
3DPCTN: Two 3D Local-Object Point-Cloud-Completion Transformer Networks Based on Self-Attention and Multi-Resolution



Abstract
:1. Introduction
- Two novel encoders are proposed for better spatial-characteristic extraction from incomplete point clouds, namely, 3DPCTN-SAE and 3DPCTN-MRE. Compared with previous methods of locally unorganized complete shape generation, 3DPCTN can decode the generation process of missing point clouds into an explicit, locally structured pattern, thus greatly improving the performance of 3D shape completion.
- We propose a novel PCT-based point-refiner network for fine tuning each point to its proper position. A PCT-based point-refiner network is introduced to solve the merging problem between the incomplete and missing point cloud, ensuring that similarity distribution between the predicted point cloud and missing part is ultimately achieved.
- Experiments show that 3DPCTN-SAE and 3DPCTN-MRE can significantly improve the ability to extract local context information. Results also show the superiority of using the PCT-based point-refiner network to local-area refinement as well as shape integrity.
2. Related Work
2.1. 3D Shape Completion
2.2. Point-Cloud Generation
2.3. Point-Cloud Transformer
3. The Proposed Method Overview
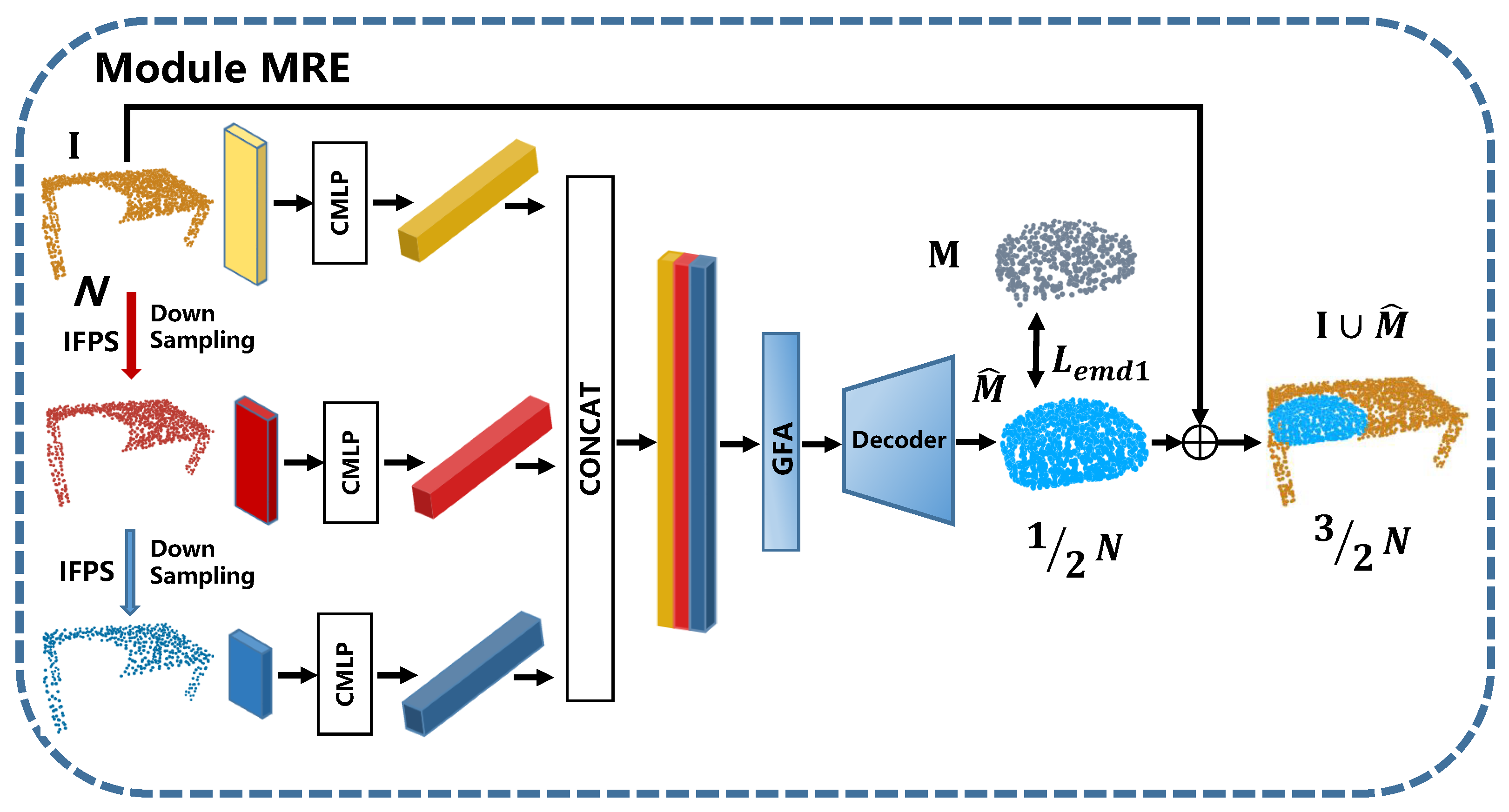
3.1. Missing-Part Prediction Network
3.1.1. Self-Attention Encoder
3.1.2. Multi-Resolution Encoder
3.1.3. Missing-Part Network Decoder
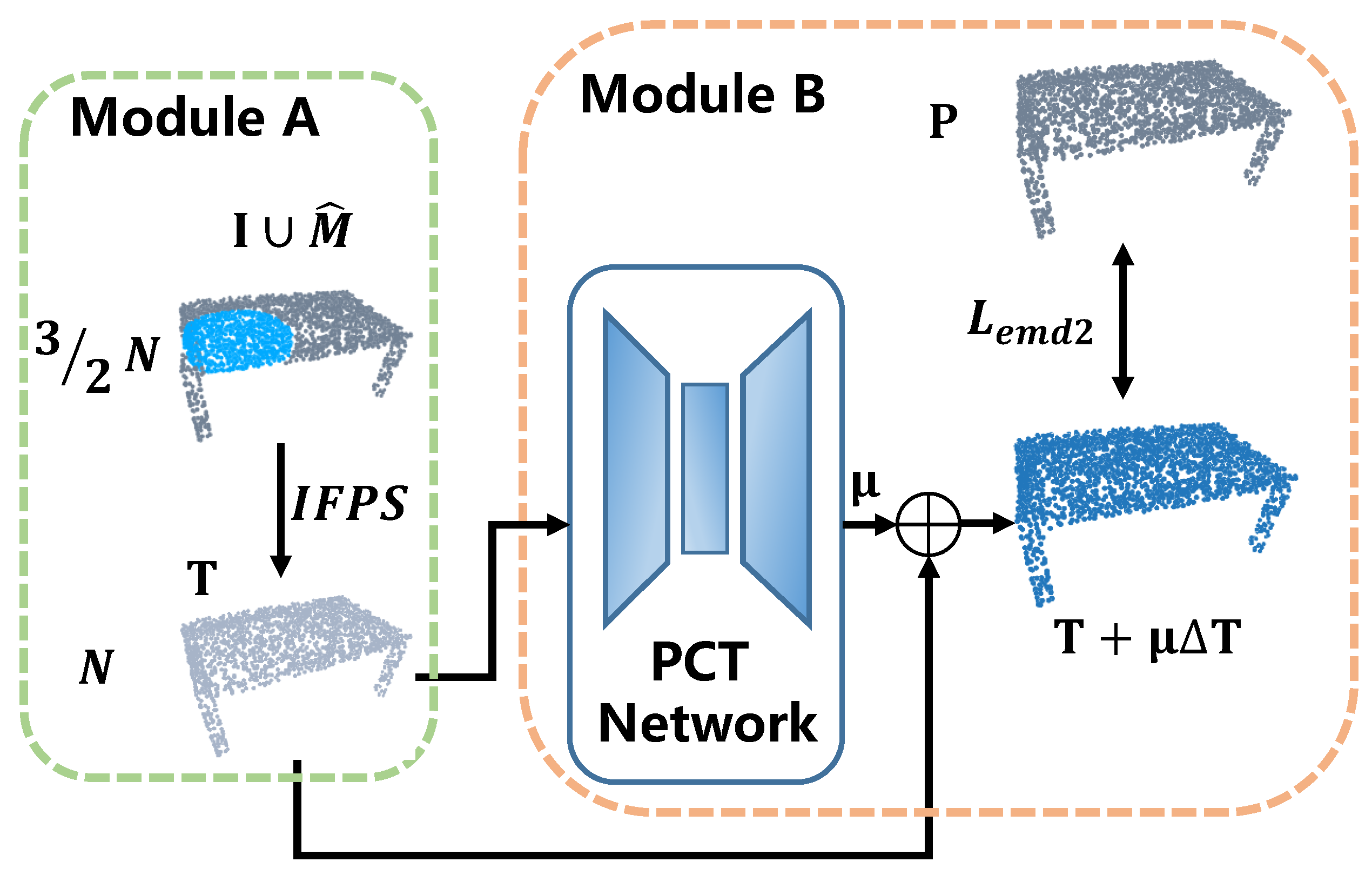
3.2. Merging and Sampling
3.3. Point-Refiner Network (PRN)
3.4. Loss Function
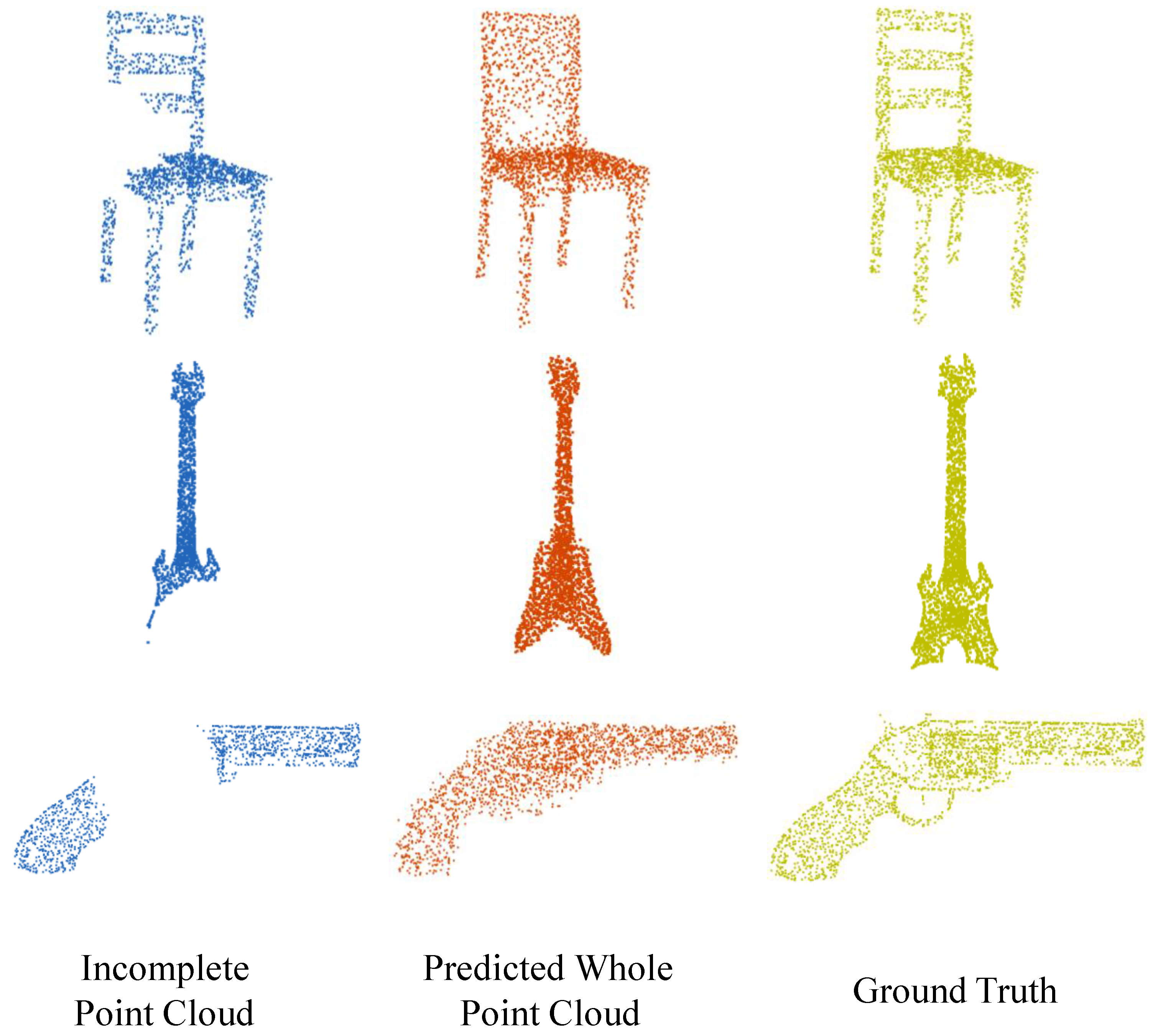
4. Experimental Results and Analysis
4.1. Data Generation and Implementation Details
4.2. Comparsions with State-of-the-Art Methods
- 3D-Capsule uses the most advanced autoencoder to process point clouds for point-cloud reconstruction, which is based on a capsule network.
