3.3. Analysis of Experimental Model
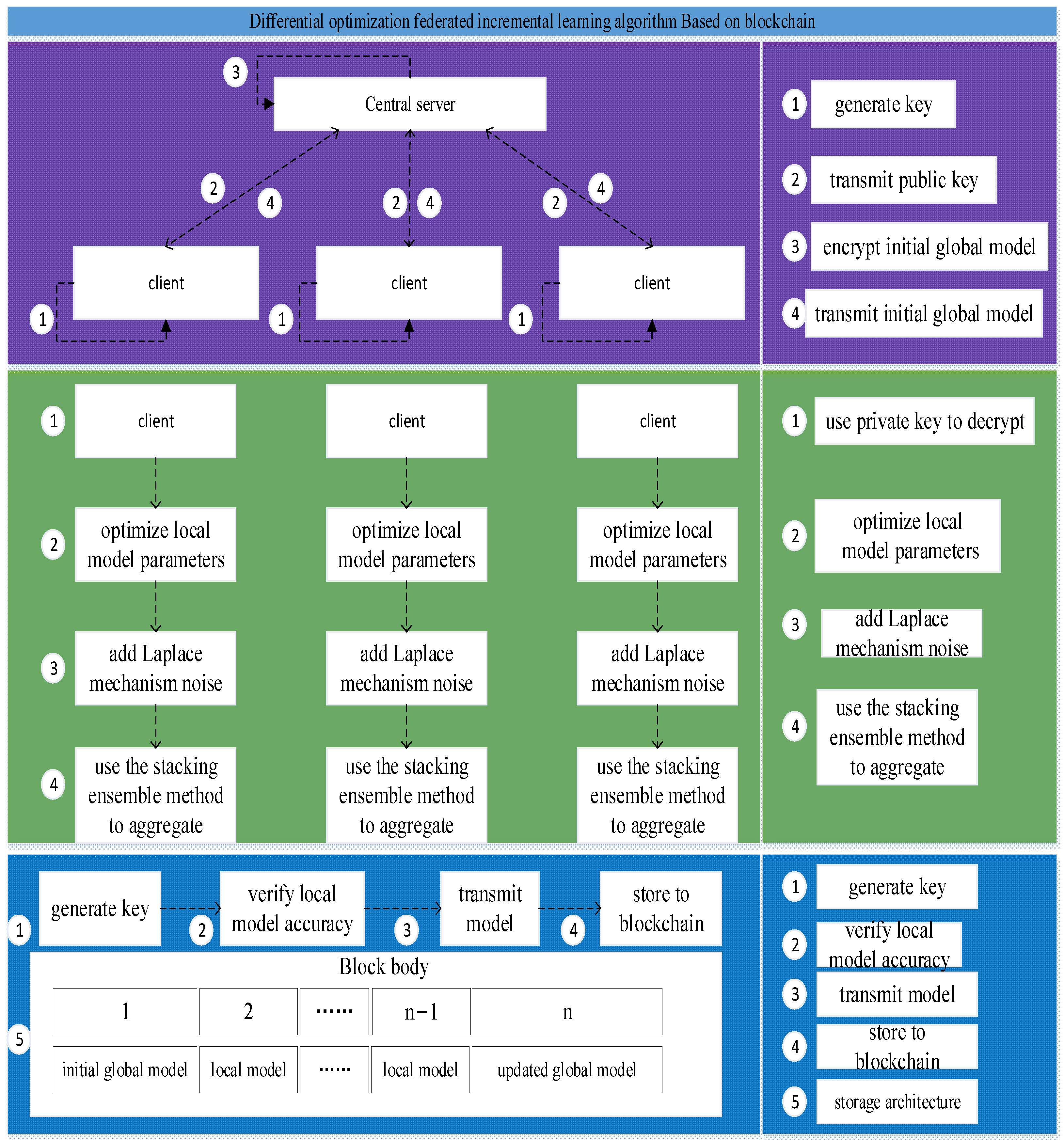
The experiment in this article is divided into three parts: model distribution, model training, and model storage. The first part is to use the random forest as the initial global model and use the public key generated by the RSA encryption algorithm to encrypt and transmit to each data source. Each data source is decrypted with a private key. The initial global model is obtained. The second part: each data source trains the acquired initial global model on incremental data, optimizes the number of trees and the number of pre-test samples , and the pre-pruning parameter , obtains the period local model, then uses the private key generated by the RSA encryption algorithm to encrypt the local model on each data source and transmit it to a trusted third party. The trusted third party uses the public key to decrypt and integrates the local model with the stacking ensemble algorithm to obtain the most effective updated global model during the period. The third part: a trusted third party uses the ECC digital signature algorithm to generate a key pair, transmits its private key to each data source, and retains a private key, and the public key is transmitted to the corresponding block. Each data source is a trusted third party that uses a private key to sign the initial global model parameters, local model parameters, and updated global model parameters in each period and transmit them to the corresponding block. The block uses the public key to verify and store it in the corresponding data block.
