1. Introduction
In recent years, research on human action recognition has developed by leaps and bounds and is now used in various fields, such as video surveillance, intelligent medical care, human–machine collaboration, and intelligent human–machine interfaces [
1,
2,
3,
4]. This also means that there are increasingly higher requirements for human action recognition algorithms in terms of performance, which is a classic and challenging topic in computer vision research. To date, many methods based on hand-crafted feature representations have been widely used for action recognition due to their advantages, such as simplicity and robustness [
5,
6,
7]. However, due to the limitations of human cognitive abilities, the method is often database-oriented and difficult to apply to real-life scenarios.
With the development of deep learning techniques, deep learning algorithms have more advantages in the field of human motion recognition than traditional methods [
8]. Currently, convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are frequently used in the field of human motion recognition. The 3D CNN [
9] is a typical algorithm studied in human action recognition tasks. In that work, 3D convolutions are employed to extract features from the spatial and temporal dimensions of video data. This works well for capturing spatial information and has a better performance in image recognition at the moment, but temporal information is inevitably lost when sequences are encoded into images, and temporal motion plays a key role in human action recognition. This problem can be mitigated with RNNs, in particular long short-term memory (LSTM), which has been shown to effectively model long-term cues of motion sequences [
10]. The gate unit in LSTM can choose whether to update specific information or not while ensuring long-term memory of valid data and forgetting or discarding useless information, thereby maximizing the utilization of data information.
Based on these facts, the accurate recognition of actions in the real world remains challenging. Current human action recognition methods solve the sequence learning problem with LSTM and gated recurrent units but do not focus on the selective information in the sequence in the selection of features. In a human action sequence, not all frames in the sequence are equally important, and there are often repetitive or redundant frames [
11] that are not so important for the recognition of the action. To solve this problem, some researchers [
12] introduced a key-frame mechanism to increase the information difference among motion frames. The key frames of a motion sequence are extracted using clustering, and the redundant frames of the motion sequence are discarded to reconstruct the motion. The method can effectively improve the recognition efficiency of the model.
Therefore, in this work, we combine the above problems and propose a human action recognition method based on LSTM with key-frame attention. The key frames of different actions are extracted using clustering. They are combined with attention mechanisms to further improve the recognition efficiency and accuracy of LSTM networks. However, most key-frame extraction methods do not take into account the time-series information between frames [
13]. When confronted with long-term motion sequences containing multiple actions, there are often large errors in the localisation of action intervals [
14]. This prevents the uniform processing of inter-class similarities in different actions of the motion sequence and tends to cause inter-frame confusion in the timing of key frames of different actions. This has an impact on the accuracy of subsequent action recognition tasks.
To this end, we combine our previous work [
15] and propose a new method for key-frame extraction. The automatic segmentation model based on the autoregressive moving average (ARMA) algorithm was combined with the K-means clustering algorithm. This method allows the automatic segmentation of different movements in a motion sequence to be performed in advance. The possibility of inter-frame confusion in the timing of key frames of different actions is effectively avoided. This method ensures that subsequent human movement recognition tasks are carried out smoothly.
Combining these two modules, we propose a key-frame-based human action recognition system. In this work, we trained the model using a 3D skeleton sequence reconstructed from MoCap (motion capture device) data based on IMU sensors. In the recognition of human movement types, 18 representative joints throughout the human body were selected to build the skeleton model of the human body. The motion sequence was constructed from the extracted human pose feature vectors.
The main innovations and contributions of the present study are as follows:
The rest of the paper is structured as follows:
Section 2 provides related work on human action recognition.
Section 3 describes the structure of the human action recognition method proposed in this paper and its associated components.
Section 4 evaluates and compares the recognition accuracy of this paper’s model with that of other human action recognition-related models. Finally,
Section 5 draws conclusions.
3. Keyframe-Based Human Action Recognition Method
We propose a key-frame-based human action recognition method, which consists of two main components: a key-frame extraction method and a recognition model:
Unsupervised learning-based key-frame extraction method. An unsupervised segmentation model based on the ARMA algorithm is used to automatically segment complex motion sequences containing multiple actions into multiple sub-motion sequences. The K-means clustering algorithm is then used to separately extract the key motion frames from the segmented sub-action sample sequences. Finally, the human action pose feature matrix is labelled and encoded by combining the temporal features of the human motion sequences.
Selection and construction of recognition models. In this chapter, three models, HMM, 3D CNN, and LSTM, are employed for the recognition task, and the LSTM network is improved by combining the attention mechanism and by designing an LSTM network based on the key-frame attention mechanism, which further optimises the LSTM network by redistributing the weights of the motion feature sequences using the attention method based on key action frames. The network structure is further optimised to improve the accuracy of human action recognition.
3.1. Construction of Skeletal Models and Feature Sequences
The primary task of recognition algorithms for human movements is to collect and process the motion data of different behavioural actions. During human limb movements, the angular information and spatial location information of the limb bones can be obtained according to the different semantics and postures of the movements.
