
Towards Enhancing Coding Productivity for GPU Programming Using Static Graphs




Abstract
1. Introduction
- Increase coding productivity of GPU programming by using Static Graphs, minimizing the overhead associated with the launch of kernels and maximizing the use of GPU capacity;
- Accelerations of up to more than one order of magnitude in OpenACC and CUDA applications;
- A new easy-to-use proposal for integration into the OpenACC Standard, which defines the use of Static Graphs into this programming model.
2. Background
2.1. CUDA
2.2. OpenACC
2.3. CUDA Graph API
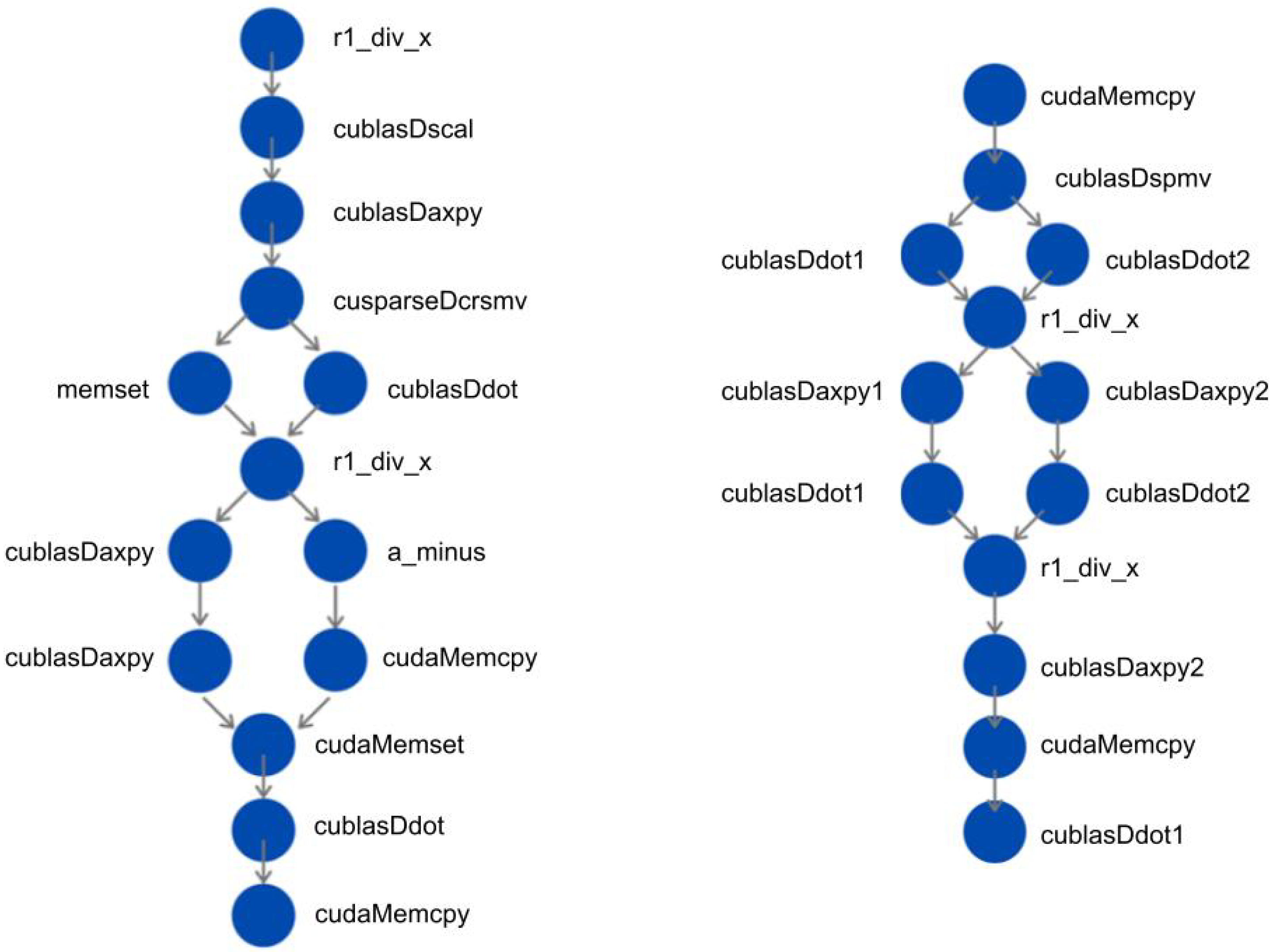
3. Use Case I: Conjugate Gradient
- Other major steps comprise very simple operations such as the division of two scalars (r1_div_x) or the copy of the components of one vector to another vector (cudaMemcpy).
