

Unified Scaling-Based Pure-Integer Quantization for Low-Power Accelerator of Complex CNNs



Abstract
1. Introduction
1.1. Background
1.2. Related Works
1.3. Paper Contribution and Organization
- Introduce a systematic quantization method called Unified Scaling-Based Pure-Integer Quantization (USPIQ), which enables pure-integer calculations for all CNN operations.
- Simplify activation scaling by combining quantization and dequantization processes into a single process for each layer using the unified scale factor (USF).
- Propose a method that can individually scale all skip (residual) connections and optimally align the quantization range of the connections of their merge points.
- Offer a considerable speedup in inference time with negligible accuracy loss compared to the previous quantization methods.
- Simplify the complex activation functions to hardware-friendly functions, which significantly saves computation time and hardware resources.
2. CNN Quantization
2.1. Training-Based Quantization
2.2. Post-Training Quantization
- Accuracy: Training-based quantization often gives higher accuracy than post-training quantization.
- Computational complexity: Post-training quantization can offer a lower computation complexity.
- Model size: Training-based quantization often produces a smaller model size since it retrains the model with reduced precision from the beginning.
- Hyperparameter selection: Post-training quantization requires fewer hyperparameters that need to be tuned.
- Dataset requirement: Post-training quantization does not require a full training dataset, whereas training-based quantization requires a full dataset.
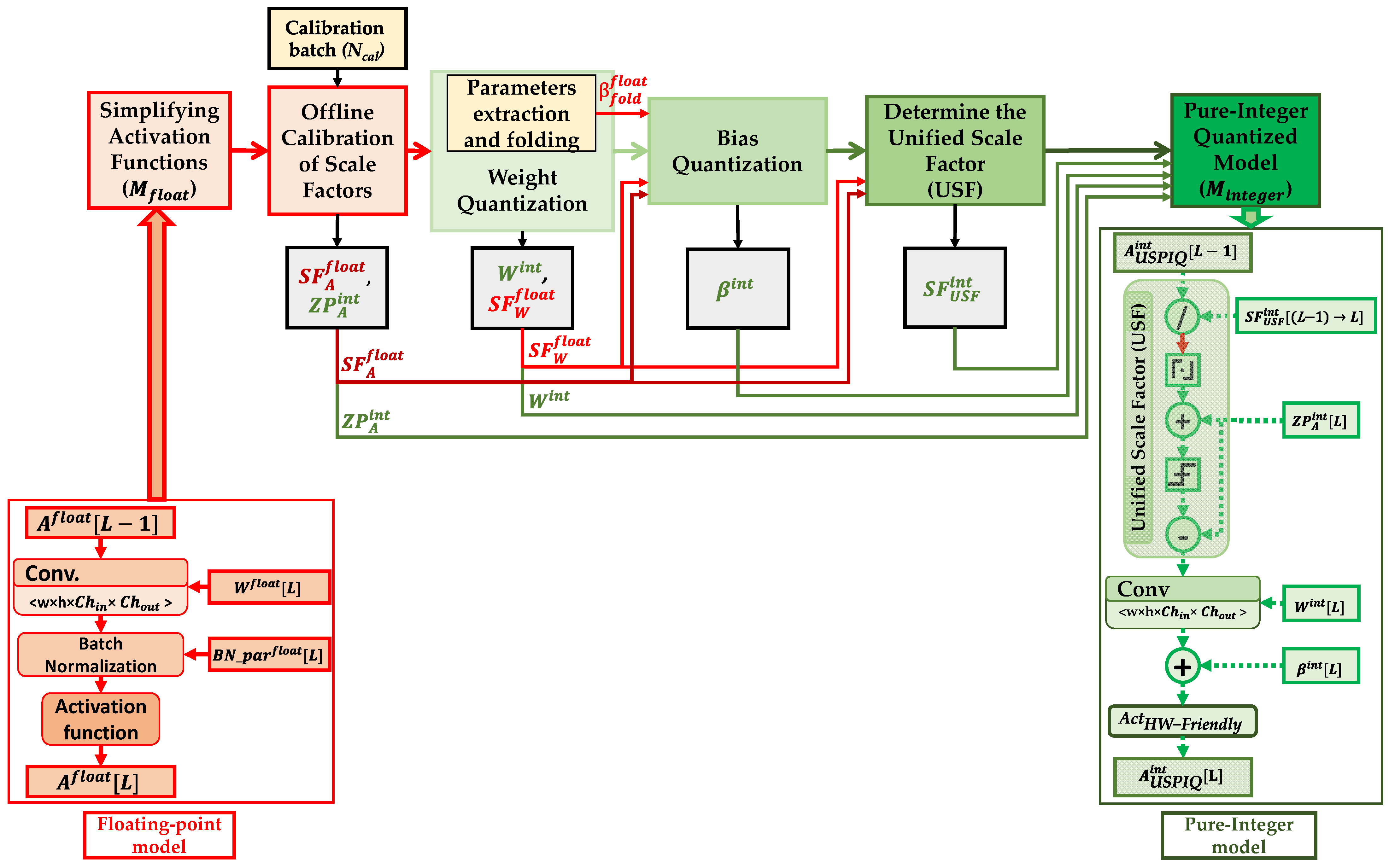
3. Proposed Unified Scaling-Based Pure-Integer Quantization
| Algorithm 1: Unified Scaling-Based Pure-Integer Quantization (USPIQ) method |
| Inputs: Pre-trained floating-point model Mfloat, a batch of images for calibration Ncal, and user-defined bit precision k. Outputs: Pure-integer CNN model Minteger, quantized (weights and biases ), per-layer unified scale factors , and zero-points . Algorithm:
|
3.1. Simplifying Activation Functions
3.2. Symmetricity of Value Range
3.3. Offline Calibration of Scale Factors
| Algorithm 2: Offline Calibration of Scale Factors |
| Inputs: Pre-trained floating-point model Mfloat, a batch of images for calibration Ncal, the number of layers , and the number of bits k for the quantized values Outputs: Mean scale factor and rounded mean zero-point for all layers. Algorithm:
|
3.4. Weight Quantization
| Algorithm 3: Weight Quantization |