- PCN completes a partial point cloud by an autoencoder. It uses a stacked version of PointNet as the encoder and generates the point cloud in a coarse-to-fine form.
- MSN is generated using two stages, first predicting the coarse point cloud, and then using the residual network to further enhance for obtaining a high-density point cloud.
- PF-Net learns multi-scale features from local shapes and regenerates missing parts at different resolutions. Additionally, an adversarial loss is included to match the distribution of predicted and actual missing regions.
- RP-MBD consists of two PointNet-based networks. The first network is based on focusing on extracting information from incomplete inputs to infer missing geometries, and the other network merges two point clouds and improves point distribution.
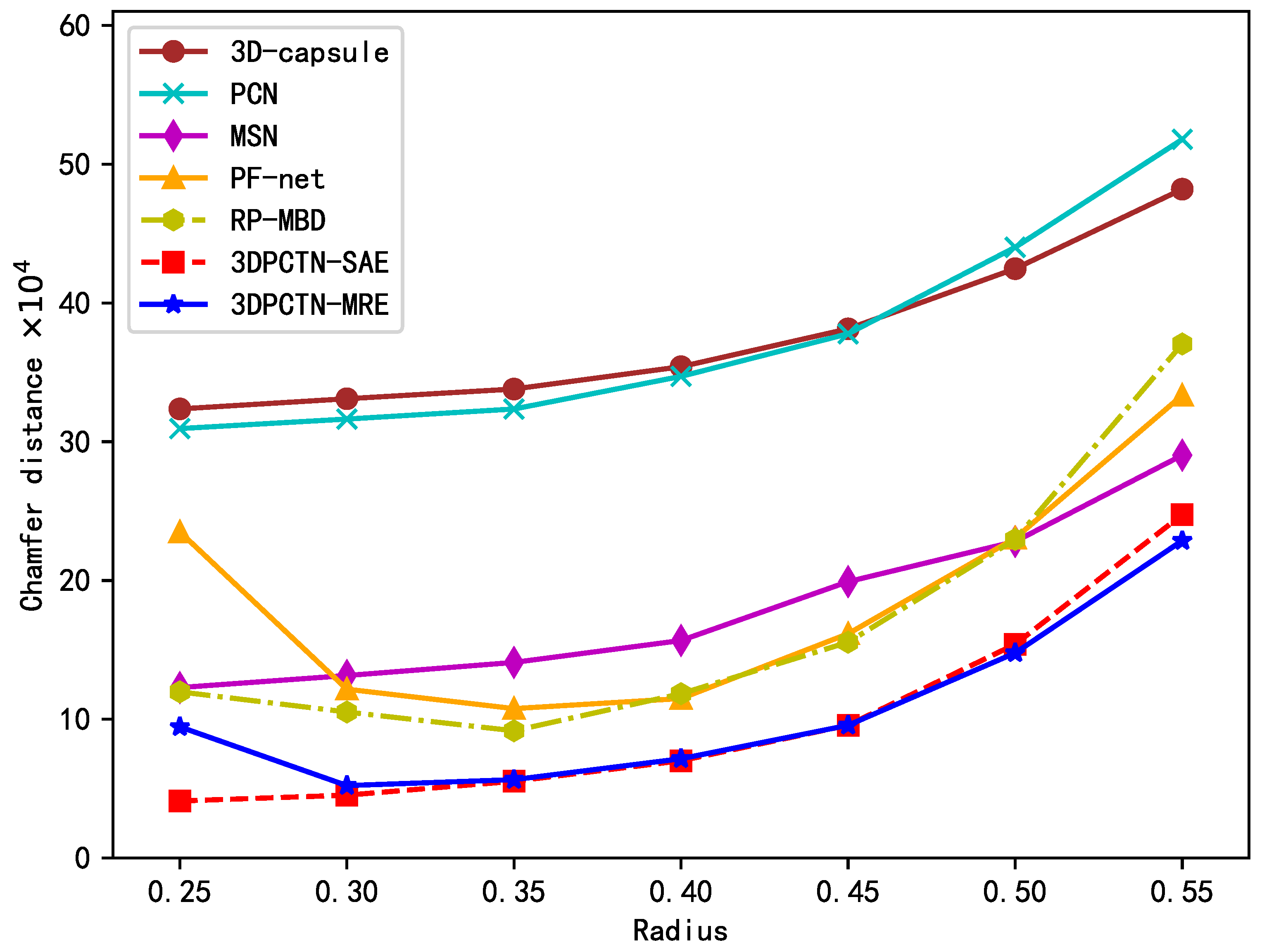
4.3. Robustness Test
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, T.; Lin, L.; Hui, X.; Chen, R.; Wu, H. Knowledge-guided multi-label few-shot learning for general image recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1371–1384. [Google Scholar] [CrossRef]
- Chen, T.; Pu, T.; Wu, H.; Xie, Y.; Liu, L.; Lin, L. Cross-domain facial expression recognition: A unified evaluation benchmark and adversarial graph learning. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Yang, Z.; Wang, L. Learning relationships for multi-view 3D object recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 7505–7514. [Google Scholar] [CrossRef]
- Wei, X.; Yu, R.; Sun, J. View-GCN: View-based graph convolutional network for 3D shape analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1850–1859. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Riegler, G.; Osman Ulusoy, A.; Geiger, A. Octnet: Learning deep 3d representations at high resolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3577–3586. [Google Scholar]
- Le, T.; Duan, Y. Pointgrid: A deep network for 3d shape understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9204–9214. [Google Scholar]
- Wang, N.; Zhang, Y.; Li, Z.; Fu, Y.; Liu, W.; Jiang, Y.G. Pixel2mesh: Generating 3d mesh models from single rgb images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 52–67. [Google Scholar]
- Zeng, W.; Ouyang, W.; Luo, P.; Liu, W.; Wang, X. 3d human mesh regression with dense correspondence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7054–7063. [Google Scholar]
