


An Extended Reality System for Situation Awareness in Flood Management and Media Production Planning

 , , ,
, , ,  and
and 
Abstract
:1. Introduction
2. Related Work
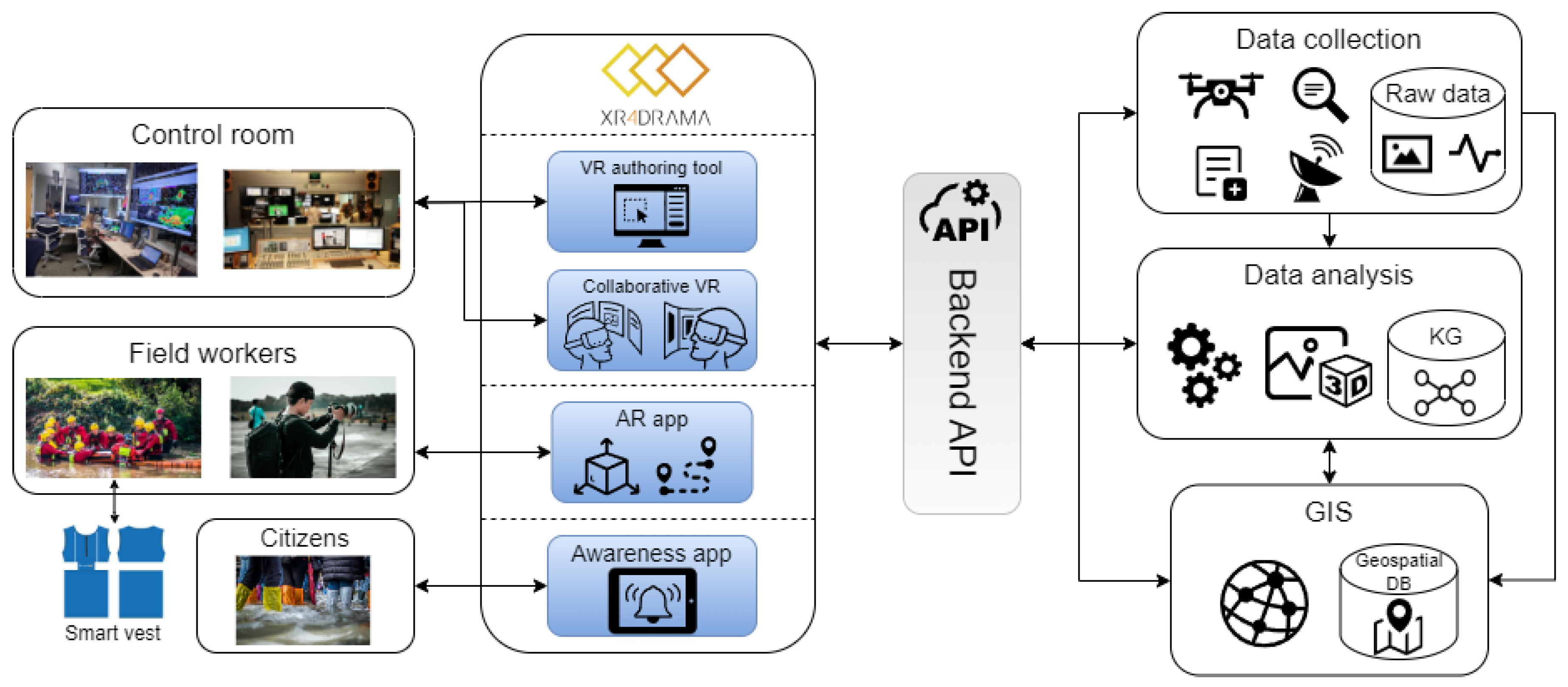
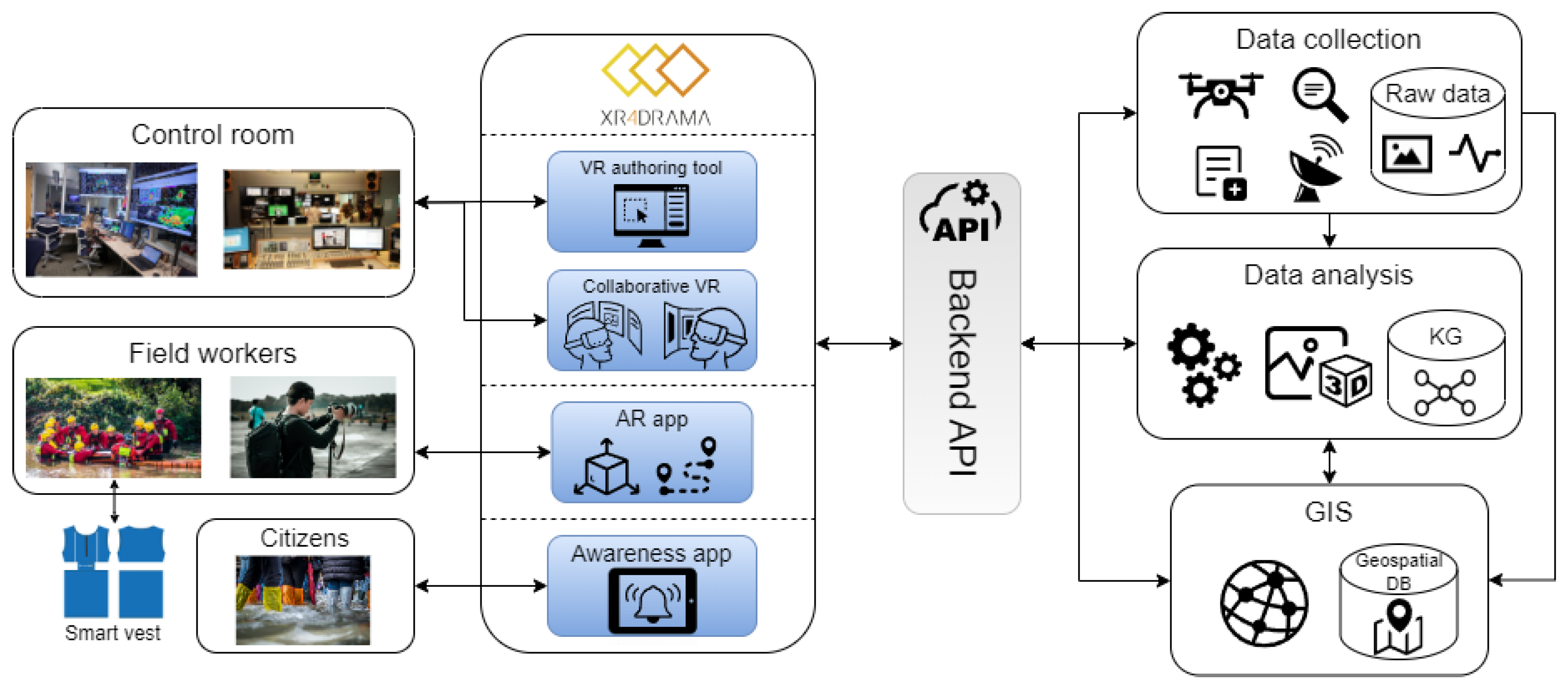
3. Framework
- Level 1 SA: An appealing, easy-to-digest representation and visualization of different content and information about a location, such as geographical data, sociographic information, cultural context, and images and videos from the Web. It is important to note that all the data presented at this point are retrieved and visualized automatically by the system.
- Level 2 SA: An enhanced representation and visualization that especially builds on recent content and information originating from people in the field (first responders or location scouts) who use a variety of tools and/or sensors in order to capture data that are most relevant to the individual use case scenario. In other words, the system processes these data “from the field” and combines them with the data about the location that were already gathered remotely from accessible web and cloud services. This representation is available to remote management in a distant control room as well as to staff in the field.
- Level 3 SA: This level denotes a more sophisticated, complex, and comprehensive virtual representation of a particular location, similar to a simulation of an event occurring in that environment. Here, users leverage rather mature XR representations that can be perceived by sophisticated tools, such as VR/XR head-mounted displays, which contribute to a higher level of (relevant) immersion and thus better situation awareness. The primary distinction between Level 3 and Level 2 SA is the ability to interactively test specific strategies and methods, e.g., simulating various possible camera movements in the media production use case.
