
Prototype-Based Self-Adaptive Distribution Calibration for Few-Shot Image Classification


Abstract
1. Introduction
- A Prototype-based Representative Mechanism (PRM) is proposed to utilize the few-shot class centers to participate in the distribution calibration, resulting in a more accurate estimation of the ground-truth distributions;
- A Self-adaptive Hyperparameter Optimization Algorithm (SHOA) is proposed for self-adaptive hyperparameter optimization for the distribution calibration of different application scenarios;
- We propose a Prototype-based Self-adaptive Distribution Calibration (PSDC) framework to estimate the ground-truth distributions and improve the model performance in the few-shot image classification task;
- Comprehensive experiments are conducted to evaluate the effectiveness of the proposed framework, including the comparison with SOTA methods, ablation studies, and visualization verification.
2. Related Work
2.1. Few-Shot Image Classification
2.2. Simulated Annealing Algorithm
3. Method
| Algorithm 1 Training process on the N-way-K-shot task |
| Input: base class data and support set . |
| Output: the optimal parameters of the classifier . |
|
3.1. Problem Definition
3.2. Distribution Calibration with a Prototype-Based Representative Mechanism
3.3. Sample Generation and Classifier Training
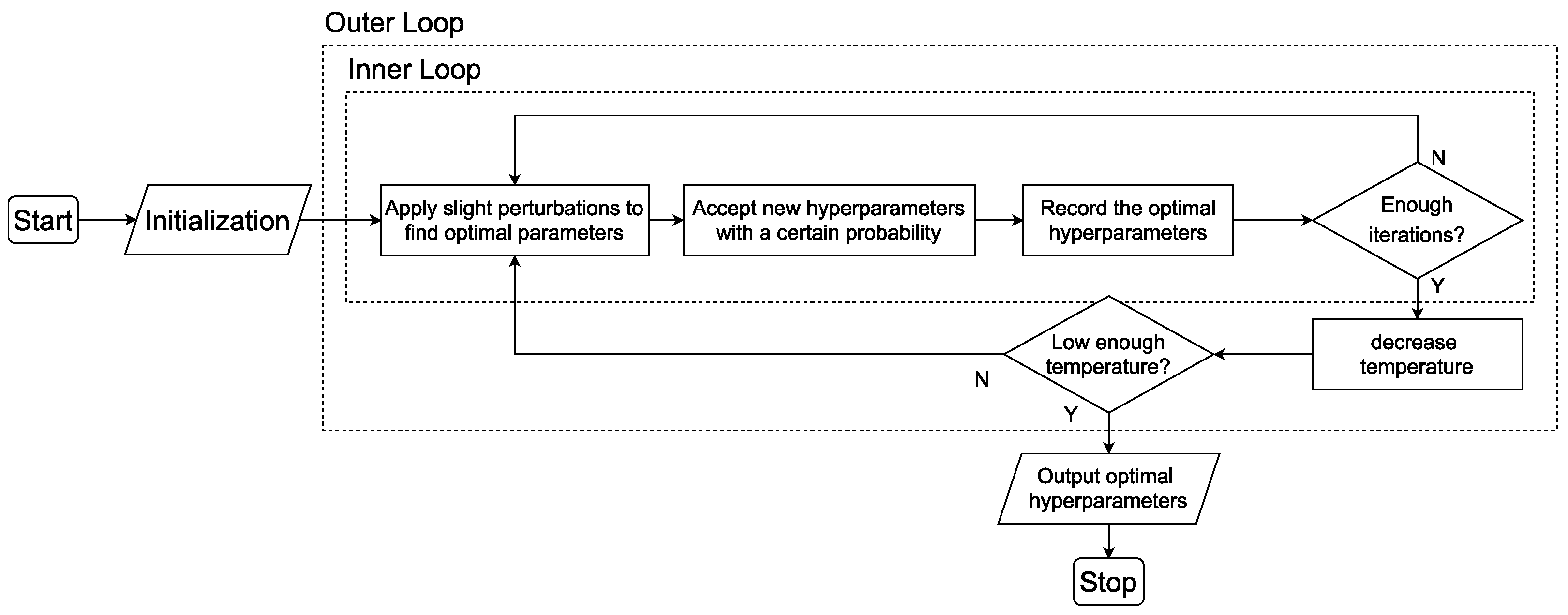
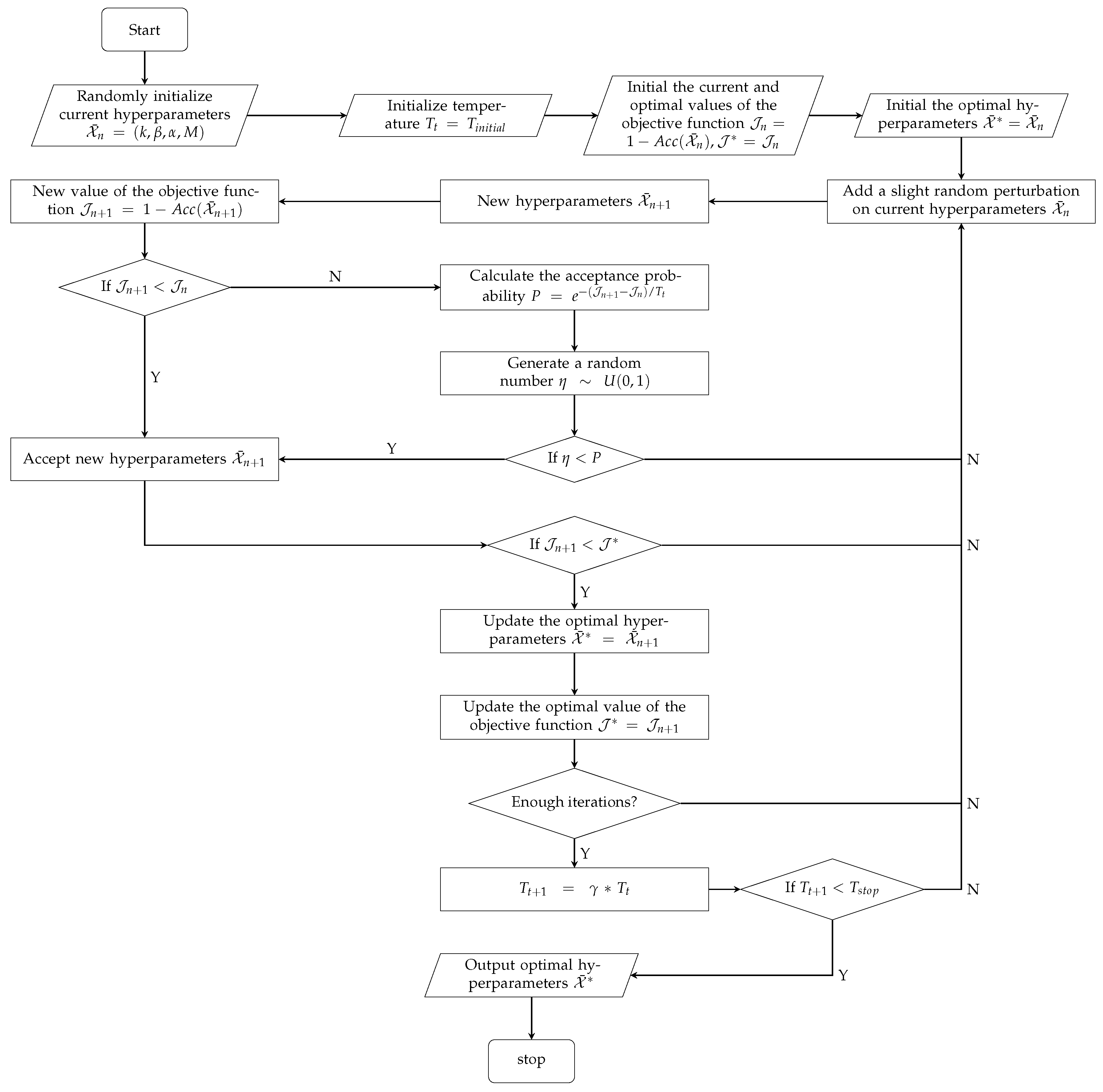
3.4. Self-Adaptive Hyperparameter Optimization Algorithm
3.4.1. Simulated Annealing Algorithm
3.4.2. Metropolis Algorithm
4. Experiments
4.1. Datasets
4.2. Evaluation Criteria
4.3. Implementation Details
4.4. Comparison to State-of-the-Art
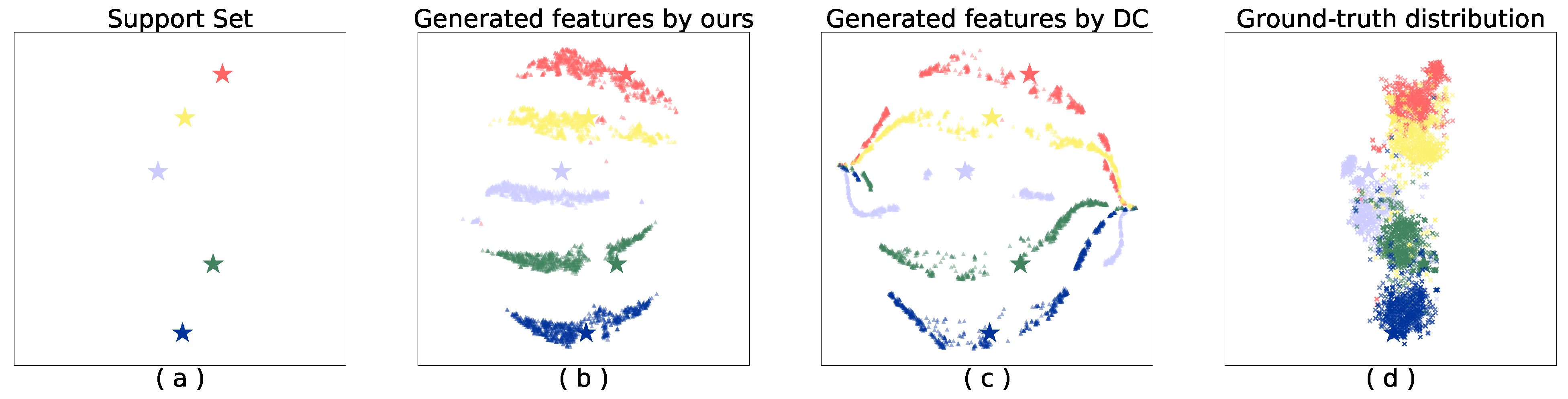
4.5. Visualization of Generated Samples
4.6. Ablation Study
4.6.1. Ablation Study on the Prototype-Based Representative Mechanism
4.6.2. Ablation Study on the Self-Adaptive Hyperparameter Optimization Algorithm
4.6.3. Ablation Study on PRM and SHOA
