Abstract
Accurate short-term load forecasting can ensure the safe and stable operation of power grids, but the nonlinear load increases the complexity of forecasting. In order to solve the problem of modal aliasing in historical data, and fully explore the relationship between time series characteristics in load data, this paper proposes a gated cyclic network model (SSA–GRU) based on sparrow algorithm optimization. Firstly, the complementary sets and empirical mode decomposition (EMD) are used to decompose the original data to obtain the characteristic components. The SSA–GRU combined model is used to predict the characteristic components, and finally obtain the prediction results, and complete the short-term load forecasting. Taking the real data of a company as an example, this paper compares the combined model CEEMD–SSA–GRU with EMD–SSA–GRU, SSA–GRU, and GRU models. Experimental results show that this model has better prediction effect than other models.
1. Introduction
With the rapid development of power systems, load forecasting attracted great attention of power companies and consumers, and became an important direction of modern power system research. Considering the periodicity, fluctuation, continuity, and randomness of power loads, the complexity and difficulty of load forecasting are increased.
Under the completely free power market operation mode, the load forecasting problem affects the power dispatching of power companies and the production plan of power-consuming enterprises [1]. Among them, short-term load forecasting plays an important role in guiding and regulating the operation of power companies. Accurate prediction results can more reasonably arrange the daily production plan. Short-term load forecasting (STLF) of the power system refers to forecasting the load in the next few hours to several days [2]. STLF is an important foundation to ensure the reliable operation of modern power systems and an important link in energy management systems. Its results play an important reference role for dispatching departments to determine the daily, weekly, and monthly dispatching plans, and to reasonably arrange the unit start–stop, load distribution, and equipment maintenance [3]. With the continuous expansion of the scale of modern power systems, higher requirements are put forward for STLF, and STLF technology of power systems is increasingly becoming a key technology in the power industry.
Short-term load forecasting methods can be divided into three categories: traditional forecasting technology, improved traditional technology, and artificial intelligence technology. Traditional techniques include regression analysis [4], least square method [5], and exponential smoothing method [6]. Improved technologies include time series method [7], autoregression and moving average based model [8], support vector machine [9], etc. However, most of the traditional technologies and improved traditional technologies are linear prediction models, and the relationship between load and other characteristic factors in load forecasting is complex and non-linear, so it is not effective in forecasting power load [10]. Artificial intelligence technology includes genetic algorithm [11], fuzzy logic [12], artificial neural network [13], and expert system [14]. However, these methods have some shortcomings. For example, artificial neural networks still need to extract features artificially in load forecasting, and human intervention is high.
In recent decades, with the rapid development of artificial intelligence technology, experts and scholars all over the world conducted in-depth research on short-term load forecasting and put forward many effective forecasting models. Imani, M [15] proposed a method to extract the non-linear relationship of load based on a convolutional neural network. Many researchers use deep learning networks to predict. Typical deep learning networks include CNN [16], deep confidence network, and recurrent neural network RNN [17]. CNN uses convolution operation to greatly reduce the data dimension and realize the learning and expression of data sample features. RNN is a special type of artificial neural network, which has a good ability to process sequence and time information. Kim, J et al. [18] combined RNN and CNN, and proposed a recursive starting convolutional neural network for load forecasting. When dealing with time series problems, the gradient of the recurrent neural network disappears, which makes it more difficult to train the RNN, resulting in poor prediction. Long- and short-term memory networks have been proposed to solve this problem [19]. However, the network structure of LSTM is complex and the convergence speed is slow. Gate-based loop architectures have been used to improve the LSTM, for example, a gated cycle unit (GRU). Compared to LSTM, GRU has one less gate function and requires fewer parameters, thus, improving the training speed. Wang, YX et al. [20] used GRU for short-term load prediction and achieved very good results.
The combination of different types of artificial neural network models is the research hotspot to solve the short-term power load forecasting problem. Rafi, SH et al. [21] proposed a neural network integrating CNN and LSTM for short-term load forecasting and achieved good results. However, the performance of CNN and LSTM should be further optimized. Shi, HF et al. [22] proposed a CNN–BiLSTM combination model optimized by attention mechanism for load forecasting. The combined model captures the data characteristics well and has a good prediction effect on long-time series. Gao, X et al. [23] proposed an EMD–GRU combined prediction model. The original sequence is decomposed by empirical mode decomposition and then predicted by GRU. EMD is prone to modal aliasing, and the combined model needs further improvement.
In addition, because it is very difficult to select super parameters in neural networks, it is easy to underfit or overfit, so parameter optimization is needed. In order to make the GRU model automatically find the optimal parameters in the training process, instead of human experience selection, the swarm intelligence optimization algorithm is used to optimize the parameter selection. Sparrow algorithm is one of the commonly used swarm intelligence optimization algorithms. Liao, GC [24] proposed an LSTM prediction model optimized by the sparrow algorithm. The prediction accuracy of LSTM model is effectively improved.