4. End-User Tools
4.1. Software
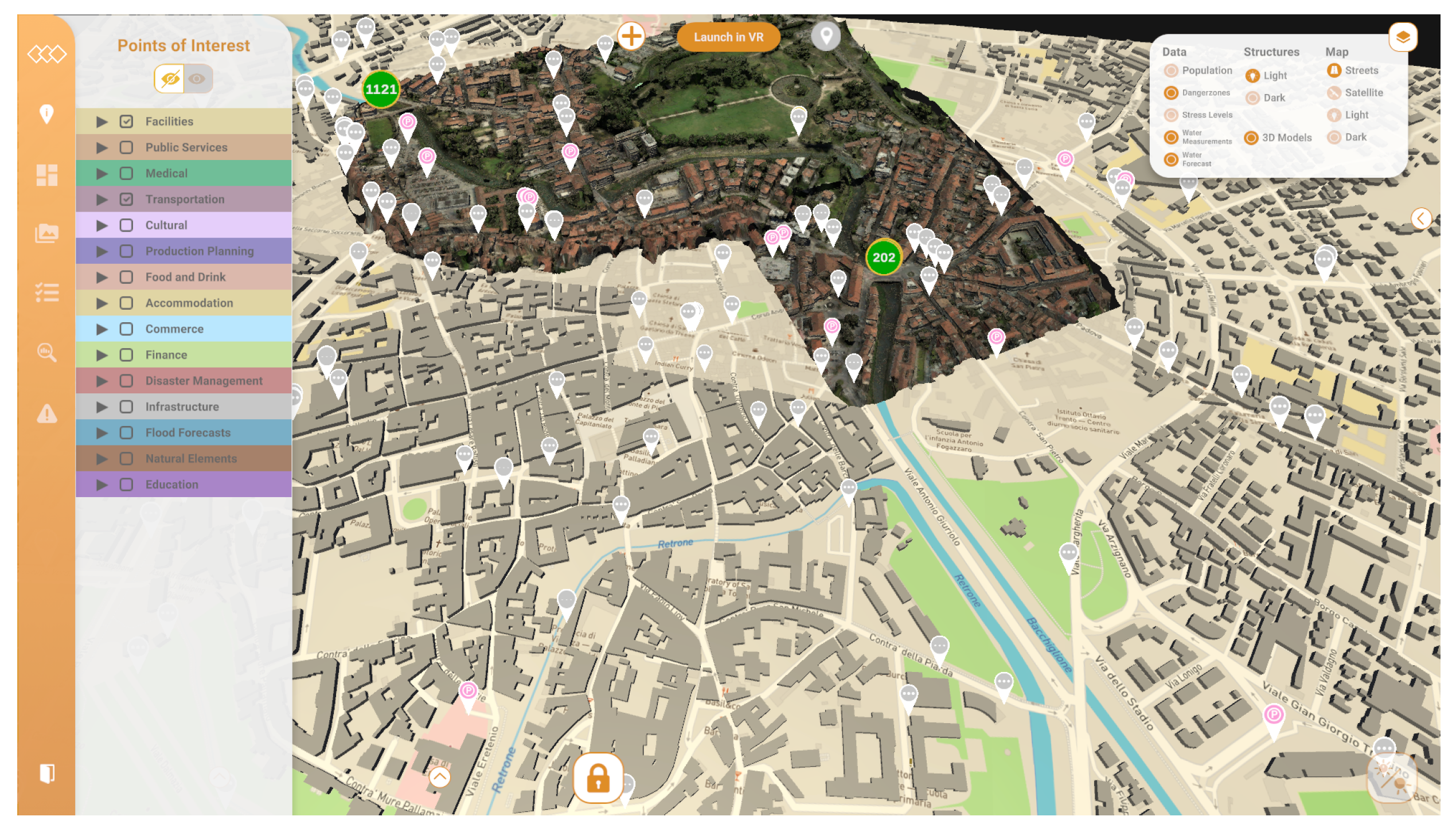
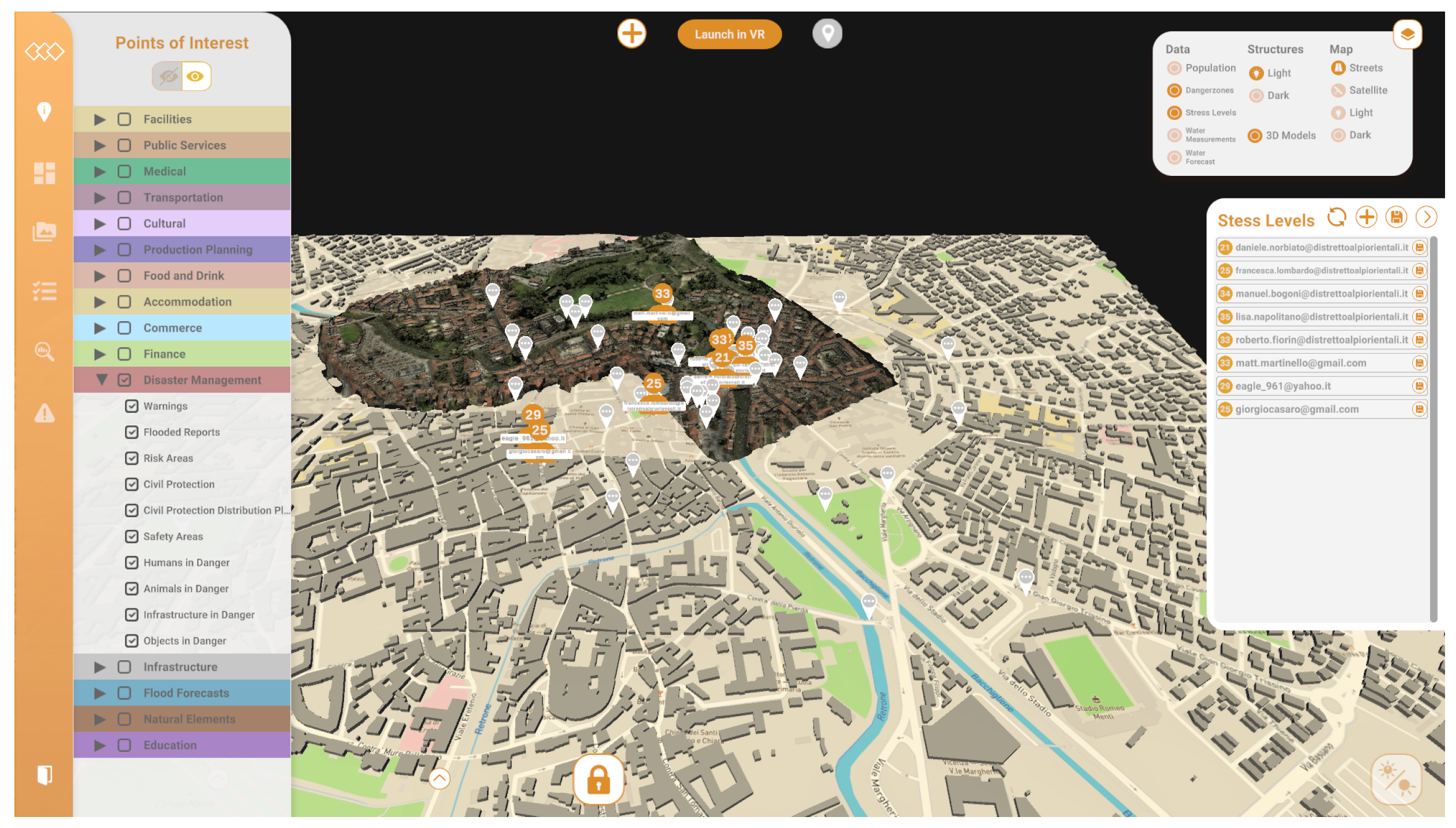
4.1.1. Authoring Tool
4.1.2. Collaborative VR Tool
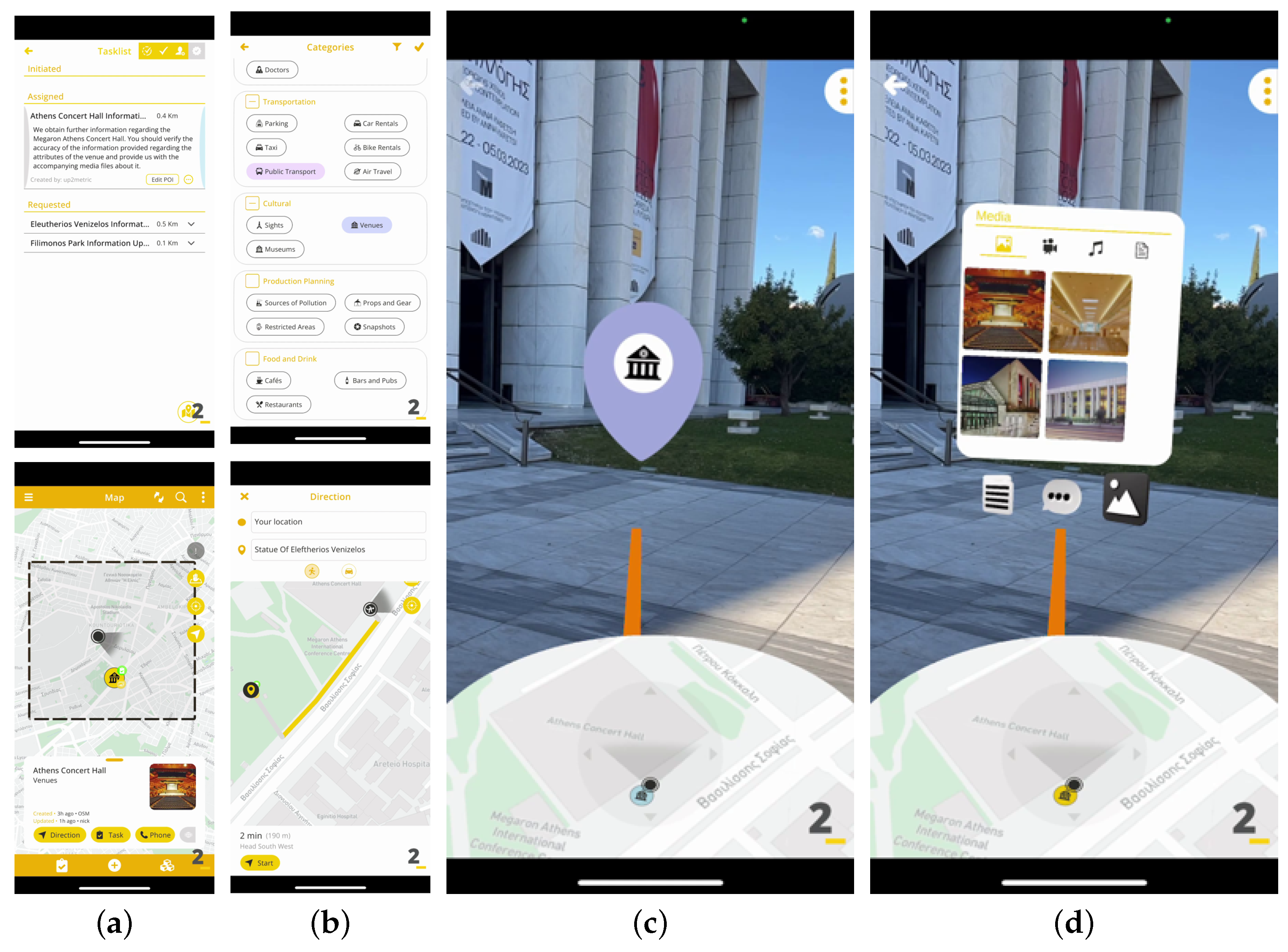
4.1.3. Location-Based Augmented Reality Application
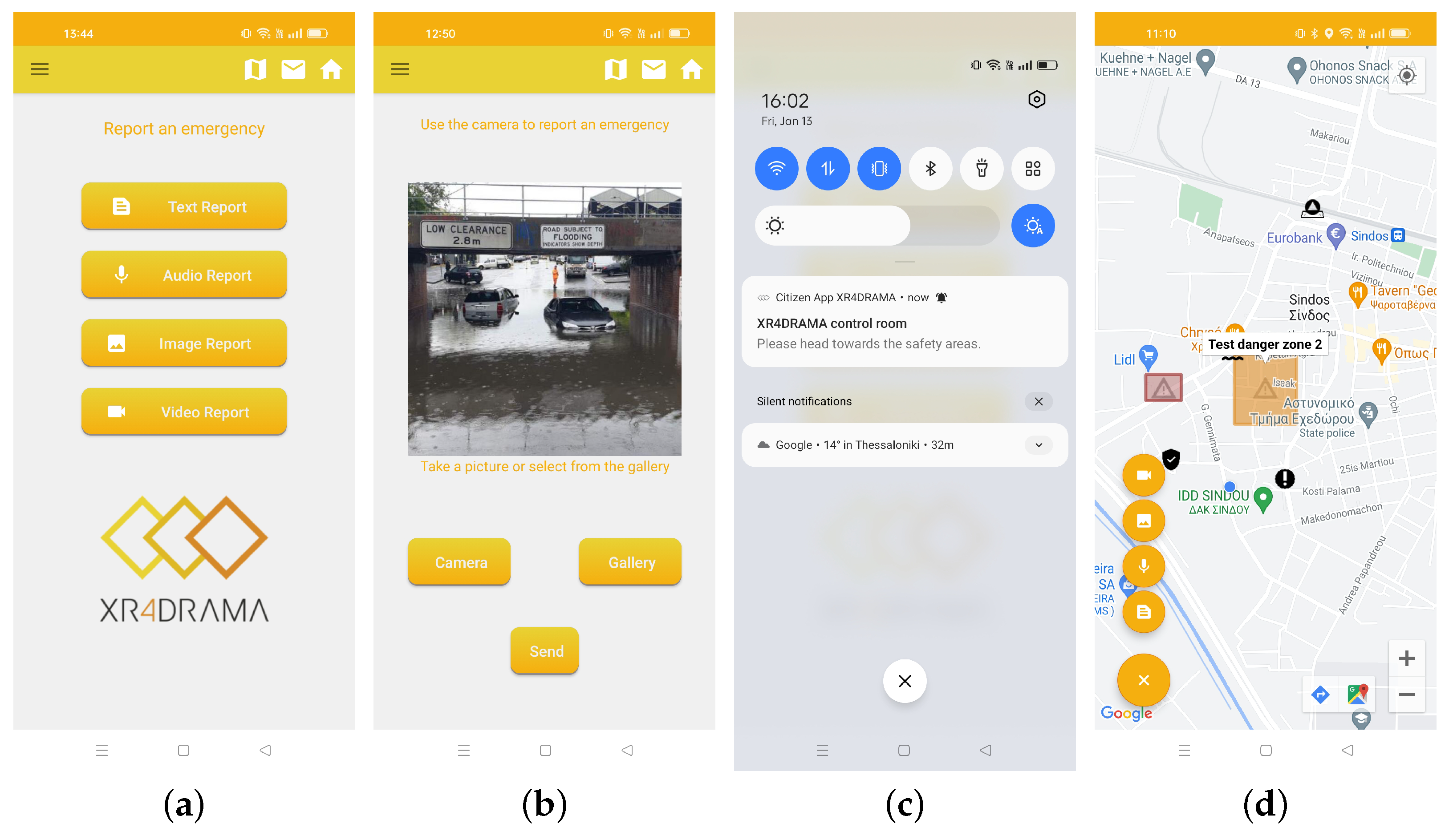
4.1.4. Citizen Awareness App
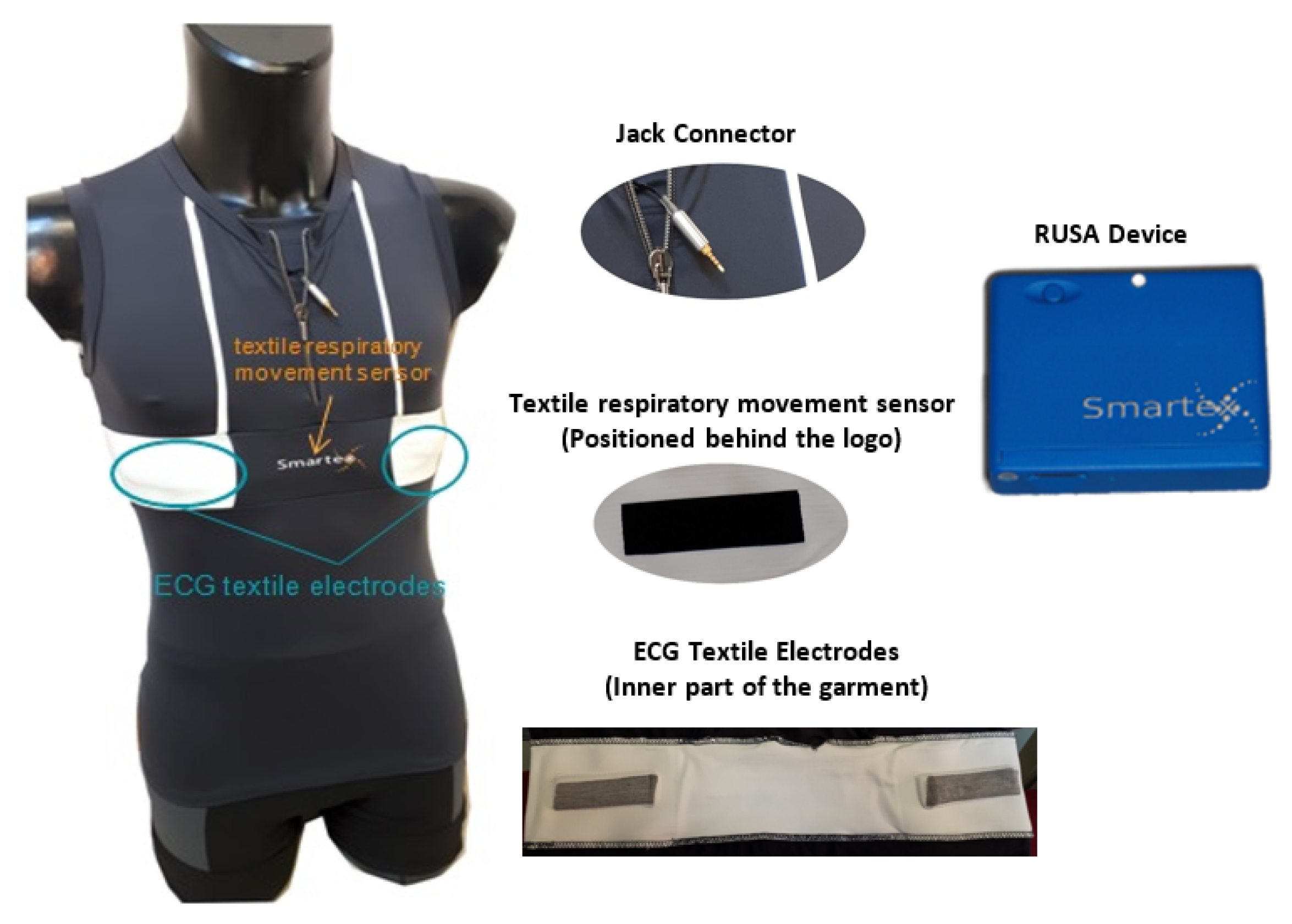
4.2. Smart Sensing Device
- Two textile electrodes to acquire an ECG signal;
- One textile respiratory movement sensor;
- A portable electronic (called a RUSA Device) in which an inertial platform (accelerometers, gyro, and IMU sensors) are integrated in order to acquire trunk movements and posture;
- One jack connector to plug the garment into the electronic device;
- A pocket to hold the electronic device during the activity.
5. Core Technologies
5.1. Data Collection
5.1.1. Web and Social Media
- Phase 1—Requirements: The input for the module is established during this phase. The requirements for data collection can be defined either as keywords forming textual queries or as URL addresses.
- Phase 2—Discovery: In situations where the exact web resources to be gathered are not known, discovery has to be conducted. Detection of relevant web resources can be achieved in three ways: (a) using web crawling, when the input is an entry URL; (b) using search, when the input is a textual query; and (c) streaming in real-time, instead of searching, where an existing API (e.g., Twitter) provides such capability. This phase is bypassed when the indicated URL resource in Phase 1 is the only one to be integrated. Web crawling uses a