| Inputs: Pre-trained floating-point model Mfloat, the number of layers , and bit precision . Outputs: Quantized weights in k-bit integer , weight scale factor , and . Algorithm:
|
3.5. Bias Quantization
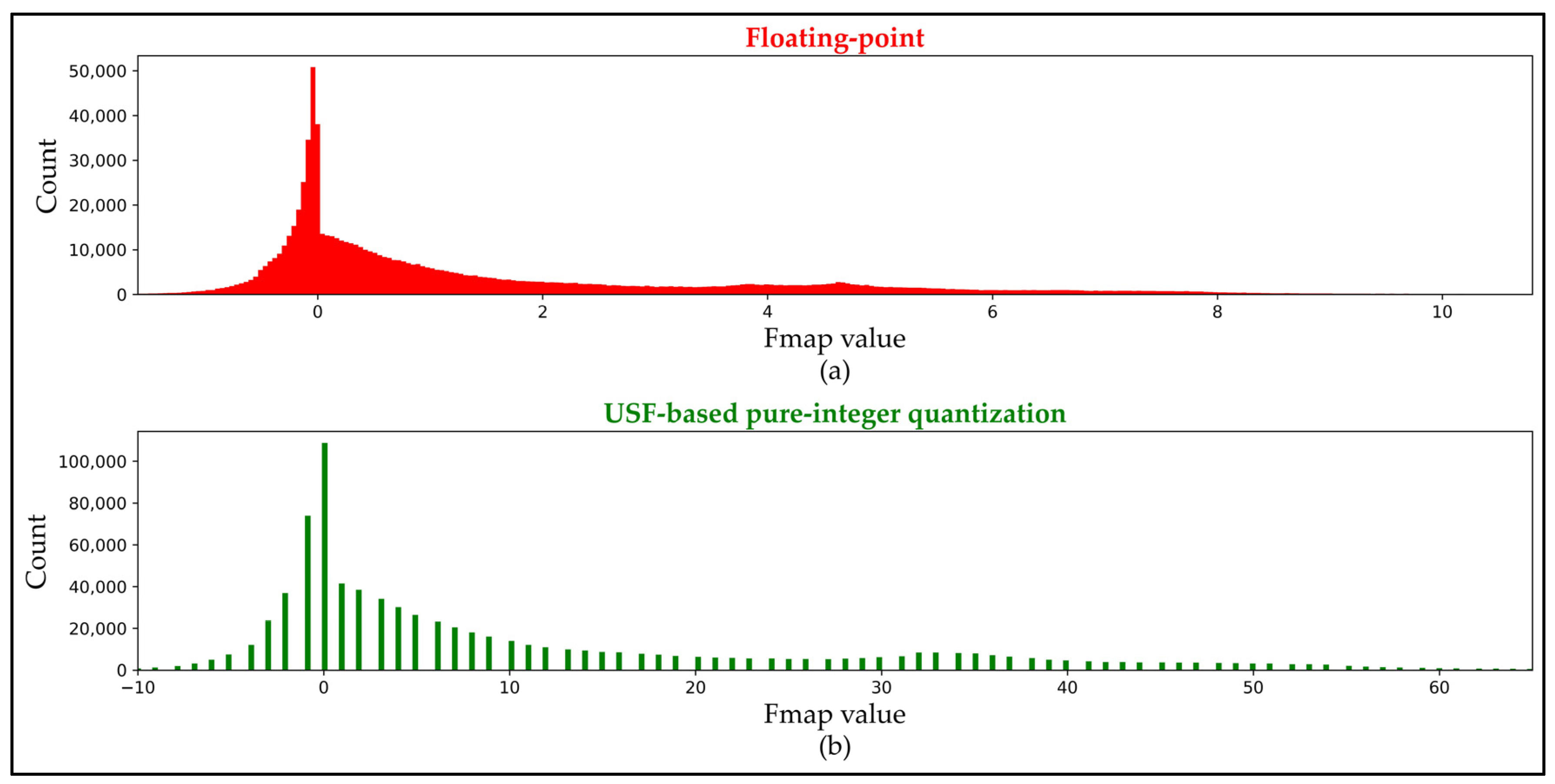
3.6. Proposed Unified Scale Factor (USF)
3.7. Proposed USF-Based Approach for Handling Skip Connections
4. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Definition | Abbreviation | Definition |
| AI | Artificial Intelligence | HAQ | Hardware-Aware Automated Quantization |
| CNN | Convolutional Neural Network | ZAQ | Zero-shot adversarial quantization |
| USPIQ | Unified Scaling-Based Pure-Integer Quantization | COCO | Microsoft Common Objects in Context |
| USF | Unified Scale Factor | LCQ | Learnable Companding Quantization |
| YOLO | You Only Look Once | NPUs | Neural Network Processor Units |
| ONNX | Open Neural Network Exchange | STE | Straight-Through Estimator |
| mAP@0.5 | Mean Average Precision@ Intersection over union = 0.5 | SiLU | Sigmoid Linear Unit |
| ILSVRC’10 | ImageNet Large Scale Visual Recognition Challenge 2010 | ReLU | Rectified Linear Unit |
| ILSVRC’12 | ImageNet Large Scale Visual Recognition Challenge 2012 | ResNets | Residual Neural Network |
| R-CNN | Regions with CNN Features | DenseNet | Densely connected convolutional networks |
| SSD | Single Shot Detector | GPU | Graphical Processing Unit |
| VBQ | Variable Bin-size Quantization | PC | Personal Computer |
| MNIST | Modified National Institute of Standards and Technology | CPU | Central Processing Units |
| CIFAR10 | Canadian Institute for Advanced Research (10) | CMOS | Complementary Metal–Oxide–Semiconductors |
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Lybrand, E.; Saab, R. A greedy algorithm for quantizing neural networks. J. Mach. Learn. Res. 2021, 22, 7007–7044. [Google Scholar]
- Li, R.; Wang, Y.; Liang, F.; Qin, H.; Yan, J.; Fan, R. Fully quantized network for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 2805–2814. [Google Scholar]
- Andriyanov, N.A.; Dementiev, V.E.; Tashlinskii, A.G. Detection of objects in the images: From likelihood relationships towards scalable and efficient neural networks. Comput. Opt. 2022, 46, 139–159. [Google Scholar] [CrossRef]
- Minderer, M.; Gritsenko, A.; Stone, A.; Neumann, M.; Weissenborn, D.; Dosovitskiy, A.; Mahendran, A.; Arnab, A.; Dehghani, M.; Shen, Z.; et al. Simple open-vocabulary object detection with vision transformers. arXiv 2022, arXiv:2205.06230. [Google Scholar]
