1. Introduction
As UAV technology improves by leaps and bounds, UAV aerial photography has become widely used in various fields, including natural disaster detection, traffic safety monitoring, search and rescue, and agricultural and forestry management. This technology has significantly reduced labor costs and improved monitoring efficiency, leading to better management and service. However, compared to the application scenarios of traditional target detection algorithms, images captured by UAVs present several challenges, including a wide range of target scales, diverse angle changes, and complex backgrounds [
1]. These factors significantly impact the accuracy rate and recall rate of target detection results.
At present, object detection algorithms can be divided into two categories: two-stage detection algorithms and one-stage detection algorithms. The two-stage detection algorithm, including convolutional neural networks [
2,
3], CNN [
4] and R-CNN [
5], generates candidate boxes that contain potential targets and then uses a region classifier to predict them. The one-stage detection algorithm, such as SSD [
6] and the YOLO [
7,
8,
9,
10,
11,
12,
13] series, directly classifies and predicts the target at each position on the feature map, resulting in a faster detection speed and increased practicality. Academically, the definition of small goals can be divided into two categories: relative scale-based, and absolute scale-based. The former defines the small target by its proportion to the whole image. Chen et al. [
14] defined small targets as follows: when the ratio of the boundary box area to the image area falls between 0.08% and 0.58%, it can be considered a small target. The latter defines small targets from the perspective of the absolute pixel size of targets, defining small targets as those with a resolution of fewer than 32 pixels on each side.
Based on the above definition, most targets in UAV aerial photography images can be defined as small targets. However, small target detection is a hugely challenging task. Lim et al. [
15] proposed FA-SSD, which aims to improve the detection of small targets by fusing feature information from F-SSD and A-SSD network structures. However, the two-stage detection algorithm used in FA-SSD results in a slow detection speed. Liu et al. [
16] improved the algorithm accuracy and generalization ability by introducing a shallow feature extraction network in the P1 layer and fusing shallow features in the FPN and PAN layer. Yang et al. [
17] aimed to improve the detection of small targets by adding the scSE attention mechanism module and a small target detection layer to enhance feature information. However, there were still issues with missing and the false detections of small targets. A novel object detection network called DCLANet was proposed by Zhang et al. [
18], which utilizes intensive clipping and local attention techniques to enhance the feature representation of small targets. They further incorporated the bottleneck attention mechanism (BAM) into the network, leading to a substantial improvement in the detection accuracy. Jin et al. [
19] proposed a scale sensing network that accurately determines the scale of predefined anchor points. This network could effectively narrow the scale search range, reduce the risk of overfitting, and improve the detection speed and accuracy of aerial images. Liu et al. [
20] constructed the SPPCSPG module and introduced the shuffle attention (SA) mechanism into YOLOv5s to achieve a new lightweight network, which greatly improved the detection efficacy. The algorithm models mentioned above have significantly improved the performance of small target detection. However, there is still a lot of space for improvement in terms of detection efficacy.
In this paper, the YOLOv5s target detection algorithm is improved and tested on the public dataset VisDrone-2019 [
21], which indicates that the proposed algorithm improves the detection efficacy. Compared with YOLOv5s, the model has been improved as follows:
The rest of the article is structured as follows: In
Section 2, we describe the related work. In
Section 3, the improved method is introduced elaborately. In
Section 4, the relevant experiments are conducted, and the corresponding results are presented to demonstrate the superior performance of the new model. In
Section 5, the paper is summarized.
2. Related Work
YOLO (You Only Look Once) is a typical one-stage detection algorithm, meaning that the network only needs to look at the picture once to output the results. Joseph Redmon et al. proposed YOLOv1 [
7] in 2015, which uses a convolutional neural network (CNN) to take the entire image as the input and output the boundary box and category of the target in a forward transmission. Compared with the two-stage detection algorithm, this algorithm has significant advantages in detection speed, but the detection accuracy and generalization ability are relatively poor. In 2017, YOLOv2 [
8] was proposed. Compared with YOLOv1, YOLOv2 used anchor boxes to predict target location and size, adopted a convolution layer instead of a full connection layer, etc. These improvements greatly improved YOLOv2 in accuracy and speed. Then, YOLOv3 [
9], YOLOv4 [
10], YOLOv5 [
11], YOLOv7 [
13], YOLOv8, and other models were proposed successively.