3.1.1. Structural Characterisation of the Human Body
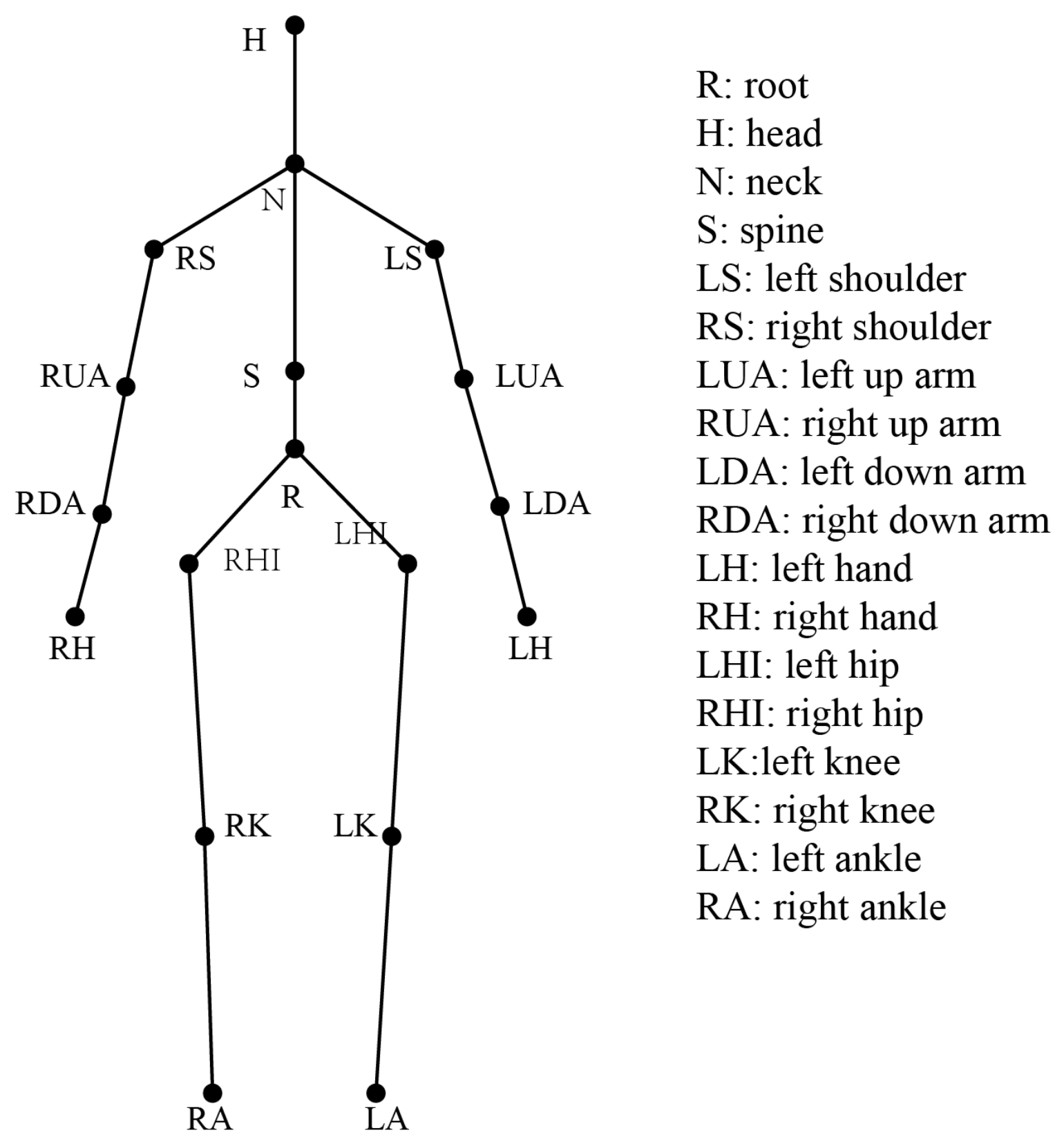
The motion data collected using a MoCap device was processed in this study in a manner consistent with previous work [
15]. As shown in
Figure 1 [
15], the human skeleton model is a tree-like hierarchical model that consists of a root node and multiple subtrees. The entire skeleton model can be roughly divided into 18 bone segments, each of which has a parent segment and a number of subsegments, with the parent segment and subsegments being connected by joints. When the human body moves, the movement of individual limbs can be described as the movement of the bone segment of that limb relative to the joints of its parent segment; human limbs periodically switch between flexed and extended postures, and the limbs then show periodic changes that form correlations among limbs. For this reason, limb segmentation angles are introduced to improve the semantic description of motion sequences. In human model building, the hip node is usually chosen as the root node of a tree human skeleton model, which constrains its children. The skeleton model is represented by the coordinates of the spatial position of each joint point; therefore, data on the rotation angle of each joint point need to be converted to the coordinates of the joint point.
where
is the rotation matrix of the joint point,
is the location of the root node, and
is the position of the child node relative to the parent node.
3.1.2. Construction of Feature Sequences
When the human body moves, the movement of each limb can be described as the movement of that limb segment relative to the joints of its parent segment. In human body modelling, the hip node is usually chosen as the root node of a tree human skeleton model, which constrains its child nodes.
Before we can perform motion analysis, we need to construct the feature matrix. The feature matrix is a prerequisite in machine learning and data analysis. It is a matrix made up of the fusion of several features that contain key information of the data, with each row representing a sample and each column representing a feature, and is one of the important steps in machine learning and data analysis. In
Table 1,
Table 2 and
Table 3, the calculation of each of the three parts of a feature is expressed.
