
Semi-Supervised Portrait Matting via the Collaboration of Teacher–Student Network and Adaptive Strategies




Abstract
:1. Introduction
- -
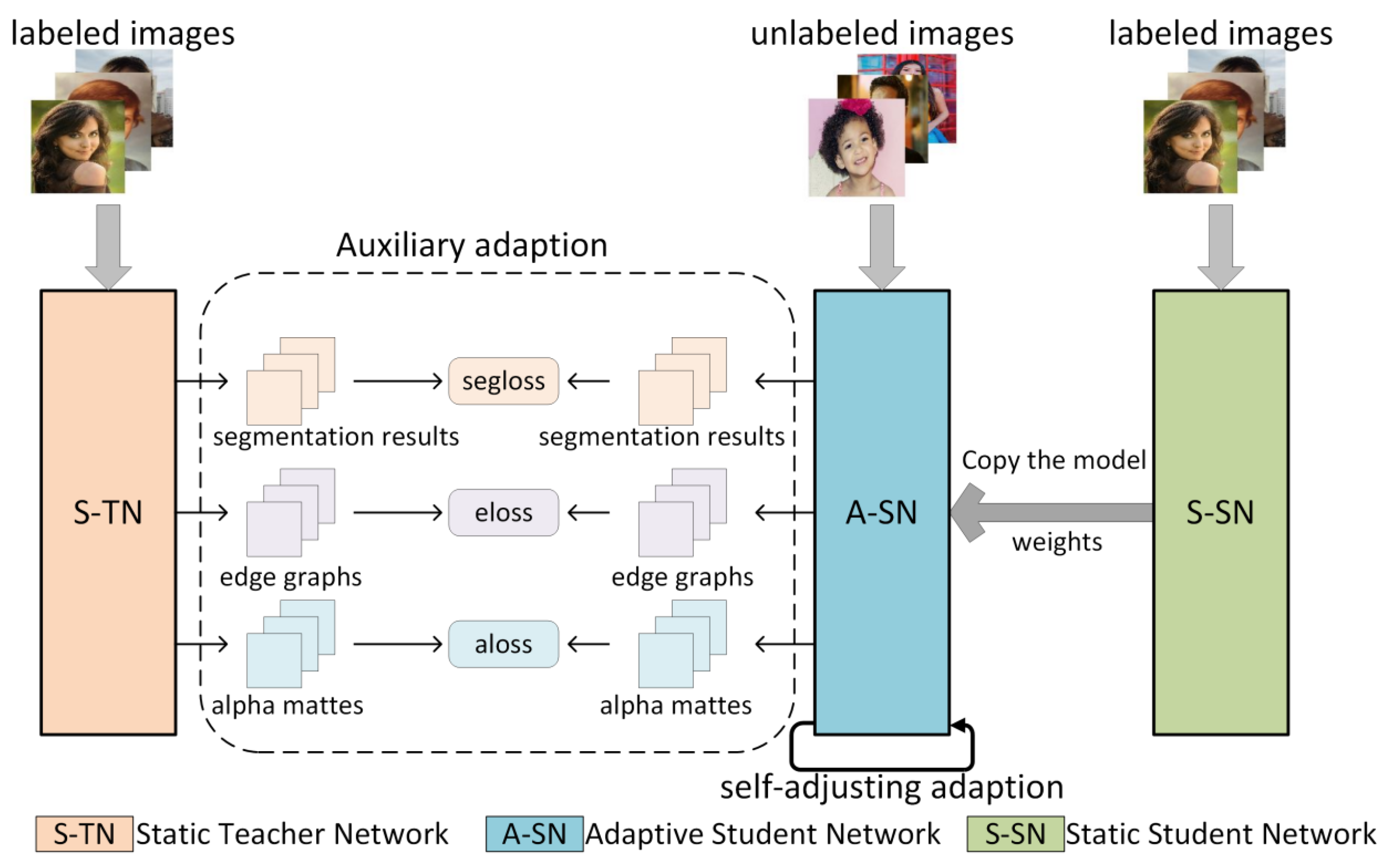
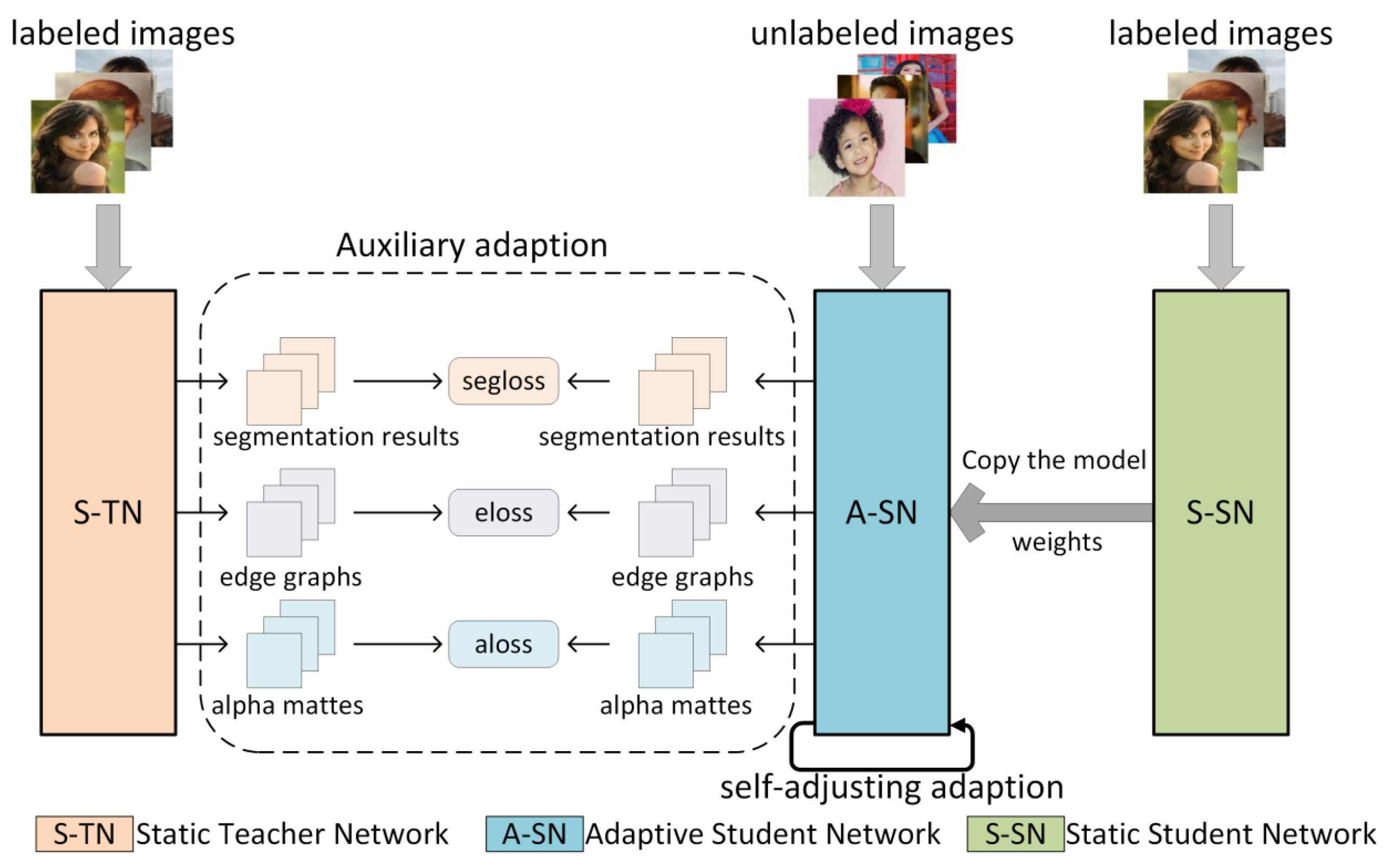
- A concrete instantiation of the semi-supervised network architecture (called ASSN). The architecture consists of three sub-networks, namely, a static teacher network (S-TN), a static student network (S-SN), and an adaptive student network (A-SN). Among them, the adaptive student network is the final applied lightweight network, which successfully acquires the ability to further improve performance on unlabeled data with the assistance of the static teacher network.
- -
- Two adaptive strategies to improve generalization on unlabeled datasets (as shown in Figure 1). Firstly, the auxiliary adaption ensures that the student network is not only supervised by the alpha mattes generated by the teacher network but also needs to receive the characteristics obtained in the middle layer of the network, including the segmentation results and edge graphs. Second, the self-adjusting adaption guarantees the similarity comparison between the characteristics of different levels in the student network.
- -
- Twenty-four groups of comparative experiments and several groups of ablation experiments are performed on several datasets.
- -
- An elaborate hand-annotated dataset has been produced and will be available to scholars in this field. We supplemented two types of images that are missing from existing datasets: images from multiple people and images taken in low-light conditions.
