
Reinforcement Learning-Based UAVs Resource Allocation for Integrated Sensing and Communication (ISAC) System





Abstract
:1. Introduction
- A novel low-cost, weight-light, and integration-high degree group UAV system is proposed. The ISAC system is mounted on UAVs, and the radar resources are used for communication and target detection together. It not only broadens the use of UAV resources but also improves the anti-jamming ability of UAVs from the common frequency ban.
- A novel reinforcement-learning-based method is proposed to solve the complex problem, where we formulate a new reward function by combining both the MI and the CR. The MI describes the radar detection performance, and the CR is for wireless communication.
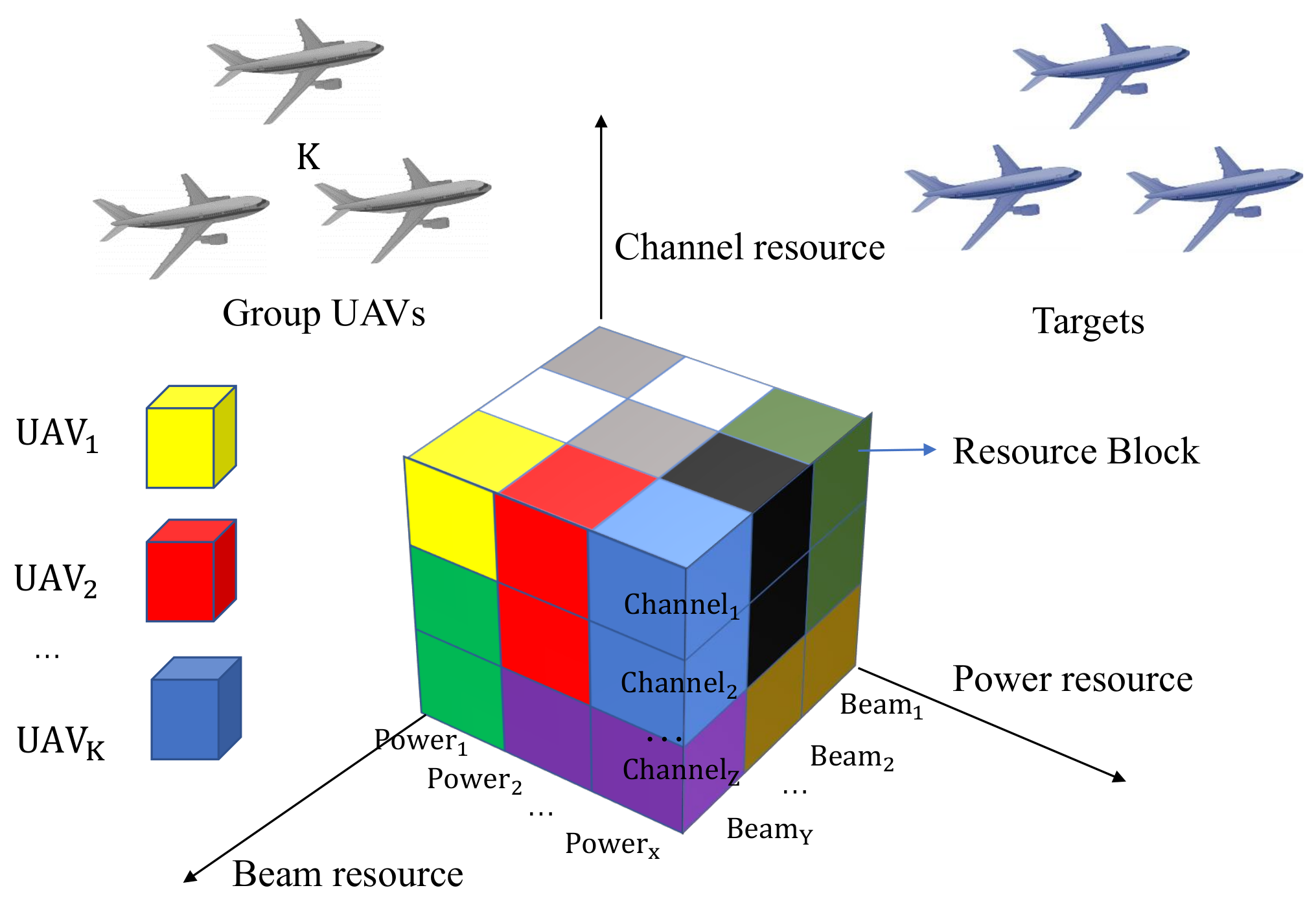
2. Groups UAVs Resource Allocation Model for ISAC System
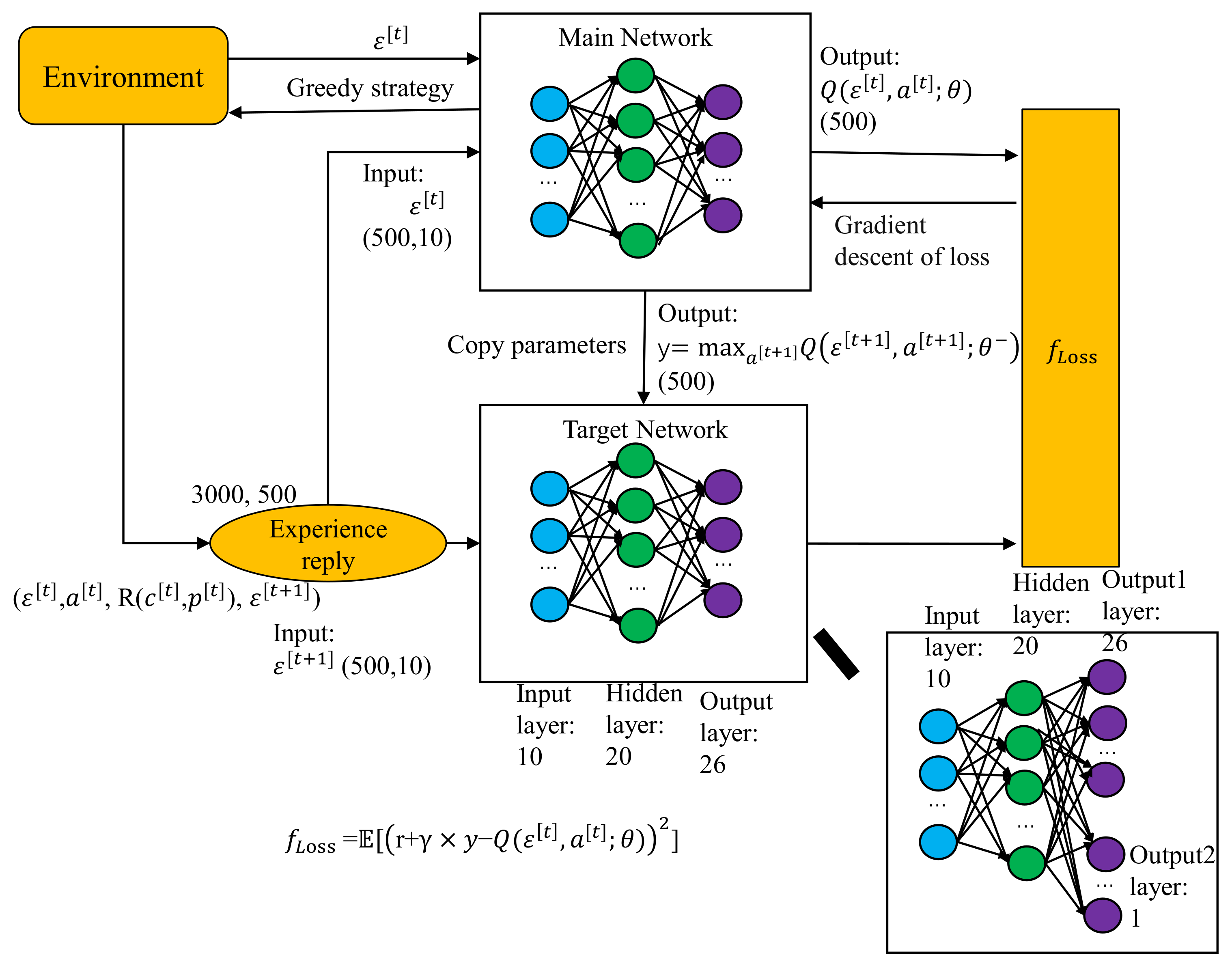
3. Reinforcement-Learning-Based UAVs Resource Allocation Method
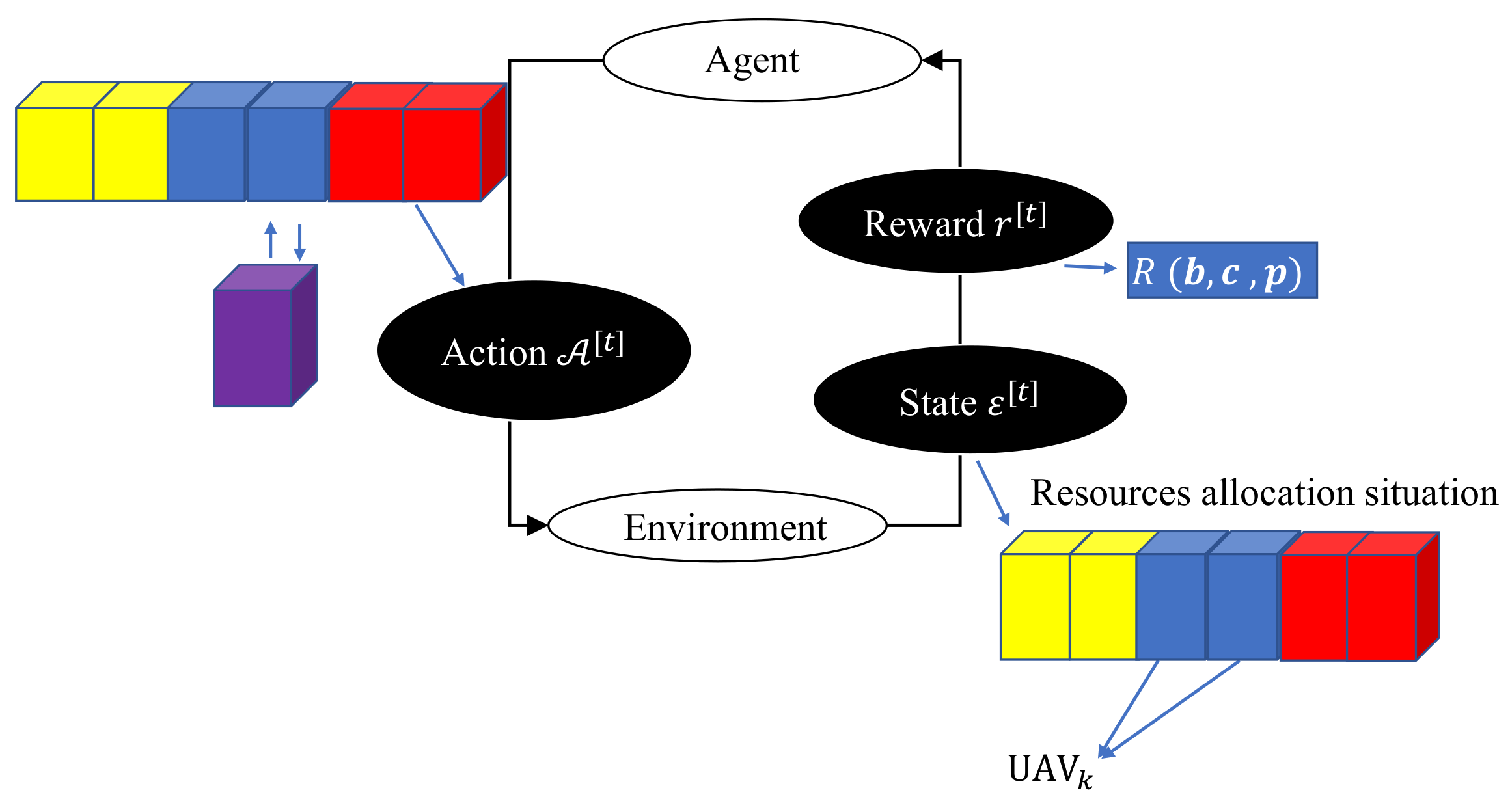
- Environment StateSince the state is the mapping and representation of the environment and also the basis for agents to take agents, the design of the environment state is very meaningful. During the t-th state, it is defined as the current resource allocation strategy and the status of the UAVs, such as their locations and velocity , the locations of targets , available energy and last time reward :where denotes the real number set. W denotes the number of targets.
