
Deep-Learning-Based Approaches for Semantic Segmentation of Natural Scene Images: A Review

 , ,
, ,  , , and
, , and
Abstract
1. Introduction
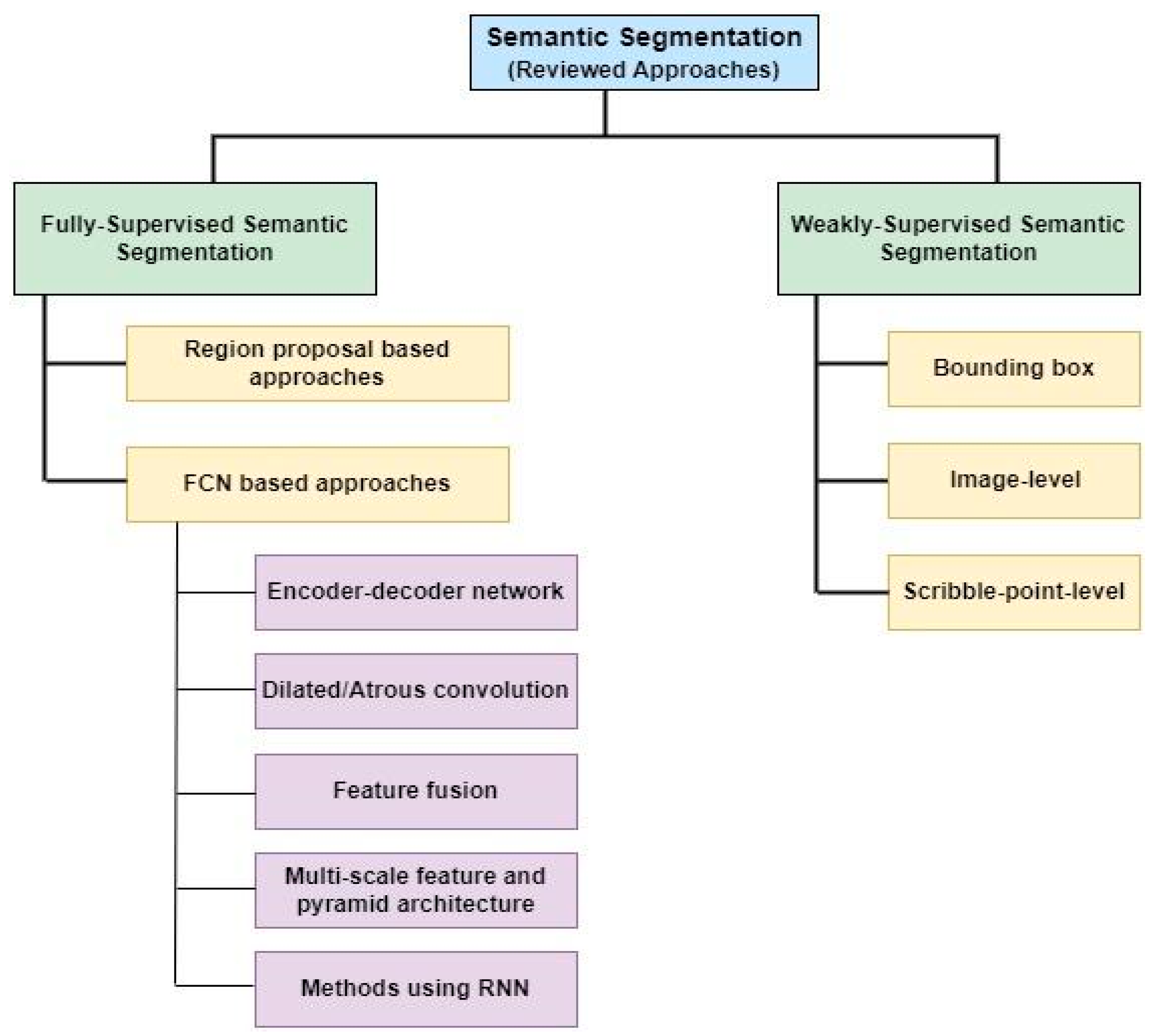
2. Fully Supervised Semantic Segmentation
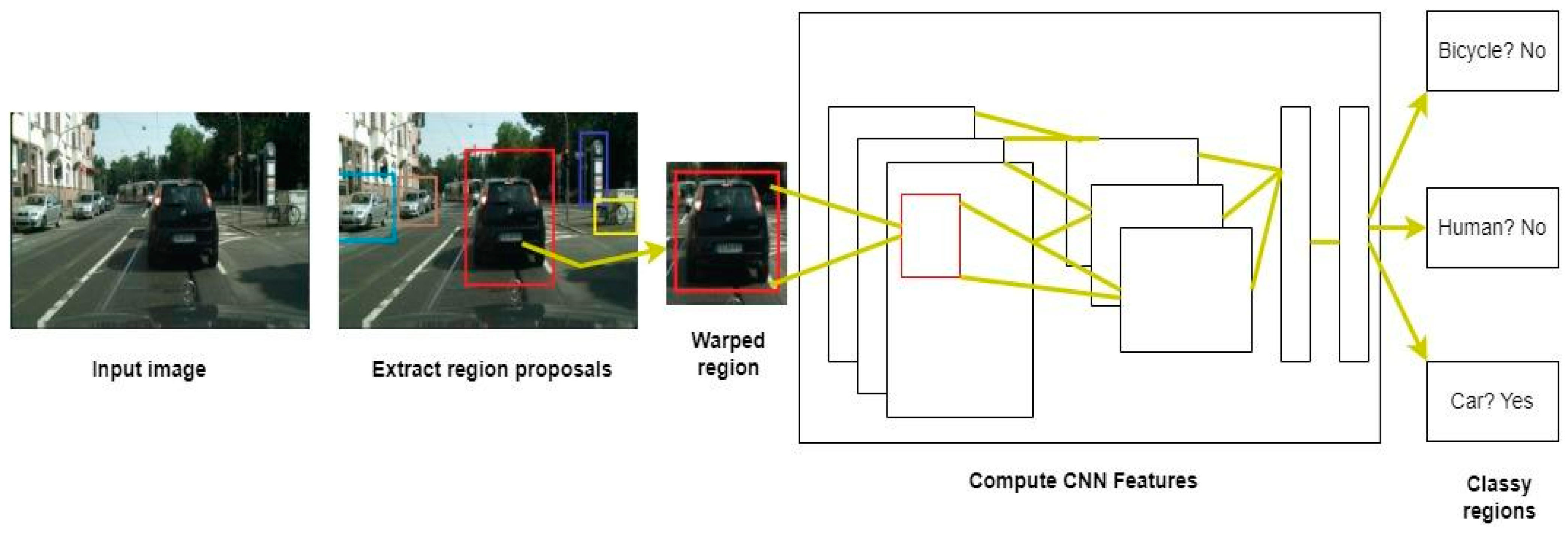
2.1. Region-Proposal-Based Approaches
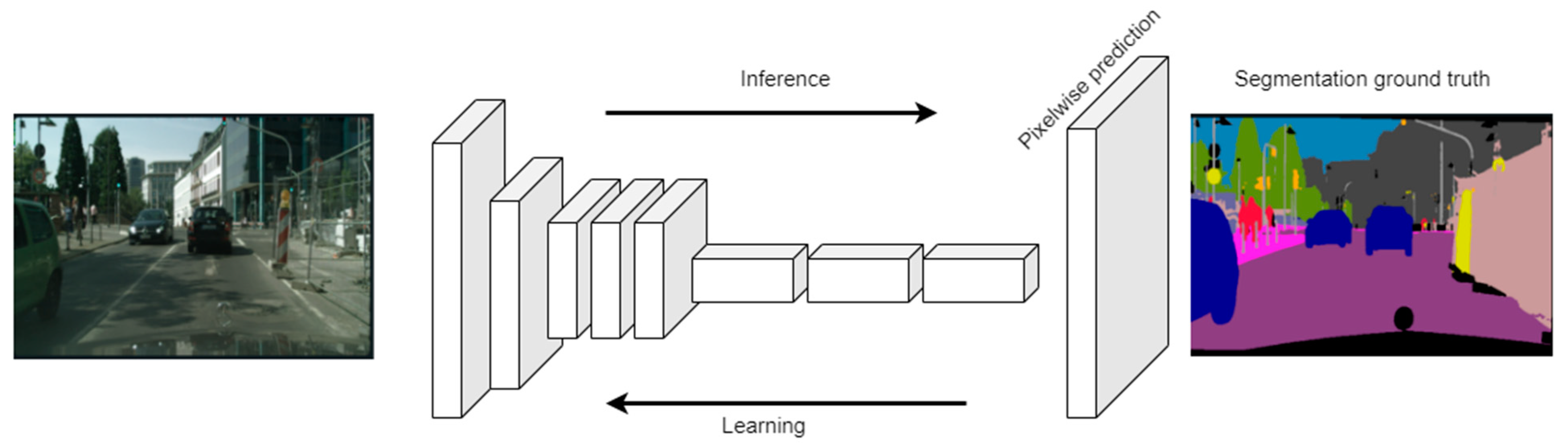
2.2. Fully Convolutional Network (FCN)-Based Approaches

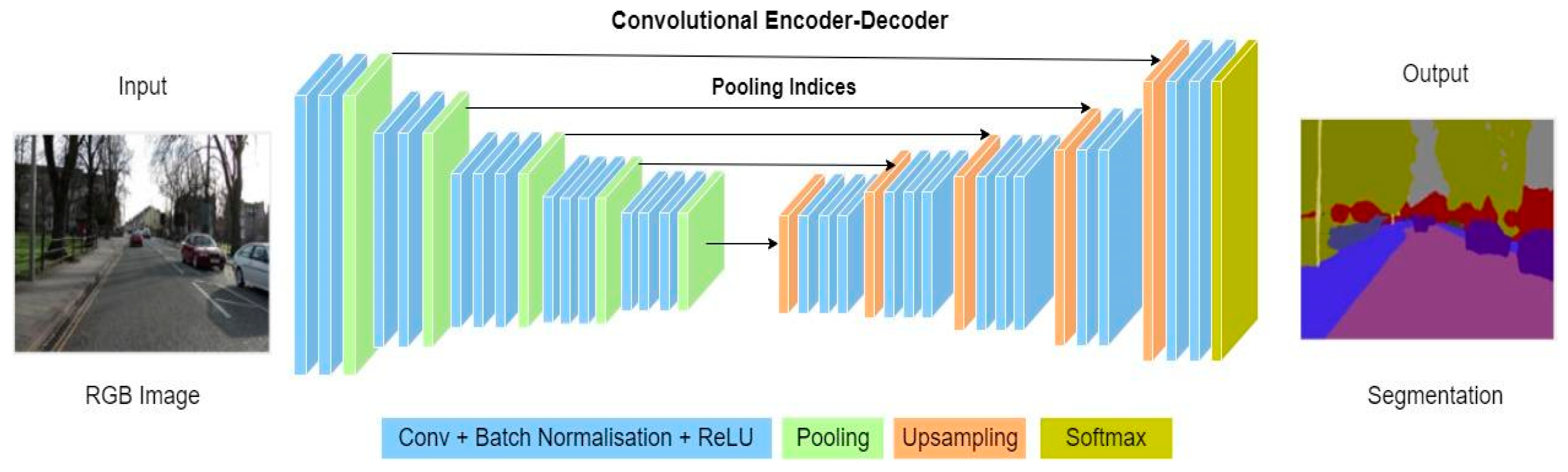
2.2.1. Encoder-Decoder Network
2.2.2. Dilated/Atrous Convolution
2.2.3. Feature Fusion
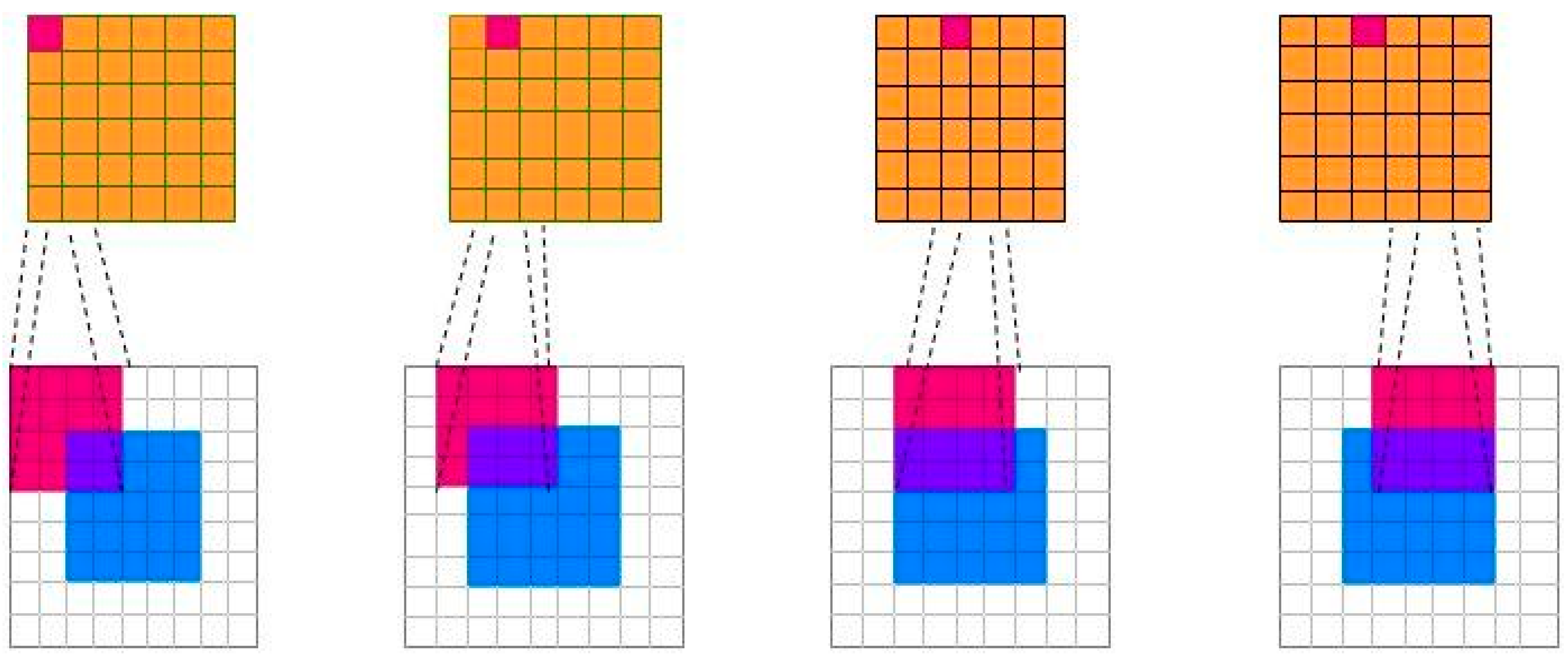
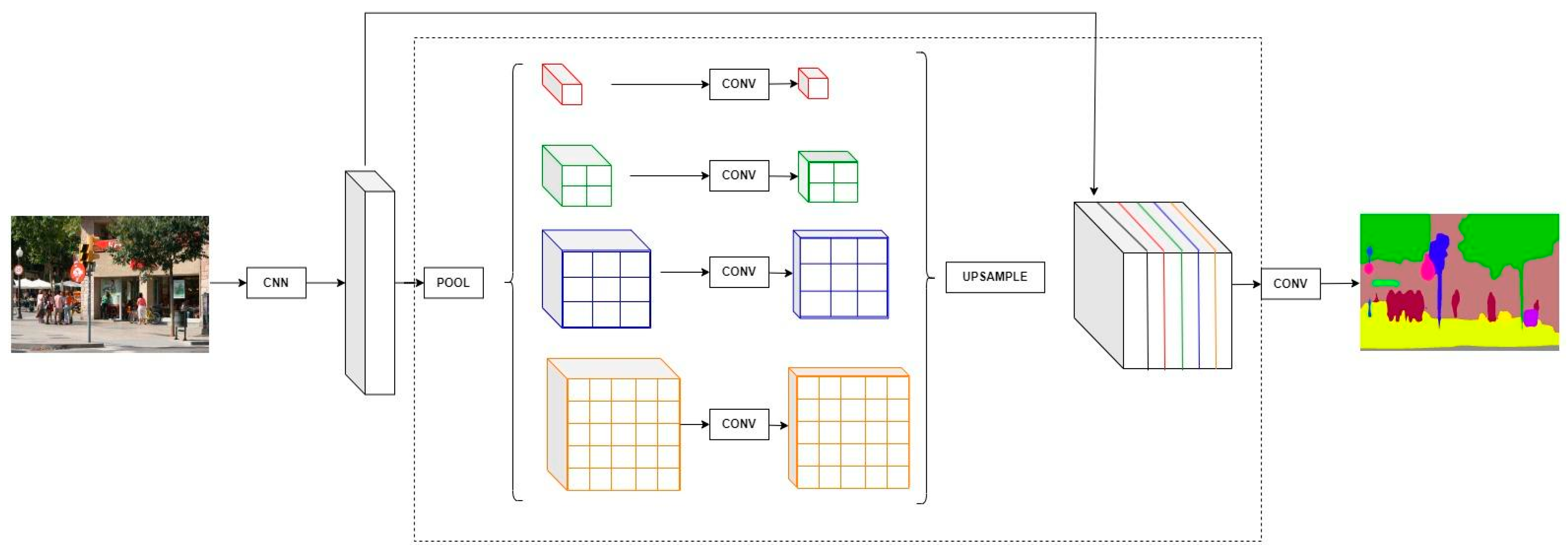
2.2.4. Multi-Scale Feature and Pyramid Architecture
2.2.5. Methods Using Recurrent Neural Networks (RNN)
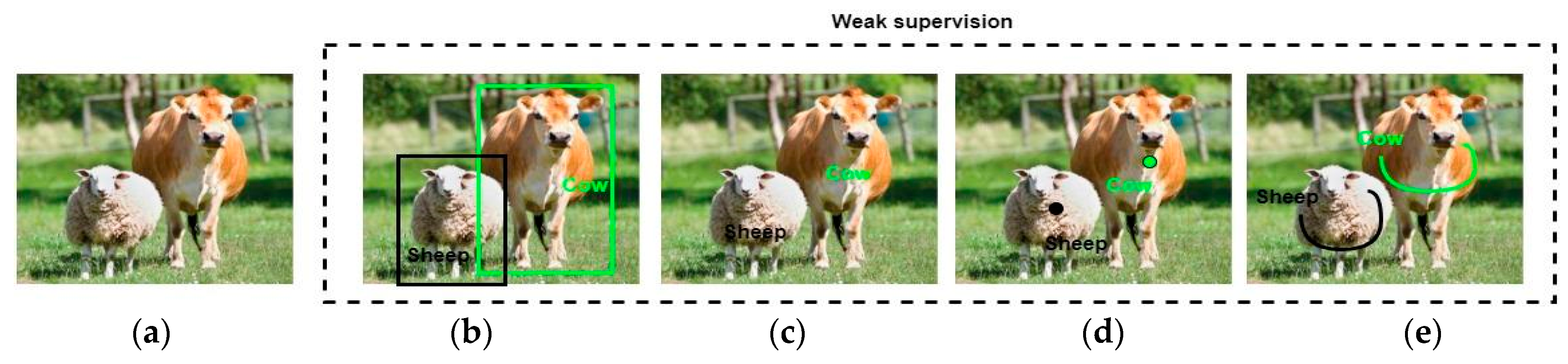
3. Weakly Supervised Semantic Segmentation
3.1. Bounding Box
3.2. Image-Level
- Multi-Instance Learning (MIL)
- Class Activation Maps (CAM)
3.3. Scribble-Point Level
4. Recent Approaches in Semantic Segmentation
4.1. Segment Anything Model (SAM)
4.2. Unsupervised Domain Adaptive in Semantic Segmentation
- The process of source domain training involves the utilization of conventional supervised learning methods to train a model on labeled data obtained from the source domain. The model that has undergone training is capable of accurately segmenting images within the source domain.
- The process of feature alignment involves utilizing the model to extract features from both the source and target domain data. The objective is to achieve a high degree of similarity in the distribution of features across both domains. Typically, this stage entails a form of adversarial training [171]. The approaches based on adversarial training, such as [172,173,174] have made remarkable progress for UDA semantic segmentation.
- Many UDA semantic segmentation techniques employ self-training or self-supervision, whereby the model’s predictions on the target domain are utilized as pseudo-labels for subsequent training. Typically, this process is executed meticulously and incrementally, whereby the model’s highly assured predictions are employed to progressively enhance its capacity to manage the intended field. Approaches based on self-training or self-supervision such as [175,176,177] have demonstrated significant advancements in UDA semantic segmentation.
