1. Introduction
With the help of advanced satellite remote sensing technology, many high-resolution remote sensing images have been produced, which often contain a wealth of information. These images also provide rich materials for the research of target detection, so the detection methods of remote sensing targets have become a hot topic for scholars [
1,
2]. Among all types of targets, aircraft have high mobility and are of great value in various fields, especially in the military. Therefore, studying the detection methods of aircraft targets in remote sensing images is significant. However, it is still a challenging task because of the top–down view of remote sensing images, which can only acquire the upper surface features of objects, and due to many aircraft types being highly similar to each other, as well as satellite photography being susceptible to external factors such as weather, light, shadows and so on [
3,
4].
In recent years, deep learning algorithms have become the prevailing method for target detection due to advances in computer techniques. Target detection using deep learning algorithms can be categorized into two types: single-stage target detection algorithm, and two-stage target detection algorithm. The single-stage algorithm treats target detection as a combination of regression and classification tasks, while the two-stage algorithm first generates a collection of candidate regions and then identifies and classifies the target object based on these regions [
5]. Two-stage algorithms, including R-CNN [
6], Fast R-CNN [
7], Faster R-CNN [
8], and Cascade R-CNN [
9], tend to have higher accuracy but suffer from high computational requirements due to the large number of candidate frames, leading to lengthy training periods and slow detection speeds. In contrast, the detection accuracy of single-stage algorithms is typically lower than the two-stage algorithms; however, the detection speed is substantially faster. Notable examples of single-stage algorithms are YOLO [
10], SSD [
11], Retinanet [
12], and FCOS [
13].
Numerous studies have explored the application of deep learning algorithms to detect aircraft targets in remote sensing images. For instance, Liu proposed a two-stage algorithm that utilizes the Harris operator to detect corners, clusters them using mean drift clustering to generate small yet precise candidate regions, and subsequently identifies the aircraft’s region by leveraging a CNN model, resulting in enhanced detection accuracy [
14]. In the DPANet, Shi introduced a deconvolution module to extract external structural features of the aircraft, which was followed by a position attention mechanism to extract internal structural features, which reduced the false detection rate and improved detection precision [
15]. Wu optimized Mask R-CNN by combining self-calibrated convolution with ResNet in the backbone, thus making the features more discriminative and resulting in improved network accuracy [
16]. For his part, Ji expanded on Fast R-CNN by incorporating a multi-angle change module that extracts target features from multiple viewpoints, thereby reducing the false detection rate. Furthermore, he employed a box detection post-processing method with a majority voting strategy to further minimize the likelihood of misjudgment [
17]. Although these algorithms are two-stage and possess unique accuracy advantages, they are still more complex relative to one-stage algorithms. Therefore, many researchers continue to focus on one-stage algorithms, particularly based on the YOLO series. For example, Cao improved the YOLOv3 model by adding a detection scale with a smaller perceptual field and using L2 regularization to combat overfitting [
18]. Zhou devised the Deeper and Wider Module (DAWM), which drew inspiration from the Inception–ResNet model. Incorporating the DAWM architecture into YOLOv3 effectively mitigated the impact of background noise and further advanced network performance [
19]. Luo added center and scale calibration at the beginning and end of the batch normalization layer in YOLOv5 to address the problem that the batch normalization layer ignores the representation differences between instances, enabling features to be corrected, which has improved the performance of the overall network [
20]. Liu proposed the YOLO-extract algorithm, which removed feature layers and prediction heads in YOLOv5 with suboptimal feature extraction ability and replaced them with a new feature extractor possessing stronger feature extraction capabilities. This modification resulted in improved accuracy and reduced computational costs [
21]. Notwithstanding the above advances in aircraft target detection algorithms, some algorithms fail to fully utilize global and local information of remote sensing images, resulting in aircraft target misdetection. To address this shortcoming, we require a novel aircraft target detection algorithm for remote sensing images that leverages global and local information more efficiently.
In this paper, we present CNTR-YOLO, which is an improved version of YOLOv5. We have made several modifications to enhance network performance. Firstly, we introduced the Dense module based on DenseNet to reinforce the feature extraction capability of the backbone. By reusing features, this module mitigates the loss of valid information. Secondly, we added the CBAM attention module to the neck to produce attention maps iteratively across both channel and spatial dimensions. This module assists in identifying areas with aircraft targets in images while reducing the impact of background noise interference. Lastly, in order to make full use of global and local information in remote sensing images, we established the C3CNTR module by combining the Transformer Block and ConvNext Block. This novel design is placed before the detection head of YOLOv5 and leverages the Transformer Block for processing global information and the ConvNext Block for processing local information.
Our contributions can be summarized as follows:
1. We propose a single-stage object detection algorithm to improve the accuracy of aircraft detection in remote sensing images.