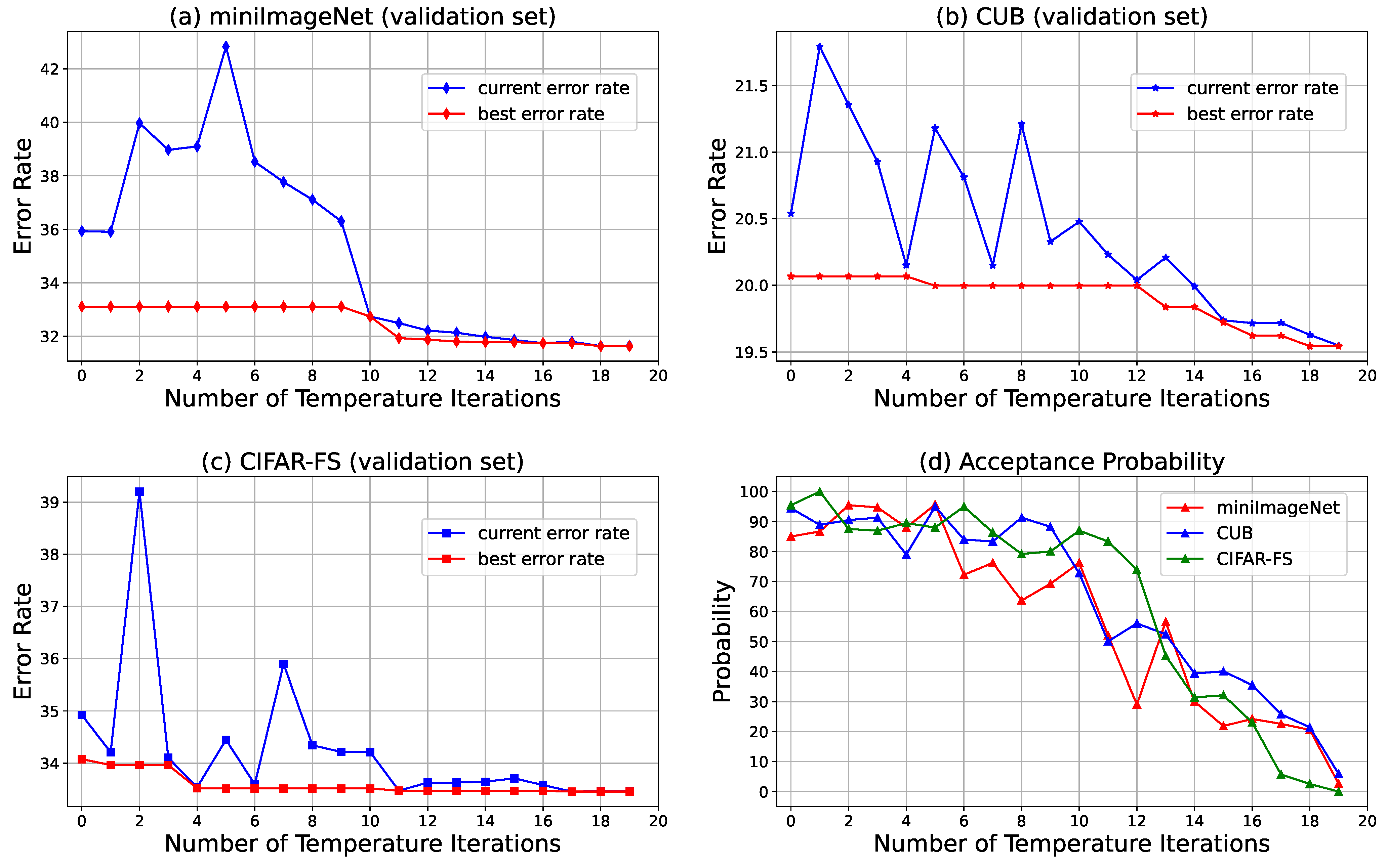
4.7. Hyperparameter Searching
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ye, H.; Hu, H.; Zhan, D. Learning Adaptive Classifiers Synthesis for Generalized Few-Shot Learning. Int. J. Comput. Vis. 2021, 129, 1930–1953. [Google Scholar] [CrossRef]
- Xu, W.; Xian, Y.; Wang, J.; Schiele, B.; Akata, Z. Attribute Prototype Network for Any-Shot Learning. Int. J. Comput. Vis. 2022, 130, 1735–1753. [Google Scholar] [CrossRef]
- Koniusz, P.; Zhang, H. Power Normalizations in Fine-Grained Image, Few-Shot Image and Graph Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 591–609. [Google Scholar] [CrossRef] [PubMed]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Raghu, A.; Raghu, M.; Bengio, S.; Oriol, V. Rapid Learning or Feature Reuse? Towards Understanding the Effectiveness of MAML. In Proceedings of the 8th International Conference on Learning Representations, Online, 26–30 April 2020. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the 30th International Conference on Neural Information Processing Systems (NIPS’16), Barcelona, Spain, 5–10 December 2016; pp. 3637–3645. [Google Scholar]
- Kang, D.; Kwon, H.; Min, J.; Cho, M. Relational Embedding for Few-Shot Classification. In Proceedings of the IEEE International Conference on Computer Vision, Online, 11–17 October 2021; pp. 8822–8833. [Google Scholar]
- Bendre, N.; Desai, K.; Najafirad, P. Generalized Zero-Shot Learning Using Multimodal Variational Auto-Encoder With Semantic Concepts. In Proceedings of the 28th IEEE International Conference on Image Processing (ICIP), Online, 19–22 September 2021; pp. 1284–1288. [Google Scholar]
- Li, K.; Zhang, Y.; Li, K.; Fu, Y. Adversarial Feature Hallucination Networks for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Online, 14–19 June 2020; pp. 13470–13479. [Google Scholar]
