5.1. Proposed Model
This paper pursues multi-objective pulsive vaccination control using an open-loop continuous variable dynamic optimization procedure to solve the epidemiological problem, using the SIR model as the dynamic system and two multi-objective optimization techniques, NSGA-II and CENSGA, to be described in
Section 5.2. Optimization is one of the most active and effective techniques used to control vaccination policies. The limited number of vaccine doses added to time constraints overwhelms the infection volume. A cost-effective vaccination campaign is crucial to mediate between the reductions in infection volume and the cost of vaccination administration.
The mathematical formulation of the problem is described as follows. Let
x ∈
Φ constitute the decision variable vector;
Φ ⊂ Rn is the decision variable space; [
f1 (
x), …,
fm (
x)] is the vector of objective functions to be minimized and
X* is the set of optimal solutions, which consist of all decision vectors for which the corresponding objective vector cannot be ameliorated in any dimension without a recession in another one (recall the definitions in
Section 2). In the optimization set-up, we must determine the chromosome representation and fitness equation that helps in examining the objective functions. For the sake of this work, we adopt the general framework methodology found in [
3,
6,
7] to test the suggested CENSGA technique under the same conditions and parameter calibrations.
- A.
Fitness Function
The fitness function contributes to determining the quality of a given chromosome (solution), and it returns numerical value(s) reflecting the evaluation status of the instance. In determining the fitness equation, it is necessary to combine the objectives and constraints to obtain a set of feasible chromosome instances. Essentially, the goal here is minimizing the volume of an infected population over time and, at the same time, to obtain a campaign that offers an effective cost within the vaccination policies [
3,
6].
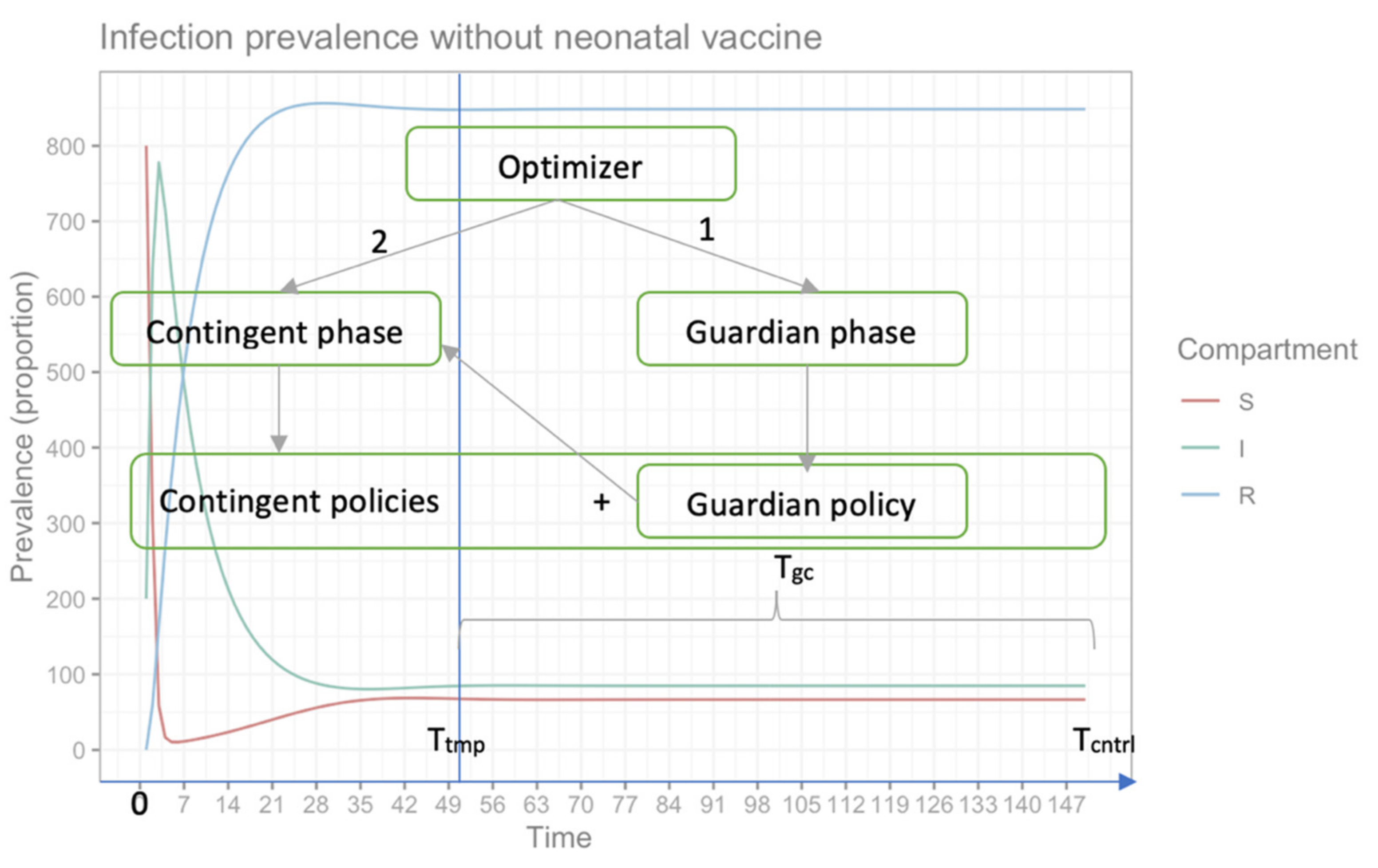
The optimization process has two phases: the guardian control determines a set of non-dominated guardian policies, and the contingent control determines a set of contingent policies. The outcome of the contingent phase is complemented with the best guardian control policy selected from the guardian phase to form a complete vaccination campaign. The purpose of two-phased optimization is to maintain an acceptable level of infected individuals in a finite time near to the disease-eradication ratio (i.e., compartment (I) ≤ tolerance ratio (> 0), which could be achieved by incorporating a fixed-guardian control policy following a contingent vaccination phase in order to avoid an/another outbreak.
The cost function employed as the second objective function follows the exact cost function defined by Cruz et al. [
6]. For the sake of comparison, the same simulation parameters and calibration values in [
6] are used here as well. There are fixed and variable cost parameters that contribute to the implementation of vaccination policies. Starting with the fixed-cost part, the constants shown in Equation (4) are assumed to be
c1 = 10,
c2 = 1 and
c3 = 1. Thereby,
c1 · Ngc is the fixed part of the cost function with the implementation of all policies in the guardian control phase, i.e.,
Ngc is the number of times the selected guardian control policy will be applied. The second term
c2 · Ngc · (1 +
vgc)
2 is the essence of the cost function that articulates the variable monetary cost related to the effort required to reach the
vgc proportion of the susceptible population in all policies. The last term,
c3 · ∑ vgc ·S[
k], stands for the cost of all vaccines in all vaccination policies. Without losing generality, the same definition principle is applicable for the cost function of the contingent control phase found in Equation (6), where
Ncc indicates the number of contingent control policies that are planned to be administrated.
