
Node Selection Algorithm for Federated Learning Based on Deep Reinforcement Learning for Edge Computing in IoT


 ,
,  , and
, and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- The node selection strategy in federated learning is not targeted enough, and there are few selection mechanisms specifically designed for IoT environments. Most selection mechanisms are based on random selection.
- There are many heterogeneous devices in IoT edge computing, with different computing power, bandwidth, and data, which leads to training imbalance and instability;
- There are some malicious devices in IoT edge computing that upload outdated or incorrect local models for various reasons, which negatively impact the convergence of the global model.
- This manuscript proposes using deep reinforcement learning methods instead of traditional heuristic methods to select terminal devices to improve the accuracy of selection;
- This manuscript proposes measuring the resource properties of IoT devices to determine their likelihood of participating in federated learning and improve the algorithm’s applicability in IoT environments;
- To address the issue of devices uploading outdated or incorrect local models, this manuscript proposes a node credibility measurement scheme to eliminate the impact of malicious nodes on federated learning in edge computing networks.
2. Related Works
2.1. Federated Learning
2.2. Federated Learning Based on Edge Computing
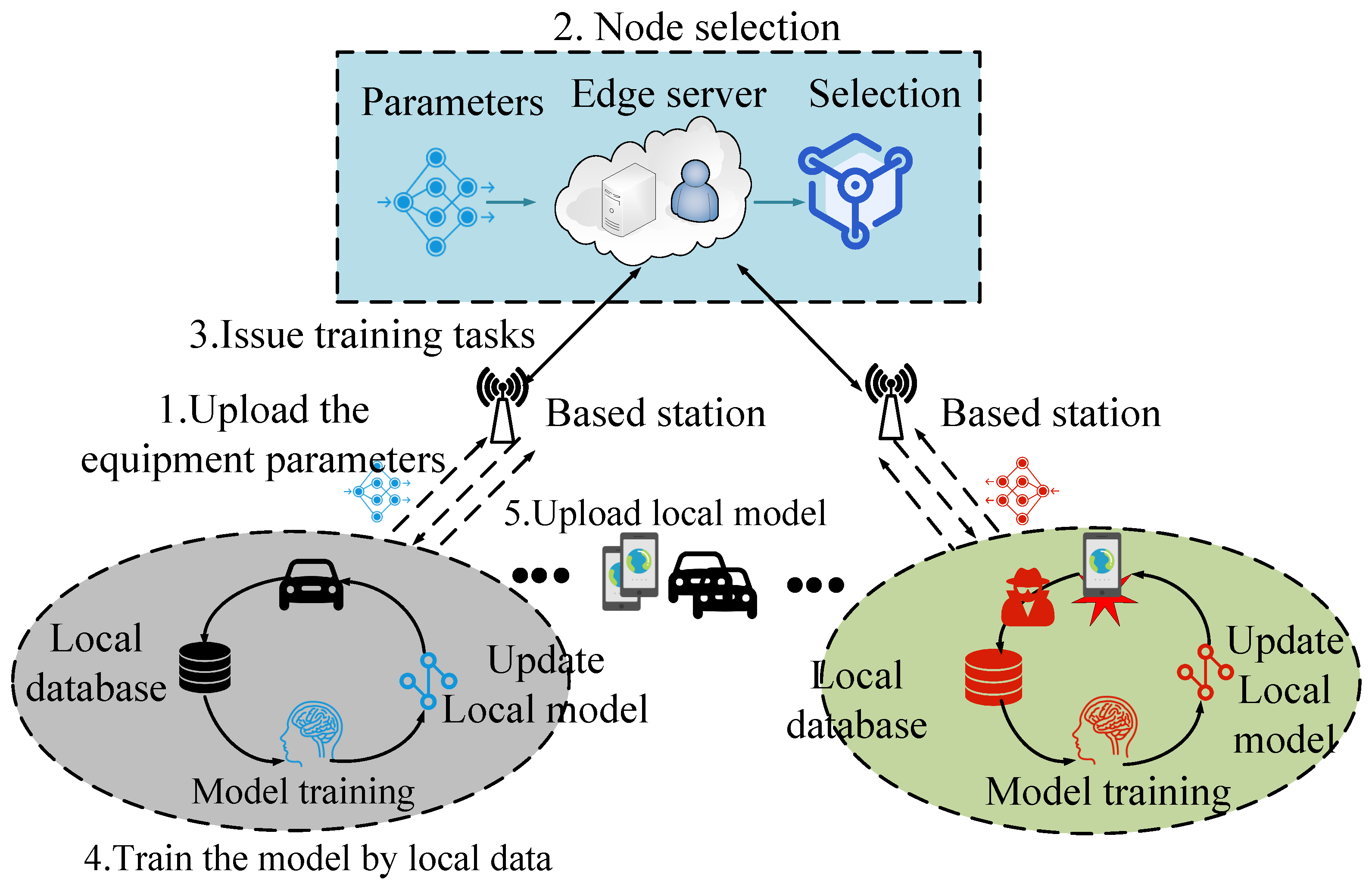