cudaGraph_t graph; cudaGraphExec_t instance; cudaStream_t stream1; cudaStreamBeginCapture(stream1, cudaStreamCaptureModelGlobal); d_b = r1_div_x<<<..., stream1>>>(d_r1, d_r0); cublasDscal(d_b, d_p) cublasDaxpy(cublasHandle, alpha, d_r, d_p); cusparseDcsrmv(cusparseHandle, A, vecp, vecAx,); memset(d_dot, 0.0); d_dot = cublasDdot(d_p, d_Ax); d_a = r1_div_x<<<..., stream1>>>(d_r1, d_dot); cublasDaxpy(cublasHandle, d_a, d_p, d_x); a_minus<<<..., stream1>>>(d_a, d_na); //d_na = d_a - 1 cublasDaxpy(cublasHandle, d_na, d_Ax, d_r); cudaMemcpyAsync(d_r0, d_r1, DeviceToDevice, stream1); cudaMemsetAsync(d_r1, 0.0, stream1); d_r1 = cublasDdot(cublasHandle, d_r, d_r); cudaMemcpyAsync(condition, d_r1, DeviceToHost, stream1); cudaStreamSynchronize(stream1); cudaStreamEndCapture(stream1, graph); cudaGraphInstantiate(instance, graph); while (condition > tolerance^2 && k <= max_iter) { cudaGraphLaunch(instance, stream); } |
3.1. NVIDIA Conjugate Gradient
3.2. Optimized Conjugate Gradient Method
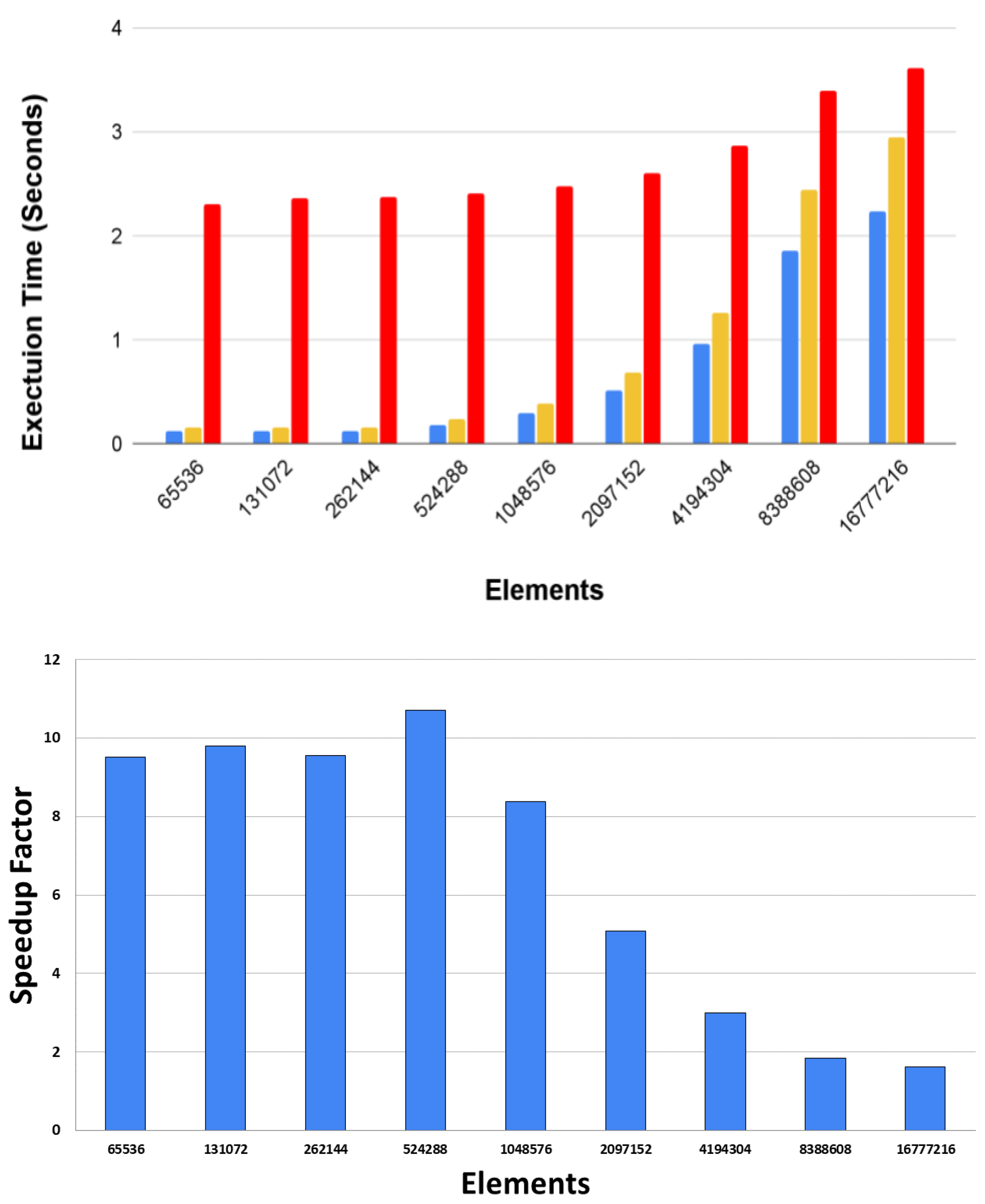
3.3. Performance Analysis
// Solve Ax=b using Conjugate Gradient method cudaGraph_t graph; cudaGraphExec_t instance; cudaStream_t stream1, stream2; cudaEvent_t kernelEvent1, kernelEvent2; // Initial setting cudaMemcpy(r, b, DeviceToDevice); cudaMemcpy(p, r, DeviceToDevice); //stream1 is the origin stream cudaStreamBeginCapture(stream1, cudaStreamCaptureModelGlobal); cudaMemcpyAsync(rOld, r, DeviceToDevice, stream1); cublasDspmv(cublasHandle, A, p, s); alpha1 = cublasDdot1(r, r); alpha2 = cublasDdot2(p, s); alpha = r1_div_x<<<..., stream1>>>(alpha1, alpha2); //AXPY Fork cublasDaxpy1(cublasHandle, alpha, p, x, stream1); cudaEventRecord(kernelEvent1, stream1); cudaStreamWaitEvent(stream2, kernelEvent1); cublasDaxpy2(cublasHandle, -alpha, s, r, stream2); //Join stream2 back to stream1 cudaEventRecord(kernelEvent2, stream2); cudaStreamWaitEvent(stream1, kernelEvent2); //DOT product Fork beta1 = cublasDdot1(cublasHandle, r, r, stream1); cudaEventRecord(kernelEvent1, stream1); cudaStreamWaitEvent(stream2, kernelEvent1); beta2 = cublasDdot2(cublasHandle, rOld, rOld, stream2); //Join stream2 back to stream1 