breadth-first algorithm to iteratively traverse webpages (starting from the entry URL) and extract a list of discovered unique URLs. The process is executed until a crawling depth of 3 is reached (i.e., the maximum distance allowed between the discovered and entry pages). Searching and streaming build upon existing third-party APIs to discover related content.
- Phase 3—Content Extraction: This procedure is straightforward when data collection is conducted using existing APIs, as it corresponds to a simple retrieval action. However, if there is no available API, web scraping techniques are applied using the Boilerpipe library [16] that makes use of shallow text features and C4.8 decision tree classifiers to identify and remove the surplus “clutter” (boilerplate, templates) around the main textual content of a web page.
- Phase 4—Storage and Integration: The final stage involves parsing and storing the content that was previously retrieved using a unified representation model that can aggregate different types of multimedia. The base data model is the SIMMO (https://github.com/MKLab-ITI/simmo (accessed on 28 May 2023)) [17] one.
5.1.2. Remote Sensing
5.2. Analysis
5.2.1. Visual Analysis
- Shot detection: It applies only to videos and automatically detects shot transitions in videos to facilitate next analysis steps. TransNet V2 [18] is deployed for this task, a deep network that reaches state-of-the-art (SoA) performance on respected benchmarks. TransNet V2 builds upon the original TransNet framework, which employs Dilated Deep Convolutional Network (DDCNN) cells. Six DDCNN cells are used, each