3. System Implementation
3.1. Feature Extraction
3.1.1. Computational Model
3.1.2. Communication Model
3.1.3. Data Quality Model
3.1.4. Equipment Contribution
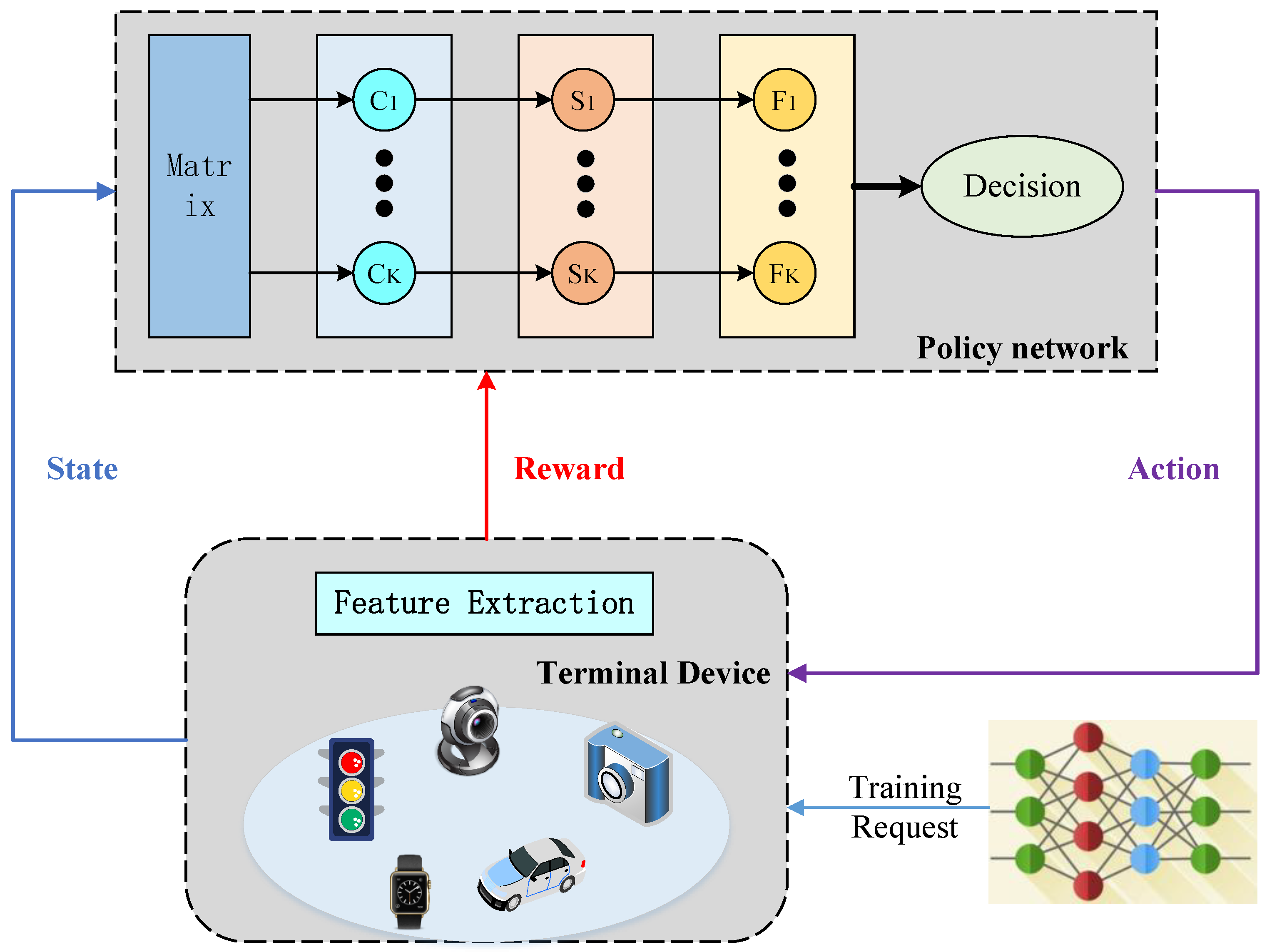
3.2. Policy Network
- Extraction layer: The extraction layer, also known as the input layer, is primarily responsible for converting the input raw data into a format that can be processed by the deep neural network, usually by standardizing, normalizing, and other processing methods. In this chapter, the extraction layer extracts the feature matrix from all terminal devices based on their current states, and uses it as the input to the policy network. The feature matrix is then transferred to the next layer of the policy network.
- Convolutional layer: The convolutional layer is a commonly used layer structure in deep learning. It uses convolutional kernels to perform convolution operations on input data in order to extract features. In this chapter, the convolutional layer performs convolution operations on the input vector according to the following equation:where denotes the output matrix, I denotes the input matrix, and K denotes the convolution kernel. denotes the element of the input matrix multiplied by the element of the convolution kernel matrix. The ReLU activation function is then used to connect the fully connected layers as follows:The generated vectors are passed to the probability layer in order to generate the probability of each node.
