
TB-NET: A Two-Branch Neural Network for Direction of Arrival Estimation under Model Imperfections




Abstract
:1. Introduction
2. Preliminaries
2.1. Signal Model
2.2. Neural Network Model
3. Proposed TB-Net
3.1. Feature Extraction Network
3.2. Parallel Prediction Network
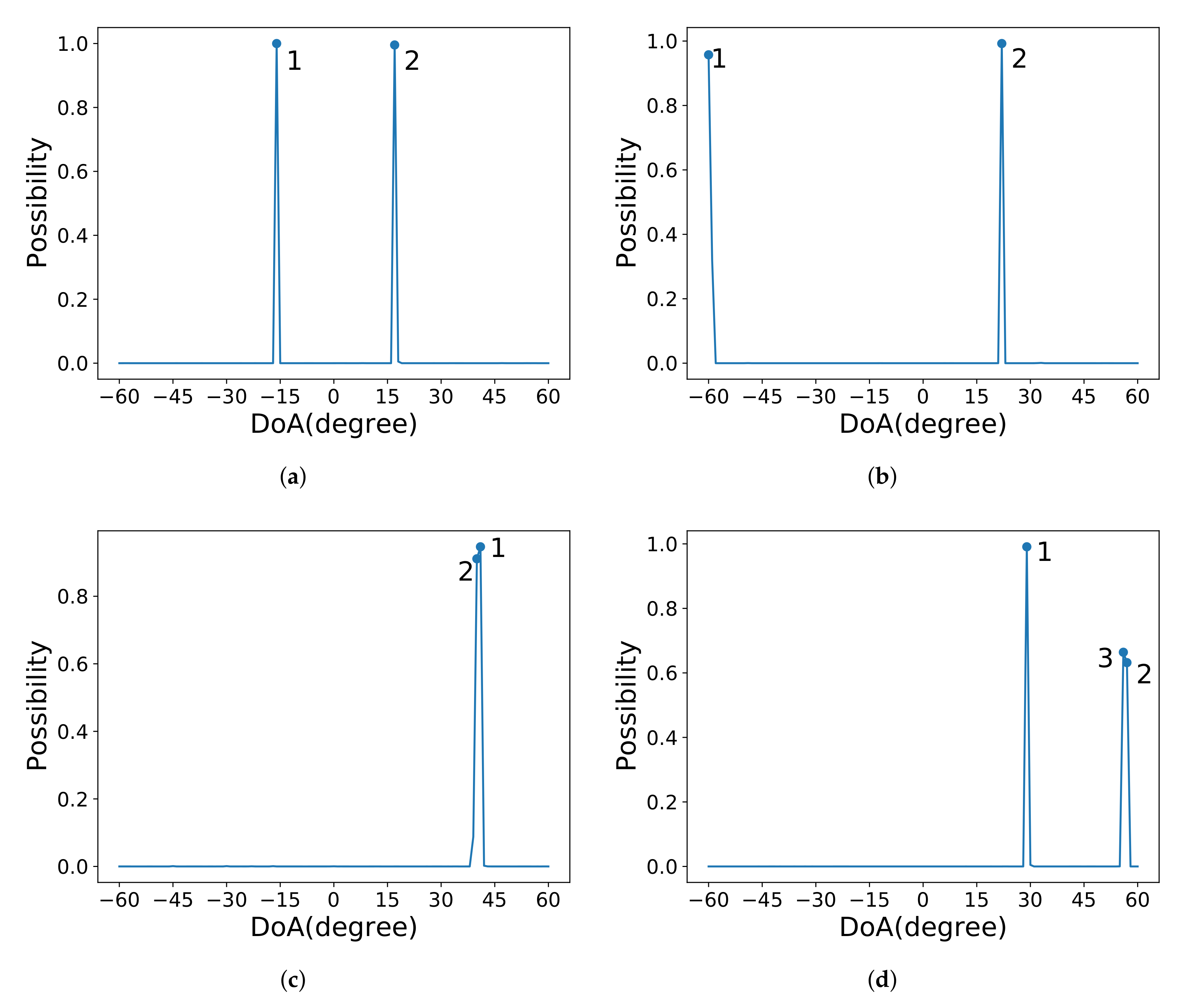
3.2.1. Classification Network
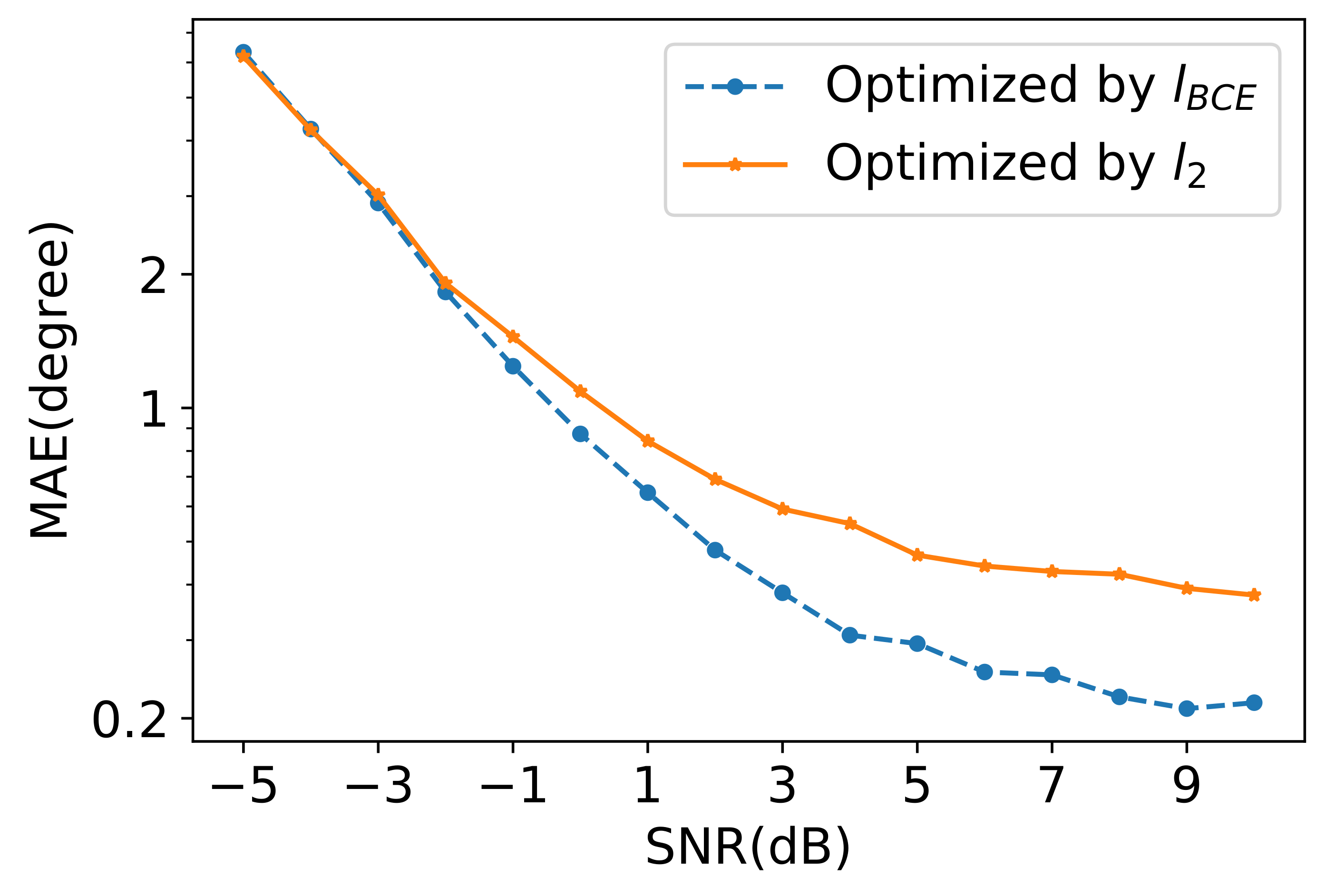
3.2.2. Regression Branch
3.2.3. Output Layer
4. Experimental Results and Discussion
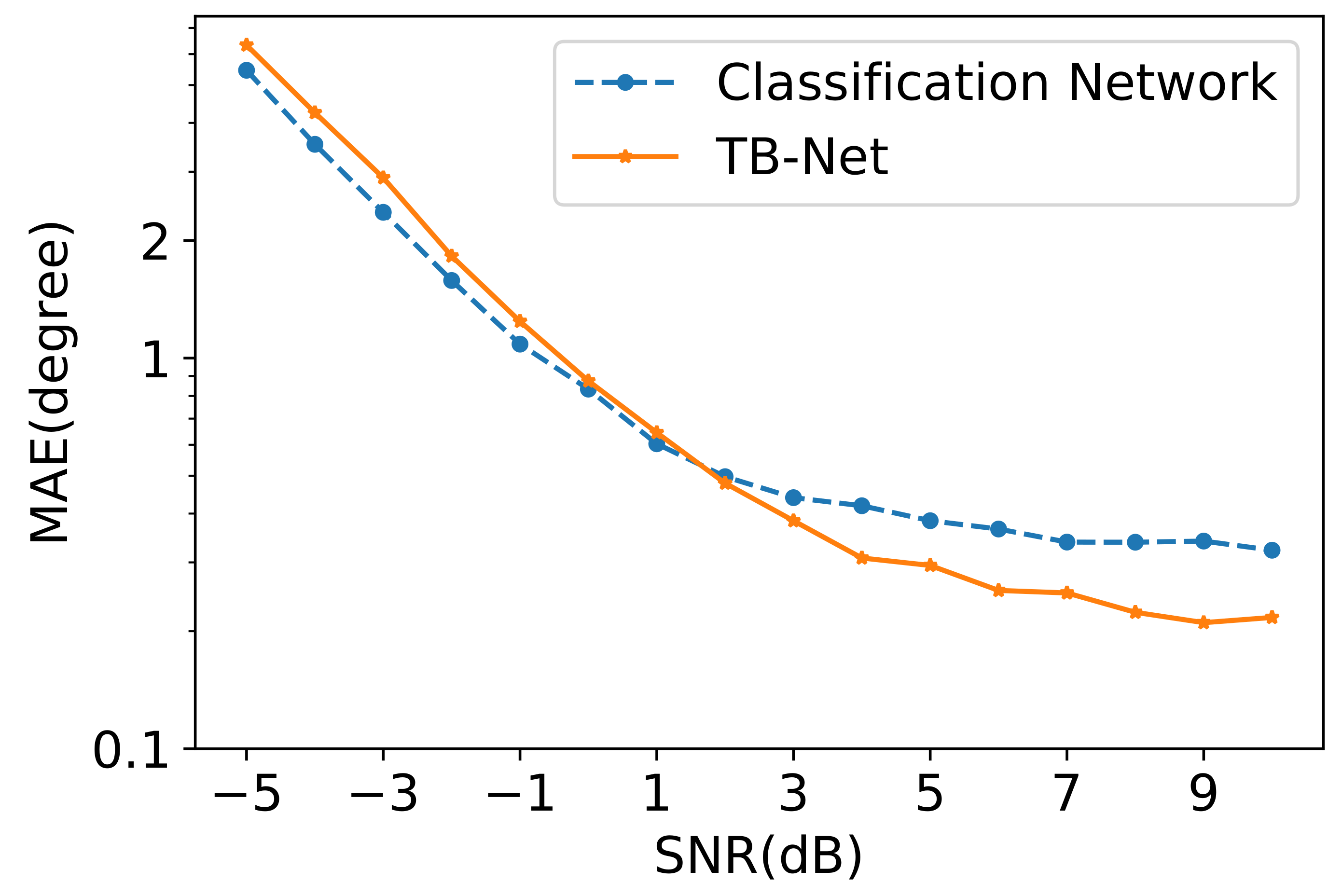
4.1. Experiments on TB-Net
4.1.1. Classification Network
4.1.2. TB-Net
4.2. Complexity Analyses
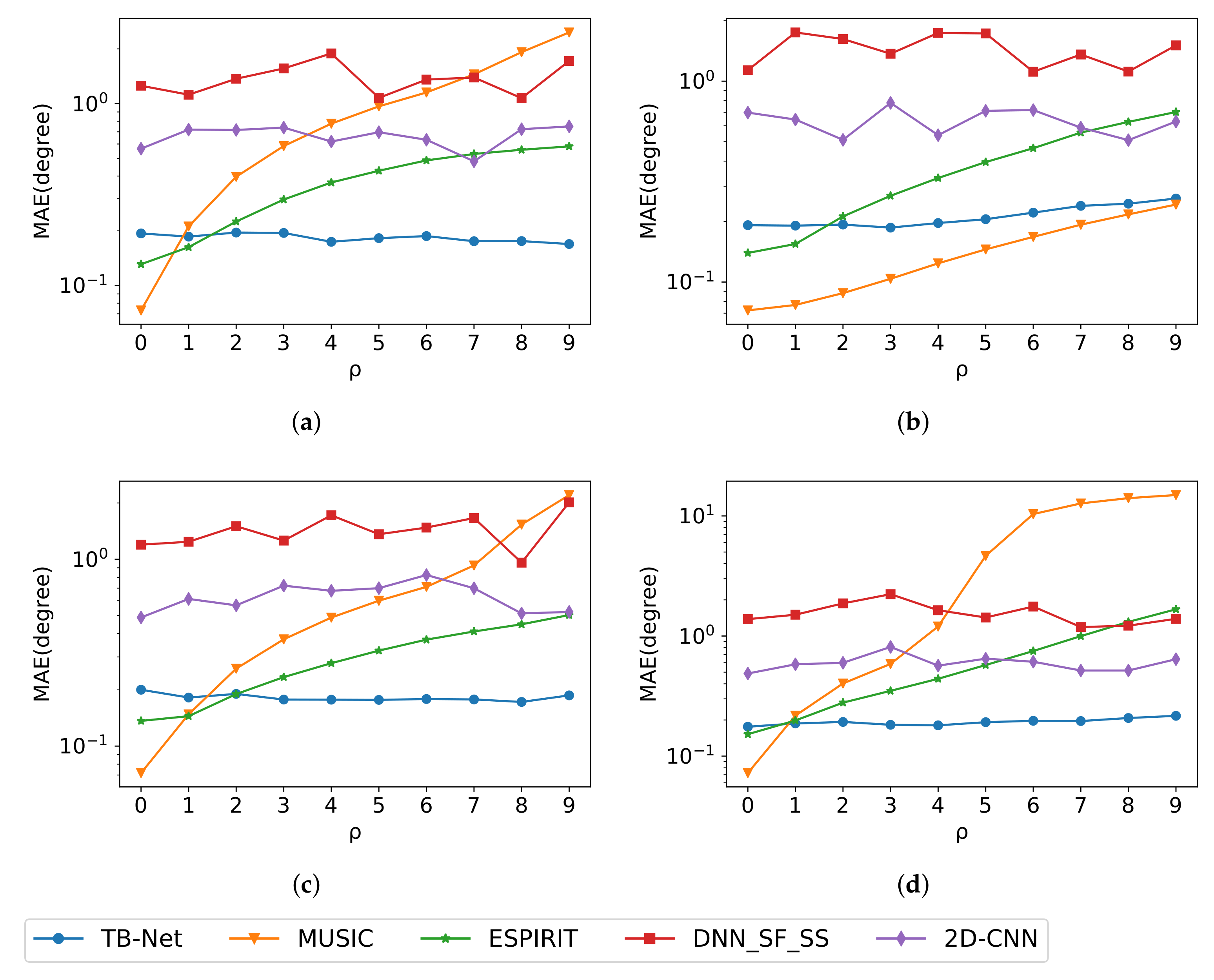
4.3. Experiments with Model Imperfections
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| TB-Net | Two-branch neural network |
| DoA | Direction of arrival |
| DNN | Deep neural network |
| CNN | Convolutional neural network |
| MUSIC | Multiple signal classification |
| ESPIRIT | Estimation of signal parameters via rotational invariance techniques |
| GRU | Gated recurrent units |
| BiLSTM | Bidirectional long short-term memory |
| SNR | Signal-to-noise ratio |
| R-Branch | Regression branch |
| C-Branch | Classification branch |
| ULA | Uniform linear array |
| BN | Batch normalization |