- Agent ActionsActions are the outputs of an agent and the inputs to the environment. Group UAVs allocates resources reasonably according to group UAV task requests and the available resource status of the system. Therefore, action can be defined as below:where all the possible resource allocation strategies during the t-th state from an action set is , the number of actions is and the m-th action is defined as: . , and denote the channel and power allocation strategy in the m-th action, respectively. Notably, considering the channel interference, once a channel is used, it cannot be selected the next time.
- RewardReward refers to the feedback after the agent taking action according to certain environmental states. The reasonability is closely related to the income that can be obtained by the agent and the performance of the dynamic resource allocation algorithm. In the ISAC system for group UAVs with dynamic resource allocation, it is necessary to give certain rewards to learn the optimal resource allocation strategy. According to the current allocation strategy , the reward is defined as below:denotes that resources have been allocated for this episode. Set the reward to 0 when the resource allocation has not ended and to when the resource allocation has ended. Finally, we try to maximize the reward .
- (1)
- DQN and Dueling-DQN use convolutional neural networks (CNN) to approximate value functions. The reinforcement learning has entered the stage of deep reinforcement learning.
- (2)
- DQN and Dueling-DQN use replay buffer training to strengthen the learning process.
- (3)
- DQN and Dueling-DQN set up the target network independently to deal with the deviation in timing difference separately.
- SARSA is an update of on-policy, and its action strategy and evaluation strategy are -greedy.
