1. Introduction
With the rapid development of Web 2.0, more and more Web services are appearing on the Internet. For instance, there were only 3261 Web services in 2011 released on the ProgrammableWeb platform, while there were more than 30,000 in 2020 [
1,
2]. Many Web services share the same or similar functionalities but provide different QoS (Quality of Service) [
3]. With SOA (Service-Oriented Architecture) techniques, the coarse-grained, loosely coupled Web services can be integrated into complex applications or software systems [
4]. The process of developing different Web services is an optimization problem regarding the global QoS. However, this optimization problem is NP-hard [
5,
6,
7]. The QoS-aware Web service composition problem becomes more difficult when many Web services possess similar QoS. In order to solve such a problem, service recommendation techniques are adopted to recommend limited QoS-optimized service candidates for service selection, so that the difficulty of service selection can be greatly alleviated for users [
8].
In recent years, some QoS-aware Web service recommendation approaches have been proposed. These approaches can significantly reduce the complexity of QoS-aware service selection by reducing the service selection space [
9]. At present, the existing service recommendation approaches can be grouped into the following categories: utility-based approaches [
10,
11], Skyline-based approaches [
12,
13], collaborative-filtering-based approaches [
14,
15], matrix-factorization-based approaches [
16,
17], and factorization-machine-based methods [
18,
19]. More specifically, the utility-based methods mainly obtain the QoS utility through the QoS attribute values. The top-k Web services with optimal QoS utility will be recommended. Skyline-based approaches select the representative Web services that are not dominated by any other services in the whole candidate service set for the final recommendation. The above two types of approaches have a default assumption that users can provide their QoS preferences explicitly, i.e., the weights for different QoS properties. However, ordinary users usually cannot provide numerical QoS preferences but provide QoS constraints instead. Thus, this assumption usually does not hold in reality [
20]. The aim of collaborative filtering, matrix factorization, and factorization machine approaches focuses on QoS (preference) prediction for Web services. However, the specific service recommendation process is not studied in detail for these types of approaches. In summary, the above approaches do not take the uncertainty of QoS preferences into account. Moreover, the personalized QoS constraints are not well handled [
21].
To consider the characteristics of the user’s QoS constraints, Zhang et al. [
22] propose the KNN-DSL and DSL-KNN approaches. However, these approaches neglect the QoS correlation between different QoS properties. The correlation among different QoS properties requires that the recommended service should be representative, i.e., there cannot be any other services that are closer to or more similar to the QoS constraints than the recommended services in all dimensions. Therefore, the services recommended to users should be diverse when the QoS preference is uncertain or not provided. In other words, the recommended services should include more representative services in as many QoS dimensions as possible. Based on the above observations, Zhang et al. [
23] propose a diversified QoS-centered service recommendation method. This approach uses the k-means clustering algorithm to divide Web services into k classes, and then a diversified service recommendation result is generated by selecting one service from each class. However, the value of k is set manually, and it may not fit the actual value of the given dataset. Moreover, the recommended services are not ranked with desirable criteria. To solve these problems, our previous work [
24] proposes a diversified recommendation approach based on the service QoS similarity network so that the recommendation result is optimized in terms of accuracy and diversity.
Although there have been some works on QoS-diversified Web service recommendations and the probability of satisfying the user’s potential QoS diversity preference is improved to some extent, these QoS-diversified Web service recommendation methods recommend Web services with a uniform diversity degree for different users, while the personalized diversified preference requirements are not considered in existing works. Consequently, this paper proposes to mine the QoS diversity preference from the user’s service invocation history and provides a personalized and diversified recommendation algorithm for Web services by introducing the PDPP (Personalized Determinantal Point Process) technique [
25], through which a personalized service recommendation list with preferred diversity is generated for the target user. To summarize, the following are the paper’s main contributions.
- -
This paper proposes to mine the potential QoS diversity preference based on the service invocation history of the user. In this way, the potential input can be provided for the service recommendation system.
- -
We propose the Personalized Determinantal Point Process algorithm for diversified service recommendation, in which the user’s potential QoS diversity preference is properly incorporated, and the diversified service recommendation results have a reasonable interpretation.
- -
We leverage a real-world Web service dataset to generate the user invocation history. Extensive studies show that the proposed approach can achieve a desirable and personalized accuracy–diversity trade-off with comparable efficiency.
The rest of this paper is organized as follows.
Section 2 reviews the related work on QoS-aware service recommendation. The problem definition and the framework of the personalized and diversified Web service recommendation approach are presented in
Section 3.
Section 4 introduces the PDPP algorithm based on the DPP algorithm and explains how it is adapted to the personalized and diversified Web service recommendation scenario.
Section 5 evaluates the proposed approach with extensive experiments.
Section 6 concludes this work and outlines future work.
2. Related Work
QoS-aware service recommendation is an important subproblem in the service computing field and can be regarded as a QoS-aware service selection optimization problem. The existing research work can be categorized as follows: utility-based methods [
26,
27,
28], Skyline-based methods [
12,
13,
29], collaborative-filtering-based methods [
14,
15], matrix-factorization-based methods [
16,
17,
30], and factorization-machine-based methods [
18,
19,
31]. Next, we introduce these methods and their application scenarios from the perspective of their advantages and disadvantages.
Utility-based recommendation methods calculate the overall QoS utility based on the QoS properties [
32,
33]. The services with the highest QoS utility are recommended as the results to users. The key to this type of method is to obtain accurate QoS preferences from the active user. The recommendation methods based on Skyline introduce the concept of Skyline from the database field. The dominant relationship among services is used to filter out all the dominant services with respect to their QoS. Specifically, Skyline is a pre-processing technique introduced by Alrifai et al. [
13] to solve the problem of QoS-aware and end-to-end constrained Web service compositions. However, both the above types of methods neglect several key points. Firstly, the QoS constraints of users may be correlated among different QoS dimensions. Moreover, users’ QoS preferences are difficult to provide.
As for collaborative-filtering-based methods, there are many approaches in the existing works, e.g., Zheng et al. [
14] use CF (Collaborative Filtering) techniques to integrate user-based and item-based information to make recommendations to target users and perform QoS prediction for Web services. Jiang et al. [
34] establish an effective personalized hybrid collaborative filtering method; it takes into account the similarity between both users and services. As for matrix-factorization-based methods, Zheng et al. [
16] propose a matrix decomposition method that systematically integrates neighborhood-based and model-based collaborative filtering methods by exploring historical Web service usage experiences to obtain a neighborhood-integrated matrix decomposition method for personalized QoS prediction. Moreover, there are many similar works of this type. As for factorization-machine-based methods, Ding et al. [
35] used a deep factorization machine (DeepFM), which used node-level attention on the created user–service bipartite graph by combing multi-component graph convolutional collaborative filtering to decompose the edges in the bipartite graph into potential spaces in order to find potential components and their relevance; the resulting user and service embedding vectors are used as inputs to the DeepFM model to make predictions on the unknown QoS. However, the above three types of methods aim to predict the missing QoS of services. These methods are not service recommendation methods in essence, since the service selection process is not studied in detail [
36].