The angular characteristics of the movement of the different bone segments are determined by the variation in the size of the angle between the individual bone segments. The calculation of the size of the angle between the bone segments of the limbs and the central bone segment, and that of the size of the angle between adjacent bone segments of the limbs are as follows:
where
,
is the direction vector on the central spinal bone segment partition, and
is the direction vector on each limb partition of the body.
The three-dimensional spatial characteristics of the movement of the different bone segments are determined by the variation in the magnitude of the spatial position distance between the individual limb bone segments and the central node. The calculation of the spatial position distances between the nodes is as follows:
where
and
are the 3D spatial position coordinates of the central node of the human skeleton (hip node) and the 3D spatial position coordinates of each limb bone segment in the Cartesian coordinate system, respectively.
3.2. Key-Frame Extraction Method Based on Unsupervised Learning Model
The key-frame extraction technique [
35] is a technique used to extract the most informative frames and eliminate pose redundancy. Various types of motion capture devices often use high sampling frequencies for sampling human motion pose data, with the accompanying disadvantage of generating a large number of repetitive redundant frames when data are collected for certain simple movements. This also has a negative impact on the efficiency of the execution of the subsequent model processing part. Therefore, it is essential to extract key frames from human motion data.
3.2.1. Segmentation of Human Limb Movement Sequences
In our previous work [
15], we proposed an unsupervised segmentation algorithm based on the structural representation of the angle between limb bone segments and the fitting of an autoregressive moving average (ARMA) model. We combined the predictive and fitting properties of the ARMA model in time series with the regularity of human motion in time series. Temporal inflection points in human motion sequences are calculated, and inflection points are identified and extracted using an adaptation algorithm to achieve motion sequence segmentation. The method overcomes the limitation that the ARMA model is only applicable to short-term sequence prediction and allows the ARMA model to perform long-motion-sequence segmentation.
Firstly, regarding the ARMA model, it is an important model for the study of time series. It consists of an autoregressive (
AR) model and a moving average (
MA) model. In the ARMA model, the data of variable
at any time
t is represented as its observation sequence
and historical random disturbance sequence
. The linear combination of
. ARMA(
p,
q) is given in Equation (
5).
where
p and
q are the orders of
AR and
MA, respectively;
and
are the calculated coefficients of
AR and
MA, respectively; and
c is the residual constant.
Secondly, the angle characteristics between each limb bone segment and the central spinal bone segment in the human limb movement sequence are combined in the ARMA model [
15]. The ARMA model for clip angle series is represented by Equation (
6).
where
are the fitted data of the limb bone segment angle,
is the linear approximation factor, and
is the residual.
After ARMA model fitting is completed for the motion sequence, a suitable segmentation window is selected, and the segmentation points of the limb bone angle feature sequence are calculated according to the ARMA model. In this work, the limb bone angle information sequence of human skeletal posture is extracted, and the median filtering method is used to obtain the final set of segmentation points.
After automatically segmenting a complex motion sequence containing multiple actions into multiple sub-action sequences using the above segmentation method, a K-means clustering algorithm is used to extract key frames from the sub-action sequences. The K-means algorithm is an unsupervised learning algorithm [
36] that is characterised by its simplicity of implementation and good clustering effect. The algorithm has a wide range of applications, and secondly, the K-means algorithm can effectively categorise similar frames in the motion sequence to achieve the purpose of key-frame extraction.
The K-means algorithm works by dividing the dataset into k class clusters, with the motion frames in each class cluster being the closest to the centroid of that cluster. For a sequence of features of motion
as input to the model, let each of these samples be of the same dimension and have the set of class clusters
. The K-means algorithm can partition these
n samples into
k class clusters, where 1 <
k <
n, such that the intra-class sum of squared errors
E is minimized.
where
is the mean vector of class cluster
, i.e., the centre of mass of the class cluster, and the calculation of
is given by Equation (
9).
During the execution of the algorithm,
k points are randomly selected as the initial clustering centres; then, for each point in the dataset, it is calculated which centroid it is the closest to. In research, the Euclidean distance is one of the most commonly used measures of spatial distance, and the method is universal and applicable in all three dimensions.
where
and
are the mean vectors of class clusters
and
, respectively. All sample points in
C are recalculated with a new centre of mass,
, until all the centre-of-mass vectors no longer change and the final output is the reclassified class cluster
. The determined
k centre of mass is extracted as the key frame of this motion feature sequence.
3.2.2. Feature Coding Based on Motion Timing Features
In this chapter, the dimensionality of the motion feature matrix is reduced using label coding, and the key gestures of the extracted human actions are coded and assigned, so that the original sequence of feature vectors representing the action gestures is transformed into a sequence of digital codes, reducing the computational complexity to improve the rate of recognition of human actions. In the process of building the code table, we need to analyse the temporal characteristics of the movements in order to better encode them, as they have temporal characteristics. Taking walking as an example,
Figure 2 shows the temporal angular characteristics of the human limbs during walking, from which it can be observed that the bone partitions of the same limb have a cyclical and causal nature in the temporal sequence. This can be used as a basis for determining the type of key gesture features.
For codebook building, a feature vector of key action gestures is first defined as , where a denotes the a action type and k denotes the k class of key gestures. The code table (codebook (CB)) contains the feature vectors of all action-critical poses, so the code table is also defined as . The feature vectors of key action gestures in the code table are arranged according to the temporal order of the training sample data and include a total of k feature vectors. These key gestures are assigned as 1,2,…,K. The key gestures of different action types are converted into numerical sequences , thus achieving the purpose of encoding and allowing the human motion analysis method of this paper to be better generalised to various behavioural tasks.