- SARSA takes action first and updates later:
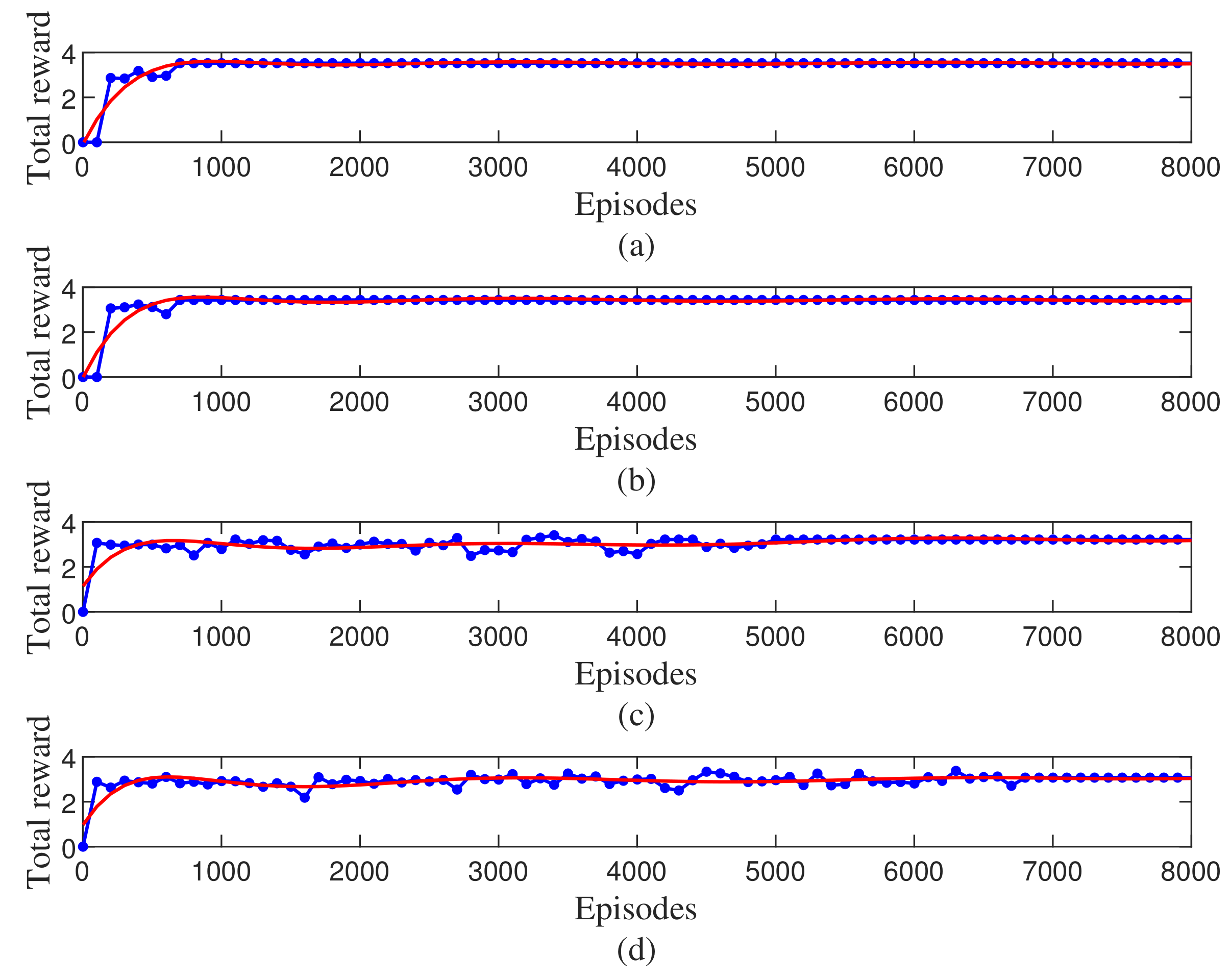
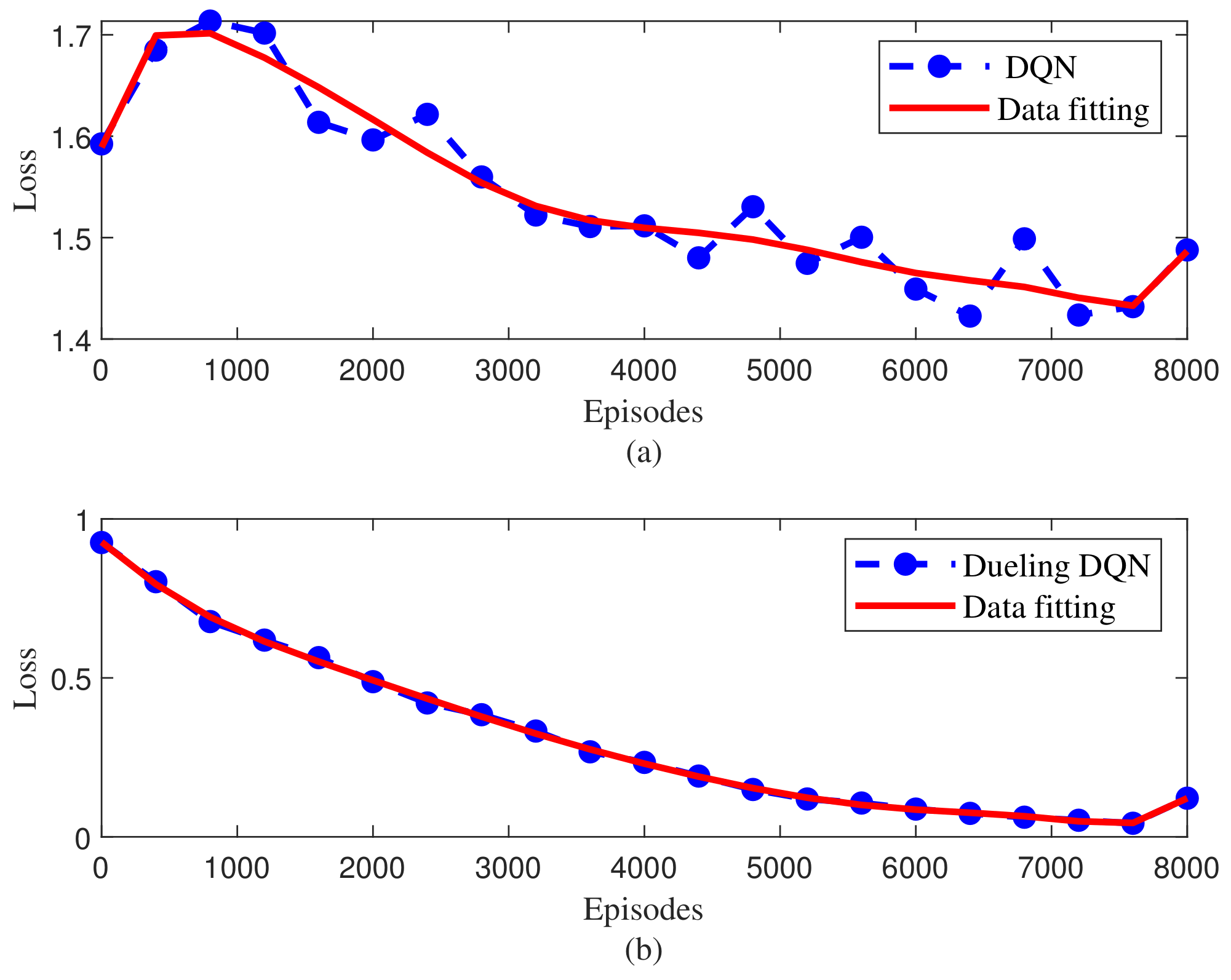
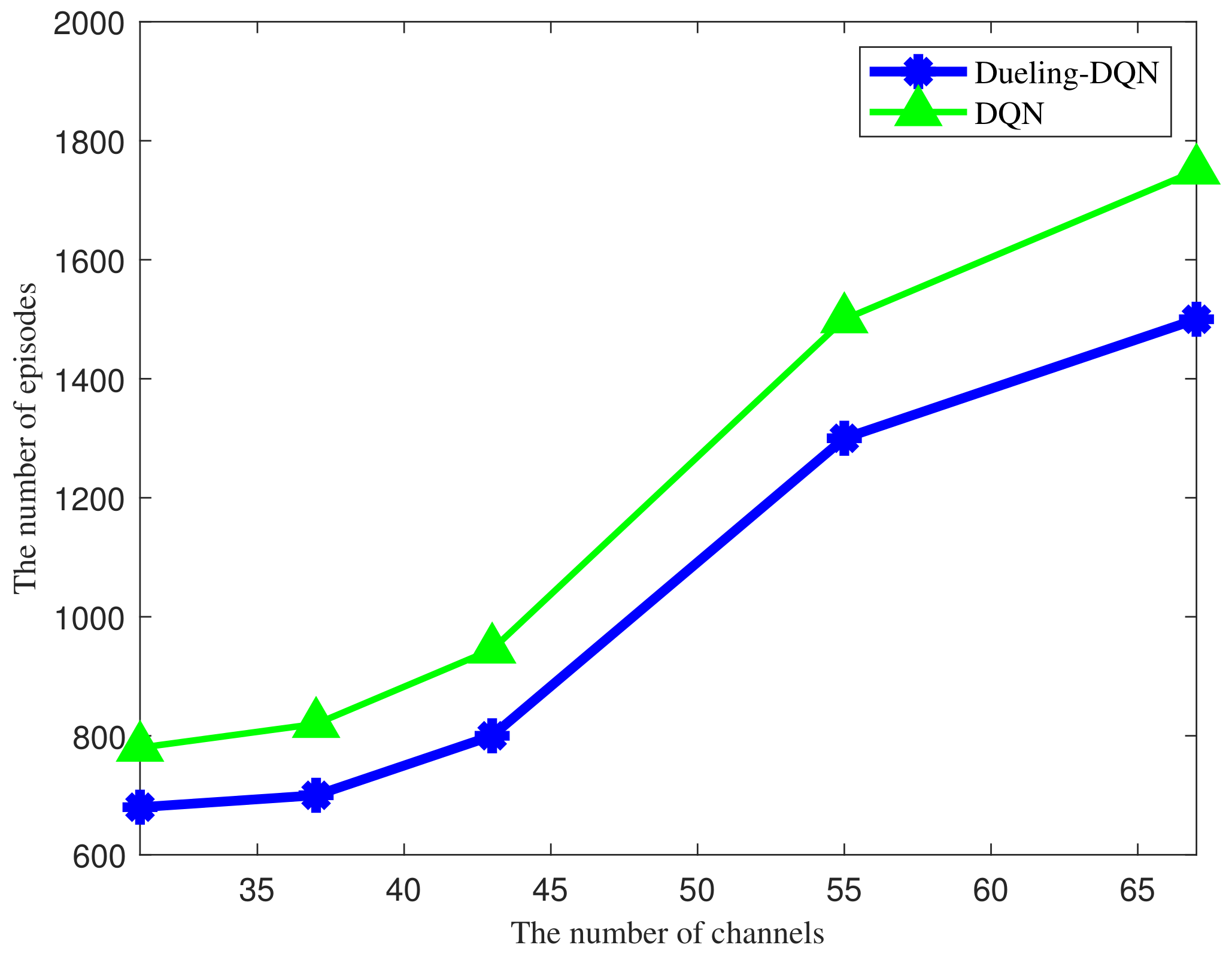
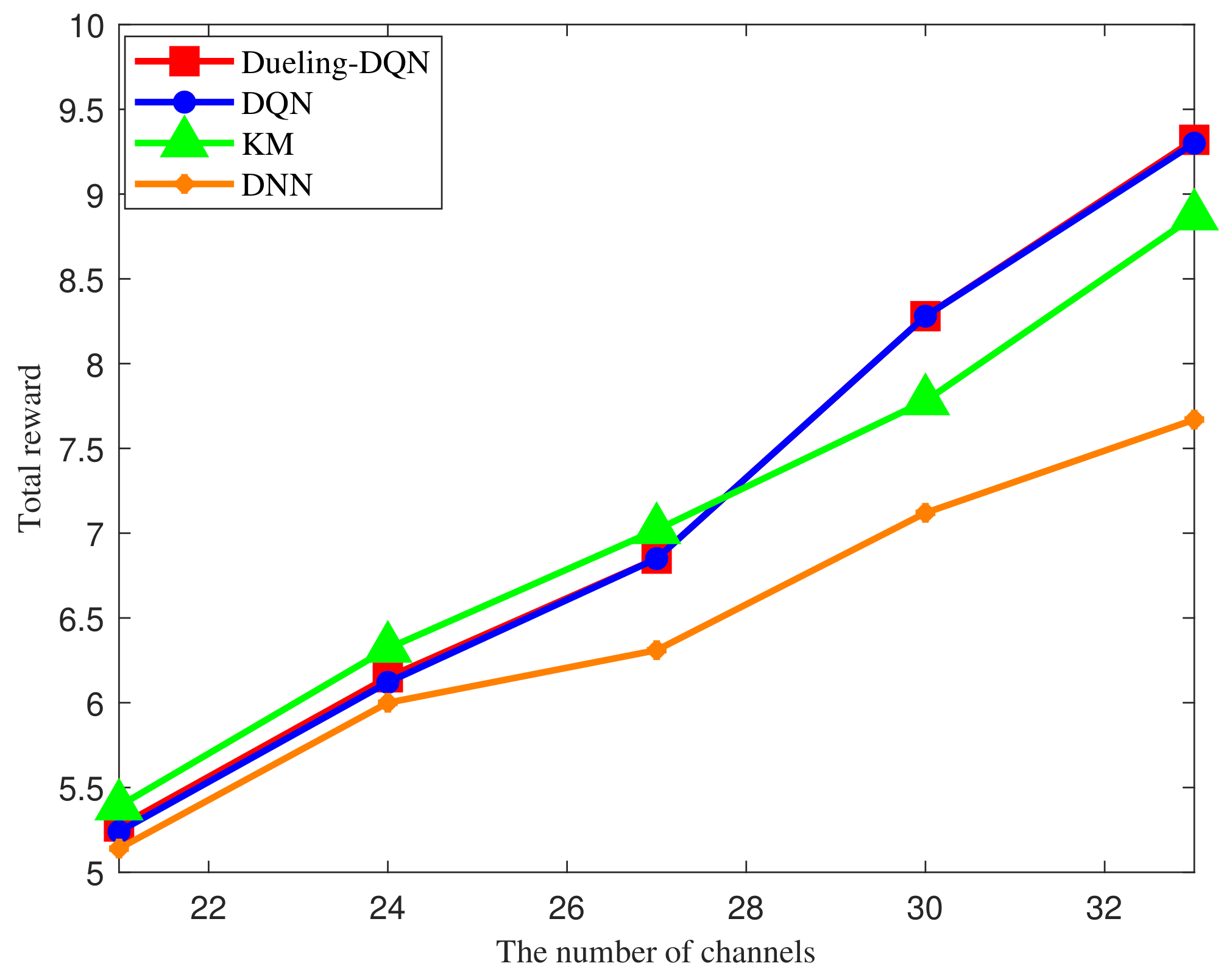
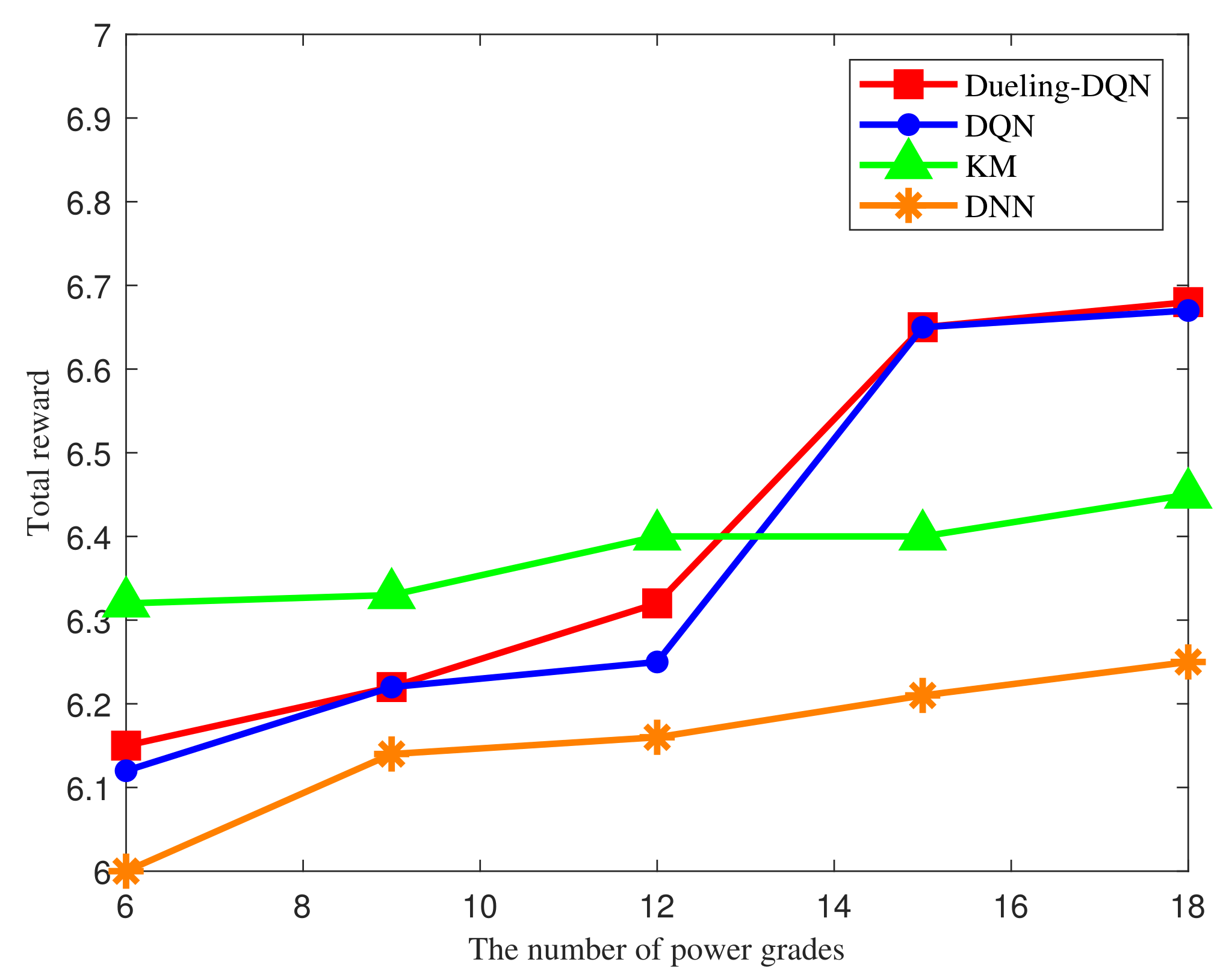
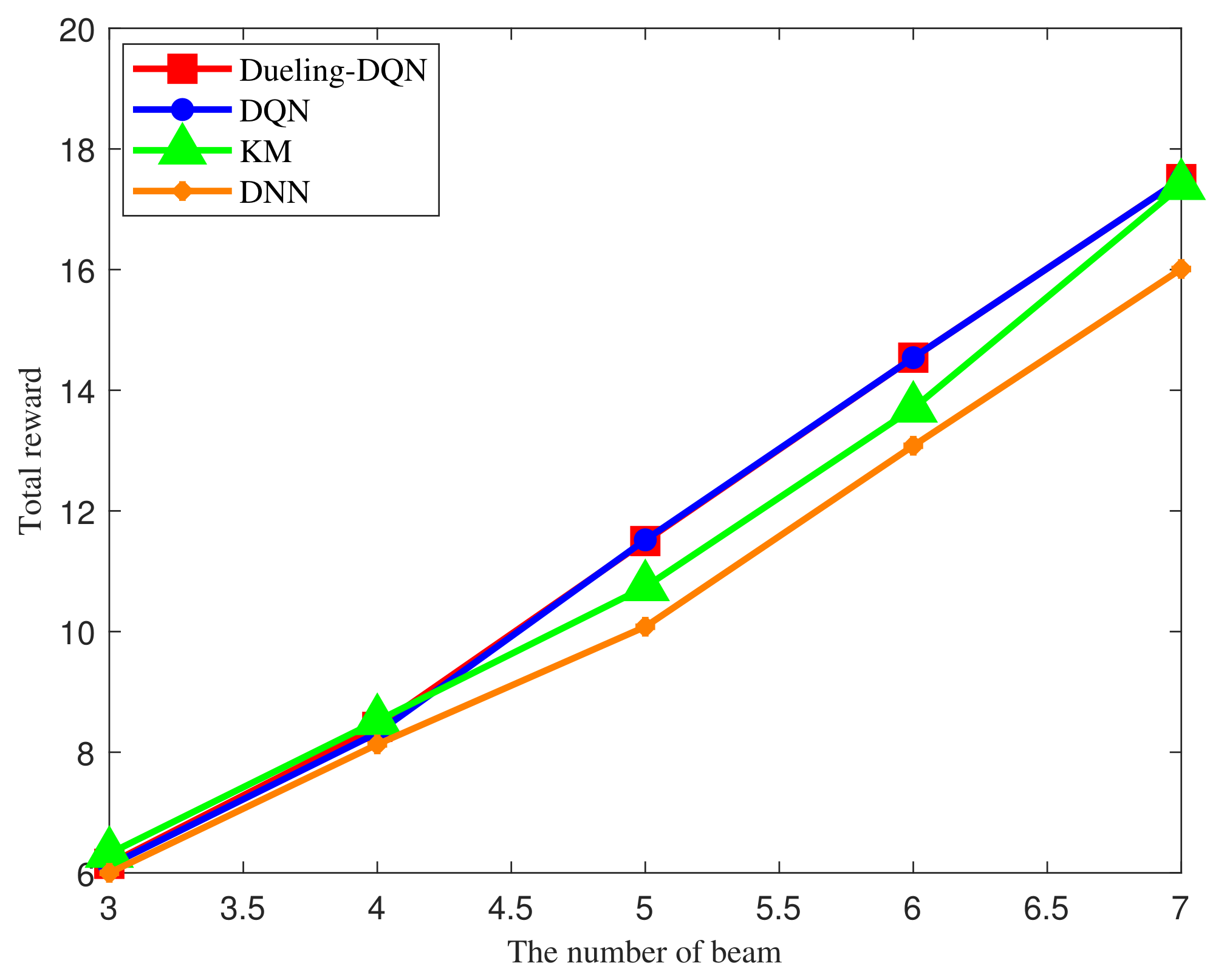
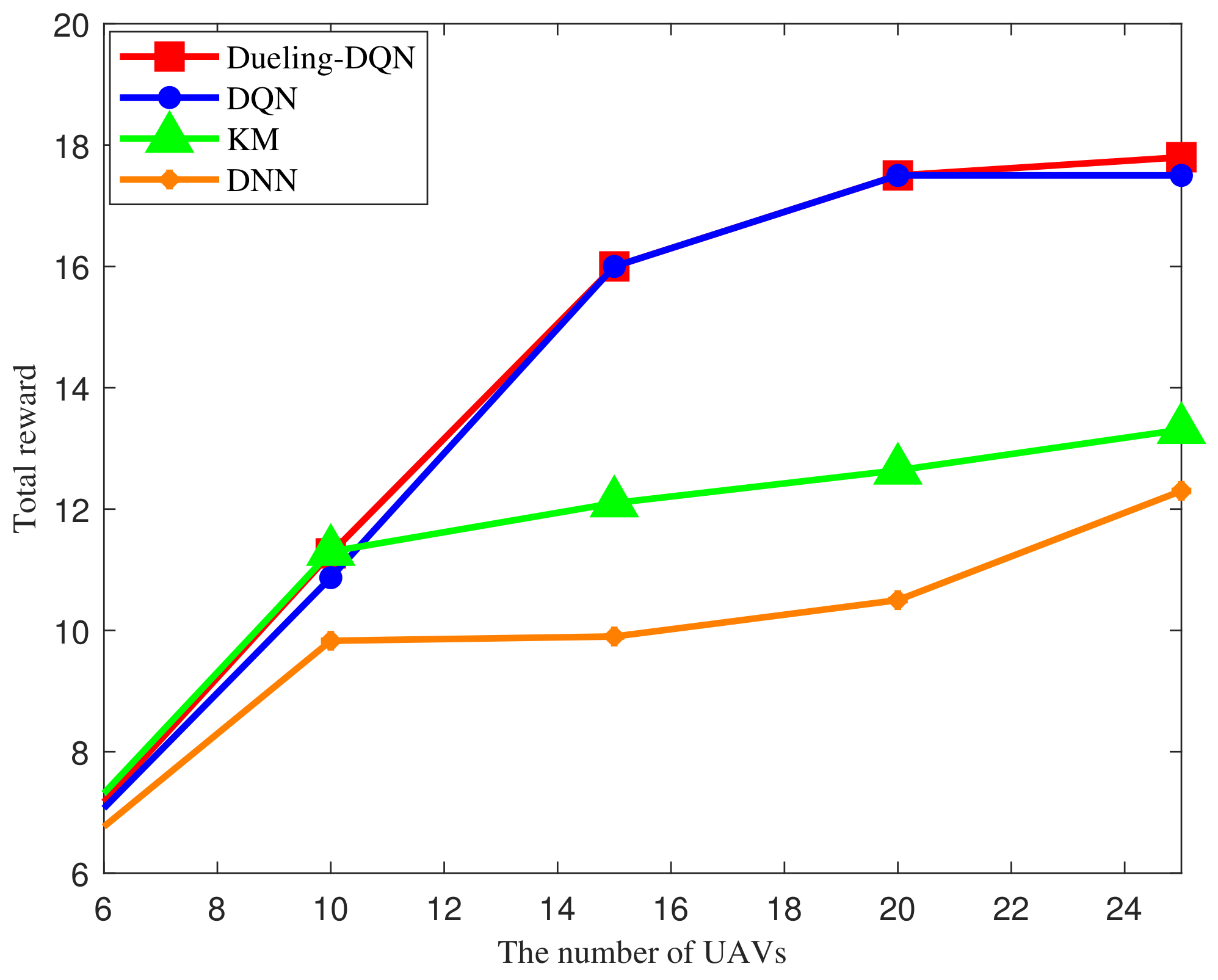
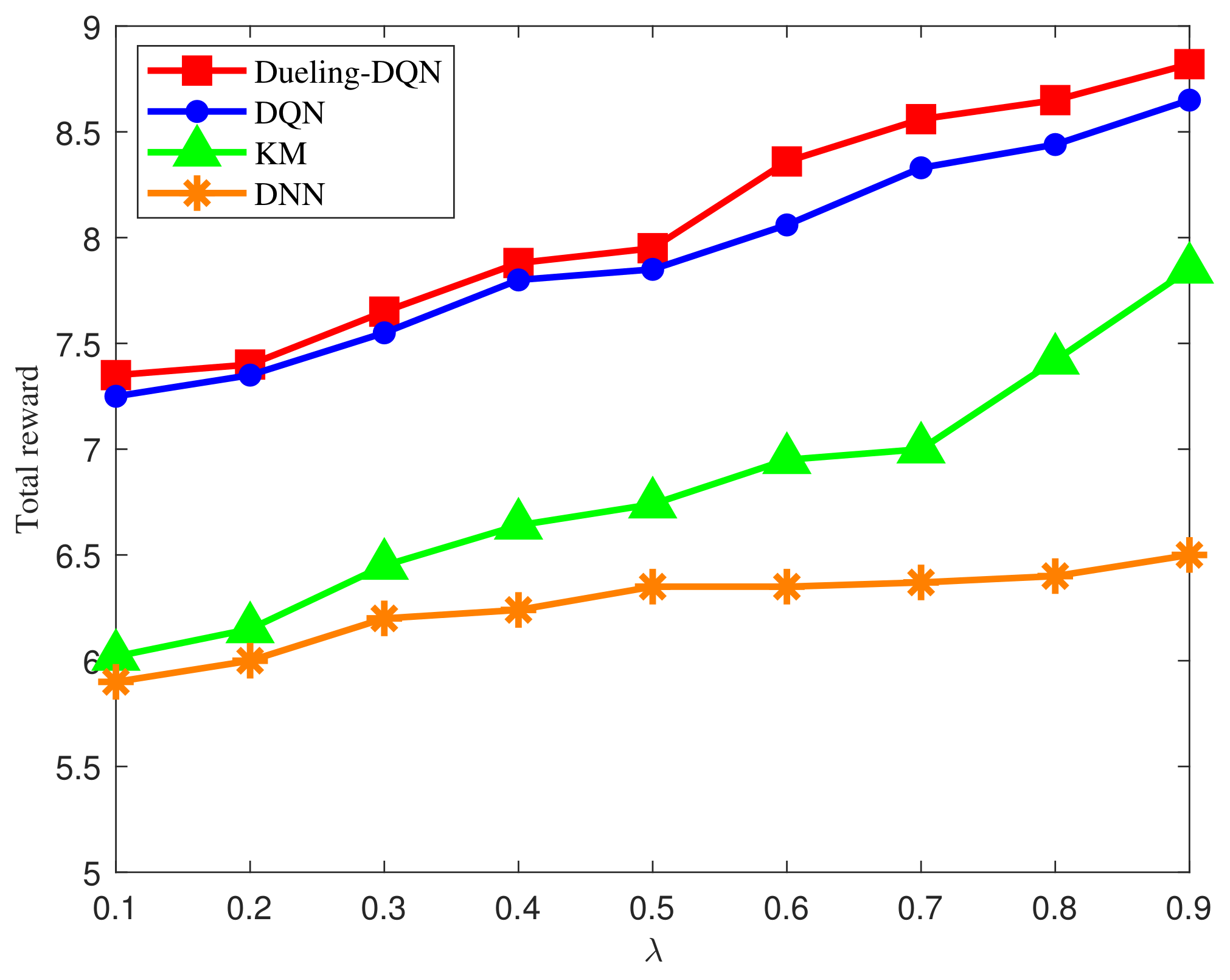
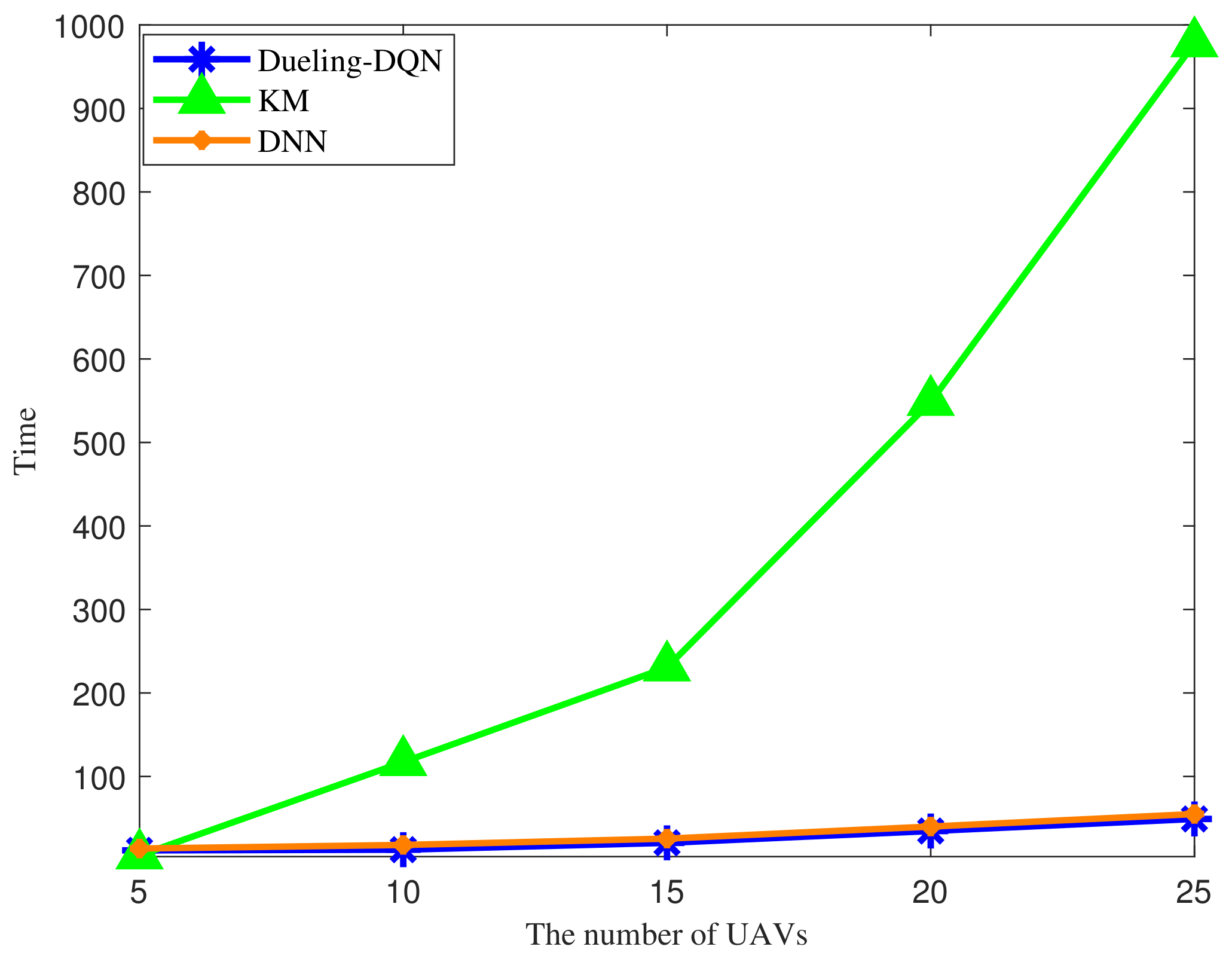
4. Simulation Results
- KM method [41]: The traditional Kuhn Munkres iterative optimization method is used for resource allocation by iterating over each resource to optimize allocation.
- DNN method [42]: The Deep Neural Network(DNN) method based on supervised learning is used for resource allocation by fitting initial data sets.
5. Summary and Prospect
Author Contributions
Funding
Conflicts of Interest
References
- Xiong, Z.; Zhang, Y.; Lim, W.; Kang, J.; Niyato, D.; Leung, C.; Miao, C. UAV-assisted wireless energy and data transfer with deep reinforcement learning. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 85–99. [Google Scholar] [CrossRef]
- Peer, M.; Bohara, V.; Srivastava, A. Multi-UAV placement strategy for disaster-resilient communication network. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), Victoria, BC, Canada, 18 November–16 December 2020; pp. 1–7. [Google Scholar]
- Li, K.; Wang, C.; Lei, M.; Zhao, M.M.; Zhao, M.J. A local reaction anti-jamming scheme for UAV swarms. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), Victoria, BC, Canada, 18 November–16 December 2020; pp. 1–6. [Google Scholar]
- Altan, A. Performance of metaheuristic optimization algorithms based on swarm intelligence in attitude and altitude control of unmanned aerial vehicle for path following. In Proceedings of the 2020 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Istanbul, Turkey, 22–24 October 2020; pp. 1–6. [Google Scholar]
- Chen, R.; Yang, B.; Zhang, W. Distributed and collaborative localization for swarming UAVs. IEEE Internet Things J. 2021, 8, 5062–5074. [Google Scholar] [CrossRef]
