

Deep Learning-Based Attack Detection and Classification in Android Devices


Abstract
1. Introduction
- Data generation and release: We have derived and released three datasets, namely CICMal-Droid2020, CICMal-Droid2017, and CIC-AndMal2017, comprising a total of 18,188 Android samples. These datasets include up-to-date samples from the year 2021 and are categorized into five distinct classes: Benign, Adware, SMS malware, Banking, and Riskware.
- In-depth analysis of static characteristics: We conducted a comprehensive examination of the most relevant static characteristics associated with malware samples. This investigation delved into understanding the intrinsic properties and features of the malware instances.
- Exploration of DL and ML algorithms: We performed an extensive exploration of various deep learning (DL) and machine learning (ML) algorithms to determine the optimal choice for achieving the best performance across different problem domains. This evaluation aimed to identify the algorithms that yielded superior results in terms of accuracy and efficiency.
- Analysis of experimental results: We meticulously analyzed the outcomes of our experiments to identify the types of malware that posed the greatest challenges in terms of detection and classification. Our findings demonstrated that our model exhibits an impressive F1 score of 98.9% and a false positive rate of 0.99%. These results instill confidence in the robustness and effectiveness of our proposed approach.
- Development of an Android application: We developed an Android application that facilitates queries and investigations into the previously studied threats. This application serves as a practical tool for evaluating the performance of our trained algorithm in real-world mobile environments. By designing and implementing this proof of concept, we validated the applicability and viability of our model in realistic scenarios.
2. Related Works
3. Methodology
- Address bar characteristics: These refer to the properties of the URL, such as the size or absence of certain characters.
- Abnormality-based characteristics: This category is used to characterize uncommon aspects that are not typically found in legitimate web pages.
- HTML and JavaScript-based functions: These functions are utilized to obscure details and make phishing detection more challenging when accessing the website.
- Domain-based characteristics: In contrast to address bar characteristics, this category focuses more on the search engine optimization (SEO) aspects of the domain.
- API calls: These are pre-programmed function calls found in the APK’s .dex files, which are used to save time by avoiding the need to create them.
- Permissions: Upon installation, permissions represent the initial requests made by an application. These play a crucial role in security as they determine the services to which the app gains access. Permissions are specified in the AndroidManifest.xml file of the APK.
- Intents: Intents are used to request an action from a component of another application. They are specified in the files.
Training and Analysis of Theoretical Models
- Data loading and separation: The labeled data were loaded into the system and randomly shuffled to prevent any biases and overfitting. Subsequently, the dataset was divided into training data (75%) and test data (25%) to effectively evaluate the accuracy of the trained model.
- Model training: Three models were chosen for study: decision tree, random forest, and SVM. For training these models, the tools provided by the sklearn library were utilized. On the other hand, training the neural network model was a more complex process that required the development of subroutines to replicate the learning process. Unlike the decision trees, random forest and SVM involve selecting and adjusting several parameters to optimize their accuracy and efficiency:
- –
- Optimization: Techniques such as gradient descent, specifically utilizing the negative log likelihood cost function, were employed to improve the weights of the neural network’s neurons. The learning rate parameter, which determines the speed of learning in each iteration, played a crucial role in effectively training the neural network. In the optimization process, the learning rate was dynamically adjusted using exponential decay rates to enhance the efficiency of learning.
- –
- Iterations and nodes: Determining the optimal number of iterations for the model was essential to avoid underfitting or overfitting. Underfitting occurs when the model fails to capture the complexities of the data due to insufficient iterations, while overfitting arises from excessive training on the same dataset, causing the model to become overly specialized and perform poorly on new data. This issue is particularly significant when dealing with small databases, as the model might become excessively biased towards certain patterns present in the training set.
- –
- Batch size: The batch size parameter defines the number of examples from the dataset used to train the model in each iteration. It is particularly useful when memory is limited, as it allows for training with smaller batches of data instead of loading the entire dataset at once. Training with batch updates accelerates the training process by updating the weights of the model after each batch iteration.
