
BiGA-YOLO: A Lightweight Object Detection Network Based on YOLOv5 for Autonomous Driving


Abstract
1. Introduction
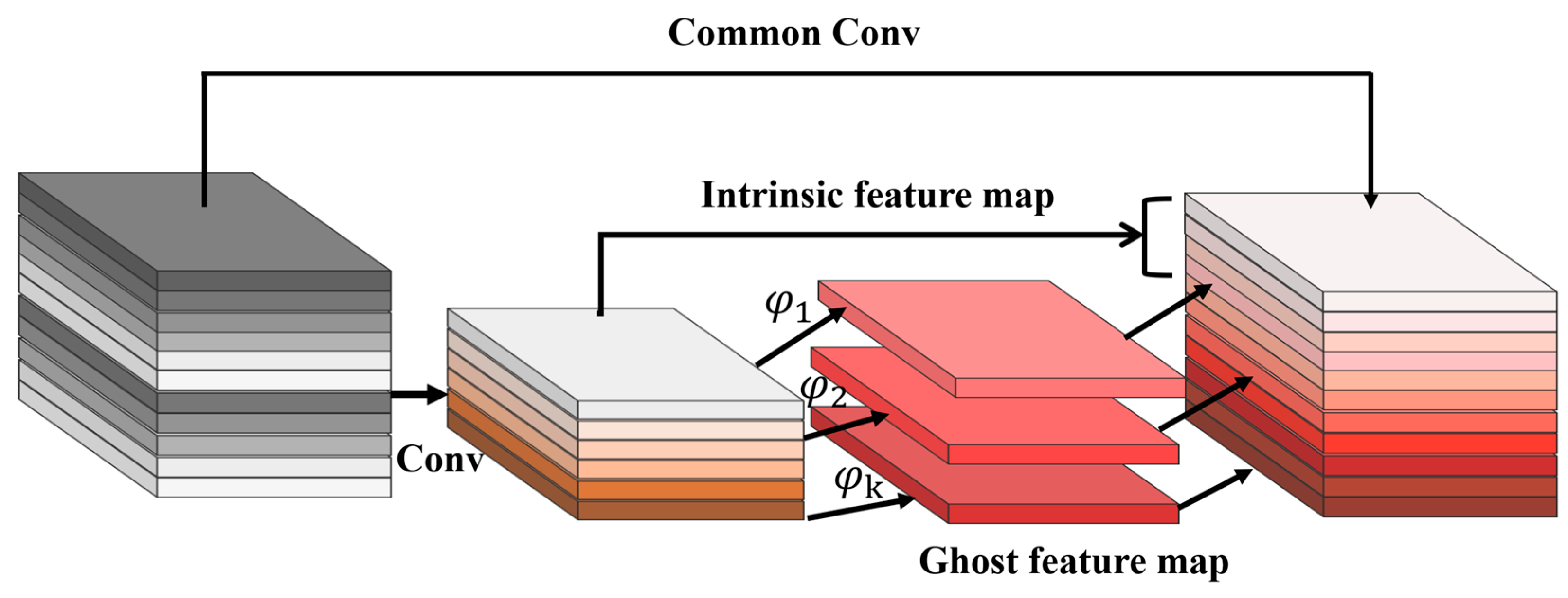
- We introduce the Ghost module [26] and design the GHConv (Ghost-HardSwish Conv) module as the main convolution method to simplify the model, and integrate the CA (Coordinate Attention) [27] to capture the spatial dependency of image information in order to more effectively extract features of targets in the image.