In summary, considering the signal noise problem in the original data sequence, this paper proposes to use the complementary set empirical mode decomposition to eliminate the noise interference in the original signal. Then the sparrow algorithm is used to optimize the parameters of GRU neural network. The CEEMD–SSA–GRU combination model is composed. Applying the model to short-term load forecasting, the network has higher forecasting accuracy and better adaptability.
2. Model Principle
2.1. GRU
In order to solve the problem that the feed forward neural network cannot retain previous information, some scholars proposed a feedback neural network, recurrent neural network (RNN), which can transfer the information between each layer in a two-way, and then form a memory for the information, allowing the information to persist, and has a certain memory capacity. Its structure is shown in Figure 1.
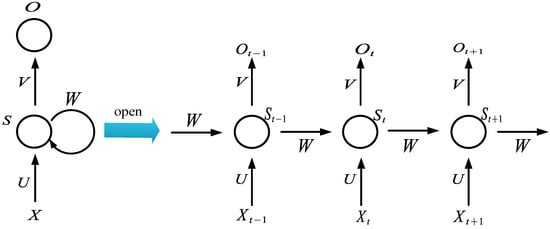
Figure 1.
Structure diagram of RNN neural network.
As can be seen from Figure 1, represents the time, represents the input layer, represents the hidden layer, and represents the output layer. The calculation formula of and is as follows:
Wherein in Formula (1) represents the hidden layer value at time , represents the activation function of the hidden layer, represents the input vector at time , represents the parameter matrix, represents the weight matrix, is the state of the hidden layer at the previous time. in Equation (2) represents the output at time , represents the parameter matrix, and represents the activation function of the output layer. generally adopts softmax function, and can choose sigmoid function or tanh function.
Although RNN solves the problem that a feed forward neural network cannot remember information, RNN neural networks have some shortcomings. It can only deal with short-term dependence. It is difficult to solve long-term dependence when using RNN, and its memory capacity is limited. Moreover, when the sequence is long, its learning ability and memory ability decline, and there is the problem that the gradient disappears.
In order to solve the problems of RNN, a variant of RNN, long short-term memory neural network (LSTM), was proposed. LSTM not only solves the problems of RNN, but also can handle the problems of short-term and long-term dependence, and realizes the function of long-term and short-term memory. The network structure diagram of LSTM is shown in Figure 2.
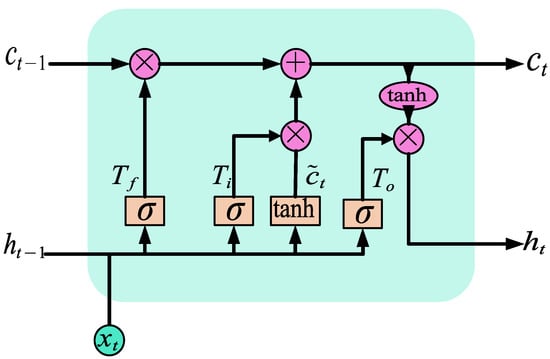
Figure 2.
LSTM network structure.
It can be seen from Figure 2 that LSTM is much more complex in network structure than RNN, and LSTM introduces cell state to memorize information. At the same time, a gating structure is introduced to maintain and control information, i.e., input gate, forgetting gate, and output gate. Although LSTM solves the problem that RNNs cannot carry out long-term memory, the network structure of LSTM is complex and the convergence speed is slow. It affects the training process and results when carrying out power load forecasting, and causes problems such as training complexity. In order to solve these problems, a variant of LSTM, gated recurrent neural network (GRU), is proposed on the basis of LSTM. It optimizes the function of LSTM and makes the network structure simple. It is a widely used neural network at present. The structure of GRU has changed from the three gates of LSTM to two gates, i.e., update gate and reset gate. The network structure is shown in Figure 3.
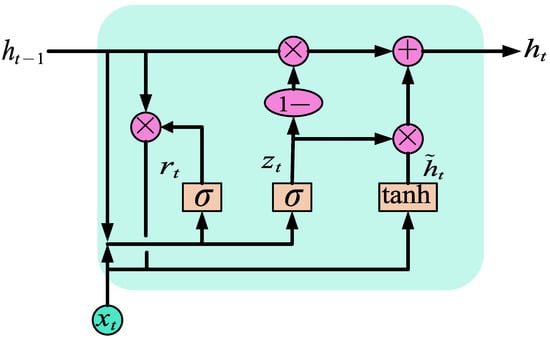
Figure 3.
GRU network structure.
in Figure 3 means update door, represents the reset door. The function of these two gates is to control the degree to which information is transferred. The inputs of both gates are the input at the current time and the hidden state at the previous time. The calculation formula of the two doors is as follows:
where represents the input at time t, represents the hidden state at the previous time, [] represents the connection of two vectors, and represent the weight matrix, and represents the sigmoid function.