cudaEventRecord(kernelEvent2, stream2); cudaStreamWaitEvent(stream1, kernelEvent2); beta = r1_div_x<<<..., stream1>>>(beta1, beta2); cudaMemcpyAsync(rAux, r, DeviceToDevice, stream1); cublasDaxpy2(beta, p, rAux); cudaMemcpyAsync(p, rAux, DeviceToDevice, stream); condition = cublasDdot(r, r); cudaStreamSynchronize(stream1); cudaStreamEndCapture(stream1, graph); cudaGraphInstantiate(instance, graph); while (condition > tolerance^2 && k <= max_iter) { cudaGraphLaunch(instance, stream1); } |
4. Use Case II: Particle Swarm Optimization
void main () { //Initialization initParticle(array_population); calculateFitness(array_population); updatePopulationBest(array_population); //Computation while(i<ITERATIONS) { //findBestParticle kernel #pragma acc kernels deviceptr(array_population) for(int i=0; i<POPULATION; i++) findBestParticle(array_population[i]); //updateParticlePosition kernel #pragma acc kernels deviceptr(array_population) for(int i=0; i<POPULATION; i++) updateParticlePosition(array_population[i]); //calculateFitness kernel #pragma acc kernels deviceptr(array_population) for(int i=0; i<POPULATION; i++) calculateFitness(array_population[i]); //updateBestPopulation kernel #pragma acc kernels deviceptr(array_population) for(int i=0; i<POPULATION; i++) updateBestPopulation(array_population[i]); } } |
4.1. OpenACC and CUDA Graph Implementations of PSO
int main (int argc, char *argv[]) { cudaGraph_t graph; cudaGraphExec_t instance; cudaStream_t stream1, stream2; cudaEvent_t event1, event2; // Initialization initParticle(array_population); calculateFitness(array_population); updatePopulationBest(array_population); // Graph definition cudaStreamCreate(&stream1); cudaStreamCreate(&stream2); void* stream = acc_get_cuda_stream(acc_async_sync); acc_set_cuda_stream(0, stream1); cudaStreamBeginCapture(stream1, cudaStreamCaptureModeGlobal); // OpenACC Kernels findBestParticle(array_population, stream1); // Fork cudaEventRecord(event1, stream1); updateParticlePosition(array_population, stream1); calculateFitness(array_population, stream2); // Join cudaEventRecord(event2, stream2); cudaStreamWaitEvent(stream1, event2); updateBestPopulation(array_population, stream1); cudaStreamEndCapture(stream1 , &graph); cudaGraphExec_t graphExec; cudaGraphInstantiate(&graphExec, graph, NULL, NULL, 0); //Computation for (int i = 0; i < ITERATIONS; i++) { cudaGraphLaunch(graphExec, stream1); } } |
