
Preserving Privacy of High-Dimensional Data by l-Diverse Constrained Slicing




Abstract
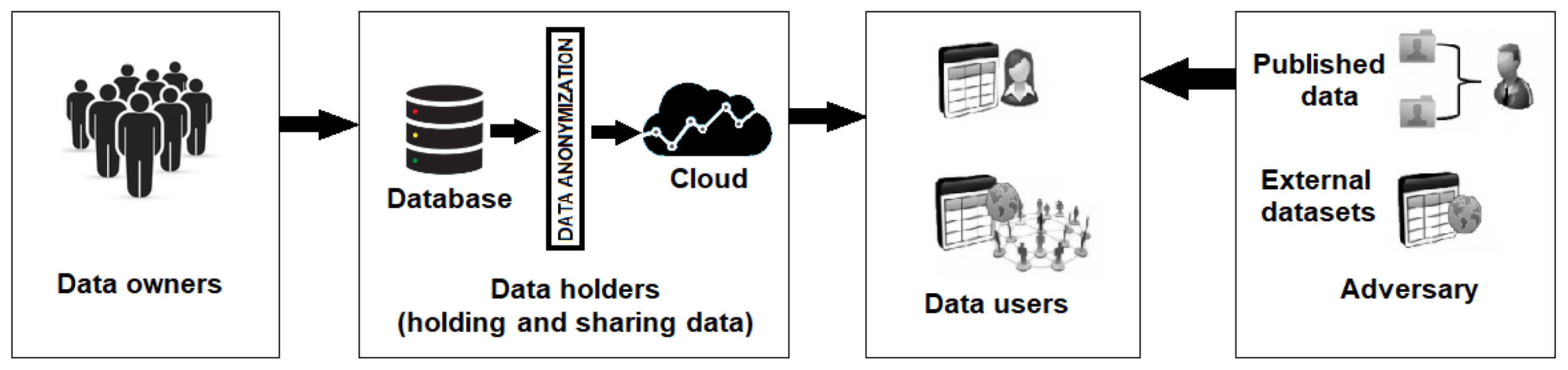
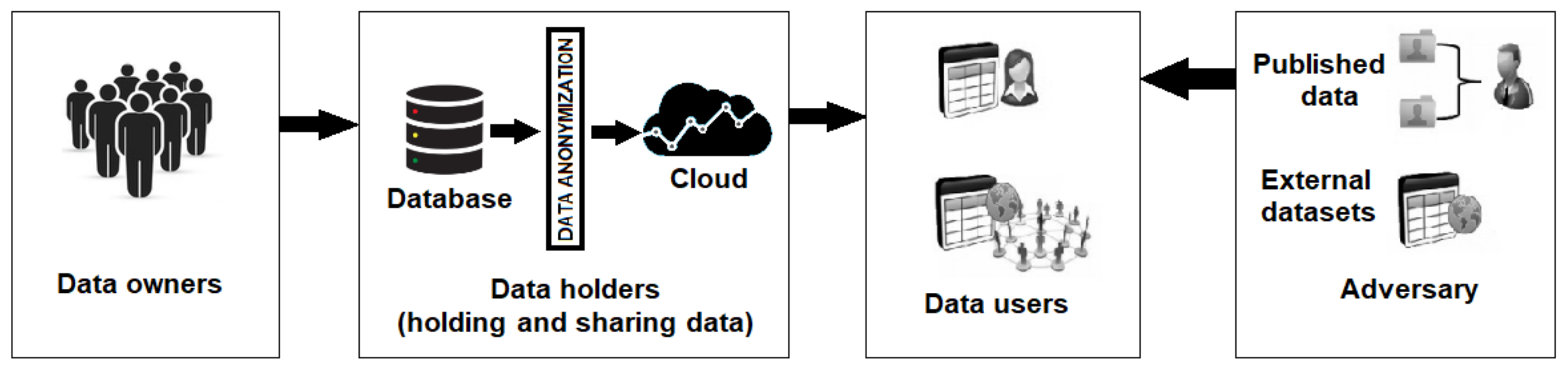
:1. Introduction
2. Literature Review
3. Preliminaries
3.1. Basic Concepts
- Explicit identifier: These are the attributes that may uniquely identify an individual/data owner in published information. The examples for explicit identifiers are ID, name, license number, social security number, etc.
- Quasi-identifying (QID) attributes: These are the general social attributes that can be used in a group (not independently) by an adversary to launch a privacy attack. The examples for quasi-identifiers are age, gender, height, weight, zip code, etc.
- Sensitive attributes: These are the attributes a data owner does not want to disclose or reveal publicly. A clear privacy leakage of someone’s sensitive attribute may lead to discrimination, job issues, social embarrassment, or even life threats. The examples for sensitive attributes are disease, salary, diagnostic criteria, symptoms, income, profit, loss, etc.
3.2. Formal Definitions
3.3. Revisiting a State-of-the-Art Privacy Approach for High-Dimensional Data
4. Proposed Model
4.1. Vertical Fragmentation
| Algorithm 1 Fragmentation of the raw data. |
| Require: D: raw data |
| A: attributes A1, A2... |
| Cls: class attribute in raw data |
| S: set of attributes in raw data D |
| Ensure: F: fragmentation of raw data; divide into two fragments based on gender |
|
4.2. l-Diverse Constrained Slicing
| Algorithm 2 Fragmentation of the raw data |
|
- 1.
- contains a column called “GID” and all tuples in except Cid.
- 2.
- Each tuple has tuple such that is the ID of the hosting group of t in , and is an interval covering . The value of also proves Property 4.
- 3.
- For each QI, quasi identifier of , might contain any tuples such that is a value in the domain of Cs, t*/c[Cg] equal to the GID of QI, and t * [Ci//qi] (1 ≤ i ≤ d) is an interval to Property 4.