consisting of four 3 × 3 × 3 convolutions with different dilation rates. The final sixth cell reaches a large receptive field of 97 frames while maintaining an acceptable number of learnable parameters. In the new version, DDCNN cells also integrate batch normalization that stabilizes gradients and adds noise during training. Every second cell contains a skip connection followed by spatial average pooling that reduces the spatial dimension by two.
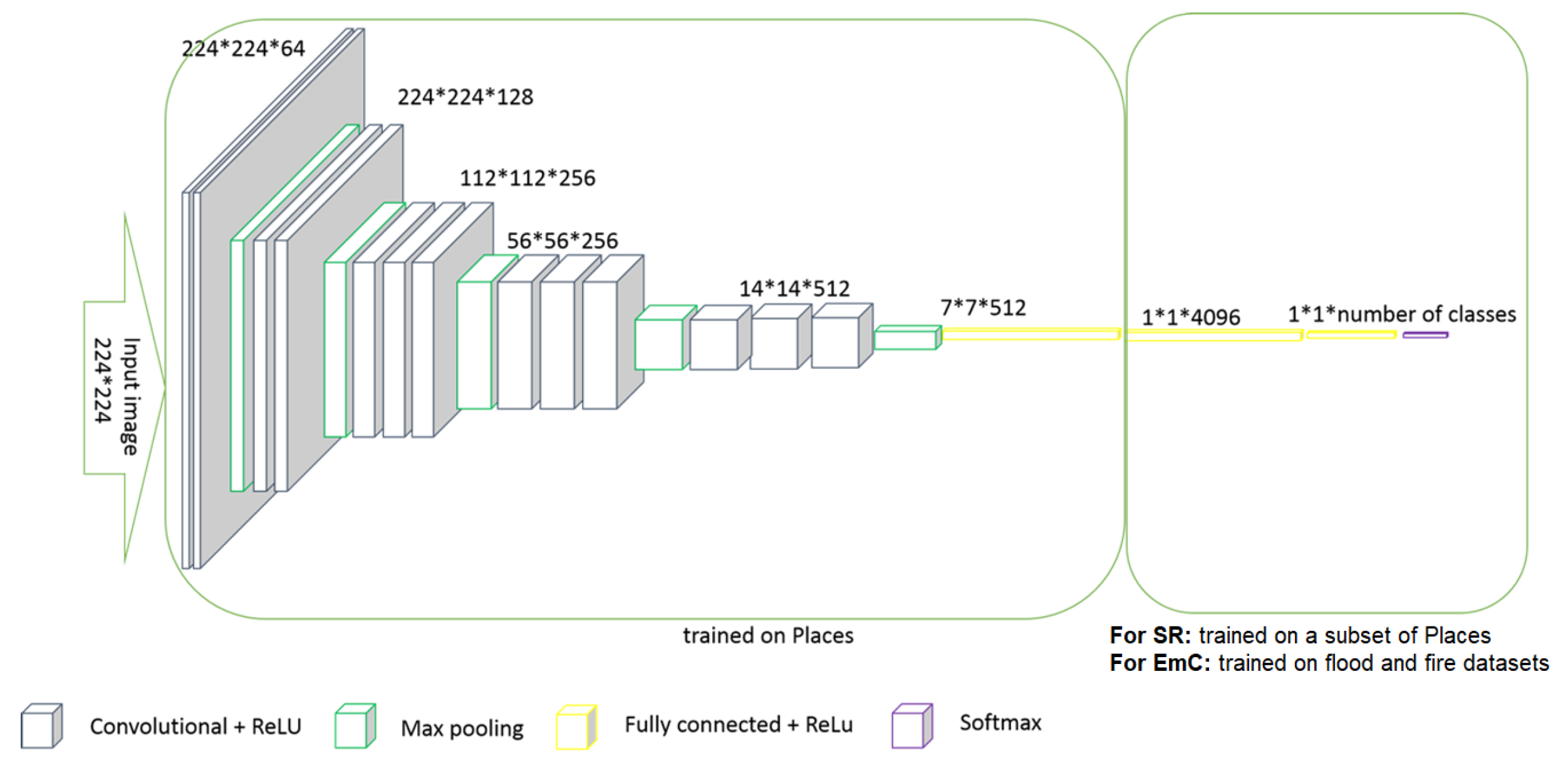
- Scene recognition (SR): It aims to classify the scenes depicted in images or videos into 99 indoor and outdoor scene categories using the VGG16 [19] Convolutional Neural Network (CNN) framework. VGG16 consists of 16 layers, not including the max-pool layers and the SoftMax activation in the last layer. In particular, the image is passed through a stack of convolutional layers, which are used with filters of a small receptive field. Spatial pooling is carried out by five max-pooling layers, which follow some of the convolutional layers. The width of convolutional layers starts at 64 in the first layers and then increases by a factor of 2 after each max-pooling layer, until it reaches 512, as depicted in Figure 13. The stack of convolutional layers is followed by three fully connected (FC) layers. The final layer is the SoftMax layer. The first 14 layers of the VGG16 framework were pre-trained on the Places dataset (http://places2.csail.mit.edu/ (accessed on 28 May 2023)), which has the initial 365 Places categories. The remaining layers were trained on a subset of 99 selected classes of Places dataset.