- –
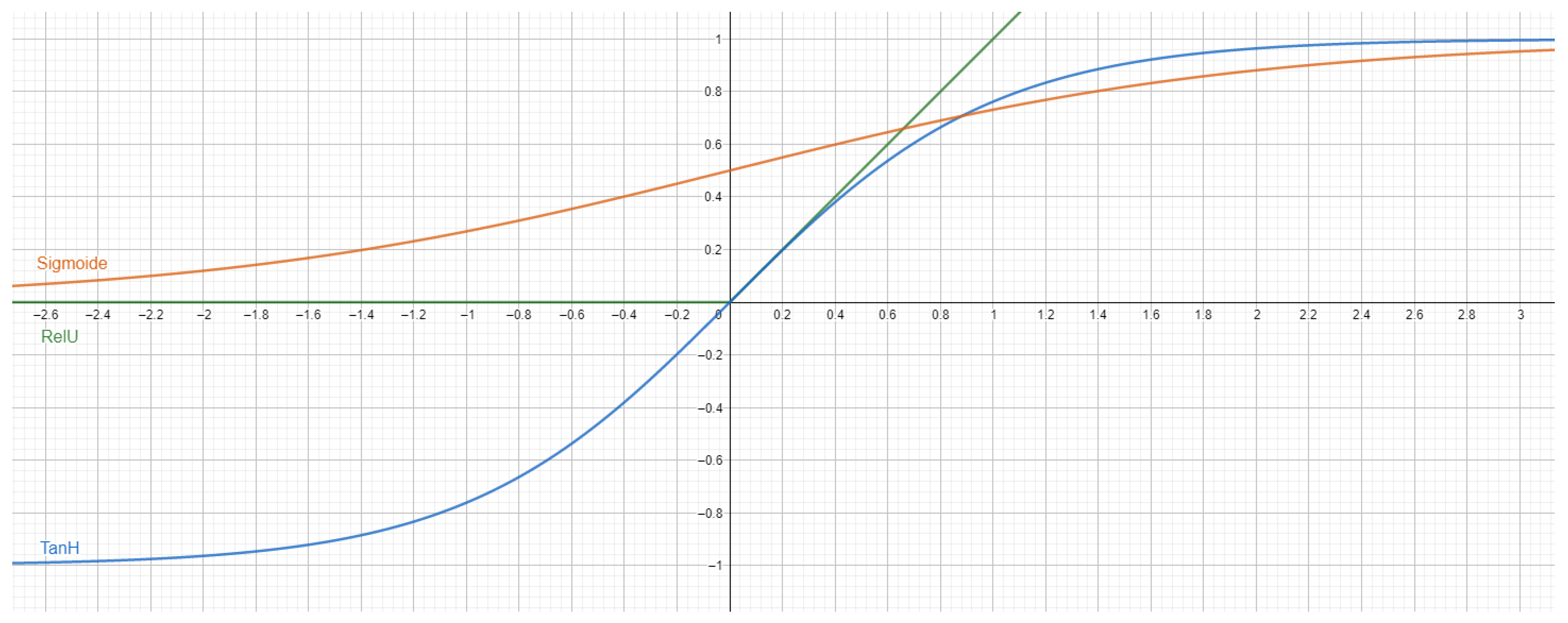
- Activation function: Activation functions are applied at the output of the weighted sum in a neural network, aiming to transmit the information derived by the combination of weights. The chosen activation functions for this study are presented in Figure 3, where each function serves a specific purpose in the network’s architecture and learning process.
4. Deep Learning Algorithm Design and Model Description
4.1. Algorithm Design
- API calls refer to pre-coded functions used to optimize time by allowing their repeated utilization. These functions are stored in the .dex files of the Android Application Package (APK).
- Permissions come into effect immediately upon starting the installation of an application, as it is the first step in the process. Permissions play a critical role in system security, as they determine the services to which the application will be granted full access. The set of permissions in Android is defined in the AndroidManifest.xml file of the APK.
- Intents are used to request actions from the components of other applications. They facilitate the runtime linkage between the code of different applications, particularly in launching activities. In this context, intents serve as the “glue” between activities hosted in files.
4.2. Learning Model Description
- Iterations and nodes: Determining the optimal number of iterations is crucial, as each iteration is computationally intensive. Additionally, the number of nodes in each layer influences the computational load and model accuracy. Overfitting and underfitting are two common problems encountered during model training. Underfitting occurs when insufficient iterations fail to reach the minimum cost of the function, while overfitting arises from excessive training with the same dataset.
- Optimization of nodes: This step aims to minimize the loss function during the backward prediction phase, enhancing the training process. Optimization algorithms rely on the learning rate, which determines the extent of weight adjustments during each iteration.
- Learning rate: The learning rate plays a crucial role in the speed of convergence and overall performance of the optimization algorithm. Selecting an appropriate learning rate is essential to achieve optimal training results and model efficiency.
- Batch size: The batch size refers to the number of examples from the dataset used to train the model in each iteration. Employing smaller batch sizes is beneficial when limited memory is available, as it allows loading and processing a single batch at a time. It can also lead to more efficient training by updating the weights after each batch iteration.
- Activation function: Activation functions play a vital role in transmitting information derived by the weighted combinations in the neurons. Several activation functions were considered, including Sigmoid [55], Hyperbolic Tangent [56], rectified linear unit (ReLU) [57], and parametric ReLU (PReLU) [58]. PReLU, a derivative of ReLU, was selected for its capability to prevent neuron death and demonstrate enhanced performance for the intermediate nodes.