- Shen, J.; Wang, S.; Zhai, Y.; Zhan, X. Cooperative relative navigation for multi-UAV systems by exploiting GNSS and peer-to-peer ranging measurements. IET Radar Sonar Navig. 2021, 15, 21–36. [Google Scholar] [CrossRef]
- Zhang, R.; Ishikawa, A.; Wang, W.; Striner, B.; Tonguz, O.K. Using reinforcement learning with partial vehicle detection for intelligent traffic signal control. IEEE Trans. Intell. Transp. Syst. 2021, 22, 404–415. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Zhou, Y.; Zhang, L.; Zhang, Q.; Du, L. Target detection for multistatic radar in the presence of deception jamming. IEEE Sens. J. 2021, 21, 8130–8141. [Google Scholar] [CrossRef]
- Thornton, C.; Kozy, M.; Buehrer, R.; Martone, A.F.; Sherbondy, K.D. Deep reinforcement learning control for radar detection and tracking in congested spectral environments. IEEE Trans. Cognit. Commun. Netw. 2020, 6, 1335–1349. [Google Scholar] [CrossRef]
- Krishnamurthy, V.; Angley, D.; Evans, R.; Moran, B. Identifying cognitive radars—Inverse reinforcement learning using revealed preferences. IEEE Trans. Signal Process. 2020, 68, 4529–4542. [Google Scholar] [CrossRef]
- Yuan, T.; Neto, W.; Rothenberg, C.; Obraczka, K.; Barakat, C.; Turletti, T. Dynamic controller assignment in software defined internet of vehicles through multi-agent deep reinforcement learning. IEEE Trans. Netw. Serv. Manag. 2021, 18, 585–596. [Google Scholar] [CrossRef]
- Aznar, J.; Garcia, A.; Egea, E.; Garcia-Haro, J. MDPRP: A q-learning approach for the joint control of beaconing rate and transmission power in VANETs. IEEE Access 2021, 9, 10166–10178. [Google Scholar] [CrossRef]
- Jang, J.; Yang, H. Deep reinforcement learning-based resource allocation and power control in small cells with limited information exchange. IEEE Trans. Veh. Technol. 2020, 69, 13768–13783. [Google Scholar] [CrossRef]
- James, S.; Raheb, R.; Hudak, A. Impact of packet loss to the motion of autonomous UAV swarms. In Proceedings of the 2020 AIAA/IEEE 39th Digital Avionics Systems Conference (DASC), San Antonio, TX, USA, 11–15 October 2020; pp. 1–9. [Google Scholar]