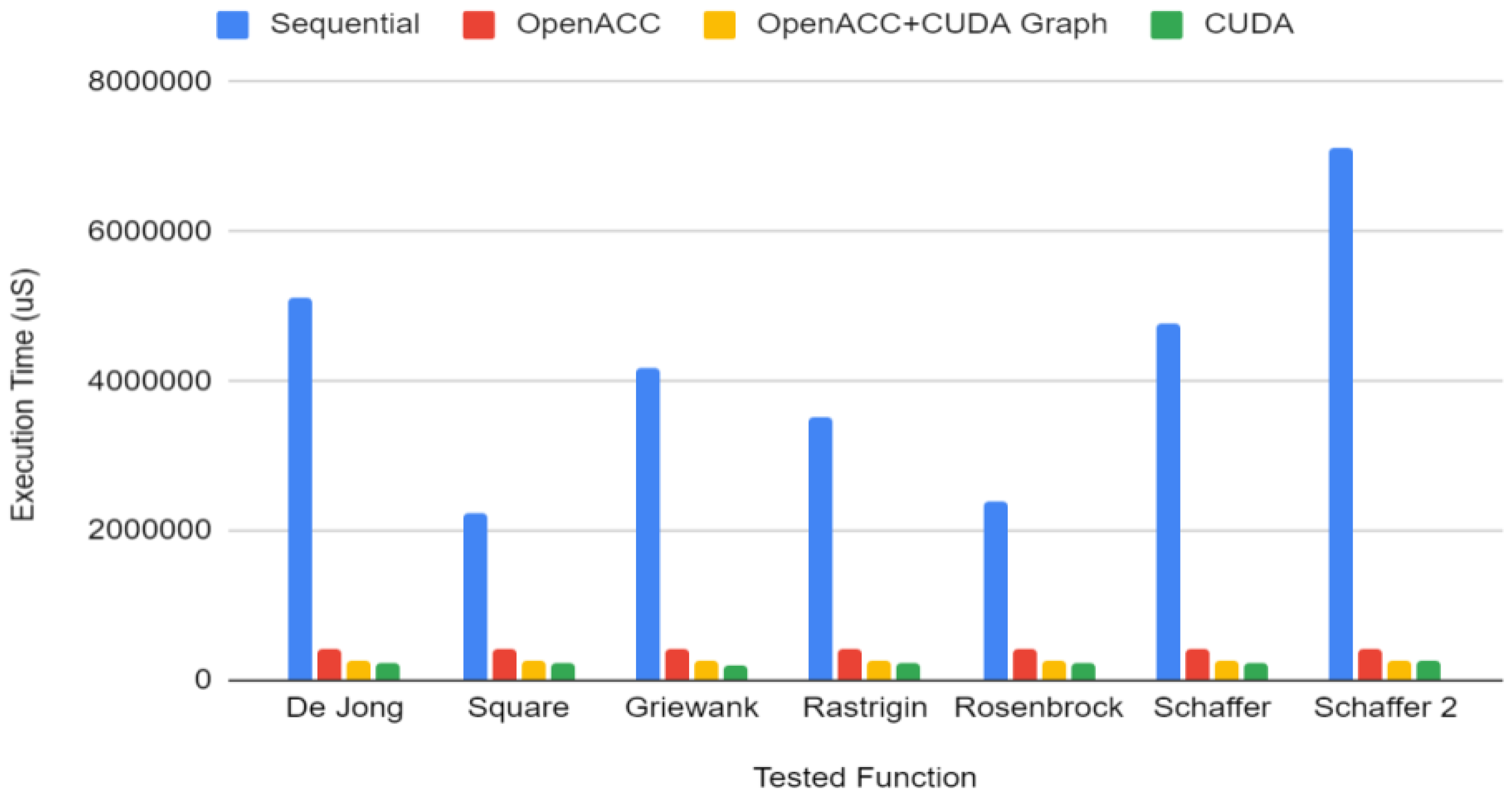
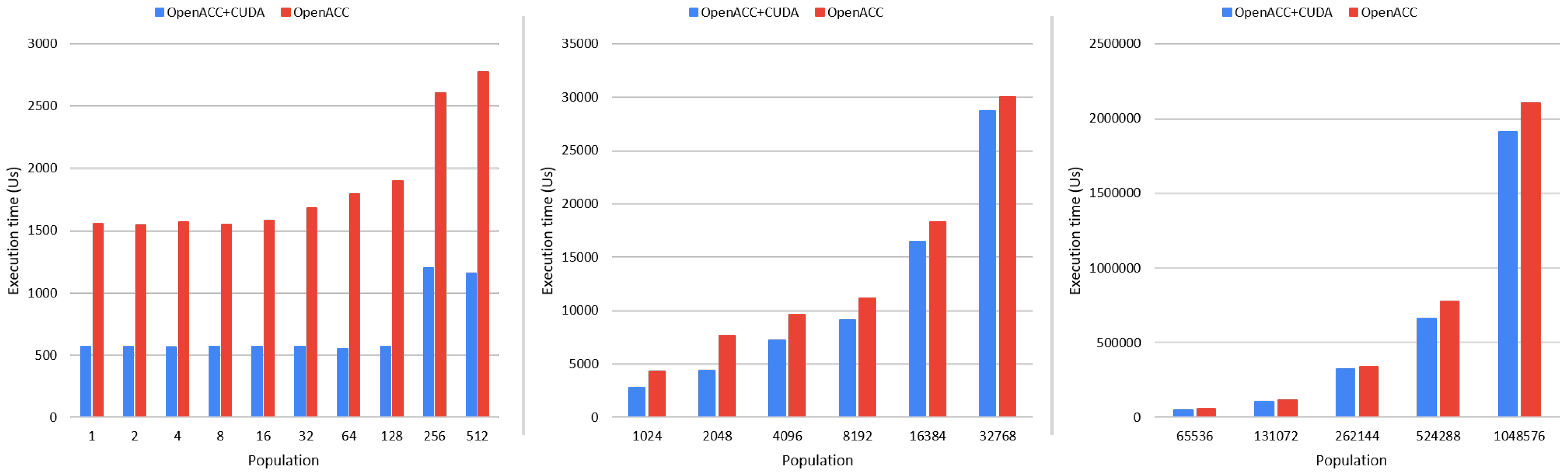
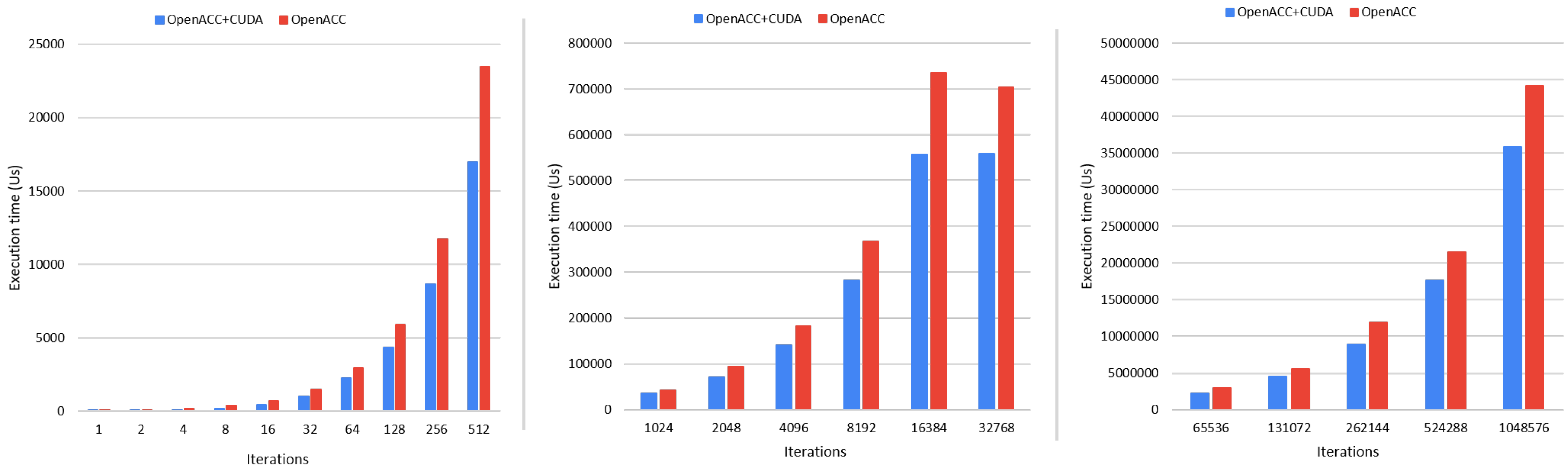
4.2. Performance Analysis
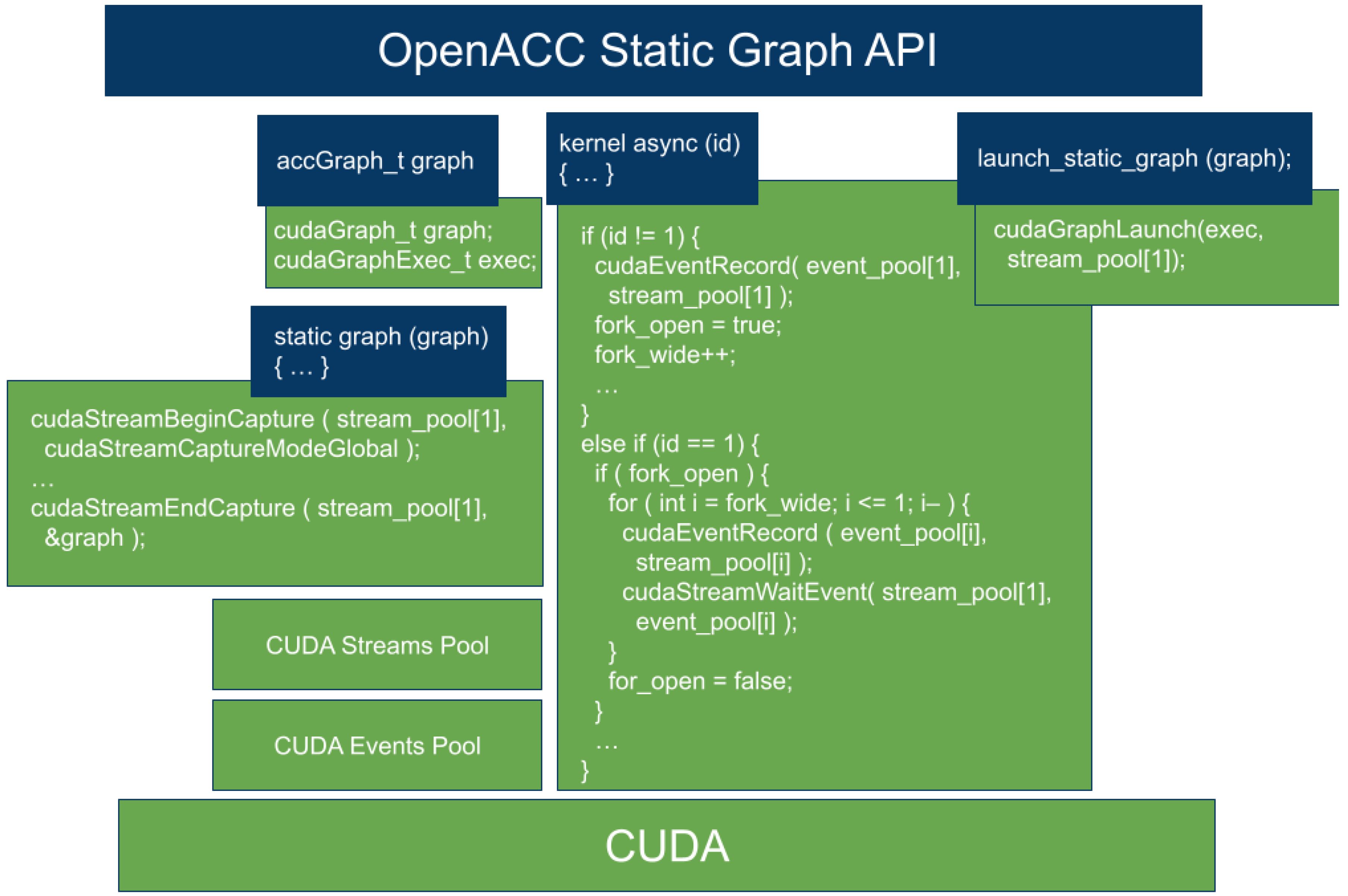
5. Directive-Based GPU Static Graph API Proposal
int main (int argc, char *argv[]) { accGraph_t graph; ... #pragma acc static_graph(graph) deviceptr(array_population) { // Enqueue #pragma acc kernels deviceptr(array_population) async(1) { findBestParticle(array_population); } // Fork & enqueue #pragma acc kernels deviceptr(array_population) async(1) { updateParticlePosition(array_population); } #pragma acc kernels deviceptr(array_population) async(2) { fitnessBestParticle(array_population); } // Join & enqueue #pragma acc kernels deviceptr(array_population) async(1) { updateBestPopulation(array_population); } } // End pragma acc static_graph for (int i = 0; i < ITERATIONS; i++) #pragma acc launch_static_graph(graph) deviceptr(array_population) } |
6. Related Work
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Toledo, L.; Peña, A.J.; Catalán, S.; Valero-Lara, P. Tasking in Accelerators: Performance Evaluation. In Proceedings of the 20th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT), Gold Coast, Australia, 5–7 December 2019; pp. 127–132. [Google Scholar]
- van der Pas, R.; Stotzer, E.; Terboven, C. Using OpenMP—The Next Step: Affinity, Accelerators, Tasking, and SIMD, 1st ed.; The MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Toledo, L.; Valero-Lara, P.; Vetter, J.; Peña, A.J. Static Graphs for Coding Productivity in OpenACC. In Proceedings of the 28th IEEE International Conference on High Performance Computing, Data, and Analytics, HiPC 2021, Bengaluru, India, 17–20 December 2021; pp. 364–369. [Google Scholar] [CrossRef]
- Valero-Lara, P.; Igual, F.D.; Prieto-Matías, M.; Pinelli, A.; Favier, J. Accelerating fluid-solid simulations (Lattice-Boltzmann & Immersed-Boundary) on heterogeneous architectures. J. Comput. Sci. 2015, 10, 249–261. [Google Scholar] [CrossRef]