- 4.
- All attributes in T*(j) with the similar Cg have an similar value on QI attribute. These tuples make a quasi-identifier group in T*(j) whose ID is the Cg value in the group.
4.3. Protection Analysis
5. Experimental Evaluation
5.1. Preparation and Setting
5.2. Evaluation Matrices
5.3. Information Loss
5.4. Counterfeits
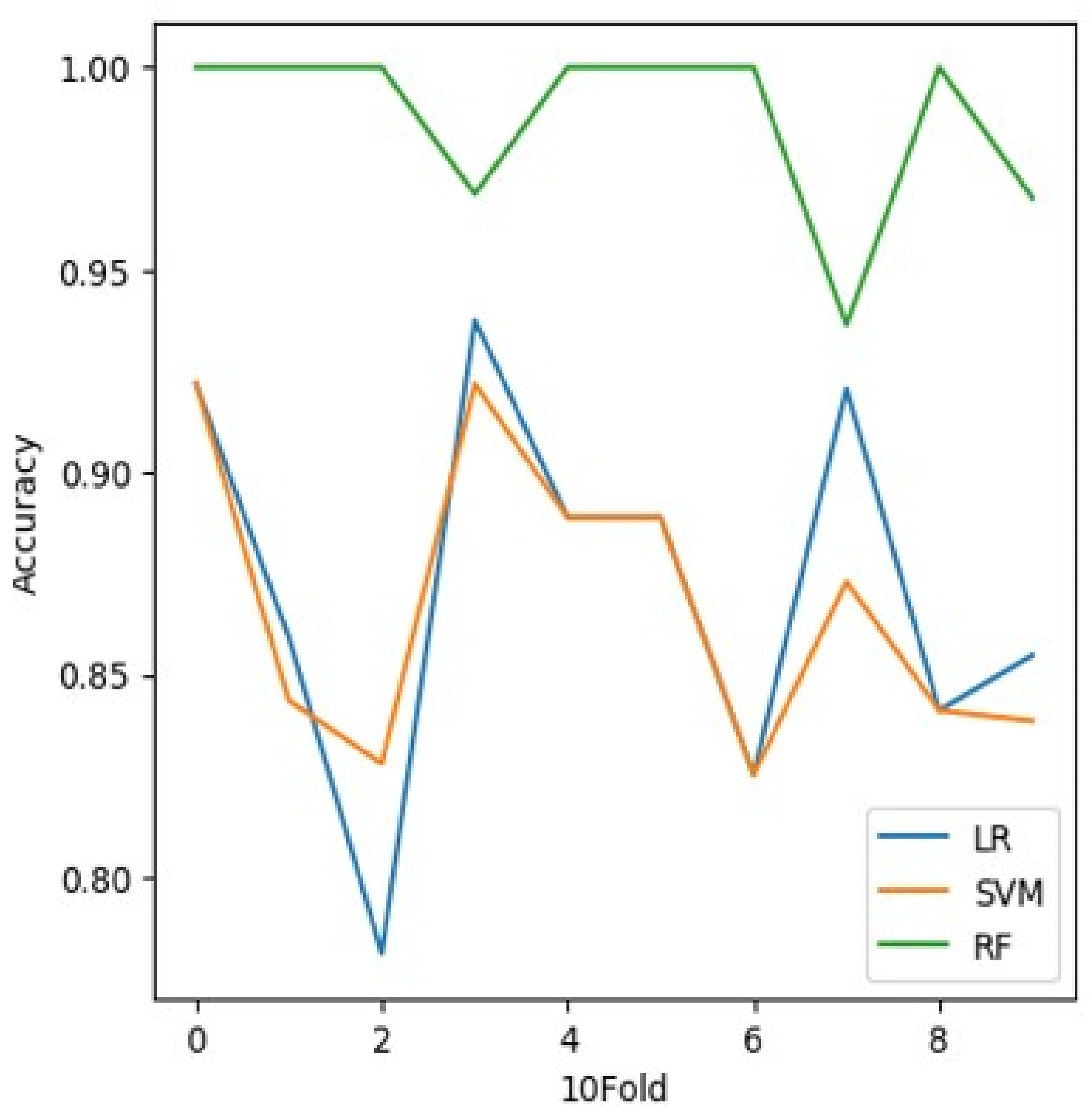
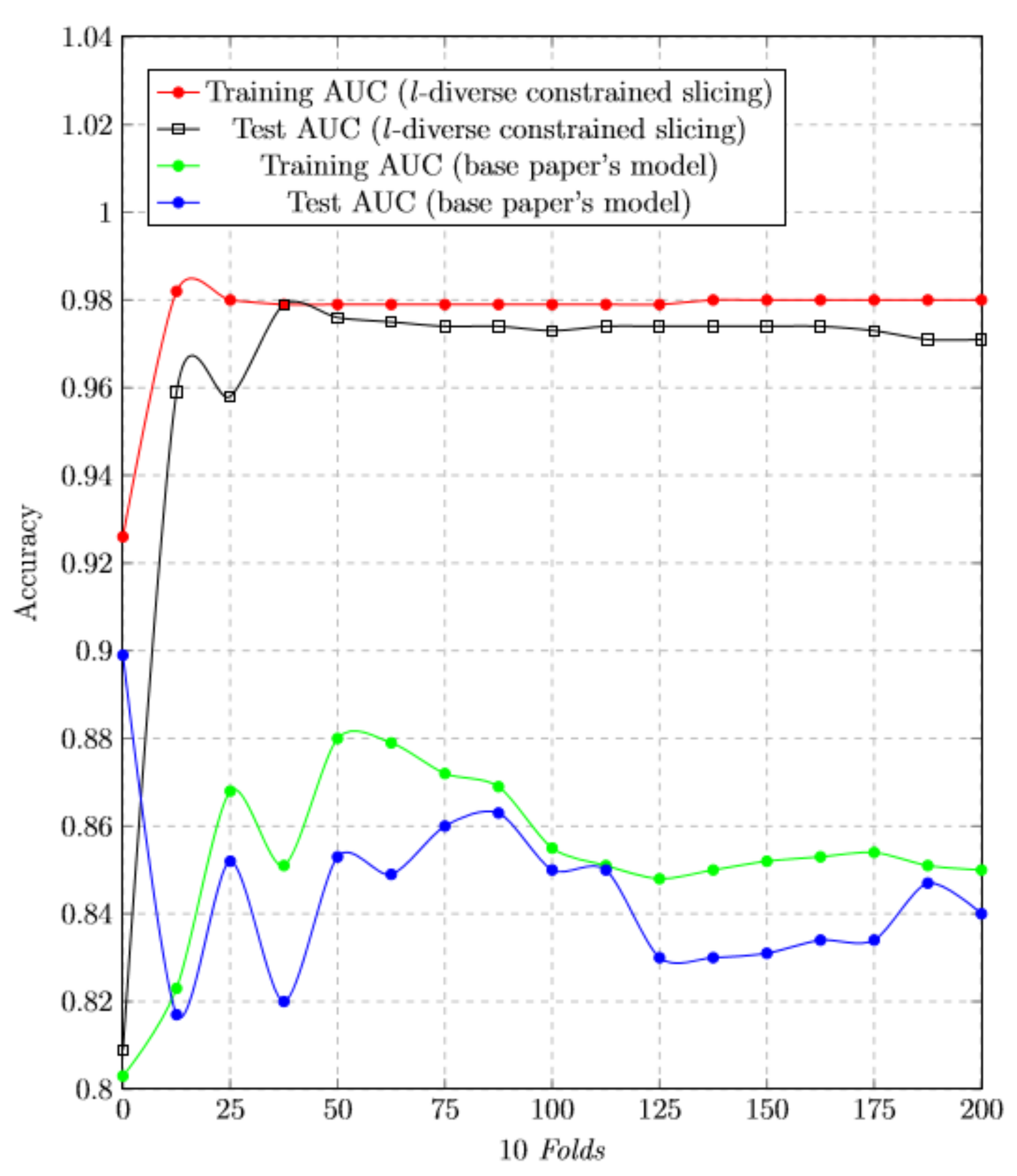
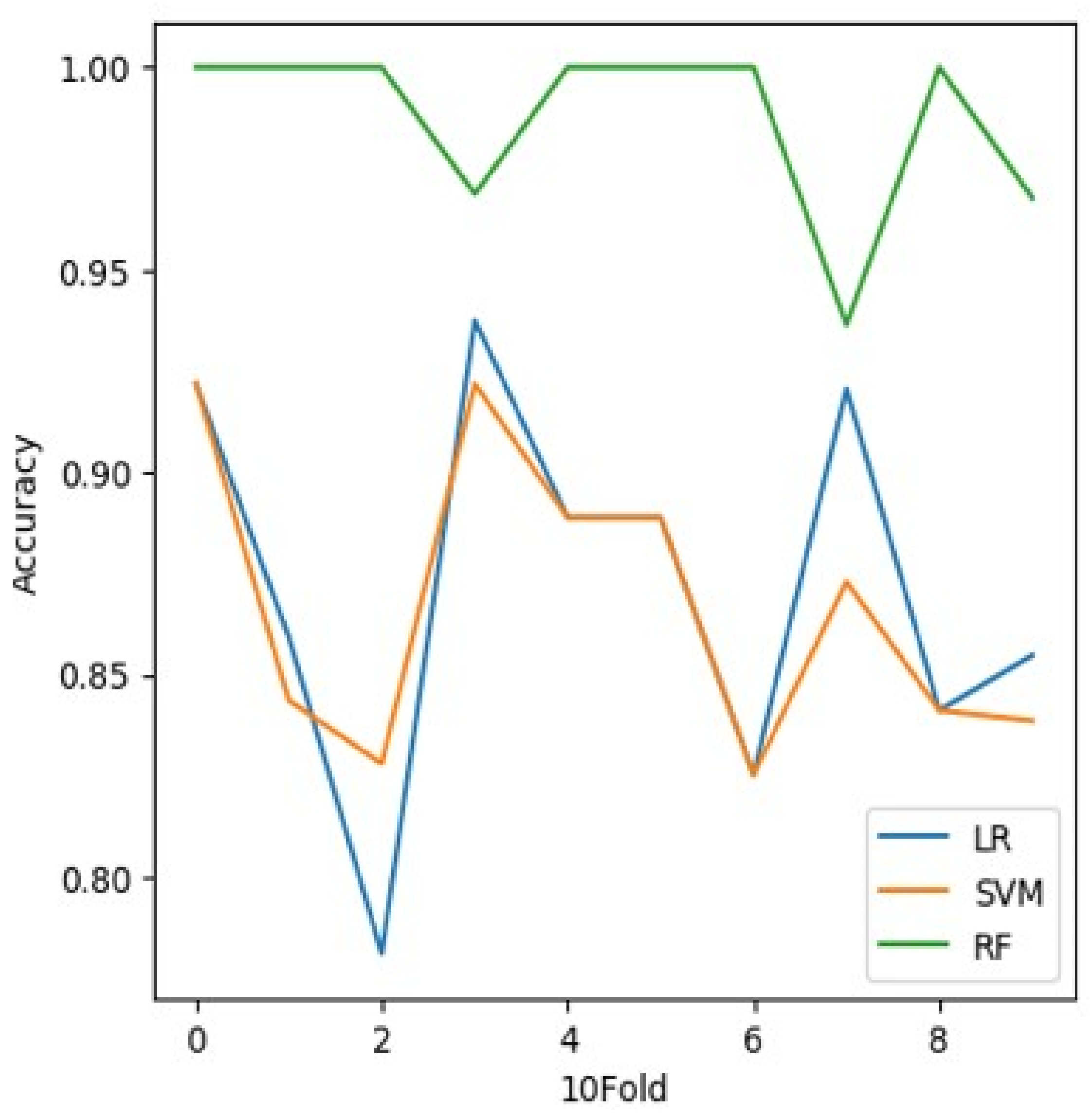
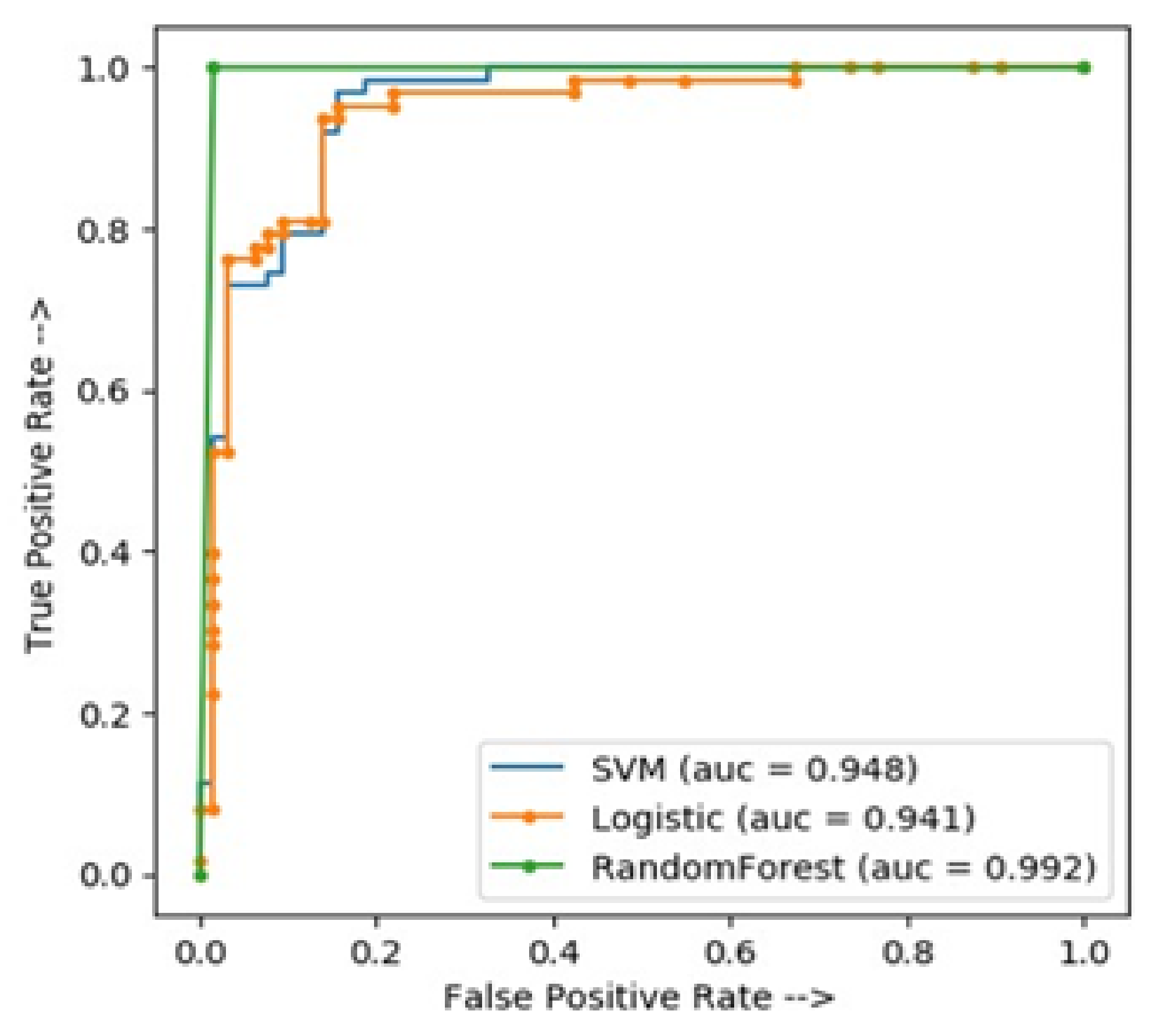
5.5. Accuracy
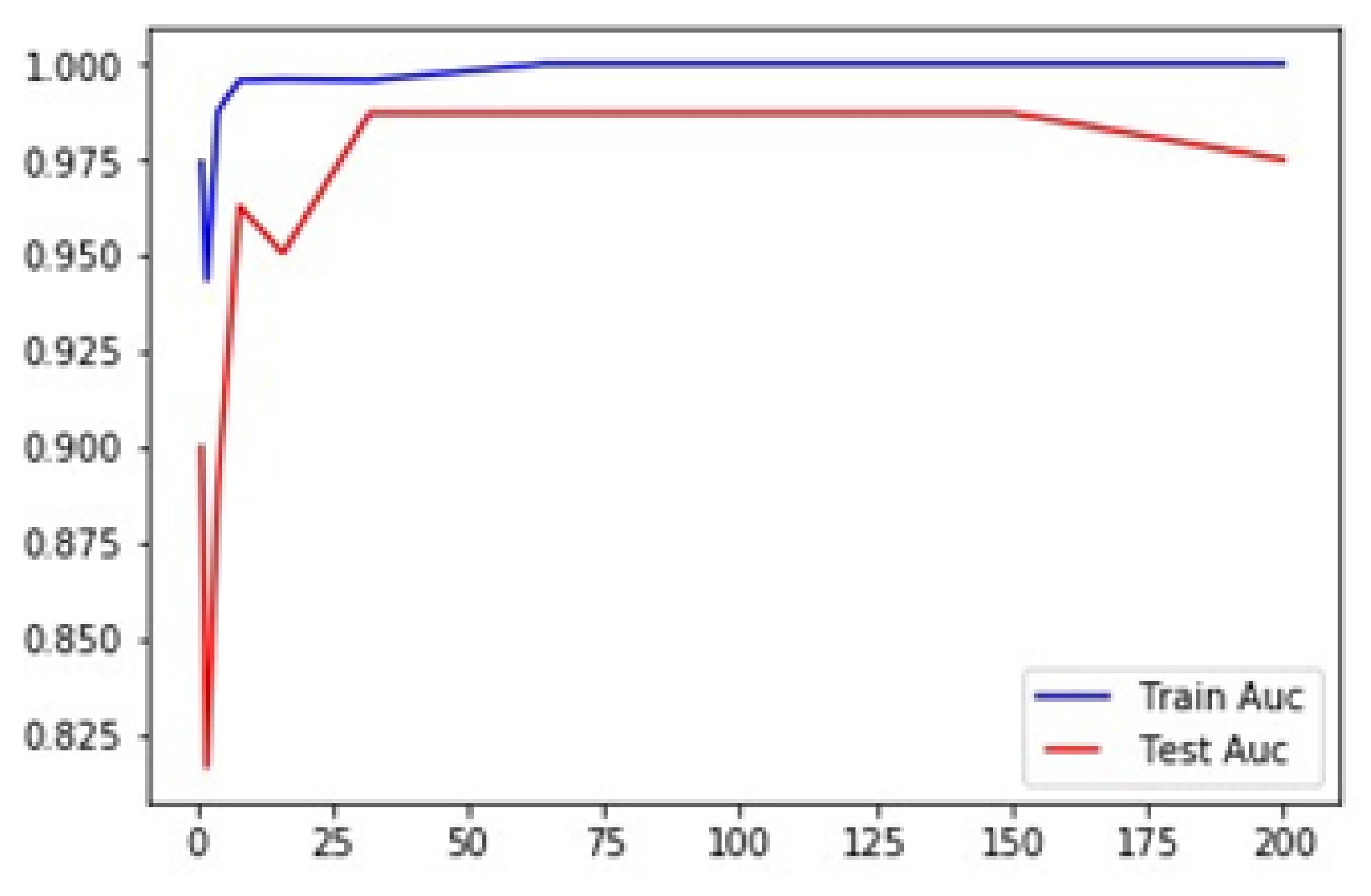
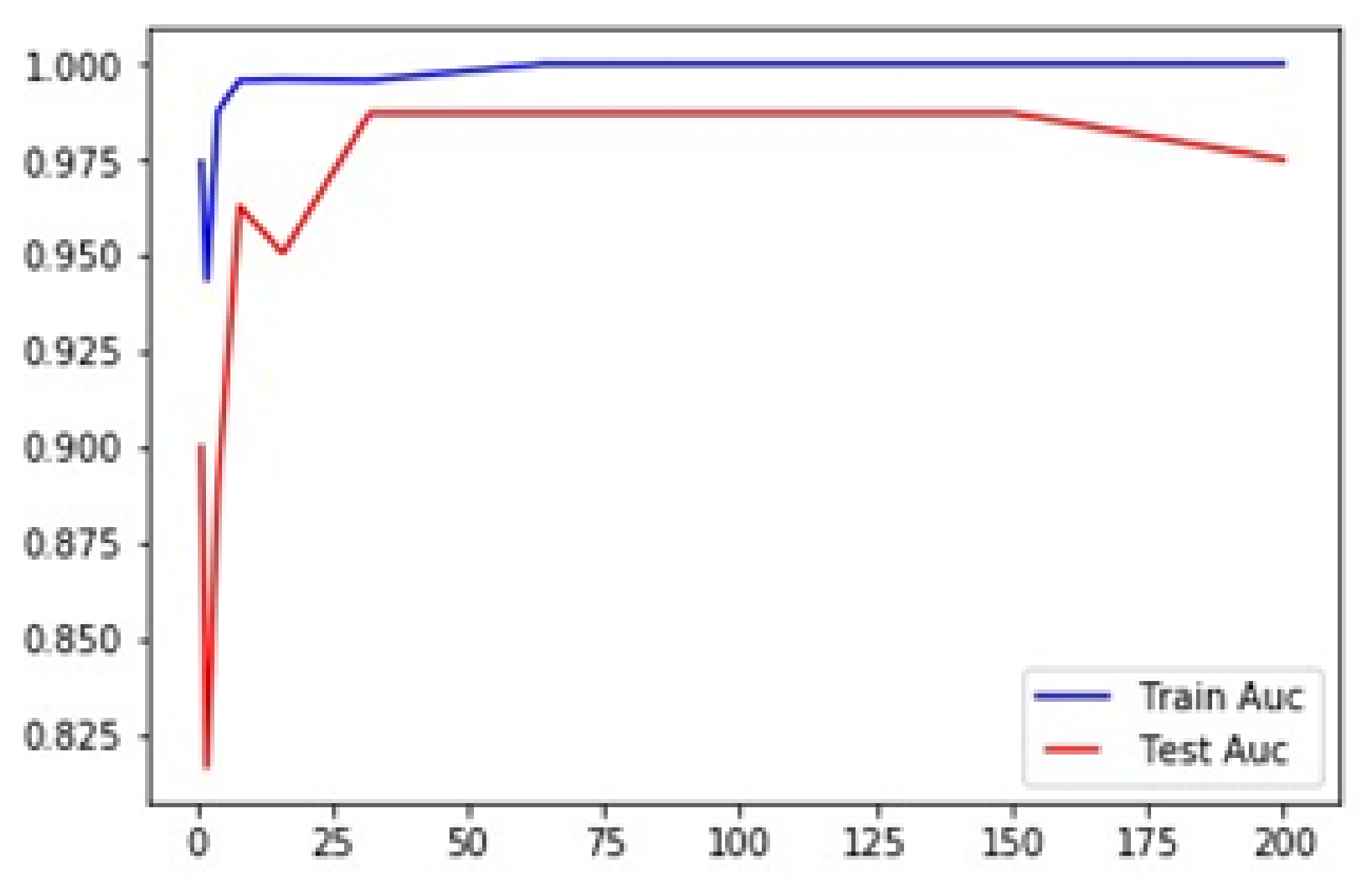
5.6. K-Fold Cross-Validation:
5.7. Training Test Accuracy of RF
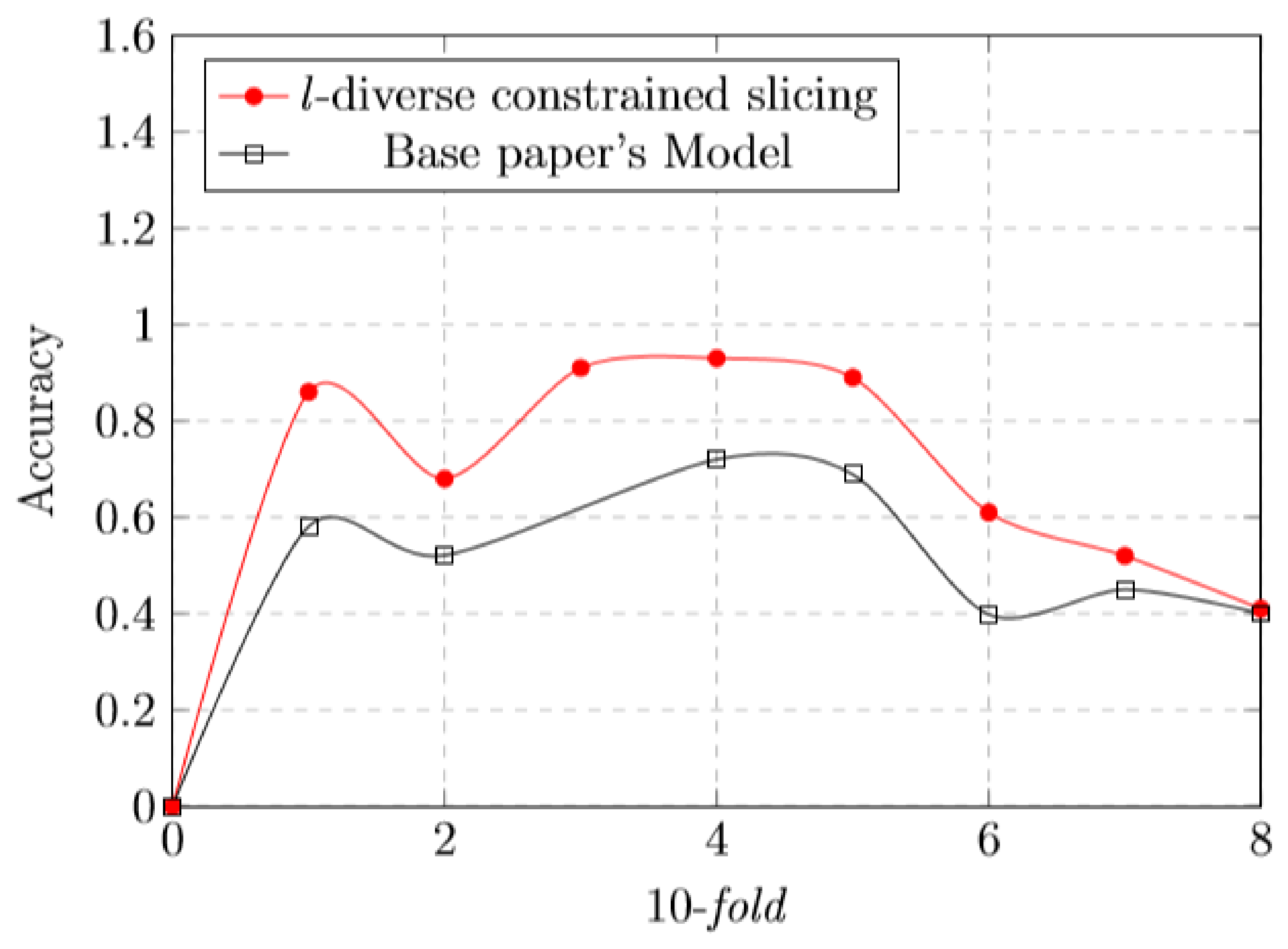
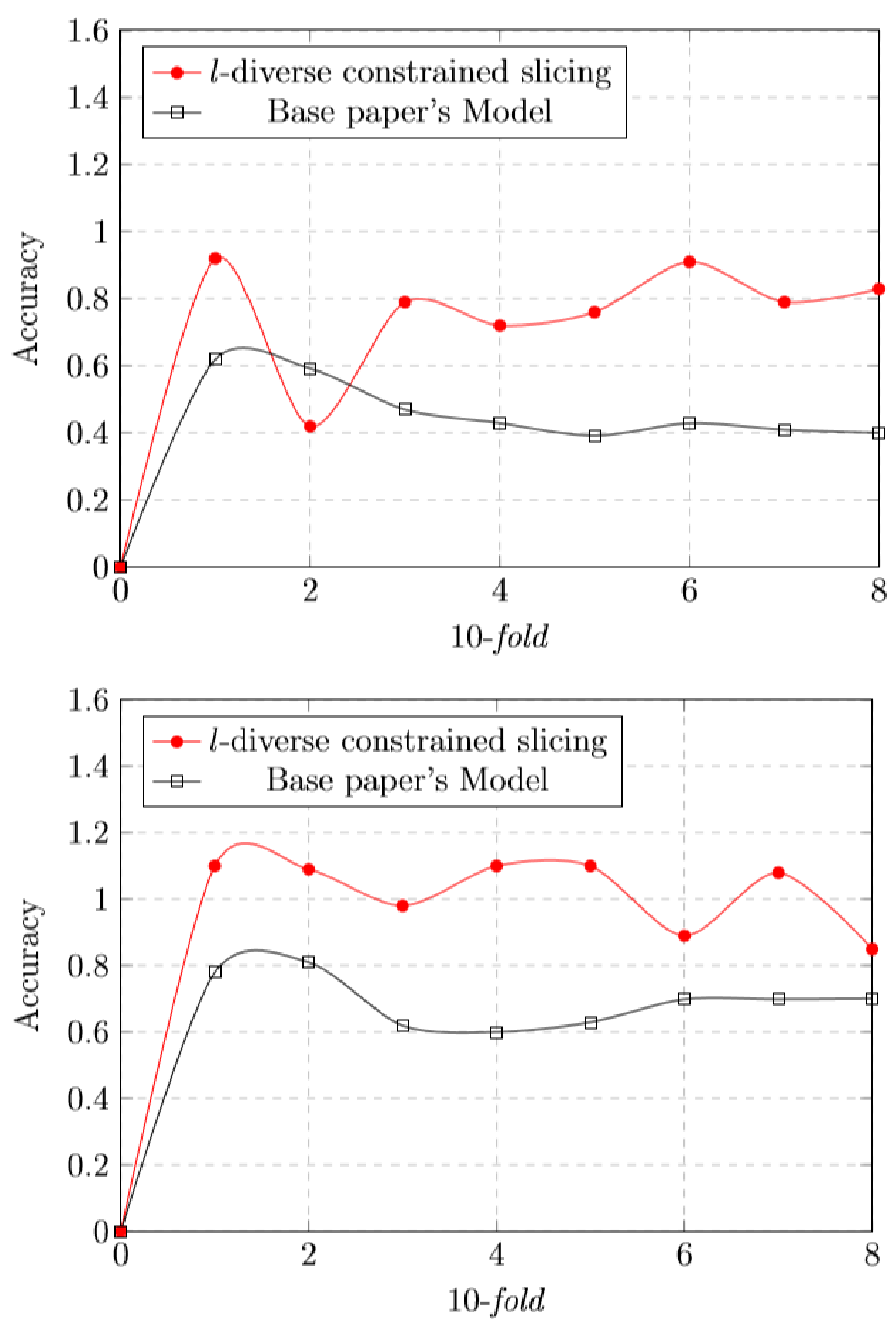
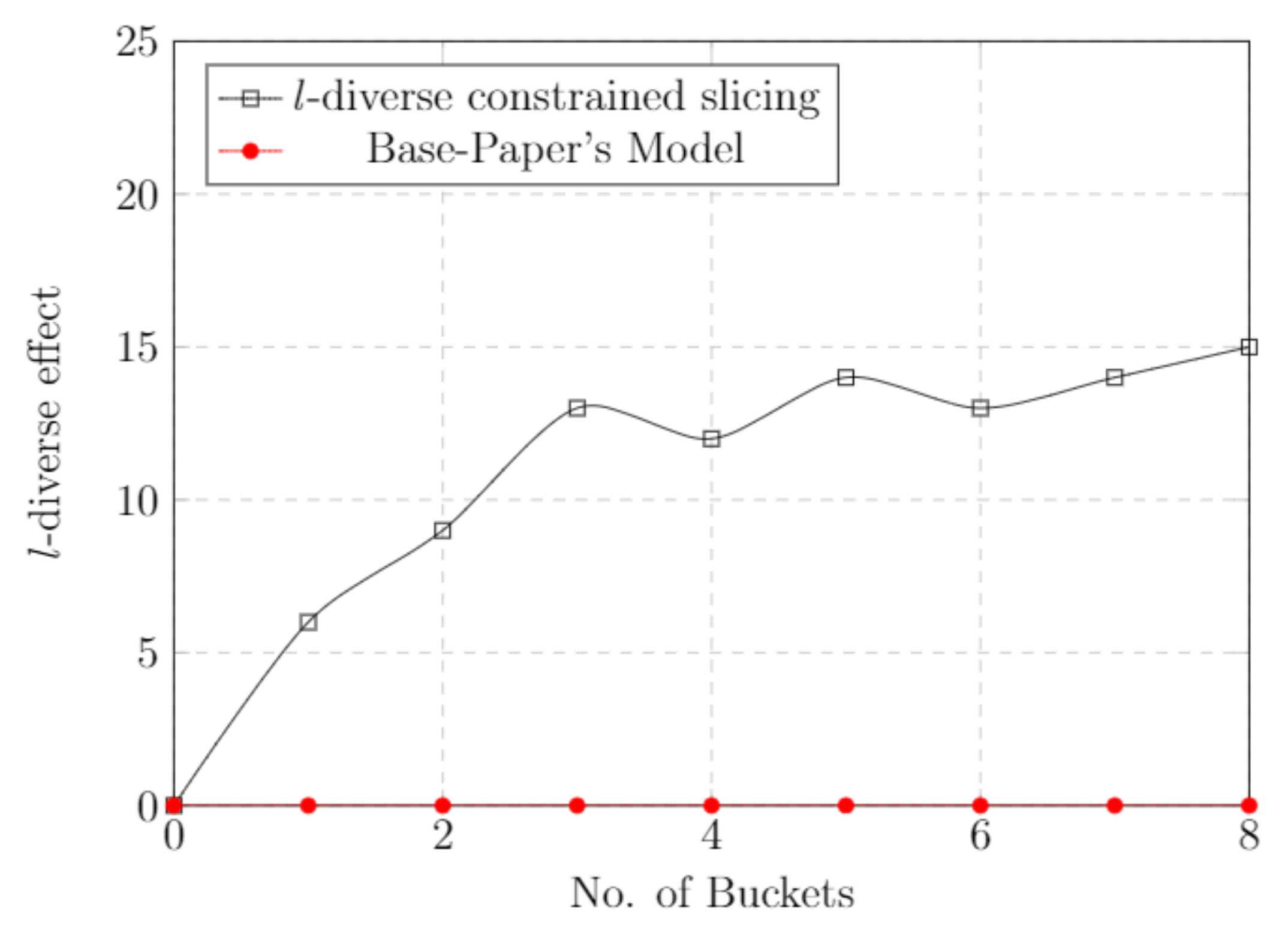
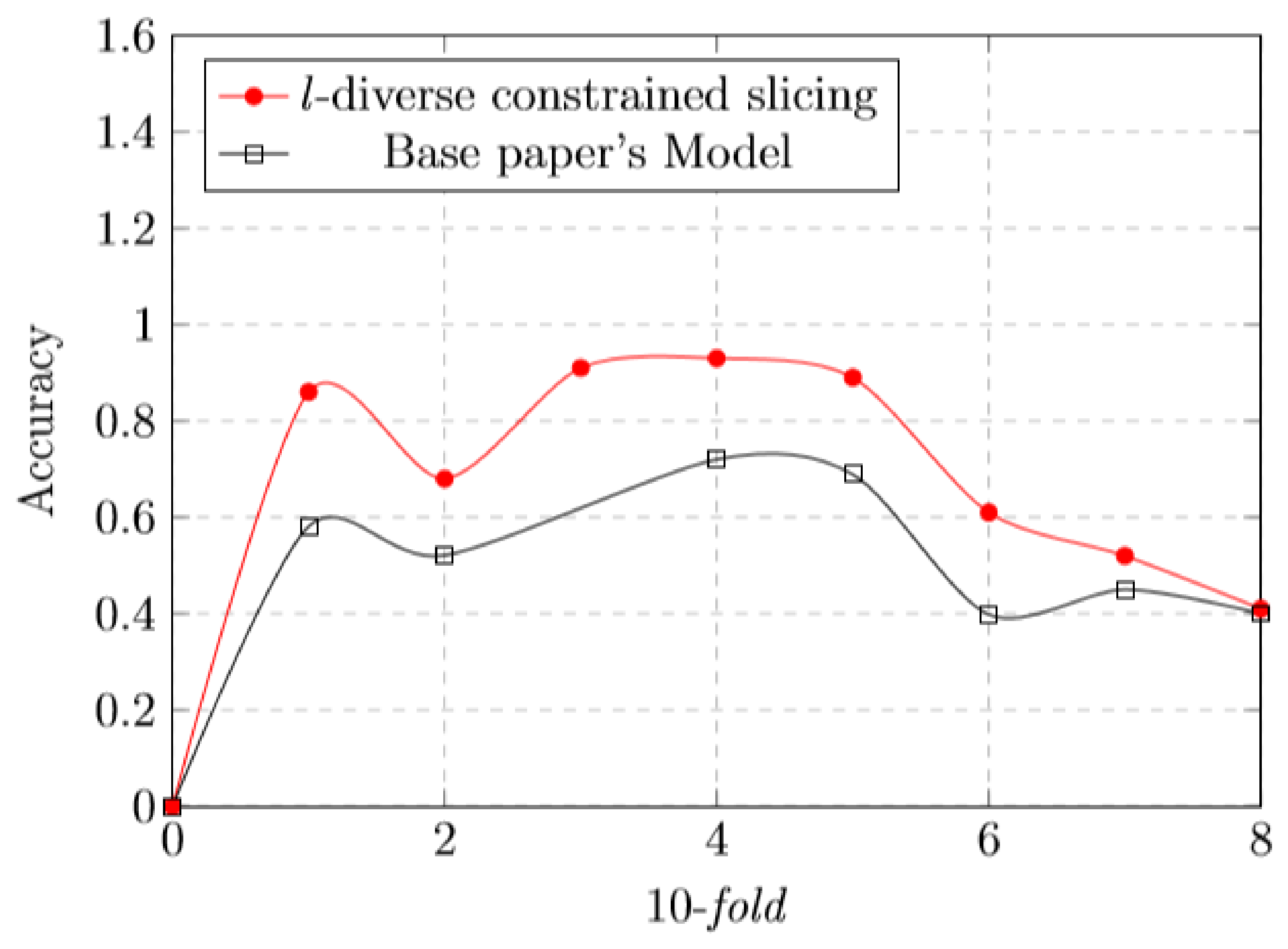
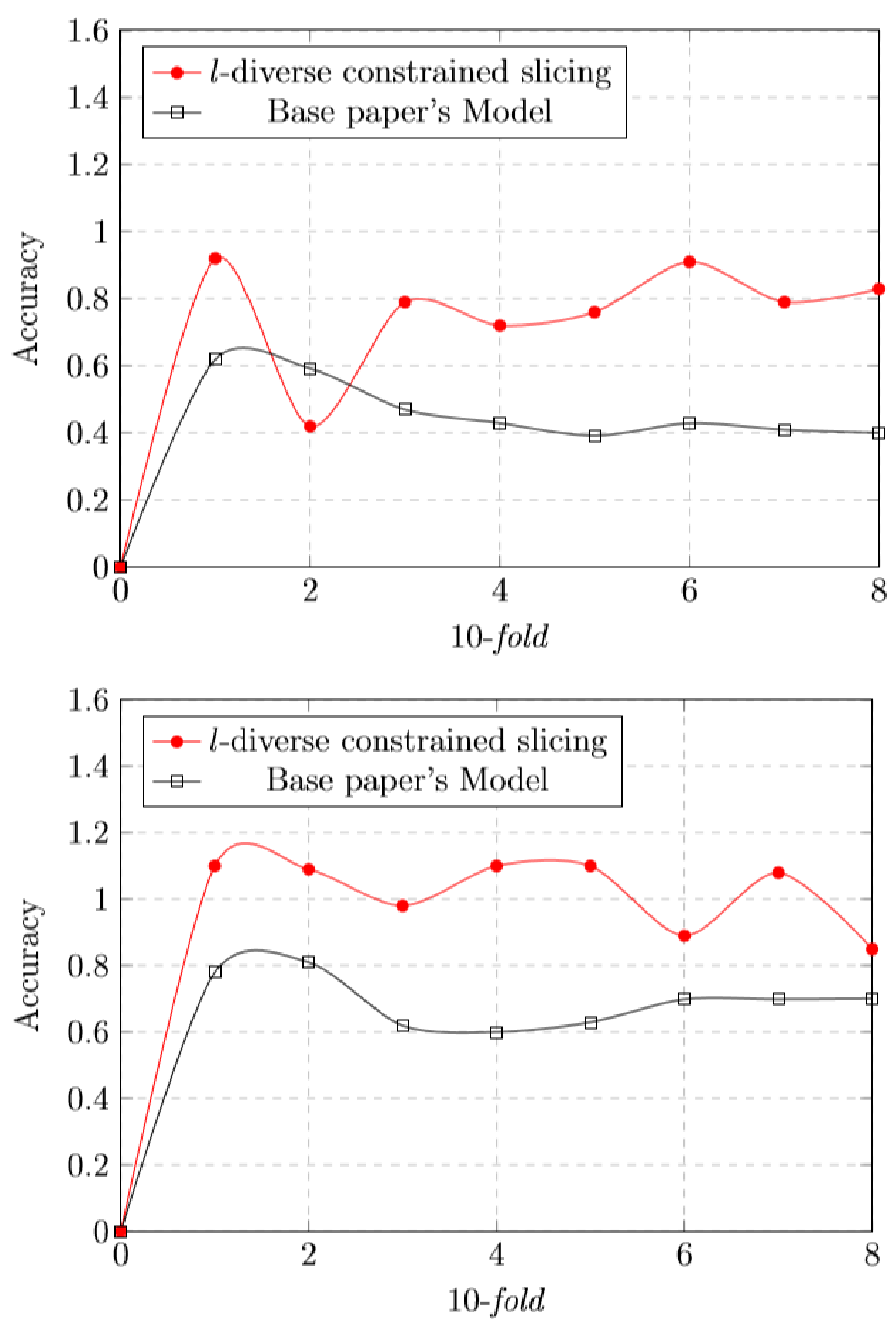
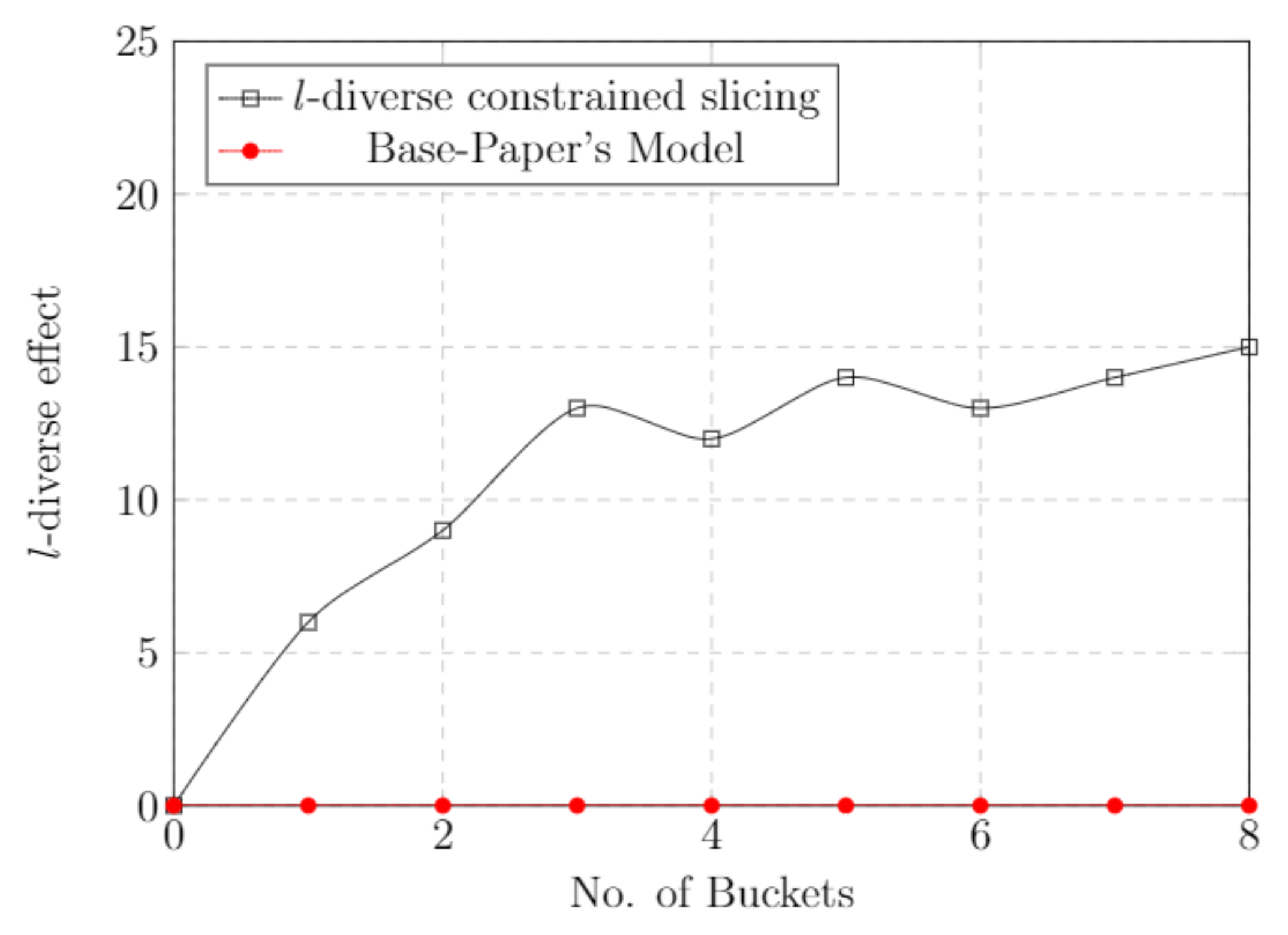
5.8. l-Diverse Effect
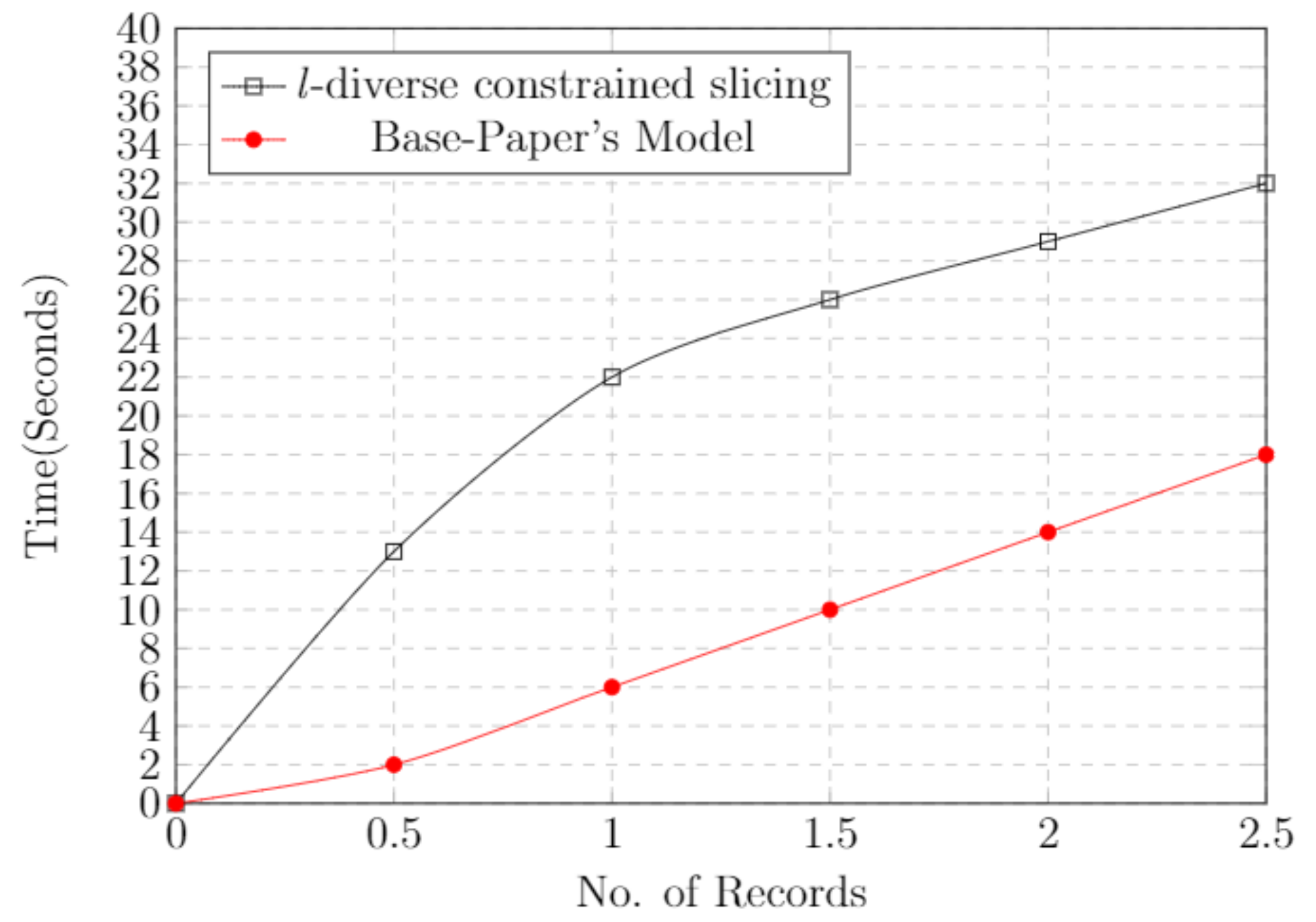
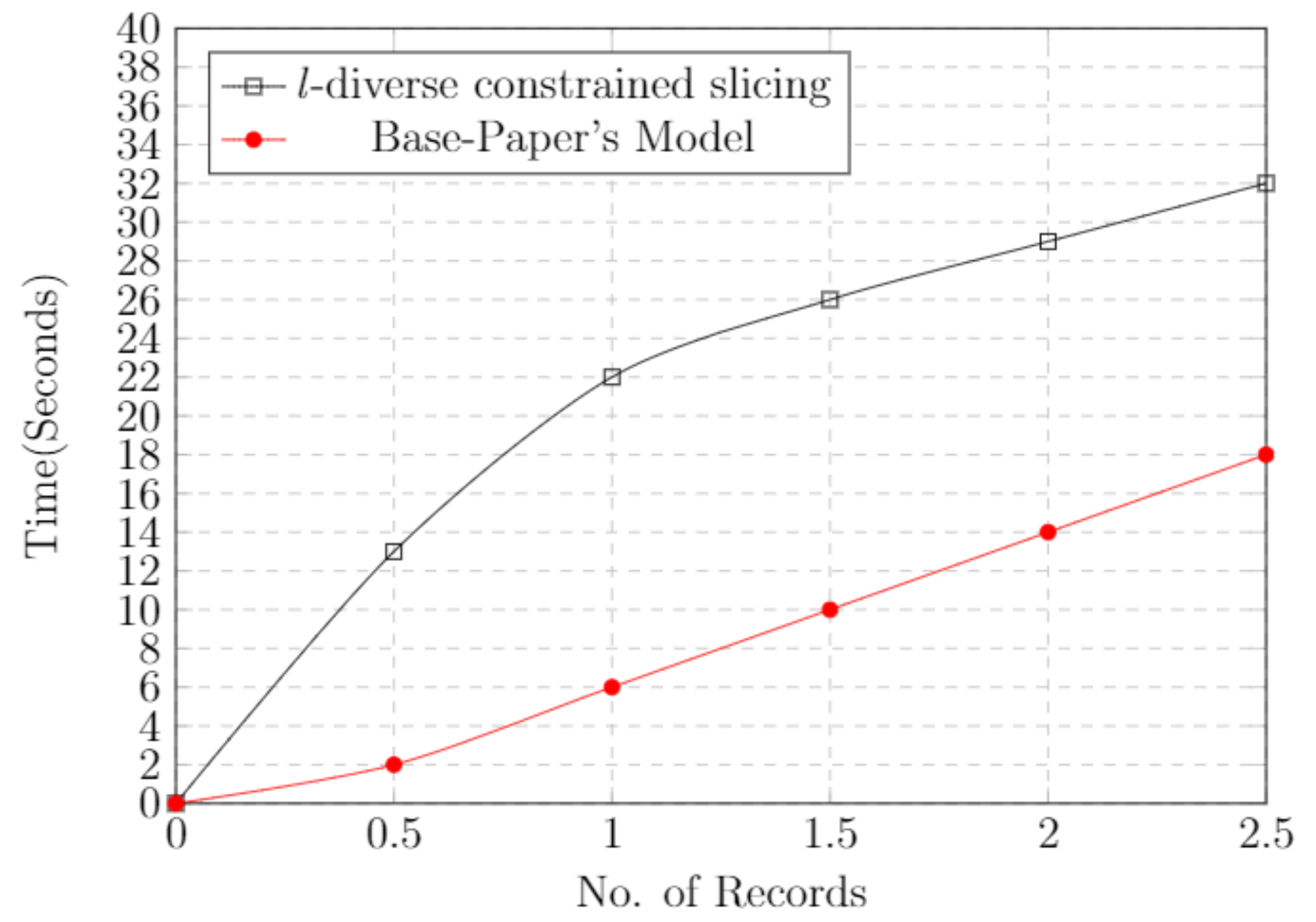
5.9. Time Cost
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mantas, J. 3.4 Electronic Health Record. In Textbook in Health Informatics; IOS Press: Amsterdam, The Netherlands, 2002; pp. 250–257. [Google Scholar]
- Ulybyshev, D.; Bare, C.; Bellisario, K.; Kholodilo, V.; Northern, B.; Solanki, A.; O’Donnell, T. Protecting electronic health records in transit and at rest. In Proceedings of the 2020 IEEE 33rd International Symposium on Computer-Based Medical Systems (CBMS), Rochester, MN, USA, 28–30 July 2020; pp. 449–452. [Google Scholar]
- Azeez, N.A.; Van der Vyver, C. Security and privacy issues in e-health cloud-based system: A comprehensive content analysis. Egypt. Inform. J. 2019, 20, 97–108. [Google Scholar] [CrossRef]
- Report to the President, Big Data and Privacy: A Technology Perspective; Executive Office of the President President’s Council of Advisors on Science and Technology: Washington, DC, USA, 2014.