- Zhang, W.; Huang, D.; Zhou, M.; Lin, J.; Wang, X. Open-Set Signal Recognition Based on Transformer and Wasserstein Distance. Appl. Sci. 2023, 13, 2151. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2014), Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NeurIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 2969239–2969250. [Google Scholar]
- Joseph, R.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part I 14. pp. 21–37. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Proceedings of the Advances in Neural Information Processing Systems 28 (NeurIPS 2015), Montreal, QC, Canada, 7–12 December 2015; pp. 1–8. [Google Scholar]
- Nguyen, D.T.; Nguyen, T.N.; Kim, H.; Lee, H.J. A high-throughput and power-efficient FPGA implementation of YOLO CNN for object detection. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 17, 1861–1873. [Google Scholar] [CrossRef]
- Nagel, M.; Fournarakis, M.; Amjad, R.A.; Bondarenko, Y.; Van Baalen, M.; Blankevoort, T. A white paper on neural network quantization. arXiv 2021, arXiv:2106.08295. [Google Scholar]
- Chen, S.; Wang, W.; Pan, S.J. Metaquant: Learning to quantize by learning to penetrate non-differentiable quantization. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 3918–3928. [Google Scholar]
- Nagel, M.; Baalen, M.V.; Blankevoort, T.; Welling, M. Data-free quantization through weight equalization and bias correction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV 2019), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1325–1334. [Google Scholar]
- Wang, Z.; Wu, Z.; Lu, J.; Zhou, J. Bidet: An efficient binarized object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Virtual Conference, 14–19 June 2020; pp. 2049–2058. [Google Scholar]
- Zhao, S.; Yue, T.; Hu, X. Distribution-aware adaptive multi-bit quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Virtual Conference, 14–19 June 2020; pp. 9281–9290. [Google Scholar]
- Gysel, P.; Pimentel, J.; Motamedi, M.; Ghiasi, S. Ristretto: A framework for empirical study of resource-efficient inference in convolutional neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5784–5789. [Google Scholar] [CrossRef] [PubMed]
- Banner, R.; Nahshan, Y.; Soudry, D. Post training 4-bit quantization of convolutional networks for rapid-deployment. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; pp. 7948–7956. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. A survey of model compression and acceleration for deep neural networks. arXiv 2017, arXiv:1710.09282. [Google Scholar]
- Wu, H.; Judd, P.; Zhang, X.; Isaev, M.; Micikevicius, P. Integer quantization for deep learning inference: Principles and empirical evaluation. arXiv 2020, arXiv:2004.09602. [Google Scholar]