3.3. LSTM Based on Key-Frame Attention Module
After the processing of human movement data using the modules mentioned above, we combined LSTM networks and introduced an attention mechanism to build a human dynamic action pose recognition model, named KF-LSTM (key-frame LSTM).
In this work, we used the LSTM network structure shown in
Figure 3. A sequence of sample motion features of length N and dimension 20 was fed into the Bi-LSTM layer along with a sequence of labels of length N and dimension 1 containing 20 classes of action states. Feature sequences with 128 hidden states were obtained. The fully connected layer (FC) was then used to output a trained state matrix of length N and dimension 20. The output of the network was converted into a probability vector for each type of action state using a softmax layer. Finally, the relevant parameters of the different action types were obtained using a classification layer.
When training samples using LSTM networks [
30], we have found that many action frames provide the same useful information on a large number of motion data and that some impressive action frames may contain the most discriminative information capable of recording the main action. We, therefore, used a key-frame-based attention mechanism for attention allocation and aggregated motion feature representations with different weights to reduce information fragmentation. Introducing attention into the human action model so that it gives more attention to key frames allows more effective human motion recognition to be achieved.
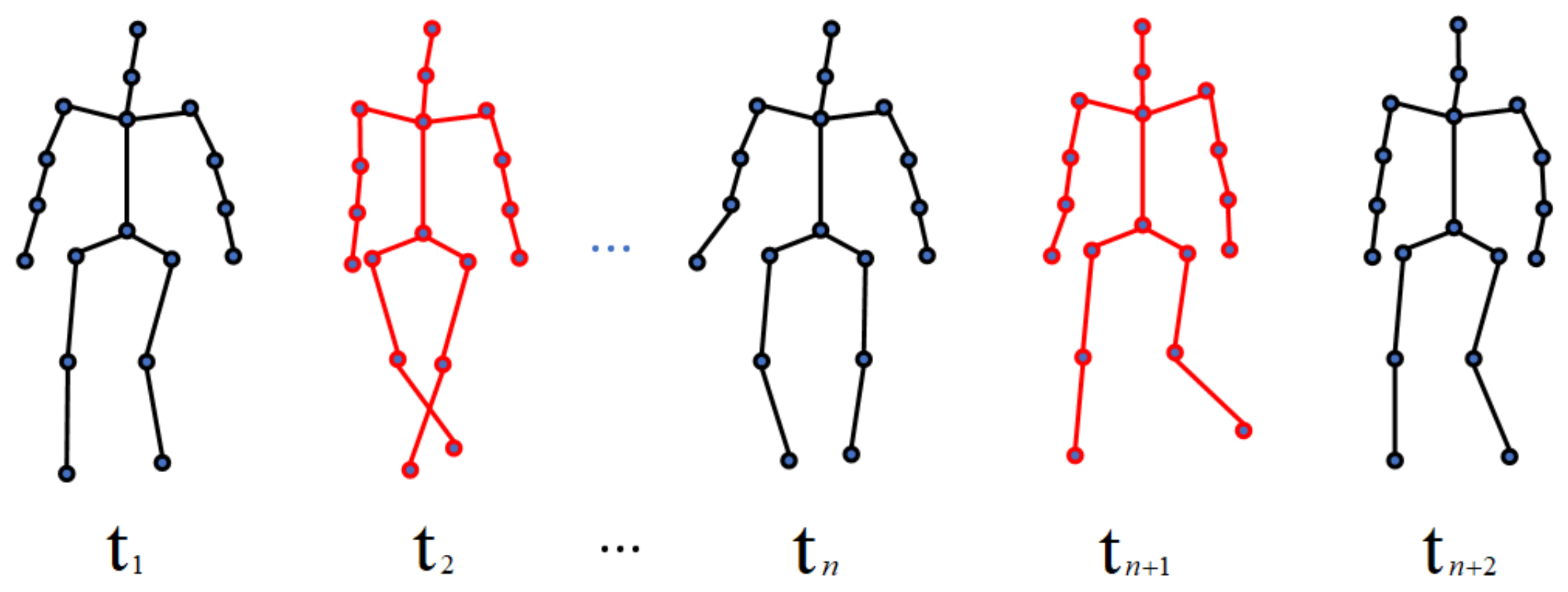
Figure 4 shows a walking action sequence after extracting the key frames.
In the recognition task based on the KF-LSTM network, 11 representative human bone segments throughout the human body were selected in this paper to build the skeleton model of the human body, and the feature sequences were built according to this method. In this paper, the attention mechanism was applied to assign weights to the key frames generated under different types of motion. The attention mechanism is a weighted summation and a weighting mechanism that filters and extracts frames in the sequence that are more similar to the key frames and then reallocates the weights of these frames according to the weighting values based on the attention mechanism. Specifically, the similarity of different frames to key frames in the feature sequence is used to determine their weighting in the reallocated weighting ratio.
The black skeleton image in
Figure 4 is a normal frame in the walking sequence, and the red skeleton image is a key frame given a higher weight with the addition of the attention mechanism.