- Majidi, M.; Erfanian, A.; Khaloozadeh, H. Prediction-discrepancy based on innovative particle filter for estimating UAV true position in the presence of the GPS spoofing attacks. IET Radar Sonar Navig. 2020, 14, 887–897. [Google Scholar] [CrossRef]
- He, C.; Yu, B.; Yi, Q. A cooperative positioning method for micro UAVs in challenge environment. In Proceedings of the 2020 3rd International Conference on Unmanned Systems (ICUS), Harbin, China, 27–28 November 2020; pp. 1157–1160. [Google Scholar]
- Chen, H.; Xian, W.; Liu, J.; Wang, J.; Ye, W. Collaborative multiple UAVs navigation with GPS/INS/UWB jammers using sigma point belief propagation. IEEE Access 2020, 8, 193695–193707. [Google Scholar] [CrossRef]
- Meng, F.; Chen, P.; Wu, L.; Cheng, J. Power allocation in multi-user cellular networks: Deep reinforcement learning approaches. IEEE Trans. Wirel. Commun. 2020, 19, 6255–6267. [Google Scholar] [CrossRef]
- Hussien, Z.; Sadi, Y. Flexible radio resource allocation for machine type communications in 5G cellular networks. In Proceedings of the 2018 26th Signal Processing and Communications Applications Conference (SIU), Izmir, Turkey, 2–5 May 2018; pp. 1–4. [Google Scholar]
- Maurício, W.; Araújo, D.; Maciel, T.; Lima, F.R.M. A framework for radio resource allocation and SDMA grouping in massive MIMO systems. IEEE Access 2021, 9, 61680–61696. [Google Scholar] [CrossRef]
- Chen, X.; Chen, B.; Guan, J.; Huang, Y.; He, Y. Space-range-doppler focus-based low-observable moving target detection using frequency diverse array MIMO radar. IEEE Access 2018, 6, 43892–43904. [Google Scholar] [CrossRef]
- Mou, X.; Chen, X.; Guan, J.; Chen, B.; Dong, Y. Marine target detection based on improved faster R-CNN for navigation radar PPI images. In Proceedings of the 2019 International Conference on Control, Automation and Information Sciences (ICCAIS), Chengdu, China, 23–26 October 2019; pp. 1–5. [Google Scholar]