- Nogami, W.; Ikegami, T.; Takano, R.; Kudoh, T. Optimizing weight value quantization for cnn inference. In Proceedings of the International Joint Conference on Neural Networks (IJCNN/IEEE), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Zhang, J.; Zhou, Y.; Saab, R. Post-training quantization for neural networks with provable guarantees. arXiv 2022, arXiv:2201.11113. [Google Scholar] [CrossRef]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Choukroun, Y.; Kravchik, E.; Yang, F.; Kisilev, P. Low-bit quantization of neural networks for efficient inference. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3009–3018. [Google Scholar]
- Wang, K.; Liu, Z.; Lin, Y.; Lin, J.; Han, S. Haq: Hardware-aware automated quantization with mixed precision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2019), Long Beach, CA, USA, 16–20 June 2019; pp. 8612–8620. [Google Scholar]
- Zhang, X.; Qin, H.; Ding, Y.; Gong, R.; Yan, Q.; Tao, R.; Li, Y.; Yu, F.; Liu, X. Diversifying sample generation for accurate data-free quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Virtual Conference, 19–25 June 2021; pp. 15658–15667. [Google Scholar]
- Nagel, M.; Amjad, R.A.; Van Baalen, M.; Louizos, C.; Blankevoort, T. Up or down? adaptive rounding for post-training quantization. In Proceedings of the International Conference on Machine Learning (PMLR 2020), Vienna, Austria, 12–18 July 2020; pp. 7197–7206. [Google Scholar]
- Liu, Y.; Zhang, W.; Wang, J. Zero-shot adversarial quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Virtual Conference, 19–25 June 2021; pp. 1512–1521. [Google Scholar]
- Chikin, V.; Antiukh, M. Data-Free Network Compression via Parametric Non-uniform Mixed Precision Quantization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), New Orleans, LA, USA, 19–24 June 2022; pp. 450–459. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 19–21 June 2018; pp. 2704–2713. [Google Scholar]
- Al-Hamid, A.A.; Kim, T.; Park, T.; Kim, H. Optimization of Object Detection CNN with Weight Quantization and Scale Factor Consolidation. In Proceedings of the International Conference on Consumer Electronics-Asia (ICCE-Asia/IEEE), Yeosu, Republic of Korea, 26–28 October 2021; pp. 1–5. [Google Scholar]
- Yamamoto, K. Learnable companding quantization for accurate low-bit neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Virtual Conference, 19–25 June 2021; pp. 5029–5038. [Google Scholar]
- Intel. Intel Distribution of OpenVINO Toolkit. Available online: https://docs.openvinotoolkit.org (accessed on 6 June 2023).