- Probability layer: The probability layer uses the softmax function to compute the feature vector and generate the probability of each terminal device. The softmax function can map the elements of a K-dimensional vector to a K-dimensional probability distribution, where each element represents a probability value in the corresponding distribution. Specifically, for a federated learning network consisting of n terminal devices, the probability layer outputs an n-dimensional probability distribution, where each element represents the probability of selecting a terminal device. In this chapter, the calculation of the probability of device i participating in federated learning can be represented by the following formula:among them, the denominator is the sum of the exponential functions of all elements, and the numerator is the exponential function of . In this way, the value of is the probability value corresponding to the dimension where is located, and the sum of all is equal to 1.
- Output layer: The output layer outputs IoT devices and their probability of participating in federated learning.
3.3. Model Training
4. Experiment
4.1. Experimental Environment
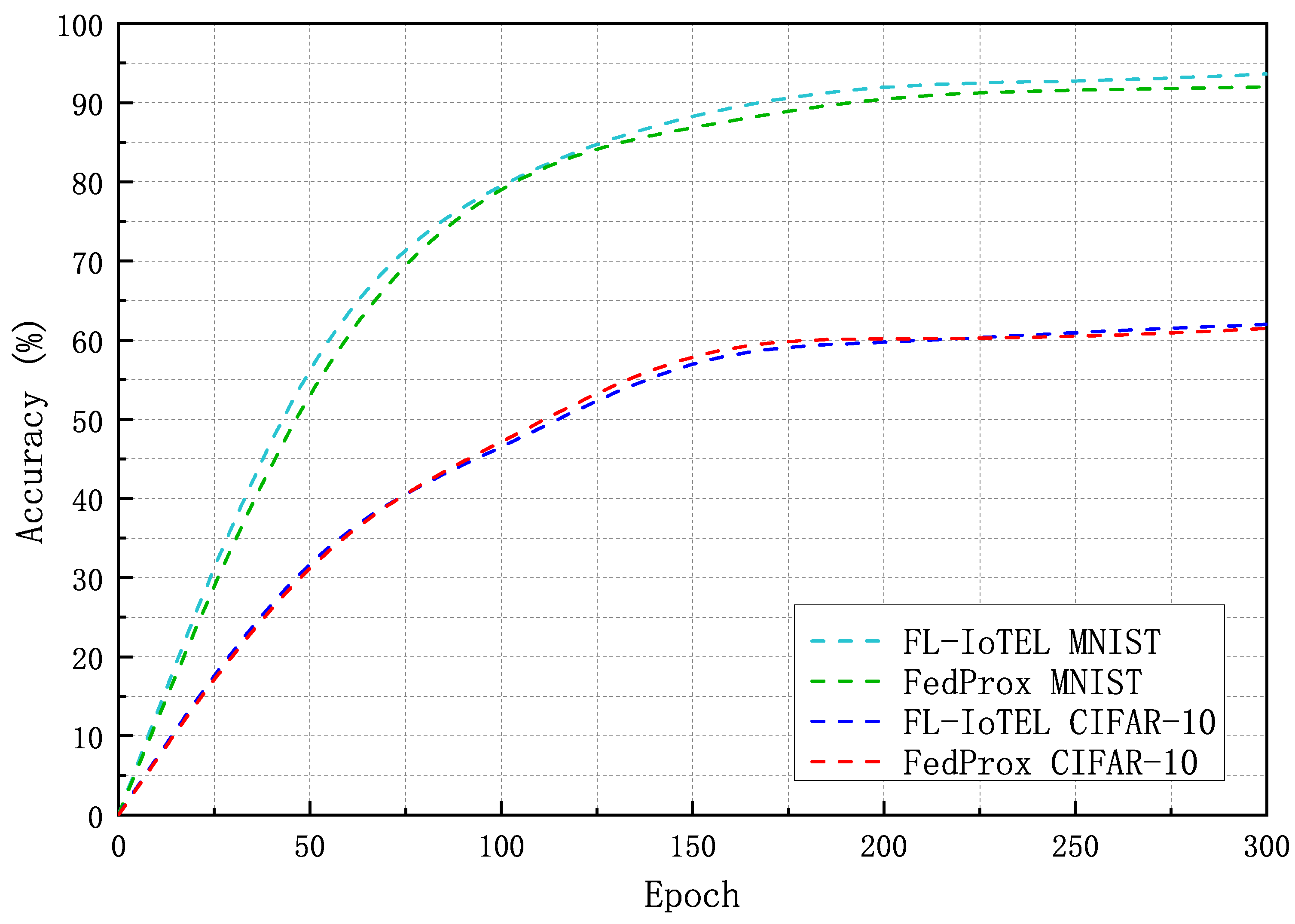
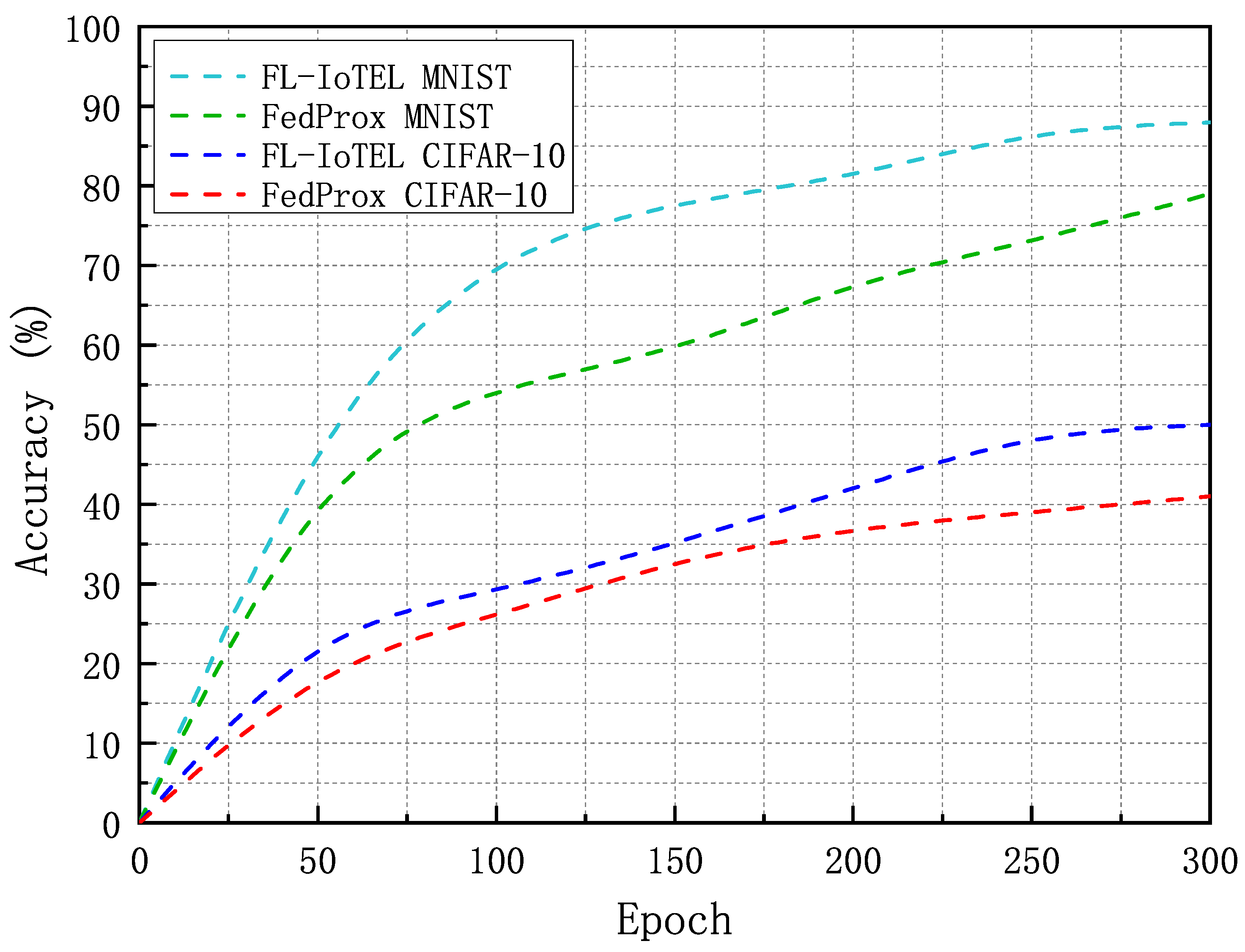
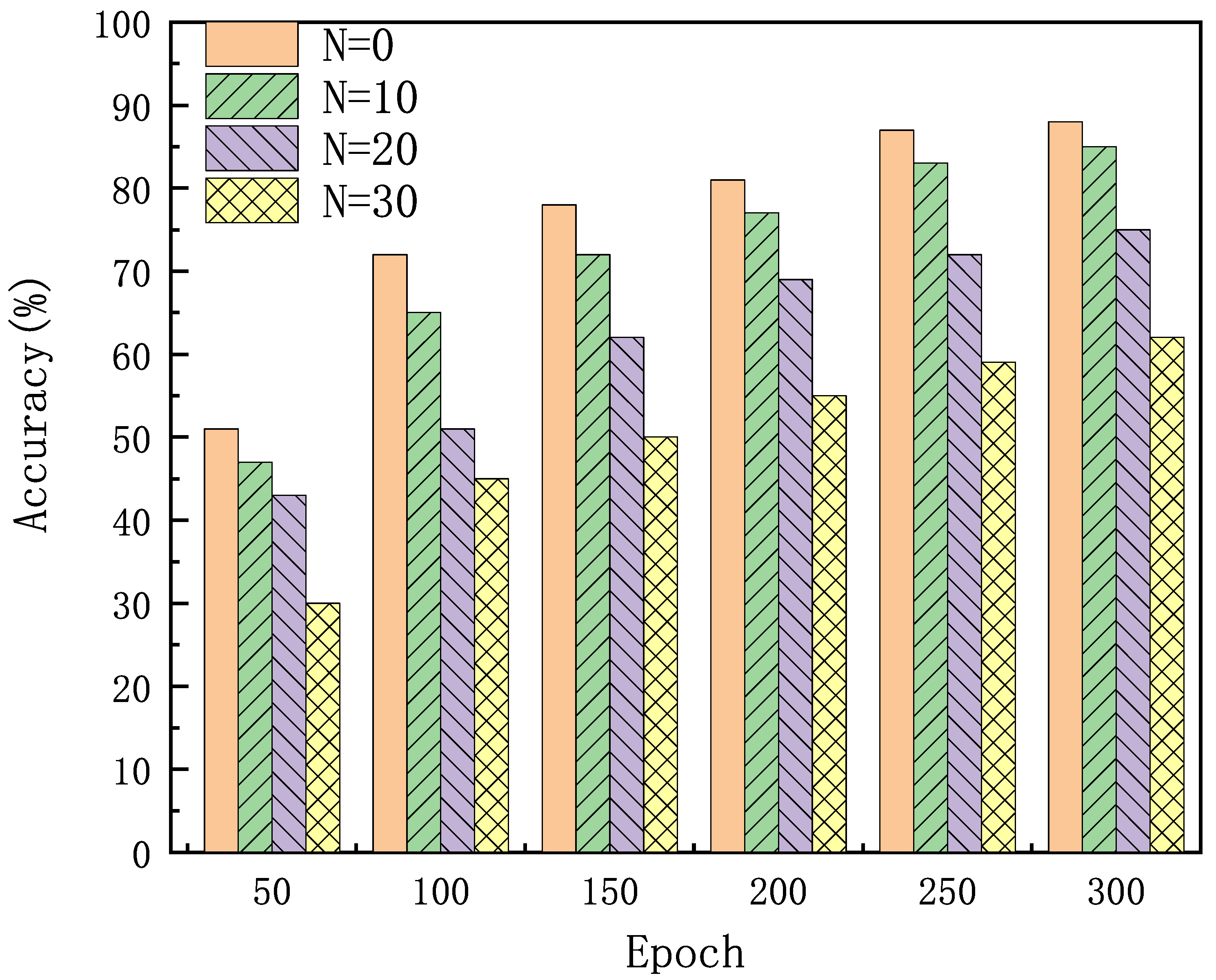
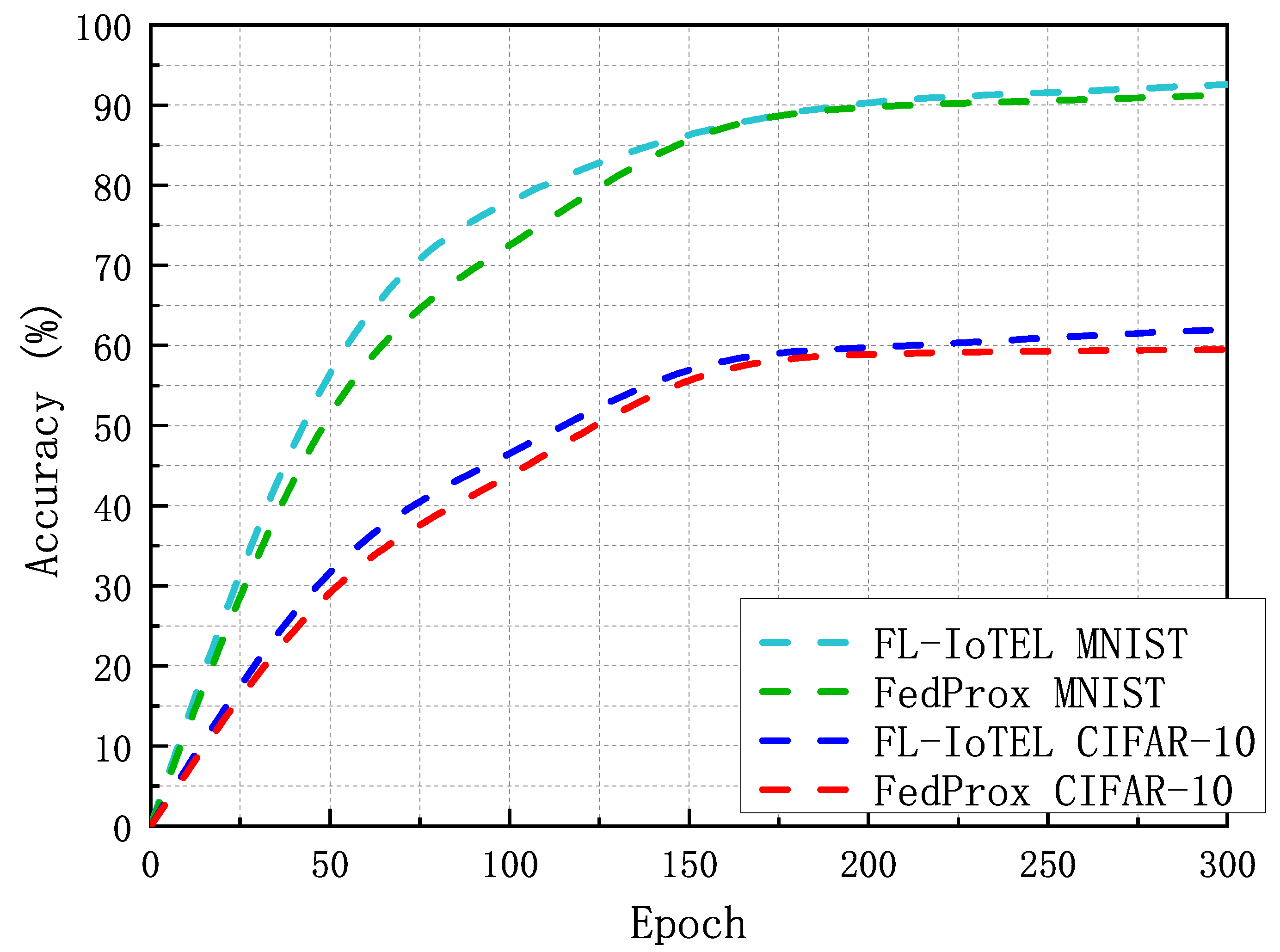
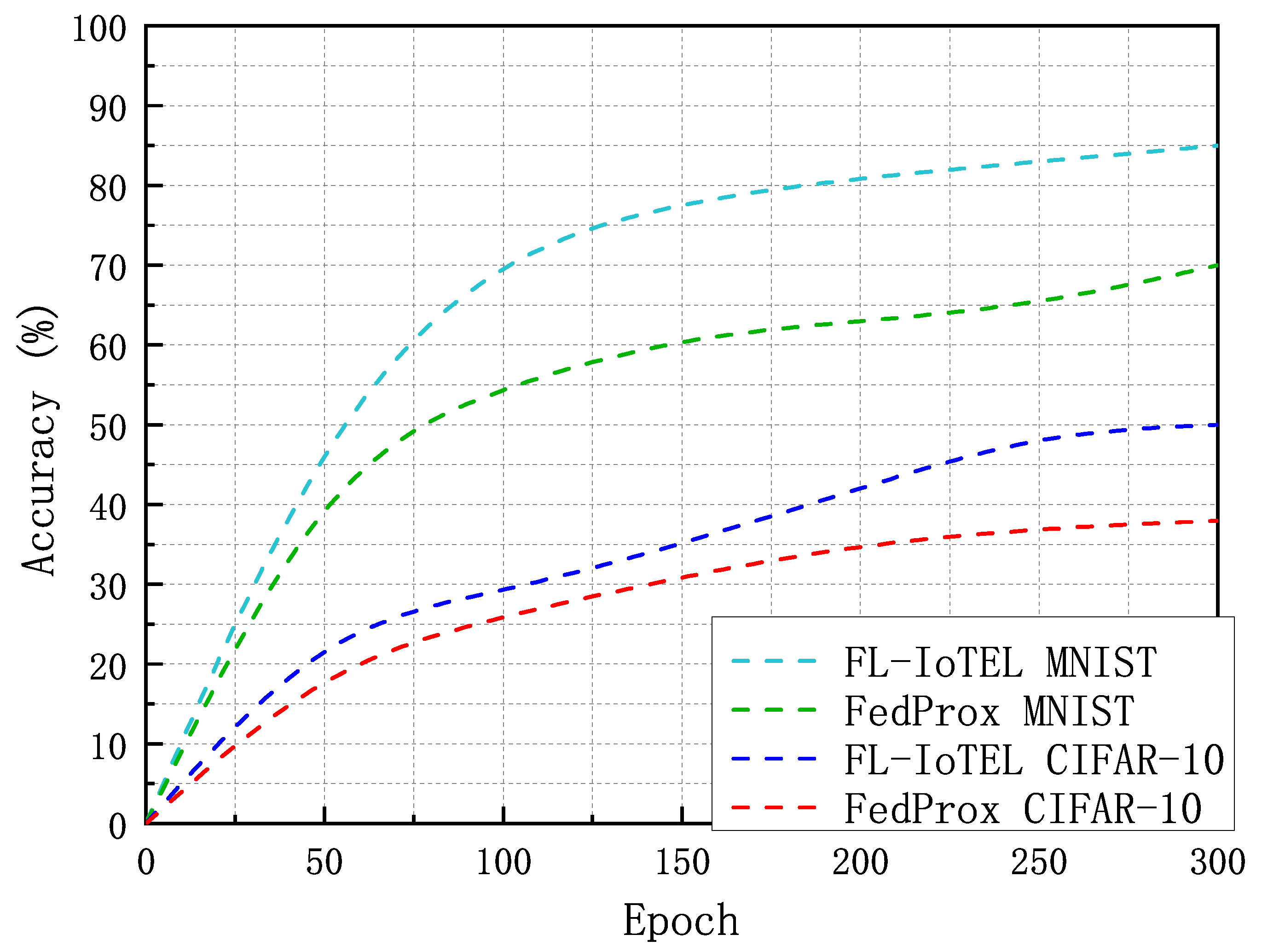
4.2. Simulation Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Deng, S.; Zhao, H.; Fang, W.; Yin, J.; Dustdar, S.; Zomaya, A.Y. Edge intelligence: The confluence of edge computing and artificial intelligence. IEEE Internet Things J. 2020, 7, 7457–7469. [Google Scholar] [CrossRef]