- Duncan, G.; Lambert, D. The risk of disclosure for microdata. J. Bus. Econ. Stat. 1989, 7, 207–217. [Google Scholar]
- Sweeney, L. k-anonymity: A model for protecting privacy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef] [Green Version]
- He, D.; Kumar, N.; Wang, H.; Wang, L.; Choo, K.K.R.; Vinel, A. A provably-secure cross-domain handshake scheme with symptoms-matching for mobile healthcare social network. IEEE Trans. Dependable Secur. Comput. 2016, 15, 633–645. [Google Scholar] [CrossRef]
- Liu, X.; Deng, R.H.; Choo, K.K.R.; Weng, J. An efficient privacy-preserving outsourced calculation toolkit with multiple keys. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2401–2414. [Google Scholar] [CrossRef]
- Joshi, M.; Joshi, K.; Finin, T. Attribute based encryption for secure access to cloud based EHR systems. In Proceedings of the 2018 IEEE 11th International Conference on Cloud Computing (CLOUD), San Francisco, CA, USA, 2–7 July 2018; pp. 932–935. [Google Scholar]
- Xhafa, F.; Li, J.; Zhao, G.; Li, J.; Chen, X.; Wong, D.S. Designing cloud-based electronic health record system with attribute-based encryption. Multimed. Tools Appl. 2015, 74, 3441–3458. [Google Scholar] [CrossRef] [Green Version]
- Machanavajjhala, A.; Kifer, D.; Gehrke, J.; Venkitasubramaniam, M. L-diversity: Privacy beyond k-anonymity. ACM Trans. Knowl. Discov. Data (TKDD) 2007, 1, 3. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-closeness: Privacy beyond k-anonymity and l-diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, 17–20 April 2007; pp. 106–115. [Google Scholar]
- Campan, A.; Truta, T.M.; Cooper, N. P-Sensitive K-Anonymity with Generalization Constraints. Trans. Data Priv. 2010, 3, 65–89. [Google Scholar]
- Sun, X.; Wang, H.; Li, J.; Truta, T.M. Enhanced p-sensitive k-anonymity models for privacy preserving data publishing. Trans. Data Priv. 2008, 1, 53–66. [Google Scholar]