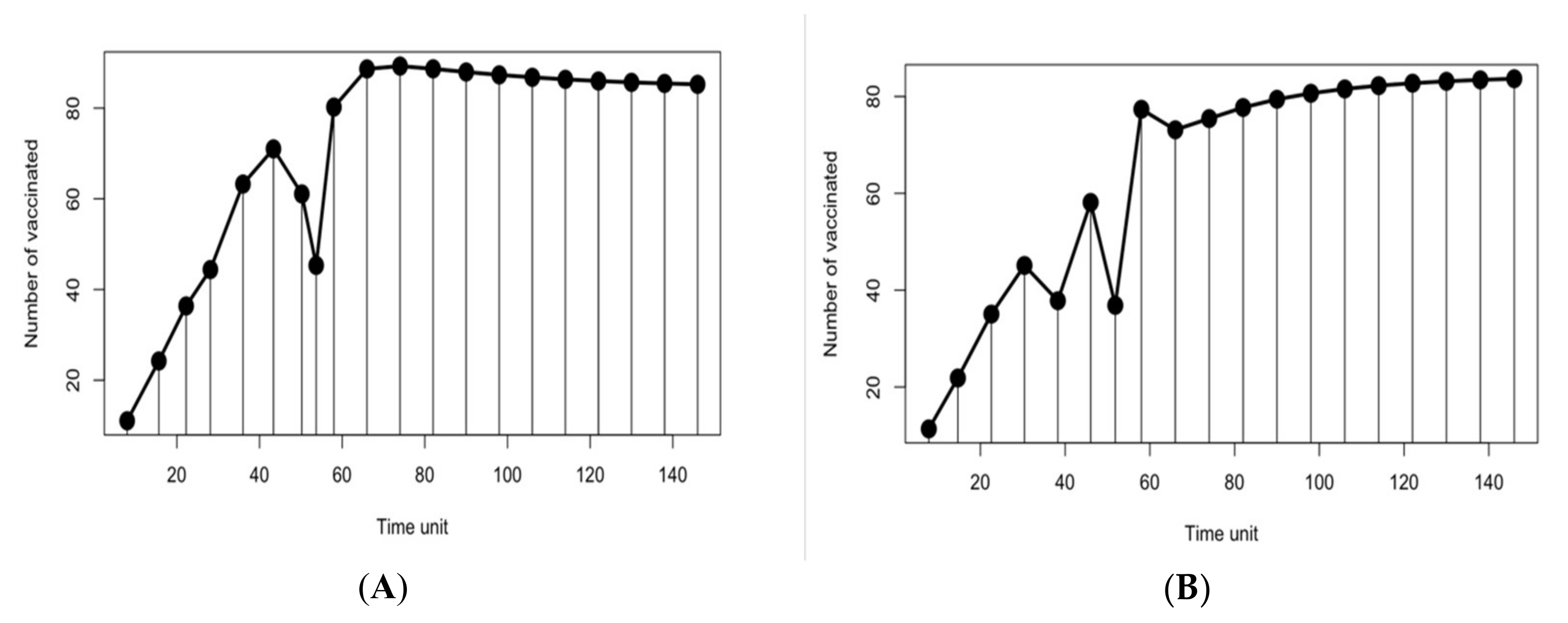
Mathematically, the time considered to determine the multi-objective control period is Tcntrl = Ttmp + Tgc, where Tcntrl belongs to the closed interval [0, Tcntrl], and has to be partitioned into a set of events Ω = {τ0, …, τN}, such that: τ0 = 0, τN = Tcntrl, and τk+1 − τk = ΔT. The time between each τk and τk+1 is considered as a state of the optimization problem. The guardian phase of the multi-objective optimization model is depicted in Equation (4). The role of this phase is to find a set of non-dominated guardian control policies, X*gc= {(Δτgc, vgc), …}; these are the decision variables used to derive a candidate solution with a constant time interval between campaigns, Δτgc, and with a constant proportion of susceptible population, which must be vaccinated at each campaign, vgc. The guardian control policy should begin at time Ttmp and be applied indefinitely, up to disease eradication or, in our multi-objective period, until Tcntrl.
The multi-objective optimization model of the contingent phase is depicted in Equation (6). The role of this phase is to determine a non-dominated set of complete vaccination campaigns. This phase appoints a fixed-guardian control policy after a set of variable contingent control policies (refer to
Figure 2 and
Figure 3). The set of non-dominated complete control policies for vaccination is described by
Each contingent control is described by
Ncc value pairs of the time interval between campaigns, Δ
τk, and the fraction of susceptible individuals to be vaccinated,
vk,
k∈ {1, 2, …,
N}. The extra pair (Δ
τgc,
vgc) is derived from phase 1, which represents a guardian control policy chosen from solutions
X*
gc. The resulting optimization problem for the guardian control phase is described by Equation (6).
subject to (5):
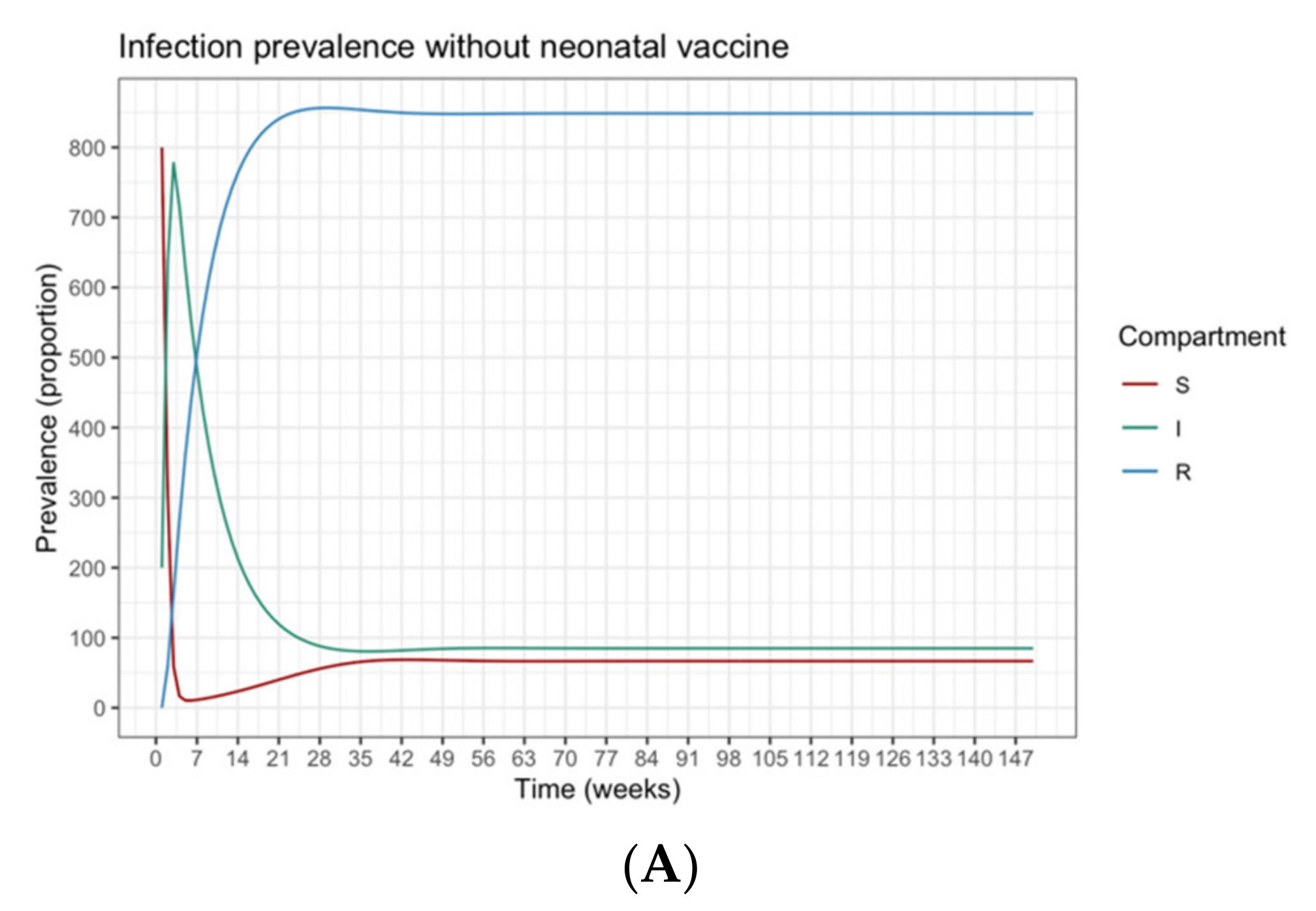
The guardian control has the following constraints, as described by Equation (5). The system dynamic is determined by the SIR model (see Equation (2)), starting at the endemic equilibrium point {
s(0),
i(0),
r(0)} = {0.067, 0.085, 0.848}, which is the infection-free value of the SIR model under constant Pulse vaccination [
6,
35]; functions
dS/
dt and
dI/
dt behave accordingly. From the beginning of guardian control, vaccination moments occur periodically
kth times in a harmonic manner
tk =
Ttmp +
k·Δ
tgc. At each unit of time (
tk), a constant Pulse vaccination policy
vgc (proportion of the susceptible to be vaccinated) is carried on, propagating the direct positive effect of vaccination on the population, as described in
S(
tk+), and
I(
tk+). The notation (+) indicates the moment after the vaccination carried out via the Pulse vaccination policy. To keep the infected population under control, during guardian control, the disease should remain below an acceptable value,
by i(
t)
itol.