2. Related Work
2.1. Portrait Matting
2.2. Knowledge Distillation
2.3. Semi-Supervised
3. Proposed Method
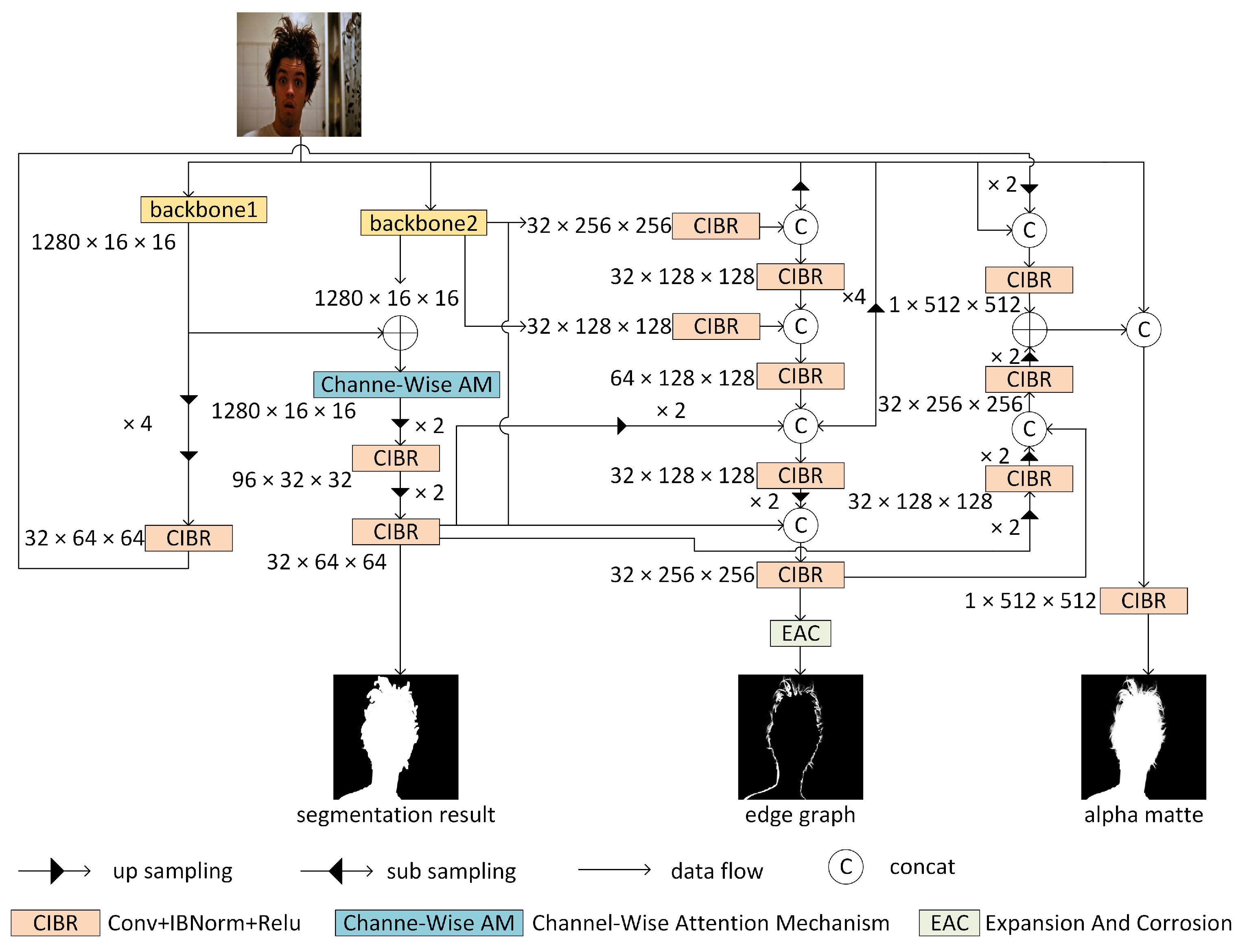
3.1. Baseline Network Architecture
3.1.1. Backbone
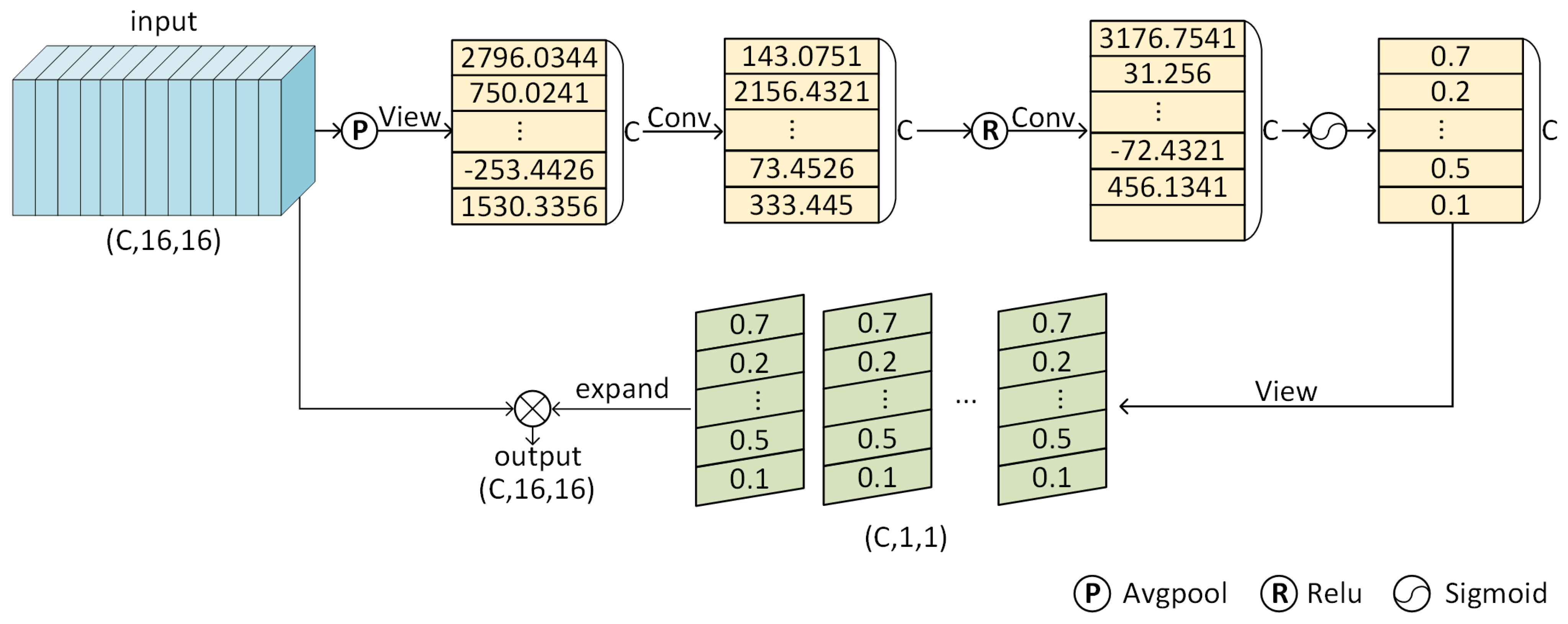
3.1.2. Channel-Wise Attention Mechanism
| Algorithm 1: The algorithm |
 |
3.1.3. CIBR
3.1.4. The Process of Data Transmission
3.1.5. Pruning the Static Student Network
3.2. Adaptive Strategies
3.2.1. Auxiliary Adaption
3.2.2. Self-Adjusting Adaption
4. Experimental Results
4.1. Self-Made Dataset

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4.2. Training Details
4.3. Comparisons Experiments
4.3.1. Comparisons of State-of-the-Art Methods
| Dataset | PPM-100 [46] | SPDDataset [54] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | GFM [59] | P3M [58] | MGM [61] | ViTAE [62] | SPKD [60] | ASSN | GFM [59] | P3M [58] | MGM [61] | ViTAE [62] | SPKD [60] | ASSN |
| year | 2022 | 2021 | 2021 | 2022 | 2020 | 2022 | 2022 | 2021 | 2021 | 2022 | 2020 | 2022 |
| SAD | 52.00 | 65.39 | 34.06 | 32.91 | 35.29 | 20.86 | 49.69 | 23.57 | 22.02 | 19.27 | 21.31 | 18.21 |
| MSE | 0.1936 | 0.1973 | 0.0502 | 0.0761 | 0.0699 | 0.0750 | 0.1868 | 0.0681 | 0.0501 | 0.3107 | 0.0538 | 0.0673 |
| MAD | 0.1983 | 0.2491 | 0.1293 | 0.1256 | 0.1967 | 0.0790 | 0.1895 | 0.0952 | 0.0771 | 0.3244 | 0.0865 | 0.0695 |
| Grad | 19.07 | 18.98 | 14.48 | 16.46 | 14.04 | 17.09 | 27.21 | 23.18 | 12.72 | 23.42 | 12.91 | 19.89 |
| Conn | 50.30 | 65.81 | 32.87 | 32.99 | 36.94 | 21.23 | 49.56 | 21.72 | 19.42 | 17.92 | 20.05 | 10.59 |
| SAD-FG | 36.37 | 20.44 | 12.08 | 13.91 | 12.33 | 10.34 | 32.11 | 5.225 | 6.174 | 5.310 | 4.061 | 10.50 |
| SAD-BG | 7.727 | 10.36 | 10.59 | 8.204 | 12.09 | 6.223 | 7.577 | 14.05 | 15.09 | 10.94 | 14.59 | 2.926 |
| Dataset | AdobeDataset [57] | AutomaticDataset [55] | ||||||||||
| Method | GFM [59] | P3M [58] | MGM [61] | ViTAE [62] | SPKD [60] | ASSN | GFM [59] | P3M [58] | MGM [61] | ViTAE [62] | SPKD [60] | ASSN |
| year | 2022 | 2021 | 2021 | 2022 | 2020 | 2022 | 2022 | 2021 | 2021 | 2022 | 2020 | 2022 |
| SAD | 77.09 | 28.54 | 25.37 | 25.62 | 26.08 | 21.79 | 60.77 | 47.58 | 45.03 | 47.27 | 45.53 | 31.68 |
| MSE | 0.2839 | 0.2131 | 0.0676 | 0.1072 | 0.0706 | 0.0734 | 0.2214 | 0.2151 | 0.1765 | 0.1072 | 0.1795 | 0.1118 |
| MAD | 0.2940 | 0.3325 | 0.2105 | 0.2613 | 0.2208 | 0.0831 | 0.2318 | 0.2195 | 0.1912 | 0.1280 | 0.2063 | 0.1208 |
| Grad | 24.13 | 20.22 | 16.60 | 17.58 | 16.97 | 17.38 | 17.89 | 15.33 | 12.62 | 13.59 | 13.06 | 9.696 |
| Conn | 70.17 | 28.18 | 24.85 | 25.21 | 25.02 | 20.77 | 59.62 | 47.43 | 44.19 | 24.44 | 44.67 | 39.37 |
| SAD-FG | 21.66 | 12.10 | 5.019 | 2.311 | 10.64 | 2.077 | 52.14 | 28.69 | 22.62 | 14.80 | 23.19 | 25.00 |
| SAD-BG | 15.47 | 9.242 | 3.628 | 2.870 | 3.766 | 2.848 | 2.569 | 2.815 | 4.180 | 6.392 | 3.547 | 1.954 |
4.3.2. CIBR vs. CBR, CIR, and CBIR
4.3.3. The Comparisons of Static Teacher Network and Static Student Network