- Emergency classification (EmC): This component recognizes emergency situations, such as floods or fires, in images or videos. It uses the same CNN framework as the scene recognition module with the difference that the last fully connected layer is changed to fit the emergency classification purposes. Specifically, the final fully connected (FC) layer was removed and replaced with a new FC layer with a width of three nodes, freezing the weights up to the previous layer. A softmax classifier was also deployed so as to enable multi-class recognition (where classes are “Flood”, “Fire”, and “Other”).
- Photorealistic style transfer: A U-Net-based network [20] is paired with wavelet transforms and Adaptive Instance Normalization to generate new images that look like they are in different lighting, times of day, or weather. The result enhances the performance of the building and object localization module for challenging images featuring poor lighting and weather conditions. The implemented network is comprised of the following three sub-components: encoder, enhancer, and decoder. The encoder has convolutional layers and downsampling dense blocks. In the latter, two convolutional layers, a dense block and a pooling layer based on Haar wavelets, are included. The decoder has four upsampling blocks creating a U-Net structure in addition to the encoder previously mentioned. An upsampling layer, three convolutional layers, and a concatenation operation make up each block. In the enhancer module, multi-scale features are transmitted from the encoder to the decoder.
- Building and object localization: This component localizes buildings and objects of interest and is based on DeepLabV3+ [21] that allows for segmenting images and visual content in general. DeepLabV3+ extends DeepLabV3 [22] by employing an encoder–decoder structure. The encoder module encodes multi-scale contextual information by applying atrous convolution at multiple scales, while the simple yet effective decoder module refines the segmentation results along object boundaries. Furthermore, a second image segmentation model is deployed for emergency localization. The model is also based on the DeepLabV3+ architecture and was trained on the ADE20K dataset [23]. Specifically, it localizes “water” or “flame” regions and, in combination with the localization of people or vehicles, it determines the exact presence of people or vehicles in danger.
5.2.2. Multilingual Audio and Text Analysis
- Concept extraction to translate an input sentence into concepts employing an adapted version of the pointer-generator model [26,27] (using separate distributions for copying attention and general attention) and the use of multi-layer long short-term memory networks (LSTMs), whose network architecture is described in [26]:
- Named entity extraction using spaCy 2.0 (http://spacy.oi (accessed on 28 May 2023)) to annotate 18 different entity types;
- Temporal expression identification with HeidelTime [28], a rule-based multilingual, domain-sensitive temporal tagger;
- Entity and word sense disambiguation by collecting and ranking candidate meanings of the words in the text transcript, calculating the salience of a meaning with respect to the whole set of candidate meanings, and determining its plausibility with respect to the context of its mention in the input texts [29,30]. Meanings are compared with each other using sense embeddings and with their context using sentence embeddings calculated from their English Wikipedia and WordNet glosses;
- Geolocation using a two-stage procedure: first, location candidate identification, and second, the search of normalized surface forms of detected candidates in a key-value index. We make use of two geographical databases, OpenStreetMap (https://www.openstreetmap.org/ (accessed on 28 May 2023)) (OSM) and GeoNames (https://www.geonames.org/ (accessed on 28 May 2023)), which we convert into a direct and inverted search index and extend with possible shortened versions of names. To reduce the number of candidates, we pre-filter the search index according to the perimeter of the geographical area of application;
- Surface language analysis via UDPipe (https://github.com/ufal/udpipe (accessed on 28 May 2023)) [31] which performs part-of-speech (POS) tagging, lemmatization, and parsing;
- Semantic parsing to output the semantic structures at the levels of deep-syntactic (or shallow-semantic) structures and semantic structures [32].
5.2.3. Stress Detection
- Physiological signals stress detection: Data gathered from the sensors are analyzed in order to extract statistical and frequency features that are fed into a trained model for the final continuous value of stress level detection. We deployed the same developed method described in [34]. In particular, a total of 314 features were extracted, consisting of 94 ECG, 28 RSP, and 192 IMU (16 per single-axis data) features. ECG features encompass statistical and frequency features related to the signal, R-R intervals, and heart rate (HR) variability. The hrv-analysis (https://pypi.org/project/hrv-analysis/ (accessed on 28 May 2023)) and neurokit toolboxes [35] were utilized to analyze the ECG features. Respiratory features include statistical and frequency features of the signal, breathing rate, respiratory rate variability, and breath-to-breath intervals, extracted using the neurokit toolbox. IMU features consist of basic statistical and frequency features, including mean, median, standard deviation, variance, maximum value, minimum value, interquartile range, skewness, kurtosis, entropy, energy, and five dominant frequencies. After the feature extraction step, we utilized the Genetic Algorithm (GA)-based feature selection method [36] and finally deployed the Extreme Gradient Boosting (XGB) tree [37] modified for regression to predict the stress values.
- Audio signals stress detection: A set of acoustic features is extracted from the audio signals using [38], known as the eGeMAPs feature set. The eGeMAPs (extended Geneva Minimalistic Acoustic Parameter Set) feature set is a collection of acoustic features extracted from speech signals. It includes various low-level descriptors (LLD) such as pitch, energy, and spectral features, as well as higher-level descriptors such as prosodic features, voice quality measures, and emotion-related features. These features capture different aspects of the speech signal and can be used for tasks such as speech emotion recognition, speaker identification, and speech synthesis. The extracted features are fed to a Support Vector Machine (SVM) [39] trained for regression.
- Fusion stress detection: The proposed fusion method is performed at the decision level of both sensor-based and acoustic methods; in other words, it follows a late fusion approach. Both unimodal results are fed into a trained SVM with the radial kernel, which showed the best-performing results during training. The results indicate that the fusion-based method improves the performance of the stress detection task compared to its unimodal counterparts.