Considering that a user’s functional requirements may be related to or similar to historical services, users’ functional interests and QoS preferences are mined by analyzing their service usage history [
37]. In Ref. [
37], a network graph is constructed based on the service similarity relation and the similarity score between candidate services and the QoS constraints. Then, a novel and diverse service ranking algorithm is proposed to identify the top-k services. Further, considering that QoS properties may be correlated with each other, Zhang et al. [
22] propose an algorithm based on KNN and dynamic Skyline services to recommend services close to the user’s QoS constraints. This method requires users to provide the probability of QoS constraints and domination, and then maps the candidate service set at each time point to the original service space according to its quality value. It then finds a dynamic Skyline service by calculating the dynamic domination probability among all services. Finally, they use the KNN algorithm to obtain the final recommendation results. However, this approach still ignores the fact that services are correlated to each other. Meanwhile, many Web services exist in the recommended list, but users only need one of these services. Therefore, recommending more types of services to users can improve users’ satisfaction with the recommendation results. Due to the uncertainty of QoS preferences, the diversity of recommendation results with respect to QoS should be incorporated. Based on these characteristics of QoS preferences, Zhang et al. [
23] put forward a diversified QoS-centered service recommendation algorithm. Given QoS constraints and candidate sets for users, all non-dominated services, namely Skyline services, are selected first. Then, they use the k-means algorithm to perform clustering operations on the candidate services. Finally, they select a service in each class to form a diversified service recommendation list and recommend it to users. These approaches obtain a high diversity of recommendations. However, k-means clustering is carried out according to the top-k; this top-k may not conform to the number of categories in the actual data. Another issue in this method is that the results are not ranked. It might be more appropriate to rank the results properly before recommending them to users. For this reason, Kang et al. [
24] constructed a QoS-based service similarity network to solve the recommended diversification issue. The aim of this approach is to maintain a balance by considering diversity while ensuring basic accuracy. However, this paper proposes that the diversified metric index is relative to all service networks among the candidates, not for services in the recommendation list. In addition to these methods, there are some approaches that use the DPP algorithm to recommend items. Chen et al. [
25] propose a Determinantal Point Process based on the greedy algorithm to improve the recommendation diversity. In addition, they explore diversity studies within sliding windows. Wilhelm et al. [
38] use pointwise quality scores for candidate items and the pairwise distances between them to leverage the DPP; they achieve good performance on YouTube by using their methods. The Diversified Contextual Combinatorial Bandit was proposed by Liu et al. [
10] in order to improve the diversity of interactive recommender systems. As a follow-up component after the ranking function, Wang et al. [
39] make recommendations by setting individual personalization parameters for each user in the re-ranking model to improve the diversity of the results. It solves the problem of consistent diversity among different users and provides personalized recommendation services for users. The above approaches aim to generate diversified recommendation results based on users’ QoS constraints. However, the above service recommendation methods recommended diversified services with a uniform degree of diversity for different users.
In summary, utility-based and Skyline-based approaches assume that QoS preferences can be provided by users, which may not hold in practice. The objective of collaborative-filtering-based, matrix-decomposition-based, and factorization-machine-based methods are to predict the missing QoS values. Moreover, the existing diversified service recommendation approaches recommend Web services with a uniform diversity degree for different users, while the diversified preference requirements are not considered. Our work seeks to mine personalized QoS diversity preferences for different users so as to provide individualized recommendations for different users, hence improving the overall recommendation performance.
3. Problem Description and Method Framework
This section first describes the problem of QoS-centric Web service recommendation with user-preferred diversity. Then, the framework of the personalized and diversified Web service recommendation approach is proposed to address the problem associated with the user’s requirements under the condition of uncertainty.
3.1. Problem Description