- Zhu, H.; Zuo, X.; Wang, S.; Cao, X.; Yang, R. Detailed human shape estimation from a single image by hierarchical mesh deformation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4491–4500. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Wu, H.; Miao, Y.; Fu, R. Point cloud completion using multiscale feature fusion and cross-regional attention. Image Vis. Comput. 2021, 111, 104193. [Google Scholar] [CrossRef]
- Liu, M.; Sheng, L.; Yang, S.; Shao, J.; Hu, S.M. Morphing and sampling network for dense point cloud completion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11596–11603. [Google Scholar]
- Huang, Z.; Yu, Y.; Xu, J.; Ni, F.; Le, X. Pf-net: Point fractal network for 3d point cloud completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7662–7670. [Google Scholar]
- Yuan, W.; Khot, T.; Held, D.; Mertz, C.; Hebert, M. Pcn: Point completion network. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 728–737. [Google Scholar]
- Xie, H.; Yao, H.; Zhou, S.; Mao, J.; Zhang, S.; Sun, W. Grnet: Gridding residual network for dense point cloud completion. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 365–381. [Google Scholar]
- Tchapmi, L.P.; Kosaraju, V.; Rezatofighi, H.; Reid, I.; Savarese, S. Topnet: Structural point cloud decoder. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 383–392. [Google Scholar]
- Wang, X.; Ang Jr, M.H.; Lee, G.H. Cascaded refinement network for point cloud completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 790–799. [Google Scholar]
- Guo, M.H.; Cai, J.X.; Liu, Z.N.; Mu, T.J.; Martin, R.R.; Hu, S.M. PCT: Point cloud transformer. arXiv 2020, arXiv:2012.09688. [Google Scholar] [CrossRef]
- Yuan, M.; Li, X.; Cheng, L.; Li, X.; Tan, H. A Coarse-to-Fine Registration Approach for Point Cloud Data with Bipartite Graph Structure. Electronics 2022, 11, 263. [Google Scholar] [CrossRef]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3d object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Achlioptas, P.; Diamanti, O.; Mitliagkas, I.; Guibas, L. Learning representations and generative models for 3d point clouds. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 40–49. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. Foldingnet: Point cloud auto-encoder via deep grid deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 206–215. [Google Scholar]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. A papier-mâché approach to learning 3d surface generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 216–224. [Google Scholar]