4.3.4. Parameters
4.4. Ablation Studies
4.4.1. Adaptive Strategies
4.4.2. Some Components in the Teacher Network
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Y.; Ding, L.; Sharma, G. Local-linear-fitting-based matting for joint hole filling and depth upsampling of RGB-D images. J. Electron. Imaging 2019, 28, 033019. [Google Scholar] [CrossRef]
- Hu, W.C.; Hsu, J.F.; Huang, D.Y. Automatic video matting based on hybrid video object segmentation and closed-form matting. J. Electron. Imaging 2013, 22, 023005. [Google Scholar] [CrossRef]
- Boda, J.; Pandya, D. A Survey on Image Matting Techniques. In Proceedings of the 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 765–770. [Google Scholar]
- Rhemann, C.; Rother, C.; Rav-Acha, A.; Sharp, T. High resolution matting via interactive trimap segmentation. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AL, USA, 24–26 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–8. [Google Scholar]
- Gupta, V.; Raman, S. Automatic trimap generation for image matting. In Proceedings of the 2016 International Conference on Signal and Information Processing (IConSIP), Nanded, India, 6–8 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–5. [Google Scholar]
- Sengupta, S.; Jayaram, V.; Curless, B.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Background matting: The world is your green screen. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2291–2300. [Google Scholar]
- Xu, Y.; Liu, B.; Quan, Y.; Ji, H. Unsupervised Deep Background Matting Using Deep Matte Prior. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4324–4337. [Google Scholar] [CrossRef]
- Javidnia, H.; Pitié, F. Background matting. arXiv 2020, arXiv:2002.04433. [Google Scholar]
- Lin, S.; Ryabtsev, A.; Sengupta, S.; Curless, B.L.; Seitz, S.M.; Kemelmacher-Shlizerman, I. Real-time high-resolution background matting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8762–8771. [Google Scholar]
- Zhou, F.; Tian, Y.; Qi, Z. Attention transfer network for nature image matting. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2192–2205. [Google Scholar] [CrossRef]
- Wang, Q.; Li, S.; Wang, C.; Dai, M. Effective background removal method based on generative adversary networks. J. Electron. Imaging 2020, 29, 053014. [Google Scholar]
- Ke, Z.; Li, K.; Zhou, Y.; Wu, Q.; Mao, X.; Yan, Q.; Lau, R.W. Is a green screen really necessary for real-time portrait matting? arXiv 2020, arXiv:2011.11961. [Google Scholar]
- Dai, Y.; Lu, H.; Shen, C. Towards Light-Weight Portrait Matting via Parameter Sharing. In Computer Graphics Forum; Wiley: Hoboken, NJ, USA, 2021; Volume 40, pp. 151–164. [Google Scholar]
- Molodetskikh, I.; Erofeev, M.; Moskalenko, A.; Vatolin, D. Temporally coherent person matting trained on fake-motion dataset. Digit. Signal Process. 2022, 126, 103521. [Google Scholar] [CrossRef]