Suppose that a user has an explicit functional requirement for Web services; he will provide the functional requirement described with natural language and the nonfunctional requirement with QoS constraints , such as s, . Here, can be seen as a dummy reference service. In other words, any Web service that is worse than in terms of QoS is not suitable for the user since it does not satisfy the QoS constraints. Besides the QoS constraints, the user also has a QoS preference, i.e., the weights for different QoS properties. However, the specific numerical expression of the QoS preference is difficult to provide for the user, so he may omit the QoS preference from his input requirements. Under such a situation, the service recommendation result should include services that can satisfy both the functional and non-functional requirements of the user. There may be services with low latency but a higher failure rate. Therefore, services with better QoS performance in each dimension should be included in the recommendation list as far as possible. The optimization objectives of the proposed method are the diversity and accuracy of the recommended results.
Based on the user’s service requirements, the system will discover the Web service candidates that meet the functional requirements of users by matching the semantics of functional requirement description and Web service description documents using natural language processing techniques. Further, the system will filter the Web services that do not satisfy the given QoS constraints. At this time, Web service candidates that satisfy the functional requirements and QoS constraints are obtained for recommendation later. However, the problem is how to rank these services and select the top-k desirable Web services, which is a challenging issue due to the unknown QoS preference. Our work will focus on this problem and propose the corresponding solution later. The main notations utilized in our work are listed in
Table 1.
3.2. Framework of Personalized and Diversified Web Service Recommendation
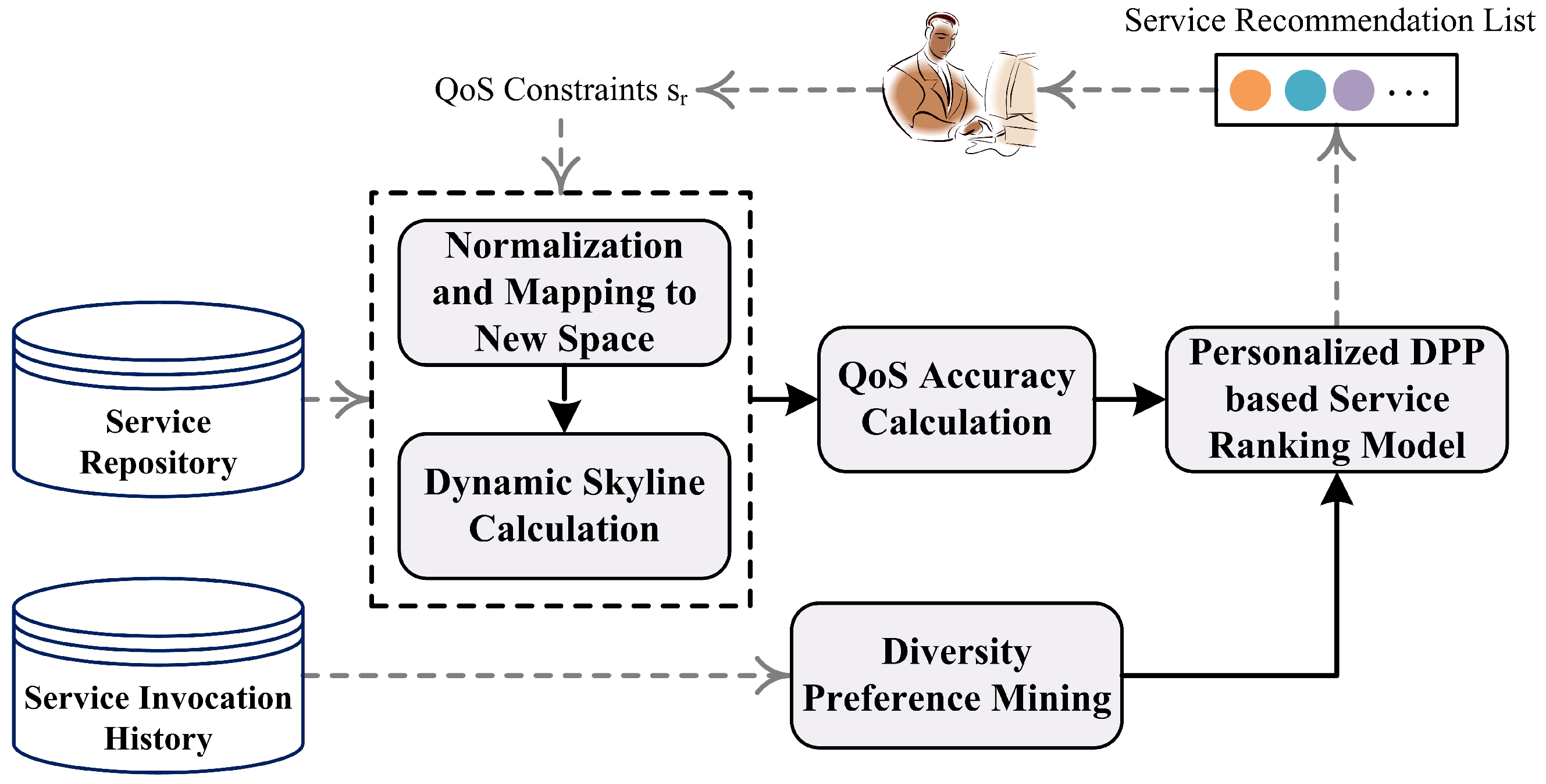
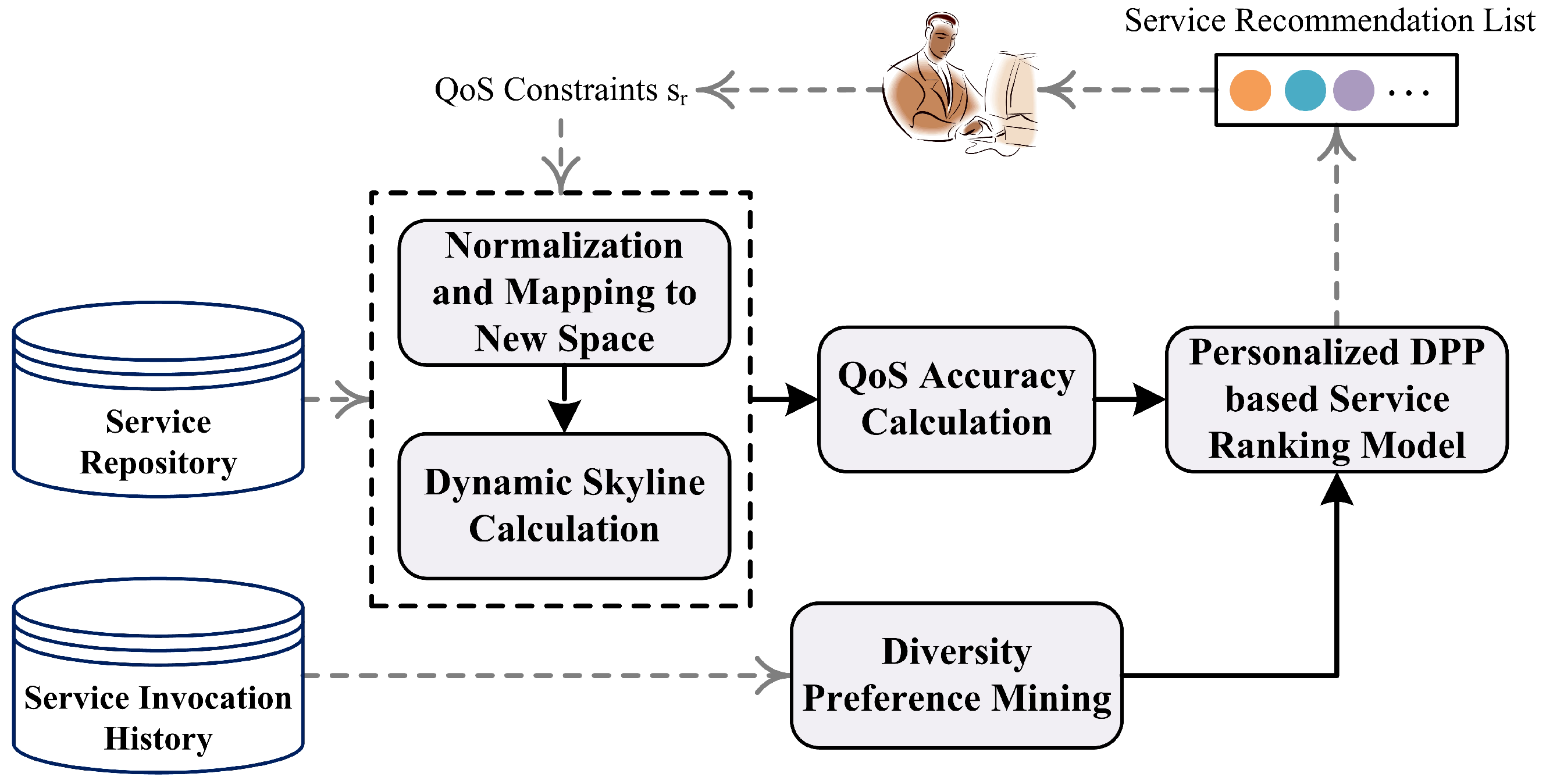
The framework of the personalized and diversified service recommendation approach is shown in
Figure 1. It mainly includes four components, i.e., the calculation of dynamic Skyline services, QoS accuracy calculation, diversity preference mining, and the personalized DPP-based service ranking model.
The procedure of the proposed framework is as follows. First, all Web services are crawled from ProgrammableWeb and stored in the service repository. Then, QoS information is normalized and the corresponding data are mapped into a new space, based on which the corresponding set of Skyline services is derived. Next, we calculate the QoS accuracy of the preprocessed candidate services, i.e., Skyline Web services, based on the user’s QoS constraints. Meanwhile, the user’s potential QoS diversity preference can be mined according to the user’s service invocation history. After this, a personalized DPP-based service ranking model is applied based on the QoS accuracy of the candidate services and the user’s potential QoS diversity preference. This model can combine the accuracy of candidate services and the potential preferences from the users’ service invocation history to provide users with personalized Web services that meet their potential QoS diversity preferences. It uses the principle of the Determinantal Point Process to select the services that can achieve the maximum marginal gain each time and add them to the recommendation list to achieve the effect of diversified recommendations. Finally, the personalized and diversified top-k Web services will be generated for the user.
4. Personalized and Diversified QoS-Centric Web Service Recommendation
We describe the proposed personalized and diversified Web service recommendation approach in this section. First, we normalize the QoS data for Web service candidates and give a definition of the dynamic Skyline services. Then, we introduce how to calculate the QoS accuracy for Web service candidates and how to mine the QoS diversity preference of an active user. Furthermore, a personalized DPP-based service ranking model is introduced. Finally, we present the algorithmic details of the personalized DPP-based service ranking algorithm.
4.1. Dynamic Skyline Services
The definition of dynamic Skyline services is based on the Skyline services derived by searching for the collection of points in a d-dimensional space that is not dominated by any other points. In the service recommendation context of this paper, a point represents the values of all QoS property dimensions. The Web services represented by these points satisfy the user’s QoS constraints.
QoS properties are divided into two categories: positive and negative. For the positive properties, the larger the value, the better the quality, such as throughput; for the negative properties, the smaller the value, the better the quality, such as the response time. To eliminate the effects of differences in the above properties, the data of QoS properties should be normalized by transforming their values into [0, 1]. After this preprocessing, larger values imply better quality for all the QoS properties. In this paper, QoS properties are normalized using the maximum difference normalization method, as shown in Formulas (
1) and (
2). Formula (
1) is used to deal with negative properties and Formula (
2) is used to deal with positive properties, where
q and
are the values of a QoS property before and after normalization processing, respectively, and
and
denote the maximum and minimum among all QoS properties, respectively. Each QoS value mentioned later in this paper is the value after normalization.