5. Analysis of Theoretical Models
5.1. Phishing
5.2. SMS Spam
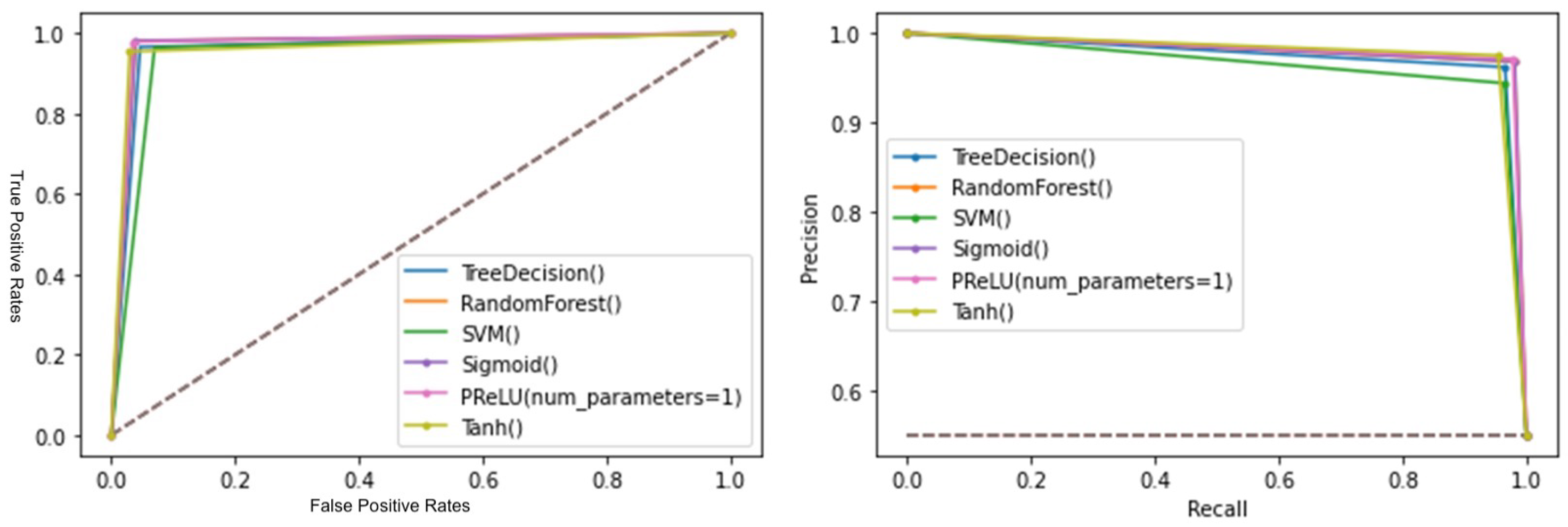
- Phishing: The PRelU model demonstrated promising results, showing fast learning and occupying a larger area in the ROC and P-R curves.
- Spam SMS: Once again, the PRelU model yielded better numerical data, demonstrated faster learning in the evolution graphs, and occupied a larger area in the ROC and P-R curves.
- Malware in APKs: The PRelU model continued to outperform other options, showing superior results in terms of classifying malignancy and different types of malware. These findings highlight the effectiveness of the PRelU model across all three types of threats studied.
6. Malware Classifier
6.1. Dataset Preparation
6.2. Model Evaluation Method
- Confusion matrix. This metric allows us to measure the number of true negatives (TNs), true positives (TPs), false negatives (FNs), and false positives (FPs) of our trained model with respect to the test data. This graph will be useful during the study, because it will show us the number of applications that are correctly predicted; and for the applications that are not correctly predicted, it shows us the threat with which they are confused.
- Precision: it is responsible for measuring the quality of the models. It is calculated with Equation (1).
- Recall: it represents the amount of relevant data that the model has been able to obtain over the total relevant data. It is calculated with Equation (2).
- Fx: this metric allows us to relate precision and recall, based on Equation (3).In order to relate it in an equitable way, F1 was used.
- Accuracy: this is a metric that allows us to see the percentage of test data that the model correctly predicted out of the total test data. It is calculated by Equation (4).
- Precision–recall curve: this curve plots the values of precision versus recall. It is used by analyzing the area under the curve, where the larger the area, the better the model. This plot becomes more important when we encounter models that have been trained with unbalanced datasets.
- ROC curve: this curve plots the values of FP versus TP. It is used by analyzing the area under the curve, where the larger the area, the better the model.