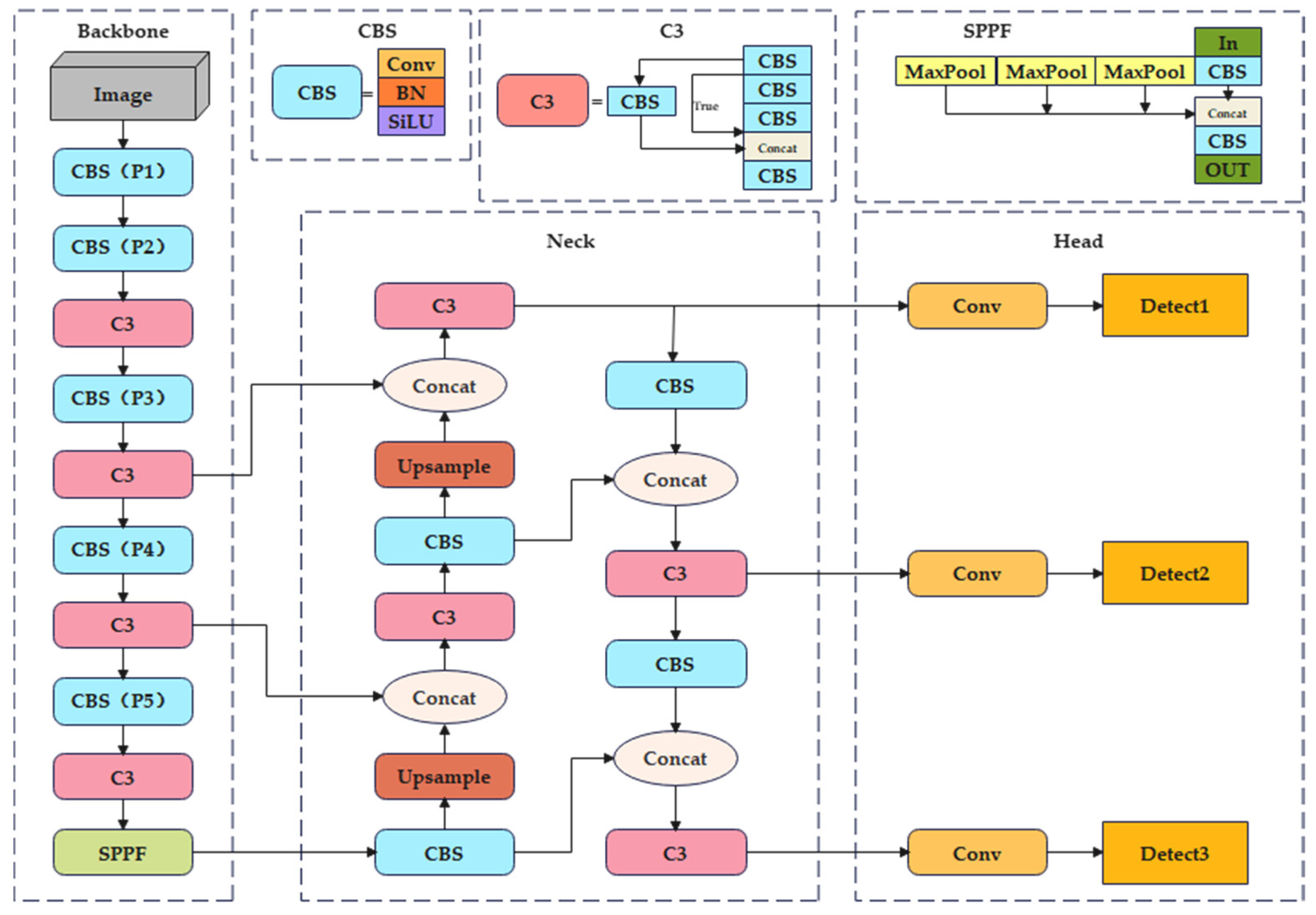
YOLOv5 is a one-stage target detection algorithm. This model has high computational efficiency and a simple structure. YOLOv5 uses a deep convolutional neural network (CNN) to detect objects. Its implementation method mainly involves dividing the entire image into a series of grids and predicting the presence of objects in each grid, as well as their location, size, category, and other information. The structure of the YOLOv5 model includes the following parts:
Backbone: The backbone of YOLOv5 consists of CBS, C3, and SPPF. It converts the original input images into multi-layer feature maps and extracts features for subsequent target detection. As a basic module commonly used in convolutional neural networks, the CBS module functions in the feature extraction of input images and is composed of Conv [
26], BatchNorm [
27], and SiLU [
28]. Conv is the most basic layer in convolutional neural networks, mainly used to extract local spatial information in input features. The BatchNorm layers are appended after the convolutional layers, which help to normalize the distribution of eigenvalues in the network. The SiLU activation function is a nonlinear function that introduces a nonlinear transformation capability to the neural network. The C3 module can significantly enhance the computational efficiency of the network and enhance the speed and efficiency of target detection while maintaining high accuracy. The SPP module is a spatial pyramid pool layer that can process input images with different resolutions and realize adaptive size output, which can increase the receptive field and extract the overall feature of the detection target. The latest version of YOLOv5 uses SPPF instead of SPP, reducing the amount of computation by half with the same effect.
Neck: YOLOv5 adopts a combination of Feature Pyramid Networks (FPN) [
29] and Path Aggregation Network PANet [
22] in the neck. Compared with FPN, PANet uses a combination of bottom-up network and top-down network structures to fuse feature maps of different scales. The feature maps of different scales complement each other to enhance the detection efficacy.
Head: The head of YOLOv5 uses three detection heads to detect target objects and predict the category and location of the target. It can detect the feature maps of , , and at different scales, respectively.
According to the different depth and width of the network, YOLOv5 has five versions: YOLOv5n, YOLOv5s, YOLOv5m, YOLOv5l, and YOLOv5x. This paper focuses on improving YOLOv5s to effectively enhance the detection of small and medium targets in aerial images. The structure of YOLOv5s is shown in
Figure 1.