- Yang, S.; Wu, S.; Liu, T.; Xu, M. Bridging the Gap between Few-Shot and Many-Shot Learning via Distribution Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9830–9843. [Google Scholar] [CrossRef] [PubMed]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Joy, T.T.; Rana, S.; Gupta, S.; Venkatesh, S. Hyperparameter tuning for big data using Bayesian optimisation. In Proceedings of the 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2574–2579. [Google Scholar]
- Yu, T.; Zhu, H. Hyper-parameter optimization: A review of algorithms and applications. arXiv 2020, arXiv:2003.05689. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-shot Learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 4080–4090. [Google Scholar]
- Chen, W.-Y.; Liu, Y.-C.; Kira, Z.; Wang, Y.-C.F.; Huang, J.-B. A Closer Look at Few-shot Classification. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Tian, Y.; Wang, Y.; Krishnan, D.; Tenenbaum, J.B.; Isola, P. Rethinking Few-Shot Image Classification: A Good Embedding is All You Need? In Computer Vision–ECCV 2020 (Lecture Notes in Computer Science); Springer: Cham, Switzerland, 2020; pp. 266–282. [Google Scholar]
- Mangla, P.; Kumari, N.; Sinha, A.; Singh, M.; Krishnamurthy, B.; Balasubramanian, V.N. Charting the Right Manifold: Manifold Mixup for Few-shot Learning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 2207–2216. [Google Scholar]
- Zhang, R.; Che, T.; Ghahramani, Z.; Bengio, Y.; Song, Y. MetaGAN: An Adversarial Approach to Few-Shot Learning. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NIPS’18), Montreal, QC, Canada, 3–8 December 2018; pp. 2371–2380. [Google Scholar]
- Schwartz, E.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Kumar, A.; Feris, R.; Giryes, R.; Bronstein, A. Delta-encoder: An effective sample synthesis method for few-shot object recognition. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NIPS’18), Montreal, QC, Canada, 3–8 December 2018; pp. 2850–2860. [Google Scholar]