6.3. Design
6.4. Neural Network Training Parameters
6.5. Results
6.6. Malware Classifier Tool: A Proof of Concept
7. Discussion
8. Conclusions and Future Works
Author Contributions
Funding
Conflicts of Interest
References
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C.E.R.T. Drebin: Effective and Explainable Detection of Android Malware in Your Pocket. In Proceedings of the 21st Annual Network and Distributed System Security Symposium, NDSS, San Diego, CA, USA, 23–26 February 2014; Volume 14, pp. 23–26. [Google Scholar]
- Liu, K.; Xu, S.; Xu, G.; Zhang, M.; Sun, D.; Liu, H. A review of android malware detection approaches based on machine learning. IEEE Access 2020, 8, 124579–124607. [Google Scholar] [CrossRef]
- Qiu, J.; Zhang, J.; Luo, W.; Pan, L.; Nepal, S.; Xiang, Y. A survey of android malware detection with deep neural models. ACM Comput. Surv. (CSUR) 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Zhang, M.; Duan, Y.; Yin, H.; Zhao, Z. Semantics-aware android malware classification using weighted contextual api dependency graphs. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AZ, USA, 3–7 November 2014; pp. 1105–1116. [Google Scholar]
- Dhalaria, M.G.; Otra, E. Risk Detection of Android Applications Using Static Permissions. In Advances in Data Computing, Communication and Security; Springer: Singapore, 2022; pp. 591–600. [Google Scholar]
- Lakshmanan, R. New Android Malware Uses VNC to Spy and Steal Passwords from Victims. 2021. Available online: https://thehackernews.com/2021/07/new-android-malware-uses-vnc-to-spy-and.html (accessed on 10 May 2022).
- Gao, H.; Xiao, J.; Yin, Y.; Liu, T.; Shi, J. A mutually supervised graph attention network for few-shot segmentation: The perspective of fully utilizing limited samples. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Jiang, H.; Turki, T.; Wang, J.T. DLGraph: Malware detection using deep learning and graph embedding. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; IEEE: Manhattan, NY, USA, 2018; pp. 1029–1033. [Google Scholar]
- Ahmad, Z.; Shahid, K.A.; Wai, S.C.; Abdullah, J.; Ahmad, F. Network intrusion detection system: A systematic study of machine learning and deep learning approaches. Trans. Emerg. Telecommun. Technol. 2021, 32, e4150. [Google Scholar] [CrossRef]
- Malware Statistics and Facts for 2022. 2022. Available online: https://www.comparitech.com/antivirus/malware-statistics-facts/ (accessed on 8 January 2022).
- Eder, J.; Shekhovtsov, V.A. Data quality for federated medical data lakes. Int. J. Web Inf. Syst. 2021, 17, 407–426. [Google Scholar] [CrossRef]
- Gao, H.; Qiu, B.; Barroso, R.J.D.; Hussain, W.; Xu, Y.; Wang, X. Tsmae: A novel anomaly detection approach for internet of things time series data using memory-augmented autoencoder. IEEE Trans. Netw. Sci. Eng. 2022, 1–11. [Google Scholar] [CrossRef]
- Jakobsson, M.; Ramzan, Z. Crimeware: Understanding New Attacks and Defenses; Addison-Wesley Professional: Boston, MA, USA, 2008. [Google Scholar]
- Kimani, K.; Oduol, V.; Langat, K. Cyber security challenges for IoT-based smart grid networks. Int. J. Crit. Infrastruct. Prot. 2019, 25, 36–49. [Google Scholar] [CrossRef]
- Tariq, N. Impact of cyberattacks on financial institutions. J. Internet Bank. Commer. 2018, 23, 1–11. [Google Scholar]
- Wong, W.; Stamp, M. Hunting for metamorphic engines. J. Comput. Virol. 2006, 2, 211–229. [Google Scholar] [CrossRef]
- Bazrafshan, Z.; Hashemi, H.; Fard, S.M.H.; Hamzeh, A. A survey on heuristic malware detection techniques. In Proceedings of the 5th Conference on Information and Knowledge Technology, Shiraz, Iran, 28–30 May 2013; IEEE: Manhattan, NY, USA, 2013; pp. 113–120. [Google Scholar]
- Christodorescu, M.; Jha, S. Static analysis of executables to detect malicious patterns. In Proceedings of the 12th USENIX Security Symposium (USENIX Security 03), Washington, DC, USA, 4–8 August 2003. [Google Scholar]
- Schultz, M.G.; Eskin, E.; Zadok, F.; Stolfo, S.J. Data mining methods for detection of new malicious executables. In Proceedings of the 2001 IEEE Symposium on Security and Privacy, S&P, Oakland, CA, USA, 14–16 May 2001; IEEE: Manhattan, NY, USA, 2011; pp. 38–49. [Google Scholar]