The attention mechanism is a popular technology used in deep learning models. Its function is to focus on the most important information for the current task and filter out irrelevant information. This can improve the model’s performance. Currently, many attention modules have been introduced into the field of target detection, among which SENet [
30], CBAM [
31], and CA [
32] are relatively classical. The SE-Net network introduces squeeze and excitation blocks to learn the relationship between feature map channels, which improves the model’s performance. The CBAM network introduces channel attention mechanisms and spatial attention mechanisms to weight feature maps and extract more effective information. The coordinate attention CA introduces spatial position information and constantly adjusts the channel and weight of each position in the feature map to obtain more important feature information.
3. Methods
3.1. Add a Small Target Detection Layer
Although YOLOv5 demonstrates exceptional performance across various application scenarios, it suffers from inadequate detection outcomes when dealing with small targets in aerial images. The underlying reason lies in the convolution-based feature extraction mechanism employed by YOLOv5. With the increasing depth of the network, it continuously reduces the size of objects due to the pooling layer and convolution kernel operations. Consequently, this phenomenon can cause missed or false detections.
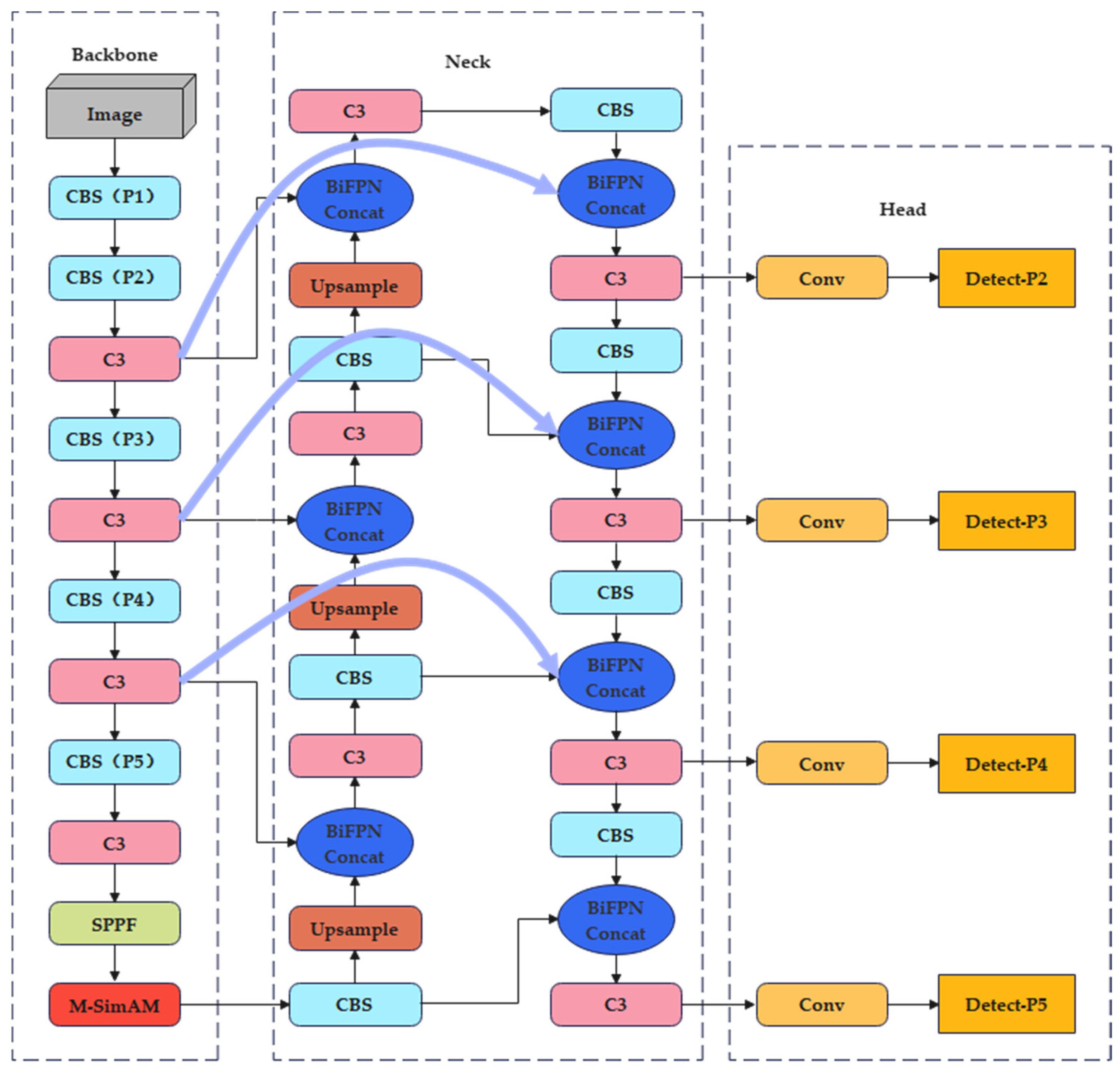
In comparison to the YOLOv5s model, we added a new Detect-P2 small target detection layer to enhance the detection performance in aerial images. Due to the loss of shallow, small target information caused by multiple convolution and pooling operations on the deep feature map, the new layer fuses shallow and deep features to process small targets. Specifically, the shallow feature contains low-level semantic features, and the deep feature contains high-level semantic features. Additionally, the new detection layer detects the shallow feature layer, which can effectively detect the feature information of small targets and improve the detection efficacy of small targets in aerial images. Our model includes four detection heads that detect feature maps of different scales, denoted as , , , and , respectively.