GRU discards and memorizes the input information through two gate structures, and then calculates the candidate hidden state value , The calculation expression is shown in Formula (5):
where represents the tanh activation function, represents the weight matrix, and represents the product of the matrix.
After the tanh activation function obtains the updated state information through the update gate, it creates vectors of all possible values according to the new input, and calculates the candidate hidden state value , Then, the final state at the current time is calculated through the network, as shown in Formula (6):
According to the above calculation formula, GRU stores and filters information through two gates, retains important features through gate functions, and captures dependencies through learning to obtain the best output value.
When the same effect is achieved, the training time of GRU is shorter. Especially in the case of large training data, the effect of training and prediction using GRU is better, and much time is saved. Therefore, this paper selects a GRU neural network model for short-term power load forecasting to achieve the purpose of short training time and good forecasting effect.
In the prediction process of the GRU model, the number of hidden layer neural units, the learning rate, the number of small batch training, and the number of iterations need to be considered. The values of these parameters can affect the model fitting effect, training duration, generalization ability, or degree of convergence. After many experiments and observing the loss value of the model, a set of empirical parameters are obtained. When the parameter selection of the GRU prediction model uses one hidden layer, the number of neurons is 50, the learning rate is 0.005, the data volume of batch training is 50, and the number of iterations is 100, and the GRU prediction model obtains relatively average calculation efficiency and prediction effect.
2.2. Comparison of GRU Model and BP Model
2.2.1. Error Evaluation Criteria
- (1)
- Mean absolute error (MAE)
- (2)
- Root mean square error (RMSE)
- (3)
- Mean absolute percentage error (MAPE)
2.2.2. Model Comparison
In this section, the GRU model and BP model are trained and predicted, and the prediction performance is compared. The power load data used in this paper are the real power load data of an industrial user’s factory. The data set is selected from the real power load data of an industrial user in the two years from 1 January 2018 to 31 December 2020 as the training set data of the experiment. The sampling point is collected at the same time node every day, with a total of 731 sampling points. The daily power consumption load data in January 2021 are taken as the test set of the experiment, with a total of 31 data points. The environment of the electrical equipment in this factory is not affected by the external weather, and it is under constant temperature and humidity all the year round. The original power load data after missing or abnormal value processing are shown in Figure 4.
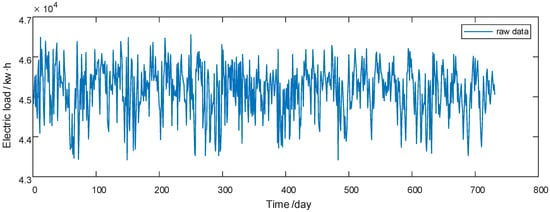
Figure 4.
Original power load training data.
The normalized power load data is shown in Figure 5.
Figure 5.
Normalized load data.
In this experiment, the GRU model and BP model are used to train the training set data. After the training, the data of the next month can be predicted. Finally, there is a comparison between the prediction results of the two models and the actual real value, using the above error evaluation indicators for analysis and comparison. The generated experimental results are shown in Table 1.

Table 1.
Comparison of BP and GRU neural network prediction results.
It can be seen from Figure 6 that the trend of the GRU model curve is closer to the test curve and smoother. However, the BP model curve has a relatively turbulent trend, and it is difficult to judge local fluctuations in time and respond quickly. The main reason is that the BP neural network cannot remember and save information, while GRU has the function of long-term memory, which can better remember and store previous data. In order to more intuitively compare the prediction results of the two models, Figure 7 shows the numerical value and curve comparison of the prediction error of the model.
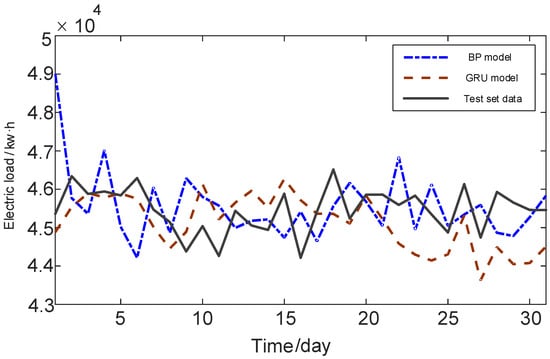
Figure 6.
Comparison of prediction curves of BP and GRU models.
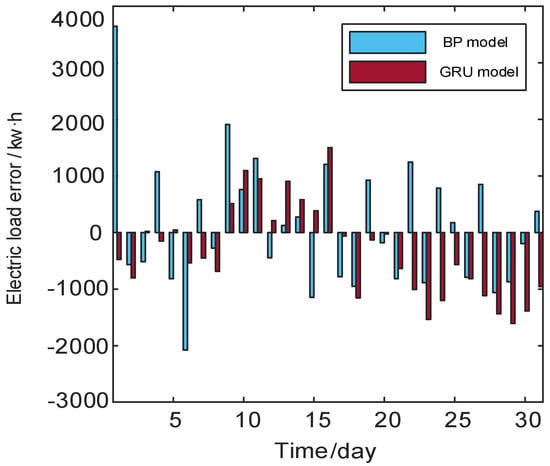
Figure 7.