- Valero-Lara, P.; Pinelli, A.; Prieto-Matías, M. Accelerating Solid-fluid Interaction using Lattice-boltzmann and Immersed Boundary Coupled Simulations on Heterogeneous Platforms. In Proceedings of the International Conference on Computational Science, ICCS 2014, Cairns, QLD, Australia, 10–12 June 2014; Abramson, D., Lees, M., Krzhizhanovskaya, V.V., Dongarra, J.J., Sloot, P.M.A., Eds.; Elsevier: Amsterdam, The Netherlands, 2014; Volume 29, pp. 50–61. [Google Scholar] [CrossRef]
- Valero-Lara, P.; Jansson, J. Heterogeneous CPU+GPU approaches for mesh refinement over Lattice-Boltzmann simulations. Concurr. Comput. Pract. Exp. 2017, 29, e3919. [Google Scholar] [CrossRef]
- Valero-Lara, P.; Jansson, J. Multi-domain Grid Refinement for Lattice-Boltzmann Simulations on Heterogeneous Platforms. In Proceedings of the 18th IEEE International Conference on Computational Science and Engineering (CSE 2015), Porto, Portugal, 21–23 October 2015; Plessl, C., Baz, D.E., Cong, G., Cardoso, J.M.P., Veiga, L., Rauber, T., Eds.; IEEE Computer Society: Montpellier, France, 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Valero-Lara, P. Multi-GPU acceleration of DARTEL (early detection of Alzheimer). In Proceedings of the 2014 IEEE International Conference on Cluster Computing (CLUSTER 2014), Madrid, Spain, 22–26 September 2014; IEEE Computer Society: Montpellier, France, 2014; pp. 346–354. [Google Scholar] [CrossRef]
- Valero-Lara, P. A GPU approach for accelerating 3D deformable registration (DARTEL) on brain biomedical images. In Proceedings of the 20th European MPI Users’s Group Meeting, EuroMPI’13, Madrid, Spain, 15–18 September 2013; Dongarra, J.J., Blas, J.G., Carretero, J., Eds.; ACM: New York, NY, USA, 2013; pp. 187–192. [Google Scholar] [CrossRef]
- Jordà, M.; Valero-Lara, P.; Peña, A.J. cuConv: CUDA implementation of convolution for CNN inference. Clust. Comput. 2022, 25, 1459–1473. [Google Scholar] [CrossRef]