The network structure after adding the new Detect-P2 detection layer is shown in
Figure 2.
3.2. Mul-BiFPN Network Structure
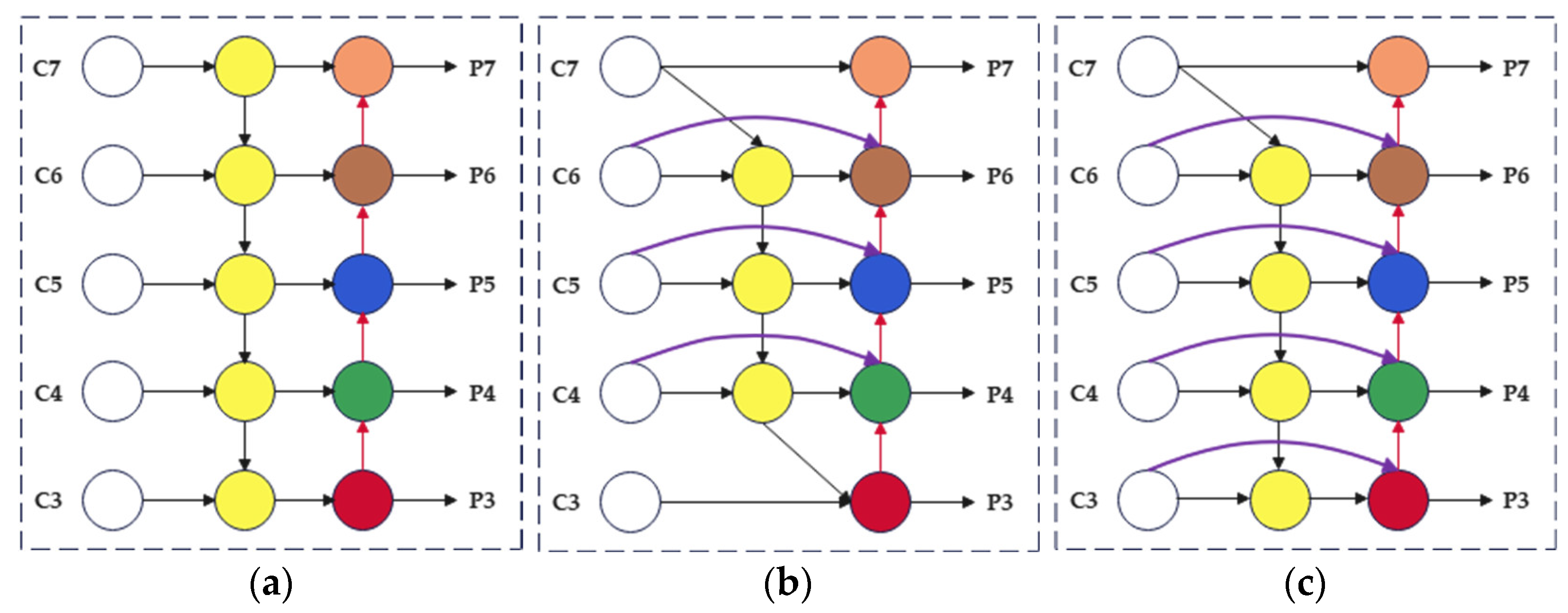
The YOLOv5s model utilizes the PANet as a neck for feature fusion, which is a pyramid-like structure that fuses feature map information from the bottom to the top. Although this network can somewhat address the problem of large mesoscale differences in detection images, it suffers from unidirectional information flow and poor scalability. To address these limitations, we introduce the Weighted Bidirectional Feature Pyramid Network (BiFPN) [
33] in this paper. BiFPN incorporates a bidirectional connection mechanism to enhance the feature transfer capability and enable better handling of targets of different scales. Additionally, it uses a weighted feature fusion mechanism to balance information transfer between feature maps of different scales, which enhances the detection performance of both small and large targets.
The BiFPN network exhibits excellent performance in various complex scenarios. However, it sometimes misses extracting characteristic information from small targets. This is due to its main focus on extracting features from deeper layers, while being relatively weaker in extracting shallow-level feature information. To solve this problem, this paper proposes an enhanced weighted bidirectional feature pyramid network called Mul-BiFPN, which is based on the BiFPN network.
Due to the presence of more shallow feature information in the C3 layer, the Mul-BiFPN network performs additional weighted feature fusion operations in this layer to strengthen the fusion of small target features. As a result, the feature layer detected by the P3 detection head contains richer, shallow, small target feature information, which can enhance the detection efficacy of small targets during the prediction process. The Mul-BiFPN network carries out multiple information exchanges and fusions between feature maps at different levels. Through multi-layer feature fusion, the network enhances features between different layers, thereby improving the receptive field and semantic expression ability of the target detection model. This leads to a significant improvement in the robustness and accuracy of target detection.
The improvement in the neck network is shown in
Figure 3.