| BCE | Binary cross-entropy |
| MAE | Mean absolute error |
References
- Schmidt, R.O. Multiple Emitter Location and Signal Parameter Estimation. IEEE Trans. Antennas Propag. 1986, 34, 276–280. [Google Scholar] [CrossRef] [Green Version]
- Roy, R.; Kailath, T. ESPRIT-Estimation of Signal Parameters Via Rotational Invariance Techniques. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 984–995. [Google Scholar] [CrossRef] [Green Version]
- Chen, P.; Yang, Z.; Chen, Z.; Guo, Z. Reconfigurable Intelligent Surface Aided Sparse DOA Estimation Method with Non-ULA. IEEE Signal Process. Lett. 2021, 28, 2023–2027. [Google Scholar] [CrossRef]
- Chen, P.; Chen, Z.; Cao, Z.; Wang, X. A New Atomic Norm for DOA Estimation with Gain-Phase Errors. IEEE Trans. Signal Process. 2020, 68, 4293–4306. [Google Scholar] [CrossRef]
- Chen, P.; Cao, Z.; Chen, Z.; Wang, X. Off-Grid DOA Estimation Using Sparse Bayesian Learning in MIMO Radar with Unknown Mutual Coupling. IEEE Trans. Signal Process. 2019, 67, 208–220. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Zhang, C.; Yu, P.S. Direction-of-Arrival Estimation Based on Deep Neural Networks with Robustness to Array Imperfections. IEEE Trans. Antennas Propag. 2018, 66, 7315–7327. [Google Scholar] [CrossRef]
