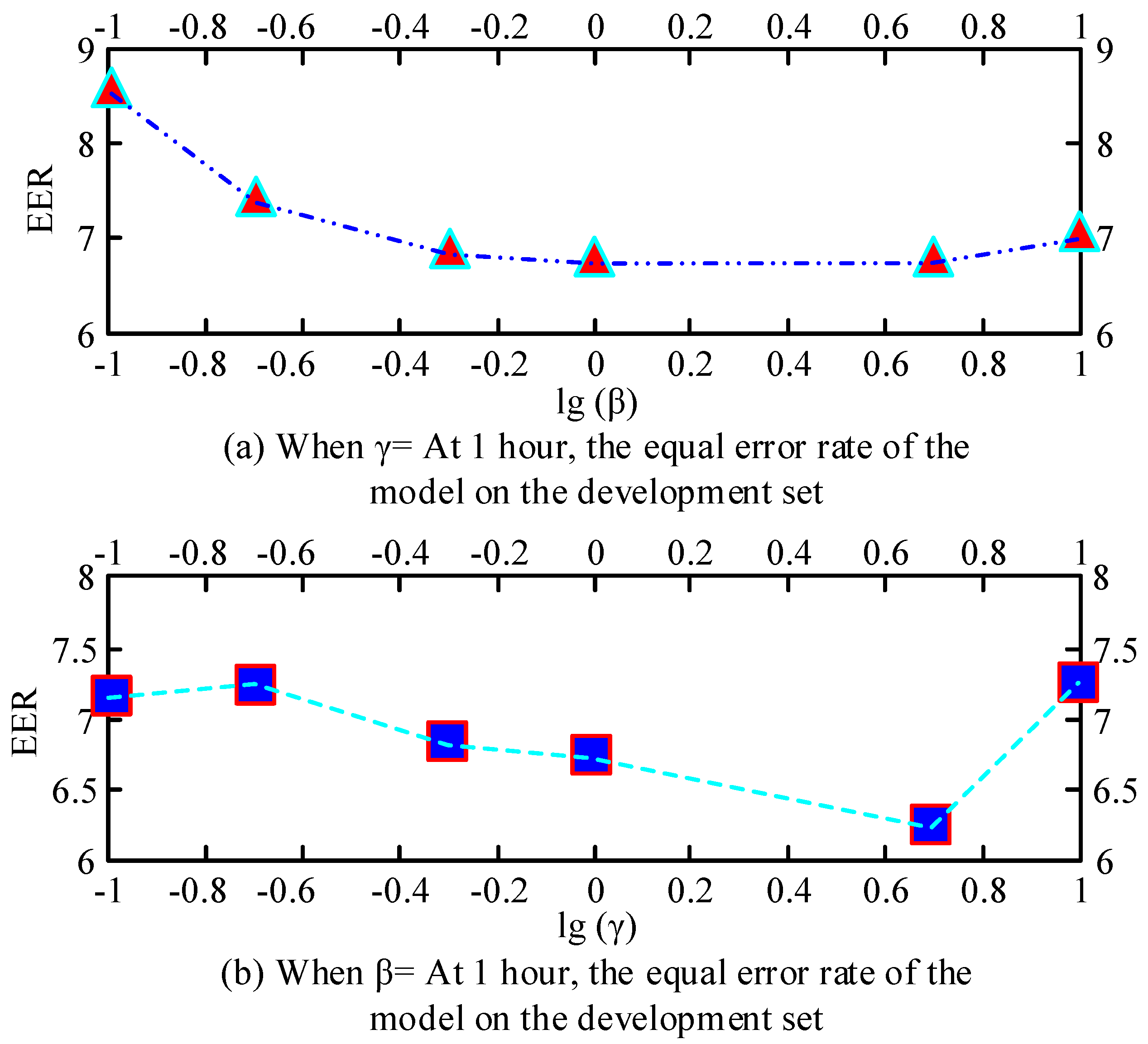
3.2. Voice Recognition Based on Channel Adversarial Training
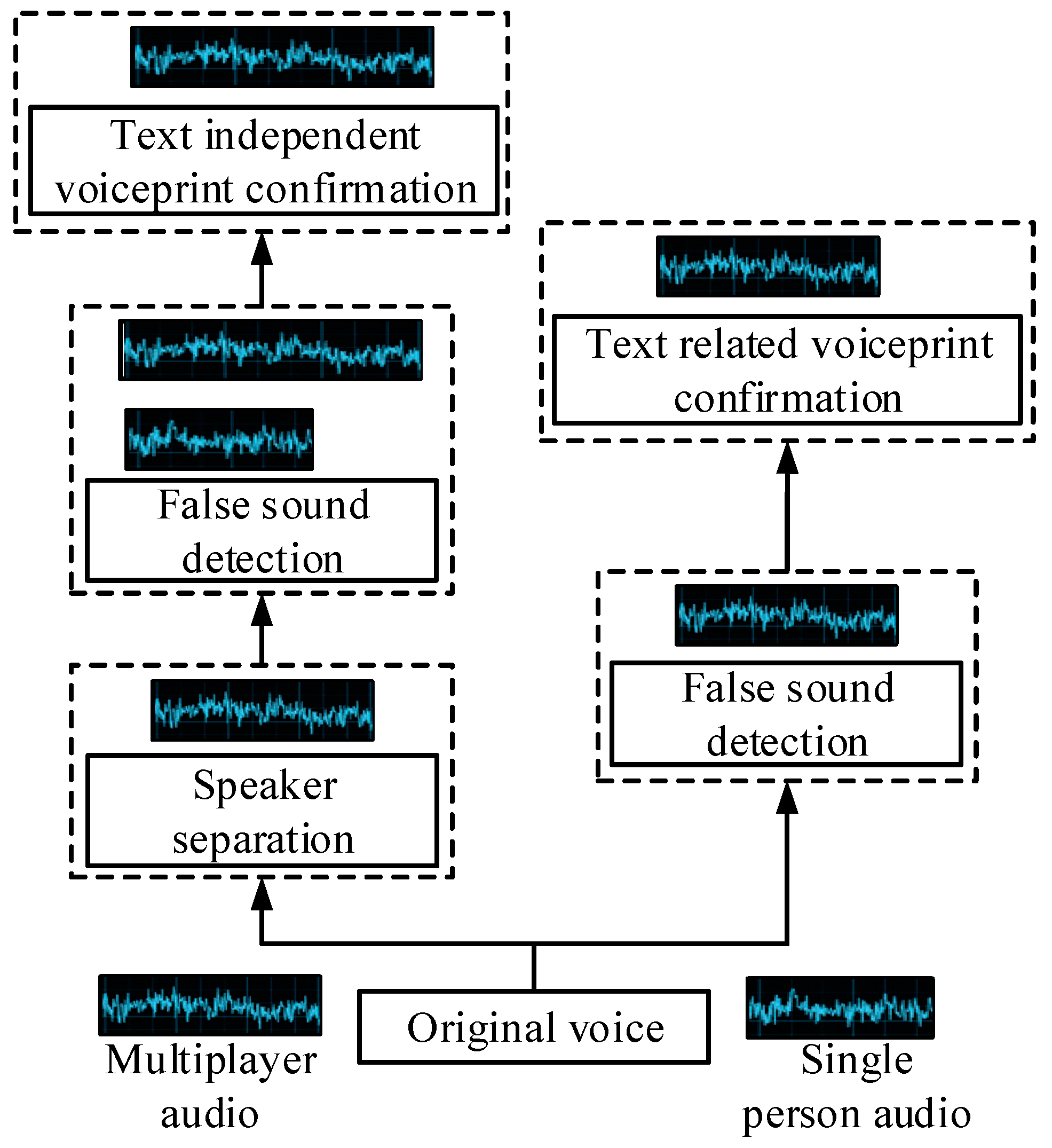
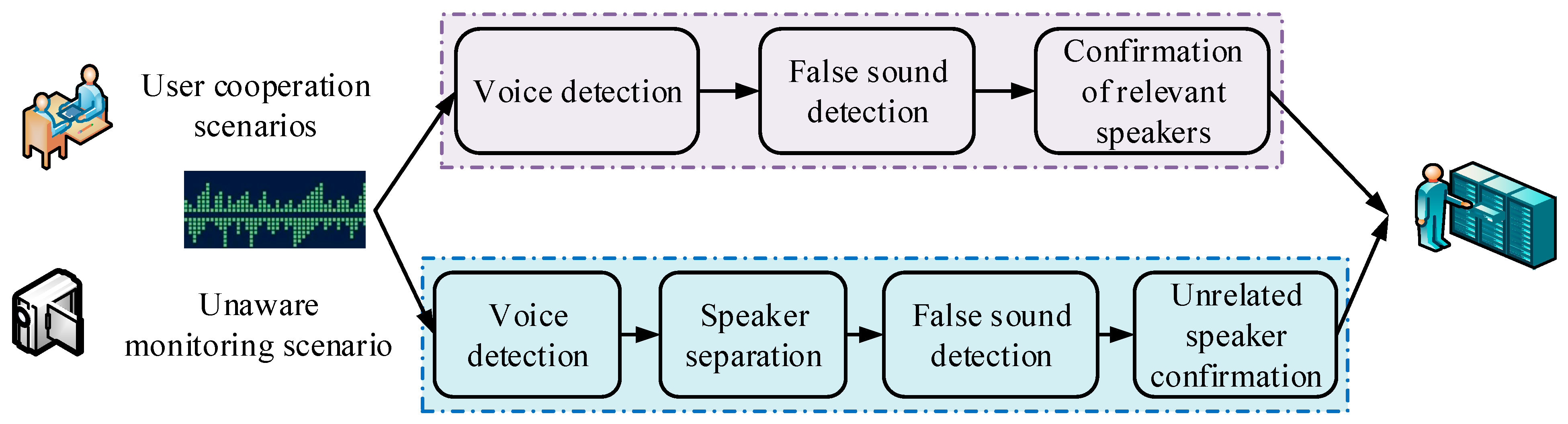
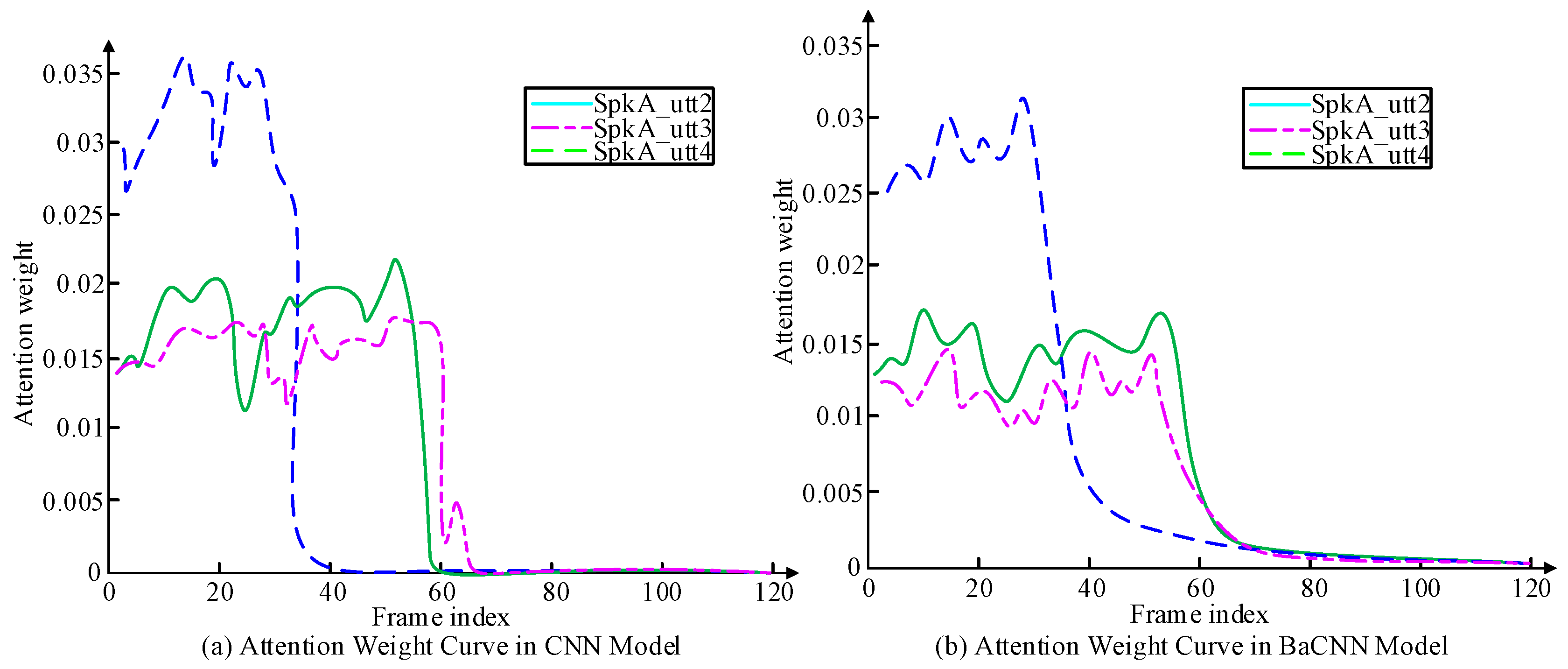
4. The Application of Speaker Technology Based on Channel Confrontation Training in the Field of Information Security
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Feng, Y. Make the rocket intelligent at IOT edge: Stepwise GAN for anomaly detection of LRE with multi-source Fusion. IEEE Internet Things J. 2021, 9, 35–49. [Google Scholar] [CrossRef]
- Li, Q.; Qu, H.; Liu, Z.; Zhou, N.; Sun, W.; Sigg, S.; Li, J. AF-DCGAN: Amplitude feature deep convolutional GAN for fingerprint construction in indoor localization systems. Netw. Internet Archit. 2021, 5, 468–480. [Google Scholar] [CrossRef]
- Shen, X.; Jiang, H.; Liu, D.; Yang, K.; Deng, F.; Lui, J.C.S.; Luo, J. PupilRec: Leveraging pupil morphology for recommending on smartphones. IEEE Internet Things J. 2022, 9, 15538–15553. [Google Scholar] [CrossRef]
- Yan, L.; Shi, Y.; Wei, M.; Wu, Y. Multi-feature fusing local directional ternary pattern for facial expressions signal recognition based on video communication system. Alex. Eng. J. 2023, 63, 307–320. [Google Scholar] [CrossRef]