3.3. Focal EIoU Loss
YOLOv5s uses the CIoU loss function, which employs a scientific and precise method to calculate the distance between target boxes. This enables accurate calculation of the actual distance between target boxes and improves training accuracy. However, the CIoU loss function places more weight on large targets, making it more sensitive to large targets and slightly insufficient for detecting small targets. To address this problem, this paper introduces a more efficient loss function called Focal EIoU [
23], which replaces the CIoU loss function to improve small target detection performance. The EIOU loss function considers the aspect ratio of the target box’s length and width when calculating the distance, enabling better handling of target boxes of different sizes and a more balanced weighting of different target sizes in the loss function. Additionally, EIOU uses a more efficient calculation method for the distance between target boxes, making the network model more efficient in training for small targets. Focal loss gives more weight to rare categories of targets, making it more sensitive to small target detection. Furthermore, by introducing a balance factor, it can alleviate category imbalance problems to some extent. Based on EIOU, Focal EIoU combines Focal loss to focus on better anchor boxes, thereby significantly improving the accuracy of detecting small targets. The Focal EIoU formula is shown below.
In Formula (1), stands for IOU loss, stands for distance loss; stands for side length loss; stands for Euclidean Distance between (center coordinates of the prediction box) and (center coordinates of the real box); stands for the square of the difference between (width of the prediction box) and (width of the real box); stands for the square of the difference between (height of the prediction box) and (height of the real box); and , respectively, represent the width and height of the minimum enclosing rectangle of the predicted box and the target box; and represents the diagonal length of the minimum enclosing rectangle. In Formula (2), is a hyperparameter used to control the curve.
3.4. M-SimAM Attention Mechanism
Aiming at the problem that most existing attention mechanisms can only focus on features in one dimension of channel or space, lacking flexibility in the simultaneous processing of space and channel. This paper introduces the non-parametric attention mechanism module called SimAM [
25], and proposes the M-SimAM module based on it. This module can help the network to extract the feature and enhance the detection performance of small targets without increasing other parameters.
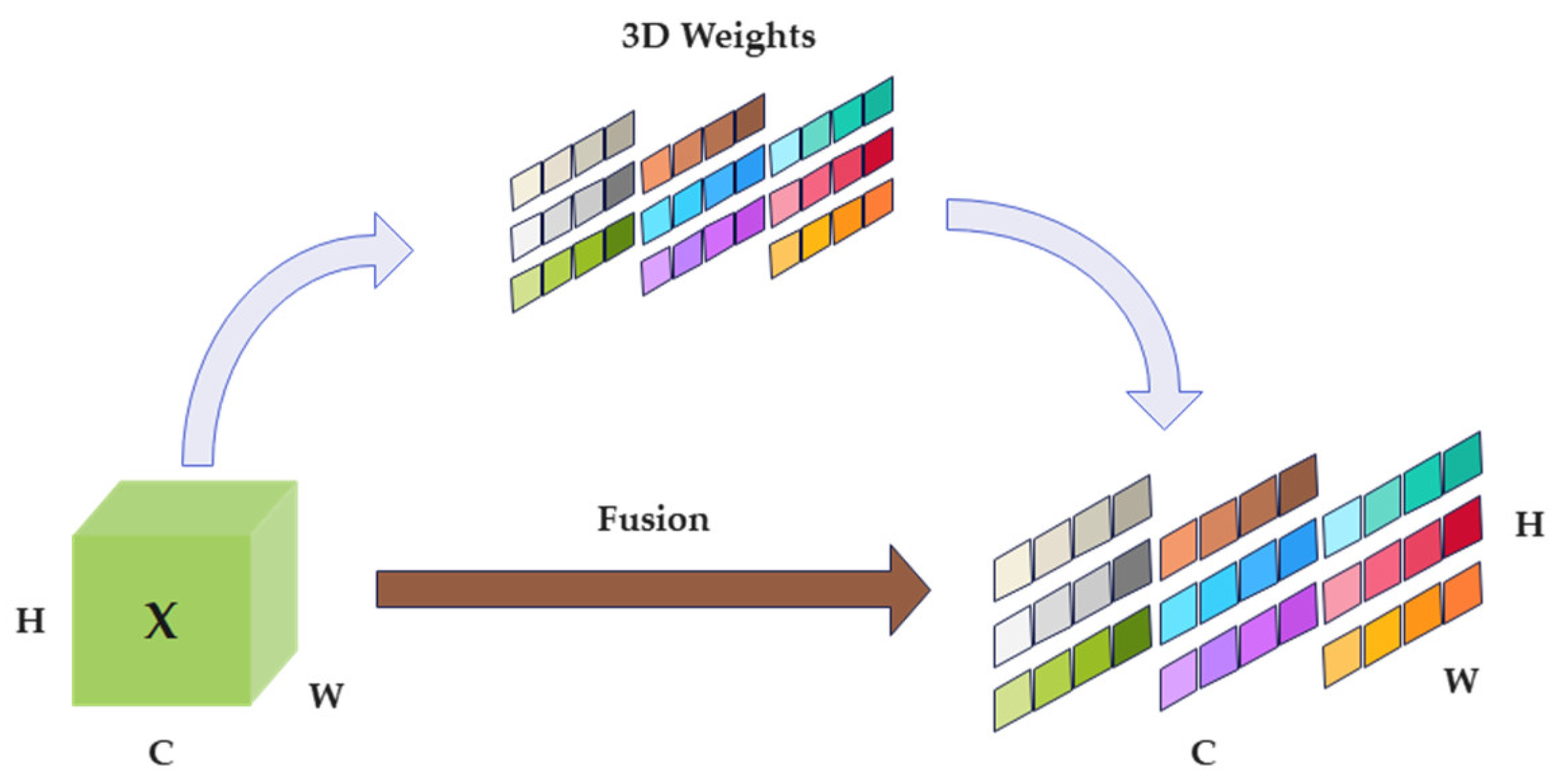
SimAM is a 3D attention module whose core idea is to focus attention on the most relevant parts using a similarity-based weighting method. SimAM calculates the attention weight by designing an energy function. Most of its operations are energy function-based solutions that can flexibly and effectively enhance the extraction of features in neural networks. The structure of the SimAM module is shown in
Figure 4.