2. For the first time, we design a structure that combines a convolutional network and Transformer in YOLOv5 to assist the prediction head, maximizing the utilization of local and global feature information.
3. We validate some effective measures to improve the performance in YOLOv5, such as using DenseNet to improve feature extraction and the CBAM attention mechanism to reduce interference from background information.
2. Related Work
In this section, we provide an overview of the key components of our proposed algorithm. Specifically, we discuss YOLOv5, Transformer, and ConvNext.
2.1. YOLOv5
YOLOv5 was released in 2020 by Ultralytics LLC and was built upon the foundation of YOLOv3 [
22]. YOLOv5 rectified the earlier issue of faster detection speed at the expense of accuracy. It also improved real-time performance and simplified the network structure. Comprised of a backbone, neck, and head, YOLOv5 features five models, ranging from YOLOv5n to YOLOv5x based on the network depth. Despite YOLOv5x exhibiting marginally superior detection accuracy compared to YOLOv5l, the latter delivers faster speeds and requires fewer hardware resources. Therefore, we conduct research based on YOLOv5l.
Figure 1 illustrates the architecture of YOLOv5. The feature extraction network of YOLOv5 is composed of a CSPDarkNet53 network [
23] and an SPPF layer. The neck utilizes a PANet [
24] structure, and the head is a YOLO detection head that comprises a convolution layer and a prediction component. In YOLOv5, the C3 module is one of the most frequently applied modules. The structure of the C3 module, as shown in
Figure 2, consists of three convolutional modules and a Bottleneck. The Bottleneck is a residual block that possesses faster computation speeds than the residual block of ResNet [
25]. Furthermore, it enables a deeper network architecture while reducing computational parameters.
While YOLOv5 has demonstrated excellent performance across various vision tasks, its direct application to aircraft target detection in remote sensing images falls short of satisfactory outcomes. Thus, this paper introduces several improvements to enhance its performance in this domain.
2.2. Transformer
In recent years, Transformer [
26] has achieved significant success in the field of natural language processing (NLP). As the size of the convolutional kernel constrains its ability to acquire local representations, researchers have looked to extend Transformer’s functionality to computer vision. To this end, Dosovitskiy et al. proposed the Vision Transformer (ViT) methodology [
27], which leverages Multiple Self-Attention (MSA) to capture long-range feature dependencies within internal information.
The details of the ViT methodology can be succinctly summarized as follows. Firstly, a two-dimensional image is converted into several one-dimensional sequences. Location encoding is then incorporated to provide information on the image’s spatial position. Subsequently, the sequences, with learnable location encoding, are passed through the Transformer encoder, which calculates global attention and extracts features via the multi-headed attention module. Lastly, the MLP layer yields the prediction categories.
Several researchers have already integrated Transformer with YOLOv5. For example, in the detection of targets during UAV shooting scenes, Zhu replaced the Bottleneck in the C3 structure of the original YOLOv5 with the Transformer Block to create the C3TR module [
28].
Figure 3 displays the structure of the C3TR module. Transformer’s unique properties enable the C3TR module to capture global information and abundant contextual information from features.
Target detection in remote sensing images presents unique challenges compared to UAV shooting scenes, including larger shooting distances, smaller objects, and a single angle of aircraft targets (which are mostly vertical). Given these difficulties, it is crucial to explore alternative approaches to integrate Transformer and address these complexities.
2.3. ConvNext
In the realm of computer vision, ViT has swiftly replaced convolutional networks as the state-of-the-art approach for image classification models. On the other hand, FAIR’s ConvNext [
29], which relies entirely on standard convolutional networks, offers comparable accuracy and generalizability to Transformer.
ConvNext does not introduce significant innovations to the overall network architecture or construction ideas. Instead, it makes some modifications to the existing ResNet network by incorporating some advanced concepts of Transformer. These changes aim to combine the advantages of both convolutional neural networks (CNNs) and Transformer networks, which ultimately leads to improved CNN performance.
In contrast to Transformer, ConvNext, built using convolutional networks, exhibits a greater capacity to capture local information. This ability plays a pivotal role in detecting high-resolution remote sensing images. The present study proposes a novel joint design that integrates the strengths of both Transformers and ConvNext to improve detection performance.
3. Theoretical Model
To address the challenges associated with detecting aircraft targets in remote sensing images, we developed CNTR-YOLO based on YOLOv5. In this section, we first present the architecture of CNTR-YOLO. Subsequently, we elaborate on the critical components of CNTR-YOLO, including the C3CNTR module, Dense module, and CBAM attention module.