Error comparison between BP and GRU.
For the maximum relative error and the average absolute error, the BP model is 8.04% and 1.96%, respectively. The GRU model is 3.51% and 1.63%, respectively. Compared with BP model, the accuracy of the maximum relative error of GRU model is increased by 56.3%, and the accuracy of the average absolute error is increased by 16.8%. The GRU neural network has some problems in the training process. The GRU model has a slow speed in the training process, and its model parameters are obtained based on experience. It is easy to fall into local optimization, complicating the training process and increasing the difficulty of training.
2.3. Sparrow Search Algorithm
In order to make the GRU model automatically find the optimal parameters in the training process instead of manually selecting through experience, the intelligent optimization algorithm sparrow search algorithm (SSA) is used to optimize the parameters in the GRU model. A new swarm intelligence optimization algorithm sparrow search algorithm (SSA) was proposed, which is mainly affected by the sparrow’s foraging and anti-predatory behavior. Assuming that there are n sparrows in a search space, the population composed of them can be expressed as:
where represents the dimension of the variable to be optimized. The fitness value of sparrow population can be expressed as:
where represents the fitness value.
2.3.1. Update Discoverer Location
In the search process, discoverers with high fitness will obtain food first, and at the same time, they provide the followers with the area and direction where the food is located. Therefore, the search scope of the discoverer is wider and the search ability is stronger. The location update is described as follows:
where is the current iteration number, is the maximum number of iterations. is the position information of the ith sparrow in the kth dimension. is a random number . is the warning value ; is the safe value . is a random number. represents a matrix.
From Equation (12), when , it means that the discoverer has not found that there are predators around the current foraging environment. At this time, the search space is safe and the discoverer can continue to perform more extensive search. When , it means that there are predators. The discoverer will quickly send an alarm and send a signal to other sparrows. At this time, all sparrows will fly to other safe places to find food.
2.3.2. Update Follower Position
When foraging, the behavior of the discoverer will be watched by some followers. If the former finds better food, the latter will quickly detect it and immediately go to fight for food. The location update is described as follows:
where , is the current best and worst position of the discoverer. is a matrix, and . When , it means that the ith follower has not found food, and it needs to continue to look for food.
2.3.3. Update the Guard Position
For the convenience of expression, we call these sparrows who are in danger without food as vigilantes. In the simulation, the number of vigilantes accounts for 10–20% of the total. The location update is described as follows:
where is the current global optimal position. and are step control parameters. represents the fitness value of the current sparrow individual. and represent the current global optimal and worst fitness values, respectively. is the minimum constant.
From Equation (15), if , it indicates that the vigilant is at the edge of the population and is easily attacked by predators. If , it indicates that the watcher is at the center of the population, and this part of sparrows has realized the threat. To prevent the predator from attacking, it must be close to other sparrows to reduce the risk of being attacked.
According to the design of sparrow search algorithm, the parameter optimization process of SSA is shown in Figure 8.
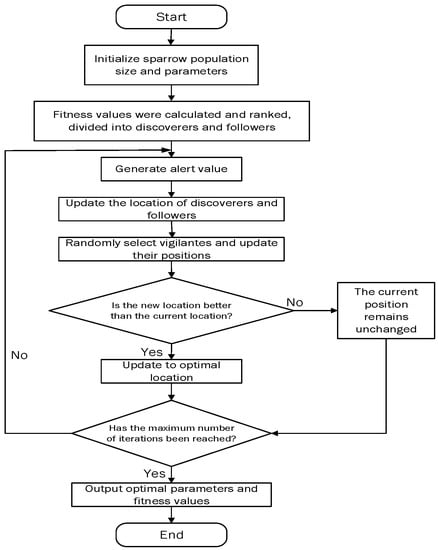
Figure 8.
Flow chart of sparrow search algorithm.
2.4. Comparison of Optimization Algorithms
In order to test the optimization ability of sparrow search algorithm, particle swarm optimization (PSO), genetic algorithm (GA), and artificial bee colony algorithm (ABC) are introduced for experimental test and comparison. We test and compare the fitness values of the four algorithms through the Griewank multi peak test function. The dimension of the Griewank test function is set to 30 and the search range is [−600, 600]. The maximum number of iterations of each algorithm is set to 1000 and the population number is set to 100. The parameter settings of the four optimization algorithms are shown in Table 2:
Table 2.
Optimization algorithm parameter setting.