In neuroscience, neurons that carry more information exhibit different firing patterns than other peripheral neurons and inhibit adjacent neurons. The simplest way to identify important neurons is to measure the linear separability between them. The energy function is defined as follows:
In the above formula,
is the target neuron in the single channel of the input feature,
is other neurons,
and
are the linear change in
and
, respectively,
and
are linear changes in weight and deviation, respectively,
is the variable, and
is the number of neurons on the channel. By minimizing Formula (3), it can be seen as training the linear separability between the target neuron
and other neurons in the identical channel. Finally, the formula is streamlined by utilizing binary labels and incorporating regular terms, as shown below:
In Formula (6),
is the coefficient. The solution of the energy formula is as follows:
In Formula (7),
and
are the variance and mean of all neurons except
. Therefore, the minimum energy can be calculated by the following formula:
From Formula (8), it is evident that lower energy corresponds to a greater disparity between the neuron and its neighboring neuron, indicating the significance of the target neuron. Therefore,
represents the weight of neurons, and the formula for incorporating the SimAM module into the feature map can be calculated using the following formula:
In Formula (9), represents the aggregation of across channel and spatial dimensions. represents the raw feature values input into the SimAM module. represents the feature output values after being enhanced by the SimAM module. The activation function is used to constrain excessively large values.
In this paper, we introduce the
activation function to replace the
activation function in the SimAM. The new module is named M-SimAM. Due to its smoothness and better gradient performance, the
activation function can enhance the model’s ability to detect small targets and avoid problems such as disappearing gradients or exploding gradients, thus improving the model’s accuracy and stability. Moreover, the
activation function can enhance the model’s generalization ability, making it perform better in more challenging scenarios. The formula for the feature map incorporating the M-SimAM attention mechanism is shown below:
In Formula (10), the activation function is introduced to replace the activation function. represents the raw feature values that are input into the M-SimAM module. represents the feature output values after being enhanced by the M-SimAM module.
Based on the aforementioned improvements, the network structure of the algorithm proposed in this paper is illustrated in
Figure 5.
4. Experiments
4.1. Dataset
The experiment in this paper utilized the VisDrone-2019 dataset, which was publicly released by the AISKYEYE team at Tianjin University. The dataset was collected by various types of drones in diverse weather, scenarios, and lighting conditions, encompassing 288 video clips, 261,908 frames, and 10,209 still images. The images are annotated with ten categories of labels, including awning-tricycle, bicycle, bus, motor, people, pedestrian, car, truck, tricycle, and van. The category distribution of examples in this dataset is shown in
Figure 6.
The VisDrone-2019 dataset contains 6471, 548, and 1610 images for training, validation, and testing, respectively.