- Anjum, A.; Ahmad, N.; Malik, S.U.; Zubair, S.; Shahzad, B. An efficient approach for publishing microdata for multiple sensitive attributes. J. Supercomput. 2018, 74, 5127–5155. [Google Scholar] [CrossRef]
- Wang, R.; Zhu, Y.; Chang, C.C.; Peng, Q. Privacy-preserving high-dimensional data publishing for classification. Comput. Secur. 2020, 93, 101785. [Google Scholar] [CrossRef]
- Xiao, X.; Tao, Y. Anatomy: Simple and effective privacy preservation. In Proceedings of the 32nd International Conference on Very Large Data Bases, VLDB Endowment, Seoul, Korea, 12–15 September 2006; pp. 139–150. [Google Scholar]
- Tao, Y.; Chen, H.; Xiao, X.; Zhou, S.; Zhang, D. Angel: Enhancing the utility of generalization for privacy preserving publication. IEEE Trans. Knowl. Data Eng. 2009, 21, 1073–1087. [Google Scholar]
- Xu, Y.; Fung, B.C.; Wang, K.; Fu, A.W.; Pei, J. Publishing sensitive transactions for itemset utility. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Washington, DC, USA, 15–19 December 2008; pp. 1109–1114. [Google Scholar]
- Terrovitis, M.; Mamoulis, N.; Kalnis, P. Privacy-preserving anonymization of set-valued data. Proc. VLDB Endow. 2008, 1, 115–125. [Google Scholar] [CrossRef] [Green Version]
- Tao, Y.; Tong, Y.; Tan, S.; Tang, S.; Yang, D. Protecting the publishing identity in multiple tuples. In IFIP Annual Conference on Data and Applications Security and Privacy, Proceedings of the DBSec 2008: Data and Applications Security XXII, London, UK, 13–16 July 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 205–218. [Google Scholar]
- Poulis, G.; Loukides, G.; Gkoulalas-Divanis, A.; Skiadopoulos, S. Anonymizing data with relational and transaction attributes. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Proceedings of the ECML PKDD 2013: Machine Learning and Knowledge Discovery in Databases, Prague, Czech Republic, 23–27 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 353–369. [Google Scholar]