Assuming that the total number of frames of feature sequence
U is
n, the transformed feature sequence
is obtained according to Equation (
11) as
where
is the feature sequence before processing and
is the weight of each action frame. The key to the method is to calculate the appropriate
.
is the degree of correlation between each frame in the feature sequence and the key frame. When the degree of relevance is higher, the corresponding frame is assigned a higher weight value; when the degree of relevance is lower, the corresponding frame is assigned a lower weight value. The relevant calculation is given in Equation (
12).
where
is the covariance between the normal frames and the key frames in the feature sequence,
is the standard deviation of the normal frames in the feature sequence, and
is the standard deviation of the key frames. After obtaining correlation degree
between each frame in the feature sequence and the key frame, the weight value is assigned to each frame in the final step.
where
is the weight assignment function between frames based on correlation
and
denotes the output probability of the current sequence. It represents the final state of the action in the motion sequence and is used as the attention weight value for each action frame.
After assigning different weight scales to the action frames in the motion sequence, the action sequences with the noted weight values and the corresponding label numbers are fed into the LSTM network for training; the action frames with larger weight values receive a larger proportion of network training, and the action frames carrying more useful information are more likely to be output as recognition results. This greatly improves data utilisation and the performance of the recognition model.
4. Experimental Results and Analysis
4.1. Experimental Platform and Data Acquisition
This study used the Matlab-based data analysis programming language for network construction and algorithm design, and Axis Neuron Pro motion capture software (V2.10) for BVH data file exporting. A Perception Neuron Pro inertial motion capture device by Noitom was also used for data acquisition.
In order to design and evaluate the proposed action recognition system, MoCap data were measured on four subjects, including three males and one female. MoCap data [
15] were collected with the Perception Neuron Pro model IMU MoCap device by Noitom Co. (Beijing, China). This device contained 17 IMUs and was located at the reference locations in
Figure 5 [
37]. Each IMU included internal adaptive filters and was calibrated before each measurement. Then, for motion segmentation analysis, the measurements were considered to contain negligible noise and bias effects. The sampling frequency of the measurements was configured to 100 Hz to cover the bandwidth of the body’s major joint movements.
Figure 6 shows the different types of action postures measured, including walking, running, hand raising, squatting, and leg lifting. In this work, the MoCap data we used referred to the human body as the experimental subject. The work in this paper is non-medically related research work; all the sensors were simply mounted on the body surface, and the human pose was recorded with the work of the sensor algorithm.
4.2. Analysis of Motion Sequence Segmentation Point Results
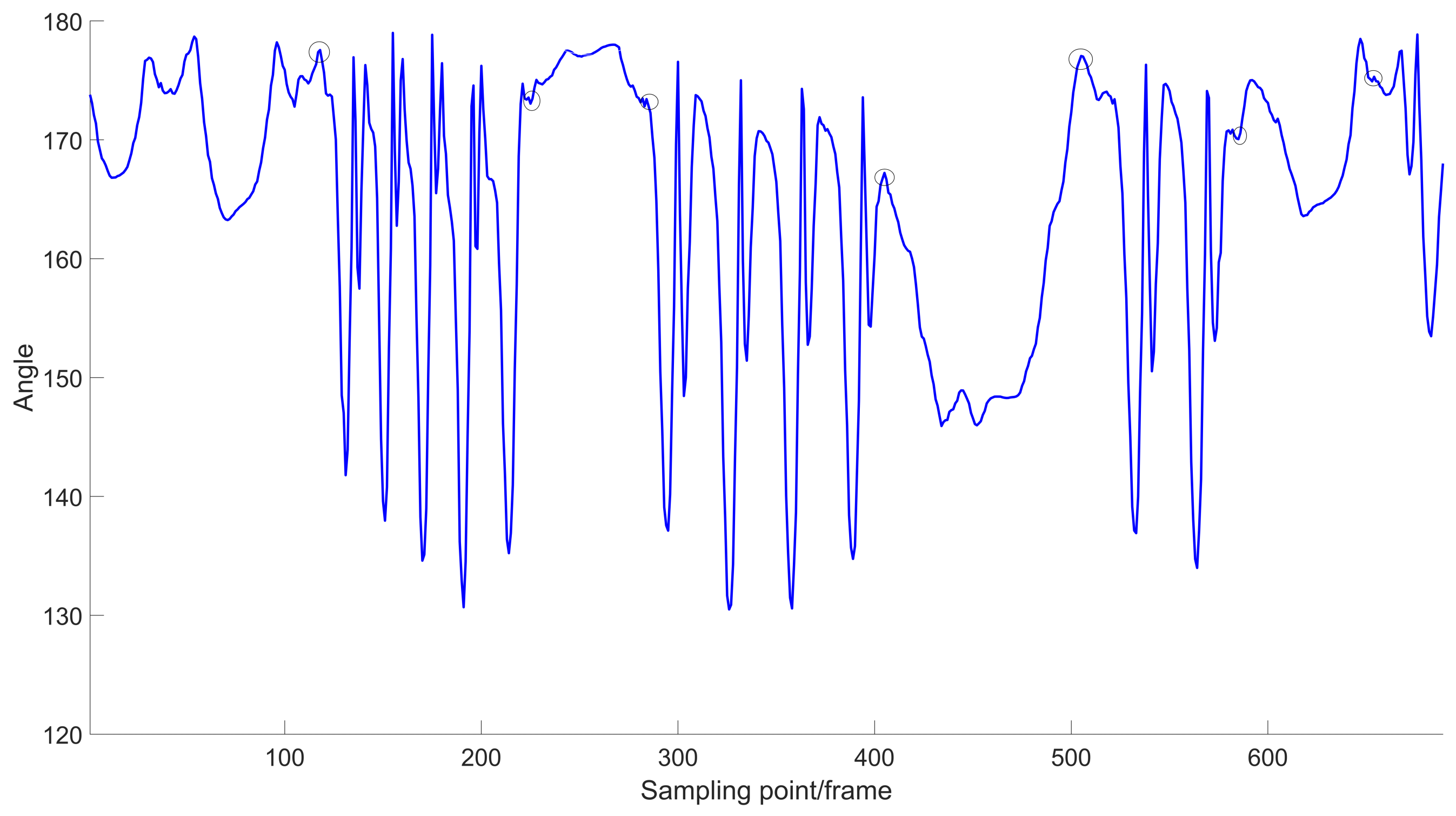
Figure 7 shows the waveforms of the angular features between adjacent bone segments in the human motion sequence in the time sequence. According to the variation in the angular magnitude, we can observe that this is a complex motion sequence containing multiple actions and that there are similar signal waveforms for different types of actions. There are often large errors in the localisation of action intervals, leading to the problem of confusion between frames in the time sequence on the subsequent clustering task, which has a serious impact on the clustering effect of the model. This has a serious impact on the clustering effect of the model. Therefore, we need to segment complex motion sequences before clustering and feature coding.