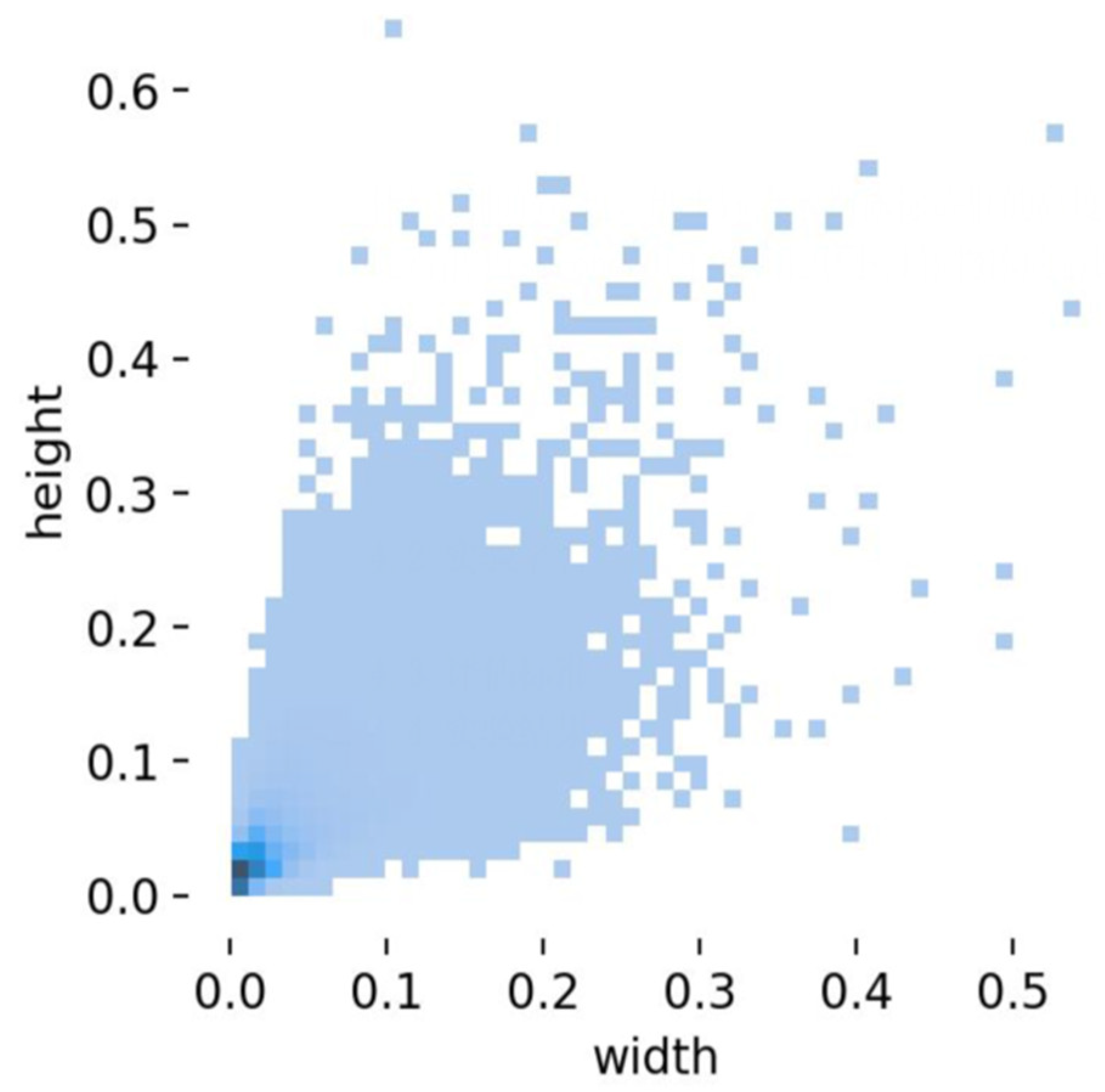
Figure 7 depicts the distribution of all category label sizes in the training dataset. The horizontal axis of the figure stands for the width of the object label frame, while the vertical axis stands for the height of the object label frame. Most of the data points are situated in the lower-left corner of the figure, indicating that the VisDrone-2019 dataset has a greater proportion of small target objects. This observation aligns with the problem explored in this paper.
4.2. Experimental Platform
The experiment employed an Ubuntu 18.04 system and utilized Python 3.9.16, Pytorch 2.0.0, and CUDA 11.8. The experimental model training platform consisted of RTX 3090 GPUs, and training, validation, and testing were conducted using identical hyperparameters. Specifically, the training epoch was set to 300, the batch size was set to 16, and the image resolution was . The pre-training model employed was YOLOv5s.pt, which was provided by the official source.
4.3. Evaluation Criteria
The experimental results were assessed using the cross-validation method. Following training and validation with the respective datasets, a final performance evaluation of the model was performed using the test dataset. In the experiment, the network’s performance was evaluated based on three performance metrics: the accuracy rate (), recall rate (), and mean average precision ().
The accuracy rate (
) stands for the percentage of targets that are correctly predicted in all detected targets. The accuracy rate can be calculated by the following formula:
stands for the correct prediction of the model and
stands for the wrong prediction of the model.
The recall rate (
) stands for the proportion of targets that are correctly predicted in all targets. The recall rate can be calculated by the following formula:
stands for the targets that need to be predicted but are incorrectly detected by the model.
The average accuracy (
) stands for the area enclosed by the axis of the curve formed by the precision rate and recall rate, and the average accuracy (
) is the mean of the average accuracy of all samples, which can be calculated by the following formula:
4.4. Experimental Results
In the experiment, the performance of the new model was evaluated on the VisDrone-2019 dataset. Comparing the experimental results of the new model and the YOLOv5s model, it can be concluded that the proposed algorithm achieves better performance in detecting small targets than YOLOv5s.
Table 1 and
Table 2 present a comparative performance evaluation of YOLOv5s and the proposed algorithm on the VisDrone-2019 validation and test dataset. The results show that the proposed algorithm outperforms the YOLOv5s model. In the validation dataset, the proposed algorithm achieves a 5.60% increase in P and a 5.90% increase in R, as well as a 6.60% increase in mAP@0.5 and a 4.60% increase in mAP@0.5:0.95, compared to the original model. In the test dataset, the proposed algorithm achieves a 5.60% increase in P and a 6.10% increase in R, as well as a 7.30% increase in mAP@0.5 and a 4.60% increase in mAP@0.5:0.95. The considerable improvement in performance of the new model on the VisDrone-2019 dataset suggests its effectiveness in small target detection.