- Anjum, A.; Farooq, N.; Malik, S.U.; Khan, A.; Ahmed, M.; Gohar, M. An effective privacy preserving mechanism for 1: M microdata with high utility. Sustain. Cities Soc. 2019, 45, 213. [Google Scholar] [CrossRef]
- Kanwal, T.; Shaukat, S.A.A.; Anjum, A.; ur Rehman Malik, S.; Choo, K.K.R.; Khan, A.; Ahmad, N.; Ahmad, M.; Khan, S.U. Privacy-preserving model and generalization correlation attacks for 1: M data with multiple sensitive attributes. Inf. Sci. 2019, 488, 238–256. [Google Scholar] [CrossRef]
- PTB-XL, a Large Publicly Available Electrocardiography Dataset. Available online: https://www.physionet.org/content/ptb-xl/1.0.1/ (accessed on 28 July 2020).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Privacy Model | Techniques | Attacks |
|---|---|---|---|
| [6] | k-anonymity | Generalization + suppression | Background knowledge + homogeneity |
| [11] | l-diversity | Domain generalization | Similarity + Skewness |
| [12] | t-closeness | Generalization + suppression + SA-value distribution | Similarity |
| [13] | p-sensitive k-anonymity | Generalization + clustering | Homogeneity + similarity + linkage |
| [14] | p+sensitive k-anonymity | Generalization | Homogeneity + linkage |
| [14] | (p/) sensitive k-anonymity | Generalization | Background knowledge + homogeneity |
| [15] | Balanced p+sensitive k-anonymity | Generalization | Skewness attack |
| [16] | High-dimensional data publishing via k-anonymity | Generalization | Attribute disclosure + high information loss |
| ID | Age | Gender | Education | Race | Marital Status | Family Members | Working Hours | Job | Class |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 40 | M | Grad school | W | Married | 3 | 46 | Engineer | Y |
| 2 | 43 | F | Bachelors | A | Unmarried | 6 | 55 | Writer | N |