- Khdier, H.Y.; Jasim, W.M.; Aliesawi, S.A. Deep learning algorithms based voiceprint recognition system in noisy environment. J. Phys. Conf. Ser. 2021, 1804, 12–42. [Google Scholar] [CrossRef]
- Sun, W.Z.; Wang, J.S.; Zheng, B.W.; Zhong-Feng, L. A novel convolutional neural network voiceprint recognition method based on improved pooling method and dropout idea. IAENG Int. J. Comput. Sci. 2021, 48, 202–212. [Google Scholar]
- Hong, Z.; Yue, L.; Wang, W.; Zeng, X. Research on end-to-end voiceprint recognition model based on convolutional neural network. J. Web Eng. 2021, 20, 1573–1586. [Google Scholar]
- Bahmaninezhad, F.; Zhang, C.; Hansen, J.H.L. An investigation of domain adaptation in speaker embedding space for speaker recognition. Speech Commun. 2021, 129, 7–16. [Google Scholar] [CrossRef]
- Yu, H.K.; Nam, S.H.; Hong, S.B.; Park, K.R. GRA-GAN: Generative adversarial network for image style transfer of gender, race, and age. Expert Syst. Appl. 2022, 198, 2–20. [Google Scholar]
- Wang, C.; Luo, D.; Liu, Y.; Xu, B.; Zhou, Y. Near-surface pedestrian detection method based on deep learning for UAVs in low illumination environments. Opt. Eng. 2022, 61, 2–19. [Google Scholar] [CrossRef]