By drawing from [
23,
24], Definition 1 defines the dominance relationship between two Web services. Based on Definition 1, the Skyline services can be defined as shown in Definition 2.
Definition 1 (Dominance). Given two services represented by two points in the d-dimensional space, dominates denoted as when is not inferior to in all QoS property dimensions and superior to in at least one QoS property dimension, i.e., we have and .
Definition 2 (Skyline Services). The Skyline services of a candidate Web service set C consist of the Web services that are not dominated by any other services, i.e., , where represents the Skyline services of a candidate service set C.
Skyline services have superior quality. However, given the QoS constraints , the user expects to find the dynamic Skyline Web services in C with respect to by transforming the points in the original space to the points in a new space. Specifically, for , it is mapped to , where and . In the transformed d-dimensional space, we can obtain the dynamic Skyline services by computing the general Skyline services. In this case, is the source point of the new space. Thus, dynamic dominance and dynamic Skyline services are described as Definitions 3 and 4, respectively.
Definition 3 (Dynamic Dominance). Given two Web services represented by two points in a d-dimensional space and a reference Web service , dynamically dominates , denoted by , if and hold.
Definition 4 (Dynamic Skyline Services). The dynamic Skyline of a candidate Web service set C consists of Web services that are not dynamically dominated by any other services, i.e., , where denotes the dynamic Skyline services of a candidate service set C.
The process of Skyline services calculation is presented in Algorithm 1 with the QoS constraints
and the candidate service set
C as the inputs. The dynamic Skyline services set
is initialized as an empty set in line 1. Lines 4–9 determine whether a service is a Skyline service or not based on the dominance relationship. If the service is a Skyline service, then it will be appended to
, as described in lines 10–12. Finally,
is returned as the output. In Algorithm 1, pairwise comparisons are needed for the determination. Thus, the time complexity of Algorithm 1 is
, where
is the number of candidate services.
| Algorithm 1: Skyline Service Calculation |
| Require: QoS Constraints , Candidate Services Set C |
| Ensure: Dynamic Skyline Service Set |
1:
2: for do
3:
4: for do
5: if then
6:
7: break
8: end if
9: end for
10: if then
11:
12: end if
13: end for
14: return |
4.2. QoS Accuracy and QoS Diversity Preference
It is necessary to evaluate the QoS accuracy of the service candidates according to the QoS constraints of the active user to recommend the appropriate Web services. With QoS accuracy, the foundation for ranking services is derived. As mentioned before, the user’s QoS constraints can be seen as a reference service that he prefers. On the basis of these observations, the service similarity between a candidate service and the user’s QoS constraints can be calculated and used to represent the QoS accuracy of the candidate Web service.
We refer to the literature [
24] to calculate the QoS similarity of the two services
and
in our approach, which takes both the Euclidean distance and the accordance of two vectors into account. The definition of QoS similarity is given in Formula (
3), where
is the Euclidean distance between
and
,
is a parameter to determine the importance of each item, and d is the dimension of a Web service QoS vector or the number of QoS properties considered.
and
in Formula (
3) are defined in Formulas (
4) and (
5), respectively, where
is the QoS property value in dimension p of
; the range of its values is
after normalization. In Formula (
5),
is the number of consistent pairs between the two rankings, and
is the number of inconsistent pairs. More specifically, if two services are in the same order in the two rankings, then they are consistent; otherwise, they are inconsistent. Therefore, the QoS accuracy of
, namely
, is equal to
, i.e., the QoS similarity between the service candidate and the reference service.
Since it is difficult for an ordinary user to provide their QoS preference, we can cover the different needs of the user by recommending multiple services to fulfill the diversification demand, i.e., guessing the user’s preferences by means of diverse recommendations. However, different users have different QoS diversity levels, which is called the diversity preference in this work. To obtain a user’s diversity preference, we try to explore the users’ service invocation history, since the QoS diversity of the selected services in the past may reflect the user’s potential diversity preference with respect to different QoS properties. To measure the historical QoS diversity preference, we use Shannon entropy over the distribution of different QoS properties to derive the potential QoS diversity preference of the active user, which is defined in Formula (
6).
where
P represents the probability that the user
u prefers the QoS property
g, i.e., the invocation frequency that services have the best QoS value in the
gth QoS property;
G is the set of QoS properties. If an invoked service has the best QoS value in the
gth QoS property, it means that the user prefers the
gth QoS property most when selecting the service. A user u with a higher
has a higher diversity propensity, i.e., he prefers more QoS properties, and vice versa. Since the preferences of users are different and vary considerably, we need to unify them into
to represent the degree of diversity for distinction. Based on this intuition, we use max-min normalization to transform
into
. The formula is as below.
where
is the maximum entropy of all users,
represents the minimum entropy of all users, and the parameter
controls the degree of personalization of
; a larger
means less personalization of all users. When
, it can be seen that
, i.e., all users have the same diversity propensity.
4.3. Personalized DPP-Based Service Ranking Model
The DPP (Determinantal Point Process) was first introduced in reference [
25] to solve the problem of recommendation diversity. The DPP was initially used to solve the distribution of Fermion subsystems in thermal equilibrium, and was then gradually applied to various machine learning tasks. The DPP is a sophisticated probabilistic model of negative global correlations. It is distinguished by a kernel matrix that defines a global measure of item similarity, assigning higher probabilities to different groupings of items. As discussed before, diversified service recommendation is to select a series of services with desirable diversity for different users. It is equivalent to finding the set
, and this set is also equivalent to the set in Formula (
8).
Thus, the DPP is desirable when describing the diversity of outcomes. Based on this intuition, we use the DPP for diversified service recommendations by adding personalized diversity preferences. For a discrete set
, a point process
P represents a probability distribution on the powerset of
, i.e., for every subset
,
characterizes the likelihood of observing
Y. There exists a matrix
such that, for
, there exists a random subset
Y drawn according to
P,
where
is a symmetric, real
matrix indexed by the elements of
;
signifies the sub-matrix of
indexed by
A; and
by default. The DPP can alternatively be formed using a real, symmetric matrix
indexed by
, where
P assigns a nonzero probability to the empty set. This is shown in Formula (10), where
is the form of the determinant of
and
is a submatrix of
, which is projected to rows and columns in
Y.
The internal definitions in kernel matrix
are defined as in Formulas (
11) and (
12), where
is the accuracy value of item
; it is calculated by the ranking function.
represents the similarity matrix among items. In our work, the similarity is defined as in Formula (
3) in
Section 4.2. In Formula (
12),
is the hyperparameter used to control the accuracy and diversity. It represents the default or common degree of diversity for all the users. In this way, the cold start problem can be alleviated to a certain extent. In the original DPP model,
is a user-defined parameter, which is used for all the users. In other words, all users have the same diversity propensity.
However, as analyzed in
Section 1, different users have different diversity preferences in practice, which can be inferred from the users’ service invocation history. Based on the above analysis, we generate a personalized parameter with Formula (
13) by revising the common parameter
with
from Formula (
7). In this way, different users will be given different diversity propensities.