- Zhang, X.; He, H.; Zhang, J.X. Multi-focus image fusion based on fractional order differentiation and closed image matting. ISA Trans. 2022, 129, 703–714. [Google Scholar] [CrossRef] [PubMed]
- Pei, Z.; Chen, X.; Yang, Y.H. All-in-focus synthetic aperture imaging using image matting. IEEE Trans. Circuits Syst. Video Technol. 2016, 28, 288–301. [Google Scholar] [CrossRef]
- Park, W.; Kim, D.; Lu, Y.; Cho, M. Relational knowledge distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–17 June 2019; pp. 3967–3976. [Google Scholar]
- Liu, T.; Lam, K.M.; Zhao, R.; Qiu, G. Deep cross-modal representation learning and distillation for illumination-invariant pedestrian detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 315–329. [Google Scholar] [CrossRef]
- Liu, J.; Yang, M.; Li, C.; Xu, R. Improving cross-modal image-text retrieval with teacher-student learning. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 3242–3253. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. arXiv 2021, arXiv:abs/2006.05525. [Google Scholar] [CrossRef]
- Zhang, K.; Zhanga, C.; Li, S.; Zeng, D.; Ge, S. Student network learning via evolutionary knowledge distillation. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2251–2263. [Google Scholar] [CrossRef]
- Song, M.; Kim, W. Decomposition and replacement: Spatial knowledge distillation for monocular depth estimation. J. Vis. Commun. Image Represent. 2022, 85, 103523. [Google Scholar] [CrossRef]
- Cho, J.H.; Hariharan, B. On the efficacy of knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 4794–4802. [Google Scholar]
- Sepahvand, M.; Abdali-Mohammadi, F. Overcoming limitation of dissociation between MD and MI classifications of breast cancer histopathological images through a novel decomposed feature-based knowledge distillation method. Comput. Biol. Med. 2022, 145, 105413. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, Z.; Li, Y.; Lu, G.; Zhang, D. Multi-label chest X-ray image classification via semantic similarity graph embedding. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2455–2468. [Google Scholar] [CrossRef]
- Song, Z.; Yang, X.; Xu, Z.; King, I. Graph-based semi-supervised learning: A comprehensive review. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Lv, Y.; Liu, B.; Zhang, J.; Dai, Y.; Li, A.; Zhang, T. Semi-supervised active salient object detection. Pattern Recognit. 2022, 123, 108364. [Google Scholar] [CrossRef]
- Wang, L.; Yoon, K.J. Semi-supervised student-teacher learning for single image super-resolution. Pattern Recognit. 2022, 121, 108206. [Google Scholar] [CrossRef]
- Zhang, X.; Gao, C.; Wang, G.; Sang, N.; Dong, H. Semi-supervised portrait matting using transformer. Digit. Signal Process. 2022, 133, 103849. [Google Scholar] [CrossRef]