| 3 | 36 | M | Senior sec. | W | Unmarried | 2 | 48 | Engineer | N |
| 4 | 58 | F | Junior sec. | B | Married | 7 | 36 | Clerk | N |
| 5 | 32 | F | Senior sec. | W | Unmarried | 3 | 48 | Writer | N |
| 6 | 39 | M | Grad school | W | Married | 5 | 46 | Engineer | Y |
| 7 | 26 | F | Grad school | A | Unmarried | 5 | 60 | Writer | N |
| 8 | 27 | M | Grad school | W | Divorced | 2 | 48 | Engineer | Y |
| 9 | 45 | F | Junior sec. | W | Married | 6 | 36 | Clerk | N |
| 10 | 24 | F | Senior sec. | B | Unmarried | 4 | 36 | Clerk | N |
| ID | Age | Race | Family Members | Working Hours | Class |
|---|---|---|---|---|---|
| 1 | [27, 40] | W | [2, 5] | [46, 48] | Y |
| 6 | [27, 40] | W | [2, 5] | [46, 48] | Y |
| 8 | [27, 40] | W | [2, 5] | [46, 48] | Y |
| 2 | [26, 43] | A | [5, 6] | [55, 60] | N |
| 7 | [26, 43] | A | [5, 6] | [55, 60] | N |
| 3 | [32, 36] | W | [2, 3] | [46, 48] | N |
| 5 | [32, 36] | W | [2, 3] | [46, 48] | N |
| 4 | [24, 58] | * | [4, 7] | 36 | N |
| 9 | [24, 58] | * | [4, 7] | 36 | N |
| 10 | [24, 58] | * | [4, 7] | 36 | N |
| ID | Gender | Education | Marital Status | Job | Class |
|---|---|---|---|---|---|
| 1 | M | Grad school | Married | Engineer | Y |
| 6 | M | Grad school | Married | Engineer | Y |
| 8 | M | Grad school | Married | Engineer | Y |
| 2 | F | University | Unmarried | Writer | N |
| 7 | F | University | Unmarried | Writer | N |
| 3 | * | Senior sec. | Unmarried | * | N |
| 5 | * | Senior sec. | Unmarried | * | N |
| 10 | * | Senior sec. | Unmarried | * | N |
| 4 | F | Junior sec. | Married | Clerk | N |
| 9 | F | Junior sec. | Marriage | Clerk | N |
| Age | Gender | Height | DOS | Weigh T | Hospital | Heart-Axis | SCP-Codes | Validated by Human |
|---|---|---|---|---|---|---|---|---|
| 64 | F | 160 | 4/12/1994 | 74 | 1 | MID | NORM | TRUE |
| 68 | M | 180 | 4/12/1994 | 86 | 1 | LAD | IMI | TRUE |
| 66 | M | 170 | 3/12/1994 | 89 | 1 | MID | NORM | TRUE |
| 76 | M | 163 | 3/12/1994 | 51 | 1 | LAD | ASM | TRUE |