- Catalán, S.; Usui, T.; Toledo, L.; Martorell, X.; Labarta, J.; Valero-Lara, P. Towards an Auto-Tuned and Task-Based SpMV (LASs Library). In Proceedings of the OpenMP: Portable Multi-Level Parallelism on Modern Systems—16th International Workshop on OpenMP (IWOMP 2020), Austin, TX, USA, 22–24 September 2020; Milfeld, K., de Supinski, B.R., Koesterke, L., Klinkenberg, J., Eds.; Springer: Berlin, Germany, 2020; Volume 12295, pp. 115–129. [Google Scholar] [CrossRef]
- Catalán, S.; Martorell, X.; Labarta, J.; Usui, T.; Díaz, L.A.T.; Valero-Lara, P. Accelerating Conjugate Gradient using OmpSs. In Proceedings of the 20th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT), Gold Coast, Australia, 5–7 December 2019; pp. 121–126. [Google Scholar]
- Valero-Lara, P.; Pinelli, A.; Prieto-Matías, M. Fast finite difference Poisson solvers on heterogeneous architectures. Comput. Phys. Commun. 2014, 185, 1265–1272. [Google Scholar] [CrossRef]
- Valero-Lara, P.; Andrade, D.; Sirvent, R.; Labarta, J.; Fraguela, B.B.; Doallo, R. A Fast Solver for Large Tridiagonal Systems on Multi-Core Processors (Lass Library). IEEE Access 2019, 7, 23365–23378. [Google Scholar] [CrossRef]
- Valero-Lara, P.; Pelayo, F.L. Full-overlapped concurrent kernels. In Proceedings of the 28th International Conference on Architecture of Computing Systems (ARCS), Porto, Portugal, 24–27 March 2015; pp. 1–8. [Google Scholar]
- Valero-Lara, P.; Nookala, P.; Pelayo, F.L.; Jansson, J.; Dimitropoulos, S.; Raicu, I. Many-task computing on many-core architectures. Scalable Comput. Pract. Exp. 2016, 17, 32–46. [Google Scholar] [CrossRef][Green Version]
- Chandrasekaran, S.; Juckeland, G. OpenACC for Programmers: Concepts and Strategies, 1st ed.; Addison-Wesley Professional: Boston, MA, USA, 2017. [Google Scholar]
- Bonati, C.; Calore, E.; Coscetti, S.; D’elia, M.; Mesiti, M.; Negro, F.; Schifano, S.F.; Tripiccione, R. Development of scientific software for HPC architectures using OpenACC: The case of LQCD. In Proceedings of the IEEE/ACM 1st International Workshop on Software Engineering for High Performance Computing in Science, Florence, Italy, 18 May 2015; pp. 9–15. [Google Scholar]
- Dietrich, R.; Juckeland, G.; Wolfe, M. OpenACC programs examined: A performance analysis approach. In Proceedings of the 44th International Conference on Parallel Processing (ICPP), Beijing, China, 1–4 September 2015; pp. 310–319. [Google Scholar]