- The model is subjected to evaluation in the target domain, employing conventional segmentation metrics such as pixel accuracy or ‘IoU’, followed by fine-tuning. If deemed essential, the second and third steps are reiterated to achieve additional adaptation.
5. Post-Processing Algorithms in Semantic Segmentation
5.1. Conditional Random Fields (CRF)
5.2. Markov Random Field (MRF)
5.3. Random Walker
5.4. Domain Transform
6. Datasets
- ADE20K
- COCO Stuff
- Pascal VOC (Visual Object Classes)
- Pascal Context
- NYU-Depth V2 (NYUDv2)
- SUN RGBD
- Berkeley Deep Drive (BDD100K)
- The Cambridge-driving Labeled Video Database (CamVid)
- Cityscapes
- DTMR-DVR
- KITTI
- GATECH
- SIFT Flow
- Stanford Background

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Content | Dataset, Year | Number of Classes | Number of Images | Samples | Image Resolution | ||
|---|---|---|---|---|---|---|---|
| Training | Validation | Testing | |||||
| Generic | ADE20K [189] (2017) | 150 | 25k | 20,210 | 2000 | 3352 | 2400 × 1800 |
| COCO Stuff [191] (2018) | 171 | 164k | 118k | 5k | 45k | variable | |
| Pascal VOC 2010 [207] (2010) | 20 | 1928 | 771 | 289 | 868 | 500 × 400 | |
| Pascal VOC 2012 [192] (2012) | 21 | 4369 | 1464 | 1449 | 1456 | variable | |
| Pascal Context [193] (2014) | 59 | 10,103 | 4998 | - | 5105 | variable | |
| Indoor | NYUDv2 [194] (2012) | 40 | 1449 | 795 | - | 654 | 480 × 640 |
| SUN RGBD [195] (2013) | 37 | 10,335 | 5285 | - | 5050 | variable | |
| BDD100K [196] (2020) | 40 | 100k video frames | 70k | 10k | 20k | 1280 × 720 | |
| CamVid [197] (2009) | 32 | 701 video frames | 367 | 100 | 233 | 960 × 720 | |
| Cityscapes [198] (2016) | 30 | 5000 | 2975 | 500 | 1525 | 2048 × 1024 | |
| DTMR-DVR [199] (2020) | 13 | 600 video frames | 400 | 100 | 100 | 1280 × 960 | |
| KITTI [200] (2012) | 19 | 580 | 289 | - | 290 | 1226 × 370 | |
| Outdoor | GATECH [201] (2013) | 84 | 20k video frames | 13k | 7k | 7k | variable |
| SIFT Flow [202] (2009) | 33 | 2688 | 2488 | - | 200 | 256 × 256 | |
| Stanford Background [204] (2009) | 8 | 725 | 572 | - | 143 | 320 × 240 | |
7. Evaluation
Accuracy
8. Discussion and Future Directions
9. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zheng, W.; Liu, X.; Ni, X.; Yin, L.; Yang, B. Improving visual reasoning through semantic representation. IEEE Access 2021, 9, 91476–91486. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Lateef, F.; Ruichek, Y. Survey on semantic segmentation using deep learning techniques. Neurocomputing 2019, 338, 321–348. [Google Scholar] [CrossRef]
- Hao, S.; Zhou, Y.; Guo, Y. A brief survey on semantic segmentation with deep learning. Neurocomputing 2020, 406, 302–321. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the state-of-the-art technologies of semantic segmentation based on deep learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Zhang, M.; Zhou, Y.; Zhao, J.; Man, Y.; Liu, B.; Yao, R. A survey of semi-and weakly supervised semantic segmentation of images. Artif. Intell. Rev. 2020, 53, 4259–4288. [Google Scholar] [CrossRef]
- Ulku, I.; Akagündüz, E. A survey on deep learning-based architectures for semantic segmentation on 2d images. Appl. Artif. Intell. 2022, 36, 2032924. [Google Scholar] [CrossRef]
- Alokasi, H.; Ahmad, M.B. Deep learning-based frameworks for semantic segmentation of road scenes. Electronics 2022, 11, 1884. [Google Scholar] [CrossRef]
- Yu, Y.; Wang, C.; Fu, Q.; Kou, R.; Huang, F.; Yang, B.; Yang, T.; Gao, M. Techniques and Challenges of Image Segmentation: A Review. Electronics 2023, 12, 1199. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 91–99. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Convolutional feature masking for joint object and stuff segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3992–4000. [Google Scholar]
- Hariharan, B.; Arbeláez, P.; Girshick, R.; Malik, J. Simultaneous detection and segmentation. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 297–312. [Google Scholar]
- Arbeláez, P.; Pont-Tuset, J.; Barron, J.T.; Marques, F.; Malik, J. Multiscale combinatorial grouping. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 328–335. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. Region-based semantic segmentation with end-to-end training. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 381–397. [Google Scholar]
- Shen, D.; Ji, Y.; Li, P.; Wang, Y.; Lin, D. Ranet: Region attention network for semantic segmentation. Adv. Neural Inf. Process. Syst. 2020, 33, 13927–13938. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Elman, J.L. Finding structure in time. Cognit. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. 2001. Available online: https://repository.upenn.edu/cis_papers/159/?ref=https://githubhelp.com (accessed on 5 April 2023).
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–14 December 2011; Volume 24. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1529–1537. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Badrinarayanan, V.; Handa, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for robust semantic pixel-wise labelling. arXiv 2015, arXiv:1505.07293. [Google Scholar]
- Kendall, A.; Badrinarayanan, V.; Cipolla, R. Bayesian segnet: Model uncertainty in deep convolutional encoder-decoder architectures for scene understanding. arXiv 2015, arXiv:1511.02680. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Bayesian convolutional neural networks with Bernoulli approximate variational inference. arXiv 2015, arXiv:1506.02158. [Google Scholar]
- Treml, M.; Arjona-Medina, J.; Unterthiner, T.; Durgesh, R.; Friedmann, F.; Schuberth, P.; Mayr, A.; Heusel, M.; Hofmarcher, M.; Widrich, M. Speeding Up Semantic Segmentation for Autonomous Driving. 2016. Available online: https://openreview.net/forum?id=S1uHiFyyg (accessed on 5 April 2023).
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1925–1934. [Google Scholar]
- Fourure, D.; Emonet, R.; Fromont, E.; Muselet, D.; Tremeau, A.; Wolf, C. Residual conv-deconv grid network for semantic segmentation. arXiv 2017, arXiv:1707.07958. [Google Scholar]
- Li, Q.; Wang, H.; Li, B.-Y.; Yanghua, T.; Li, J. IIE-SegNet: Deep semantic segmentation network with enhanced boundary based on image information entropy. IEEE Access 2021, 9, 40612–40622. [Google Scholar] [CrossRef]
- Weng, X.; Yan, Y.; Chen, S.; Xue, J.-H.; Wang, H. Stage-aware feature alignment network for real-time semantic segmentation of street scenes. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4444–4459. [Google Scholar] [CrossRef]
- Tang, Q.; Liu, F.; Zhang, T.; Jiang, J.; Zhang, Y.; Zhu, B.; Tang, X. Compensating for Local Ambiguity With Encoder-Decoder in Urban Scene Segmentation. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19224–19235. [Google Scholar] [CrossRef]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Islam, M.A.; Naha, S.; Rochan, M.; Bruce, N.; Wang, Y. Label refinement network for coarse-to-fine semantic segmentation. arXiv 2017, arXiv:1703.00551. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Amirul Islam, M.; Rochan, M.; Naha, S.; Bruce, N.D.; Wang, Y. Gated Feedback Refinement Network for Coarse-to-Fine Dense Semantic Image Labeling. arXiv 2018, arXiv:1806.11266. [Google Scholar]
- Bilinski, P.; Prisacariu, V. Dense decoder shortcut connections for single-pass semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6596–6605. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1492–1500. [Google Scholar]
- Fu, J.; Liu, J.; Wang, Y.; Zhou, J.; Wang, C.; Lu, H. Stacked deconvolutional network for semantic segmentation. IEEE Trans. Image Process. 2019. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4700–4708. [Google Scholar]
- Li, J.; Yu, J.; Yang, D.; Tian, W.; Zhao, L.; Hu, J. A Novel Semantic Segmentation Algorithm Using a Hierarchical Adjacency Dependent Network. IEEE Access 2019, 7, 150444–150452. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1251–1258. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Lu, Y.; Liu, H. Semantic segmentation with step-by-step upsampling of the fusion context. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 28–30 June 2021; pp. 156–161. [Google Scholar]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 7262–7272. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Jiang, D.; Qu, H.; Zhao, J.; Zhao, J.; Liang, W. Multi-level graph convolutional recurrent neural network for semantic image segmentation. Telecommun. Syst. 2021, 77, 563–576. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Wu, L.; Xiao, J.; Zhang, Z. Improved Lightweight DeepLabv3+ Algorithm Based on Attention Mechanism. In Proceedings of the 2022 14th International Conference on Advanced Computational Intelligence (ICACI), Wuhan, China, 15–17 July 2022; pp. 314–319. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Yu, A.; Palefsky-Smith, R.; Bedi, R. Deep reinforcement learning for simulated autonomous vehicle control. Course Proj. Rep. Winter 2016, 2016, 1–7. [Google Scholar]
- Lv, L.; Li, X.; Jin, J.; Li, X. Image semantic segmentation method based on atrous algorithm and convolution CRF. In Proceedings of the 2019 IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019; pp. 160–165. [Google Scholar]
- Wang, X.; You, S.; Li, X.; Ma, H. Weakly-supervised semantic segmentation by iteratively mining common object features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1354–1362. [Google Scholar]
- Jin, R.; Yu, T.; Han, X.; Liu, Y. The Segmentation of Road Scenes Based on Improved ESPNet Model. Secur. Commun. Netw. 2021, 2021, 1681952. [Google Scholar] [CrossRef]
- Jiang, J.; Zhang, Z.; Huang, Y.; Zheng, L. Incorporating depth into both cnn and crf for indoor semantic segmentation. In Proceedings of the 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 24–26 November 2017; pp. 525–530. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7151–7160. [Google Scholar]