In the model distribution stage, to ensure that each initial global model can be safely transmitted to each data source, the initial global model needs to be encrypted with a 4096-bit public key for transmission.
In the model training phase, each data source uses the private key to decrypt to obtain the initial global model—random forest—uses the random forest to train on each data source, and optimizes the tree
and the number of pre-test samples
, and pre-pruning parameters
. The optimal parameter model in the
period is obtained. Detailed parameter optimization is shown in the
Supplementary Material.
The accuracy of the random forest in the
period can be expressed as the average of the training accuracy of the random forest on the incremental data generated by each data source in the
period, which can ensure the accuracy of each data. Three local models
are generated each time. To test the performance of the local model, the average value and variance are used to measure.
Table 1 shows the performance of the initial global model
on each data source.
Among them, indicates the number of data sources. To see the difference between the variances more clearly, the original variance is magnified by . In the following table, indicates the data source, and the variances are all magnified by .
It is obvious from
Table 1 that the accuracy of the initial global model
trained on the data generated in the
period is above 74.5%, and the variance is very small, indicating that the performance of multiple local models is good, and weighting is slightly better than unweighting, and the model without differential privacy is significantly better than the differential privacy protection model with different privacy protection budgets. When the privacy protection budget is 0.25, the accuracy of the model is slightly better than 0.5 and 0.75, indicating privacy while the protection is guaranteed, and the accuracy of the model is also improved.
It can be seen from
Table 2 that when no differential privacy is added, the accuracy of the weighted model is slightly better than that of the unweighted model. The variance of the weighted model is greater than that of the non-unweighted model, but the variances in
Table 2 are all less than
. For the model with differential privacy, when the privacy protection budget is 0.25, the accuracy of the model is the lowest, followed by the privacy protection budgets of 0.5 and 0.75. It shows that the smaller the privacy protection budget, the lower the availability of the model, but the higher the privacy of the data and the model; compared with the federated average algorithm, the accuracy of the updated global model obtained by the stacking ensemble algorithm is increased by about 5%, and at the same time it is smaller than the variance of the federated average algorithm, indicating that the stability and generalization ability of the model are better than that of the federated average algorithm.
To test the training results of the global model
updated in the
period, the global model
updated in the
period is used as the initial global model
in the
period, and training is performed on the data generated in the
period. The initial global model
is used to train on each data source, the tree
L of the tree, the number of pre-test samples
, and the pre-pruning parameter
are optimized, and the model of the optimal parameter in the
period is obtained. Detailed parameter optimization is shown in the
Supplementary Material.
The accuracy of the random forest in the
period can be expressed as the average of the training accuracy of the random forest on the incremental data generated by each data source in the
period, which can ensure the accuracy of each data. Three local models are generated each time. To test the performance of the local model, the average value and variance are used to measure.
Table 3 and
Table 4 indicate that the initial global model
is the update of each data source using a stacking ensemble during the
period. The performance of the updated global model was obtained by the global model and the federated average algorithm in the
period.
It is obvious from
Table 3 that the accuracy of the initial global model
trained on the data generated by the
period is above 83.5%, and the variance is very small, indicating that the performance of multiple local models is good, the weighted and unweighted accuracy rates are almost equal because the model trained on the data generated in the
period have converged, and compared with the
period, the accuracy of the differential privacy protection model with different privacy protection budgets is the same as the accuracy of the model without differential privacy.
It is obvious from
Table 4 that when the initial global model
is a federated average algorithm, the accuracy of the model trained on the data generated in the
period is all above 80%, and the variance is very small, indicating multiple local models compared with the
period, and the accuracy of the differential privacy protection model with different privacy protection budgets increased by about 5%, indicating that the model has strong generalization.
It can be seen from
Table 5 that when differential privacy is not added, the accuracy of the weighted model is almost equal to that of the unweighted model. The variance of the weighted model is greater than that of the non-weighted model, but the variances in the table are all less than
; for the model with differential privacy, when the privacy protection budget is 0.25, the accuracy of the model is the lowest, followed by the privacy protection budgets of 0.5 and 0.75. It shows that the smaller the privacy protection budget, the lower the availability of the model, but the higher the privacy of the data and the model; compared with the federated average algorithm, the accuracy of the updated global model obtained by the stacking ensemble algorithm is increased by about 2%, and at the same time it is smaller than the variance of the federated average algorithm, indicating that the stability and generalization ability of the model are better than that of the federated average algorithm.