- Bai, Z.; Zhang, X.L. Speaker recognition based on deep learning: An overview. Neural Netw. 2021, 140, 65–99. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Guo, S.; Huang, R.; Li, L.; Zhang, X.; Jiao, L. Dual-channel capsule generation adversarial network for hyperspectral image classification. Trans. Geosci. Remote Sens. 2021, 60, 2–16. [Google Scholar] [CrossRef]
- Shan, S.; Liu, J.; Dun, Y. Prospect of voiceprint recognition based on deep learning. J. Phys. Conf. Ser. 2021, 18, 12–46. [Google Scholar] [CrossRef]
- Ji, H.; Lei, X.; Xu, Q.; Huang, C.; Ye, T.; Yuan, S. Research on characteristics of acoustic signal of typical partial discharge models. Glob. Energy Interconnect. 2022, 5, 118–130. [Google Scholar] [CrossRef]
- Cai, R.; Wang, Q.; Hou, Y.; Liu, H. Event monitoring of transformer discharge sounds based on voiceprint. J. Phys. Conf. Ser. 2021, 2066, 66–67. [Google Scholar] [CrossRef]
- Qian, W.; Xu, Y.; Zuo, W.; Li, H. Self-sparse generative adversarial networks. CAAI Artif. Intell. Res. 2022, 1, 68–78. [Google Scholar] [CrossRef]