- Shafique, K.; Khawaja, B.A.; Sabir, F.; Qazi, S.; Mustaqim, M. Internet of things (IoT) for next-generation smart systems: A review of current challenges, future trends and prospects for emerging 5G-IoT scenarios. IEEE Access 2020, 8, 23022–23040. [Google Scholar] [CrossRef]
- Khan, L.U.; Saad, W.; Han, Z.; Hossain, E.; Hong, C.S. Federated learning for internet of things: Recent advances, taxonomy, and open challenges. IEEE Commun. Surv. Tutor. 2021, 23, 1759–1799. [Google Scholar] [CrossRef]
- Niknam, S.; Dhillon, H.S.; Reed, J.H. Federated learning for wireless communications: Motivation, opportunities, and challenges. IEEE Commun. Mag. 2020, 58, 46–51. [Google Scholar] [CrossRef]
- Wang, X.; Ning, Z.; Guo, L.; Guo, S.; Gao, X.; Wang, G. Mean-Field Learning for Edge Computing in Mobile Blockchain Networks. IEEE Trans. Mob. Comput. 2022, 1–17. [Google Scholar] [CrossRef]
- Zhu, Z.; Hong, J.; Zhou, J. Data-free knowledge distillation for heterogeneous federated learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 12878–12889. [Google Scholar] [CrossRef]
- Ning, Z.; Zhang, K.; Wang, X.; Guo, L.; Hu, X.; Huang, J.; Hu, B.; Kwok, R.Y.K. Intelligent Edge Computing in Internet of Vehicles: A Joint Computation Offloading and Caching Solution. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2212–2225. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, H.; Wang, J.; Pu, Y.; Pal, N.R. Feature Selection Using a Neural Network With Group Lasso Regularization and Controlled Redundancy. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 1110–1123. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, J.; Sun, Z.; Zurada, J.M.; Pal, N.R. Feature Selection for Neural Networks Using Group Lasso Regularization. IEEE Trans. Knowl. Data Eng. 2020, 32, 659–673. [Google Scholar] [CrossRef]