4.4. Personalized DPP-Based Service Ranking Algorithm
The DPP-based re-ranking model is an NP-hard problem. Its time complexity is
. Fast Greedy MAP Inference, an efficient and effective approximation approach, enables the model to be applied in the actual environment by reordering within an acceptable time [
25]. Formally, it selects the item with the maximum marginal gain in each round, as in Formula (
14). For any
and any
, when adding an item, this marginal gain function satisfies Formula (
15). Therefore, the marginal gain function is a nonincreasing sub-modular function.
It is known that the sub-modularity can result in an impactful greedy algorithm in polynomial time. The PDPP-based re-ranking model is described in Algorithm 2, and it is similar to the greedy algorithm in the DPP method. The difference is that different parameters are used for different users when constructing the kernel matrix
. Algorithm 2 is an approximation algorithm used to solve the combinatorial optimization problem; its time complexity is
. Line 1 initializes the re-ranking list
Y as an empty set, and lines 2–6 select the item that promotes the determinant of the updated submatrix the most according to Formula (
14) in each round. Therefore, only
k rounds are needed in the greedy algorithm. Finally, line 7 returns the re-ranking list
Y as the final recommendation list. Thus, the PDPP model is an improvement of the DPP model without additional parameter tuning.
| Algorithm 2: Personalized DPP-Based Service Ranking |
| Require: Candidate Items ; Kernel Matrix L; Number of Required Items k |
| Ensure: Re-ranking List Y |
1:
2: while and do
3:
4:
5:
6: end while
7: returnY |
To summarize, the whole recommendation procedure mainly contains three parts: Skyline service calculation, kernel matrix calculation, and personalized DPP-based service ranking. The time complexity of Skyline service calculation is and that of kernel matrix calculation is . Thus, the overall time complexity of the proposed approach is .
5. Experiments
This section evaluates the proposed approach over a real-world dataset and a simulated dataset by comparison with several representative approaches for QoS-centric Web service recommendations.
5.1. Experimental Setup
Dataset. We use the publicly released QWS dataset (
https://qwsdata.github.io/, accessed on 1 January 2023), which contains 2507 Web services. Each Web service contains 8 QoS properties, including the
Response Time,
Availability,
Throughput, etc. In order to generate users and their service invocation histories, we simulate 10 users and select 5∼15 services randomly from the dataset for each user as the historical service invocation. For each user, a service’s QoS is selected randomly as the QoS constraint for the present service requirement. Information about the statistical analysis of the QWS dataset is provided in
Table 2.
Moreover, to make the experimental results more robust, we simulate a new dataset with 2500 Web services, named the SQWS dataset. The data generation of this dataset is based on the data of the QWS dataset, and the value of each datum is within the range of the QWS dataset. In the simulation, it is supposed that all QoS properties are normally distributed and normalized at the same time.
Comparison Approaches. We compare the PDPP approach with other QoS-centric diversified service recommendation approaches in the existing literature. The comparison approaches are listed as follows.
- -
DSL-RS: This baseline approach first chooses all non-dominated services as Skyline services, named , and then randomly selects k services from .
- -
DSL-KNN [
22]: This is the first approach to solve the personalized QoS-centric service recommendation problem. It models service recommendation as a
k nearest neighbor problem. The core aspect is that it selects
k services from
, which are most similar to
.
- -
DQCSR-CC and
DQCSR-CR [
23]: This is the first approach to cope with users’ uncertain quality correlation. It first identifies
. Using the k-means algorithm,
can be clustered. There are also differences between the two methods. DQCSR-CC chooses from each cluster that is the closest to its cluster center, while DQCSR-CR chooses from each cluster with the smallest coverage region radius.
- -
DiQoS [