Figure 8 shows the segmentation points obtained after the calculation of the motion sequence performed by the ARMA-based automatic segmentation model, the segmentation of the motion sequence conducted by observing the presence of inflection points in the sequence, and finally the segmented segment-by-segment action sequence.
4.3. Analysis of Clustering Results
Figure 9 shows the clustering results of the K-means algorithm on which this experiment was based. We used the pre-set parameters shown in
Table 4 to cluster the motion sequences.
In this part of the work, we used the elbow method [
38] to measure the cohesion of clusters and thus evaluate the clustering effectiveness of the K-means algorithm. The cohesiveness of a cluster is a key indicator of how closely related data are in the cluster. The core idea of the elbow method is that the larger the number of k class clusters is and the finer the sample division is, the more clustering each class gradually increases, and the progressively smaller the sum of squared errors naturally becomes. In the elbow method, the
WSS derived from Equation (
14) is used as an assessment indicator of the cohesiveness of class clusters.
The results of the elbow method on the five movements of walking, running, hand raising, squatting, and leg lifting are shown in
Figure 10, where the y-axis labels are the
WSS values and the x-axis labels are the values of the number of class clusters,
k. It can be noted that there is a clear point of inflection for individual movements when the number of class clusters,
k, is four. By continuing to increase the value of
k after this point, there is no longer a significant change in intra-class error.
4.4. KF-LSTM Parameter Setting
In general, the parameters of a network training model need to be set before training is considered. The selection of a reasonable set of parameters often enables the learning efficiency and training results of the network model to be optimized. The parameter settings for the network model in this paper are shown in
Table 5 below.
For training, we combined the processed motion data into a total training packet of approximately 234,000 frames, which was fed into the network for training. In order to improve the efficiency of data utilisation, a strategy of extracting 1 frame every 5 frames was used, resulting in a total training packet of approximately 46,700 frames. For the tests, the total number of test sets was 40, and the length of each test sequence was between 500 and 1600 frames. After the frame-drawing strategy, the length of each test sequence was between 100 and 400 frames.
4.5. Setting and Analysis of Correlation Recognition Models
To verify the recognition effectiveness of the proposed recognition method in this study on five action types, we compared it with an HMM-based approach [
39], a 3D CNN-based approach [
9], and a dual-stream attention-based LSTM approach [
30] on human action recognition tasks for experimental and analytical discussion.
4.5.1. Identification Method Based on HMM Algorithm
In this study, the traditional HMM algorithm [
39] was used in conjunction with a motor action database to perform the task of action recognition on test samples containing five types of actions: walking, running, hand raising, squatting, and leg lifting. For the human action recognition task, we used a left-to-right polymorphic Markov model. For a finite number of different pose states
, N is the number of states in the model, and the state at moment n can only be one of
. For a random vector
, where T represents the length of the time series, each observation vector has a corresponding output probability for a different state. Each action can be effectively modelled by a set of Hidden Markov Model parameters as
. The Bayesian rule
(where parameter A is a matrix representing the state transfer probabilities, parameter
is the initial state distribution probability, and parameter B represents the output probability of all states) is used as a way to calculate the probability of the actions generated by this model.
Let us suppose that the frequency count of the sample transfer from hidden state
to
is
; then, the calculation of the state transfer matrix is given by Equation (
15).
Let us suppose that the sample hidden state is
and the frequency count of observation state
is
. We compare the similarity between each action frame in the observed state
and the 20 types of key action frames extracted before using (
14) to obtain the output probability of all states.
where
m and
n represent the rows and columns of each action frame, and
and
are the mean values of the state matrix and observation matrix, respectively.
Let us suppose that the frequency count of all samples with initial hidden state
is
; then, the initial probability distribution is Equation (
17).