- Zhou, X.; Liang, W.; She, J.; Yan, Z.; Kevin, I.; Wang, K. Two-layer federated learning with heterogeneous model aggregation for 6g supported internet of vehicles. IEEE Trans. Veh. Technol. 2021, 70, 5308–5317. [Google Scholar] [CrossRef]
- Xue, G.; Chang, Q.; Wang, J.; Zhang, K.; Pal, N.R. An Adaptive Neuro-Fuzzy System With Integrated Feature Selection and Rule Extraction for High-Dimensional Classification Problems. IEEE Trans. Fuzzy Syst. 2022, 1–15. [Google Scholar] [CrossRef]
- Zhang, P.; Sun, H.; Situ, J.; Jiang, C.; Xie, D. Federated transfer learning for IIoT devices with low computing power based on blockchain and edge computing. IEEE Access 2021, 9, 98630–98638. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Ning, Z.; Zhang, K.; Wang, X.; Obaidat, M.S.; Guo, L.; Hu, X.; Hu, B.; Guo, Y.; Sadoun, B.; Kwok, R.Y.K. Joint Computing and Caching in 5G-Envisioned Internet of Vehicles: A Deep Reinforcement Learning-Based Traffic Control System. IEEE Trans. Intell. Transp. Syst. 2021, 22, 5201–5212. [Google Scholar] [CrossRef]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar] [CrossRef]
- Sattler, F.; Wiedemann, S.; Müller, K.R.; Samek, W. Robust and communication-efficient federated learning from non-iid data. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 3400–3413. [Google Scholar] [CrossRef] [PubMed]
- Mills, J.; Hu, J.; Min, G. User-Oriented Multi-Task Federated Deep Learning for Mobile Edge Computing. arXiv 2020, arXiv:2007.09236. [Google Scholar] [CrossRef]