3.1. Overview of CNTR-YOLO
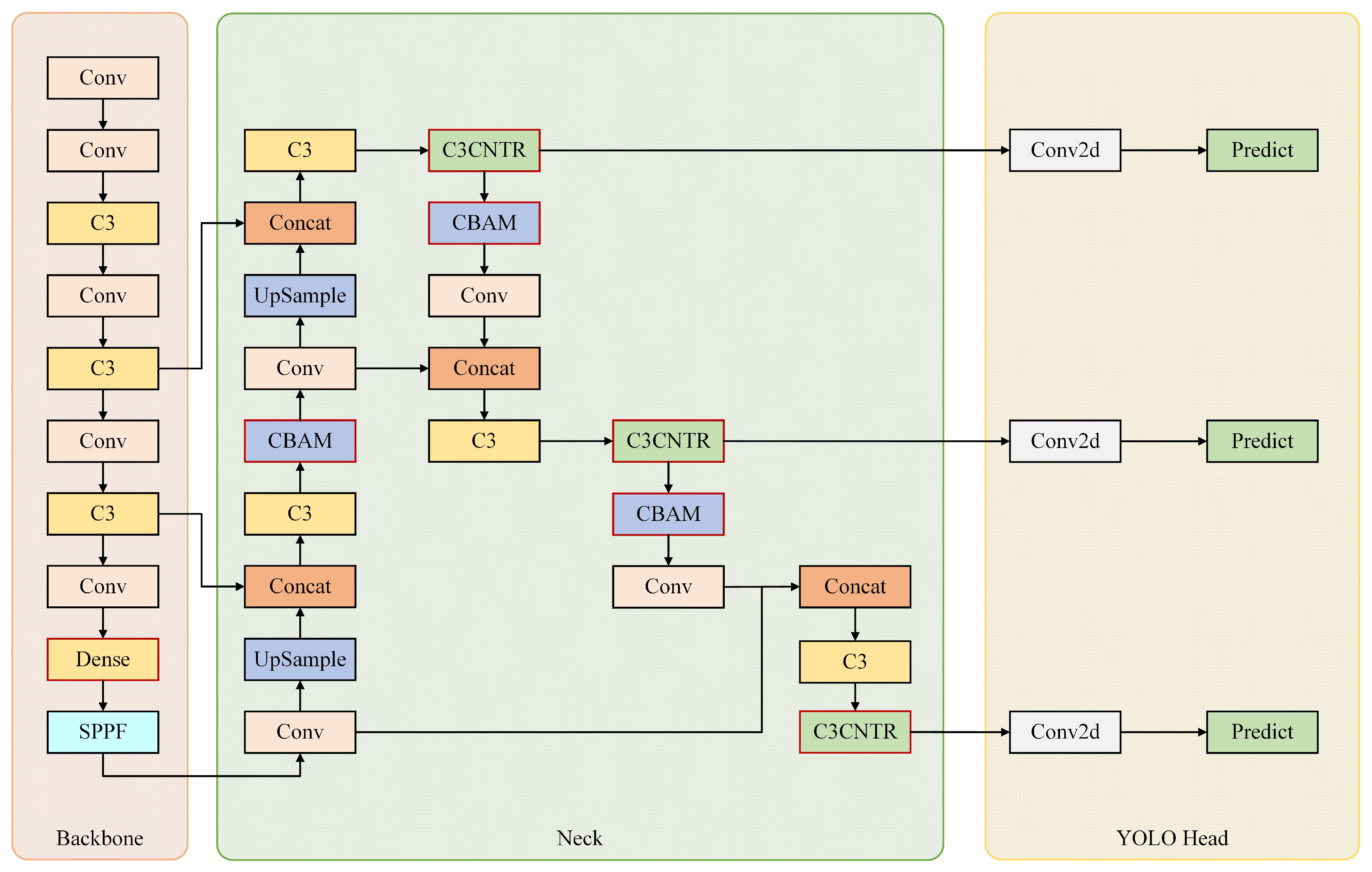
The architecture of the proposed CNTR-YOLO module is shown in
Figure 4. Compared with YOLOv5, CNTR-YOLO has a total of seven differences. First, we replaced a C3 module with a Dense module at the end of the Backbone, then inserted a CBAM attention module after each of the first three C3 modules in the neck, and finally, the C3CNTR module is inserted before the detection head.
3.2. C3-ConvNext-Transformer (C3CNTR) Module
To enhance YOLOv5’s understanding of global and local information, we have drawn inspiration from the success of incorporating Transformer in YOLOv5 and designing the C3TR module in reference [
28]. In light of this experience, we introduce ConvNext and Transformer to develop the C3CNTR module. ConvNext enhances the utilization of local information, while Transformer improves the utilization of global information.
Figure 5 illustrates the structure of the C3CNTR module.
Figure 4.
The architecture of CNTR-YOLO.
Figure 4.
The architecture of CNTR-YOLO.