After the test function is tested, the fitness value of each algorithm is shown in Figure 9:
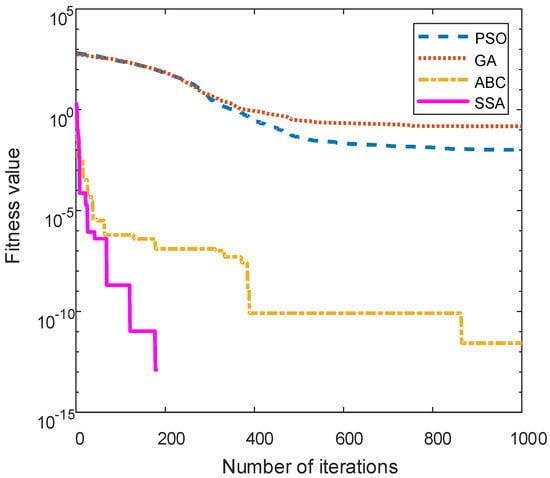
Figure 9.
Fitness value of each optimization algorithm.
In the comparison of the four algorithms, the SSA algorithm has the fastest convergence speed and the highest convergence accuracy. The SSA algorithm obtains the best fitness value at the fastest speed in the iterative process, and its optimization ability is the best. It can be concluded that it has the advantages of high search accuracy, fast convergence speed, and strong stability. Therefore, the SSA algorithm is used to optimize the neural network parameters in this paper.
2.5. CEEMD
Empirical mode decomposition (EMD) is an adaptive data mining method for signal analysis. It analyzes the signal based on the time scale characteristics of the data themselves, and decomposes the original signal into a series of intrinsic mode components (IMF) and a residual component. However, the EMD method has serious mode aliasing. In 2010, Yeh et al. proposed the complementary set empirical mode decomposition algorithm (CEEMD), which is an improved algorithm of EMD and can solve this phenomenon.
CEEMD changes the extreme point of the original signal by adding a pair of white noise signals with opposite signs, and cancels the noise in the signal through multiple average processing. The decomposition process is shown in Figure 10.
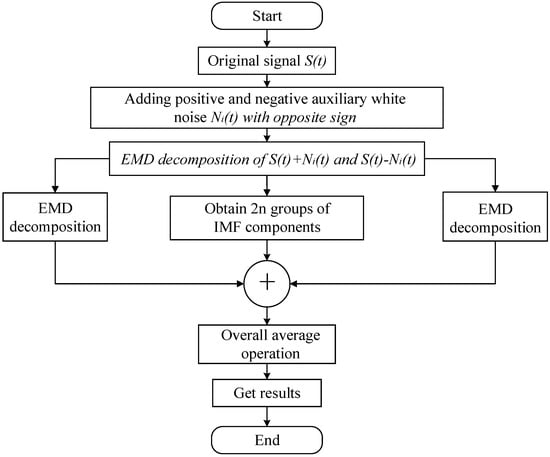
Figure 10.
CEEMD decomposition flow chart.
- (1)
- First, groups of white noise with opposite signs are added to the original signal to obtain a pair of new signals, which can be expressed as shown in Equation (15):where represents added white noise; denotes signals obtained by adding positive and negative white noise, respectively;
- (2)
- Then, EMD decomposition is performed on the 2n signals obtained, and a group of IMF components are obtained for each signal, and the jth IMF component of the ith signal is recorded as ; the last IMF component is taken as the residual component RES;
- (3)
- Finally, the 2n groups of IMF components obtained are averaged, and the components obtained by CEEMD decomposition of the original signal are expressed as:where represents the jth IMF component obtained after decomposition.
3. Combined Forecasting Model
3.1. Introduction to Combination Model
The essence of CEEMD–SSA–GRU model prediction is equivalent to adding the complementary set empirical mode decomposition algorithm CEEMD on the basis of the SSA–GRU prediction model. From the original training and prediction of the training set load data directly, the CEEMD algorithm decomposes the training set load data to obtain several subsequences, and then predicts through the SSA–GRU prediction model.
3.2. Model Example Analysis
In the process of CEEMD decomposition, the signal-to-noise ratio Nstd of 0.01–0.5, the number of white noise additions NR of 50–300, and the parameter value of the maximum iteration number Maxiter of no more than 5000 are usually added to obtain a good decomposition effect. After several decomposition tests, the parameter values selected for the final decomposition in this paper are set as Nstd = 0.2, NR = 200, and Maxiter = 5000. This section selects the preprocessed training set load data in Section 2.2.2, and decomposes the training set data with CEEMD and EMD algorithms. The decomposition results are shown in Figure 11 and Figure 12.
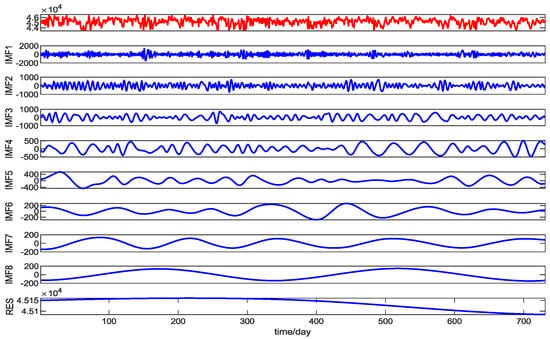
Figure 11.