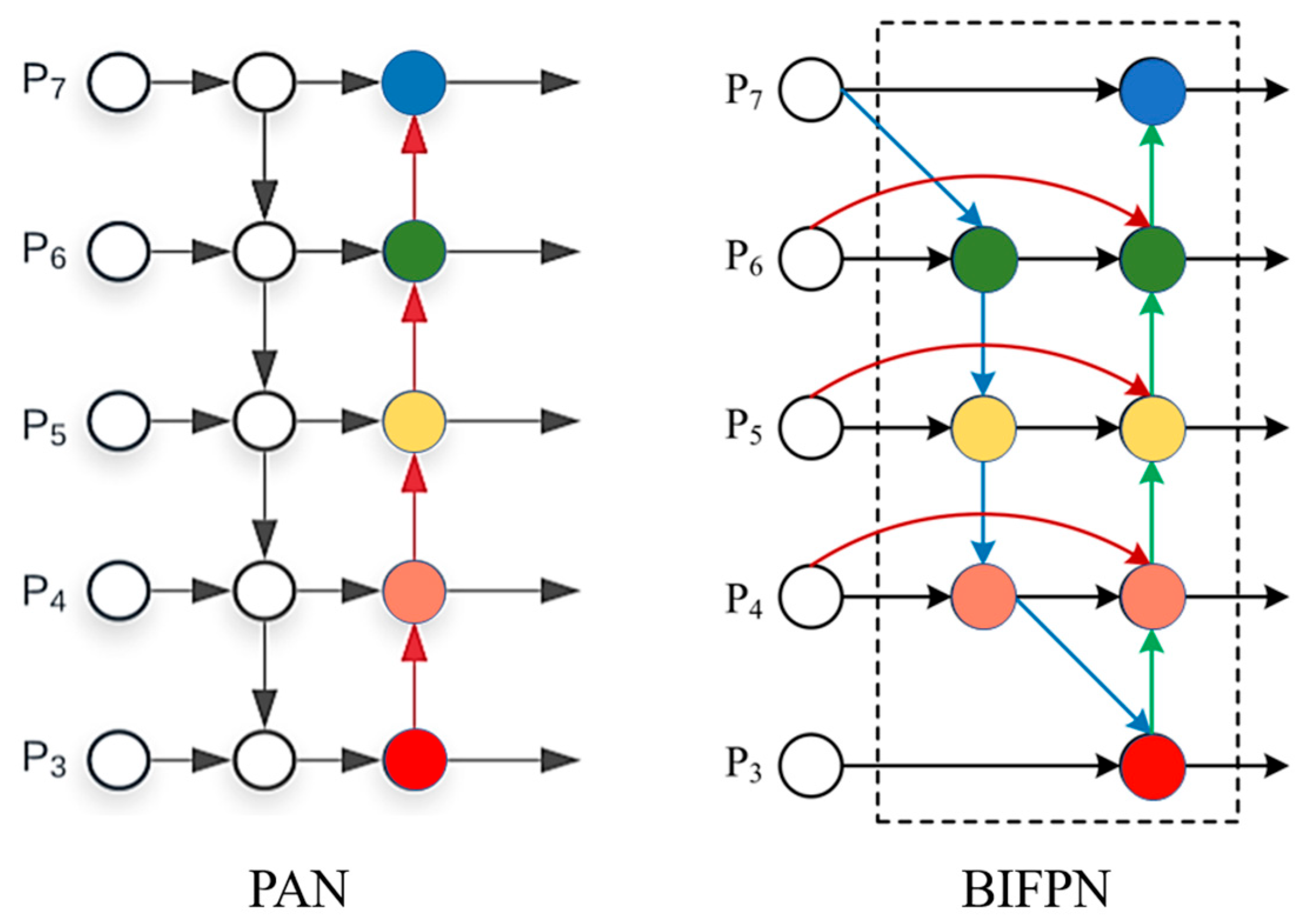
- We integrate the BiFPN (Bi-directional Feature Pyramid Network) [28] architecture, which learns the features of different resolutions with different weights and horizontally connects them with residual structures to fuse multi-scale feature information, to improve the PANet architecture in YOLOv5.
- We propose the BiGA (Bidrectional-Ghost conv-Attention)-YOLO network by integrating the above-mentioned improvement methods, and conduct experiments on the KITTI dataset, achieving a mAP@0.5 of 92.2% and a mAP@0.5:0.95 of 68.3%. Furthermore, the model is simplified by 15.7% and detection speed is raised by 6.3 FPS, which achieves a balance among model size, detection accuracy, and speed.