- Zhong, M.; Verma, B.; Affum, J. Multi-Receptive Atrous Convolutional Network for Semantic Segmentation. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Zhao, L.; Wang, Y.; Duan, Z.; Chen, D.; Liu, S. Multi-Source Fusion Image Semantic Segmentation Model of Generative Adversarial Networks Based on FCN. IEEE Access 2021, 9, 101985–101993. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6881–6890. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. Exfuse: Enhancing feature fusion for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Park, S.-J.; Hong, K.-S.; Lee, S. Rdfnet: Rgb-d multi-level residual feature fusion for indoor semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4980–4989. [Google Scholar]
- Sun, J.; Li, Y. Multi-feature fusion network for road scene semantic segmentation. Comput. Electr. Eng. 2021, 92, 107155. [Google Scholar] [CrossRef]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1915–1929. [Google Scholar] [CrossRef]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Chen, L.-C.; Barron, J.T.; Papandreou, G.; Murphy, K.; Yuille, A.L. Semantic image segmentation with task-specific edge detection using cnns and a discriminatively trained domain transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4545–4554. [Google Scholar]
- Mostajabi, M.; Yadollahpour, P.; Shakhnarovich, G. Feedforward semantic segmentation with zoom-out features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3376–3385. [Google Scholar]
- Lin, G.; Shen, C.; Van Den Hengel, A.; Reid, I. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3194–3203. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), New York, NY, USA, 17–22 June 2006; pp. 2169–2178. [Google Scholar]
- Ding, H.; Jiang, X.; Shuai, B.; Liu, A.Q.; Wang, G. Context contrasted feature and gated multi-scale aggregation for scene segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2393–2402. [Google Scholar]
- Zheng, W.; Liu, X.; Yin, L. Research on image classification method based on improved multi-scale relational network. PeerJ Comput. Sci. 2021, 7, e613. [Google Scholar] [CrossRef]
- Zheng, W.; Tian, X.; Yang, B.; Liu, S.; Ding, Y.; Tian, J.; Yin, L. A few shot classification methods based on multiscale relational networks. Appl. Sci. 2022, 12, 4059. [Google Scholar] [CrossRef]
- Lu, S.; Ding, Y.; Liu, M.; Yin, Z.; Yin, L.; Zheng, W. Multiscale feature extraction and fusion of image and text in VQA. Int. J. Comput. Intell. Syst. 2023, 16, 54. [Google Scholar] [CrossRef]
- Adelson, E.H.; Anderson, C.H.; Bergen, J.R.; Burt, P.J.; Ogden, J.M. Pyramid methods in image processing. RCA Eng. 1984, 29, 33–41. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Venice, Italy, 22–29 October 2017; pp. 2881–2890. [Google Scholar]
- Zhou, Y.; Sun, X.; Zha, Z.-J.; Zeng, W. Context-reinforced semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4046–4055. [Google Scholar]
- Li, X.; Yang, Y.; Zhao, Q.; Shen, T.; Lin, Z.; Liu, H. Spatial pyramid based graph reasoning for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8950–8959. [Google Scholar]
- Zheng, W.; Yin, L.; Chen, X.; Ma, Z.; Liu, S.; Yang, B. Knowledge base graph embedding module design for Visual question answering model. Pattern Recognit. 2021, 120, 108153. [Google Scholar] [CrossRef]
- Grangier, D.; Bottou, L.; Collobert, R. Deep convolutional networks for scene parsing. In Proceedings of the ICML 2009 Deep Learning Workshop, Montreal, QC, Canada, 14–18 June 2009. [Google Scholar]
- Ghiasi, G.; Fowlkes, C.C. Laplacian pyramid reconstruction and refinement for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 519–534. [Google Scholar]
- Sharma, A.; Tuzel, O.; Liu, M.-Y. Recursive context propagation network for semantic scene labeling. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Sharma, A.; Tuzel, O.; Jacobs, D.W. Deep hierarchical parsing for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 530–538. [Google Scholar]
- Chen, L.-C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Raj, A.; Maturana, D.; Scherer, S. Multi-Scale Convolutional Architecture for Semantic Segmentation; Tech. Rep. CMU-RITR-15-21; Robotics Institute, Carnegie Mellon University: Pittsburgh, PA, USA, 2015. [Google Scholar]
- Roy, A.; Todorovic, S. A multi-scale cnn for affordance segmentation in rgb images. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 186–201. [Google Scholar]
- Chandra, S.; Kokkinos, I. Fast, exact and multi-scale inference for semantic image segmentation with deep gaussian crfs. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 402–418. [Google Scholar]
- Lin, G.; Shen, C.; Van Den Hengel, A.; Reid, I. Exploring context with deep structured models for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1352–1366. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Liu, Z.; Luo, P.; Change Loy, C.; Tang, X. Not all pixels are equal: Difficulty-aware semantic segmentation via deep layer cascade. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3193–3202. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA USA, 4–9 February 2017. [Google Scholar]
- Ji, J.; Lu, X.; Luo, M.; Yin, M.; Miao, Q.; Liu, X. Parallel fully convolutional network for semantic segmentation. IEEE Access 2020, 9, 673–682. [Google Scholar] [CrossRef]
- Shen, F.; Gan, R.; Yan, S.; Zeng, G. Semantic segmentation via structured patch prediction, context crf and guidance crf. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1953–1961. [Google Scholar]
- Pinheiro, P.; Collobert, R. Recurrent convolutional neural networks for scene labeling. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Byeon, W.; Breuel, T.M.; Raue, F.; Liwicki, M. Scene labeling with lstm recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3547–3555. [Google Scholar]
- Visin, F.; Ciccone, M.; Romero, A.; Kastner, K.; Cho, K.; Bengio, Y.; Matteucci, M.; Courville, A. Reseg: A recurrent neural network-based model for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 27–30 June 2016; pp. 41–48. [Google Scholar]
- Visin, F.; Kastner, K.; Cho, K.; Matteucci, M.; Courville, A.; Bengio, Y. Renet: A recurrent neural network based alternative to convolutional networks. arXiv 2015, arXiv:1505.00393. [Google Scholar]
- Shuai, B.; Zuo, Z.; Wang, B.; Wang, G. Scene segmentation with dag-recurrent neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1480–1493. [Google Scholar] [CrossRef]
- Arnab, A.; Jayasumana, S.; Zheng, S.; Torr, P.H. Higher order conditional random fields in deep neural networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 524–540. [Google Scholar]
- Shuai, B.; Zuo, Z.; Wang, B.; Wang, G. Dag-recurrent neural networks for scene labeling. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27-30 June 2016; pp. 3620–3629. [Google Scholar]
- Fan, H.; Ling, H. Dense recurrent neural networks for scene labeling. arXiv 2018, arXiv:1801.06831. [Google Scholar]
- Fan, H.; Mei, X.; Prokhorov, D.; Ling, H. Multi-level contextual rnns with attention model for scene labeling. IEEE Trans. Intell. Transp. Syst. 2018, 19, 3475–3485. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, X.; Lin, M.; Chiu, B.; Zhao, M. Deep-recursive residual network for image semantic segmentation. Neural Comput. Appl. 2020, 32, 12935–12947. [Google Scholar] [CrossRef]
- Ding, H.; Jiang, X.; Shuai, B.; Liu, A.Q.; Wang, G. Semantic segmentation with context encoding and multi-path decoding. IEEE Trans. Image Process. 2020, 29, 3520–3533. [Google Scholar] [CrossRef]
- Xia, W.; Domokos, C.; Dong, J.; Cheong, L.-F.; Yan, S. Semantic segmentation without annotating segments. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 1–8 December 2013; pp. 2176–2183. [Google Scholar]
- Dai, J.; He, K.; Sun, J. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1635–1643. [Google Scholar]
- Khoreva, A.; Benenson, R.; Hosang, J.; Hein, M.; Schiele, B. Simple does it: Weakly supervised instance and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 876–885. [Google Scholar]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Box-driven class-wise region masking and filling rate guided loss for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3136–3145. [Google Scholar]
- Carreira, J.; Sminchisescu, C. CPMC: Automatic object segmentation using constrained parametric min-cuts. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 1312–1328. [Google Scholar] [CrossRef]
- Xu, X.; Meng, F.; Li, H.; Wu, Q.; Ngan, K.N.; Chen, S. A new bounding box based pseudo annotation generation method for semantic segmentation. In Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP), Macau, China, 1–4 December 2020; pp. 100–103. [Google Scholar]
- Oh, Y.; Kim, B.; Ham, B. Background-aware pooling and noise-aware loss for weakly-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6913–6922. [Google Scholar]
- Ma, T.; Wang, Q.; Zhang, H.; Zuo, W. Delving deeper into pixel prior for box-supervised semantic segmentation. IEEE Trans. Image Process. 2022, 31, 1406–1417. [Google Scholar] [CrossRef]
- Maron, O.; Lozano-Pérez, T. A framework for multiple-instance learning. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 2–5 December 1997; Volume 10. [Google Scholar]
- Pathak, D.; Shelhamer, E.; Long, J.; Darrell, T. Fully convolutional multi-class multiple instance learning. arXiv 2014, arXiv:1412.7144. [Google Scholar]
- Pinheiro, P.O.; Collobert, R. From image-level to pixel-level labeling with convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1713–1721. [Google Scholar]
- Kolesnikov, A.; Lampert, C.H. Seed, expand and constrain: Three principles for weakly-supervised image segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 695–711. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Sun, K.; Shi, H.; Zhang, Z.; Huang, Y. Ecs-net: Improving weakly supervised semantic segmentation by using connections between class activation maps. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Nashville, TN, USA, 20–25 June 2021; pp. 7283–7292. [Google Scholar]
- Wei, Y.; Feng, J.; Liang, X.; Cheng, M.-M.; Zhao, Y.; Yan, S. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1568–1576. [Google Scholar]
- Li, K.; Wu, Z.; Peng, K.-C.; Ernst, J.; Fu, Y. Tell me where to look: Guided attention inference network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9215–9223. [Google Scholar]