- Guo, H.; Liu, A.; Lau, V.K. Analog gradient aggregation for federated learning over wireless networks: Customized design and convergence analysis. IEEE Internet Things J. 2020, 8, 197–210. [Google Scholar] [CrossRef]
- Wu, Y.; Wang, Z.; Zeng, D.; Shi, Y.; Hu, J. Enabling on-device self-supervised contrastive learning with selective data contrast. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 655–660. [Google Scholar] [CrossRef]
- Sonmez, C.; Ozgovde, A.; Ersoy, C. Edgecloudsim: An environment for performance evaluation of edge computing systems. Trans. Emerg. Telecommun. Technol. 2018, 29, e3493. [Google Scholar] [CrossRef]
- Hu, Y.C.; Patel, M.; Sabella, D.; Sprecher, N.; Young, V. Mobile edge computing—A key technology towards 5G. ETSI White Pap. 2015, 11, 1–16. [Google Scholar]
- Ning, Z.; Sun, S.; Wang, X.; Guo, L.; Guo, S.; Hu, X.; Hu, B.; Kwok, R.Y.K. Blockchain-Enabled Intelligent Transportation Systems: A Distributed Crowdsensing Framework. IEEE Trans. Mob. Comput. 2022, 21, 4201–4217. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A survey on mobile edge computing: The communication perspective. IEEE Commun. Surv. Tutor. 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Shi, W.; Zhou, S.; Niu, Z.; Jiang, M.; Geng, L. Joint device scheduling and resource allocation for latency constrained wireless federated learning. IEEE Trans. Wirel. Commun. 2020, 20, 453–467. [Google Scholar] [CrossRef]
- Liu, Y.; Yuan, X.; Xiong, Z.; Kang, J.; Wang, X.; Niyato, D. Federated learning for 6G communications: Challenges, methods, and future directions. China Commun. 2020, 17, 105–118. [Google Scholar] [CrossRef]
- Zhang, P.; Zhang, Y.; Kumar, N.; Guizani, M. Dynamic SFC Embedding Algorithm Assisted by Federated Learning in Space–Air–Ground-Integrated Network Resource Allocation Scenario. IEEE Internet Things J. 2023, 10, 9308–9318. [Google Scholar] [CrossRef]