- Andriyanov, N.; Papakostas, G. Optimization and Benchmarking of Convolutional Networks with Quantization and OpenVINO in Baggage Image Recognition. In Proceedings of the VIII International Conference on Information Technology and Nanotechnology (ITNT/IEEE), Samara, Russia, 23–27 May 2022; pp. 1–4. [Google Scholar]
- Demidovskij, A.; Tugaryov, A.; Fatekhov, M.; Aidova, E.; Stepyreva, E.; Shevtsov, M.; Gorbachev, Y. Accelerating object detection models inference within deep learning workbench. In Proceedings of the International Conference on Engineering and Emerging Technologies (ICEET/IEEE), Istanbul, Turkey, 27–28 October 2021; pp. 1–6. [Google Scholar]
- Feng, H.; Mu, G.; Zhong, S.; Zhang, P.; Yuan, T. Benchmark analysis of yolo performance on edge intelligence devices. Cryptography 2022, 6, 16. [Google Scholar] [CrossRef]
- Kryzhanovskiy, V.; Balitskiy, G.; Kozyrskiy, N.; Zuruev, A. Qpp: Real-time quantization parameter prediction for deep neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2021), Virtual Conference, 19–25 June 2021; pp. 10684–10692. [Google Scholar]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefanet: Training low bitwidth convolutional neural networks withlow bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Park, E.; Ahn, J.; Yoo, S. Weighted-Entropy-Based Quantization for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 5456–5464. [Google Scholar]
- Yang, Y.; Deng, L.; Wu, S.; Yan, T.; Xie, Y.; Li, G. Training high-performance and large-scale deep neural networks with full 8-bit integers. Neural Netw. 2020, 125, 70–82. [Google Scholar] [CrossRef] [PubMed]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Glenn, J.; Stoken, A.; Chaurasia, A.; Borovec, J.; Kwon, Y.; Michael, K.; Liu, C.; Fang, J.; Abhiram, V.; Skalski, S.P. ultralytics/yolov5: v6.0—YOLOv5n ‘Nano’models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support; Zenodo Tech. Rep. 2021. Available online: https://zenodo.org/record/5563715 (accessed on 12 May 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- ONNX: Open Neural Network Exchange. Available online: https://github.com/onnx/onnx/ (accessed on 13 April 2023).