To fully test the influence of increasing or reducing data sources on the algorithm, the
period is reduced by one data source (two data sources) for training, and the global model
updated in the
period is used as the initial global model
in the
period. Training on the data generated in the
period is carried out. The initial global model is used to train on each data source, the tree
of the tree, the number of pre-test samples
, and the pre-pruning parameter
are optimized, and the model of the optimal parameter in the
period is obtained. Detailed parameter optimization is shown in the
Supplementary Material.
The accuracy of the random forest in the
period can be expressed as the average of the training accuracy of the random forest on the incremental data generated by each data source in the
period, which can ensure the accuracy of each data. Two local models
are generated each time. To test the performance of the local model, the average value and variance are used to measure.
Table 6 and
Table 7 indicate that the initial global model
is the update of each data source using a stacking ensemble during the
period. The performance of the updated global model was obtained by the global model and the federated average algorithm in the
period.
It is obvious from
Table 6 that the accuracy of the initial global model
trained on the data generated in the
period is more than 83.5%, and the variance is very small, which shows that the performance of multiple local models is good and has good stability. Compared with the accuracy of the model in the
period, the accuracy of the model is improved, which indicates that the initial global model
has a strong generalization ability.
It is obvious from
Table 7 that the accuracy of the initial global model
trained on the data generated in the
period is more than 83.5%, and the variance is very small, which shows that the performance of multiple local models is good and has good stability. Compared with the accuracy of the model in the
period, the accuracy of the model is improved by more than 3%, which indicates that the initial global model
has a strong generalization ability.
It can be seen from
Table 8 that the accuracy of the weighted model is almost equal to that of the unweighted model without adding differential privacy, and the variance of the weighted model is greater than that of the non-weighted model, but the variance in the table is less than
; for the model with differential privacy, when the privacy protection budget is 0.25, 0.5, 0.75, the accuracy of the model is almost equal, compared with the federated average algorithm, and the accuracy of the updated global model obtained by the stacking ensemble algorithm is almost equal to that obtained by the federal average algorithm, but the security of the model is improved.
To fully test the influence of increasing or reducing data sources on the algorithm, one data source (four data sources) was added for training in the
period, and the global model
updated during the
period was used as the initial global model
in the
period. Training on the data generated in the
period is carried out. The initial global model
is used to train on each data source, and the number
of the tree, the number of pre-test samples
, and the pre-pruning parameter
are optimized, to obtain the model of the optimal parameter in the
period. Detailed parameter optimization is shown in the
Supplementary Material.
The accuracy of random forest in the
period can be expressed as the average value of training accuracy of 20 iterations on incremental data generated by each data source, which can ensure the accuracy of each data and, at the same time, the four local models
were generated each time. To test the performance of local models, the average value and variance were used to measure.
Table 9 and
Table 10 show the performance of the initial global model
in the
period of the updated global model obtained by the stacking ensemble algorithm and the federated average algorithm for each data source in the
period.
From
Table 9, it can be seen that the initial global model is the updated global model of the stacking ensemble. The accuracy rate of most of the models trained on the data generated in the
period is more than 84%, and the variance is very small, indicating that the performance of several local models is good and has good stability.
From
Table 10, it can be clearly seen that the initial global model
is the updated global model of the federated average algorithm, and the accuracy rate of most of the models trained on the data generated in the
period is more than 84%, and the variance is very small, indicating that the performance of several local models is good and has good stability.
It is obvious from
Table 8 that when the initial global model
is a federated average algorithm, the accuracy of the model trained on the data generated in the
period is all above 80%, and the variance is very small, indicating multiple local models compared with the period
, and the accuracy of the differential privacy protection model with different privacy protection budgets increased by about 5%, indicating that the model has strong generalization.
It can be seen from
Table 11 that the accuracy of the weighted model is greater than that of the unweighted model, and the variance of the weighted model is greater than that of the non-weighted model, but the variances in the table are less than
, which meets the experimental requirements. For the model with differential privacy, the accuracy of the model is almost equal when the privacy protection budget is 0.25, 0.5, and 0.75. Compared with the federated average algorithm, the accuracy of the updated global model obtained by the stacking ensemble algorithm is almost the same as that obtained by the federated averaging algorithm, but the security of the model is improved.
In the model storage phase, the trusted third party uses the ECC encryption algorithm to generate the key pair with a length of 512. The public key is broadcast to the corresponding block, and the private key is transmitted to each data source separately, and at the same time, one reservation is maintained.