2. Related Works
2.1. CNN-Based Object Detection
2.2. Attention Mechanism
2.3. Model Lightweight
3. Method
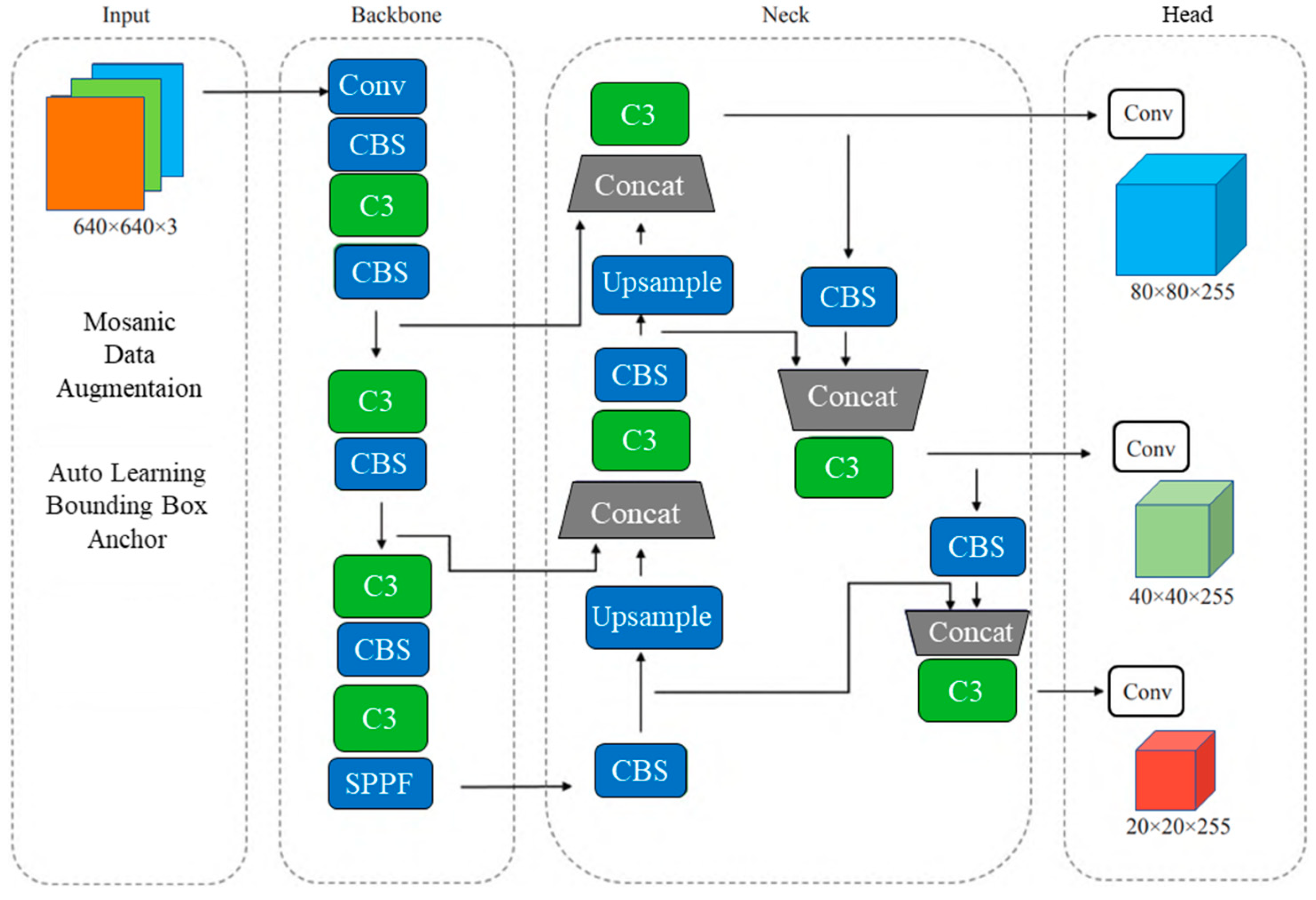
3.1. Overview and Key Components of YOLOv5
3.1.1. Input
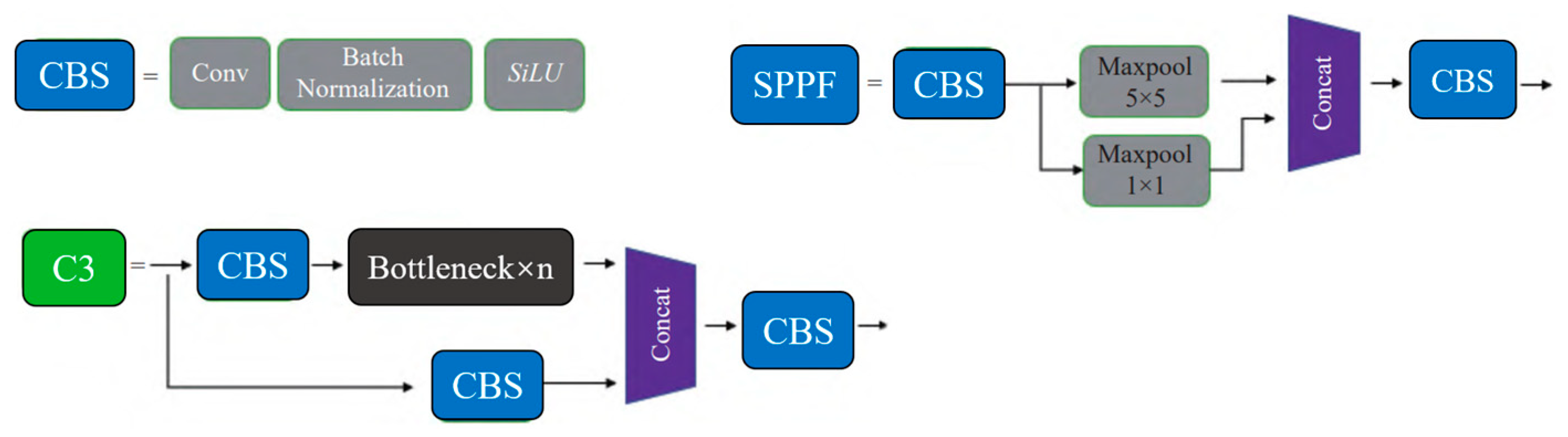
3.1.2. Backbone
3.1.3. Neck
3.1.4. Head
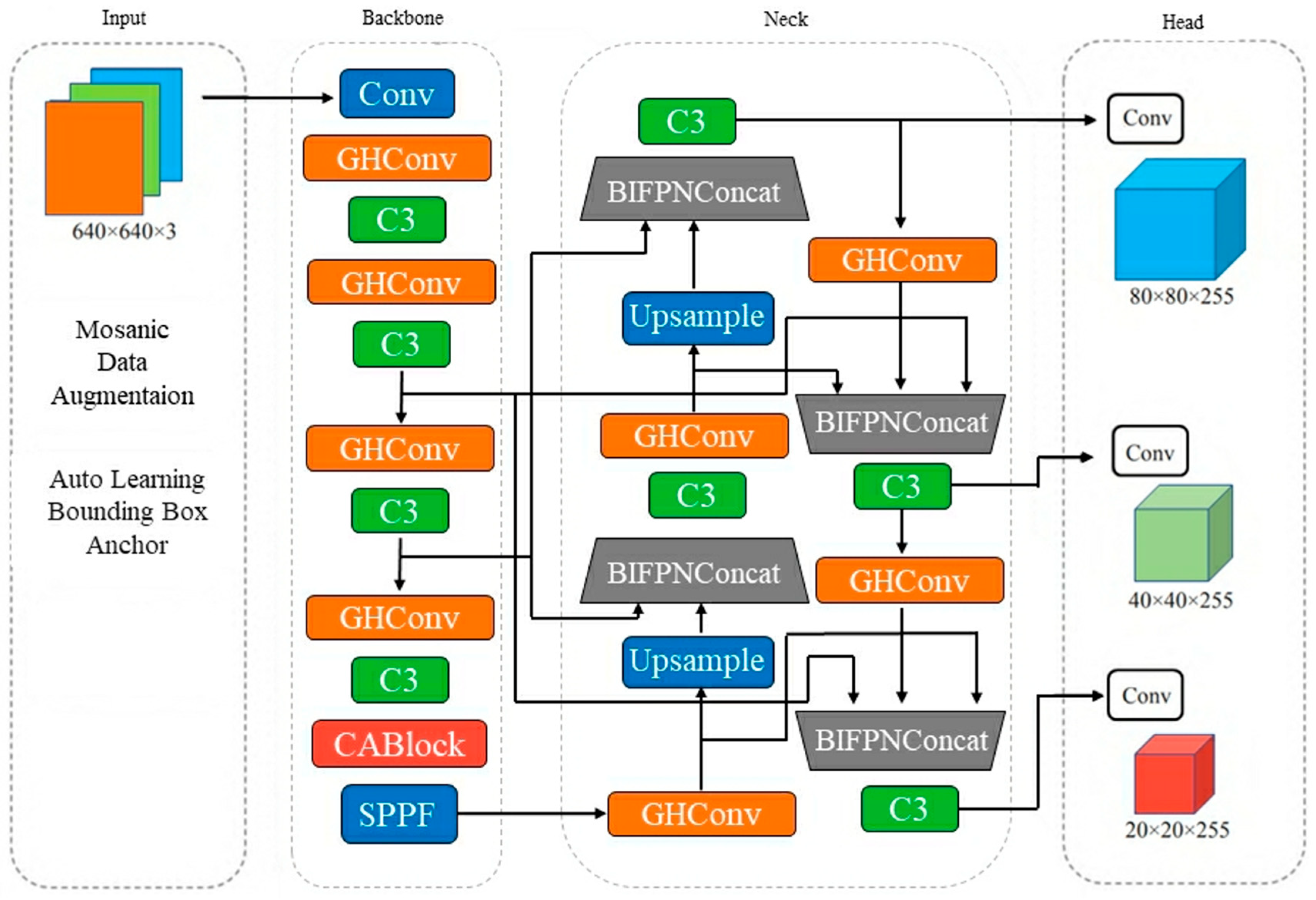
3.2. BiGA-YOLO
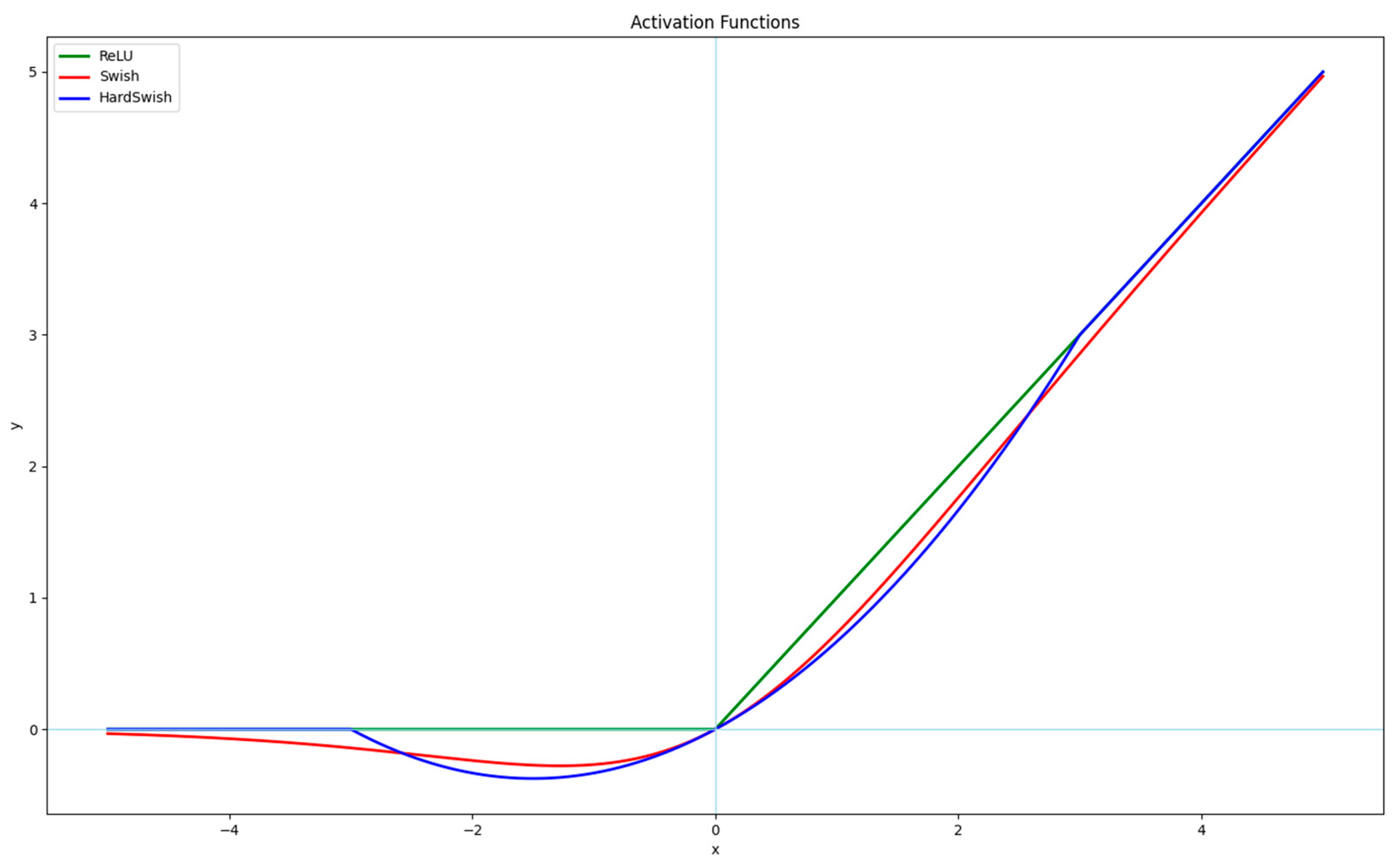
3.2.1. GHConv Module
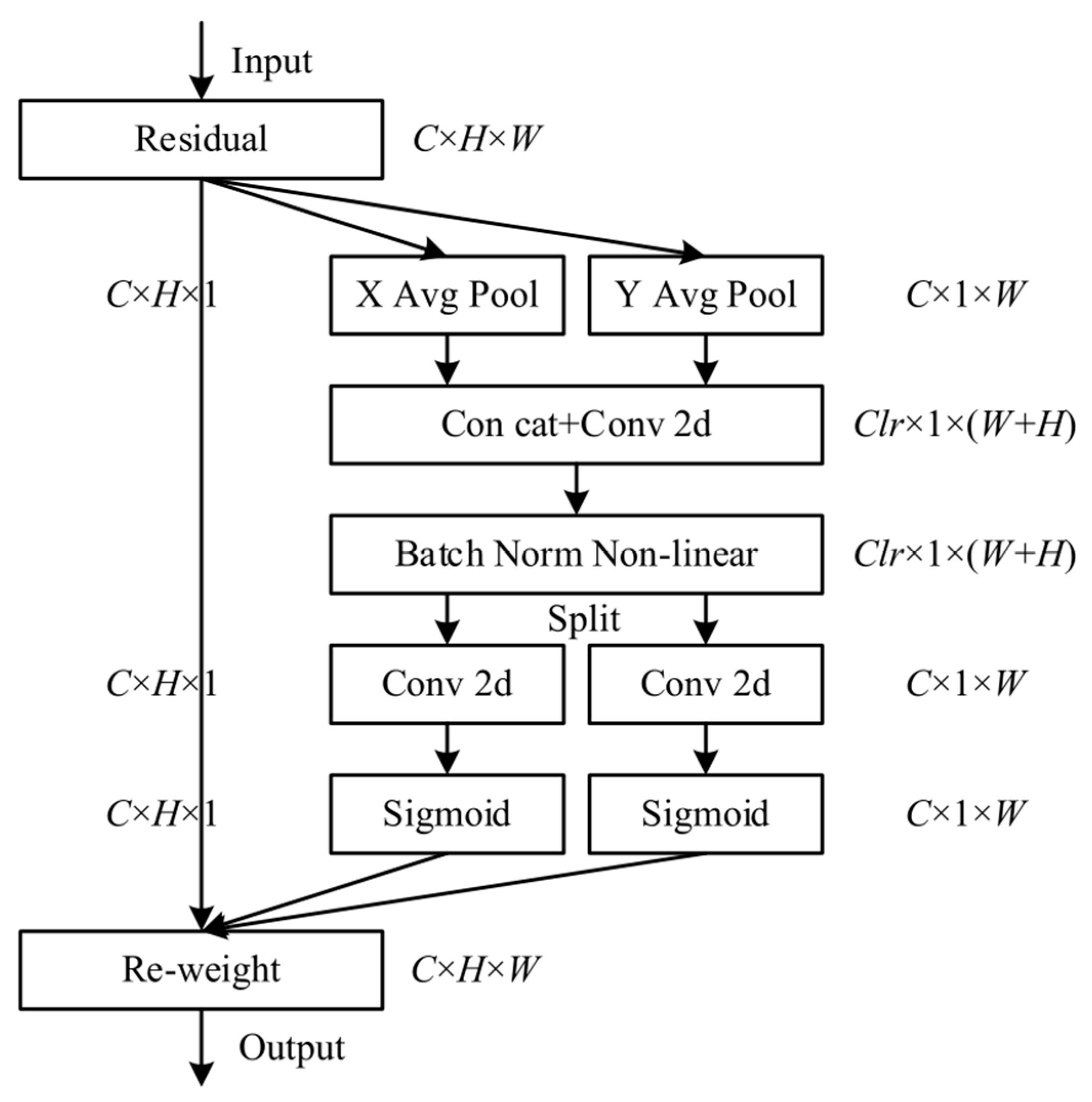
3.2.2. CA Module
3.2.3. BiFPN
4. Experiments
4.1. Experimental Introduction
4.1.1. Data Description
4.1.2. Implementation and Settings
4.1.3. Evaluation Metrics
4.2. Results
4.3. Comparisons
4.4. Ablation Study
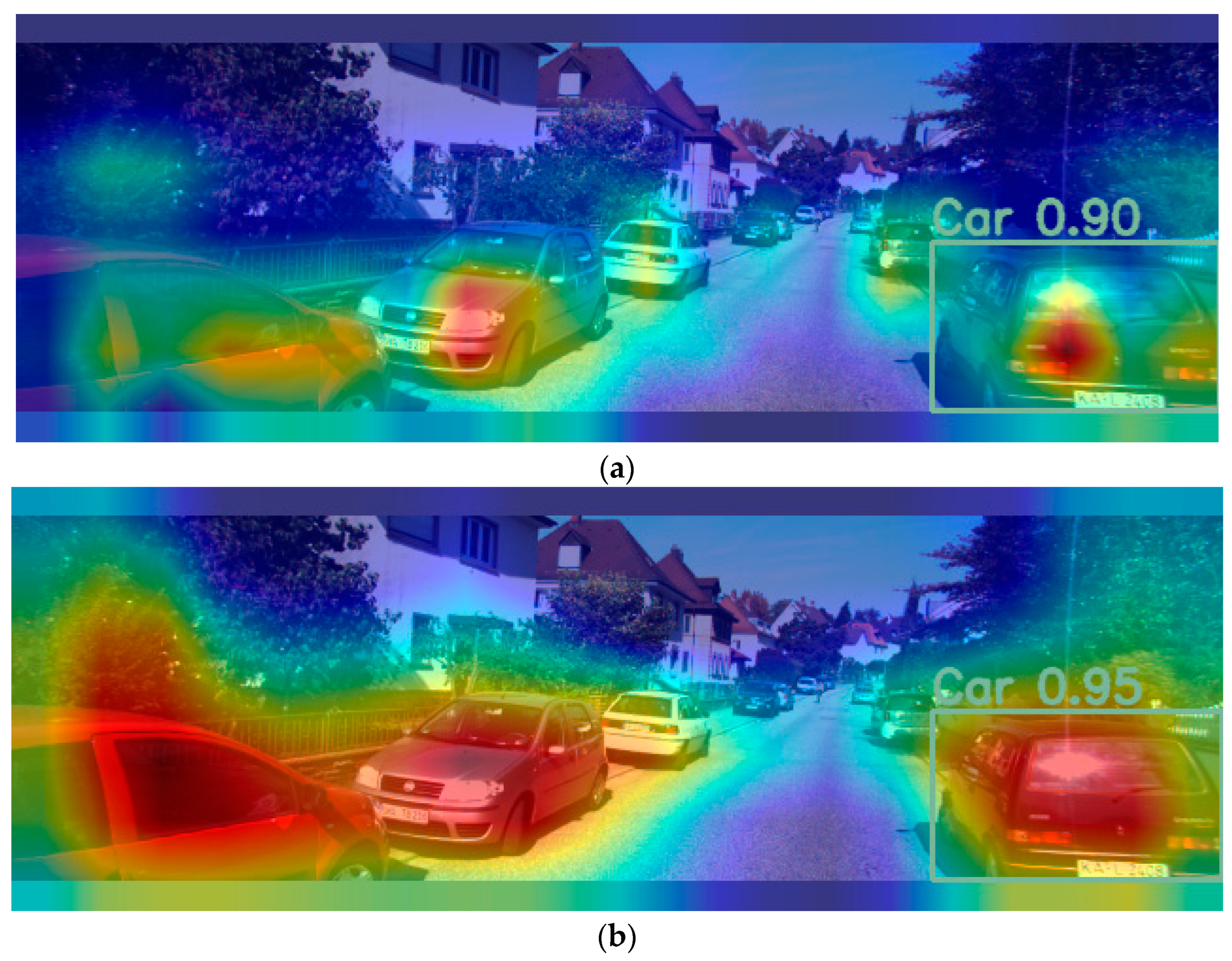
4.5. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Liao, L.; Li, B.; Zou, F.; Huang, D. MFGCN: A Multimodal Fusion Graph Convolutional Network for Online Car-hailing Demand Prediction. IEEE Intell. Syst. 2023, 38, 21–30. [Google Scholar] [CrossRef]