- Kim, J.I.; Gang, H.S.; Pyun, J.Y.; Goo-Rak, K. Implementation of QR code recognition technology using smartphone camera for indoor positioning. Energies 2021, 14, 2759. [Google Scholar] [CrossRef]
- Zhu, K.; Ma, H.; Wang, J.; Yu, C. Optimization research on abnormal diagnosis of transformer voiceprint recognition based on improved wasserstein GAN. J. Phys. Conf. Ser. 2021, 17, 12–67. [Google Scholar] [CrossRef]
- Yang, Y.; Song, X. Research on face intelligent perception technology integrating deep learning under different illumination intensities. J. Comput. Cogn. Eng. 2022, 1, 32–36. [Google Scholar] [CrossRef]
- Amin, S.N.; Shivakumara, P.; Jun, T.X. An augmented reality-based approach for designing interactive food menu of restaurant using android. Artif. Intell. Appl. 2023, 1, 26–34. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | EER | |||
|---|---|---|---|---|
| First Training | Second Training | Third Training | Fourth Training | |
| I-vector | 8.71% | 8.82% | 8.62% | 8.83% |
| CNN | 6.23% | 6.13% | 6.24% | 6.34% |
| CAT without D2 | 6.42% | 6.41% | 6.57% | 6.42% |
| CAT | 5.81% | 5.91% | 5.70% | 5.83% |
| System | Recall | ||
|---|---|---|---|
| Top1 | Top5 | Top10 | |