- Zhao, Y.; Birdal, T.; Deng, H.; Tombari, F. 3D point capsule networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1009–1018. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.; Koltun, V. Point transformer. arXiv 2020, arXiv:2012.09164. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10076–10085. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Yi, L.; Kim, V.G.; Ceylan, D.; Shen, I.C.; Yan, M.; Su, H.; Lu, C.; Huang, Q.; Sheffer, A.; Guibas, L. A scalable active framework for region annotation in 3d shape collections. ACM Trans. Graph. (ToG) 2016, 35, 1–12. [Google Scholar] [CrossRef]
- Mendoza, A.; Apaza, A.; Sipiran, I.; Lopez, C. Refinement of Predicted Missing Parts Enhance Point Cloud Completion. arXiv 2020, arXiv:2010.04278. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Categories | 3D-Capsule | PCN | MSN | PF-Net | RP-MBD | 3DPCTN-SAE | 3DPCTN-MRE |
|---|---|---|---|---|---|---|---|
| Airplane | 2.277 | 1.579 | 0.661 | 0.533 | 0.467 | 0.325 | 0.326 |
| Bag | 6.501 | 4.872 | 2.333 | 2.252 | 1.670 | 0.598 | 0.580 |
| Cap | 6.939 | 5.782 | 2.266 | 1.927 | 1.109 | 0.408 | 0.390 |
| Car | 5.467 | 3.882 | 1.543 | 0.853 | 0.946 | 0.655 | 0.597 |
| Chair | 4.496 | 2.560 | 1.036 | 0.745 | 0.663 | 0.396 | 0.395 |
| Guitar | 3.741 | 0.809 | 0.859 | 0.437 | 0.381 | 0.280 | 0.390 |
| Lamp | 9.258 | 5.466 | 2.969 | 2.358 | 2.325 | 1.489 | 1.527 |
| Laptop | 2.565 | 1.708 | 0.745 | 0.516 | 0.379 | 0.335 | 0.305 |
| Motorbike | 4.770 | 3.121 | 1.398 | 0.854 | 1.084 | 0.784 | 0.804 |
| Mug | 6.219 | 5.108 | 1.453 | 1.025 | 0.743 | 0.644 | 0.546 |
| Pistol | 3.411 | 2.277 | 1.144 | 0.855 | 0.867 | 0.546 | 0.547 |
| Skateboard | 3.015 | 1.923 | 0.720 | 0.571 | 0.454 | 0.332 | 0.308 |
| Table | 4.099 | 2.982 | 1.196 | 1.071 | 0.833 | 0.400 | 0.424 |
| Average | 4.827 | 3.236 | 1.409 | 1.077 | 0.917 | 0.553 | 0.549 |
| Categories | 3D-Capsule | PCN | MSN | PF-Net | RP-MBD | 3DPCTN-SAE | 3DPCTN-MRE |
|---|---|---|---|---|---|---|---|
| Airplane | 4.038 | 4.122 | 2.078 | 1.474 | 1.394 | 1.131 | 1.119 |
| Bag | 7.480 | 8.263 | 3.903 | 2.199 | 2.438 | 1.863 | 1.723 |
| Cap | 6.818 | 7.224 | 3.299 | 1.937 | 2.074 | 1.382 | 1.438 |
| Car | 6.157 | 5.953 | 3.336 | 1.758 | 2.140 | 1.733 | 1.701 |
| Chair | 5.322 | 5.646 | 2.439 | 1.575 | 1.638 | 1.318 | 1.288 |
| Guitar | 3.769 | 3.866 | 2.107 | 1.528 | 1.234 | 1.103 | 1.232 |