- Liao, L.; Hu, Z.; Zheng, Y.; Bi, S.; Zou, F.; Qiu, H.; Zhang, M. An improved dynamic Chebyshev graph convolution network for traffic flow prediction with spatial-temporal attention. Appl. Intell. 2022, 52, 16104–16116. [Google Scholar] [CrossRef]
- Liao, L.; Hu, Z.; Hsu, C.-Y.; Su, J. Fourier Graph Convolution Network for Time Series Prediction. Mathematics 2023, 11, 1649. [Google Scholar] [CrossRef]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. Adv. Neural Inf. Process. Syst. 2013, 26, 10–15. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 21–23. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceeding of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Cui, L.; Ma, R.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Xu, M. MDSSD: Multi-scale deconvolutional single shot detector for small objects. arXiv 2018, arXiv:1805.07009. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 based on transformer prediction head for object detection on drone-captured scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Li, A.; Sun, S.; Zhang, Z.; Feng, M.; Wu, C.; Li, W. A Multi-Scale Traffic Object Detection Algorithm for Road Scenes Based on Improved YOLOv5. Electronics 2023, 12, 878. [Google Scholar] [CrossRef]
- Li, S.; Li, Y.; Li, Y.; Li, M.; Xu, X. Yolo-firi: Improved yolov5 for infrared image object detection. IEEE Access 2021, 9, 141861–141875. [Google Scholar] [CrossRef]
- Benjumea, A.; Teeti, I.; Cuzzolin, F.; Bradley, A. YOLO-Z: Improving small object detection in YOLOv5 for autonomous vehicles. arXiv 2021, arXiv:2112.11798. [Google Scholar]
- Inam, H.; Islam, N.U.; Akram, M.U.; Ullah, F. Smart and Automated Infrastructure Management: A Deep Learning Approach for Crack Detection in Bridge Images. Sustainability 2023, 15, 1866. [Google Scholar] [CrossRef]
- Mahaur, B.; Mishra, K.K. Small-object detection based on YOLOv5 in autonomous driving systems. Pattern Recognit. Lett. 2023, 168, 115–122. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Liu, C.; Zhang, W.; Lin, X.; Zhang, W.; Tan, X.; Han, J.; Li, X.; Ding, E.; Wang, J. Ambiguity-Resistant Semi-Supervised Learning for Dense Object Detection. arXiv 2023, arXiv:2303.14960. [Google Scholar]