- Shabtai, A.; Moskovitch, R.; Elovici, Y.; Glezer, C. Detection of malicious code by applying machine learning classifiers on static features: A state-of-the-art survey. Inf. Secur. Tech. Rep. 2009, 14, 16–29. [Google Scholar] [CrossRef]
- Dang, Q.V. Improving the performance of the intrusion detection systems by the machine learning explainability. Int. J. Web Inf. Syst. 2021, 17, 537–555. [Google Scholar] [CrossRef]
- Saxe, J.; Berlin, K. Deep neural network based malware detection using two dimensional binary program features. In Proceedings of the 2015 10th International Conference on Malicious and Unwanted Software (MALWARE), Fajardo, PR, USA, 20–22 October 2015; IEEE: Manhattan, NY, USA, 2015; pp. 11–20. [Google Scholar]
- Ucci, D.; Aniello, L.; Baldoni, R. Survey of machine learning techniques for malware analysis. Comput. Secur. 2019, 81, 123–147. [Google Scholar] [CrossRef]
- Abusitta, A.; Li, M.Q.; Fung, B.C. Malware classification and composition analysis: A survey of recent developments. J. Inf. Secur. Appl. 2021, 59, 102828. [Google Scholar] [CrossRef]
- Dahl, G.E.; Stokes, J.W.; Deng, L.; Yu, D. Large-scale malware classification using random projections and neural networks. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Cananda, 26–31 May 2013; IEEE: Manhattan, NY, USA, 2013; pp. 3422–3426. [Google Scholar]
- Huang, W.; Stokes, J.W. MtNet: A multi-task neural network for dynamic malware classification. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, San Sebastián, Spain, 7–8 July 2016; Springer: Cham, Switzerland, 2016; pp. 399–418. [Google Scholar]
- Kolosnjaji, B.; Zarras, A.; Webster, G.; Eckert, C. Deep learning for classification of malware system call sequences. In Australasian Joint Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2016; pp. 137–149. [Google Scholar]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial examples for malware detection. In European Symposium on Research in Computer Security; Springer: Cham, Switzerland, 2017; pp. 62–79. [Google Scholar]
- Suciu, O.; Coull, S.E.; Johns, J. Exploring adversarial examples in malware detection. In Proceedings of the 2019 IEEE Security and Privacy Workshops (SPW), Francisco, CA, USA, 19–23 May 2019; IEEE: Manhattan, NY, USA, 2019; pp. 8–14. [Google Scholar]
- Wang, Q.; Guo, W.; Zhang, K.; Ororbia, A.G.; Xing, X.; Liu, X.; Giles, C.L. Adversary resistant deep neural networks with an application to malware detection. In Proceedings of the 23rd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, Halifax, NS, USA, 13–17 August 2017; pp. 1145–1153. [Google Scholar]
- Chen, L.; Ye, Y.; Bourlai, T. Adversarial machine learning in malware detection: Arms race between evasion attack and defense. In Proceedings of the 2017 European intelligence and Security Informatics Conference (EISIC), Athens, Greece, 11–13 September 2017; IEEE: Manhattan, NY, USA, 2017; pp. 99–106. [Google Scholar]
- Jang, J.; Brumley, D.; Venkataraman, S. Bitshred: Feature hashing malware for scalable triage and semantic analysis. In Proceedings of the 18th ACM Conference on Computer and Communications Security, New York, NY, USA, 17–21 October 2011; pp. 309–320. [Google Scholar]
- Mishra, P.; Varadharajan, V.; Tupakula, U.; Pilli, E.S. A detailed investigation and analysis of using machine learning techniques for intrusion detection. IEEE Commun. Surv. Tutor. 2018, 21, 686–728. [Google Scholar] [CrossRef]
- Santos, R.; Souza, D.; Santo, W.; Ribeiro, A.; Moreno, E. Machine learning algorithms to detect DDoS attacks in SDN. Concurr. Comput. Pract. Exp. 2020, 32, e5402. [Google Scholar] [CrossRef]
- Upchurch, J.; Zhou, X. Variant: A malware similarity testing framework. In Proceedings of the 2015 10th International Conference on Malicious and Unwanted Software (MALWARE), Fajardo, PR, USA, 20–22 October 2015; IEEE: Manhattan, NY, USA, 2015; pp. 31–39. [Google Scholar]
- Ahmadi, M.; Ulyanov, D.; Semenov, S.; Trofimov, M.; Giacinto, G. Novel feature extraction, selection and fusion for effective malware family classification. In Proceedings of the Sixth ACM Conference on Data and Application Security and Privacy, New York, NY, USA, 9–11 March 2016; pp. 183–194. [Google Scholar]