- Wan, A.; Dai, X.; Zhang, P.; He, Z.; Tian, Y.; Xie, S.; Wu, B.; Yu, M.; Xu, T.; Chen, K.; et al. Fbnetv2: Differentiable neural architecture search for spatial and channel dimensions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12965–12974. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Saha, A.; Bhatnagar, G.; Wu, Q.J. Mutual spectral residual approach for multifocus image fusion. Digit. Signal Process. 2013, 23, 1121–1135. [Google Scholar] [CrossRef]
- Li, F.; Li, W.; Shu, Y.; Qin, S.; Xiao, B.; Zhan, Z. Multiscale receptive field based on residual network for pancreas segmentation in CT images. Biomed. Signal Process. Control. 2020, 57, 101828. [Google Scholar] [CrossRef]
- Sander, M.E.; Ablin, P.; Blondel, M.; Peyré, G. Momentum residual neural networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 9276–9287. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Finney, D.J. Probit Analysis: A Statistical Treatment of the Sigmoid Response Curve; Cambridge University Press: Cambridge, UK, 1952. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar] [CrossRef]
- Kohl, S.; Bonekamp, D.; Schlemmer, H.P.; Yaqubi, K.; Hohenfellner, M.; Hadaschik, B.; Radtke, J.P.; Maier-Hein, K. Adversarial networks for the detection of aggressive prostate cancer. arXiv 2017, arXiv:1702.08014. [Google Scholar]
- Pecha, M.; Horák, D. Analyzing l1-loss and l2-loss support vector machines implemented in PERMON toolbox. In Proceedings of the International Conference on Advanced Engineering Theory and Applications, Bogota, Colombia, 6–8 November 2018; pp. 13–23. [Google Scholar]
- Gedraite, E.S.; Hadad, M. Investigation on the effect of a Gaussian Blur in image filtering and segmentation. In Proceedings of the 53rd International Symposium ELMAR-2011, Zadar, Croatia, 14–16 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 393–396. [Google Scholar]
- Ge, Y.; Chen, D.; Li, H. Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification. arXiv 2020, arXiv:abs/2001.01526. [Google Scholar]
- He, T.; Shen, L.; Guo, Y.; Ding, G.; Guo, Z. SECRET: Self-Consistent Pseudo Label Refinement for Unsupervised Domain Adaptive Person Re-identification. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022. [Google Scholar]
- Ji, D.; Wang, H.; Tao, M.; Huang, J.; Hua, X.; Lu, H. Structural and Statistical Texture Knowledge Distillation for Semantic Segmentation. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 16855–16864. [Google Scholar]
- Zhai, S.; Wang, G.; Luo, X.; Yue, Q.; Li, K.; Zhang, S. PA-Seg: Learning from Point Annotations for 3D Medical Image Segmentation using Contextual Regularization and Cross Knowledge Distillation. arXiv 2022, arXiv:abs/2208.05669. [Google Scholar]
- Ke, Z.; Sun, J.; Li, K.; Yan, Q.; Lau, R.W. MODNet: Real-Time Trimap-Free Portrait Matting via Objective Decomposition; AAAI: Menlo Park, CA, USA, 2022. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; Keutzer, K. Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–17 June 2019; pp. 10734–10742. [Google Scholar]