N, where
i(
t) is an instance of
dI/
dt at time (
tk). The number of times the guardian control policy is going to applied is determined by
Ngc, taking into consideration the total sum of time periods, must not exceed
Tgc. The proportion of susceptible population to be vaccinated in each policy is bounded in the range [
vmin,
vmax] = [0.40, 0.95], while the time between two successful vaccination policies must be in the
range [
tmin,
tmax ] = [
1,
20]. This search range includes values that theoretically prove that the infected population tends to zero over time [
35]. The effects on compartment (
R) are omitted for the sake of brevity, but this will not have any effects on the resulting output, as the system is an open system.
In contrast to the fixed-time policy applied during the guardian phase, time-variant control policies are considered for the contingent control phase, as described by Equation (6). The objective functions of the contingent phase are close to the ones anticipated in the guardian phase. In addition, the contingent phase objective functions consider the entire time horizon, which combines the contingent policies to stabilize disease fluctuation with the guardian policy to keep the infection volume under control. To sum up, a selected guardian control policy will be applied repeatedly on the time interval [
Ttmp,
Tcntrl], while the contingent control policies are administrated on the time window [0,
Ttmp]. In the contingent control phase, both policies’ parts are connected to form a complete vaccination campaign that operates on the entire optimization time horizon [0,
Tcntrl].
subject to (7):
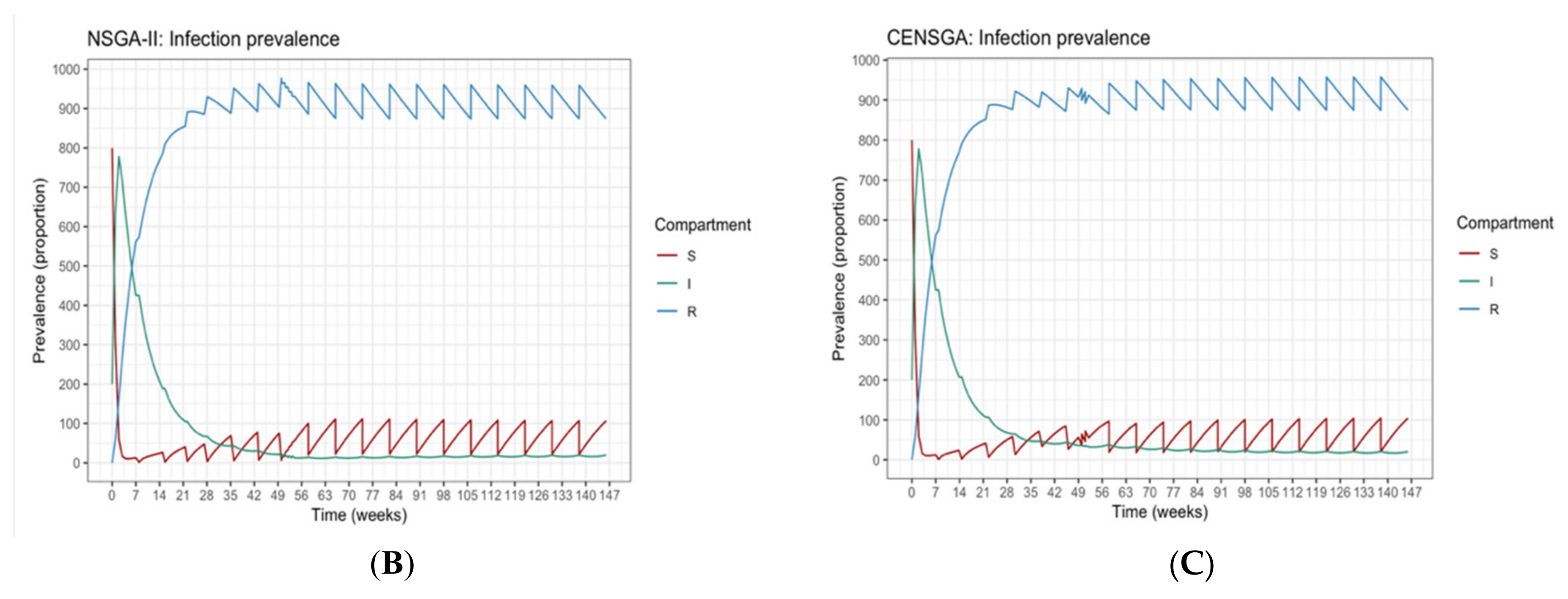
The contingent phase combines guardian and contingent policies to form a final vaccination campaign. This considers the optimization problem in the contingent phase as an extension of the former optimization problem with their mutual set of constraints, as described by Equation (7). The system still behaves dynamically using the SIR model with the same parameters as before. The initial state of susceptible, infected and recovered populations is assumed to be {s(0), i(0), r(0)} = {0.80, 0.20, 0}. Each k policy is indicated by the pair (tk,vk), representing the times and fractions of the susceptible population to be vaccinated. In the contingent control time window, again, the term (tk,vk) has variant values. In contrast, in the timeframe of guardian control, (tk,vk) has constant value. The sum of time intervals must not exceed their bounds Ttmp and Tgc. The number of policies, Ncc, in the contingent control can vary from ⌊Ttmp/Δtmax⌋ to ⌊Ttmp/Δtmin⌋, while the number of guardian control stages, Ngc, is the same as Equation (4). The terms vk and Δτκ are vaccination proportion and time periods for the entire system time horizon, where the contingent control starts first and proceeds until administrating Ncc vaccination policies; this is followed by the application of Ngc guardian control vaccination policies. For both stages, there are Ncc different contingent control vaccination policies and Ngc constant guardian control vaccination polices to be applied in the duration [0, Tcntrl]. Henceforth, dividing the time limit of each stage Ttmp and Tgc over the possible policies’ durations Δtgc and {Δt1, …, Δtcc} produces the number of policies in each stage Ngc and Ncc, respectively. The total number of policies in the final vaccination campaign is NTotal = Ncc + Ngc. Following the same condition employed in phase 1, the disease should remain below an acceptable value, where (I) ≤ itol·N (i.e., itol = 0.01), to be maintained by applying the selected policy from the guardian control stage repeatedly until Tcntrl. To simplify the system, (R) compartment again is not mentioned, as declared earlier.
- B.
Chromosome Representation
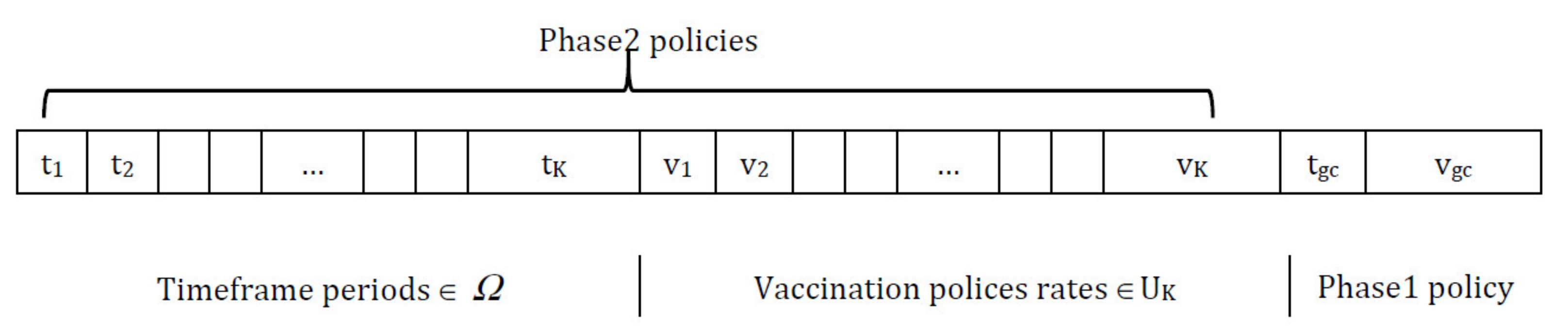
The representation of a chromosome is composed of a series of genes. The chromosome is mainly divided into three sub-lists; genes in the first part symbolize the timeframe period in each gene to represent
τk+1 –
τk = Δ
tk, while the second part of the chromosome indicates the set of vaccination polices, as each gene represents a proportion of the vaccination
vK. The last part shows the policy chosen from the guardian phase, where
tgc is the time period between two consecutive vaccination policies and
vgc is the proportion to be vaccinated, as shown in
Figure 3.