- Alzaylaee, M.K.; Yerima, S.Y.; Sezer, S. DL-Droid: Deep learning based android malware detection using real devices. Comput. Secur. 2020, 89, 101663. [Google Scholar] [CrossRef]
- Elsayed, M.S.; Le-Khac, N.A.; Dev, S.; Jurcut, A.D. Ddosnet: A deep-learning model for detecting network attacks. In Proceedings of the 2020 IEEE 21st International Symposium on “A World of Wireless, Mobile and Multimedia Networks” (WoWMoM), Cork, Ireland, 31 August–3 September 2020; IEEE: Manhattan, NY, USA, 2020; pp. 391–396. [Google Scholar]
- Polino, M.; Scorti, A.; Maggi, F.; Zanero, S. Jackdaw: Towards automatic reverse engineering of large datasets of binaries. In Proceedings of the International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment, Milan, Italy, 9–10 July 2015; Springer: Cham, Switzerland, 2015; pp. 121–143. [Google Scholar]
- Farajzadeh-Zanjani, M.; Hallaji, E.; Razavi-Far, R.; Saif, M.; Parvania, M. Adversarial semi-supervised learning for diagnosing faults and attacks in power grids. IEEE Trans. Smart Grid 2021, 12, 3468–3478. [Google Scholar] [CrossRef]
- Tamersoy, A.; Roundy, K.; Chau, D.H. Guilt by association: Large scale malware detection by mining file-relation graphs. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1524–1533. [Google Scholar]
- Hsieh, W.C.; Wu, C.C.; Kao, Y.W. A study of android malware detection technology evolution. In Proceedings of the 2015 International Carnahan Conference on Security Technology (ICCST), Taipei, Taiwan, 21–24 September 2015; IEEE: Manhattan, NY, USA, 2015; pp. 135–140. [Google Scholar]
- Muttoo, S.K.; Badhani, S. Android malware detection: State of the art. Int. J. Inf. Technol. 2017, 9, 111–117. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Y.; Zeng, Y. Accurate mobile malware detection and classification in the cloud. SpringerPlus 2015, 4, 583. [Google Scholar] [CrossRef]
- Richter, L. Common weaknesses of android malware analysis frameworks. In IT Security Conference; University of Erlangen-Nuremberg during Summer Term: Erlangen, Germany, 2015; pp. 1–10. [Google Scholar]
- Mahdavifar, S.; Kadir, A.F.A.; Fatemi, R.; Alhadidi, D.; Ghorbani, A.A. Dynamic Android Malware Category Classification using Semi-Supervised Deep Learning. In Proceedings of the (DASC/PiCom/CBDCom/CyberSciTech), Calgary, AB, Canada, 17–22 August 2020; pp. 515–522. [Google Scholar]
- Mahdavifar, S.; Alhadidi, D.; Ghorbani, A.A. Effective and Efficient Hybrid Android Malware Classification Using Pseudo-Label Stacked Auto-Encoder. J. Netw. Syst. Manag. 2022, 30, 22. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, Irvine, School of Information and Computer Sciences: Irvine, CA, USA, 2017; Available online: http://archive.ics.uci.edu/ml (accessed on 24 July 2023).
- Mohammad, R.M.; Thabtah, F.; McCluskey, L. Intelligent rule-based phishing websites classification. Iet Inf. Secur. 2014, 8, 153–160. [Google Scholar] [CrossRef]
- Rho Lall. SMS Spam Collection. 2018. Available online: https://www.kaggle.com/assumewisely/sms-spam-collection (accessed on 24 July 2023).
- Taheri, L.; Kadir, A.F.A.; Lashkari, A.H. Extensible android malware detection and family classification using network-flows and API-calls. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; IEEE: Manhattan, NY, USA, 2019; pp. 1–8. [Google Scholar]
- Moonsamy, V.; Rong, J.; Liu, S. Mining permission patterns for contrasting clean and malicious android applications. Future Gener. Comput. Syst. 2014, 36, 122–132. [Google Scholar] [CrossRef]
- Sharma, A.; Dash, S.K. Mining api calls and permissions for android malware detection. In Cryptology and Network Security, Proceedings of the 13th International Conference, CANS 2014, Heraklion, Crete, Greece, 22–24 October 2014; Proceedings 13; Springer International Publishing: Cham, Switzerland, 2014; pp. 191–205. [Google Scholar]