- Chorowski, J.K.; Bahdanau, D.; Serdyuk, D.; Cho, K.; Bengio, Y. Attention-based models for speech recognition. Adv. Neural Inf. Process. Syst. 2015, 28, 18–20. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 25–29. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. Xnor-net: Imagenet classification using binary convolutional neural networks. In Proceeding of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV; Springer International Publishing: Cham, Switzerland, 2016; pp. 525–542. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Fullform |
|---|---|
| CNN | Convolutional Neural Network |
| RCNN | Region-based Convolutional Neural Network |
| SSD | Single Shot MultiBox Detector |
| FPN | Feature Pyramid Network |
| PAN | Pixel Aggregation Network |
| CA | Coordinate Attention |
| CBAM | Convolutional Block Attention Module |
| BiFPN | Bi-directional Feature Pyramid Network |
| mAP | Mean Average Precision |
| FLOPs | Floating Point Operations |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | FLOPS (G) | Weights (M) | FPS (Hz) |
|---|---|---|---|---|---|
| YOLOv5s | 90.3 | 63.6 | 16.5 | 14.0 | 108.6 |
| Fast-RCNN | 76.9 | 44.9 | 223.4 | 160.1 | 70.5 |
| SSD | 74.3 | 42.2 | 93.57 | 131.0 | 101.3 |
| YOLOv5s-MobileNetv3 | 87.6 | 57.8 | 6.3 | 7.2 | 106.3 |
| YOLOv5s-Shufflenetv2 | 88.4 | 59.9 | 8.0 | 7.7 | 110.2 |
| Multi-scale YOLOv5s | 91.1 | 63.9 | 32.1 | 31.8 | 98.7 |
| Ours | 92.2 | 68.3 | 13.8 | 11.8 | 114.9 |
| Model | Car | Pedestrian | Cyclist |
|---|---|---|---|
| YOLOv5s | 97.2 | 83.6 | 90.1 |
| Fast-RCNN | 84.8 | 70.5 | 75.4 |
| SSD | 80.3 | 68.5 | 74.1 |
| YOLOv5s-MobileNetv3 | 96.7 | 80.7 | 85.4 |
| YOLOv5s-Shufflenetv2 | 96.1 | 82.3 | 86.8 |
| Multi-scale YOLOv5s | 96.5 | 87.3 | 89.5 |
| Ours | 98.1 | 91.5 | 87.0 |
| Model | mAP@0.5 (%) | mAP@0.5:0.95 (%) | FLOPS (G) | Weights (M) | FPS (Hz) |
|---|---|---|---|---|---|
| YOLOv5s | 90.3 | 63.6 | 16.5 | 14.0 | 108.6 |
| YOLOv5s + GHConv | 89.6 | 60.4 | 12.3 | 11.3 | 110.4 |
| YOLOv5s + GHConv + CA | 89.4 | 61.5 | 12.6 | 11.4 | 110.1 |