- Bae, Y.; Shin, J.; Lee, S.; Kim, H. Field experiment of photonic radar for low-RCS target detection and high-resolution image acquisition. IEEE Access 2021, 9, 63559–63566. [Google Scholar] [CrossRef]
- Zhu, S.; Li, X.; Yang, R.; Zhu, X. A low probability of intercept OFDM radar communication waveform design method. In Proceedings of the 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 15–17 January 2021; pp. 653–657. [Google Scholar]
- Zhang, W.; Zhang, H. The design of integrated waveform based on MSK-LFM signal. In Proceedings of the 2020 15th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 6–9 December 2020; pp. 565–569. [Google Scholar]
- Sanson, J.; Tomé, P.; Castanheira, D.; Gameiro, A.; Monteiro, P.P. High-resolution delay-doppler estimation using received communication signals for OFDM radar-communication system. IEEE Trans. Veh. Technol. 2020, 69, 13112–13123. [Google Scholar] [CrossRef]
- Ma, Q.; Lu, J.; Maoxiang, Y. Integrated waveform design for 64QAM-LFM radar communication. In Proceedings of the 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 March 2021; pp. 1615–1625. [Google Scholar]
- Zhang, Z.; Zhu, G.; Sabahi, M. Poster abstract: Array resource allocation based on KKT optimization for radar and communication integration. In Proceedings of the 2019 18th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Montreal, QC, Canada, 15–18 April 2019; pp. 307–308. [Google Scholar]
- Rihan, M.; Huang, L. Optimum co-design of spectrum sharing between MIMO radar and MIMO communication systems: An interference alignment approach. IEEE Trans. Veh. Technol. 2018, 67, 11667–11680. [Google Scholar] [CrossRef]
- Ahmed, A.; Zhang, Y.; Himed, B. Distributed dual-function radar-communication MIMO system with optimized resource allocation. In Proceedings of the 2019 IEEE Radar Conference (RadarConf), Boston, MA, USA, 22–26 April 2019; pp. 1–5. [Google Scholar]
- Zhang, X.; Wang, X. Investigation on range sidelobe modulation effect of co-designed radar-communications shared waveforms. In Proceedings of the 2019 International Applied Computational Electromagnetics Society Symposium—China (ACES), Nanjing, China, 8–11 August 2019; pp. 1–2. [Google Scholar]