- Chen, C.; Yang, C.; Tang, T.; Wu, Q.; Zhang, P. OpenACC to Intel Offload: Automatic translation and optimization. In Computer Engineering and Technology; Springer: Berlin/Heidelberg, Germany, 2013; pp. 111–120. [Google Scholar]
- Herdman, J.A.; Gaudin, W.P.; McIntosh-Smith, S.; Boulton, M.; Beckingsale, D.A.; Mallinson, A.C.; Jarvis, S.A. Accelerating hydrocodes with OpenACC, OpenCL and CUDA. In Proceedings of the SC Companion: High Performance Computing, Networking Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012. [Google Scholar]
- Alan, G. Getting Started with CUDA Graphs. 2019. Available online: https://developer.nvidia.com/blog/cuda-graphs/ (accessed on 13 April 2022).
- Shewchuk, J.R. An Introduction to the Conjugate Gradient Method without the Agonizing Pain; Technical Report; Carnegie Mellon University: Pittsburgh, PA, USA, 1994. [Google Scholar]
- Corp., N. NVIDIA CUDA-Samples. 2022. Available online: https://github.com/NVIDIA/cuda-samples/tree/master/Samples/4_CUDA_Libraries/conjugateGradientCudaGraphs (accessed on 13 April 2022).
- Ruiz, D.; Spiga, F.; Casas, M.; Garcia-Gasulla, M.; Mantovani, F. Open-source shared memory implementation of the HPCG benchmark: Analysis, improvements and evaluation on Cavium ThunderX2. In Proceedings of the 17th International Conference on High Performance Computing & Simulation (HPCS), Dublin, Ireland, 15–19 July 2019; pp. 225–232. [Google Scholar]
- Eberhart; Shi, Y. Particle Swarm Optimization: Developments, applications and resources. In Proceedings of the 2001 Congress on Evolutionary Computation (IEEE Cat. No. 01TH8546), Seoul, Korea, 27–30 May 2001; pp. 81–86. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the International Conference on Neural Networks (ICNN), Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle Swarm Optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Benchmark Set. In Particle Swarm Optimization; John Wiley and Sons, Ltd.: Hoboken, NJ, USA, 2010; Chapter 4; pp. 51–58. Available online: https://onlinelibrary.wiley.com/doi/pdf/10.1002/9780470612163.ch4 (accessed on 13 April 2022).