- Zhang, J.; Zhao, C.; Ni, B.; Xu, M.; Yang, X. Variational Few-Shot Learning. In Proceedings of the IEEE International Conference on Computer Vision, Long Beach, CA, USA, 16–20 June 2019; pp. 1685–1694. [Google Scholar]
- Hong, Y.; Niu, L.; Zhang, J.; Zhang, L. Matchinggan: Matching-Based Few-Shot Image Generation. In Proceedings of the IEEE International Conference on Multimedia and Expo, Online, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt Jr, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Kassaymeh, S.; Al-Laham, M.; Al-Betar, M.A.; Alweshah, M.; Abdullah, S.; Makhadmeh, S.N. Backpropagation Neural Network optimization and software defect estimation modelling using a hybrid Salp Swarm optimizer-based Simulated Annealing Algorithm. Knowl. Based. Syst. 2022, 244, 108511. [Google Scholar] [CrossRef]
- Bandyopadhyay, R.; Basu, A.; Cuevas, E.; Sarkar, R. Harris Hawks optimisation with Simulated Annealing as a deep feature selection method for screening of COVID-19 CT-scans. Appl. Soft Comput. 2021, 111, 107698. [Google Scholar] [CrossRef] [PubMed]
- Rere, L.M.R.; Fanany, M.I.; Arymurthy, A.M. Simulated Annealing Algorithm for Deep Learning. Procedia Comput. Sci. 2015, 72, 137–144. [Google Scholar] [CrossRef]
- Ayumi, V.; Rere, L.M.R.; Fanany, M.I.; Arymurthy, A.M. Optimization of convolutional neural network using microcanonical annealing algorithm. In Proceedings of the 8th International Conference on Advanced Computer Science and Information Systems, Malang, Indonesia, 15–16 October 2016; pp. 506–511. [Google Scholar]
- Hu, Z.; Zhou, L.; Jin, B.; Liu, H. Applying improved convolutional neural network in image classification. Mob. Netw. Appl. 2020, 25, 133–141. [Google Scholar] [CrossRef]
- Tukey, J.W. Exploratory Data Analysis; Addison-Wesley: Reading, MA, USA, 1977; pp. 1–704. [Google Scholar]
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Welinder, P.; Branson, S.; Mita, T.; Wah, C.; Schroff, F.; Belongie, S.; Perona, P. The Caltech-ucsd Birds-200; CNS-TR-2010-001; California Institute of Technology: Pasadena, CA, USA, 2010. [Google Scholar]