- Hou, Q.; Jiang, P.; Wei, Y.; Cheng, M.-M. Self-erasing network for integral object attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Wei, Y.; Xiao, H.; Shi, H.; Jie, Z.; Feng, J.; Huang, T.S. Revisiting dilated convolution: A simple approach for weakly-and semi-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7268–7277. [Google Scholar]
- Lee, J.; Kim, E.; Lee, S.; Lee, J.; Yoon, S. Ficklenet: Weakly and semi-supervised semantic image segmentation using stochastic inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5267–5276. [Google Scholar]
- Zeng, Y.; Zhuge, Y.; Lu, H.; Zhang, L. Joint learning of saliency detection and weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 15–20 June 2019; pp. 7223–7233. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Darrell, T. Constrained convolutional neural networks for weakly supervised segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Boston, MA, USA, 7–12 June 2015; pp. 1796–1804. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv 2013, arXiv:1312.6229. [Google Scholar]
- Saleh, F.; Aliakbarian, M.S.; Salzmann, M.; Petersson, L.; Gould, S.; Alvarez, J.M. Built-in foreground/background prior for weakly-supervised semantic segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 413–432. [Google Scholar]
- Saleh, F.S.; Aliakbarian, M.S.; Salzmann, M.; Petersson, L.; Alvarez, J.M.; Gould, S. Incorporating network built-in priors in weakly-supervised semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1382–1396. [Google Scholar] [CrossRef] [PubMed]
- Papandreou, G.; Chen, L.-C.; Murphy, K.P.; Yuille, A.L. Weakly-and semi-supervised learning of a deep convolutional network for semantic image segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1742–1750. [Google Scholar]
- Qi, X.; Liu, Z.; Shi, J.; Zhao, H.; Jia, J. Augmented feedback in semantic segmentation under image level supervision. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 90–105. [Google Scholar]
- Wei, Y.; Liang, X.; Chen, Y.; Jie, Z.; Xiao, Y.; Zhao, Y.; Yan, S. Learning to segment with image-level annotations. Pattern Recognit. 2016, 59, 234–244. [Google Scholar] [CrossRef]
- Wei, Y.; Xia, W.; Huang, J.; Ni, B.; Dong, J.; Zhao, Y.; Yan, S. CNN: Single-label to multi-label. arXiv 2014, arXiv:1406.5726. [Google Scholar]
- Ahn, J.; Kwak, S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4981–4990. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, X.; Wang, J.; Liu, W.; Wang, J. Weakly-supervised semantic segmentation network with deep seeded region growing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7014–7023. [Google Scholar]
- Jiang, P.-T.; Hou, Q.; Cao, Y.; Cheng, M.-M.; Wei, Y.; Xiong, H.-K. Integral object mining via online attention accumulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2070–2079. [Google Scholar]
- Jo, S.; Yu, I.-J. Puzzle-cam: Improved localization via matching partial and full features. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 639–643. [Google Scholar]
- Chang, R.-H.; Guo, J.-M.; Seshathiri, S. Saliency Guidance and Expansion Suppression on PuzzleCAM for Weakly Supervised Semantic Segmentation. Electronics 2022, 11, 4068. [Google Scholar] [CrossRef]
- Fan, J.; Zhang, Z.; Song, C.; Tan, T. Learning integral objects with intra-class discriminator for weakly-supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13-19 June 2020; pp. 4283–4292. [Google Scholar]
- Shimoda, W.; Yanai, K. Distinct class-specific saliency maps for weakly supervised semantic segmentation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 218–234. [Google Scholar]
- Hong, S.; Yeo, D.; Kwak, S.; Lee, H.; Han, B. Weakly supervised semantic segmentation using web-crawled videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7322–7330. [Google Scholar]
- Wei, Y.; Liang, X.; Chen, Y.; Shen, X.; Cheng, M.-M.; Feng, J.; Zhao, Y.; Yan, S. Stc: A simple to complex framework for weakly-supervised semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2314–2320. [Google Scholar] [CrossRef]
- Jin, B.; Ortiz Segovia, M.V.; Susstrunk, S. Webly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3626–3635. [Google Scholar]
- Luo, P.; Wang, G.; Lin, L.; Wang, X. Deep dual learning for semantic image segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2718–2726. [Google Scholar]
- Saleh, F.; Aliakbarian, M.S.; Salzmann, M.; Petersson, L.; Alvarez, J.M. Bringing background into the foreground: Making all classes equal in weakly-supervised video semantic segmentation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2125–2135. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Vernaza, P.; Chandraker, M. Learning random-walk label propagation for weakly-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7158–7166. [Google Scholar]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the point: Semantic segmentation with point supervision. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 549–565. [Google Scholar]
- Pu, M.; Huang, Y.; Guan, Q.; Zou, Q. GraphNet: Learning image pseudo annotations for weakly-supervised semantic segmentation. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 26 October 2018; pp. 483–491. [Google Scholar]
- Tang, M.; Djelouah, A.; Perazzi, F.; Boykov, Y.; Schroers, C. Normalized cut loss for weakly-supervised cnn segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1818–1827. [Google Scholar]
- Tang, M.; Perazzi, F.; Djelouah, A.; Ben Ayed, I.; Schroers, C.; Boykov, Y. On regularized losses for weakly-supervised cnn segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 507–522. [Google Scholar]
- Wang, B.; Qi, G.; Tang, S.; Zhang, T.; Wei, Y.; Li, L.; Zhang, Y. Boundary perception guidance: A scribble-supervised semantic segmentation approach. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Macau, China, 10–16 August 2019. [Google Scholar]
- Xu, J.; Zhou, C.; Cui, Z.; Xu, C.; Huang, Y.; Shen, P.; Li, S.; Yang, J. Scribble-supervised semantic segmentation inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 15354–15363. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y. Segment anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Huang, Y.; Yang, X.; Liu, L.; Zhou, H.; Chang, A.; Zhou, X.; Chen, R.; Yu, J.; Chen, J.; Chen, C. Segment anything model for medical images? arXiv 2023, arXiv:2304.14660. [Google Scholar]
- Mazurowski, M.A.; Dong, H.; Gu, H.; Yang, J.; Konz, N.; Zhang, Y. Segment anything model for medical image analysis: An experimental study. arXiv 2023, arXiv:2304.10517. [Google Scholar]
- Piva, F.J.; de Geus, D.; Dubbelman, G. Empirical Generalization Study: Unsupervised Domain Adaptation vs. Domain Generalization Methods for Semantic Segmentation in the Wild. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 499–508. [Google Scholar]
- Shafahi, A.; Najibi, M.; Ghiasi, M.A.; Xu, Z.; Dickerson, J.; Studer, C.; Davis, L.S.; Taylor, G.; Goldstein, T. Adversarial training for free! In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.-Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. Cycada: Cycle-consistent adversarial domain adaptation. Proc. Int. Conf. Mach. Learn. 2018, 80, 1989–1998. [Google Scholar]
- Tsai, Y.-H.; Hung, W.-C.; Schulter, S.; Sohn, K.; Yang, M.-H.; Chandraker, M. Learning to adapt structured output space for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7472–7481. [Google Scholar]
- Vu, T.-H.; Jain, H.; Bucher, M.; Cord, M.; Pérez, P. Advent: Adversarial entropy minimization for domain adaptation in semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2517–2526. [Google Scholar]
- Araslanov, N.; Roth, S. Self-supervised augmentation consistency for adapting semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15384–15394. [Google Scholar]
- Zou, Y.; Yu, Z.; Kumar, B.; Wang, J. Unsupervised domain adaptation for semantic segmentation via class-balanced self-training. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 289–305. [Google Scholar]
- Jiang, Z.; Li, Y.; Yang, C.; Gao, P.; Wang, Y.; Tai, Y.; Wang, C. Prototypical contrast adaptation for domain adaptive semantic segmentation. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 36–54. [Google Scholar]
- Lai, X.; Tian, Z.; Xu, X.; Chen, Y.; Liu, S.; Zhao, H.; Wang, L.; Jia, J. DecoupleNet: Decoupled network for domain adaptive semantic segmentation. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 369–387. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. HRDA: Context-aware high-resolution domain-adaptive semantic segmentation. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 372–391. [Google Scholar]
- Hoyer, L.; Dai, D.; Van Gool, L. Daformer: Improving network architectures and training strategies for domain-adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9924–9935. [Google Scholar]
- Tranheden, W.; Olsson, V.; Pinto, J.; Svensson, L. Dacs: Domain adaptation via cross-domain mixed sampling. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 1379–1389. [Google Scholar]
- Wang, Q.; Dai, D.; Hoyer, L.; Van Gool, L.; Fink, O. Domain adaptive semantic segmentation with self-supervised depth estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 8515–8525. [Google Scholar]
- Zhang, P.; Zhang, B.; Zhang, T.; Chen, D.; Wang, Y.; Wen, F. Prototypical pseudo label denoising and target structure learning for domain adaptive semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12414–12424. [Google Scholar]
- Wang, Q.; Fink, O.; Van Gool, L.; Dai, D. Continual test-time domain adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Waikola, HI, USA, 4–8 January 2022; pp. 7201–7211. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Teichmann, M.T.; Cipolla, R. Convolutional CRFs for semantic segmentation. arXiv 2018, arXiv:1805.04777. [Google Scholar]
- Vemulapalli, R.; Tuzel, O.; Liu, M.-Y.; Chellapa, R. Gaussian conditional random field network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3224–3233. [Google Scholar]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.C.; Tang, X. Deep learning markov random field for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1814–1828. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; Las Vegas, NV, USA, 27–30 June 2016, pp. 1209–1218.