3.2.1. Transformer Block
In the Transformer Block shown in
Figure 6, we employ a classic Transformer Encoder architecture. In contrast to the standard convolutional network, this architecture utilizes certain special operations that will be elaborated on shortly.
- 1.
Flatten
A Flatten operation is located at the outset of the Transformer Encoder and serves to convert two-dimensional feature maps into one-dimensional sequences of feature maps. Given an input feature map , it becomes after Flatten, where .
- 2.
Multi-head attention
Multi-head attention is a global operation that allows the Transformer Encoder to discover correlation information on a feature’s entire range. The feature map undergoes conversion into
with different linear mappings following Flatten and LayerNorm to serve as input for multi-head attention. Comprising several single-head attentions, multi-head attention executes one operation on
with each single-head attention. The output expression of the
i-th single-head attention is as follows:
where
is the multiplication of
and the
i-th single-head attention’s weight matrix, while
represents the attention matrix, revealing the correlation between each element of the feature map and other elements.
refers to the feature that consolidates global information. After each single-head attention completes its operation, the resulting outputs are unified via the concatenation layer. The ultimate output expression is shown as follows:
where
h is the number of multi-head attention heads.
- 3.
FFN
The output of multi-head attention advances to FFN once it undergoes LayerNorm. FFN refers to a Feed-Forward Network that essentially comprises two fully connected layers; one of which has Relu activation, while there is a Dropout between the two layers. The expression for FFN processing is shown below:
where
x is the sequence of input feature maps,
and
are the weights and offsets of the first fully connected layer, and
and
are the weights and offsets of the second fully connected layer.
3.2.2. ConvNext Block
The ConvNext Block’s structure is shown in
Figure 7, which adopts the standard ConvNext network structure.
While ConvNext is essentially a convolutional network, its design delineates some similarities to Transformer, which are elaborated upon below.
A group convolution employs multiple groups of convolutional filters for convolution. On the other hand, DWConv (depthwise convolution) refers to a special group convolution in which the number of groups equals the number of channels. Similar to multi-head attention in Transformer, depthwise convolution plays a pivotal role in ConvNext’s architecture. Depthwise convolution, akin to the weighted sum operation in multi-head attention, performs operations on a channel-by-channel basis, amalgamating information only in the spatial dimension. The combination of depthwise convolution and 1 × 1 convolution allows for a separation of the spatial and channel dimensions of the feature maps. Each operation, by mixing information either across the spatial dimension or channel dimension, is performed independently, which is analogous to Transformers. Comprised of only pure convolutional networks, ConvNext’s global perceptual field differs from that of Transformers. To compensate for this limitation, ConvNext uses 7 × 7 convolution kernels in depthwise convolution.
- 2.
Inverted Bottleneck
The ConvNext Block culminates in an inverted bottleneck, which is a design element also found in Transformer. In Transformer Encoder, a crucial design specification entails incorporating an inverted bottleneck at the end, amplifying the hidden dimensions of the two fully connected layers in FFN to four times the input dimensions. Following the advent of Transformer, various cutting-edge convolutional networks adopted the inverted bottleneck design, such as MobileNetV2 [
30]. Similar in approach to Transformer, ConvNext creates the Inverted Bottleneck at the end via two 1 × 1 convolutions. The role of 1 × 1 convolution is commensurate to that of a fully connected layer. The first 1 × 1 convolution expands the input channel four times, while the latter restores the number of input channels. The authors of ConvNext have also validated that this design enhances network performance across multiple tasks, encompassing classification and detection.