- Shi, C.; Wang, F.; Salous, S.; Zhou, J. Low probability of intercept-based optimal OFDM waveform design strategy for an integrated radar and communications system. IEEE Access 2018, 6, 57689–57699. [Google Scholar] [CrossRef]
- Nijsure, Y.; Chen, Y.; Yuen, C.; Chew, Y.H. Location-aware spectrum and power allocation in joint cognitive communication-radar networks. In Proceedings of the 2011 6th International ICST Conference on Cognitive Radio Oriented Wireless Networks and Communications (CROWNCOM), Yokohama, Japan, 1–3 June 2011; pp. 171–175. [Google Scholar]
- Mishra, K.; Martone, A.; Zaghloul, A. Power allocation games for overlaid radar and communications. In Proceedings of the 2019 URSI Asia-Pacific Radio Science Conference (AP-RASC), New Delhi, India, 9–15 March 2019; pp. 1–4. [Google Scholar]
- Wang, F.; Li, H. Joint power allocation for radar and communication co-existence. IEEE Signal Process Lett. 2019, 26, 1608–1612. [Google Scholar] [CrossRef]
- Ye, H.; Li, G.Y.; Juang, B.H.F. Deep reinforcement learning based resource allocation for V2V communications. IEEE Trans. Veh. Technol. 2019, 68, 3163–3173. [Google Scholar] [CrossRef] [Green Version]
- Liang, L.; Ye, H.; Li, G.Y. Spectrum sharing in vehicular networks based on multi-agent reinforcement learning. IEEE J. Sel. Areas Commun. 2019, 37, 2282–2292. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Xie, X.; Kadoch, M. Intelligent resource management based on reinforcement learning for ultra-reliable and low-latency IoV communication networks. IEEE Trans. Veh. Technol. 2019, 68, 4157–4169. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, C. Application of Dueling DQN and DECGA for Parameter Estimation in Variogram Models. IEEE Access 2020, 8, 38112–38122. [Google Scholar] [CrossRef]
- Ban, T. An Autonomous Transmission Scheme Using Dueling DQN for D2D Communication Networks. IEEE Trans. Veh. Technol. 2020, 69, 16348–16352. [Google Scholar] [CrossRef]