- Everingham, M.; Winn, J. The PASCAL visual object classes challenge 2012 (VOC2012) development kit. Pattern Anal. Stat. Model. Comput. Learn. Tech. Rep. 2012, 2007, 1–45. [Google Scholar]
- Mottaghi, R.; Chen, X.; Liu, X.; Cho, N.-G.; Lee, S.-W.; Fidler, S.; Urtasun, R.; Yuille, A. The role of context for object detection and semantic segmentation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 891–898. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 746–760. [Google Scholar]
- Xiao, J.; Owens, A.; Torralba, A. Sun3d: A database of big spaces reconstructed using sfm and object labels. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 1625–1632. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. Bdd100k: A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2636–2645. [Google Scholar]
- Brostow, G.J.; Fauqueur, J.; Cipolla, R. Semantic object classes in video: A high-definition ground truth database. Pattern Recognit. Lett. 2009, 30, 88–97. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Pfeiffer, D.; Gehrig, S.; Schneider, N. Exploiting the power of stereo confidences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 297–304. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Hussain Raza, S.; Grundmann, M.; Essa, I. Geometric context from videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3081–3088. [Google Scholar]
- Liu, C.; Yuen, J.; Torralba, A. Nonparametric scene parsing: Label transfer via dense scene alignment. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 1972–1979. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image. Int. J. Comput. Vis. 2005, 77, 157–173. [Google Scholar] [CrossRef]
- Gould, S.; Fulton, R.; Koller, D. Decomposing a scene into geometric and semantically consistent regions. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1–8. [Google Scholar]
- Hoiem, D.; Efros, A.A.; Hebert, M. Recovering surface layout from an image. Int. J. Comput. Vis. 2007, 75, 151–172. [Google Scholar] [CrossRef]
- Shotton, J.; Winn, J.; Rother, C.; Criminisi, A. Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context. Int. J. Comput. Vis. 2009, 81, 2–23. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Xu, M.; Yoon, S.; Fuentes, A.; Park, D.S. A comprehensive survey of image augmentation techniques for deep learning. Pattern Recognit. 2023, 137, 109347. [Google Scholar] [CrossRef]
- Py, E.; Gherbi, E.; Pinto, N.F.; Gonzalez, M.; Hajri, H. Real-time Weather Monitoring and Desnowification through Image Purification. In Proceedings of the AAAI 2023 Spring Symposium Series, San Francisco, CA, USA, 27–29 March 2023. [Google Scholar]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 21405–21417. [Google Scholar] [CrossRef]
- Vanschoren, J. Meta-learning. In Automated Machine Learning: Methods, Systems, Challenges; Springer: New York, NY, USA, 2019; pp. 35–61. [Google Scholar]
- Cohn, D.A.; Ghahramani, Z.; Jordan, M.I. Active learning with statistical models. J. Artif. Intell. Res. 1996, 4, 129–145. [Google Scholar] [CrossRef]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Chen, Y.; Zhan, W.; Jiang, Y.; Zhu, D.; Guo, R.; Xu, X. LASNet: A Light-Weight Asymmetric Spatial Feature Network for Real-Time Semantic Segmentation. Electronics 2022, 11, 3238. [Google Scholar] [CrossRef]
- Zhuang, J.; Yang, J.; Gu, L.; Dvornek, N. Shelfnet for fast semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Agrawal, A.; Choi, J.; Gopalakrishnan, K.; Gupta, S.; Nair, R.; Oh, J.; Prener, D.A.; Shukla, S.; Srinivasan, V.; Sura, Z. Approximate computing: Challenges and opportunities. In Proceedings of the 2016 IEEE International Conference on Rebooting Computing (ICRC), San Diego, CA, USA, 17–19 October 2016; pp. 1–8. [Google Scholar]
- Zhang, Q.; Wang, T.; Tian, Y.; Yuan, F.; Xu, Q. ApproxANN: An approximate computing framework for artificial neural network. In Proceedings of the 2015 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 701–706. [Google Scholar]
- Kim, J. Quantization Robust Pruning With Knowledge Distillation. IEEE Access 2023, 11, 26419–26426. [Google Scholar] [CrossRef]
- Looks, M.; Herreshoff, M.; Hutchins, D.; Norvig, P. Deep learning with dynamic computation graphs. arXiv 2017, arXiv:1702.02181. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Le, T.; Duan, Y. Pointgrid: A deep network for 3d shape understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9204–9214. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. Rangenet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Tchapmi, L.; Choy, C.; Armeni, I.; Gwak, J.; Savarese, S. Segcloud: Semantic segmentation of 3d point clouds. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017; pp. 537–547. [Google Scholar]
- Miao, Z.; Song, S.; Tang, P.; Chen, J.; Hu, J.; Gong, Y. MFFRand: Semantic Segmentation of Point Clouds Based on Multi-Scale Feature Fusion and Multi-Loss Supervision. Electronics 2022, 11, 3626. [Google Scholar] [CrossRef]
- Liu, M.; Zhou, Y.; Qi, C.R.; Gong, B.; Su, H.; Anguelov, D. Less: Label-efficient semantic segmentation for lidar point clouds. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 70–89. [Google Scholar]
- Hu, Q.; Yang, B.; Fang, G.; Guo, Y.; Leonardis, A.; Trigoni, N.; Markham, A. Sqn: Weakly-supervised semantic segmentation of large-scale 3d point clouds. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 600–619. [Google Scholar]







| Paper, Year | Method | Backbone Network | Dataset | Accuracy mIoU (%) |
|---|---|---|---|---|
| [12] (2014) | Regional CNN (R-CNN) | AlexNet [17] | Pascal VOC 2010 Pascal VOC 2012 | 53.7 47.9 |
| [23] (2014) | Simultaneous Detection& Segment. (SDS) | MCG [24] | Pascal VOC 2010 Pascal VOC 2012 | 52.6 51.6 |
| [18] (2015) | Fast R-CNN | VGG-16 [14] | Pascal VOC 2010 Pascal VOC 2012 | 66.1 65.7 |
| [22] (2015) | Convolutional feature masking (CFM) | VGG + MCG | Pascal VOC 2012 | 61.8 |
| [25] (2016) | Multi-scale, overlapping regions | VGG-16 | Pascal Context SIFT Flow | 49.9 64.0 |
| [26] (2020) | Region Attention Network (RANet) | ResNet-101 [16] | Cityscapes Pascal Context COCO Stuff | 81.9 54.9 40.7 |
| Author, Year | Method | CRF Used? | Backbone Network | Dataset | Accuracy mIoU (%) |
|---|---|---|---|---|---|
| [35] (2015) | DeconvNet | yes | VGG-16 | Pascal VOC 2012 | 70.5 |
| [36] (2015) | SegNet | yes | VGG-16 | CamVid NYUDv2 KITTI | 62.5 41.0 58.4 |
| [37] (2015) | Bayesian SegNet | no | VGG-16 | Pascal VOC 2012 CamVid | 60.5 63.1 |
| [46] (2016) | Efficient neural network (ENet) | no | ResNet | CamVid Cityscapes SUN RGBD | 55.6 58.3 19.7 |
| [40] (2016) | SqueezeNet + SharpMask | no | VGG-16 | Cityscapes | 59.8 |
| [41] (2017) | RefineNet | yes (just Pascal dataset) | ResNet-101 | Pascal VOC 2012 Cityscapes SUN RGBD ADE20K | 83.4 73.6 45.7 40.2 |
| [42] (2017) | Residual Conv-Deconv Grid Network | no | ResNet-101 | Cityscapes | 69.4 |
| [47] (2017) | Label refinement network (LRN) | no | VGG-16 | Pascal VOC 2012 CamVid SUN RGBD | 62.8 61.7 33.1 |
| [48] (2018) | DeepLabV3+ | no | ResNet-101 | Pascal VOC 2012 Cityscapes | 87.8 82.1 |
| [49] (2018) | Gated Feedback Refinement Network (G-FRNet) | yes (just Pascal dataset) | VGG-16 ResNet-101 | Pascal VOC 2012 | 70.4VGG16 79.3ResNet101 |
| CamVid | 68.0VGG16 | ||||
| [50] (2018) | Dense Decoder Shortcut Connections | no | ResNeXt [51] | Pascal VOC 2012 CamVid NYUDv2 Pascal Context | 81.2 70.9 48.1 47.8 |
| [52] (2019) | Stacked Deconvolutional Network (SDN) | no | DenseNet161 [53] | Pascal VOC 2012 CamVid GATECH RGBD COCO Stuff | 83.5 69.6 53.5 35.9 |
| [54] (2019) | Hierarchical adjacency dependent network (HadNet) | no | Xception [55] + ASPP [56] | Pascal VOC 2012 | 87.9 |
| [43] (2021) | IIE-SegNet | no | Deeplab-v3 [48] | Pascal VOC 2012 | 89.6 |
| [57] (2021) | HRNet | yes | ResNet + ASPP | Pascal VOC 2012 | 79.5 |
| [44] (2021) | Stage-aware Feature AlignmentNetwork (SFANet) | no | ResNet-18 [16] | Cityscapes CamVid | 78.1 74.7 |
| [58] (2021) | Segmenter | no | ViT-L/16 [59] | ADE20K Pascal Context Cityscapes | 53.6 59.0 81.3 |
| [60] (2021) | Multi-level graph conv.RNN (MGCRNN) | no | VGG-16 | Pascal VOC 2012 Cityscapes | 74.2 73.6 |