- Son, H.; Na, Y.; Kim, T.; Al-Hamid, A.A.; Kim, H. CNN Accelerator with Minimal On-Chip Memory Based on Hierarchical Array. In Proceedings of the 18th International SoC Design Conference (ISOCC/IEEE), Jeju, Republic of Korea, 6–9 October 2021; pp. 411–412. [Google Scholar]
- Son, H.; Al-Hamid, A.A.; Na, Y.; Lee, D.; Kim, H. CNN Accelerator Based on Diagonal Cyclic Array Aimed at Minimizing Memory Accesses. Comput. Mater. Contin. 2023; accepted. [Google Scholar]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2022), New Orleans, LA, USA, 19–24 June 2022; pp. 2637–2646. [Google Scholar]
- Choi, D.; Kim, H. Hardware-friendly log-scale quantization for CNNs with activation functions containing negative values. In Proceedings of the 18th International SoC Design Conference (ISOCC/IEEE), Jeju, Republic of Korea, 6–9 October 2021; pp. 415–416. [Google Scholar]
- Wu, Q.; Li, Y.; Chen, S.; Kang, Y. DRGS: Low-Precision Full Quantization of Deep Neural Network with Dynamic Rounding and Gradient Scaling for Object Detection. In Proceedings of the Data Mining and Big Data: 7th International Conference, (DMBD), Beijing, China, 21–24 November 2022; pp. 137–151. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN Model | Number of Parameterized Layers | Floating-Point 32 | ONNX Run-Time | USPIQ (Proposed) | |
|---|---|---|---|---|---|
| Dynamic | Static | ||||
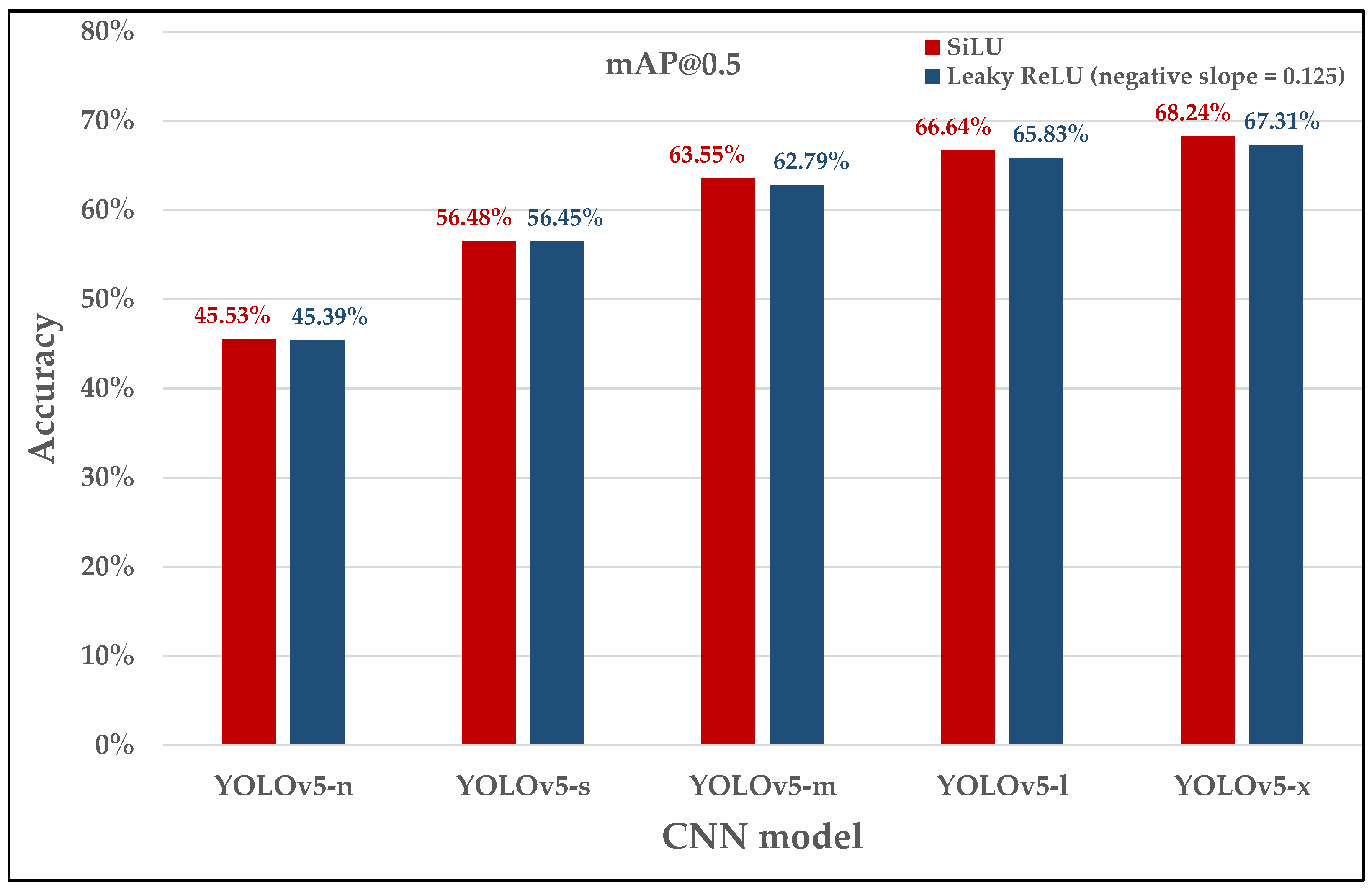
| YOLOv5-n (3) | 60 (Layer 0 kernel 3 × 3) | 43.45% | 43.18% | 42.91% | 43.44% |
| YOLOv5-n (6) | 60 (Layer 0 kernel 6 × 6) | 45.39% | 43.13% | 42.52% | 44.80% |
| YOLOv5-s | 60 (Higher channels depth) | 56.45% | 55.70% | 55.09% | 55.90% |
| YOLOv5-m | 82 | 62.58% | 62.00% | 61.82% | 62.18% |
| YOLOv5-l | 104 | 65.83% | 63.39% | 65.23% | 65.34% |
| YOLOv5-x | 126 | 67.31% | 66.09% | 66.29% | 66.70% |
| CNN Model | ONNX Run-Time (Dynamic) | USPIQ (Proposed) |
|---|---|---|
| YOLOv5-n (3) | 42.00 | 25.56 |
| YOLOv5-n (6) | 48.36 | 29.28 |
| YOLOv5-s | 85.32 | 41.53 |
| YOLOv5-m | 134.41 | 63.25 |
| YOLOv5-l | 282.49 | 100.20 |
| YOLOv5-x | 458.72 | 162.07 |
| Process | Operation | ONNX Run-Time (Dynamic) | USPIQ (Proposed) |
|---|---|---|---|
| Convolutional | MAC | 4.56 | 4.56 |
| Bias adding | 1.09 | 0.55 | |
| Activation function | Shifting | -/- | Negligible |