The modal components are obtained by EMD decomposition.
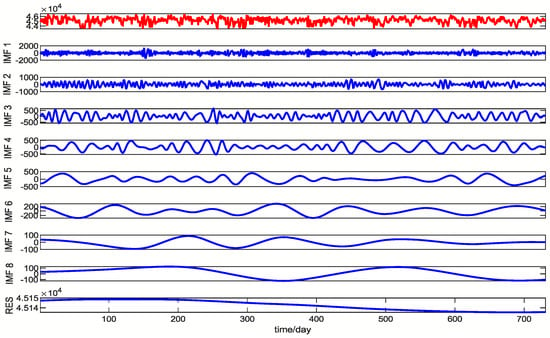
Figure 12.
CEEMD decomposition to obtain modal components.
The prediction results based on CEEMD prediction model and EMD prediction model are compared and analyzed.
The parameter settings of the CEEMD algorithm are the same as those above. The range of parameters in the SSA–GRU model are initialized to [10, 200], [0.001, 0.01], [50, 256], and [100, 1000]. The SSA initialization parameters are set according to Table 3. Through the construction of CEEMD–SSA–GRU model and EMD–SSA–GRU model, the experimental simulation is carried out on the two models to predict the data in the next month. The prediction results of the two models are shown in Table 4, and the result curves are shown in Figure 13 and Figure 14.
Table 3.
SSA initialization parameter setting.
Table 4.
Comparison of prediction results of two models.
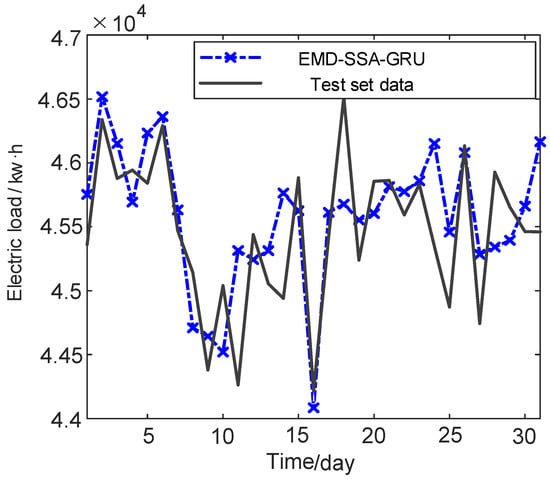
Figure 13.
EMD–SSA–GRU model prediction data.
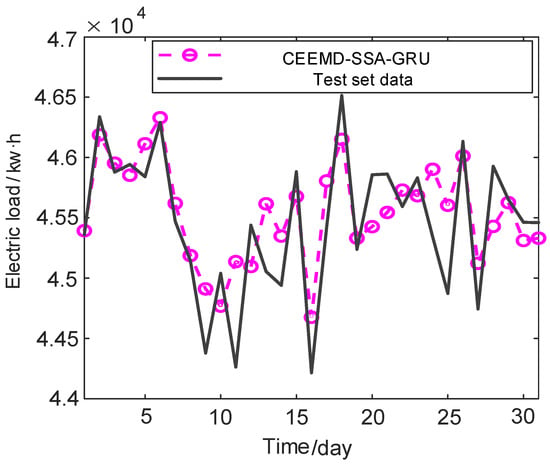
Figure 14.
CEEMD–SSA–GRU model prediction data.
The curve fitting degree of the CEEMD–SSA–GRU model is higher than that of the EMD–SSA–GRU model, and the number of extreme points close to the real value is higher. In order to more intuitively see the prediction of the two models, the prediction errors of the two models are calculated. The comparison of the errors of the two models is shown in Figure 15.
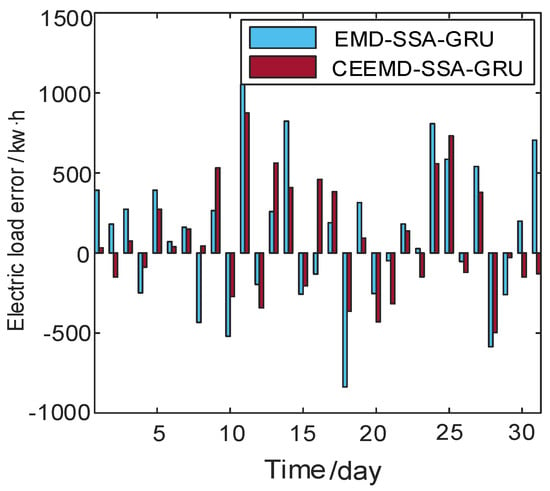
Figure 15.
Comparison of power load error.
For the maximum relative error and average absolute error, the EMD–SSA–GRU model is 2.038% and 0.80%, respectively; the CEEMD–SSA–GRU model is 1.98% and 0.64%, respectively. Through comparison, the accuracy of the maximum relative error of CEEMD–SSA–GRU model is increased by 16.8%, and the accuracy of the average relative error is increased by 20.0%. From the most direct prediction error analysis, we can see that the CEEMD–SSA–GRU model has higher prediction accuracy and accuracy.