| [45] (2022) | Context Aggregation Network (CANet) | no | ResNet-101 | Cityscapes CamVid BDD100K | 81.8 78.6 66.5 |
| Author, Year | Method | CRF Used? | Backbone Network | Dataset | Accuracy mIoU (%) |
|---|---|---|---|---|---|
| [31] (2014) | DeepLab-v1 (LargeFOV) | yes | VGG-16 | Pascal VOC 2012 | 67.6 |
| [63] (2015) | DilatedNet | yes | VGG-16 | Pascal VOC 2012 | 67.6 |
| [46] (2016) | Efficient neural network (ENet) | no | ResNet | CamVid Cityscapes SUN RGBD | 55.6 58.3 19.7 |
| [64] (2016) | Dilated Residual Network (DRN) | no | ResNet-101 | Cityscapes | 66.6 |
| [56] (2017) | DeepLab-v2 (ASPP) | yes | ResNet-101 | Pascal VOC 2012 Cityscapes | 79.7 70.4 |
| [61] (2017) | DeepLab-v3 | no | ResNet | Pascal VOC 2012 Cityscapes | 85.7 81.3 |
| [68] (2017) | Depth fully-connected CRF (DFCN-DCRF) | yes | VGG-16 | SUN RGBD | 39.3 |
| [48] (2018) | DeepLab-v3+ | no | ResNet-101 | Pascal VOC 2012 Cityscapes | 87.8 82.1 |
| [66] (2018) | Dense upsampling convolution (DUC) + Hybrid Dilated Convolution (HDC) | yes | DeepLab-v2 ResNet-101 | Pascal VOC 2012 Cityscapes | 83.1 77.6 |
| [69] (2018) | Context Encoding Network (EncNet) | no | ResNet | Pascal VOC 2012 Pascal Context ADE20K | 82.9 51.7 44.6 |
| [65] (2019) | Atrous Conv. + fully connected CRFs | yes | ResNet-101 | Pascal VOC 2012 | 77.6 |
| [70] (2020) | Multi-Receptive Atrous Convolutional Network (MRACN) | no | ResNet-101 | Pascal VOC 2012 DTMR-DVR | 80.2 60.4 |
| [71] (2021) | Multi-source fusion generative adver.net.(SCAGAN ) | no | DeepLab-v2 | Pascal VOC 2012 | 70.1 |
| [72] (2021) | SEgmentation TRansformer (SETR) | no | T-Large [72] | ADE20K Pascal Context Cityscapes | 50.2 55.8 82.1 |
| [67] (2021) | Efficient Spatial Pyramid of Dilated Conv.(ESPNet) | yes | DeepLab-v2 | Cityscapes | 60.3 |
| [62] (2022) | Cascade Waterfall ASPP Module (CWASPP) | no | MobileNetv2 [73] | Pascal VOC 2012 | 73.3 |
| Author | Method | CRF Used? | Backbone Network | Dataset | Accuracy mIoU (%) |
|---|---|---|---|---|---|
| [75] (2015) | ParseNet | yes | DeepLab-v1 | Pascal VOC 2012 Pascal Context | 65.8 36.6 |
| [76] (2017) | RGB-D fusion network (RDFNet) | no | ResNet-101 | NYUDv2 SUN RGBD | 50.1 47.7 |
| [74] (2018) | ExFuse | no | ResNet-101 | Pascal VOC 2012 | 86.2 |
| [77] (2021) | Self-attention feature fusion network (SA-FFNet) | no | ResNet-18 | Cityscapes CamVid | 75.0 69.5 |
| [67] (2021) | Efficient Spatial Pyramid of Dilated Conv.(ESPNet) | yes | DeepLab-v2 | Cityscapes | 60.3 |
| Author | Method | CRF Used? | Backbone Network | Dataset | Accuracy mIoU (%) | |
|---|---|---|---|---|---|---|
| Multi-scale pyramid architecture | [78] (2012) | Multiscale ConvNet | yes | ConvNet [94] | SIFT Flow Stanford Background | 50.8 (MACC) 76.0 (MACC) |
| [82] (2016) | FeatMap-Net | yes | VGG-16 | Pascal VOC 2012 Pascal Context SIFT Flow NYUDv2 (40 class) | 75.3 43.3 44.9 40.6 | |
| [95] (2016) | Laplacian Pyramid Reconst.&Refine. (LRR) | yes | VGG-16 ResNet-101 | Pascal VOC 2012 Cityscapes | 74.7ResNet101 69.7VGG16 | |
| [90] (2017) | Pyramid scene parsing network (PSPNet) | no | ResNet-101 | Pascal VOC 2012 Cityscapes ADE20K | 82.6 78.4 41.9 | |
| [91] (2019) | Context-reinforced Network (CiSS-Net) | no | ResNet-50 | Cityscapes ADE20K Pascal Context | 79.2 42.5 48.7 | |
| [92] (2020) | Spatial Pyramid Based Graph Reasoning (SpyGR) | no | ResNet-101 | Cityscapes COCO Stuff Pascal Context | 81.6 39.9 52.8 | |
| [96] (2014) | Recursive Context Propagation Network (RCPN) | yes | Multiscale ConvNet [78] | Stanford Background. SIFT Flow | 78.8 (MACC) 48.0 (MACC) | |
| [97] (2015) | pure-node (PN) RCPN tree-MRF (TM) RCPN | yes | RCPN [96] | Stanford Background | 64.0PN-RCPN 64.5TM- RCPN | |
| SIFT Flow | 30.2PN-RCPN 31.4TM- RCPN | |||||
| [31] (2014) | DeepLab-MSc | yes | VGG-16 | Pascal VOC 2012 | 71.6 | |
| [98] (2016) | DeepLab-CRF-Attention | yes | DeepLab-v1 | Pascal VOC 2012 COCO Stuff | 75.1 35.7 | |
| [56] (2017) | DeepLab-v2 (ASPP) | yes | ResNet-101 | Pascal VOC 2012 Cityscapes | 79.7 70.4 | |
| [63] (2015) | DilatedNet | yes | VGG-16 | Pascal VOC 2012 | 67.6 | |
| [79] (2015) | Multiscale Convolutional Network | no | AlexNet VGG-16 | Pascal VOC 2012 | 72.4VGG (MACC) | |
| SIFT Flow | 48.2AlexNet 55.7VGG | |||||
| NYUDv2 | 41.3AlexNet 45.1VGG | |||||
| NYUDv2 (4 class) | 79.1AlexNet 82.0VGG | |||||
| [81] (2015) | Zoom-out | yes | VGG-16 | Pascal VOC 2012 | 69.6 | |
| [99] (2015) | Multi-scale deep ConvNet VGGM | no | VGG-16 | NYUDv2 (4 class) | 70.4 (PACC) | |
| [100] (2016) | A network composed by four multi-scale CNNs | no | VGG-16 | NYUDv2 | 49.5 | |
| [101] (2016) | Quadratic Optimization (QO) | yes | Deeplab-v1 | Pascal VOC 2012 | 75.4 | |
| [61] (2017) | DeepLab-v3 | no | ResNet | Pascal VOC 2012 Cityscapes | 85.7 81.3 | |
| [102] (2017) | Contextual deep structured model | yes | VGG-16 | Pascal VOC 2012 Pascal Context SIFT Flow Cityscapes SUN RGBD KITTI NYUDv2 | 75.3 43.3 44.9 71.6 42.3 70.3 40.6 | |
| [103] (2017) | Deep layer cascade (LC) | no | IRNet [104] | Pascal VOC 2012 Cityscapes | 80.3 (PACC) 71.1 | |
| [84] (2018) | Context Contrasted Local (CCL) | yes | ResNet-101 | Pascal Context SUN RGBD COCO Stuff | 51.6 47.1 35.7 | |
| [52] (2019) | Stacked Deconvolutional Network (SDN) | no | DenseNet [49] | Pascal VOC 2012 CamVid GATECH RGBD COCO Stuff | 83.5 69.6 53.5 35.9 | |
| [105] (2020) | Parallel fully convolutional neural network | no | FCN + HED [96] | Pascal VOC 2012 Pascal Context Cityscapes | 66.7 43.6 67.1 | |
| [57] (2021) | HRNet | yes | ResNet + ASPP | Pascal VOC 2012 | 79.5 | |
| [106] (2017) | Structured patch prediction (SegModel) | yes | ResNet-101 | Pascal VOC 2012 Cityscapes ADE20K | 82.5 79.2 54.5 |
| Author | Method | CRF Used? | Backbone Network | Dataset | Accuracy mIoU (%) |
|---|---|---|---|---|---|
| [107] (2014) | Recurrent CNN (RCNN) | no | RCNN | Stanford Background SIFT Flow | 69.5 (MACC) 30.0 (MACC) |
| [108] (2015) | Two-dimensional LSTM Network (2D LSTM) | no | Multidimensional RNNs | Stanford Background SIFT Flow | 68.2 (MACC) 22.5 (MACC) |
| [33] (2015) | CRFasRNN | yes | VGG-16 | Pascal VOC 2012 Pascal Context | 72.0 39.2 |
| [112] (2016) | Higher order CRF-RNN | yes | VGG-16 | Pascal VOC 2012 Pascal Context | 77.9 41.3 |
| [109] (2016) | ReSeg | no | ReNet [110] | CamVid | 58.8 |
| [113] (2016) | Directed acyclic graph RNN (DAG-RNN) | no | VGG-16 | SiftFlow CamVid | 55.7 (MACC) 78.1 (MACC) |
| [111] (2017) | DAG-RNN + CRF | yes | VGG-16 | SIFT Flow Pascal Context COCO Stuff | 44.8 43.7 31.2 |
| [114] (2018) | Dense RNN (DD-RNN) | yes | VGG-16 | Pascal Context ADE20K SIFT Flow | 45.3 36.3 46.3 |
| [115] (2018) | Multi-Level Contextual RNN (ML-CRNN) | no | VGG-16 | CamVid KITTI SIFT Flow Stanford Background Cityscapes | 66.8 60.1 44.7 65.7 71.2 |
| [116] (2020) | Recursive conv. with residual unit | no | VGG-16 | Pascal VOC 2012 Cityscapes | 55.1 44.0 |
| [117] (2020) | CGBNet | yes | ResNet-101 | Pascal Context SUN RGBD SIFT Flow COCO Stuff ADE20K Cityscapes | 53.4 48.2 46.8 36.9 44.9 81.2 |
| [60] (2021) | Multi-level graph conv.RNN (MGCRNN) | no | VGG-16 | Pascal VOC 2012 Cityscapes | 74.2 73.6 |
| Author | Method | CRF Used? | Backbone Network | Dataset | Accuracy mIoU (%) |
|---|---|---|---|---|---|
| [118] (2013) | DET3 | no | CPMC [122] | Pascal VOC 2012test | 48.0 |
| [119] (2015) | Bounding Boxes to Supervise CNN (BoxSup) | yes | DeepLab-v1 | Pascal VOC 2012val Pascal Contextval | 62.0 40.5 |
| [120] (2017) | SimpleDoselt (SDI) | no | DeepLab-v1 | Pascal VOC 2012val | 65.7 |
| [121] (2019) | Box-driven class-wise masking (BCM + FR-loss) | yes | DeepLab-v1 ResNet-101 | Pascal VOC 2012val | 66.8DeepLabv1 70.2ResNet101 |
| [123] (2020) | FCN+Cartesian/ Polar Coordinate System (CCS) + (PCS) | yes | VGG-16 | Pascal VOC 2012val | 68.7 |
| [124] (2021) | Background-Aware Pooling (BAP) and Noise-Aware Loss (NAL) | yes | DeepLab-v1 | Pascal VOC 2012val | 68.1 |
| [125] (2022) | Pixel-as-Instance Prior (PIP) | yes | DeepLab-v1 | Pascal VOC 2012val | 67.9 |
| Content | Author | Method | CRF Used? | Backbone network | Dataset | Accuracy mIoU (%) | |
|---|---|---|---|---|---|---|---|
| MIL based method | [127] (2014) | Multiple instance learning (MIL-FCN) | no | VGG-16 | Pascal VOC 2012test | 25.6 | |