The first two parts of the chromosome belong to the contingent phase. The chromosome is depicted as a sequence of times followed by a sequence of vaccination proportions that will be employed at each abovementioned time period. It is worth noting that the chromosome lengths are of variable size, related to the number of vaccination policies applied over the indicated time horizon. The use of variable-length chromosomes (VLC) is motivated by many works found in the literature, such as [
24,
25,
40,
41,
42,
43]; for this work, no mapping from genotype to phenotype is needed, so there is no encoding/decoding process. To serve the purpose of this paper, VLC is utilized without adding an extra burden on the CPU time or memory utilization during the evolutionary processes (i.e., crossover/mutation). The condition applied to the chromosome length is that the number of timeframe periods must be the same as the number of vaccination policies. In other words, for each timeframe, an associate vaccination policy is to be applied.
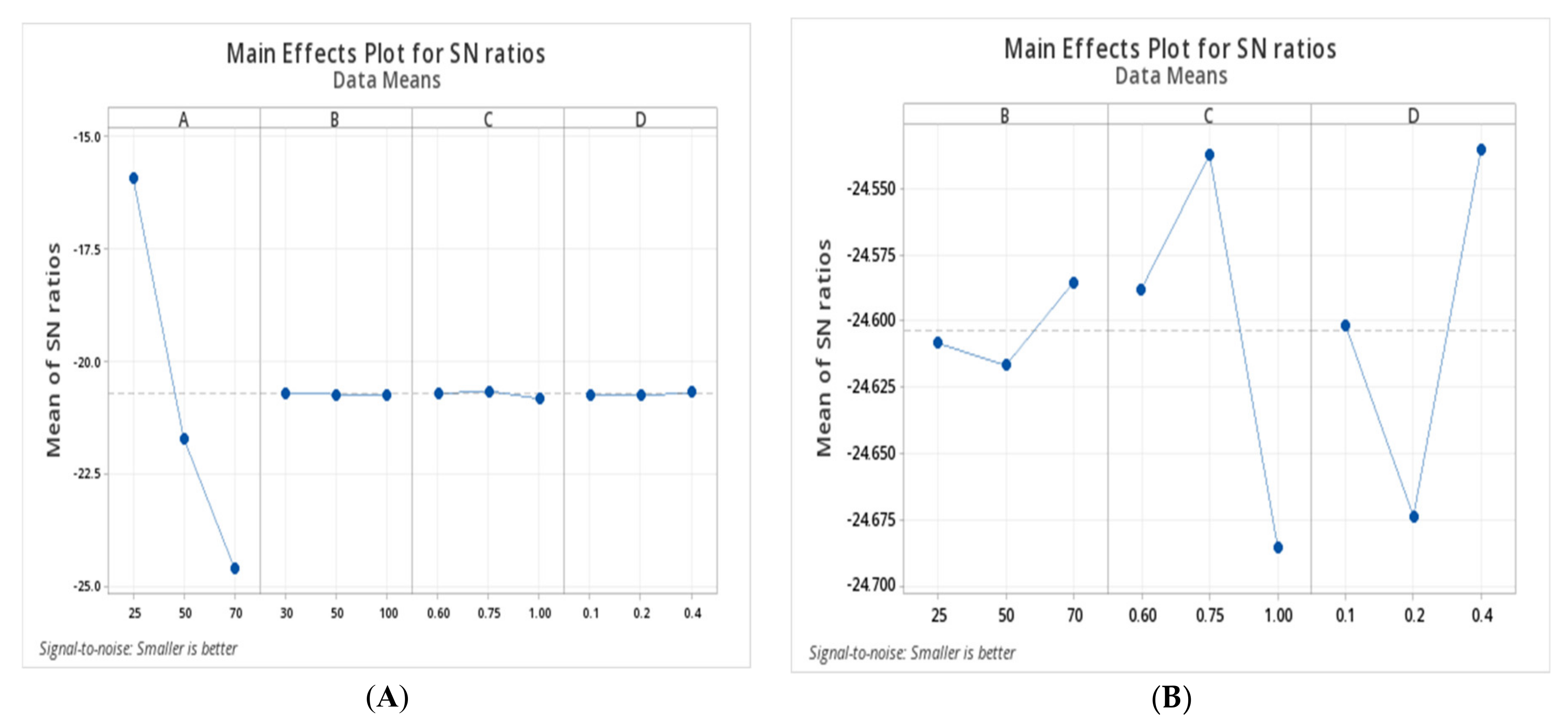
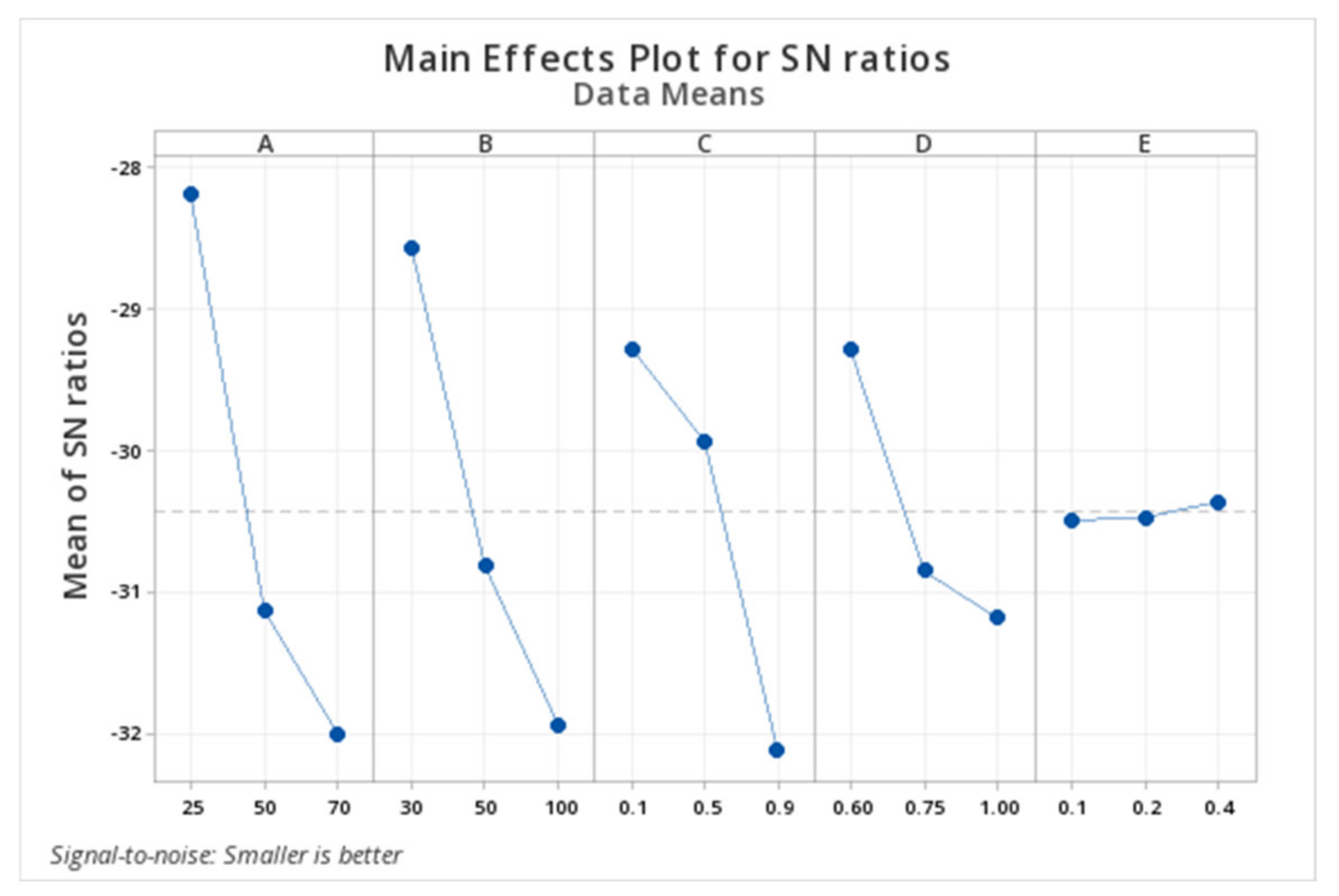
The lower and upper limits of policies in a chromosome are fixed. We begin by defining a particular limit to the number of policies in a chromosome, say, 1 ≤ k ≤ 20. However, we do not know exactly how many policies are required. This should also be identified by Δtk on the fitness function, where 0 ≤ ∑Δtk ≤ T. So, the chromosome should be able to increase or decrease the number of policies from individual to individual, or from generation to generation.