Figure 8 illustrates the comparison of detection effects between the YOLOv5s model and the proposed model on the VisDrone-2019 test dataset. We can directly observe from the figure that, compared to
Figure 8a, more small targets have been successfully detected in
Figure 8b. The experimental results explain how the algorithm in this paper enhances the detection ability of small target objects, significantly solving the problem of small targets being easily missed and incorrectly detected in the existing object detection literature. At the same time, the detection confidence of almost all objects is improved, and the accuracy of detection is significantly enhanced.
4.5. Ablation Experiment
To further verify the effectiveness of the proposed algorithm, an ablation experiment was conducted on the VisDrone-2019 dataset. Using YOLOv5s as the baseline model, multiple improved methods mentioned in this paper were added one-by-one or in combination to verify the improvement in the target detection performance of each method.
Table 3 shows the results of the ablation experiment conducted on the VisDrone-2019 validation dataset. The experiment involved adding various improvements to the basic YOLOv5s model, including a P2 layer small target detection head (shown in table +P2), BiFPN (shown in table +BF), Mul-BiFPN network structures (shown in table +MBF), Focal EIoU (shown in table +FE), M-SimAM attention module (shown in table +MSimA), and combinations of these improvements. The results in
Table 3 show that each improvement significantly enhances P, R, mAP@0.5, and mAP@0.5:0.95 on the VisDrone-2019 validation dataset compared to the YOLOv5s model. For instance, the final model proposed in this paper achieved a 5.60% increase in P and a 5.90% increase in R, along with a 6.60% increase in mAP@0.5 and a 4.60% increase in mAP@0.5:0.95, compared to the original model on this validation dataset.
Table 4 shows the ablative experiment results of the VisDrone-2019 test dataset, which is utilized to reflect the detection effect of the new model in unknown and complex scenarios. Through our analysis, we discovered that adding the Detect-P2 detection layer can significantly enhance the detection performance of smaller targets, resulting in an increase of 3.40% in P, 4.00% in R, and 5.00% in mAP@50. Furthermore, the Mul-BiFPN and BiFPN proposed in this paper were individually added to YOLOv5s for comparative testing, and it was concluded that Mul-BiFPN has better detection performance than BiFPN. With the addition of Focal EIoU and M-SimAM Attention, the detection efficacy of small targets in aerial images was significantly enhanced. Compared to YOLOv5s, the proposed algorithm achieved a 5.60% increase in P and a 6.10% increase in R on the VisDrone-2019 test dataset, as well as a 7.30% increase in mAP@50 and a 4.60% increase in mAP@0.5:0.95, which validates the effectiveness of the proposed algorithm improvements.
Table 5 presents the accuracy of various target detections in the VisDrone-2019 test dataset. According to our data analysis, the accuracy of various target detections in unknown scenarios has been significantly improved in the proposed algorithm. The detection accuracy of bicycles, truck, and motor showed the greatest improvement, increasing by 12.90%, 8.10%, and 6.20%, respectively. Although the accuracy of some types of target detections may decrease to some extent with the addition of each module, the overall detection accuracy is still improved.
The ablation experiment under the same scenario of different models is shown among (a)~(i) in
Figure 9. As can be seen clearly from the picture comparison, when a module is added or improved to the original model (a), the image detection effect will be improved compared with the (a) model. When there are target groups with a large density and coverage in the images, the (a) model has a high probability of missing and false detection, but the (i) model can deal with this situation well, greatly improving the recall rate and accuracy rate and improving the detection confidence of each target.
To verify the proposed algorithm’s significant improvement in detecting small targets, a comparative evaluation experiment was conducted between the proposed algorithm and other models, including YOLOv3, YOLOv5s, YOLOv5l, YOLOv7 [
13], and YOLOv8s. The comparison of different models is presented in
Table 6.
As shown in
Table 6, our model outperforms other models in terms of performance evaluation on the VisDrone-2019 test dataset. Compared to the YOLOv5s model, the new model achieves an improvement of 5.60% in detection accuracy, surpassing YOLOv5l and YOLOv8s as well. Furthermore, compared to other mainstream algorithms, the proposed algorithm exhibits better performance in detection accuracy (P), recall rate (R), and mAP@0.5. Notably, it achieves higher detection accuracy for pedestrians and buses than other models. In summary, the proposed algorithm shows superiority in detecting small targets, which validates the feasibility of the algorithm.
5. Conclusions
In this paper, we propose a new model based on YOLOv5s that significantly enhances the small target detection efficacy in UAV aerial photography images with large scale differences and high overlap rates. We achieve this by adding a new Detect-P2 detection layer to the original YOLOv5s model to enhance the detection of shallow, small target information. Furthermore, we replace the PANet network with the Mul-BiFPN network to enhance the fusion of information from different feature layers. To improve regression accuracy, we introduce the Focal EIoU loss function, which also accelerates network convergence. Lastly, we add the proposed M-SimAM module to the last layer of the backbone to enhance effective information extraction and improve detection accuracy.
The results of the experiment demonstrate that our model outperforms YOLOv5s in detecting objects in the VisDrone-2019 dataset. It significantly reduces false detection and missing detection of small targets and greatly improves the detection accuracy of various objects. Furthermore, the new model shows superior detection performance compared to other models.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}