- Hu, D.; Zhang, Y.; He, L.; Wu, J. Low-Complexity Deep-Learning-Based DOA Estimation for Hybrid Massive MIMO Systems with Uniform Circular Arrays. IEEE Wirel. Commun. Lett. 2020, 9, 83–86. [Google Scholar] [CrossRef]
- Wu, L.; Liu, Z.; Huang, Z. Deep Convolution Network for Direction of Arrival Estimation with Sparse Prior. IEEE Signal Process. Lett. 2019, 26, 1688–1692. [Google Scholar] [CrossRef]
- Papageorgiou, G.K.; Sellathurai, M. Fast Direction-of-arrival Estimation of Multiple Targets Using Deep Learning and Sparse Arrays. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4632–4636. [Google Scholar]
- Barthelme, A.; Utschick, W. A Machine Learning Approach to DoA Estimation and Model Order Selection for Antenna Arrays with Subarray Sampling. IEEE Trans. Signal Process. 2021, 69, 3075–3087. [Google Scholar] [CrossRef]
- Barthelme, A.; Utschick, W. DoA Estimation Using Neural Network-Based Covariance Matrix Reconstruction. IEEE Signal Process. Lett. 2021, 28, 783–787. [Google Scholar] [CrossRef]
- Barthelme, A.; Utschick, W. Robust DOA Estimation Method for MIMO Radar via Deep Neural Networks. IEEE Sens. J. 2021, 21, 7498–7507. [Google Scholar]