| Division | 2.18 | -/- | |
| Floating-point quantization | 5.46 | -/- | |
| Integer unified scaling of activations | -/- | 1.91 | |
| Element-wise adder | 0.023 | 0.006 | |
| Concatenation | 0.014 | 0.004 | |
| Max-pooing | 0.006 | 0.002 | |
| Up-sampling (Resize) | 0.0013 | 0.0003 | |
| Total computational time per image | 13.33 | 7.03 | |
| Process | Operation | ONNX Run-Time | USPIQ (Proposed) | |
|---|---|---|---|---|
| Dynamic | Static | |||
| Convolutional | Multiplication | 1681.08 | 7775.01 | 1681.08 |
| Addition | 210.14 | 1891.22 | 210.14 | |
| Bias adding | 12.57 | 12.57 | 1.19 | |
| Activation function | Shifting | -/- | -/- | Negligible |
| Division | 44.00 | 44.00 | -/- | |
| Floating-point quantization | 256.06 | 193.61 | -/- | |
| Integer unified scaling of activations | -/- | -/- | 21.65 | |
| Element-wise adder | 1.06 | 1.06 | 0.06 | |
| Concatenation | 0.29 | 0.29 | 0.14 | |
| Max-pooing | 0.28 | 0.28 | 0.02 | |
| Up-sampling (Resize) | 0.06 | 0.06 | 0.03 | |
| Total energy consumption | 2205.54 | 9918.10 | 1914.31 | |
| CNN Model | Floating-Point 32 | [50] 8-bit | [51] 8-bit | [52] 4-bit | USPIQ (Proposed) |
|---|---|---|---|---|---|
| YOLOv5-s6_960_relu (AP50) | 86.7% | 81.1% | -/- | -/- | 85.90% (8-bit) |
| YOLOv5-m (mAP@0.5) | 62.58% | -/- | 61.7% | -/- | 62.18% (8-bit) |
| YOLOv5-s (mAP@0.5) | 56.45% | -/- | -/- | 33.4% | 33.90% (4-bit) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Hamid, A.A.; Kim, H. Unified Scaling-Based Pure-Integer Quantization for Low-Power Accelerator of Complex CNNs. Electronics 2023, 12, 2660. https://doi.org/10.3390/electronics12122660
Al-Hamid AA, Kim H. Unified Scaling-Based Pure-Integer Quantization for Low-Power Accelerator of Complex CNNs. Electronics. 2023; 12(12):2660. https://doi.org/10.3390/electronics12122660
Chicago/Turabian StyleAl-Hamid, Ali A., and HyungWon Kim. 2023. "Unified Scaling-Based Pure-Integer Quantization for Low-Power Accelerator of Complex CNNs" Electronics 12, no. 12: 2660. https://doi.org/10.3390/electronics12122660
APA StyleAl-Hamid, A. A., & Kim, H. (2023). Unified Scaling-Based Pure-Integer Quantization for Low-Power Accelerator of Complex CNNs. Electronics, 12(12), 2660. https://doi.org/10.3390/electronics12122660