- Yerima, S.Y.; Sezer, S. Droidfusion: A novel multilevel classifier fusion approach for android malware detection. IEEE Trans. Cybern. 2018, 49, 453–466. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Moraga, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In International Workshop on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 1995; pp. 195–201. [Google Scholar]
- Anastassiou, G.A. Univariate hyperbolic tangent neural network approximation. Math. Comput. Model. 2011, 53, 1111–1132. [Google Scholar] [CrossRef]
- Bracewell, R.N.; Bracewell, R.N. The Fourier Transform and Its Applications; McGraw-Hill: New York, NY, USA, 1986; Volume 31999, p. 1986. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Arp, D.; Quiring, E.; Pendlebury, F.; Warnecke, A.; Pierazzi, F.; Wressnegger, C.; Rieck, K. Dos and do nots of machine learning in computer security. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 3971–3988. [Google Scholar]
- Chio, C.; Freeman, D. Machine Learning and Security: Protecting Systems with Data and Algorithms; O’Reilly Media, Inc.: Newton, MA, USA, 2018. [Google Scholar]
- Cortes, C.; Mohri, M.; Riley, M.; Rostamizadeh, A. Sample selection bias correction theory. In Proceedings of the Conference on Algorithmic Learning Theory (ALT), Budapest, Hungary, 13–16 October 2008. [Google Scholar]
- Allix, K.; Bissyé, T.F.; Klein, J.; Traon, Y.L. Androzoo: Collecting millions of android apps for the research community. In Proceedings of the Conference on Mining Software Repositories (MSR), Austin, TX, USA, 14–15 May 2016. [Google Scholar]
- Wei, F.; Li, Y.; Roy, S.; Ou, X.; Zhou, W. Deep ground truth analysis of current android malware. In Proceedings of the Conference on Detection of Intrusions and Malware & Vulnerability Assessment (DIMVA), Bonn, Germany, 6–7 July 2017. [Google Scholar]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding data augmentation for classification: When to warp? In Proceedings of the Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, Australia, 30 November–2 December 2016. [Google Scholar]
- Zhu, Y.; Xi, D.; Song, B.; Zhuang, F.; Chen, S.; Gu, X.; He, Q. Modeling users’ behavior sequences with hierarchical explainable network for cross-domain fraud detection. In Proceedings of the International World Wide Web Conference (WWW), Taipei, Taiwan, 20–24 April 2020. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2021, 1091, 43–76. [Google Scholar] [CrossRef]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K.-R. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1096. [Google Scholar] [CrossRef]
- Warnecke, A.; Arp, D.; Wressnegger, C.; Rieck, K. Evaluating explanation methods for deep learning in security. In Proceedings of the IEEE European Symposium on Security and Privacy (EuroS&P), Genoa, Italy, 7–11 September 2020. [Google Scholar]
- Hooker, S.; Erhan, D.; Kindermans, P.J.; Kim, B. A benchmark for interpretability methods in deep neural networks. arXiv 2019, arXiv:1806.10758. [Google Scholar]
- Tomsett, R.; Harborne, D.; Chakraborty, S.; Gurram, P.; Preece, A. Sanity checks for saliency metrics. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sandeep, H.R. Static Analysis of Android Malware Detection using Deep Learning. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 841–845. [Google Scholar]
- Lashkari, A.H.; Kadir, A.F.A.; Taheri, L.; Ghorbani, A.A. Toward Developing a Systematic Approach to Generate Benchmark Android Malware Datasets and Classification. In Proceedings of the 2018 International Carnahan Conference on Security Technology (ICCST), Montreal, QC, Canada, 22–25 October 2018; pp. 1–7. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | Accuracy | F1 | AUC ROC | AUC P-R | |
|---|---|---|---|---|---|---|
| Decision Tree | 0.962 | 0.966 | 96.02% | 0.964 | 0.96 | 0.973 |
| Random Forest | 0.968 | 0.980 | 97.18% | 0.974 | 0.971 | 0.980 |
| SVM | 0.943 | 0.964 | 94.9% | 0.954 | 0.947 | 0.964 |
| Sigmoid | 0.968 | 0.982 | 97.21% | 0.975 | 0.971 | 0.981 |
| Hyperbolic Tangent | 0.967 | 0.982 | 97.18% | 0.975 | 0.971 | 0.979 |
| PRelU | 0.971 | 0.981 | 97.32% | 0.976 | 0.972 | 0.981 |
| Precision | Recall | Accuracy | F1 | AUC ROC | AUC P-R | |
|---|---|---|---|---|---|---|
| Decision Tree | 0.9 | 0.923 | 90.12% | 0.911 | 0.899 | 0.933 |