4.5.2. Recognition Method Based on 3D CNN
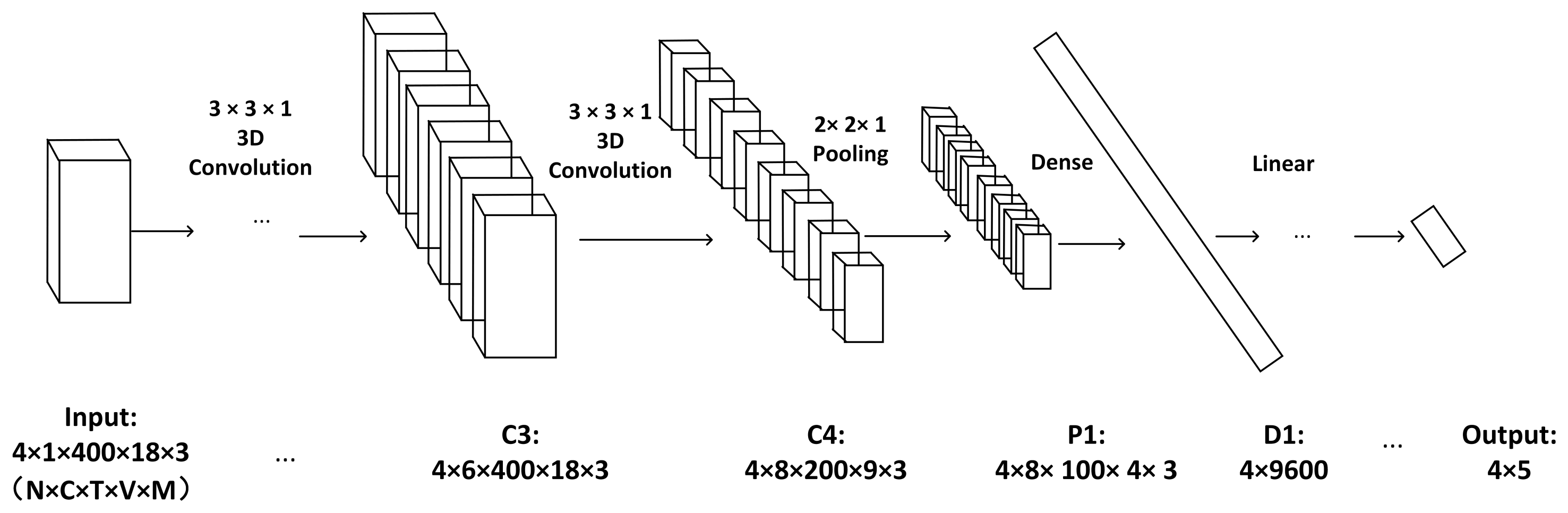
When using the 3D CNN approach [
9] for recognition tasks, 3D convolution is achieved by convolving 3D kernels into a cube formed by superimposing multiple consecutive frames on top of each other. As shown in
Figure 11, the input data dimension of each network layer is
, where
N is the batch size of the data entering the network,
C refers to the dimensional size of the features in each node,
T refers to the maximum number of frames per sample sequence input,
V refers to the number of nodes, and
M refers to the number of coordinates. The input initial dimensions are
, and the features in spatial and temporal dimensions are extracted using four convolutional layers with convolutional kernel size (3, 3, 1) and convolutional kernel step (1, 1, 1), pooled, and then connected to a linear layer for classification, using cross-entropy as the loss function, finally obtaining a
category probability matrix; the maximum value of this dimension is taken as the final classification result.
4.6. Experimental Results and Analysis of the Recognition Tasks
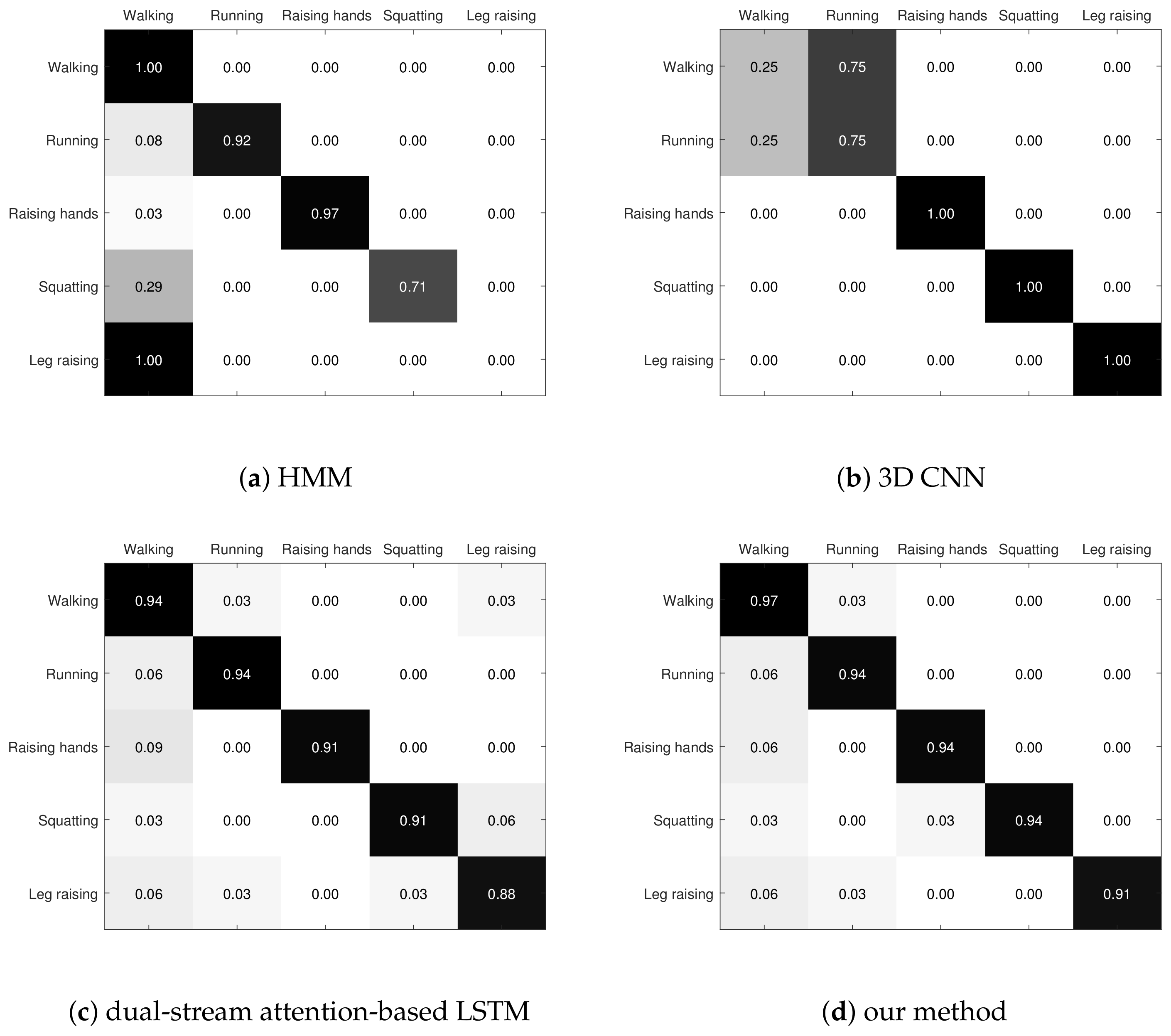
This experiment separately tested each recognition method using the test set, and the results are shown in the confusion matrix plot in
Figure 12.
Figure 12 shows the confusion matrix for the recognition accuracy of the HMM-based method, the 3D CNN-based method, the dual-stream attention-based LSTM method, and our method on five types of action: walking, running, hand raising, squatting, and kicking. The numbers on the diagonal are the accuracy rates for each type of action. We take the average of the numbers on the diagonal of each confusion matrix as the average recognition accuracy of each recognition model.
Table 6 demonstrates average recognition accuracy rates of
for the HMM-based method,
for the 3D CNN-based method,
for the dual-stream attention-based LSTM, and
for our method. It can be found that the recognition system constructed in this paper has high accuracy in the recognition task. Compared with past LSTM-based methods, it has gained some performance improvement and achieved the expected recognition results.
The HMM-based method has good results in the recognition tasks of walking, running, and hand raising. However, the recognition of the squatting and leg-lifting movements is too poor. This is due to the fact that HMM is an algorithm that relies entirely on the statistical characteristics of the data, and the parameters need to be set in the context of an existing action database, which may have a large bias towards the real environment. Moreover, the calculation of the probability distribution matrix relies on the judgement of similarity. In particular, for the leg-lifting action, there is an excessive correlation with the walking action. This also leads to the fact that purely statistical features cannot correctly determine the action category as