- Bertinetto, L.; Henriques, J.F.; Torr, P.; Vedaldi, A. Meta-learning with differentiable closed-form solvers. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-SGD: Learning to Learn Quickly for Few-Shot Learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Munkhdalai, T.; Yuan, X.; Mehri, S.; Trischler, A. Rapid Adaptation with Conditionally Shifted Neurons. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 3664–3673. [Google Scholar]
- Rusu, A.A.; Rao, D.; Sygnowski, J.; Vinyals, O.; Pascanu, R.; Osindero, S.; Hadsell, R. Meta-Learning with Latent Embedding Optimization. In Proceedings of the 7th International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Liu, Y.; Schiele, B.; Sun, Q. An Ensemble of Epoch-Wise Empirical Bayes for Few-Shot Learning. In Computer Vision–ECCV 2020 (Lecture Notes in Computer Science); Springer: Cham, Switzerland, 2020; pp. 404–421. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.; Schiele, B. Meta-Transfer Learning for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 403–412. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.S.; Hospedales, T.M. Learning to Compare: Relation Network for Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Hou, R.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Cross Attention Network for Few-shot Classification. In Proceedings of the 33th International Conference on Neural Information Processing Systems (NIPS’19), Vancouver, BC, Canada, 8–14 December 2019; pp. 4003–4014. [Google Scholar]
- Ma, R.; Fang, P.; Drummond, T.; Harandi, M. Adaptive Poincaré Point to Set Distance for Few-Shot Classification. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 1926–1934. [Google Scholar]