- Adavanne, S.; Politis, A.; Virtanen, T. Direction of Arrival Estimation for Multiple Sound Sources Using Convolutional Recurrent Neural Network. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1462–1466. [Google Scholar]
- Ahmed, A.M.; Thanthrige, U.S.K.P.M.; Gamal, A.E.; Sezgin, A. Deep Learning for DOA Estimation in MIMO Radar Systems via Emulation of Large Antenna Arrays. IEEE Commun. Lett. 2021, 25, 1559–1563. [Google Scholar] [CrossRef]
- Liu, W. Super resolution DOA estimation based on deep neural network. Sci. Rep. 2020, 10, 19859. [Google Scholar] [CrossRef] [PubMed]
- Xiang, H.; Chen, B.; Yang, M.; Xu, S. Angle Separation Learning for Coherent DOA Estimation with Deep Sparse Prior. IEEE Commun. Lett. 2021, 25, 465–469. [Google Scholar] [CrossRef]
- Papageorgiou, G.K.; Sellathurai, M.; Eldar, Y.C. Deep Networks for Direction-of-Arrival Estimation in Low SNR. IEEE Trans. Signal Process. 2021, 69, 3714–3729. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Ioffe, S.; Szagedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 448–456. [Google Scholar]
- Kingma, D.P.; Ba, J.L. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Convolution Kernel (C_IN, C_OUT, H, W) | Stride | Activation and BN |
|---|---|---|---|