- Luo, S.; Chen, X.; Wu, Q.; Zhou, Z.; Yu, S. HFEL: Joint edge association and resource allocation for cost-efficient hierarchical federated edge learning. IEEE Trans. Wirel. Commun. 2020, 19, 6535–6548. [Google Scholar] [CrossRef]
- Hosseinalipour, S.; Brinton, C.G.; Aggarwal, V.; Dai, H.; Chiang, M. From federated to fog learning: Distributed machine learning over heterogeneous wireless networks. IEEE Commun. Mag. 2020, 58, 41–47. [Google Scholar] [CrossRef]
- Xue, Z.; Zhou, P.; Xu, Z.; Wang, X.; Xie, Y.; Ding, X.; Wen, S. A resource-constrained and privacy-preserving edge-computing-enabled clinical decision system: A federated reinforcement learning approach. IEEE Internet Things J. 2021, 8, 9122–9138. [Google Scholar] [CrossRef]
- Bowo, W.A.; Suhanto, A.; Naisuty, M.; Ma’mun, S.; Hidayanto, A.N.; Habsari, I.C. Data Quality Assessment: A Case Study of PT JAS Using TDQM Framework. In Proceedings of the 2019 Fourth International Conference on Informatics and Computing (ICIC), Semarang, Indonesia, 16–17 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-real transfer in deep reinforcement learning for robotics: A survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 737–744. [Google Scholar] [CrossRef]
- Ibarz, J.; Tan, J.; Finn, C.; Kalakrishnan, M.; Pastor, P.; Levine, S. How to train your robot with deep reinforcement learning: Lessons we have learned. Int. J. Robot. Res. 2021, 40, 698–721. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Rudin, N.; Hoeller, D.; Reist, P.; Hutter, M. Learning to walk in minutes using massively parallel deep reinforcement learning. In Proceedings of the Conference on Robot Learning, PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 91–100. [Google Scholar] [CrossRef]