| [138] (2015) | Constrained CNN (CCNN) | yes | VGG-16 | Pascal VOC 2012val | 45.1 | ||
| [128] (2015) | Log-Sum-Exp (LSE) | no | OverFeat [139] | Pascal VOC 2012val | 42.0 | ||
| [140] (2016) | Built-in Fore/Backgr. Prior for WSS | yes | VGG-16 | Pascal VOC 2012val Pascal VOC 2012test | 46.6 52.9 | ||
| [129] (2016) | Seed, Expand and Constrain (SEC): | yes | DeepLab-v1 | Pascal VOC 2012val | 51.7 | ||
| CAM used method | [141] (2017) | (multi-class masks) +CRF | yes | VGG-16 | Pascal VOC 2012val Pascal VOC 2012test | 50.9 52.6 | |
| EM Alg. used method | [142] (2015) | Weakly Semi-Supervised Learning (WSSL) | yes | DeepLab-v1 | Pascal VOC 2012val | 60.6Bound.box | |
| 38.2Image-level | |||||||
| [143] (2016) | Augmented Feedback | yes | DeepLab-v1 | Pascal VOC 2012val | 52.6SS 54.3MCG | ||
| Pseudo mask-based method | [144] (2016) | (HCP) [145]-(MCG) [24] | no | VGG-16 | Pascal VOC 2012val Pascal VOC 2012test | 41.9 43.2 | |
| CAM used method | [132] (2017) | Adversarial erasing (AE)-Prohibitive seg. learn. (PSL) | yes | DeepLab-v1 | Pascal VOC 2012val Pascal VOC 2012test | 55.0 55.7 | |
| [133] (2018) | Guided attention inference Netw. (GAIN) | yes | VGG-16 | Pascal VOC 2012val Pascal VOC 2012test | 60.5 62.1 | ||
| [134] (2018) | Self-Erasing Network (SeeNet) | yes | VGG-16 ResNet-101 | Pascal VOC 2012val | 61.1VGG16 63.1ResNet101 | ||
| Pascal VOC 2012test | 60.7VGG16 62.8ResNet101 | ||||||
| [135] (2018) | Multi-dilated convolu-tional (MDC) | yes | VGG-16 | Pascal VOC 2012val Pascal VOC 2012test | 60.4 60.8 | ||
| [146] (2018) | AffinityNet | yes | DeepLab ResNet-38 [147] | Pascal VOC 2012val | 58.4DeepLab 61.7ResNet38 | ||
| Pascal VOC 2012test | 60.5DeepLab 63.7ResNet38 | ||||||
| [148] (2018) | Deep seeded region growing (DSRG) | yes | VGG-16 ResNet-101 | Pascal VOC 2012val | 59.0VGG16 61.4ResNet101 | ||
| Pascal VOC 2012test | 60.4VGG16 63.2ResNet101 | ||||||
| [136] (2019) | Ficklenet | no | VGG-16 ResNet-101 | Pascal VOC 2012val | 61.2VGG16 64.9ResNet101 | ||
| Pascal VOC 2012test | 61.9VGG16 65.3ResNet101 | ||||||
| [66] (2018) | Mining Common Object Features (MCOF) | no | VGG-16 ResNet-101 | Pascal VOC 2012val | 56.2VGG16 60.3ResNet101 | ||
| Pascal VOC 2012test | 57.6VGG16 61.2ResNet101 | ||||||
| [149] (2019) | Online attention accumulation (OAA) | no | VGG-16 ResNet-101 | Pascal VOC 2012val | 63.1VGG16 65.2ResNet101 | ||
| Pascal VOC 2012test | 62.8VGG16 66.4ResNet101 | ||||||
| [150] (2021) | PuzzleCAM | yes | ResNet-101 | Pascal VOC 2012val Pascal VOC 2012test | 66.9 67.7 | ||
| [151] (2022) | Suppression Module (SUPM) + Saliency Map Guidance Module (SMGM) | yes | ResNet-101 | Pascal VOC 2012val Pascal VOC 2012test | 73.3 73.5 | ||
| [152] (2020) | Intra-Class Discriminator (ICD) | yes | VGG-16 ResNet-101 | Pascal VOC 2012val | 64.0VGG16 67.8ResNet101 | ||
| Pascal VOC 2012test | 63.9VGG16 68.0ResNet101 | ||||||
| [137] (2019) | Saliency& segm. network (SSNet) | yes | VGG-16 Densenet | Pascal VOC 2012val | 63.3VGG16 57.1Densenet | ||
| Pascal VOC 2012test | 64.3VGG16 58.6Densenet | ||||||
| [153] (2016) | Distinct Class Saliency Maps (DCSM)+CRF | yes | VGG-16 | Pascal VOC 2012val Pascal VOC 2012test | 44.1 45.1 | ||
| Web-based methods | CAM used method | [154] (2017) | Web-Crawled Videos | no | VGG-16 | Pascal VOC 2012val Pascal VOC 2012test | 58.1 58.7 |
| [155] (2016) | Simple to complex (STC) | yes | VGG-16 | Pascal VOC 2012val Pascal VOC 2012test | 49.8 51.2 | ||
| [156] (2017) | WebS-i2 | yes | VGG-16 | Pascal VOC 2012val | 53.4 | ||
| [157] (2017) | Dual image segmentation (DIS) | no | ResNet-101 | Pascal VOC 2012test | 86.8 | ||
| [158] (2017) | Weakly supervised Two-stream Network | yes | VGG-16 | Camvidtest Cityscapestest | 29.7 47.2 | ||
| Content | Author | Method | CRF Used? | Backbone Network | Dataset | Accuracy mIoU (%) |
|---|---|---|---|---|---|---|
| point | [161] (2016) | Sem.Seg.with Point Supervision | yes | VGG-16 | Pascal VOC 2012val | 42.9 |
| scribble | [159] (2016) | Scribble-Supervised CNN (ScribbleSup) | yes | VGG-16 | Pascal VOC 2012val Pascal Contextval | 63.1 39.3 |
| [160] (2017) | Random-walk based label propagation mech. (RAWKS) | yes | ResNet-101 | Pascal VOC 2012val Pascal Contextval | 60.0 37.4 | |
| [162] (2018) | GraphNet | yes | VGG-16 | Pascal VOC 2012val Pascal Contextval | 63.3 39.7 | |
| [163] (2018) | NormalCut | yes | ResNet-101 | Pascal VOC 2012val | 74.5 | |
| [164] (2018) | KernelCut | yes | ResNet-101 | Pascal VOC 2012val | 75.0 | |
| [165] (2019) | Boundary Perception Guidance (BPG) | yes | ResNet-101 | Pascal VOC 2012val | 76.0 | |
| [166] (2021) | Progressive segmentation inference (PSI) | no | ResNet-101 | Pascal VOC 2012val Pascal Contextval | 74.9 43.1 |
| Author | Method | CRF Used? | Backbone Network | Accuracy mIoU (%) |
|---|---|---|---|---|
| [176] (2018) | Class-balanced self-training (CBST) | no | ResNet-38 | 48.4 |
| [181] (2021) | Domain Adaptation Cross Sampling (DACS) | no | ResNet-101 | 52.1 |
| [182] (2021) | Correlation-Aware Domain Adaptation (CorDA) | no | ResNet-101 | 56.6 |
| [183] (2021) | Prototypical pseudo label denoising (ProDA) | no | ResNet-101 | 57.5 |
| [184] (2022) | Continual test-time adaptation approach (CoTTA) | no | ResNeXt-29 [51] SegFormer [185] | 32.5ResNeXt-29 |
| 58.6SegFormer | ||||
| [180] (2022) | DAFormer | no | SegFormer | 68.3 |
| Method | Model Structure | Accuracy mIoU (%) |
|---|---|---|
| FCN-8s [27] | FCN | 62.2 |
| Fast R-CNN [18] | Region proposal | 65.7 |
| DeconvNet [35] | Encoder-decoder | 70.5 * |
| DeepLab-v1 [31] | Dilated convolution | 70.3 * |
| DilatedNet [63] | Dilated convolution | 67.6 * |
| ParseNet [75] | Feature fusion | 69.8 * |
| FeatMap-Net [82] | Multi-scale and pyramid | 75.3 * |
| CRFasRNN [33] | RNN | 72.0 * |
| BoxSup [119] | Weakly (box) | 64.6 * |
| SEC [129] | Weakly (image) | 51.7 * |
| Point-level [161] | Weakly (point) | 42.9 * |
| ScribbleSup [159] | Weakly (scribble) | 64.7 * |
| Method | Backbone Accuracy mIoU (%) | |
|---|---|---|
| VGG-16 | ResNet-101 | |
| SeeNet [134] | 60.7 | 62.8 |
| DSRG [148] | 60.4 | 63.2 |
| Ficklenet [136] | 61.9 | 65.3 |
| MCOF [66] | 57.6 | 61.2 |
| OAA [149] | 62.8 | 66.4 |
| ICD [152] | 63.9 | 68.0 |
| Method | Model Structure | Backbone | Accuracy mIoU (%) |
|---|---|---|---|
| CANet [45] | Encoder-decoder | ResNet-101 | 81.8 |
| DeepLab-v3+ [48] | Encoder-decoder + Dilated convolutions | ResNet-101 | 82.1 |
| SA-FFNet [77] | Feature fusion | ResNet-18 | 75.0 |
| SpyGR [92] | Multi-scale and pyramid | ResNet-101 | 81.6 |
| CGBNet [117] | Methods using RNN | ResNet-101 | 81.2 |
| Weakly super. Two-stream Network [158] | Weakly supervised (Image-level labels) | VGG-16 | 47.2 |
| DAFormer [180] | UDA | SegFormer | 68.3 |
| Dataset | Average Accuracy mIoU (%) |
|---|---|
| ADE20K | 44.8 |
| COCO Stuff | 36.2 |
| Pascal VOC 2012 | 74.0 |
| Pascal Context | 48.2 |
| NYUDv2 | 44.0 |
| SUN RGBD | 38.1 |
| BDD100K | 66.5 |
| CamVid | 63.7 |
| Cityscapes | 71.9 |
| DTMR-DVR | 60.4 |
| KITTI | 62.9 |
| GATECH | 53.5 |
| SIFT Flow | 45.9 |
| Stanford Background | 64.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Emek Soylu, B.; Guzel, M.S.; Bostanci, G.E.; Ekinci, F.; Asuroglu, T.; Acici, K. Deep-Learning-Based Approaches for Semantic Segmentation of Natural Scene Images: A Review. Electronics 2023, 12, 2730. https://doi.org/10.3390/electronics12122730
Emek Soylu B, Guzel MS, Bostanci GE, Ekinci F, Asuroglu T, Acici K. Deep-Learning-Based Approaches for Semantic Segmentation of Natural Scene Images: A Review. Electronics. 2023; 12(12):2730. https://doi.org/10.3390/electronics12122730
Chicago/Turabian StyleEmek Soylu, Busra, Mehmet Serdar Guzel, Gazi Erkan Bostanci, Fatih Ekinci, Tunc Asuroglu, and Koray Acici. 2023. "Deep-Learning-Based Approaches for Semantic Segmentation of Natural Scene Images: A Review" Electronics 12, no. 12: 2730. https://doi.org/10.3390/electronics12122730
APA StyleEmek Soylu, B., Guzel, M. S., Bostanci, G. E., Ekinci, F., Asuroglu, T., & Acici, K. (2023). Deep-Learning-Based Approaches for Semantic Segmentation of Natural Scene Images: A Review. Electronics, 12(12), 2730. https://doi.org/10.3390/electronics12122730