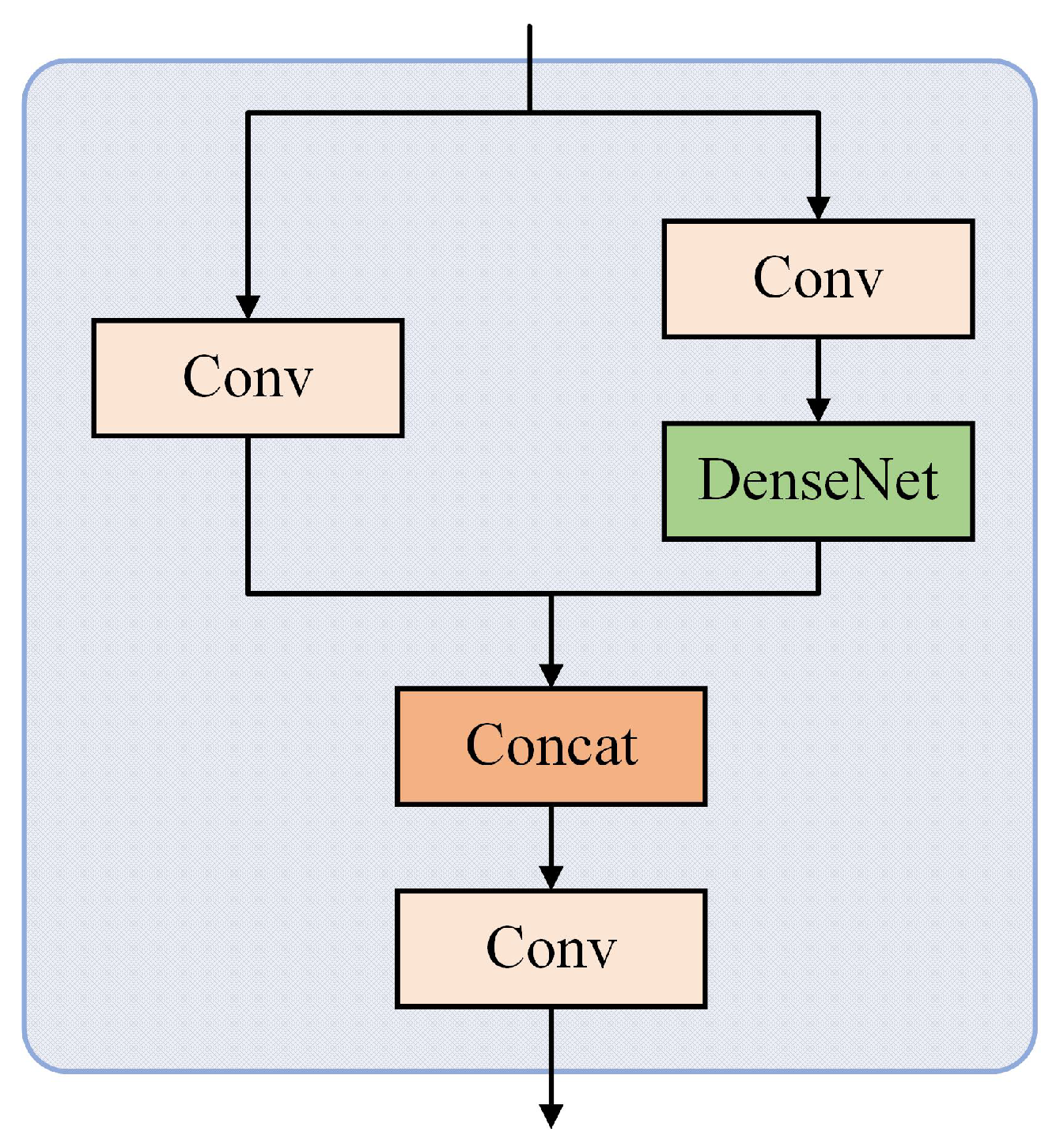
3.3. Dense Module
Toward the end of the feature extraction network, we exchanged a C3 module for a Dense module, aiming to heighten the network’s efficiency in utilizing feature information. The Dense module follows the structure of C3, as depicted in
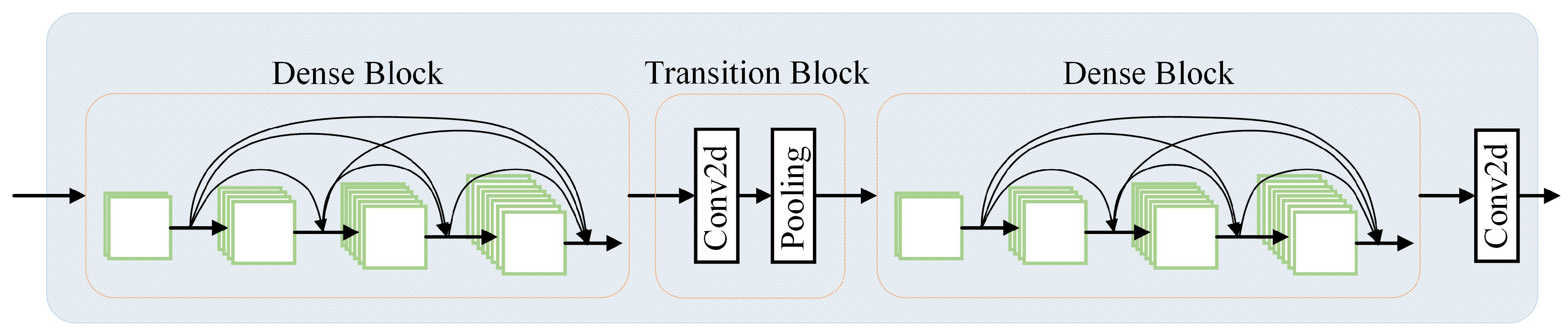
Figure 8, and it contains the architecture of DenseNet [
31], which is delineated in
Figure 9.