- Cai, H.; Zhu, L.; Han, S. Proxylessnas: Direct neural architecture search on target task and hardware. arXiv 2018, arXiv:1812.00332. [Google Scholar]
- Dai, X.; Zhang, P.; Wu, B.; Yin, H.; Sun, F.; Wang, Y.; Dukhan, M.; Hu, Y.; Wu, Y.; Jia, Y.; et al. Chamnet: Towards efficient network design through platform-aware model adaptation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–17 June 2019; pp. 11398–11407. [Google Scholar]
- Targ, S.; Almeida, D.; Lyman, K. Resnet in resnet: Generalizing residual architectures. arXiv 2016, arXiv:1603.08029. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Mei, J.; Li, Y.; Lian, X.; Jin, X.; Yang, L.; Yuille, A.; Yang, J. Atomnas: Fine-grained end-to-end neural architecture search. arXiv 2019, arXiv:1912.09640. [Google Scholar]
- Supervisely Person Dataset. 2018. Available online: supervise.ly (accessed on 1 September 2022).
- Shen, X.; Tao, X.; Gao, H.; Zhou, C.; Jia, J. Deep automatic portrait matting. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 92–107. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Xu, N.; Price, B.; Cohen, S.; Huang, T. Deep image matting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2970–2979. [Google Scholar]
- Li, J.; Ma, S.; Zhang, J.; Tao, D. Privacy-preserving portrait matting. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 3501–3509. [Google Scholar]
- Li, J.; Zhang, J.; Maybank, S.J.; Tao, D. Bridging composite and real: Towards end-to-end deep image matting. Int. J. Comput. Vis. 2022, 130, 246–266. [Google Scholar] [CrossRef]
- Yoon, D.; Park, J.; Cho, D. Lightweight deep CNN for natural image matting via similarity-preserving knowledge distillation. IEEE Signal Process. Lett. 2020, 27, 2139–2143. [Google Scholar] [CrossRef]
- Yu, Q.; Zhang, J.; Zhang, H.; Wang, Y.; Lin, Z.; Xu, N.; Bai, Y.; Yuille, A. Mask guided matting via progressive refinement network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1154–1163. [Google Scholar]
- Ma, S.; Li, J.; Zhang, J.; Zhang, H.; Tao, D. Rethinking Portrait Matting with Privacy Preserving. arXiv 2022, arXiv:2203.16828. [Google Scholar]




| Datasets | PPM-100 [46] | SPD Dataset [54] | Adobe Portrait Matting Dataset [57] | Automatic Portrait Matting Dataset [55] | P3M-10k [58] |
|---|---|---|---|---|---|
| Train Samples | 0 | 3210 | 0 | 1700 | 0 |
| Test Samples | 100 | 3210 | 636 | 300 | 1000 |
| Testset Rename | - | SPD Dataset | Adobe Dataset | Automatic Dataset | P3M |
| Module | CIBR | CBR | CIR | CBIR |
|---|---|---|---|---|
| SAD | 20.86 | 29.93 | 35.37 | 23.18 |
| MSE | 0.0750 | 0.0757 | 0.1023 | 0.0805 |
| MAD | 0.0790 | 0.1072 | 0.1319 | 0.0937 |
| Grad | 17.09 | 21.33 | 23.15 | 20.92 |
| Conn | 21.23 | 22.50 | 32.91 | 21.42 |
| SAD-FG | 10.34 | 12.72 | 14.57 | 13.81 |
| SAD-BG | 6.223 | 8.184 | 14.53 | 7.106 |
| Before (the Original Algorithms) | After (Algorithms with the Adaptive Strategies) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Method | GFM [59] | P3M [58] | MGM [61] | ViTAE [62] | Ours w/o Strategies | GFM [59] | P3M [58] | MGM [61] | ViTAE [62] | Ours |