5.2.4. Semantic Integration and Decision Support
5.2.5. Text Generation
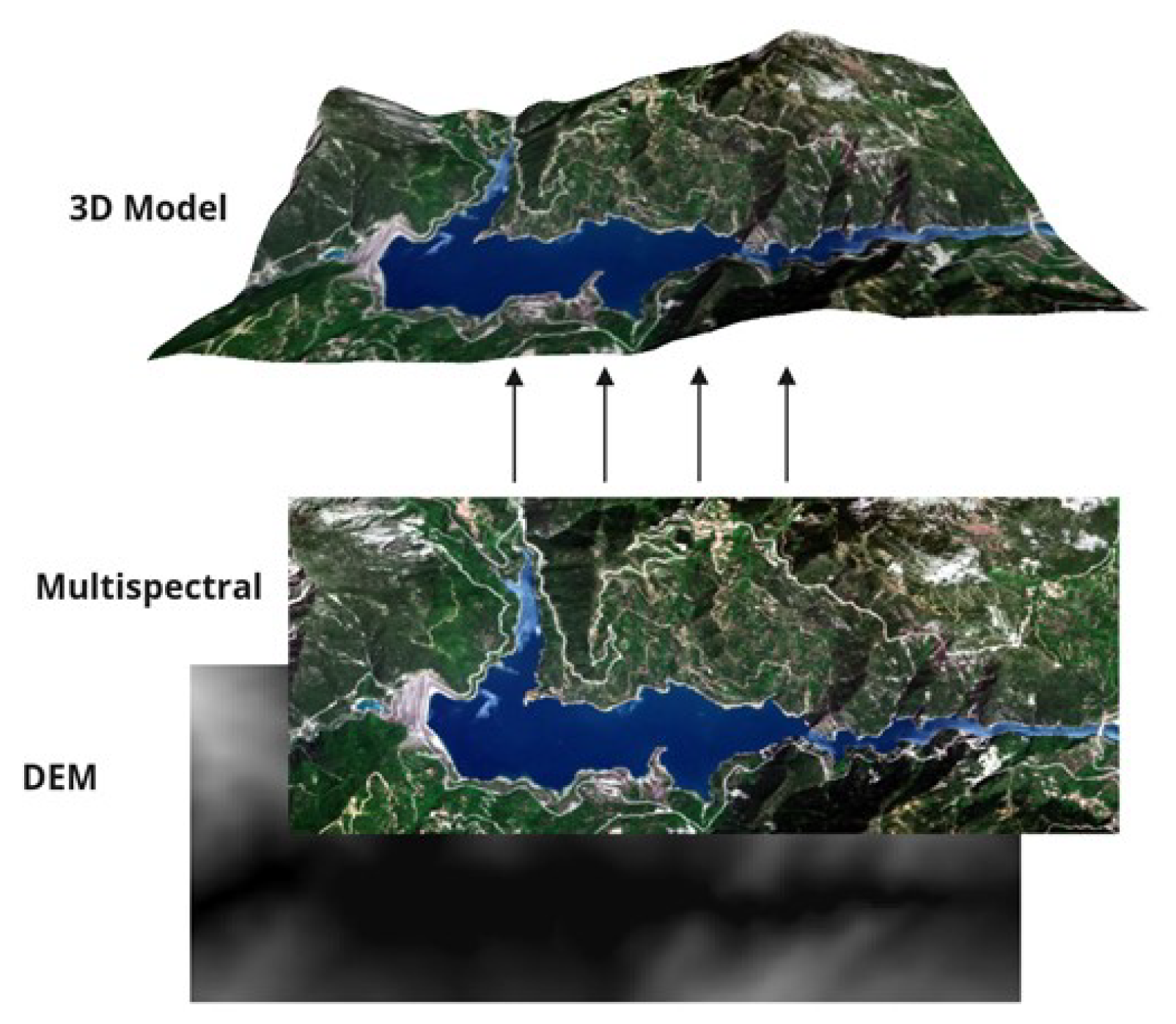
5.2.6. 3D Model Reconstruction
5.3. GIS Service
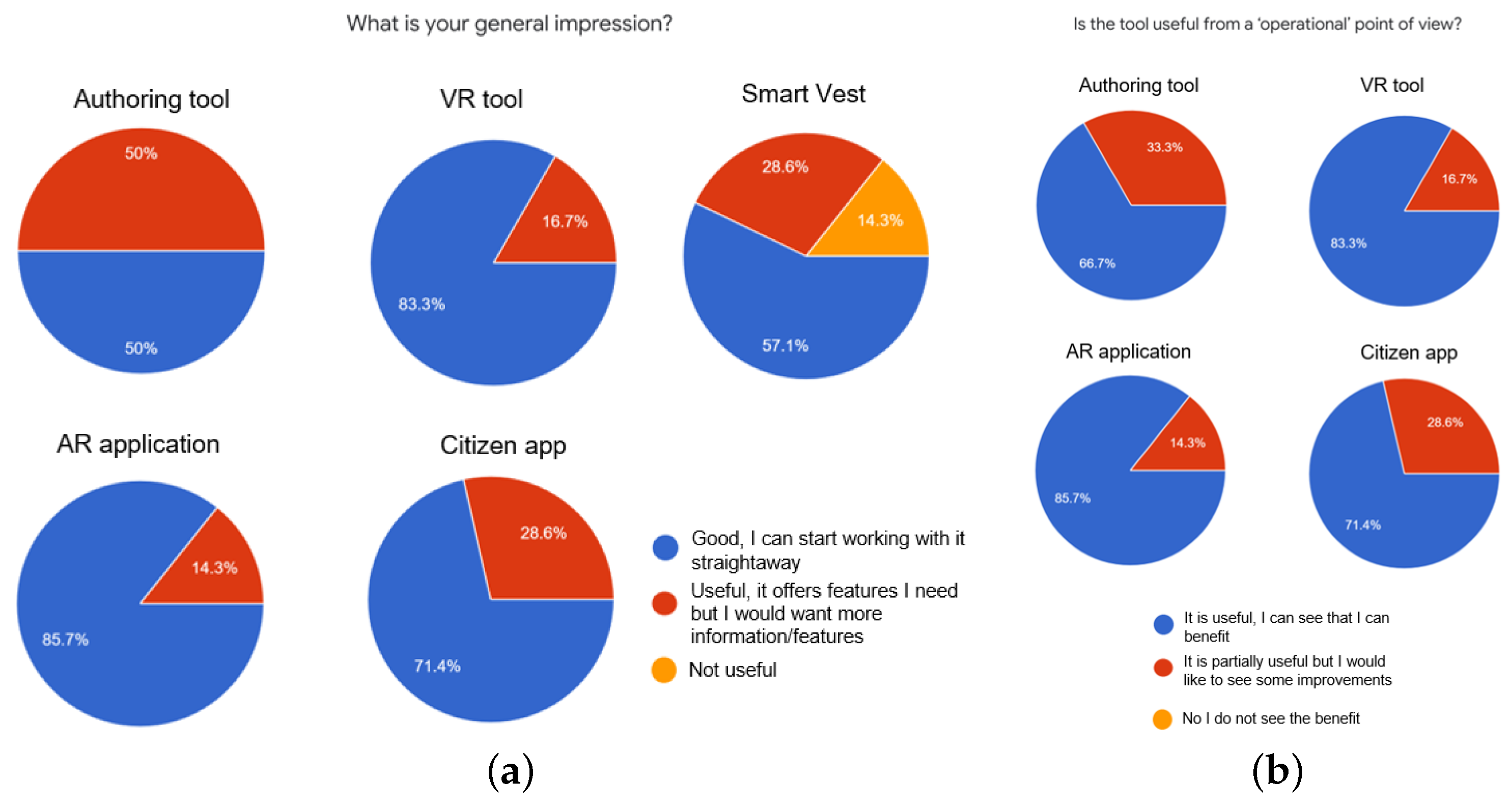
6. Evaluation and Results
6.1. Flood Management Use Case
- Control room operators: These operators used the authoring tool to obtain forecasts, conduct real-time monitoring of the crisis’s progression, issue region-wide notifications to citizens, and establish bidirectional contact with and from first responders equipped with the AR application. The people who performed these roles stayed in the control room during the pilot. This role was carried out by members of the Vicenza Municipality and the Alto Adriatico Water Authority (AAWA).
- Civil protection volunteer teams: During the pilot, there were two teams of first responders positioned in different locations according to the storyline. The leaders of each team used the XR4DRAMA AR application to communicate with the control room; provide incident reports including text, image, and video; and receive tasks. The teams were formed by AAWA personnel.
- Citizens: Citizens used the XR4DRAMA citizen awareness mobile application to send incident reports (i.e., text, audio, image, video) and to receive notifications from the first responders. During the pilot, the participants who were assigned the role of citizens were located in specific areas of the city, according to the use case story. The role of the citizens was also carried out by AAWA personnel.
6.2. Media Production Use Case
- Technical setup (laptops, XR equipment etc.);
- Download and initial startup of the latest project software;
- Preparation of related documents/spreadsheets to record the scenario steps, the associated requirements, the expected performance, and important notes;
- Testing of the platform for the first step of the scenario in a space used as a control room;
- Execution of second step of the scenario, i.e., location scouting, media recording, and data verification on site on the island (in Corfu City);
- Testing of the platform for the third step of the scenario in the same control room space;
- More system test runs and documentation (including post-processing of the notes kept during each scenario step execution);
- Evaluation (based on qualitative questions) and technical discussion towards further improving the platform,
- How stable and mature is the system?