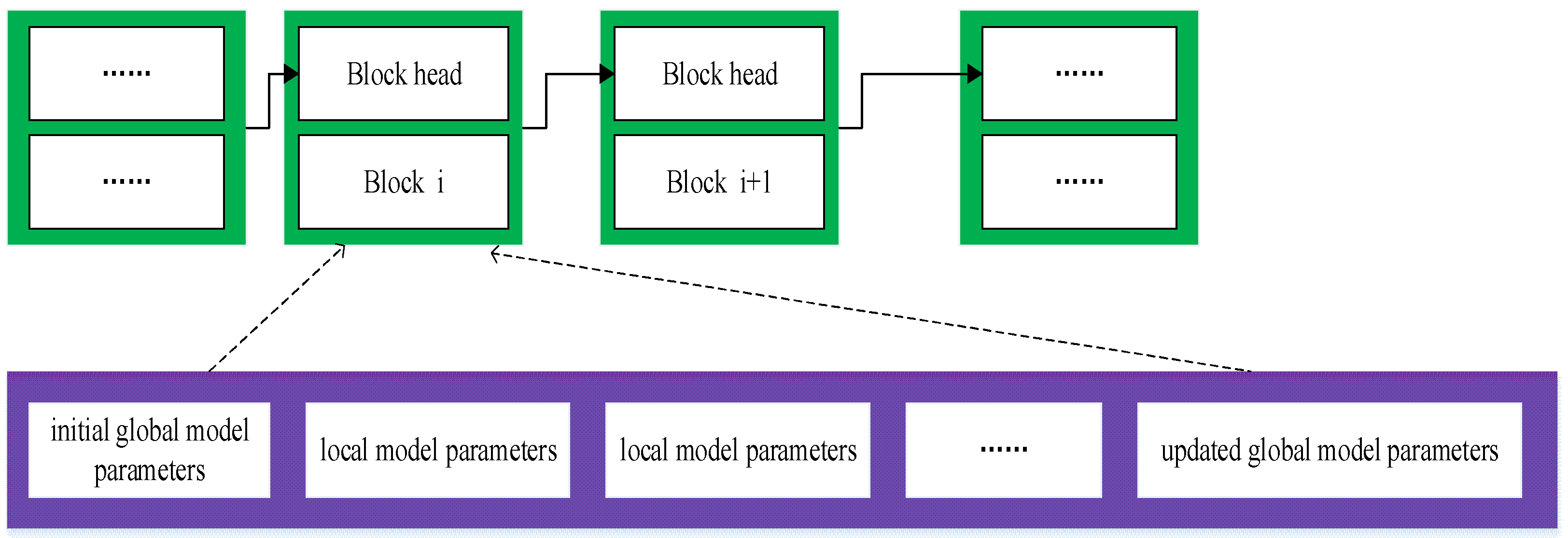
The Raybaas platform can quickly and efficiently build blockchain-based services and applications. The hardware devices have an Intel(R) Core i5-4200 m CPU 2.50 GHz processor. The underlying blockchain is deployed based on a CentOS 7.6 operating system. The stored data include initial global model parameters, local model parameters, and updated global model parameters in the period.
For storing the initial global model parameters, the trusted third party encrypts the initial global model in the period by using the private key retained in the period and transfers it to the block . The verification nodes in the blockchain are decrypted using the corresponding public key and verified by the consensus mechanism based on the training parameter quality. If 2/3 verification nodes consider that the initial global model parameters in the period are the same as the updated global model parameters in the previous period, namely, the formula , then the initial global model parameters in the period will be stored in the corresponding data block 1 in the generated block .
For storing local model parameters, the private key within the time of each data source encrypts the local model in the period and uploads it to the corresponding block . The verification nodes in the blockchain are encrypted using the corresponding public key and the consensus mechanism based on the training parameter quality is used for verification. The verification node in the blockchain uses the corresponding public key to decrypt, and uses a consensus mechanism based on the quality of training parameters for verification. If the accuracy rate of the local model trained in this period cannot reach the minimum accuracy rate determined by the node, the data source needs to further optimize the local model to improve the accuracy of the local model until the accuracy of the local model of the data source meets the requirements, that is, the formula ( is the minimum accuracy rate determined by 2/3 nodes) can be met, and the local model parameters can be stored in data block 2 to .
For the updated global model parameters, the trusted third party encrypts the updated global model in the period by using the private key retained in the period and transfers it to the block . The verification nodes in the blockchain are decrypted using the corresponding public key and verified by the consensus mechanism based on the training parameter quality. If 2/3 nodes believe that the updated global model parameters in this period are comparable with the updated global model in the previous period, the accuracy fluctuates within an acceptable range, that is, ( is the acceptable fluctuation range of 2/3 nodes), then the global model parameters updated in the period can be stored in the data block n corresponding to the block.






{kind=link}
{kind=link}