5.2. Non-Dominated Sorting Genetic Algorithm (NSGA)
A new paradigm of multi-objective algorithms has recently been dominating in the literature. These algorithms do not switch multi-objective problems into single-objective ones; instead, they are heuristics oriented towards guiding the multi-objective search. In order to tackle the complex vaccination problem with its contradictory objectives, a compromise-based approach must be applied to find the set of near-optimal solutions. In principle, the evolutionary multi-objective problem produces a set of optimal solutions (known as non-dominated or Pareto-optimal solutions), rather than a single optimal solution.
The motivation for using the multi-objective approach in solving complex problems in optimization is that it does not require special equations, which helps to simplify the problem. The nature of multi-objective optimization allows for a compromise (tradeoff) between some contradictory issues, and then leaving the final decision to the policymaker. In other words, there is no single best solution for all dimensions, but rather there are several candidate solutions [
29]. In the current paper, the proposed mathematical model is solved by applying two Pareto-based metaheuristic algorithms: NSGA-II and CENSGA.
- A.
NSGA-II
A non-elitist multi-objective genetic algorithm NSGA (or NSGA-I), proposed by Deb, Agarwal and Meyarivan [
44], was one of the first EAs that was able find multiple Pareto-optimal solutions in one single simulation run. Several drawbacks were noted, such as the high computational complexity O(MN
3), lack of elitism and the necessity of a sharing parameter. NSGA serves as a basis of two other metaheuristic algorithms, NSGA-II and CENSGA, whose implementations differ in several aspects. The powerful NSGA-II is one of the most widely implemented algorithms within this category; it is well known for its outstanding enhanced features, such as its fast non-dominating sorting-procured O(MN
2), elitist-preserving mechanism and no-niching parameter. The main idea of NSGA-II is to reproduce a new population from an initial population without losing good solutions, and assure better convergence to the optimal Pareto-optimal front with a good spread of the solutions [
44].
The best solutions and Pareto fronts are obtained by prioritizing solutions using non-dominated sorting. Non-dominated sorting considers two parameters:
Np, which represents the number of solutions dominating a certain solution, and
Sp, which represents the set of solutions derived by a certain solution. The sorting process is a labelling procedure carried out repeatedly, wherein each solution must be ranked with a number, potentially non-unique, that indicates the front it belongs to. For minimization problems, the best solution is assigned to the first front, the second solution is assigned to the second front, and so on. The ranking of the solutions works as a measure of fitness. The fast non-dominated sorting operator is used to associate a rank to each solution relative to its dominance level. However, within the same rank, a set of solutions is assigned. Thereby, a measure of the density of solutions belonging to the same rank (front) is applied, which is denoted as the crowding distance (
CD) [
14]. Algorithm 1 outlines a summary of the NSGA-II algorithm [
12].
| Algorithm 1. Template for NSGA-II algorithm [12] |
| Rt = Pt ∪ Qt //combine parent Pt and children population Qt |
| F = fast-non-dominated-sort (Rt) //rank all non-dominated fronts of Rt |
| Pt+1 = ∅ and i = 1 |
| until |Pt+1| + |Fi| ≤ N //until the new population is filled |
| Pt+1 = Pt+1 ∪ Fi //include i-th non-dominated front in Pt+1 |
| //calculate crowding distance for each solution in Fi for partial inclusion |
| crowding-distance-assignment (Fi) |
| i = i + 1 |
| Sort (Fi, ≺n) //sort in ascending order using ≺n |
| Pt+1 = Pt+1 ∪ Fi [1:(N − |Pt+1|)] //choose the first N elements inFi |
| Qt+1 = make-new-pop (Pt+1) //using selection, crossover, and mutation |
| t = t + 1 |
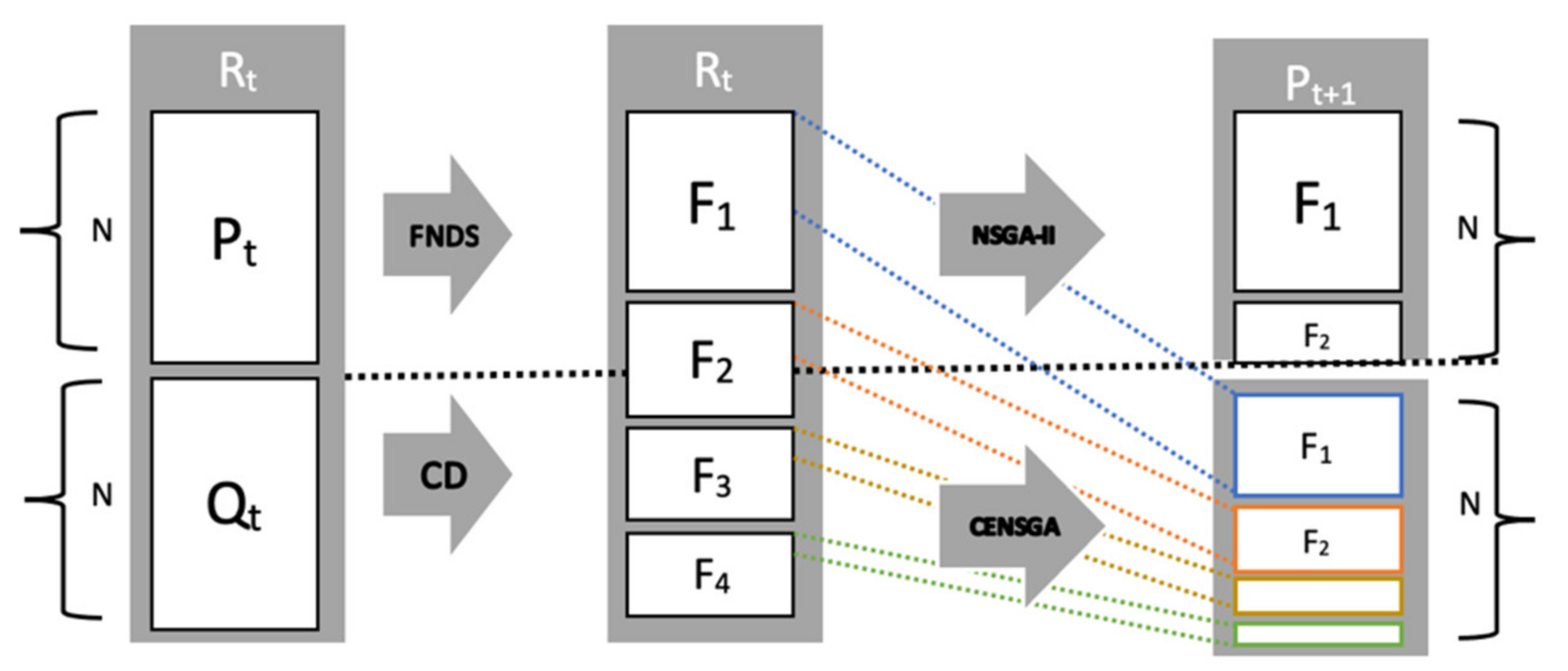
The new population pool
Pt+1 is created by adding solutions from fronts in a consecutive manner, starting from the first front
F1, until the size of the parenting pool reaches
N. Individuals on all fronts are ordered using a crowding distance that calculates the distance between neighboring solutions. Thereafter, the best fronts are included entirely in NSGA-II, while solutions of the last-accepted front are sorted and selected according to a crowded comparison criterion. The crowded comparison criterion uses a special relation ≺
n to promote diversity in the solutions within this front, where ≺
n is defined as follows:
In other words, the solutions with lower ranks are preferred when there are differences in the non-dominated ranks. Apart from that, if both solutions are on the same front, then the larger crowding distance (i.e., solutions from less dense regions) is preferred. This forms the population
Pt+1 of size
N. At this point, the parent population
Pt+1 proceeds for selection, crossover, and mutation to construct a new population
Qt+1 of size
N [
12]. In our work, the bounded Simulated Binary Crossover (
SBX) [
45] and bounded Polynomial Mutation [
46] are used as recombination operators, where these are the same GA operators used in [
6].