DenseNet melds concepts from ResNet and Inception networks [
32], possessing four fundamental benefits, comprising: retaining low-latitude features; enhancing feature reuse; mitigating the gradient disappearance problem; and considerably diminishing the number of parameters. Its architecture principally incorporates numerous DenseNet Blocks and Transition Blocks, and we select two and one, respectively, for each. A DenseNet Block with
N layers of convolution possesses
connections, with each layer’s input deriving from all previous layers’ output, which is a stark contrast to the
N connections in a traditional convolutional neural network with
N layers. This unique connection methodology in a DenseNet Block optimizes a better utilization of features and obviates the need for learning a considerable mass of irrelevant feature information, thereby preventing gradient explosion and diminishing the likelihood of overfitting. Elevated feature extraction in the network is achieved while reducing computation and the number of parameters. Assuming
N convolution layers exist in a Dense Block, the expression for the
n-th layer of output is as follows:
where
represents the nonlinear operation at the
n-th layer, and
represents the operation of concatenating all the outputs before the
n-th layer. Concatenation is distinguishable from residual connection, the latter which simply adds the values of two features together. Whereas concatenation, by comparison, increases the number of channels to enable preservation of the previous feature information in its entirety. To ensure consistency in the number of channels of input features across each DenseNet Block, a Transition Block is implemented to restore the number of channels in the output feature from the previous DenseNet Block.
3.4. CBAM
The Convolutional Block Attention Module (CBAM) [
33] comprises two sub-modules: the Channel Attention Module (CAM) and the Spatial Attention Module (SAM). Through its attention mechanism, CBAM simultaneously regulates the channel and space features, thus enabling the network to capture a comprehensive range of information contained in the feature map. Illustratively,
Figure 10 below depicts the diagram of CBAM.
The input feature map will first pass through the CAM. At the beginning of CAM is a global max pooling layer and a global average pooling layer. These two pooling layers will pool the feature maps based on height and width to obtain two feature maps (C is the number of channels), and then, the obtained feature maps will be fed into a two-layer MLP network, which is shared by the two input features. The MLP-processed feature maps are summed element-wise, and finally, the sigmoid activation function is used to generate the channel attention feature. The channel attention feature will be multiplied element-wise with the input feature map to obtain the input feature map of SAM.
In SAM, first, the input feature map from CAM will undergo a channel-based global maximum pooling and global average pooling to obtain two feature maps; H and W are the height and width of the feature maps, respectively. Then, the two feature maps are concatenated in the channel dimension, and the number of channels of the feature map is doubled. Next, the number of channels of the feature map is reduced by a convolutional layer followed by a sigmoid activation function, which generates a spatial attention feature. Finally, the spatial attention feature is multiplied based on element-wise with the input features of SAM to obtain the final features generated by CBAM.
4. Experiments
In this section, we first introduce the dataset used in the experiments, namely the MAR20 dataset. Subsequently, we also explain the evaluation metrics and implementation details of the experiments. The experiments can be broadly summarized as the comparison of CNTR-YOLO with other algorithms alongside the ablation study.
4.1. Dataset
The MAR20 dataset [
34], presently the largest dataset for remote sensing military aircraft target recognition, is utilized in this paper to validate the proposed algorithm’s performance. The dataset contains 3842 images and 22,341 instances of mostly 800 × 800 pixels gathered from 60 military airports across the United States, Russia, and other countries using Google Earth. The MAR20 dataset specifically includes 20 aircraft models, with six of them being the Russian SU-35 fighter, TU-160 bomber, TU-22 bomber, TU-95 bomber, SU-34 fighter-bomber, and SU-24 fighter-bomber. The remaining 14 aircraft models include the U.S. C-130 transport, C-17 transport, C-5 transport, F16 fighter, E-3 AWACS, B-52 bomber, P-3C ASW, B-1B bomber, E-8 joint battlefield surveillance aircraft, F-15 fighter, KC-135 air refueling aircraft, F-22 fighter, F/A-18 combat attack aircraft, and KC-10 air refueling aircraft. These aircraft model types are denoted with abbreviations A1 to A20. The dataset is split into a training set of 1331 images and 7870 instances and a testing set of 2511 images and 14471 instances, as shown in this paper’s experimentation.
The DOTA dataset [
35] is a large remote sensing image dataset consisting of 2806 high-resolution images obtained from Google Earth and multiple satellite sensors with image sizes ranging from 800 × 800 pixels to 4000 × 4000 pixels. In comparison to the MAR20 dataset, DOTA includes a more comprehensive range of object categories, including Plane, Baseball diamond, Bridge, Ground field track, Small vehicle, Large vehicle, Ship, Tennis court, Basketball court, Storage tank, Soccer ball field, Roundabout, Harbor, Swimming pool, and Helicopter. Due to the large size of the DOTA dataset images, they cannot be directly used for training neural networks. Therefore, we divided the images into sub-images of size 608 × 608 pixels at intervals of 100 pixels. The sub-images were randomly extracted in an 8:1:1 ratio to create the training set, validation set, and testing set.