- How much situation awareness does the system provide?
- What about user experience (UX), user interface (UI), usability?
- To what extent is the user able to fulfill their task and achieve their goals? (effectiveness)
- How much effort does the user need to invest to come up with accurate and complete results? (efficiency)
- How satisfied is the user with the system? (satisfaction)
6.3. Summary
7. Discussion, Conclusions, and Future Work
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Shin, Y.; Jiang, Y.; Wang, Q.; Zhou, Z.; Qin, G.; Yang, D.K. Flexoelectric-effect-based light waveguide liquid crystal display for transparent display. Photonics Res. 2022, 10, 407–414. [Google Scholar] [CrossRef]
- Cheng, D.; Duan, J.; Chen, H.; Wang, H.; Li, D.; Wang, Q.; Hou, Q.; Yang, T.; Hou, W.; Wang, D.; et al. Freeform OST-HMD system with large exit pupil diameter and vision correction capability. Photonics Res. 2022, 10, 21–32. [Google Scholar] [CrossRef]
- Pandey, A.; Min, J.; Malhotra, Y.; Reddeppa, M.; Xiao, Y.; Wu, Y.; Mi, Z. Strain-engineered N-polar InGaN nanowires: Towards high-efficiency red LEDs on the micrometer scale. Photonics Res. 2022, 10, 2809–2815. [Google Scholar] [CrossRef]
- Chittaro, L.; Sioni, R. Serious games for emergency preparedness: Evaluation of an interactive vs. a non-interactive simulation of a terror attack. Comput. Hum. Behav. 2015, 50, 508–519. [Google Scholar] [CrossRef]
- Tanes, Z.; Cho, H. Goal setting outcomes: Examining the role of goal interaction in influencing the experience and learning outcomes of video game play for earthquake preparedness. Comput. Hum. Behav. 2013, 29, 858–869. [Google Scholar] [CrossRef]
- Rydvanskiy, R.; Hedley, N. Mixed Reality Flood Visualizations: Reflections on Development and Usability of Current Systems. ISPRS Int. J. Geo-Inf. 2021, 10, 82. [Google Scholar] [CrossRef]
- Haynes, P.; Hehl-Lange, S.; Lange, E. Mobile Augmented Reality for Flood Visualisation. Environ. Model. Softw. 2018, 109, 380–389. [Google Scholar] [CrossRef]
- Sermet, Y.; Demir, I. Flood action VR: A virtual reality framework for disaster awareness and emergency response training. In ACM SIGGRAPH 2019 Posters; Association for Computing Machinery: New York City, NY, USA, 2019; pp. 1–2. [Google Scholar]
- Itamiya, T.; Kanbara, S.; Yamaguchi, M. XR and Implications to DRR: Challenges and Prospects. In Society 5.0, Digital Transformation and Disasters: Past, Present and Future; Kanbara, S., Shaw, R., Kato, N., Miyazaki, H., Morita, A., Eds.; Springer Nature: Singapore, 2022; pp. 105–121. [Google Scholar] [CrossRef]
- Bösch, M.; Gensch, S.; Rath-Wiggins, L. Immersive Journalism: How Virtual Reality Impacts Investigative Storytelling. In Digital Investigative Journalism: Data, Visual Analytics and Innovative Methodologies in International Reporting; Springer: Berlin/Heidelberg, Germany, 2018; pp. 103–111. [Google Scholar]
- Symeonidis, S.; Meditskos, G.; Vrochidis, S.; Avgerinakis, K.; Derdaele, J.; Vergauwen, M.; Bassier, M.; Moghnieh, A.; Fraguada, L.; Vogler, V.; et al. V4Design: Intelligent Analysis and Integration of Multimedia Content for Creative Industries. IEEE Syst. J. 2022, 1–4. [Google Scholar] [CrossRef]
- Avgerinakis, K.; Meditskos, G.; Derdaele, J.; Mille, S.; Shekhawat, Y.; Fraguada, L.; Lopez, E.; Wuyts, J.; Tellios, A.; Riegas, S.; et al. V4design for enhancing architecture and video game creation. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality Adjunct (ISMAR-Adjunct), Munich, Germany, 16–20 October 2018; IEEE: Manhattan, NY, USA, 2018; pp. 305–309. [Google Scholar]
- Brescia-Zapata, M. Culture meets immersive environments: A new media landscape across Europe. Avanca Cine. 2021, 1029–1033. [Google Scholar] [CrossRef]
- Wu, H.; Cai, T.; Liu, Y.; Luo, D.; Zhang, Z. Design and development of an immersive virtual reality news application: A case study of the SARS event. Multimed. Tools Appl. 2021, 80, 2773–2796. [Google Scholar] [CrossRef] [PubMed]
- Forsberg, K.; Mooz, H. The relationship of system engineering to the project cycle. In INCOSE International Symposium; Wiley Online Library: Hoboken, NJ, USA, 1991; Volume 1, pp. 57–65. [Google Scholar]
- Kohlschütter, C.; Fankhauser, P.; Nejdl, W. Boilerplate detection using shallow text features. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, Association for Computing Machinery, New York City, NY, USA, 4–6 February 2010; pp. 441–450. [Google Scholar]
- Tsikrika, T.; Andreadou, K.; Moumtzidou, A.; Schinas, E.; Papadopoulos, S.; Vrochidis, S.; Kompatsiaris, I. A unified model for socially interconnected multimedia-enriched objects. In Proceedings of the MultiMedia Modeling: 21st International Conference, MMM 2015, Sydney, NSW, Australia, 5–7 January 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 372–384. [Google Scholar]
- Souček, T.; Lokoč, J. Transnet V2: An effective deep network architecture for fast shot transition detection. arXiv 2020, arXiv:2008.04838. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Batziou, E.; Ioannidis, K.; Patras, I.; Vrochidis, S.; Kompatsiaris, I. Low-Light Image Enhancement Based on U-Net and Haar Wavelet Pooling. In Proceedings of the MultiMedia Modeling: 29th International Conference, MMM 2023, Bergen, Norway, 9–12 January 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 510–522. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 633–641. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 6, 679–698. [Google Scholar] [CrossRef]
- Pratap, V.; Hannun, A.; Xu, Q.; Cai, J.; Kahn, J.; Synnaeve, G.; Liptchinsky, V.; Collobert, R. Wav2letter++: A fast open-source speech recognition system. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Manhattan, NY, USA, 2019; pp. 6460–6464. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- Gu, J.; Lu, Z.; Li, H.; Li, V.O. Incorporating copying mechanism in sequence-to-sequence learning. arXiv 2016, arXiv:1603.06393. [Google Scholar]
- Strötgen, J.; Gertz, M. Heideltime: High quality rule-based extraction and normalization of temporal expressions. In Proceedings of the 5th International Workshop on Semantic Evaluation, Uppsala, Sweden, 15–16 July 2010; pp. 321–324. [Google Scholar]
- Casamayor, G. Semantically-Oriented Text Planning for Automatic Summarization. Ph.D. Thesis, Universitat Pompeu Fabra, Barcelona, Spain, 2021. [Google Scholar]
- Camacho-Collados, J.; Pilehvar, M.T.; Navigli, R. Nasari: Integrating explicit knowledge and corpus statistics for a multilingual representation of concepts and entities. Artif. Intell. 2016, 240, 36–64. [Google Scholar] [CrossRef] [Green Version]
- Straka, M.; Straková, J. Tokenizing, pos tagging, lemmatizing and parsing ud 2.0 with udpipe. In Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, Vancouver, BC, Canada, 3–4 August 2017; pp. 88–99. [Google Scholar]
- Ballesteros, M.; Bohnet, B.; Mille, S.; Wanner, L. Data-driven deep-syntactic dependency parsing. Nat. Lang. Eng. 2016, 22, 939–974. [Google Scholar] [CrossRef] [Green Version]
- Bohnet, B.; Wanner, L. Open Source Graph Transducer Interpreter and Grammar Development Environment. In Proceedings of the LREC, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Xefteris, V.R.; Tsanousa, A.; Symeonidis, S.; Diplaris, S.; Zaffanela, F.; Monego, M.; Pacelli, M.; Vrochidis, S.; Kompatsiaris, I. Stress Detection Based on Wearable Physiological Sensors: Laboratory and Real-Life Pilot Scenario Application. In Proceedings of the Eighth International Conference on Advances in Signal, Image and Video Processing (SIGNAL), Barcelona, Spain, 13–17 March 2023; pp. 7–12. [Google Scholar]
- Makowski, D.; Pham, T.; Lau, Z.J.; Brammer, J.C.; Lespinasse, F.; Pham, H.; Schölzel, C.; Chen, S.A. NeuroKit2: A Python toolbox for neurophysiological signal processing. Behav. Res. Methods 2021, 53, 1689–1696. [Google Scholar] [CrossRef]
- Siedlecki, W.; Sklansky, J. A note on genetic algorithms for large-scale feature selection. Pattern Recognit. Lett. 1989, 10, 335–347. [Google Scholar] [CrossRef]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. Xgboost: Extreme Gradient Boosting. Available online: https://cran.microsoft.com/snapshot/2017-12-11/web/packages/xgboost/vignettes/xgboost.pdf (accessed on 28 May 2023).