| 51 | M | 168 | 8/3/1995 | 72 | 4 | MID | NORM | FALSE |
| 80 | M | 177 | 8/3/1995 | 66 | 2 | MID | NST | TRUE |
| 75 | M | 158 | 9/8/1995 | 48 | 1 | ALAD | ASMI | FALSE |
| 64 | M | 165 | 9/8/1995 | 93 | 1 | ALAD | NDT | TRUE |
| 65 | F | 155 | 8/4/1996 | 70 | 1 | RAD | INJALLA | TRUE |
| 50 | M | 167 | 8/4/1996 | 75 | 8 | RAD | ASMI | TRUE |
| 55 | F | 170 | 3/5/1998 | 73 | 7 | NORM | ASMI | FALSE |
| Age | Gender | Heigh | DOS | Weight | Hospital | Heart-Axis | SCP-Codes | Validated by Human |
|---|---|---|---|---|---|---|---|---|
| 68 | M | 180 | 4/12/1994 | 86 | 1 | LAD | IMI | TRUE |
| 51 | M | 168 | 8/3/1995 | 72 | 4 | MID | NORM | TRUE |
| 64 | M | 165 | 9/8/1995 | 93 | 1 | ALAD | NDT | TRUE |
| 66 | M | 170 | 3/12/1994 | 89 | 1 | MID | NORM | TRUE |
| 80 | M | 177 | 8/3/1995 | 66 | 2 | MID | NST | TRUE |
| 76 | M | 163 | 3/12/1994 | 51 | 1 | LAD | ASM | TRUE |
| 75 | M | 158 | 9/8/1995 | 48 | 1 | ALAD | ASMI | TRUE |
| 50 | M | 167 | 8/4/1996 | 75 | 8 | RAD | ASMI | TRUE |
| Age | Gender | Height | DOS | Weight | Hospital | Heart-Axis | SCP-CODES | Validated by Human |
|---|---|---|---|---|---|---|---|---|
| 64 | F | 160 | 4/12/1994 | 74 | 1 | MID | NORM | TRUE |
| 55 | F | 170 | 3/5/1998 | 73 | 7 | NORM | ASMI | FALSE |
| 65 | F | 155 | 8/4/1996 | 70 | 1 | RAD | INJALLA | TRUE |
| Age | Gender | Height | DOS | SCP-Codes |
|---|---|---|---|---|
| 74 | 1 | MID | NORM | TRUE |
| 86 | 1 | LAD | IMI | TRUE |
| 89 | 1 | MID | NORM | TRUE |
| 51 | 1 | LAD | ASM | TRUE |
| 72 | 4 | MID | NORM | TRUE |
| 66 | 2 | MID | NST | TRUE |
| 48 | 1 | ALAD | ASMI | TRUE |
| 93 | 1 | ALAD | NDT | TRUE |
| 70 | 1 | RAD | INJALLA | TRUE |
| 75 | 8 | RAD | ASMI | TRUE |
| BID | (Age, Gender, Height) | (DOS, SCP-Codes) |
|---|---|---|
| 1 | (31, M, 180) | (4/12/1994, IMI) |
| (35, M, 168) | (8/3/1995, NORM) | |
| (33, M, 165) | (9/8/1995, NDT) | |
| (34, M, 170) | (3/12/1994, NORM) | |