Each error evaluation index formula calculates each error of the prediction results of the two models, as shown in Table 5.
Table 5.
Prediction error evaluation index.
Compared with the EMD–SSA–GRU model, the accuracy of the MAPE, MAE, and RMSE of the CEEMD–SSA–GRU prediction model increases by 20.0%, 20.1%, and 19.5%, respectively.
4. Results
We compare the prediction effect of CEEMD–SSA–GRU model with that of single GRU model, the GRU model optimized by SSA, and the EMD–SSA–GRU model. The comparison of the prediction curves of the four models is shown in Figure 16 and the comparison of prediction errors is shown in Figure 17.
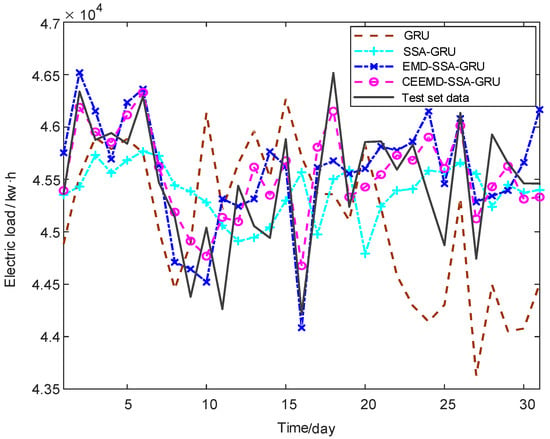
Figure 16.
Comparison of prediction curves of four models.
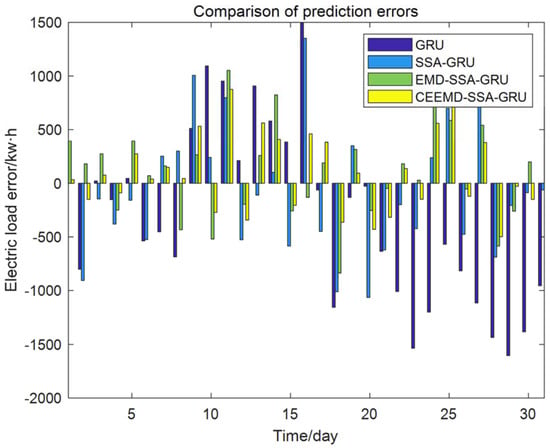
Figure 17.
Comparison of prediction errors of four models.
According to the calculation of error evaluation index formula, the comparison of various error evaluation indexes is shown in Table 6.
Table 6.
Prediction error evaluation index.
5. Conclusions
The fitting degree of the prediction curve of each model from high to low is the CEEMD–SSA–GRU model, the EMD–SSA–GRU model, the SSA–GRU model, and the GRU model, and the predicted value of each point in the prediction curve of CEEMD–SSA–GRU model is closest to the extreme point of the real curve. It can be seen from Table 4 that for MAPE, the CEEMD–SSA–GRU model is 60.7% lower than the GRU model, 39.0% lower than the SSA–GRU model, and 20.0% lower than the EMD–SSA–GRU model. For MAE, the CEEMD–SSA–GRU model is 60.8% lower than the GRU model, 39.1% lower than the SSA–GRU model, and 20.1% lower than the EMD–SSA–GRU model. For RMSE, the CEEMD–SSA–GRU model is 59.2% lower than the GRU model, 38.5% lower than the SSA–GRU model, and 19.5% lower than the EMD–SSA–GRU model.
The prediction accuracy of the CEEMD–SSA–GRU model reaches 99.36%, and the prediction result of the CEEMD–SSA–GRU model is the most accurate. Its prediction accuracy is obviously better than the other three models, and the fitting degree of the curve is the closest to the real curve. Therefore, the CEEMD–SSA–GRU model has more advantages in short-term power load forecasting and can better provide reliable forecasting trends for industrial users.
Author Contributions
Conceptualization, C.L.; formal analysis, L.S.; methodology, C.L. and J.L.; resources, L.S.; supervision, J.L. and H.W.; validation, Q.G.; visualization, Q.G.; writing—original draft, Q.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The load forecasting data used to support the results of this study have not been provided because they are private data of enterprises.
Conflicts of Interest
The authors declare that there are no conflicts of interest regarding the publication of this paper.