24]: This approach improves the QoS similarity measurement. Based on the QoS similarity relationship, a QoS similarity network is constructed and a diversified service ranking model is proposed based on the network.
- -
DPP: Although this approach has not been used for service recommendation before, it is the predecessor of our approach, and it uses a common diversity propensity for all users. Thus, we take it as a comparison approach.
Evaluation Metrics. We use the DCG (Discounted Cumulative Gain) value, Diversity, and RMSDE (Root Mean Square Diversity Error) as the evaluation metrics in our experiments.
- •
DCG is usually used to estimate the quality of the top-
k recommendation results, which is defined as in Formula (
16), where
is the rank position of the
i-th service. In our work, the quality is the QoS accuracy. Higher DCG values indicate accurate results relative to the user’s QoS constraints.
- •
Diversity is used to evaluate the diversity of the recommended results
I from the perspective of QoS. Diversity is defined as the average dissimilarity of any pair of services contained in the recommendation list, calculated by Formula (
17), where dissimilarity is the opposite of similarity, i.e.,
, and
. A large diversity value means that the recommended results are more diverse.
- •
RMSDE is proposed here to measure the distance between the QoS diversity of the recommendation list and the QoS diversity of the user’s service invocation history, defined as in Formula (
18), where
U is the collection of users,
is the users’ invoked services set, and
is the set of services recommended to the user
u. A small RMSDE means that the diversity of the recommendation results is close to the user’s preference.
5.2. Performance Comparison and Analysis
Among the comparison approaches, some of them have the quality of randomness. Therefore, we take the average values of the experimental results after five rounds for these approaches. To explore the performance under different Web service recommendation scenarios, three series of experiments are conducted for performance comparison. In each series, only one experiment parameter is varied.
Table 3 shows the related parameters.
Based on the parameter settings, we test the superiority of our approach through experiments.
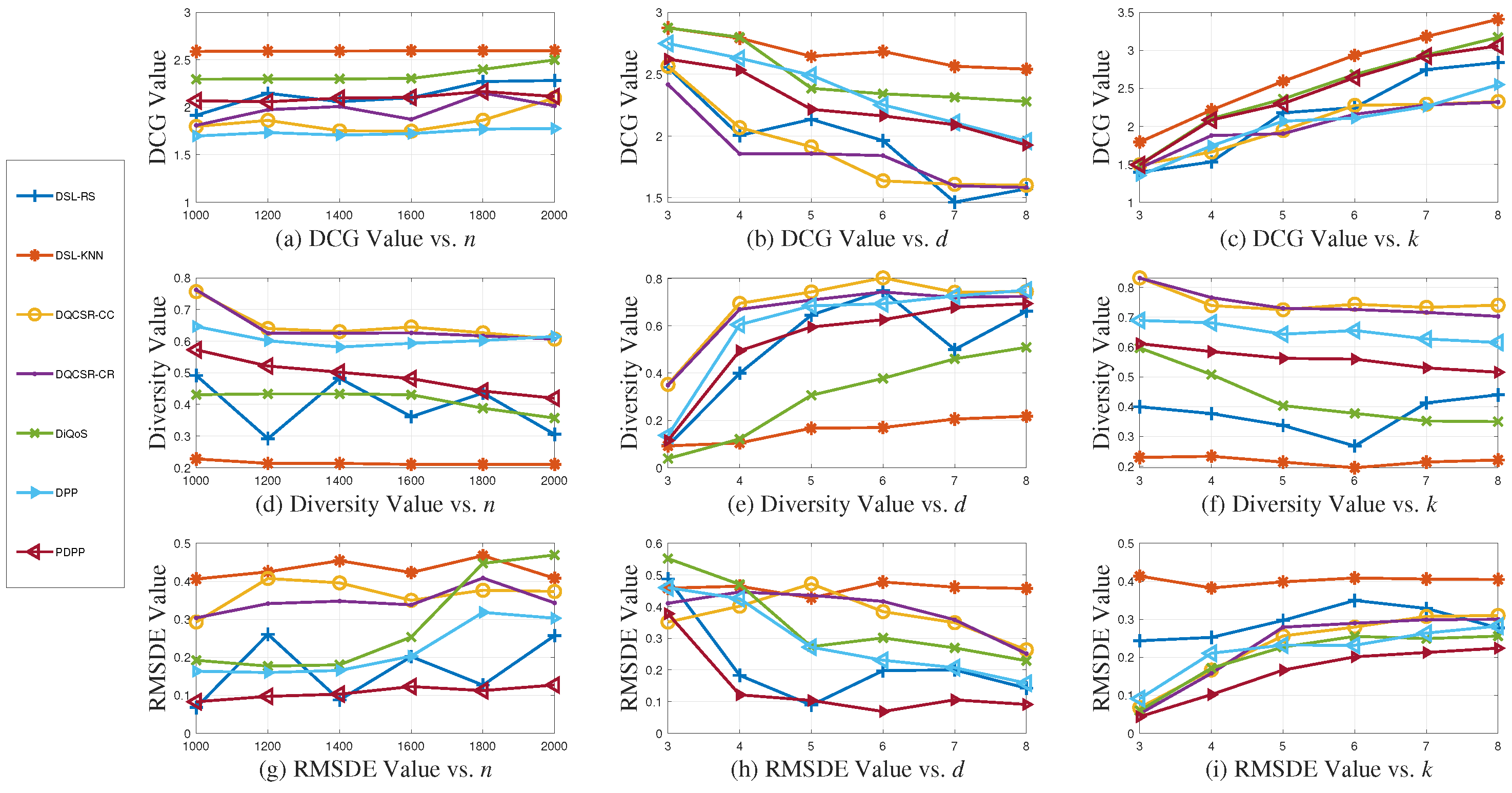
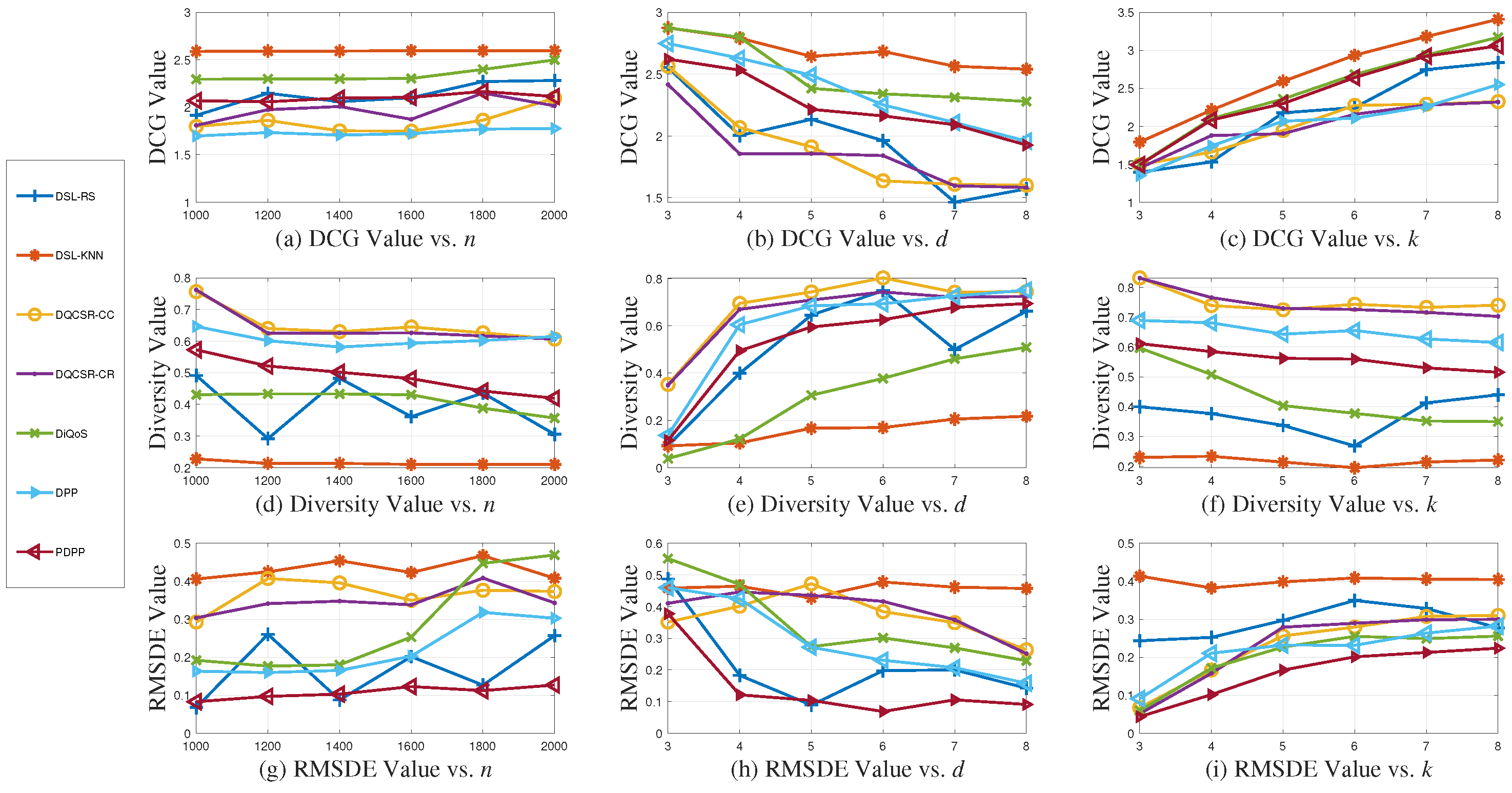
Figure 2 and
Figure 3 show the performance comparison between PDPP and the other comparison approaches under the evaluation metrics mentioned in
Section 5.1. The default parameters are as follows:
,
,
,
,
.
Experimental Results on QWS Dataset. As can be seen from
Figure 2a–c, PDPP has a comparatively high DCG value. Specifically, DSL-KNN has the highest DCG value since it recommends the services that are most similar to
, so the recommended services are the top-
k most accurate ones and are ranked well. DiQoS achieves the second highest DCG value, because it also considers diversity. DQCSR-CC and DQCSR-CR obtain the lowest DCG value. Among the service classes, one may be close to
, while the other classes are far away from
. Thus, selecting one service from each service class may result in a low DCG value. PDPP has a higher DCG value than DPP since PDPP updates the common diversity preference
with
, which is smaller than its initial value. Thus, it is more diverse when personalized diversity is taken into account. As for the trend of the DCG values,
n does not have a strong impact. Moreover, with the increase in
d, the DCG values show an overall downward trend, because the accuracy decreases when
d increases. However, with the increase in
k, the DCG values show an upward trend for all the approaches, since more recommended services contribute to the DCG value.
In contrast, the diversity values of the comparison approaches in
Figure 2d–f show the opposite trend, since the DCG value and diversity value are two conflicting metrics to some extent. The PDPP has comparatively high diversity. DQCSR-CC and DQCSR-CR basically achieve the highest diversity, so it is suggested that the recommended results may be too diverse for users. DSL-KNN has the lowest diversity since it recommends the most top-
k similar services to the user. With the increase in n, the variation in the diversity is not obvious. With the increase in
d, the diversity shows an increasing trend for all approaches. However, with the increase in
k, the diversity shows a slightly decreasing trend.