a motion sequence of leg lifting. Regarding the 3D CNN-based approach, it has good recognition results in the recognition tasks of the action categories of hand raising, squatting, and kicking. However, in the recognition of the two movements of walking and running, there is a problem of mutual interference. This is also due to the high similarity between the two types of movement, and the model misidentified some of the test datasets as walking or running movements. The dual-stream attention-based LSTM approach worked well for the recognition of each action type. However, relatively speaking, the method is slightly less effective than our method in the recognition of leg-lifting movements. Regarding our proposed recognition method, it can be found that the method has the highest recognition accuracy in the walking action type and has better recognition performance than other models in other actions. By comparing the overall recognition accuracy, it can be found that our method outperforms several other recognition methods in all recognition tasks, better recognises human action posture features in different motion states, and improves recognition accuracy.
5. Conclusions
Performance improvement has always been a concern in human action recognition research. For our proposed recognition method, we first designed a key-frame extraction method based on the automatic segmentation model and the K-means clustering algorithm, which can accurately extract key frames of different actions and avoid inter-frame confusion between different key action frames and provides a reliable guarantee for the accuracy and robustness of the subsequent action recognition task of the KF-LSTM network. At the same time, we further optimised the network structure by combining the key-frame-based attention mechanism with the previous LSTM-based recognition method to construct a key-frame-based attention LSTM network. In the experimental section, we analyse and discuss the calculation of segmentation points, the clustering effect, and the comparison of the recognition accuracy of different recognition models. In this section, the calculation process and results of the segmentation points are analysed; the variation in model performance and the rationality of K-means clustering with different K values are verified; finally, the recognition accuracy of our method is compared with that of several other methods using a test dataset containing five different motion states. The experimental results demonstrate that our method outperforms similar recognition models in terms of recognition performance and has better results in human motion recognition.
In the present work, only five different types of movement were used for the task of action recognition for experimentation and analysis, and in future work, additional types of movement will be considered to further improve research on relevant methods.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}