- Liu, B.; Cao, Y.; Lin, Y.; Li, Q.; Zhang, Z.; Long, M.; Hu, H. Negative Margin Matters: Understanding Margin in Few-Shot Classification. In Computer Vision–ECCV 2020 (Lecture Notes in Computer Science); Springer: Cham, Switzerland, 2020; pp. 438–455. [Google Scholar]
- Chen, Z.; Fu, Y.; Zhang, Y.; Jiang, Y.; Xue, X.; Sigal, L. Multi-Level Semantic Feature Augmentation for One-Shot Learning. IEEE Trans. Image Process. 2019, 28, 4594–4605. [Google Scholar] [CrossRef] [PubMed]
- Park, S.; Han, S.; Baek, J.; Kim, I.; Song, J.; Lee, H.B.; Han, J.; Hwang, S.J. Meta Variance Transfer: Learning to Augment from the Others. In Proceedings of the 37th International Conference on Machine Learning, Online, 13–18 July 2020; pp. 7510–7520. [Google Scholar]
- Lee, K.; Maji, S.; Ravichandran, A.; Soatto, S. Meta-Learning With Differentiable Convex Optimization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10649–10657. [Google Scholar]
- Ravichandran, A.; Bhotika, R.; Soatto, S. Few-Shot Learning With Embedded Class Models and Shot-Free Meta Training. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 26 October–2 November 2019; pp. 331–339. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | miniImageNet | ||
|---|---|---|---|
| 5-way-1-shot | 5-way-5-shot | ||
| Optimization-based | ICML17’ MAML [4] | ||
| Meta-SGD [35] | |||
| ICML18’ adaResNet [36] | |||
| ICLR19’ LEO [37] | |||
| ECCV20’ E3BM [38] | |||
| CVPR19’ Meta Transfer Learning [39] | |||
| Metric-based | NIPS16’ MatchingNet [6] | ||
| NIPS17’ ProtoNet [14] | |||
| CVPR18’ RelationNet [40] | |||
| NIPS19’ CAN [41] | |||
| AAAI22’ AAP2S [42] | |||
| Fine-tuning-based | ICLR19’ Baseline++ [15] | ||
| ECCV20’ RFS-simple [16] | |||
| WACV20’ S2M2 [17] | |||
| ECCV20’ Negative-Cosine [43] | |||
| Generation-based | TPAMI21’ DC [10] | ||
| NIPS18’ MetaGAN [18] | |||
| NIPS18’ Delta-Encoder [19] | |||
| TIP19’ TriNet [44] | |||
| ICML20’ Meta Variance Transfer [45] | - | ||
| Ours | PSDC | ||
| Method | CUB-200-2011 | ||
|---|---|---|---|
| 5-way-1-shot | 5-way-5-shot | ||