- B.
CENSGA
In this paper, we present an extended version of NSGA-II that is denoted by Controlled NSGA-II or CENSGA. CENSGA was first proposed by Deb and Goel [
12], with the main differences related to the selection strategy. In particular, CENSGA gives all fronts the ability to participate in the selection process through a geometric distribution with various priorities that reflect the front level.
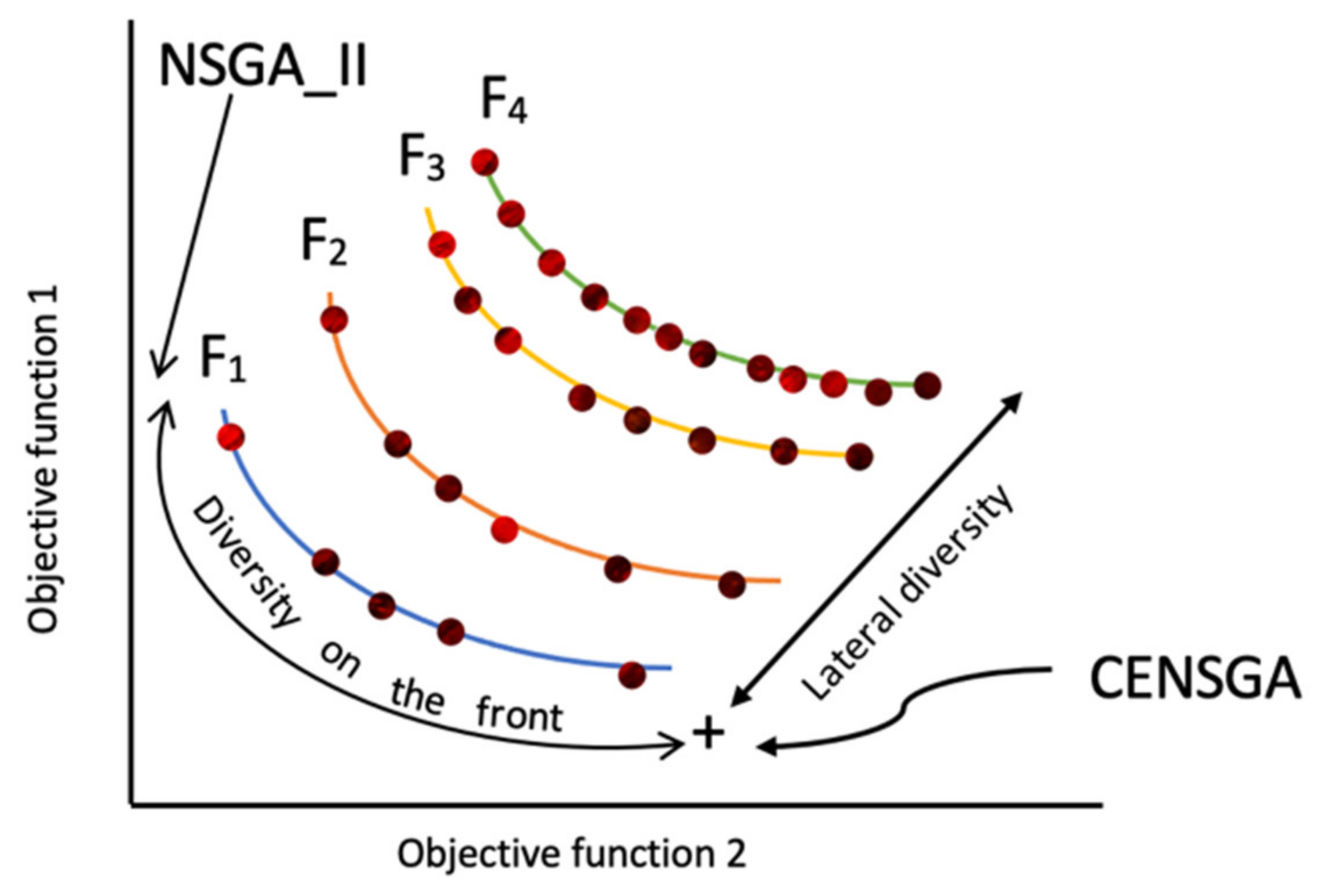
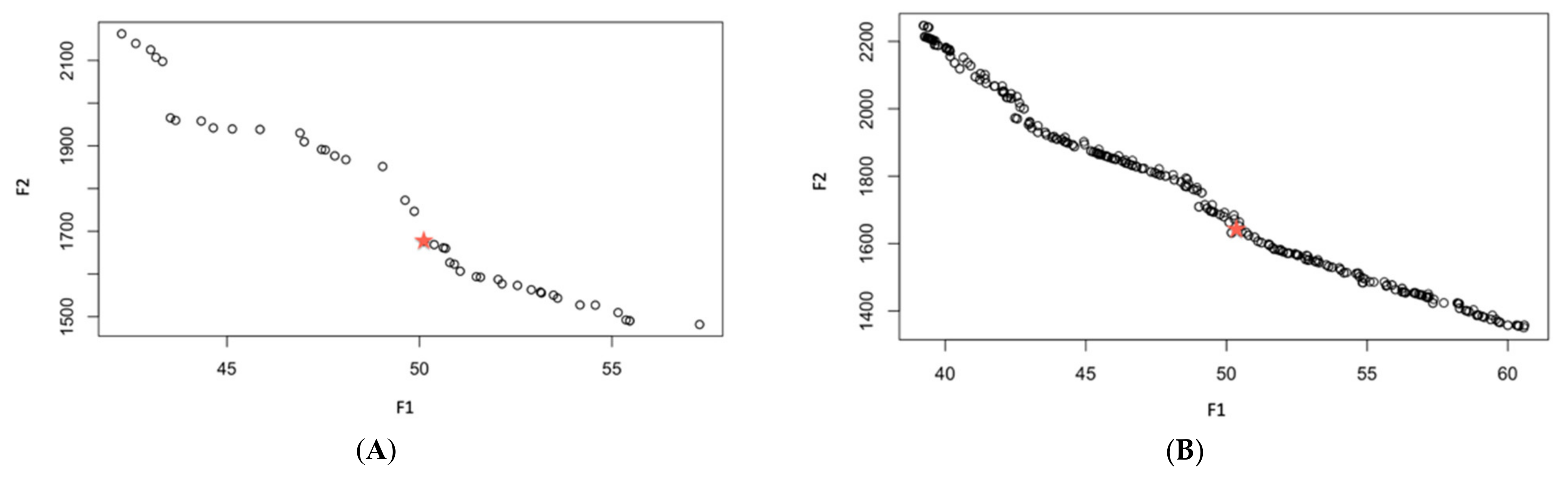
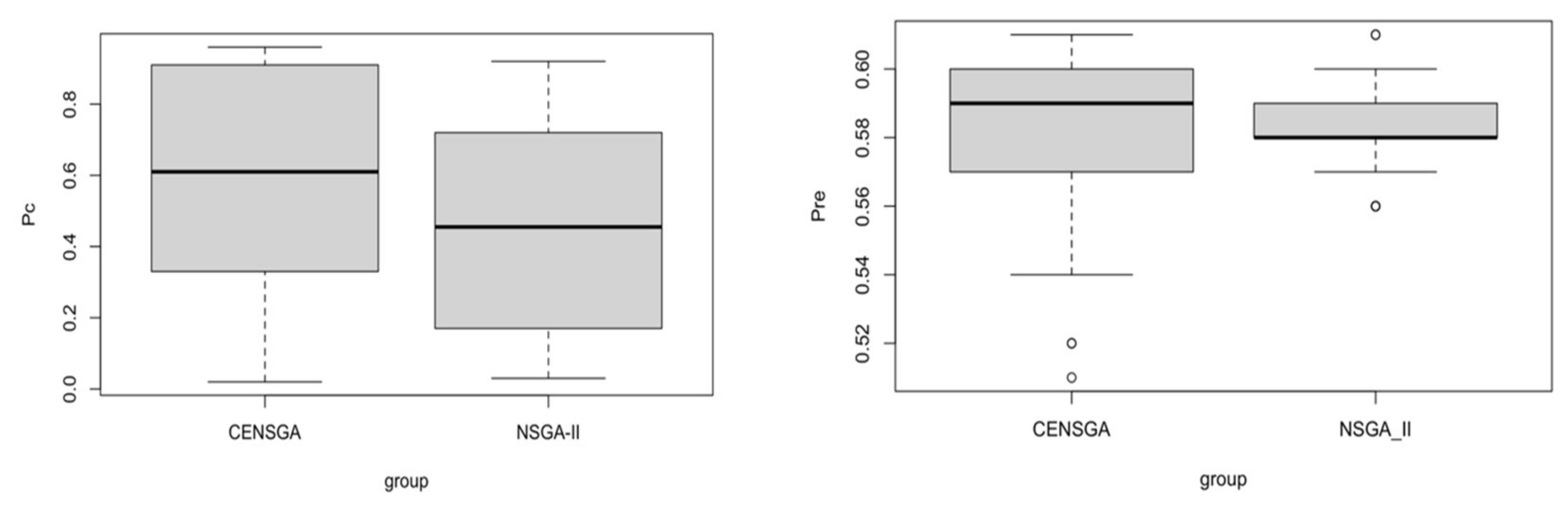
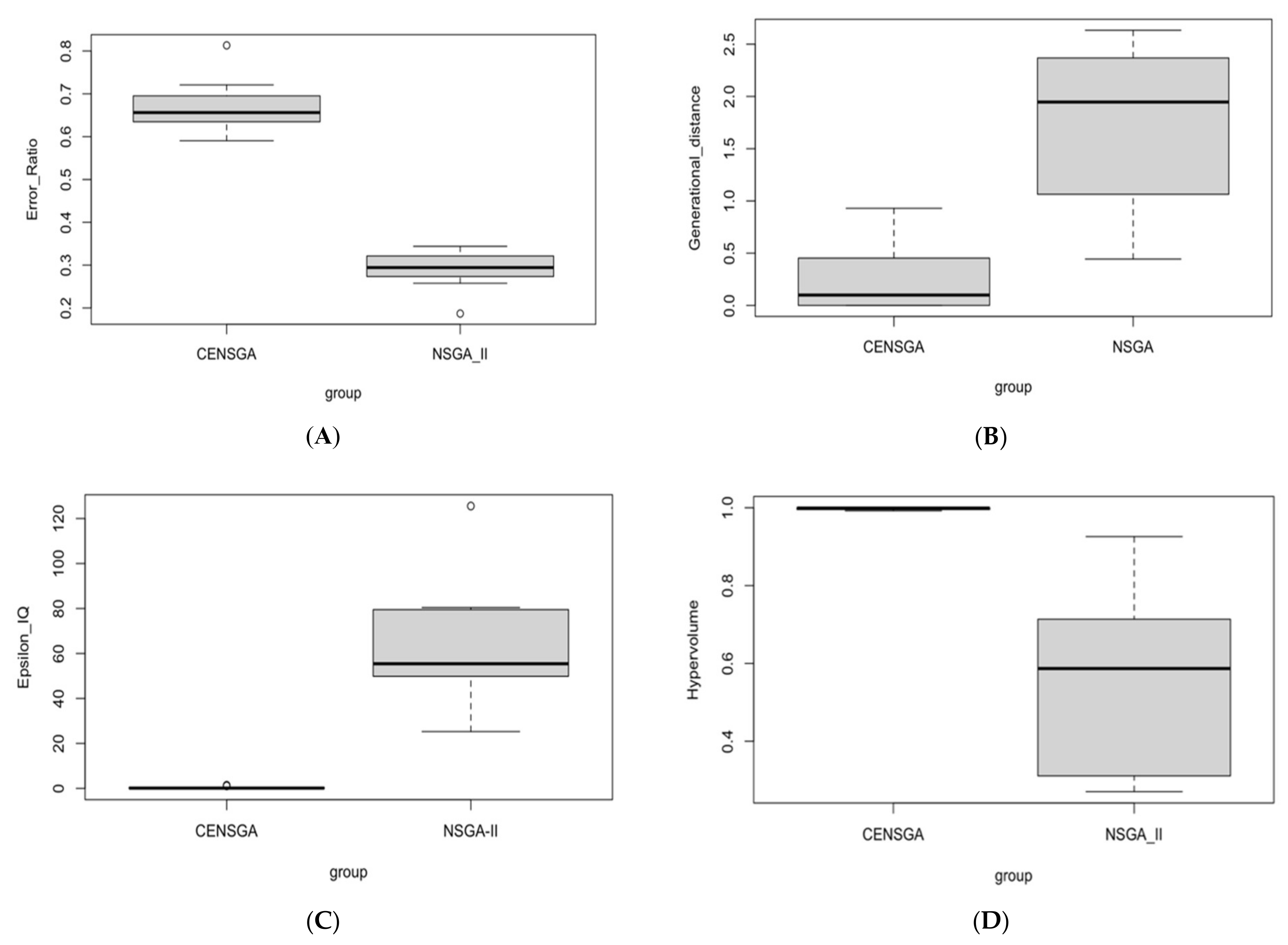
Figure 4 shows that the reproduction of the new population under CENSGA is more varied than under NSGA-II.
The two-fold affirmation of elitist solutions in NSGA-II will cause a rapid exclusion of solutions belonging to non-elitist fronts. Although the
CD operator will preserve diversity along the current non-dominated front, lateral diversity will be absent. Basically, under such conditions, the search may wane due to the lack of diversity in certain decision variables. Thus, the ability to direct the search towards better regions of optimality may be paralyzed. Therefore, in order to prevent premature convergence, a search algorithm more effectively adopts diversity in both directions—along the Pareto-optimal front and lateral to the Pareto-optimal front [
12], as presented in
Figure 5.