References
- Haq, R.; Ni, Z. A New Hybrid Model for Short-Term Electricity Load Forecasting. IEEE Access 2019, 7, 125413–125423. [Google Scholar] [CrossRef]
- Chen, K.; Chen, K.; Wang, Q.; He, Z.; Hu, J.; He, J. Short-Term Load Forecasting With Deep Residual Networks. IEEE Trans. Smart Grid 2019, 10, 3943–3952. [Google Scholar] [CrossRef]
- Jie, C. Research on Short-term Power Load Forecasting Model and its Improvement Method. Master’s Thesis, China University of Mining and Technology, Beijing, China, 2020. [Google Scholar]
- Živanović, R. Local Regression-Based Short-Term Load Forecasting. J. Intell. Robot. Syst. 2001, 31, 115–127. [Google Scholar] [CrossRef]
- Mastorocostas, P.; Theocharis, J.; Bakirtzis, A. Fuzzy modeling for short term load forecasting using the orthogonal least squares method. IEEE Trans. Power Syst. 1999, 14, 29–36. [Google Scholar] [CrossRef]
- Tsaur, R.-C. Forecasting by fuzzy double exponential smoothing model. Int. J. Comput. Math. 2003, 80, 1351–1361. [Google Scholar] [CrossRef]
- Amjady, N. Short-term hourly load forecasting using time-series modeling with peak load estimation capability. IEEE Trans. Power Syst. 2001, 16, 498–505. [Google Scholar] [CrossRef]
- Ma, T.; Wang, F.; Wang, J.; Yao, Y.; Chen, X. A combined model based on seasonal autoregressive integrated moving average and modified particle swarm optimization algorithm for electrical load forecasting. J. Intell. Fuzzy Syst. 2017, 32, 3447–3459. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, Z.Z.; Li, S. Research on power load forecasting based on support vector machine. J. Balk. Tribol. Assoc. 2016, 22, 151–159. [Google Scholar]
- Ribeiro, G.T.; Sauer, J.G.; Fraccanabbia, N.; Mariani, V.C.; Coelho, L.D.S. Bayesian Optimized Echo State Network Applied to Short-Term Load Forecasting. Energies 2020, 13, 2390. [Google Scholar] [CrossRef]
- Farahat, M.A.; Talaat, M. The Using of Curve Fitting Prediction Optimized by Genetic Algorithms for Short-Term Load Forecasting. Int. Rev. Electr. Eng. 2012, 7, 6209–6215. [Google Scholar] [CrossRef]
- Pandian, S.C.; Duraiswamy, K.; Rajan, C.C.A.; Kanagaraj, N. Fuzzy approach for short term load forecasting. Electr. Power Syst. Res. 2006, 76, 541–548. [Google Scholar] [CrossRef]
- Hernández, L.; Baladron, C.; Aguiar, J.M.; Calavia, L.; Carro, B.; Sánchez-Esguevillas, A.; Pérez, F.; Fernández, A.; Lloret, J. Artificial Neural Network for Short-Term Load Forecasting in Distribution Systems. Energies 2014, 7, 1576–1598. [Google Scholar] [CrossRef]
- Kim, K.H.; Park, J.K.; Hwang, K.J.; Kim, S.H.; Han, H.G.; Kang, S.H. Implementation of short-term load forecasting expert systems in a real environment. Eng. Intell. Syst. Electr. Eng. Commun. 2000, 8, 139–144. [Google Scholar]
- Imani, M. Electrical load-temperature CNN for residential load forecasting. Energy 2021, 227, 120480. [Google Scholar] [CrossRef]
- Itoh, M.; Chua, L.O. DESIGNING CNN GENES. Int. J. Bifurc. Chaos 2003, 13, 2739–2824. [Google Scholar] [CrossRef]
- Shi, H.; Xu, M.; Li, R. Deep Learning for Household Load Forecasting—A Novel Pooling Deep RNN. IEEE Trans. Smart Grid 2017, 9, 5271–5280. [Google Scholar] [CrossRef]
- Kim, J.; Moon, J.; Hwang, E.; Kang, P. Recurrent inception convolution neural network for multi short-term load forecasting. Energy Build. 2019, 194, 328–341. [Google Scholar] [CrossRef]
- Hochreiter, S. The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, M.; Bao, Z.; Zhang, S. Short-Term Load Forecasting with Multi-Source Data Using Gated Recurrent Unit Neural Networks. Energies 2018, 11, 1138. [Google Scholar] [CrossRef]
- Rafi, S.H.; Masood, N.A.; Deeba, S.R.; Hossain, E. A Short-Term Load Forecasting Method Using Integrated CNN and LSTM Network. IEEE Access 2021, 9, 32436–32448. [Google Scholar] [CrossRef]
- Shi, H.; Miao, K.; Ren, X. Short-term load forecasting based on CNN-BiLSTM with Bayesian optimization and attention mechanism. Concurr. Comput. Pr. Exp. 2021, 12606, e6676. [Google Scholar] [CrossRef]
- Gao, X.; Li, X.; Zhao, B.; Ji, W.; Jing, X.; He, Y. Short-Term Electricity Load Forecasting Model Based on EMD-GRU with Feature Selection. Energies 2019, 12, 1140. [Google Scholar] [CrossRef]
- Liao, G.-C. Fusion of Improved Sparrow Search Algorithm and Long Short-Term Memory Neural Network Application in Load Forecasting. Energies 2021, 15, 130. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).