| Random Forest | 0.892 | 0.931 | 90.09% | 0.912 | 0.897 | 0.931 |
| SVM | 0.868 | 0.944 | 89.07% | 0.905 | 0.885 | 0.922 |
| Sigmoid | 0.91 | 0.914 | 90.27% | 0.912 | 0.901 | 0.935 |
| Hyperbolic Tangent | 0.918 | 0.9 | 89.98% | 0.908 | 0.9 | 0.936 |
| PRelU | 0.889 | 0.945 | 90.48% | 0.916 | 0.9 | 0.932 |
| Precision | Recall | Accuracy | F1 | AUC ROC | AUC P-R | |
|---|---|---|---|---|---|---|
| Decision Tree | 0.832 | 0.862 | 95.76% | 0.847 | 0.918 | 0.856 |
| Random Forest | 0.987 | 0.835 | 97.63% | 0.905 | 0.917 | 0.923 |
| SVM | 1.0 | 0.613 | 94.76% | 0.761 | 0.807 | 0.833 |
| Sigmoid | 0.994 | 0.915 | 98.78% | 0.953 | 0.957 | 0.961 |
| Hyperbolic Tangent | 0.933 | 0.952 | 98.42% | 0.942 | 0.971 | 0.946 |
| PRelU | 0.958 | 0.963 | 98.92% | 0.96 | 0.978 | 0.963 |
| Precision | Recall | Accuracy | F1 | AUC ROC | AUC P-R | |
|---|---|---|---|---|---|---|
| Decision Tree | 0.934 | 0.966 | 92.89% | 0.949 | 0.906 | 0.962 |
| Random Forest | 0.910 | 0.972 | 91.47% | 0.940 | 0.879 | 0.951 |
| SVM | 0.903 | 0.965 | 90.52% | 0.934 | 0.867 | 0.947 |
| Sigmoid | 0.923 | 0.979 | 92.89% | 0.950 | 0.897 | 0.958 |
| Hyperbolic Tangent | 0.934 | 0.973 | 93.36% | 0.953 | 0.909 | 0.963 |
| PRelU | 0.929 | 0.986 | 93.84% | 0.957 | 0.909 | 0.962 |
| Precision | Recall | Accuracy | F1 | AUC ROC | AUC P-R | |
|---|---|---|---|---|---|---|
| Benign | 0.934 | 0.877 | 94.31% | 0.905 | 0.925 | 0.925 |
| Adware | 0.778 | 0.808 | 94.79% | 0.792 | 0.888 | 0.805 |
| Ransomware | 0.905 | 0.826 | 97.15% | 0.864 | 0.908 | 0.875 |
| Scareware | 0.714 | 0.8 | 93.84% | 0.755 | 0.878 | 0.769 |
| SMS | 0.773 | 0.74 | 94.79% | 0.756 | 0.856 | 0.77 |
| Banking | 0.942 | 0.999 | 98.58% | 0.97 | 0.991 | 0.971 |
| Precision | Recall | Accuracy | F1 | AUC ROC | AUC P-R | |
|---|---|---|---|---|---|---|
| Phishing | 0.889 | 0.945 | 90.48% | 0.916 | 0.9 | 0.932 |
| Spam SMS | 0.958 | 0.963 | 98.92% | 0.96 | 0.978 | 0.963 |
| APK’s Malwares | 0.929 | 0.986 | 93.84% | 0.957 | 0.909 | 0.962 |
| Class | Benign | Adware | Riskware | SMS | Banking | Total |
|---|---|---|---|---|---|---|
| Samples | 4251 | 2356 | 3865 | 4901 | 2815 | 18,188 |
| Precision | Recall | Accuracy | F1 | AUC ROC | AUC P-R | |
|---|---|---|---|---|---|---|
| Decision Tree Classifier | 0.979 | 0.979 | 97.92% | 0.979 | 0.97 | 0.991 |
| Random Forest Classifier | 0.919 | 0.972 | 97.63% | 0.906 | 0.917 | 0.923 |
| SVM Classifier | 0.903 | 0.944 | 94.9% | 0.954 | 0.947 | 0.964 |
| Sigmoid | 0.987 | 0.994 | 98.58% | 0.991 | 0.978 | 0.993 |
| PRelU | 0.993 | 0.994 | 99.01% | 0.993 | 0.986 | 0.996 |
| TanH | 0.99 | 0.99 | 98.47% | 0.99 | 0.979 | 0.994 |
| Iteractions | Lr | Batch | |
|---|---|---|---|
| Phishing | 200 | 0.0035 | 150 |
| 0.006 only for Sigmoid | |||
| Spam SMS | 50 | 0.02 | 1500 |
| APK Malware | 75 | 0.02 | 100 |
| Precision | Recall | Accuracy | F1 | AUC ROC | AUC P-R | |
|---|---|---|---|---|---|---|
| Benign vs. Malware | 0.994 | 0.993 | 99.01% | 0.989 | 0.986 | 0.996 |
| Precision | Recall | Accuracy | F1 | AUC ROC | AUC P-R | |
|---|---|---|---|---|---|---|
| Benign | 0.982 | 0.972 | 98.89% | 0.977 | 0.983 | 0.981 |
| Adware | 0.915 | 0.904 | 98.28% | 0.91 | 0.948 | 0.914 |
| Riskware | 0.93 | 0.956 | 97.31% | 0.943 | 0.967 | 0.948 |
| SMS | 0.977 | 0.974 | 98.56% | 0.975 | 0.982 | 0.979 |
| Banking | 0.908 | 0.894 | 97.33% | 0.900 | 0.94 | 0.908 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gómez, A.; Muñoz, A. Deep Learning-Based Attack Detection and Classification in Android Devices. Electronics 2023, 12, 3253. https://doi.org/10.3390/electronics12153253
Gómez A, Muñoz A. Deep Learning-Based Attack Detection and Classification in Android Devices. Electronics. 2023; 12(15):3253. https://doi.org/10.3390/electronics12153253
Chicago/Turabian StyleGómez, Alfonso, and Antonio Muñoz. 2023. "Deep Learning-Based Attack Detection and Classification in Android Devices" Electronics 12, no. 15: 3253. https://doi.org/10.3390/electronics12153253
APA StyleGómez, A., & Muñoz, A. (2023). Deep Learning-Based Attack Detection and Classification in Android Devices. Electronics, 12(15), 3253. https://doi.org/10.3390/electronics12153253