- Eyben, F.; Wöllmer, M.; Schuller, B. Opensmile: The munich versatile and fast open-source audio feature extractor. In Proceedings of the 18th ACM International Conference on Multimedia, Firenze, Italy, 25–29 October 2010; pp. 1459–1462. [Google Scholar]
- Hearst, M.A.; Dumais, S.T.; Osuna, E.; Platt, J.; Scholkopf, B. Support vector machines. IEEE Intell. Syst. Their Appl. 1998, 13, 18–28. [Google Scholar] [CrossRef] [Green Version]
- Vassiliades, A.; Symeonidis, S.; Diplaris, S.; Tzanetis, G.; Vrochidis, S.; Bassiliades, N.; Kompatsiaris, I. XR4DRAMA Knowledge Graph: A Knowledge Graph for Disaster Management. In Proceedings of the 2023 IEEE 17th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 1–3 February 2023; IEEE: Manhattan, NY, USA, 2023; pp. 262–265. [Google Scholar]
- Vassiliades, A.; Symeonidis, S.; Diplaris, S.; Tzanetis, G.; Vrochidis, S.; Kompatsiaris, I. XR4DRAMA Knowledge Graph: A Knowledge Graph for Media Planning. In Proceedings of the 15th International Conference on Agents and Artificial Intelligence—Volume 3: ICAART, Lisbon, Portugal, 22–24 February 2023; pp. 124–131. [Google Scholar]
- Mel’čuk, I.A. Dependency Syntax: Theory and Practice; SUNY Press: Albany, NY, USA, 1988. [Google Scholar]
- Mille, S.; Dasiopoulou, S.; Wanner, L. A portable grammar-based NLG system for verbalization of structured data. In Proceedings of the 34th ACM/SIGAPP Symposium on Applied Computing, Limassol, Cyprus, 8–12 April 2019; pp. 1054–1056. [Google Scholar]
- Du, S. Exploring Neural Paraphrasing to Improve Fluency of Rule-Based Generation. Master’s Thesis, Universitat Pompeu Fabra, Barcelona, Spain, 2021. [Google Scholar]
- Thompson, B.; Post, M. Paraphrase generation as zero-shot multilingual translation: Disentangling semantic similarity from lexical and syntactic diversity. arXiv 2020, arXiv:2008.04935. [Google Scholar]
- Stentoumis, C. Multiple View Stereovision. In Digital Techniques for Documenting and Preserving Cultural Heritage; Collection ed.; Bentkowska-Kafel, A., MacDonald, L., Eds.; Amsterdam University Press: Amsterdam, The Netherlands, 2017; Chapter 18; pp. 141–143. [Google Scholar] [CrossRef] [Green Version]
- Bradski, G. The OpenCV Library. Dr. Dobb’S J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Moulon, P.; Monasse, P.; Marlet, R. Adaptive structure from motion with a contrario model estimation. In Proceedings of the Computer Vision–ACCV 2012: 11th Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 257–270. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Data Sources | Analysis Modules |
|---|---|
| Smart sensors (Heart rate, Breath rate, Inertial measurement unit) | Visual analysis |
| Web content | Audio analysis |
| Social media posts | Text analysis |
| Satellite data | Stress level detection (Fusion from sensor-based and audio-based data) |
| GIS services | Semantic integration |
| POIs and tasks created/edited by the professionals (in the control room and in the field) | Text generation |
| Multimedia uploaded by the professionals | 3D reconstruction |
| Citizen reports (audio, text, photo, video) | GIS functionalities (e.g., navigation) |
| Authoring Tool | VR Collaborative Tool | AR Application | Citizen Awareness App | Backend | |
|---|---|---|---|---|---|
| Operating System | Windows 10 | Windows 10 | Android 8.0 and newer or iOS 14 and newer | Android 6.0 and newer | Windows 10 or Linux |
| CPU model | Intel i5/i7/i9 | Intel i7/i9 | Snapdragon 636 or higher | Snapdragon 636 or higher | Any model with 1.8 GHz or higher and at least 4 threads |
| RAM | 16 GB or higher | 32 GB or higher | 3 GB or higher | 3 GB or higher | 16 GB or higher |
| Hard Disk Drive | Minimum 5 GB | Minimum 5 GB | Minimum 200 MB | Minimum 50 MB | Minimum 100 GB |
| Graphics Card | Dedicated card | NVIDIA GTX 2080 or above | Not applicable | Not applicable | NVIDIA GPU with at least 8 GB VRAM |
| VR Headset | Not applicable | HTC Vive | Not applicable | Not applicable | Not applicable |
| Internet connection | YES | YES | YES | YES | YES |
| ARCore * | Not applicable | Not applicable | YES | Not applicable | Not applicable |
| DepthAPI | Not applicable | Not applicable | YES | Not applicable | Not applicable |
| Use case | Location | Phases | End User Tools | Participants | Evaluation Tools |
|---|---|---|---|---|---|
| Flood management | Vicenza, Italy | Phase 1: Emergency preparation Phase 2: Information update by field workers and emergency management | Authoring tool (Phase 1, Phase 2) VR tool (Phase 1, Phase 2) AR application (Phase 2) Citizen app (Phase 2) Smart vest (Phase 2) | Control room operators (Phase 1, Phase 2) Civil protection teams (Phase 2) Citizens (Phase 2) | Observation sheets Questionnaires Pilot debriefing session |
| Media Production | Corfu city, Greece | Phase 1: Project creation Phase 2: Information gathering and updates from location scouts Phase 3: Immersive mode | Authoring tool (Phase 1, Phase 2) AR application (Phase 2) VR tool (Phase 3) | Production management team (Phase 1, Phase 2, Phase 3) Location scouts (Phase 2) | Assignment checklist Qualitative questions User interviews |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Symeonidis, S.; Samaras, S.; Stentoumis, C.; Plaum, A.; Pacelli, M.; Grivolla, J.; Shekhawat, Y.; Ferri, M.; Diplaris, S.; Vrochidis, S. An Extended Reality System for Situation Awareness in Flood Management and Media Production Planning. Electronics 2023, 12, 2569. https://doi.org/10.3390/electronics12122569
Symeonidis S, Samaras S, Stentoumis C, Plaum A, Pacelli M, Grivolla J, Shekhawat Y, Ferri M, Diplaris S, Vrochidis S. An Extended Reality System for Situation Awareness in Flood Management and Media Production Planning. Electronics. 2023; 12(12):2569. https://doi.org/10.3390/electronics12122569
Chicago/Turabian StyleSymeonidis, Spyridon, Stamatios Samaras, Christos Stentoumis, Alexander Plaum, Maria Pacelli, Jens Grivolla, Yash Shekhawat, Michele Ferri, Sotiris Diplaris, and Stefanos Vrochidis. 2023. "An Extended Reality System for Situation Awareness in Flood Management and Media Production Planning" Electronics 12, no. 12: 2569. https://doi.org/10.3390/electronics12122569
APA StyleSymeonidis, S., Samaras, S., Stentoumis, C., Plaum, A., Pacelli, M., Grivolla, J., Shekhawat, Y., Ferri, M., Diplaris, S., & Vrochidis, S. (2023). An Extended Reality System for Situation Awareness in Flood Management and Media Production Planning. Electronics, 12(12), 2569. https://doi.org/10.3390/electronics12122569