| I-vector | 57.11% | 66.22% | 70.13% |
| CNN | 69.21% | 77.23% | 79.91% |
| CAT without D2 | 68.92% | 77.81% | 79.84% |
| CAT | 76.21% | 83.15% | 84.92% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gui, S.; Zhou, C.; Wang, H.; Gao, T. Application of Voiceprint Recognition Technology Based on Channel Confrontation Training in the Field of Information Security. Electronics 2023, 12, 3309. https://doi.org/10.3390/electronics12153309
Gui S, Zhou C, Wang H, Gao T. Application of Voiceprint Recognition Technology Based on Channel Confrontation Training in the Field of Information Security. Electronics. 2023; 12(15):3309. https://doi.org/10.3390/electronics12153309
Chicago/Turabian StyleGui, Suying, Chuan Zhou, Hao Wang, and Tiegang Gao. 2023. "Application of Voiceprint Recognition Technology Based on Channel Confrontation Training in the Field of Information Security" Electronics 12, no. 15: 3309. https://doi.org/10.3390/electronics12153309
APA StyleGui, S., Zhou, C., Wang, H., & Gao, T. (2023). Application of Voiceprint Recognition Technology Based on Channel Confrontation Training in the Field of Information Security. Electronics, 12(15), 3309. https://doi.org/10.3390/electronics12153309