- Li, X.; Zhu, B. Full-duplex D2D user clustering resource allocation scheme based on Kuhn-Munkres algorithm. Comput. Eng. Des. 2019, 40, 959–963. [Google Scholar]
- Bhandari, S.; Kim, H.; Ranjan, N.; Zhao, H.P.; Khan, P. Optimal cache resource allocation based on deep deural detworks for fog radio access networks. Internet Technol. 2020, 21, 967–975. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of UAVs | 5 |
| Total number of available channels | 24 |
| Total number of beams | 3 |
| Total number of power grades | 6 |
| Communication transmitting power | 100 W |
| Radar transmitting power | 100 KW |
| System noise temperature | 290 K |
| Boltzmann constant | |
| The wavelength | m |
| Parameter | Q-Learning | SARSA | DQN | Dueling DQN |
|---|---|---|---|---|
| Learning rate | ||||
| Input layer | - | - | Linear, | Linear, |
| Hidden layer | - | - | ReLU, 20 | ReLU, 20 |
| Output layer 1 | - | - | Linear, | state function layer:Linear, |
| Output layer 2 | - | - | - | advantage function layer:Linear, 1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Chen, P.; Cao, Z.; Chen, Y. Reinforcement Learning-Based UAVs Resource Allocation for Integrated Sensing and Communication (ISAC) System. Electronics 2022, 11, 441. https://doi.org/10.3390/electronics11030441
Wang M, Chen P, Cao Z, Chen Y. Reinforcement Learning-Based UAVs Resource Allocation for Integrated Sensing and Communication (ISAC) System. Electronics. 2022; 11(3):441. https://doi.org/10.3390/electronics11030441
Chicago/Turabian StyleWang, Min, Peng Chen, Zhenxin Cao, and Yun Chen. 2022. "Reinforcement Learning-Based UAVs Resource Allocation for Integrated Sensing and Communication (ISAC) System" Electronics 11, no. 3: 441. https://doi.org/10.3390/electronics11030441
APA StyleWang, M., Chen, P., Cao, Z., & Chen, Y. (2022). Reinforcement Learning-Based UAVs Resource Allocation for Integrated Sensing and Communication (ISAC) System. Electronics, 11(3), 441. https://doi.org/10.3390/electronics11030441