| Feature extraction network | (2, 8, 1, 5) | 2 | BN + ReLU |
| (8, 32, 1, 5) | 2 | BN + ReLU | |
| (32, 64, 1, 5) | 2 | BN + ReLU | |
| (64, 128, 1, 5) | 2 | BN + ReLU | |
| (128, 128, 1, 3) | 2 | BN + ReLU | |
| C-Branch | (128, 121, 1, 1) | 1 | Sigmoid |
| R-Branch | (128, 121, 1, 1) | 1 | Tanh |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, L.; She, C.; Chen, Y.; Guo, Z.; Zeng, X. TB-NET: A Two-Branch Neural Network for Direction of Arrival Estimation under Model Imperfections. Electronics 2022, 11, 220. https://doi.org/10.3390/electronics11020220
Lin L, She C, Chen Y, Guo Z, Zeng X. TB-NET: A Two-Branch Neural Network for Direction of Arrival Estimation under Model Imperfections. Electronics. 2022; 11(2):220. https://doi.org/10.3390/electronics11020220
Chicago/Turabian StyleLin, Liyu, Chaoran She, Yun Chen, Ziyu Guo, and Xiaoyang Zeng. 2022. "TB-NET: A Two-Branch Neural Network for Direction of Arrival Estimation under Model Imperfections" Electronics 11, no. 2: 220. https://doi.org/10.3390/electronics11020220
APA StyleLin, L., She, C., Chen, Y., Guo, Z., & Zeng, X. (2022). TB-NET: A Two-Branch Neural Network for Direction of Arrival Estimation under Model Imperfections. Electronics, 11(2), 220. https://doi.org/10.3390/electronics11020220