| 2 | (56, M, 177) | (8/3/1995, NST) |
| (57, M, 163) | (3/12/1994, ASM) | |
| (60, M, 158) | (9/8/1995, ASMI) | |
| (58, M, 167) | (8/4/1996, ASMI) |
| Weight | Hospital | H-Axis | SCP-Code | Validated |
|---|---|---|---|---|
| 86 | 1 | LAD | IMI | TRUE |
| 72 | 4 | MID | NORM | TRUE |
| 93 | 1 | ALAD | NDT | TRUE |
| 89 | 1 | MID | NORM | TRUE |
| 66 | 2 | MID | NST | TRUE |
| 51 | 1 | LAD | ASM | TRUE |
| 48 | 1 | ALAD | ASMI | TRUE |
| 75 | 8 | RAD | ASMI | TRUE |
| BID | (Weight, Hospital, H-Axis) | (SCP-Codes, Validated) |
|---|---|---|
| 1 | (86, 1, LAD) | (IMI, TRUE) |
| (72, 4, MID) | (NORM, TRUE) | |
| (93, 1, ALAD) | (NDT, TRUE) | |
| (89, 1, MID) | (NORM, TRUE) | |
| 2 | (66, 2MID) | (ASMI, TRUE) |
| (51, 1, LAD) | (NST, TRUE) | |
| (48, 1, ALAD) | (ASMI, TRUE) | |
| (75, 8, RAD) | (ASM, TRUE) |
| Classifier | Accuracy in (%) |
|---|---|
| LR | 0.941 |
| SVM | 0.948 |
| RF | 0.992 |
| Precision | Recall | F1-Score |
|---|---|---|
| 0.97 | 0.95 | 0.98 |
| 0.95 | 0.98 | 0.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amin, Z.; Anjum, A.; Khan, A.; Ahmad, A.; Jeon, G. Preserving Privacy of High-Dimensional Data by l-Diverse Constrained Slicing. Electronics 2022, 11, 1257. https://doi.org/10.3390/electronics11081257
Amin Z, Anjum A, Khan A, Ahmad A, Jeon G. Preserving Privacy of High-Dimensional Data by l-Diverse Constrained Slicing. Electronics. 2022; 11(8):1257. https://doi.org/10.3390/electronics11081257
Chicago/Turabian StyleAmin, Zenab, Adeel Anjum, Abid Khan, Awais Ahmad, and Gwanggil Jeon. 2022. "Preserving Privacy of High-Dimensional Data by l-Diverse Constrained Slicing" Electronics 11, no. 8: 1257. https://doi.org/10.3390/electronics11081257
APA StyleAmin, Z., Anjum, A., Khan, A., Ahmad, A., & Jeon, G. (2022). Preserving Privacy of High-Dimensional Data by l-Diverse Constrained Slicing. Electronics, 11(8), 1257. https://doi.org/10.3390/electronics11081257