- Landaverde, R.; Zhang, T.; Coskun, A.K.; Herbordt, M. An investigation of Unified Memory access performance in CUDA. In Proceedings of the IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 9–11 September 2014. [Google Scholar]
- Jarzabek, U.; Czarnul, P. Performance Evaluation of Unified Memory and Dynamic Parallelism for selected parallel CUDA applications. J. Supercomput. 2017, 73, 5378–5401. [Google Scholar] [CrossRef]
- Li, X. Comparing programmer productivity in OpenACC and CUDA: An empirical investigation. Int. J. Comput. Sci. Eng. Appl. (IJCSEA) 2016, 6, 1–15. [Google Scholar] [CrossRef]
- Calore, E.; Gabbana, A.; Kraus, J.; Schifano, S.F.; Tripiccione, R. Performance and portability of accelerated Lattice Boltzmann applications with OpenACC. arXiv 2017, arXiv:1703.00186. [Google Scholar] [CrossRef]
- Valero-Lara, P.; Pelayo, F.L. Analysis in performance and new model for multiple kernels executions on many-core architectures. In Proceedings of the IEEE 12th International Conference on Cognitive Informatics and Cognitive Computing (ICCI*CC), New York, NY, USA, 16–18 July 2013; pp. 189–194. [Google Scholar]
- Pallipuram, V.; Bhuiyan, M.; Smith, M. A comparative study of GPU programming models and architectures using neural networks. J. Supercomput.-TJS 2011, 61, 673–718. [Google Scholar] [CrossRef]
- Memeti, S.; Li, L.; Pllana, S.; Kołodziej, J.; Kessler, C. Benchmarking OpenCL, OpenACC, OpenMP, and CUDA: Programming productivity, performance, and energy consumption. In Proceedings of the Workshop on Adaptive Resource Management and Scheduling for Cloud Computing, New York, NY, USA, 28 July 2017. [Google Scholar]
- Ashraf, M.U.; Alburaei Eassa, F.; Ahmad Albeshri, A.; Algarni, A. Performance and power efficient massive parallel computational model for HPC heterogeneous exascale systems. IEEE Access 2018, 6, 23095–23107. [Google Scholar] [CrossRef]
- Augonnet, C.; Thibault, S.; Namyst, R.; Wacrenier, P.A. StarPU: A unified platform for task scheduling on heterogeneous multicore architectures. Concurr. Comput. Pract. Exper. 2011, 23, 187–198. [Google Scholar] [CrossRef]
- Duran, A.; Ayguadé, E.; Badia, R.M.; Labarta, J.; Martinell, L.; Martorell, X.; Planas, J. OmpSs: A proposal for programming heterogeneous multi-core architectures. Parallel Process. Lett. 2011, 21, 173–193. [Google Scholar] [CrossRef]
- Kato, S.; Lakshmanan, K.; Rajkumar, R.; Ishikawa, Y. TimeGraph: GPU scheduling for real-time multi-tasking environments. In Proceedings of the USENIX Annual Technical Conference (ATC), Portland, OR, USA, 15–17 June 2011. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Function | Formula |
|---|---|
| Sphere | |
| De Jong | |
| Griewank | |
| Rastrigin | |
| Rosenbrock | |
| Schaffer | |
| Schaffer 2 |
| Application | |
|---|---|
| Conjugate Gradient | |
| NVIDIA Ref./CUDA + Static Graph | CUDA/CUDA + Static Graph |
| 2×–11× | ≈1.3× |
| Particle Swarm Optimization | |
| OpenACC/OpenACC + Static Graph | CUDA/OpenACC + Static Graph |
| 1.3×–4× | 0.9×–0.95× |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Toledo, L.; Valero-Lara, P.; Vetter, J.S.; Peña, A.J. Towards Enhancing Coding Productivity for GPU Programming Using Static Graphs. Electronics 2022, 11, 1307. https://doi.org/10.3390/electronics11091307
Toledo L, Valero-Lara P, Vetter JS, Peña AJ. Towards Enhancing Coding Productivity for GPU Programming Using Static Graphs. Electronics. 2022; 11(9):1307. https://doi.org/10.3390/electronics11091307
Chicago/Turabian StyleToledo, Leonel, Pedro Valero-Lara, Jeffrey S. Vetter, and Antonio J. Peña. 2022. "Towards Enhancing Coding Productivity for GPU Programming Using Static Graphs" Electronics 11, no. 9: 1307. https://doi.org/10.3390/electronics11091307
APA StyleToledo, L., Valero-Lara, P., Vetter, J. S., & Peña, A. J. (2022). Towards Enhancing Coding Productivity for GPU Programming Using Static Graphs. Electronics, 11(9), 1307. https://doi.org/10.3390/electronics11091307