| SAD | 66.50 | 30.74 | 35.21 | 23.75 | 17.59 | 43.72 | 4.520 | 5.641 | 2.368 | 2.074 |
| MSE | 0.2500 | 0.1071 | 0.1246 | 0.0898 | 0.0648 | 0.1620 | 0.0125 | 0.0115 | 0.0048 | 0.0031 |
| MAD | 0.2536 | 0.1172 | 0.1366 | 0.0917 | 0.0706 | 0.1668 | 0.0172 | 0.0215 | 0.0090 | 0.0075 |
| Grad | 20.22 | 33.31 | 28.42 | 29.91 | 20.59 | 22.67 | 6.876 | 3.820 | 4.838 | 4.575 |
| Conn | 64.86 | 36.89 | 32.06 | 22.41 | 10.93 | 42.96 | 4.276 | 5.027 | 2.249 | 2.084 |
| SAD-FG | 54.79 | 13.04 | 10.63 | 8.635 | 9.42 | 33.07 | 1.083 | 0.8738 | 0.3509 | 0.3018 |
| SAD-BG | 2.436 | 6.303 | 14.81 | 10.62 | 2.834 | 2.503 | 0.9829 | 3.341 | 0.1132 | 0.0948 |
| Num | backbone1 | backbone2 | Channel-Wise AM | CIBR | SAD | MSE | MAD | Grad | Conn | SAD-FG | SAD-BG |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | ✓ | ✗ | ✗ | ✗ | 54.25 | 0.1256 | 0.1726 | 18.72 | 53.21 | 42.06 | 9.825 |
| 2 | ✗ | ✓ | ✗ | ✗ | 60.94 | 0.2355 | 0.2286 | 21.48 | 54.28 | 42.85 | 8.572 |
| 3 | ✓ | ✓ | ✗ | ✗ | 42.57 | 0.1547 | 0.1703 | 23.83 | 41.64 | 20.58 | 7.852 |
| 4 | ✓ | ✗ | ✓ | ✗ | 50.17 | 0.1102 | 0.1653 | 14.95 | 49.83 | 38.01 | 9.194 |
| 5 | ✓ | ✗ | ✗ | ✓ | 46.82 | 0.1053 | 0.1493 | 11.15 | 43.03 | 33.92 | 8.083 |
| 6 | ✗ | ✓ | ✓ | ✗ | 56.28 | 0.1738 | 0.1841 | 17.74 | 50.92 | 39.61 | 7.440 |
| 7 | ✗ | ✓ | ✗ | ✓ | 48.67 | 0.1383 | 0.1618 | 13.47 | 46.92 | 30.04 | 7.052 |
| 8 | ✗ | ✓ | ✓ | ✓ | 26.30 | 0.0961 | 0.1075 | 10.31 | 23.72 | 14.10 | 7.228 |
| 9 | ✓ | ✗ | ✓ | ✓ | 13.94 | 0.0619 | 0.0690 | 16.36 | 9.186 | 2.330 | 4.124 |
| 10 | ✓ | ✓ | ✗ | ✓ | 8.813 | 0.0135 | 0.0171 | 5.446 | 8.350 | 0.9182 | 1.843 |
| 11 | ✓ | ✓ | ✓ | ✗ | 10.72 | 0.0979 | 0.0893 | 20.49 | 10.18 | 3.483 | 6.421 |
| 12 | ✓ | ✓ | ✓ | ✓ | 2.074 | 0.0031 | 0.0075 | 4.575 | 2.084 | 0.3018 | 0.0948 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Wang, G.; Chen, C.; Dong, H.; Shao, M. Semi-Supervised Portrait Matting via the Collaboration of Teacher–Student Network and Adaptive Strategies. Electronics 2022, 11, 4080. https://doi.org/10.3390/electronics11244080
Zhang X, Wang G, Chen C, Dong H, Shao M. Semi-Supervised Portrait Matting via the Collaboration of Teacher–Student Network and Adaptive Strategies. Electronics. 2022; 11(24):4080. https://doi.org/10.3390/electronics11244080
Chicago/Turabian StyleZhang, Xinyue, Guodong Wang, Chenglizhao Chen, Hao Dong, and Mingju Shao. 2022. "Semi-Supervised Portrait Matting via the Collaboration of Teacher–Student Network and Adaptive Strategies" Electronics 11, no. 24: 4080. https://doi.org/10.3390/electronics11244080
APA StyleZhang, X., Wang, G., Chen, C., Dong, H., & Shao, M. (2022). Semi-Supervised Portrait Matting via the Collaboration of Teacher–Student Network and Adaptive Strategies. Electronics, 11(24), 4080. https://doi.org/10.3390/electronics11244080