As can be seen from
Figure 2g–i, PDPP achieves the lowest RMSDE, since it considers a personalized diversity preference for each user. Therefore, although the DCG value and diversity of PDPP are not the best ones in terms of the size of the value, this is insignificant. The most important outcome is that the diversity is suitable for the user and the QoS accuracy is at an acceptable level. DSL-KNN, DQCSR-CC, and DQCSR-CR achieve a comparatively higher RMSDE, much higher than DSL-RS and DiQoS, because their diversities are beyond the user’s demand.
Experimental Results on SQWS Dataset. We also conduct a series of experiments over the simulated dataset SQWS. The results are shown in
Figure 3. Both the overall trends and experimental results are found to be similar to the results on the QWS dataset under the evaluation metrics. As for the RMSDE metric, the PDPP method achieves the minimum value, demonstrating the generalization ability of our approach. It is worth mentioning that we find that due to the randomness of the generated data, to some extent, the QoS diversity level of the simulated users could be low, which leads to lower RMSDE values for certain recommendation methods. Thus, the RMSDE values may be very close to those of the PDPP methods. Although this phenomenon may arise by chance sometimes, the PDPP method can always recommend Web services that align with the user’s QoS diversity level.
To summarize, PDPP has comparatively high QoS accuracy, proper diversity, and the best RMSDE. Therefore, whether the diversity of the recommended results is high or not is of little significance; the most important aspect is whether the diversity is suitable for the user.
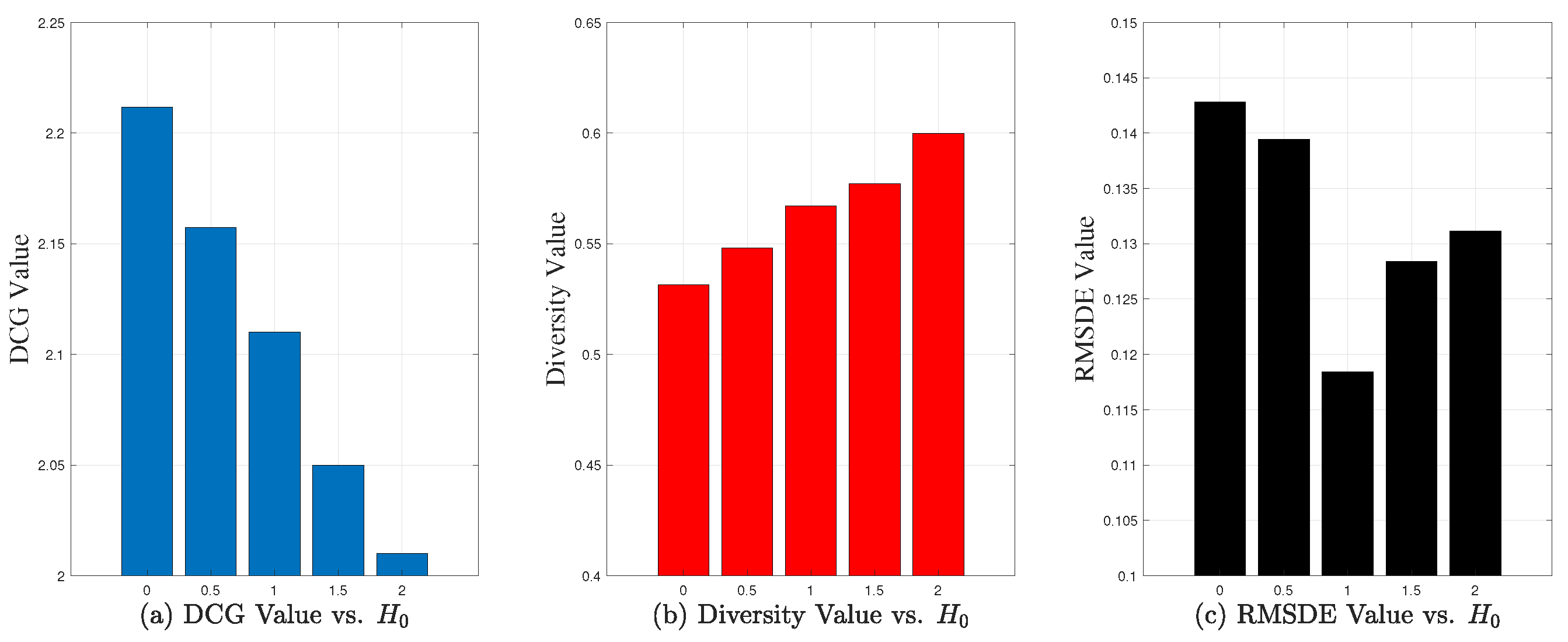
5.3. Impact of Hyperparameters
Next, we design a series of experiments to explore the impact of the variety of different hyperparameters in the PDPP algorithm, including the common diversity parameter
and normalization parameter
in Formula (
7). When
or
varies, other parameters are set as default values.
Experimental Results on QWS Dataset. (1)
The impact of .
represents the coefficient of diversification. Selecting an appropriate
can effectively construct the kernel matrix. Therefore, we need to consider the influence of the value of
on the performance of the recommendation results. The results are shown in
Figure 4. As can be seen from
Figure 4a,b, with the increase in
, the accuracy of the results decreases, while the diversity increases. As shown in
Figure 4c, when the value of
reaches 0.9, PDPP achieves the lowest RMSDE, which indicates that the diversity is aligned with the user’s diversity preference. At this time, both the accuracy and diversity indicators of the results are at the desirable level. Based on the above results, for the selected dataset in our experiments, 0.9 is set as the default value of
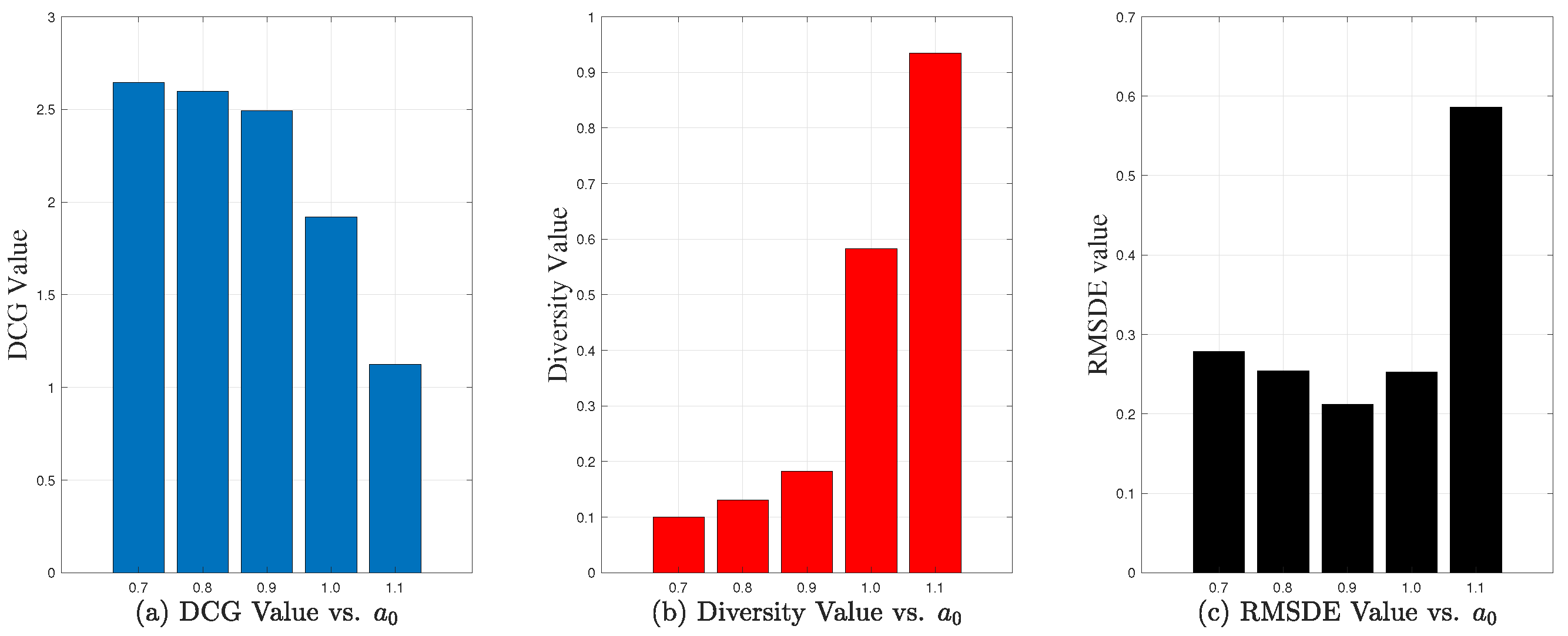
. (2)
The impact of . According to Formula (
7),
controls the personalization degree of
. When
is infinite, the PDPP method downgrades to the DPP algorithm. In our experiments, the minimum value of
among the simulated users is about 2, so
varies from 0 to 2. Similarly to
,
has a contribution to the value of
, i.e., the user’s final diversity preference. Therefore, selecting an appropriate
can effectively generate different desirable diversities for different users. The impact of
is shown in
Figure 5. It can be seen that
has an impact on both the accuracy and diversity in
Figure 5. With the increase in
, the accuracy decreases but the diversity increases, as shown in
Figure 5a,b. From the perspective of users, it is necessary to find a suitable diversity list by controlling the personalized parameter to derive the diversity preference of the user, so as to improve the accuracy, but a larger value will have an impact on the Shannon entropy of users. From
Figure 5c, when the value is 1, the accuracy and diversity can achieve a good balance. Thus, we choose 1 as the default value of
in our experiments.