| Optimization-based | ICML17’ MAML [4] | ||
| Meta-SGD [35] | |||
| Metric-based | NIPS16’ MatchingNet [6] | ||
| NIPS17’ ProtoNet [14] | |||
| CVPR18’ RelationNet [40] | |||
| AAAI22’ AAP2S [42] | |||
| Fine-tuning-based | ICLR19’ Baseline++ [15] | ||
| ECCV20’ Negative-Cosine [43] | |||
| Generation-based | TPAMI21’ DC [10] | ||
| NIPS18’ Delta-Encoder [19] | |||
| TIP19’ TriNet [44] | |||
| ICML20’ Meta Variance Transfer [45] | - | ||
| Ours | PSDC | ||
| Method | CIFAR-FS | ||
|---|---|---|---|
| 5-way-1-shot | 5-way-5-shot | ||
| Optimization-based | ICML17’ MAML [4] | ||
| ICLR19’ R2D2 [32] | |||
| CVPR19’ MetaOptNet [46] | |||
| Metric-based | NIPS17’ ProtoNet [14] | ||
| CVPR18’ RelationNet [40] | |||
| AAAI22’ AAP2S [42] | |||
| CVPR19’ Shot-Free [47] | |||
| Fine-tuning-based | ICLR19’ Baseline++ [15] | ||
| Ours | PSDC | ||
| PRM | SHOA | miniImageNet | CUB-200-2011 | ||
|---|---|---|---|---|---|
| 5-way-1-shot | 5-way-5-shot | 5-way-1-shot | 5-way-5-shot | ||
| × | × | ||||
| ✓ | × | - | - | ||
| × | ✓ | ||||
| ✓ | ✓ | - | - | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, W.; Hu, X.; Wei, X.; Zuo, K. Prototype-Based Self-Adaptive Distribution Calibration for Few-Shot Image Classification. Electronics 2023, 12, 134. https://doi.org/10.3390/electronics12010134
Du W, Hu X, Wei X, Zuo K. Prototype-Based Self-Adaptive Distribution Calibration for Few-Shot Image Classification. Electronics. 2023; 12(1):134. https://doi.org/10.3390/electronics12010134
Chicago/Turabian StyleDu, Wei, Xiaoping Hu, Xin Wei, and Ke Zuo. 2023. "Prototype-Based Self-Adaptive Distribution Calibration for Few-Shot Image Classification" Electronics 12, no. 1: 134. https://doi.org/10.3390/electronics12010134
APA StyleDu, W., Hu, X., Wei, X., & Zuo, K. (2023). Prototype-Based Self-Adaptive Distribution Calibration for Few-Shot Image Classification. Electronics, 12(1), 134. https://doi.org/10.3390/electronics12010134