| Lamp | 8.535 | 7.798 | 3.603 | 2.588 | 2.848 | 2.235 | 2.233 |
| Laptop | 4.303 | 4.068 | 2.180 | 1.428 | 1.435 | 1.312 | 1.268 |
| Motorbike | 6.005 | 5.769 | 3.295 | 2.183 | 2.291 | 1.936 | 1.989 |
| Mug | 6.822 | 7.226 | 2.780 | 1.620 | 1.628 | 1.622 | 1.519 |
| Pistol | 4.873 | 4.994 | 2.643 | 2.034 | 1.938 | 1.521 | 1.502 |
| Skateboard | 4.309 | 4.035 | 1.958 | 1.509 | 1.341 | 1.103 | 1.100 |
| Table | 5.565 | 5.403 | 2.424 | 1.606 | 1.617 | 1.253 | 1.262 |
| Average | 5.692 | 5.720 | 2.772 | 1.803 | 1.847 | 1.501 | 1.490 |
| Categories | 3DPCTN-SAE | 3DPCTN-SAE w/o PCT | 3DPCTN-MRE | 3DPCTN-MRE w/o PCT | Only PCT w/o SAE and MRE |
|---|---|---|---|---|---|
| Airplane | 0.325 | 0.493 | 0.326 | 0.448 | 0.329 |
| Bag | 0.598 | 1.375 | 0.580 | 1.305 | 0.610 |
| Cap | 0.408 | 1.092 | 0.390 | 0.85 | 1.300 |
| Car | 0.655 | 1.080 | 0.597 | 0.857 | 0.632 |
| Chair | 0.396 | 0.701 | 0.395 | 0.622 | 0.404 |
| Guitar | 0.280 | 0.724 | 0.390 | 0.33 | 0.334 |
| Lamp | 1.489 | 7.157 | 1.527 | 2.275 | 1.550 |
| Laptop | 0.335 | 0.522 | 0.305 | 0.379 | 0.323 |
| Motorbike | 0.784 | 0.926 | 0.804 | 0.925 | 0.784 |
| Mug | 0.644 | 0.646 | 0.546 | 0.779 | 0.626 |
| Pistol | 0.546 | 0.702 | 0.547 | 0.736 | 0.575 |
| Skateboard | 0.332 | 0.428 | 0.308 | 0.436 | 0.314 |
| Table | 0.400 | 0.638 | 0.424 | 0.764 | 0.438 |
| Average | 0.553 | 1.271 | 0.549 | 0.824 | 0.632 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, S.; Yang, Z.; Shi, Y.; Tan, J.; Li, H.; Cheng, Y. 3DPCTN: Two 3D Local-Object Point-Cloud-Completion Transformer Networks Based on Self-Attention and Multi-Resolution. Electronics 2022, 11, 1351. https://doi.org/10.3390/electronics11091351
Huang S, Yang Z, Shi Y, Tan J, Li H, Cheng Y. 3DPCTN: Two 3D Local-Object Point-Cloud-Completion Transformer Networks Based on Self-Attention and Multi-Resolution. Electronics. 2022; 11(9):1351. https://doi.org/10.3390/electronics11091351
Chicago/Turabian StyleHuang, Shuyan, Zhijing Yang, Yukai Shi, Junpeng Tan, Hao Li, and Yongqiang Cheng. 2022. "3DPCTN: Two 3D Local-Object Point-Cloud-Completion Transformer Networks Based on Self-Attention and Multi-Resolution" Electronics 11, no. 9: 1351. https://doi.org/10.3390/electronics11091351
APA StyleHuang, S., Yang, Z., Shi, Y., Tan, J., Li, H., & Cheng, Y. (2022). 3DPCTN: Two 3D Local-Object Point-Cloud-Completion Transformer Networks Based on Self-Attention and Multi-Resolution. Electronics, 11(9), 1351. https://doi.org/10.3390/electronics11091351