4.2. Evaluation Metrics
We adopt commonly used evaluation metrics, namely
P (precision),
R (recall), mAP (mean average precision), and mAP
(mean average precision at IOU = 0.5) in the experiments. Specifically, the expressions for
P and
R are defined as follows:
In this regard,
represents the number of positive samples that were correctly identified,
represents the number of negative samples that were identified as positive samples, and
represents the number of positive samples that were identified as negative samples. Based on
P and
R, we can compute AP (average precision), mAP, and mAP
as follows:
where
N represents the number of classifications of the targets.
4.3. Implementation Details
The implementation of CNTR-YOLO utilizes PyTorch (version v1.8.0) as the underlying framework, and the operating system used is Ubuntu 20.4. An NVIDIA RTX3060 GPU with 12 GB memory served as the platform for training and testing. During training, an SGD optimizer was used with the momentum and weight decay set to 0.937 and 0.01, respectively. A warmup strategy was employed to enhance the training process’s stability. The learning rate gradually decreased at a rate of 0.01 for the first three epochs and continued training with 0.001. Moreover, the images were resized to 640 × 640 pixels, and considering the hardware limitations, the batch size was set to 2.
The other models, including Faster R-CNN, YOLOv4, YOLOv5m, YOLOv5l, and YOLOv5x, were tested and trained under the same settings as CNTR-YOLO, with images also resized to 640 × 640 pixels during training. Notably, we adopted the default settings of each model’s referenced research articles concerning other parameters.
4.4. Experimental Results
In line with the implementation settings in
Section 4.3, we evaluate CNTR-YOLO on
P,
R, mAP, mAP
, and Latency. To show the advantages of the proposed algorithm, we compare it with Faster R-CNN, YOLOv4, YOLOv5m, YOLOv5l, and YOLOv5x. We first present experimental results on the MAR20 dataset, and then, to demonstrate the robustness of the proposed algorithm, we also show experimental results on the DOTA dataset.
4.4.1. Experimental Results on the MAR20 Dataset
The overall comparison results are shown in
Table 1. The comparison results of different categories are shown in
Table 2.
Table 1 presents the comparative results of six target detection algorithms using different metrics. CNTR-YOLO outperforms the others in terms of
P,
R, mAP
, and mAP. Specifically, CNTR-YOLO attains mAP
and mAP scores of 91.1% and 70.1%, respectively, which are 1.4% and 2.1% higher than YOLOv5x, and 2.6% and 3.3% higher than YOLOv5l. In addition, CNTR-YOLO’s mAP is 13.0% and 5.8% higher when compared against other non-YOLOv5 series algorithms, Faster R-CNN and YOLOv4, respectively. Notably, the proposed algorithm distinguishes different types of aircraft features with remarkable accuracy, achieving a recall rate of 87.5%, which is 4.1% and 1.6% higher than YOLOv5l and YOLOv5x, respectively. This ability significantly reduces recognition errors compared to other algorithms. Despite a 14.2 ms higher inference time than YOLOv5l, CNTR-YOLO’s improved detection performance still ensures that it is 4.0 ms faster than YOLOv5x.
Table 2 illustrates the mean average precision of the six methods across the twenty classifications in the MAR20 dataset. Overall, CNTR-YOLO outperforms the other five algorithms in most categories, with only three categories being inferior to YOLOv5l or YOLOv5, but the gaps are all within 2%. Notably, in category A14, where each method had the lowest mAP, CNTR-YOLO surpasses YOLOv5l and YOLOv5x by 9.7% and 5%, respectively. Additionally, CNTR-YOLO exhibits a significant performance advantage of 11.2% and 5.3%, respectively, over YOLOv5l and YOLOv5x in category A16. This gap is the largest among all categories. A comparison of the detection results between CNTR-YOLO and YOLOv5l on the same image is illustrated in
Figure 11. CNTR-YOLO correctly identifies all instances, whereas YOLOv5l misidentifies an aircraft of A16 in the bottom right corner as belonging to A18. These two categories are visually similar from the perspective of remote sensing satellites (vertical direction), but CNTR-YOLO with its stronger detail discrimination ability can identify them correctly.
4.4.2. Experimental Results on the DOTA Dataset
Similarly, we show the general comparison results on the DOTA dataset in
Table 3 and then show the comparison results on the specific categories in
Table 4.