In CENSGA, the selection operator is modified to encourage more diversity by allowing all fronts to participate in the selection strategy. The participation of fronts is controlled by a geometric distribution that prioritizes them, ensuring that better fronts have a greater influence in shaping the next generation. This process is calculated by Equation (8):
where
ni represents the number of individuals in the
ith front and
r (<1) identifies the reduction rate. In a population of size
N, let k be the number of non-dominated fronts; then, the maximum number of individuals allowed in each front
fi ∈ (1, 2,
…,
k) is computed as follows:
At front
fi, the selection of
ni individuals is performed by the
CD operator. The geometric distribution ensures an exponential reduction in the number of solutions over the fronts [
14,
47]. Algorithm 2 shows the pseudo-code for the controlled selection, while
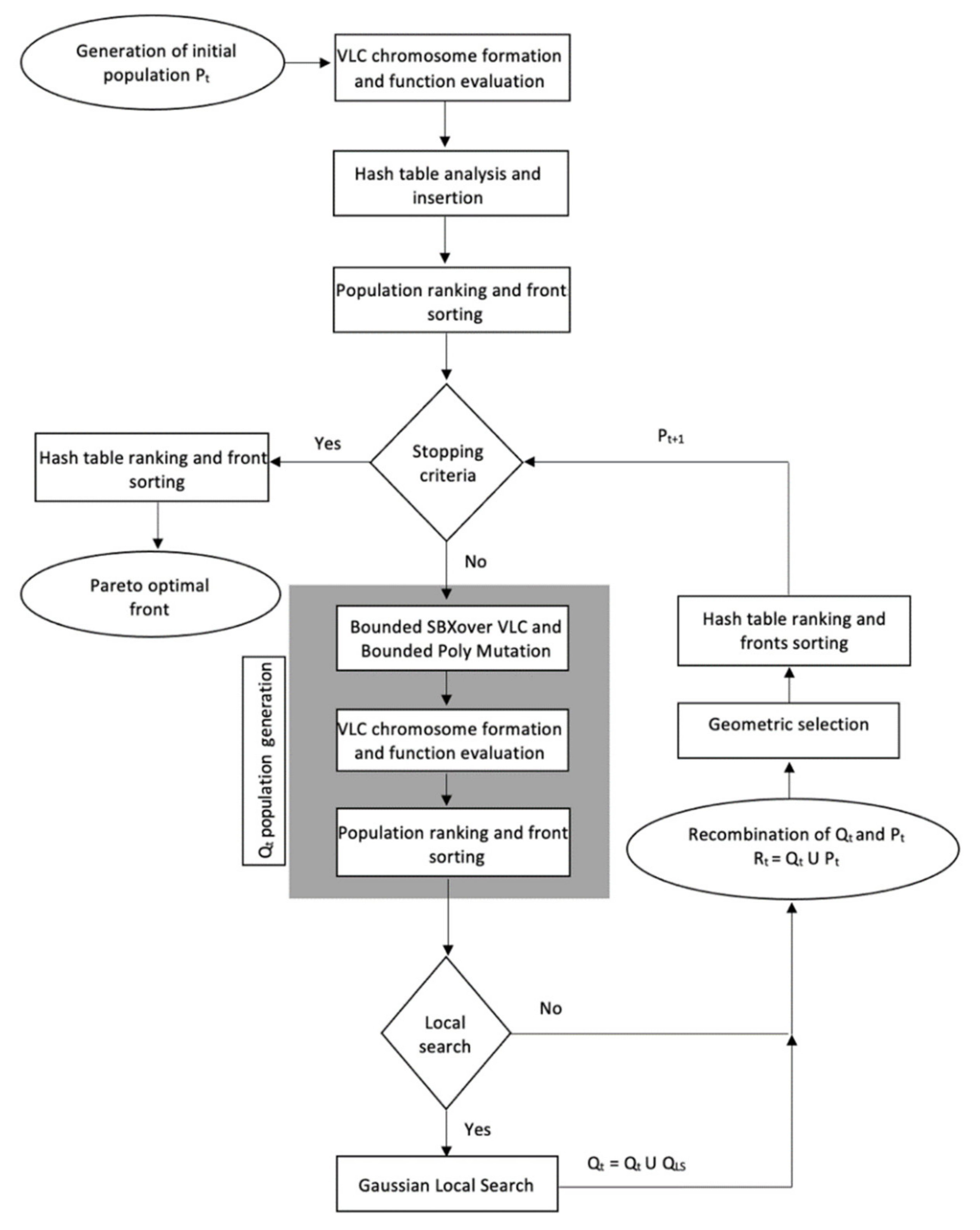
Figure A1 presents a flowchart of the CENSGA algorithm.
| Algorithm 2. Pseudo-code for CENSGA Controlled geometric selection |
| Rt = Pt ∪ Qt //combine parent Pt and children population Qt |
| F = fast-non-dominated-sort (Rt) //rank all non-dominated fronts of Rt |
| Pt+1 = ∅ and i = 1 |
| repeat |
| //Geometric distribution to decide |
| number of individuals at front i |
| crowding-distance-assignment (Fi)//calculate crowding distance for each solution in |
| Fi for partial inclusion |
| Sort(Fi, ≺n) //sort in ascending order using ≺n |
| Pt+1 = Pt+1 ∪ Fi [1:ni] //include ni non-dominated front in |
| Pt+1 according to Geometric distribution |
| i = i + 1 |
| until |Pt+1| + | Fi [1:ni]| ≤ N //until the new population is filled |
| Qt+1 = make-new-pop (Pt+1) //using selection, crossover, and mutation |
| t = t + 1 |
- C.
Local search via Gaussian approximation.
Deterministic search methods were proven to find the local optimal solution with fast and precise convergence properties. A promising means to enhance the local search beyond local optimality is by combining evolutionary algorithms and classical deterministic search methods. Our work is inspired by a local search scheme proposed in [
6] that boosts the convergence and improves the quality of solutions. This hybrid method selects solutions from the non-dominated front (recombined population) to feed the local search’s initial population. The Gaussian approximation with scalarized weighted sums [
29] is used as a function to generate newly approximated Pareto-optimal solutions, which may yield new opportunities to search areas closer to the true optimal front.
The hybrid scheme embeds the local search in the canonical NSGA-II and CENSGA algorithms, such that the process of the local search is triggered every 20 generations. The local search has the following fundamental actions: (1) A set of (r) solutions is chosen at random from the existing non-dominated front. (2) Around each solution (r) chosen in the former step, a set of (m) new points is created autonomously, by Gaussian distribution, with standard deviations equal to 0.01 times the size of the search space for each decision dimension. (3) The fitness value is evaluated on the new points to associate their objective values. (4) The new r × m solutions are introduced into the current population.
The setup of the experiments conducted here is as follows: (r) is set to hold four randomly chosen solutions selected from the existing non-dominated front, with m = 2s, and s = 2·n + 1, where (n) is the search space dimension of the problem. The number of newly produced solutions for each set of approximated functions has been set as p = N/2, where N is the population size of the evolutionary algorithm. In other words, in each iteration, when the local search is triggered, 2N new solutions are produced; then, the selection operator is performed over 4N solutions, with 2N solutions coming from the current iteration of the optimization process and 2N coming from the local search.
- D.
Evolutionary algorithm using a hash table
In order to maintain a unique set of solutions and most effectively utilize the processor time, a hash table was incorporated into the evolutionary algorithm, as proposed in [
6]. A good data structure and a good hashing function has a mean search time computationally equivalent to O(1) for an element in the array [
48].
The current research benefits from a hash table in storing the non-repetitive generated solutions during the evolutionary iterations in the optimization process. When a new offspring is obtained by a genetic operator, it passes through a verification process to acknowledge that there is no comparable member on the hash relation. This step assures there is no repetition among the hash relation members. When an offspring matches a member stored in the hash table, a random vector with Gaussian distribution (zero-mean and standard deviation equal to 1.0 percent of the search space dimension) is added to the offspring coordinates, generating a new offspring around the original member. In this way, the hash table encourages diversity, and only new solutions are evaluated.
During the optimization run, the algorithm is executed for several generations, and on each iteration, the hash table is updated accordingly. Hence, the relation of solutions is set with the initial population and expands in each iteration of the optimization process. In the final iteration, non-dominated sorting is applied over all stored solutions during the optimization process. The return result is a set with all non-dominated solutions that were involved in all executions. An outline of the CENSGA algorithm is presented in Algorithm 3.
| Algorithm 3. CENSGA Outline Algorithm |
| P1 ← InitialPopulation() //P1 is the initial population generations |
| [H, P1 ] ← AnalyzeInsertHashTable(H, P1) //H is the hash table |
| [H, P1 ] ← EvaluatePopulation(H, P1) |
| NDS1 ← NonDominatedSorting(P1) //NDS contains First Pareto front of P1 |
| NDS1 ← CrowdingDistance(NDS1) |
| for t from 1 to t step 1 do //t is the number of generations |
| Qt ←GeometricSelectionAndRecombination(Pt) |
| Qt ←Crossover&Mutation(Qt) |
| [H, Qt ] ← AnalyzeInsertHashTable(H, Qt) |
| if it is desired to execute local search then |
| L ← LocalSearch(NDSt, H) |
| Qt←Qt ∪ L |
| end if |
| [H, Qt ] ← EvaluatePopulation(H, Qt) |
| Rt ←Pt ∪ Qt |
| NDSt← NonDominatedSorting(Rt) |
| NDSt ← CrowdingDistance(NDSt) |
| Pt+1 ← FillNondominated(GeometricSelection(NDSt)) |
| end for |
| PF ← NonDominatedSorting(H) //Final pareto front PF |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}