| Ours | 92.2 | 68.3 | 13.8 | 11.8 | 114.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Cai, Q.; Zou, F.; Zhu, Y.; Liao, L.; Guo, F. BiGA-YOLO: A Lightweight Object Detection Network Based on YOLOv5 for Autonomous Driving. Electronics 2023, 12, 2745. https://doi.org/10.3390/electronics12122745
Liu J, Cai Q, Zou F, Zhu Y, Liao L, Guo F. BiGA-YOLO: A Lightweight Object Detection Network Based on YOLOv5 for Autonomous Driving. Electronics. 2023; 12(12):2745. https://doi.org/10.3390/electronics12122745
Chicago/Turabian StyleLiu, Jun, Qiqin Cai, Fumin Zou, Yintian Zhu, Lyuchao Liao, and Feng Guo. 2023. "BiGA-YOLO: A Lightweight Object Detection Network Based on YOLOv5 for Autonomous Driving" Electronics 12, no. 12: 2745. https://doi.org/10.3390/electronics12122745
APA StyleLiu, J., Cai, Q., Zou, F., Zhu, Y., Liao, L., & Guo, F. (2023). BiGA-YOLO: A Lightweight Object Detection Network Based on YOLOv5 for Autonomous Driving. Electronics, 12(12), 2745. https://doi.org/10.3390/electronics12122745