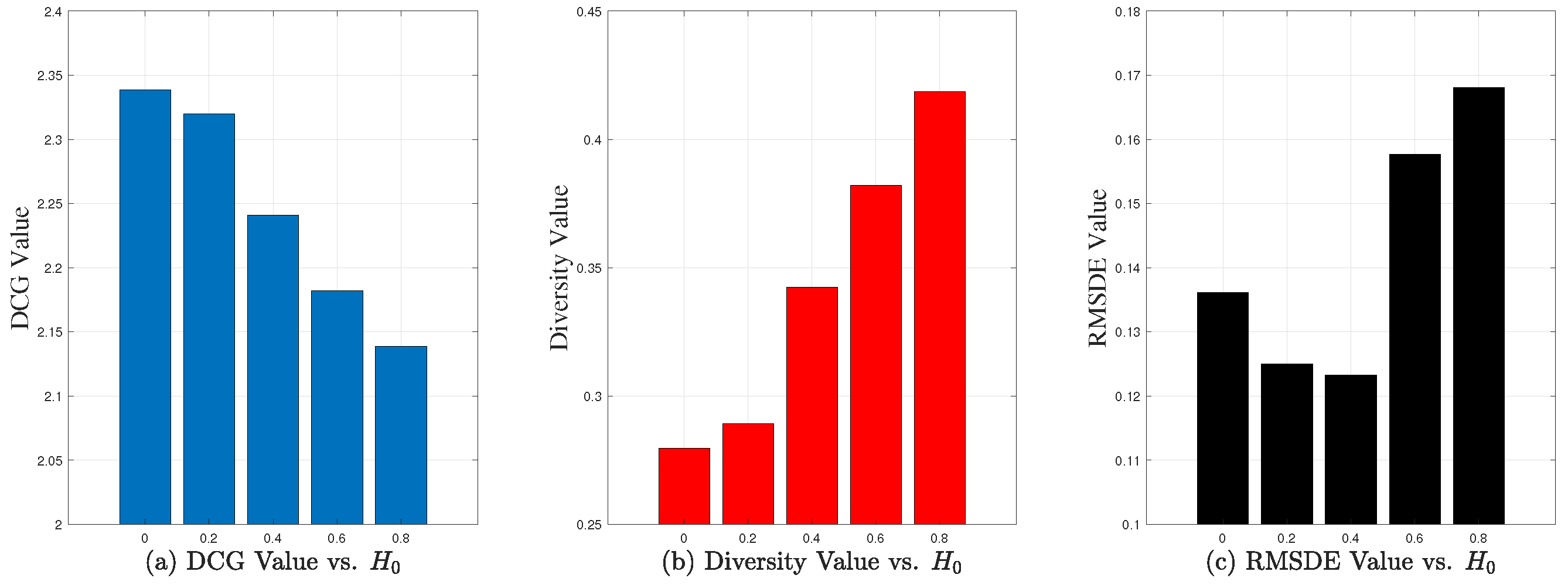
Experimental Results on SQWS Dataset. (1)
The impact of . The experimental results are displayed in
Figure 6. As can be seen from
Figure 6a,b, with the increase in
, the accuracy of the results decreases, while the diversity increases. As shown in
Figure 6c, when the value of
reaches 0.9, PDPP achieves the lowest RMSDE, which indicates that the diversity is aligned with the user’s diversity preference. The accuracy and diversity of the recommendation results are currently at a satisfactory level. In our experiments, the default value of
is set as 0.9 based on the previous results. (2)
The impact of . The impact of
is shown in
Figure 7, in which it can be found that
has an impact on both the accuracy and diversity. With the increase in
, the accuracy decreases but the diversity increases, as shown in
Figure 7a,b. From the perspective of users, it is necessary to find a suitable diversity list by controlling the personalized parameter to derive the diversity preference of the user, so as to improve the accuracy, but a larger value will have an impact on the Shannon entropy of users. As can be seen from
Figure 7c, when the value is 0.4, the accuracy and diversity can achieve a desirable balance. Thus, we choose 0.4 as the default value of
in our experiments.
To summarize, we find the default optimal values of and via experiments on both the QWS and SQWS datasets. When is larger or smaller than the default value, the RMSDE will increase; a similar situation occurs for . However, different parameters may be needed for different Web service datasets, which should be determined through extensive experiments.
6. Conclusions
When a user’s requirement has the quality of uncertainty, recommending diversified results is an effective solution by reducing the redundant items and expanding the selection space. The existing QoS-diversified service recommendation approaches use a uniform diversity degree for all users for diversified results. However, different users have different QoS preferences in practice, i.e., they have different QoS diversity degrees for the results, which can be inferred from the service invocation history. Based on this motivation, this paper proposes to mine a user’s personalized QoS diversity degree from the user’s service invocation history and provides an improved diversified recommendation algorithm for Web services, named the personalized DPP, through which a personalized and diversified service recommendation list with preferred diversity is generated for the user. Comprehensive experimental results on different datasets show that the proposed approach can not only provide personalized and diversified services but also ensures the overall accuracy of the recommendation results.
In this paper, we propose a QoS-centric Web service recommendation approach with personalized diversity to alleviate the problem of the uncertainty of QoS preferences, instead of dealing with uncertainty directly. In future work, we will take into account the removal of the QoS preference’s degree of uncertainty as much as possible by providing some auxiliary means for users. In addition, the users’ service invocation histories were simulated in our experiments. Next, we will attempt to implement our approach in an actual Web service recommendation system to verify its effectiveness further.


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}