- Vithayathil Varghese, N.; Mahmoud, Q.H. A survey of multi-task deep reinforcement learning. Electronics 2020, 9, 1363. [Google Scholar] [CrossRef]
- Thakkar, V.; Tewary, S.; Chakraborty, C. Batch Normalization in Convolutional Neural Networks—A comparative study with CIFAR-10 data. In Proceedings of the 2018 Fifth International Conference on Emerging Applications of Information Technology (EAIT), Kolkata, India, 12–13 January 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, S.; Zhang, P.; Huang, S.; Wang, J.; Sun, H.; Zhang, Y.; Tolba, A. Node Selection Algorithm for Federated Learning Based on Deep Reinforcement Learning for Edge Computing in IoT. Electronics 2023, 12, 2478. https://doi.org/10.3390/electronics12112478
Yan S, Zhang P, Huang S, Wang J, Sun H, Zhang Y, Tolba A. Node Selection Algorithm for Federated Learning Based on Deep Reinforcement Learning for Edge Computing in IoT. Electronics. 2023; 12(11):2478. https://doi.org/10.3390/electronics12112478
Chicago/Turabian StyleYan, Shuai, Peiying Zhang, Siyu Huang, Jian Wang, Hao Sun, Yi Zhang, and Amr Tolba. 2023. "Node Selection Algorithm for Federated Learning Based on Deep Reinforcement Learning for Edge Computing in IoT" Electronics 12, no. 11: 2478. https://doi.org/10.3390/electronics12112478
APA StyleYan, S., Zhang, P., Huang, S., Wang, J., Sun, H., Zhang, Y., & Tolba, A. (2023). Node Selection Algorithm for Federated Learning Based on Deep Reinforcement Learning for Edge Computing in IoT. Electronics, 12(11), 2478. https://doi.org/10.3390/electronics12112478