From
Table 3, it can be observed that on the DOTA dataset, the proposed algorithm yields superior mAP
and mAP compared to other algorithms. This indicates the robustness of the proposed algorithm. When compared to YOLOv5l, CNTR-YOLO achieves 2.8% and 2.5% higher mAP
and mAP, respectively. When compared to YOLOv5x, CNTR-YOLO achieves 1.6% and 1.7% higher mAP
and mAP, respectively. In comparison to other algorithms, CNTR-YOLO outperforms them to a greater extent. The inference time results are very similar to those shown in
Table 1, which is reasonable.
From
Table 4, we can find that CNTR-YOLO outperforms other algorithms in most categories, which indicates that the proposed algorithm has a certain universality in the target detection of remote sensing images. Specifically, in the category of Plane, which represents the Aircraft considered in this paper, CNTR-YOLO yields mAP values of 83.2% that are 2.7% and 3.5% higher than those of YOLOv5x and YOLOv5l, respectively. This indicates that the proposed algorithm has superior performance in Aircraft detection compared to other algorithms on the DOTA dataset.
4.5. Ablation Study
The improvements of CNTR-YOLO include the substitution of a C3 with a Dense module, the application of the CBAM attention module, and the introduction of the C3CNTR module. These measures provide different levels of enhancements to YOLOv5l, which we will evaluate in this section. Although adding a small-scale detection head is common in YOLO-related object detection studies, such as TPH-YOLO, the approach is not utilized in this paper. The reason for this omission will be explained below. Furthermore, since C3CNTR is an improvement of C3TR, we will also inspect the enhancement effect of C3TR on the network (at the same position where C3CNTR is implemented). This assessment is essential to differentiate the performance variations between the two. The experimental results are displayed in
Table 5, where the “tiny head” represents the small target detection head. It should be noted that to save table space, the suffixes “module” or “attention module” in the nouns of the tables are omitted in this paper.
Table 5 indicates that adding a small-scale target detection head reduces all metrics. This outcome is due to the majority of instances in the MAR20 dataset not being smaller than 32 × 32 pixels. Consequently, this approach is not employed in this paper. After incorporating the Dense module, all the performance metrics improved noticeably, and the mAP rose by 1.2% compared to YOLOv5l. Following the integration of the CBAM attention module, there were slight enhancements in all measures, resulting in a 0.2% increase in the mAP. In addition to these enhancements, the introduction of C3TR and C3CNTR produced different outcomes. While C3TR produced an increase of 1.1% in the mAP, C3CNTR resulted in a 1.9% increase, indicating that C3CNTR outperforms C3TR. Finally, after implementing all the improvements, CNTR-YOLO experiences a 3.3% enhancement in the mAP compared to YOLOv5l.
Regarding the use of attention mechanisms, several alternatives to CBAM were investigated, including Coordinate Attention (CA), Squeeze-and-Excitation Attention (SE), Normalization-based Attention (NAM), and Efficient Channel Attention (ECA); however, none of them achieved the anticipated outcome. After conducting experiments, we present the comparison results of the CBAM attention module and the aforementioned four alternatives on the MAR20 dataset in
Table 6. It is worth noting that the experiments were based on the YOLOv5l+Dense module and represented by YOLOv5l*.
Table 6 reveals that CA and SE did not enhance the network’s performance; instead, they caused a decline of 0.3% and 0.2% on mAP, respectively. NAM maintained the same level of performance, while ECA and CBAM elevated mAP by 0.1% and 0.2%, respectively.
5. Conclusions
In this paper, we propose the CNTR-YOLO algorithm for detecting aircraft targets in remote sensing images by improving the existing YOLOv5 algorithm. Our work includes the first attempt to combine a convolutional network and Transformer to design a new module in YOLOv5 as well as validates some improved measures to help YOLOv5 achieve better performance in aircraft detection. Specifically, our proposed C3CNTR module absorbs the local observation capability of ConvNext and the global analysis capability of Transformer, making a greater contribution to improving detection accuracy compared to the C3TR module that uses only Transformer. Next, during the feature extraction stage, the Dense module significantly improves the network’s exploitation of features by utilizing multiple connections between convolutional layers, also avoiding the problem of gradient vanishing. Finally, we integrate the CBAM attention module to reduce interference from background information on the network, allowing the network to focus more on valuable areas and further improve the detection accuracy of the network. The mAP of the proposed CNTR-YOLO is 3.3% higher than YOLOv5l on the MAR20 dataset and exceeds other comparative methods, such as Faster R-CNN and YOLOv4. The results on the DOTA dataset show that the mAP of CNTR-YOLO reached 63.7%, also surpassing other compared methods. Particularly, for the specific category of Plane (which refers to aircraft in this paper), CNTR-YOLO achieved an mAP of 83.2%, which is 3.5% higher than YOLOv5l. This also reflects that our proposed algorithm has a certain robustness.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}